
Twenty Significant Problems in AI Research, with Potential Solutions via the SP Theory of Intelligence and Its Realisation in the SP Computer Model

Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
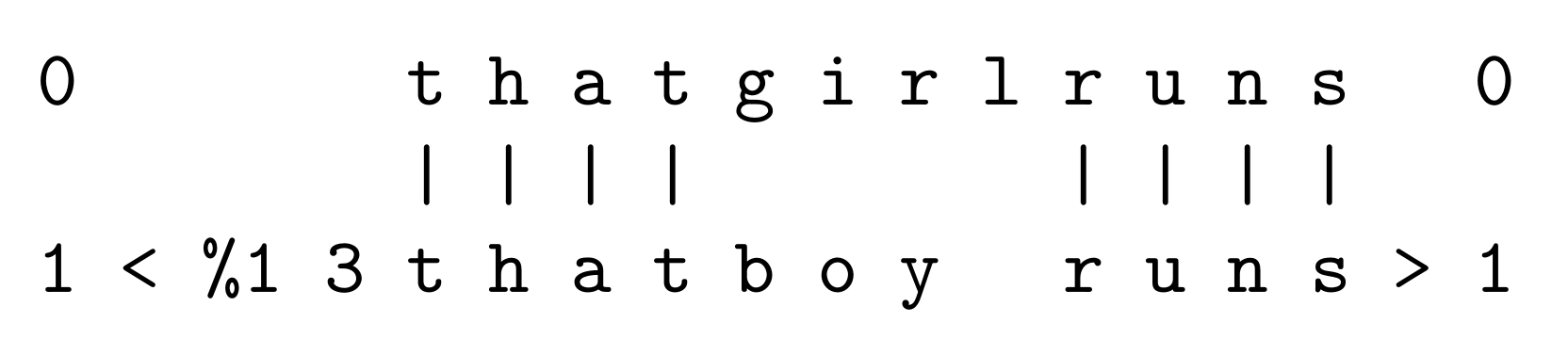{kind=link}
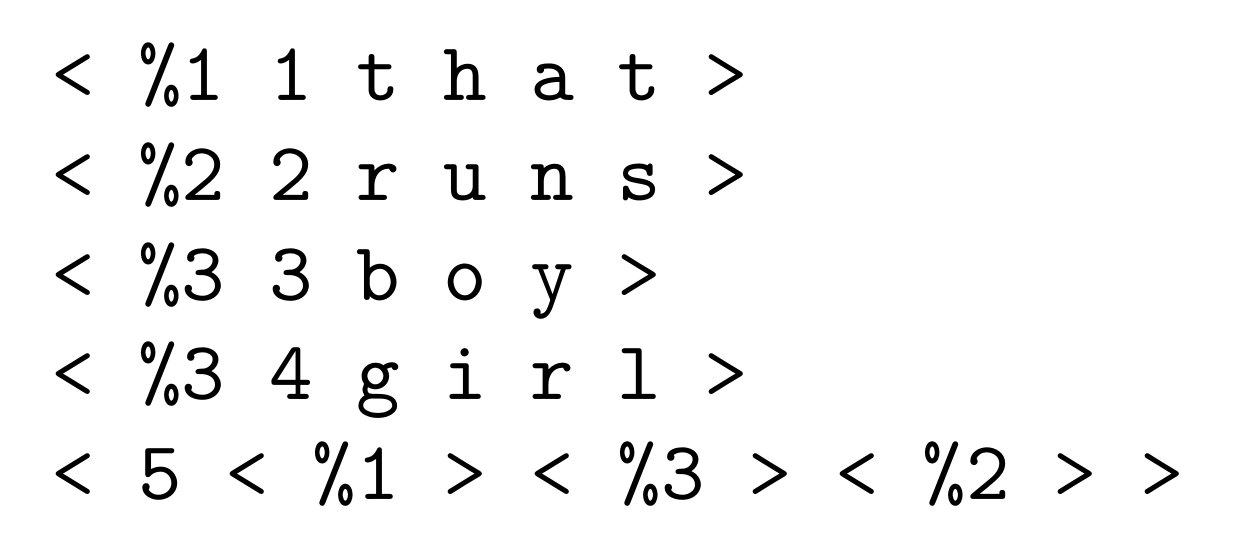{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
1.1. The Potential of the SPTI as Part of the Foundation for Each of Four Different Disciplines
- Mainstream computing. There is evidence that the SPTI, at least when is more mature, is or will be Turing complete, meaning that it can be used to simulate any Turing machine ([2], Chapter 2). And, of course, the SPTI has strengths in AI which are largely missing from the Turing machine concept of computing, as evidenced by Alan Turing’s own research on AI [4,5].Since the SPTI works entirely via the compression of information, the evidence, just mentioned, that it is or will be Turing complete, implies—contrary to how computing is normally understood—that all kinds of computing may be achieved via IC. There is potential in this idea for a radically-new approach to programming and software engineering, including the potential for the automation or semi-automation of aspects of software development, and a dramatic simplification in the current plethora of programming languages and systems.
- Mathematics, logic, and computing. Since mathematics has been developed as an aid to human thinking, and since mathematics is the product of human minds, and in view of evidence for the importance of IC in HLPC (Appendix B.4), it should not be surprising to find that much of mathematics, perhaps all of it, may be understood as a set of techniques for IC and their application (Appendix B.5).In keeping with what has just been said, similar things may be said about logic and (as above) computing Section 7 in [6].
- Human learning, perception, and cognition. In view of evidence for the importance of IC in HLPC (Appendix B.4), the central importance of IC in the SPTI (Appendix A.1), the way in which the SPTI models several features of human intelligence (Appendix B.1), and the biological foundations for this research (Appendix B.7), suggest that the SPTI has potential as a foundation for the study of HLPC.
1.2. Presentation
2. The Need to Bridge the Divide between Symbolic and Sub-Symbolic Kinds of AI
“Many people will tell a story that in the early days of AI we thought intelligence was symbolic, but then we learned that was a terrible idea. It didn’t work, because it was too brittle, couldn’t handle noise and couldn’t learn from experience. So we had to get statistical, and then we had to get neural. I think that’s very much a false narrative. The early ideas that emphasize the power of symbolic reasoning and abstract languages expressed in formal systems were incredibly important and deeply right ideas. I think it’s only now that we’re in the position, as a field, and as a community, to try to understand how to bring together the best insights and the power of these different paradigms.” Josh Tenenbaum ([1], pp. 476–477).
- The concept of SP-symbol in the SPTI (Appendix A) can represent a relatively large ‘symbolic’ kind of thing such as a word, or it can represent a relatively fine-grained kind of thing such as a pixel in an image.
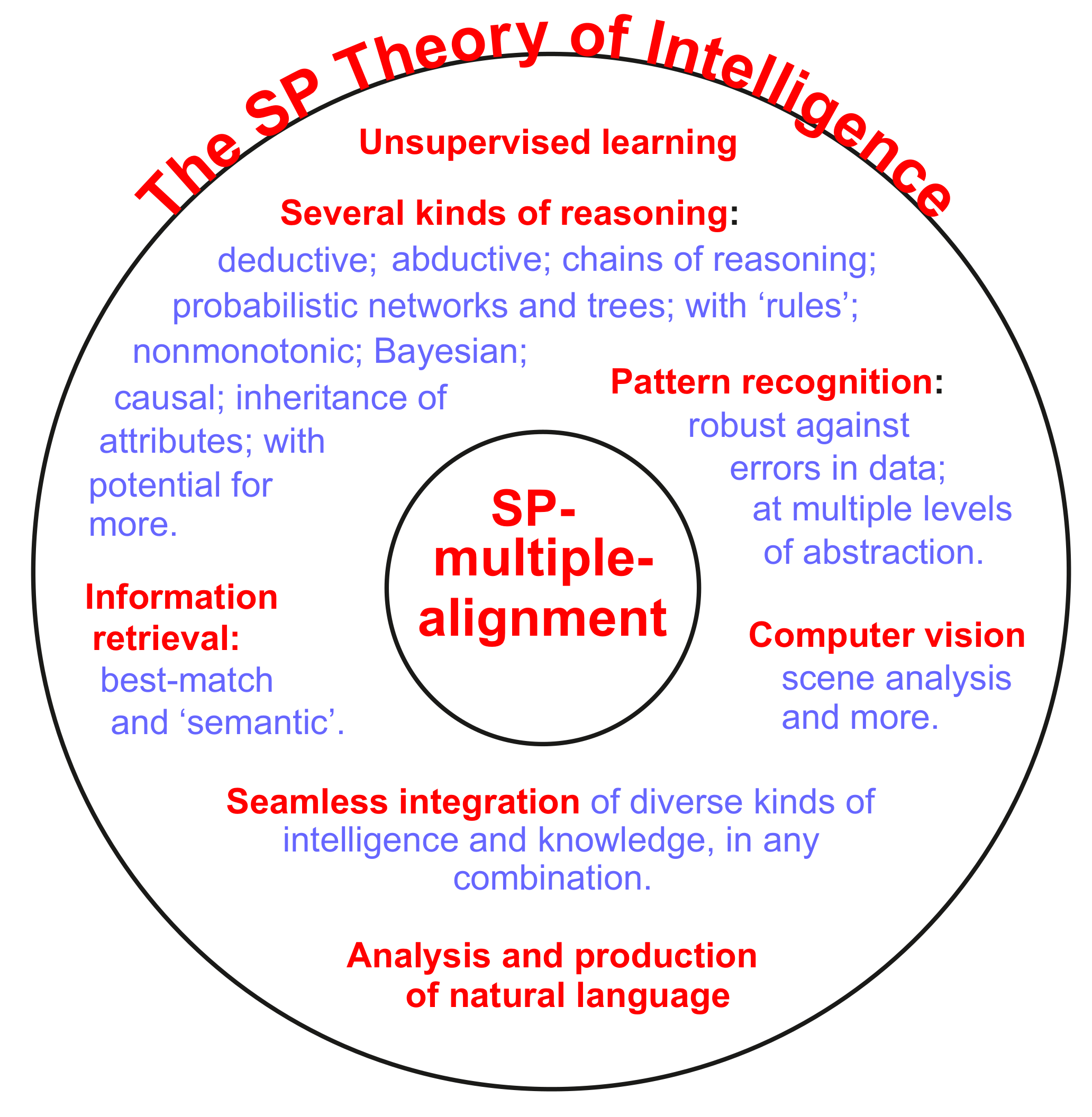
- The concept of SP-multiple-alignment (SPMA, see Appendix A.3) can facilitate the seamless integration of diverse kinds of knowledge (see Appendix B.1.4), and that facilitation extends to the seamless integration of symbolic and sub-symbolic kinds of knowledge.
- The SPTI has IC as a unifying principle (Appendix A.1), a principle which embraces both symbolic and sub-symbolic kinds of knowledge.
3. The Tendency of Deep Neural Networks to Make Large and Unexpected Errors in Recognition
“In [a recent] paper [8], [the authors] show how you can fool a deep learning system by adding a sticker to an image. They take a photo of a banana that is recognized with great confidence by a deep learning system and then add a sticker that looks like a psychedelic toaster next to the banana in the photo. Any human looking at it would say it was a banana with a funny looking sticker next to it, but the deep learning system immediately says, with great confidence, that it’s now a picture of a toaster.” Gary Marcus ([1], p. 318).
Demonstrations of the SPCM’S Robustness
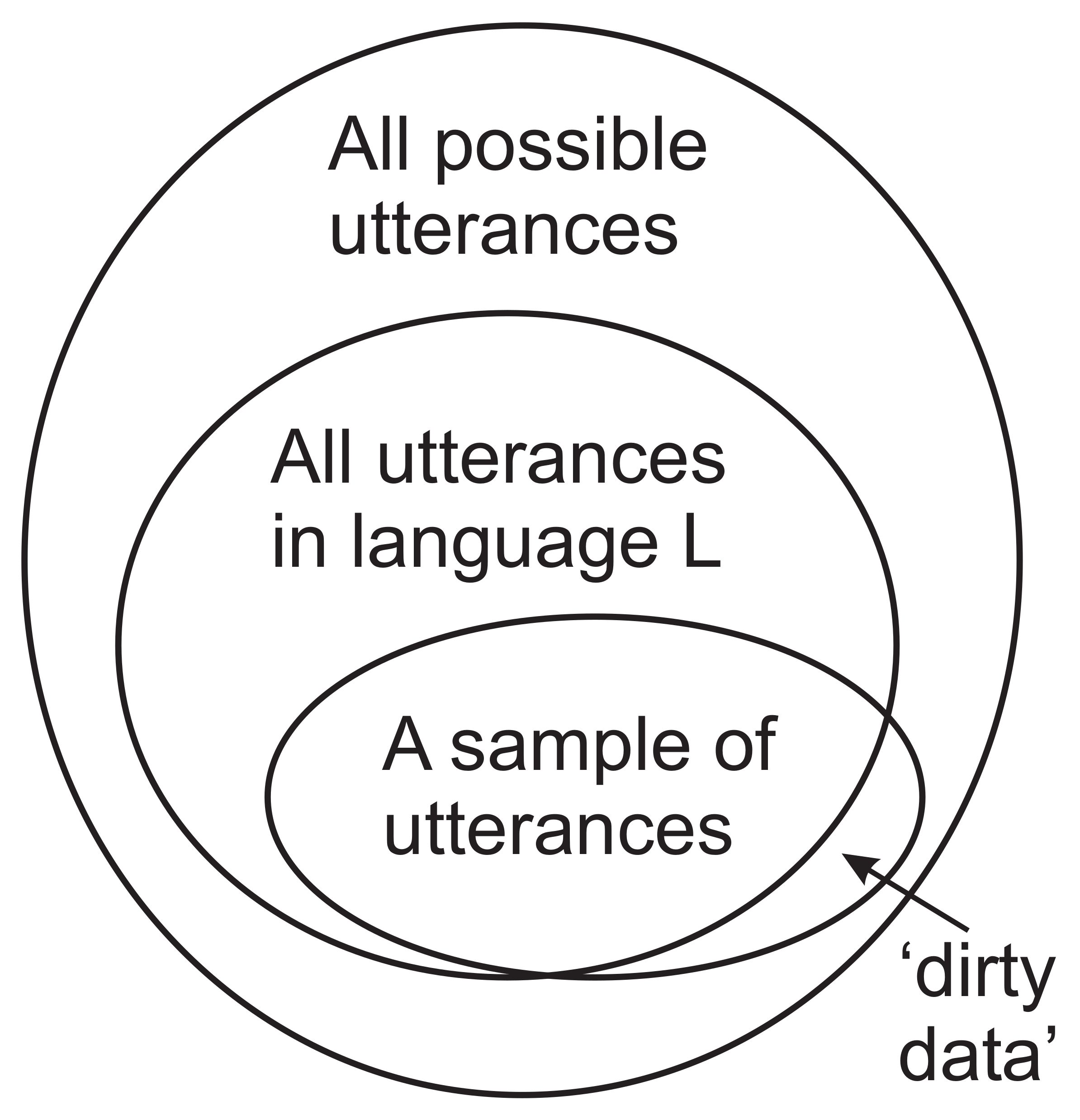
- Generalisation via unsupervised learning (Section 6.1). There is evidence (described in Section 6.1) that the SPCM, and earlier models that learn via IC, can, via unsupervised learning, develop intuitively ‘correct’ SP-grammars for corresponding bodies of knowledge despite the existence of ‘dirty data’ in the input data. Hence, the SPCM reduces the corrupting effect of any errors in the input data.
- Generalisation via perception (Section 6.2). The SPCM demonstrates an ability to parse a sentence in a manner that is intuitively ‘correct’, despite errors of omission, addition, and substitution in the sentence that is to be parsed (see Section 6.2). Again, the SPCM has a tendency to correct errors rather than introduce them.
4. The Need to Strengthen the Representation and Processing of Natural Languages
“⋯ I think that many of the conceptual building blocks needed for human-like intelligence [AGI] are already here. But there are some missing pieces. One of them is a clear approach to how natural language can be understood to produce knowledge structures upon which reasoning processes can operate.” Stuart J. Russell ([1], p. 51).
…with all their impressive advantages, neural networks are not a silver bullet for natural-language understanding and generation. …[In natural language processing] the core challenges remain: language is discreet and ambiguous, we do not have a good understanding of how it works, and it is not likely that a neural network will learn all the subtleties on its own without careful human guidance. …The actual performance on many natural language tasks, even low-level and seemingly simple ones …is still very far from being perfect.… Yoav Goldberg ([13], Section 21.2).
4.1. Demonstrations of the SPCM’s Strengths in the Processing of Natural Language
4.1.1. Parsing via SP-Multiple-Alignment
4.1.2. Discontinuous Dependencies
4.1.3. Discontinuous Dependencies in English Auxiliary verbs
4.1.4. Parsing Which Is Robust against Errors of Omission, Addition, and Substitution
4.1.5. The Representation and Processing of Semantic Structures
4.1.6. The Integration of Syntax and Semantics
4.1.7. One Mechanism for Both the Parsing and Production of NL
5. Overcoming the Challenges of Unsupervised Learning
“Until we figure out how to do this unsupervised/self-supervised/predictive learning, we’re not going to make significant progress because I think that’s the key to learning enough background knowledge about the world so that common sense will emerge.” Yann Lecun ([1], p. 130).
5.1. Outline of Unsupervised Learning in the SPCM
5.2. Demonstrations of Unsupervised Learning with the SPCM
6. The Need for a Coherent Account of Generalisation
“The theory [worked on by Roger Shepard and Joshua Tenenbaum] was of how humans, and many other organisms, solve the basic problem of generalization, which turned out to be an incredibly deep problem. ⋯ The basic problem is, how do we go beyond specific experiences to general truths? Or from the past to the future?” Joshua Tenenbaum ([1], p. 468).
6.1. Generalisation via Unsupervised Learning
- 1.
- Unsupervised learning in the SP Theory of Intelligence may be seen as a process of compressing a body of information, I, to achieve lossless compression of I into a structure T, where the size of T is at or near the minimum that may be achieved with the available computational resources.
- 2.
- T may be divided into two parts:
- An SP-grammar of I called (G). Provided the compression of I has been done quite thoroughly, G may be seen to be a theory of I which generalises ‘correctly’ beyond I, without either over- or under-generalisations.
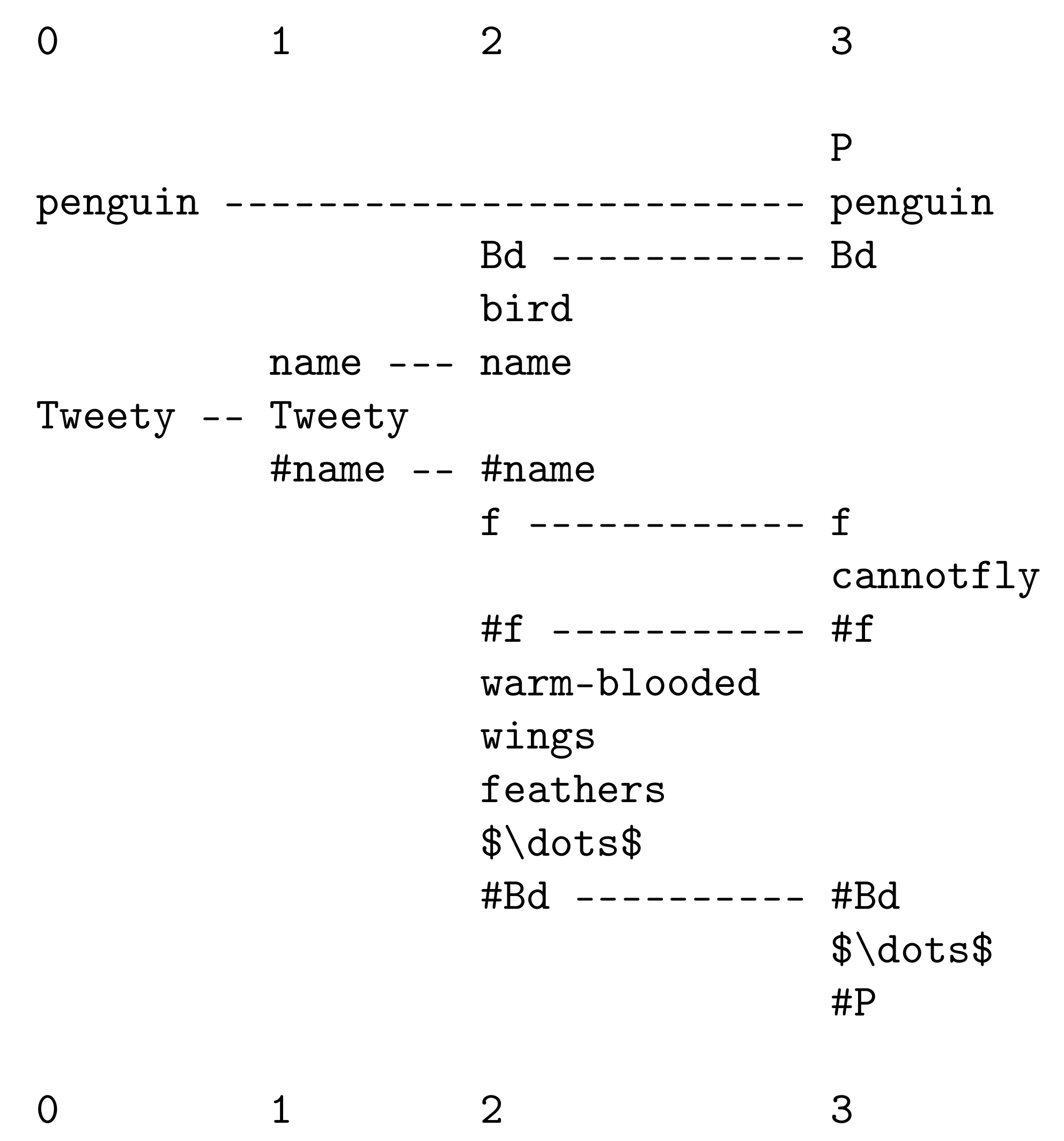
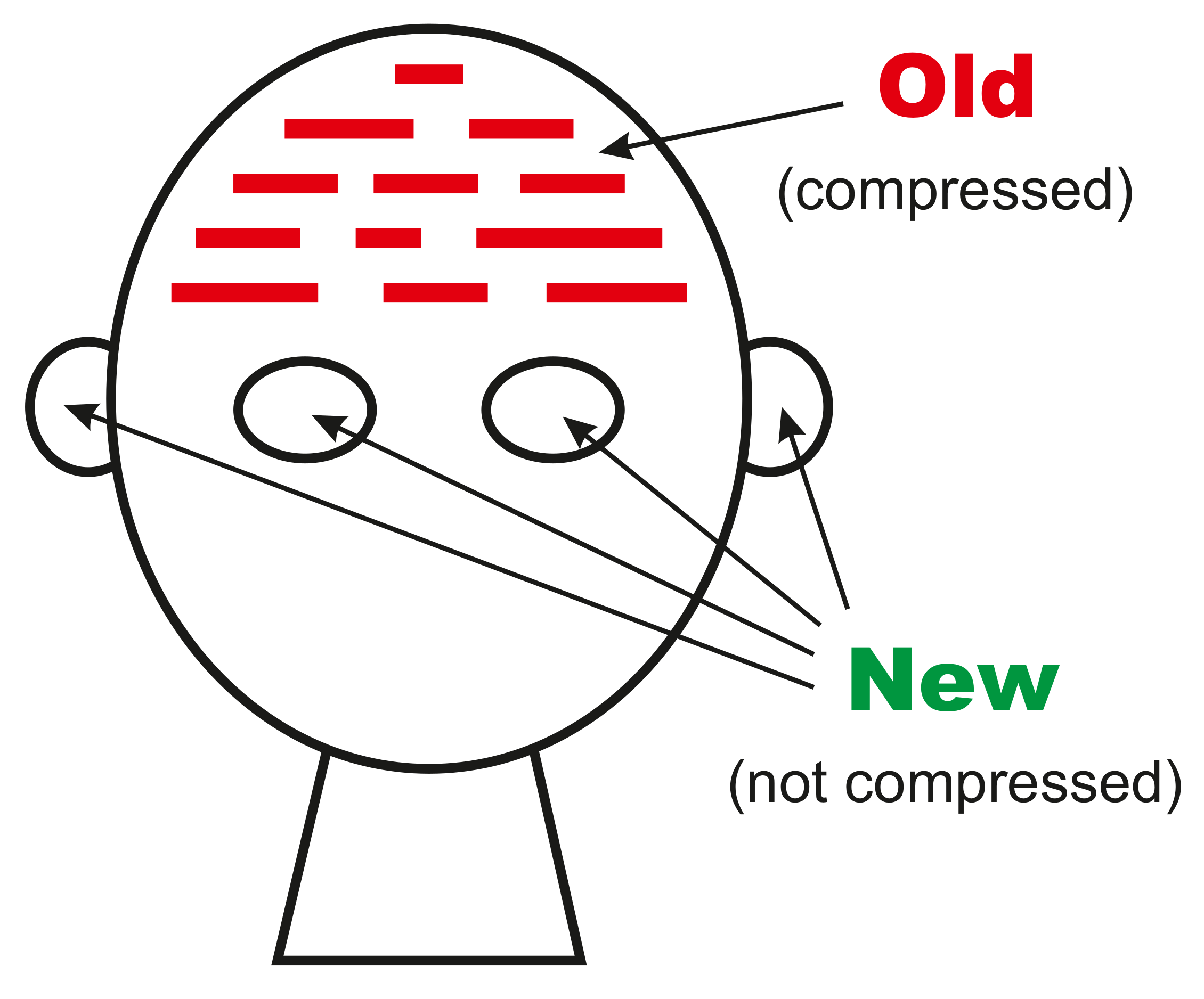
- An encoding of I in terms of G, called E. In addition to being an encoding of I, E contains all the information in I which occurs only once in I, and that is likely to include all or most of the ‘dirty data’ in I, illustrated in Figure 2.
- 3.
- Discard E and retain G, for the following reasons:
- G is a distillation of what is normally regarded as the most interesting parts of I which should be retained.
- The encodings in E are not normally of much interest, and E is likely to contain all the ‘dirty data’ in I which may be discarded.
Demonstrations Relating to Generalisation via Unsupervised Learning
6.2. Generalisation via Perception
Demonstration of Generalisation via Perception
7. How to Learn Usable Knowledge from a Single Exposure or Experience
“How do humans learn concepts not from hundreds or thousands of examples, as machine learning systems have always been built for, but from just one example? ⋯ Children can often learn a new word from seeing just one example of that word used in the right context, ⋯ You can show a young child their first giraffe, and now they know what a giraffe looks like; you can show them a new gesture or dance move, or how you use a new tool, and right away they’ve got it ⋯” Joshua Tenenbaum ([1], p. 471).
“⋯ a problem setup in machine learning, where at test time, a learner observes samples from classes, which were not observed during training, and needs to predict the class that they belong to. Zero-shot methods generally work by associating observed and non-observed classes through some form of auxiliary information, which encodes observable distinguishing properties of objects. ⋯ For example, given a set of images of animals to be classified, along with auxiliary textual descriptions of what animals look like, an artificial intelligence model which has been trained to recognize horses, but has never been given a zebra, can still recognize a zebra when it also knows that zebras look like striped horses.” ‘Zero-shot learning’, Wikipedia, tinyurl.com/yyybvm8x, accessed on 29 August 2022.
7.1. Demonstration of One-Trial Learning
7.2. Slow Learning of Complex Knowledge or Skills
8. How to Achieve Transfer Learning
“We need to figure out how to think about problems like transfer learning, because one of the things that humans do extraordinarily well is being able to learn something, over here, and then to be able to apply that learning in totally new environments or on a previously unencountered problem, over there.” James Manyika ([1], p. 276).
Demonstration of Transfer Learning with the SPCM
- At the beginning, there is one Old SP-pattern already stored, namely: ‘< %1 3 t h a t b o y r u n s >’.
- Then a New SP-pattern is received: ‘t h a t g i r l r u n s’.
- The best SP-multiple alignment for these two SP-patterns is shown in Figure 5.
- From that SPMA, the SPCM derives SP-patterns as shown in Figure 6. This is the beginnings of an SP-grammar for sentences of a given form.
- Because IC in the SPCM is always lossless, the SP-grammar in Figure 6 generates the original two SP-patterns from which the SP-grammar is derived.
9. How to Increase the Speed of Learning, and Reduce Demands for Large Amounts of Data and for Large Computational Resources
“[A] stepping stone [towards artificial general intelligence] is that it’s very important that [AI] systems be a lot more data-efficient. So, how many examples do you need to learn from? If you have an AI program that can really learn from a single example, that feels meaningful. For example, I can show you a new object, and you look at it, you’re going to hold it in your hand, and you’re thinking, ‘I’ve got it.’ Now, I can show you lots of different pictures of that object, or different versions of that object in different lighting conditions, partially obscured by something, and you’d still be able to say, ‘Yep, that’s the same object.’ But machines can’t do that off of a single example yet. That would be a real stepping stone to [artificial general intelligence] for me.” Oren Etzioni ([1], p. 502).
- Learning via a single exposure or experience. Take advantage of the way in which the SPCM can, as a normal part of how it works, learn usable knowledge from a single exposure or experience (Section 7).
- Transfer learning. Take advantage of the way in which the SPCM can, and frequently does, incorporate already-stored knowledge in the learning of something new (Section 8).
10. The Need for Transparency in the Representation and Processing of Knowledge
“The current machine learning concentration on deep learning and its non-transparent structures is such a hang-up.” Judea Pearl ([1], p. 369).
- All knowledge in the SPCM is represented transparently by SP-patterns, in structures, some of which are likely to be familiar to people such as part-whole hierarchies, class-inclusion hierarchies, and more (see ([6], Section 5).
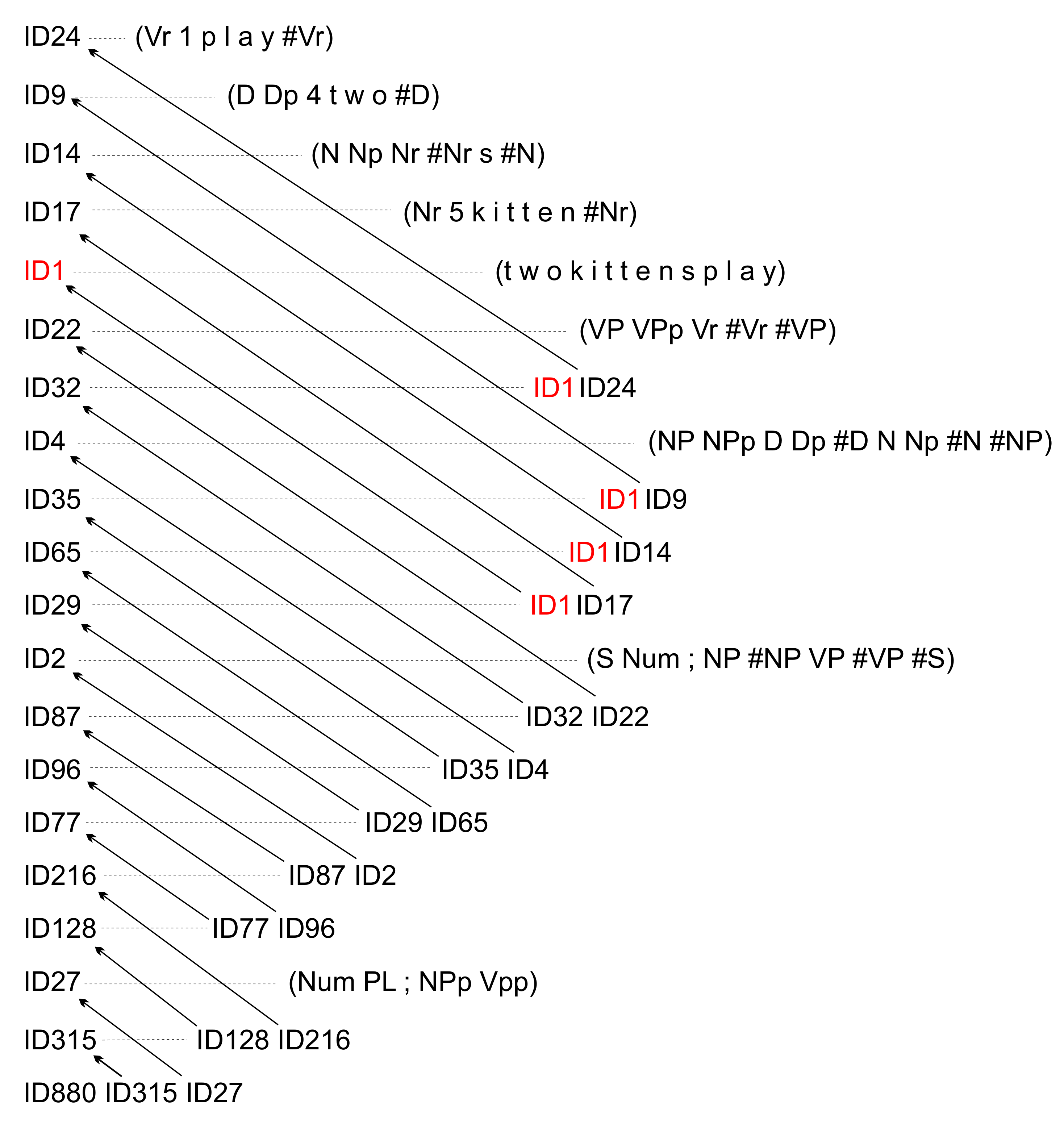
- There is a comprehensive audit trail for the creation of each SPMA. The structure of one such audit trail is shown in Figure 7.
- There is also a comprehensive audit trail for the learning of SP-grammars by the SPCM.
Demonstrations Relating to Transparency
11. How to Achieve Probabilistic Reasoning That Integrates with Other Aspects of Intelligence
“What’s going on now in the deep learning field is that people are building on top of these deep learning concepts and starting to try to solve the classical AI problems of reasoning and being able to understand, program, or plan.” Yoshua Bengio ([1], p. 21), emphasis added.
Demonstrations Relating to Probabilistic Reasoning
12. The Challenges of Commonsense Reasoning and Commonsense Knowledge
“We don’t know how to build machines that have human-like common sense. We can build machines that can have knowledge and information within domains, but we don’t know how to do the kind of common sense we all take for granted.” Cynthia Breazeal ([1], p. 456).
Demonstrations Relating to Commonsense Reasoning and Commonsense Knowledge
13. How to Minimise the Risk of Accidents with Self-Driving Vehicles
“⋯ the principal reason [for pessimism about the early introduction of driverless cars for all situations is] that if you’re talking about driving in a very heavy metropolitan location like Manhattan or Mumbai, then the AI will face a lot of unpredictability. It’s one thing to have a driverless car in Phoenix, where the weather is good and the population is a lot less densely packed. The problem in Manhattan is that anything goes at any moment, nobody is particularly well-behaved and everybody is aggressive, the chance of having unpredictable things occur is much higher.” Gary Marcus ([1], p. 321).
14. The Need for Strong Compositionality in the Structure of Knowledge
“By the end of the ’90s and through the early 2000s, neural networks were not trendy, and very few groups were involved with them. I had a strong intuition that by throwing out neural networks, we were throwing out something really important. ⋯
Part of that [intuition] was because of something that we now call compositionality: The ability of these systems to represent very rich information about the data in a compositional way, where you compose many building blocks that correspond to the neurons and the layers.” Yoshua Bengio ([1], pp. 25–26).
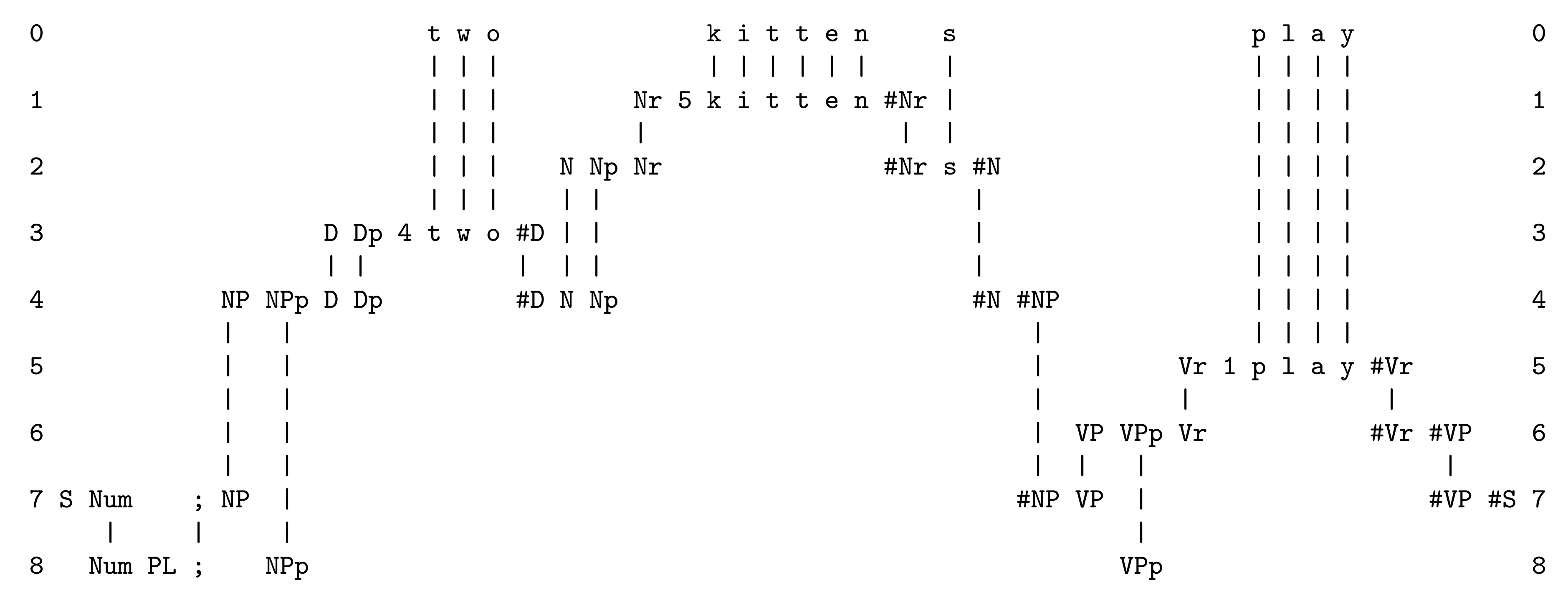
Demonstrations of Compositionality with the SPTI
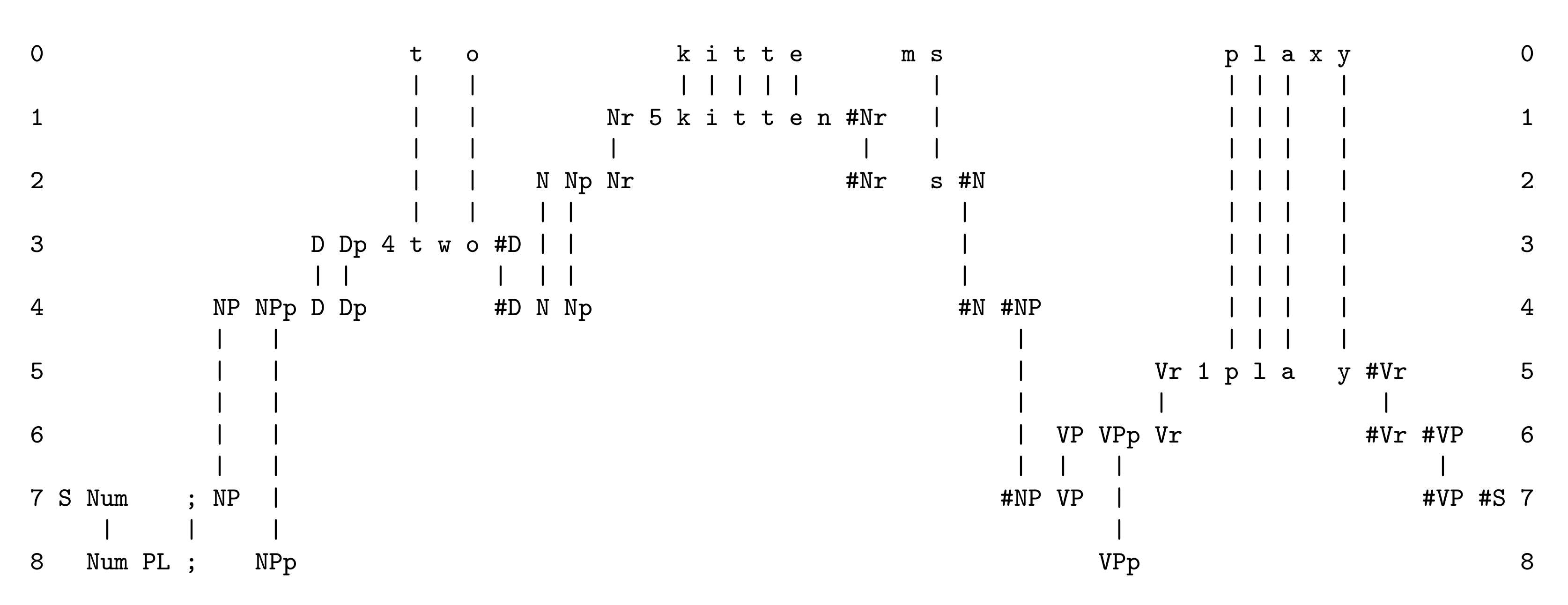
- The word ‘t w o’ is part of the ‘determiner’ category as shown in the SP-pattern ‘D Dp 4 t w o #D’ in row 3;
- The word ‘k i t t e n’ is the ‘root’ of a noun represented by the SP-pattern ‘Nr 5 k i t t e n #Nr’ in row 1, and this is part of the ‘noun’ category represents by ‘N Np Nr #Nr s #N’ in row 2;
- Both ‘D Dp 4 t w o #D’ and ‘N Np Nr #Nr s #N’ are part of the ‘noun phrase’ structure represented by the SP-pattern ‘NP NPp D Dp #D N Np #N #NP’ in row 4;
- There is a similar but simpler hierarchy for the ‘verb phrase’ category represented by the SP-pattern ‘VP VPp Vr #Vr #VP’ in row 6;
- The noun phrase structure, ‘NP NPp D Dp #D N Np #N #NP’, and the verb phrase structure, ‘VP VPp Vr #Vr #VP’, are the two main components of a sentence, represented by the SP-pattern ‘S Num; NP #NP VP #VP #S’ in row 7.
15. Establishing the Importance of Information Compression in AI Research
“Autoencoders have changed quite a bit since [the] original vision. Now, we think of them in terms of taking raw information, like an image, and transforming it into a more abstract space where the important, semantic aspect of it will be easier to read. That’s the encoder part. The decoder works backwards, taking those high-level quantities—that you don’t have to define by hand—and transforming them into an image. That was the early deep learning work. Then a few years later, we discovered that we didn’t need these approaches to train deep networks, we could just change the nonlinearity.” Yoshua Bengio ([1], pp. 26–27).
- 1.
- 2.
- IC is bedrock in the design of the SPTI ([3], Section 2.1).
- 3.
- Via the SPMA concept, IC appears to be largely responsible for the strengths and potential of the SPTI in AI-related functions (Appendix B.1), and largely responsible for potential benefits and applications of the SPTI in other areas (Appendix B.2).
16. Establishing the Importance of a Biological Perspective in AI Research
“Deep learning will do some things, but biological systems rely on hundreds of algorithms, not just one algorithm. [AI researchers] will need hundreds more algorithms before we can make that progress, and we cannot predict when they will pop.” Rodney Brooks ([1], p. 427).
16.1. IC and the Biological Foundations of the SPTI
16.2. SP-Neural and Inputs from Neuroscience
17. Establishing Whether Knowledge in Brains or AI Systems Should Best Be Represented in ‘Distributed’ or ‘Localist’ Form
“In a hologram, information about the scene is distributed across the whole hologram, which is very different from what we’re used to. It’s very different from a photograph, where if you cut out a piece of a photograph you lose the information about what was in that piece of the photograph, it doesn’t just make the whole photograph go fuzzier.” Geoffrey Hinton ([1], p. 79).
- In DNNs, knowledge is distributed in the sense that the knowledge is encoded in the strengths of connections between many neurons across several layers of each DNN. Since DNNs provide the most fully developed examples of AI systems with distributed knowledge, the discussion here assumes that DNNs are representative of such systems.
- The SPTI, in both its abstract form (Appendix A) and as SP-Neural [39], is unambiguously localist.
- Mike Page ([40], pp. 461–463) discusses several studies that provide direct or indirect evidence in support of localist encoding of knowledge in the brain.
- It is true that if knowledge of one’s grandmother is contained within a neural SP-pattern, death of that neural SP-pattern would destroy knowledge of one’s grandmother. But:
- As Barlow points out ([41], pp. 389–390), a small amount of replication will give considerable protection against this kind of catastrophe.
- Any person who has suffered a stroke, or is suffering from dementia, may indeed lose the ability to recognise close relatives or friends.
- In connection with the ‘localist’ view of brain organisation, an important question is whether or not there are enough neurons in the human brain to store the knowledge that a typical person, or, more to the point, an exceptionally knowledgeable person, will have?Arguments and calculations relating to this issue suggest that it is indeed possible for us to store what we know in localist form, and with substantial room to spare for multiple copies ([2], Section 11.4.9). A summary of the arguments and calculations is in ([39], Section 4.4).Incidentally, multiple copies of a localist representation in which each copy is localist, or a neural SP-pattern for the representation of each concept, is not the same as the diffuse representation of knowledge in a distributed representation.
18. The Learning of Structures from Raw Data
“Evolution does a lot of architecture search; it designs machines. It builds very differently, structured machines across different species or over multiple generations. We can see this most obviously in bodies, but there’s no reason to think it’s any different in [the way that] brains [learn].” Josh Tenenbaum ([1], p. 481).
Demonstrations of the Unsupervised Learning of Structures from Raw Data
19. The Need to Re-Balance Research towards Top-Down Strategies
“The central problem, in a word: current AI is narrow; it works for particular tasks that it is programmed for, provided that what it encounters isn’t too different from what it has experienced before. That’s fine for a board game like Go—the rules haven’t changed in 2500 years—but less promising in most real-world situations. Taking AI to the next level will require us to invent machines with substantially more flexibility. ⋯ To be sure, ⋯ narrow AI is certainly getting better by leaps and bounds, and undoubtedly there will be more breakthroughs in the years to come. But it’s also telling: AI could and should be about so much more than getting your digital assistant to book a restaurant reservation.” Gary Marcus and Ernest Davis ([45], pp. 12–14), emphasis in the original.
- 1.
- Broad scope. Achieving generality requires that the data from which a theory is derived should have a broad scope, like the overarching goal of the SP programme of research, summarised above.
- 2.
- Ockham’s razor, Simplicity and Power. That broad scope is important for two reasons:
- In accordance with Ockham’s razor, a theory should be as Simple as possible but, at the same time, it should retain as much as possible of the descriptive and explanatory Power of the data from which the theory is derived.
- But measures of Simplicity and Power are more important when they apply to a wide range of phenomena than when they apply only to a small piece of data.
- 3.
- If you can’t solve a problem, enlarge it. A broad scope, as above, can be challenging, but it can also make things easier. Thus Dwight D. Eisenhower is reputed to have said: “If you can’t solve a problem, enlarge it”, meaning that putting a problem in a broader context may make it easier to solve. Good solutions to a problem may be hard to see when the problem is viewed through a keyhole, but become visible when the door is opened.
- 4.
- Micro-theories rarely generalise well. Apart from the potential value of ‘enlarging’ a problem (point 2 above), and broad scope (point 1), a danger of adopting a narrow scope is that any micro-theory or theories that is developed for that narrow area are unlikely to generalise well to a wider context—with correspondingly poor results in terms of Simplicity and Power (see also Appendix B.6).
- 5.
- Bottom-up strategies and the fragmentation of research. The prevailing view about how to reach AGI seems to be “⋯ that we’ll get to general intelligence step by step by solving one problem at a time.” expressed by Ray Kurzweil ([1], p. 234). And much research in AI has been, and to a large extent still is, working with this kind of bottom-up strategy: developing ideas in one area, and then trying to generalise them to another area, and so on.But it seems that in practice the research rarely gets beyond two areas, and, as a consequence, there is much fragmentation of research (see also Appendix B.6).
20. How to Overcome the Limited Scope for Adaptation in Deep Neural Networks
- Each concept in the SPTI is represented by one SP-pattern which, as a single array of SP-symbols, would normally be much simpler than the multiple layers of a DNN, with multiple links between layers, normally many than in knowledge structures created by the SPCM.
- There is no limit to the number of ways in which a given SP-pattern can be connected to other SP-patterns within SPMAs, in much the same way that there is no limit to the number of ways in which a given web page can be connected to other web pages.
- Together, these features of the SPTI provide much greater scope than with DNNs for the representation and learning of many concepts and their many inter-connections.
21. How to Eliminate the Problem of Catastrophic Forgetting
“We find that the CF [catastrophic forgetting] effect occurs universally, without exception, for deep LSTM-based [Long Short-Term Memory based] sequence classifiers, regardless of the construction and provenance of sequences. This leads us to conclude that LSTMs, just like DNNs [Deep Neural Networks], are fully affected by CF, and that further research work needs to be conducted in order to determine how to avoid this effect (which is not a goal of this study).” Monika Schak and Alexander Gepperth [46].
- In DNNs there is a single structure for the learning and storage of new knowledge, a concept like ‘my house’ is encoded in the strengths of connections between artificial neurons in that single structure, so that the later learning of a concept like ‘my car’ is likely to disturb the strengths of connections for ‘my house’;
- By contrast, the SPCM has an SP-pattern for each concept in its repository of knowledge, there is no limit to the number of such SP-patterns that can be stored (apart from the limit imposed by the available storage space in the computer and associated information storage), and, although there can be many connections between SP-patterns, there is no interference between any one SP-pattern and any other.
- As noted in Section 8, one may make a copy of a DNN that has already learned something, and then train it on some new concept that is related to what has already been learned. The prior knowledge may help in the learning of the new concept.
- If, for example, one wishes to train a DNN in, say, 50 new concepts, one can do it with a giant DNN that has space allocated to each of the 50 new concepts, each with multiple layers. Then providing that the training data for each concept is applied at the appropriate part of the giant DNN, there should be no catastrophic forgetting [23].
22. Conclusions
23. Software Availability
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| AGI | Artificial General Intelligence |
| CSRK | Commonsense Reasoning and Commonsense Knowledge |
| DNN | Deep Neural Network |
| FDAGI | Foundation for the Development of AGI |
| HLPC | Human Learning, Perception, and Cognition |
| IC | Information Compression |
| ICMUP | Information Compression via the Matching and Unification of Patterns |
| NL | Natural Language |
| SPCM | SP Computer Model |
| SPMA | SP-multiple-alignment |
| SPTI | SP Theory of Intelligence |
Appendix A. High Level View of the SPTI

Appendix A.1. Information Compression and Intelligence
Appendix A.2. Origin of the Name ‘SP’
- The SPTI aims to simplify and integrate observations and concepts across a broad canvass (Section 19), which means applying IC to those observations and concepts;
- IC is a central feature of the structure and workings of the SPTI itself (Appendix A.1);
- And IC may be seen as a process that increases the Simplicity of a body of information, I, whilst retaining as much as possible of the descriptive and explanatory Power of I.
Appendix A.3. SP-Multiple-Alignment
Appendix A.3.1. The SPMA Concept Is Inspired by and Derived from the Bioinformatics Concept of ‘Multiple Sequence Alignment’

Appendix A.3.2. How SPMAs Differ from Multiple Sequence Alignments
- Each row contains one SP-pattern;
- The top row is normally a single New SP-pattern, newly received from the system’s environment. Sometimes there is more than one New SP-pattern in row 0.
- Each of the other rows contain one Old SP-pattern, drawn from a store which normally contains many Old SP-patterns;
- A ‘good’ SPMA is one where the New SP-pattern(s) may be encoded economically in terms of the Old SP-patterns, as explained in ([3], Section 4.1).

Appendix A.4. Unsupervised Learning in the SPCM
Appendix A.5. Future Developments

Appendix B. Strengths of the SPTI in AI and Beyond
Appendix B.1. AI-Related Strengths of the SPCM
Appendix B.1.1. Several Kinds of Intelligent Behaviour
Appendix B.1.2. Several Kinds of Probabilistic Reasoning
Appendix B.1.3. The Representation and Processing of Several Kinds of AI-Related Knowledge
Appendix B.1.4. The Seamless Integration of Diverse Aspects of Intelligence, and Diverse Kinds of Knowledge, in Any Combination

Appendix B.1.5. How to Make Generalisations without over- or under-Generalisation; and How to Minimise the Corrupting Effect of ‘Dirty Data’
Appendix B.2. Other Potential Benefits and Applications of the SPTI
- Overview of potential benefits and applications. Several potential areas of application of the SPTI are described in [43]. The ones that relate fairly directly to AI include: best-match and semantic forms of information retrieval; the representation of knowledge, reasoning, and the semantic web.
- The development of intelligence in autonomous robots. The SPTI opens up a radically new approach to the development of intelligence in autonomous robots [44].
- An intelligent database system. The SPTI has potential in the development of an intelligent database system with several advantages compared with traditional database systems [20].
- Medical diagnosis. The SPTI may serve as a vehicle for medical knowledge and to assist practitioners in medical diagnosis, with potential for the automatic or semi-automatic learning of new knowledge [50].
- Sustainability. The SPTI has clear potential for substantial reductions in the very large demands for energy of standard DNNs, and applications that need to manage huge quantities of data such as those produced by the Square Kilometre Array [51]. Where those demands are met by the burning of fossil fuels, there would be corresponding reductions in the emissions of CO2.
- Transparency in computing. By contrast with applications with DNNs, the SPTI provides a very full and detailed audit trail of all its processing, and all its knowledge may be viewed. Also, there are reasons to believe that, when the system is more fully developed, its knowledge will normally be structured in forms that are familiar such as class-inclusion hierarchies, part-whole hierarchies, run-length coding, and more. Strengths of the SPTI in these area are described in [26].
Appendix B.3. The Clear Potential of the SPTI to Solve 20 Significant Problems in AI Research
Appendix B.4. Evidence for the Importance of IC in HLPC Suggests That IC Should Be Central in the SPCM
“⋯ the operations needed to find a less redundant code have a rather fascinating similarity to the task of answering an intelligence test, finding an appropriate scientific concept, or other exercises in the use of inductive reasoning. Thus, redundancy reduction may lead one towards understanding something about the organization of memory and intelligence, as well as pattern recognition and discrimination.” ([56], p. 210).
- Evidence for the importance of IC in HLPC has provided the motivation for making IC central in the structure and workings of the SPCM;
- In view of the same evidence, it seems clear that IC should be central in the workings of any system that aspires to AGI;
- The central role for IC in the SPCM—mediated by the concept of SPMA (Appendix A.3)—is largely responsible for the strengths of the SPTI (Appendix B);
- In both natural and artificial systems:
- For a given body of information, I, to be stored, IC means that a smaller store is needed. Or for a store of a given capacity, IC facilitates the storage of a larger I ([18], Section 4);
- For a given body of information, I, to be transmitted along a given channel, IC means an increase in the speed of transmission. Or for the transmission of I at a given speed, IC means a reduction in the bandwidth which is needed ([18], Section 4).
- Because of the intimate relation between IC and concepts of inference and probability (Section 11), and because of the central role of IC in the SPTI, the SPTI is intrinsically probabilistic.Correspondingly, it is relatively straightforward to calculate absolute and relative probabilities for all aspects of intelligence exhibited by the SPTI, including several kinds of reasoning (([3], Section 4.4), ([2], Section 3.7)), in keeping with the probabilistic nature of human inferences and reasoning.
Appendix B.4.1. A Resolution of the Apparent Paradox That IC May Achieve Decompression as Well as Compression of Data
Appendix B.4.2. The Working Hypothesis That IC May Always Be Achieved via the Matching and Unification of Patterns
- Basic ICMUP. Two or more instances of any pattern may be merged or ‘unified’ to make one instance ([6], Section 5.1).
- Chunking-with-codes. Any pattern produced by the unification of two or more instances is termed a ‘chunk’. A ‘code’ is a relatively short identifier for a unified chunk which may be used to represent the unified pattern in each of the locations of the original patterns ([6], Section 5.2).
- Schema-plus-correction. A ‘schema’ is a chunk that contains one or more ‘corrections’ to the schema. For example, a menu in a restaurant may be seen as a schema that may be ‘corrected’ by a choice of starter, a choice of main course, and a choice of pudding ([6], Section 5.3).
- Run-length coding. In run-length coding, a pattern that repeats two or more times in a sequence may be reduced to a single instance with some indication that it repeats, or perhaps with some indication of when it stops, or even more precisely, with the number of times that it repeats ([6], Section 5.4).
- Class-inclusion hierarchies. Each class in a hierarchy of classes represents a group of entities that have the same attributes. Each level in the hierarchy inherits all the attributes from all the classes, if any, that are above it ([6], Section 5.5).
- Part-whole hierarchies. A part-whole hierarchy is similar to a class-inclusion hierarchy but it is a hierarchy of part-whole groupings ([6], Section 5.6).
Appendix B.5. The SPTI Provides an Entirely Novel Perspective on the Foundations of Mathematics
Appendix B.6. The Benefits of a Top-Down, Breadth-First Research Strategy with Wide Scope
“The goals once articulated with debonair intellectual verve by AI pioneers appeared unreachable ⋯ Subfields broke off—vision, robotics, natural language processing, machine learning, decision theory—to pursue singular goals in solitary splendor, without reference to other kinds of intelligent behaviour.” ([64], p. 417).
Later, she writes of “the rough shattering of AI into subfields ⋯ and these with their own sub-subfields—that would hardly have anything to say to each other for years to come.” ([64], p. 424).
She adds: “Worse, for a variety of reasons, not all of them scientific, each subfield soon began settling for smaller, more modest, and measurable advances, while the grand vision held by AI’s founding fathers, a general machine intelligence, seemed to contract into a negligible, probably impossible dream.” ([64], p. 424).
Appendix B.7. The Benefits of a Biological Perspective in the Development of AGI
- Earlier research developing computer models of the unsupervised learning of a first language [14], mentioned elsewhere in this paper, has provided an inspiration and foundation for the development of the SPTI.
- Recognition of the importance of IC in HLPC (Appendix B.4), which depends on studies in psychology and neuroscience.
- The author of this paper, and the main driver in developing the SPTI, has a first degree from Cambridge University in the Natural Sciences Tripos, comprising studies in experimental psychology and other biology-related sciences.
Appendix C. Definitions of Terms
| SP-grammar | Section 5.1, Appendix A.4 |
| SP-multiple-alignment | Appendix A.3 |
| SP-pattern | Appendix A |
| SP-symbol | Appendix A |
| unification | Section 18, Appendix A.1 |
References
- Ford, M. Architects of Intelligence: The Truth about AI from the People Building It, Kindle ed.; Packt Publishing: Birmingham, UK, 2018. [Google Scholar]
- Wolff, J.G. Unifying Computing and Cognition: The SP Theory and Its Applications; CognitionResearch.org: Menai Bridge, UK, 2006; ISBNs: 0-9550726-0-3 (ebook edition), (print edition), 0-9550726-1-1. [Google Scholar]
- Wolff, J.G. The SP Theory of Intelligence: An overview. Information 2013, 4, 283–341. [Google Scholar] [CrossRef] [Green Version]
- Muggleton, S. Alan turing and the development of articial intelligence. AI Commun. 2014, 27, 3–10. [Google Scholar] [CrossRef] [Green Version]
- Webster, C.S. Alan turing’s unorganized machines and artificial neural networks: His remarkable early work and future possibilities. Evolution. Intellig. 2012, 5, 35–43. [Google Scholar] [CrossRef]
- Wolff, J.G. Mathematics as information compression via the matching and unification of patterns. Complexity 2019, 2019, 6427493. [Google Scholar] [CrossRef] [Green Version]
- Wolff, J.G. How the SP System May Be Applied with Advantage in Science. Technical Report, CognitionResearch.org, 2022. Available online: https://tinyurl.com/42j2vczu (accessed on 2 September 2022).
- Brown, T.B.; Mané, D.; Roy, A.; Abadi, M.; Gilmer, J. Adversarial patch. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing Properties of Neural Networks. arXiv 2014, arXiv:1312.6199. [Google Scholar] [CrossRef]
- Nguyen, A.; Yosinski, J.; Clune, J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015; pp. 427–436. [Google Scholar]
- Nassif, A.B.; Shahin, I.; Attili, I.; Azzeh, M.; Shaalan, K. Speech recognition using deep neural networks: A systematic review. IEEE Access 2019, 7, 19143–19165. [Google Scholar] [CrossRef]
- Singh, S.P.; Kumar, A.; Darbari, H.; Singh, L.; Rastogi, A.; Jain, S. Machine translation using deep learning: An overview. In Proceedings of the 2017 International Conference on Computer, Communications and Electronics (Comptelix), Jaipur, India, 1–2 July 2017; pp. 162–167. [Google Scholar]
- Goldberg, Y. Neural Network Methods for Natural Language Processing; Morgan and Claypool Publishers: Williston, VT, USA, 2017. [Google Scholar]
- Wolff, J.G. Learning syntax and meanings through optimization and distributional analysis. In Categories and Processes in Language Acquisition; Levy, Y., Schlesinger, I.M., Braine, M.D.S., Eds.; Lawrence Erlbaum: Hillsdale, NJ, USA, 1988; pp. 179–215. Available online: http://bit.ly/ZIGjyc (accessed on 2 September 2022).
- Palade, V.; Wolff, J.G. A roadmap for the development of the ‘SP Machine’ for artificial intelligence. Comput. J. 2019, 62, 1584–1604. [Google Scholar] [CrossRef]
- Brown, C. My Left Foot; Kindle, Ed.; Vintage Digital: London, UK, 2014. First published in 1954. [Google Scholar]
- Lenneberg, E.H. Understanding language without the ability to speak: A case report. J. Abnorm. Soc. Psychol. 1962, 65, 419–425. [Google Scholar] [CrossRef]
- Wolff, J.G. Information compression as a unifying principle in human learning, perception, and cognition. Complexity 2019, 2019, 1879746. [Google Scholar] [CrossRef]
- Wolff, J.G. Application of the SP Theory of Intelligence to the understanding of natural vision and the development of computer vision. SpringerPlus 2014, 3, 552–570. [Google Scholar] [CrossRef]
- Wolff, J.G. Towards an intelligent database system founded on the SP Theory of Computing and Cognition. Data Knowl. Eng. 2007, 60, 596–624. [Google Scholar] [CrossRef] [Green Version]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models from Natural Language Supervision; Technical Report; OpenAI: San Francisco, CA, USA, 2021. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar] [CrossRef]
- Schmidhuber, J. One Big Net for Everything; Technical Report; The Swiss AI Lab, IDSIA: Lugano, Switzerland, 2018. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H. A comprehensive survey on transfer learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and policy considerations for deep learning in NLP. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), Florence, Italy, 18 July–2 August 2019. [Google Scholar]
- Wolff, J.G. Transparency and granularity in the SP Theory of Intelligence and its realisation in the SP Computer Model. In Interpretable Artificial Intelligence: A Perspective of Granular Computing; Pedrycz, W., Chen, S.-M., Eds.; Springer: Heidelberg, Germany, 2021; ISBN 978-3-030-64948-7. [Google Scholar] [CrossRef]
- Solomonoff, R.J. A formal theory of inductive inference. Parts I and II. Inf. Control. 1964, 7, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Solomonoff, R.J. The discovery of algorithmic probability. J. Comput. Syst. Sci. 1997, 55, 73–88. [Google Scholar] [CrossRef] [Green Version]
- Li, M.; Vitányi, P. An Introduction to Kolmogorov Complexity and Its Applications, 4th ed.; Springer: New York, NY, USA, 2019. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Wan, Y.; He, L.; Peng, H.; Yu, P.S. Kg-bart: Knowledge graph-augmented bart for generative commonsense reasoning. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21), virtual, 2–9 February 2021; pp. 6418–6425. [Google Scholar]
- Zellers, R.; Bisk, Y.; Farhadi, A.; Choi, Y. From recognition to cognition: Visual commonsense reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6720–6731. [Google Scholar]
- Wolff, J.G. Interpreting Winograd Schemas via the SP Theory of Intelligence and Its Realisation in the SP Computer Model; Technical Report; CognitionResearch.org: Menai Bridge, UK, 2018. [Google Scholar]
- Wolff, J.G. Commonsense Reasoning, Commonsense Knowledge, and the SP Theory of Intelligence; Technical Report; CognitionResearch.org: Menai Bridge, UK, 2019. [Google Scholar]
- Wolff, J.G. A Proposed Solution to Problems in Learning the Knowledge Needed by Self-Driving Vehicles; Technical Report; CognitionResearch.org: Menai Bridge, UK, 2021; Submitted for publication. [Google Scholar]
- Subramanian, J.; Sinha, A.; Seraj, R.; Mahajan, A. Approximate information state for approximate planning and reinforcement learning in partially observed systems. J. Mach. Learn. Res. 2022, 23, 1–83. [Google Scholar]
- Marcus, G. Kluge: The Hapharzard Construction of the Human Mind, Paperback ed.; Faber and Faber: London, UK, 2008. [Google Scholar]
- The Society of Mind; Minsky, M. (Ed.) Simon & Schuster: New York, NY, USA, 1986. [Google Scholar]
- Wolff, J.G. Information compression, multiple alignment, and the representation and processing of knowledge in the brain. Front. Psychol. 2016, 7, 1584. [Google Scholar] [CrossRef] [Green Version]
- Page, M. Connectionist modelling in psychology: A localist manifesto. Behav. Brain Sci. 2000, 23, 443–512. [Google Scholar] [CrossRef] [Green Version]
- Barlow, H.B. Single units and sensation: A neuron doctrine for perceptual psychology? Perception 1972, 1, 371–394. [Google Scholar] [CrossRef]
- Choy, C.; Gwak, J.; Savarese, S. 4d spatio-temporal convnets: Minkowski convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3075–3084. [Google Scholar]
- Wolff, J.G. The SP Theory of Intelligence: Benefits and applications. Information 2014, 5, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Wolff, J.G. Autonomous robots and the SP Theory of Intelligence. IEEE Access 2014, 2, 1629–1651. [Google Scholar] [CrossRef] [Green Version]
- Marcus, G.F.; Davis, E. Rebooting AI: Building Artificial Intelligence We Can Trust, Kindle ed.; Pantheon Books: New York, NY, USA, 2019. [Google Scholar]
- Schak, M.; Gepperth, A. A study on catastrophic forgetting in deep LSTM networks. In Artificial Neural Networks and Machine Learning—ICANN 2019: Deep Learning. ICANN 2019; Lecture Notes in Computer Science; Tetko, I., Kůrková, V., Karpov, P., Theis, F., Eds.; Springer: Cham, Switzerland, 2019; Volume 11728. [Google Scholar]
- Goodfellow, I.J.; Mirza, M.; Xiao, D.; Courville, A.; Bengio, Y. An Empirical Investigation of Catastrophic Forgetting in Gradient-Based Neural Networks; Technical Report; Département d’informatique et de recherche opérationnelle, Université de Montréal: Montréal, QC, Canada, 2015. [Google Scholar]
- Wolff, J.G. Software Engineering and the SP Theory of Intelligence; Technical Report; CognitionResearch.org: Menai Bridge, UK, 2017. [Google Scholar]
- Davis, E.; Marcus, G. Commonsense reasoning and commonsense knowledge in artificial intelligence. Commun. ACM 2015, 58, 92–103. [Google Scholar] [CrossRef]
- Wolff, J.G. Medical diagnosis as pattern recognition in a framework of information compression by multiple alignment, unification and search. Decis. Support Syst. 2006, 42, 608–625. [Google Scholar] [CrossRef] [Green Version]
- Wolff, J.G. How the SP System may promote sustainability in energy consumption in IT systems. Sustainability 2021, 13, 4565. [Google Scholar] [CrossRef]
- Wolff, J.G. The potential of the SP System in machine learning and data analysis for image processing. Big Data Cogn. Comput. 2021, 5, 7. [Google Scholar] [CrossRef]
- Attneave, F. Some informational aspects of visual perception. Psychol. Rev. 1954, 61, 183–193. [Google Scholar] [CrossRef]
- Attneave, F. Applications of Information Theory to Psychology; Holt, Rinehart and Winston: New York, NY, USA, 1959. [Google Scholar]
- Barlow, H.B. Sensory mechanisms, the reduction of redundancy, and intelligence. In The Mechanisation of thought Processes; Her Majesty’s Stationery Office: London, UK, 1959; pp. 535–559. [Google Scholar]
- Barlow, H.B. Trigger features, adaptation and economy of impulses. In Information Processes in the Nervous System; Leibovic, K.N., Ed.; Springer: New York, NY, USA, 1969; pp. 209–230. [Google Scholar]
- Chater, N. Reconciling simplicity and likelihood principles in perceptual organisation. Psychol. Rev. 1996, 103, 566–581. [Google Scholar] [CrossRef] [Green Version]
- Chater, N.; Vitányi, P. Simplicity: A unifying principle in cognitive science? Trends Cogn. Sci. 2003, 7, 19–22. [Google Scholar] [CrossRef] [Green Version]
- Hsu, A.S.; Chater, N.; Vitányi, P. Language learning from positive evidence, reconsidered: A simplicity-based approach. Top. Cogn. Sci. 2013, 5, 35–55. [Google Scholar] [CrossRef]
- Wolff, J.G. Information Compression via the Matching and Unification of Patterns (ICMUP) as a Foundation for AI; Technical Report; CognitionResearch.org: Menai Bridge, UK, 2021. [Google Scholar]
- Newell, A. You can’t play 20 questions with nature and win: Projective comments on the papers in this symposium. In Visual Information Processing; Chase, W.G., Ed.; Academic Press: New York, NY, USA, 1973; pp. 283–308. [Google Scholar]
- Newell, A. (ed.) Unified Theories of Cognition; Harvard University Press: Cambridge, MA, USA, 1990. [Google Scholar]
- Laird, J.E. The Soar Cognitive Architecture; The MIT Press: Cambridge, MA, USA, 2012; ISBN 13:978-0-262-12296-2. [Google Scholar]
- McCorduck, P. Machines Who Think: A Personal Inquiry into the History and Prospects of Artificial Intelligence, 2nd ed.; A. K. Peters Ltd.: Natick, MA, USA, 2004. [Google Scholar]









Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wolff, J.G. Twenty Significant Problems in AI Research, with Potential Solutions via the SP Theory of Intelligence and Its Realisation in the SP Computer Model. Foundations 2022, 2, 1045-1079. https://doi.org/10.3390/foundations2040070
Wolff JG. Twenty Significant Problems in AI Research, with Potential Solutions via the SP Theory of Intelligence and Its Realisation in the SP Computer Model. Foundations. 2022; 2(4):1045-1079. https://doi.org/10.3390/foundations2040070
Chicago/Turabian StyleWolff, J. Gerard. 2022. "Twenty Significant Problems in AI Research, with Potential Solutions via the SP Theory of Intelligence and Its Realisation in the SP Computer Model" Foundations 2, no. 4: 1045-1079. https://doi.org/10.3390/foundations2040070