2.3.1. Description of the Data
We use publicly available Freddie Mac (FHLMC) mortgage origination and performance data on single-family homes to evaluate the above formulations. Freddie Mac is one of two GSEs that securitizes mortgages into guaranteed MBS, and provides loan-level credit performance data on all mortgages they purchased or guaranteed from 1999 to 2021. Their Standard Dataset includes single-family fixed-rate conventional mortgages, typically meeting securitization criteria (see [
34] for details on loan types and the role of GSEs in the U.S. Housing Market). Using this dataset, we can observe loan-level origination data and monthly performance data for mortgages that meet the GSEs’ securitization standards. Origination data refer to variables used to undersign a loan (e.g. a borrower’s credit score, debt-to-income (DTI), and loan-to-value (LTV) measures), mortgage contract details (e.g. time-to-maturity, interest rate, and loan amount), and property characteristics (e.g. home value and geographic data). Monthly performance data capture information on a mortgage at a given point in time; this typically entails data on the amount of payments made (delinquency), modifications made to the loan, and snapshots of mortgage characteristics such as unpaid balances, remaining time to maturity, and current property value.
We design our study around Hurricane Harvey, a Category 4 hurricane that struck Texas and Louisiana in August 2017. Hundreds of thousands of homes were flooded and approximately 70% of homeowners were uninsured [
35], causing approximately USD 42.5 billion in property damage [
36]. We consider the universe of loans originated in Texas from 2000 to 2017 with associated performance data from January 2017 to December 2018 in Freddie Mac’s Single-Family Standard Dataset. We extract two samples from this universe to evaluate our proposed models: the non-default sample aims to capture the ’ideal’ processes, i.e., outstanding loan balance and property home values as the bank intended when extending the loan. The climate default sample includes households with an observed disaster-related missed payment and who also defaulted within 6 months of Harvey, since many homes that did not qualify for disaster delinquency might have still defaulted due to the climate event. A household can apply for a delinquency due to disaster if the borrower experiences a financial hardship impacting his or her ability to pay the contractual monthly amount when (1) the property securing the mortgage loan experienced an insured loss, (2) the property securing the mortgage loan is located in a FEMA-Declared Disaster Area eligible for Individual Assistance, or (3) the borrower’s place of employment is located in a FEMA-Declared Disaster Area eligible for Individual Assistance. Defaults due to climate can also occur indirectly and are not captured by the explicit ’Disaster Delinquency’ flag in the data; a household may never apply due to delinquency disaster aid because their home was not damaged, but there might be significant damage to the neighborhood infrastructure, commercial properties, etc., that also affects the borrower’s ability and willingness to repay. Delays in insurance payouts and outdated flood zone maps may also decrease eligibility for aid; only 10% of flooded structures in counties with FEMA declarations in Texas during Hurricane Harvey had National Flood Insurance Policy (NFIP) insurance [
3]. Even those who had insurance during Harvey faced payout delays; more than three months after Harvey hit, nearly half of Houston residents stated that they still were experiencing financial or housing-related challenges, including loss of income or ability to repair their home [
37]. And so many households might have defaulted due to climate-related reasons that were not marked as delinquent due to disaster. A total of 2000 households are randomly selected for the non-default and climate default definitions to create sizeable and representative samples while avoiding computational constraints (see
Table 1 for sample details).
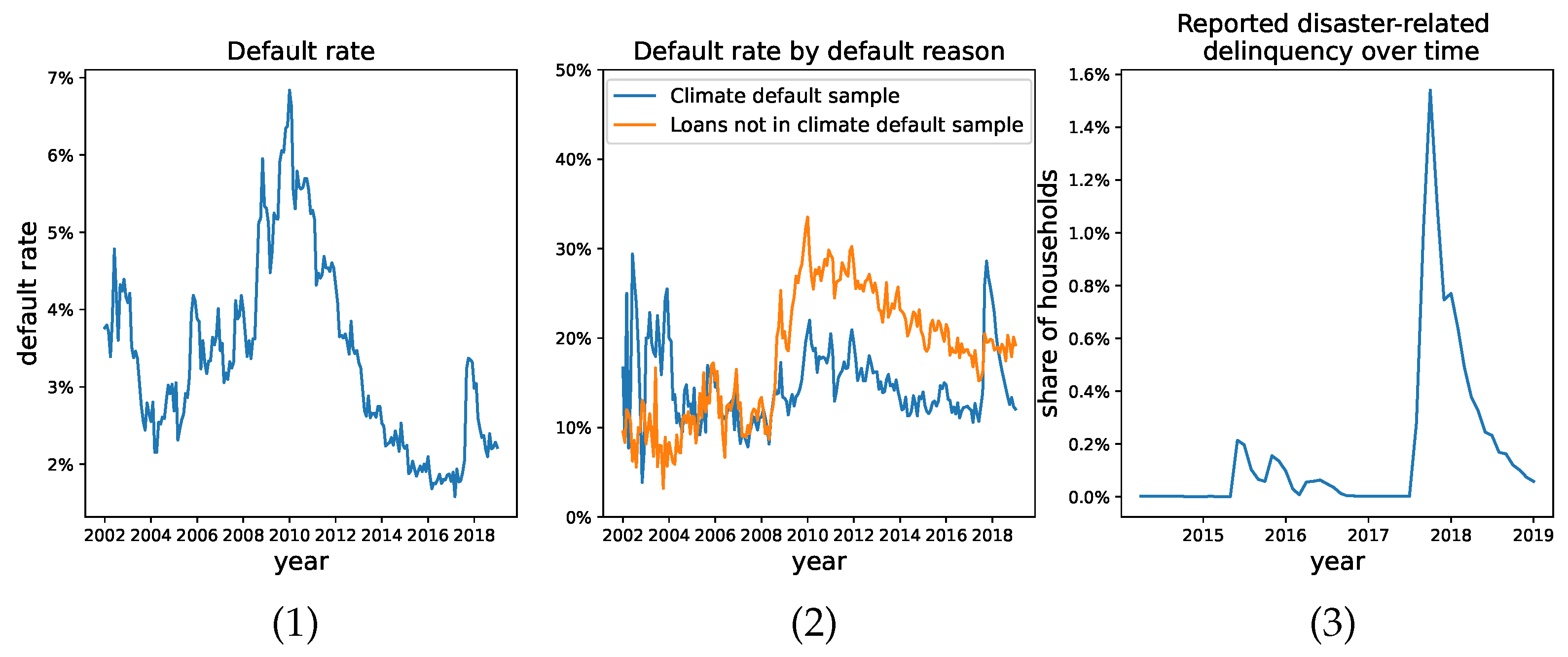
In order to validate that the second sample we constructed has different statistical features than the loans that have defaulted and were not included in the second sample, we show the default rate trends in
Figure 1. We define the default rate as the number of mortgages that missed more than three payments over all active loans. The left figure shows the default rate in our universe of considered loans from 2000 to 2018, comparable to those reported in [
38]. Note the increase from 2% to 3% in the default rate shortly following Hurricane Harvey. The middle figure shows the sharp increase in share of households reporting disaster-related delinquency in August 2017 that remained elevated through 2018. The right-most figure aims to compare the default rate due to Hurricane Harvey (i.e., the climate default sample) to non-Harvey-related default. This figure articulates visually that the categorization of default due to non-climate- versus climate-related events is imperfect, but still captures two different processes.
2.3.2. Methodology
We use FHLMC data to evaluate whether or not the models above are specified correctly given the observed data. For both house prices and cashflow models, we explicitly connect the data to our proposed models, estimate parameters, compare specifications, test for the presence of climate-specific effects, and finally compare probability of default curves using the moments derived in the previous sections.
Turning first to the housing price models proposed in
Section 2.1, recall that we have defined the default process
. To measure
, we use reported property values in the data (refer to
Table 2 for full details on how variables in the FHLMC data are used in this analysis). Then, we observe log-returns of home values
across households from January 2017 to December 2018 for each sample in
Figure 2;
seems to follow a bimodal distribution, with the group with decreasing home values much more pronounced for the climate default sample. It is worth adding that these log-returns actually pass the Shapiro–Wilk test for a normal distribution; however, as illustrated in
Figure 3, the distribution of the log returns at the single household level is heavy-tailed for most households in each sample.
Next, for the purpose of testing whether there are climate-related jumps in the data, we use the credit risk models introduced in
Section 2.1, which are based on default being defined as the log-returns on home value falling below a predetermined threshold.
with parameters
describes a household-specific default process, so we propose the following approach. Suppose we have
N households, and that for each household
, we have a separate default process
, we estimate household-level parameters using Maximum Likelihood Estimation (MLE) and acquire a vector of household-level estimates
for each sample. In
Section 3, we report and compare the mean estimated coefficients and their associated 95% confidence intervals across samples and model specifications. It is worth acknowledging that the likelihood functions above are not well-behaved, a given when we are expecting discontinuous jumps. Furthermore, the sample sizes are very small at the household level, with some households having less that 20 observations. Following the MLE estimation technique proposed in [
39], we define the following hypotheses to test:
Using (
3), (
6), and (
10), we define corresponding (log-)likelihood functions used in the optimization procedure, where
K denotes the number of observations in a given household:
In practice, is reported instead of Log L, and so a good fit results in a high Log L and low (with a perfect fit resulting in Log L = 1, = 0). The continuous time variable is approximated by discrete intervals of 1-month length. Note that we have truncated the number of jumps in the above likelihood functions. We estimate the upper bound on the number of jumps in the summation to be 3 for non-climate jumps and 1 for climate jumps; we have run experiments for different values of the upper bound (up to 10), with estimations stabilizing with the chosen values. Moreover, this choice is in agreement with our intuition; indeed, homes are not valuated often, and climate jumps have been historically rare (in this case we are considering one single climate event).
Next, we test for the best-fitting sample–model pair using the mean Log L returned under each hypothesis and a Likelihood Ratio (LR) test to evaluates the goodness-of-fit. With nested models, we use the simpler model as the null hypothesis and the model with additional terms as the alternate hypothesis. If the ratio is sufficiently small, we reject the simpler model. In this case, we compare , , and for each sample using the maximum likelihoods , and . We conclude our testing for climate jumps with comparing the default probability curves by computing the first four moments as described in earlier sections.
Secondly, we turn to the cashflow models of
Section 2.2. For the cashflows models, the default process has been defined earlier as
. The outstanding loan balance that is provided in the monthly data corresponds to the time-discretized variable
with time intervals of 1-month length. Furthermore, the correspondence between the data and
is shown in
Table 2. Recall that
signifies a Poisson process for climate disaster-related jumps. To estimate
, we count the number of times a payment is not equal to the scheduled payment amount, given a household reported delinquency due to a natural disaster. We similarly define
, after excluding the jumps used to estimate
.
Given that
is a household-level process, we again consider the set of default processes
, where parameters
. In accordance with (
14) and (
17), we define our hypotheses for the debt process
as
We assume that there is a maximum of one jump per reporting period (1 month).
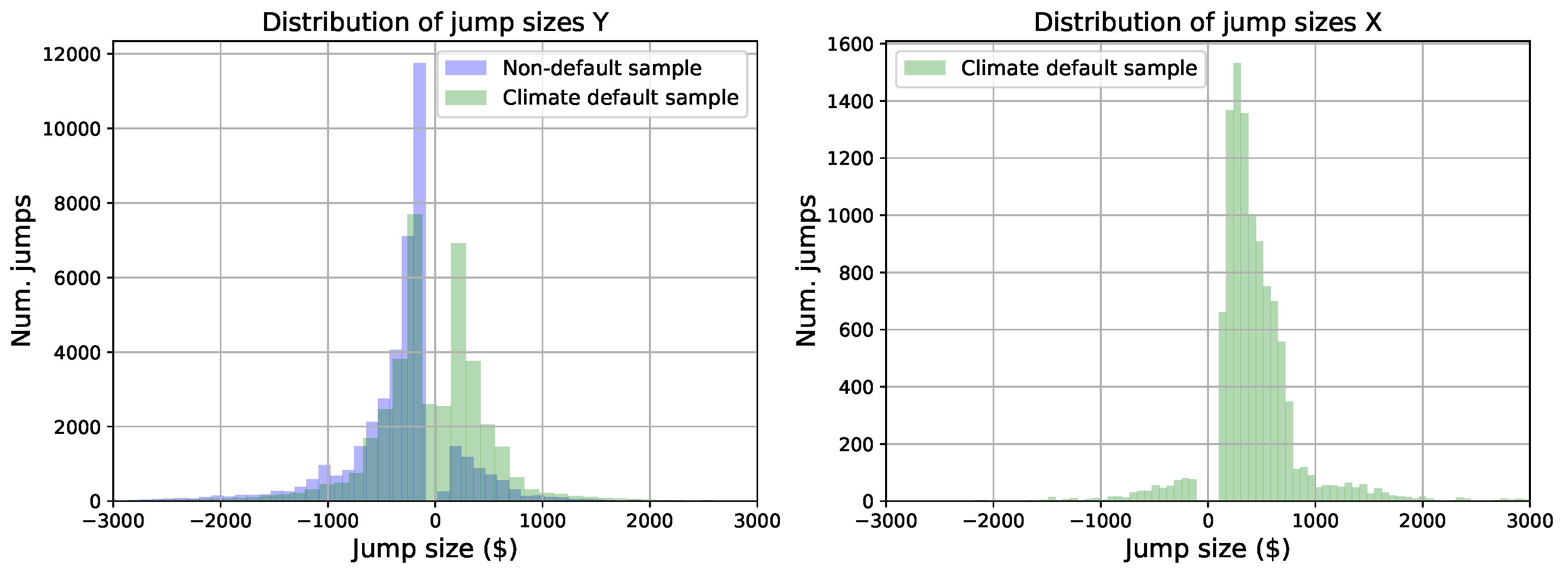
On the one hand, a visual inspection of the histograms of the jump sizes
X and
Y (which represent any deviation from the scheduled payments) across all the households and for each sample (see
Figure 4) suggests that these variables have a continuous distribution with a wide range. Consequently, we postulate that
X and
Y can be considered normally distributed and we validate this hypothesis using the Shapiro–Wilk test. On the other hand, since we did not identify the distribution of
, it is natural to consider using the Generalized Method of Moments (GMM), which makes no distributional assumptions and is widely used for economics and finance applications (see [
40] for details on GMM). In the end, we chose to design a two-step procedure combining MLE and GMM. First, we use MLE to estimate
(and
) by fitting a normal distribution to the jump sizes
Y (and
X), and secondly, we apply a GMM procedure to estimate the remaining parameters
(and
). Specifically, the moment conditions
are functions of the parameters
, and GMM finds parameter estimates such that
. To test whether the model is correctly specified, we can check whether the estimated parameters
get the moments sufficiently close to zero, i.e.,
. For this purpose, we use the Sargan–Hansen J-test, where the calculated J-statistic is used to test the hypotheses:
and
, to determine goodness-of-fit of
and
with respect to both samples. We also evaluate which of
and
is the best model for each sample using the returned J-statistic of an LR test. Note that since
has no parameters to estimate and we know that jumps exist in the data (see
Table 3), we exclude it from the model comparison. Finally, we compare moments across the three specifications; to compare to
, we calculate
directly from the data and use its sample moments. All analysis was carried out using open-source software in Python and in R, with all code available here:
https://bitbucket.org/al6257/credit-risk-modeling/src/master/ (accessed on 3 September 2023).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




