2.1. Mathematical Ground for Regular Pointwise Convolutions
Let
be a set of input feature maps (2D lattices) for a convolutional layer
i in a DCNN, where
denotes the number of input channels for this layer. Let
be a set of filters containing the weights for convolutions, where
denotes the number of filters at layer
i, which is also the number of output channels of this layer. Following the notation proposed in [
30], a regular DCNN convolution can be mathematically expressed as in Equation (
1):
where the ⨂ operator indicates that filters in
are convolved with feature maps in
, using the ∗ operator to indicate a 3D tensor multiplication and shifting of a filter
across all patches of the size of the filter in all feature maps. For simplicity, we are ignoring the bias terms. Consequently,
will contain
feature maps that will feed the next layer
. The tensor shapes of involved elements are the following:
where
is the size (height, width) of feature maps, and
is the size of a filter (usually square). In this paper we work with
because we are focused on pointwise convolutions. In this case, each filter
carries
weights. The total number of weights
in layer
i is obtained with a simple multiplication:
2.2. Definition of Grouped Pointwise Convolutions
For expressing a grouped pointwise convolution, let us split the input feature maps and the set of filters in
groups, as
and
. Assuming that both
and
are divisible by
, the elements in
and
can be evenly distributed through all their subset
and
. Then, Equation (
1) can be reformulated as Equation (
4):
The shapes of the subsets are the following:
where
is the number of filters per group, namely,
. Since each filter
only convolves on a fraction of input channels
, the total number of weights per subset
is
. Multiplying the last expression by the number of groups provides the total number of weights
in a grouped pointwise convolutional layer
i:
Equation (
6) shows that the number of trainable parameters is inversely proportional to the number of groups. However, grouping has the evident drawback that it prevents the filters to be connected with all input channel, which reduces the possible connections of input channels for learning new patterns. As it may lead to a lower learning capacity of the DCNN, one must be cautious with using such grouping technique.
2.3. Improved Scheme for Reducing the Complexity of Pointwise Convolutions
Two major limitations of our previous method were inherited from constraints found in most deep learning APIs:
The present work circumvents the first limitation by replicating channels from the input. The second limitation is circumvented by adding a second parallel path with another pointwise grouped convolution when required.
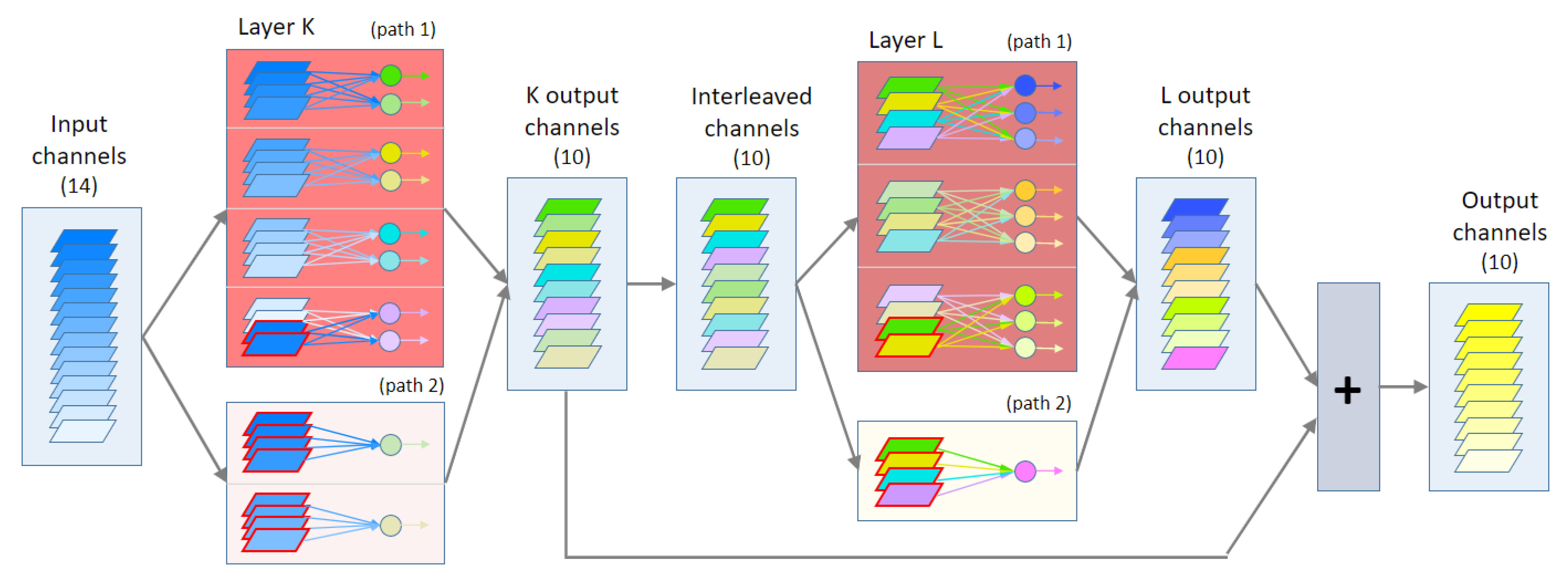
Figure 1 shows an example of our updated architecture.
Details of this process are described below, which is applied to substitute each pointwise convolutional layer
i found in the original architecture. To explain the method, we start detailing the construction of the layer K shown in
Figure 1. For simplicity, we drop the index
i and use the index
K to refer to the original hyperparameters, i.e., we use
instead of
,
instead of
. Also, we will use the indexes
and
to refer the parameters of the two parallel paths that may exist in layer K.
First of all, we must manually specify the value of the hyperparameter
. In the graphical example shown in
Figure 1, we set
. The rest of hyperparameters such as number of groups in layers K and L are determined automatically by the rules of our algorithm, according to the chosen value of
, the number of input channels
and the number of filters
. We do not have a procedure to find the optimal value of
, hence we must apply ablation studies on a range of
values as shown in the results section. For the example in
Figure 1, we have chosen the value of
to obtain a full variety of situations that must be tackled by our algorithm, i.e., non-divisibility conditions.
2.4. Definition of Layer K
The first step of the algorithm is to compute the number of groups in branch K1, as in Equation (
7):
Since the number of input channels
may not be divisible by Ch, we use the ceiling operator on the division to obtain an integer number of groups. In the example,
. Thus, the output of filters in branch K1 can be defined as in (
8):
The subsets
are composed of input feature maps
, collected in a sorted manner, i.e.,
,
, etc. Equation (
9) provides a general definition of which feature maps
are included in any feature subset
:
However, if
is not divisible by
, the last group
would not have
channels. In this case, the method will complete this last group replicating
initial input channels, where
b is computed as stated in Equation (
10):
It can be proved that b will always be less or equal than , since b is the excess of the integer division , i.e., will always be above or equal to , but less than , because otherwise would increase its value (as a quotient of ). In the example, , hence .
Then, the method calculates the number of filters per group
as in (
11):
To avoid divisibility conflicts, this time we have chosen the floor integer division. For the first path K1, each of the filter subsets shown in (
8) will contain the following filters:
For the first path of the example, the number of filters per group is . So, the first path has 4 groups () of 2 filters (), each filter being connected to 4 input channels ().
If
is not divisible by
, a second path K2 will provide as many groups as filters not provided in K1, with one filter per group, to complete the total number of filters
:
In the example,
. The required input channels for the second path is
. The method obtains those channels reusing the same subsets of input feature maps
shown in (
9). Hence, the output of filters in path
can be defined as in (
14):
where
. Therefore, each filter in
operates on exactly the same subset of input channels than the corresponding subset of filters in
. Hence, each filter in the second path can be considered as belonging to one of the groups of the first path.
It must be noticed that
will always be less than
. This is true because
is the reminder of the integer division
, as can be deduced from (
11) and (
13). This property warranties that there will be enough subsets
for this second path.
After defining paths K1 and K2 in layer K, the output of this layer is the concatenation of both paths:
The total number of channels after the concatenation is equal to .
2.5. Interleaving Stage
As mentioned above, grouped convolutions inherently face a limitation: each parallel group of filters computes its output from their own subset of input channels, preventing combinations of channels connected to different groups. To alleviate this limitation, we propose to interleave the output channels from the convolutional layer K.
The interleaving process simply consists in arranging the odd channels first and the even channels last, as noted in Equation (
16):
Here we are assuming that is even. Otherwise, the list of odd channels will include an extra channel .
2.6. Definition of Layer L
The interleaved output feeds the grouped convolutions in layer L to process data coming from more than one group from the preceding layer K.
To create layer L, we apply the same algorithm as for layer K, but now the number of input channels is equal to instead of .
The number of groups in path L1 is computed as:
Note that may not be equal to . In the example, .
Then, the output of L1 is computed as in (
18), where the input channel groups
come from the interleaving stage. Each group is composed of
channels, whose indexes are generically defined in (
19):
Again, the last group of indexes may not contain
channels due to a non-exact division condition in (
17). Similar to path K1, for path L1 the missing channels in the last group will be supplied by replicating
initial interleaved channels, where
b is computed as stated in Equation (
20):
The number of filters per group
is computed as in (
21):
In the example,
. Each group of filters
shown in (
18) can be defined as in (
22), each one containing
convolutional filters of
inputs:
It should be noted that if the division in (
21) is not exact, the number of output channels from layer L may not reach the required
outputs. In this case, a second path L2 will be added, with the following parameters:
In the example,
. The output of path L2 is computed as in (
24), defining one extra convolutional filter for some initial groups of interleaved channels declared in (
18) and (
19), taking into account that
will always be less than
according to the same reasoning done for
and
:
The last step in defining the output of layer L is to join the outputs of paths L1 and L2:
2.7. Joining of Layers
Finally, the output of both convolutional layers K and L are summed to create the output of the original layer:
Compared to concatenation, summation has the advantage of allowing a residual learning in the filters of layer L, because gradient can be backpropagated through L filters or directly to K filters. In other words, residual layers provide more learning capacity with low degree of downsides due to increasing the number of layers (i.e., overfitting, longer training time, etc.) In the results section, we present an ablation study that contains experiments done without the interleaving and the L layers (rows labeled with “no L”). These experiments empirically prove that the interleaving mechanism and the secondary L layer help in improving the sub-architecture accuracy, with low impact.
It is worth mentioning that we only add the layer L an the interleaving when the number of input channels is bigger or equal to the number of filters in layer K.
2.8. Computing the Number of Parameters
We can compute the total number of parameters of our sub-architecture. First, Equation (
27) shows that the number of filters in layer K is equal to the number of filters in layer L, which in turn is equal to the total number of filters in the original convolutional layer
:
Then, the total number of parameters
is twice the number of original filters multiplied by the number of input channels per filter:
Therefore, comparing Equation (
28) with (
3), it is clear that
must be significantly less than
to reduce the number of parameters of a regular pointwise convolutional layer. Also, comparing Equation (
28) with (
6), our sub-architecture provides a parameter reduction similar to a plain grouped convolutional layer when
is around
, although we cannot specify a general
term because of the complexity of our pair of layers with possibly two paths per layer.
The requirement for a low value of
is also necessary to ensure that divisions in Equations (
7) and (
17) provide quotients above one, otherwise our method will not create grouping. Hence,
must be less or equal to
and
. These are the only two constraints that our method is restricted by.
As shown in
Table 1, pointwise convolutional layers found in real networks such as EfficientNet-B0 have significant Figures for
and
, either hundreds or thousands. Therefore, values of
less or equal than 32 will ensure a good ratio of parameter reduction for most of these pointwise convolutional layers.
EfficientNet is one of the most complex (but efficient) architectures that can be found in the literature. To our method, the degree of complexity of a DCNN is mainly related to the maximum number of input channels and output features in any pointwise convolutional layer. Our method does not care about the number of layers, neither in depth nor in parallel, because it works on each layer independently. Therefore, the degree of complexity of EfficientNet-B0 can be considered significantly high, taking into account the values shown in the last row of
Table 1. Arguably, other versions of EfficientNet (B1, B2, etc.) and other types of DCNN can exceed those values. In such cases, higher values of
may be necessary, but we cannot provide any rule to forecast its optimum value for the configuration of any pointwise convolutional layer.
2.10. Implementation Details
We tested our optimization by replacing original pointwise convolutions in the EfficientNet-B0 and named it as “kEffNet-B0 V2”. With CIFAR-10, we tested an additional modification that skips the first 4 convolutional strides, allowing input images with 32 × 32 pixels instead of the original resolution of 224 × 224 pixels.
In all our experiments, we saved the trained network from the epoch that achieved the lowest validation loss for testing with the test dataset. Convolutional layers are initialized with Glorot’s method [
32]. All experiments were trained with RMSProp optimizer, data augmentation [
33] and cyclical learning rate schedule [
34]. We worked with various configurations of hardware with NVIDIA video cards. Regarding software, we did our experiments with K-CAI [
35] and Keras [
36] on the top of Tensorflow [
37].


 ,
, 

{kind=link}