
A-DSCNN: Depthwise Separable Convolutional Neural Network Inference Chip Design Using an Approximate Multiplier

Abstract
:1. Introduction
2. Related Works
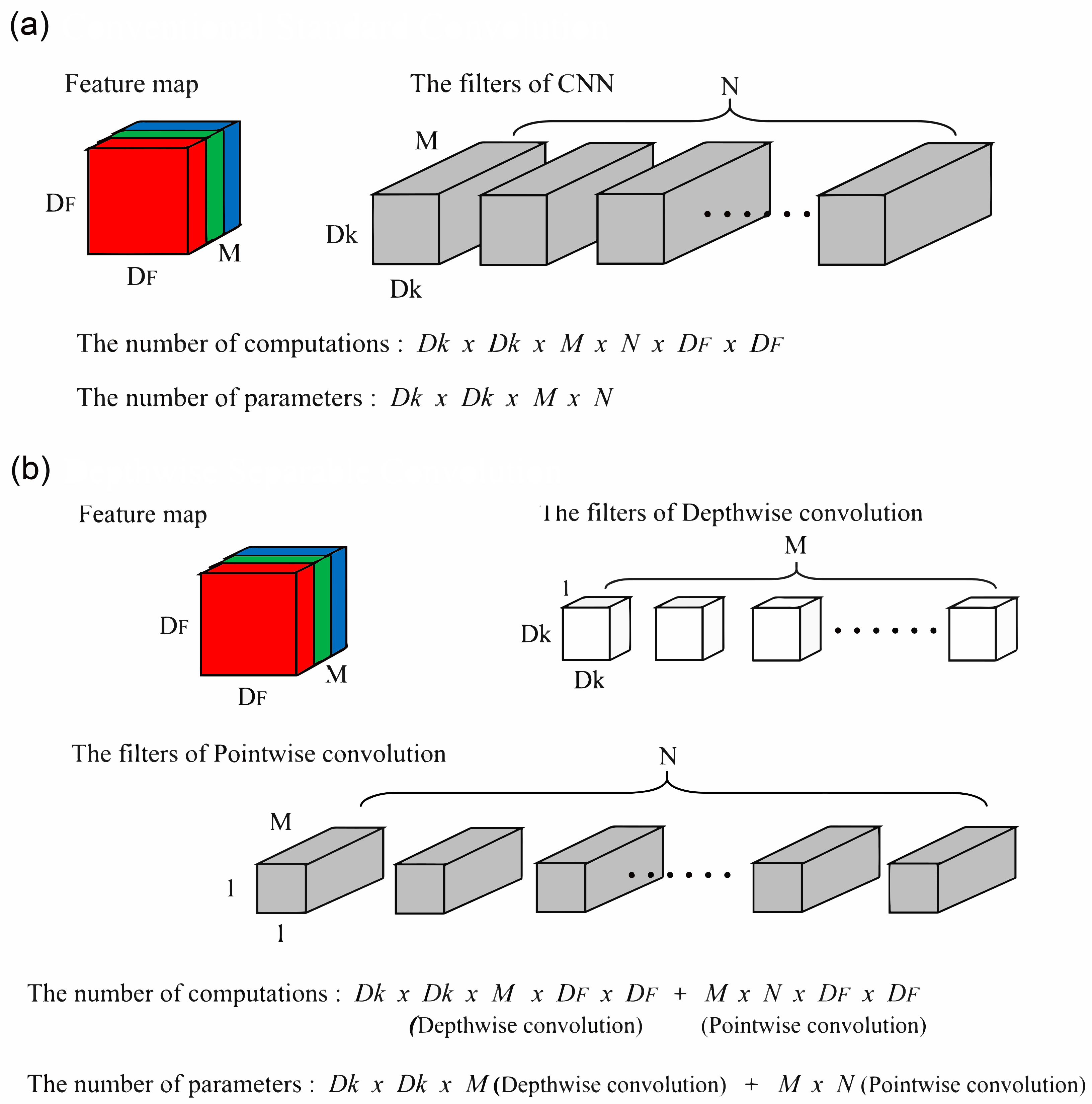
2.1. Convolutional Neural Network (CNN)
2.2. Approximate Neural Networks
2.3. Depthwise Separable Convolution (DSC)
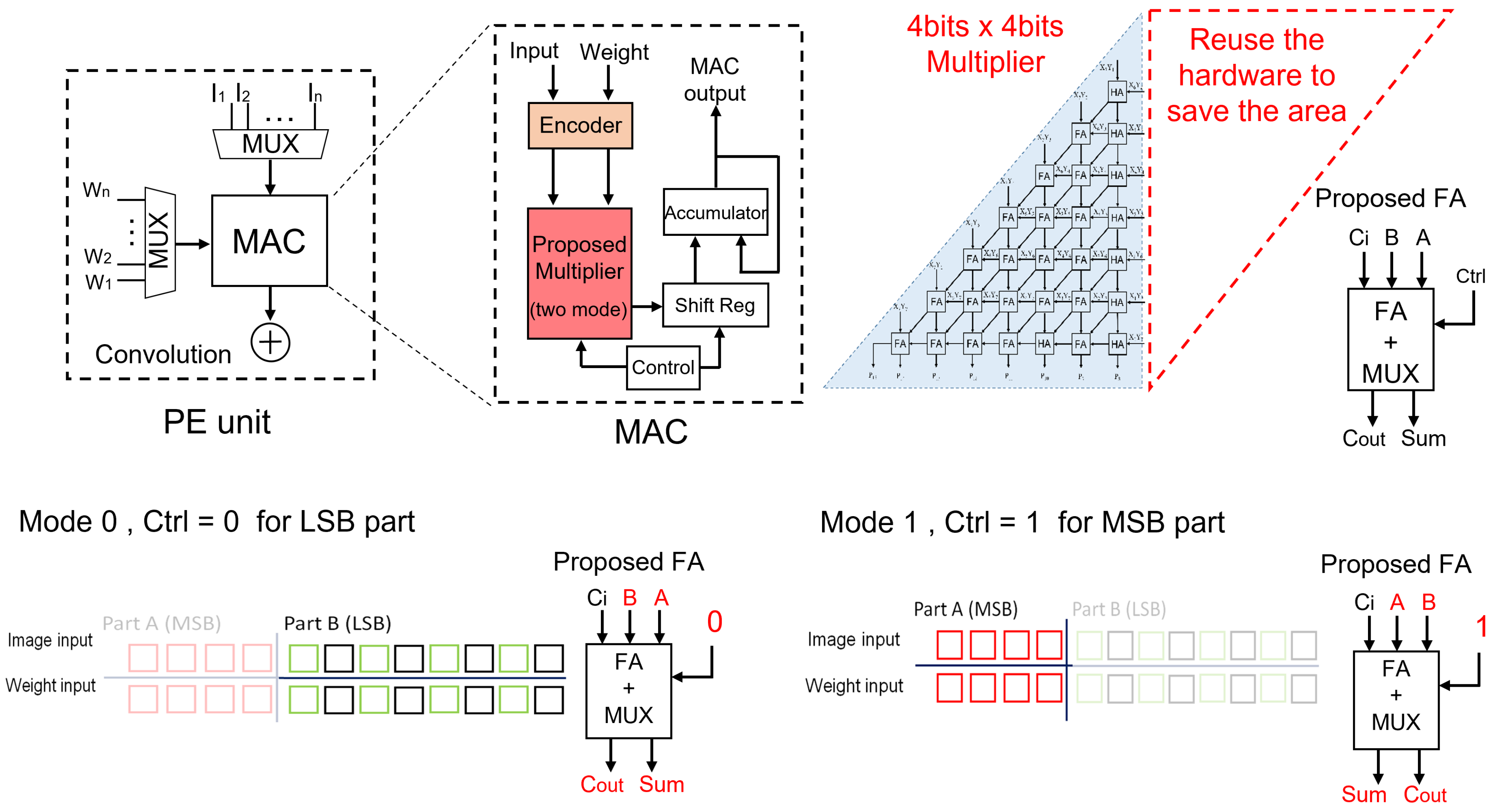
3. Proposed Method
3.1. Multi-Mode Approximate Multiplier
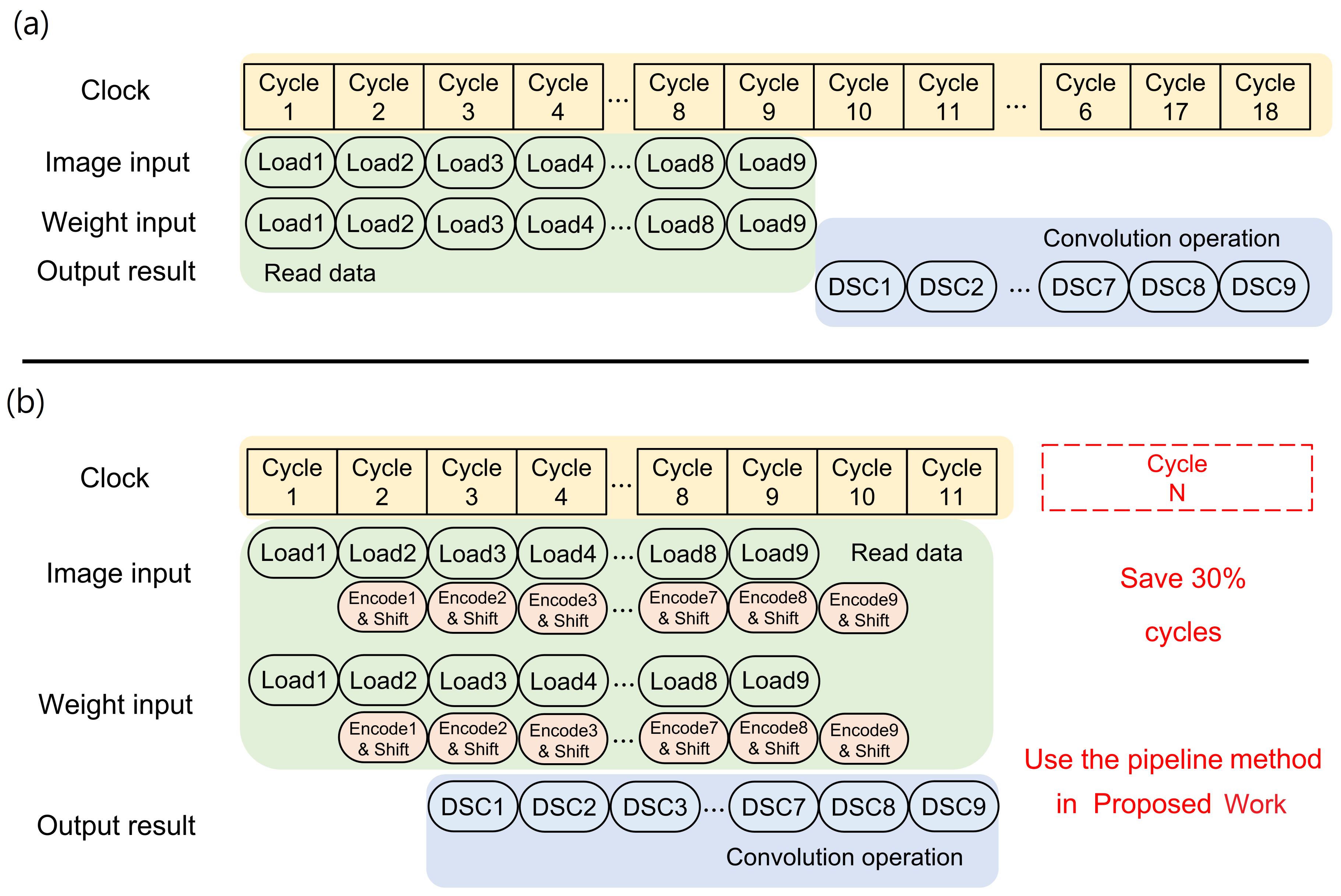
3.2. DSCNN with Multi-Mode Approximate Multiplier
- Initially, the image input and weight inputs are loaded from an off-chip memory by the control unit and stored in the input buffer and weight buffer, respectively.
- The encoder control determines whether the input buffer and weight buffer data should undergo encoding, and accordingly, the reformatted data are obtained.
- The reformatted data are then supplied to the convolution core in the A-DSCNN PE array for computation.
- The convolution control unit within the A-DSCNN PE array decides whether to perform depthwise convolution and pointwise convolution, generating a new job.
- The newly created job comprises a set of instructions pipelined for processing.
- After scheduling, individual instructions are sent to the multi-mode approximate multiplier for computation. Control signals determine if the computed data need to be shifted.
- Once the computations are complete, the computed results are accumulated and sent back to the output buffer to finalize the convolution operation.
4. Performance Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| A-DSCNN | Approximate-DSCNN. |
| AI | Artificial Intelligence. |
| ASIC | Application Specific Integrated Circuit. |
| CIFAR | Canadian Institute for Advanced Research. |
| CMOS | Complimentary Metal Oxide Semiconductor. |
| CNN | Convolutional Neural Network. |
| DSC | Depthwise Separable Convolution. |
| DSCNN | Depthwise Separable CNN. |
| DWC | Depthwise Convolution. |
| EDA | Electronic Design Automation. |
| HDL | Hardware Descriptor Language. |
| IC | Integrated Circuits. |
| LSB | Least Significant Bit. |
| MAC | Multiply-Accumulate. |
| MSB | Most Significant Bit. |
| PE | Processing Element. |
| PnR | Place and Route. |
| PWC | Pointwise Convolution. |
| ReLU | Rectified Linear Unit. |
| TSMC | Taiwan Semiconductor Manufacturing Company. |
| VGG | Visual Geometry Group. |
References
- Chua, S.H.; Teo, T.H.; Tiruye, M.A.; Wey, I.C. Systolic Array Based Convolutional Neural Network Inference on FPGA. In Proceedings of the 2022 IEEE 15th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC), Penang, Malaysia, 19–22 December 2022; pp. 128–133. [Google Scholar] [CrossRef]
- Kulkarni, P.; Gupta, P.; Ercegovac, M. Trading Accuracy for Power with an Underdesigned Multiplier Architecture. In Proceedings of the 2011 24th Internatioal Conference on VLSI Design, Chennai, India, 2–7 January 2011; pp. 346–351. [Google Scholar] [CrossRef]
- Shin, D.; Gupta, S.K. Approximate logic synthesis for error tolerant applications. In Proceedings of the 2010 Design, Automation and Test in Europe Conference and Exhibition (DATE 2010), Dresden, Germany, 8–12 March 2010; pp. 957–960. [Google Scholar] [CrossRef]
- Gupta, V.; Mohapatra, D.; Raghunathan, A.; Roy, K. Low-Power Digital Signal Processing Using Approximate Adders. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2013, 32, 124–137. [Google Scholar] [CrossRef]
- Mahdiani, H.R.; Ahmadi, A.; Fakhraie, S.M.; Lucas, C. Bio-Inspired Imprecise Computational Blocks for Efficient VLSI Implementation of Soft-Computing Applications. IEEE Trans. Circuits Syst. I Regul. Pap. 2010, 57, 850–862. [Google Scholar] [CrossRef]
- Shin, D.; Gupta, S.K. A Re-design Technique for Datapath Modules in Error Tolerant Applications. In Proceedings of the 2008 17th Asian Test Symposium, Hokkaido, Japan, 24–27 November 2008; pp. 431–437. [Google Scholar] [CrossRef]
- Elbtity, M.E.; Son, H.W.; Lee, D.Y.; Kim, H. High Speed, Approximate Arithmetic Based Convolutional Neural Network Accelerator. In Proceedings of the 2020 International SoC Design Conference (ISOCC), Yeosu, Republic of Korea, 21–24 October 2020; pp. 71–72. [Google Scholar] [CrossRef]
- Jou, J.M.; Kuang, S.R.; Chen, R.D. Design of low-error fixed-width multipliers for DSP applications. IEEE Trans. Circuits Syst. II Analog. Digit. Signal Process. 1999, 46, 836–842. [Google Scholar] [CrossRef] [Green Version]
- Guo, C.; Zhang, L.; Zhou, X.; Qian, W.; Zhuo, C. A Reconfigurable Approximate Multiplier for Quantized CNN Applications. In Proceedings of the 2020 25th Asia and South Pacific Design Automation Conference (ASP-DAC), Beijing, China, 13–16 January 2020; pp. 235–240. [Google Scholar] [CrossRef]
- Chen, Y.H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks. IEEE J. Solid-State Circuits 2017, 52, 127–138. [Google Scholar] [CrossRef] [Green Version]
- Yue, J.; Liu, Y.; Yuan, Z.; Wang, Z.; Guo, Q.; Li, J.; Yang, C.; Yang, H. A 3.77TOPS/W Convolutional Neural Network Processor With Priority-Driven Kernel Optimization. IEEE Trans. Circuits Syst. II Express Briefs 2019, 66, 277–281. [Google Scholar] [CrossRef]
- Spagnolo, F.; Perri, S.; Corsonello, P. Approximate Down-Sampling Strategy for Power-Constrained Intelligent Systems. IEEE Access 2022, 10, 7073–7081. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Chen, Y.G.; Chiang, H.Y.; Hsu, C.W.; Hsieh, T.H.; Jou, J.Y. A Reconfigurable Accelerator Design for Quantized Depthwise Separable Convolutions. In Proceedings of the 2021 18th International SoC Design Conference (ISOCC), Jeju Island, Republic of Korea, 6–9 October 2021; pp. 290–291. [Google Scholar] [CrossRef]
- Li, B.; Wang, H.; Zhang, X.; Ren, J.; Liu, L.; Sun, H.; Zheng, N. Dynamic Dataflow Scheduling and Computation Mapping Techniques for Efficient Depthwise Separable Convolution Acceleration. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 3279–3292. [Google Scholar] [CrossRef]
- Chong, Y.S.; Goh, W.L.; Ong, Y.S.; Nambiar, V.P.; Do, A.T. An Energy-Efficient Convolution Unit for Depthwise Separable Convolutional Neural Networks. In Proceedings of the 2021 IEEE International Symposium on Circuits and Systems (ISCAS), Daegu, Republic of Korea, 22–28 May 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Balasubramanian, P.; Nayar, R.; Maskell, D.L. Approximate Array Multipliers. Electronics 2021, 10, 630. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Convolutional Deep Belief Networks on CIFAR-10. Master’s Thesis, University of Toronto, Toronto, ON, Canada, 2010. [Google Scholar]
- Lin, K.P.; Liu, J.H.; Wu, J.Y.; Liao, H.C.; Huang, C.T. VISTA: A 704mW 4K-UHD CNN Processor for Video and Image Spatial/Temporal Interpolation Acceleration. In Proceedings of the 2023 IEEE International Solid- State Circuits Conference (ISSCC), San Francisco, CA, USA, 19–23 February 2023; pp. 48–50. [Google Scholar] [CrossRef]
- Liu, X.; Cao, C.; Duan, S. A Low-Power Hardware Architecture for Real-Time CNN Computing. Sensors 2023, 23, 2045. [Google Scholar] [CrossRef] [PubMed]
- Cadence: Computational Software for Intelligent System Design. Available online: https://www.cadence.com/en_US/home.html (accessed on 30 March 2023).
- Synopsys: EDA Tools, Semiconductor IP and Application Security Solutions. Available online: https://www.synopsys.com/ (accessed on 30 March 2023).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mode-0/1 | Standard Multiplier | |
|---|---|---|
| Number of Bits | 12 | |
| Input Pattern | Random Numbers () | |
| RMSE | 19,259.06 | 19,017.31 |
| Normalized | 1.2% | - |
| Maximum: 12 bits × 12 bits = 16,777,216 (4096 × 4096) | ||
| Performance | JSSCC16 [10] | TCAS19 [11] | ISCAS21 [16] | ISSCC23 [20] | Sensors23 [21] | A-DSCNN (VGG16) | A-DSCNN (VGGnet) |
|---|---|---|---|---|---|---|---|
| (This Work) | |||||||
| Process | 65-nm | 65-nm | 40-nm | 40-nm | 65-nm | 40-nm | |
| (post- | (post- | (post- | (post- | (post- | (post- | ||
| silicon) | layout) | synthesis) | silicon) | synthesis) | layout) | ||
| Frequency | 200 MHz | 200 MHz | 100 MHz | 200 MHz | 62.5 MHz | 200 MHz | |
| Voltage | 1.0 V | 1.0 V | 0.85 V | 1.06 V | - | 0.9 V | |
| Power | 278 mW | 72 mW | 25.3 mW | 704 mW | 147.95 mW | 486.81 mW | 95.04 mW |
| Area (mm) | 12.25 | 3.98 | 1.03 (CONV) | 8.70 | - | 1.16 | 0.398 |
| Efficiency (GOPs/mW) | 0.24 | 1.25 | 3.13 | 4.0 | 4.08 | 4.78 | 4.89 |
| VGG16 | Modified VGGnet |
|---|---|
| { Conv, 64, ReLU} | DSC, 8, ReLU |
| Max-pooling | DSC, 8, ReLU |
| { Conv, 128, ReLU} | Max-pooling |
| Max-pooling | DSC, 16, ReLU |
| { Conv, 256, ReLU} | DSC, 16, ReLU |
| Max-pooling | Max-pooling |
| { Conv, 512, ReLU} | DSC, 32, ReLU |
| Max-pooling | DSC, 32, ReLU |
| { Conv, 512, ReLU} | Max-pooling |
| Max-pooling | Flatten, 128 |
| Dense, 4096, ReLU | Dense, 10, Softmax |
| Dense, 4096, ReLU | |
| Dense, 10, Softmax |
| Network | Core Type | Size/Number of Values | Buffer Size (kB) | ||||
|---|---|---|---|---|---|---|---|
| Input Map | Parameters | Output Map | Input | Weight | Output | ||
| VGG16 | DSConv | 8;8;256 | 68,096 | 8;8;256 | 16 | 532 | 16 |
| Maxpool | 4;4;512 | - | 2;2;512 | 8 | - | 4 | |
| Dense | 1;4096 | - | 1;4096 | 4 | - | 4 | |
| VGGnet | DSConv | 8;8;32 | 1344 | 8;8;32 | 2 | 1.31 | 2 |
| Maxpool | 16;16;16 | - | 8;8;16 | 4 | - | 2 | |
| Dense | 1;128 | - | 1;10 | 0.125 | - | 0.00976 | |
| Performance | Specifications |
|---|---|
| Process Technology | TSMC 40-nm CMOS |
| Frequency | 200 MHz |
| Voltage Supply | 0.9 V |
| Chip Size | 1.24 mm × 1.24 mm |
| Chip Area | 1.54 mm |
| Core Area | 1.16 mm |
| (Main: 78%, Register/Control: 22%) | |
| Chip Power | 486.81 mW |
| (Main: 90%, Register/Control: 10%) | |
| Efficiency | 4.78 GOPs/mW |
| Precision | 4-bit/8-bit |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shang, J.-J.; Phipps, N.; Wey, I.-C.; Teo, T.H. A-DSCNN: Depthwise Separable Convolutional Neural Network Inference Chip Design Using an Approximate Multiplier. Chips 2023, 2, 159-172. https://doi.org/10.3390/chips2030010
Shang J-J, Phipps N, Wey I-C, Teo TH. A-DSCNN: Depthwise Separable Convolutional Neural Network Inference Chip Design Using an Approximate Multiplier. Chips. 2023; 2(3):159-172. https://doi.org/10.3390/chips2030010
Chicago/Turabian StyleShang, Jin-Jia, Nicholas Phipps, I-Chyn Wey, and Tee Hui Teo. 2023. "A-DSCNN: Depthwise Separable Convolutional Neural Network Inference Chip Design Using an Approximate Multiplier" Chips 2, no. 3: 159-172. https://doi.org/10.3390/chips2030010