1. Introduction
In recent years, underwater acoustic target recognition has been widely used to detect marine ships, evaluate the impact of ship radiated noise, and recognize marine life [
1]. However, feature identification of underwater acoustic targets has become difficult due to the time-varying nature of underwater acoustic channels, the correlated absorption and scattering of sound, and the increasingly complex marine noise environment. Usually, underwater acoustic target recognition is performed by well-trained sonar specialists. The identification results are unstable due to the different experiences of the specialists and lousy weather [
2]. Therefore, using an underwater acoustic target recognition algorithm to identify ship radiated noise becomes particularly important.
Thanks to the development of deep learning methods, the accuracy of recognition and recognition algorithms in the field of audio signal processing has improved significantly. The deep learning method is used to process massive amounts of data, extracting more useful sample features for recognition and showing good performance in underwater acoustic target recognition [
3,
4]. Li et al. [
5] introduced slope entropy into underwater acoustic signal processing to obtain higher recognition rate. Hong et al. [
6] used fused features to train an 18-layer residual neural network containing the central loss function of the embedding layer (namely ResNet18 in this paper) and adopted various strategies to prevent model overfitting, which improved the accuracy to 94.3% on the ShipsEar dataset. Hong et al. [
6] used a joint loss function containing a central loss function to monitor the characteristics of different underwater acoustic targets. However, using the joint loss function will equally monitor all features, including ocean background noise and other interference information, reducing the network’s recognition effect. At the same time, for the identification of data in different environments, the number of channels required is different, the number of channels is small, and the features of each dimension cannot be fully extracted, while the number of channels is large, which will contain more ocean background noise and other interference information, which will affect the recognition effect. In addition, when ResNet18 is applied to other ship-radiated noise datasets, it may lead to overfitting problems due to the small number of samples available for training.
The attention mechanism has made gratifying progress in solving the problem that residual networks are affected by interference information. Chen et al. [
7] use reverse attention to guide the side output residual learning in a top-down manner, which improves the residual network’s attention to residual details and improves the detection performance. Lu et al. [
8] used the three-layer parallel residual network structure to learn the spectrum and spatial features, and then used the three-dimensional attention module to enhance the expressiveness of the features from the channel and spatial domain, achieving better classification results. Fan et al. [
9] use the trunk branch of the residual structure to extract features, and mask branches imitate the attention mechanism to add soft weights to the features extracted from the trunk branch to optimize the extracted features and obtain better performance. Tripathi and Mishra [
10] used four two-layer residual blocks to build the network. After the fourth layer, they used attention modules to deal with intra-class inconsistencies, which improved the compactness and increased by 11.50% and 19.50%, respectively, over the benchmark model on the two datasets.
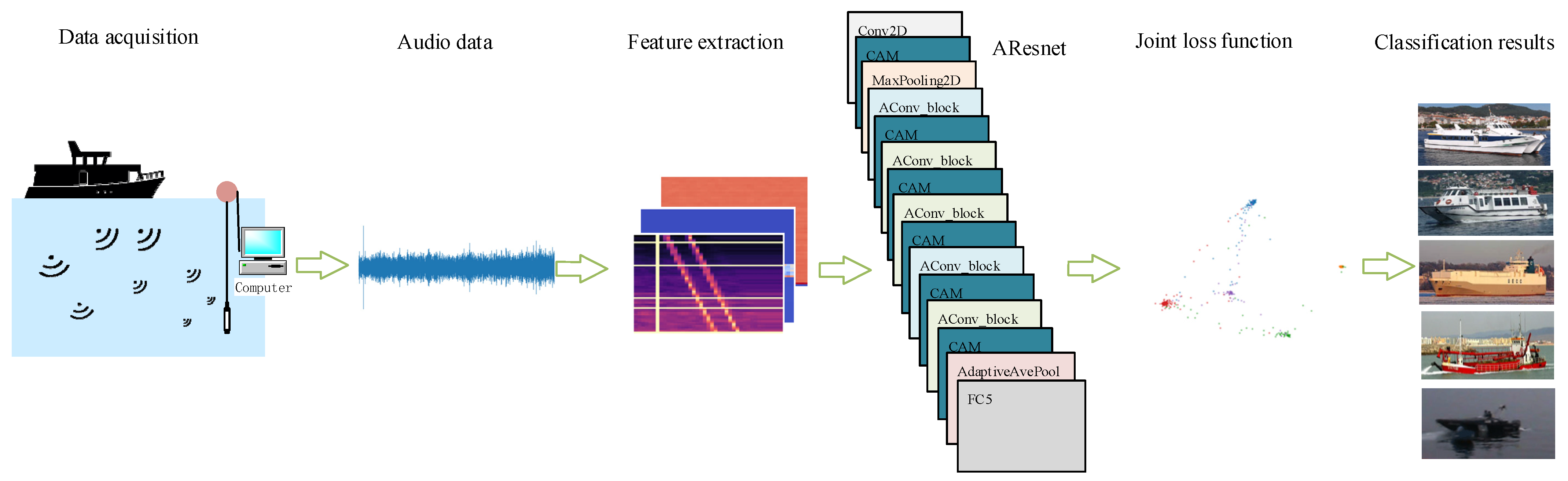
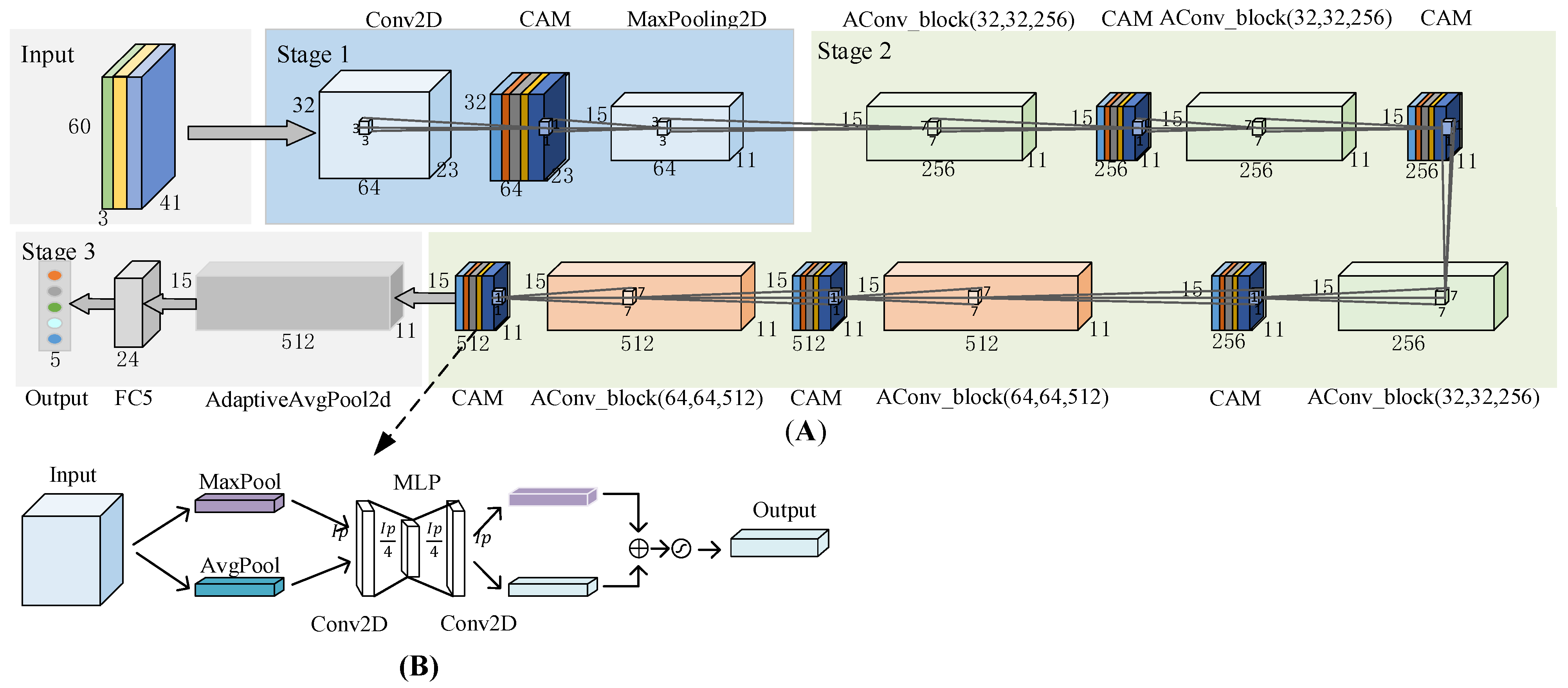
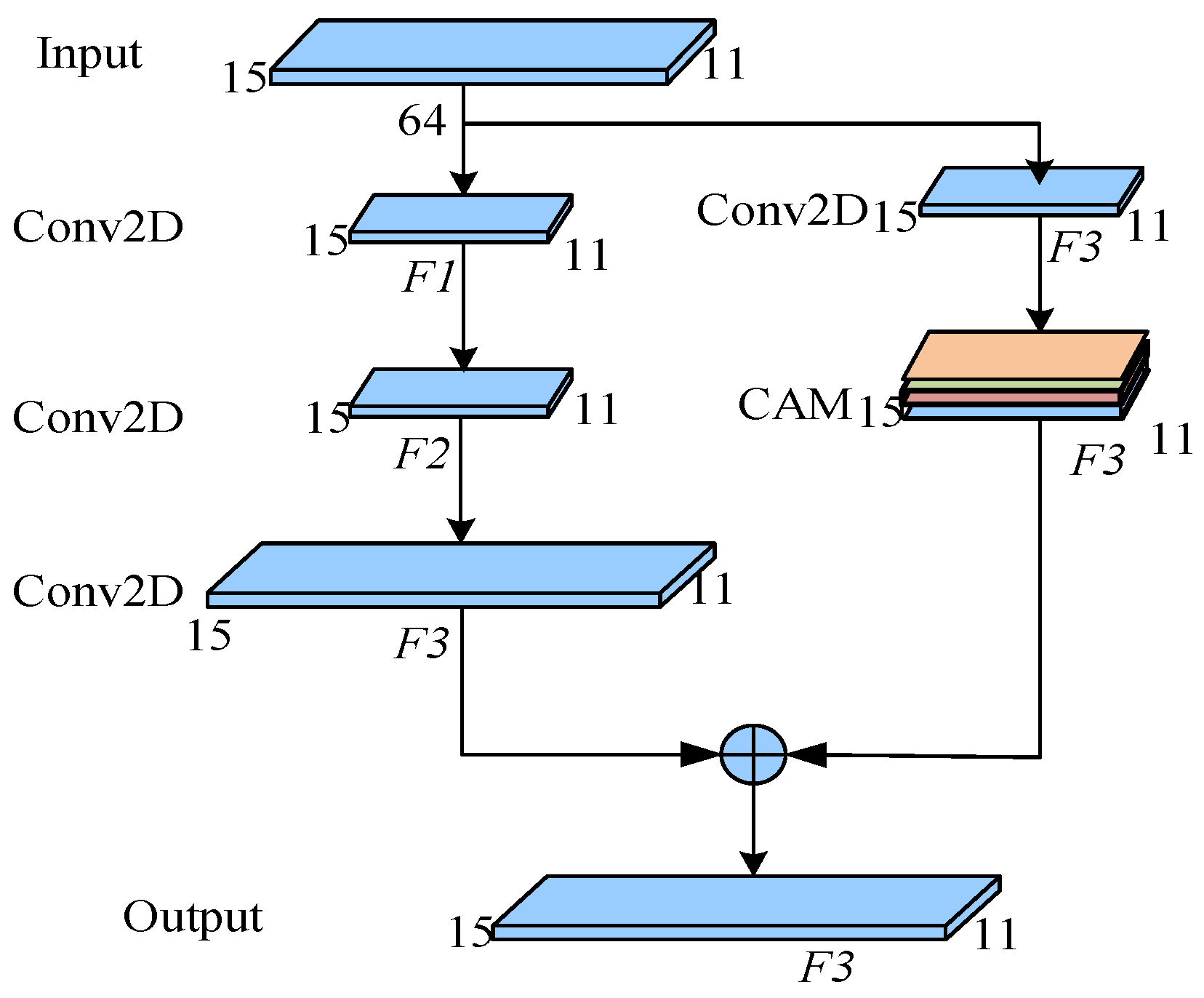
Inspired by the success of the attention mechanism and overcoming the problems of residual networks, we propose a new recognition method based on attention residual networks (AResnet). We use a three-layer residual block. The trunk branch of the residual block uses a 7 × 7 convolution kernel, and the mask branch uses a 1 × 1 convolution kernel. Each mask branch is followed by a spatial attention module to weight different channels. In order to adapt the network to different environments, we use residual blocks with 256 channels in three layers and 512 channels in two layers to fully extract features. After each residual block, we use channel attention module to suppress ocean background noise and other interference information and enhance features that can better represent target features.
There is also some literature that introduces attention mechanisms into underwater acoustic target recognition. Xiao et al. [
11] placed the attention module in front of the hidden layer of DNN, and only retained the features related to the target to suppress environmental noise and marine ship interference, thus achieving high accuracy of target detection and recognition. Hu et al. [
12] used the depth direction separable convolution filter to decompose the original time-domain ship radiated noise signal into different frequency components, and then extracted the signal features based on auditory perception. Deep functions are integrated into the integration layer. Time-extended convolution is used for long-term context modeling. Liu et al. [
13] used the multi-resolution pooled convolution scheme based on the Inception model to build the MCNN architecture, then used the first eight layers of the ResNet50 model to extract features, and finally used the location attention module and spatial attention module to optimize the feature information in parallel. The average recognition accuracy on ShipsEar was 95.6%. Yang et al. [
14] designed a set of multi-scale depth convolution filters to decompose the original time domain signal into signals with different frequency components, which realized the effective classification of ship-radiated noise. Xue et al. [
15] used a set of one-dimensional convolutions to decompose the acoustic signal into the basic signal and used two two-layer residual blocks to extract the basic signal features. After the residual block, the channel attention mechanism was added to enhance the energy of residual convolution stable spectrum features and obtain better recognition results.
We also introduce an attention mechanism into underwater acoustic target recognition. Different from the above literature, we have constructed a new residual block, the attention-based convolution residual block, in which the main branch of the residual block has three layers of convolution, the size of the convolution core is 7 × 7, and the mask branch uses 1 × 1 convolution core, and then uses the channel attention module to assign weights to different channels of the mask branch. At the same time, in order to make the network adapt to the recognition of different environments, we use three 256-channel residual blocks and two 512-channel residual blocks to fully extract target features by increasing the number of channels of the attention-based residual blocks. At the same time, in order to reduce the interference of ocean background noise and multi-target noise, a channel attention module is used after each residual block to reduce the feature weight of ocean background noise and multi-target noise, enhance the feature weight of the target, and improve the recognition effect. Finally, the joint loss function, including the cross-entropy loss function and the center loss function, can differentially supervise the abstract features of different channels, effectively suppress the ocean background noise, and improve the adaptability of AResnet in different environments. The network can fully extract the features of different dimensions of underwater acoustic targets and adaptively enhance the abstract features of different channels. The joint loss function is used to differentially supervise the abstract features of different channels so that the features that can better represent the signal characteristics are concentrated in the class center distribution, effectively improving the recognition effect.
The difficulty and number of samples obtained are different in different environments. Although the early stopping strategy and the method of dynamically adjusting the learning rate are adopted in the model’s design to avoid overfitting, there is still a problem of insufficient samples when applied to the ship radiated noise dataset with a small sample size. For this, we use the idea of transfer learning. First, AResnet is pre-trained on the DeepShip dataset. The network structure is then fine-tuned and applied to the small-sample ship radiated noise dataset. The proposed method is validated on two datasets of different sizes. After training and testing on the DeepShip dataset, the average accuracy on the test set is 99.0%. The pre-trained AResnet is trained and tested on the ShipsEar dataset, and the average accuracy on the test set is 98.0%, which is a 3.6% improvement over the ResNet18 method proposed by Hong et al. [
6].
The main contributions of this paper are as follows:
The joint loss function, including the center loss function and cross-entropy loss function, combined with the channel attention module, improves the problem of equal supervision of all features when mining discriminative information of fused features. These features will contain other interfering information, such as ocean background noise, and the same supervision will reduce the recognition effect of the model.
The proposed AResnet method enhances different channels by increasing the width of the residual network and combining the channel attention module, which not only meets the requirements of network width due to environmental changes but also suppresses background noise interference.
Aiming at the problem of insufficient samples, when the AResnet method is applied to the small sample ship radiated noise data set, the trained network parameters are migrated, and the structure is adjusted, which greatly improves the recognition effect of ship radiated noise collected in different environments.
The proposed AResnet model is validated on datasets of different environments and scales. The results are better than other methods.
The rest of this article is organized as follows.
Section 2 describes the feature extraction method and the proposed method for recognition.
Section 3 presents the experimental data and preprocessing methods, while
Section 4 presents the recognition results and analysis. Finally,
Section 5 concludes the paper.
4. Experimental Results and Analysis
The AResnet is built using Pytorch 1.8.1 as the backend and verified on a computer with Nvidia GeForce RTX 3060 and AMD R7-5800H CPU to verify the effectiveness of the proposed architecture.
Training used an Adam optimizer with a dynamically adjusted learning rate and joint loss function, including center loss function and cross-entropy loss function as the loss function. The initial value of the learning rate is 0.0001, and the learning rate is dynamically adjusted by decreasing 50% every 10 cycles. The batch size during training is set to 128, the maximum number of the training is set to 300, and the training is performed using the early stopping method. The training stops when the loss on the validation dataset drops below 0.00005 for 20 consecutive epochs. This strategy can effectively reduce training time and avoid overfitting.
In the demonstration of experimental results, we use precision, recall, and F1-score to evaluate the recognition performance of the network. The formula of each index is as follows:
where
TP is true positive,
FP is false positive, and
FN is false negative.
4.1. Experimental Results and Analysis of DeepShip Dataset
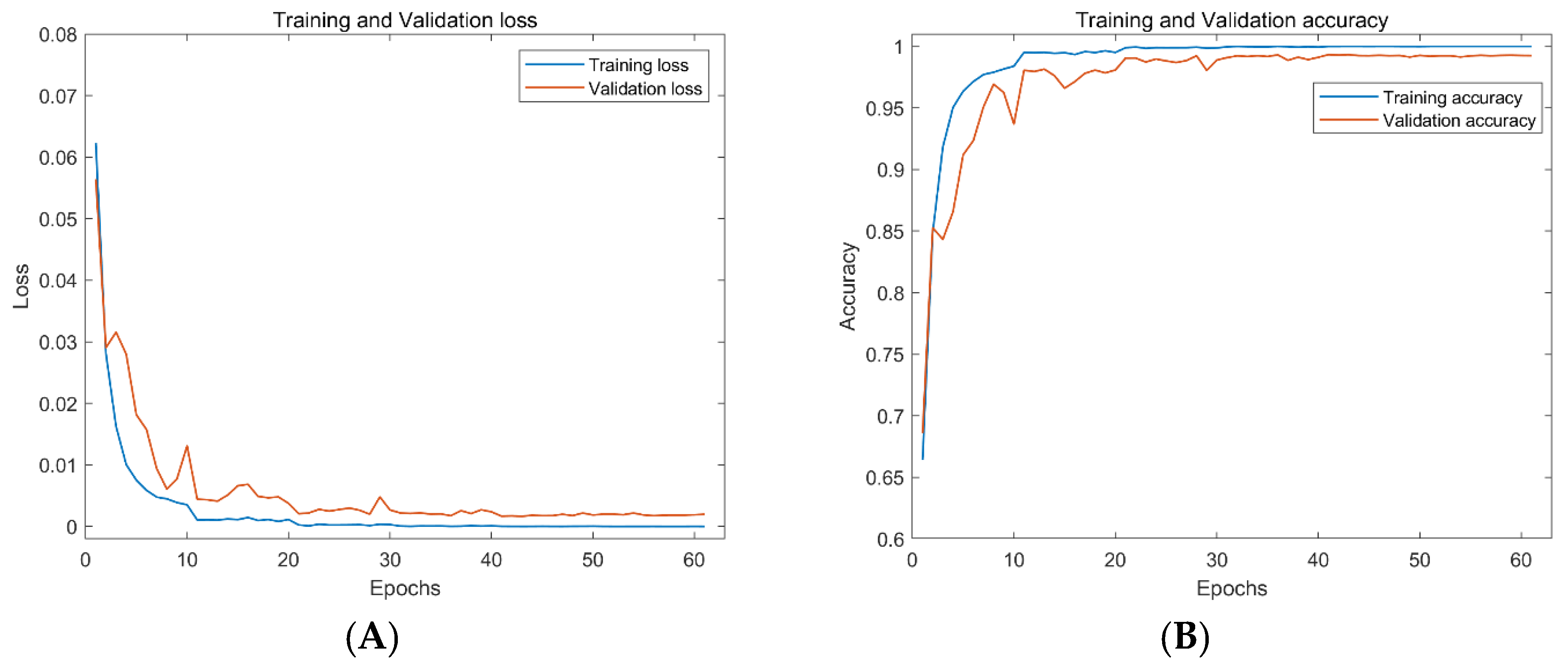
To verify the performance of the architecture proposed in this paper, the DeepShip dataset is used, and the experimental results are shown in
Figure 9. The training loss and validation loss decrease rapidly in about 10 cycles. For the convention of comparison, classifier performance is measured using classification accuracy, defined as the average precision. In contrast, the training accuracy and validation datasets increase quickly and soon reach a relatively stable process. The best accuracy on the validation dataset is 99.3%.
Table 3 shows that AResnet achieves an average precision, recall, and F1-score of 99.0% on the four types of ship-radiated noise. Support represents the number of samples for each class on the test dataset. Taking the average accuracy rate as the reference standard, class A (tugboat) has the best recognition effect, with an average accuracy rate of 99.3%. The least effective is class B (cargo ships), with an average accuracy of 98.2%.
The recognition results are compared with DNN, CNN, and CRNN, and the average precision, recall, and F1-score are shown in
Table 4. The network is optimized using the Adam optimizer with a learning rate of 0.001. The best network parameters are selected for testing after training 100 times. The structure of DNN is 2048-1024-512-256-128-64-4, in which a Relu activation function follows each layer, and its average precision, recall, and F1-score are 98%. The convolutional layer structure of CNN is 48-128-192-192-128, where each layer is followed by a Relu activation function and uses 3 × 3 convolution kernels to extract features. Zero padding is used to maintain the output size. The convolutional layer of 1, 2, and 5 are followed by the max-pooling layer to compress the output. After the max-pooling layer, a drop of 0.5 is used, and the output result of the fully connected layer with the number of input nodes is 2048-2048-4. Its average precision, recall, and F1-score are all 96.4%. CRNN shows higher performance than DNN and CNN, with 98.6% precision in average precision, recall, and F1-score. The convolutional layer of CRNN uses the structure 64-128-256-256. After each layer, the Relu activation function and the maximum pooling layer are used. The convolutional layers use 3 × 3 convolution kernels to extract features. Two layers of LSTM follow the last convolutional layer for recognition.
These four optimized network structures all show high performance on the DeepShip dataset, but the AResnet proposed in this paper has higher accuracy than other methods.
4.2. Experimental Results and Analysis of ShipsEar Dataset
The method proposed in this paper is further tested on the ShipsEar dataset to show the method’s performance in the small sample ship radiated noise dataset. In this work, the ResNet18 is compared with AResnet to verify the effectiveness of the proposed method. ResNet18 used an 18-layer residual network with a central loss function in the embedding layer to train the fused features at an adaptive learning rate. This paper uses the same processing method for data preprocessing and feature extraction for the ShipsEar dataset. We apply the transfer learning idea to data training. The transfer learning framework uses the network trained on the DeepShip dataset to fine-tune the recognition layer of the network model to make it suitable for the recognition of the ShipsEar dataset. The experimental results show that ResNet18 has an accuracy of 94.4% on the test dataset. The accuracy of the attention residual neural network based on transfer learning is 98.0% on the test dataset and is increased by 3.6%.
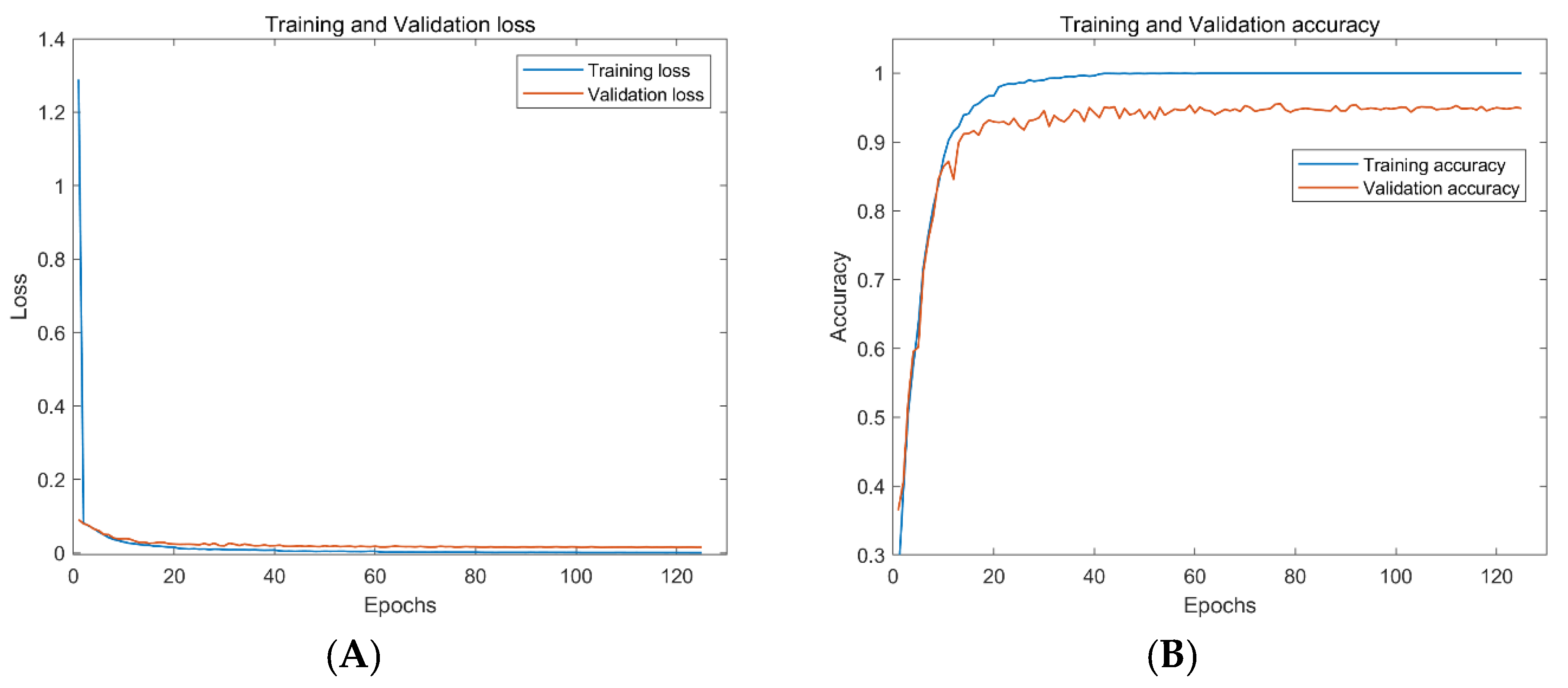
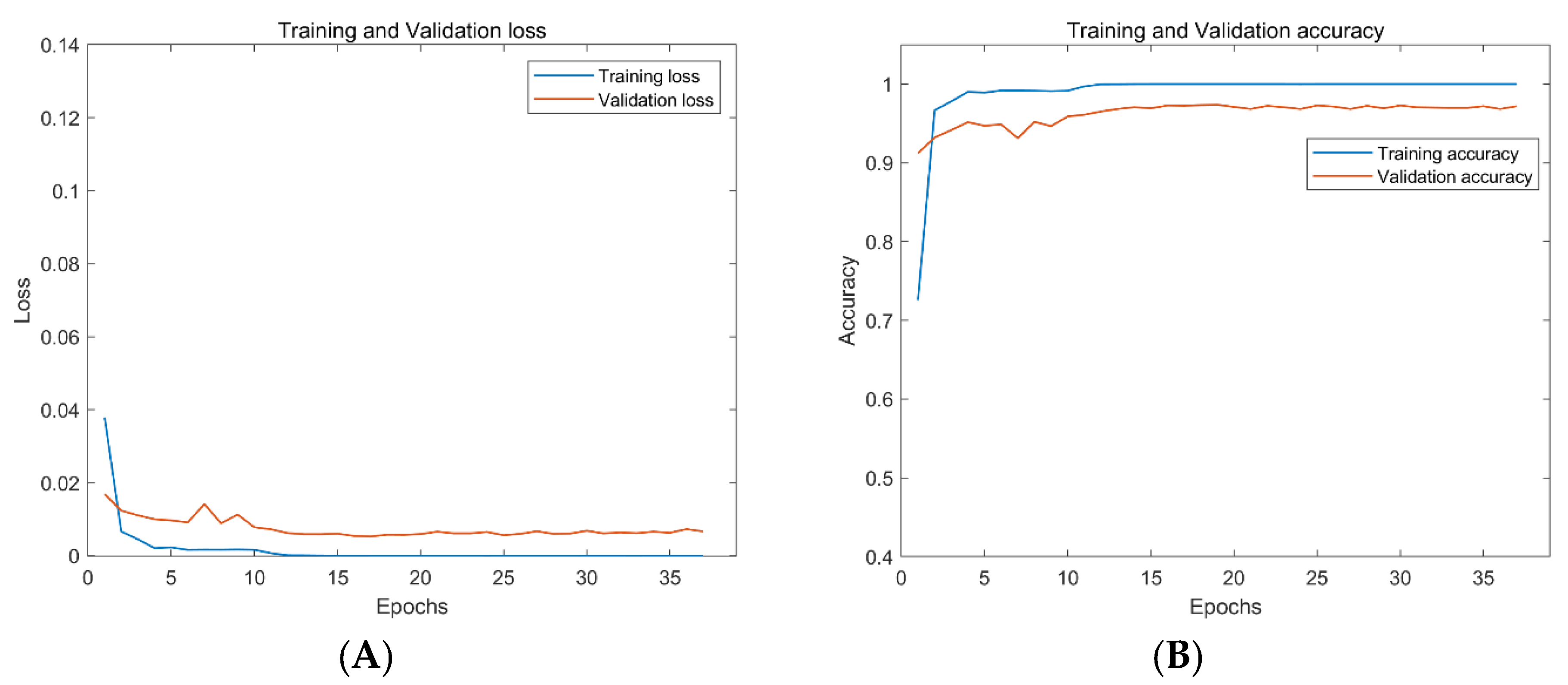
As can be seen from
Figure 10 and
Figure 11, both networks show good performance in preventing overfitting. However, the ResNet18 takes 125 epochs to train, and the best accuracy on the validation dataset is 95.4%. The AResnet only needs 37 epochs, and the best accuracy of the validation dataset is 97.4%. The AResnet has shorter training epochs and higher accuracy compared with ResNet18. This proves that the proposed attention-based residual network performs better on passive underwater acoustic target recognition.
Table 5 describes the details of the two recognition models in terms of precision, recall, and F1-score. The average precision, recall, and F1-score of ResNet18 is 94.4%, and support represents the number of each category on the test dataset. The AResnet has an average precision, recall, and F1-score of 98.0%. AResnet outperforms ResNet18 by the classifier performance validated on the test dataset. To further compare the recognition effect of each category, the average precision is uniformly selected for measurement. In ResNet18, the best results are class B (natural environment noise), with an average accuracy of 98.3%. The worst results are class C (motorboats, sailboats, and pilot boats), with an average accuracy of 90.9%. The best and worst recognition results on the test dataset in AResnet are also the average accuracy of 100% and 96.6% for classes B and C. The recognition effect of class C is not high performance on these two methods. One possible reason is that the training datasets for class C (motorboats, sailboats, pilot boats) are small and undertrained. Moreover, the radiation noise generated by class C is small, and it is easy to be mixed into the background noise, and the average accuracy of the two methods is low. Overall, AResnet outperforms ResNet18 in recognition.
In order to evaluate the robustness, standard deviation (STD) and arithmetic mean are used to characterize the robustness of the model. The lowest STD reflects the strong robustness of the method. The calculation formula is as follows:
The statistical results of the mean and variance of AResnet and ResNet18 listed in
Table 6. The results show that the AResnet method achieves the minimum STD, which indicates that the AResnet method is more robust than the ResNet18 method.
We will perform five-fold cross-validation on ShipsEar, and then perform paired t-tests on the results of each fold cross-validation to show the statistical significance of the classification results obtained by the methods used in this paper.
Table 7 shows the AResnet and ResNet18 t-test results for 3D fusion features. It can be observed that the AResnet method is more significant than Resnet 18 method.
4.3. Comparison in Computational Efficiency and Floating-Point Operation
To calculate the total calculation time of a single era of the network, the time required for forward and backward transmission of a single batch is calculated as follows:
where
n is the number of layers in the network, and
is the layer
i and
belongs to the type of layer I. The total execution time of the network is calculated as follows:
where
m is the number of batches required to process data, and
o is the number of cycles required to train the network.
The
Table 8 shows the computational efficiency of all methods used in this study in terms of the number of floating-point operations (FLOP) and the computational time spent in each period of the model. The results in
Table 8 were obtained using a system containing Nvidia GeForce RTX 3060 and AMD R7-5800H CPUs. It can be seen that the number of FLOPs of the proposed method AResnet is far more than the models based on CRNN, CNN, DNN, and ResNet18. In terms of calculation time, the proposed method also takes more time than the models based on CRNN, CNN, DNN, and ResNet18. Compared with other models, AResnet has no advantage in computing floating point numbers and computing time.
5. Conclusions
We propose a residual network underwater acoustic identification method based on attention, which performs better on different ship-radiated noise data sets. By increasing the width of the model and combining it with the channel attention module, we can fully extract the features of different samples and enhance the differences in the features of different channels so as to suppress the interference of ocean background noise and improve the applicability of the model in different environments. At the same time, the joint loss function, which includes the cross-entropy loss function and central loss function, monitors different features differently, solving the problem of equal monitoring of all features, including interference information, when mining the distinguishing information of different sample features. The recognition accuracy of this method on the DeepShip dataset is 99.0%. The AResnet trained on DeepShip is used as a migration learning framework. After fine-tuning, it is applied to the ShipsEar dataset. The average recognition rate reaches 98.0%, which is better than the comparison method.
The residual network based on attention focuses on target characteristics, suppresses multi-source interference, avoids gradient disappearance or gradient explosion, and can show good performance when the training data are sufficient. The residual network based on transfer learning and attention has a wide range of applications, shows good performance in underwater acoustic target recognition in different environments, and can be easily applied to other marine target recognition tasks. As part of future work, we intend to adaptively increase or decrease the number of hidden nodes during training to adapt to changing marine environments with fewer parameters.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}