
Some Families of Jensen-like Inequalities with Application to Information Theory

The Viterbi Faculty of Electrical and Computer Engineering, Technion—Israel Institute of Technology, Technion City, Haifa 3200003, Israel
Entropy 2023, 25(5), 752; https://doi.org/10.3390/e25050752
Submission received: 4 April 2023
/
Revised: 23 April 2023
/
Accepted: 3 May 2023
/
Published: 4 May 2023
(This article belongs to the Collection Feature Papers in Information Theory)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:It is well known that the traditional Jensen inequality is proved by lower bounding the given convex function, , by the tangential affine function that passes through the point , where is the expectation of the random variable X. While this tangential affine function yields the tightest lower bound among all lower bounds induced by affine functions that are tangential to f, it turns out that when the function f is just part of a more complicated expression whose expectation is to be bounded, the tightest lower bound might belong to a tangential affine function that passes through a point different than . In this paper, we take advantage of this observation by optimizing the point of tangency with regard to the specific given expression in a variety of cases and thereby derive several families of inequalities, henceforth referred to as “Jensen-like” inequalities, which are new to the best knowledge of the author. The degree of tightness and the potential usefulness of these inequalities is demonstrated in several application examples related to information theory.
| In memory of Jacob Ziv, a shining star in the sky of information theory, whose legacy as a researcher will continue to inspire me and many others for years to come. |
1. Introduction
As is well known, the Jensen inequality is one of the most fundamental and useful mathematical tools in a variety of fields, including information theory. Interestingly, it includes many other very well-known inequalities, which are important on their own, as special cases. Among many examples, we mention the Shwartz–Cauchy inequality (which in turn supports uncertainty principles and the Cramér–Rao bound), the Lyapunov inequality, the Hölder inequality, and the inequalities among the harmonic, geometric and arithmetic means. In the field of information theory, the Jensen inequality stands at the basis of the information inequality (i.e., the non-negativity of the relative entropy), the data processing inequality (which in turn leads to the Fano inequality), and the inequality between conditional and unconditional entropies. Moreover, it plays a central role in support of the derivation of single-letter formulas in Shannon theory and in the theory of maximum entropy under moment constraints (see, for example, Chapter 12 of [1]).
During the last two decades, there have been many research efforts around Jensen’s inequality, which included refinements [2,3,4,5], variations [6,7,8], improvements [9,10,11], and extensions [12], just to name a few. There have also many derivations of reversed versions of the Jensen inequality. For a non-exhaustive list of works, see, e.g., ref. [13] for mixtures of exponential families, refs. [14,15,16,17] for global bounds on the difference between the two sides of Jensen’s inequality, ref. [18] for functions of self-adjoint operators in Hibert spaces, refs. [19,20] for inequalities via Green functions, refs. [21,22] for inequalities via Chebychev and Chernoff bounds, ref. [23] for quantum Simpson’s and quantum Newton’s inequalities, and ref. [24] for new quantum Hermite–Hadamard-like inequalities. In most of them, the derived inequalities are exemplified in many applications, for instance, useful relationships between arithmetic and geometric means, converse bounds on the entropy, the relative entropy, as well as the more general f-divergence, converse forms of the Hölder inequality, and so on. In many of these works, the main results are given in the form of an upper bound on the difference, , where f is a convex function, is the expectation operator, and X is the random variable. However, those bounds depend mostly on global parameters associated with f, for example, its range and domain, but not particularly on the underlying probability function (probability density function in the continuous case, or probability mass function in the discrete case), of X. For one thing, a desirable property of a reverse Jensen inequality would be that it is tight when X is well concentrated in the vicinity of its mean, just like the same well-known property of the ordinary Jensen inequality. In [22], there is an attempt to address this issue.
This paper revisits the Jensen inequality from a completely different angle. It is not meant to be another improvement of earlier bounds in an existing line of work. It is meant to propose a different approach for generating useful inequalities in the spirit of Jensen’s inequality. It is based on the following simple observation, which is rooted in the proof of Jensen’s inequality: The given convex function, , is lower bounded by the tangential affine function, , where a is an arbitrary number in the domain of x and is the derivative of f at (provided that f is differentiable at ). By selecting and taking expectations of both sides of the inequality, , the Jensen inequality is readily proved. The point to be remembered is that here, is the optimal choice of a in the sense of maximizing over all possible values of a, thus yielding the tightest lower bound within this class of lower bounds on . The optimal choice of a, however, might be different than when the function is only a part of a more complicated expression whose expectation is to be lower bounded. For example, one might be interested in lower bounding , where g is a monotonically non-decreasing function, or , where g is a non-negative and/or convex function, or a combination of both, etc.
To demonstrate this fact, consider the example (to be treated in detail in Section 2) of lower bounding , where g is a non-negative function. In this case,
and by maximizing the right-hand side (r.h.s.) over a, we easily obtain that the optimal choice of a here is , yielding the inequality,
which is useful as long as g is such that we can easily calculate both and . While this particular inequality could have been obtained also by applying the (ordinary) Jensen inequality, , with respect to (with respect to) the density, , we will see in the sequel also various examples of inequalities with no apparent simple interpretations such as this. We henceforth refer to these classes of inequalities as Jensen-like inequalities, since they are derived using the same general idea that underlies the proof the classical Jensen inequality. We will also demonstrate the usefulness of these inequalities in information theory.
Our contributions, in this work, have the following features:
- In many cases (such as the one above), the optimal value of the parameter(s) (e.g., the parameter a in the above discussion) can be found in closed form. In other cases, the resulting expressions may not lend themselves to closed-form optimization, and then we have two possibilities: (i) carry out the optimization numerically, and (ii) select an arbitrary choice of a and obtain a valid lower bound, bearing in mind that an educated guess can potentially result in a good bound.
- Our inequalities provide two types of bounds: (i) bounds that require the calculation of the first two moments (or equivalently, the first two cumulants) of X, and (ii) bounds that require the calculation of the moment-generating function (MGF) of X and its derivative, or equivalently, the cumulant-generating function (CGF) of X and its derivative. All these types of moments are often easily calculable in closed form, especially in situations where X is given by the sum of independent and identically distributed (i.i.d.) random variables, which is frequently encountered in information–theoretic applications.
- Most of our derivations extend to convex functions of more than one variable.
- The classes of Jensen-like inequalities that we consider allow enough flexibility to obtain derivations of lower bounds on functions that are not necessarily convex, and even for some concave functions, and thereby open the door for another route to reverse Jensen inequalities. This can be accomplished by representing the given function in one of the categories discussed (e.g., a product of a convex function and a non-negaive function, a product of two non-negative convex functions, a composition of a monotone function and a convex function, etc.).
- We demonstrate the utility of the Jensen-like inequalities in several examples of information–theoretic relevance. We also display numerical results that exemplify the degree of tightness of these bounds.
- Our Jensen-like inequalities have the desirable property of becoming tighter as X becomes more and more concentrated around its mean, just like the ordinary Jensen inequality.
- Throughout the paper, we confine ourselves to lower bounds on expectations of expressions that include a convex function f, but it should be understood that they all continue to apply also if f is concave and the inequalities are reversed.
- It should be understood that the classes of Jensen-like inequalities that we derive in this work are just examples that demonstrate the basic underlying idea of optimizing the point of tangency to the given convex function for the specific expression at hand. It is conceivable that the same idea can be applied to many more situations of theoretical and practical interest.
In all forthcoming derivations, it will be assumed that the convex functions involved are weakly convex and differentiable. In other words, we will rely on the well-known fact that a differentiable convex function, , is nowhere below the supporting line, , for every value of the parameter a in the domain of the independent variable, x [25] (p. 69, eq. (3.2)). In order to show that the point of zero-derivative of the lower bound (w.r.t. a) indeed yields a maximum (and not a minimum, etc.) of the lower bound, we will need to further assume that f is twice differentiable, but such an assumption will not limit the applicability of the claimed lower bound, because the lower bound applies to any value of a, including the point of zero-derivative, even if this point cannot be proved to yield the maximum of the lower bound using the standard methods. Similar comments apply when the lower bound will depend on more than one parameter.
In the remaining part of this article, each section is devoted to a different class of Jensen-like inequalities, which corresponds to a different form of an expression that includes the convex function, f.
2. A Product of a Convex Function and a Non-Negative Function
In this section, we focus on lower bounding expressions of the form , where f is convex and g is non-negative. Indeed, let be a convex function and let be a non-negative function. Then, for any ,
To find the value of a that maximizes the r.h.s., we equate the derivative to zero and obtain:
or equivalently,
whose solution is readily obtained as
and it is easy to verify that the second derivative at is , which means that it is a maximum (at least a local one). The resulting lower bound on is then given by
This result extends straightforwardly to the case where X is a vector provided that f is jointly convex and differentiable in all components of X. In particular, it extends to the case where f and g act as different random variables, X and Y, with a joint distribution:
We next consider several examples.
Example 1.
Let and , . Applying Inequality (8),
Note that the function is concave, rather than convex, yet we have here a lower bound (rather than an upper bound) to its expectation, namely, a reversed Jensen inequality. The first term on the right-most side is the (ordinary) Jensen upper bound on , and the second term is the gap, which depends not only on the expectation of X but also on its variance, which manifests the fluctuations around . Clearly, if , the second term vanishes, which makes sense, because when X is a degenerated random variable, Jensen’s inequality is achieved with equality and there is no gap. This inequality has an immediate application for obtaining a lower bound to the expectation of the empirical entropy of a sequence drawn by a memoryless source, which is relevant in the context of universal source coding [26]. Each term of the empirical entropy is of the form , where , is the number of occurrences of a letter u in a randomly drawn N-tuple from a memoryless source, P, with a finite alphabet, . Clearly, each is a binomial random variable with N trials and probability of success, . In this case, and . Thus, denoting the entropy and the empirical entropy, respectively, by
with the convention that , we have:
where is the cardinality of . The use of the ordinary Jensen inequality yields an upper bound rather than a lower bound, . We conclude that the expected empirical entropy, , is sandwiched between H and , which is reasonable because the variance of the empirical probabilities, , decays at the rate of .
Example 2.
Let s and t be two real numbers whose difference, , is either negative or larger than unity. Now, let , and . Then,
In particular, for and , this becomes
which is, once again, a bound that depends only on the first two moments of X. For , the function is concave, and so, this is a reversed version of the Jensen inequality. For and , the function is convex, and so, this is an improved version of the Jensen inequality: While the first factor, , corresponds to the ordinary Jensen inequality, the second factor expresses the improvement, which depends on the relative fluctuation term, . The degree of improvement depends, of course, on the variance of X. If the variance vanishes, there is nothing to improve because the ordinary Jensen inequality becomes an equality. On the other hand, the larger the variance, the larger the gap between the ordinary Jensen bound, , and the improved one. Accordingly, this also demonstrates the role of the optimization of the parameter a as opposed to the default choice of of the ordinary Jensen inequality.
To particularize this example even further, consider the problem of randomized guessing under a distribution Q (see, e.g., [27] and many references therein). Then, the probability of a single success in guessing a discrete alphabet random variable, X, given that we know that (but not the guesser), is . In sequential guessing until the first success, the number of guesses, G, is a geometric RV with parameter , whose mean and variance are and , respectively. For ,
Example 3.
Let f be an arbitrary convex function and let , where s is a given real number. Then, Inequality (8) becomes:
where
is the CGF of X and is its derivative. This gives a lower bound in terms of the CGF of X and its derivative. The ordinary Jensen inequality is obtained as the special case of , where and .
3. A Composition of a Monotone Function and a Convex Function
Another family of Jensen-like inequalities corresponds to the need to lower bound an expression of the form , where f is convex as before and g is a monotonically non-decreasing function. The general idea is to carry out the optimization of the r.h.s. of the following inequality.
In the important special case where , we have:
where is again the CGF of X. The optimal value, , of a, is the solution to the equation obtained by equating the derivative of the exponent to zero, i.e.,
where and are the first and the second derivatives of , respectively.
Example 4.
Consider the case where and , where , as otherwise, . In this case, the condition is equivalent to , and we have , , and so, , which means that . The equation for the optimal a becomes then
whose solution is
which yields
The ordinary Jensen inequality yields
which does not capture the singularity at . The exact calculation yields
namely, the Jensen-like bound (24) gives the correct exponential term (along with the singularity at ) and differs from the exact quantity only in the pre-exponential factor. Once again, this demonstrates the fact that optimizing the point of tangency, a, rather than using the default value, , can make a significant difference.
4. A Product of a Convex Function and a Monotone-Convex Composition
Yet another class of Jensen-like inequalities corresponds to lower bounding the expectation of the product of two functions, where one is convex and the other is a composition of a non-negative monotonically non-decreasing function and a convex function, i.e.,
where f and g are convex and h is monotonically non-decreasing and non-negative. For the case where , we end up with a bound that depends on the CGF of X and its derivative:
Maximizing with respect to b while a is kept fixed yields , and we obtain:
Example 5.
Considering the case where and , we may obtain a reversed Jensen-like inequality, namely, a lower bound to the expectation of the concave function :
Defining the MGF , we have:
We obtained a lower bound in terms of the MGF and its derivative (or, equivalently, the CGF and its derivative), which is appealing in cases where X is the sum of i.i.d. random variables.
Accordingly, we now particularize this example further by examining the case where , with , , being independent random variables. The motivation of assessing an expression of the form, , is two-fold. The first is that it is useful for bounding the ergodic capacity of the single-input, multiple-output (SIMO) channel, where designates random channel transfer coefficients (see, e.g., [22,28,29] and references therein). The second is that it is relevant for bounding the joint differential entropy associated with the multivariate Cauchy density. Here, are not Gaussian as defined above, but their multivariate Cauchy density can be represented as a continuous mixture of i.i.d. zero-mean Gaussian random variables, where the mixture is taken over all possible variances—see [22] (Example 6) for the details. In this case,
Thus,
and
It follows that
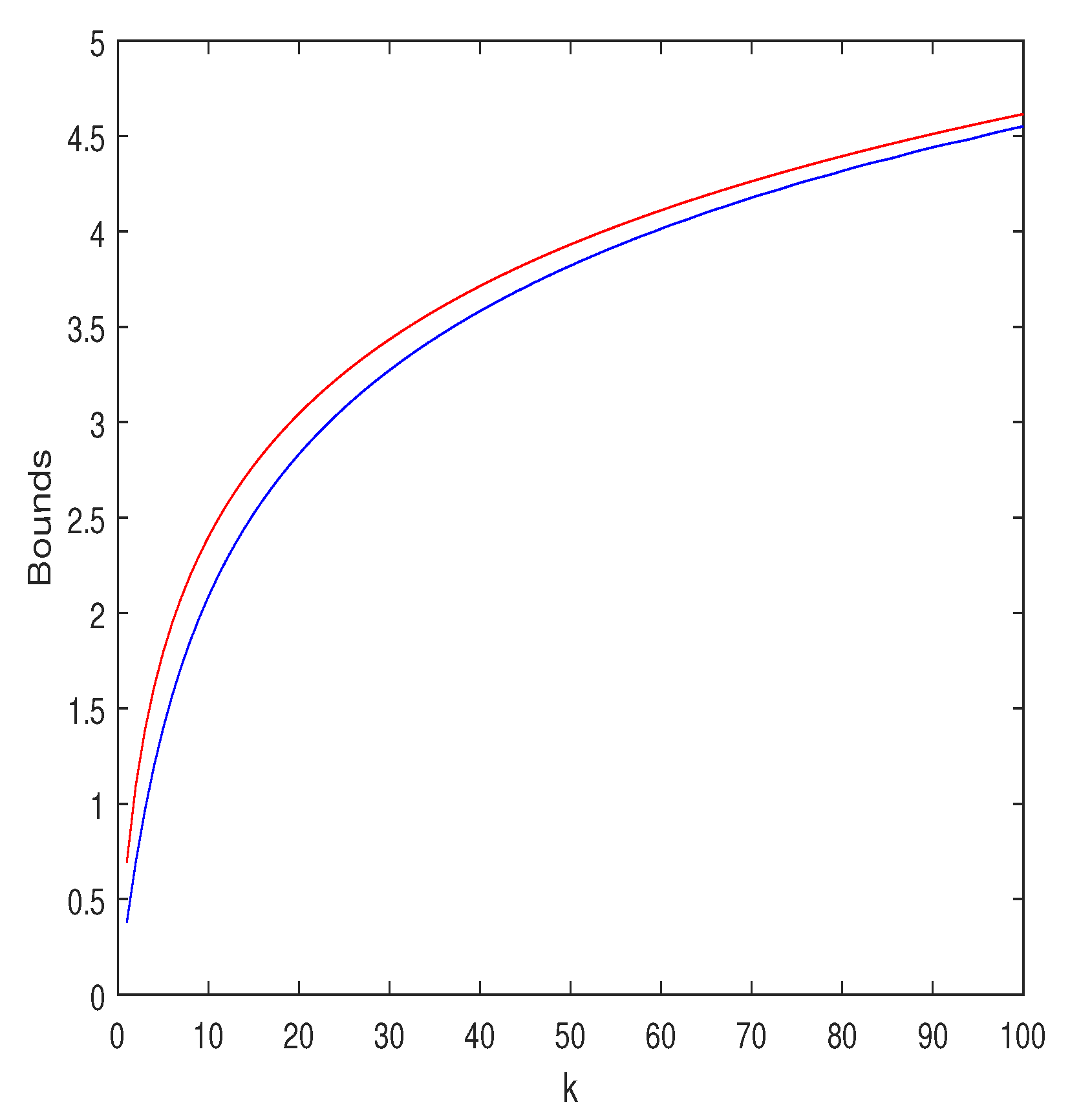
The Jensen upper bound, , and the lower bound (45) are displayed in Figure 1 for and . As can be seen, the bounds are quite close. Interestingly, the choice yields results that are very close to those of the optimal .
Another instance of this example is the circularly symmetric complex Gaussian channel whose signal-to-noise ratio (SNR), Z, is a random variable (e.g., due to fading), which is known to both the transmitter and the receiver. The capacity is given by , where g is a certain deterministic gain factor and the expectation is with respect to the randomness of Z. For simplicity, let us assume that Z is distributed exponentially, i.e.,
where the parameter is given. In this case,
and
and so,
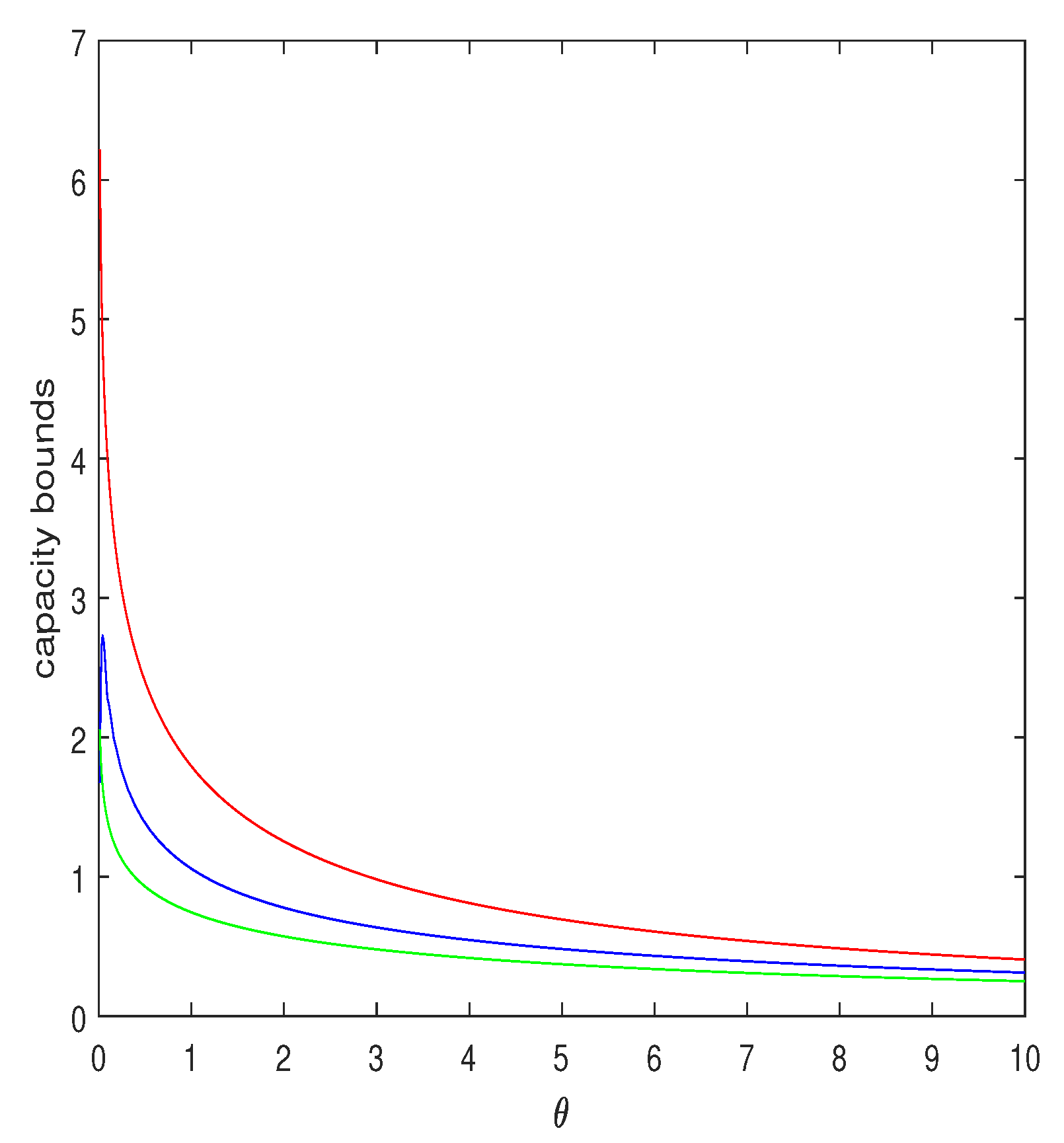
In Figure 2, we plot this lower bound as a function of for and compare it to the Jensen upper bound, (red curve) and to the lower bound of [22] (Sect. 4.1, Example 1). As can be seen, the lower bound proposed here is considerably tighter, especially for small .
Example 6.
Yet another example of this family of Jensen-like inequalities applies to obtaining a lower bound to , where t is an arbitrary real. For a given t, let be either larger than or smaller than , and consider the case where , and . Then,
Choosing , and changing the optimization variable a into , we obtain
More specifically, if , where are Bernoulli i.i.d., with parameter p, then , where . We then obtain
Selecting , we obtain
The first factor is . The second factor tends to unity as n grows, because , and so, . For and , the function is convex, and so, is the ordinary Jensen lower bound. In this case, the bound is valuable if the multiplicative factor,
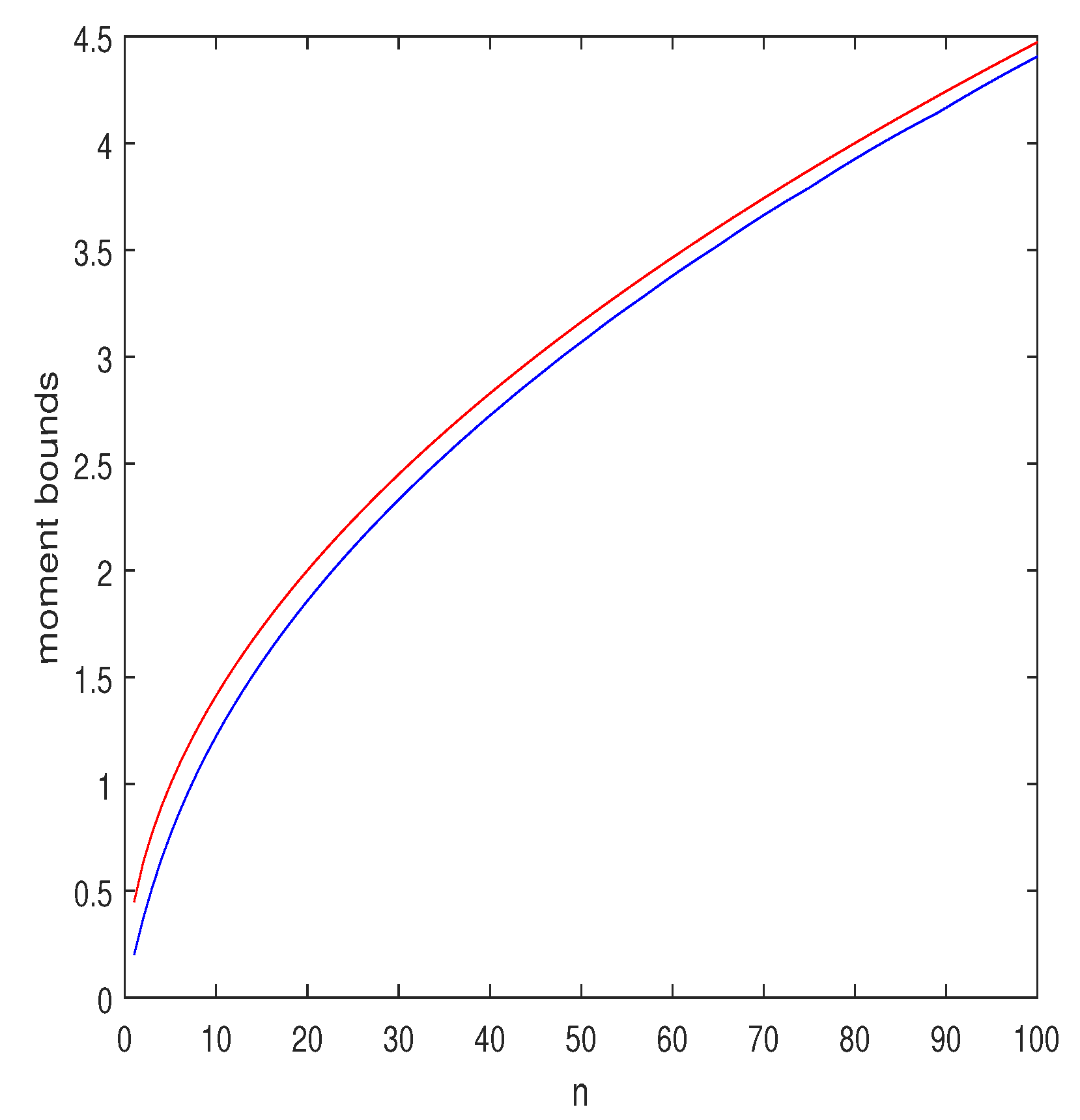
is larger than unity. If , the function is concave, and then is an upper bound. Of course, the parameter s can be optimized, too. Some numerical results for are depicted in Figure 3. As can be seen, the upper and the lower bounds are fairly close.
Another application of this example is related to estimation theory. Let and let be i.i.d., with mean and variance . Consider the t-th moment of the estimation error, . Defining , we have
and so,
with either or . For ( being a constant), we have:
where for , the first factor, , is the Jensen upper bound. The second factor,
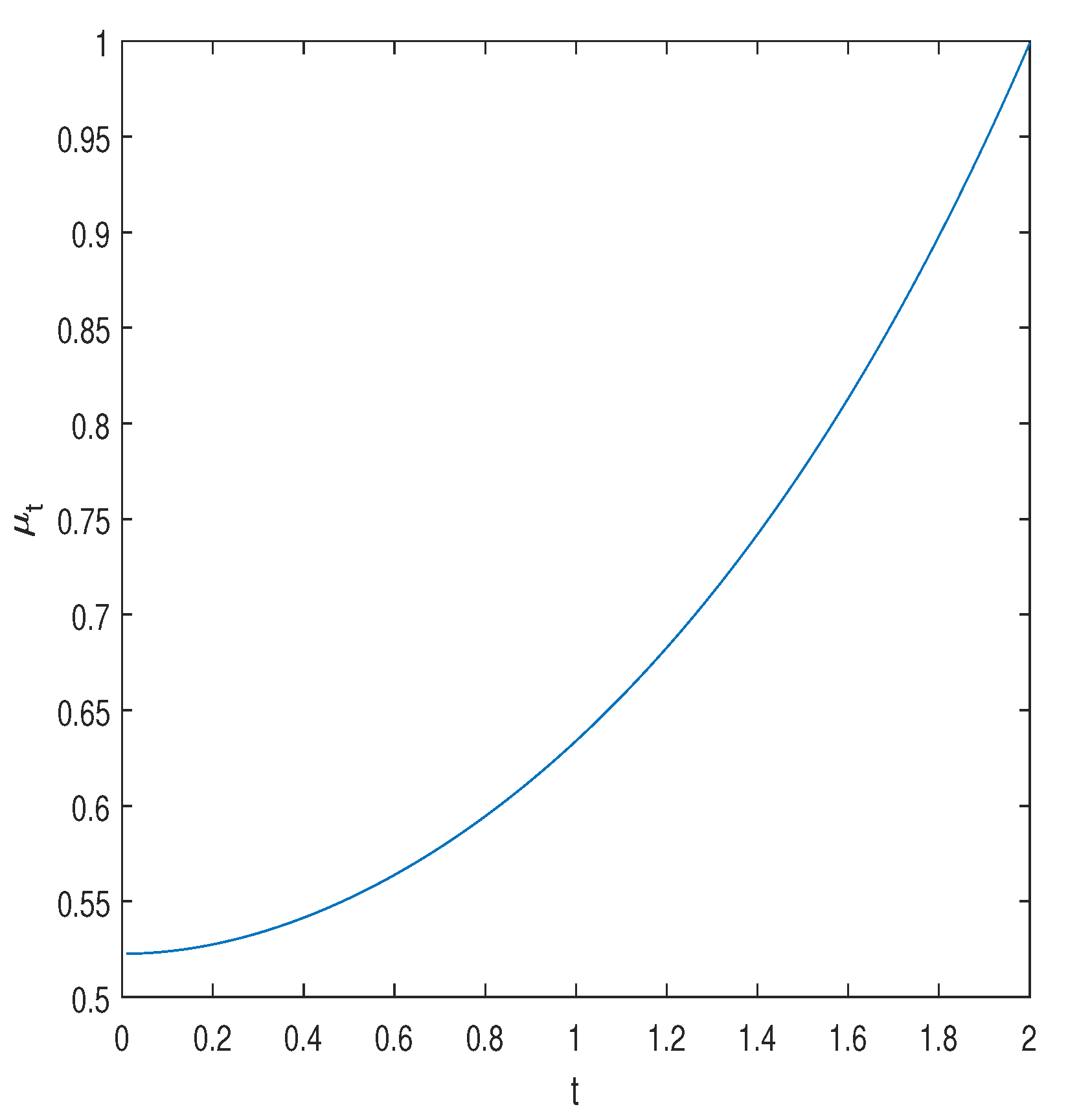
is the gap between the Jensen upper bound and the proposed lower bound. In Figure 4, we display this factor. The result is expected, because for and , the calculation is trivially exact. Note that the maximization over , for a given s, can be carried out in closed form by equating to zero the partial derivative of with respect to . The optimal turns out to be equal to (independently of s), and so,
Finally, it should be pointed out that this family of Jensen-like bounds opens the door also to lower-bound calculations on the form , where f is non-negative convex and g is non-negative and concave. Using the fact the identity , we have:
and we can apply the same ideas as before to the integrand, having the freedom to optimize the bound parameters with possible dependence on t.
5. A Product of Two Non-Negative Convex Functions
The last family of Jensen-like bounds that we present in this work is associated with the product of two non-negative convex functions. Let both f and g be non-negative convex functions of . Then,
The optimal b and c are and , respectively. Thus,
Let
and assume that . Then, is the optimal value of a, which yields
More generally, when X and Y are two random variables with a joint distribution, the above derivation easily extends to
If f and g are both concave, rather than convex, then the inequalities are reversed.
Example 7.
Consider again the example of the capacity of the AWGN with a random SNR, , and suppose that we wish to bound the variance of in order to assess the fluctuations (e.g., for the purpose of bounding the outage probability). Then, obviously,
To upper bound , we may derive an upper bound to and a lower bound to . For the latter, a lower bound was already proposed earlier in Example 5. For the former, we may use the present inequality with the choice , which can easily be shown to satisfy the requirements. We then obtain the following upper bound, which depends merely on the first two moments of Z:
Interestingly, the function is neither convex nor concave, yet our approach offers an upper bound, which is fairly easy to calculate provided that one can compute the first two moments of Z.
6. Conclusions
In this work, we have revisited the Jensen inequality on the basis of taking advantage of the freedom to optimize the choice of the supporting line that is tangential to the given convex function. This optimal choice might be different than the ordinary one when the convex function does not stand alone, but it is rather only part of a more complicated expression. This more complicated expression can sometimes be created in an artificial manner, such as in Examples 2, 5 and 6. The resulting bounds depend on either the first two moments of the independent variable, X, or on its MGF and its derivative. Both types of moments often lend themselves to relatively easy calculations. The proposed methodology can be used both for improving on the ordinary Jensen inequality (such as in Examples 2 and 4), and for generating lower bounds to expectations of non-convex or even concave (rather than convex) functions (such as in Examples 1, 2, 5 and 7). Several families of Jensen-like inequalities have been derived along with a demonstration of numerical examples with application to information theory. The tightness of the inequalities obtained was also demonstrated in those examples.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The author declares no conflict of interest.
References
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Xiao, L.; Lu, G. A new refinement of Jensen’s inequality with applications in information theory. Open Math. 2020, 18, 1748–1759. [Google Scholar] [CrossRef]
- Deng, Y.; Ullah, H.; Khan, M.A.; Iqbal, S.; Wu, S. Refinements of Jensen’s inequality via majorization results with applications in information theory. Hindawi J. Math. 2021, 2021, 1951799. [Google Scholar] [CrossRef]
- Wu, S.; Khan, M.A.; Saeed, T.; Sayed, Z.M.M.M. A refined Jensen inequality connected to an arbitrary positive finite sequence. Mathematics 2022, 10, 4817. [Google Scholar] [CrossRef]
- Sayyari, Y.; Barsam, H.; Sattarzadeh, A.R. On new refinement of the Jensen inequality using uniformly convex functions with applications. Appl. Anal. 2023. [Google Scholar] [CrossRef]
- Jaafari, E.; Asgari, M.S.; Hosseini, M.S.; Moosavi, B. On the Jensen’s inequality and its variants. AIMS Math. 2020, 5, 1177–1185. [Google Scholar] [CrossRef]
- Matković, A.; Pečarić, J. A variant of Jensen’s inequality for convex functions of several variables. J. Math. 2007, 1, 45–51. [Google Scholar] [CrossRef] [Green Version]
- Bakula, M.K.; Matković, A.; Pečarić, J. On a variant of Jensen’s inequality for functions of nondecreasing increments. J. Korean Math. Soc. 2008, 45, 821–834. [Google Scholar] [CrossRef] [Green Version]
- Seuret, A.; Gouaisbaut, F. Reducing the Gap of Jensen’s Inequality by Using Wirtinger Inequality. Preprint Submitted to Automatica. 12 July 2012. Available online: https://www.semanticscholar.org/paper/Reducing-the-gap-of-Jensen’s-inequality-by-using-Seuret-Gouaisbaut/1751273aa96d157ee143e3e7212fa04e1798ef11 (accessed on 23 March 2023).
- Walker, S.G. On a lower bound for the Jensen inequality. SIAM J. Math. Anal. 2014, 46, 3151–3157. [Google Scholar] [CrossRef]
- Liao, J.G.; Berg, A. Sharpening Jensen’s inequality. Am. Stat. 2019, 73, 278–281. [Google Scholar] [CrossRef] [Green Version]
- Simić, S.; Almohsen, B. Some generalizations of Jensen’s inequality. Contemp. Math. 2021, 2, 1–14. [Google Scholar] [CrossRef]
- Jebara, T.; Pentland, A. On reversing Jensen’s inequality. In Proceedings of the 13th International Conference on Neural Information Processing Systems (NIPS 2000), Denver, CO, USA, 1 January 2000; pp. 213–219. [Google Scholar]
- Budimir, I.; Dragomir, S.S.; Pečarić, J. Further reverse results for Jensen’s discrete inequality and applications in information theory. J. Inequalities Pure Appl. Math. 2001, 2, 1–14. [Google Scholar]
- Simić, S. On an upper bound for Jensen’s inequality. J. Inequalities Pure Appl. Math. 2009, 10, 60. [Google Scholar]
- Simić, S. On a new converse of Jensen’s inequality. Publ. L’inst. Math. 2009, 85, 107–110. [Google Scholar] [CrossRef]
- Dragomir, S.S. Some reverses of the Jensen inequality with applications. Bull. Aust. Math. Soc. 2013, 87, 177–194. [Google Scholar] [CrossRef] [Green Version]
- Dragomir, S.S. Some reverses of the Jensen inequality for functions of selfadjoint operators in Hilbert spaces. J. Inequalities Appl. 2010, 2010, 496821. [Google Scholar] [CrossRef] [Green Version]
- Khan, S.; Khan, M.A.; Chu, Y.-M. New converses of Jensen inequality via Green functions with applications. Rev. Real Acad. Cienc. Exactas Fis. Nat. Ser. A Mat. 2020, 114, 1–14. [Google Scholar] [CrossRef]
- Khan, S.; Khan, M.A.; Chu, Y.-M. Converses of Jensen inequality derived from the Green functions with applications in information theory. Math. Methods Appl. Sci. 2020, 43, 2577–2587. [Google Scholar] [CrossRef]
- Wunder, G.; Groß, B.; Fritschek, R.; Schaefer, R.F. A reverse Jensen inequality result with application to mutual information estimation. In Proceedings of the 2021 IEEE Information Theory Workshop (ITW 2021), Kanazawa, Japan, 17–21 October 2021; Available online: https://arxiv.org/pdf/2111.06676.pdf (accessed on 25 March 2023).
- Merhav, N. Reversing Jensen’s inequality for information–theoretic analyses. Information 2022, 13, 39. [Google Scholar] [CrossRef]
- Ali, M.A.; Budak, H.; Zhang, Z. A new extension of quantum Simpson’s and quantum Newton’s inequalities for quantum differentiable convex functions. Math. Methods Appl. Sci. 2022, 45, 1845–1863. [Google Scholar] [CrossRef]
- Budak, H.; Ali, M.A.; Tarhanaci, M. Some new quantum Hermite-Hadamard like inequalities for co-ordinated convex functions. J. Optim. Appl. 2020, 186, 899–910. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Krichevsky, R.E.; Trofimov, V.K. The performance of universal encoding. IEEE Trans. Inform. Theory 1981, 27, 199–207. [Google Scholar] [CrossRef] [Green Version]
- Merhav, N.; Cohen, A. Universal randomized guessing with application to asynchronous decentralized brute-force attacks. IEEE Trans. Inform. Theory 2020, 66, 114–129. [Google Scholar] [CrossRef]
- Dong, A.; Zhang, H.; Wu, D.; Yuan, D. Logarithmic expectation of the sum of exponential random variables for wireless communication performance evaluation. In Proceedings of the 2015 IEEE 82nd Vehicular Technology Conference (VTC2015-Fall), Boston, MA, USA, 6–9 September 2015. [Google Scholar]
- Tse, D.; Viswanath, P. Fundamentals of Wireless Communication; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
Figure 1.
Upper and lower bounds on , where are i.i.d., for and . The red curve is the upper bound, , which is obtained by applying the ordinary Jensen inequality. The blue curve is the lower bound of Equation (45), where the search over was carried out with a resolution of .
Figure 1.
Upper and lower bounds on , where are i.i.d., for and . The red curve is the upper bound, , which is obtained by applying the ordinary Jensen inequality. The blue curve is the lower bound of Equation (45), where the search over was carried out with a resolution of .

Figure 2.
Upper and lower bounds on , where Z is distributed exponentially with parameter , as functions of , for . The red curve is the upper bound, , obtained by applying the ordinary Jensen inequality. The blue curve is the lower bound of of Equation (49), where the search over was carried out with resolution of . The green curve is the lower bound of [22] (Example 1).
Figure 2.
Upper and lower bounds on , where Z is distributed exponentially with parameter , as functions of , for . The red curve is the upper bound, , obtained by applying the ordinary Jensen inequality. The blue curve is the lower bound of of Equation (49), where the search over was carried out with resolution of . The green curve is the lower bound of [22] (Example 1).

Figure 3.
Upper and lower bounds on as functions of n, where are i.i.d., Bernoulli . The red curve is the Jensen upper bound, , and the blue curve is the proposed lower bound where is optimized in the range and s is optimized in the range , both with resolution of .
Figure 3.
Upper and lower bounds on as functions of n, where are i.i.d., Bernoulli . The red curve is the Jensen upper bound, , and the blue curve is the proposed lower bound where is optimized in the range and s is optimized in the range , both with resolution of .

Figure 4.
The gap factor, , as a function of t. The parameter s is optimized in the range with a resolution of .
Figure 4.
The gap factor, , as a function of t. The parameter s is optimized in the range with a resolution of .

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Merhav, N. Some Families of Jensen-like Inequalities with Application to Information Theory. Entropy 2023, 25, 752. https://doi.org/10.3390/e25050752
AMA Style
Merhav N. Some Families of Jensen-like Inequalities with Application to Information Theory. Entropy. 2023; 25(5):752. https://doi.org/10.3390/e25050752
Chicago/Turabian StyleMerhav, Neri. 2023. "Some Families of Jensen-like Inequalities with Application to Information Theory" Entropy 25, no. 5: 752. https://doi.org/10.3390/e25050752
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.