




Sensors 2023, 23(19), 8103; https://doi.org/10.3390/s23198103 - 27 Sep 2023
Viewed by 849
Abstract
►
Show Figures
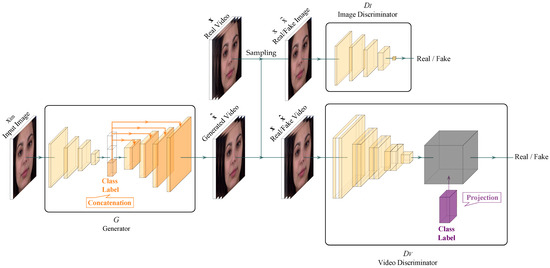
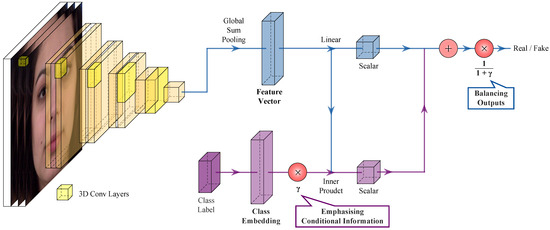
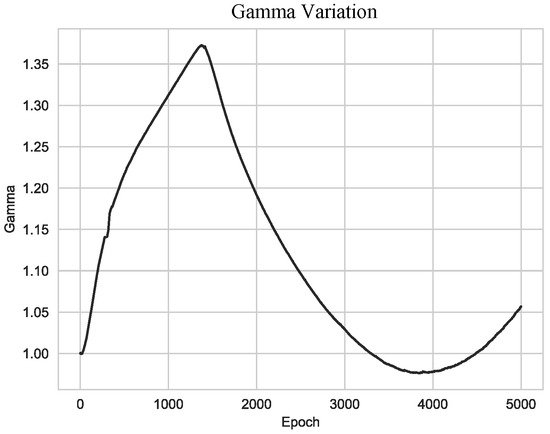
In this paper, we propose a new model for conditional video generation (GammaGAN). Generally, it is challenging to generate a plausible video from a single image with a class label as a condition. Traditional methods based on conditional generative adversarial networks (cGANs) often
[...] Read more.
In this paper, we propose a new model for conditional video generation (GammaGAN). Generally, it is challenging to generate a plausible video from a single image with a class label as a condition. Traditional methods based on conditional generative adversarial networks (cGANs) often encounter difficulties in effectively utilizing a class label, typically by concatenating a class label to the input or hidden layer. In contrast, the proposed GammaGAN adopts the projection method to effectively utilize a class label and proposes scaling class embeddings and normalizing outputs. Concretely, our proposed architecture consists of two streams: a class embedding stream and a data stream. In the class embedding stream, class embeddings are scaled to effectively emphasize class-specific differences. Meanwhile, the outputs in the data stream are normalized. Our normalization technique balances the outputs of both streams, ensuring a balance between the importance of feature vectors and class embeddings during training. This results in enhanced video quality. We evaluated the proposed method using the MUG facial expression dataset, which consists of six facial expressions. Compared with the prior conditional video generation model, ImaGINator, our model yielded relative improvements of 1.61%, 1.66%, and 0.36% in terms of PSNR, SSIM, and LPIPS, respectively. These results suggest potential for further advancements in conditional video generation.
Full article
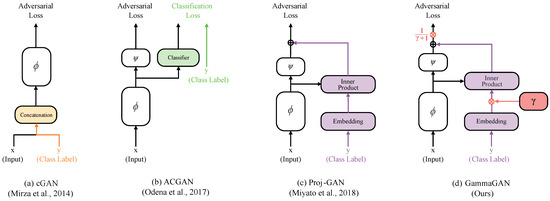
Figure 1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}