


Improving Text-to-SQL with a Hybrid Decoding Method

Abstract
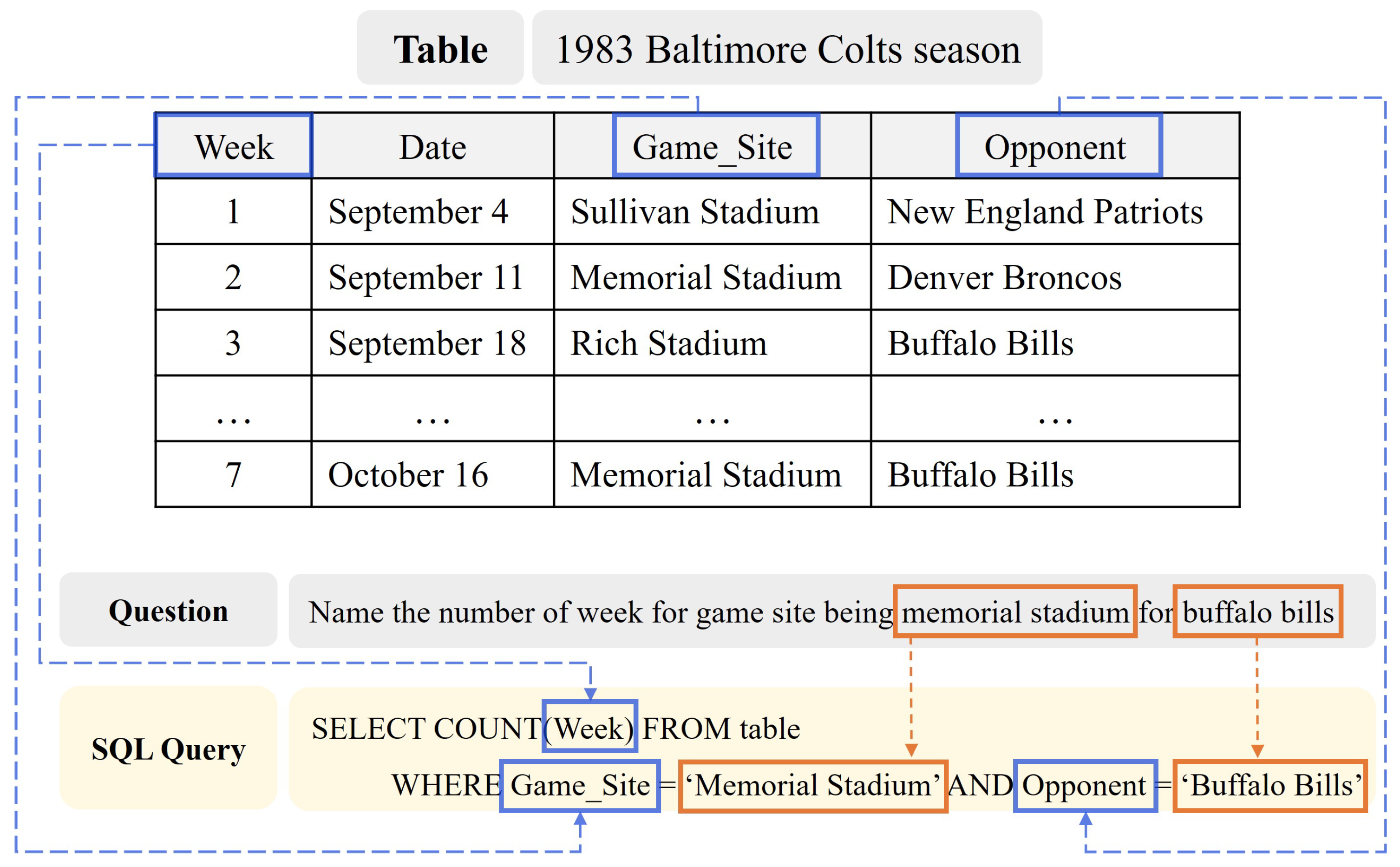
:1. Introduction
- We point out the limitations of existing decoding methods, sketch-based and generation-based methods, and propose a new decoding method called Hybrid decoder, which combines the advantages of both methods and overcomes their disadvantages.
- Our proposed model achieved superior performance compared to models that applied the sketch-based method. This is because our proposed model is based on the method of sequentially generating tokens, which effectively reflects the information of the SQL elements and predicts an accurate SQL query.
- The proposed method guarantees the syntactic accuracy of the predicted SQL query. To evaluate the syntactic accuracy of the query, we designed a new evaluation measure called Syntactic Error Rate (SER). When evaluated using SER, our proposed model showed comparable performance to sketch-based methods, despite using a generation-based method.
- Our proposed method is more efficient than existing decoding methods in terms of the decoding process and vocabulary composition than existing decoding methods. It simplifies the decoding process by predicting values through sequence labeling and minimizes the size of the generation vocabulary. Consequently, our proposed method shows a faster inference speed compared to not only the generation-based method (BRIDGE [12]) but also the sketch-based method (HydraNet [14]).
2. Related Works
2.1. Dataset
2.2. Method
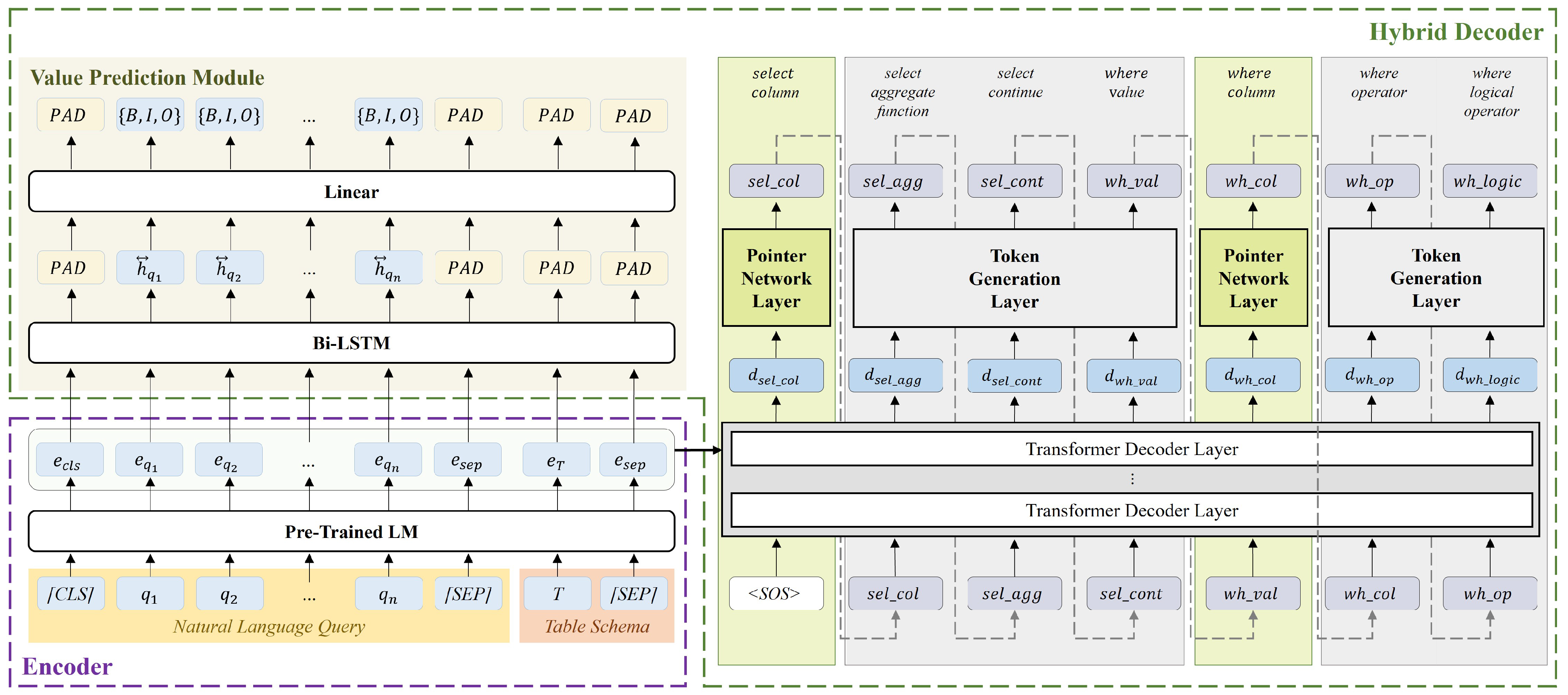
3. Methodology
3.1. Encoder
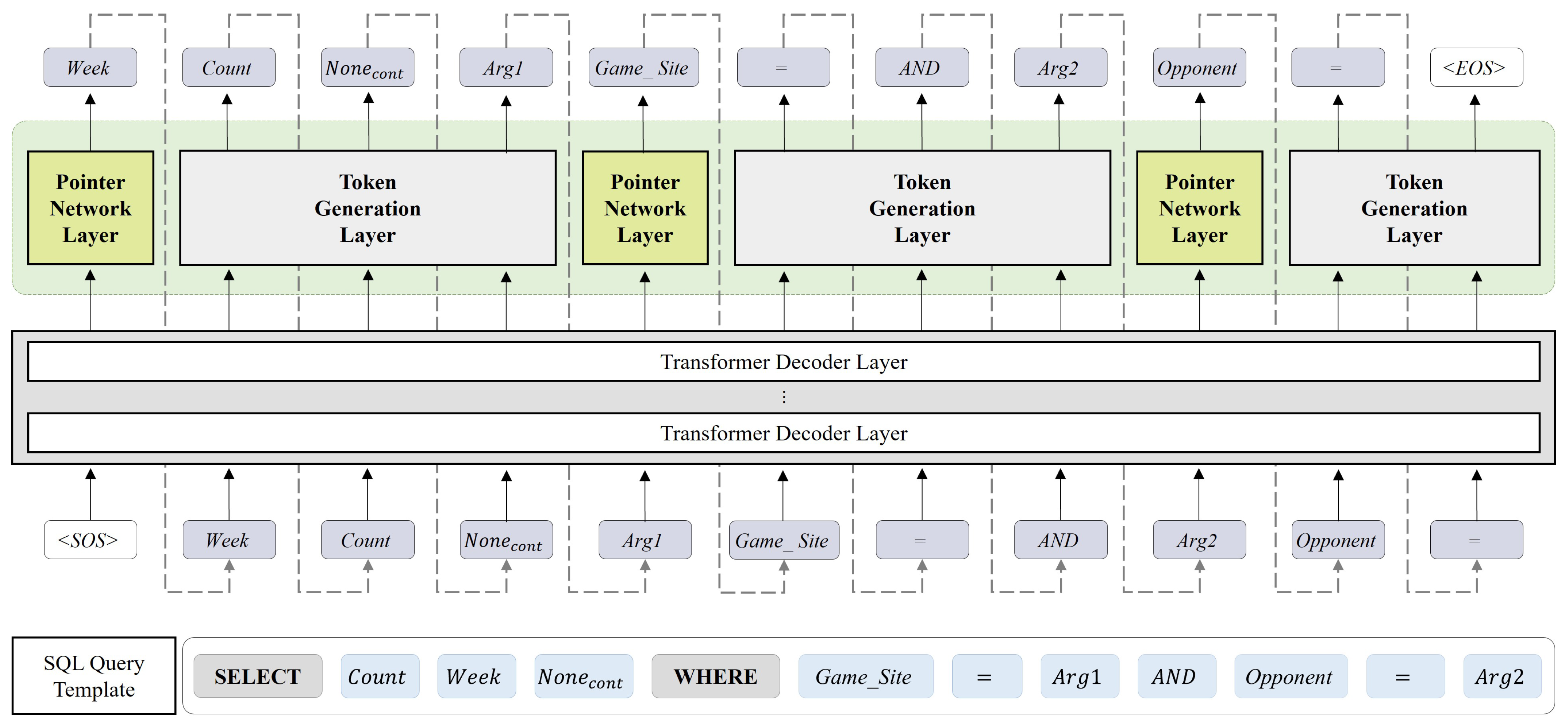
3.2. Hybrid Decoder
3.2.1. Token Generation Layer
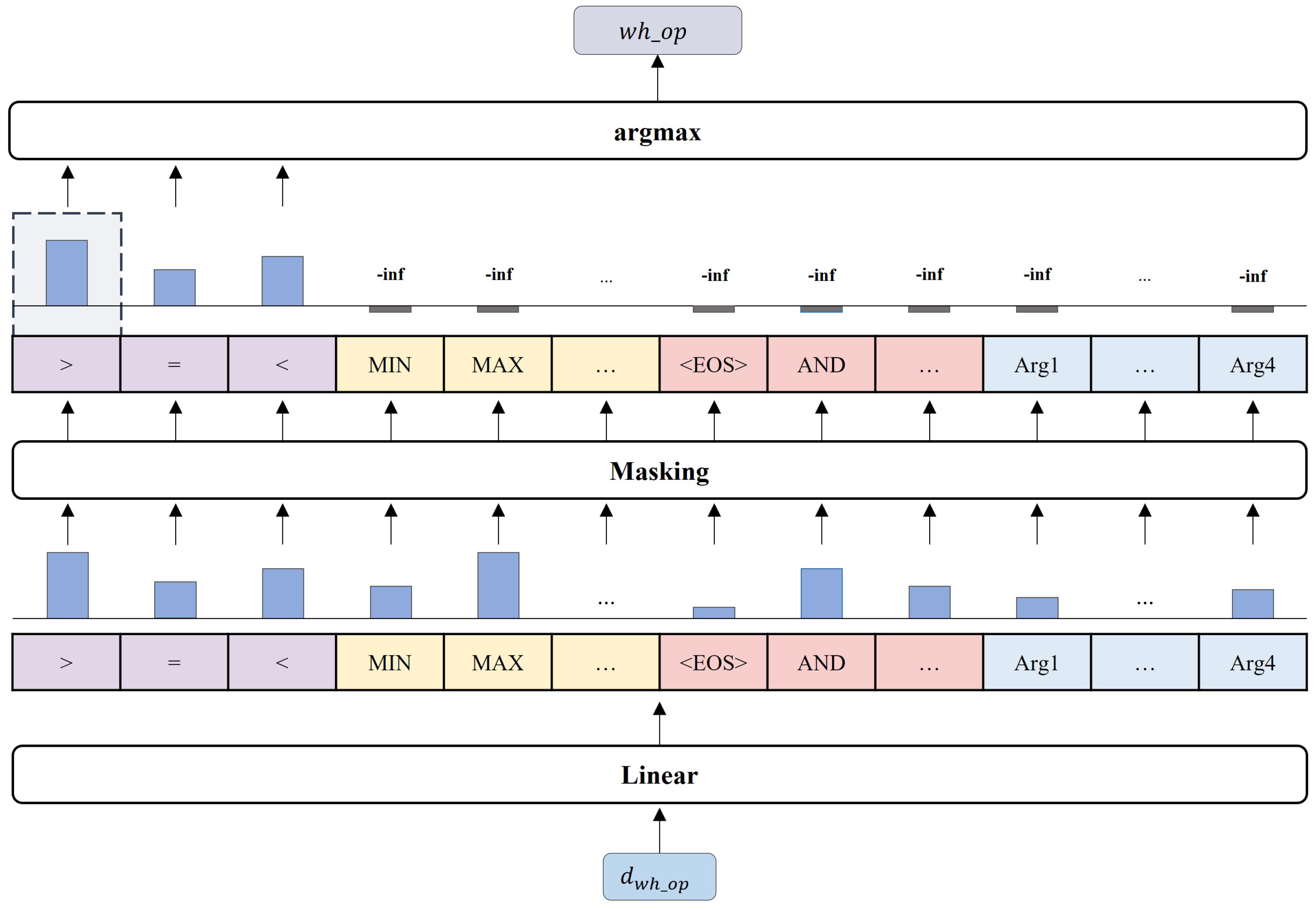
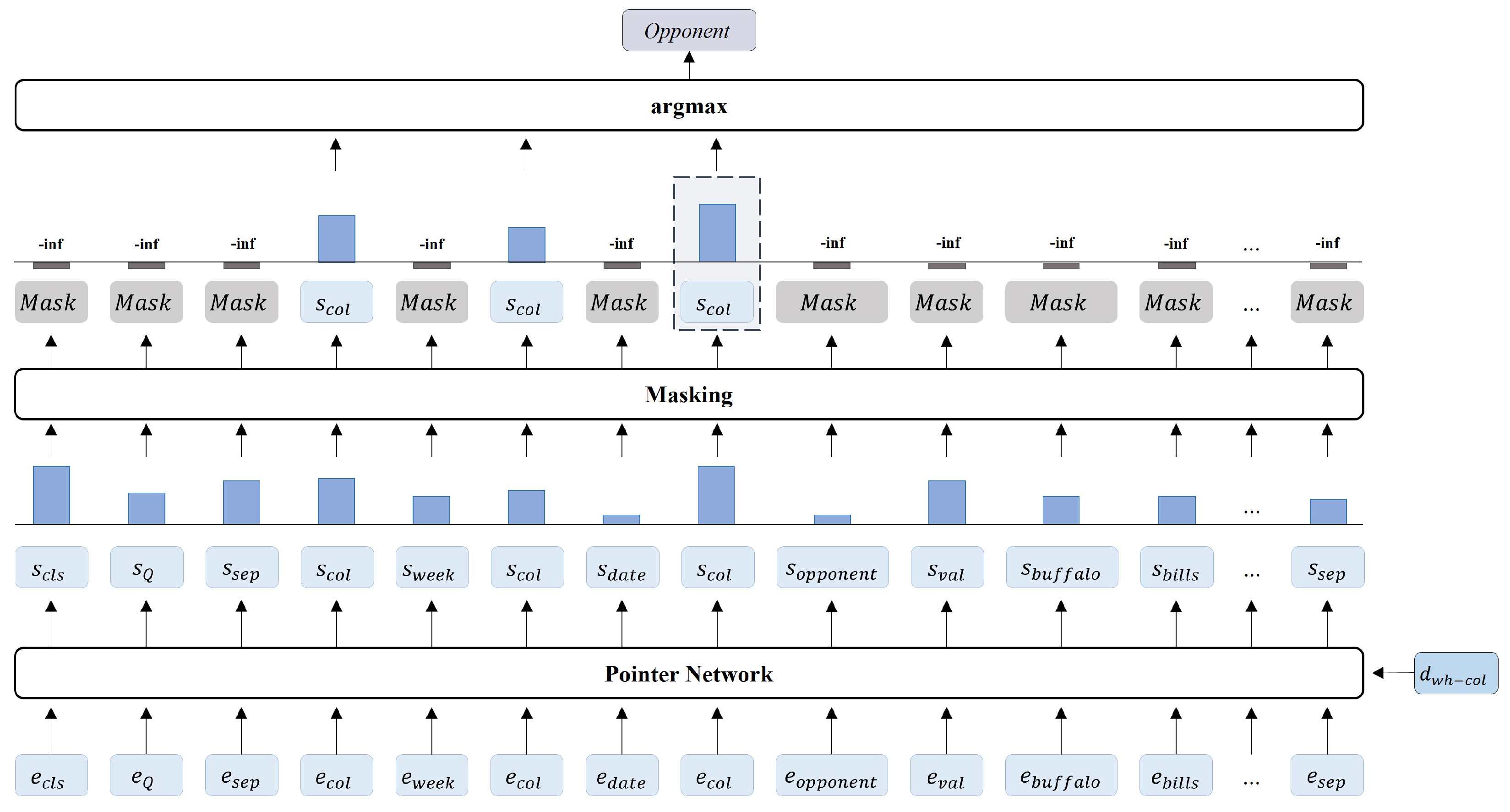
3.2.2. Pointer Network Layer
3.2.3. Value Prediction Module
3.3. Training
4. Experiments
4.1. Metric
4.2. Dataset
4.3. Experimental Parameters and Environment
4.4. Comparison of Overall Performance
4.5. Comparison of Performance by Each SQL Element
4.6. Comparison of Syntactic Error
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Luz, F.F.; Finger, M. Semantic Parsing: Syntactic assurance to target sentence using LSTM Encoder CFG-Decoder. arXiv 2018, arXiv:1807.07108. Available online: http://arxiv.org/abs/1807.07108 (accessed on 30 January 2023).
- Soliman, A.S.; Hadhoud, M.M.; Shaheen, S.I. MarianCG: A code generation transformer model inspired by machine translation. J. Eng. Appl. Sci. 2022, 69, 104. [Google Scholar] [CrossRef]
- Yin, P.; Neubig, G. A Syntactic Neural Model for General-Purpose Code Generation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 440–450. [Google Scholar] [CrossRef] [Green Version]
- Hristidis, V.; Papakonstantinou, Y.; Gravano, L. Efficient IR-style keyword search over relational databases. In Proceedings of the 2003 VLDB Conference, Berlin, Germany, 9–12 September 2003; Elsevier: Amsterdam, The Netherlands, 2003; pp. 850–861. [Google Scholar]
- Hristidis, V.; Papakonstantinou, Y. Discover: Keyword search in relational databases. In Proceedings of the VLDB’02: Proceedings of the 28th International Conference on Very Large Databases, Hong Kong, China, 20–23 August 2002; Elsevier: Amsterdam, The Netherlands, 2002; pp. 670–681. [Google Scholar]
- Luo, Y.; Lin, X.; Wang, W.; Zhou, X. Spark: Top-k keyword query in relational databases. In Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data, Beijing, China, 11–14 June 2007; pp. 115–126. [Google Scholar]
- Zhong, Z.; Lee, M.L.; Ling, T.W. Answering Keyword Queries involving Aggregates and Group-Bys in Relational Databases. Technical Report. 2015. Available online: https://dl.comp.nus.edu.sg/bitstream/handle/1900.100/5163/TRA7-15.pdf?sequence=2&isAllowed=y (accessed on 30 January 2023).
- Popescu, A.M.; Armanasu, A.; Etzioni, O.; Ko, D.; Yates, A. Modern natural language interfaces to databases: Composing statistical parsing with semantic tractability. In Proceedings of the COLING 2004: Proceedings of the 20th International Conference on Computational Linguistics, Geneva, Switzerland, 23–27 August 2004; pp. 141–147. [Google Scholar]
- Kamath, A.; Das, R. A survey on semantic parsing. arXiv 2018, arXiv:1812.00978. [Google Scholar]
- Yu, T.; Zhang, R.; Yasunaga, M.; Tan, Y.C.; Lin, X.V.; Li, S.; Er, H.; Li, I.; Pang, B.; Chen, T.; et al. SParC: Cross-Domain Semantic Parsing in Context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 4511–4523. [Google Scholar] [CrossRef]
- Yu, T.; Zhang, R.; Er, H.; Li, S.; Xue, E.; Pang, B.; Lin, X.V.; Tan, Y.C.; Shi, T.; Li, Z.; et al. CoSQL: A Conversational Text-to-SQL Challenge Towards Cross-Domain Natural Language Interfaces to Databases. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 1962–1979. [Google Scholar] [CrossRef]
- Lin, X.V.; Socher, R.; Xiong, C. Bridging Textual and Tabular Data for Cross-Domain Text-to-SQL Semantic Parsing. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 4870–4888. [Google Scholar] [CrossRef]
- Kim, H.; Kim, H. Fine-grained named entity recognition using a multi-stacked feature fusion and dual-stacked output in Korean. Appl. Sci. 2021, 11, 10795. [Google Scholar] [CrossRef]
- Lyu, Q.; Chakrabarti, K.; Hathi, S.; Kundu, S.; Zhang, J.; Chen, Z. Hybrid Ranking Network for Text-to-SQL. arXiv 2020, arXiv:2008.04759. [Google Scholar] [CrossRef]
- Qin, B.; Hui, B.; Wang, L.; Yang, M.; Li, J.; Li, B.; Geng, R.; Cao, R.; Sun, J.; Si, L.; et al. A Survey on Text-to-SQL Parsing: Concepts, Methods, and Future Directions. arXiv 2022, arXiv:2208.13629. Available online: https://arxiv.org/abs/2208.13629 (accessed on 30 January 2023).
- Popescu, A.M.; Etzioni, O.; Kautz, H. Towards a Theory of Natural Language Interfaces to Databases. In Proceedings of the 8th International Conference on Intelligent User Interfaces, IUI ’03, Miami, FL, USA, 12–15 January 2003; Association for Computing Machinery: New York, NY, USA, 2003; pp. 149–157. [Google Scholar] [CrossRef]
- Iyer, S.; Konstas, I.; Cheung, A.; Krishnamurthy, J.; Zettlemoyer, L. Learning a Neural Semantic Parser from User Feedback. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 963–973. [Google Scholar] [CrossRef] [Green Version]
- Zettlemoyer, L.S.; Collins, M. Learning to Map Sentences to Logical Form: Structured Classification with Probabilistic Categorial Grammars. In Proceedings of the Twenty-First Conference on Uncertainty in Artificial Intelligence, UAI’05, Edinburgh, UK, 26–29 July 2005; AUAI Press: Arlington, VA, USA, 2005; pp. 658–666. [Google Scholar]
- Yaghmazadeh, N.; Wang, Y.; Dillig, I.; Dillig, T. SQLizer: Query Synthesis from Natural Language. Proc. ACM Program. Lang. 2017, 1, 63. [Google Scholar] [CrossRef] [Green Version]
- Sinha, A.; Shen, Z.; Song, Y.; Ma, H.; Eide, D.; Hsu, B.J.P.; Wang, K. An Overview of Microsoft Academic Service (MAS) and Applications. In Proceedings of the 24th International Conference on World Wide Web, WWW ’15 Companion, Florence, Italy, 18–22 May 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 243–246. [Google Scholar] [CrossRef]
- Zhong, V.; Xiong, C.; Socher, R. Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning. arXiv 2017, arXiv:1709.00103. [Google Scholar]
- Yu, T.; Zhang, R.; Yang, K.; Yasunaga, M.; Wang, D.; Li, Z.; Ma, J.; Li, I.; Yao, Q.; Roman, S.; et al. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3911–3921. [Google Scholar] [CrossRef]
- Mrkšić, N.; Ó Séaghdha, D.; Wen, T.H.; Thomson, B.; Young, S. Neural Belief Tracker: Data-Driven Dialogue State Tracking. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1777–1788. [Google Scholar] [CrossRef] [Green Version]
- Guo, J.; Si, Z.; Wang, Y.; Liu, Q.; Fan, M.; Lou, J.G.; Yang, Z.; Liu, T. Chase: A Large-Scale and Pragmatic Chinese Dataset for Cross-Database Context-Dependent Text-to-SQL. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 2316–2331. [Google Scholar] [CrossRef]
- Deng, N.; Chen, Y.; Zhang, Y. Recent Advances in Text-to-SQL: A Survey of What We Have and What We Expect. In Proceedings of the 29th International Conference on Computational Linguistics, International Committee on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 2166–2187. [Google Scholar]
- Li, F.; Jagadish, H.V. Constructing an Interactive Natural Language Interface for Relational Databases. Proc. VLDB Endow. 2014, 8, 73–84. [Google Scholar] [CrossRef] [Green Version]
- Mahmud, T.; Azharul Hasan, K.M.; Ahmed, M.; Chak, T.H.C. A rule based approach for NLP based query processing. In Proceedings of the 2015 2nd International Conference on Electrical Information and Communication Technologies (EICT), Khulna, Bangladesh, 10–12 December 2015; pp. 78–82. [Google Scholar] [CrossRef]
- Tang, L.R.; Mooney, R.J. Automated Construction of Database Interfaces: Integrating Statistical and Relational Learning for Semantic Parsing. In Proceedings of the 2000 Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora: Held in Conjunction with the 38th Annual Meeting of the Association for Computational Linguistics—Volume 13, EMNLP ’00, Hong Kong, China, 7–8 October 2000; Association for Computational Linguistics: Stroudsburg, PA, USA, 2000; pp. 133–141. [Google Scholar] [CrossRef] [Green Version]
- Kate, R.J.; Wong, Y.W.; Mooney, R.J. Learning to Transform Natural to Formal Languages. In Proceedings of the 20th National Conference on Artificial Intelligence—Volume 3, AAAI’05, Pittsburgh, PA, USA, 9–13 July 2005; AAAI Press: Washington, DC, USA, 2005; pp. 1062–1068. [Google Scholar]
- Xu, X.; Liu, C.; Song, D. SQLNet: Generating Structured Queries From Natural Language without Reinforcement Learning. arXiv 2018, arXiv:1711.04436. [Google Scholar]
- Hwang, W.; Yim, J.; Park, S.; Seo, M. A Comprehensive Exploration on WikiSQL with Table-Aware Word Contextualization. arXiv 2019, arXiv:1902.01069. Available online: https://arxiv.org/abs/1902.01069 (accessed on 30 January 2023).
- Guo, T.; Gao, H. Content Enhanced BERT-based Text-to-SQL Generation. arXiv 2019, arXiv:1910.07179. [Google Scholar] [CrossRef]
- Wang, B.; Shin, R.; Liu, X.; Polozov, O.; Richardson, M. RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7567–7578. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Gu, J.; Lu, Z.; Li, H.; Li, V.O. Incorporating Copying Mechanism in Sequence-to-Sequence Learning. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 1631–1640. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Terms | Abbreviations | Description |
|---|---|---|
| select-column | column of SELECT clause | |
| select-aggregate function | aggregate function of SELECT clause | |
| select-continue | Indicates whether an SQL syntax continues, e.g., denotes the termination of the SQL, and indicates the continuation of the SQL and the start of the WHERE clause. | |
| where-column | column of WHERE clause | |
| where-operator | comparison operator of WHERE clause | |
| where-logical operator | logical operator of WHERE clause | |
| where-number | condition number of WHERE clause | |
| where-value | value of WHERE clause |
| Generation Order | |
| Written Order |
| Group | Token | Description |
|---|---|---|
| operator | =, >, < | tokens that indicate operators |
| aggregate function | , MAX, MIN, COUNT, SUM, AVG | tokens that indicate aggregate function |
| logical operator | AND, | tokens that indicate the continuation of where condition |
| value of where condition | , , , | tokens that indicate the value of where condition |
| else | , , | tokens that are not directly included in SQL statement, but used as a tool in the generation process |
| Parameter Type | Parameter Value |
|---|---|
| batch size | 128 |
| learning rate | 0.00005 |
| dropout | 0.3 |
| epoch | 30 |
| number of transformer decoder layer | 8 |
| number of heads for attention head in the decoder layer | 8 |
| size of the vector of head for attention head in decoder layer | 128 |
| Object | Environment |
|---|---|
| system | Ubuntu 18.04.6 LTS |
| GPU | NVIDIA RTX 8000 |
| Python version | Python 3.8.15 |
| Pytorch | 1.13.1 |
| transformers library | 4.25.1 |
| CUDA version | 11.6 |
| Model | Base Model | Decoding Method | Test (LF) | Text (EX) | Inference Time (ms/Sentence) |
|---|---|---|---|---|---|
| SQLova | Bert-Large | sketch-based | 80.7 | 86.2 | 41.1 |
| X-SQL | MT-DNN | sketch-based | 83.3 | 88.7 | - |
| HydraNet | Bert-Large | sketch-based | 83.4 | 88.6 | 85.2 |
| BRIDGE | Bert-Large | generation-based | 85.7 | 91.1 | 124.6 |
| Ours | Bert-Large | hybrid | 83.5 | 89.1 | 71.5 |
| Model | Base Model | Decoding Method | ||||||
|---|---|---|---|---|---|---|---|---|
| SQLova | Bert-Large | sketch-based | 96.8 | 90.6 | 98.5 | 94.3 | 97.3 | 95.4 |
| X-SQL | MT-DNN | sketch-based | 97.2 | 91.1 | 98.6 | 95.4 | 97.6 | 96.6 |
| HydraNet | Bert-Large | sketch-based | 97.6 | 91.4 | 98.4 | 95.4 | 97.4 | 96.1 |
| Ours | Bert-Large | hybrid | 97.2 | 91.0 | 99.3 | 94.0 | 98.4 | 97.3 |
| Group | Precision | Recall | F1-Score | Tag Count |
|---|---|---|---|---|
| B | 98 | 99 | 99 | 21,337 |
| I | 100 | 98 | 99 | 39,001 |
| O | 100 | 100 | 100 | 177,605 |
| Macro average | 99 | 99 | 99 | 237,943 |
| Model | Decoding Method | SER (%) |
|---|---|---|
| SQLova | sketch-based | 0.14 |
| HydraNet | sketch-based | 0.12 |
| Ours | hybrid | 0.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, G.; Han, M.; Kim, S.; Lee, Y.; Lee, J.; Park, S.; Kim, H. Improving Text-to-SQL with a Hybrid Decoding Method. Entropy 2023, 25, 513. https://doi.org/10.3390/e25030513
Jeong G, Han M, Kim S, Lee Y, Lee J, Park S, Kim H. Improving Text-to-SQL with a Hybrid Decoding Method. Entropy. 2023; 25(3):513. https://doi.org/10.3390/e25030513
Chicago/Turabian StyleJeong, Geunyeong, Mirae Han, Seulgi Kim, Yejin Lee, Joosang Lee, Seongsik Park, and Harksoo Kim. 2023. "Improving Text-to-SQL with a Hybrid Decoding Method" Entropy 25, no. 3: 513. https://doi.org/10.3390/e25030513