1. Introduction
With the rapid development of data-driven intelligent applications and the increasing attention on data security, distributed machine learning (DML) has been one of the hottest research fields in machine learning. The goal of DML is to deploy tasks with a huge quantity of data and computations to multiple machines in a distributed way, so as to improve the speed and scalability of data computation, reduce the time consumption of tasks, and improve the privacy performance. In Ref. [
1], the authors summarized the design principles of a DML platform and algorithm from four aspects: program deployment and execution, task communication mode, and communication content. In Ref. [
2], the authors analyzed and summarized the research status of machine learning algorithms and parallel algorithms based on big data. In Ref. [
3], the authors compared the scale and availability of the current mainstream DML platforms, analyzed the fault tolerance and bottlenecks of these platforms, and compared their effects on handwritten data sets. In Ref. [
4], the authors reviewed the research status and application of parallel machine learning algorithms, and looked forward to its development trend. In Ref. [
5], the authors reviewed some popular algorithms and optimization techniques in the field of machine learning, and focused on the current status, applications, and future development trends of related platforms and algorithms for DML.
However, with the problem of privacy leakage caused by data sharing in DML, researchers have tried to study protection schemes in DML. Specifically, Ref. [
6] considered the privacy protection in DML in the case of arbitrary worker collusion. Random quantization was used to convert the data set and weight vector of each round into a finite field, and Lagrange coding was used to encode the quantized value and random matrix to protect privacy. Subsequently, Ref. [
7] proposed a DML framework for privacy protection, which eliminated the assumption of trusted servers and provided users with differentiated privacy according to the sensitivity of data and the trust of servers. In addition, Ref. [
8] proposed a distributed learning algorithm based on differential privacy, which kept both the data and the model information theoretically private, while allowing an efficient parallelization of training across distributed workers. Recently, Ref. [
9] compared the impact of two different privacy protection methods, local differential privacy and federated learning, on DML. The results showed that differential privacy could achieve the best misclassification rate below 20 percent. To sum up, existing discussions about data privacy in DML mainly focus on Lagrange coding, differential privacy, and federated learning. Since differential privacy is promising in the privacy preserving of DML, in this paper, we choose a differential privacy mechanism as our main tool for analyzing the properties of distributed machine learning systems.
In differential privacy, data need to be added by noise to ensure data privacy. Utility is used to characterize the usefulness of the polluted data generated by applying differential privacy to the original data. From an information theory aspect, mutual information characterizes the correlation between two random variables, and [
10] used the mutual information as a way to characterize the utility of the polluted data generated by differential privacy. Hence, in this paper, we also used mutual information to define utility in a differential privacy mechanism.
In order to avoid reverse data retrieval in DML, the differential privacy mechanism was introduced to add noise to the parameters uploaded by clients, which protects the privacy of each client data. DP is a privacy protection mechanism proposed by Dwork et al. [
11,
12,
13,
14,
15,
16]. This mechanism uses random noise to ensure that the public output does not leak the client’s privacy. The kinds of added noise generally include Laplacian noise [
6], Gaussian noise [
17], and exponential noise [
18]. However, among the differential privacy mechanism studies, most of them focus on how to reduce the amount of privacy leakage and ignore the utility of the data after noise addition. There is little literature on the relationship between the utility and privacy of the data after noise addition. For example, Ref. [
19] used the minimum entropy to quantify the amount of information leakage and calculated the upper bound of information leakage
when the DP conditions were satisfied. Ref. [
20] and others defined a formula for information privacy by defining the posterior probability of the same query result of adjacent data sets and proved that if a mechanism satisfies the information privacy with the security parameter, then it also satisfied the differential privacy
, and proved the upper limit
of mutual information between the data sets and the query return value. In [
21], the authors proved that in the joint differential privacy of two data sets, the upper bound of mutual information between data sets and query results was further reduced, and the maximum value was
. In [
22], the authors studied the boundary between the maximum allowable distortion and the privacy budget in the case of noninteractive data release. At the same time, they compared the privacy protection strength of differential privacy with that of reconfigurable privacy and mutual information privacy under the same distortion. The degree of distortion could directly measure the utility of the algorithm mechanism. The optimization problem was established in the paper, which solved the problem of the maximum degree of distortion of different privacy protection mechanisms under the condition of satisfying differential privacy.
As is known to all, utility is one of the important indicators to measure the performance of algorithms in DP. Hence, we aim to find the utility–privacy trade-off of DML from an information-theoretic point of view in this paper. Specifically, three cases including independent clients’ local parameters with independent DP noise and dependent clients’ local parameters with independent/dependent DP noise are considered. We assume that the local parameters and added noise in distributed machine learning are subject to a Gaussian distribution. This is because Gaussian distribution models are widely used in machine learning. Many machine-learning models with probability distribution as the core mostly assume that the data have Gaussian distributions, e.g., logistic regression models, naive Bayes models, and so on. Why can some data be assumed to follow a Gaussian distribution? The intuitive reason is that real-life examples generally satisfy Gaussian distribution, such as the distribution of students’ grades. Furthermore, a Gaussian distribution has many advantages: (1) It is easy to describe, and only two parameters are needed to describe it, the mean and variance, which are the essential information of the distribution. (2) A Gaussian distribution is easy to calculate. It has some good mathematical properties. The data that obey a Gaussian distribution still obey a Gaussian distribution after some operations. For example, a linear combination of normal random variables is still a normal random variable. (3) Many random variables in reality are formed by the combined influence of a large number of independent random factors, and each of the individual factors plays a small role in the overall impact. Such random variables tend to approximately obey a Gaussian distribution (objective background to the central limit theorem). (4) When the mean and variance are known, the entropy of the Gaussian distribution is the largest among all distributions. When the data distribution is unknown, the model with the largest entropy is usually selected. Therefore, it is reasonable to assume that the local parameters and the added noise in our distributed machine learning follow a Gaussian distribution.
Based on the above three cases, the main research methods of this paper are as follows. First, we establish the utility–privacy trade-off for these three cases. Then, we determine the optimum noise variances that achieve the maximal utility under a certain level of privacy. Finally, we further explain the results of this paper by numerical examples.
The remainder of this paper is organized as follows.
Section 2 mainly introduces the background knowledge of DML and DP, gives the framework of DML–DP established in this paper, and uses mutual information and conditional mutual information to characterize utility and privacy.
Section 3 analyzes the relationship between utility and privacy in DML based on the DP framework and gives the noise level that can obtain the maximum utility under the condition of privacy with three different cases, including independent clients’ local parameters with independent DP noise and dependent clients’ local parameters with independent/dependent DP noise.
Section 4 summarizes all the results and discusses the limitations of this paper and future work.
2. Preliminaries and Model Formulation
In this section, the preliminary background knowledge of DML and DP is introduced. In addition, we present the distributed machine learning–(mutual information-differential privacy) (DML–(MI-DP)) model that is discussed in the next section.
2.1. Preliminaries
Distributed machine learning: The goal of DML is to solve how to coordinate and utilize a large number of GPU clusters and massive data to complete the training of a deep learning model and obtain good convergence, so as to achieve relatively high performance. DML involves how to allocate training tasks, how to allocate computing resources, and coordinate various functional modules to achieve the balance between training speed and accuracy. A DML system usually includes the following main modules: data model partition module, single machine optimization module, communication module, and model and data aggregation module. Each module has a variety of implementations, and each implementation method can also be arranged and combined, which makes the methods of DML diverse.
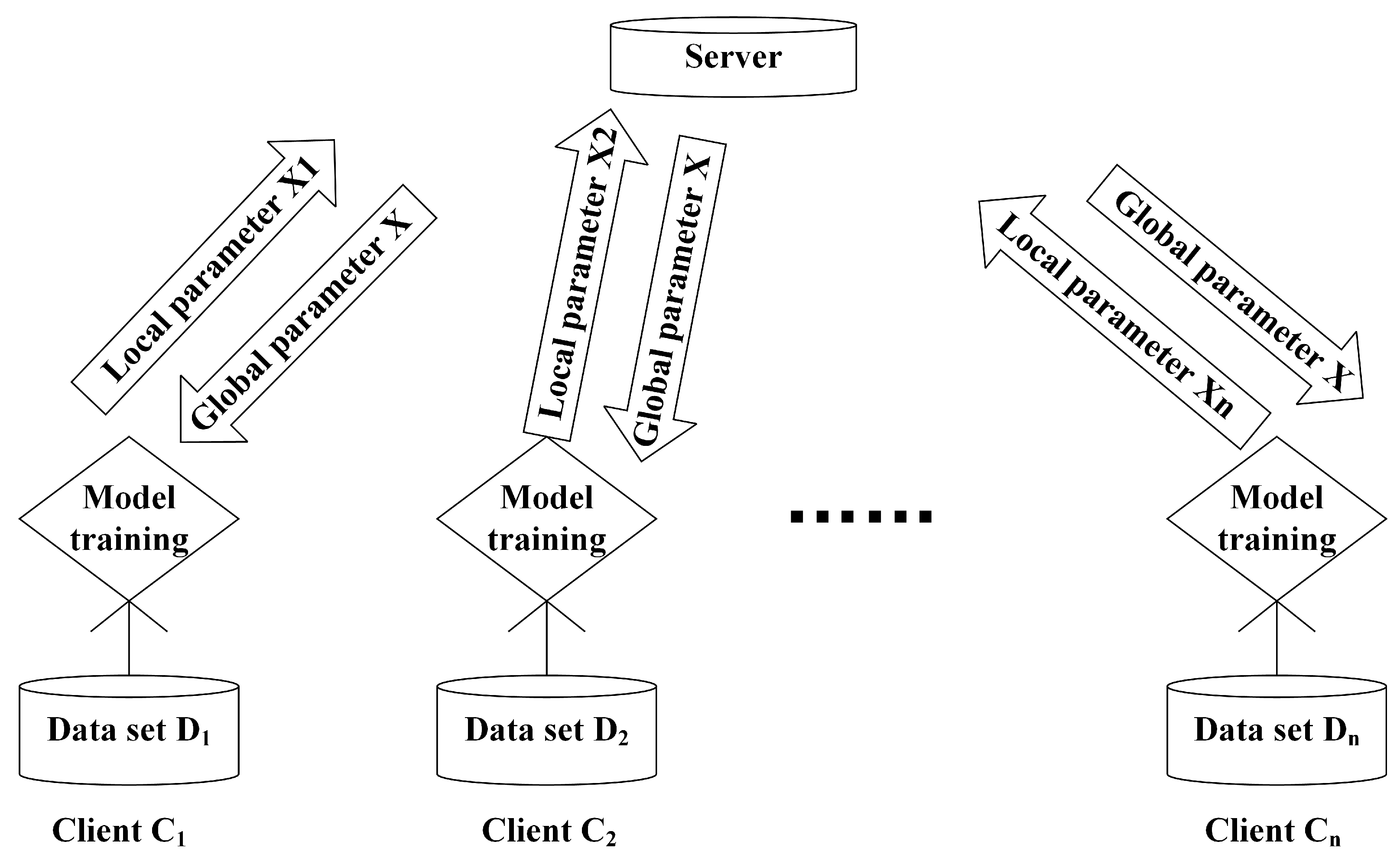
In this paper, we mainly studied the privacy disclosure problem from the DML framework of data partitioning. In order to visualize the problems studied, this paper adopts the following framework, as shown in
Figure 1. The main learning process is as follows: There is a central server and
n clients. An active client inputs the locally owned data set into the model, and after the model is trained, the model parameter is obtained by the client and then uploaded to the server. On the server side, after it has received the model parameters (also called local parameters) provided by each client, it integrates the local parameters into a global parameter in some way. Here, note that
represents the data set owned by the client
, and
,
is the gradient variable of the model trained locally.
Differential privacy: DP prevents differential attacks. The goal of DP is to protect the privacy of each entry in the database while answering queries about the total quantity of data. There are several definitions of DP, such as traditional DP [
23] and Renyi DP [
24,
25,
26]. Since Shannon’s definition of mutual information has been widely adopted in DP, we also used Shannon’s definition of mutual information in differential privacy (MI-DP) in this paper. In [
10], the authors proposed the concept of MI-DP by defining similarity and demonstrated the relationship between MI-DP and the two types of traditional DP in terms of security strength. In fact, the MI-DP is sandwiched between
-differential privacy and (
,
)-differential privacy in terms of its strength [
27]. MI-DP is fundamentally related to conditional mutual information. The conceptual advantage of using mutual information, aside from yielding a simpler and more intuitive definition of differential privacy, is that its properties are well understood. Several properties of differential privacy are easily verified for the conditional mutual information [
27].
Definition 1 (Mutual-Information Differential Privacy [
10]).
A randomized mechanism satisfies ϵ-mutual-information differential privacy ifwhere R is the output of randomized mechanism , is a database, denotes the other data in the database except for the element, and represents the privacy budget: the larger ϵ, the lower the privacy requirements, and the smaller ϵ, the stronger the privacy. This definition clearly reveals what kind of privacy is guaranteed by DP and what kind of privacy is not, which is easy to understand intuitively. For example, we can suppose that an adversary already knows about all except a certain data element, and they want to use the randomized mechanism to analyze the remaining data information. This is also known as the strong adversary hypothesis. This hypothesis is clearly revealed in MI-DP by conditional mutual information [
10].
By adding random noise, DP ensures that the public output results will not be significantly changed due to an entity being in the data set and gives a quantitative model for the degree of privacy leakage. Different kinds of noise can be added to this model. For example, Laplace noise, exponential noise, or Gaussian noise can be chosen.
2.2. Model Formulation
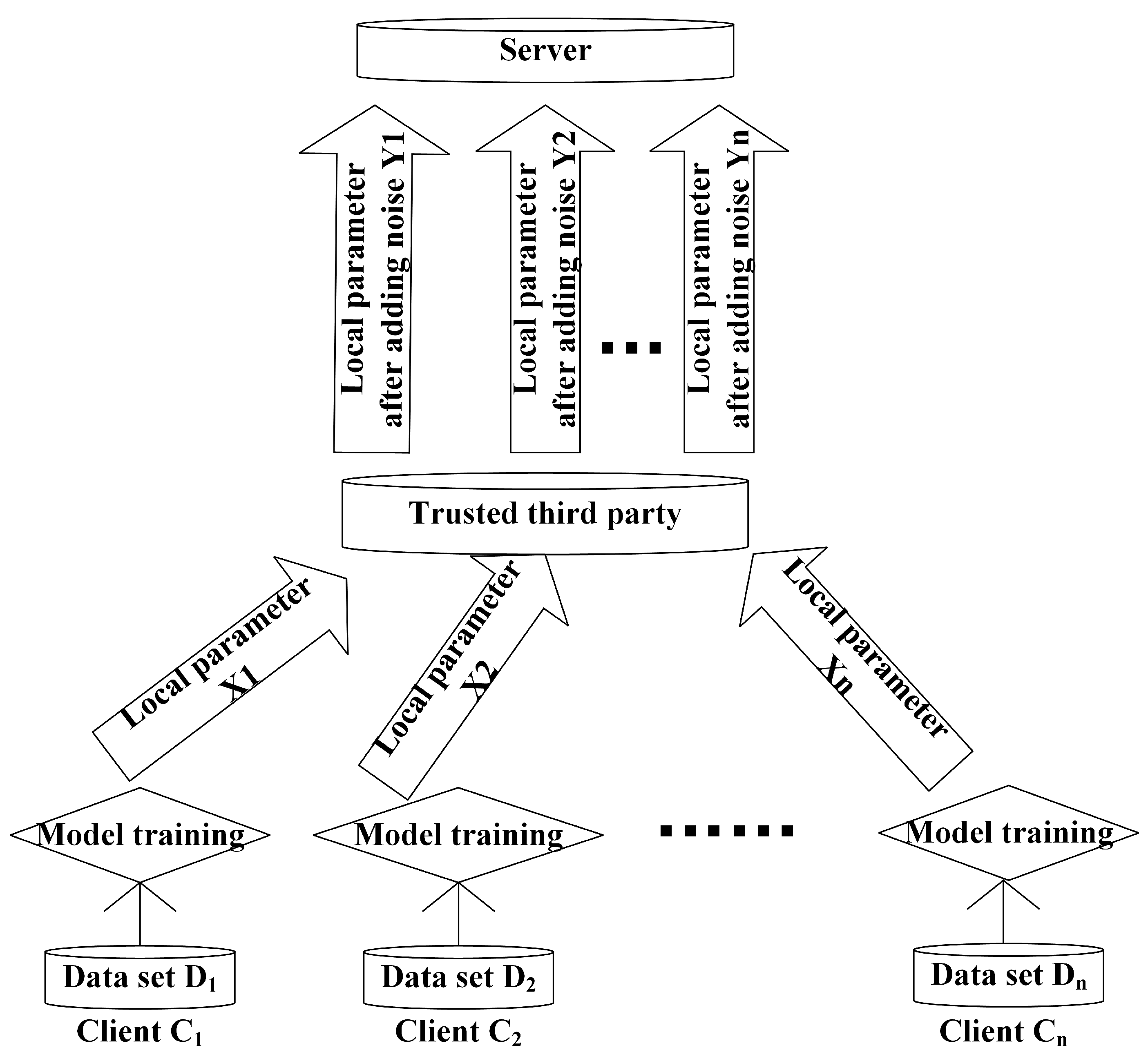
Our framework, a general distributed machine learning framework based on differential privacy: DML can train large quantities of data locally due to its distributed structure. However, in the process of DML, an attacker can analyze the model parameters
(
) uploaded by each client to obtain the client’s sensitive information [
28,
29]. Therefore, we use the method of combining DP with Gaussian noise and distributed machine learning to deal with the risk of such privacy leakage. The model architecture is shown in
Figure 2. In fact, it adds random noise on the basis of the general DML framework to complete DP. After the clients have trained the model locally, the model parameters
(
) are not directly uploaded to the server, but are handed over to a trusted third party. We assume that the channel through which the clients transmit the local parameters to the trusted third party is absolutely safe and reliable. The third party adds random Gaussian noise
to each local parameter
(
), and finally, after adding noise, the local parameters are transmitted to the server by a trusted third party to complete the aggregation and obtain the global parameter.
In this model, the key step is to design the noise
(
), which should not only meet the MI-DP condition, but also maximize the utility of local parameters after adding noise. The relationship between
,
and
is represented by
Figure 3,
Here, note that , , , is the set of local parameters obtained from the local training model of all clients, and is the set of Gaussian random noise added to the local parameters. is the set of all local parameters after adding noise.
Through the definition of MI-DP, we know that
,
and
(
) must meet the following condition:
where
. In this paper, we regard the left side of (
3) as the expression of satisfying privacy.
By the meaning of mutual information, the expression that measures the utility of the noisy local parameters is denoted by,
which is regarded as the expression of utility.
In the next section, we mainly introduce the two important tasks of this paper: The first part focuses on how to design the variance of the noise to make the noisy local parameters have the best utility (the maximum value of (
4) while satisfying the Equation (
3)). The second part focuses on exploring the relationship between the utility and privacy of the noisy local parameters, in other words, the relationship between
U and
.
3. Analysis of the Amount of Noise Added and Exploration of the Relationship between Utility and Privacy
In this section, the local parameter () obtained by the client’s local training is a Gaussian random variable, and the added noise () is also a random Gaussian variable. We used the conditional expression of privacy and the expression of utility so that the most suitable noise variance could be designed after calculation, and the designed noise could not only meet the definition of DP, but also optimize the utility of noisy local parameters.
Therefore, this problem could be mathematized and expressed as: How should the variance of the added noise be designed to make maximum under the conditions ? The three cases are described below:
Case 1: independent noise added to the independent local parameters.
Case 2: independent noise added to the dependent local parameters.
Case 3: dependent noise added to the dependent local parameters.
After solving this problem, the most suitable noise variances were designed. Next, we studied theoretically the relationship between the utility and privacy of the noisy local parameters in the DML based on the DP framework.
3.1. Case 1: Independent Noise Added to Independent Local Parameters
In Case 1, we assumed that the parameters of each client were independent of each other. Consequently, this case corresponded to the actual application scenario, which could be used for training data with little or no correlation between them, e.g., word recognition, spam classification, etc.
The clients’ local parameters were independent of each other, where ∼ denoted “distributed as”, and varied with i (), that is to say, the distribution of local parameters of each client was different. The noise added to each local parameter was also independent and is distributed as .
Theorem 1. The optimum Gaussian noise variance in Case 1 is given bywhere , and achieves the maximal utility under a certain secrecy level . Proof of Theorem 1. Since the relationship between
,
and
is
(
), we easily obtain that
are independent of each other and distributed as
. From the definition of (
3), we have
From (
5) we deduce that the variance
of the designed noise
should satisfy the following inequality
where
. After clarifying the value range of the noise variance under the privacy condition, the next step is to select the most suitable variance value in the value range to get the best utility (make
maximal). From (
4), we have
From (
8), it can be clearly observed that
is a monotonically decreasing function of
. Therefore, when
takes the minimum value
the expression of utility U takes the maximum value
□
In summary, the problem of how to design the size of the noise variance in Case 1 was solved and the first part of the work of Case 1 completed.
After obtaining the optimum noise variance, the next step was to study the relationship between utility and privacy in Case 1 (that is, the relationship between
and
), where (
9) is the functional relationship between
and
.
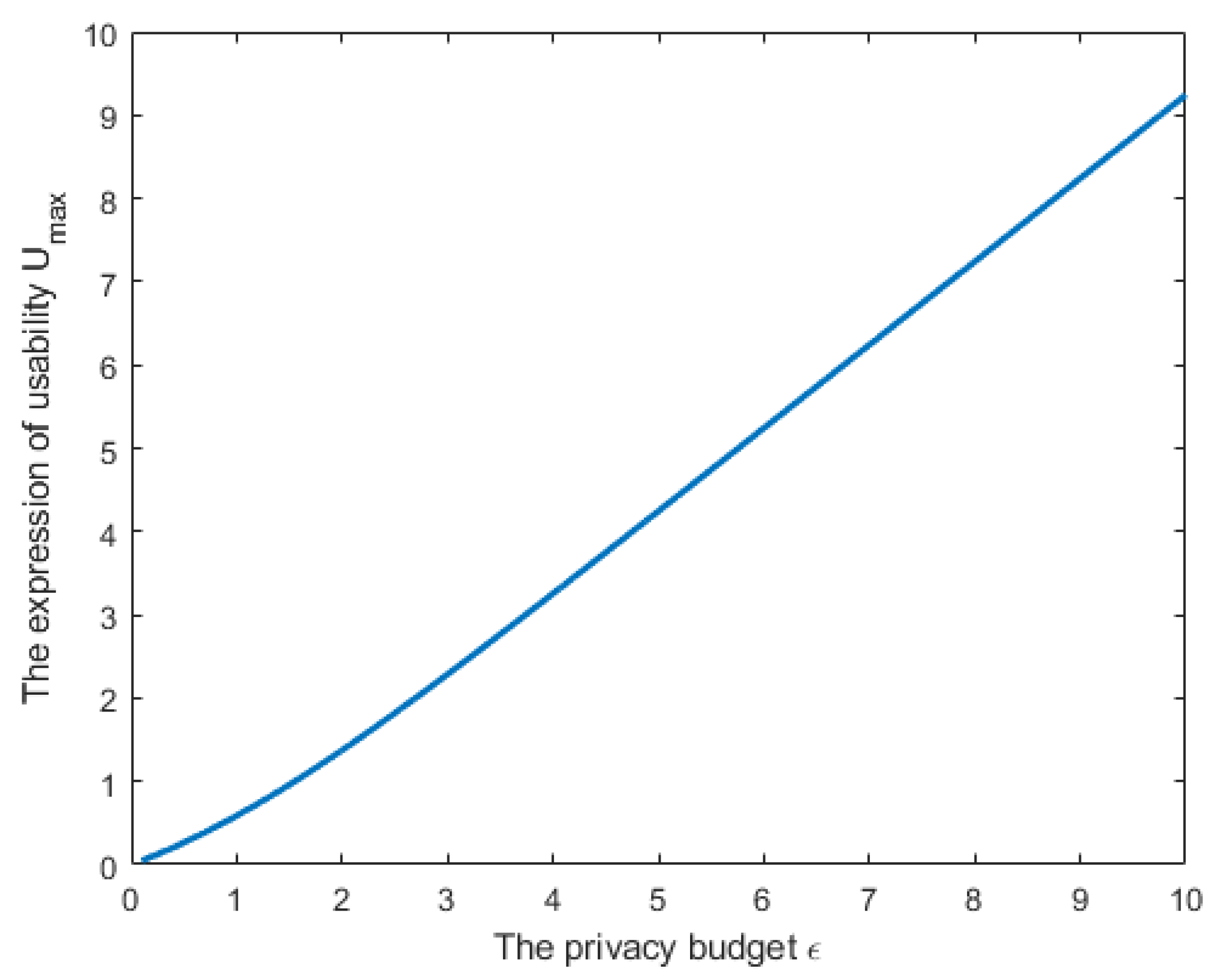
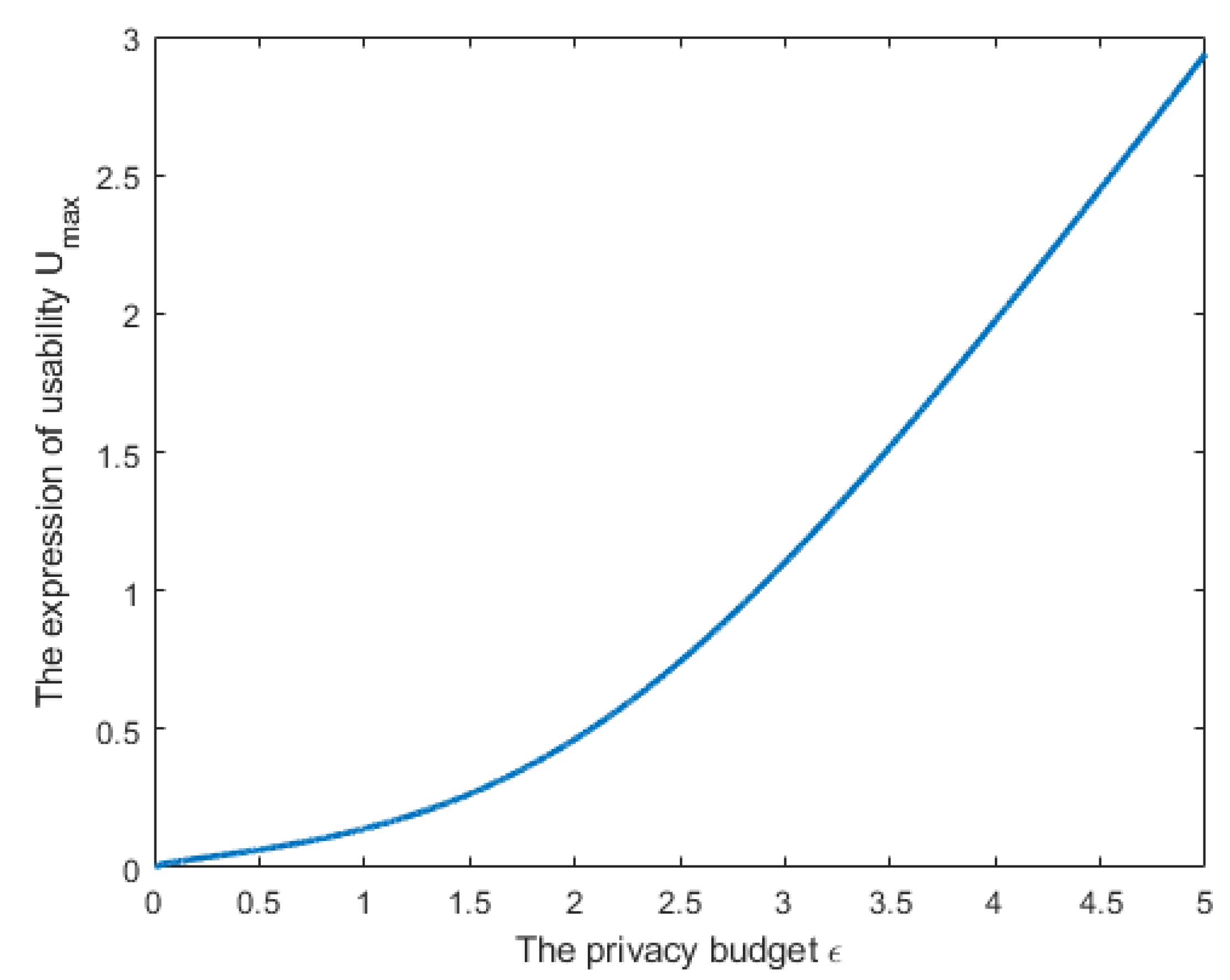
Figure 4 plots the relationship between
and
based on (
9). In this figure, we assumed that
,
(
) to be a random value between 0 and 1. It can be seen from the figure that when the local parameters of clients are independent of each other, and the noise is also designed to be independent, the amounts of the privacy budget and utility are proportional. The larger the privacy budget value (the greater the risk of privacy leakage), the bigger the value of utility.
3.2. Case 2: Independent Noise Added to Dependent Local Parameters
Case 2 was different from Case 1, as we assumed that the clients’ local parameters were dependent of each other. This case is used for practical application scenarios of correlation between training data. For example, machine learning can be applied to explore the impact of age on health in humans. It is well known that there is a certain correlation between age and human health indicators.
The clients’ local parameters were dependent of each other. When , (). The distributions of local parameters of each client were the same. The noise added to each local parameter () was independent.
Theorem 2. The optimum Gaussian noise variance in Case 2 is given bywhich achieves the maximal utility under a certain secrecy level . Proof of Theorem 2. Since
(
) and
are dependent of each other,
are dependent of each other. We assume that when
,
(
). We put the value of each variable into the expression of satisfying privacy, and it is calculated as
for
and
, we have
According to (
11), (
12) and (
10) can be expressed as
From (
13), we deduce that the variance
of the designed noise
should satisfy the following inequality
After clarifying the value range of the noise variance under the privacy condition, the next step is to select the most suitable variance value in the value range to get the best utility (make
maximal).
For
, we have
From (
16) and (
15), this can be expressed as
From (
17), it can be clearly observed that
is a monotonically decreasing function of
. Therefore, when
takes its minimum value (
is denoted as
), the expression of utility U takes its maximum value
□
In summary, the problem of how to design the size of the noise variance in Case 2 was solved and the first part of the work of Case 2 completed.
Next, we carried out the second part of the work: After obtaining the optimal noise variance, the next step was to study the relationship between utility and privacy in Case 2 (the relationship between
and
), where (
18) is the functional relationship between
and
.
Figure 5 plots the relationship between
and
based on (
18). In this figure, we assumed that
,
, and
. It can be seen from the figure that when the local parameters of clients are dependent of each other, and the added noise is designed to be independent, the amounts of the privacy budget and utility are proportional. We conclude that the larger the privacy budget value (the greater the risk of privacy leakage), the bigger the value of utility.
3.3. Case 3: Dependent Noise Added to Local Parameters
Case 3 was different from Case 2, as we assumed that the noise added to each local parameter was dependent. In order to check whether dependent noise performed better than independent noise, we studied Case 3. The application scenario of Case 3 is still that the parameters are correlated, for example, the study of the correlation between human lifespan and gender.
In Case 3, the noise added to each local parameter () was dependent. When , , . The clients’ local parameters were also dependent of each other. When , , . The distributions of local parameters of each client were the same.
For the problem to be solved, we made the following analysis. Case 3 was different from Cases 1 and 2. There were two noise parameters in Case 3. We had to design the most suitable noise to make
maximum under the conditions
. Thus, the computational difficulty was also much higher than in Cases 1 and 2. As we know,
,
, so
are dependent of each other. We assumed that when
,
,
,
. We put the value of each variable into the expression of satisfying privacy, which could be calculated as
Lemma 1. For , even if takes different values, the result of determinant is the same.
Proof. Consequently, . Similarly, we can prove that . That is to say, no matter what value takes, the result of the determinant is the same. So the proof of Lemma 1 is completed. □
Therefore, we could calculate
as
,
For
, we had
From (
12), we calculated
. Thus, (
19) could be expressed as
where
,
,
, and
As shown, Equation (
24) is very complicated, and it was difficult for us to directly derive the range of values of
and
, the two parameters of the noise. Instead, we calculated the utility expression
, and then we used the nonlinear constraint optimization function to obtain the optimal values of
and
which could maximize the
U.
Equation (
4) could be further computed as
For
, we had
We calculated
. Thus, (
25) could be expressed as
The next step was to combine (
24) with (
27). The aim was to find the most suitable values of
and
so that (
27) could obtain the maximum value under the condition of (
24). In order to solve this problem, we used MATLAB’s nonlinear optimization function for the simulation. We varied the privacy budget
values and searched for
and
that would maximize utility.
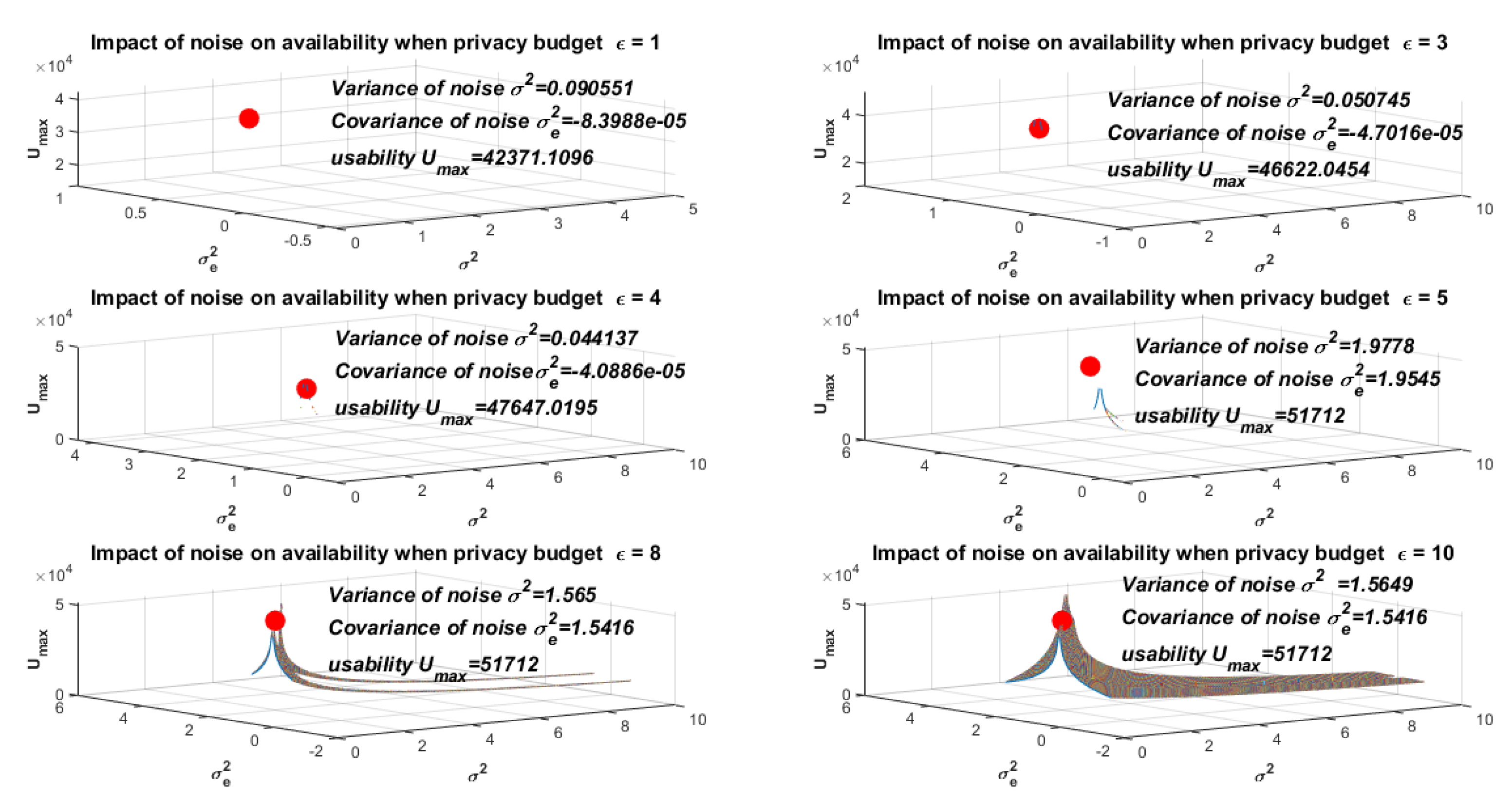
Figure 6 shows the simulation results when the privacy budget
takes different values (
). In this figure, we assumed that
,
, and
. We found that when the privacy budget
increased within a certain range, the value for measuring utility also increased. However, there was an upper bound, that is, when the privacy budget
was out of range, the value of
remained unchanged.
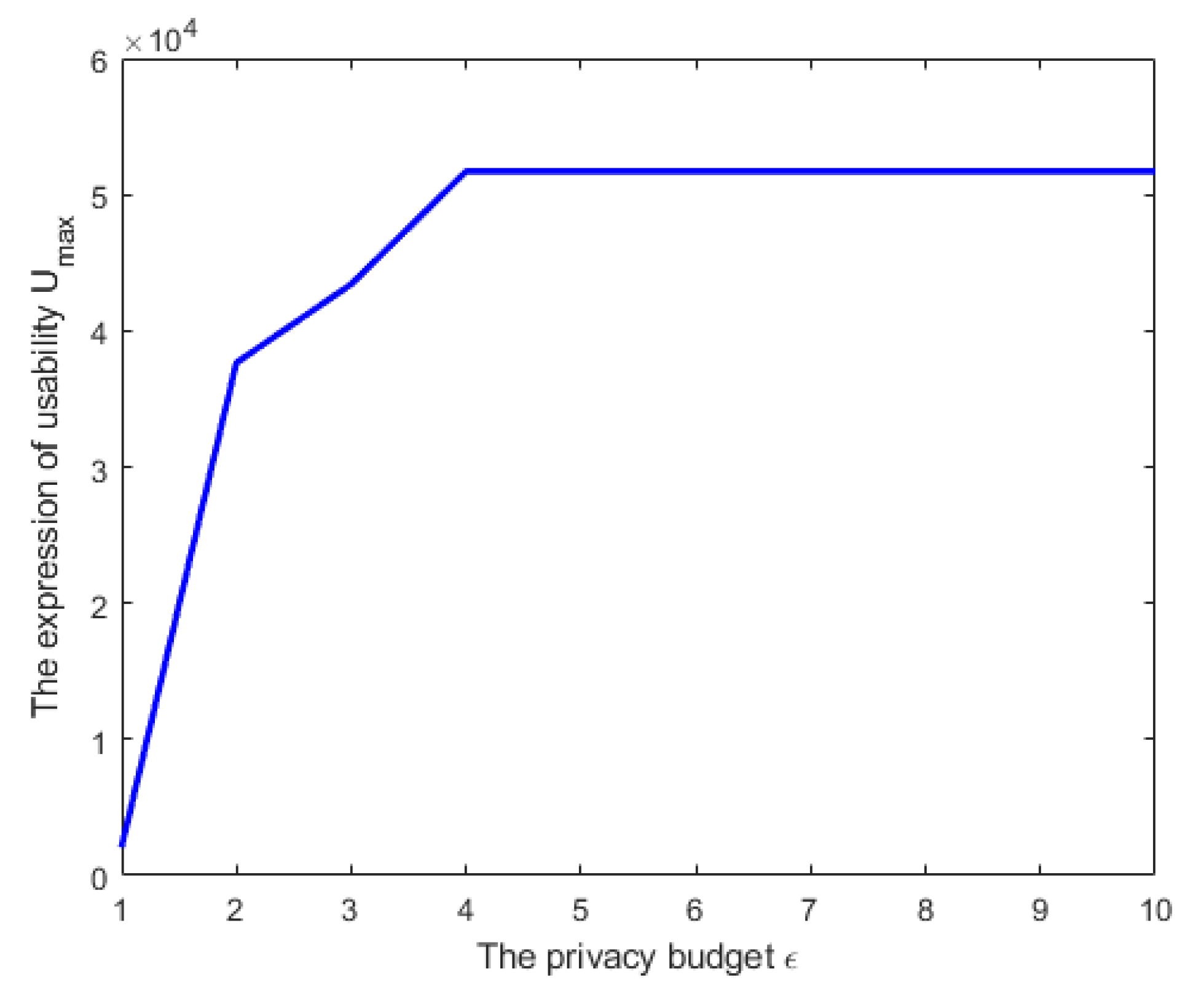
Figure 7 plots the relationship between
and
. In
Figure 7, we obtained the value of the expression of utility when the privacy budget
. In this figure, we assumed that
,
, and
. The ten points (
) were connected into a line, and finally we obtained the relationship trend between
and
.



{kind=link}
{kind=link}
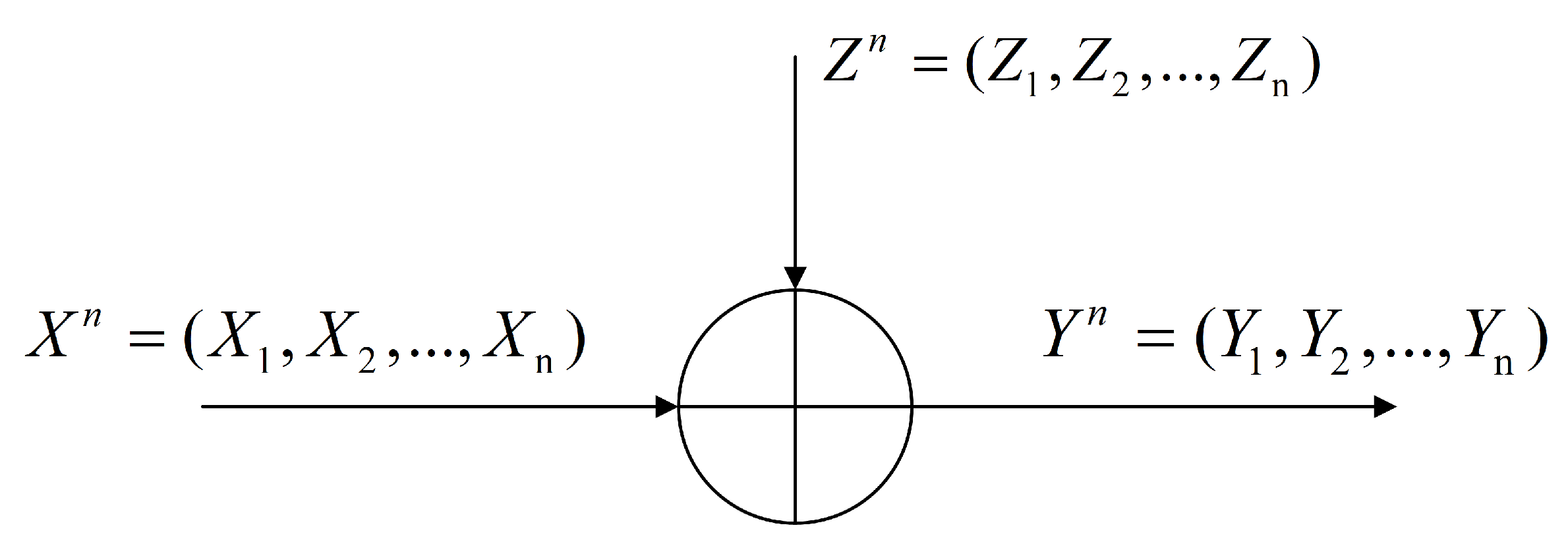{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






