
Preconditioned Monte Carlo for Gradient-Free Bayesian Inference in the Physical Sciences †


Abstract
:1. Introduction
2. Methods
2.1. Sequential Monte Carlo
2.1.1. Background
2.1.2. Bridging the Prior and Posterior
2.1.3. Key Steps
- Correction—The importance weights of the particles are calculated as:and then they are used to estimate the normalizing constant (i.e., marginal likelihood) of :Initially, all weights are equal such that with .
- Selection—the particles are resampled according to their importance weights. The goal is to retain those particles that are highly represented in the new distribution , while eliminating those that are less represented. Particles with high weights are more likely to be selected, thus forming the resampled set .
- Mutation—The resampled particles are perturbed to generate diversity and explore more of the parameter space. This step uses a transition kernel . In practice, takes the form of an MCMC kernel (e.g., several steps of an Metropolis–Hastings (MH) transition). The careful design of the transition kernel is required to ensure that the SMC sampler maintains good mixing properties and computational efficiency.
2.1.4. Adaptive Temperature Schedule
2.2. Past Resampling
2.3. Preconditioning
2.3.1. Background
2.3.2. Normalizing Flows
2.3.3. Preconditioned Crank–Nicolson
2.4. Preconditioned Monte Carlo
| Algorithm 1 Preconditioned Monte Carlo |
|
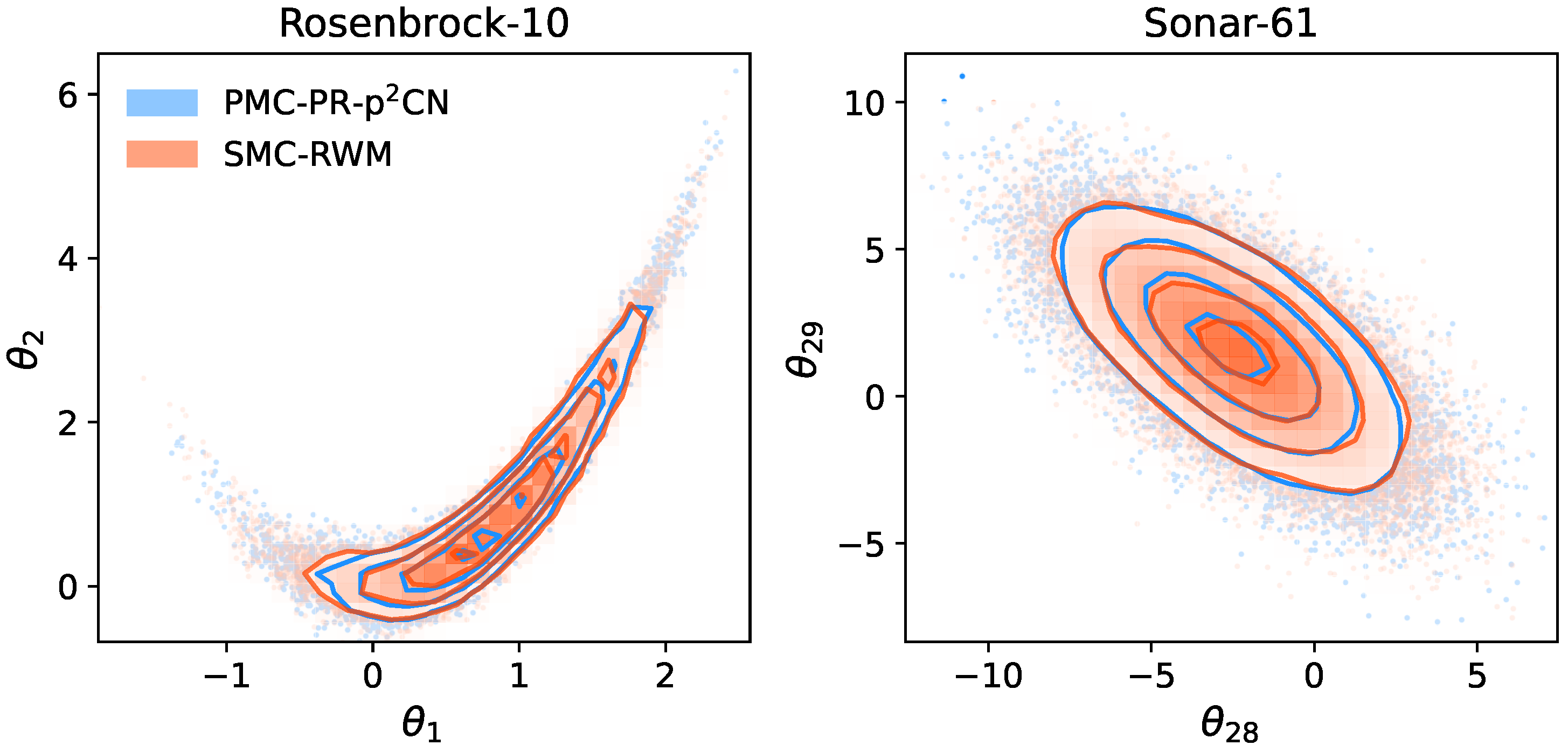
3. Results
3.1. Rosenbrock Distribution in 10-D
3.2. The 61-D Logistic Regression with Sonar Data
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jaynes, E.T. Probability Theory: The Logic of Science; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Gregory, P. Bayesian Logical Data Analysis for the Physical Sciences: A Comparative Approach with Mathematica® Support; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- MacKay, D.J. Information Theory, Inference and Learning Algorithms; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Trotta, R. Bayesian methods in cosmology. arXiv 2017, arXiv:1701.01467. [Google Scholar]
- Sharma, S. Markov chain Monte Carlo methods for Bayesian data analysis in astronomy. Annu. Rev. Astron. Astrophys. 2017, 55, 213–259. [Google Scholar] [CrossRef]
- Del Moral, P.; Doucet, A.; Jasra, A. Sequential monte carlo samplers. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2006, 68, 411–436. [Google Scholar] [CrossRef]
- Chopin, N.; Papaspiliopoulos, O. An Introduction to Sequential Monte Carlo; Springer: Berlin/Heidelberg, Germany, 2020; Volume 4. [Google Scholar]
- Naesseth, C.A.; Lindsten, F.; Schön, T.B. Elements of sequential monte carlo. arXiv 2019, arXiv:1903.04797. [Google Scholar]
- Hastings, W.K. Monte Carlo Sampling Methods using Markov Chains and their Applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]
- Neal, R.M. Slice sampling. Ann. Stat. 2003, 31, 705–767. [Google Scholar] [CrossRef]
- Papamakarios, G.; Nalisnick, E.; Rezende, D.J.; Mohamed, S.; Lakshminarayanan, B. Normalizing flows for probabilistic modeling and inference. J. Mach. Learn. Res. 2021, 22, 1–64. [Google Scholar]
- Karamanis, M.; Beutler, F.; Peacock, J.A.; Nabergoj, D.; Seljak, U. Accelerating astronomical and cosmological inference with preconditioned Monte Carlo. Mon. Not. R. Astron. Soc. 2022, 516, 1644–1653. [Google Scholar] [CrossRef]
- Karamanis, M.; Nabergoj, D.; Beutler, F.; Peacock, J.A.; Seljak, U. pocoMC: A Python package for accelerated Bayesian inference in astronomy and cosmology. arXiv 2022, arXiv:2207.05660. [Google Scholar] [CrossRef]
- Moss, A. Accelerated Bayesian inference using deep learning. Mon. Not. R. Astron. Soc. 2020, 496, 328–338. [Google Scholar] [CrossRef]
- Beskos, A.; Roberts, G.; Stuart, A.; Voss, J. MCMC methods for diffusion bridges. Stochastics Dyn. 2008, 8, 319–350. [Google Scholar] [CrossRef]
- Cotter, S.L.; Roberts, G.O.; Stuart, A.M.; White, D. MCMC methods for functions: Modifying old algorithms to make them faster. Stat. Sci. 2013, 28, 424–446. [Google Scholar] [CrossRef]
- Le Thu Nguyen, T.; Septier, F.; Peters, G.W.; Delignon, Y. Improving SMC sampler estimate by recycling all past simulated particles. In Proceedings of the 2014 IEEE Workshop on Statistical Signal Processing (SSP), Gold Coast, QLD, Australia, 29 June–2 July 2014; pp. 117–120. [Google Scholar]
- Gramacy, R.; Samworth, R.; King, R. Importance tempering. Stat. Comput. 2010, 20, 1–7. [Google Scholar] [CrossRef]
- Hoffman, M.; Sountsov, P.; Dillon, J.V.; Langmore, I.; Tran, D.; Vasudevan, S. Neutra-lizing bad geometry in hamiltonian monte carlo using neural transport. arXiv 2019, arXiv:1903.03704. [Google Scholar]
- Papamakarios, G.; Pavlakou, T.; Murray, I. Masked autoregressive flow for density estimation. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 2335–2344. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Sejnowski, T.; Gorman, R. Connectionist Bench (Sonar, Mines vs. Rocks). UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu (accessed on 16 July 2023).
- Chopin, N.; Ridgway, J. Leave Pima Indians alone: Binary regression as a benchmark for Bayesian computation. Stat. Sci. 2017, 32, 64–87. [Google Scholar] [CrossRef]
- Dau, H.D.; Chopin, N. Waste-free sequential monte carlo. J. R. Stat. Soc. Ser. B Stat. Methodol. 2022, 84, 114–148. [Google Scholar] [CrossRef]


{kind=link}
| Algorithm | Rosenbrock-10 | Sonar-61 | Rosenbrock-10 | Sonar-61 |
|---|---|---|---|---|
| (Calls ) | (Calls ) | () | () | |
| PMC-PR-pCN | ||||
| PMC-PR-RWM | ||||
| PMC-pCN | 0.21 | |||
| PMC-RWM | 0.48 | |||
| SMC-PR-RWM | 0.62 | |||
| SMC-RWM | 1.12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karamanis, M.; Seljak, U. Preconditioned Monte Carlo for Gradient-Free Bayesian Inference in the Physical Sciences. Phys. Sci. Forum 2023, 9, 23. https://doi.org/10.3390/psf2023009023
Karamanis M, Seljak U. Preconditioned Monte Carlo for Gradient-Free Bayesian Inference in the Physical Sciences. Physical Sciences Forum. 2023; 9(1):23. https://doi.org/10.3390/psf2023009023
Chicago/Turabian StyleKaramanis, Minas, and Uroš Seljak. 2023. "Preconditioned Monte Carlo for Gradient-Free Bayesian Inference in the Physical Sciences" Physical Sciences Forum 9, no. 1: 23. https://doi.org/10.3390/psf2023009023