Extravaganza Feature Papers on Hot Topics in Machine Learning and Knowledge Extraction
Share This Topical Collection
Editor
 Prof. Dr. Andreas Holzinger
Prof. Dr. Andreas Holzinger
Prof. Dr. Andreas Holzinger
E-Mail
Website
Collection Editor
1. Human-Centered AI Lab, Institute of Forest Engineering, Department of Forest and Soil Sciences, University of Natural Resources and Life Sciences, 1190 Vienna, Austria
2. xAI Lab, Alberta Machine Intelligence Institute, University of Alberta, Edmonton, AB T5J 3B1, Canada
Interests: human-centered AI; explainable AI; interactive machine-learning; decision support; trustworthy AI
Special Issues, Collections and Topics in MDPI journals
Topical Collection Information
Dear Colleagues,
As Editors-in-Chief of MAKE, we are pleased to announce a call for papers for the upcoming Feature Papers Topical Collection. This is a collection of high-quality open access papers written by Editorial Board Members or those invited by the editorial office and the Editor-in-Chief. Submitted work should take the form of long research papers (or survey or review papers) with a full and detailed summary of the author’s own work carried out so far.
Papers accepted for this Special Issue will be published free of charge in open access format. You are welcome to send short proposals for submissions of feature papers to our Editorial Office (make@mdpi.com).
Prof. Dr. Andreas Holzinger
Collection Editor
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. Manuscripts can be submitted until the deadline. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the collection website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 100 words) can be sent to the Editorial Office for announcement on this website.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-blind peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Machine Learning and Knowledge Extraction is an international peer-reviewed open access quarterly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript.
The Article Processing Charge (APC) for publication in this open access journal is 1800 CHF (Swiss Francs).
Submitted papers should be well formatted and use good English. Authors may use MDPI's
English editing service prior to publication or during author revisions.
Published Papers (13 papers)
Open AccessArticle
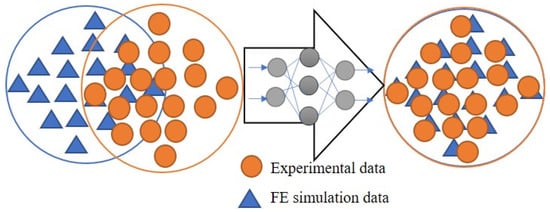
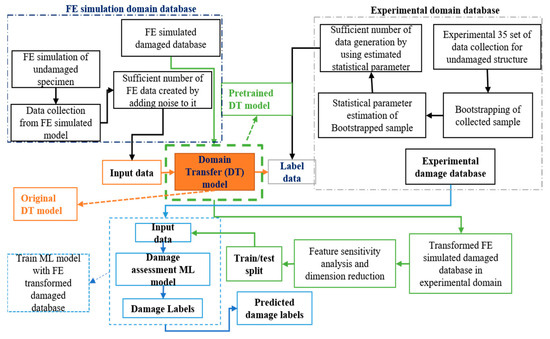
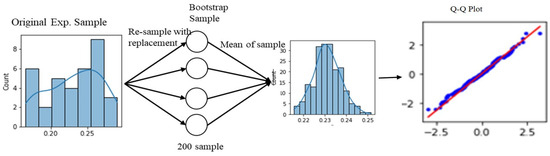
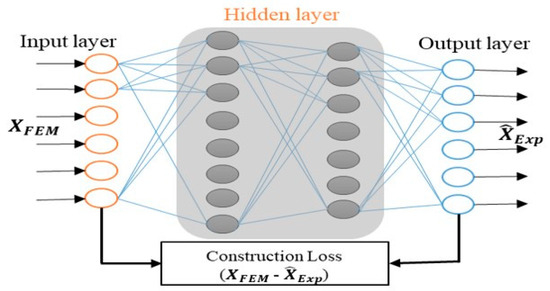
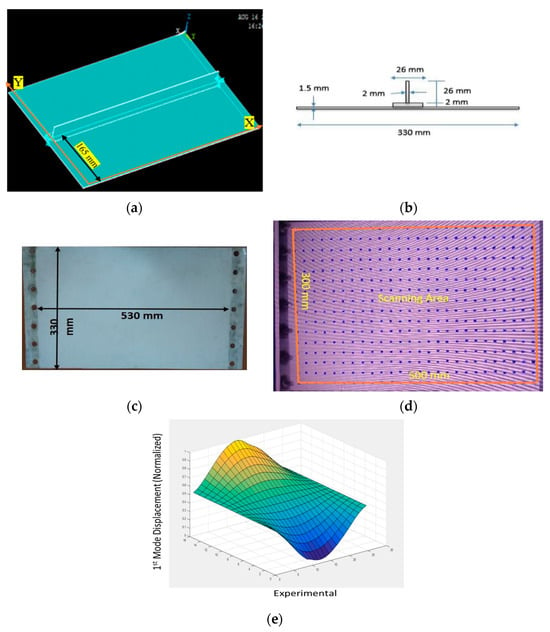
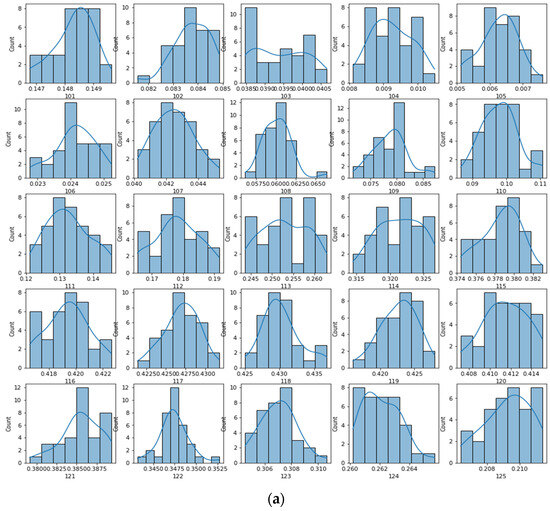
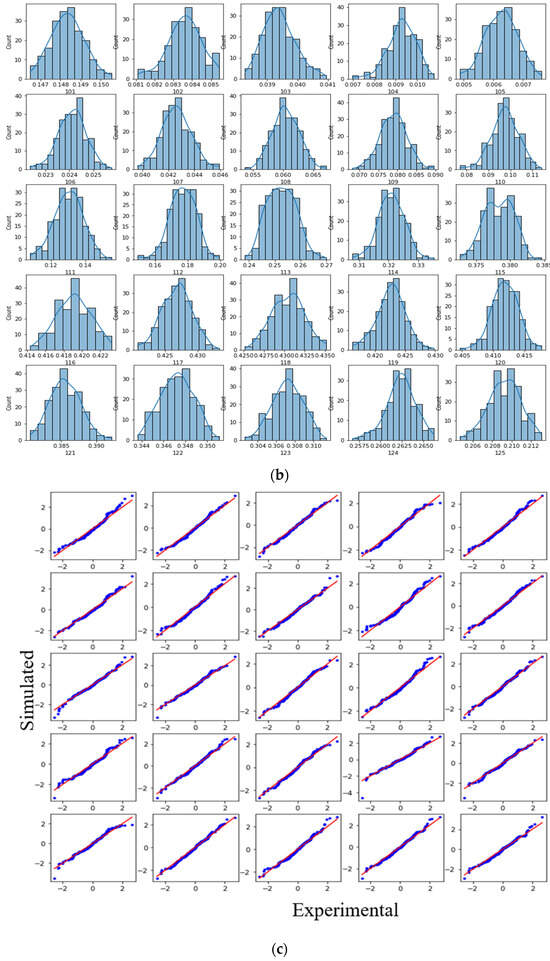
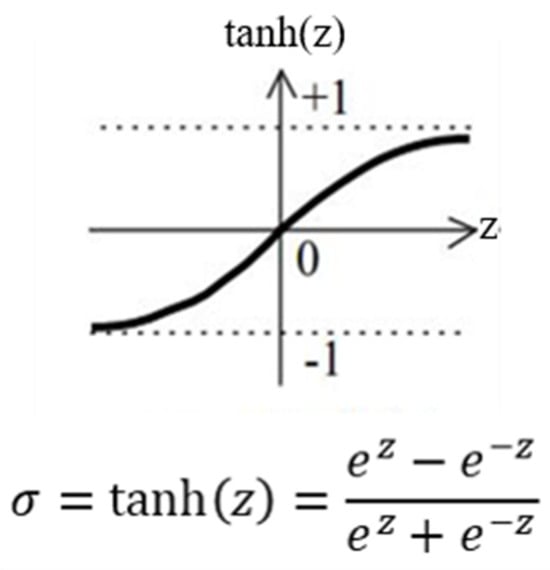
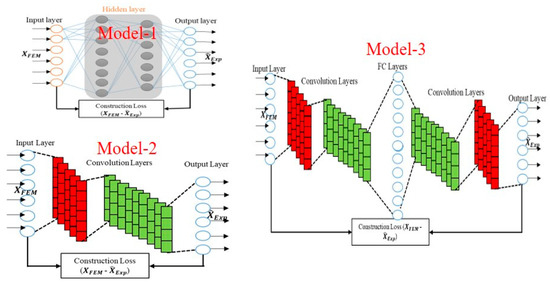
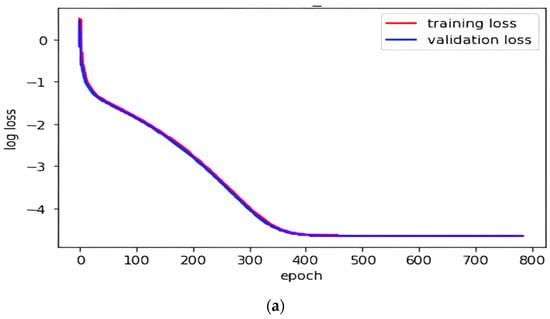
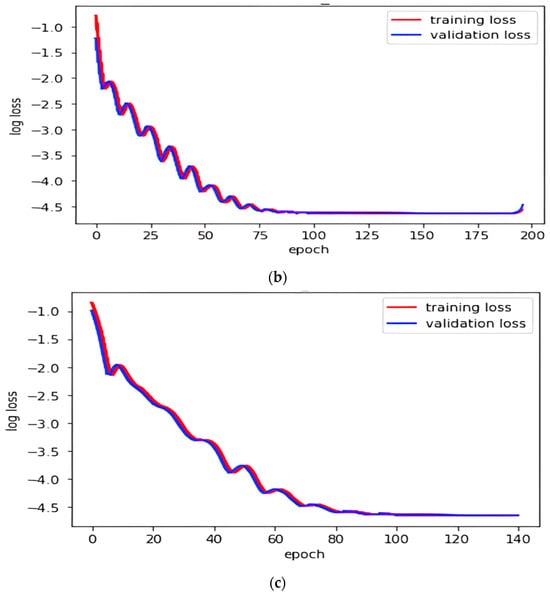
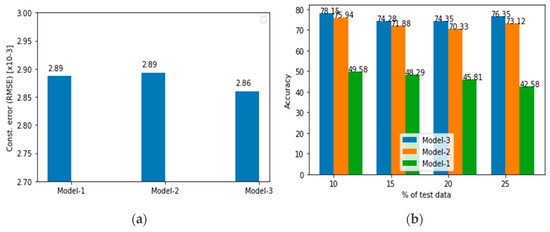
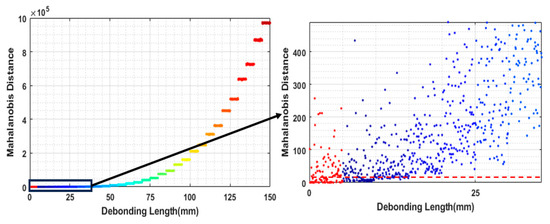
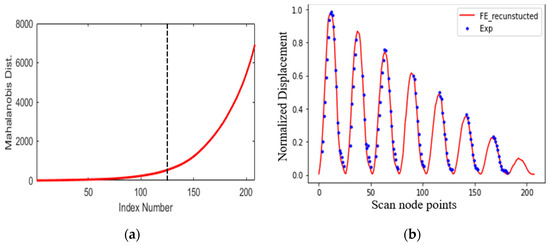
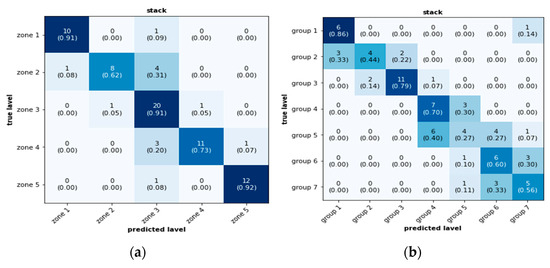
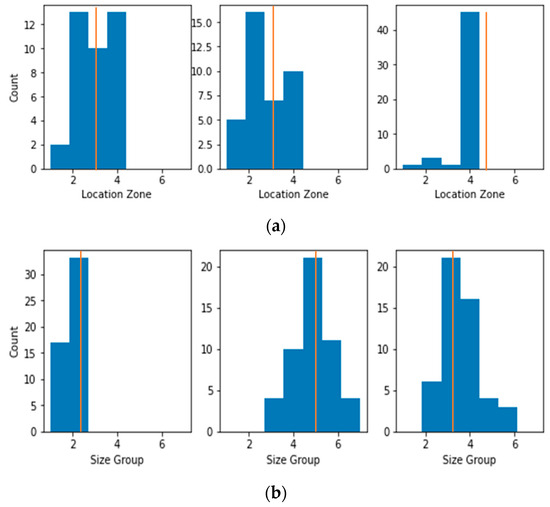
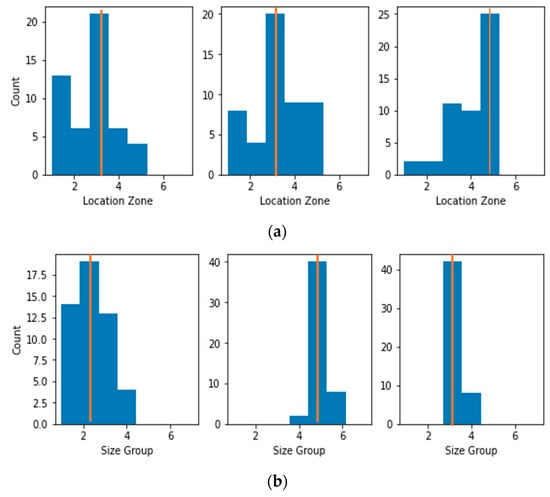
Transforming Simulated Data into Experimental Data Using Deep Learning for Vibration-Based Structural Health Monitoring
by
Abhijeet Kumar, Anirban Guha and Sauvik Banerjee
Viewed by 1662
Abstract
While machine learning (ML) has been quite successful in the field of structural health monitoring (SHM), its practical implementation has been limited. This is because ML model training requires data containing a variety of distinct instances of damage captured from a real structure
[...] Read more.
While machine learning (ML) has been quite successful in the field of structural health monitoring (SHM), its practical implementation has been limited. This is because ML model training requires data containing a variety of distinct instances of damage captured from a real structure and the experimental generation of such data is challenging. One way to tackle this issue is by generating training data through numerical simulations. However, simulated data cannot capture the bias and variance of experimental uncertainty. To overcome this problem, this work proposes a deep-learning-based domain transformation method for transforming simulated data to the experimental domain. Use of this technique has been demonstrated for debonding location and size predictions of stiffened panels using a vibration-based method. The results are satisfactory for both debonding location and size prediction. This domain transformation method can be used in any field in which experimental data for training machine-learning models is scarce.
Full article
►▼
Show Figures
Open AccessArticle
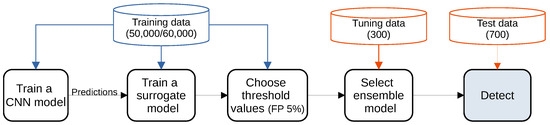
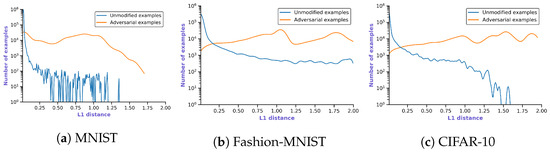
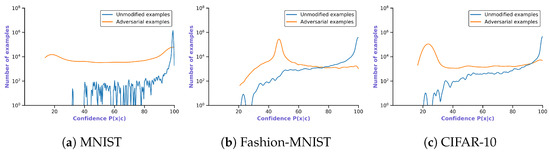
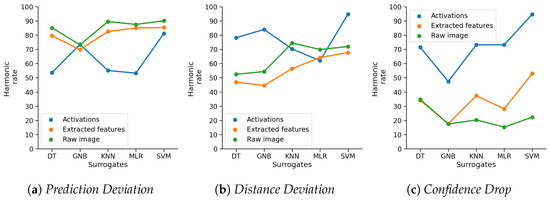
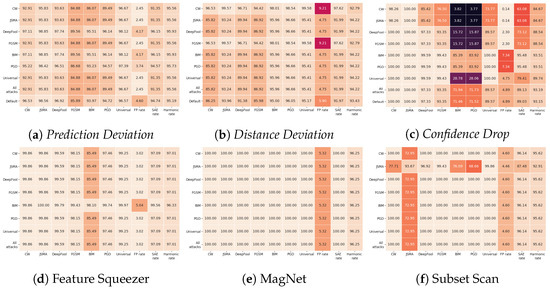
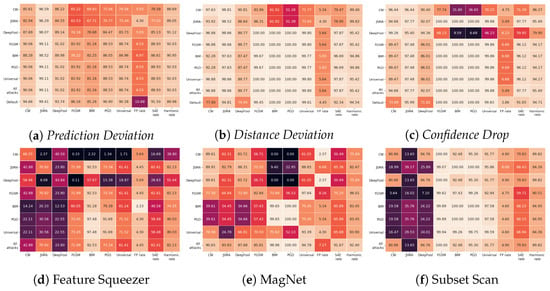
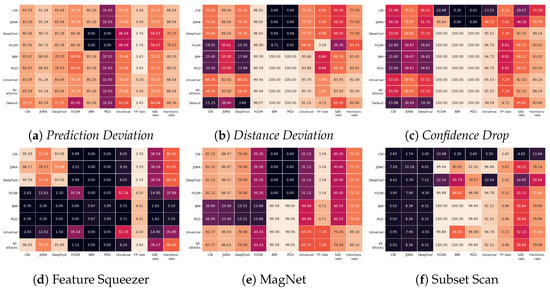
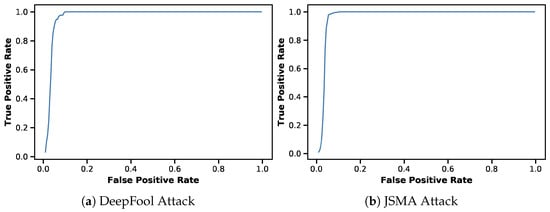
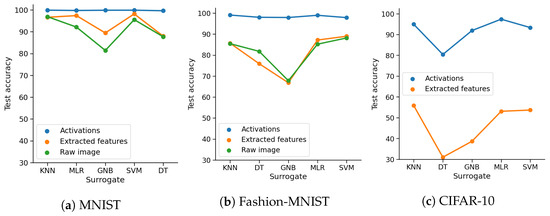
Detecting Adversarial Examples Using Surrogate Models
by
Borna Feldsar, Rudolf Mayer and Andreas Rauber
Viewed by 1628
Abstract
Deep Learning has enabled significant progress towards more accurate predictions and is increasingly integrated into our everyday lives in real-world applications; this is true especially for Convolutional Neural Networks (CNNs) in the field of image analysis. Nevertheless, it has been shown that Deep
[...] Read more.
Deep Learning has enabled significant progress towards more accurate predictions and is increasingly integrated into our everyday lives in real-world applications; this is true especially for Convolutional Neural Networks (CNNs) in the field of image analysis. Nevertheless, it has been shown that Deep Learning is vulnerable against well-crafted, small perturbations to the input, i.e.,
adversarial examples. Defending against such attacks is therefore crucial to ensure the proper functioning of these models—especially when autonomous decisions are taken in safety-critical applications, such as autonomous vehicles. In this work, shallow machine learning models, such as Logistic Regression and Support Vector Machine, are utilised as
surrogates of a CNN based on the assumption that they would be differently affected by the minute modifications crafted for CNNs. We develop three detection strategies for adversarial examples by analysing differences in the prediction of the surrogate and the CNN model: namely, deviation in (i) the prediction, (ii) the distance of the predictions, and (iii) the confidence of the predictions. We consider three different feature spaces: raw images, extracted features, and the activations of the CNN model. Our evaluation shows that our methods achieve state-of-the-art performance compared to other approaches, such as Feature Squeezing, MagNet, PixelDefend, and Subset Scanning, on the MNIST, Fashion-MNIST, and CIFAR-10 datasets while being robust in the sense that they do not entirely fail against selected single attacks. Further, we evaluate our defence against an adaptive attacker in a grey-box setting.
Full article
►▼
Show Figures
Open AccessArticle
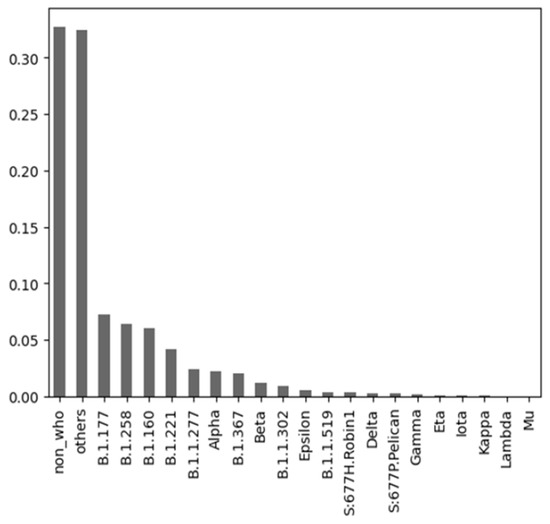
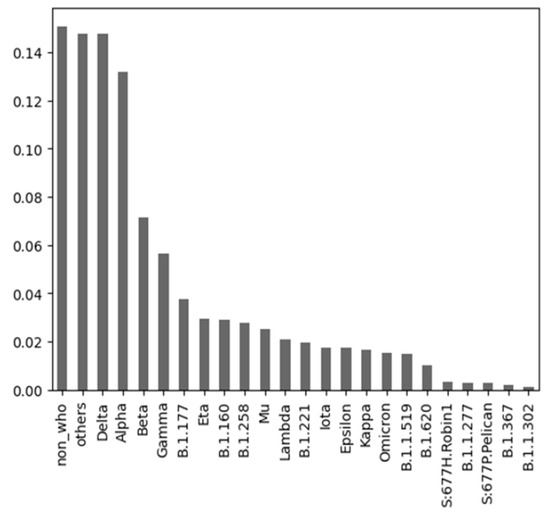
Unraveling COVID-19 Dynamics via Machine Learning and XAI: Investigating Variant Influence and Prognostic Classification
by
Oliver Lohaj, Ján Paralič, Peter Bednár, Zuzana Paraličová and Matúš Huba
Cited by 1 | Viewed by 1633
Abstract
Machine learning (ML) has been used in different ways in the fight against COVID-19 disease. ML models have been developed, e.g., for diagnostic or prognostic purposes and using various modalities of data (e.g., textual, visual, or structured). Due to the many specific aspects
[...] Read more.
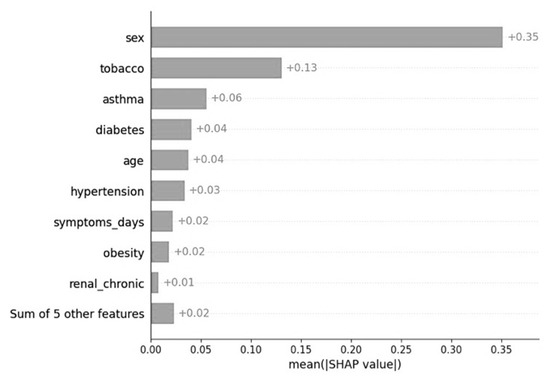
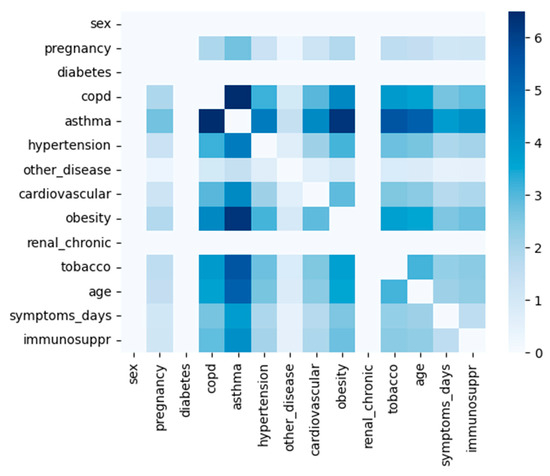
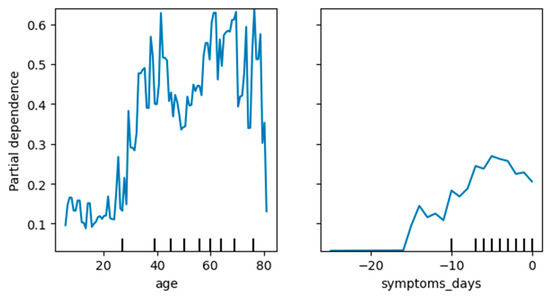
Machine learning (ML) has been used in different ways in the fight against COVID-19 disease. ML models have been developed, e.g., for diagnostic or prognostic purposes and using various modalities of data (e.g., textual, visual, or structured). Due to the many specific aspects of this disease and its evolution over time, there is still not enough understanding of all relevant factors influencing the course of COVID-19 in particular patients. In all aspects of our work, there was a strong involvement of a medical expert following the human-in-the-loop principle. This is a very important but usually neglected part of the ML and knowledge extraction (KE) process. Our research shows that explainable artificial intelligence (XAI) may significantly support this part of ML and KE. Our research focused on using ML for knowledge extraction in two specific scenarios. In the first scenario, we aimed to discover whether adding information about the predominant COVID-19 variant impacts the performance of the ML models. In the second scenario, we focused on prognostic classification models concerning the need for an intensive care unit for a given patient in connection with different explainability AI (XAI) methods. We have used nine ML algorithms, namely XGBoost, CatBoost, LightGBM, logistic regression, Naive Bayes, random forest, SGD, SVM-linear, and SVM-RBF. We measured the performance of the resulting models using precision, accuracy, and AUC metrics. Subsequently, we focused on knowledge extraction from the best-performing models using two different approaches as follows: (a) features extracted automatically by forward stepwise selection (FSS); (b) attributes and their interactions discovered by model explainability methods. Both were compared with the attributes selected by the medical experts in advance based on the domain expertise. Our experiments showed that adding information about the COVID-19 variant did not influence the performance of the resulting ML models. It also turned out that medical experts were much more precise in the identification of significant attributes than FSS. Explainability methods identified almost the same attributes as a medical expert and interesting interactions among them, which the expert discussed from a medical point of view. The results of our research and their consequences are discussed.
Full article
►▼
Show Figures
Open AccessArticle
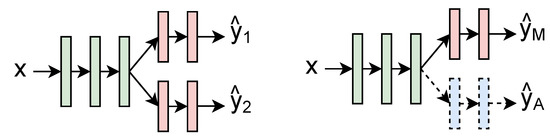
Improving Spiking Neural Network Performance with Auxiliary Learning
by
Paolo G. Cachi, Sebastián Ventura and Krzysztof J. Cios
Viewed by 1823
Abstract
The use of back propagation through the time learning rule enabled the supervised training of deep spiking neural networks to process temporal neuromorphic data. However, their performance is still below non-spiking neural networks. Previous work pointed out that one of the main causes
[...] Read more.
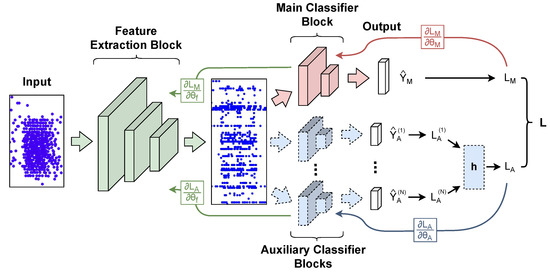
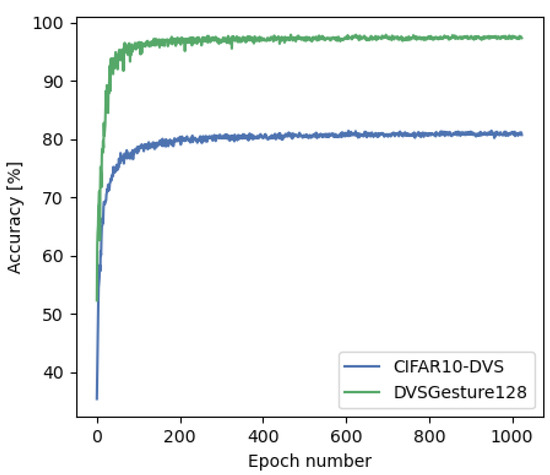
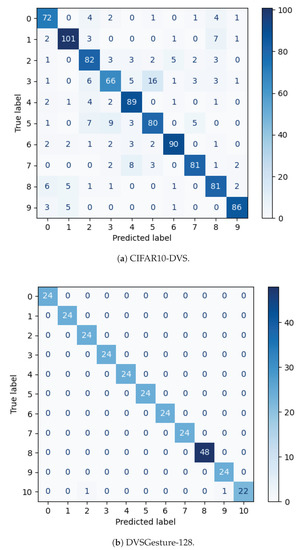
The use of back propagation through the time learning rule enabled the supervised training of deep spiking neural networks to process temporal neuromorphic data. However, their performance is still below non-spiking neural networks. Previous work pointed out that one of the main causes is the limited number of neuromorphic data currently available, which are also difficult to generate. With the goal of overcoming this problem, we explore the usage of auxiliary learning as a means of helping spiking neural networks to identify more general features. Tests are performed on neuromorphic DVS-CIFAR10 and DVS128-Gesture datasets. The results indicate that training with auxiliary learning tasks improves their accuracy, albeit slightly. Different scenarios, including manual and automatic combination losses using implicit differentiation, are explored to analyze the usage of auxiliary tasks.
Full article
►▼
Show Figures
Open AccessArticle
Classification Confidence in Exploratory Learning: A User’s Guide
by
Peter Salamon, David Salamon, V. Adrian Cantu, Michelle An, Tyler Perry, Robert A. Edwards and Anca M. Segall
Viewed by 1333
Abstract
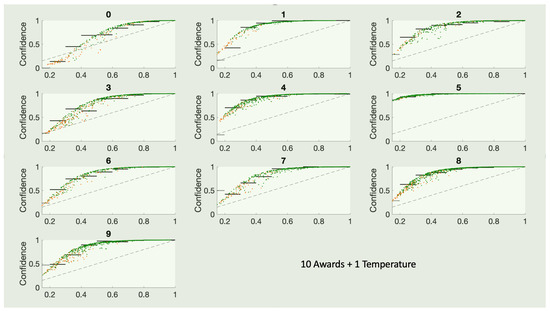
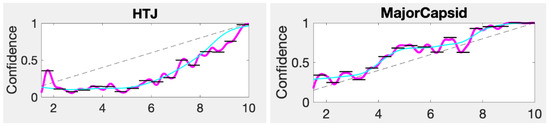
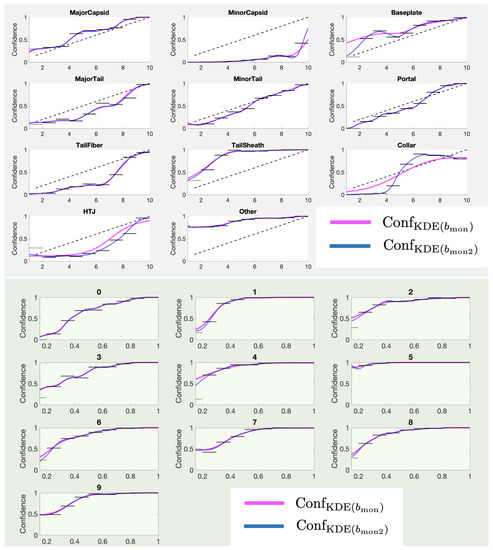
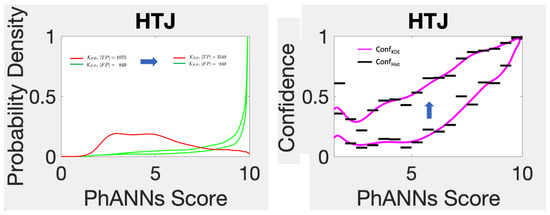
This paper investigates the post-hoc calibration of confidence for “exploratory” machine learning classification problems. The difficulty in these problems stems from the continuing desire to push the boundaries of which categories have enough examples to generalize from when curating datasets, and confusion regarding
[...] Read more.
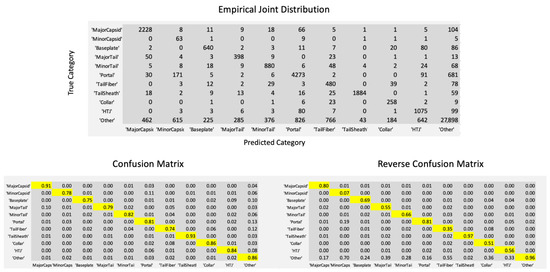
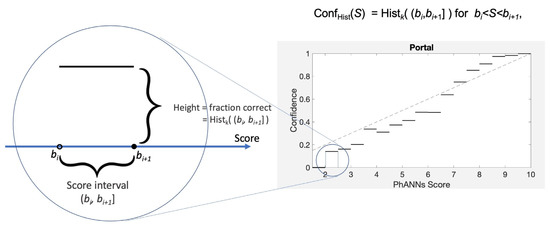
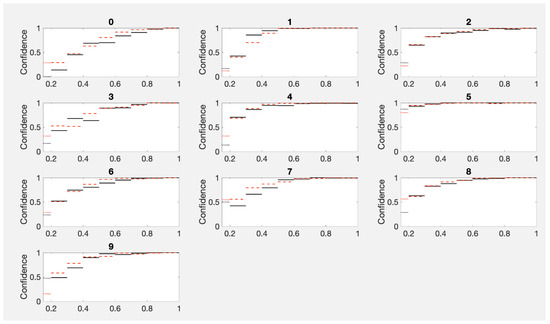
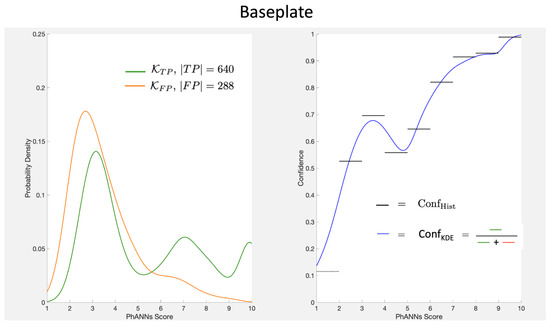
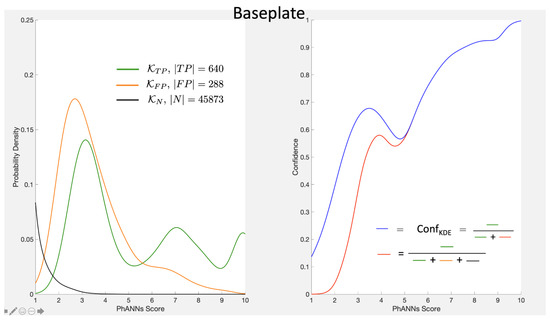
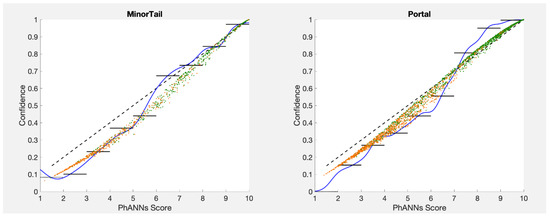
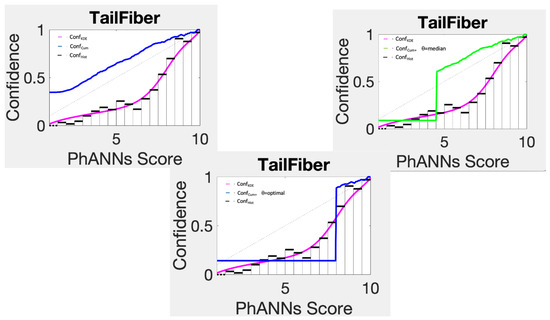
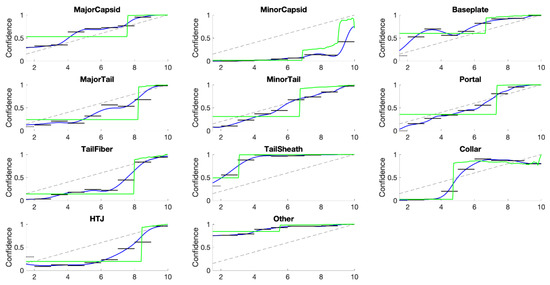
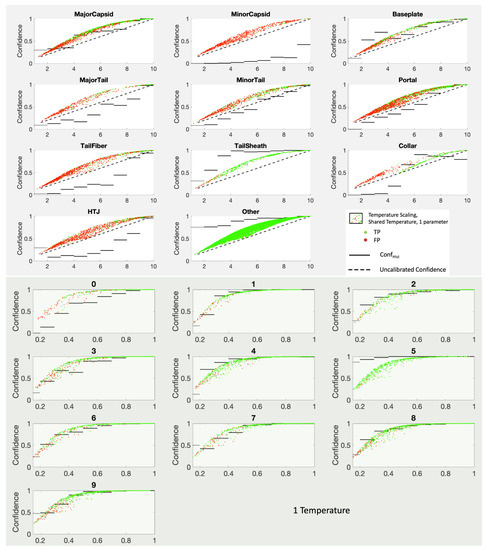
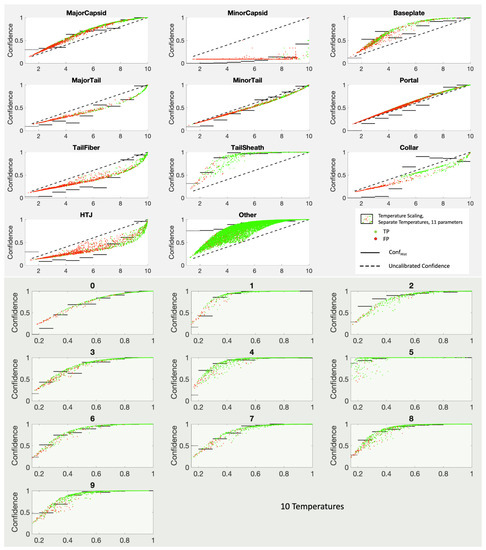
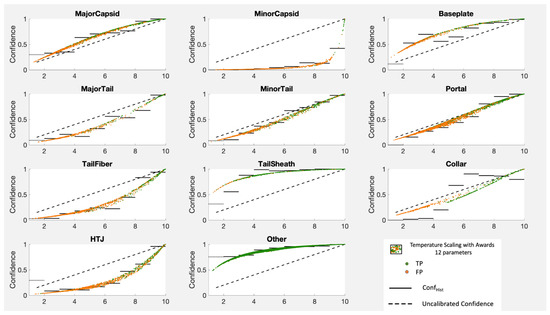
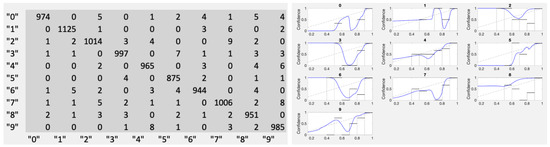
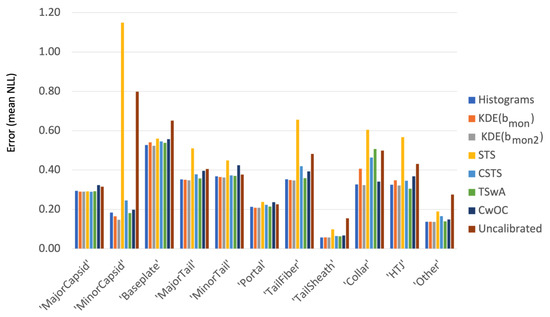
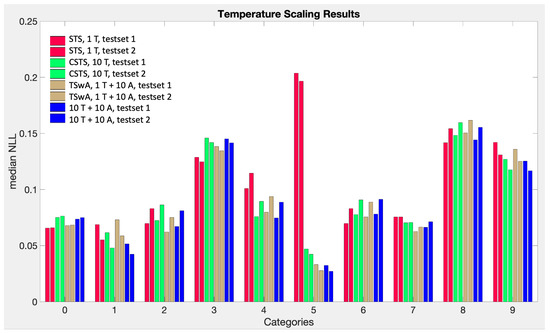
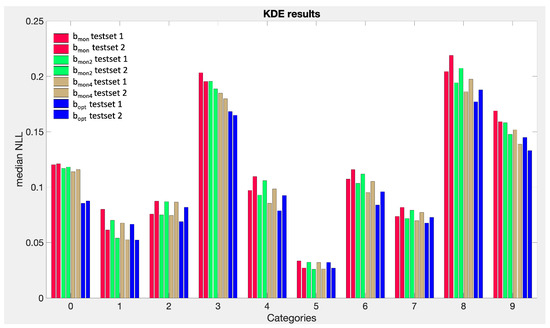
This paper investigates the post-hoc calibration of confidence for “exploratory” machine learning classification problems. The difficulty in these problems stems from the continuing desire to push the boundaries of which categories have enough examples to generalize from when curating datasets, and confusion regarding the validity of those categories. We argue that for such problems the “one-versus-all” approach (top-label calibration) must be used rather than the “calibrate-the-full-response-matrix” approach advocated elsewhere in the literature. We introduce and test four new algorithms designed to handle the idiosyncrasies of category-specific confidence estimation using only the test set and the final model. Chief among these methods is the use of kernel density ratios for confidence calibration including a novel algorithm for choosing the bandwidth. We test our claims and explore the limits of calibration on a bioinformatics application (PhANNs) as well as the classic MNIST benchmark. Finally, our analysis argues that post-hoc calibration should always be performed, may be performed using only the test dataset, and should be sanity-checked visually.
Full article
►▼
Show Figures
Open AccessArticle
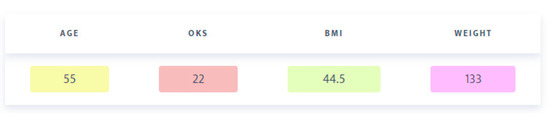
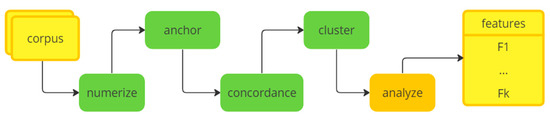
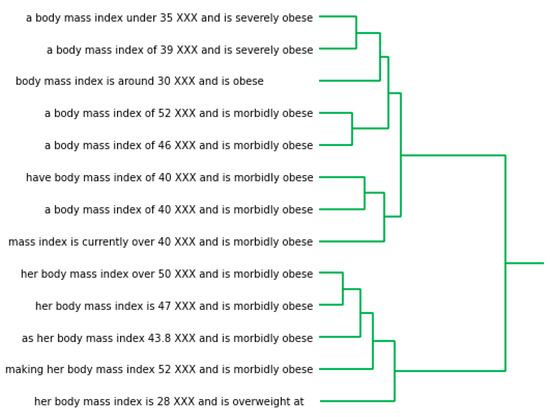
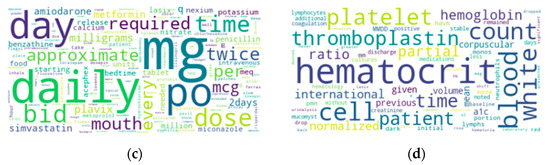
The Value of Numbers in Clinical Text Classification
by
Kristian Miok, Padraig Corcoran and Irena Spasić
Cited by 1 | Viewed by 2015
Abstract
Clinical text often includes numbers of various types and formats. However, most current text classification approaches do not take advantage of these numbers. This study aims to demonstrate that using numbers as features can significantly improve the performance of text classification models. This
[...] Read more.
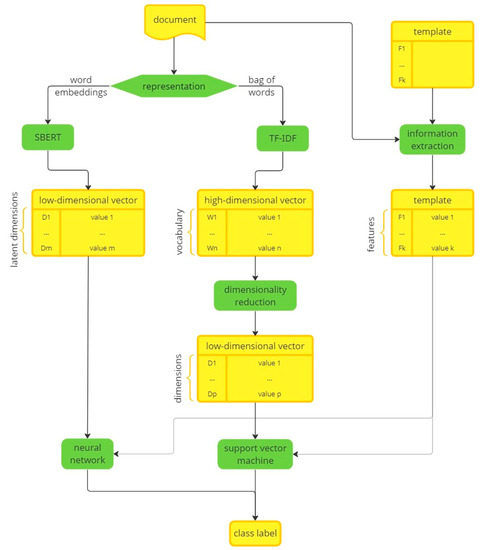
Clinical text often includes numbers of various types and formats. However, most current text classification approaches do not take advantage of these numbers. This study aims to demonstrate that using numbers as features can significantly improve the performance of text classification models. This study also demonstrates the feasibility of extracting such features from clinical text. Unsupervised learning was used to identify patterns of number usage in clinical text. These patterns were analyzed manually and converted into pattern-matching rules. Information extraction was used to incorporate numbers as features into a document representation model. We evaluated text classification models trained on such representation. Our experiments were performed with two document representation models (vector space model and word embedding model) and two classification models (support vector machines and neural networks). The results showed that even a handful of numerical features can significantly improve text classification performance. We conclude that commonly used document representations do not represent numbers in a way that machine learning algorithms can effectively utilize them as features. Although we demonstrated that traditional information extraction can be effective in converting numbers into features, further community-wide research is required to systematically incorporate number representation into the word embedding process.
Full article
►▼
Show Figures
Open AccessArticle
Using Machine Learning with Eye-Tracking Data to Predict if a Recruiter Will Approve a Resume
by
Angel Pina, Corbin Petersheim, Josh Cherian, Joanna Nicole Lahey, Gerianne Alexander and Tracy Hammond
Viewed by 1900
Abstract
When job seekers are unsuccessful in getting a position, they often do not get feedback to inform them on how to develop a better application in the future. Therefore, there is a critical need to understand what qualifications recruiters value in order to
[...] Read more.
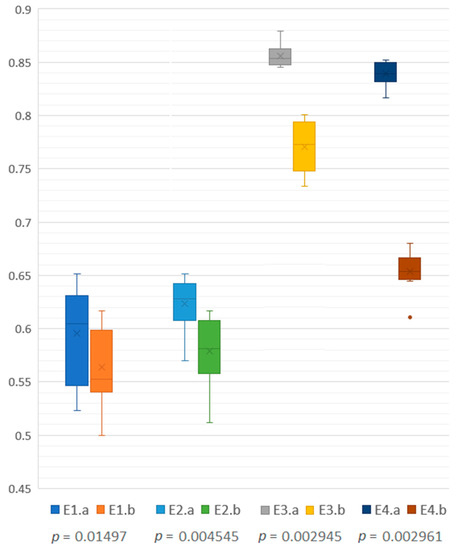
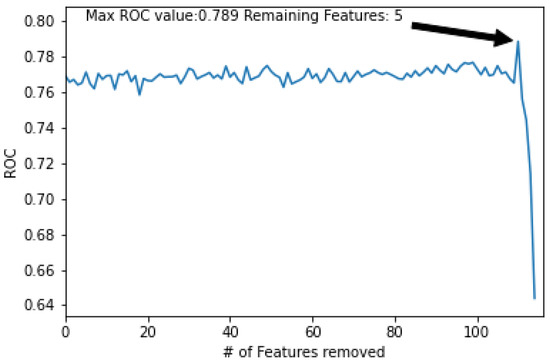
When job seekers are unsuccessful in getting a position, they often do not get feedback to inform them on how to develop a better application in the future. Therefore, there is a critical need to understand what qualifications recruiters value in order to help applicants. To address this need, we utilized eye-trackers to measure and record visual data of recruiters screening resumes to gain insight into which Areas of Interest (AOIs) influenced recruiters’ decisions the most. Using just this eye-tracking data, we trained a machine learning classifier to predict whether or not a recruiter would move a resume on to the next level of the hiring process with an AUC of 0.767. We found that features associated with recruiters looking outside the content of a resume were most predictive of their decision as well as total time viewing the resume and time spent on the Experience and Education sections. We hypothesize that this behavior is indicative of the recruiter reflecting on the content of the resume. These initial results show that applicants should focus on designing clear and concise resumes that are easy for recruiters to absorb and think about, with additional attention given to the Experience and Education sections.
Full article
►▼
Show Figures
Open AccessArticle
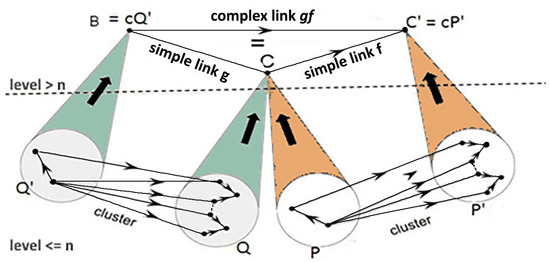
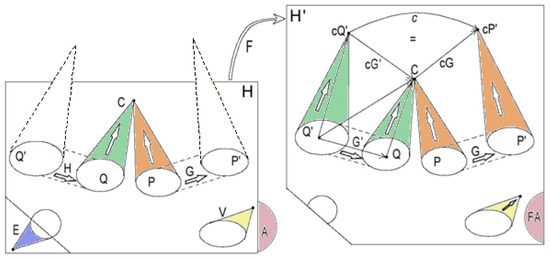
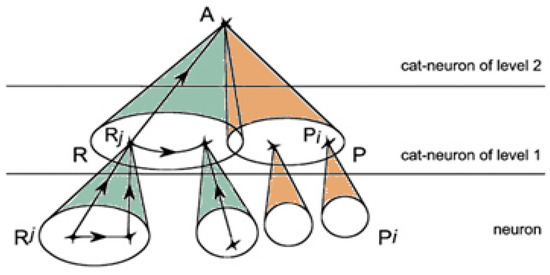
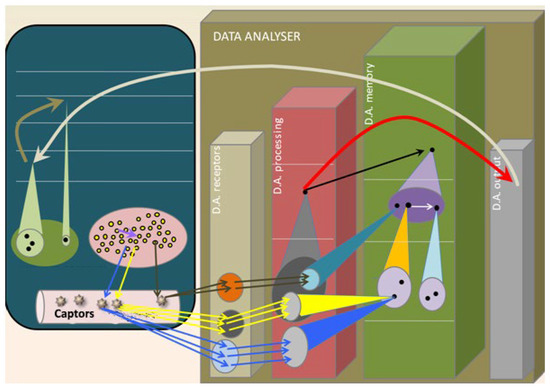
A Mathematical Framework for Enriching Human–Machine Interactions
by
Andrée C. Ehresmann, Mathias Béjean and Jean-Paul Vanbremeersch
Viewed by 1421
Abstract
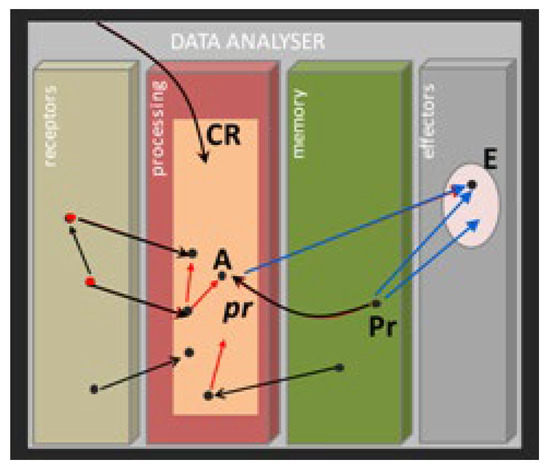
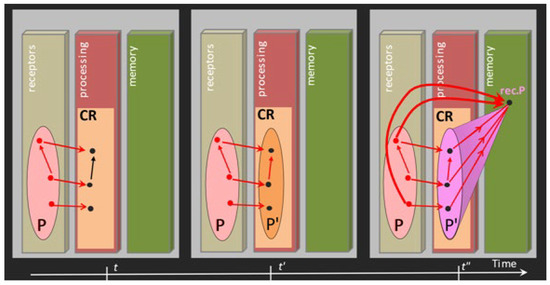
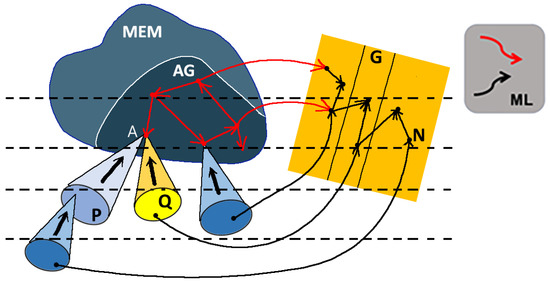
This paper presents a conceptual mathematical framework for developing rich human–machine interactions in order to improve decision-making in a social organisation, S. The idea is to model how S can create a “multi-level artificial cognitive system”, called a data analyser (DA), to collaborate
[...] Read more.
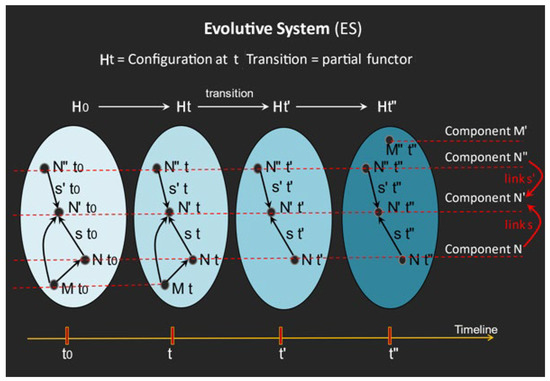
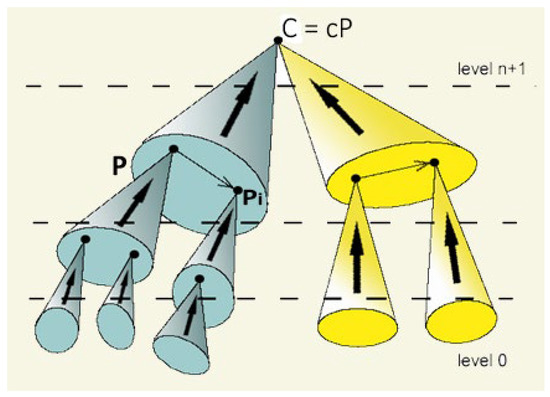
This paper presents a conceptual mathematical framework for developing rich human–machine interactions in order to improve decision-making in a social organisation, S. The idea is to model how S can create a “multi-level artificial cognitive system”, called a data analyser (DA), to collaborate with humans in collecting and learning how to analyse data, to anticipate situations, and to develop new responses, thus improving decision-making. In this model, the DA is “processed” to not only gather data and extend existing knowledge, but also to learn how to act autonomously with its own specific procedures or even to create new ones. An application is given in cases where such rich human–machine interactions are expected to allow the DA+S partnership to acquire deep anticipation capabilities for possible future changes, e.g., to prevent risks or seize opportunities. The way the social organization S operates over time, including the construction of DA, is described using the conceptual framework comprising “memory evolutive systems” (MES), a mathematical theoretical approach introduced by Ehresmann and Vanbremeersch for evolutionary multi-scale, multi-agent and multi-temporality systems. This leads to the definition of a “data analyser–MES”.
Full article
►▼
Show Figures
Open AccessArticle
Multimodal AutoML via Representation Evolution
by
Blaž Škrlj, Matej Bevec and Nada Lavrač
Cited by 2 | Viewed by 2364
Abstract
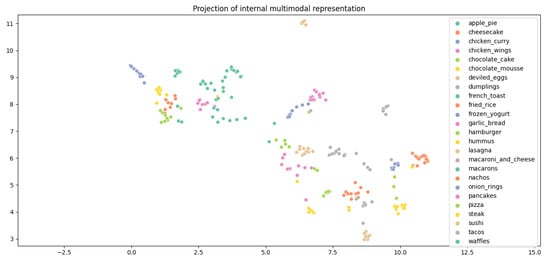
With the increasing amounts of available data, learning simultaneously from different types of inputs is becoming necessary to obtain robust and well-performing models. With the advent of representation learning in recent years, lower-dimensional vector-based representations have become available for both images and texts,
[...] Read more.
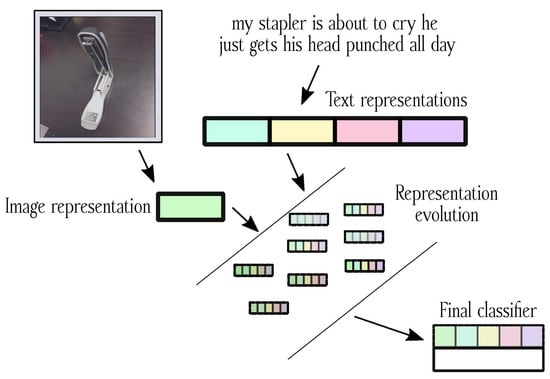
With the increasing amounts of available data, learning simultaneously from different types of inputs is becoming necessary to obtain robust and well-performing models. With the advent of representation learning in recent years, lower-dimensional vector-based representations have become available for both images and texts, while automating simultaneous learning from multiple modalities remains a challenging problem. This paper presents an AutoML (automated machine learning) approach to automated machine learning model configuration identification for data composed of two modalities: texts and images. The approach is based on the idea of representation evolution, the process of automatically amplifying heterogeneous representations across several modalities, optimized jointly with a collection of fast, well-regularized linear models. The proposed approach is benchmarked against 11 unimodal and multimodal (texts and images) approaches on four real-life benchmark datasets from different domains. It achieves competitive performance with minimal human effort and low computing requirements, enabling learning from multiple modalities in automated manner for a wider community of researchers.
Full article
►▼
Show Figures
Open AccessArticle
Ontology Completion with Graph-Based Machine Learning: A Comprehensive Evaluation
by
Sebastian Mežnar, Matej Bevec, Nada Lavrač and Blaž Škrlj
Viewed by 3655
Abstract
Increasing quantities of semantic resources offer a wealth of human knowledge, but their growth also increases the probability of wrong knowledge base entries. The development of approaches that identify potentially spurious parts of a given knowledge base is therefore highly relevant. We propose
[...] Read more.
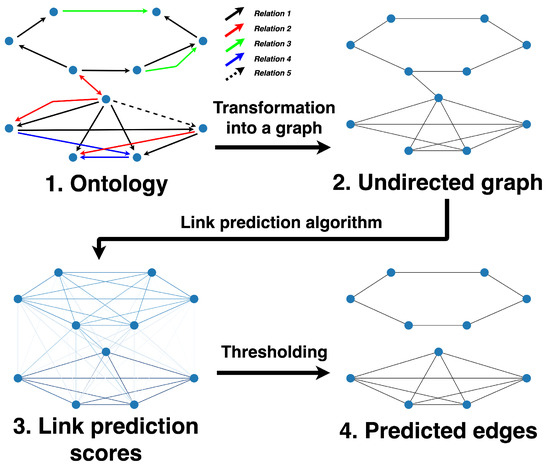
Increasing quantities of semantic resources offer a wealth of human knowledge, but their growth also increases the probability of wrong knowledge base entries. The development of approaches that identify potentially spurious parts of a given knowledge base is therefore highly relevant. We propose an approach for ontology completion that transforms an ontology into a graph and recommends missing edges using structure-only link analysis methods. By systematically evaluating thirteen methods (some for knowledge graphs) on eight different semantic resources, including Gene Ontology, Food Ontology, Marine Ontology, and similar ontologies, we demonstrate that a structure-only link analysis can offer a scalable and computationally efficient ontology completion approach for a subset of analyzed data sets. To the best of our knowledge, this is currently the most extensive systematic study of the applicability of different types of link analysis methods across semantic resources from different domains. It demonstrates that by considering symbolic node embeddings, explanations of the predictions (links) can be obtained, making this branch of methods potentially more valuable than black-box methods.
Full article
►▼
Show Figures
Open AccessFeature PaperArticle
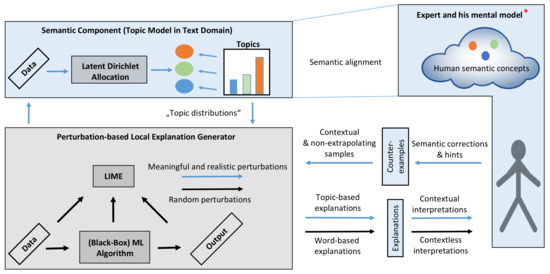
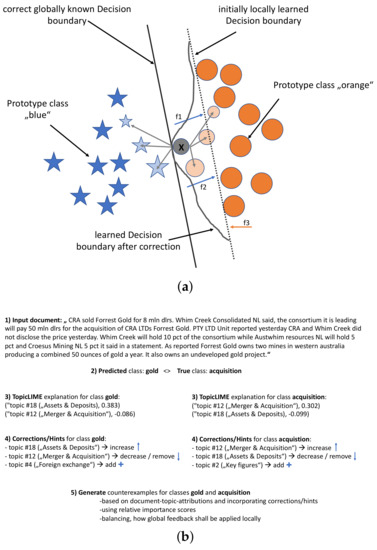
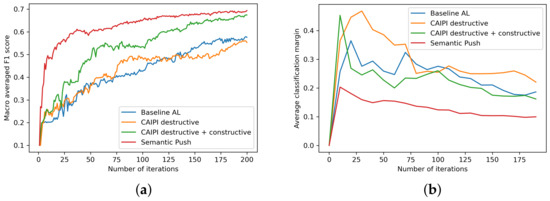
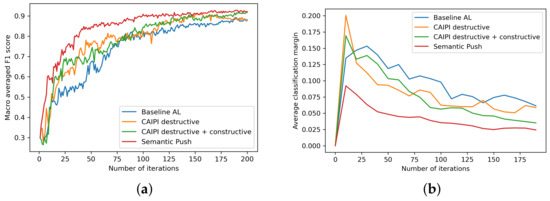
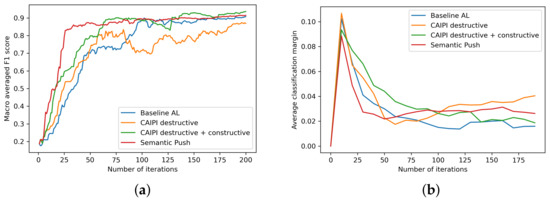
Semantic Interactive Learning for Text Classification: A Constructive Approach for Contextual Interactions
by
Sebastian Kiefer, Mareike Hoffmann and Ute Schmid
Cited by 1 | Viewed by 2091
Abstract
Interactive Machine Learning (IML) can enable intelligent systems to interactively learn from their end-users, and is quickly becoming more and more relevant to many application domains. Although it places the human in the loop, interactions are mostly performed via mutual explanations that miss
[...] Read more.
Interactive Machine Learning (IML) can enable intelligent systems to interactively learn from their end-users, and is quickly becoming more and more relevant to many application domains. Although it places the human in the loop, interactions are mostly performed via mutual explanations that miss contextual information. Furthermore, current model-agnostic IML strategies such as CAIPI are limited to ’destructive’ feedback, meaning that they solely allow an expert to prevent a learner from using irrelevant features. In this work, we propose a novel interaction framework called
Semantic Interactive Learning for the domain of document classification, located at the intersection between Natural Language Processing (NLP) and Machine Learning (ML). We frame the problem of incorporating constructive and contextual feedback into the learner as a task involving finding an architecture that enables more semantic alignment between humans and machines while at the same time helping to maintain the statistical characteristics of the input domain when generating user-defined counterexamples based on meaningful corrections. Therefore, we introduce a technique called SemanticPush that is effective for translating conceptual corrections of humans to non-extrapolating training examples such that the learner’s reasoning is pushed towards the desired behavior. Through several experiments we show how our method compares to CAIPI, a state of the art IML strategy, in terms of Predictive Performance and Local Explanation Quality in downstream multi-class classification tasks. Especially in the early stages of interactions, our proposed method clearly outperforms CAIPI while allowing for contextual interpretation and intervention. Overall, SemanticPush stands out with regard to data efficiency, as it requires fewer queries from the pool dataset to achieve high accuracy.
Full article
►▼
Show Figures
Open AccessFeature PaperArticle
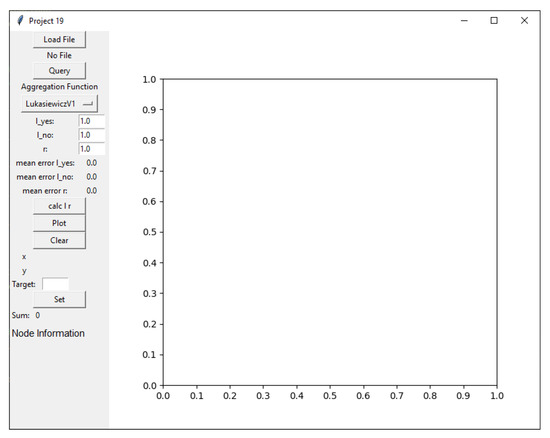
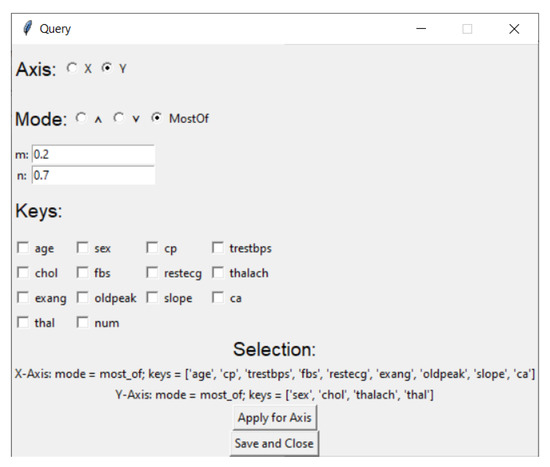
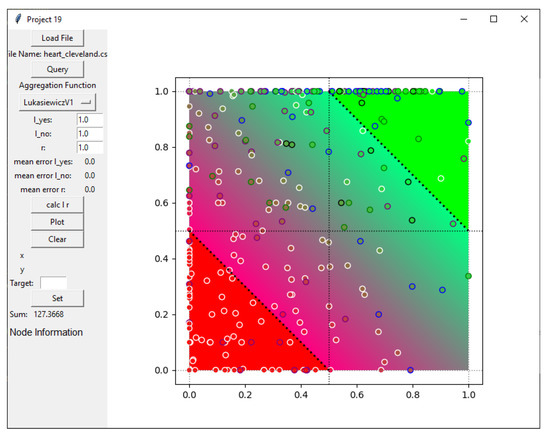
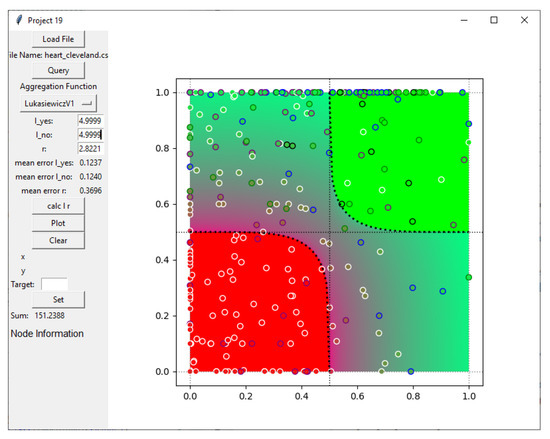
Actionable Explainable AI (AxAI): A Practical Example with Aggregation Functions for Adaptive Classification and Textual Explanations for Interpretable Machine Learning
by
Anna Saranti, Miroslav Hudec, Erika Mináriková, Zdenko Takáč, Udo Großschedl, Christoph Koch, Bastian Pfeifer, Alessa Angerschmid and Andreas Holzinger
Cited by 14 | Viewed by 3375
Abstract
In many domains of our daily life (e.g., agriculture, forestry, health, etc.), both laymen and experts need to classify entities into two binary classes (yes/no, good/bad, sufficient/insufficient, benign/malign, etc.). For many entities, this decision is difficult and we need another class called “maybe”,
[...] Read more.
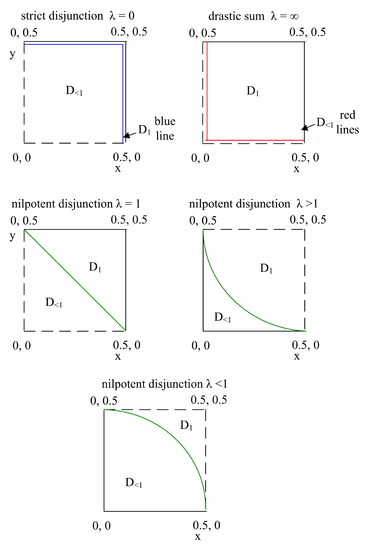
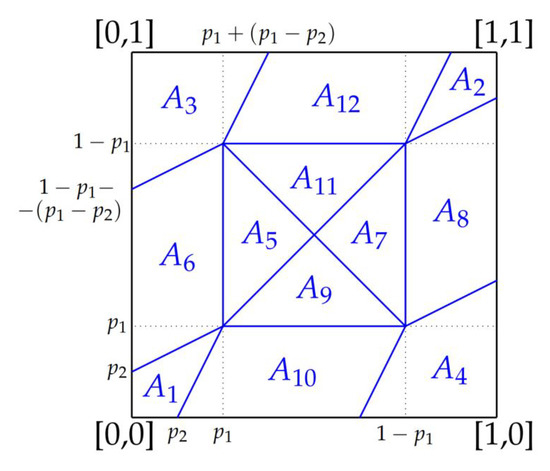
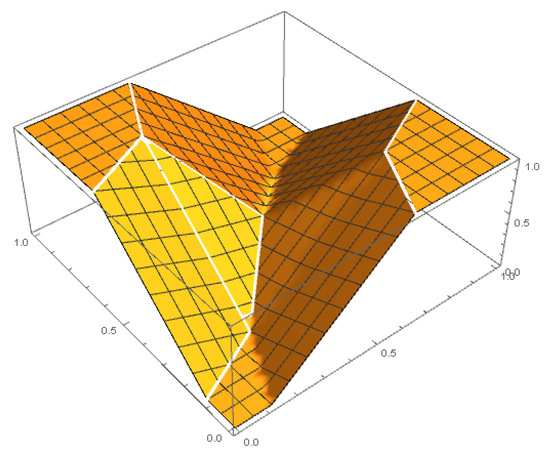
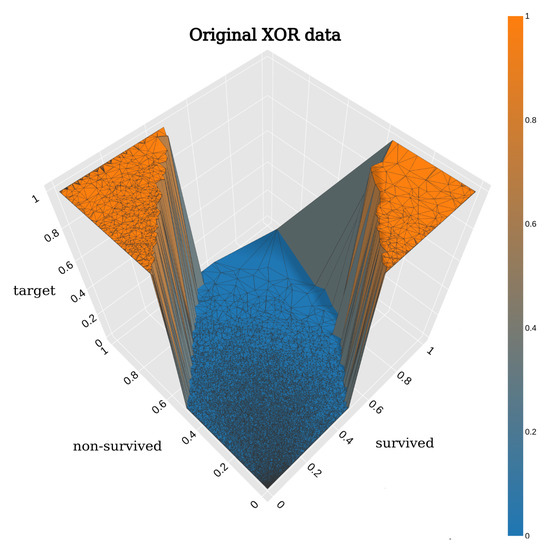
In many domains of our daily life (e.g., agriculture, forestry, health, etc.), both laymen and experts need to classify entities into two binary classes (yes/no, good/bad, sufficient/insufficient, benign/malign, etc.). For many entities, this decision is difficult and we need another class called “maybe”, which contains a corresponding quantifiable tendency toward one of these two opposites. Human domain experts are often able to mark any entity, place it in a different class and adjust the position of the slope in the class. Moreover, they can often explain the classification space linguistically—depending on their individual domain experience and previous knowledge. We consider this human-in-the-loop extremely important and call our approach actionable explainable AI. Consequently, the parameters of the functions are adapted to these requirements and the solution is explained to the domain experts accordingly. Specifically, this paper contains three novelties going beyond the state-of-the-art: (1) A novel method for detecting the appropriate parameter range for the averaging function to treat the slope in the “maybe” class, along with a proposal for a better generalisation than the existing solution. (2) the insight that for a given problem, the family of t-norms and t-conorms covering the whole range of nilpotency is suitable because we need a clear “no” or “yes” not only for the borderline cases. Consequently, we adopted the Schweizer–Sklar family of t-norms or t-conorms in ordinal sums. (3) A new fuzzy quasi-dissimilarity function for classification into three classes: Main difference, irrelevant difference and partial difference. We conducted all of our experiments with real-world datasets.
Full article
►▼
Show Figures
Open AccessReview
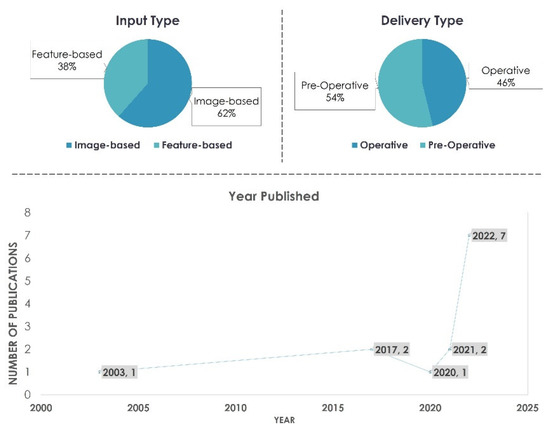
Artificial Intelligence Methods for Identifying and Localizing Abnormal Parathyroid Glands: A Review Study
by
Ioannis D. Apostolopoulos, Nikolaos I. Papandrianos, Elpiniki I. Papageorgiou and Dimitris J. Apostolopoulos
Cited by 4 | Viewed by 2122
Abstract
Background: Recent advances in Artificial Intelligence (AI) algorithms, and specifically Deep Learning (DL) methods, demonstrate substantial performance in detecting and classifying medical images. Recent clinical studies have reported novel optical technologies which enhance the localization or assess the viability of Parathyroid Glands (PG)
[...] Read more.
Background: Recent advances in Artificial Intelligence (AI) algorithms, and specifically Deep Learning (DL) methods, demonstrate substantial performance in detecting and classifying medical images. Recent clinical studies have reported novel optical technologies which enhance the localization or assess the viability of Parathyroid Glands (PG) during surgery, or preoperatively. These technologies could become complementary to the surgeon’s eyes and may improve surgical outcomes in thyroidectomy and parathyroidectomy. Methods: The study explores and reports the use of AI methods for identifying and localizing PGs, Primary Hyperparathyroidism (PHPT), Parathyroid Adenoma (PTA), and Multiglandular Disease (MGD). Results: The review identified 13 publications that employ Machine Learning and DL methods for preoperative and operative implementations. Conclusions: AI can aid in PG, PHPT, PTA, and MGD detection, as well as PG abnormality discrimination, both during surgery and non-invasively.
Full article
►▼
Show Figures




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}