
Wind Turbine Surface Defect Detection Method Based on YOLOv5s-L
Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset Preparation
2.2. The Experimental Environment
2.3. Experimental Parameter Setting
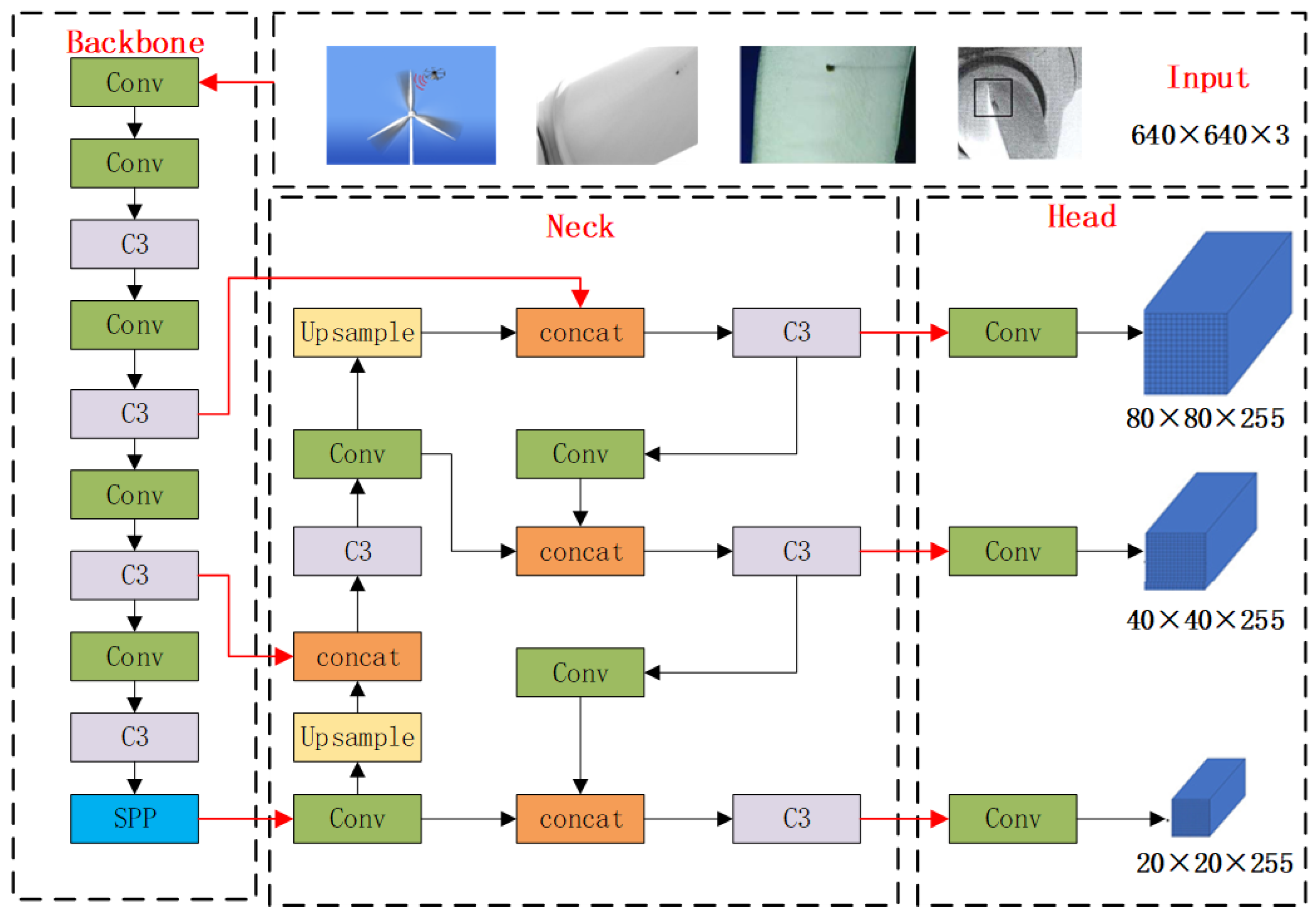
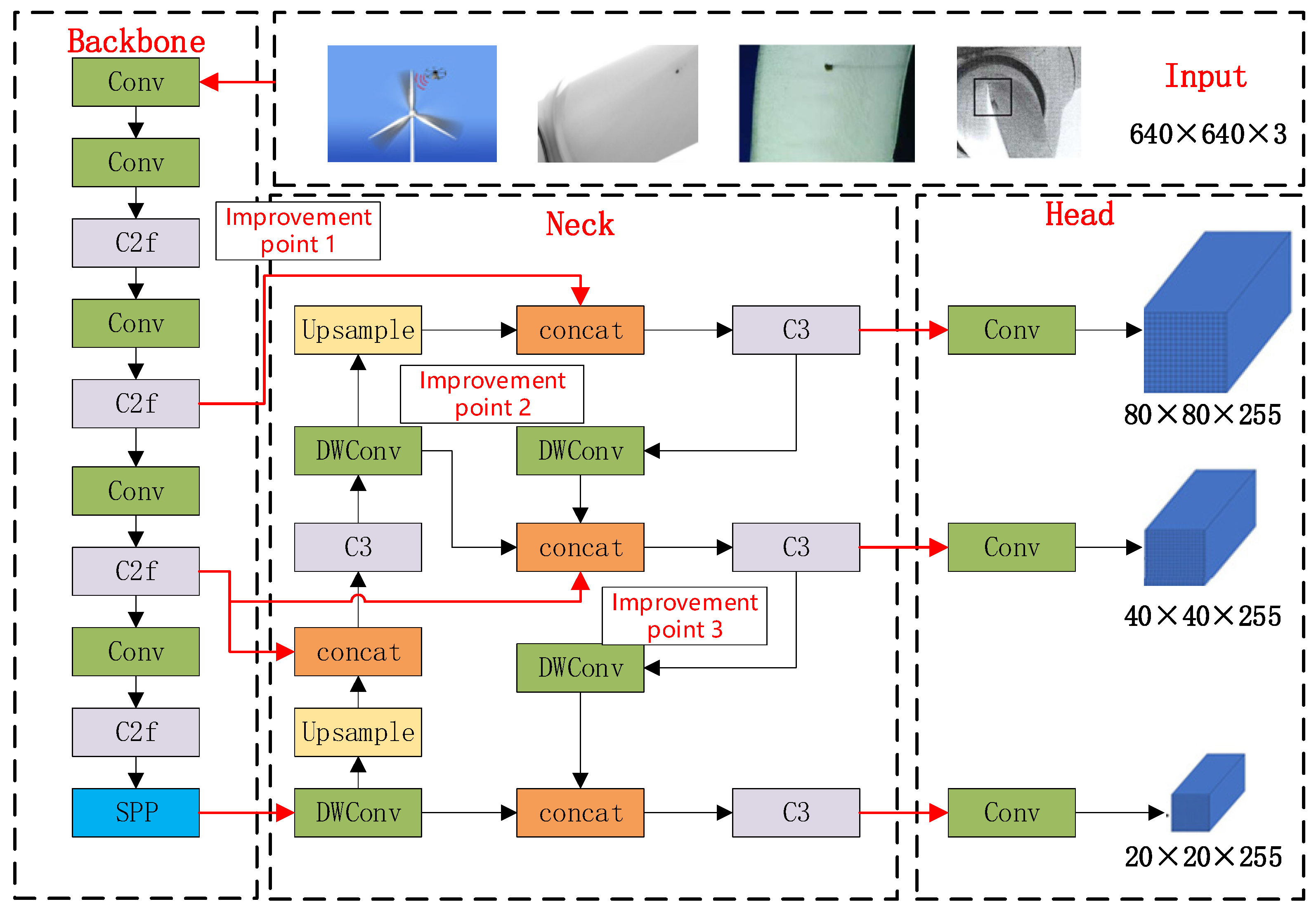
2.4. YOLOv5 Algorithm Improvement
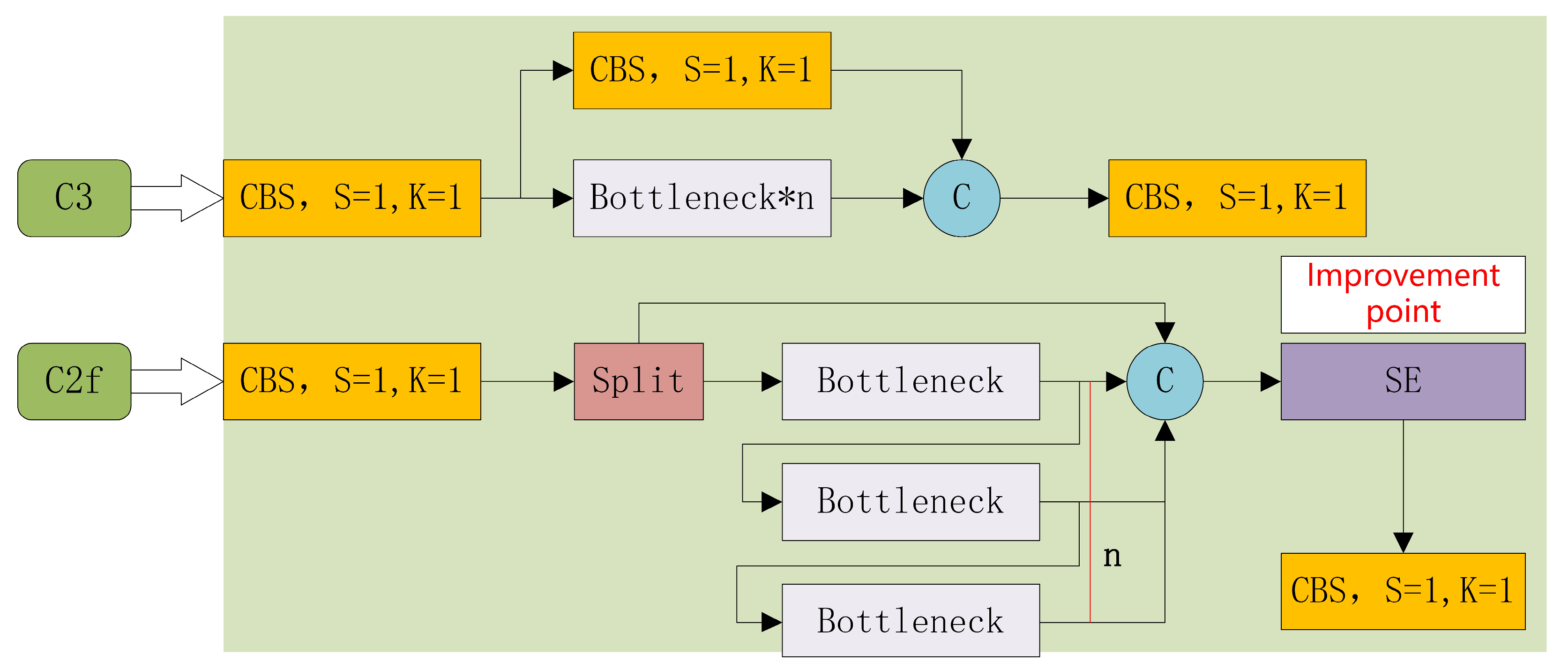
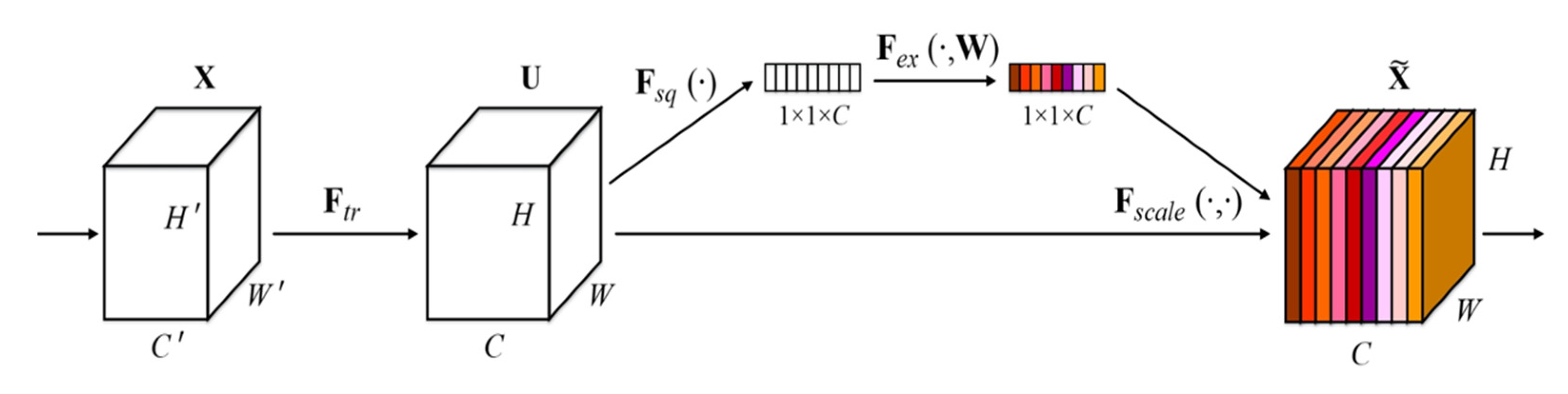
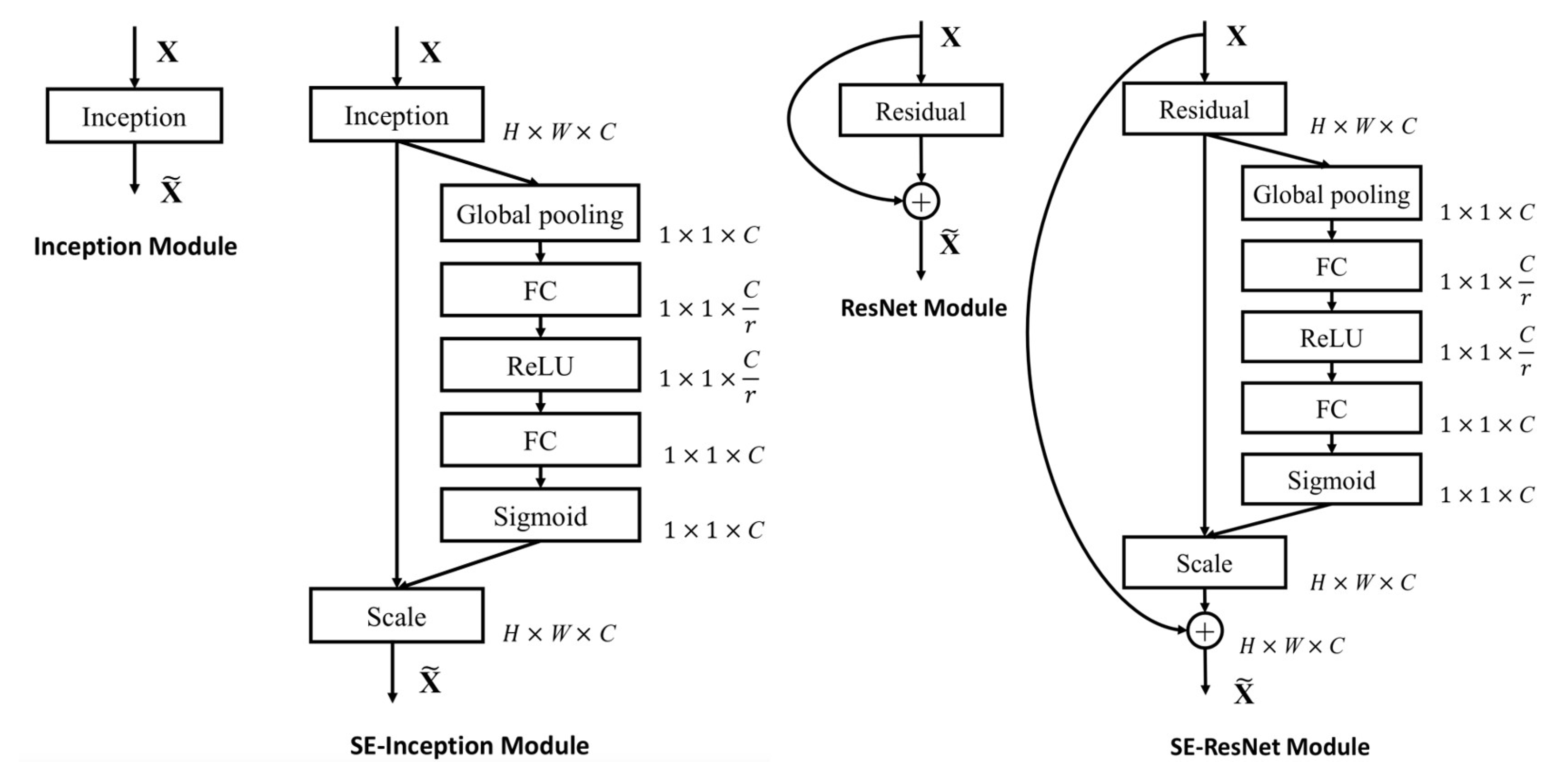
2.4.1. C2f Module Improvement
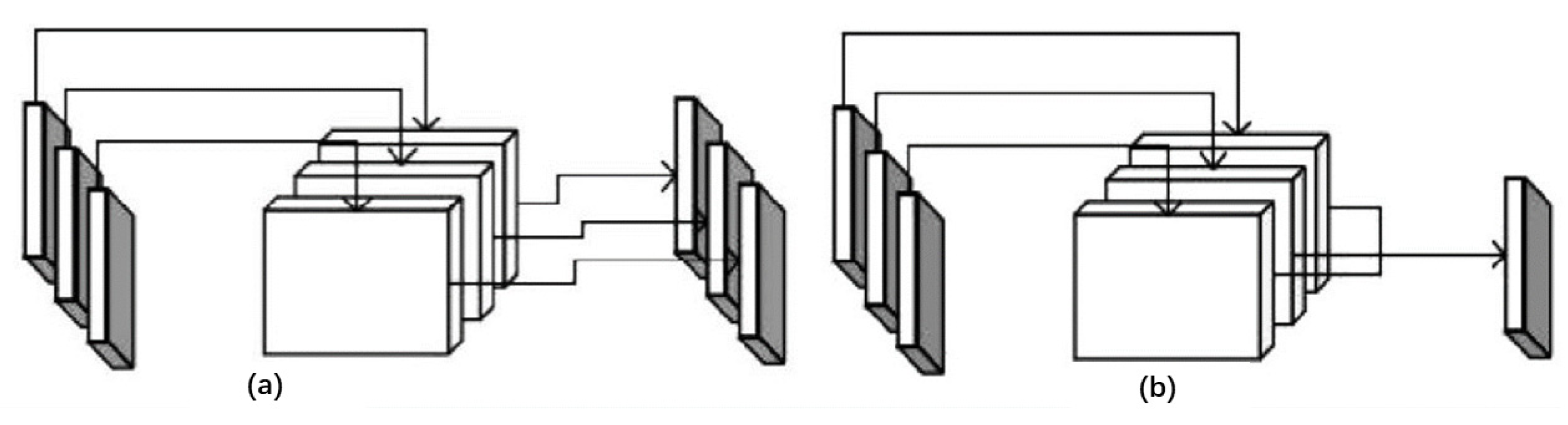
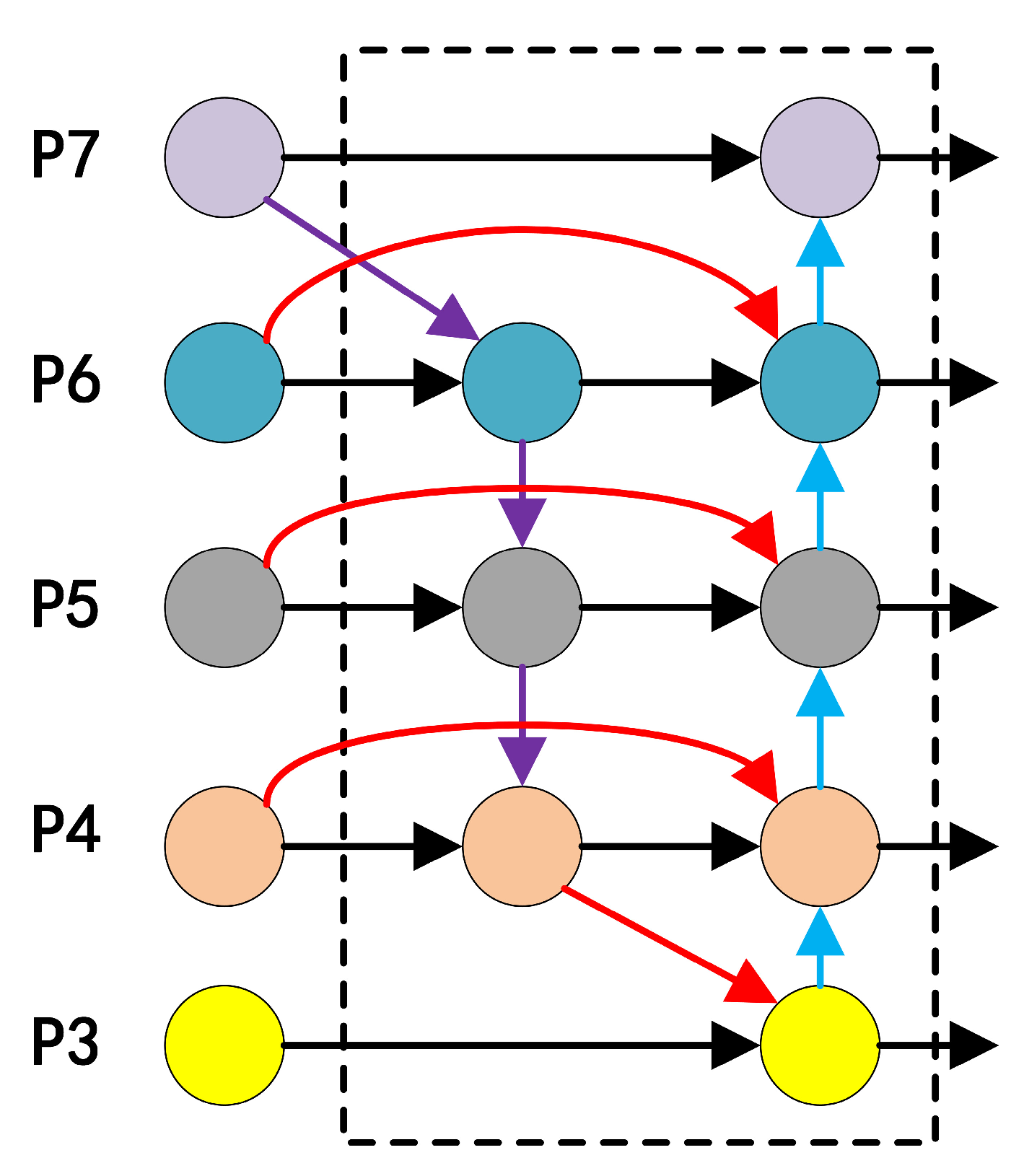
2.4.2. Neck Network Improvement
2.4.3. Classification Loss Function Improvement
2.5. Evaluating Indicator
3. Results
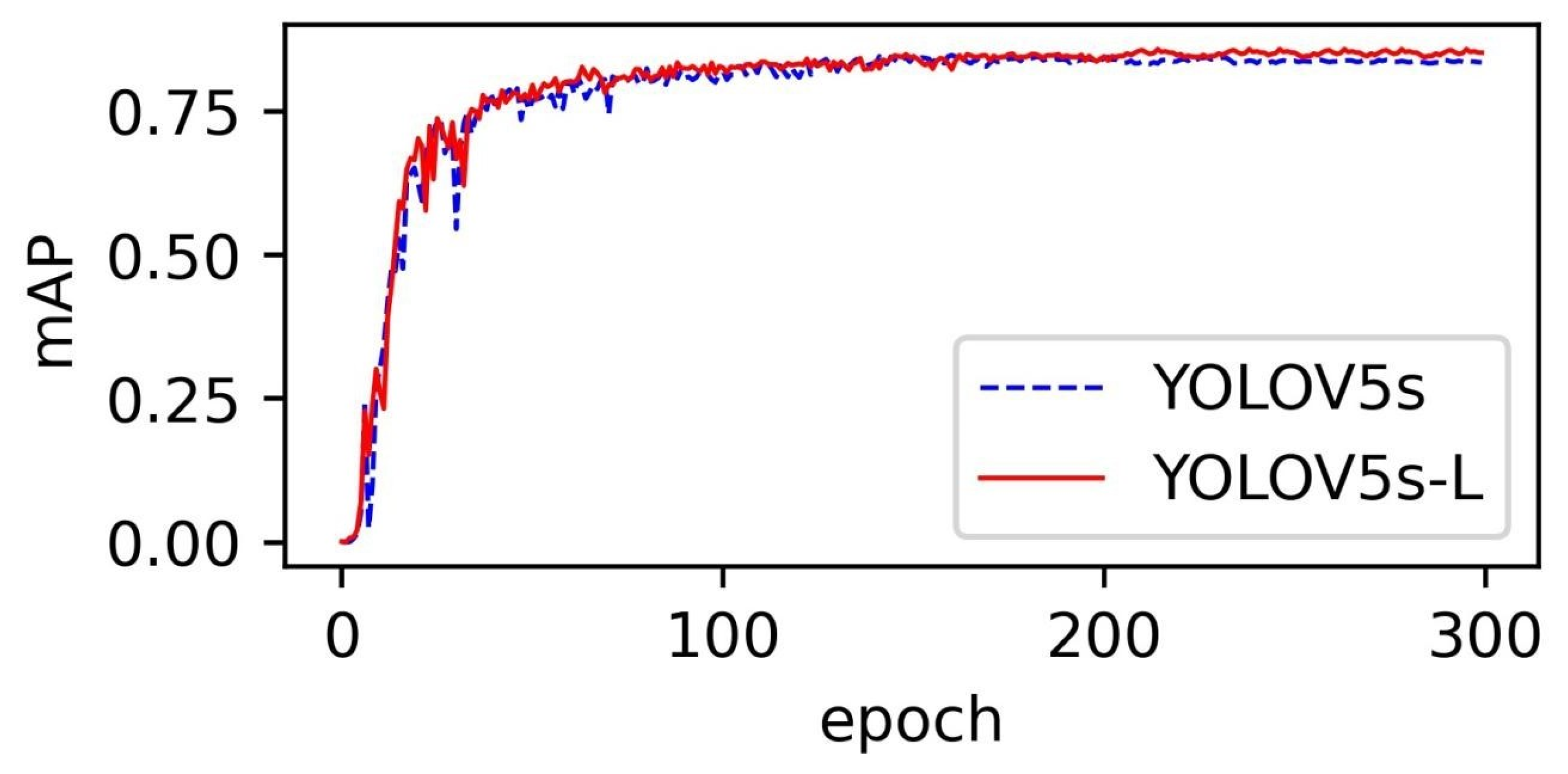
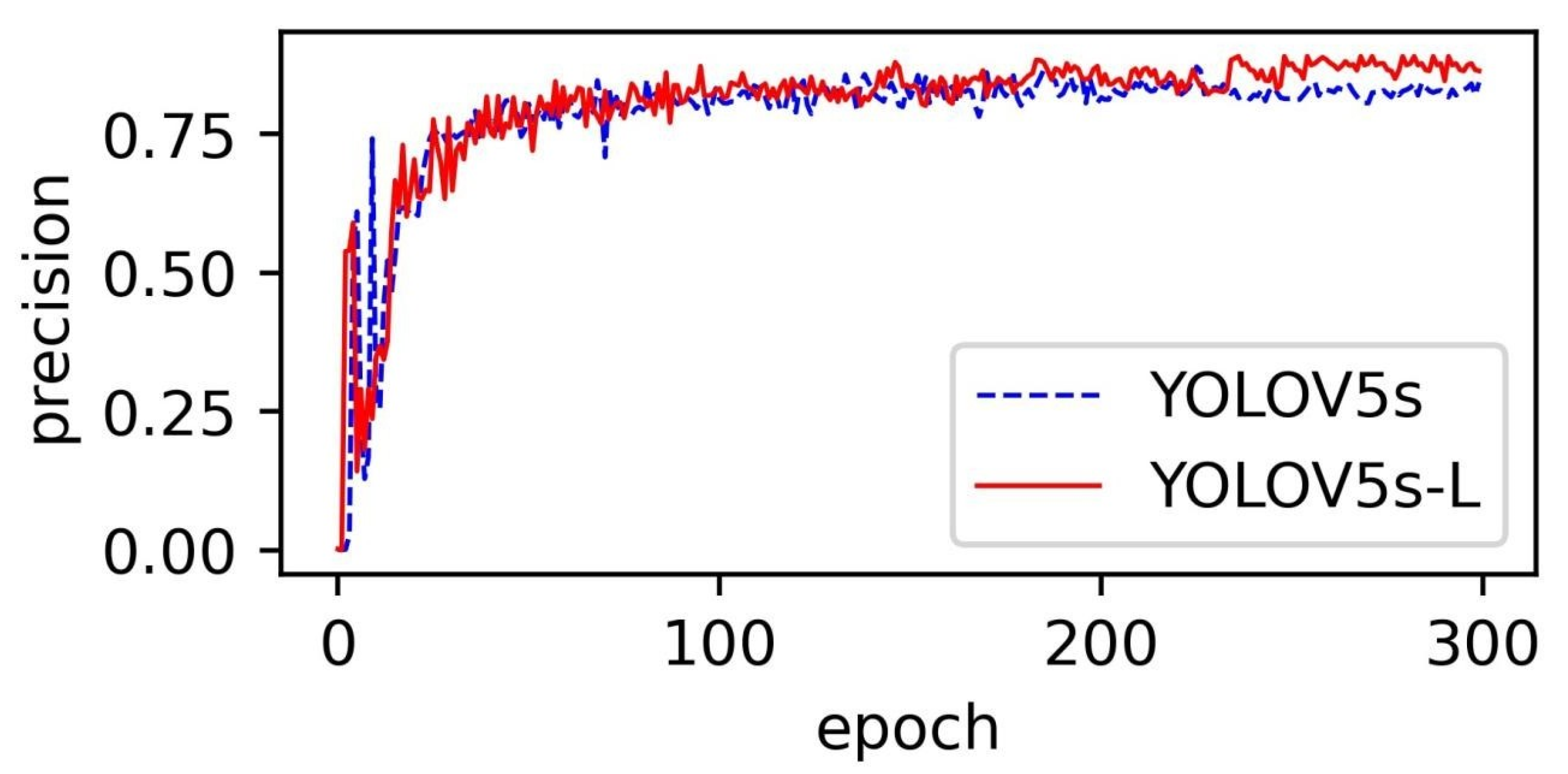
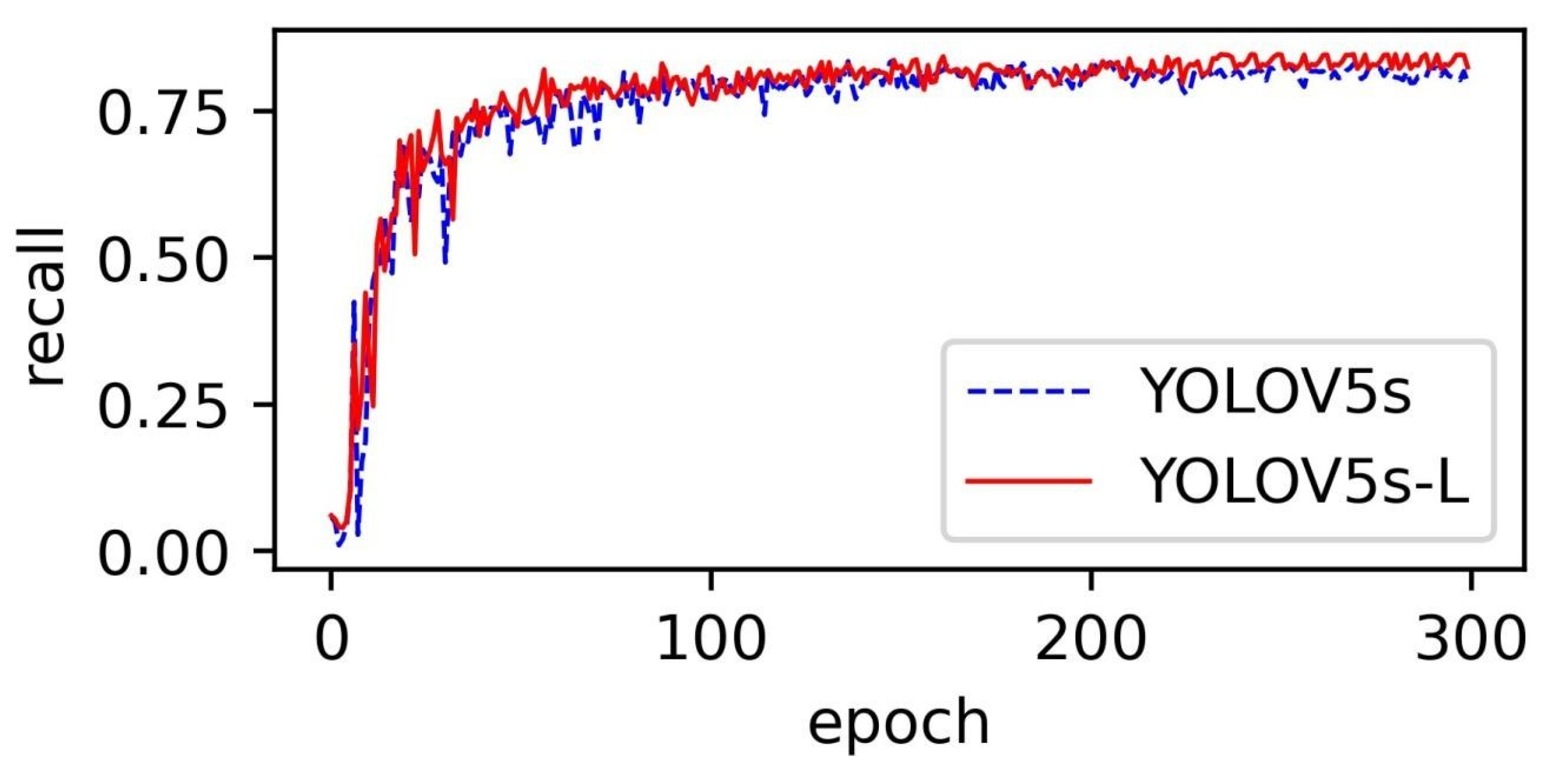
3.1. Comparison of Detection Algorithms
3.2. Contrast Analysis of Detection Effect
4. Conclusions
- (1)
- The introduction of C2f modules to optimize the neural network, increasing the accuracy;
- (2)
- The SE attention mechanism extracts important characteristic information and enhances attention to small targets;
- (3)
- BiFPN is introduced to optimize Neck networks for multi-scale fusion;
- (4)
- DWconv ensures lightweight network accuracy.
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hsu, J.Y.; Wang, Y.F.; Lin, K.C. Wind turbine fault diagnosis and predictive maintenance through statistical process control and machine learning. IEEE Access 2020, 8, 23427–23439. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, Z.; Long, H.; Xu, J.; Liu, R. Wind Turbine Gearbox Failure Identification With Deep Neural Networks. IEEE Trans. Ind. Inform. 2017, 13, 1360–1368. [Google Scholar] [CrossRef]
- Wang, L.; Long, H.; Zhang, Z.; Xu, J.; Liu, R. Wind turbine gearbox failure monitoring based on SCADA data analysis. In Proceedings of the 2016 IEEE Power and Energy Society General Meeting (PESGM), Boston, MA, USA, 17–21 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–5. [Google Scholar]
- Long, H.; Wang, L.; Zhang, Z.; Song, Z.; Xu, J. Data-driven wind turbine power generation performance monitoring. IEEE Trans. Ind. Electron. 2015, 62, 6627–6635. [Google Scholar] [CrossRef]
- Ruiz, M.; Mujica, L.E.; Alferez, S.; Acho, L.; Tutiven, C.; Vidal, Y.; Rodellar, J.; Pozo, F. Wind turbine fault detection and classification by means of image texture analysis. Mech. Syst. Signal Process. 2018, 107, 149–167. [Google Scholar] [CrossRef]
- Zhuang, Y.; Ruan, C.; Qiu, K.; Xu, H. Comparison of non-destructive testing methods for fan blade defects. Technol. Innov. 2016, 57, 106. [Google Scholar]
- David, G.; Dmitri, T. An experimental study on the data-driven structural health monitoring of large wind turbine blades using a single accelerometer and actuator. Mech. Syst. Signal Process. 2019, 127, 102–119. [Google Scholar]
- Munteanu, E.; Zaporojan, S.; Dulgheru, V. Intelligent Condition Monitoring of Wind Turbine Blades: A Preliminary Approach. In Proceedings of the 2022 IEEE 18th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 22–24 September 2022; pp. 9–16. [Google Scholar]
- Worzewski, T.; Krankenhagen, R.; Doroshtnasir, M. Thermographic inspection of wind turbine rotor blade segment utili-zing natural conditions as excitation source, Part Il;The effectof climatic conditions on thermographic inspections-A longterm outdoor experiment. Infrared Physics. Technology 2016, 76, 767–776. [Google Scholar]
- Li, J.; Ye, D.H.; Chung, T. Multi-target detection and tracking from a single camera in Unmanned Aerial Vehicles (UAVs). In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 4992–4997. [Google Scholar]
- Wang, L.; Zhang, Z.; Luo, X. A two-stage data-driven approach for image-based wind turbine blade crack inspections. IEEE/ASME Trans. Mechatron. 2019, 24, 1271–1281. [Google Scholar] [CrossRef]
- Neupane, D.; Seok, J. A review on deep learning-based approaches for automatic sonar target recognition. Electronics 2020, 9, 1972. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Wang, G.; Chen, S.; Hu, G.; Pang, D.; Wang, Z. Detection algorithm of abnormal flow state fluid on closed vibrating screen based on improved YOLOv5. Eng. Appl. Artif. Intell. 2023, 123, 106272. [Google Scholar] [CrossRef]
- Yu, Y.; Zhao, J.; Gong, Q.; Huang, C.; Zheng, G.; Ma, J. Real-time underwater maritime object detection in side-scan sonar images based on transformer-YOLOv5. Remote Sens. 2021, 13, 3555. [Google Scholar] [CrossRef]
- Shihavuddin, A.S.M.; Chen, X.; Fedorov, V.; Nymark Christensen, A.; Andre Brogaard Riis, N.; Branner, K.; Dahl, A.B.; Reinhold Paulsen, R. Wind turbine surface damage detection by deep learning aided drone inspection analysis. Energies 2019, 12, 676. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware/System | Model/Version |
|---|---|
| Operating system | Windows 10 |
| CPU | Intel Core i7-8700 |
| GPU | NVIDIA GeForce RTX 2080Ti 32 GB |
| Deep Learning Framework | Pytorch 1.13.1 |
| Evelopment language | Python 3.8 |
| Algorithms | C2f | SE | BiFPN | DWconv | Focal-Loss | mAP@0.5 | Weight (m) |
|---|---|---|---|---|---|---|---|
| YOLOv5s- | - | - | - | - | - | 0.839 | 13.7 |
| YOLOv5s-C2f | * | - | - | - | - | 0.846 | 14.9 |
| YOLOv5s-SE | - | * | - | - | - | 0.843 | 13.8 |
| YOLOv5s-BiFPN | - | - | * | - | - | 0.842 | 13.7 |
| YOLOv5s-DW | - | - | - | * | - | 0.838 | 12.2 |
| YOLOv5s-F | - | - | - | - | * | 0.841 | 13.7 |
| YOLOv5s-L | * | * | * | * | * | 0.858 | 13.9 |
| Algorithms | mAP@0.5 | Weight (m) |
|---|---|---|
| Faster R-CNN | 0.877 | 331.1 |
| SSD | 0.782 | 181 |
| YOLOV5s | 0.839 | 13.7 |
| YOLOV5s-L | 0.858 | 13.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; An, C.; Yang, Y. Wind Turbine Surface Defect Detection Method Based on YOLOv5s-L. NDT 2023, 1, 46-57. https://doi.org/10.3390/ndt1010005
Liu C, An C, Yang Y. Wind Turbine Surface Defect Detection Method Based on YOLOv5s-L. NDT. 2023; 1(1):46-57. https://doi.org/10.3390/ndt1010005
Chicago/Turabian StyleLiu, Chang, Chen An, and Yifan Yang. 2023. "Wind Turbine Surface Defect Detection Method Based on YOLOv5s-L" NDT 1, no. 1: 46-57. https://doi.org/10.3390/ndt1010005