Graph Machine Learning
A project collection of Electronics (ISSN 2079-9292). This project collection belongs to the section "Computer Science & Engineering".
Papers displayed on this page all arise from the same project. Editorial decisions were made independently of project staff and handled by the Editor-in-Chief or qualified Editorial Board members.
Viewed by 41212
Share This Project Collection
Editor
Project Overview
Dear Colleagues,
Graph-structured data are ubiquitous in many fields and, in particular, electronics and computer science. Graphs allow modelling complex system, but to unlock the potential of these data, machine learning plays an important role. However, existing learning algorithms are mostly adapted to Euclidean (non-graph) structures. Therefore, there is an increasing interest in extending machine learning approaches for graph and manifold data.
In this Project Collection, we welcome submissions (both of research papers and reviews) related to machine and deep learning with graphs in computer sciences. The topics of interest include, but are not limited to:
- Learning representations of non-Euclidean data;
- Advanced information processing and architectures (graph neural networks, graph filtering, graph pooling, parameter learning, etc.);
- Training frameworks (unsupervised, semi-supervised, weakly, self- or supervised learning, as well as active learning, domain adaptation, or transfer learning);
- Theoretical aspects (expressive power, scalability trade-off, etc.).
Prof. Dr. Gemma Piella
Collection Editor
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. Manuscripts can be submitted until the deadline. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the collection website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 100 words) can be sent to the Editorial Office for announcement on this website.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-blind peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Electronics is an international peer-reviewed open access semimonthly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript.
The Article Processing Charge (APC) for publication in this open access journal is 2400 CHF (Swiss Francs).
Submitted papers should be well formatted and use good English. Authors may use MDPI's
English editing service prior to publication or during author revisions.
Keywords
- graphs
- non-Euclidean data
- manifolds
- machine learning
- geometrical deep learning
Published Papers (20 papers)
Open AccessArticle
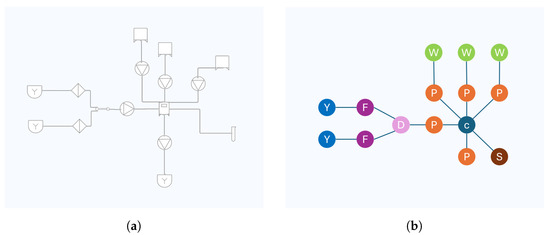
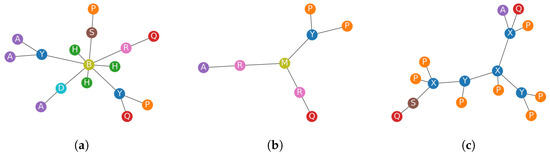
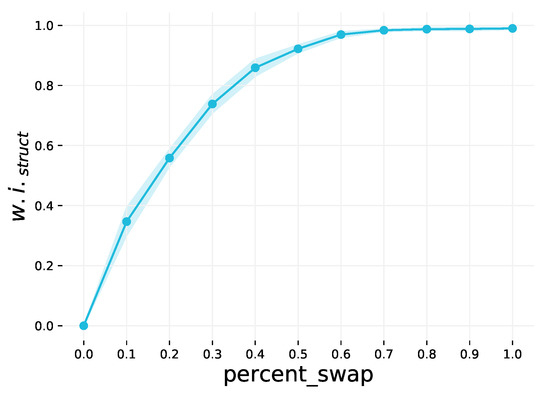
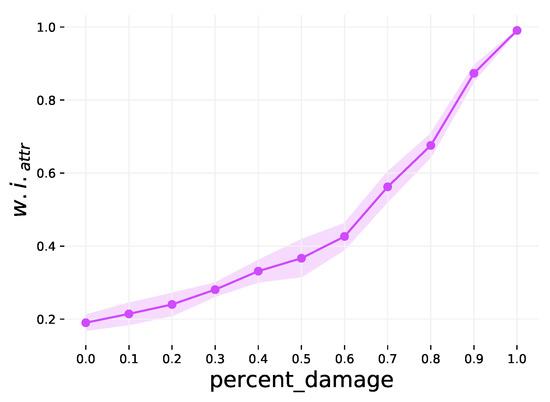
Schematics Retrieval Using Whole-Graph Embedding Similarity
by
Feras Almasri and Olivier Debeir
Viewed by 396
Abstract
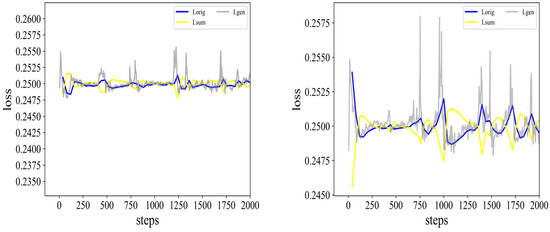
This paper addresses the pressing environmental concern of plastic waste, particularly in the biopharmaceutical production sector, where single-use assemblies (SUAs) significantly contribute to this issue. To address and mitigate this problem, we propose a unique approach centered around the standardization and optimization of
[...] Read more.
This paper addresses the pressing environmental concern of plastic waste, particularly in the biopharmaceutical production sector, where single-use assemblies (SUAs) significantly contribute to this issue. To address and mitigate this problem, we propose a unique approach centered around the standardization and optimization of SUA drawings through digitization and structured representation. Leveraging the non-Euclidean properties of SUA drawings, we employ a graph-based representation, utilizing graph convolutional networks (GCNs) to capture complex structural relationships. Introducing a novel weakly supervised method for the similarity-based retrieval of SUA graph networks, we optimize graph embeddings in a low-dimensional Euclidean space. Our method demonstrates effectiveness in retrieving similar graphs that share the same functionality, offering a promising solution to reduce plastic waste in pharmaceutical assembly processes.
Full article
►▼
Show Figures
Open AccessReview
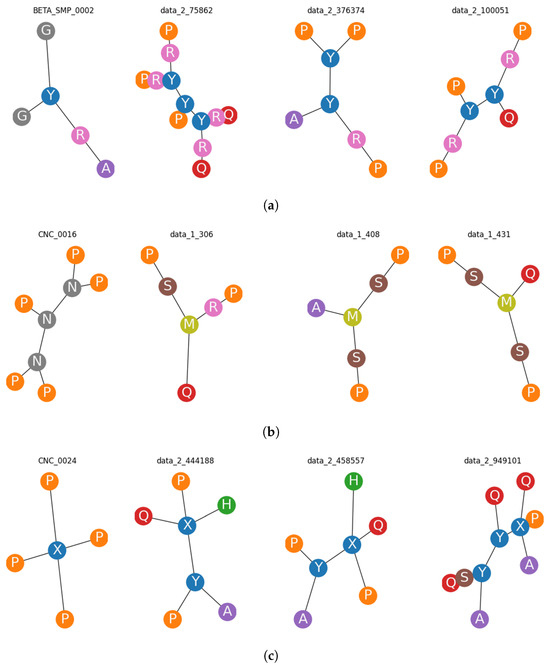
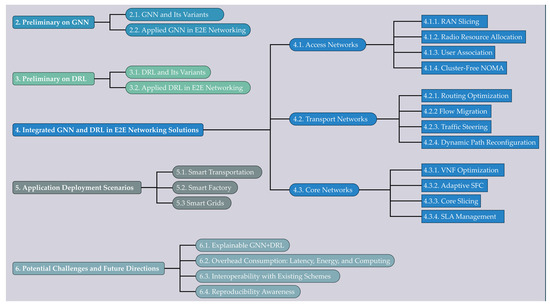
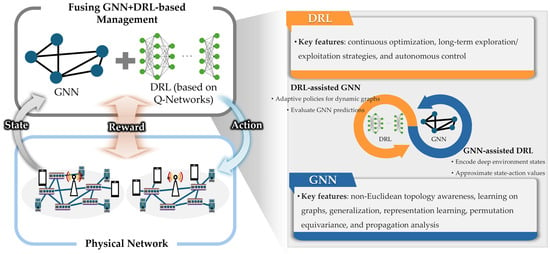
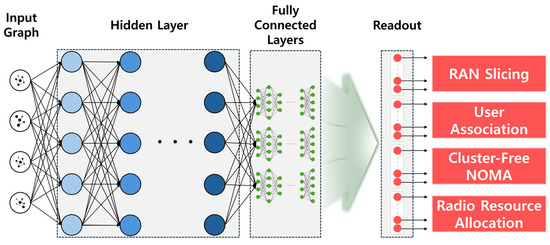
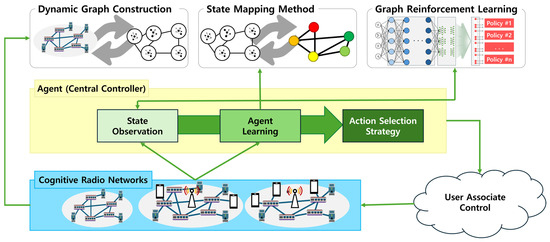
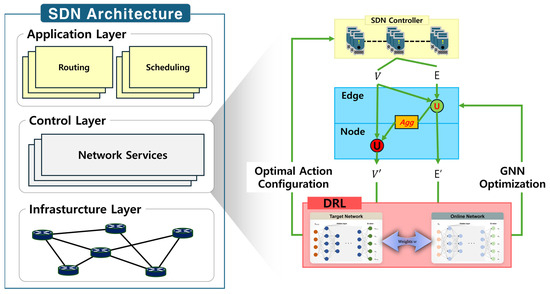
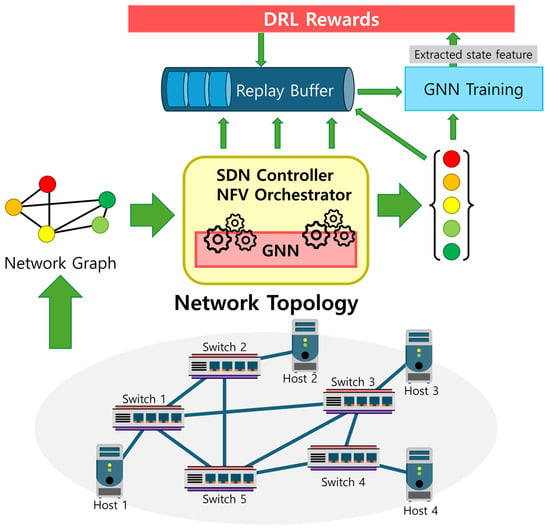
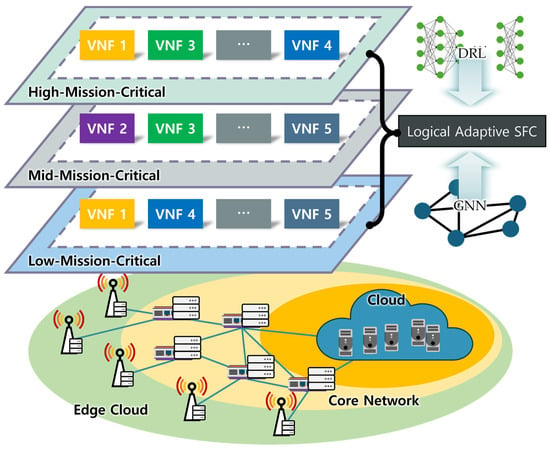
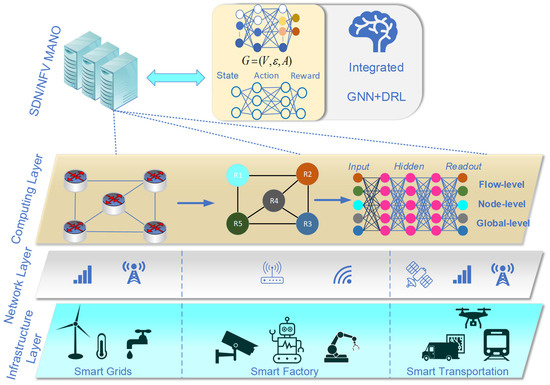
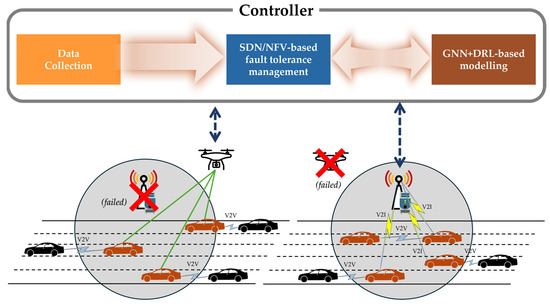
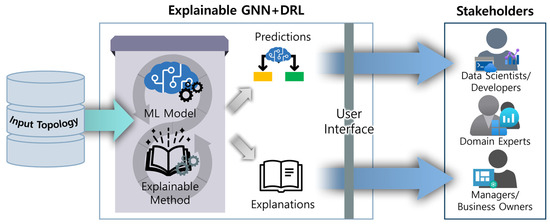
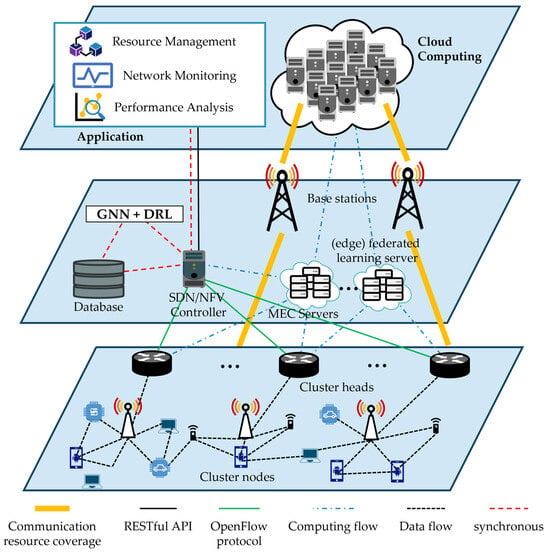
A Survey of Intelligent End-to-End Networking Solutions: Integrating Graph Neural Networks and Deep Reinforcement Learning Approaches
by
Prohim Tam, Seyha Ros, Inseok Song, Seungwoo Kang and Seokhoon Kim
Viewed by 886
Abstract
This paper provides a comprehensive survey of the integration of graph neural networks (GNN) and deep reinforcement learning (DRL) in end-to-end (E2E) networking solutions. We delve into the fundamentals of GNN, its variants, and the state-of-the-art applications in communication networking, which reveal the
[...] Read more.
This paper provides a comprehensive survey of the integration of graph neural networks (GNN) and deep reinforcement learning (DRL) in end-to-end (E2E) networking solutions. We delve into the fundamentals of GNN, its variants, and the state-of-the-art applications in communication networking, which reveal the potential to revolutionize access, transport, and core network management policies. This paper further explores DRL capabilities, its variants, and the trending applications in E2E networking, particularly in enhancing dynamic network (re)configurations and resource management. By fusing GNN with DRL, we spotlight novel approaches, ranging from radio access networks to core management and orchestration, across E2E network layers. Deployment scenarios in smart transportation, smart factory, and smart grids demonstrate the practical implications of our survey topic. Lastly, we point out potential challenges and future research directions, including the critical aspects for modelling explainability, the reduction in overhead consumption, interoperability with existing schemes, and the importance of reproducibility. Our survey aims to serve as a roadmap for future developments in E2E networking, guiding through the current landscape, challenges, and prospective breakthroughs in the algorithm modelling toward network automation using GNN and DRL.
Full article
►▼
Show Figures
Open AccessArticle
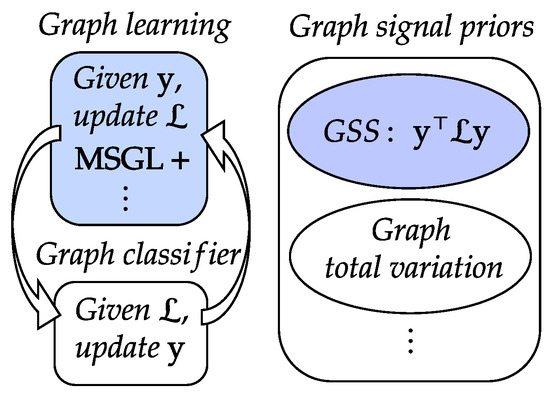
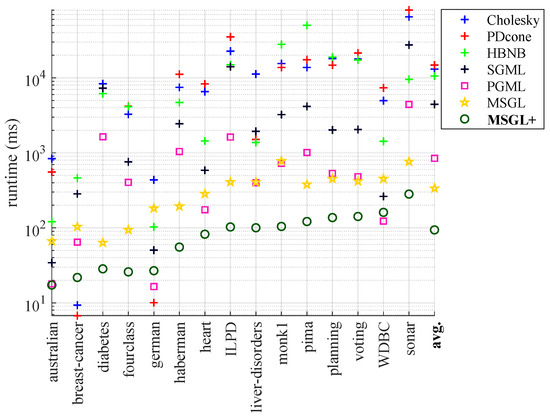
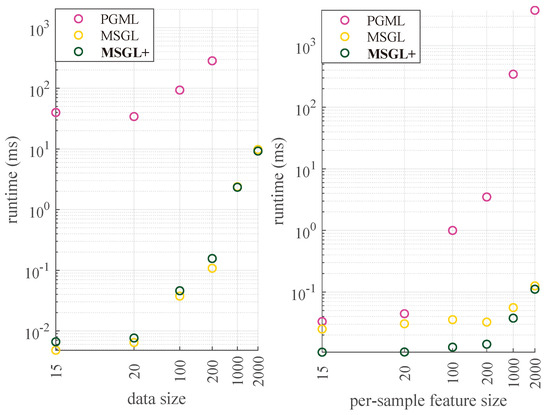
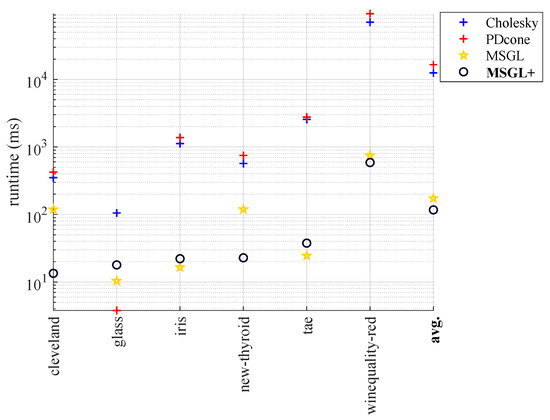
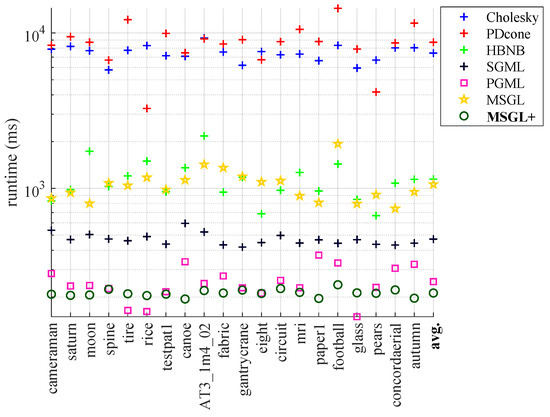
MSGL+: Fast and Reliable Model Selection-Inspired Graph Metric Learning
by
Cheng Yang, Fei Zheng, Yujie Zou, Liang Xue, Chao Jiang, Shuangyu Liu, Bochao Zhao and Haoyang Cui
Viewed by 568
Abstract
The problem of learning graph-based data structures from data has attracted considerable attention in the past decade. Different types of data can be used to infer the graph structure, such as graphical Lasso, which is learned from multiple graph signals or graph metric
[...] Read more.
The problem of learning graph-based data structures from data has attracted considerable attention in the past decade. Different types of data can be used to infer the graph structure, such as graphical Lasso, which is learned from multiple graph signals or graph metric learning based on node features. However, most existing methods that use node features to learn the graph face difficulties when the label signals of the data are incomplete. In particular, the pair-wise distance metric learning problem becomes intractable as the dimensionality of the node features increases. To address this challenge, we propose a novel method called MSGL+. MSGL+ is inspired from model selection, leverages recent advancements in graph spectral signal processing (GSP), and offers several key innovations: (1) Polynomial Interpretation: We use a polynomial function of a certain order on the graph Laplacian to represent the inverse covariance matrix of the graph nodes to rigorously formulate an optimization problem. (2) Convex Formulation: We formulate a convex optimization objective with a cone constraint that optimizes the coefficients of the polynomial, which makes our approach efficient. (3) Linear Constraints: We convert the cone constraint of the objective to a set of linear ones to further ensure the efficiency of our method. (4) Optimization Objective: We explore the properties of these linear constraints within the optimization objective, avoiding sub-optimal results by the removal of the box constraints on the optimization variables, and successfully further reduce the number of variables compared to our preliminary work, MSGL. (5) Efficient Solution: We solve the objective using the efficient linear-program-based Frank–Wolfe algorithm. Application examples, including binary classification, multi-class classification, binary image denoising, and time-series analysis, demonstrate that MSGL+ achieves competitive accuracy performance with a significant speed advantage compared to existing graphical Lasso and feature-based graph learning methods.
Full article
►▼
Show Figures
Open AccessArticle
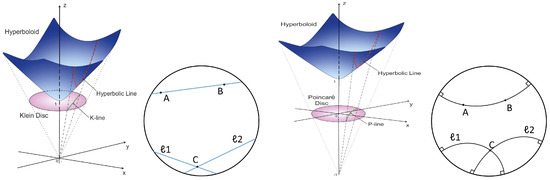
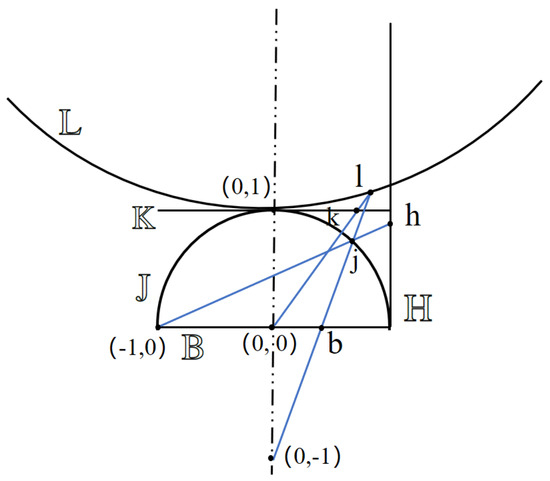
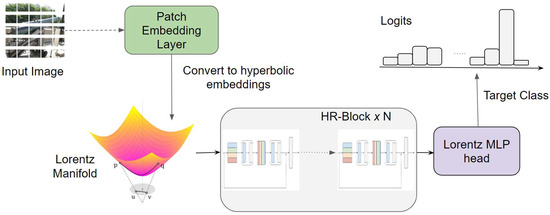
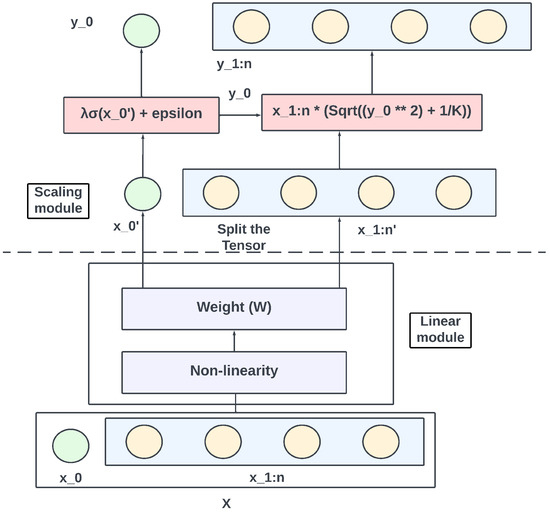
Efficient Hyperbolic Perceptron for Image Classification
by
Ahmad Omar Ahsan, Susanna Tang and Wei Peng
Viewed by 958
Abstract
Deep neural networks, often equipped with powerful auto-optimization tools, find widespread use in diverse domains like NLP and computer vision. However, traditional neural architectures come with specific inductive biases, designed to reduce parameter search space, cut computational costs, or introduce domain expertise into
[...] Read more.
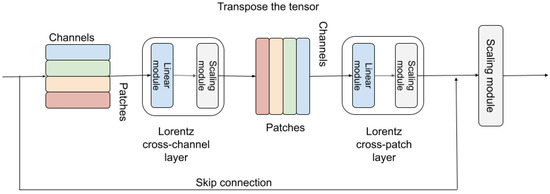
Deep neural networks, often equipped with powerful auto-optimization tools, find widespread use in diverse domains like NLP and computer vision. However, traditional neural architectures come with specific inductive biases, designed to reduce parameter search space, cut computational costs, or introduce domain expertise into the network design. In contrast, multilayer perceptrons (MLPs) offer greater freedom and lower inductive bias than convolutional neural networks (CNNs), making them versatile for learning complex patterns. Despite their flexibility, most neural architectures operate in a flat Euclidean space, which may not be optimal for various data types, particularly those with hierarchical correlations. In this paper, we move one step further by introducing the hyperbolic Res-MLP (HR-MLP), an architecture extending the attention-free MLP to a non-Euclidean space. HR-MLP leverages fully hyperbolic layers for feature embeddings and end-to-end image classification. Our novel Lorentz cross-patch and cross-channel layers enable direct hyperbolic operations with fewer parameters, facilitating faster training and superior performance compared to Euclidean counterparts. Experimental results on CIFAR10, CIFAR100, and MiniImageNet confirm HR-MLP’s competitive and improved performance.
Full article
►▼
Show Figures
Open AccessArticle
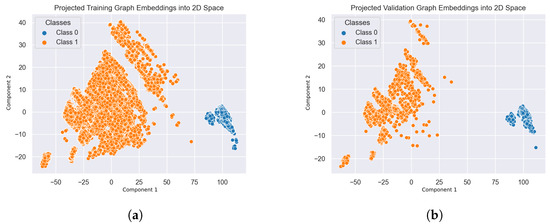
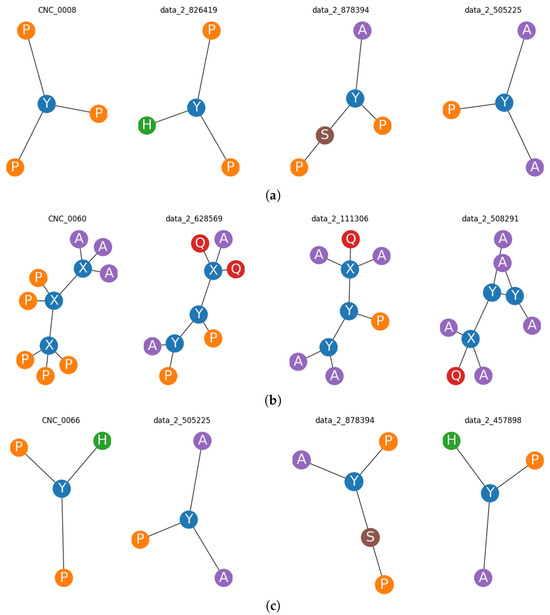
Embedding-Based Deep Neural Network and Convolutional Neural Network Graph Classifiers
by
Sarah G. Elnaggar, Ibrahim E. Elsemman and Taysir Hassan A. Soliman
Viewed by 2065
Abstract
One of the most significant graph data analysis tasks is graph classification, as graphs are complex data structures used for illustrating relationships between entity pairs. Graphs are essential in many domains, such as the description of chemical molecules, biological networks, social relationships, etc.
[...] Read more.
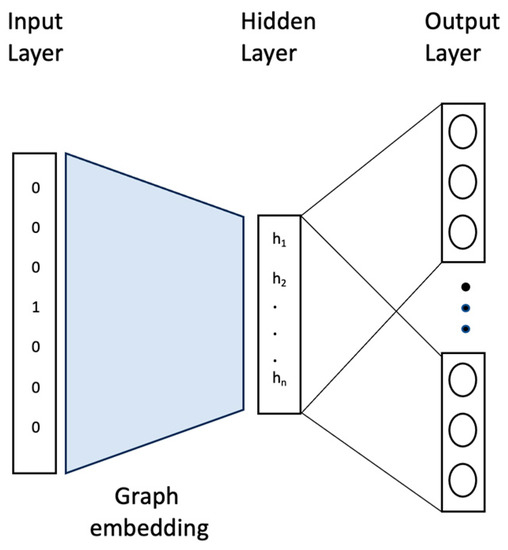
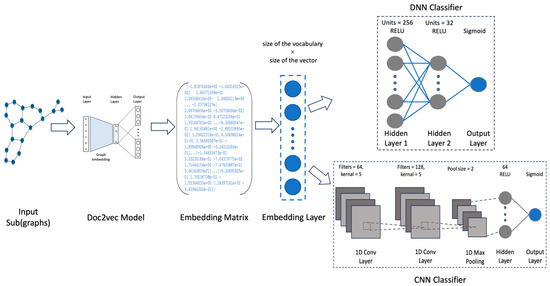
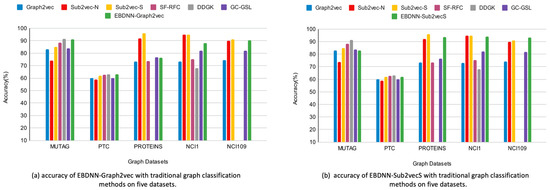
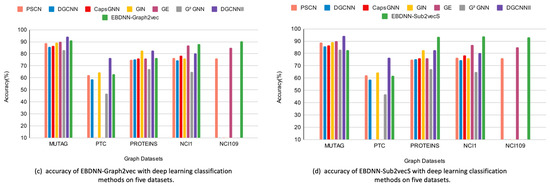
One of the most significant graph data analysis tasks is graph classification, as graphs are complex data structures used for illustrating relationships between entity pairs. Graphs are essential in many domains, such as the description of chemical molecules, biological networks, social relationships, etc. Real-world graphs are complicated and large. As a result, there is a need to find a way to represent or encode a graph’s structure so that it can be easily utilized by machine learning models. Therefore, graph embedding is considered one of the most powerful solutions for graph representation. Inspired by the Doc2Vec model in Natural Language Processing (NLP), this paper first investigates different ways of (sub)graph embedding to represent each graph or subgraph as a fixed-length feature vector, which is then used as input to any classifier. Thus, two supervised classifiers—a deep neural network (DNN) and a convolutional neural network (CNN)—are proposed to enhance graph classification. Experimental results on five benchmark datasets indicate that the proposed models obtain competitive results and are superior to some traditional classification methods and deep-learning-based approaches on three out of five benchmark datasets, with an impressive accuracy rate of 94% on the NCI1 dataset.
Full article
►▼
Show Figures
Open AccessArticle
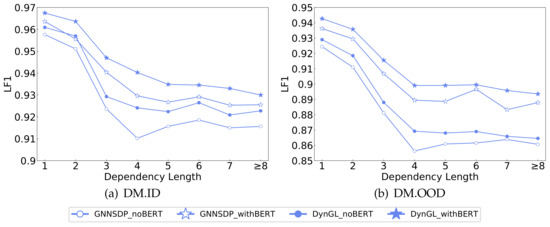
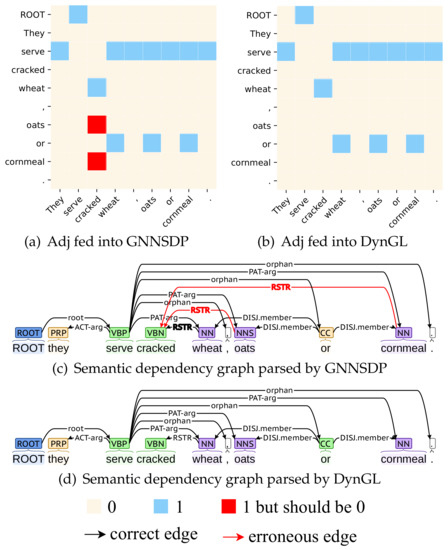
A Joint-Learning-Based Dynamic Graph Learning Framework for Structured Prediction
by
Bin Li, Yunlong Fan, Miao Gao, Yikemaiti Sataer and Zhiqiang Gao
Viewed by 1197
Abstract
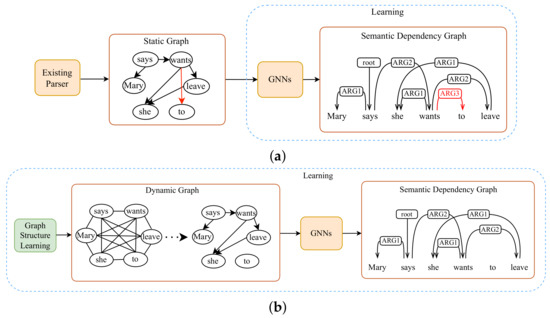
Graph neural networks (GNNs) have achieved remarkable success in structured prediction, owing to the GNNs’ powerful ability in learning expressive graph representations. However, most of these works learn graph representations based on a static graph constructed by an existing parser, suffering from two
[...] Read more.
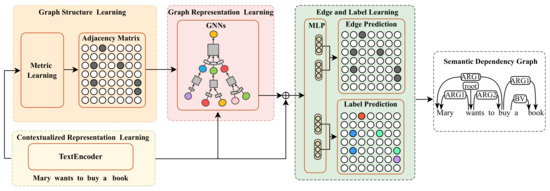
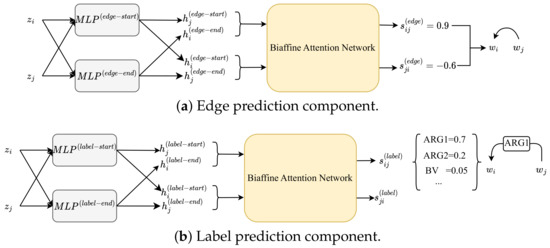
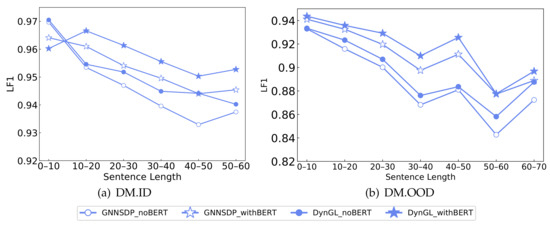
Graph neural networks (GNNs) have achieved remarkable success in structured prediction, owing to the GNNs’ powerful ability in learning expressive graph representations. However, most of these works learn graph representations based on a static graph constructed by an existing parser, suffering from two drawbacks: (1) the static graph might be error-prone, and the errors introduced in the static graph cannot be corrected and might accumulate in later stages, and (2) the graph construction stage and graph representation learning stage are disjoined, which negatively affects the model’s running speed. In this paper, we propose a joint-learning-based dynamic graph learning framework and apply it to two typical structured prediction tasks: syntactic dependency parsing, which aims to predict a labeled tree, and semantic dependency parsing, which aims to predict a labeled graph, for jointly learning the graph structure and graph representations. Experiments are conducted on four datasets: the Universal Dependencies 2.2, the Chinese Treebank 5.1, the English Penn Treebank 3.0 in 13 languages for syntactic dependency parsing, and the SemEval-2015 Task 18 dataset in three languages for semantic dependency parsing. The experimental results show that our best-performing model achieves a new state-of-the-art performance on most language sets of syntactic dependency and semantic dependency parsing. In addition, our model also has an advantage in running speed over the static graph-based learning model. The outstanding performance demonstrates the effectiveness of the proposed framework in structured prediction.
Full article
►▼
Show Figures
Open AccessArticle
An Evaluation of Link Prediction Approaches in Few-Shot Scenarios
by
Rebecca Braken, Alexander Paulus, André Pomp and Tobias Meisen
Viewed by 1155
Abstract
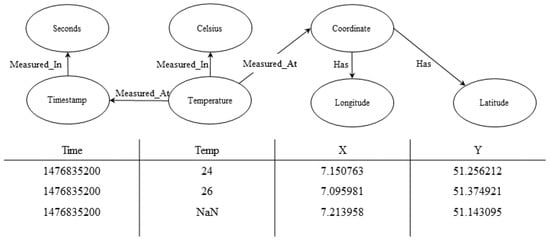
Semantic models are utilized to add context information to datasets and make data accessible and understandable in applications such as dataspaces. Since the creation of such models is a time-consuming task that has to be performed by a human expert, different approaches to
[...] Read more.
Semantic models are utilized to add context information to datasets and make data accessible and understandable in applications such as dataspaces. Since the creation of such models is a time-consuming task that has to be performed by a human expert, different approaches to automate or support this process exist. A recurring problem is the task of link prediction, i.e., the automatic prediction of links between nodes in a graph, in this case semantic models, usually based on machine learning techniques. While, in general, semantic models are trained and evaluated on large reference datasets, these conditions often do not match the domain-specific real-world applications wherein only a small amount of existing data is available (the cold-start problem). In this study, we evaluated the performance of link prediction algorithms when datasets of a smaller size were used for training (few-shot scenarios). Based on the reported performance evaluation, we first selected algorithms for link prediction and then evaluated the performance of the selected subset using multiple reduced datasets. The results showed that two of the three selected algorithms were suitable for the task of link prediction in few-shot scenarios.
Full article
►▼
Show Figures
Open AccessArticle
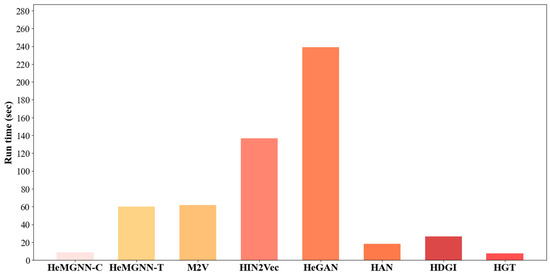
HeMGNN: Heterogeneous Network Embedding Based on a Mixed Graph Neural Network
by
Hongwei Zhong, Mingyang Wang and Xinyue Zhang
Cited by 2 | Viewed by 1505
Abstract
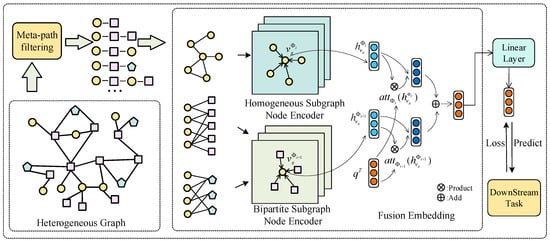
Network embedding is an effective way to realize the quantitative analysis of large-scale networks. However, mainstream network embedding models are limited by the manually pre-set metapaths, which leads to the unstable performance of the model. At the same time, the information from homogeneous
[...] Read more.
Network embedding is an effective way to realize the quantitative analysis of large-scale networks. However, mainstream network embedding models are limited by the manually pre-set metapaths, which leads to the unstable performance of the model. At the same time, the information from homogeneous neighbors is mostly focused in encoding the target node, while ignoring the role of heterogeneous neighbors in the node embedding. This paper proposes a new embedding model, HeMGNN, for heterogeneous networks. The framework of the HeMGNN model is divided into two modules: the metapath subgraph extraction module and the node embedding mixing module. In the metapath subgraph extraction module, HeMGNN automatically generates and filters out the metapaths related to domain mining tasks, so as to effectively avoid the excessive dependence of network embedding on artificial prior knowledge. In the node embedding mixing module, HeMGNN integrates the information of homogeneous and heterogeneous neighbors when learning the embedding of the target nodes. This makes the node vectors generated according to the HeMGNN model contain more abundant topological and semantic information provided by the heterogeneous networks. The Rich semantic information makes the node vectors achieve good performance in downstream domain mining tasks. The experimental results show that, compared to the baseline models, the average classification and clustering performance of HeMGNN has improved by up to 0.3141 and 0.2235, respectively.
Full article
►▼
Show Figures
Open AccessArticle
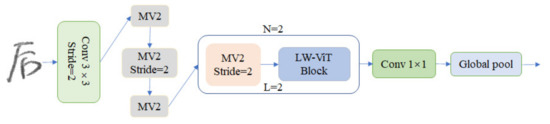
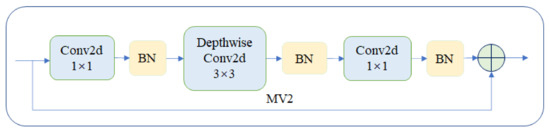
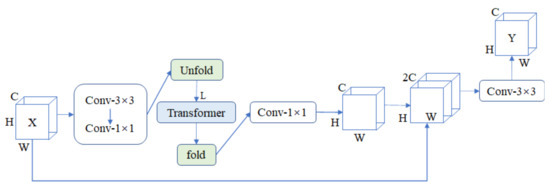
LW-ViT: The Lightweight Vision Transformer Model Applied in Offline Handwritten Chinese Character Recognition
by
Shiyong Geng, Zongnan Zhu, Zhida Wang, Yongping Dan and Hengyi Li
Cited by 3 | Viewed by 2219
Abstract
In recent years, the transformer model has been widely used in computer-vision tasks and has achieved impressive results. Unfortunately, these transformer-based models have the common drawback of having many parameters and a large memory footprint, causing them to be difficult to deploy on
[...] Read more.
In recent years, the transformer model has been widely used in computer-vision tasks and has achieved impressive results. Unfortunately, these transformer-based models have the common drawback of having many parameters and a large memory footprint, causing them to be difficult to deploy on mobiles as lightweight convolutional neural networks. To address these issues, a Vision Transformer (ViT) model, named the lightweight Vision Transformer (LW-ViT) model, is proposed to reduce the complexity of the transformer-based model. The model is applied to offline handwritten Chinese character recognition. The design of the LW-ViT model is inspired by MobileViT. The lightweight ViT model reduces the number of parameters and FLOPs by reducing the number of transformer blocks and the MV2 layer based on the overall framework of the MobileViT model. The number of parameters and FLOPs for the LW-ViT model was 0.48 million and 0.22 G, respectively, and it ultimately achieved a high recognition accuracy of 95.8% on the dataset. Furthermore, compared to the MobileViT model, the number of parameters was reduced by 53.8%, and the FLOPs were reduced by 18.5%. The experimental results show that the LW-ViT model has a low number of parameters, proving the correctness and feasibility of the proposed model.
Full article
►▼
Show Figures
Open AccessArticle
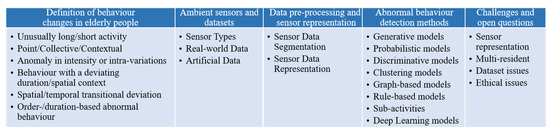
A Survey on Ambient Sensor-Based Abnormal Behaviour Detection for Elderly People in Healthcare
by
Yan Wang, Xin Wang, Damla Arifoglu, Chenggang Lu, Abdelhamid Bouchachia, Yingrui Geng and Ge Zheng
Cited by 3 | Viewed by 2110
Abstract
With advances in machine learning and ambient sensors as well as the emergence of ambient assisted living (AAL), modeling humans’ abnormal behaviour patterns has become an important assistive technology for the rising elderly population in recent decades. Abnormal behaviour observed from daily activities
[...] Read more.
With advances in machine learning and ambient sensors as well as the emergence of ambient assisted living (AAL), modeling humans’ abnormal behaviour patterns has become an important assistive technology for the rising elderly population in recent decades. Abnormal behaviour observed from daily activities can be an indicator of the consequences of a disease that the resident might suffer from or of the occurrence of a hazardous incident. Therefore, tracking daily life activities and detecting abnormal behaviour are significant in managing health conditions in a smart environment. This paper provides a comprehensive and in-depth review, focusing on the techniques that profile activities of daily living (ADL) and detect abnormal behaviour for healthcare. In particular, we discuss the definitions and examples of abnormal behaviour/activity in the healthcare of elderly people. We also describe the public ground-truth datasets along with approaches applied to produce synthetic data when no real-world data are available. We identify and describe the key facets of abnormal behaviour detection in a smart environment, with a particular focus on the ambient sensor types, datasets, data representations, conventional and deep learning-based abnormal behaviour detection methods. Finally, the survey discusses the challenges and open questions, which would be beneficial for researchers in the field to address.
Full article
►▼
Show Figures
Open AccessArticle
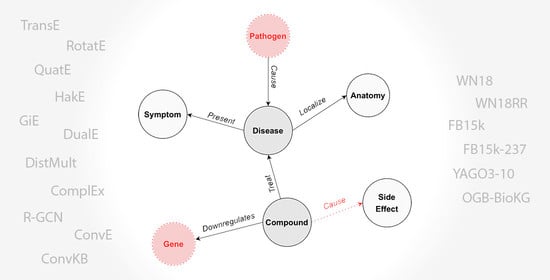
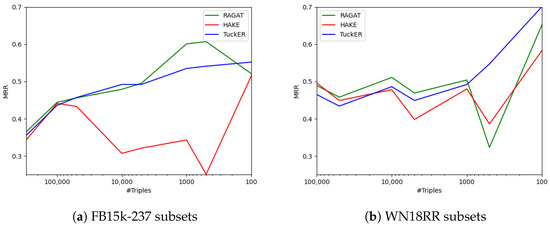
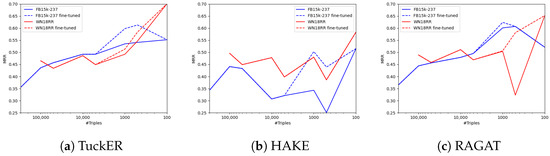
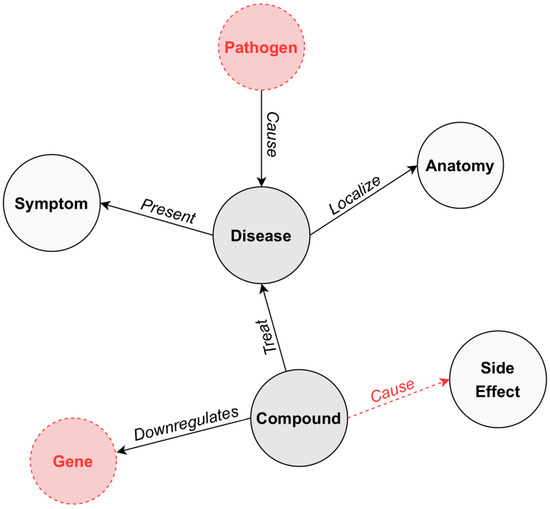
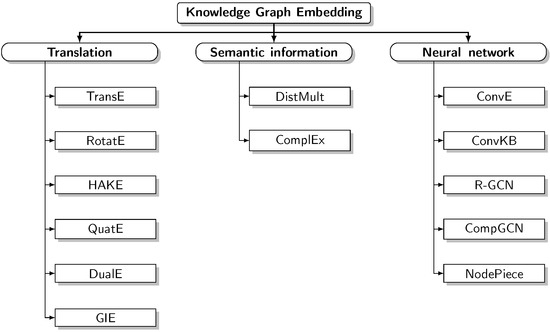
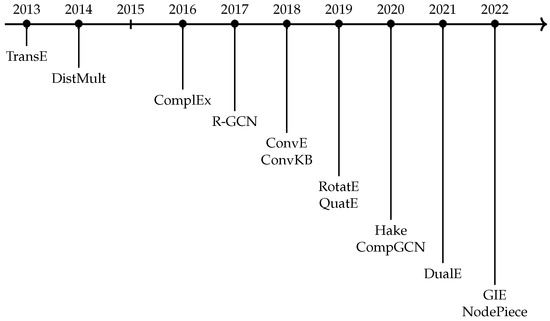
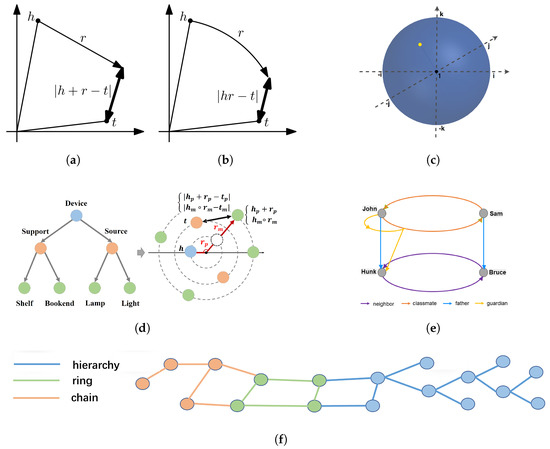
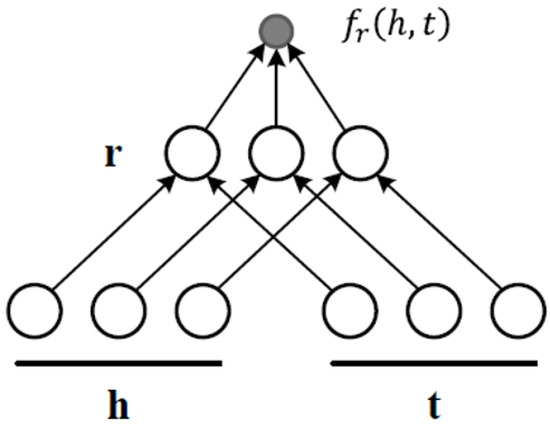
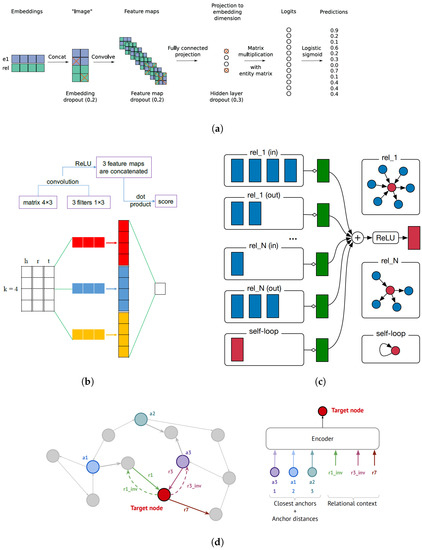
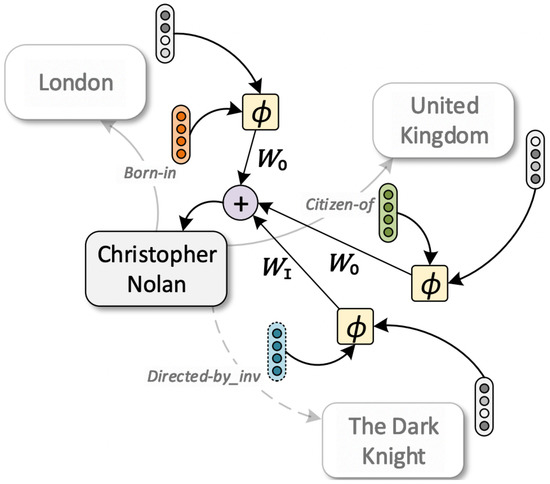
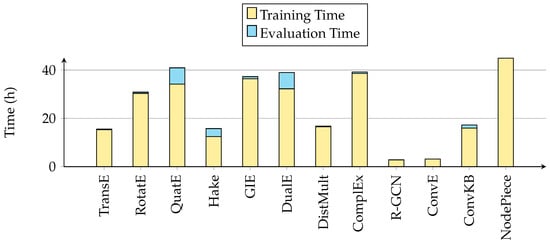
Comprehensive Analysis of Knowledge Graph Embedding Techniques Benchmarked on Link Prediction
by
Ilaria Ferrari, Giacomo Frisoni, Paolo Italiani, Gianluca Moro and Claudio Sartori
Cited by 7 | Viewed by 4814
Abstract
In knowledge graph representation learning, link prediction is among the most popular and influential tasks. Its surge in popularity has resulted in a panoply of orthogonal embedding-based methods projecting entities and relations into low-dimensional continuous vectors. To further enrich the research space, the
[...] Read more.
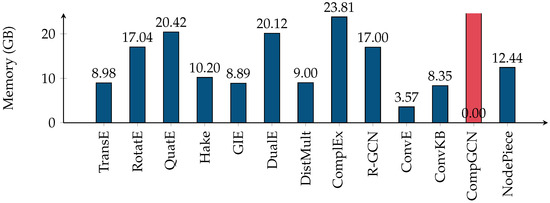
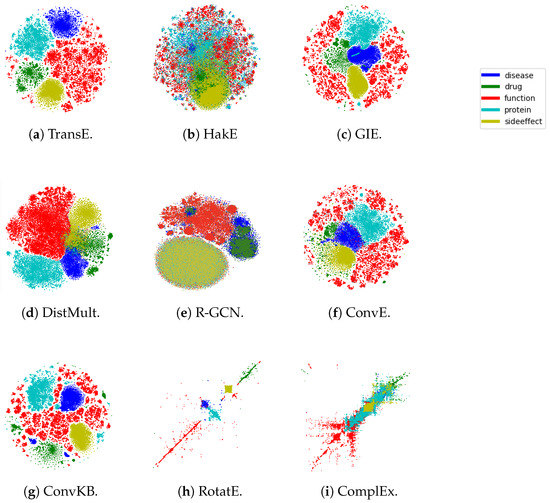
In knowledge graph representation learning, link prediction is among the most popular and influential tasks. Its surge in popularity has resulted in a panoply of orthogonal embedding-based methods projecting entities and relations into low-dimensional continuous vectors. To further enrich the research space, the community witnessed a prolific development of evaluation benchmarks with a variety of structures and domains. Therefore, researchers and practitioners face an unprecedented challenge in effectively identifying the best solution to their needs. To this end, we propose the most comprehensive and up-to-date study to systematically assess the effectiveness and efficiency of embedding models for knowledge graph completion. We compare 13 models on six datasets with different sizes, domains, and relational properties, covering translational, semantic matching, and neural network-based encoders. A fine-grained evaluation is conducted to compare each technique head-to-head in terms of standard metrics, training and evaluation times, memory consumption, carbon footprint, and space geometry. Our results demonstrate the high dependence between performance and graph types, identifying the best options for each scenario. Among all the encoding strategies, the new generation of translational models emerges as the most promising, bringing out the best and most consistent results across all the datasets and evaluation criteria.
Full article
►▼
Show Figures
Open AccessFeature PaperArticle
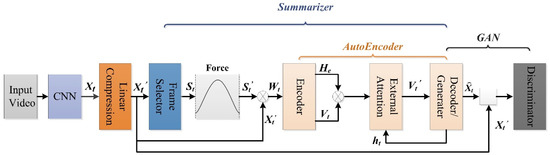
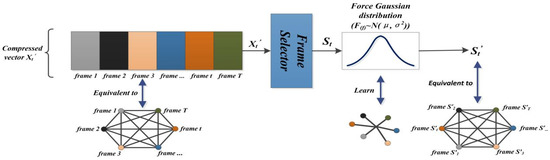
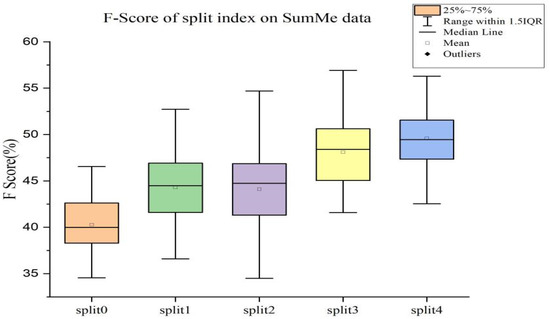
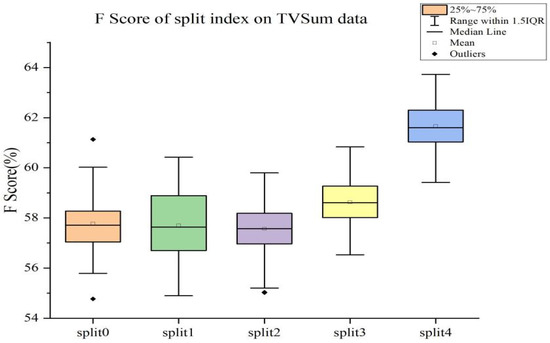
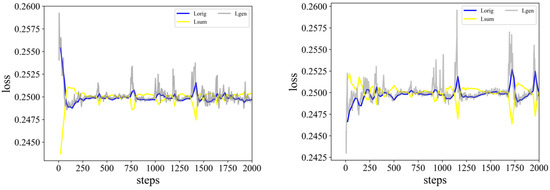
SUM-GAN-GEA: Video Summarization Using GAN with Gaussian Distribution and External Attention
by
Qinghao Yu, Hui Yu, Yongxiong Wang and Tuan D. Pham
Cited by 1 | Viewed by 1837
Abstract
Video summarization aims to generate a sparse subset that is more concise and less redundant than the original video while containing the most informative parts of the video. However, previous works ignore the prior knowledge of the distribution of interestingness of video frames,
[...] Read more.
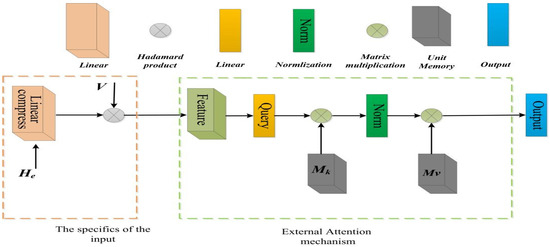
Video summarization aims to generate a sparse subset that is more concise and less redundant than the original video while containing the most informative parts of the video. However, previous works ignore the prior knowledge of the distribution of interestingness of video frames, making it hard for the network to learn the importance of different frames. Furthermore, traditional models alone (such as RNN and LSTM) are not robust enough in capturing global features of the video sequence since the video frames are more in line with non-Euclidean data structure. To this end, we propose a new summarization method based on the graph model concept to learn the feature relationship connections between video frames, which can guide the summary generator to generate a robust global feature representation. Specifically, we propose to use adversarial learning to integrate Gaussian distribution and external attention mechanism (SUM-GAN-GEA). The Gaussian function is a priori mapping function that considers the distribution of the interestingness of actual video frames and the external attention can reduce the inference time of the model. Experimental results on two popular video abstraction datasets (SumMe and TVSum) demonstrate the high superiority and competitiveness of our method in robustness and fast convergence.
Full article
►▼
Show Figures
Open AccessReview
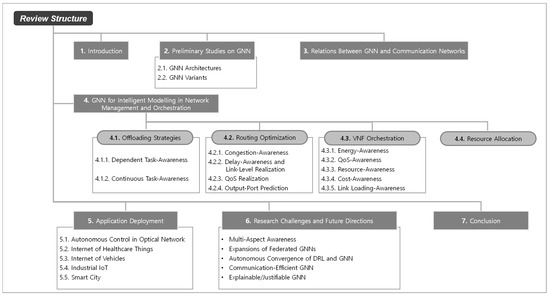
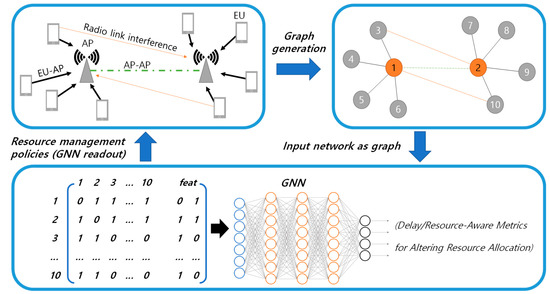
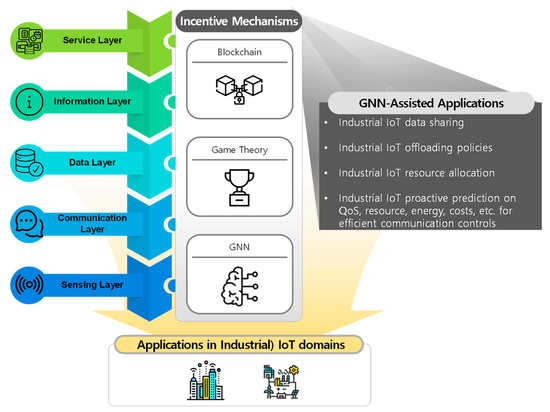
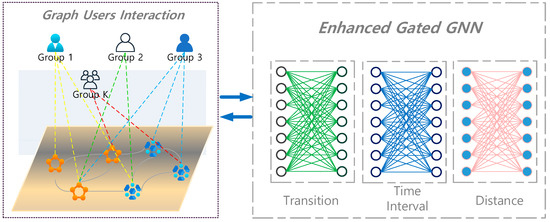
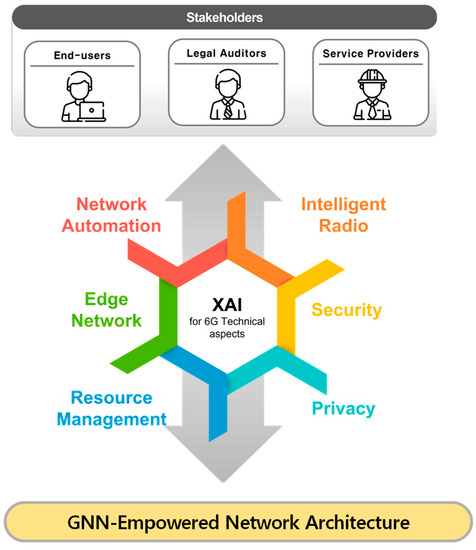
Graph Neural Networks for Intelligent Modelling in Network Management and Orchestration: A Survey on Communications
by
Prohim Tam, Inseok Song, Seungwoo Kang, Seyha Ros and Seokhoon Kim
Cited by 13 | Viewed by 4729
Abstract
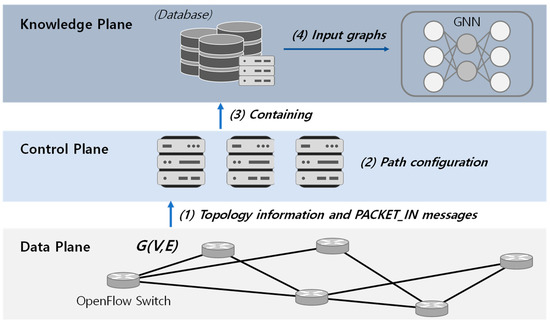
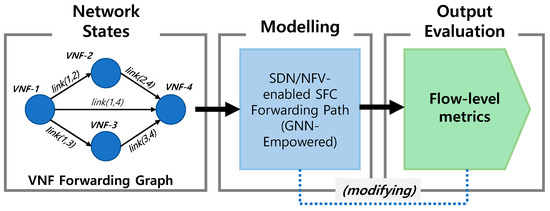
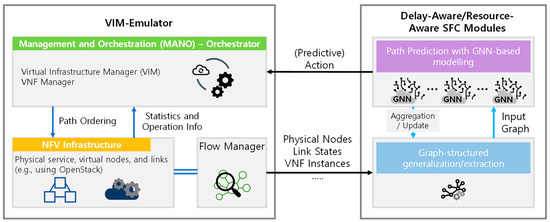
The advancing applications based on machine learning and deep learning in communication networks have been exponentially increasing in the system architectures of enabled software-defined networking, network functions virtualization, and other wired/wireless networks. With data exposure capabilities of graph-structured network topologies and underlying data
[...] Read more.
The advancing applications based on machine learning and deep learning in communication networks have been exponentially increasing in the system architectures of enabled software-defined networking, network functions virtualization, and other wired/wireless networks. With data exposure capabilities of graph-structured network topologies and underlying data plane information, the state-of-the-art deep learning approach, graph neural networks (GNN), has been applied to understand multi-scale deep correlations, offer generalization capability, improve the accuracy metrics of prediction modelling, and empower state representation for deep reinforcement learning (DRL) agents in future intelligent network management and orchestration. This paper contributes a taxonomy of recent studies using GNN-based approaches to optimize the control policies, including offloading strategies, routing optimization, virtual network function orchestration, and resource allocation. The algorithm designs of converged DRL and GNN are reviewed throughout the selected studies by presenting the state generalization, GNN-assisted action selection, and reward valuation cooperating with GNN outputs. We also survey the GNN-empowered application deployment in the autonomous control of optical networks, Internet of Healthcare Things, Internet of Vehicles, Industrial Internet of Things, and other smart city applications. Finally, we provide a potential discussion on research challenges and future directions.
Full article
►▼
Show Figures
Open AccessCommunication
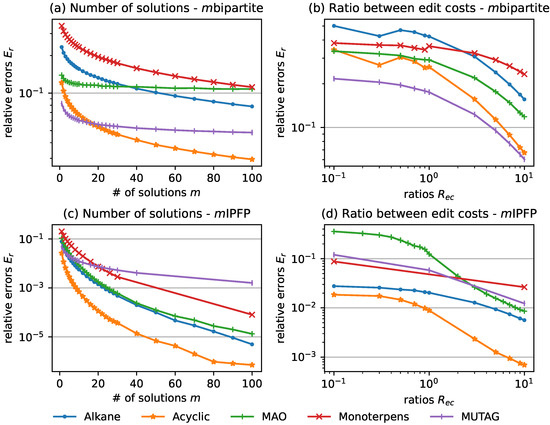
A Study on the Stability of Graph Edit Distance Heuristics
by
Linlin Jia, Vincent Tognetti, Laurent Joubert, Benoit Gaüzère and Paul Honeine
Viewed by 1174
Abstract
Graph edit distance (GED) is a powerful tool to model the dissimilarity between graphs. However, evaluating the exact GED is NP-hard. To tackle this problem, estimation methods of GED were introduced, e.g., bipartite and IPFP, during which heuristics were employed. The stochastic nature
[...] Read more.
Graph edit distance (GED) is a powerful tool to model the dissimilarity between graphs. However, evaluating the exact GED is NP-hard. To tackle this problem, estimation methods of GED were introduced, e.g., bipartite and IPFP, during which heuristics were employed. The stochastic nature of these methods induces the stability issue. In this paper, we propose the first formal study of stability of GED heuristics, starting with defining a measure of these (in)stabilities, namely the relative error. Then, the effects of two critical factors on stability are examined, namely, the number of solutions and the ratio between edit costs. The ratios are computed on five datasets of various properties. General suggestions are provided to properly choose these factors, which can reduce the relative error by more than an order of magnitude. Finally, we verify the relevance of stability to predict performance of GED heuristics, by taking advantage of an edit cost learning algorithm to optimize the performance and the k-nearest neighbor regression for prediction. Experiments show that the optimized costs correspond to much higher ratios and an order of magnitude lower relative errors than the expert cost.
Full article
►▼
Show Figures
Open AccessArticle
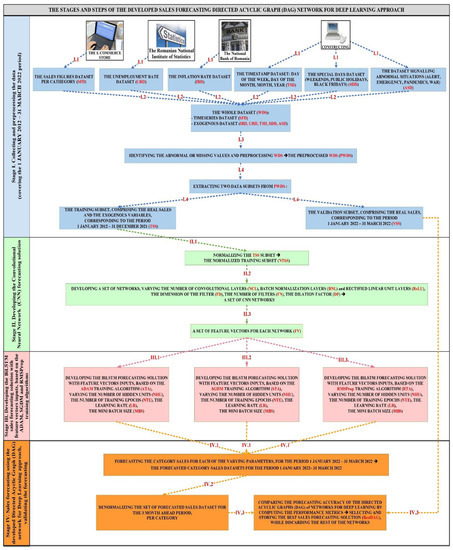
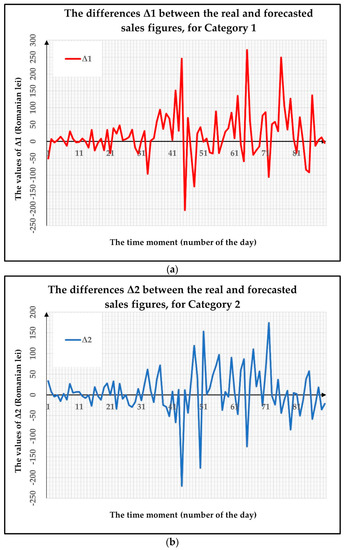
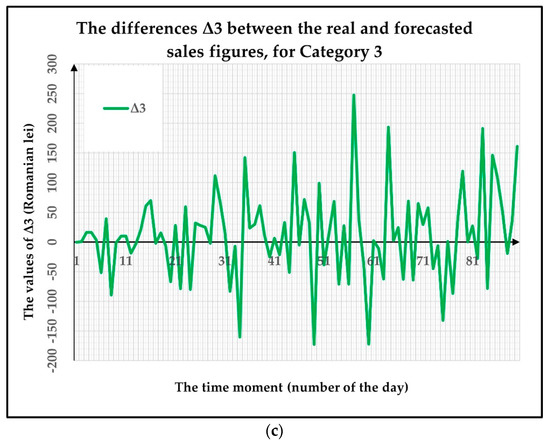
E-Commerce Sales Revenues Forecasting by Means of Dynamically Designing, Developing and Validating a Directed Acyclic Graph (DAG) Network for Deep Learning
by
Dana-Mihaela Petroșanu, Alexandru Pîrjan, George Căruţaşu, Alexandru Tăbușcă, Daniela-Lenuța Zirra and Alexandra Perju-Mitran
Cited by 4 | Viewed by 2642
Abstract
As the digitalization process has become more and more important in our daily lives, during recent decades e-commerce has greatly increased in popularity, becoming increasingly used, therefore representing an extremely convenient alternative to traditional stores. In order to develop and maintain profitable businesses,
[...] Read more.
As the digitalization process has become more and more important in our daily lives, during recent decades e-commerce has greatly increased in popularity, becoming increasingly used, therefore representing an extremely convenient alternative to traditional stores. In order to develop and maintain profitable businesses, traders need accurate forecasts concerning their future sales, a very difficult task considering that these are influenced by a wide variety of factors. This paper proposes a novel e-commerce sales forecasting method that dynamically builds a Directed Acyclic Graph Neural Network (DAGNN) for Deep Learning architecture. This will allow for long-term, fine-grained forecasts of daily sales revenue, refined up to the level of product categories. The developed forecasting method provides the e-commerce store owner an accurate forecasting tool for predicting the sales of each category of products for up to three months ahead. The method offers a high degree of scalability and generalization capability due to the dynamically incremental way in which the constituent elements of the DAGNN’s architecture are obtained. In addition, the proposed method achieves an efficient use of data by combining the numerous advantages of its constituent layers, registering very good performance metrics and processing times. The proposed method can be generalized and applied to forecast the sales for up to three months ahead in the case of other e-commerce stores, including large e-commerce businesses.
Full article
►▼
Show Figures
Open AccessArticle
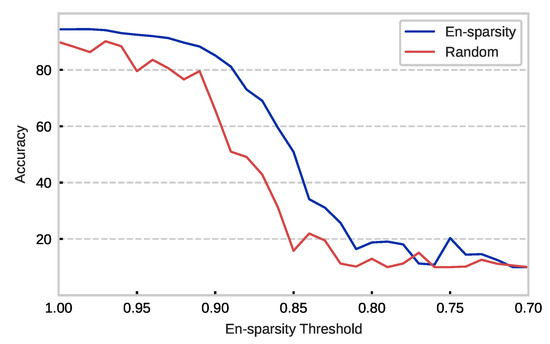
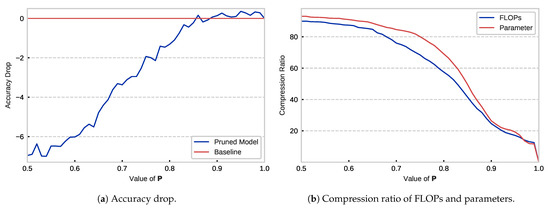
Feature Map Analysis-Based Dynamic CNN Pruning and the Acceleration on FPGAs
by
Qi Li, Hengyi Li and Lin Meng
Cited by 5 | Viewed by 1439
Abstract
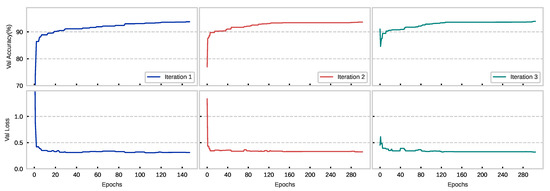
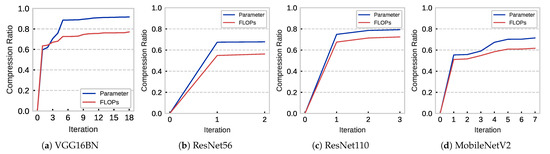
Deep-learning-based applications bring impressive results to graph machine learning and are widely used in fields such as autonomous driving and language translations. Nevertheless, the tremendous capacity of convolutional neural networks makes it difficult for them to be implemented on resource-constrained devices. Channel pruning
[...] Read more.
Deep-learning-based applications bring impressive results to graph machine learning and are widely used in fields such as autonomous driving and language translations. Nevertheless, the tremendous capacity of convolutional neural networks makes it difficult for them to be implemented on resource-constrained devices. Channel pruning provides a promising solution to compress networks by removing a redundant calculation. Existing pruning methods measure the importance of each filter and discard the less important ones until reaching a fixed compression target. However, the static approach limits the pruning effect. Thus, we propose a dynamic channel-pruning method that dynamically identifies and removes less important filters based on a redundancy analysis of its feature maps. Experimental results show that 77.10% of floating-point operations per second (FLOPs) and 91.72% of the parameters are reduced on VGG16BN with only a 0.54% accuracy drop. Furthermore, the compressed models were implemented on the field-programmable gate array (FPGA) and a significant speed-up was observed.
Full article
►▼
Show Figures
Open AccessArticle
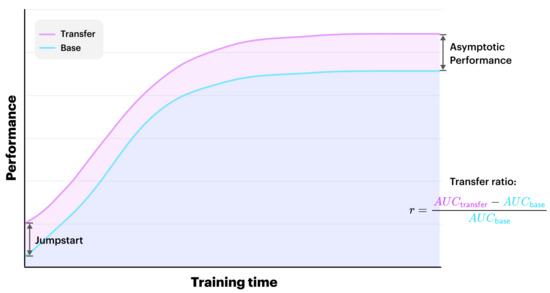
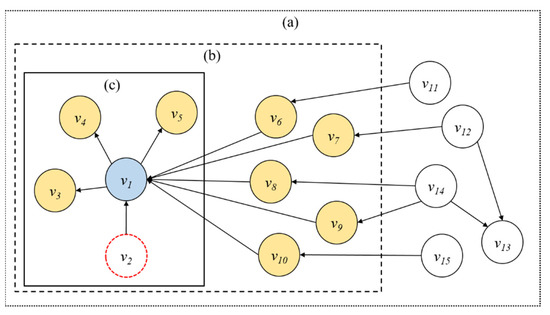
Investigating Transfer Learning in Graph Neural Networks
by
Nishai Kooverjee, Steven James and Terence van Zyl
Cited by 2 | Viewed by 3135
Abstract
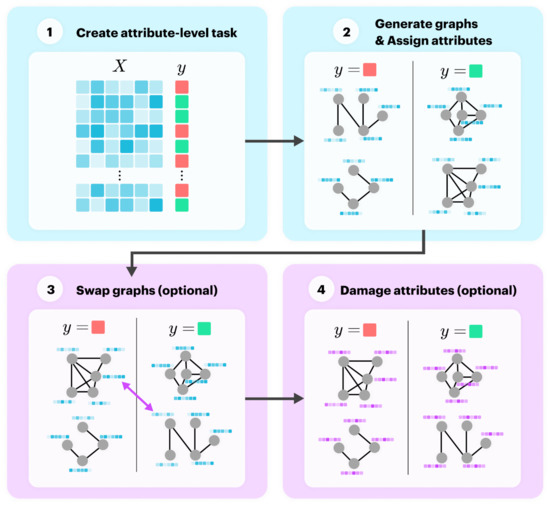
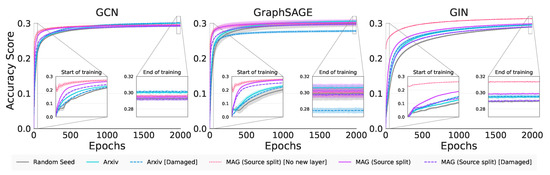
Graph neural networks (GNNs) build on the success of deep learning models by extending them for use in graph spaces. Transfer learning has proven extremely successful for traditional deep learning problems, resulting in faster training and improved performance. Despite the increasing interest in
[...] Read more.
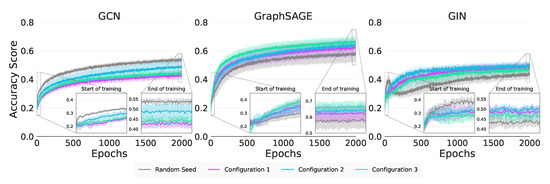
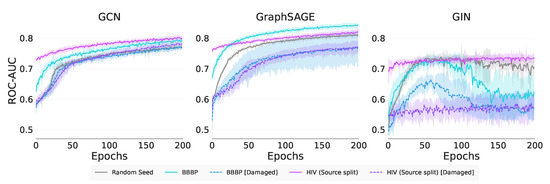
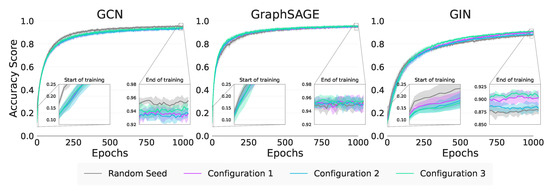
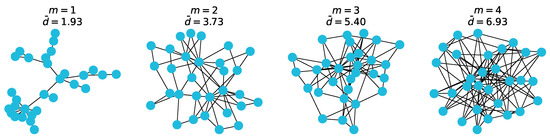
Graph neural networks (GNNs) build on the success of deep learning models by extending them for use in graph spaces. Transfer learning has proven extremely successful for traditional deep learning problems, resulting in faster training and improved performance. Despite the increasing interest in GNNs and their use cases, there is little research on their transferability. This research demonstrates that transfer learning is effective with GNNs, and describes how source tasks and the choice of GNN impact the ability to learn generalisable knowledge. We perform experiments using real-world and synthetic data within the contexts of node classification and graph classification. To this end, we also provide a general methodology for transfer learning experimentation and present a novel algorithm for generating synthetic graph classification tasks. We compare the performance of GCN, GraphSAGE and GIN across both synthetic and real-world datasets. Our results demonstrate empirically that GNNs with inductive operations yield statistically significantly improved transfer. Further, we show that similarity in community structure between source and target tasks support statistically significant improvements in transfer over and above the use of only the node attributes.
Full article
►▼
Show Figures
Open AccessArticle
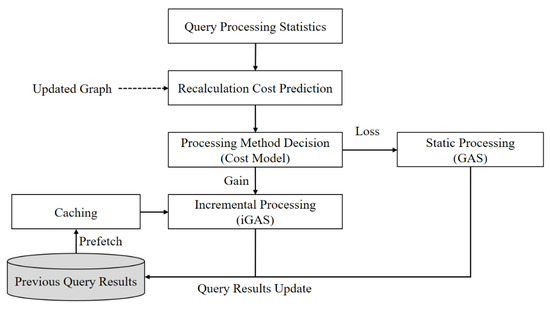
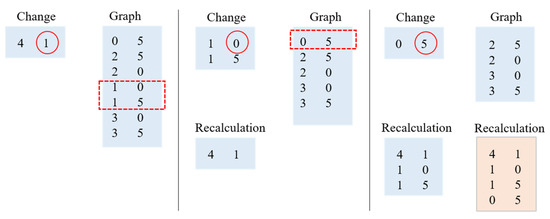
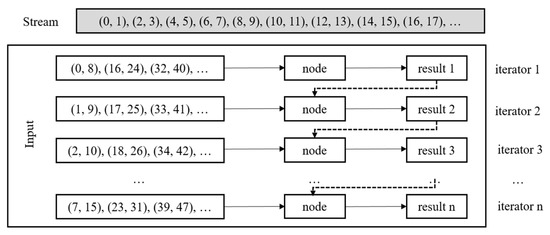
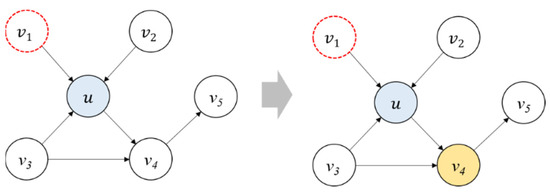
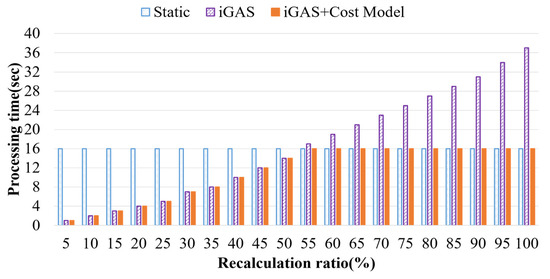
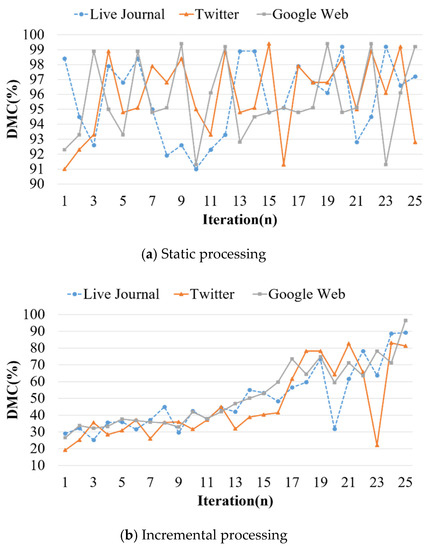
Cost Model Based Incremental Processing in Dynamic Graphs
by
Kyoungsoo Bok, Jungkwon Cho, Hyeonbyeong Lee, Dojin Choi, Jongtae Lim and Jaesoo Yoo
Cited by 1 | Viewed by 1714
Abstract
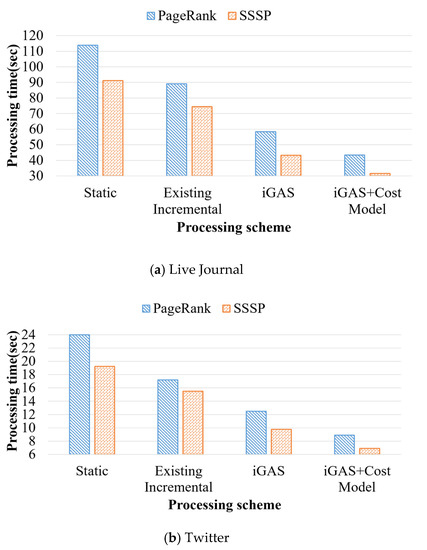
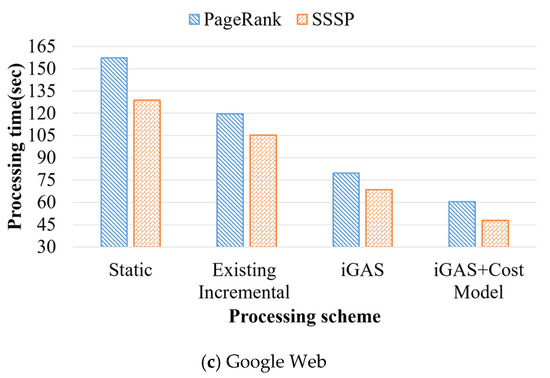
Incremental graph processing has been developed to reduce unnecessary redundant calculations in dynamic graphs. In this paper, we propose an incremental dynamic graph-processing scheme using a cost model to selectively perform incremental processing or static processing. The cost model calculates the predicted values
[...] Read more.
Incremental graph processing has been developed to reduce unnecessary redundant calculations in dynamic graphs. In this paper, we propose an incremental dynamic graph-processing scheme using a cost model to selectively perform incremental processing or static processing. The cost model calculates the predicted values of the detection cost and processing cost of the recalculation region based on the past processing history. If there is a benefit of the cost model, incremental query processing is performed. Otherwise, static query processing is performed because the detection cost and processing cost increase due to the graph change. The proposed incremental scheme reduces the amount of computation by processing only the changed region through incremental processing. Further, it reduces the detection and disk I/O costs of the vertex, which are calculated by reusing the subgraphs from the previous results. The processing structure of the proposed scheme stores the data read from the cache and the adjacent vertices and then performs only memory mapping when processing these graph. It is demonstrated through various performance evaluations that the proposed scheme outperforms the existing schemes.
Full article
►▼
Show Figures
Open AccessArticle
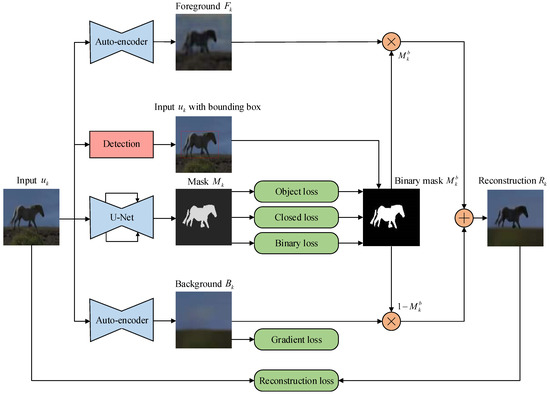
Image Segmentation from Sparse Decomposition with a Pretrained Object-Detection Network
by
Yulin Wu, Chuandong Lv, Baoqing Ding, Lei Chen, Bin Zhou and Hongchao Zhou
Cited by 1 | Viewed by 1648
Abstract
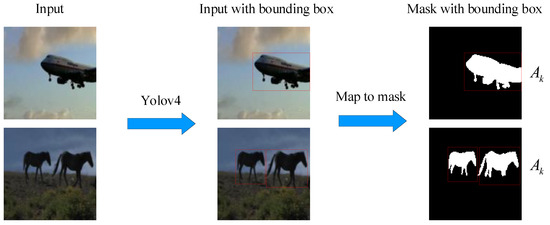
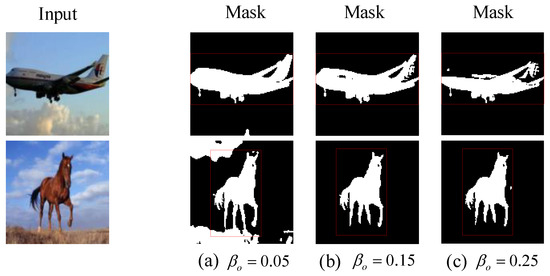
Annotations for image segmentation are expensive and time-consuming. In contrast to image segmentation, the task of object detection is in general easier in terms of the acquisition of labeled training data and the design of training models. In this paper, we combine the
[...] Read more.
Annotations for image segmentation are expensive and time-consuming. In contrast to image segmentation, the task of object detection is in general easier in terms of the acquisition of labeled training data and the design of training models. In this paper, we combine the idea of unsupervised learning and a pretrained object-detection network to perform image segmentation, without using expensive segmentation labels. Specially, we designed a pretext task based on the sparse decomposition of object instances in videos to obtain the segmentation mask of the objects, which benefits from the sparsity of image instances and the inter-frame structure of videos. To improve the accuracy of identifying the ’right’ object, we used a pretrained object-detection network to provide the location information of the object instances, and propose an Object Location Segmentation (OLSeg) model of three branches with bounding box prior. The model is trained from videos and is able to capture the foreground, background and segmentation mask in a single image. The performance gain benefits from the sparsity of object instances (the foreground and background in our experiments) and the provided location information (bounding box prior), which work together to produce a comprehensive and robust visual representation for the input. The experimental results demonstrate that the proposed model boosts the performance effectively on various image segmentation benchmarks.
Full article
►▼
Show Figures
Open AccessArticle
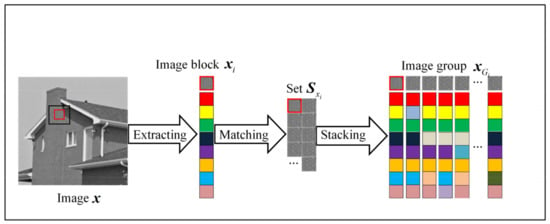
Group-Based Sparse Representation for Compressed Sensing Image Reconstruction with Joint Regularization
by
Rongfang Wang, Yali Qin, Zhenbiao Wang and Huan Zheng
Cited by 6 | Viewed by 1740
Abstract
Achieving high-quality reconstructions of images is the focus of research in image compressed sensing. Group sparse representation improves the quality of reconstructed images by exploiting the non-local similarity of images; however, block-matching and dictionary learning in the image group construction process leads to
[...] Read more.
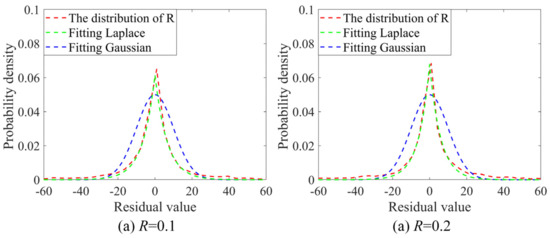
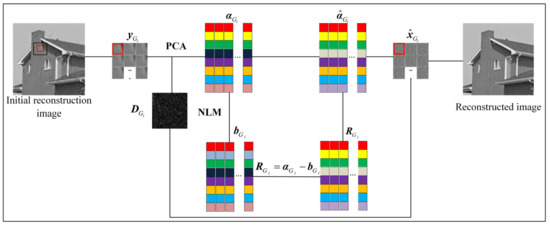
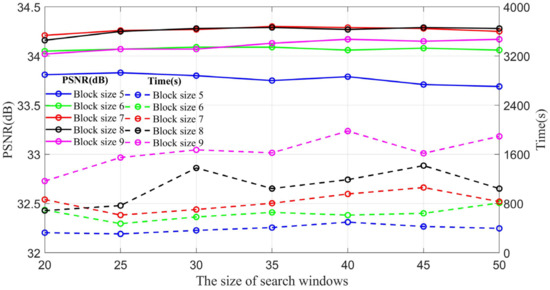
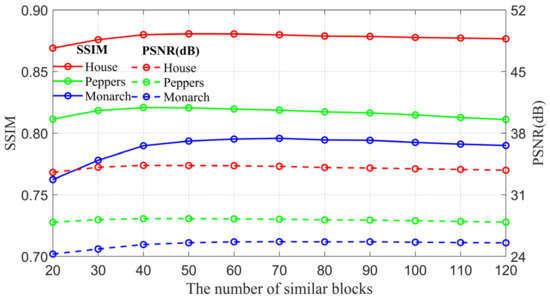
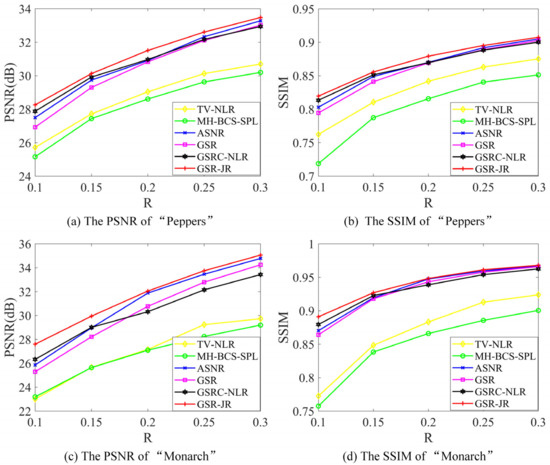
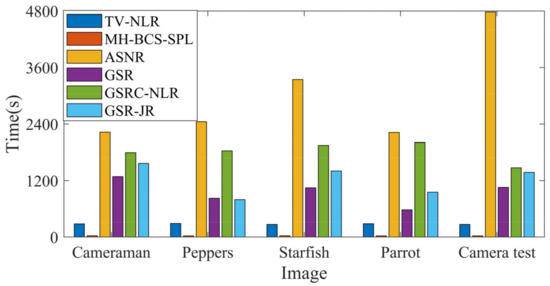
Achieving high-quality reconstructions of images is the focus of research in image compressed sensing. Group sparse representation improves the quality of reconstructed images by exploiting the non-local similarity of images; however, block-matching and dictionary learning in the image group construction process leads to a long reconstruction time and artifacts in the reconstructed images. To solve the above problems, a joint regularized image reconstruction model based on group sparse representation (GSR-JR) is proposed. A group sparse coefficients regularization term ensures the sparsity of the group coefficients and reduces the complexity of the model. The group sparse residual regularization term introduces the prior information of the image to improve the quality of the reconstructed image. The alternating direction multiplier method and iterative thresholding algorithm are applied to solve the optimization problem. Simulation experiments confirm that the optimized GSR-JR model is superior to other advanced image reconstruction models in reconstructed image quality and visual effects. When the sensing rate is 0.1, compared to the group sparse residual constraint with a nonlocal prior (GSRC-NLR) model, the gain of the peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) is up to 4.86 dB and 0.1189, respectively.
Full article
►▼
Show Figures



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}