1. Introduction
Graph-structured data are widely used in various fields, such as social networks [
1,
2], knowledge graphs [
3,
4], and citation networks [
5,
6]. Graph Neural Networks (GNNs) have been widely used and have achieved state-of-the-art performance in many related applications, such as node classification [
5,
6,
7,
8], link prediction [
9,
10,
11], and graph classification [
12,
13]. Feature propagation is a simple, efficient, and powerful GNN paradigm [
14,
15]. The main idea behind it is to obtain new node representations by stacking multiple GNN layers to aggregate the neighbor information of nodes using nonlinear transformations [
16]. Graph Convolutional Network [
5] is one of the representative methods, which iteratively aggregates the features of neighboring nodes using a normalized adjacency matrix. However, it can only work with two to four layers, and when the model is deeper, the representation ability will degrade rapidly. The reason is that when the GCN layers are continuously stacked, the representations of nodes eventually converge to a specific value and become indistinguishable [
17]. Some studies believe that GCN is a smoothing operation on the graph using the Laplacian operator [
18], so the above problem is also called the over-smoothing problem [
19].
In order to learn high-level node representations in large, sparsely connected graphs, we have to increase model depth. For this sake, approaches that can alleviate over-smoothing have been developed.
Some approaches simply modify the connections between GNN layers, such as using residual connections and identity maps [
20,
21], skip connections [
17], inception structures [
22], and self-attention for different neighbors [
23,
24]. However, the increase in performance is still limited [
21].
In addition to these approaches, network decoupling is an important way to alleviate over-smoothing. Traditional GNNs map from input to output space using feature transformation operation after feature propagation. However, recent studies have shown that too many feature transformations can increase unnecessary redundant computation [
25], cause over-fitting [
22], and accelerate over-smoothing [
18,
26]. Decoupled GNNs can solve such problems by separating the transformation and propagation process, such as propagating features multiple times and then performing a few feature transformations [
26,
27,
28,
29], or reversely [
30,
31]. Since the feature propagation process does not involve parameter training, decoupled GNNs are also beneficial to the offline computation of the feature propagation process for some giant graphs, which significantly reduces the training time.
However, these approaches can not adaptively learn the number of optimal transformations.
Another way to solve over-smoothing is to use a flexible receptive field for each node. Traditional GNNs usually use a fixed receptive field, and the node representations output by the last layer of a model only consider the neighborhood within a specific distance. Thus, information during the propagation process is not fully utilized and not adjustable [
32]. Some works try to make the receptive field of the node adaptively adjusted by combining the outputs from different GNN layers [
27,
28,
33]. Some methods choose to concatenate multiple levels of features together [
34], and some methods choose to add these features by weights [
28,
30]. However, these approaches bring additional computational complexity.
In this work, we propose a novel decoupling approach, called a Block-Based Adaptive Decoupling (BBAD) Framework, to improve the performance further with less computational complexity for deep networks. We use decoupled blocks to replace multi-layer GNNs for feature propagation in this framework. Different backbone networks can be used in each block, and we use an attention mechanism to assign weights to adjust the receptive field. We also propose a method to automatically adjust the number of layers in each block based on identity mapping and L1 regularization so that it can adaptively balance the number of operations for feature transformation and propagation. Experiments for semi-supervised and fully supervised node classification show that our framework can improve the performance of backbone networks significantly and outperform existing deep models with fewer parameters. The main contributions of this paper are as follows:
We propose an adaptive block-based decoupling framework. It can combine shallow models into a deep one, producing high-level feature representations and providing flexible receptive fields for different nodes while reducing over-smoothing and over-fitting. We also propose a layer regularization approach to automatically adjust the propagation depth in decoupling blocks to control the decoupling rate.
We prove that the traditional coupled GNNs are more likely to suffer from over-smoothing when they become deep. We explore the importance of an appropriate decoupling rate and demonstrate the diversity of outputs from different blocks of our framework.
We conduct semi-supervised and fully supervised node classifications on benchmark datasets. The results verify that our method can not only improve the ability of various backbone networks to acquire deep features, but also outperform existing deep graph neural networks with fewer parameters.
2. Related Work
GNNs typically aim to find a convolution kernel suitable for graph structure data. Some researchers have proven that the convolution operation on a graph could be approximated by the k-order polynomial of the Laplace operator of the graph [
5,
35]. For example, Kipf et al. proposed that the graph convolution network (vanilla GCN) simplifies the previous graph convolution model by the first-order approximation of the k-order polynomial [
5], and the representation of the graph convolution layer is obtained as
where
,
is a normalized adjacency matrix,
is the feature matrix of layer
l,
W represents the learnable parameters of the linear transformation layer, and
represents a nonlinear activation function, such as
RELU. GCN aggregates neighboring node features by iteratively stacking multiple graph convolutional layers. GCN makes the convolution operation on graphs simple, but as mentioned above, GCN suffers from over-smoothing, so that GCN cannot take advantage of deep neural networks to learn high-level representations.
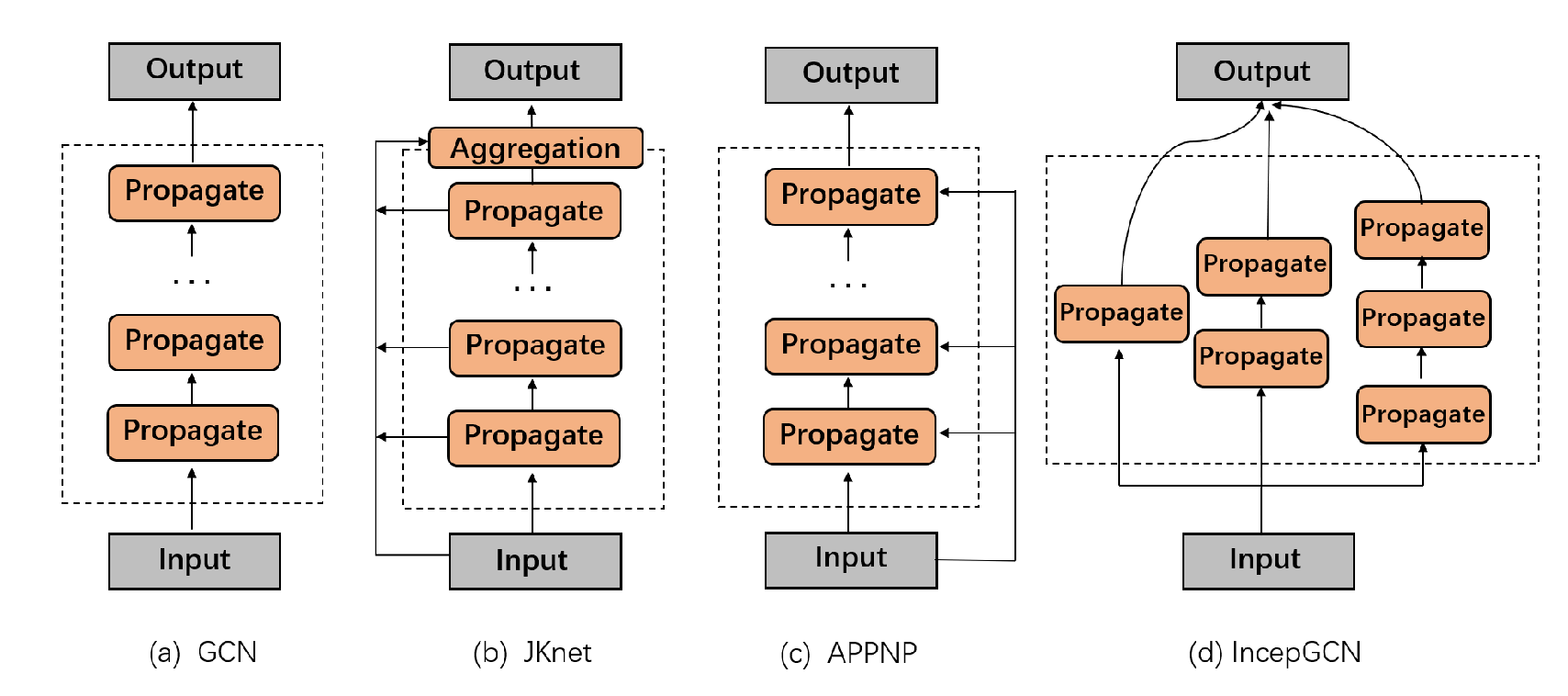
Many approaches have been proposed to solve this issue. Modifying the structure of feature propagation in the model is one of them, as shown in
Figure 1. For example, JKnet analyzed the failures in GCN from the spatial domain and proposed a feasible deep GNN model, which adopts the structure of dense connections for feature propagation [
17]. It concatenates the outputs from all the layers together,
, and solves the over-smoothing problem by combining node representations with different hops.
Some research demonstrates the necessity and superiority of decoupled GNNs theoretically, and removes feature transformation operations while only retaining feature propagation layers, and the final classification layer [
25]. Decoupling GNNs can improve the flexibility of feature propagation and remove redundant parameters, which helps to improve the ability of GNNs to acquire deep features. The feature propagation layer can be expressed as
where
,
,
is the graph convolution output feature of the
lth layer.
On the other hand, Klicpera et al. argue that the size of the aggregated neighborhood required in GNNs and the depth of the feature transformation are two completely orthogonal aspects, so they propose APPNP based on personalized PageRank to solve the problem of over-smoothing [
31]. Formally, the definition of the aggregation layer is as follows
where
is the same normalized adjacency matrix as in GCN,
, and
W represents the learnable parameter and is shared for each APPNP layer to decouple the model. Thus, multi-layer information aggregation performed from multi-hop neighbors will not significantly increase the computational cost. To avoid over-smoothing, the input feature is partially maintained by adding skip connections between the input layer and the current layer.
DAGNN adopts a similar shared feature transformation method [
30]. It performs feature transformation on the initial features of nodes, and then performs feature propagation. The outputs of the different layers are adaptively fused as follows
where
represents the node representation of the output of the
lth layer. By fusing the node features of different neighborhoods, DAGNN effectively alleviates the over-smoothing problem at the cost of computational complexity.
3. Block-Based Adaptive Decoupling Framework
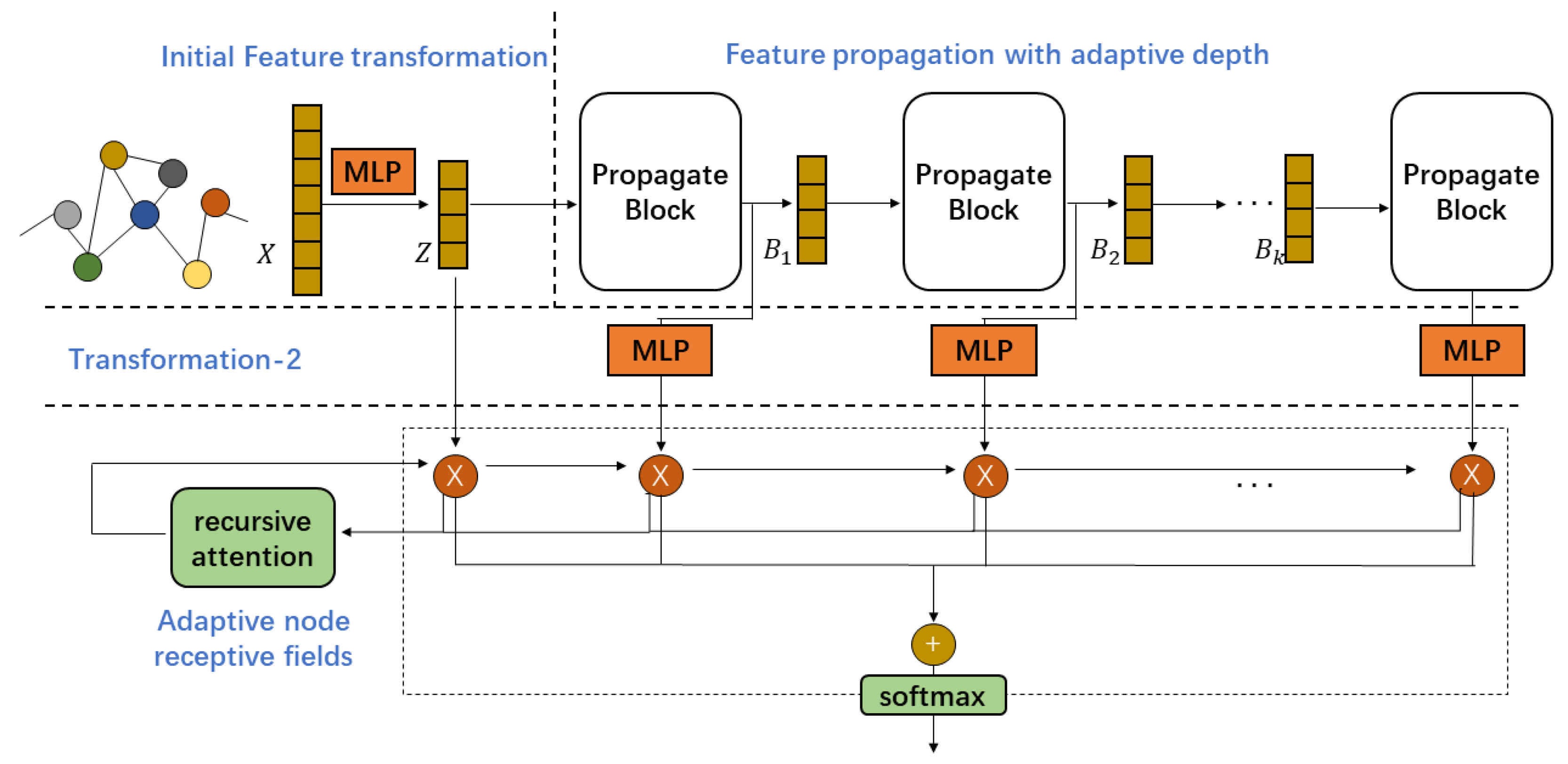
We introduce our proposed adaptive block-based decoupling framework in this section. Using blocks as the basic feature propagation units enables our architecture to be flexible and versatile enough to be applied to different backbone GNNs.
3.1. Main Model
Our proposed framework comprises three parts: feature transformation, feature propagation with adaptive depth, and flexible node receptive fields. An illustration of our proposed framework is provided in
Figure 2.
3.1.1. Initial Feature Transformation
Initial feature transformation is performed on the input features of nodes through a single layer. As shown in Equation (
6),
where
W is the linear transformation parameter shared by all feature propagation blocks,
X is the input feature of nodes, and
is the activation function. We use RELU by default. This step is similar to other decoupled GNN models.
3.1.2. Feature Propagation with Adaptive Depth
The core of GNN is feature propagation, because feature transformation alone cannot use the neighborhood information. In order to alleviate over-smoothing and over-fitting due to too many feature transformations in each block, we remove all feature transformation operations and only retain the feature propagation operations between neighboring nodes. Therefore, the
k-th feature propagation layer in each block can be written as follows
where
is the feature representation of the local node
v after
k feature propagation operations,
is a neighborhood information aggregation function, and
is the feature representation of node
u;
contains the neighboring nodes of
v, and
is a function that decides how to combine
and
. Different GNNs have different definitions of
and
; for example, in GCN,
and
.
The depth of feature propagation significantly affects the performance. Thus, each block should control its depth to achieve the best performance. For this sake, we adopt an identity map to control the depth of feature propagation of a single block. The overall node representation in a block after
k layers can be written as
where
is the feature matrix composed of all node representation after feature propagation for
k times; that is,
.
is the output from the previous layer, and
is the final output of the
k-th layer.
corresponds to the control parameters used by the
k-th layer for identity mapping. When
is close to zero, it means that the operation of the
k-th layer will be skipped, and the input is directly mapped to the output. When
is close to one, it means that the operation of the
k-th layer will be passed to the next layer. In this manner, the depth of the entire block can be adaptively tuned by changing the value of
. We also add an L1-regularization term
to control the sparseness of
. Continuously minimizing the loss function through backpropagation can adaptively optimize depth.
A decoupling block comprises multiple feature propagation layers without any feature transformation layer. The feature propagation within the block is carried out layer by layer, and any propagation structure as shown in
Figure 1 can be used between layers to improve the propagation ability. The calculation is as follows:
where
represents multi-layer feature propagation, and
represents the output of the
i-th block and also the input of the next block.
We also need to choose an appropriate ratio of the feature propagation layer number to the feature transformation layers number; namely, the decoupling rate. In our framework, we fix the number of feature transformation layers to be one, which means that only a single feature transformation is performed at the end of each block. Since the number of feature propagation of each block is adaptively changed, the decoupling rate of each block can be adjusted automatically. These two steps can be written as follows:
where
represents the linear transformation parameters corresponding to the
i-th block, and
represents the feature representations that will be taken as input to the adaptive node receptive fields and not passed to the next block.
3.1.3. Adaptive Node Receptive Fields
The output of each block in the framework corresponds to the node representation after feature propagation with different hops. In the adaptive adjustment of node receptive field, we aim to assign receptive fields of different sizes to different nodes, which can be achieved by aggregating features from low-order and high-order neighbors from different blocks using different weights. From the perspective of spectral domain analysis, it works similarly to a filter for different frequencies to better use the signals on the graph at various frequencies. The calculation of this step is as follows
where
is the final output of the
l-th block,
measures the impact of the output of the
l-th block on the final node representation, and
is the final output of the entire framework.
To determine weights, we use a recursive attention mechanism. It recursively calculates how much discriminative information the current feature can bring to the previous combined features to guide the weight assignment. Its calculation form is as follows
where ‖ means the concatenation of two block outputs, and
s is a learnable vector.
combines features from different propagation hops. If it contains most of the information in
; this means that the features of the neighborhood are very smooth, and
should be assigned with a smaller weight to avoid over-smoothing. On the other hand, if the weight assigned to
is large, it means that
can contribute for more discriminative information.
Our proposed framework can be applied to multiple graph-related downstream tasks, and eventually, we will update all parameters in the whole architecture by optimizing the loss function. Taking node classification as an example, we use the cross-entropy to measure the differences between the softmax predictions and the ground-truth labels. The final loss function can be as follows
where the first term is the cross-entropy loss function, and
is to balance the two loss terms.
3.2. Comparing with Existing Decoupling GNNs
In this section, we compare the similarities and differences between our framework and existing decoupling approaches.
Comparison with Deep Adaptive Graph Neural Network (
DAGNN) [
30]: The decoupling method of this approach is to transform features first and then propagate these features. Our framework can adopt different feature propagation structures in each block, as shown in
Figure 1, while DAGNN can only perform simple layer-by-layer propagation. DAGNN is forced to output the results of each feature propagation layer. Although it can fuse multi-hop neighborhoods, it ignores gains from the layer-to-layer connections, such as skip residual connections, initial residual connections, etc. Meanwhile, our model is block-based, utilizing the output of each block to construct an adaptive receptive field, and different propagation structures can be flexibly adopted within the block. So, our framework is more lightweight when computing adaptive receptive fields. For example, if 64 layers of feature propagation are to be performed, DAGNN needs to assign weights for 64 weights. In comparison, our model propagates eight layers per block and finally, it only needs to assign weights for eight features. Experimental results also show that our method outperforms DAGNN in both performance and complexity.
Comparison with Decoupled GCN (
DGCN) [
26]: Alternatively, DGCN propagates features first and then transforms them. The number of feature propagation layers is the same as that of the feature transformation layer. DGCN assigns a parameter to each layer to control the proportion of feature transformation, so that the parameters of the model are generally unchanged. Our framework uses adaptive decoupling blocks to reduce the number of model parameters.
3.3. Theoretical Analysis
We can consider the adaptive node receptive field as an ensemble approach by treating different GNN network layers as different basic learners. Since the ensemble effectiveness of basic learners depends on the diversity of learned features, we demonstrate that our approach can provide diversified basic solutions before feeding into Equation (
12). In this analysis, we assume that node features are generated using normal distributions with varying parameters, and the probability that a node shares the same feature distribution parameters with another node is inversely proportional to their distance. Hereby, we define the probability that two nodes have the same distribution as
, where
, and
k is the distance between two nodes.
Without loss of generality, we can define two independent distributions as follows, for a given node with its feature generated from . Thus, the proportion of its k-hop neighbors obtaining features from the same distribution is , and the features of the remaining k-hop nodes are generated from .
Theorem 1. The correlation between the output of the -th feature propagation block and that of the -th block iswhere with or .
Proof. We use
and
to represent the corresponding random variables, and
i is an identifier. For the
k-th block, we define the number of aggregated features from neighborhoods as
. According to the definition of feature propagation, the aggregated feature can be represented as follows
The corresponding expectation and variation are
Therefore, the covariance of the output from the
-th block and that from the
-th block is
Thus, the correlation between the outputs of two blocks is
where
,
,
, and
are calculated by Equations (
18) and (), with
or
.
Theorem 1 is proved. □
Next, we demonstrate the relationship between the decoupling rate and the over-smoothing phenomenon. As matrix is symmetric, its eigenvalues are all real numbers.
Lemma 1. (Augmented Spectral Property [18]) When the multiplicity of the largest eigenvalue is M, there are the following properties: , , and . Definition 1. (M-dimensional sub-space [36]) An M-dimensional sub-space in is defined as follows: where contains the bases of the largest eigenvalue of in Lemma 1. Namely, , where if node i belongs to the m-th connected components, and vice versa. The subspace only contains the degree information of the nodes, and is the space to which the node representation converges when oversmoothing occurs.
Lemma 2. (Distance measure [18]) The distance between matrix and M is , with the following propertieswhere η is the second largest eigenvalue of , φ is the supremum of all singular values of all , and both of them are less than one. We define that the output of a vanilla GCN with l feature propagation layers is . We also define the output of a block-based framework with multiple vanilla GCNs as , with decoupling rate .
Theorem 2. With the definitions above, the following properties hold
Proof. For layer-based GCN, using Equations (
32) and (
33), we can have
Then, we have the relationship between the input feature
X and
For the block-based decoupling GCNs, the relationship between the blocks is
so the relation between
and the input feature
X is
Theorem 2 is proven. □
From this theorem, we can find that, given the same number of feature propagation layers, our approach is less likely to converge to the over-smoothing state.
For different GNNs,
is different, and so is
. For example, for ResGCN,
is calculated as follows
Therefore, we have
The calculation method is the same as that of Equations (
34) and (
37)–(
39), so for GNNs with different propagation structures, the required decoupling rates are different. Our architecture solves this problem by adaptively adjusting the decoupling rate.
3.4. Importance of the Decoupling Rate
In this section, we discuss the importance of the decoupling rate with respect to the number of layers in different models. In traditional GNNs, each feature propagation layer is followed by a feature transformation layer, and the two operations are fully coupled. When we allow multiple feature propagation or transformation layers, we can define the decoupling rate as follows:
where
is the number of feature propagation layers and
is the number of feature transformation layers. Typically, as non-decoupled GNNs force feature propagation and transformation to be performed simultaneously, we can have
. Using decoupled GNNs usually increases the number of propagations to expand the range of the aggregated neighborhood, so that
. Therefore, with
, the decoupling rate is in
. Thus,
is one minus the ratio of feature transformation layers to the feature propagation layers.
Graphs are a kind of complex data, and feature propagation can effectively utilize the topological characteristics of the node’s local neighborhoods, while feature transformation can utilize the correlation between the node labels and features. Some studies believe that too many feature transformations can damage the performance of GNNs [
25,
31], so only a small number of feature transformations are retained after decoupling. For example, SGC removes all the feature transformations before the output layer in GCN [
25]. However, it can achieve good performance with shallow layers, but does not perform well when using deep layers. In the following examples, we demonstrate that an appropriate decoupling rate is essential when the number of network layers varies.
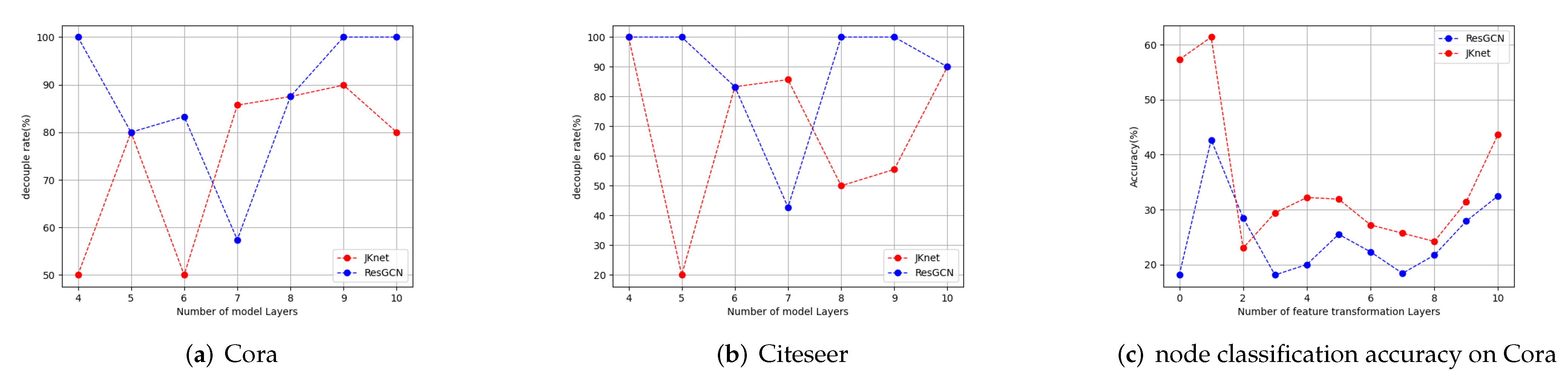
We conduct node classification experiments on Cora and Citeseer, which are graphs with sparse edges and which are likely to suffer from over-smoothing. In
Figure 3a,b, we can find that when the number of layers indicated by the horizontal axis changes, the best choice of decoupling rate indicated by the vertical axis also changes. In
Figure 3c, when the depth is 4, 9, or 10, ResGCN requires one 100% decoupling rate, which means that removing all feature transformation layers before the output layer is best. The decoupling rate required by JKnet is less than that by ResGCN. The relationship between the two is complex and cannot be described by a simple expression.
We can also interpret these figures from another perspective. When we use a total of 10 layers, we can see from
Figure 3c that the accuracy varies as the number of feature transformation layers changes. When the number of feature transformation layers is one, it corresponds to the case that the total layer number is 10 and the decoupling rate is 90%. in
Figure 3b. From
Figure 3c, we can see that the optimal decoupling rate is different for different model depths, and that the differences in node classification accuracy under different decoupling rates can be as much as 40%. Therefore, although both JKnet and ResGCN have the ability to alleviate over-smoothing, their performances are still limited decoupling rates, and an approach to automatically control the decoupling rate is necessary.
4. Experiment
In this section, we perform experiments on node classifications to verify that our proposed framework can effectively overcome over-smoothing problems when deepening the backbone GNNs, which significantly improves the performance.
4.1. Dataset
In our experiments, assortative datasets and disassortative datasets are both verified. Neighboring nodes are more likely to be in the same category in assortative networks.
Citation networks such as Cora, Citeseer, and Pubmed are assortative benchmark datasets [
37]. Each edge in these networks represents a citation relationship between two research papers, and node features are the bag-of-words vectors of corresponding paper abstracts. Each label indicates the category that the corresponding paper belongs to. Webpage networks such as Texas, Cornell, Wisconsin, and Chameleon are disassortative benchmark datasets. Edges in these networks represent hyperlinks between two web pages, and features of nodes contain webpage information. Each label indicates the category that the corresponding webpage belongs to.
Details of these datasets are recorded in
Table 1.
4.2. Baseline and Setting
We compare our framework with a number of baseline approaches, including GCN, GAT [
5,
17,
22,
23,
31], which are shallow models that are prone to have over-smoothing and over-fitting issues. JKnet, IncepGCN, and APPNP [
17,
22,
31] are the models that try to alleviate over-smoothing by modify the propagation structure. DAGNN is a model that tries to overcome over-smoothing through decoupling feature transformation and propagation [
30]. In order to verify that our framework can not only extend the depth of any kinds of GNNs, but also improve their performance to outperform existing deep models, we adopt a variety of backbones: GCN, JKnet, IncepGCN, and APPNP.
We use the Adam SGD optimizer with a learning rate of 0.01 and an early stopping patience of 100 epochs. We set the weight regularization as 5 , the dropout of shared MLP as 0.6, and the dropout of MLP corresponding to each block as 0.2.
4.3. Experimental Results Analysis
For the semi-supervised node classification task, we use Cora, Citeseer, and PubMed datasets, applying the standard fixed training/verification/testing splitting with 20 nodes per class for training, 500 nodes for validation, and 1000 nodes for testing [
38]. For the fully supervised node classification, we use seven datasets: the Cora, Citeseer, PubMed, Chameleon, Texas, Cornell, and Wisconsin datasets. We randomly split nodes of each class into 60%, 20%, and 20% for training, validation, and testing, respectively. For each experiment, we run them 10 times and report the mean classification accuracy.
Table 2 and
Table 3 show the results.
Our proposed framework has superior generality. Whether the backbone GNN is likely to over-smooth, it can significantly improve its performance and outperform existing deep models. The results on both semi-supervised and fully supervised tasks confirm our view. It can effectively utilize deep model architectures to extract features from higher-order neighbors. This performance gain is due to the decoupling blocks that can aggregate multi-hop neighborhood features with adaptive depth, and the adaptive node receptive fields that allow the model to adaptively adjust the ratio of low-pass and high-pass node information.
4.4. Model Depth Analysis
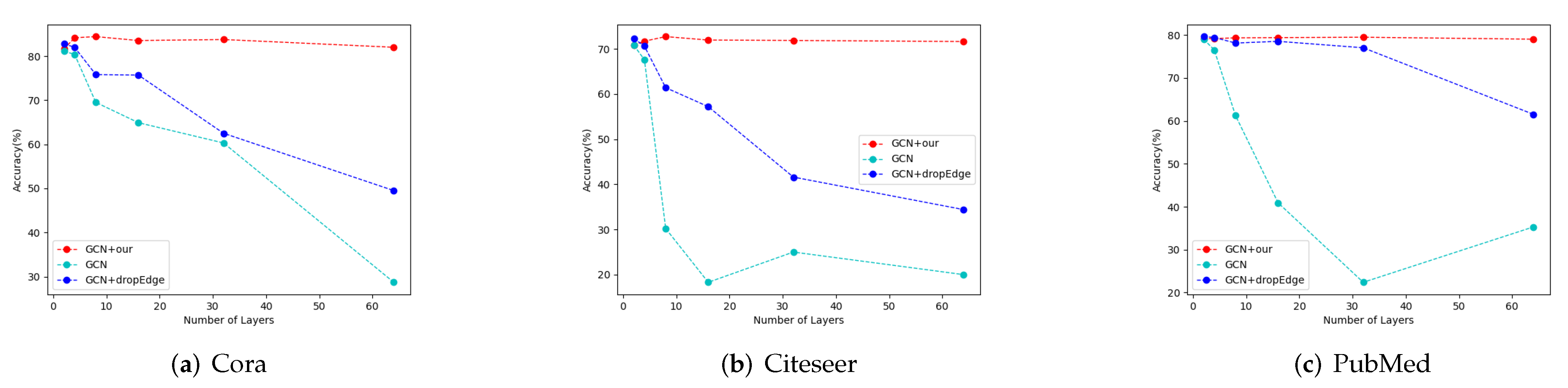
In order to verify that our framework can alleviate over-smoothing issues with too many layers, we compare our GCN-BBAD with the Vanilla GCN and the DropEdge GCN under the same model depth. DropEdge is a framework for increasing model depth by randomly dropping edges [
22].
Figure 4 reports the results of comparative experiments with different model depth. We perform experiments with 2/4/8/16/32/64 network layers on datasets, including Cora, Citeseer, and Pubmed. The performance of the Vanilla GCN degrades rapidly when the depth exceeds four layers. Although DropEdge performs better than Vanilla GCN, our framework can significantly reduce the over-smoothing issue. We attribute this phenomenon to the adaptive decoupling rate and the adaptive propagation depth in each block. As shown in
Table 2, our framework is also applicable to complex backbone models such as JKnet, IncepGCN, and APPNP.








{kind=link}
{kind=link}
{kind=link}
{kind=link}