
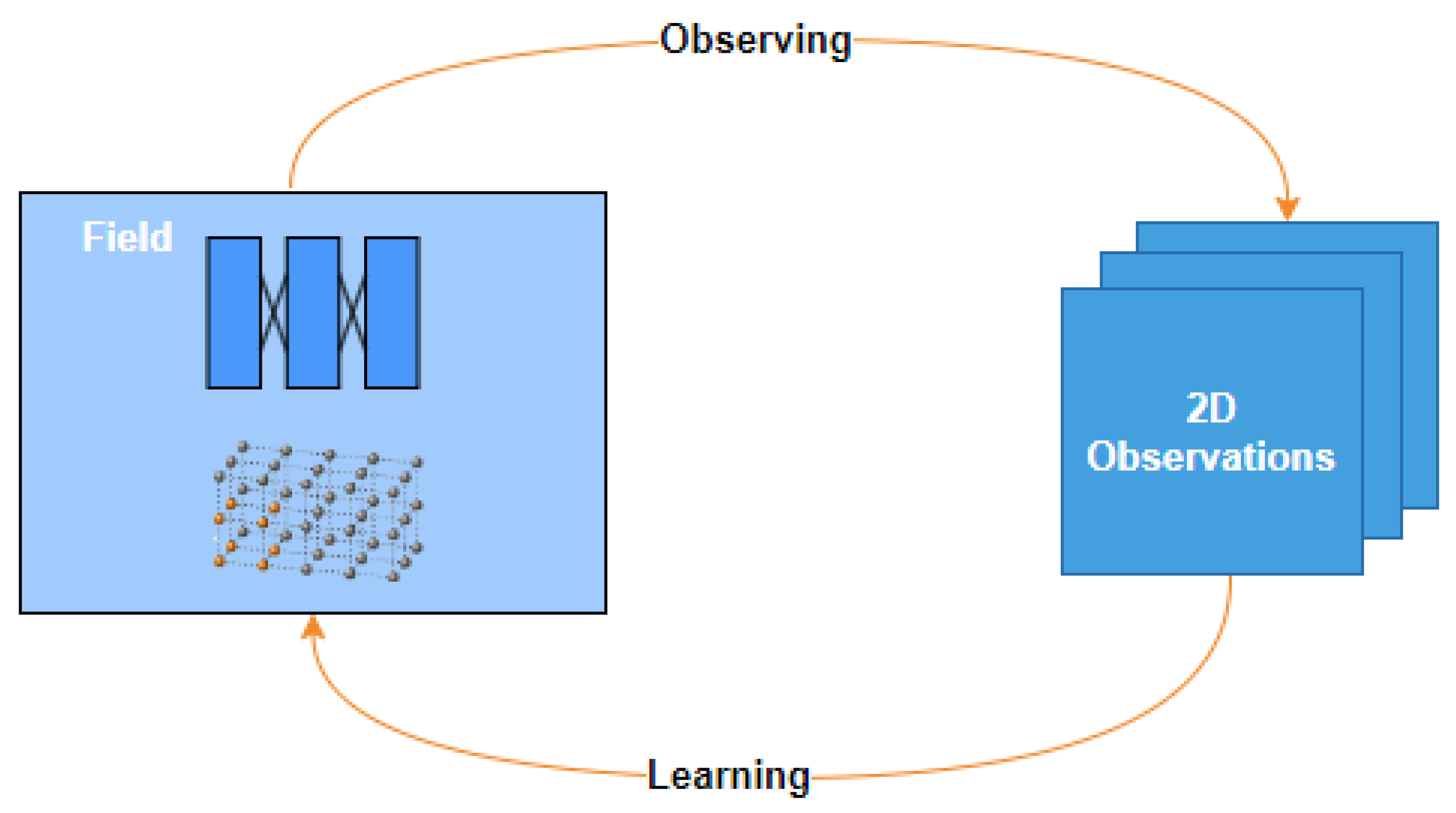
Data-Driven Field Representations and Measuring Processes

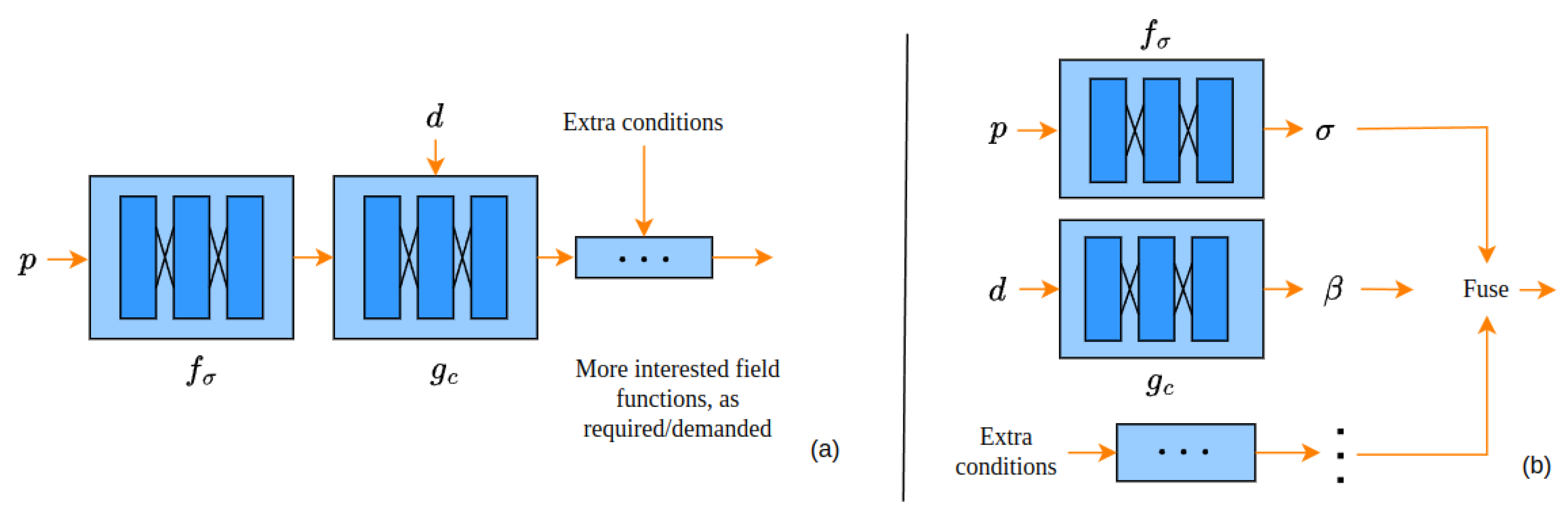{kind=link}
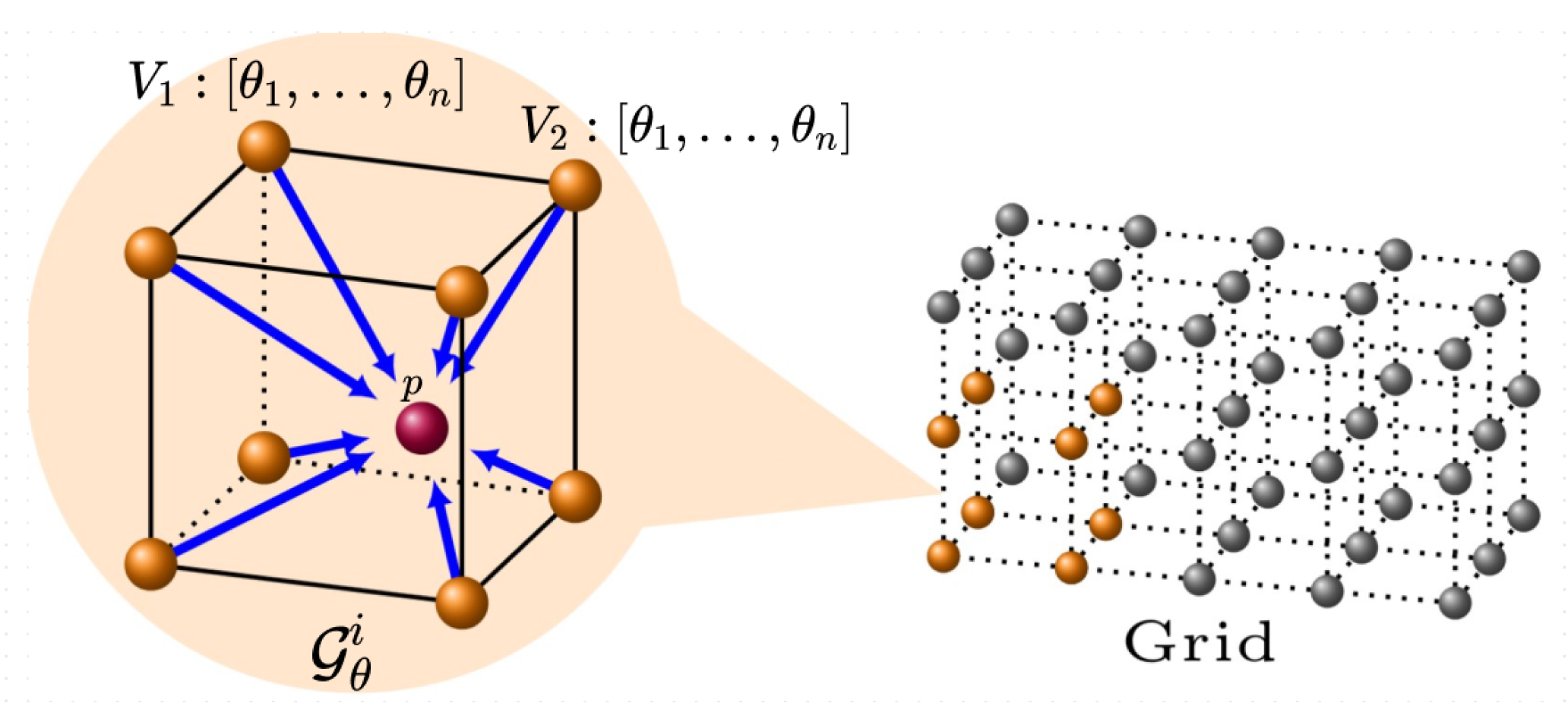{kind=link}
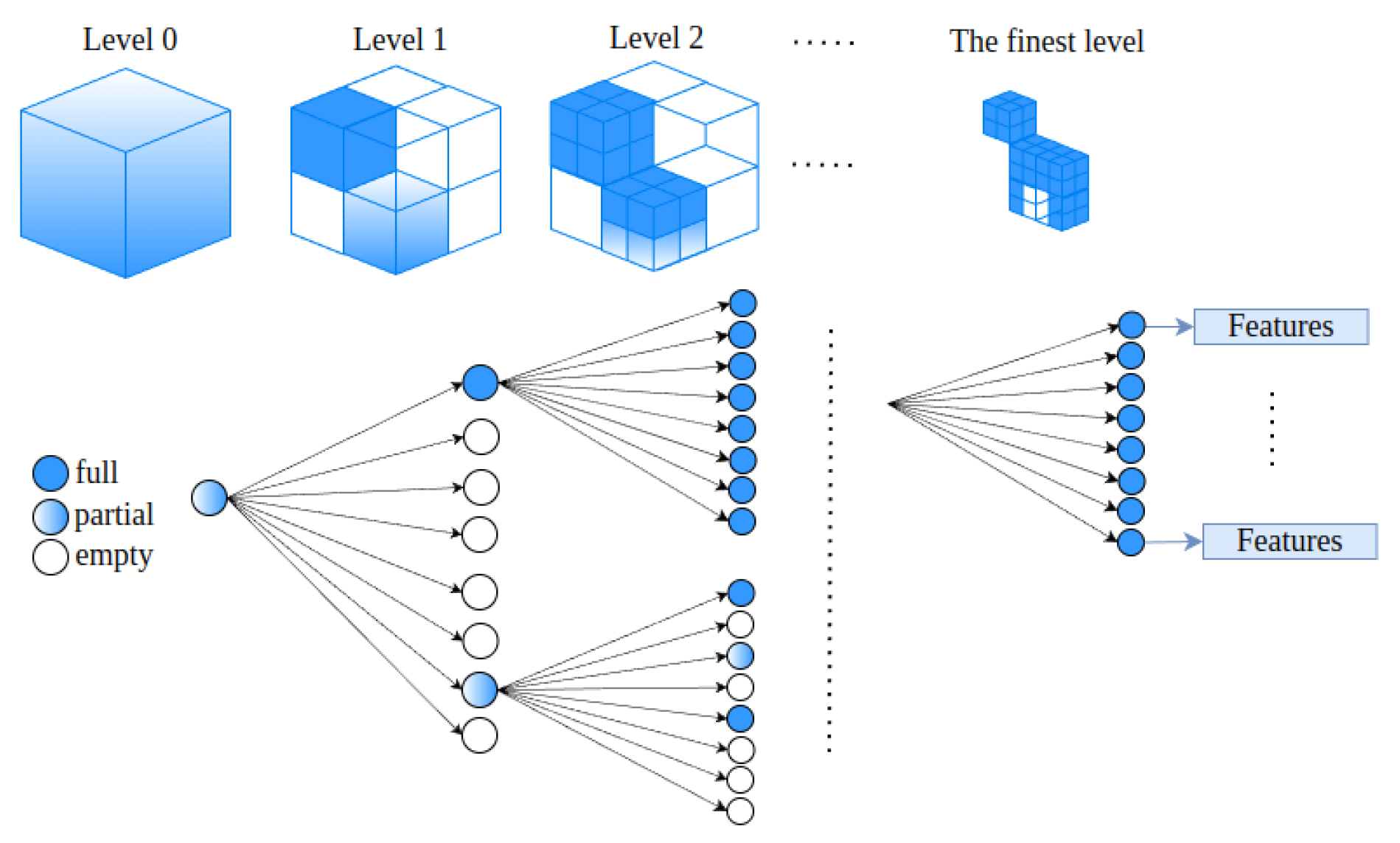{kind=link}
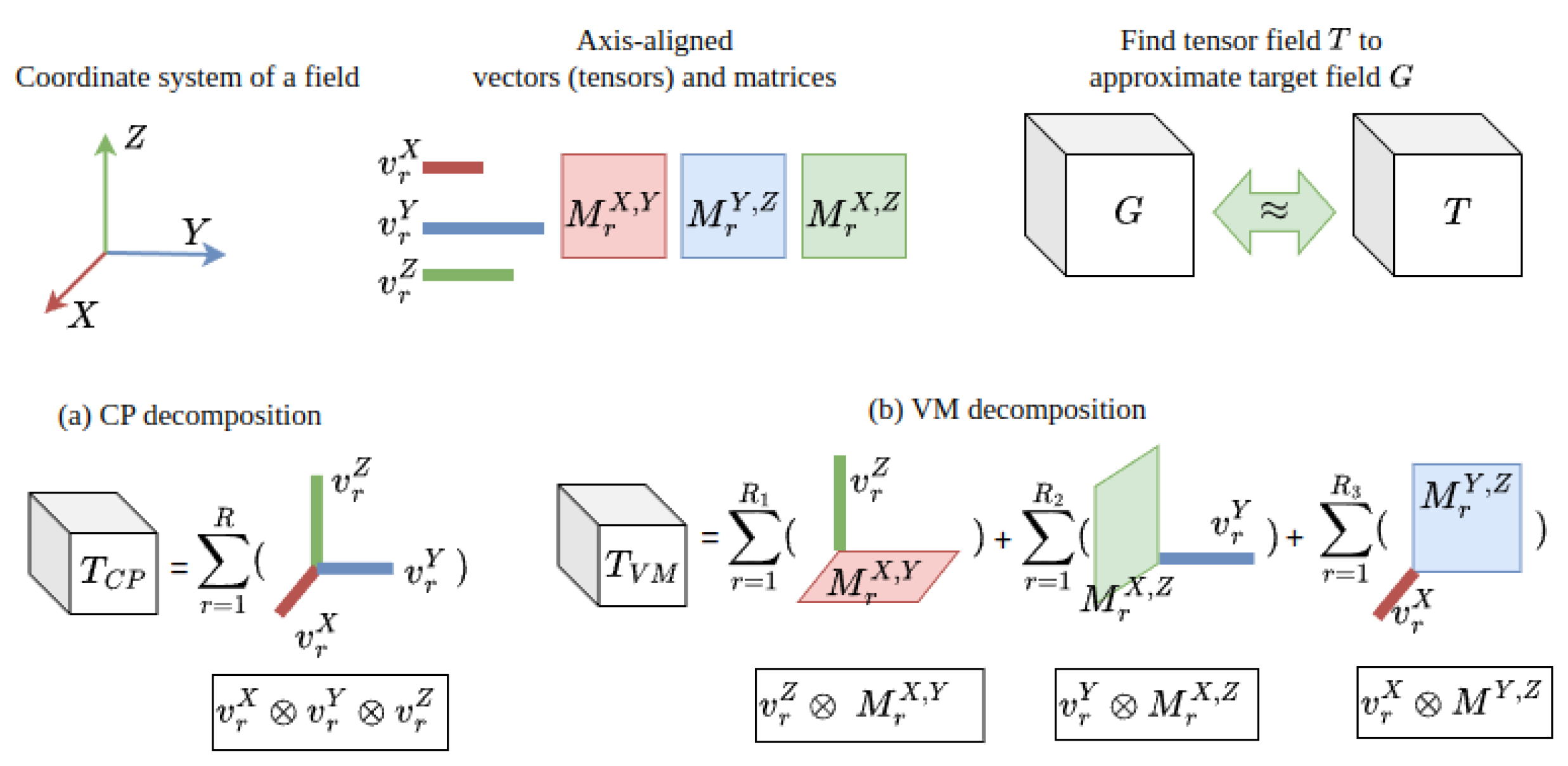{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Background
Neural Networks as Function Approximator
3. Computational Model of Learnable Field
3.1. Neural Network-Based Approximator
3.2. Eulerian Representation via Parameters on Spacial Grids
4. Computational Models of the Measurement Process
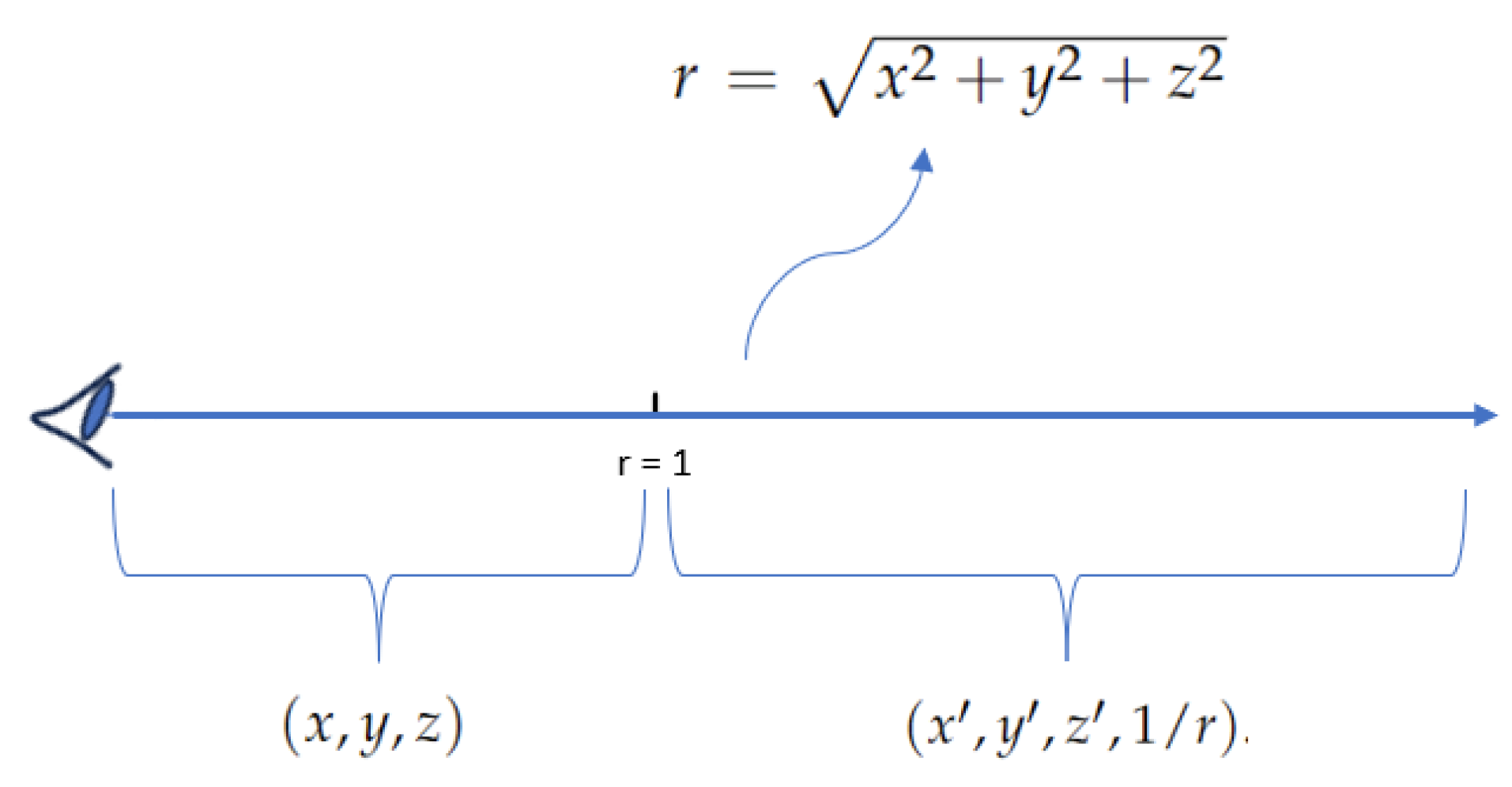
4.1. Integration Adjustments
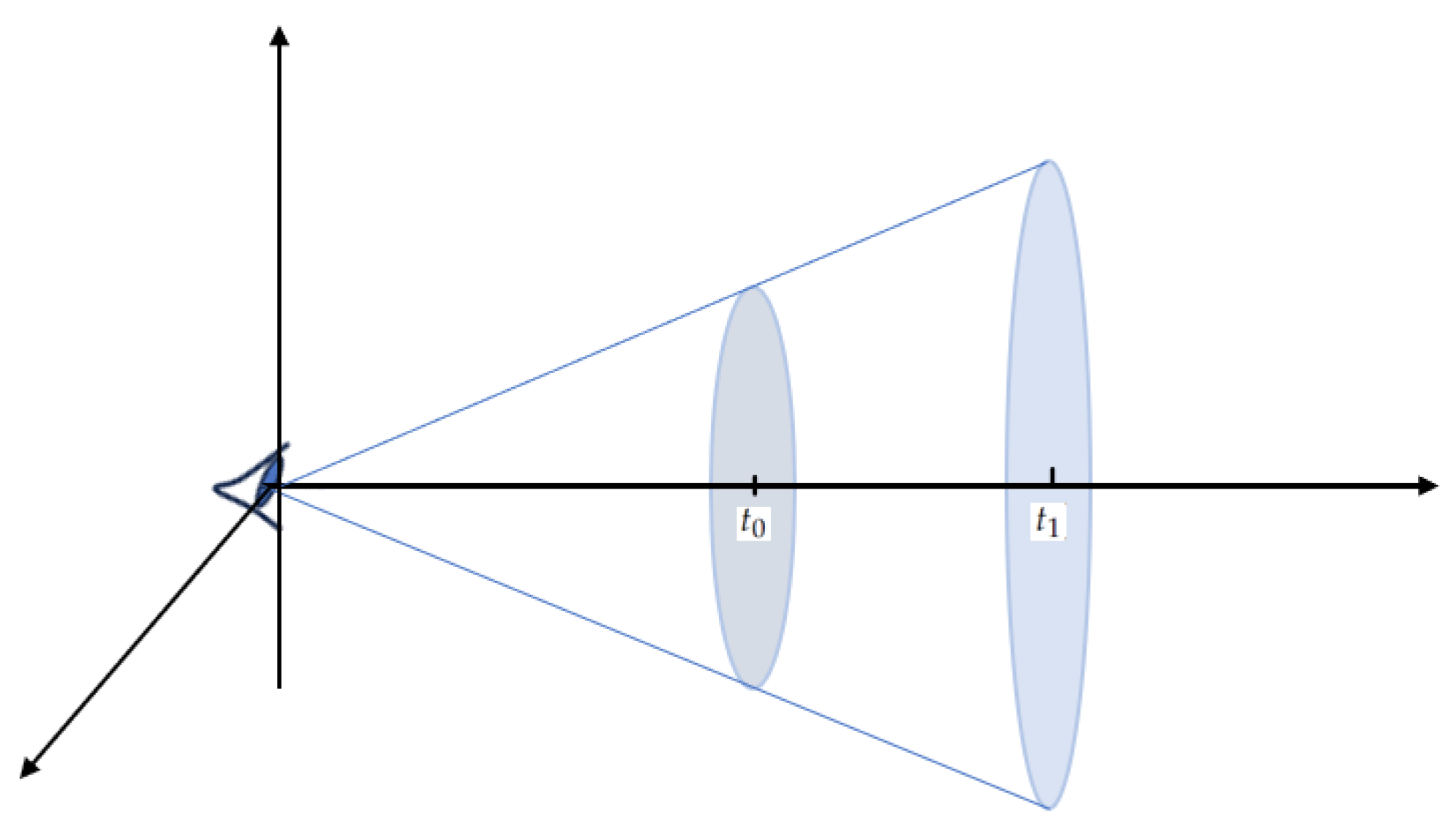
4.2. Discretization of the Integration
4.3. Computational Process of Summing over Sampled Points
5. Conclusions
- Global model with shared parameters: The most common choice in this way is neural networks, which update the entire field. It tends to smooth out local changes or details in the data and may face challenges in capturing and representing small variations. Also, its time consumption has been shown to be heavy in the studies mentioned above.
- Local model with parametric grid: Regardless of the smallest unit of a grid, such as an indexed cube or an element in tensor, in the grid-based method, the field space is arranged, offering efficient spatial querying, allowing for the rapid retrieval of objects or data points within a specific region of interest. When a change is observed, only its surrounding area needs to be updated. Furthermore, this approach allows for skipping or pruning unimportant areas and the adaptive concentration of parameters in areas containing more significant and informative data. However, this approach may not be suitable for certain physical phenomena, such as light phenomena, which often require additional techniques like spherical harmonics for accurate representation [33]. Additionally, the resolution limitations of the grid can restrict its ability to capture fine-grained details, and the memory requirements can grow rapidly as the complexity of the problem increases.
- In the area of integration adjustments, our synthesis of the literature revealed the diverse reparameterization strategies employed to accommodate varying scene scopes. This encompasses scenarios ranging from a limited depth of the scene to an infinite depth and extends to the intricate challenges posed by a 360-degree unbounded scene.
- When it comes to the discretization of integration, our exploration encompasses a discussion on how existing methods strategically sample from space. This sampling is intricately tied to the specific design choices made in integration adjustments, forming a crucial aspect of the computational framework.
- In describing the computational processes, we delved into the widely adopted method and the nuanced numerical integration approach embraced by AutoInt.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Peskin, M.E.; Schroeder, D.V. An Introduction To Quantum Field Theory; CRC Press: Boca Raton, FL, USA, 1995. [Google Scholar]
- Anastopoulos, C.; Plakitsi, M.E. Relativistic Time-of-Arrival Measurements: Predictions, Post-Selection and Causality Problems. Foundations 2023, 3, 724–737. [Google Scholar] [CrossRef]
- Santos, E. Stochastic Interpretation of Quantum Mechanics Assuming That Vacuum Fields Are Real. Foundations 2022, 2, 409–442. [Google Scholar] [CrossRef]
- Misner, C.; Thorne, K.; Wheeler, J.; Kaiser, D. Gravitation; Princeton University Press: Princeton, NJ, USA, 2017. [Google Scholar]
- Olver, P.J. Introduction to Partial Differential Equations; Springer: Cham, Switzerland, 2014; Volume 1. [Google Scholar]
- Mikki, S. On the Topological Structure of Nonlocal Continuum Field Theories. Foundations 2022, 2, 20–84. [Google Scholar] [CrossRef]
- Saari, P.; Besieris, I.M. Conditions for Scalar and Electromagnetic Wave Pulses to Be “Strange” or Not. Foundations 2022, 2, 199–208. [Google Scholar] [CrossRef]
- Liu, G.; Quek, S. Finite Element Method: A Practical Course; Elsevier Science: Oxford, UK, 2003. [Google Scholar]
- Koschier, D.; Bender, J.; Solenthaler, B.; Teschner, M. Smoothed Particle Hydrodynamics Techniques for the Physics Based Simulation of Fluids and Solids. In Proceedings of the 40th Annual Conference of the European Association for Computer Graphics, Eurographics 2019-Tutorials, Genoa, Italy, 6–10 May 2019. [Google Scholar]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer Feedforward Networks Are Universal Approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Sanchez-Gonzalez, A.; Godwin, J.; Pfaff, T.; Ying, R.; Leskovec, J.; Battaglia, P. Learning to Simulate Complex Physics with Graph Networks. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 8459–8468. [Google Scholar]
- Li, L.; Wang, L.G.; Teixeira, F.L.; Liu, C.; Nehorai, A.; Cui, T.J. DeepNIS: Deep Neural Network for Nonlinear Electromagnetic Inverse Scattering. IEEE Trans. Antennas Propag. 2018, 67, 1819–1825. [Google Scholar] [CrossRef]
- Nowack, P.; Braesicke, P.; Haigh, J.; Abraham, N.L.; Pyle, J.; Voulgarakis, A. Using Machine Learning to Build Temperature-based Ozone Parameterizations for Climate Sensitivity Simulations. Environ. Res. Lett. 2018, 13, 104016. [Google Scholar] [CrossRef]
- Zhong, C.; Jia, Y.; Jeong, D.C.; Guo, Y.; Liu, S. Acousnet: A Deep Learning Based Approach to Dynamic 3D Holographic Acoustic Field Generation from Phased Transducer Array. IEEE Robot. Autom. Lett. 2021, 7, 666–673. [Google Scholar] [CrossRef]
- Zang, G.; Idoughi, R.; Li, R.; Wonka, P.; Heidrich, W. IntraTomo: Self-supervised Learning-based Tomography via Sinogram Synthesis and Prediction. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 1940–1950. [Google Scholar]
- Wu, Q.; Feng, R.; Wei, H.; Yu, J.; Zhang, Y. Self-supervised Coordinate Projection Network for Sparse-view Computed Tomography. IEEE Trans. Comput. Imaging 2023, 9, 517–529. [Google Scholar] [CrossRef]
- Li, H.; Chen, H.; Jing, W.; Li, Y.; Zheng, R. 3D Ultrasound Spine Imaging with Application of Neural Radiance Field Method. In Proceedings of the 2021 IEEE International Ultrasonics Symposium (IUS), Xi’an, China, 11–16 September 2021; pp. 1–4. [Google Scholar]
- Shen, L.; Pauly, J.M.; Xing, L. NeRP: Implicit Neural Representation Learning with Prior Embedding for Sparsely Sampled Image Reconstruction. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 770–782. [Google Scholar] [CrossRef]
- Reed, A.W.; Blanford, T.E.; Brown, D.C.; Jayasuriya, S. Implicit Neural Representations for Deconvolving SAS Images. In Proceedings of the IEEE OCEANS 2021: San Diego–Porto, San Diego, CA, USA, 20–23 September 2021; pp. 1–7. [Google Scholar]
- Pumarola, A.; Corona, E.; Pons-Moll, G.; Moreno-Noguer, F. D-NeRF: Neural Radiance Fields for Dynamic Scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10318–10327. [Google Scholar]
- Huang, X.; Zhang, Q.; Ying, F.; Li, H.; Wang, X.; Wang, Q. HDR-NeRF: High Dynamic Range Neural Radiance Fields. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18377–18387. [Google Scholar]
- Liu, J.W.; Cao, Y.P.; Mao, W.; Zhang, W.; Zhang, D.J.; Keppo, J.; Shan, Y.; Qie, X.; Shou, M.Z. DeVRF: Fast Deformable Voxel Radiance Fields for Dynamic Scenes. Adv. Neural Inf. Process. Syst. 2022, 35, 36762–36775. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.; Tancik, M.; Barron, J.; Ramamoorthi, R.; Ng, R. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; Volume 12346, pp. 405–421. [Google Scholar]
- Sitzmann, V.; Martel, J.N.P.; Bergman, A.W.; Lindell, D.B.; Wetzstein, G. Implicit Neural Representations with Periodic Activation Functions. Adv. Neural Inf. Process. Syst. 2020, 33, 7462–7473. [Google Scholar]
- Tancik, M.; Srinivasan, P.P.; Mildenhall, B.; Fridovich-Keil, S.; Raghavan, N.; Singhal, U.; Ramamoorthi, R.; Barron, J.T.; Ng, R. Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains. Adv. Neural Inf. Process. Syst. 2020, 33, 7537–7547. [Google Scholar]
- Sun, Y.; Liu, J.; Xie, M.; Wohlberg, B.; Kamilov, U.S. CoIL: Coordinate-Based Internal Learning for Tomographic Imaging. IEEE Trans. Comput. Imaging 2021, 7, 1400–1412. [Google Scholar] [CrossRef]
- Garbin, S.J.; Kowalski, M.; Johnson, M.; Shotton, J.; Valentin, J.P.C. FastNeRF: High-Fidelity Neural Rendering at 200FPS. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 14326–14335. [Google Scholar]
- Liu, L.; Gu, J.; Lin, K.Z.; Chua, T.S.; Theobalt, C. Neural Sparse Voxel Fields. Adv. Neural Inf. Process. Syst. 2020, 33, 15651–15663. [Google Scholar]
- Sun, C.; Sun, M.; Chen, H.T. Direct Voxel Grid Optimization: Super-fast Convergence for Radiance Fields Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5449–5459. [Google Scholar]
- Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant Neural Graphics Primitives with A Multiresolution Hash Encoding. ACM Trans. Graph. 2022, 41, 102. [Google Scholar] [CrossRef]
- Zha, R.; Zhang, Y.; Li, H. NAF: Neural Attenuation Fields for Sparse-View CBCT Reconstruction. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; Springer: Cham, Switzerland, 2022; pp. 442–452. [Google Scholar]
- Xu, J.; Moyer, D.; Gagoski, B.; Iglesias, J.E.; Grant, P.E.; Golland, P.; Adalsteinsson, E. NeSVoR: Implicit Neural Representation for Slice-to-Volume Reconstruction in MRI. IEEE Trans. Med. Imaging 2023, 42, 1707–1719. [Google Scholar] [CrossRef]
- Yu, A.; Fridovich-Keil, S.; Tancik, M.; Chen, Q.; Recht, B.; Kanazawa, A. Plenoxels: Radiance Fields without Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5491–5500. [Google Scholar]
- Green, R. Spherical Harmonic Lighting: The Gritty Details. In Proceedings of the Archives of the Game Developers Conference, San Jose, CA, USA, 4–8 March 2003; Volume 56, p. 4. [Google Scholar]
- Rückert, D.; Wang, Y.; Li, R.; Idoughi, R.; Heidrich, W. NeAT: Neural Adaptive Tomography. ACM Trans. Graph. 2022, 41, 55. [Google Scholar] [CrossRef]
- Chen, A.; Xu, Z.; Geiger, A.; Yu, J.; Su, H. TensoRF: Tensorial Radiance Fields. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 333–350. [Google Scholar]
- Hitchcock, F.L. The Expression of a Tensor or a Polyadic as a Sum of Products. J. Math. Phys. 1927, 6, 164–189. [Google Scholar] [CrossRef]
- Zhang, K.; Kolkin, N.I.; Bi, S.; Luan, F.; Xu, Z.; Shechtman, E.; Snavely, N. ARF: Artistic Radiance Fields. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 717–733. [Google Scholar]
- Shao, R.; Zheng, Z.; Tu, H.; Liu, B.; Zhang, H.; Liu, Y. Tensor4D: Efficient Neural 4D Decomposition for High-Fidelity Dynamic Reconstruction and Rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16632–16642. [Google Scholar]
- Jin, H.; Liu, I.; Xu, P.; Zhang, X.; Han, S.; Bi, S.; Zhou, X.; Xu, Z.; Su, H. TensoIR: Tensorial Inverse Rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 165–174. [Google Scholar]
- Khan, A.; Ghorbanian, V.; Lowther, D. Deep Learning for Magnetic Field Estimation. IEEE Trans. Magn. 2019, 55, 7202304. [Google Scholar] [CrossRef]
- Kajiya, J.T.; Herzen, B.V. Ray Tracing Volume Densities. In Proceedings of the 11th Annual Conference on Computer Graphics and Interactive Techniques, Minneapolis, MN, USA, 23–27 July 1984. [Google Scholar]
- Wang, P.; Liu, L.; Liu, Y.; Theobalt, C.; Komura, T.; Wang, W. NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction. Adv. Neural Inf. Process. Syst. 2021, 34, 27171–27183. [Google Scholar]
- Wizadwongsa, S.; Phongthawee, P.; Yenphraphai, J.; Suwajanakorn, S. Nex: Real-time view synthesis with neural basis expansion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8534–8543. [Google Scholar]
- Yariv, L.; Gu, J.; Kasten, Y.; Lipman, Y. Volume Rendering of Neural Implicit Surfaces. Adv. Neural Inf. Process. Syst. 2021, 34, 4805–4815. [Google Scholar]
- Oechsle, M.; Peng, S.; Geiger, A. UNISURF: Unifying Neural Implicit Surfaces and Radiance Fields for Multi-View Reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 5569–5579. [Google Scholar]
- Goel, S.; Gkioxari, G.; Malik, J. Differentiable Stereopsis: Meshes from multiple views using differentiable rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8625–8634. [Google Scholar]
- Worchel, M.; Diaz, R.; Hu, W.; Schreer, O.; Feldmann, I.; Eisert, P. Multi-View Mesh Reconstruction with Neural Deferred Shading. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6177–6187. [Google Scholar]
- Munkberg, J.; Hasselgren, J.; Shen, T.; Gao, J.; Chen, W.; Evans, A.; Müller, T.; Fidler, S. Extracting Triangular 3D Models, Materials, and Lighting From Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8270–8280. [Google Scholar]
- Chen, Z.; Funkhouser, T.A.; Hedman, P.; Tagliasacchi, A. MobileNeRF: Exploiting the Polygon Rasterization Pipeline for Efficient Neural Field Rendering on Mobile Architectures. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16569–16578. [Google Scholar]
- Xiang, F.; Xu, Z.; Havsan, M.; Hold-Geoffroy, Y.; Sunkavalli, K.; Su, H. NeuTex: Neural Texture Mapping for Volumetric Neural Rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7115–7124. [Google Scholar]
- Lorensen, W.E.; Cline, H.E. Marching Cubes: A High Resolution 3D Surface Construction Algorithm. ACM Siggraph Comput. Graph. 1987, 21, 163–169. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, H. Neural Marching Cubes. ACM Trans. Graph. 2021, 40, 251. [Google Scholar] [CrossRef]
- Remelli, E.; Lukoianov, A.; Richter, S.R.; Guillard, B.; Bagautdinov, T.M.; Baqué, P.; Fua, P. MeshSDF: Differentiable Iso-Surface Extraction. Adv. Neural Inf. Process. Syst. 2020, 33, 22468–22478. [Google Scholar]
- Gao, J.; Chen, W.; Xiang, T.; Tsang, C.F.; Jacobson, A.; McGuire, M.; Fidler, S. Learning Deformable Tetrahedral Meshes for 3D Reconstruction. Adv. Neural Inf. Process. Syst. 2020, 33, 9936–9947. [Google Scholar]
- Shen, T.; Gao, J.; Yin, K.; Liu, M.Y.; Fidler, S. Deep Marching Tetrahedra: A Hybrid Representation for High-Resolution 3D Shape Synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 6087–6101. [Google Scholar]
- Yang, B.; Bao, C.; Zeng, J.; Bao, H.; Zhang, Y.; Cui, Z.; Zhang, G. NeuMesh: Learning Disentangled Neural Mesh-based Implicit Field for Geometry and Texture Editing. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 597–614. [Google Scholar]
- Tang, J.; Zhou, H.; Chen, X.; Hu, T.; Ding, E.; Wang, J.; Zeng, G. Delicate Textured Mesh Recovery from NeRF via Adaptive Surface Refinement. arXiv 2023, arXiv:2303.02091. [Google Scholar]
- Wei, X.; Xiang, F.; Bi, S.; Chen, A.; Sunkavalli, K.; Xu, Z.; Su, H. NeuManifold: Neural Watertight Manifold Reconstruction with Efficient and High-Quality Rendering Support. arXiv 2023, arXiv:2305.17134. [Google Scholar]
- Barron, J.T.; Mildenhall, B.; Tancik, M.; Hedman, P.; Martin-Brualla, R.; Srinivasan, P.P. Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 5835–5844. [Google Scholar]
- Lindell, D.B.; Martel, J.N.P.; Wetzstein, G. AutoInt: Automatic Integration for Fast Neural Volume Rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14551–14560. [Google Scholar]
- Reiser, C.; Peng, S.; Liao, Y.; Geiger, A. KiloNeRF: Speeding up Neural Radiance Fields with Thousands of Tiny MLPs. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 14315–14325. [Google Scholar]
- Hedman, P.; Srinivasan, P.P.; Mildenhall, B.; Barron, J.T.; Debevec, P.E. Baking Neural Radiance Fields for Real-Time View Synthesis. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 5855–5864. [Google Scholar]
- Hu, T.; Liu, S.; Chen, Y.; Shen, T.; Jia, J. EfficientNeRF: Efficient Neural Radiance Fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12902–12911. [Google Scholar]
- Levoy, M. Efficient Ray Tracing of Volume Data. ACM Trans. Graph. 1990, 9, 245–261. [Google Scholar] [CrossRef]
- Max, N.L. Optical Models for Direct Volume Rendering. IEEE Trans. Vis. Comput. Graph. 1995, 1, 99–108. [Google Scholar] [CrossRef]
- Barron, J.T.; Mildenhall, B.; Verbin, D.; Srinivasan, P.P.; Hedman, P. Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5460–5469. [Google Scholar]
- Zhang, K.; Riegler, G.; Snavely, N.; Koltun, V. NeRF++: Analyzing and Improving Neural Radiance Fields. arXiv 2020, arXiv:2010.07492. [Google Scholar]
- McReynolds, T.; Blythe, D. Advanced Graphics Programming Using OpenGL; Elsevier: Amsterdam, The Netherlands, 2005. [Google Scholar]
- Wang, Y.; Han, Q.; Habermann, M.; Daniilidis, K.; Theobalt, C.; Liu, L. NeuS2: Fast Learning of Neural Implicit Surfaces for Multi-view Reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 3295–3306. [Google Scholar]
- Li, Z.; Muller, T.; Evans, A.; Taylor, R.H.; Unberath, M.; Liu, M.Y.; Lin, C.H. Neuralangelo: High-Fidelity Neural Surface Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 8456–8465. [Google Scholar]
- Zhang, J.; Yao, Y.; Li, S.; Fang, T.; McKinnon, D.N.R.; Tsin, Y.; Quan, L. Critical Regularizations for Neural Surface Reconstruction in the Wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6260–6269. [Google Scholar]
- Yu, Z.; Peng, S.; Niemeyer, M.; Sattler, T.; Geiger, A. MonoSDF: Exploring Monocular Geometric Cues for Neural Implicit Surface Reconstruction. Adv. Neural Inf. Process. Syst. 2022, 35, 25018–25032. [Google Scholar]
- Fu, Q.; Xu, Q.; Ong, Y.; Tao, W. Geo-Neus: Geometry-Consistent Neural Implicit Surfaces Learning for Multi-View Reconstruction. Adv. Neural Inf. Process. Syst. 2022, 35, 3403–3416. [Google Scholar]
- Grabocka, J.; Schmidt-Thieme, L. NeuralWarp: Time-Series Similarity with Warping Networks. arXiv 2018, arXiv:1812.08306. [Google Scholar]
- Rosu, R.A.; Behnke, S. PermutoSDF: Fast Multi-View Reconstruction with Implicit Surfaces Using Permutohedral Lattices. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 8466–8475. [Google Scholar]
- Wang, Y.; Skorokhodov, I.; Wonka, P. Improved surface reconstruction using high-frequency details. Adv. Neural Inf. Process. Syst. 2022, 35, 1966–1978. [Google Scholar]
- Zhang, Y.; Hu, Z.; Wu, H.; Zhao, M.; Li, L.; Zou, Z.; Fan, C. Towards Unbiased Volume Rendering of Neural Implicit Surfaces with Geometry Priors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 4359–4368. [Google Scholar]
- Mildenhall, B. Local Light Field Fusion: Practical View Synthesis with Prescriptive Sampling Guidelines. ACM Trans. Graph. 2019, 38, 29. [Google Scholar] [CrossRef]
- Davis, P.J.; Rabinowitz, P. Methods of Numerical Integration; Courier Corporation: North Chelmsford, MA, USA, 2007. [Google Scholar]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, W.; Zhu, S.; Li, J. Data-Driven Field Representations and Measuring Processes. Foundations 2024, 4, 61-79. https://doi.org/10.3390/foundations4010006
Hong W, Zhu S, Li J. Data-Driven Field Representations and Measuring Processes. Foundations. 2024; 4(1):61-79. https://doi.org/10.3390/foundations4010006
Chicago/Turabian StyleHong, Wanrong, Sili Zhu, and Jun Li. 2024. "Data-Driven Field Representations and Measuring Processes" Foundations 4, no. 1: 61-79. https://doi.org/10.3390/foundations4010006