
Multimodal AutoML via Representation Evolution


Abstract
:1. Introduction
- We propose MuRE (Multimodal Representation Evolution), an AutoML system for low-resource multimodal classification based on the idea of representation evolution.
- The proposed system is evaluated on a collection of four real-life multimodal datasets, which include both text and image-based data.
- The performance is compared against strong baselines, such as MobileNets and BERT, including fused inputs of the spaces obtained by such models. Qualitative aspects of the final (evolved) representations are also considered.
- Theoretical properties of MuRE are discussed alongside the current limitations of the approach.
2. Related Work
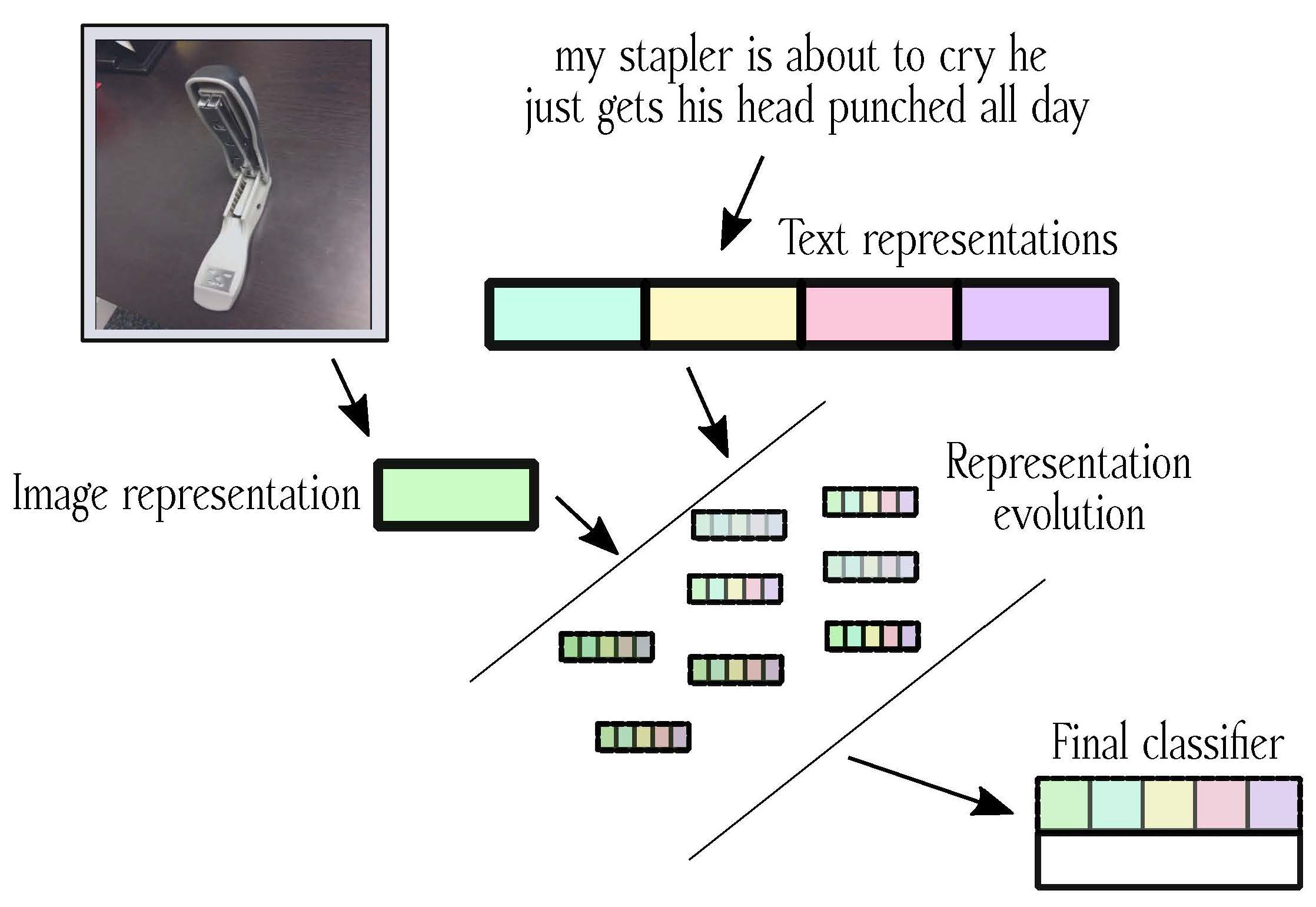
3. MuRE: Multimodal Representation Evolution
3.1. Representation Learning Phase
3.2. Representation Evolution
4. Experiments
4.1. Datasets
4.2. Baselines and Evaluation
4.2.1. Image-Only Baselines
- MobileNet + SVMOutputs from the second-to-last layer of a pre-trained MobileNetV3 [40] model are taken as image features and fed into a linear SVM for classification. Specifically, we use the MobileNet V3 Large architecture, pretrained on ImageNet. We choose the same configuration whenever MobileNet is utilized. The SVM classifier is trained using hingle loss for a maximum of 10,000 iterations with regularization constant and other parameters equal to scikit-learn defaults. (https://scikit-learn.org/stable/modules/generated/sklearn.svm.LinearSVC.html, accessed on 10 November 2022).
- MobileNet + NNOutputs of the second-to-last layer of a pre-trained MobileNetV3 model are fed into a two-layer fully-connected network for classification. The neural classifier uses a 100-dimensional hidden layer and ReLU activation. It is trained for 30 epochs at a base learning rate of using the Adam optimizer [41] with an L2 penalty of .
- Fine-tuned MobileNetThe final classification layer of a pre-trained MobileNetV3 is replaced to conform to the desired output (i.e., a single fully-connected layer). The whole network is then fine-tuned for 20 epochs, at a base learning rate of using the Adam optimizer with an L2 penalty of .
4.2.2. Text-Only Baselines
- N-grams + SVMWord and character n-grams are TF-IDF-vectorized and fed into a linear SVM for classification. Nine different regularization values of C (from 0.1 to 500) are tested when training, with the best performing model being chosen for the final prediction. Maximum iterations are set to 100,000 and other parameters equal to scikit-learn defaults. (https://scikit-learn.org/stable/modules/generated/sklearn.svm.LinearSVC.html, accessed on 10 November 2022) This baseline represents a “traditional” text classification approach.
- Fine-tuned BERTA pre-trained BERT language model, configured as a classifier, is fine-tuned on our data. We use the base uncased pretrained model, trained on an English language corpus using an MLM objective [43]. The fine-tuning is performed for 20 epochs using the AdamW optimizer [44] at a base learning rate of .
- TPOTTPOT [8,45] is an easy-to-use AutoML tool that automatically evolves scikit-learn pipelines based on tree ensemble learners to optimize performance on a classification task. We deploy TPOT on a vectorized word n-gram space with default settings (http://epistasislab.github.io/tpot/api/, accessed on 1 November 2022).
4.2.3. Multimodal Baselines
- Late fusion (sum)An image-only classifier (MobileNet + SVM) and a text-only classifier (N-grams + SVM), both as described above, are trained independently. Class probability distributions are extracted from both models and combined by a sum. Combined probability for class i is defined as:
- Late fusion (max)Class probabilities are obtained from both models and combined by a maximum. Combined probability for class i is defined as:
- Early fusion + SVMImage features are extracted with a MobileNetV3 model, much like in Section 4.2.1. Text features are extracted using a pre-trained Sentence-BERT sentence embedding model [46], trained using a multilingual MPNet objective [47]. Features from both modalities are then concatenated and fed into a linear SVM for prediction. The SVM classifier is trained for a maximum of 1000 iterations with .
- Early fusion + NNAgain, image features are extracted with a MobileNetV3 model and text features are extracted using a Sentence-BERT model. Features from both modalities are then concatenated and fed into a two-layer fully-connected network. The neural classifier uses a 100-dimensional hidden layer and ReLU activation and is trained for 30 epochs, at a base learning rate of using the Adam optimizer with an L2 penalty of .
5. Results
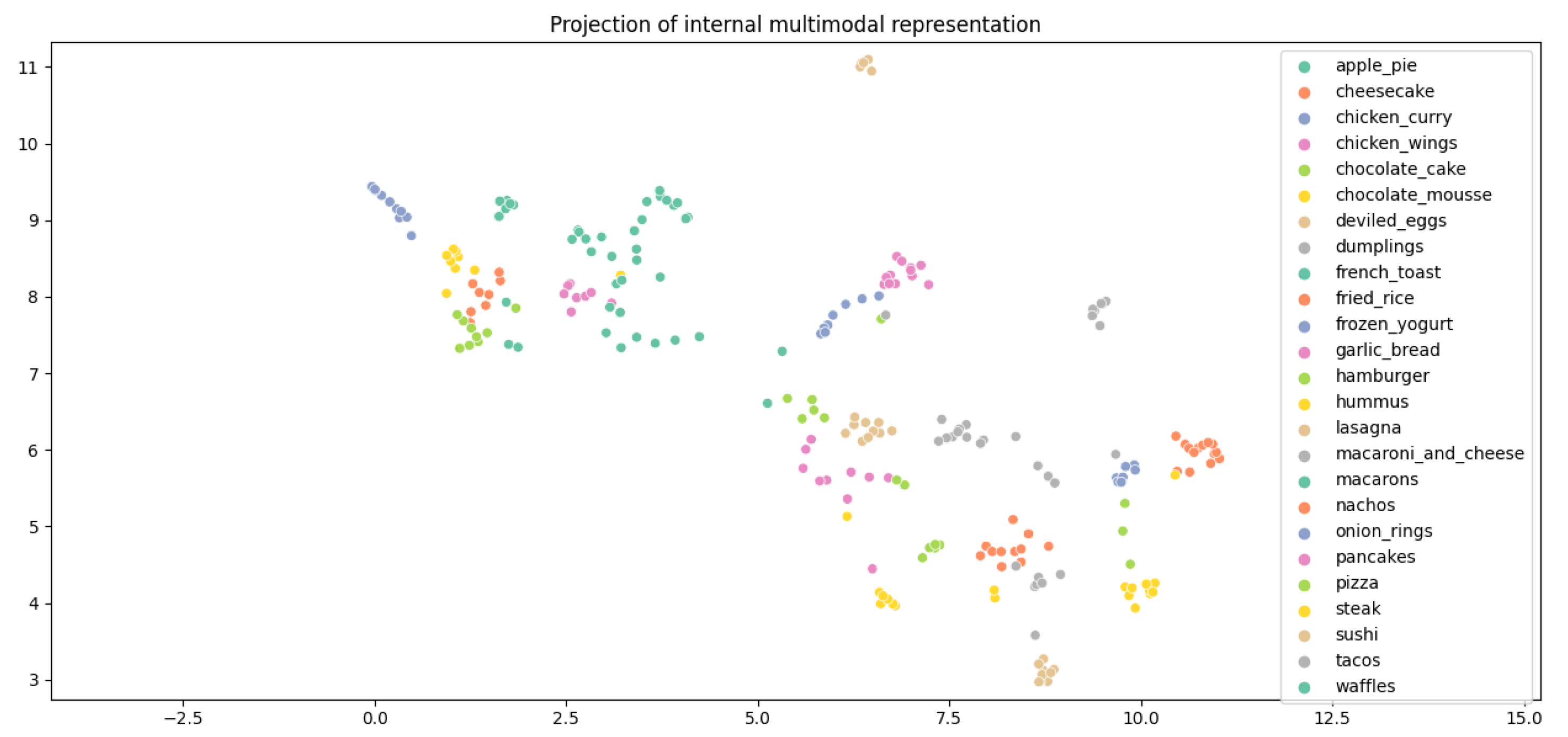
5.1. Quantitative Results
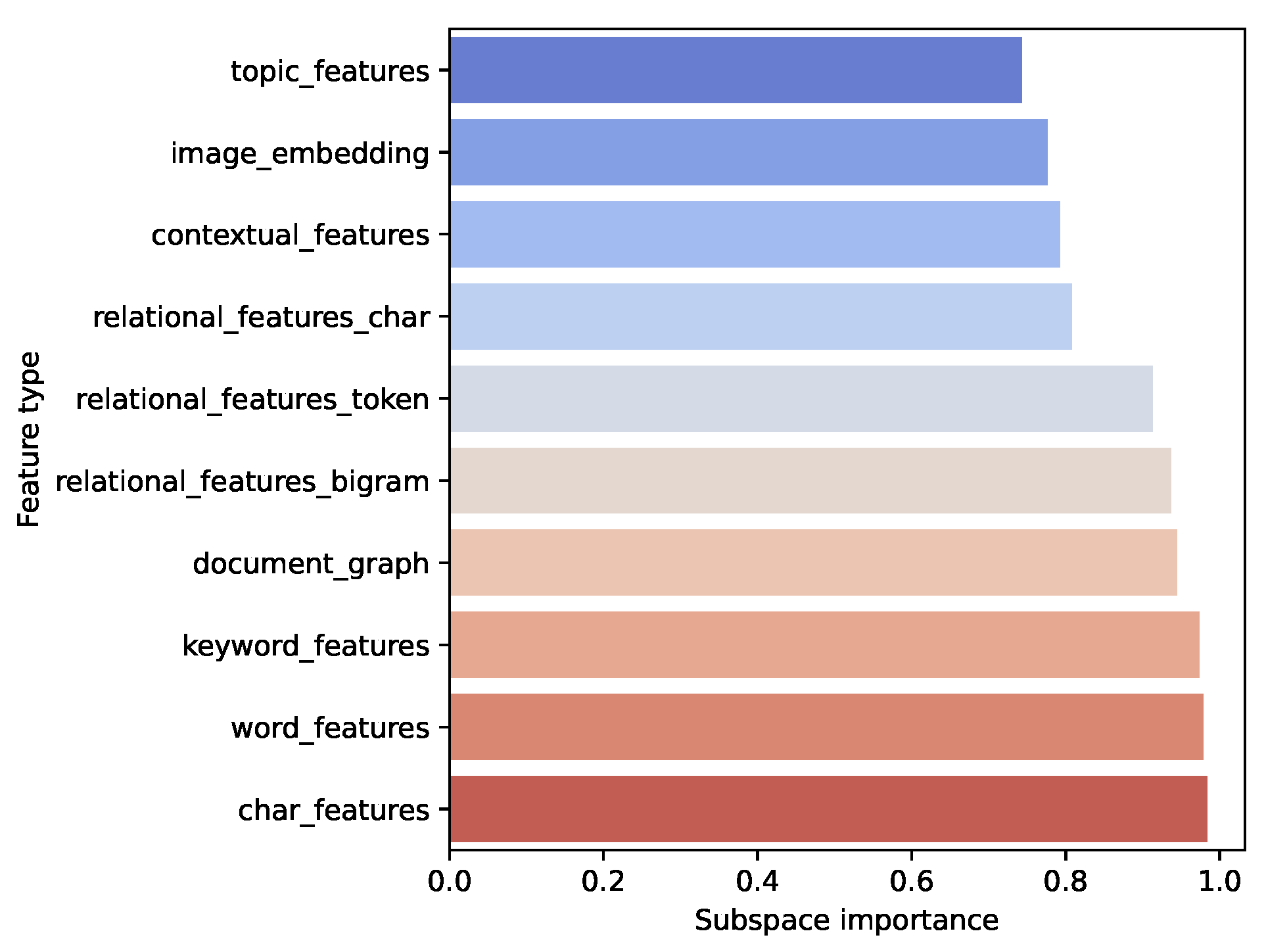
5.2. Ablation Study—Subspace Importances
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, X.; Zhao, K.; Chu, X. AutoML: A Survey of the State-of-the-Art. Knowl.-Based Syst. 2021, 212, 106622. [Google Scholar] [CrossRef]
- Theis, T.N.; Wong, H.S.P. The end of moore’s law: A new beginning for information technology. Comput. Sci. Eng. 2017, 19, 41–50. [Google Scholar] [CrossRef]
- Lemke, C.; Budka, M.; Gabrys, B. Metalearning: A survey of trends and technologies. Artif. Intell. Rev. 2015, 44, 117–130. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hutter, F.; Kotthoff, L.; Vanschoren, J. (Eds.) Meta-Learning. In Automated Machine Learning: Methods, Systems, Challenges; Springer International Publishing: Cham, Switzerland, 2019; pp. 35–61. [Google Scholar] [CrossRef] [Green Version]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Kotthoff, L.; Thornton, C.; Hoos, H.H.; Hutter, F.; Leyton-Brown, K. Auto-WEKA: Automatic model selection and hyperparameter optimization in WEKA. In Automated Machine Learning; Springer: Cham, Switzerland, 2019; pp. 81–95. [Google Scholar]
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.T.; Blum, M.; Hutter, F. Auto-sklearn: Efficient and robust automated machine learning. In Automated Machine Learning; Springer: Cham, Switzerland, 2019; pp. 113–134. [Google Scholar]
- Olson, R.S.; Moore, J.H. TPOT: A tree-based pipeline optimization tool for automating machine learning. In Proceedings of the Workshop on Automatic Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 66–74. [Google Scholar]
- Yang, C.; Akimoto, Y.; Kim, D.W.; Udell, M. OBOE: Collaborative filtering for AutoML model selection. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1173–1183. [Google Scholar]
- Wang, C.; Wu, Q.; Weimer, M.; Zhu, E.E. FLAML: A Fast and Lightweight AutoML Library. In Proceedings of the 4th Conference on Machine Learning and Systems (MLSys 2021), San Jose, CA, USA, 4–7 April 2021. [Google Scholar]
- Mohr, F.; Wever, M.; Hüllermeier, E. ML-Plan: Automated machine learning via hierarchical planning. Mach. Learn. 2018, 107, 1495–1515. [Google Scholar] [CrossRef] [Green Version]
- Thomas, J.; Coors, S.; Bischl, B. Automatic Gradient Boosting. In Proceedings of the International Workshop on Automatic Machine Learning at ICML, Stockholm, Sweden, 14 July 2018. [Google Scholar]
- Gijsbers, P.; Vanschoren, J. GAMA: A General Automated Machine learning Assistant. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Bilbao, Spain, 13 September 2021. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Pareja, A.; Domeniconi, G.; Chen, J.; Ma, T.; Suzumura, T.; Kanezashi, H.; Kaler, T.; Schardl, T.B.; Leiserson, C.E. EvolveGCN: Evolving Graph Convolutional Networks for Dynamic Graphs. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Jin, H.; Song, Q.; Hu, X. Auto-Keras: An efficient neural architecture search system. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1946–1956. [Google Scholar]
- Thornton, C.; Hutter, F.; Hoos, H.H.; Leyton-Brown, K. Auto-WEKA: Combined selection and hyperparameter optimization of classification algorithms. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 847–855. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. arXiv 2018, arXiv:1707.07012. [Google Scholar]
- Elsken, T.; Staffler, B.; Metzen, J.H.; Hutter, F. Meta-Learning of Neural Architectures for Few-Shot Learning. arXiv 2020, arXiv:1911.11090. [Google Scholar]
- Jomaa, H.S.; Schmidt-Thieme, L.; Grabocka, J. Dataset2vec: Learning dataset meta-features. Data Min. Knowl. Discov. 2021, 35, 964–985. [Google Scholar] [CrossRef]
- Humm, B.G.; Zender, A. An ontology-based concept for meta automl. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Hersonissos, Greece, 17–20 June 2021; pp. 117–128. [Google Scholar]
- Davis, L. Handbook of Genetic Algorithms, 1st ed.; Van Nostrand Reinhold: Washington, DC, USA, 1991. [Google Scholar]
- Doerr, B.; Le, H.P.; Makhmara, R.; Nguyen, T.D. Fast genetic algorithms. In Proceedings of the Genetic and Evolutionary Computation Conference, Berlin, Germany, 15–19 July 2017; pp. 777–784. [Google Scholar]
- Corus, D.; Oliveto, P.S. Standard steady state genetic algorithms can hillclimb faster than mutation-only evolutionary algorithms. IEEE Trans. Evol. Comput. 2017, 22, 720–732. [Google Scholar] [CrossRef] [Green Version]
- Leonori, S.; Paschero, M.; Mascioli, F.M.F.; Rizzi, A. Optimization strategies for Microgrid energy management systems by Genetic Algorithms. Appl. Soft Comput. 2020, 86, 105903. [Google Scholar] [CrossRef]
- Li, D.; Deng, L.; Cai, Z. Intelligent vehicle network system and smart city management based on genetic algorithms and image perception. Mech. Syst. Signal Process. 2020, 141, 106623. [Google Scholar] [CrossRef]
- Shi, X.; Mueller, J.; Erickson, N.; Li, M.; Smola, A. Multimodal AutoML on Structured Tables with Text Fields. In Proceedings of the 8th ICML Workshop on Automated Machine Learning (AutoML), Virtual, 23 July 2021. [Google Scholar]
- Shi, X.; Mueller, J.; Erickson, N.; Li, M.; Smola, A.J. Benchmarking Multimodal AutoML for Tabular Data with Text Fields. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, Online, 6–14 December 2021. [Google Scholar]
- Ramachandram, D.; Taylor, G.W. Deep Multimodal Learning: A Survey on Recent Advances and Trends. IEEE Signal Process. Mag. 2017, 34, 96–108. [Google Scholar] [CrossRef]
- Beyer, H.G.; Schwefel, H.P. Evolution strategies—A comprehensive introduction. Nat. Comput. 2002, 1, 3–52. [Google Scholar] [CrossRef]
- Škrlj, B.; Martinc, M.; Lavrač, N.; Pollak, S. autoBOT: Evolving neuro-symbolic representations for explainable low resource text classification. Mach. Learn. 2021, 110, 989–1028. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–14 August 2021; pp. 8748–8763. [Google Scholar]
- Kaplenko, M. Multimodal Classification. 2019. Available online: https://github.com/xkaple01/multimodal-classification (accessed on 20 November 2022).
- Reed, S.; Akata, Z.; Lee, H.; Schiele, B. Learning deep representations of fine-grained visual descriptions. In Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 49–58. [Google Scholar]
- Welinder, P.; Branson, S.; Mita, T.; Wah, C.; Schroff, F.; Belongie, S.; Perona, P. Caltech-UCSD Birds 200; Technical Report CNS-TR-2010-001; California Institute of Technology: Pasadena, CA, USA, 2010. [Google Scholar]
- Zlatkova, D.; Nakov, P.; Koychev, I. Fact-checking meets fauxtography: Verifying claims about images. arXiv 2019, arXiv:1908.11722. [Google Scholar]
- Nakamura, K.; Levy, S.; Wang, W.Y. r/fakeddit: A new multimodal benchmark dataset for fine-grained fake news detection. arXiv 2019, arXiv:1911.03854. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32 (NeurIPS 2019); Curran Associates, Inc.: Red Hook, NY, USA, 2019. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Le, T.T.; Fu, W.; Moore, J.H. Scaling tree-based automated machine learning to biomedical big data with a feature set selector. Bioinformatics 2020, 36, 250–256. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reimers, N.; Gurevych, I. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv 2019, arXiv:1908.10084. [Google Scholar]
- Song, K.; Tan, X.; Qin, T.; Lu, J.; Liu, T.Y. Mpnet: Masked and permuted pre-training for language understanding. Adv. Neural Inf. Process. Syst. 2020, 33, 16857–16867. [Google Scholar]
- McInnes, L.; Healy, J.; Saul, N.; Großberger, L. UMAP: Uniform Manifold Approximation and Projection. J. Open Source Softw. 2018, 3, 861. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Feature Type | Description | Representation Type |
|---|---|---|
| Concept-based features | Features based on triplet groundings | symbolic |
| Relational tokens | Tokens at a given distance | symbolic |
| Relational characters | Characters at a given distance | symbolic |
| Relational bi-grams | Character pairs at a given distance | symbolic |
| Topics | TF-IDF matrix, transposed and clustered (topics) | symbolic |
| Keywords | Keyword-based features | symbolic |
| Words | Word n-grams | symbolic |
| Characters | Character n-grams | symbolic |
| Contextual | MPNet-based document embeddings | sub-symbolic |
| Image embeddings | Obtained with CLIP [32] | sub-symbolic |
| Document graph | Jaccard-based document graph’s node embeddings | sub-symbolic |
| Dataset | #Instances | Task | Data | Target |
|---|---|---|---|---|
| Tasty Recipes [33] | 271 | multiclass classification | Textual recipes and images of the described dishes | 25 food categories |
| Fauxtography [36] | 1354 | binary classification | Images and descriptions of world news | True if image-text pair is factual and matching, False otherwise. |
| Fakeddit 5 k [37] | 4880 | binary classification | Titles and images associated with Reddit posts from various communities ("subreddits") | True if image-text pair is factual and matching, False otherwise. |
| Caltech Birds [34] | 11788 | multiclass classification | Images of various bird species and descriptions of their physical features | 192 bird species |
| Metric | Macro F1 | Accuracy | Precision | Recall | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Approach/Data Set | Recipes | Faux | Fake | Birds | Recipes | Faux | Fake | Birds | Recipes | Faux | Fake | Birds | Recipes | Faux | Fake | Birds |
| Majority classifier | 0.002 | 0.354 | 0.378 | 0.0 | 0.03 | 0.547 | 0.608 | 0.002 | 0.001 | 0.274 | 0.304 | 0.0 | 0.042 | 0.5 | 0.5 | 0.005 |
| (I) MobileNet + SVM | 0.623 | 0.683 | 0.712 | 0.699 | 0.671 | 0.685 | 0.726 | 0.702 | 0.667 | 0.684 | 0.713 | 0.708 | 0.646 | 0.684 | 0.713 | 0.707 |
| (I) MobileNet + NN | 0.423 | 0.745 | 0.742 | 0.692 | 0.476 | 0.748 | 0.754 | 0.694 | 0.471 | 0.747 | 0.742 | 0.707 | 0.473 | 0.745 | 0.742 | 0.7 |
| (I) Fine-tuned MobileNet | 0.512 | 0.354 | 0.378 | 0.192 | 0.568 | 0.547 | 0.608 | 0.199 | 0.567 | 0.274 | 0.304 | 0.23 | 0.554 | 0.5 | 0.5 | 0.202 |
| (T) N-grams + SVM | 0.852 | 0.801 | 0.753 | 0.602 | 0.875 | 0.805 | 0.768 | 0.618 | 0.872 | 0.807 | 0.758 | 0.611 | 0.889 | 0.799 | 0.75 | 0.624 |
| (T) Fine-tuned BERT | 0.777 | 0.813 | 0.829 | 0.593 | 0.804 | 0.818 | 0.836 | 0.595 | 0.814 | 0.825 | 0.828 | 0.613 | 0.819 | 0.811 | 0.83 | 0.597 |
| (T) TPOT | 0.861 | 0.791 | 0.732 | 0.612 | 0.889 | 0.803 | 0.75 | 0.617 | 0.877 | 0.832 | 0.739 | 0.632 | 0.889 | 0.788 | 0.729 | 0.622 |
| (I+T) Late fusion (sum) | 0.79 | 0.76 | 0.773 | 0.781 | 0.822 | 0.764 | 0.786 | 0.782 | 0.813 | 0.765 | 0.777 | 0.789 | 0.818 | 0.758 | 0.771 | 0.787 |
| (I+T) Late fusion (max) | 0.73 | 0.76 | 0.773 | 0.762 | 0.771 | 0.764 | 0.786 | 0.764 | 0.761 | 0.765 | 0.777 | 0.771 | 0.763 | 0.758 | 0.771 | 0.769 |
| (I+T) Late fusion (stacking) | 0.711 | 0.72 | 0.781 | 0.768 | 0.756 | 0.722 | 0.792 | 0.768 | 0.751 | 0.72 | 0.783 | 0.779 | 0.739 | 0.72 | 0.78 | 0.773 |
| (I+T) Early fusion + NN | 0.5 | 0.796 | 0.82 | 0.694 | 0.568 | 0.801 | 0.828 | 0.697 | 0.534 | 0.806 | 0.82 | 0.704 | 0.568 | 0.794 | 0.821 | 0.701 |
| (I+T) Early fusion + SVM | 0.746 | 0.784 | 0.816 | 0.721 | 0.808 | 0.788 | 0.824 | 0.726 | 0.782 | 0.789 | 0.816 | 0.728 | 0.773 | 0.783 | 0.817 | 0.732 |
| (I+T) MuRE-1h | 0.913 | 0.812 | 0.766 | 0.911 | 0.952 | 0.817 | 0.776 | 0.948 | 0.911 | 0.824 | 0.773 | 0.911 | 0.923 | 0.813 | 0.773 | 0.919 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Škrlj, B.; Bevec, M.; Lavrač, N. Multimodal AutoML via Representation Evolution. Mach. Learn. Knowl. Extr. 2023, 5, 1-13. https://doi.org/10.3390/make5010001
Škrlj B, Bevec M, Lavrač N. Multimodal AutoML via Representation Evolution. Machine Learning and Knowledge Extraction. 2023; 5(1):1-13. https://doi.org/10.3390/make5010001
Chicago/Turabian StyleŠkrlj, Blaž, Matej Bevec, and Nada Lavrač. 2023. "Multimodal AutoML via Representation Evolution" Machine Learning and Knowledge Extraction 5, no. 1: 1-13. https://doi.org/10.3390/make5010001