

Supervised Contrastive Learning and Intra-Dataset Adversarial Adaptation for Iris Segmentation
 , ,
, ,
Abstract
:1. Introduction
- Training of deep convolutional neural networks requires a large amount of data, whereas the available dataset of iris images is very limited and is not enough to effectively train the network [7]. In addition, labeling data for the iris semantic segmentation task is expensive and time-consuming as it requires dense pixel-level annotations. The common practice for training with limited annotated data is to first pretrain using commonly used large classical databases such as ImageNet [13] and then fine-tune the network. However, ImageNet is designed for academic research and not for commercial applications. It may be not suitable for developing practical iris recognition products. In addition, ImageNet does not effectively help the semantic segmentation problem of non-natural images [14];
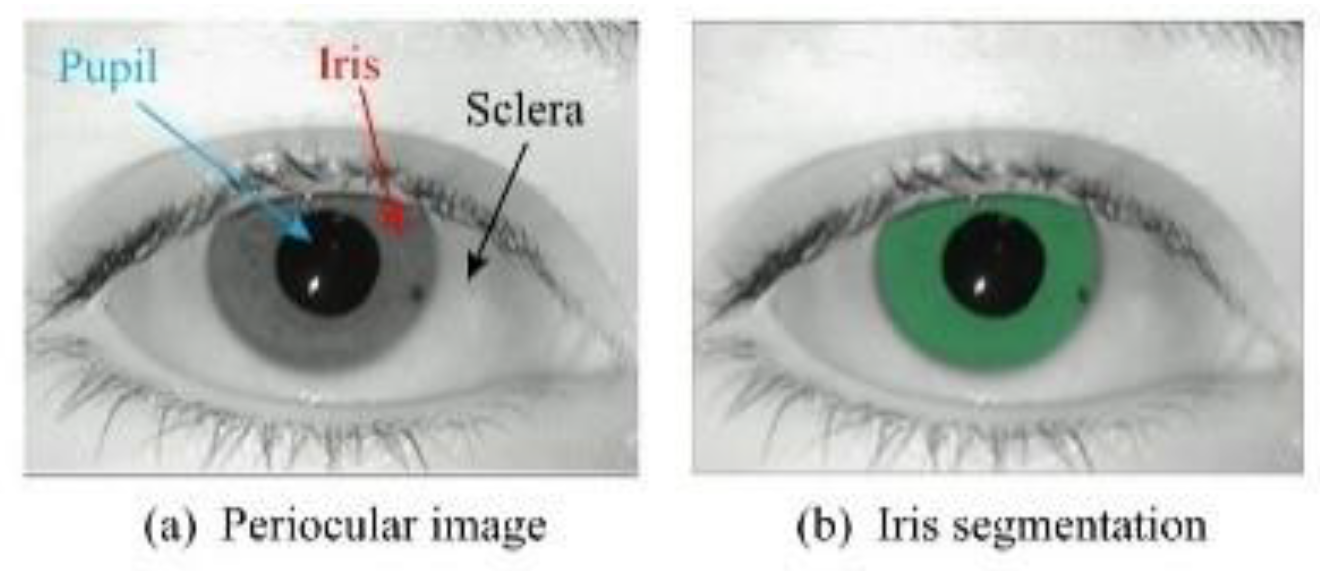
- Iris acquisition is usually unconstrained and non-cooperative, so the quality of the obtained images is very limited, which can lead to degraded performance of segmentation [15]. For example, the images may contain non-uniform illumination, bokeh, blurring, reflections, and eyelid/eyelash occlusion [16].
- (1)
- We propose a three-stage iris segmentation training algorithm. It offers an alternative training pipeline for iris segmentation networks on small and non-ideal datasets;
- (2)
- The supervised contrastive learning is proposed to pretrain the iris segmentation feature extraction model to bring features of similar pixels close to each other and to keep the features of dissimilar pixels away from each other. It reduces the need for large amounts of dense pixel-level labeled data and additional large-scale data such as ImageNet;
- (3)
- Intra-dataset adversarial adaptation is proposed to align the distribution of sample features with different noise levels, improving the robustness of the model on non-ideal datasets;
- (4)
- Our approach achieves state-of-the-art results in some metrics such as F1 score, Nice-1, mIoU, etc. on several commonly used datasets including those with few samples;
- (5)
- To the best of our knowledge, this work pioneers the use of contrastive learning and domain adaptation to improve iris segmentation performance.
2. Related Work
3. Technical Details
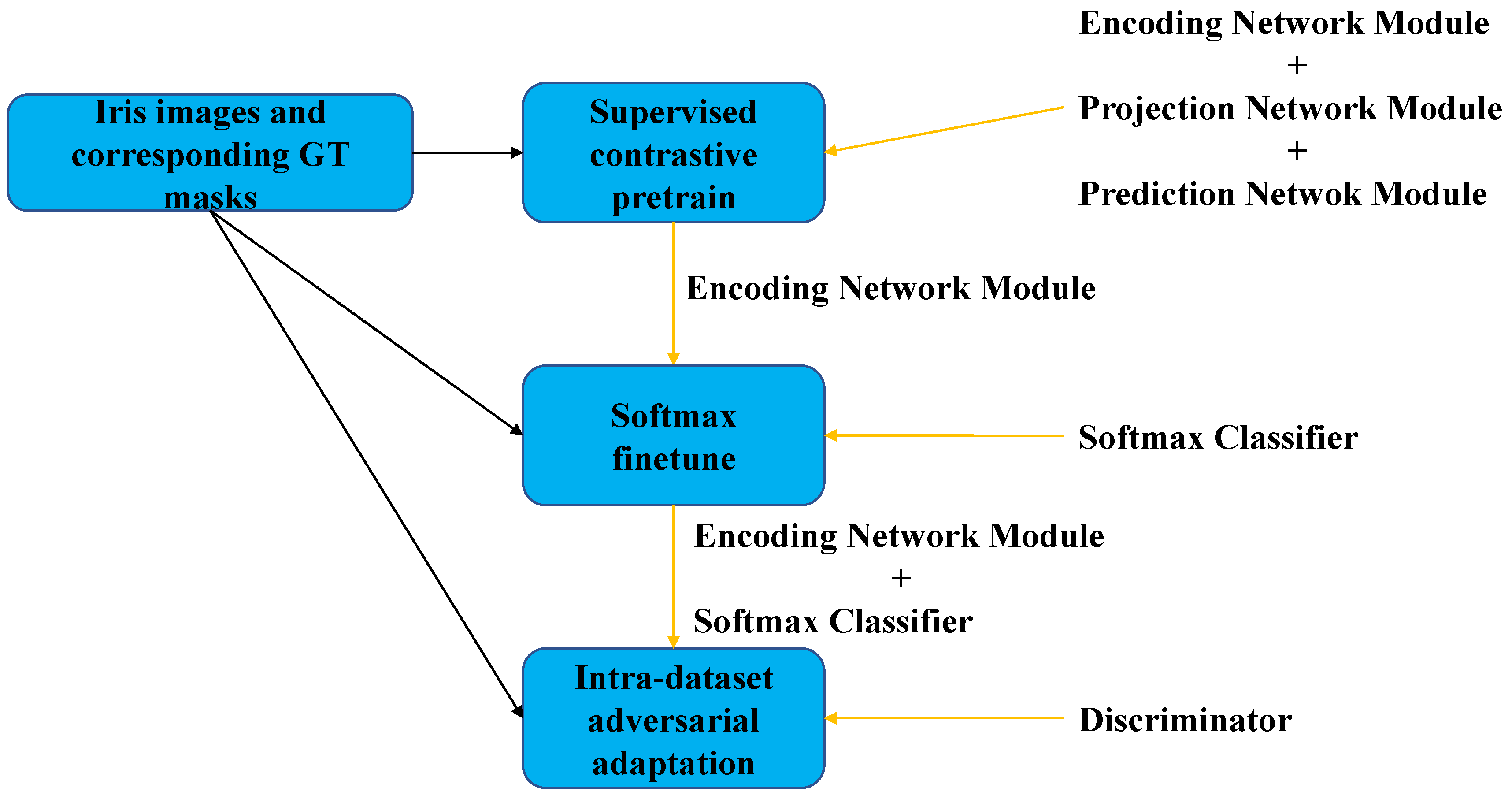
3.1. Overview of the Proposed Method
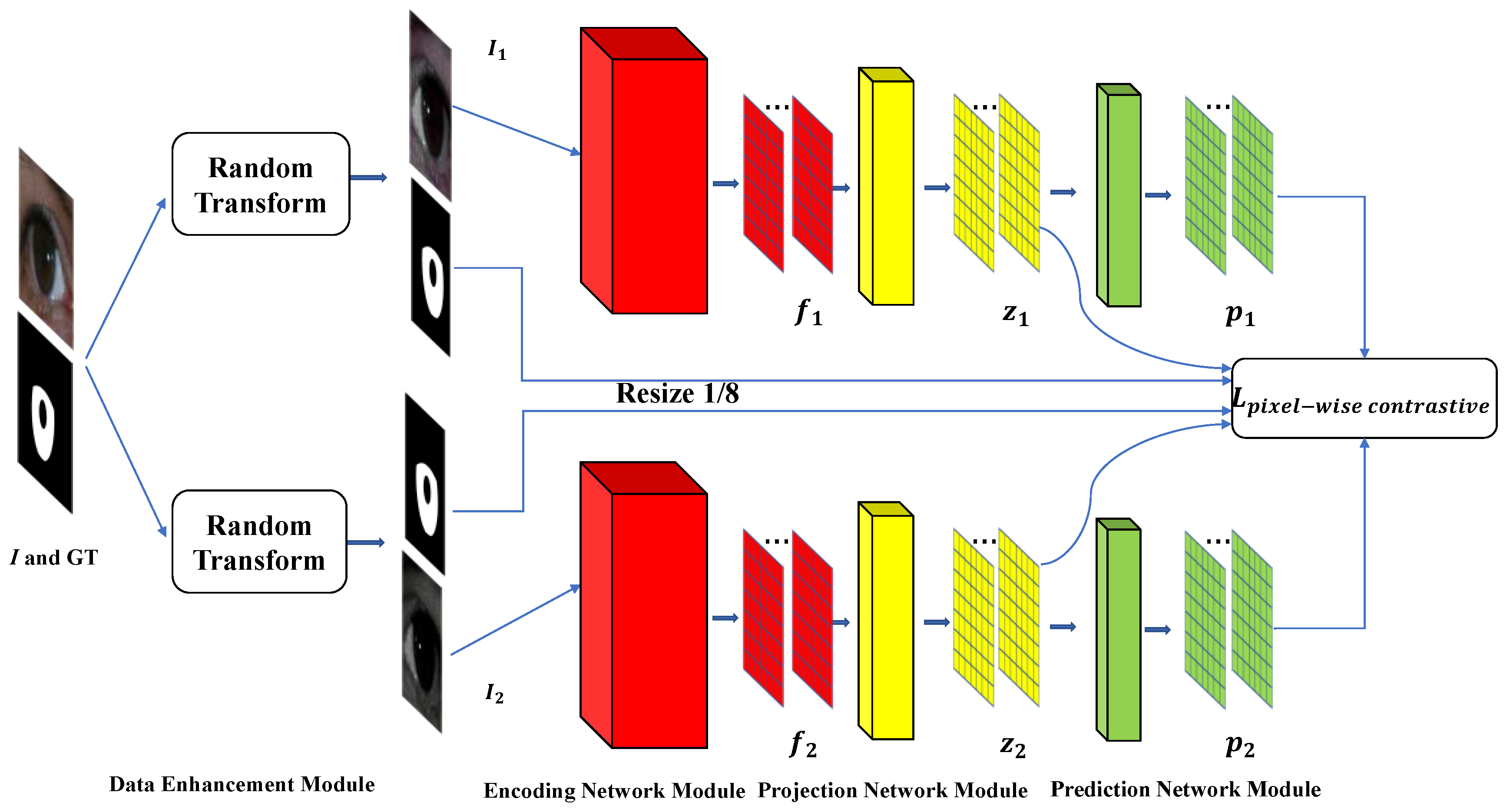
3.2. Supervised Contrastive Learning for Iris Segmentation Pretraining
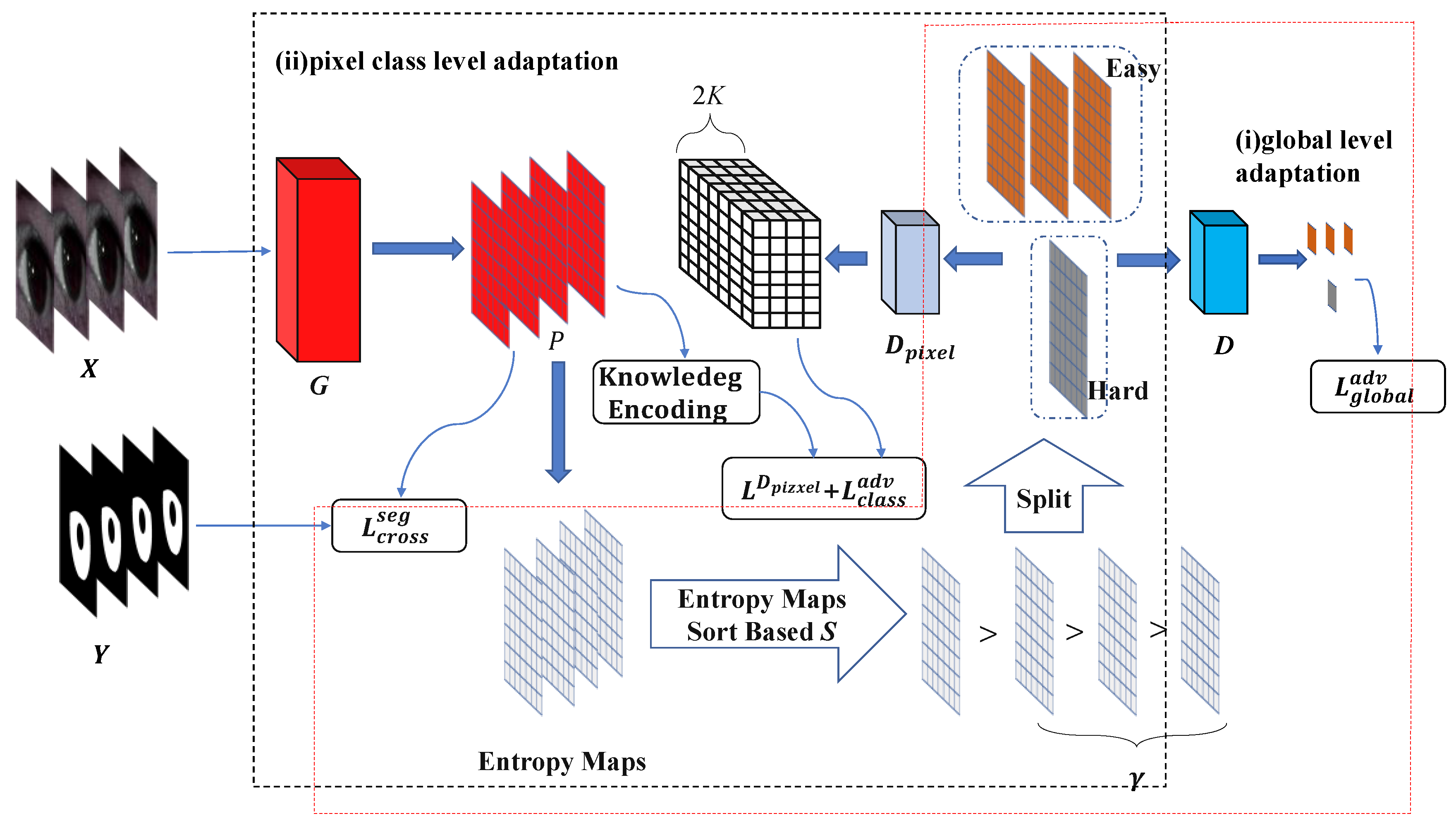
3.3. Intra-Dataset Adaptation for Iris Segmentation
3.3.1. Global Spatial Level Adaptation
| Algorithm 1: Global spatial level adaptation |
| Input: iris data , pixel label , training epochs , ratio coefficient |
| Initialize: binary discriminator |
| For t = 1,…,T do |
| Unfreeze the D and freeze the G |
| Sort the logit maps based the |
| Split the iris data corresponding to sorted into and by ratio coefficient |
| Compute the D’s loss: |
| to train |
| Unfreeze the G and freeze the D |
| to train |
3.3.2. Pixel Class Level Adaptation
| Algorithm 2: Pixel class level adaptation |
| Input: iris data , pixel label , training epochs , ratio coefficient |
| Initialize: extended discriminator |
| For t = 1,…, do |
| Unfreeze the and freeze the |
| Extract class constraint knowledge: |
| Compute the ’s loss: |
| to train |
| Unfreeze the and freeze the |
| Compute the class level adversarial loss: |
| to train |
4. Experiments
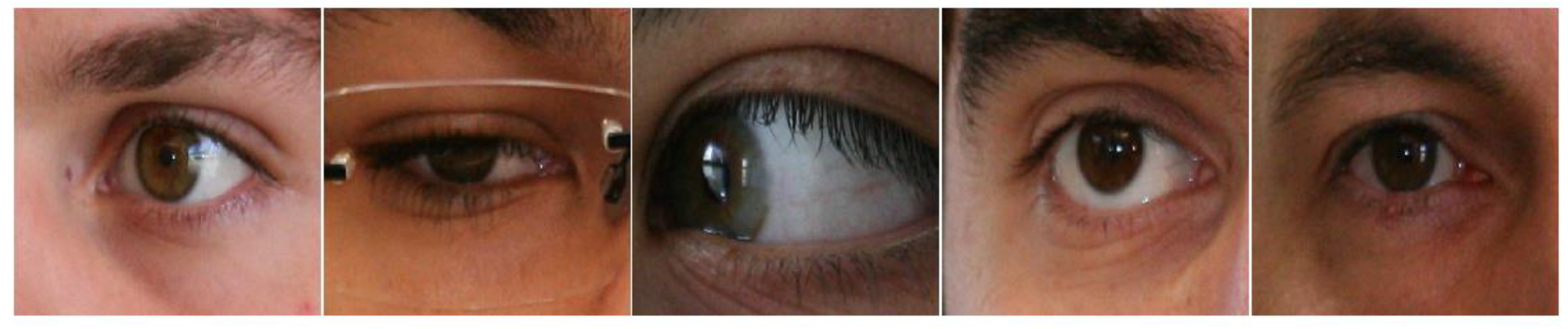
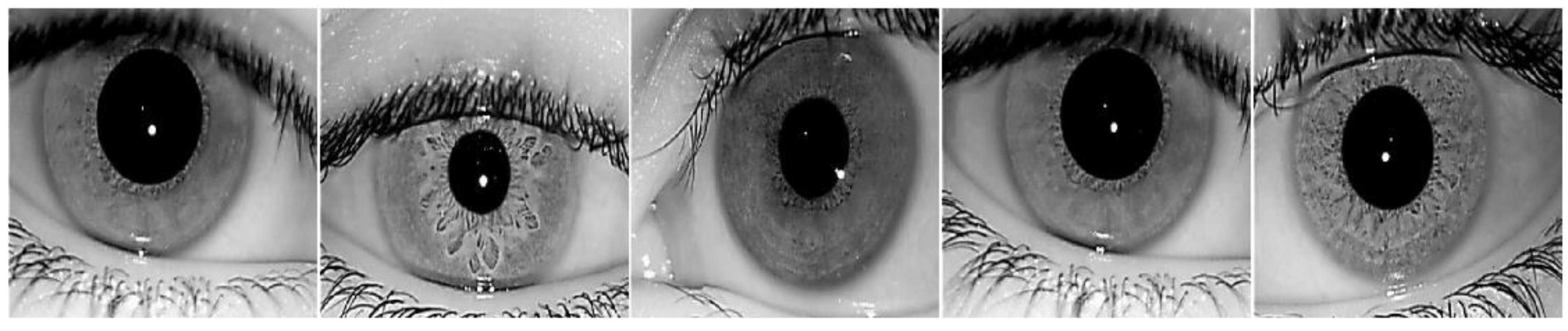
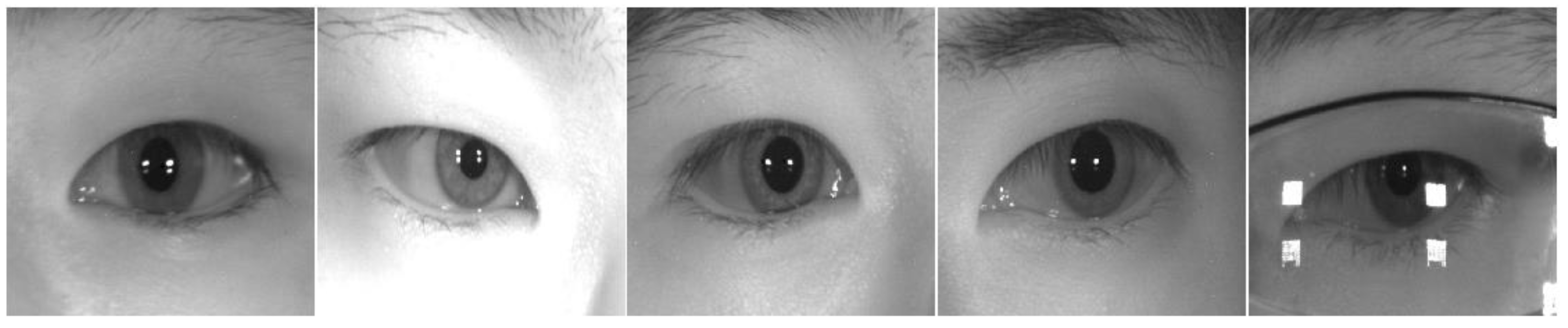
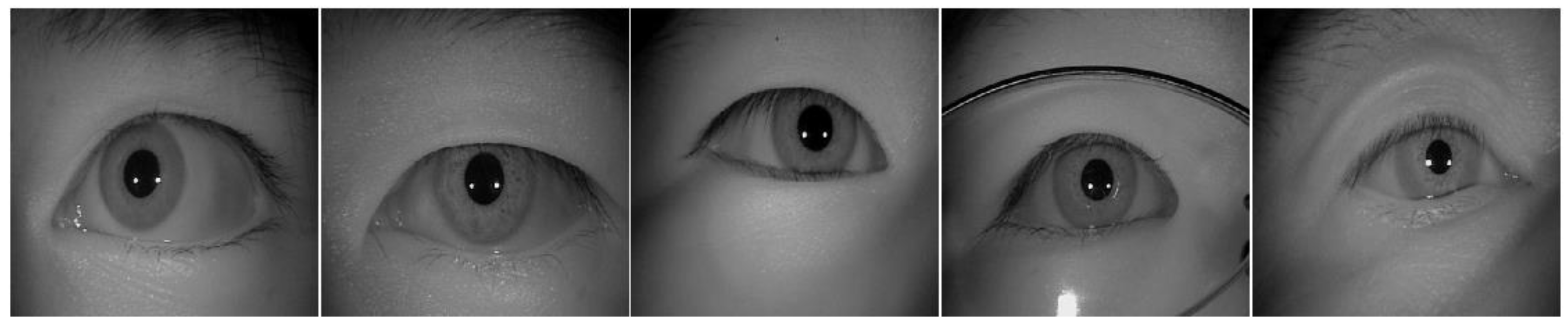
4.1. Datasets
4.2. Implementation Details
4.2.1. Evaluation Metrics
4.2.2. Model Structure
4.2.3. Training Setup
4.3. Ablation Experiments
4.3.1. Impact of Supervised Contrastive Learning on Segmentation Performance
4.3.2. The Impact of Intra-Dataset Adaptation on Segmentation Performance
4.3.3. Comparison of Performance under Different Strategies
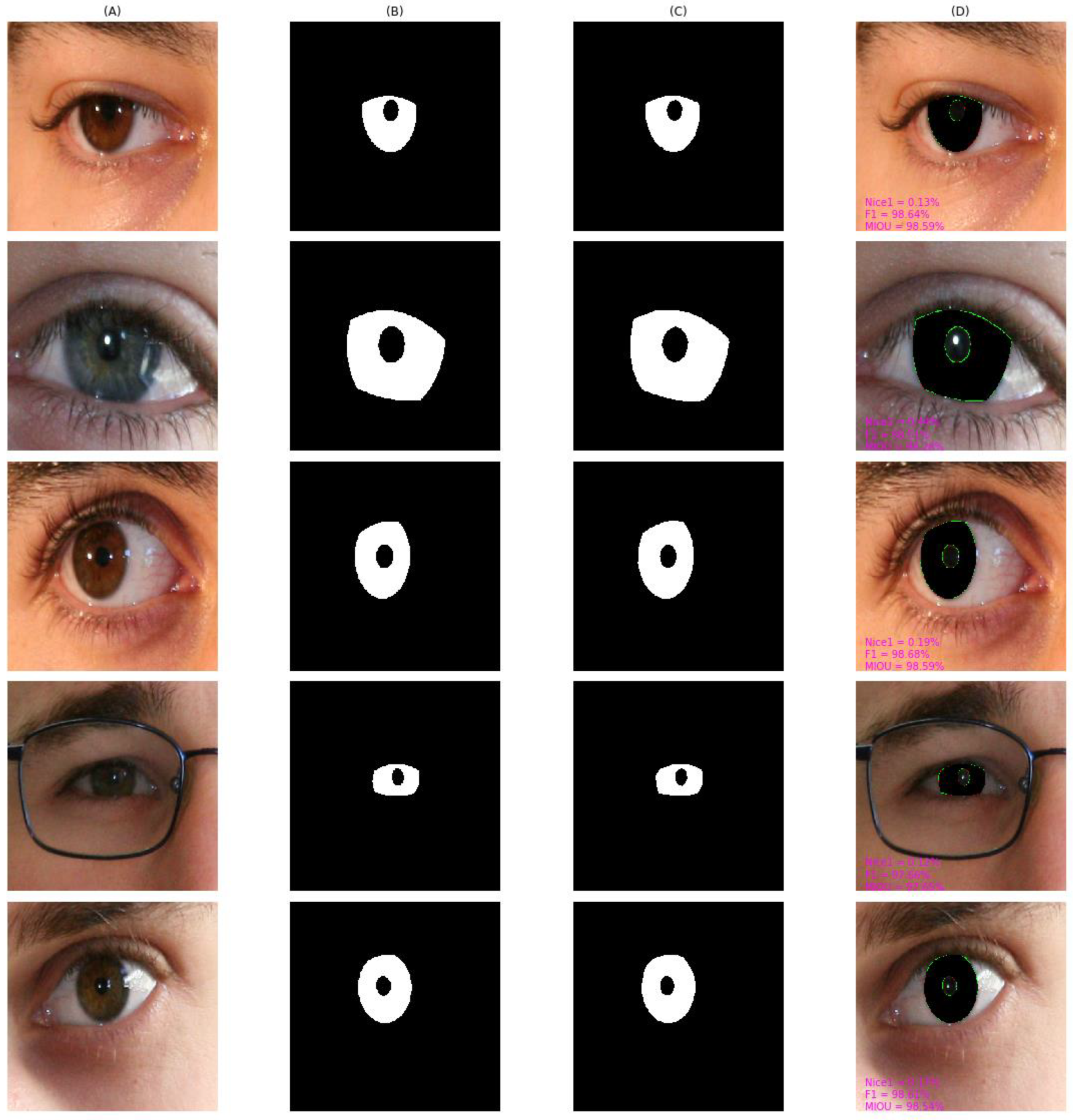
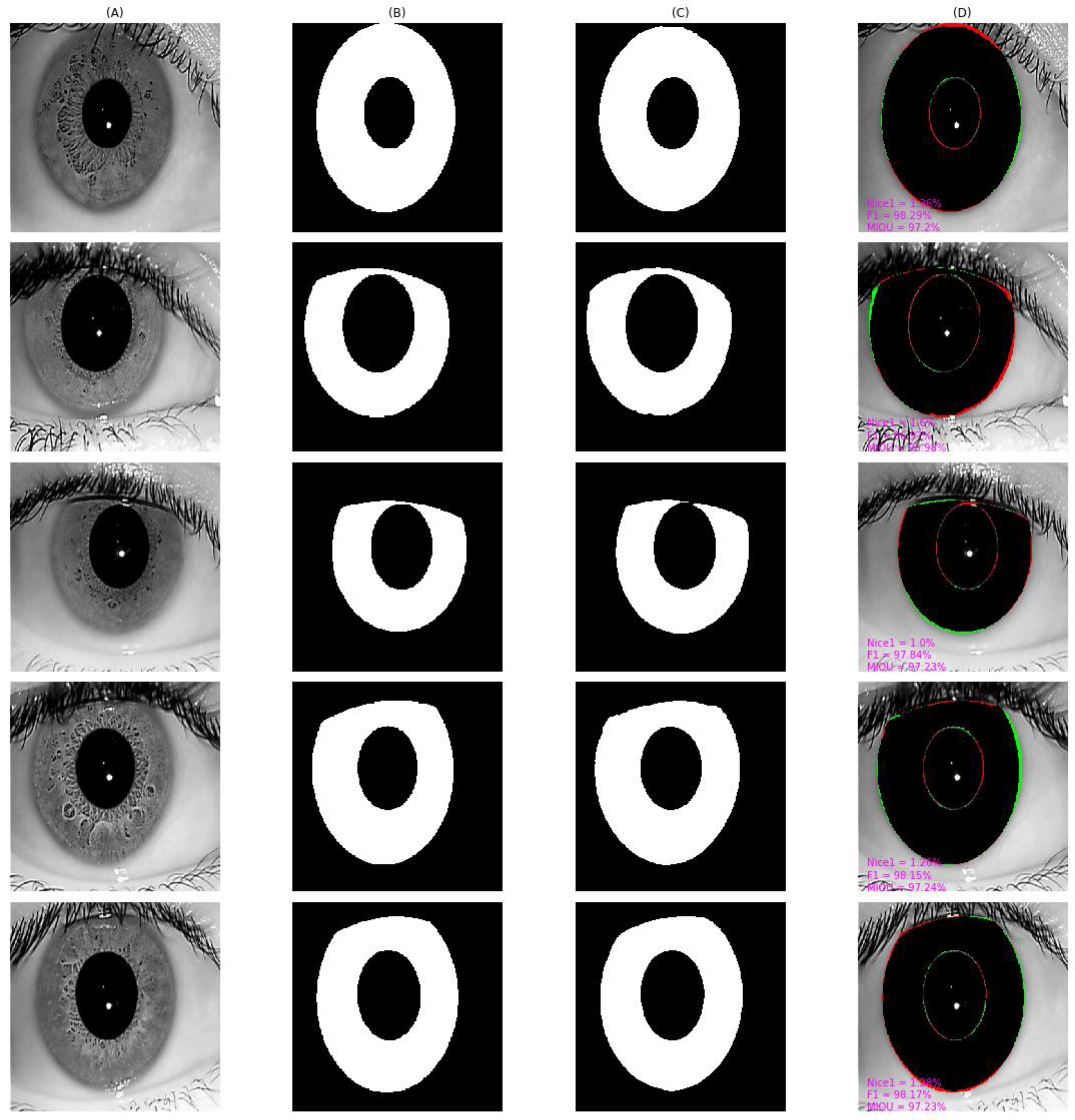
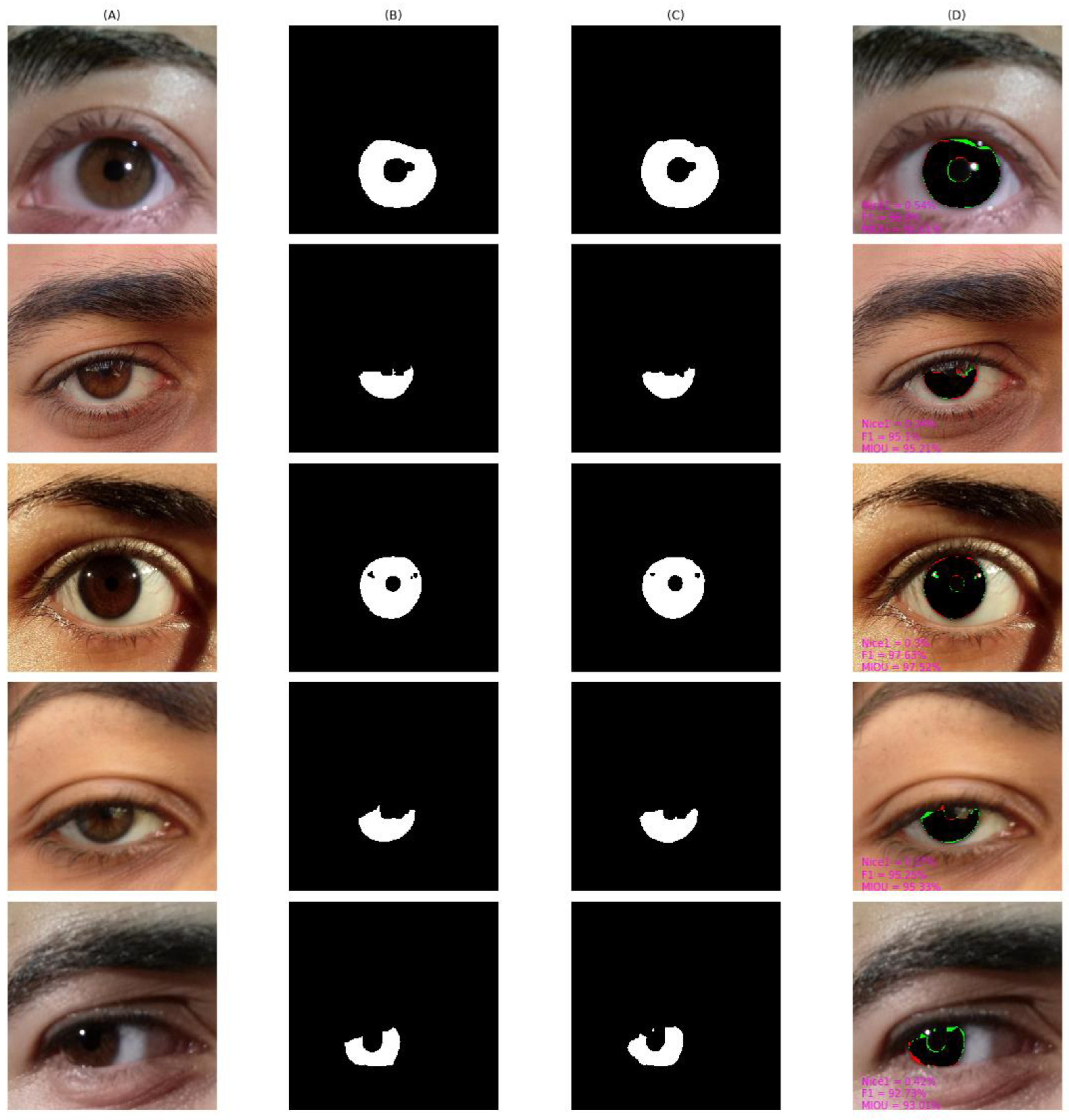
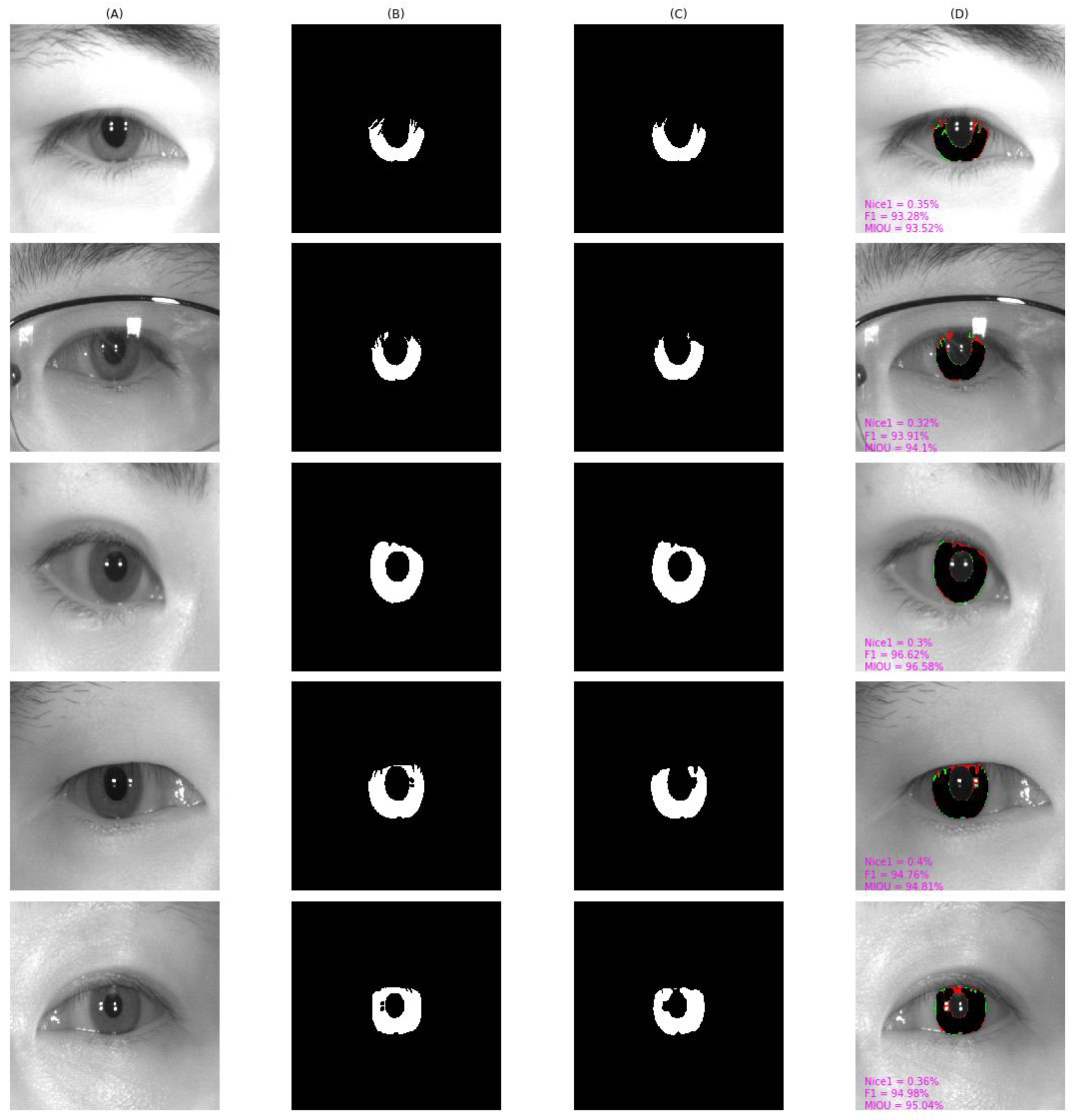
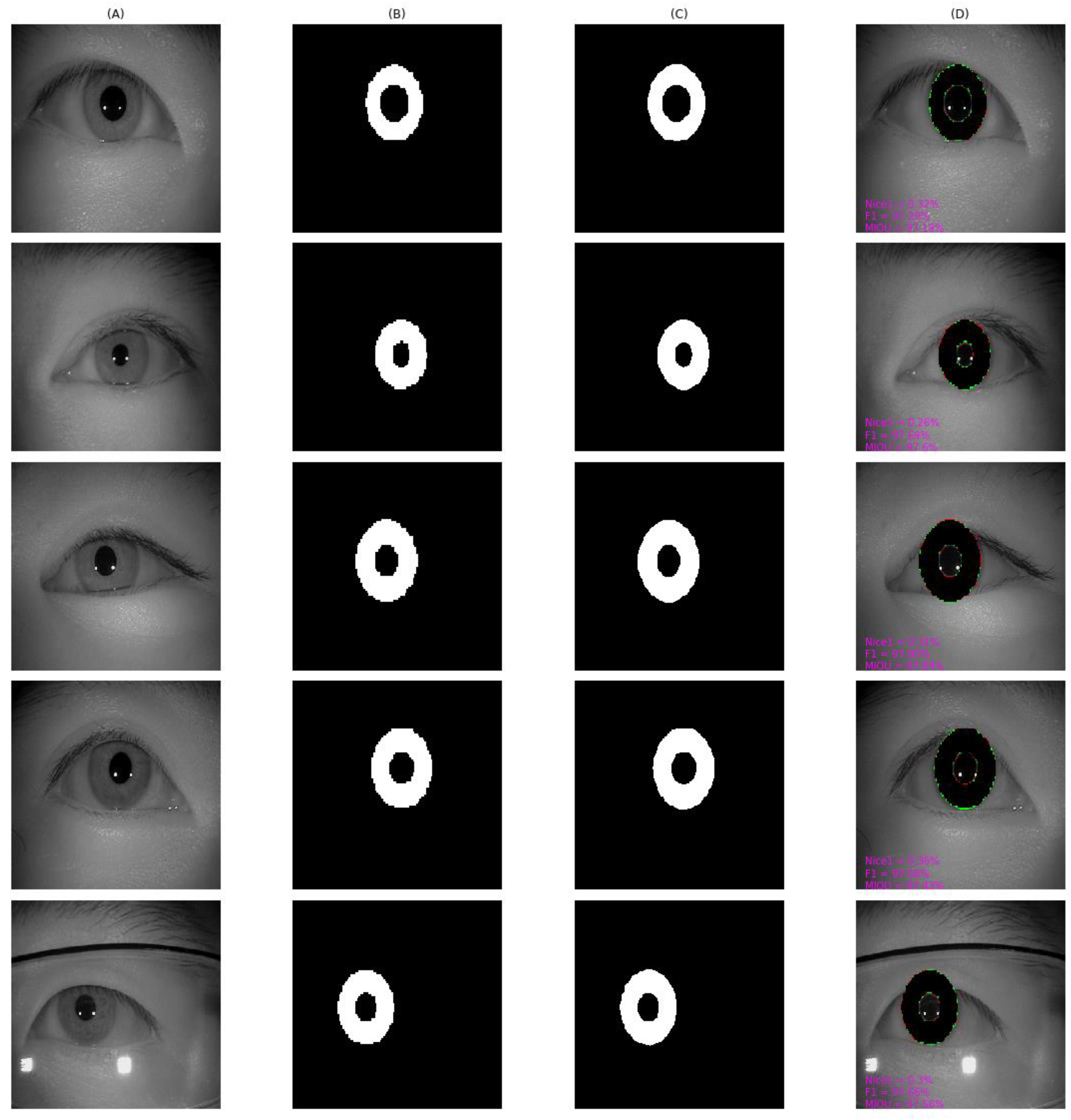
4.4. Qualitative Result and Analysis
4.5. Comparison with Other State-of-the-Art Iris Segmentation Methods
4.6. Storage and Computational Time
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, C.; Zhou, W.; Yuan, S. Iris recognition based on a novel variation of local binary pattern. Visual Comput. 2015, 31, 1419–1429. [Google Scholar] [CrossRef]
- Ma, L.; Tan, T.; Wang, Y.; Zhang, D. Efficient iris recognition by characterizing key local variations. IEEE Trans. Image Process. 2004, 13, 739–750. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Sun, Z. A Benchmark for Iris Segmentation. J. Comput. Res. Dev. 2020, 57, 395. [Google Scholar]
- Biometrics: Personal Identification in Networked Society; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1999.
- Umer, S.; Dhara, B.C.; Chanda, B. NIR and VW iris image recognition using ensemble of patch statistics features. Visual Comput. 2019, 35, 1327–1344. [Google Scholar] [CrossRef]
- He, Z.; Tan, T.; Sun, Z.; Qiu, X. Toward Accurate and Fast Iris Segmentation for Iris Biometrics. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 1670–1684. [Google Scholar]
- Zhao, Z.; Ajay, K. An accurate iris segmentation framework under relaxed imaging constraints using total variation model. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3828–3836. [Google Scholar]
- Hofbauer, H.; Alonso-Fernandez, F.; Bigun, J.; Uhl, A. Experimental analysis regarding the influence of iris segmentation on the recognition rate. IET Biom. 2016, 5, 200–211. [Google Scholar] [CrossRef]
- Daugman, J. New methods in iris recognition. IEEE Trans. Syst. Man Cybern. B Cybern 2007, 3, 1167–1175. [Google Scholar] [CrossRef]
- Wildes, R.P. Iris Recognition: An Emerging Biometric Technology. Proc.-IEEE 1997, 85, 1348–1363. [Google Scholar] [CrossRef]
- Tan, C.W.; Kumar, A. Unified framework for automated iris segmentation using distantly acquired face images. IEEE Trans. Image Proc. 2012, 21, 4068–4079. [Google Scholar] [CrossRef]
- Proenca, H. Iris recognition: On the segmentation of degraded images acquired in the visible wavelength. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1502–1516. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Raghu, M.; Zhang, C.; Kleinberg, J.; Bengio, S. Transfusion: Understanding Transfer Learning for Medical Imaging. Adv. Neural Inf. Process. Syst. 2019, 32, 3347–3357. [Google Scholar]
- Wang, C.; Muhammad, J.; Wang, Y.; He, Z.; Sun, Z. Towards complete and accurate iris segmentation using deep multi-task attention network for non-cooperative iris recognition. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2944–2959. [Google Scholar] [CrossRef]
- Jan, F.; Alrashed, S.; Min-Allah, N. Iris segmentation for non-ideal Iris biometric systems. Multimed. Tools Appl. 2021, 1–29. [Google Scholar] [CrossRef]
- Liu, N.; Li, H.; Zhang, M.; Liu, J.; Sun, Z.; Tan, T. Accurate iris segmentation in non-cooperative environments using fully convolutional networks. In Proceedings of the 2016 International Conference on Biometrics (ICB), Halmstad, Sweden, 13–16 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–8. [Google Scholar]
- Bazrafkan, S.; Thavalengal, S.; Corcoran, P. An end to end deep neural network for iris segmentation in unconstrained scenarios. Neural Netw. 2018, 106, 79–95. [Google Scholar] [CrossRef] [PubMed]
- Arsalan, M.; Naqvi, R.A.; Kim, D.S.; Nguyen, P.H.; Owais, M.; Park, K.R. IrisDenseNet: Robust iris segmentation using densely connected fully convolutional networks in the images by visible light and near-infrared light camera sensors. Sensors 2018, 18, 1501. [Google Scholar] [CrossRef] [PubMed]
- Arsalan, M.; Kim, D.S.; Lee, M.B.; Park, K.R. FRED-Net: Fully residual encoder–decoder network for accurate iris segmentation. Expert Syst. Appl. 2019, 122, 217–241. [Google Scholar] [CrossRef]
- Lakra, A.; Tripathi, P.; Keshari, R.; Vatsa, M.; Singh, R. Segdensenet: Iris segmentation for pre-and-post cataract surgery. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 3150–3155. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning PMLR. Virtual Event, 6–18 November 2020; pp. 1597–1607. [Google Scholar]
- Pan, F.; Shin, I.; Rameau, F.; Lee, S.; Kweon, I.S. Unsupervised intra-domain adaptation for semantic segmentation through self-supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3764–3773. [Google Scholar]
- Vu, T.H.; Jain, H.; Bucher, M.; Cord, M.; Pérez, P. Advent: Adversarial entropy minimization for domain adaptation in semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2517–2526. [Google Scholar]
- Radman, A.; Jumari, K.; Zainal, N. Iris segmentation in visible wavelength environment. Procedia Eng. 2012, 41, 743–748. [Google Scholar] [CrossRef]
- Bendale, A.; Nigam, A.; Prakash, S.; Gupta, P. Iris segmentation using improved hough transform. In Emerging Intelligent Computing Technology and Applications; Springer: Berlin/Heidelberg, Germany, 2012; pp. 408–415. [Google Scholar]
- Uhl, A.; Wild, P. Weighted adaptive Hough and ellipsopolar transforms for real-time iris segmentation. In Proceedings of the 2012 5th IAPR international conference on biometrics (ICB), New Delhi, India, 29 March–1 April 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 283–290. [Google Scholar]
- Pundlik, S.J.; Woodard, D.L.; Birchfield, S.T. Non-ideal iris segmentation using graph cuts. In Proceedings of the 2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Anchorage, AK, USA, 23–28 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–6. [Google Scholar]
- Banerjee, S.; Mery, D. Iris segmentation using geodesic active contours and grabcut. In Image and Video Technology; Springer: Cham, Switzerland, 2015; pp. 48–60. [Google Scholar]
- Radman, A.; Zainal, N.; Suandi, S.A. Automated segmentation of iris images acquired in an unconstrained environment using HOG-SVM and GrowCut. Digit. Signal Processing 2017, 64, 60–70. [Google Scholar] [CrossRef]
- Tan, T.; He, Z.; Sun, Z. Efficient and robust segmentation of noisy iris images for non-cooperative iris recognition. Image Vision Comput. 2010, 28, 223–230. [Google Scholar] [CrossRef]
- Tan, C.W.; Kumar, A. Towards online iris and periocular recognition under relaxed imaging constraints. IEEE Trans. Image Process. 2013, 22, 3751–3765. [Google Scholar] [CrossRef]
- Chen, Y.; Gan, H.; Zeng, Z.; Chen, H. DADCNet: Dual attention densely connected network for more accurate real iris region segmentation. Int. J. Intell. Syst. 2021, 37, 829–858. [Google Scholar] [CrossRef]
- Wang, Q.; Meng, X.; Sun, T.; Zhang, X. A light iris segmentation network. Visual Comput. 2021, 38, 2591–2601. [Google Scholar] [CrossRef]
- Miron, C.; Pasarica, A.; Manta, V.; Timofte, R. Efficient and robust eye images iris segmentation using a lightweight U-net convolutional network. Multimed. Tools Appl. 2022, 81, 14961–14977. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-contextual representations for semantic segmentation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 173–190. [Google Scholar]
- Zhang, X.; Xu, H.; Mo, H.; Tan, J.; Yang, C.; Wang, L.; Ren, W. Dcnas: Densely connected neural architecture search for semantic image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13956–13967. [Google Scholar]
- Ramana, K.; Kumar, M.R.; Sreenivasulu, K.; Gadekallu, T.R.; Bhatia, S.; Agarwal, P.; Idrees, S.M. Early prediction of lung cancers using deep saliency capsule and pre-trained deep learning frameworks. Front. Oncol. 2022, 12, 886739. [Google Scholar] [CrossRef]
- Gao, Y.; Zhou, M.; Metaxas, D.N. UTNet: A hybrid transformer architecture for medical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2021; pp. 61–71. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 1290–1299. [Google Scholar]
- Ma, J.; Chen, J.; Ng, M.; Huang, R.; Li, Y.; Li, C.; Yang, X.; Martel, A.L. Loss odyssey in medical image segmentation. Med. Image Anal. 2021, 71, 102035. [Google Scholar] [CrossRef]
- Liu, X.; Guo, Z.; Li, S.; Xing, F.; You, J.; Kuo, C.C.J.; El Fakhri, G.; Woo, J. Adversarial unsupervised domain adaptation with conditional and label shift: Infer, align and iterate. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 10367–10376. [Google Scholar]
- Yan, L.; Fan, B.; Xiang, S.; Pan, C. CMT: Cross Mean Teacher Unsupervised Domain Adaptation for VHR Image Semantic Segmentation. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Fan, B.; Yang, Y.; Feng, W.; Wu, F.; Lu, J.; Liu, H. Seeing through Darkness: Visual Localization at Night via Weakly Supervised Learning of Domain Invariant Features. IEEE Trans. Multimed. 2022. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality reduction by learning an invariant mapping. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; IEEE: Piscataway, NJ, USA, 2006; Volume 2, pp. 1735–1742. [Google Scholar]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Bachman, P.; Trischler, A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. arXiv 2018, arXiv:1808.06670. [Google Scholar]
- Bachman, P.; Hjelm, R.D.; Buchwalter, W. Learning representations by maximizing mutual information across views. arXiv 2019, arXiv:1906.00910. [Google Scholar]
- Chen, X.; He, K. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15750–15758. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Chen, C.; Xie, W.; Huang, W.; Rong, Y.; Ding, X.; Huang, Y.; Xu, T.; Huang, J. Progressive feature alignment for unsupervised domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 627–636. [Google Scholar]
- Wang, H.; Shen, T.; Zhang, W.; Duan, L.Y.; Mei, T. Classes matter: A fine-grained adversarial approach to cross-domain semantic segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 642–659. [Google Scholar]
- De Marsico, M.; Nappi, M.; Riccio, D.; Wechsler, H. Mobile iris challenge evaluation (MICHE)-I, biometric iris dataset and protocols. Pattern Recognit. Lett. 2015, 57, 17–23. [Google Scholar] [CrossRef]
- Proença, H.; Filipe, S.; Santos, R.; Oliveira, J.; Alexandre, L.A. The UBIRIS. v2: A database of visible wavelength iris images captured on-the-move and at-a-distance. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1529–1535. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Passi, A. Comparison and combination of iris matchers for reliable personal authentication. Pattern Recognit. 2010, 43, 1016–1026. [Google Scholar] [CrossRef]
- Chinese Academy of Sciences Institute of Automation. Casia Iris Image Databases. Available online: http://biometrics.idealtest.org/#/datasetDetail/4 (accessed on 12 April 2022).
- Proença, H.; Alexandre, L.A. The nice. i: Noisy iris challenge evaluation-part i. In Proceedings of the 2007 First IEEE International Conference on Biometrics: Theory, Applications, and Systems, Crystal City, VA, USA, 27–29 September 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 1–4. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Petrovska, D.; Mayoue, A. Description and Documentation of the Biosecure Software Library. Project No IST-2002-507634-BioSecure, Deliverable. BioScreen Inc.: Torrance, CA, USA, 2009. [Google Scholar]
- Uhl, A.; Wild, P. Multi-stage visible wavelength and near infrared iris segmentation framework. In Image Analysis and Recognition; Springer: Berlin/Heidelberg, Germany, 2012; pp. 1–10. [Google Scholar]
- Alonso-Fernandez, F.; Bigun, J. Iris boundaries segmentation using the generalized structure tensor. A study on the effects of image degradation. In Proceedings of the 2012 IEEE Fifth International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 23–27 September 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 426–431. [Google Scholar]
- Haindl, M.; Krupička, M. Unsupervised detection of non-iris occlusions. Pattern Recognit. Lett. 2015, 57, 60–65. [Google Scholar] [CrossRef]
- Gangwar, A.; Joshi, A.; Singh, A.; Alonso-Fernandez, F.; Bigun, J. IrisSeg: A fast and robust iris segmentation framework for non-ideal iris images. In Proceedings of the 2016 International Conference on Biometrics (ICB), Halmstad, Sweden, 13–16 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–8. [Google Scholar]
- Varkarakis, V.; Bazrafkan, S.; Corcoran, P. Deep neural network and data augmentation methodology for off-axis iris segmentation in wearable headsets. Neural Netw. 2020, 121, 101–121. [Google Scholar] [CrossRef]
- Jalilian, E.; Uhl, A. Iris segmentation using fully convolutional encoder–decoder networks. In Deep Learning for Biometrics; Springer: Cham, Switzerland, 2017; pp. 133–155. [Google Scholar]
- Hofbauer, H.; Jalilian, E.; Uhl, A. Exploiting superior CNN-based iris segmentation for better recognition accuracy. Pattern Recognit. Lett. 2019, 120, 17–23. [Google Scholar] [CrossRef]
- Bezerra, C.S.; Laroca, R.; Lucio, D.R. Robust iris segmentation based on fully convolutional networks and generative adversarial networks. In Proceedings of the 2018 31st SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Parana, Brazil, 29 October–1 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 281–288. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Category | Characteristics |
|---|---|---|
| Daugman, J [9] | Boundary-based | Integro-differential operator and gradient |
| Wildes et al. [10] | Boundary-based | Hough transform and vote |
| Radman et al. [26] | Boundary-based | Integro-differential operator and Hough transform |
| Bendale et al. [27] | Boundary-based | Improved Hough transform by one-dimensional space |
| Uhl et al. [28] | Boundary-based | Adaptive Hough transform |
| Pundlik et al. [29] | Pixel-based | Graph cut based on entropy minimization |
| Banerjee et al. [30] | Pixel-based | Geometry of garbcut |
| Radman et al. [31] | Pixel-based | HOG-SVM and cellular automata through GrowCut |
| Tan et al. [32] | Boundary-based and Pixel-based | Eight-neighbor connection based clustering and integrodifferential constellation |
| Kumar et al. [33] | Boundary-based and Pixel-based | Random walker and graph-based modeling |
| Liu et al. [17] | Deep learning | HCNNS and MFCNS without pre- and post-processing |
| Bazrafkan et al. [18] | Deep learning | Merged networks by SPDNN at layer level |
| Wang et al. [15] | Deep learning | Multi-task learning and parameterized inner and outer boundaries |
| Chen et al. [34] | Deep learning | Mask images by the DADCNET as GTs |
| Wang et al. [35] | Deep learning | A light network for mobile iris segmentation |
| Miron et al. [36] | Deep learning | A U-Net with model downscaling |
| Dataset | Non-Iris Weight | Iris Weight |
|---|---|---|
| UBIRIS.v2 | 0.53 | 7.37 |
| MICHE-I | 0.52 | 9.94 |
| IITD | 0.70 | 1.72 |
| CASIA-D | 0.51 | 14.33 |
| CASIA-T | 0.53 | 4.42 |
| Dataset | Method | PA(%) | F1(%) | MIOU(%) |
|---|---|---|---|---|
| UBIRIS.v2 | From Scratch | 98.57 | 88.28 | 88.87 |
| ImageNet+FineTune | (0.55)99.12 | (4.94)93.22 | (4.46)93.24 | |
| SCL+FineTune | (0.52)99.09 | (5.05)93.33 | (4.52)93.30 | |
| IITD | From Scratch | 95.98 | 93.36 | 91.16 |
| ImageNet+FineTune | (1.55)97.53 | (2.32)95.95 | (3.20)94.36 | |
| SCL+FineTune | (1.90)97.88 | (2.94)96.57 | (4.07)95.17 | |
| CASIA-D | From Scratch | 98.90 | 84.19 | 85.83 |
| ImageNet+FineTune | (0.40)99.30 | (6.32)90.51 | (5.16)90.99 | |
| SCL+FineTune | (0.45)99.35 | (7.27)91.46 | (5.97)91.80 | |
| MICHE-I | From Scratch | 98.85 | 88.50 | 89.15 |
| ImageNet+FineTune | (0.37)99.22 | (3.45)91.95 | (3.01)92.16 | |
| SCL+FineTune | (0.40)99.25 | (3.73)92.23 | (3.26)92.41 | |
| CASIA-T | From Scratch | 99.30 | 95.26 | 95.11 |
| ImageNet+FineTune | (0.13)99.43 | (0.86)96.13 | (0.87)95.98 | |
| SCL+FineTune | (0.14)99.44 | (0.91)96.17 | (0.91)96.02 |
| Dataset | Method | PA(%) | F1(%) | MIOU(%) |
|---|---|---|---|---|
| UBIRIS.v2 | From Scratch | 98.57 | 88.28 | 88.87 |
| From Scratch+GLA | (0.28)98.85 | (2.99)91.27 | (2.55)91.42 | |
| From Scratch+CLA | (0.56)99.13 | (4.53)92.81 | (4.03)92.90 | |
| IITD | From Scratch | 95.98 | 93.36 | 91.16 |
| From Scratch+GLA | (0.97)96.95 | (1.31)94.94 | (1.91)93.07 | |
| From Scratch+CLA | (1.27)97.25 | (1.88)95.51 | (2.67)93.83 | |
| CASIA-D | From Scratch | 98.90 | 84.19 | 85.83 |
| From Scratch+GLA | (0.25)99.15 | (3.89)88.08 | (3.12)88.95 | |
| From Scratch+CLA | (0.29)99.19 | (4.50)88.69 | (3.64)89.47 | |
| MICHE-I | From Scratch | 98.85 | 88.50 | 89.15 |
| From Scratch+GLA | (0.23)99.08 | (2.43)90.93 | (2.08)91.23 | |
| From Scratch+CLA | (0.33)99.18 | (3.05)91.55 | (2.66)91.81 | |
| CASIA-T | From Scratch | 99.30 | 95.26 | 95.11 |
| From Scratch+GLA | (0.03)99.33 | (0.25)95.51 | (0.24)95.35 | |
| From Scratch+CLA | (0.06)99.36 | (0.41)95.67 | (0.41)95.52 |
| Dataset | Method | PA(%) | F1(%) | MIOU(%) | ||
|---|---|---|---|---|---|---|
| SCL | GLA | CLA | ||||
| UBIRIS.v2 | ✗ | ✗ | ✗ | 98.57 | 88.28 | 88.87 |
| ✓ | ✗ | ✗ | (0.52)99.09 | (5.05)93.33 | (4.52)93.30 | |
| ✗ | ✓ | ✗ | (0.28)98.85 | (2.99)91.27 | (2.55)91.42 | |
| ✗ | ✗ | ✓ | (0.56)99.13 | (4.53)92.81 | (4.03)92.90 | |
| ✓ | ✓ | ✗ | (0.79)99.36 | (7.18)95.46 | (6.45)95.32 | |
| ✓ | ✗ | ✓ | (0.99)99.56 | (8.38)96.66 | (7.67)96.54 | |
| IITD | ✗ | ✗ | ✗ | 95.98 | 93.36 | 91.16 |
| ✓ | ✗ | ✗ | (1.90)97.88 | (2.94)96.57 | (4.07)95.17 | |
| ✗ | ✓ | ✗ | (0.97)96.95 | (1.31)94.94 | (1.91)93.07 | |
| ✗ | ✗ | ✓ | (1.27)97.25 | (1.88)95.51 | (2.67)93.83 | |
| ✓ | ✓ | ✗ | (2.30)98.28 | (3.86)97.22 | (4.91)96.07 | |
| ✓ | ✗ | ✓ | (2.99)98.97 | (5.36)98.72 | (6.72)97.88 | |
| MICHE-I | ✗ | ✗ | ✗ | 98.85 | 88.50 | 89.15 |
| ✓ | ✗ | ✗ | (0.40)99.25 | (3.73)92.23 | (3.26)92.41 | |
| ✗ | ✓ | ✗ | (0.23)99.08 | (2.43)90.93 | (2.08)91.23 | |
| ✗ | ✗ | ✓ | (0.33)99.18 | (3.05)91.55 | (2.66)91.81 | |
| ✓ | ✓ | ✗ | (0.44)99.29 | (4.26)92.76 | (3.74)92.89 | |
| ✓ | ✗ | ✓ | (0.49)99.34 | (4.71)93.21 | (4.11)93.26 | |
| CASIA-D | ✗ | ✗ | ✗ | 98.90 | 84.19 | 85.83 |
| ✓ | ✗ | ✗ | (0.45)99.35 | (7.27)91.46 | (5.97)91.80 | |
| Dataset | Method | Nice1 (%) | F1(%) | MIOU(%) |
|---|---|---|---|---|
| UBIRIS.v2 | Osiris [64] | N/A | 18.65 | N/A |
| WAHET [28] | N/A | 23.68 | N/A | |
| IFFP [65] | N/A | 28.52 | N/A | |
| GST [66] | N/A | 39.93 | N/A | |
| TVBM [7] | 1.21 | N/A | N/A | |
| MFCN [17] | 0.90 | N/A | N/A | |
| FCDNN [16] | N/A | 93.90 | N/A | |
| DADCNet [34] | N/A | 96.14 | N/A | |
| IrisParseNet [15] | 0.84 | 91.78 | N/A | |
| Wang and Meng [35] | 0.70 | N/A | 95.35 | |
| FCEDN-Bay [70] | 3.06 | 84.07 | 72.51 | |
| Miron and Pasarica [36] | 0.53 | 96.14 | 92.56 | |
| Ours | 0.44 | 96.66 | 96.54 |
| Dataset | Method | Nice1(%) | F1(%) | MIOU(%) |
|---|---|---|---|---|
| IITD | Osiris [64] | 4.37 | 92.23 | 85.52 |
| WAHET [28] | N/A | 87.02 | N/A | |
| IFFP [65] | N/A | 85.83 | N/A | |
| GST [66] | N/A | 86.6 | N/A | |
| DADCNet [34] | N/A | 98.43 | N/A | |
| IrisSeg [68] | N/A | 94.37 | N/A | |
| FCEDN-B [70] | 5.39 | 84.92 | 80.05 | |
| IrisDenseNet [19] | N/A | 97.56 | N/A | |
| FRED-Net [20] | N/A | 97.61 | N/A | |
| RefineNet [71] | 1.50 | 97.40 | 94.93 | |
| Miron and Pasarica [36] | 0.90 | 98.48 | 97.09 | |
| Ours | 1.03 | 98.72 | 97.88 |
| Dataset | Method | Nice1(%) | F1(%) | MIOU(%) |
|---|---|---|---|---|
| MICHE-I | DADCNet [34] | N/A | 93.19 | N/A |
| TVBM [7] | 1.21 | 79.24 | N/A | |
| Haindl and Krupička [67] | 3.86 | 70.17 | N/A | |
| MFCN [17] | 0.74 | 92.01 | N/A | |
| RefineNet [71] | 0.80 | 91.41 | N/A | |
| IrisParseNet [15] | 0.66 | 93.05 | N/A | |
| Ours | 0.66 | 93.21 | 93.26 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Z.; Liu, Y.; Zhu, X.; Liu, S.; Zhang, S.; Li, Y. Supervised Contrastive Learning and Intra-Dataset Adversarial Adaptation for Iris Segmentation. Entropy 2022, 24, 1276. https://doi.org/10.3390/e24091276
Zhou Z, Liu Y, Zhu X, Liu S, Zhang S, Li Y. Supervised Contrastive Learning and Intra-Dataset Adversarial Adaptation for Iris Segmentation. Entropy. 2022; 24(9):1276. https://doi.org/10.3390/e24091276
Chicago/Turabian StyleZhou, Zhiyong, Yuanning Liu, Xiaodong Zhu, Shuai Liu, Shaoqiang Zhang, and Yuanfeng Li. 2022. "Supervised Contrastive Learning and Intra-Dataset Adversarial Adaptation for Iris Segmentation" Entropy 24, no. 9: 1276. https://doi.org/10.3390/e24091276