1. Introduction
The observation of the evolution of various time-dependent phenomena, as well as the decision-making based on structures predicting their future behavior have greatly shaped the course of human history. The emergence of the need of the human species for knowledge of the possible future outcomes of various events could only lead to the development and use of methods aimed at extracting reliable predictions.Their success, however, is not necessarily inferred from the emergence of need.The research field of predicting sequential and time-dependent phenomena is called time series forecasting.
Specifically, time series forecasting is the process in which the future values of a variable describing features of a phenomenon are predicted based on existing historical data using a specific fit abstraction, i.e., a model. All such time-dependent features containing past observations are represented as time series. The latter then constitute the input of each forecasting procedure. Time series are sequences of time-dependent observations extracted at specific time points used as their indexes. The sampling rate varies according to the requirements and the nature of the problem. In addition, depending on the number of attributes, i.e., the dependent variables describing observations recorded sequentially over the predefined time steps, whose values are collected at any given time, a distinction is made between univariate and multivariate time series [
1]. Such methods find application in a wide range of time-evolving problems. Some examples include rainfall forecasts [
2], gold [
3] or stock price market predictions [
4], as well as forecasting the evolution of epidemics such as the current COVID-19 pandemic [
5,
6]. The domain has flourished in recent decades, as the demand for better and better models remains increasingly urgent, as their use can greatly contribute to the optimization of decision-making and thus lead to better results in various areas of human interest.
In terms of forecasting procedures, during the first decades of development, methods derived from statistics dominated the field. This was based on the reasonable assumption that, given the nature of the problem, knowing the statistical characteristics of time series is the key to understanding their structure, and therefore predicting their future behavior. Currently, these methods—although still widely used—have been largely surpassed in performance by methods derived from the field of machine learning. Numerous such predictive schemes are based on regression models [
7,
8], while recently, deep-machine-learning architectures such as long short-term memory (LSTM) [
9,
10] are gaining ground. In addition, advances in natural language processing in conjunction with the fact that many time-dependent phenomena are influenced by public opinion lead to the hypothesis that the use of linguistic modeling containing information related to the phenomenon in question could improve the performance of forecasting procedures. Data containing relevant information is now easy to retrieve due to the rapid growth of the World Wide Web initially and social networks in recent years, and it is therefore reasonable to examine the utilization of such textual content in predictive schemes.
This work is a continuation of a previous comparative study of statistical methods for univariate time series forecasting [
11], which now focuses on methods belonging to the category of machine learning. Comparisons involve results from an extended experimental procedure regarding mainly a wide range of multivariate-time-series-forecasting setups, which include sentiment scores, tested in the field of financial time series forecasting. Below, the presentation of the results is grouped as follows: Two distinct case studies were investigated, the first of which concerns the use of sentiment analysis in time series forecasting, while the second contains the comparison of different time-series-prediction methods, all of which were fit in datasets containing sentiment score representations. In each of these two scenarios, the evaluation of the results was performed by calculating six different metrics. Three forecast scenarios were implemented: single-day, seven-day, and fourteen-day forecasts, for each of which the results are presented separately.
2. Related Work
The field of time series forecasting constitutes—as already mentioned—a very active area of research. Growing demand for accurate forecasts has been consistently established over the last few decades for many real-world tasks. Various organizations, from companies and cooperatives to governments, frequently rely on the outcomes of forecasting models for their decisions to reduce risk and improvement. A constant pursuit of increasing predictive accuracy and robustness has led the scientific community in several different research directions. In this context, and provided there is a strong correlation between the views of individuals and the course of specific sequential and time-dependent phenomena, it is both reasonable and expected to approach such problems by intersecting the field of forecasting with that of opinion mining [
12,
13]. Thus, there are several approaches that focus on trying to integrate information extracted using sentiment analysis techniques in predictive scenarios. This section tracks the relevant literature, focusing on works that investigate the aforementioned approach.
Time-series-forecasting problems can be reduced to two broad categories. The first one consists of tasks in which the general future behavior of a time series must be predicted. Such problems can be considered classification problems. On the other hand, when the forecast outputs the specific future values that a time series is expected to take, then the whole process can be reframed as a regression task. Regarding the first class of problems, the relevant literature contains a number of quite interesting works. In [
14], a novel method that estimates social attention to stocks by sentiment analysis and influence modeling was proposed to predict the movement of the financial market when the latter is formalized as a classification problem. Five well-known classifiers in Chinese stock data were used to test the efficiency of the method. For the same purpose, a traditional ARIMA model was used, together with information derived from the analysis of Twitter data [
15], strongly suggesting that the exploitation of public opinion enhances the possibility of correctly predicting the rise or fall of stock markets. Similar results were achieved in [
16], where the application of text-mining technology to quantify the unstructured data containing social media views on stock-related news into sentiment scores increased the performance of the logistic regression algorithm. A more sophisticated approach that employs deep sentiment analysis was used to improve the performance of an SVM-based method in [
17], indicating once again that sentiment features have a beneficial effect on the prediction.
Predicting the actual future values of a time series, on the other hand, is a task far more difficult than predicting merely the direction of a time series. Therefore, there are a significant number of studies directed towards this research area as well. In [
18], different text preprocessing strategies for correlating the sentiment scores from Twitter scraped textual data with Bitcoin prices during the COVID-19 pandemic were compared, to identify the optimum preprocessing strategy that would prompt machine learning prediction models to achieve better accuracy. Twitter data were also used in [
19] to predict the future value of the SSECI (Shanghai Stock Exchange Composite Index) by applying a NARX time series model combined with a weighted sentiment representation extracted from tweets. In [
20], given that the experimental procedure involved both data related only to a certain stock, as well as a small number of compared algorithms, sentiment analysis of RSS news feeds combined with the information of SENSEX points was used to improve the accuracy of stock market prediction, indicating that the use of the sentiment polarity improves the prediction.
As recent research work has indicated, given that there is a series of applications where deep-learning methods tend to perform better than either the traditional statistical [
21] and the machine-learning-based ones [
22], it is expected that such methods would also be used along with sentiment analysis techniques to achieve even greater accuracy in forecasting tasks. In [
23], an improved LSTM model with an attention mechanism was used on AAPL (NASDAQ ticker symbol for Apple Inc) stock data, after adopting empirical modal decomposition (EMD) on complex sequences of stock price data, utilizing investors’ sentiment to forecast stocks, while in [
24], the experimental procedure over six different datasets indicated that the fusion of network public opinion and realistic transaction data can significantly improve the performance of LSTMs. Both works demonstrated that the use of sentiment modeling improves the performance of LSTMs, but the amount of data used does not seem to be sufficient to substantiate a clear and general conclusion.
In addition, in several works [
25,
26] ensemble-based techniques have also been utilized together with sentiment analysis for time series forecasting in order to exploit the benefits of ensemble theory. In [
27], an ensemble method, formed by combining LSTMs and ARIMA models under a feedforward neural network scheme, was proposed in order to predict future values of stock prices, utilizing sentiment analysis on data provided by scraping news related to the stock from the Internet. Moreover, an ensemble scheme that combines two well-known machine-learning algorithms, namely support vector machine (SVM) and random forest, utilizing information related to the public’s opinion about certain companies by incorporating sentiment analysis by the use of a trained word2vec model was proposed in [
28]. Despite the results taken from the experimental procedure indicating that there were cases in which the ensemble model performed better than its constituents, the overall performance of the model depended on both the volume and the nature of the data available.
In terms of extended studies that focus on the extensive comparison of several different methods, given that multiple sentiment analysis schemes are also incorporated to predict the future values of time series, to our knowledge, only a relatively more limited number of works seem to exist in the current literature. Some of them are listed below. Various traditional ML algorithms, as well as LSTM architectures were tested over financial data by exploiting the use of sentiment analysis on Twitter data in [
29], while a survey of articles that focused on methods that touch up the predictions of stock market time series using financial news from Twitter, along with a discussion regarding the improvement of their performance by speeding up the computation, can be found in [
30]. Given the above, the present work aspires to constitute a credible insight into the subject, specifically regarding the behavior of a large number of forecasting methods in light of their integration with sentiment analysis techniques.
3. Experimental Procedure
In the extensive series of experiments performed, a total of 27 algorithms were tested for their performance in relation to a corresponding multivariate dataset consisting, on the one hand, of the time series containing the daily closing values of each stock as a fixed input component and, on the other, of one of a plurality of 22 different sentiment score setups. A total of 16 initial datasets of stocks containing such closing price values from a period of three years, starting from 2 January 2018 to 24 December 2020, were used. Three different sentiment analysis methods were utilized to generate sentiment scores from linked textual data extracted from the Twitter microblogging platform. Moreover, a seven-day rolling mean strategy was applied to the sentiment scores, leading to six distinct time-dependent features. A number of 22 combinations, per algorithm, of distinct input components, from the calculated sentiment scores together with the closing values, were tested under the multivariate forecasting scheme. Thus, given the aforementioned number of features and setups, a total of 28,512 experiments were performed.
3.1. Datasets
As already mentioned, 16 different initial datasets containing the time series of the closing values of sixteen well-known listed companies were used. All sets include data from the aforementioned three-year period, meaning dates starting from 2 January 2018 to 24 December 2020.
Table 1 shows the names and abbreviations of all the shares used.
However, each of the above time series containing the closing prices of the shares was only one of the features of the final multivariate dataset. For each share, the final datasets were composed by introducing features derived from a sentiment analysis process, which was applied to an extended corpus of tweets related to each such stock.
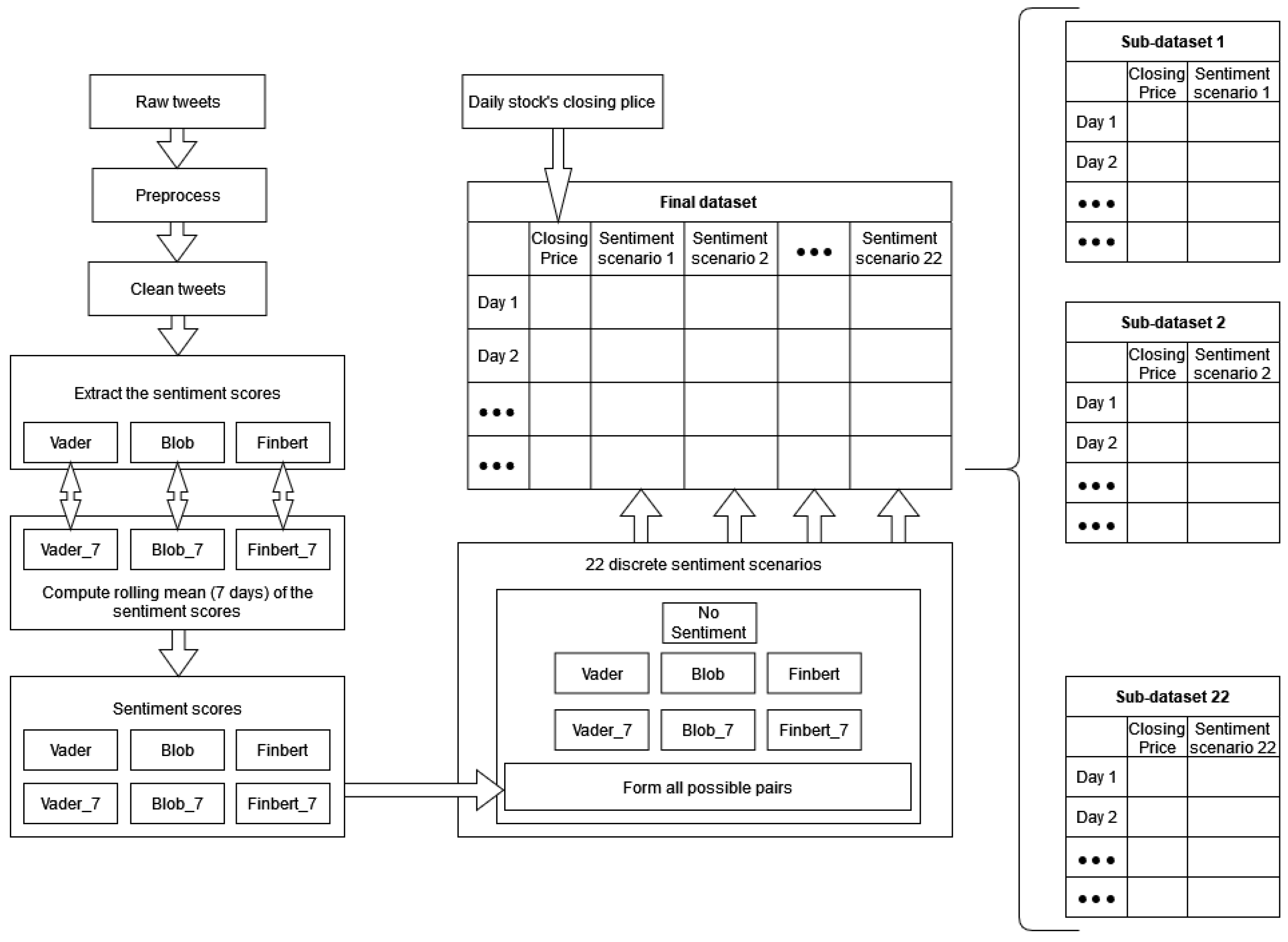
Figure 1 depicts a representation of the whole process, from data collection to the creation of the final sets. Below is a brief description of each stage of the final-dataset-construction process.
3.1.1. Raw Textual Data
First, a large number of—per stock—related posts were collected from Twitter and grouped per day. These text data include tweets written exclusively in English. Specifically, the tweets were downloaded using the Twitter Intelligence Tool (TWINT) [
31], an easy-to-use Python-based Twitter scraper. TWINT is an advanced, standalone, yet relatively straightforward tool for downloading data from user profiles. With this tool, a thorough search for stock-related reports to be investigated—that is, tweets that were directly or indirectly linked to the share under consideration—resulted in a rather extensive body of text data, consisting of day-to-day views or attitudes towards stocks of interest. These collections were then preprocessed and moved to the sentiment quantification extraction modules.
3.1.2. Text Preprocessing
Next, the text-preprocessing step schematically presented in
Figure 2 followed. Specifically, after the initial removal of irrelevant hyperlinks and URLs, using the
re Python library [
32], each tweet was converted to lowercase and split into words. A series of numerical strings and terms of no interest taken from a manually created set was then removed. Lastly, on the one hand—and after the necessary joins to bring each text to its initial structure—each tweet was tokenized according to its sentences using the
NLTK [
33,
34] library, and on the other, using the
string [
35] module, targeted punctuation removal was applied.
3.1.3. Sentiment Scores
The next step involved generating the sentiment scores from the collected tweets. In this work, three distinct sentiment analysis methods, that is the sentiment modules from
TextBlob [
36], the
Vader [
37] Sentiment Analysis tool, and
FinBERT [
38], a financial-based fine-tuning of the
BERT [
39] language representation model, were used. For each of the above, and given the day-to-day sentiment scores extracted with the use of each one of them, a daily mean value formed the final collection of sequential and time-dependent instances that constituted the sentiment-valued time series of every corresponding method. It should be noted that, in addition to the three valuations extracted by the above procedures, a seven-day moving average scheme was also utilized as applied to the sentiment-valued time series. Thus, six distinct sentiment-valued time series were generated, the combinations of which, along with the
no-sentiment and the univariate case scenario, led to the 22 different study cases. These, combined with the closing price data, constituted a single distinct experimental procedure for every algorithm. Below is a rough description of the three methods mentioned earlier:
TextBlob: TextBlob is a Python-based framework for manipulating textual data. In this work, using the sentiment property from the above library, the polarity score—that is, a real number within the interval—was generated for every downloaded tweet. As has already been pointed out, a simple averaging scheme was then applied to the numerical output of the algorithm to produce a single sentiment value that represents the users’ attitude per day. The method, being a rule-based sentiment-analysis algorithm, works by calculating the value attributed to the corresponding sentiment score by simply applying a manually created set of rules. For example, counting the number of times a particular term appears in a given section adjusts the overall estimated sentiment score values in proportion to the way this term is evaluated;
Vader: Vader is also a simple rule-based method for general sentiment analysis realization. The Vader Sentiment Analysis tool in practice works as follows: given a string—in this work, the textual elements of each tweet—SentimentIntensityAnalyzer() returns a dictionary, containing negative, neutral, and positive sentiment values, and a compound score produced by a normalization of the three latter. Again, maintaining only the “compound” value for each tweet, a normalized average of all such scores was generated for each day, resulting in a final time series that had those—ranging within the interval—daily sentiment scores as its values;
FinBERT: FinBERT is a sentiment analysis pre-trained
natural-language-processing (NLP) model that is produced by fine-tuning the BERT model over financial textual data. BERT, standing for
bidirectional encoder representations from transformers, is an architecture for NLP problems based on the
transformers. Multi-layer deep representations of linguistic data are trained under a bidirectional attention strategy from unlabeled data in a way that the contexts of each token constitute the content of its embedding. Moreover, targeting specific tasks, the model can be fine-tuned using just another layer. In essence, it is a pre-trained representational model, according to the principles of transfer learning. Here, using the implementation contained in [
40], and especially the model trained on the
PhraseBank presented in [
41], the daily sentiment scores were extracted, and—according to the same pattern as before—a daily average was produced.
3.2. Algorithms
Now, regarding the algorithms used, it was already reported that 27 different methods were compared. From this, it is easy to conclude that it is practically impossible to present in detail such a number of algorithms in terms of their theoretical properties. Instead, a simple reference is provided while encouraging the reader to consult the corresponding citations for further information.
Table 2 contains alphabetically all the algorithms used during the experimental process.
Experiments were run in the
Python programming language using the
Keras [
67] open-source software library and
PyCaret [
68,
69], an open-source, low-code machine-learning framework. It should also be noted that the problem of predicting the future values of the given time series was essentially addressed and consequently formalized as a regression problem. The forecasts were exported under one single-step and two multi-step prediction scenarios. Specifically, regarding multi-step forecasts, estimates were predicted for a seven-day window, on the one hand, and a fourteen-day window, on the other. All algorithms tested were utilized in a basic configuration with no optimization process taking place whatsoever.
3.3. Metrics
Moving on to the prediction performance estimates, given the comparative nature of the present work, the forthcoming description of the evaluation metrics to be presented is be a little more detailed. The following six metrics were used: MSE, RMSE, RMSLE, MAE, MAPE, and R. The abbreviations are defined within the following subsections. Specifically, below is a presentation of these metrics, along with some insight regarding their interpretation. In what follows, the actual values of the observations are denoted by and the forecast values by .
3.3.1. MSE
The mean squared error (MSE) is simply the average of the squares of the differences between the actual values and the predicted values.
The square power ensures the absence of negative values while making small error information usable, i.e., minor deviations between the forecast and the actual values. It is evident, of course, that the greater the deviation of the predicted value from the actual one, the greater the penalty provided for under the MSE. A direct consequence of this is that the metric is greatly affected by the existence of outliers. Conversely, when the difference between the forecast and the actual value is less than one, the above interpretation works—in a sense—in reverse, resulting in an overestimation of the model’s predictive capacities. Because it is differentiable and can easily be optimized, the MSE constitutes a rather common forecast evaluation metric. It should be noted that the unit of measurement of the MSE is the square of the unit of measurement of the variable to predict.
3.3.2. RMSE
The RMSE seems almost as an extension of the MSE. To compute it, one just calculates the root of the above.
That is, in our case, this is the quadratic mean (root mean square) of the differences between forecasts and actual, previously observed values. The formalization gives a representation of the average distance of the actual values from the predicted ones. The latter becomes easier to understand if one ignores the denominator in the formula: we observe that the formula is the same as that of the Euclidean distance, so dividing by the number
n of the observations results in the RMSE being considered as some normalized distance. As with the MSE, the RMSE is affected by the existence of outliers. An essential role in the interpretability and, consequently, in the use of the RMSE is played by the fact that it is expressed in the same units with the target variable and not in its square, as in the MSE. It should also be noted that this metric is scale-dependent and can only be used to compare forecast errors of different models or model variations for a particular specific given variable.
3.3.3. RMSLE
Below, in Equation (
3), looking inside the square root, one notices that the RMSLE metric is a modified version of the MSE, a modification that is preferred in cases where the forecasts exhibit a significant deviation.
As already mentioned, the MSE imposes a large “penalty” in cases where the forecast value deviates significantly from the actual value, a fact that the RMSLE compensates. As a result, this metric is resistant to the existence of both outliers, as well as noise. For this purpose, it utilizes the logarithms of the actual and the forecast value. The value of one is added to both the predicted and actual values in order to avoid cases where there is a logarithm of zero. It is straightforward that the RMSLE cannot be used when there exist negative values. Using the property:
, it becomes clear that this metric actually works as the relative error between the actual value and the predicted value. It is worth noting that the RMSLE attributes more weight in cases where the predicted value is lower than the actual one than in cases where the forecast is higher than the observation. It is, therefore, particularly useful in certain types of forecasts (e.g., sales, where lower forecasts may lead to stock shortages if there is more than the projected demand).
3.3.4. MAE
The MAE is probably the most straightforward metric to calculate. It is the arithmetic mean of the absolute errors (where the “
error” is the difference between the predicted value and the actual value), assuming that all of them have the same weight.
The result is expressed (as in the RMSE) in the unit of measurement of the target variable. Regarding the existence of outliers, and given the absence of exponents in the formula, the MAE metric displays quite good behavior. Lastly, this metric—as the RMSE—depends on the scale of the observations. It can be used mainly to compare methods when predicting the same specific variable rather than different ones.
3.3.5. MAPE
The MAPE stands for
mean absolute percentage error. This metric is quite common for calculating the accuracy of forecasts, as it represents a relative and not an absolute error measure.
A percentage represents accuracy: In Equation (
5), we observe that the MAPE is calculated as the average of the absolute differences of the prediction from the actual value, divided by the observation. A multiplication by 100 can then transform the output value as a percentage. The MAPE cannot be calculated when the actual value is equal to zero. Moreover, it should be noted that if the forecast values are much higher than the actual ones, then the MAPE may exceed the
rate, while when both the prediction and the observation are low, it may not even approach
, leading to the erroneous conclusion that the predictive capacities of the model are limited, when in fact the error values may be low (Although, in theory, the MAPE is a percentage of 100, in practice, it can take values in
). The way it is calculated also tends to give more weight in cases where the predicted value is higher than the observation, thus leading to more significant errors. Therefore, there is a preference for using this metric in methods with low prediction values. Its main advantage is that it is not scale-dependent, so it can be used to evaluate comparisons of different time series, unlike the metrics presented above.
3.3.6. R
Lastly, the coefficient of determination
is the ratio of the variance of the estimated values of the dependent variable to the fluctuation of the actual values of the dependent variable.
This metric is a measure of good fitting, as it attempts to quantify how well the regression model
fits the data. Therefore, it is essentially not a measure of the reliability of the model. Typically, the values of
range from 0–1. The value of zero corresponds to the case where the explanatory variables do not explain the variance of the dependent variable at all, while the value of one corresponds to the case where the explanatory variables fully explain the dependent variable. In other words, the closer the value of
is to one, the better the model fits the observations (historical data), meaning the forecast values will be closer to the actual ones. However, there are cases where the output of
goes beyond the above range and takes negative values. In this case (which is one allowed by its calculation formula), we conclude that our model has a worse performance (where “performance” means “data fitting”) than the simple horizontal line; in other words, the model does not follow the data trend. Concluding, values outside the above range—i.e., either greater than one or less than zero—either suggest the unsuitability of the model or indicate other errors in its implementation, such as the use of meaningless constraints.
4. Results and Discussion
Moving on to the results, as was already pointed out, the purpose of this work was twofold. The aim was to investigate two separate case studies through an extensive experimental procedure. Below are the results of the experiments categorized into these two separate cases. The first section deals with the utilization of textual data in light of sentiment analysis for the task of time series forecasting and the investigation of whether or not and when their use has a beneficial effect on improving predictions. The second involves comparing the performance of different forecast algorithms, aiming to fill the corresponding gap in the literature, where although there is serious research effort, it mainly concerns the comparison of a small number of methods.
Table A1 presents the 22 sentiment score scenarios along with their respective abbreviations.
Apparently, the large number of experiments make any attempt to present numerical results in their raw form, that is, in the form of individual exported numerical predictions, impossible. It was therefore deemed necessary to use some performance measures that are well known and, in some ways, established in similar comparisons and capture the general behavior of each scenario. Moreover, it was already mentioned that the time series forecasting problem can be considered a regression one, and we see that in the present research—which presupposes a thorough study of the problem—six commonly accepted metrics were used. The choice of a number of various metrics was considered a necessary one, as each of them has advantages and disadvantages, presenting different aspects of the results that form a diverse set of guides for their evaluation.
Regarding aggregate comparisons, the first way of monitoring results to draw valid general conclusions was by the exploitation of the
Friedman ranking test [
70]. Thus, on the one hand, the H0 hypothesis—that is, whether all 22 different scenarios produce similar results—would have been tested, and on the other, it would have been made possible to classify the methods based on their efficiency. The Friedman statistical test is a non-parametric statistical test that checks whether the mean values of three or more
treatments—in our case, the results of the twenty-two scenarios—differ significantly. Of the total six metrics used, five involved errors (MSE, RMSE, RMSLE, MAE, MAPE), which means that in order for one approach to be considered better than another, it must have a lower average. Therefore, the Friedman ranking error results follow an increasing order; the smaller the Friedman ranking score, the more efficient the method is. The opposite is the case only with
, where higher values indicate better performance.
After the Friedman test was performed, in case the null hypothesis was rejected—this rejection means that there is even one method that behaves differently—then the
Bonferroni–Dunn post hoc test [
71], also known as the Bonferroni inequality procedure, followed. This test generally reveals which pairs of treatments differ in their mean values, acting as follows: first the critical difference value is extracted, and then, for each pair of treatments, the absolute value of the difference in their rankings is calculated. If the latter is greater than or equal to the critical difference value, H0 is rejected, i.e., the corresponding treatments differ. The most efficient way to present the results of the Bonferroni inequality procedure is through
CD-diagrams, where treatments whose performances do not differ are joined by horizontal dark lines. Below are tables with the results of the Friedman tests, boxplots with the error distributions, as well as CD-diagrams, which, due to the limited space available, show the relations between the top-10 best approaches according to the Friedman rankings.
4.1. Case Study: Sentiment Scores’ Comparison
Let us initially give a summary of the case. First, the aim was to answer whether and under what conditions the use of sentiment analysis in data derived from social media has a positive effect on the prediction of future prices of financial time series. Here, the combinations—seen in
Table A1—of scores from three different sentiment analysis methods together with their seven-day rolling means and the univariate case created a total of twenty-two cases to compare.
Table A2,
Table A3 and
Table A4 present the final Friedman rankings in terms of their corresponding single-day, seven-day and fourteen-day forecasts.
4.1.1. Single-Day Prediction
First, regarding the forecast for the next day only,
Table A2 shows the general superiority of the univariate case over the use of sentiment analysis. As for the boxplots and CD-diagrams, the top-ten combinations of sentiment time series for each metric presented are ranked with the same performance dominance of the univariate scenario (note that in boxplots, the top-down layout is sorted by median).
One can also observe the statistical dependencies that emerged from the examination of each pair of cases. These dependencies can be further analyzed by comparing
Table A2 with the representations in
Figure 3. For example, it was observed that the statistical dependence of the univariate case with that of the additional use of TextBlob shown in
Figure 3 followed the ranking of the two versions extracted from the results in the Friedman tables.
Figure 4 shows the performance distributions for each sentiment setup, i.e., all the values that resulted from applying a given setting to each dataset for each algorithm. Here, the apparent similarity of the performances of the methods is, on the one hand, a matter of the scale of the representation, while on the other, it reflects a possible uniformity. From all three different representations of the results, there was a predominance of the univariate version followed by the use of TextBlob and FinBERT.
4.1.2. One-Week Prediction
However, in the case of weekly forecasts, one can observe, from
Table A3 and
Figure 5 and
Figure 6, that things do not remain the same. There was a noticeable decline in the performance ranking of the univariate setup, with the simultaneous improvement of configurations that utilize sentiment scores.
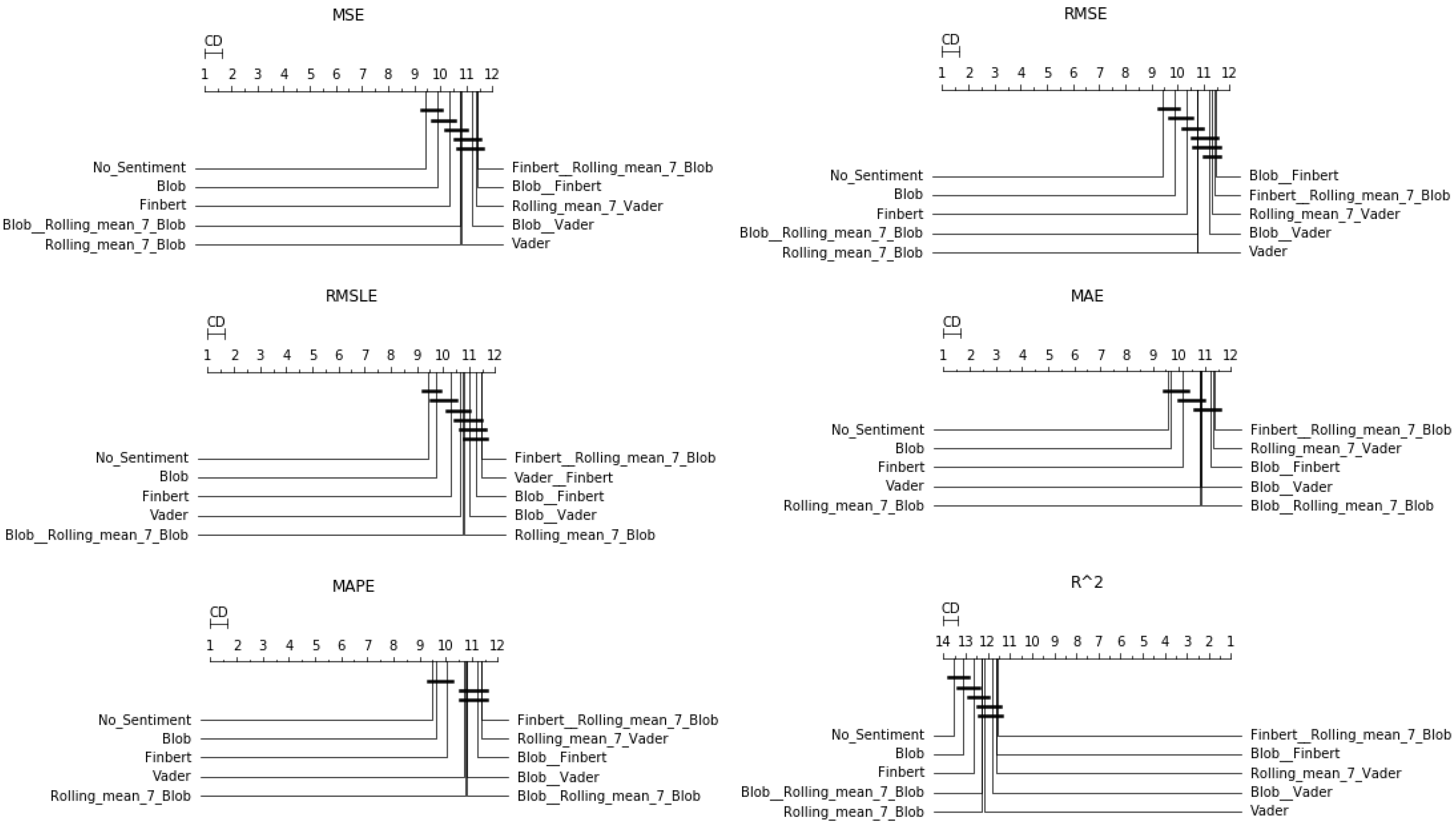
In particular, in four of the measurements used, FinBERT seemed to be superior, while in the other two, the combination of FinBERT with TextBlob lied in the first place of the ranking. Apart from that, Vader, Blob, and the combination of Vader and FinBERT seemed to perform almost equal to the above, as the differences in their corresponding rankings were minimal. In addition, regarding the use of rolling means, there seemed to be no particular improvement under the current framework except—in rare cases—when applied in combination with the use of a raw sentiment score. The only one of the representations of the results where the univariate configuration is presented in high positions is via boxplots, where the sorting of the layout is only based on the median of the values. In terms of Friedman scores, at best, it ranked sixth.
4.1.3. Two-Week Prediction
Results from the fourteen-day forecasts exhibited similar behavior as in the seven-day prediction case, except for the performance of the averaging schemes, some of which tended to move up to higher positions. Indeed, here, again, Friedman’s ranking in all evaluations seemed to suggest that the use of information extracted from social networks is beneficial under the current forecasting framework. In addition, there was an apparent improvement in schemes exploiting rolling means. This becomes easily noticeable in both
Figure 7 and
Figure 8, showing the CD-diagrams and boxplots, respectively, and in
Table A4. One can observe the configuration of TextBlob that incorporates the weekly rolling mean to be in the first place of the Friedman ranking in terms of three valuations, that is in terms of the RMSE, MAE, and MAPE metrics. Thus, apart from the conclusions that can be drawn from the study of the representations of the results and that constitute evaluations similar in form to those of the above cases, something new seemed to emerge here: there was a gradual increase in the performance of the combinations that use weighted information. Moreover, this increase in performance seemed to be related to the long forecast period.
4.2. Case Study: Methods’ Comparison
We can now turn to the presentation of the results of the comparison of the algorithms. The reader is first asked to refer to
Table 2, containing the methods with their respective abbreviations, as well as to
Table A5,
Table A6 and
Table A7, containing the Friedman rankings. The Friedman rankings here are structured as a generalization derived from the performance of each algorithm in terms of each dataset and under each of the 22 input schemes.
4.2.1. One-Day Prediction
Starting with the simple one-day prediction, from the results presented in
Table A5 and in
Figure 9 and
Figure 10, one can easily conclude an almost universal predominance of LSTM methods.
Regarding the three best-performing methods, the CD-diagrams show a statistical dependence between the LSTM and Bi-LSTM methods, while the scheme incorporating both the above algorithmic processes in a stacked configuration is presented as statistically independent of all. This supposed independence, and according to what has been reported about how these diagrams are derived, can easily be identified in the differences in the results of the Friedman table, where the deviations between the methods are significant.
The latter is eminent in the boxplots as well. Both the dispersion and the values of the evaluations of the top-three methods stand out clearly from those of all the other techniques.
4.2.2. One-Week Prediction
It can be observed that the same interpretation applies in the case of weekly forecasts. Again, in all metrics, the top-three best-performing methods were the three LSTM variants (
Figure 11).
Table A6 depicts both the latter and the distinctions presented on the CD-diagrams of
Figure 12. Essentially, however, a simple comparison of the representations of the results showed that in all cases, the predominant methods were by far the LSTM and Bi-LSTM procedures.
In the boxplots, despite the fact that the LSTM variants appear as if they tend to form a group of similarly performing methods, the Friedman scores point to the independence—in terms of the evaluation of numerical outputs—of only the top-two aforementioned methods from all the others. Thus, based on these results, it is relatively easy to suggest a clear choice of strategy in terms of methods.
4.2.3. Two-Week Prediction
Finally, regarding the case of the 14-day forecasts, the general remarks given in the previous section can be extended here as well. The results can be found below, in
Figure 13 and
Figure 14, as well as in
Table A7.
An additional final remark, however, should be the following: in the boxplots, in the results of the , there seems to be a difference in the median ranking. This ranking, however, was not found in the case of the Friedman scores.
4.3. Discussion
Having presented the results, below are some general remarks. Here, the following discussion is structured according to the bilateral distinction of the case studies presented and contains summarizing comments regarding elements that preceded:
Sentiment setups: The main point that emerged from the above results has to do with the fact that the use of sentiment analysis seemed to improve the models when used for long-term predictions. Thus, while the use of the univariate configuration is seen as more efficient in one-step predictions, when the predictions applied to the seven-day and fourteen-day cases, the use of sentiment scores under a multivariate topology seemed to improve the forecasts overall. Specifically, in the weekly forecasts, all three single-sentiment-score setups outperformed the use of the univariate configuration, with FinBERT performing best in terms of the MSE, RMSE, RMSLE, and , while the combination of Blob and FinBERT outperformed the rest in the MAE and MAPE. When the prediction shift doubles to 14 days, one notices that Blob and Rolling Mean 7 Blob dominated the other sentiment configurations, followed by the combination of Blob and FinBERT, as well as FinBERT. Vader appeared to rank lower in all metrics and was, therefore, weaker than in the previous two cases.
However, two general questions need to and can be answered by looking at the results. These are not about choosing an algorithm, as one can assume that in a working scenario where reliable predictions would be needed, one would have a number of methods at one’s disposal. Thus, this is a query about a reliable methodology. Therefore, first of all, one should evaluate whether the use of sentiment scores helps and, if so, in which cases. Second, an answer must be provided as to what form the sentiment score time series should have depending on the forecasting case. Regarding the first question, the answer seems to be clear: multivariate configurations improve forecasts in non-trivial forecast cases. As for the second one, it seems that, in cases of long-term forecasts, an argument in favor of the use of rolling mean can be substantiated. Concluding, it should be noted that when the forecast window grows, then even seemingly small improvements, such as those seen through the use of sentiment analysis, can be of particular importance;
Algorithms: As for the algorithms, the comparisons seemed to provide direct and clear interpretations. From the results here, it is also possible to safely substantiate—at least—a central conclusion. It is apparent that in all scenarios, the configurations exploiting neural networks—that is, LSTM variations—were superior in terms of performance to the classical regression algorithms. Among them, LSTM outperformed the BiLSTM architecture in every single case, while the stacked combination of the two followed. In addition, the aforementioned superiority of the two dominant methods was clear, with their performance forming a threshold, below which—and at a considerable distance—all the other methods examined were placed. Therefore, concluding, if one considers that the neural network architectures used did not contain sophisticated configurations—in terms of, for example, depth—then, on the basis that any additional computational costs become negligible, the use of LSTMs constitutes the clear choice.
5. Conclusions
In this work, a study of the exploitation of sentiment scores in various multivariate time-series-forecasting schemes regarding financial data was conducted. The overall structure and results of an extensive experimental procedure were presented, in which 22 different input configurations were tested, utilizing information extracted from social networks, in a total of 16 different datasets, using 27 different algorithms. The survey consisted of two case studies, the first of which was to investigate the performance of various multivariate time series forecasting schemes utilizing sentiment analysis and the second to compare the performance of a large number of machine-learning algorithms using the aforementioned multivariate input setups.
From the results, and in relation to the first case study, that is, after the use of sentiment analysis configurations, a conditional performance improvement can be safely deduced in cases where the methods were applied to predict long-term time frames. Of all the sentiment score combinations tested, the TextBlob and FinBERT variations generally appeared to perform best. In addition, there was a gradual improvement in the performance of combinations containing rolling averages as the forecast window grew. This may imply that a broader study of the use of different versions of the same time series in a range of different multivariate configurations may reveal methodological strategies as to how to exploit input data manipulations to increase accuracy.
Regarding the second case study, the results indicated a clear predominance of LSTM variations. In particular, this superiority became even clearer in terms of its generalization when the basic configurations of the architectures used in the neural networks under consideration were taken into account, which means that any computational cost cannot be a counterweight to the dominance of the LSTM methods.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













