1. Introduction
Data center deployments are ever growing because of the increase in IoT environments [
1]. In order to improve performance, it is convenient to optimize the allocation strategy of virtual resources [
2], with the target of minimizing the number of hops among nodes, which results in shorter migration times [
3] and decreases energy consumption [
4]. Diverse proposals in the literature have been made to reach efficiency in data centers, such as deploying an online mechanism design for demand response [
5], implementing a mobility-based strategy [
6] or using a specific query engine [
7]. Furthermore, holistic approaches have been proposed, such as a sustainability-based [
8], security-based [
9] or federated learning-based [
10].
It is to be noted that data centersin the cloud are composed ofmultiple nodes with greater processing and storage resources, as their scope is usually global in order for them to be accessed anywhere and anytime by many users [
11]. However, data centerson the edge have a restricted scope to the network where they are located, although they oftentimes employ cloud servers as backup solutions [
12]. This limited scope establishes a reduced number of users in an edge environment, thus requiring a small number of servers to deal with traffic flows [
13].Anyway, there are some general strategies to be followed when trying to optimize data center performance [
14], such as employing the right cooling system so as to dissipate heat faster, monitoring the environment by using data center infrastructure management (DCIM) solutions so as to facilitate decision making, taking advantage of automation to respond faster to management and maintenance tasks, maximizing flexibility and scalability to be able to adapt to dynamic environments and aligning budgets with business requirements to enhance innovation in the organization [
15].
Performance is also often related to energy consumption, as energy sources deliver power to data center components such as switchgears, generators, panels, uninterrupted power systems (UPS) and power distribution units (PDU) [
16]. In turn, that power goes to either ICT or non-ICT equipment, where the former refers to servers, storage or networking, whilst the latterrefers to cooling, lightning or security [
17].Regarding large data centers, performance is related to data distribution analysis to support big data analysis across geo-distributed data centers [
18].An appropriate replication scheme is necessary to store replicas whilst satisfying quality-of-service (QoS) requirements and storage capacity constraints [
19]. In those cases, measurements are made through profiling-based evaluation methods along with an approach based on multiview comparative workload trace analysis to properly assess efficiency [
20].
Hyperscale data centers (HDC) require huge demands in terms of scale and quantity related to data storage and processing [
21]. In this sense, network technologies employed in supercomputers and data centers have many common points [
22], leading to convergence at multiple layers, which may result in the emergence of smart networking solutions to accelerate such a convergence [
23]. Furthermore, high-density data centers are catching on due to the ever-growing demands of remote computation power, which is achieved by the use of ultra-high-performance hardware, such as NVRAM and GPUs [
24]. Traditional data centers have issues related to bandwidth bottlenecks and failures of critical links and critical switches; thus, high-density data centers need larger bandwidth and better fault tolerance [
25].
In order to properly utilize that bandwidth and robustness, different techniques need be employed, such as implementing multipath TCP for different flows to take different paths [
26] or the development of optimal row-based cooling systems [
27]. It is estimated that power distribution consumes around 15% of the total energy consumption, whilst cooling systems use around 45%, thus leaving the remaining approximately 40% to the IT equipment, which is shared between networking equipment (taking between 30% and 50%, depending on the load level) and computing servers (taking the rest of it) [
28]. In this sense, it is to be noted that some part of that energy is consumed in over-provisioning of resources to meet requirements during demand at peak times [
29]. Hence, it is crucial to undertake an appropriate network design to optimize the overall performance [
30].
The approach to achieve efficiencyin this paper is set on data center topology. Some strategies have been presented in the literature, such as employing deep learning tools [
31] or focusing on wireless environments [
32]. However, the strategy proposed herein is about network topology: that being the logical topologythat links together all nodes belonging toa data center [
33] and its influence in the overall performance [
34]. In this sense, a specific coefficient is going to be defined so as to combine the average number of hops to reach any destination withina data center architecture and the average number of links per node in that architecture, which is known as the degree in graph theory. This way, the former stands for a measure of performance, whereas the latter does it for a measure of simplicity, thus obtaining a metric that showsa trade-off between performance and simplicity, similar to the reasoning behind the metric proposed in [
35].
It is to be noted that the concept of performance taken in this paper is related to communications among the nodes within the data center, which is usually measured in time units. However, if it is considered a data center where all nodes are interconnected with ethernet cables that have the same length and the same speed, then performance may also be measured in distance units, as speed is the result of dividing distance by time, which accounts for distance as the result of multiplying speed by time. Hence, as speed is a constant value because all cable links have the same featuresin this case, then performance measured in distance units is directly proportional to that measured in time units, as the measure given in distance units equals the speed of the wire multiplied by the measure given in time units. In other words, performance in distance units equals to that quoted in time units multiplied by a constant of proportionality, which happens todepend on the wirespeed thus, there is a proportional relationship between both ways of expressing performance.
Furthermore, as all cabling has the same length, then it is possible to easily convert performance given in distance units into the minimum number of cables to be traversed from a source node all the way to a destination node by just dividing the former by the length of each cable given in distance units. This way, the measure of performance in distance units may also be exposed as the number of links among nodes, which is expressed in natural numbers as it is an adimensional quantity. Therefore, this is the reason why the average number of hops between any pair of nodes is considered as a measure of performance of a certain data center topology in this paper. Additionally, in order to clarify concepts in this context, the number of hops between a given pair of nodes is also called the distance between them both, with the result being that the shorter the distance, the better the performance. In other words, the shorter the average number of hops between any pair of nodes, the better the performance of the data center network topology interconnecting those nodes.
With respect to the concept of simplicity, it has been considered as a measurement of the ease of a topology to manage the routing and forwarding processes, as the smaller the number of links in a device, the simpler the algorithm to handle traffic is, as there are fewer possible cases to be evaluated. Hence, this measurement has positive implications for lower values, such as that a small value results in faster regular operations and maintenance (O&M) due to the relative straightforwardness of the algorithm being employed. Therefore, this is the reason why the average number of links per node is considered as a measure of simplicity of a certain data center topology in this paper.
Consequently, the metrics applied to performance of a given data center topology in the context of this paper are measured as the average number of hops between any pair of nodes within that topology. In this sense, it is to be considered that the lower the value, the better the performance, as reaching a particular destination node from a given source node will be shorter in average, meaning that pairs of nodes are a smaller number of hops away on average. Likewise, the metrics applied to simplicity of a particular data center architecture in the context of this manuscript are measured as the average number of links per device, either switches or nodes, hence giving consideration to all devices within a given topology. In this sense, it is to be taken into account that the lower the value, the simpler the topology; thus, traffic forwarding will be carried out by a shorter algorithm, which implies faster processing times.
This way, the units to measure performance in this context are adimensional, as the average number of hops between nodes does not imply any physical measurement units, such as time in seconds or length in meters. Analogously, the units to measure simplicity in this context are also adimensional, as the average number of links per device does not involve any physical measurement units at all. Therefore, the metrics forthe coefficient proposed to obtain balance between performance and simplicity will also be adimensional, as the metrics of both its parameters are adimensional as well. Furthermore, as both parameters display better results with lower values, it yields that the lower the coefficient value, the better. On the other hand, the values obtained for the coefficient regarding many of the most commonly used topologies in data center topologies will be calculated and compared in further sections.
The main merit of this approach of crafting this coefficient is to have an easy way to obtain an approximation of performance for a network topology within a data center, as both factors to calculate it are pretty straightforward to obtain. This coefficient does not need to be seen as a key parameter, but it is just another parameter that may be used as a sort of tie-breaker when other variables such as throughput or security offer different solutions. With respect to the demerits, this coefficient does benefit non-redundant topologies over redundant ones, as the lower the number of links, the better is the obtained outcome. Hence, the condition of redundancy must be imposed prior to using this coefficient.
Regarding the motivation of this paper dedicated to network topology data centers, the following considerations have been made:
Define an easy metric based on arithmetic calculations to be applied to classify network topologies of data centers.
Craft such a metric as a combination of performance and simplicity of a network topology data center.
Impose redundant layouts as a restriction to find out that metric so that it does not apply to non-redundant designs.
Provide that metric as a complementary measurement to the most common parameters typically found in data centers, such as throughput or latency.
Create a coefficient related to data centers that is not focused on energy efficiency, as is the case for the existing coefficients in this field.
The organization of the rest of the paper is as follows:
Section 2 introduces some topology designs fora data center. Next,
Section 3 exposes some related work about network topologies for data centers. Then,
Section 4 presents the coefficient proposed for these designs. After that,
Section 5 develops some typical use cases. Afterwards,
Section 6 undertakes some discussion about the results obtained. Eventually,
Section 7 draws some final conclusions.
3. Related Work
After having presented some of the main network topologies being used in data centers, it is time to report some of the related work among them. There are some papers comparing the main features of the most typically used topologies. For instance, Couto et al. [
56] undertake an analysis of reliability and survivability of data center network topologies where Fat Tree, BCube and DCell are compared, which concludes that BCube is the most robust to link failures, whilst DCell isthe most robust regarding switch failures, and that robustness is related to the number of interfaces per node.
Negara et al. [
57] compare BCube and DCell, obtaining better speed in data transmission for the latter, although the former has better security and integrity because it is able to forward data completely without any failures. Cortes et al. [
58] confront Fat Tree and BCube, with the outcome indicating that the latter obtains better results than the former.Al Makhlafi et al. [
59] state that data center networks may be classified into two broad groups, such as switch-centric and server-centric, where switches are mainly responsible for routing and networking in the former, whilst servers aremainly accountable in the latter, which allows the use of commodity switches [
60]. Examples of the former are fat tree and leaf and spine, whereas instances of the latter are FiConn, DCell and BCube.
Yao et al. [
61] carry out a comparative analysis among several well-known data center network topologies, such as Multi-tiered, Fat Tree, Flattened Butterfly, Camcube and BCube, regarding a variety of metrics, such as scalability, path diversity, hop count, throughput and cost, finding that different topologies scale differently for various metrics and concluding that designers must consider maximizing certain features whilst minimizing cost and power. Touihri et al. [
62] propose a camcube design (
k-ary
n-cube) following the SDN paradigm such that the control plane is hosted in an SDN controller and including QoS into the decision-making process. After running several simulations using Mininet software, the results obtained are better than those attained with the shortest-path approach regarding packet error rate and latency.
Daryin et al. [
63] undertake a comparison among diverse topologies for InfiniBand networks, such as tori, hypercube, Dragonfly, Flattened Butterfly and Slim Fly, and their results seem interesting in the field of data center networks. After having executed the necessary simulations, they conclude that the best outcome is obtained by Flattened Butterfly and a combination of this with Slim Fly.Rao et al. [
64] carry out a comparison among different topologies for Network-on-Chip (NoC), such as Dragon Fly, Flattened Butterfly, Torus topology and Mesh topology; their results may be extrapolated to data center networks. Those comparisons were made with diverse figures of trade-offs, such as packet latency, network latency, throughput change and hop average; the authors concluded that Torus topology is the most efficient one for being adaptive in nature as well as for having less latency and time complexity.
Azizi et al. [
65] compare a novel DCCube design with fat tree, Flattened Butterfly, BCube and SWCube, where the former achieves both higher performance and lower cost consideringthe number of switches, server NICs, server CPUs and cabling. Furthermore, Aguirre et al. [
66] propose a greedy forwarding strategy that is independent of the network topology in place and obtains acceptable results, whilst Mohamed et al. [
67] present average networking equipment power consumption for different topologies, showing that fat tree, leaf and spine, BCube and DCell obtain the highest outcome.In terms of creating a specific coefficient to measure performance in a data center, most efforts have been focused on energy efficiency. For instance, Sego et al. [
68] come up with a metric called Data Center Energy Productivity (DCeP) as the ratio of useful work produced to the energy consumed to get that work done. Likewise, Santos et al. [
69] propose a metric called Perfect Design Data Center (PDD) as a redefinition of Energy Usage Effectiveness Design (EUED), which reflects the efficiency in the power consumption.
Basically all the papers devoted to efficiency in data centers are focused on evaluation metrics about energy efficiency. In this sense, Shao et al. [
70] make a review of energy efficiency evaluation metrics, combining energy conservation and eco-design, whilst Levy et al. [
71] examine performance as a combination of productivity, efficiency, sustainability and operations. Kumar et al. [
72] establish power usage effectiveness (PUE) as the metric to measure efficiency and study different machine learning techniques so as to make accurate predictions. Furthermore, Brocklehurs [
73] proposes other usage effectiveness measurements, such as carbon (CUE) and water (WUE), along with a coefficient of performance (CoP) defined as the ratio of useful cooling provided to the energy input, where efficiency grows as the coefficient rises. Eventually, Reddy et al. [
74] expose a systematic overview of data center metrics divided into categories such as energy efficiency, cooling, greenness, performance, thermal and air management, network, storage, security and financial impact. Among these metrics, a green energy coefficient (GEC) is defined as a percentage represented by green energy compared to the total energy consumed.
In summary, this section has been devoted to comment on relevant related work, where different papers have been presentedand diverse comparisons have been carried out among the most common data center network topologies, such as fat tree, leaf and spine, k-ary n-cube, BCube, DCell, FiConn, Flattened Butterfly, DragonFly and SlimFly, to quote the main ones. In those papers, a lot of metrics have been utilized so as to rate the different topologies by means of undertaking various tests, such as network size, bisection bandwidth, cost, throughput, latency, load balancing, mean time to failure or resilience to failure. However, the contribution of this paper is not to repeat those tests but to craft a new coefficient to obtain balance between performance and simplicity as defined in the terms exposed in the introduction. The goal herein is to be able to obtain a valuable figure in order to help the decision-making process when it comes to selecting a certain data center network architecture among a range of topologies, where each one may present different features, and that will be the target in the rest of the paper.
4. Coefficient Proposed to Obtain Balance between Performance and Simplicity
The coefficient proposed to measure efficiency of the different network topologies proposed for data centers needs to take into account both performance and simplicity of use along with maintenance in a way to achieve a trade-off between them. Regarding the former, it is measured by means of the average distance among nodes, whereas the latter it is stated as the average number of links per node (its degree) for graph-like designs, or otherwise, the average number of links per device (considering both nodes and switches) for tree-like designs.
Anyway, both averages should be as small as possible in order to obtain both performance and simplicity, such that the smaller the coefficient, the better. Regarding the average distance among nodes, it is going to be measured as the average number of hops between all pairs of nodes and denoted as . With respect to the average number of links per device, it is going to be measured as stated above and described as .
Putting everything together, the coefficient proposed is going to be obtained by multiplying both averages, namely,
. In this sense, the lower the result obtained, the better the combination of both factors; hence, better balance between performance and simplicity will be attained. That is why the coefficient is branded
, which is the Greek letter used in physics and engineering for efficiency. Therefore, it may be said that (
1) defines
.
The main motivation of this paper is to calculate a coefficient involving a compromise between performance and simplicity—defined in the terms exposed in the introduction—in a way that such a value may help decide which data center network topology is more suitable, thus acting as a sort of tie-breaker to select among diverse interesting options. Therefore, this coefficient is just another tool for making the decision as to which data center is more convenient among diverse options along with other tests related to throughput, latency, cost or robustness.
As a practical-use case, let us focus on the situation exposed in the first two paragraphs of
Section 3, which is devoted to related work. In the first one, it is stated that after the analysis carried out on reliability and survivability, BCube is the most robust design regarding link failures, whereas DCell isthe most robust regarding switch failures. Likewise, in the second one, it is claimed that after the tests were undertaken, BCube provided better security and data integrity, whilst DCellprovided better speed in data transmission. Hence, the coefficient proposed may act as a tie-breaker for the selection of the data center network architecture, as it presents a compromise between performance and simplicity for each of the possible options available.
5. Developing Some Typical Use Cases
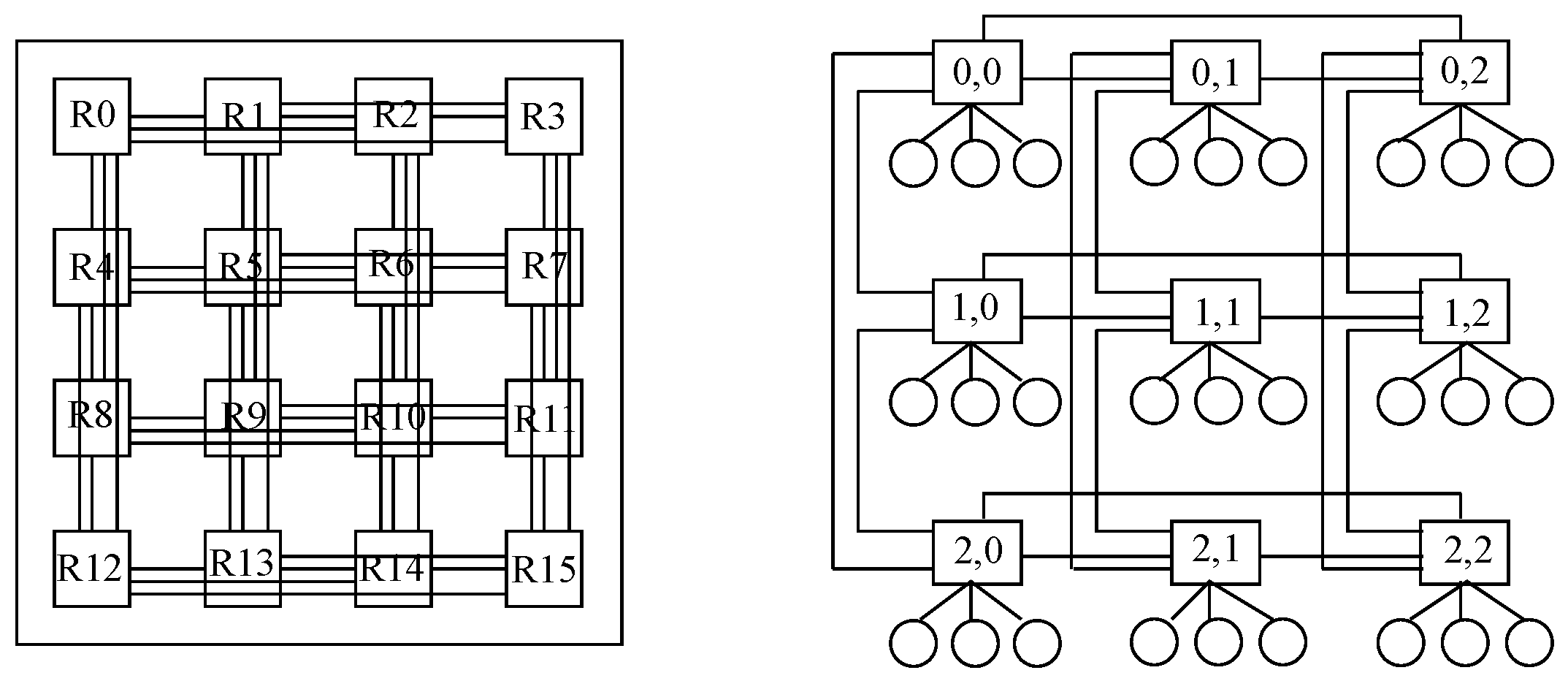
After having presented some instances of network topologies fit for data centers along with the definition of coefficient , some typical use cases are going to be developed, taking into account that the number of nodes that will be up and runningis considered to be small to medium. In order to cope with this, a limit of 16 nodes per topology is going to be imposed, although smaller numbers are going to be exposed as well. Basically, a systematic approach by means of powers of two is going to be described in the following subsections. Additionally, another one is going to be devoted to fit those designs not matching any power of two, and eventually, a further one is dedicated to some other commonly used network topologies in larger data centers.
Regarding the calculations for all topologies, the average number of hops has been undertaken by first selecting a given end host and, in turn, adding up the number of hops to reach all its peers within the topology and dividing into the count of such peers. Otherwise, the average number of links has been carried out by adding up the links of each device, no matter if they are end hosts or switches, and dividing into the count of all those devices.
It is to be reminded that data center network topologies need to avoid single points of failure in critical points; thus, redundancy is a must. From that point of view, single hub and spoke topologies have not been taken into account, whilst redundant hub and spoke topologies have been included into this study. Further, it happens that the definition of this coefficient gives advantage to topologies with fewer average links, which may benefit non-redundant topologies against redundant ones. Hence, in order to avoid this situation, this coefficient was restricted only to redundant topologies. On the other hand, topologies with more than two redundant links are penalized against topologies with just two of such links, although those cases are not considered herein, as the most common layout is to have just two redundant devices.
5.1. One Node within the Topology
This is a trivial case as the number of nodes is
. Then, there is just one single node in the topology; thus, obviously there are no alternative topology designs for this condition, neither for tree-like designs nor for graph-like ones. Hence, the average distance among nodes and the average number of links per node are both zero. Therefore, as
and
, then
for both types of topologies, as stated in
Table 1.
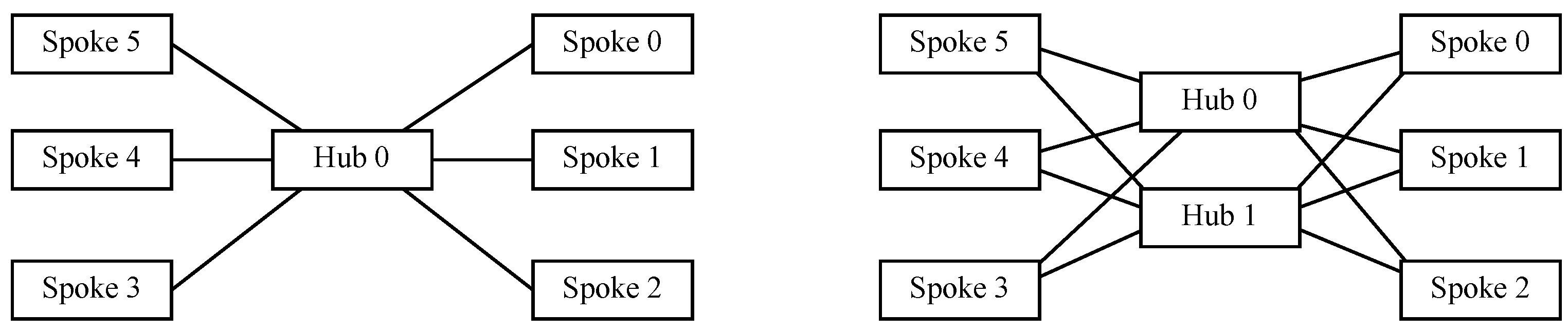
5.2. Two Nodes within the Topology
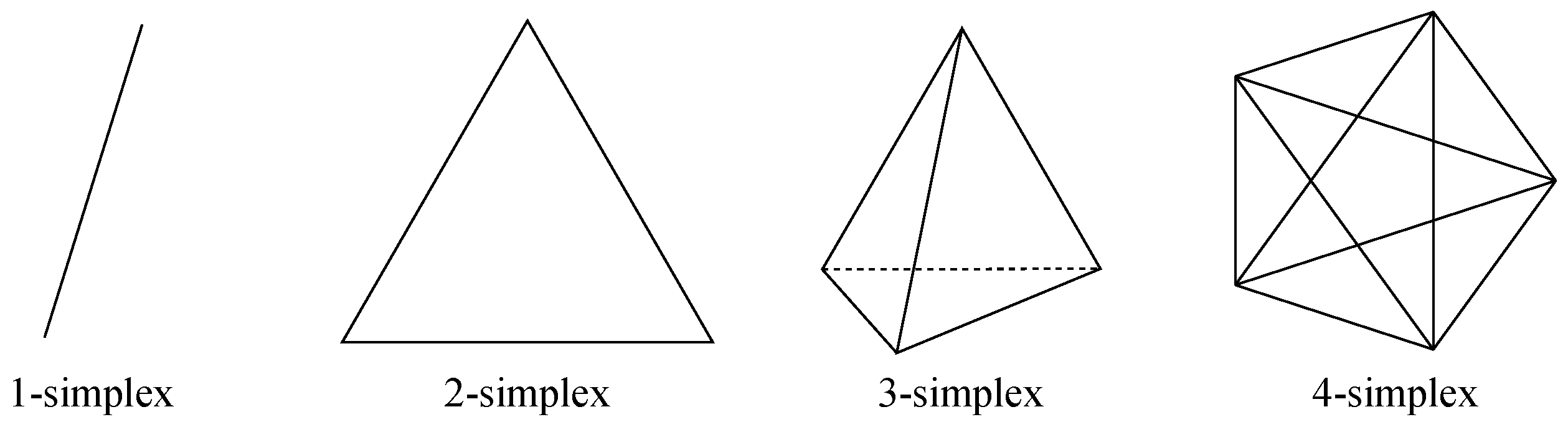
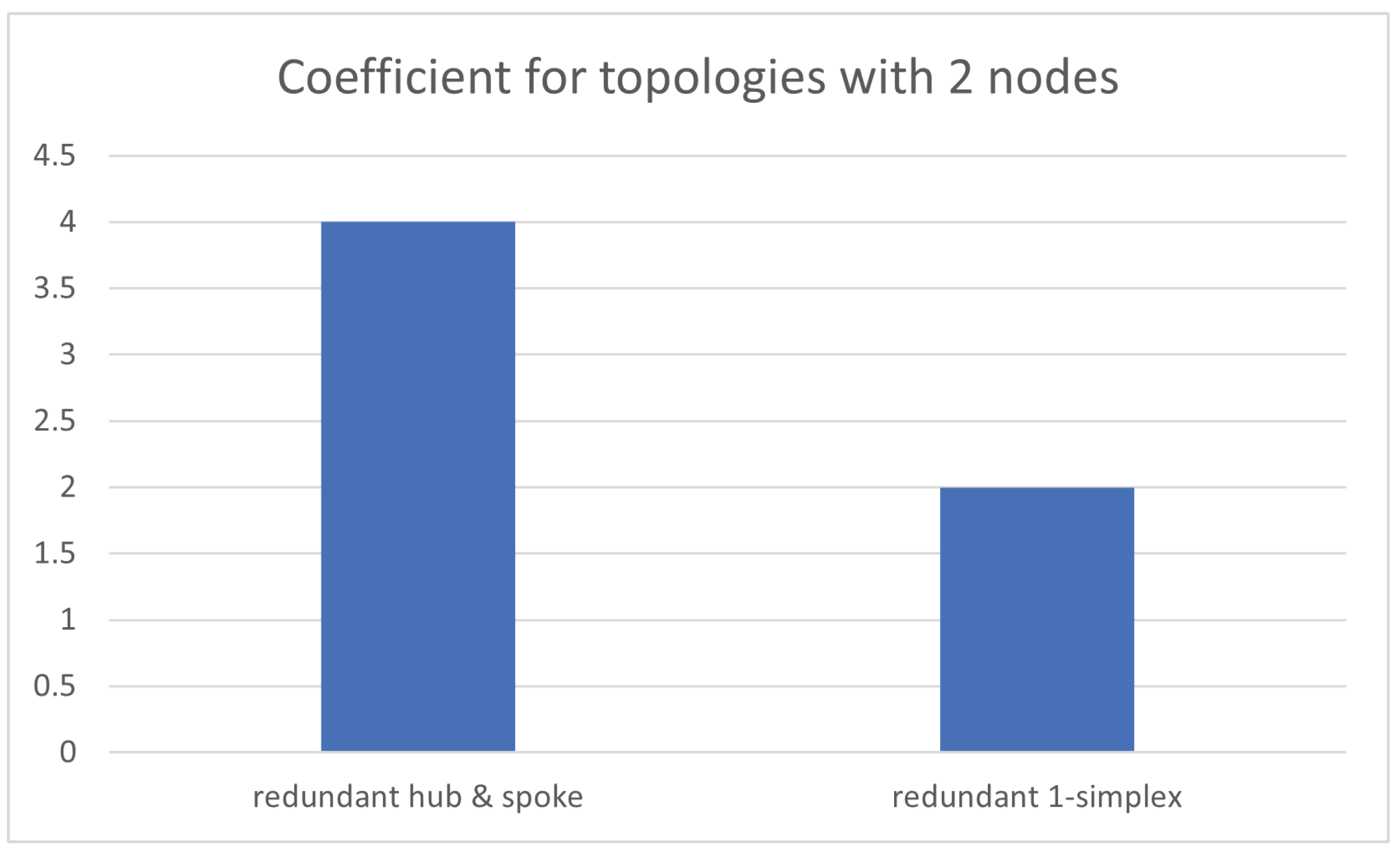
In this case, the number of nodes is . This is straightforward, as the only tree-like option is hub and spoke; thus, both nodes act as spokes which are linked together through a hub, whereas the only graph-like option is a direct link among nodes, provided no multiple links are considered. However, as redundancy needs to be considered when dealing with Data Center Network (DCN) architectures, then a redundant hub and spoke will be considered for the tree-like case, whereas a double direct linkbetween both nodes will be done for the graph-like case, which accounts for a redundant 1-simplex.
Hence, on the one hand, the average distance among nodes forredundant hub and spoke is
because two hops are needed to go from one node to the other, whilst it is
inredundant 1-simplex because just one hop is necessary to move to the other node. On the other hand, the average number of links for tree-like environments is two for both hubs and both spokes so as to build up the redundant hub and spoke, thus accounting for
, whereas it is also
for graph-like environments, as each node hastwo redundant links towards the other one. Therefore, for the tree-like design,
, whilst for the graph-like design,
, as stated in
Table 2.
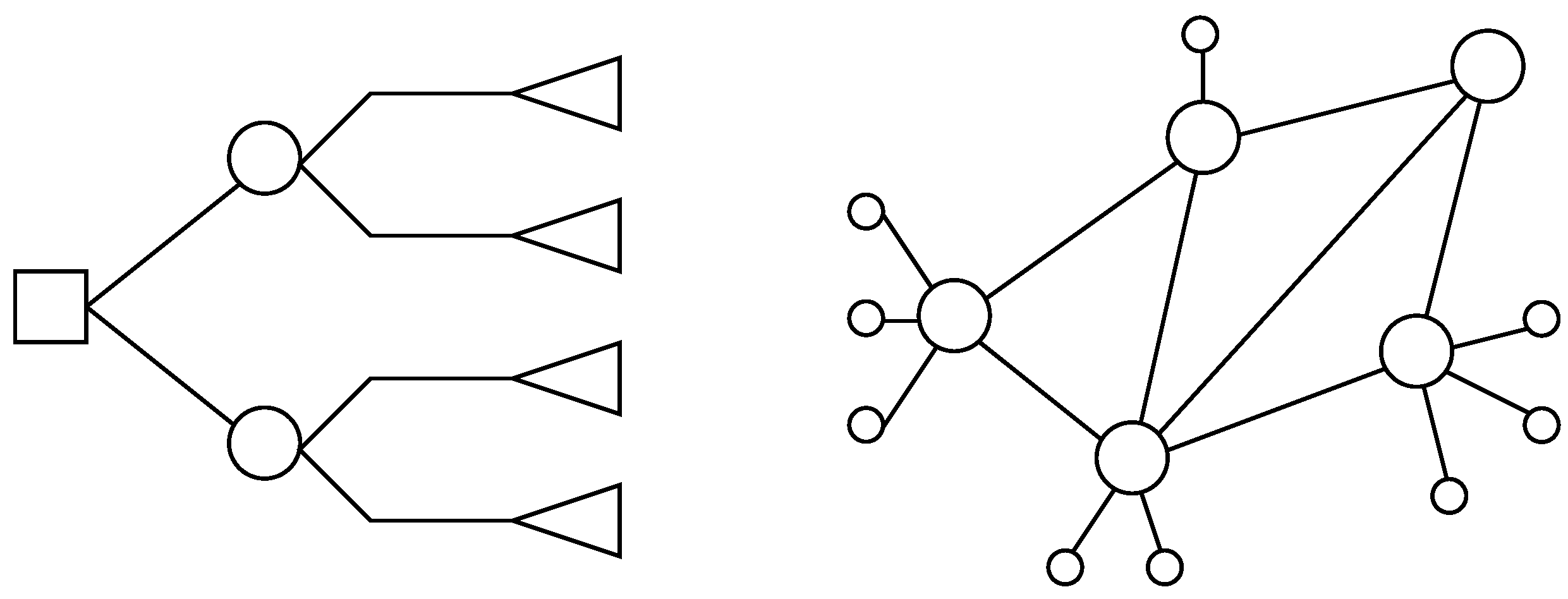
5.3. Four Nodes within the Topology
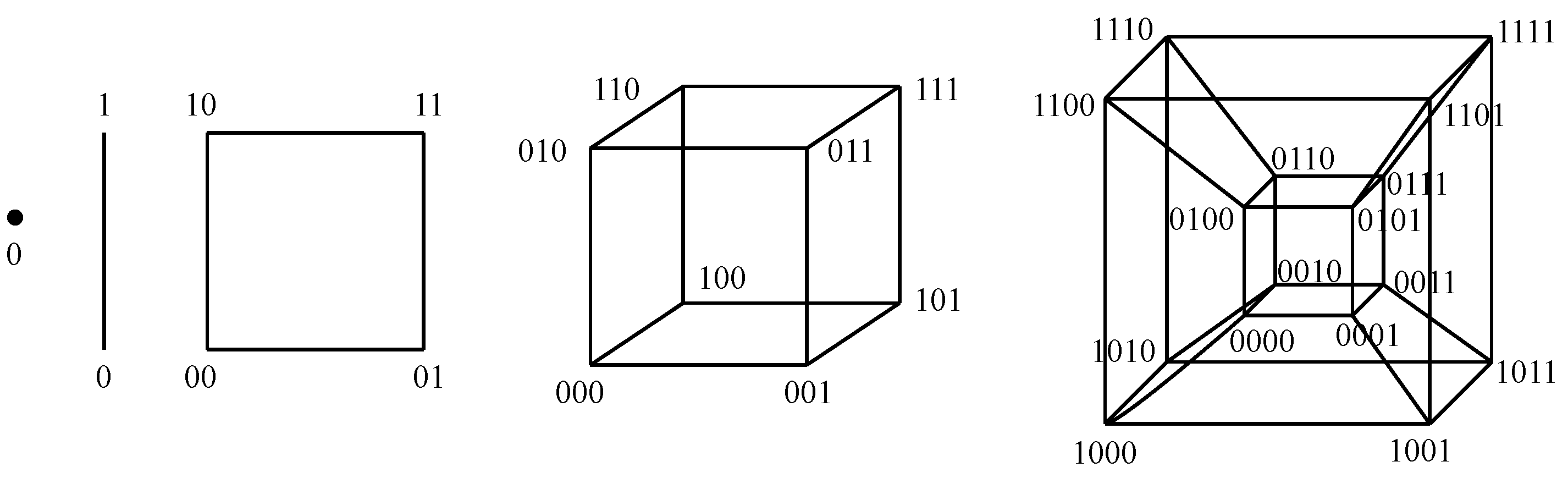
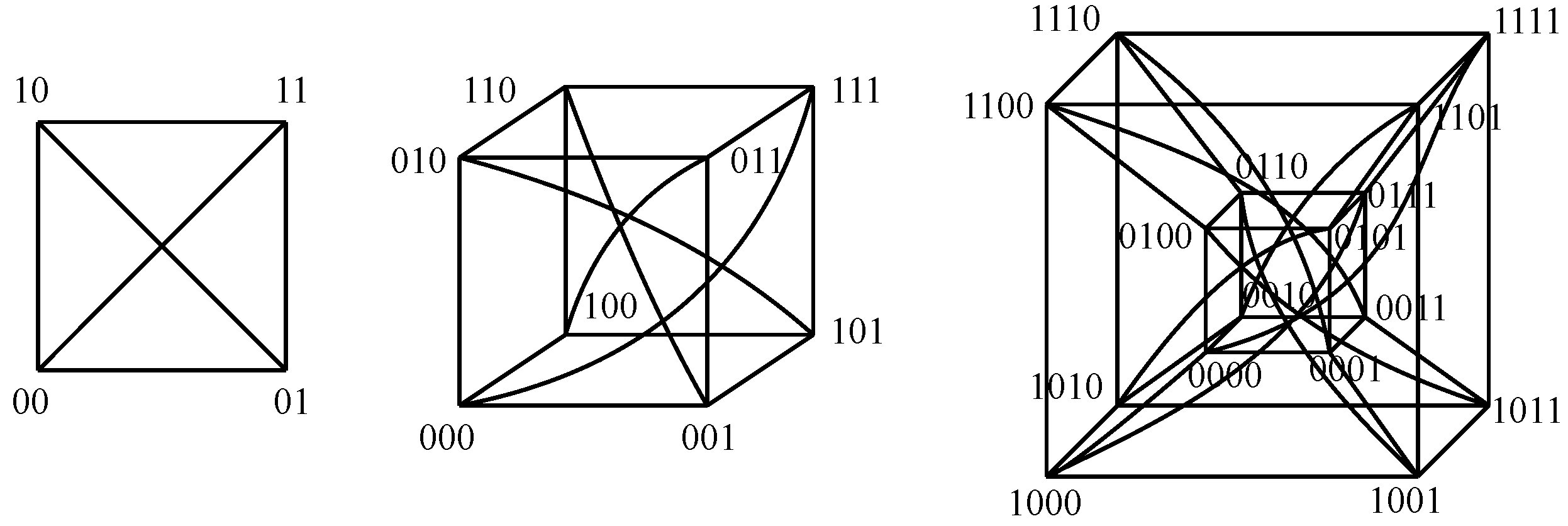
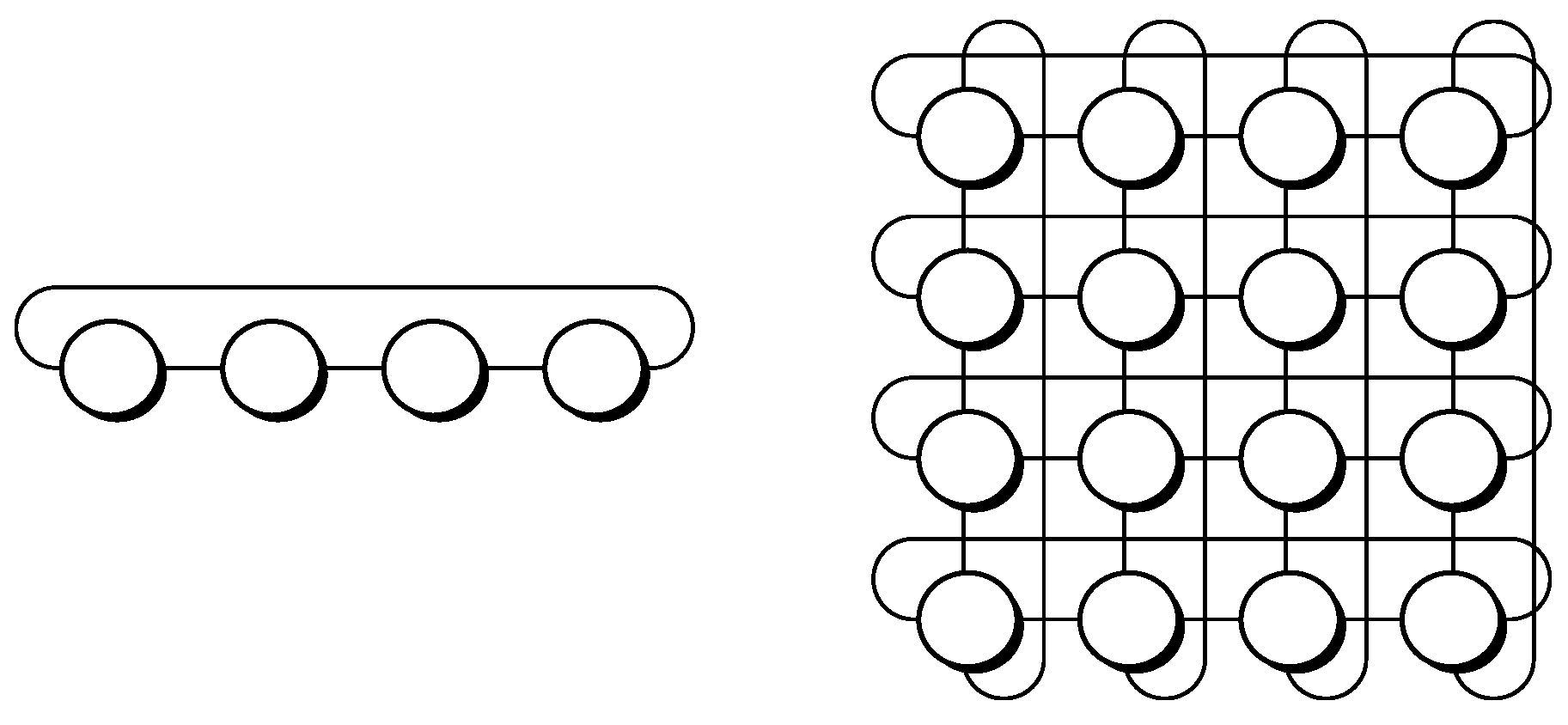
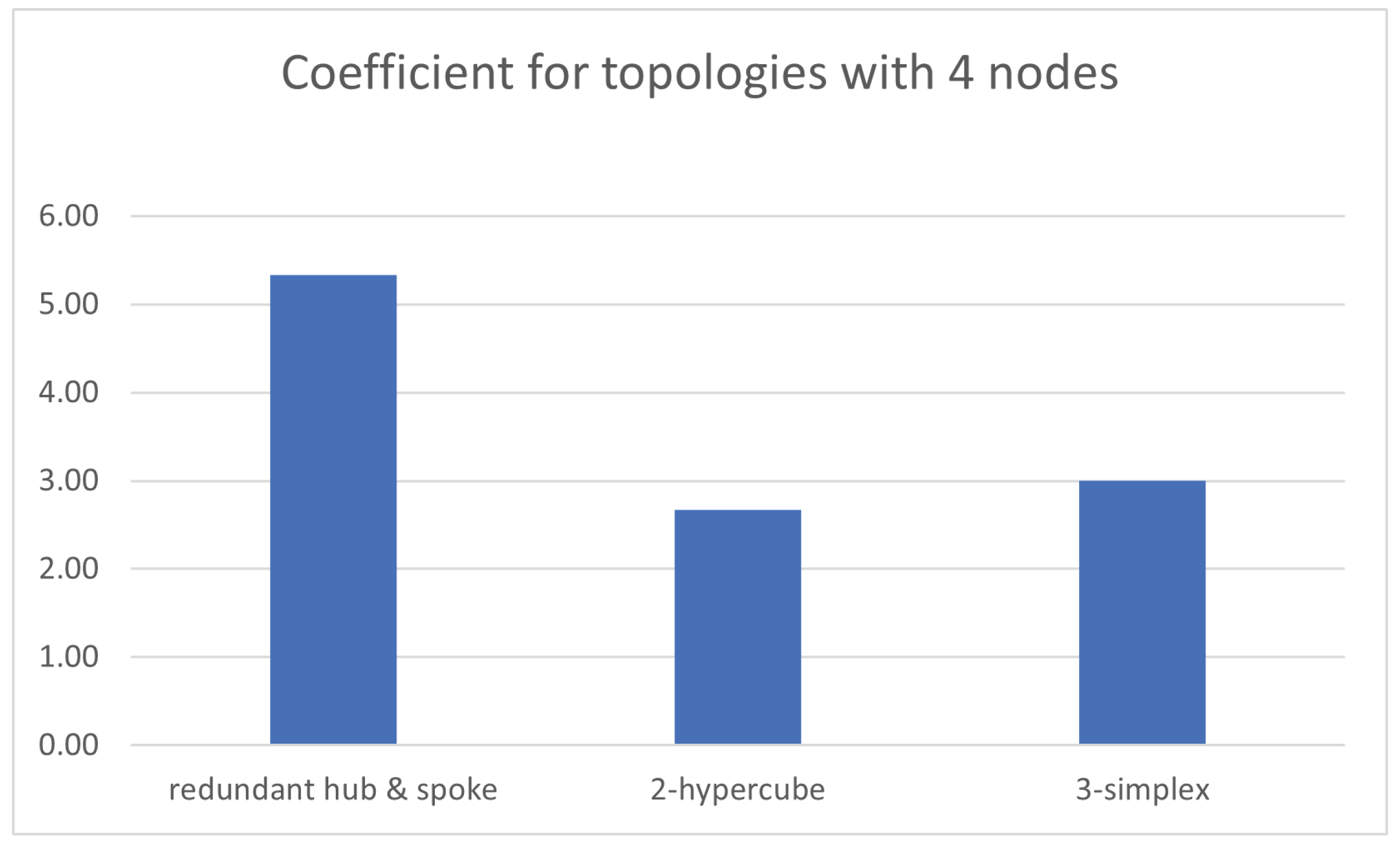
Now, the number of nodes is
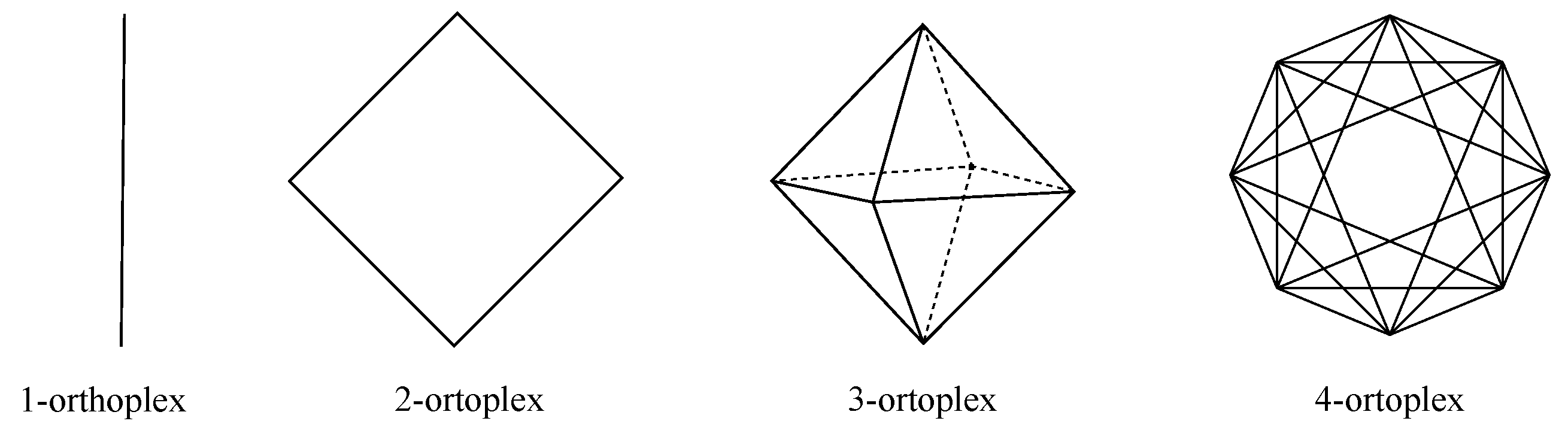
. Regarding tree-like options, it is possible to deploy a redundant hub and spoke, which is equivalent to a leaf and spine with four leaves and two spines. With respect to graph-like choices, it is possible to deploy a square, which accounts for a 2-hypercube, that being equivalent toboth a 2-orthoplex and a 2-ary 2-cube, or otherwise, to deploy a full-mesh, which represents a 3-simplex, that being equivalent toboth a folded 2-hypercube and a Hamming graph
.
Table 3 exhibits the relevant values of
for each instance proposed.
Focusing on tree-like designs, the value for redundant hub and spoke is two hops among any pair of nodes, whilst it results in as there are four spokes with two links (one connection to each hub) and two hubs with four links each (one connection to each spoke).
On the other hand, centering on graph-like designs, 2-hypercube presents two nodes at one hop and another node at two hops, resulting in and as each node has two links, whereas 3-simplex results in because all nodes are only one hop away, and as all nodes have just three links.
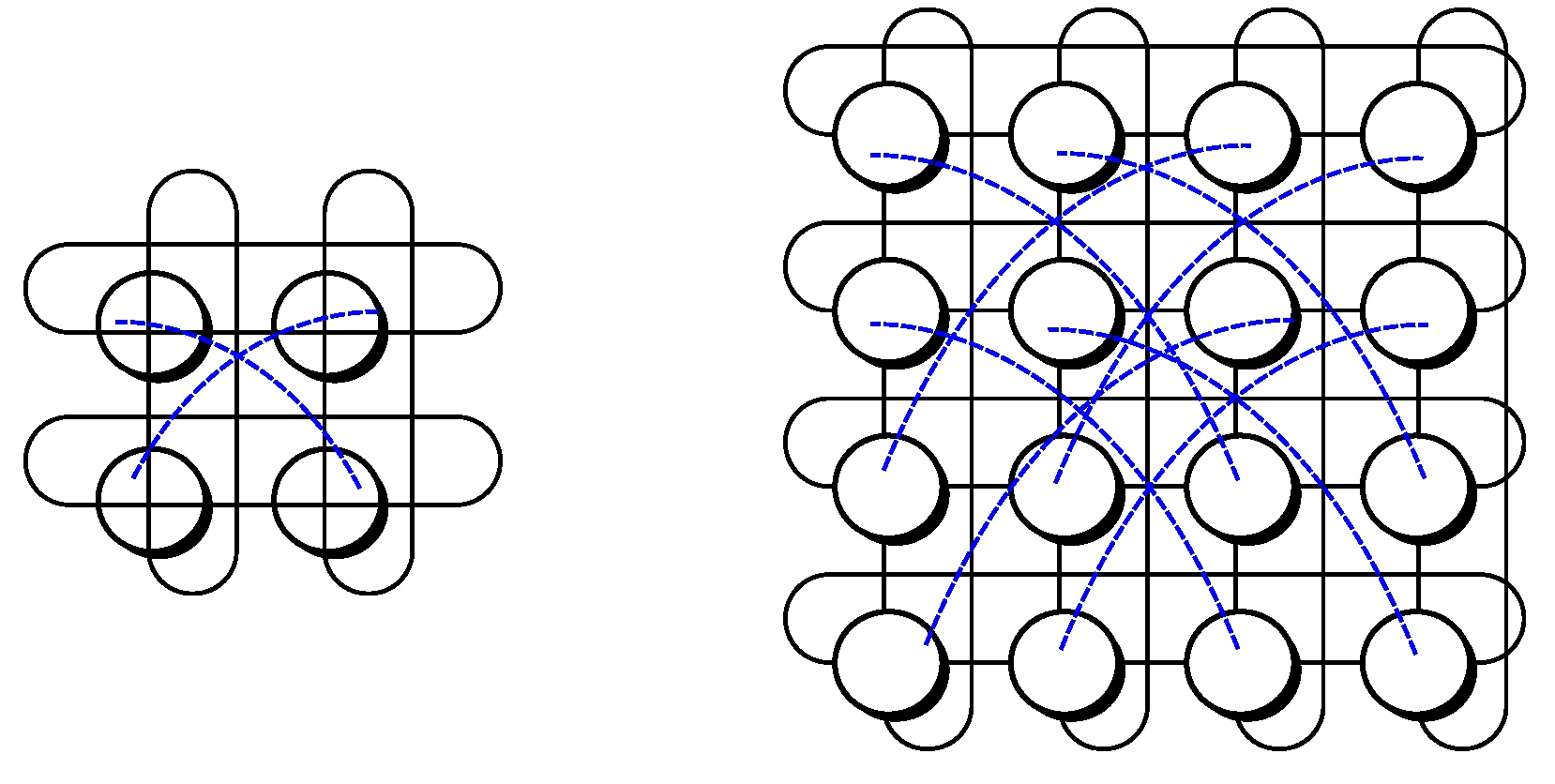
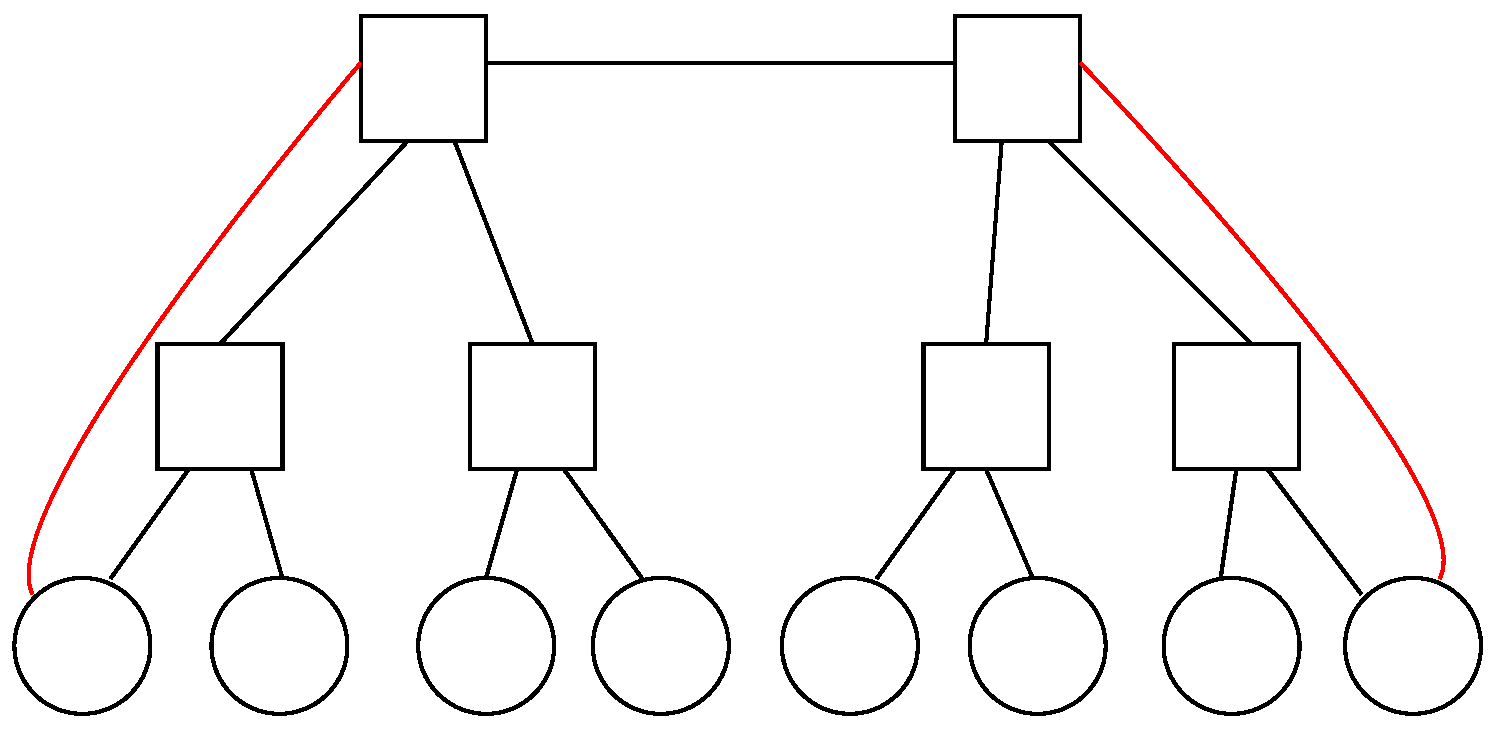
5.4. Eight Nodes within the Topology
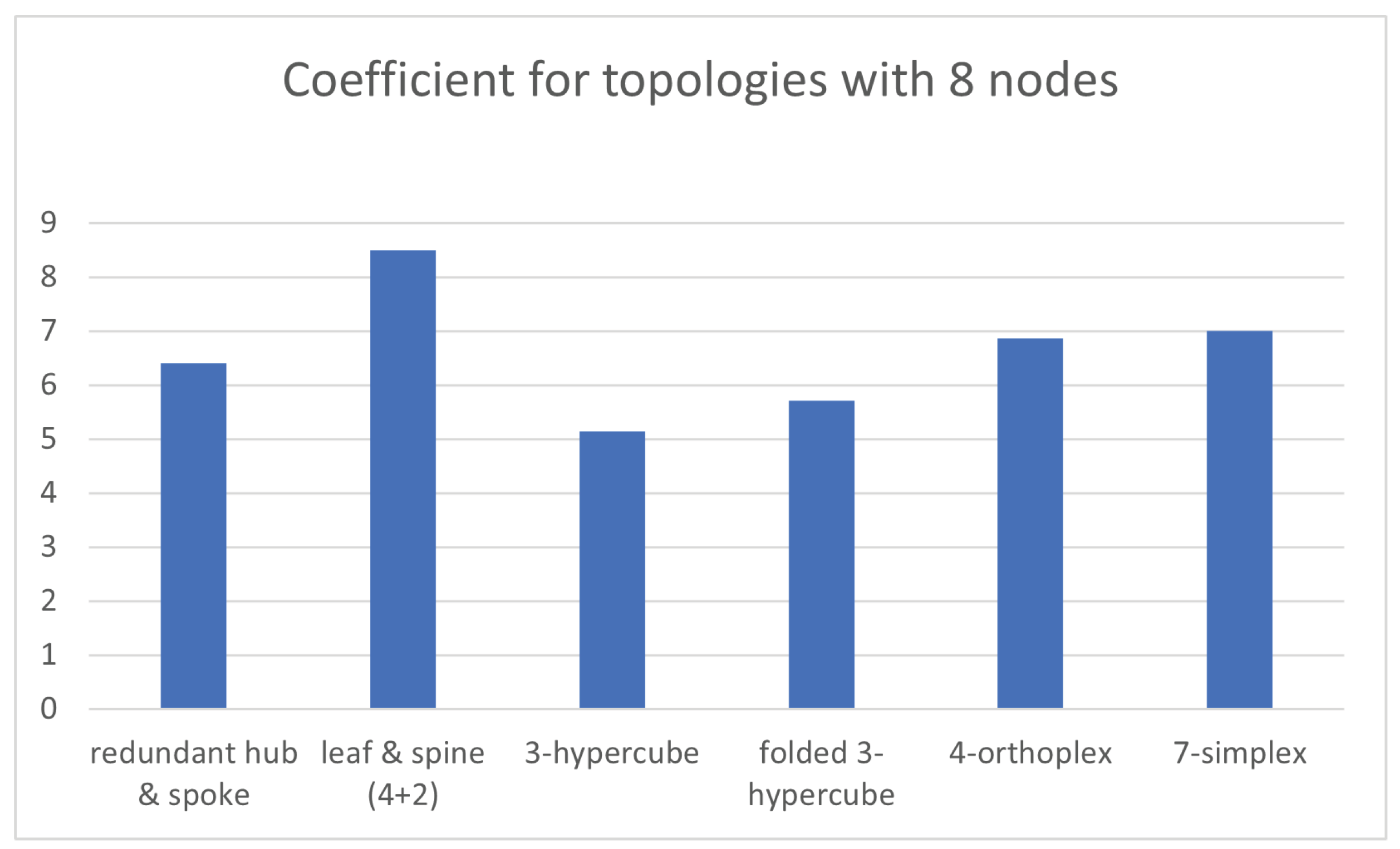
At this point, the number of nodes is
. Regarding tree-like choices, it is possible to deploy a redundant hub and spoke and a leaf and spine with two spines and four leaves, where two hostsare connected to each of them. Otherwise, with respect to graph-like alternatives, it is possible to go for a 3-hypercube, a folded 3-hypercube, a 4-orthoplex and a 7-simplex.
Table 4 exhibits the relevant values of
for those instances.
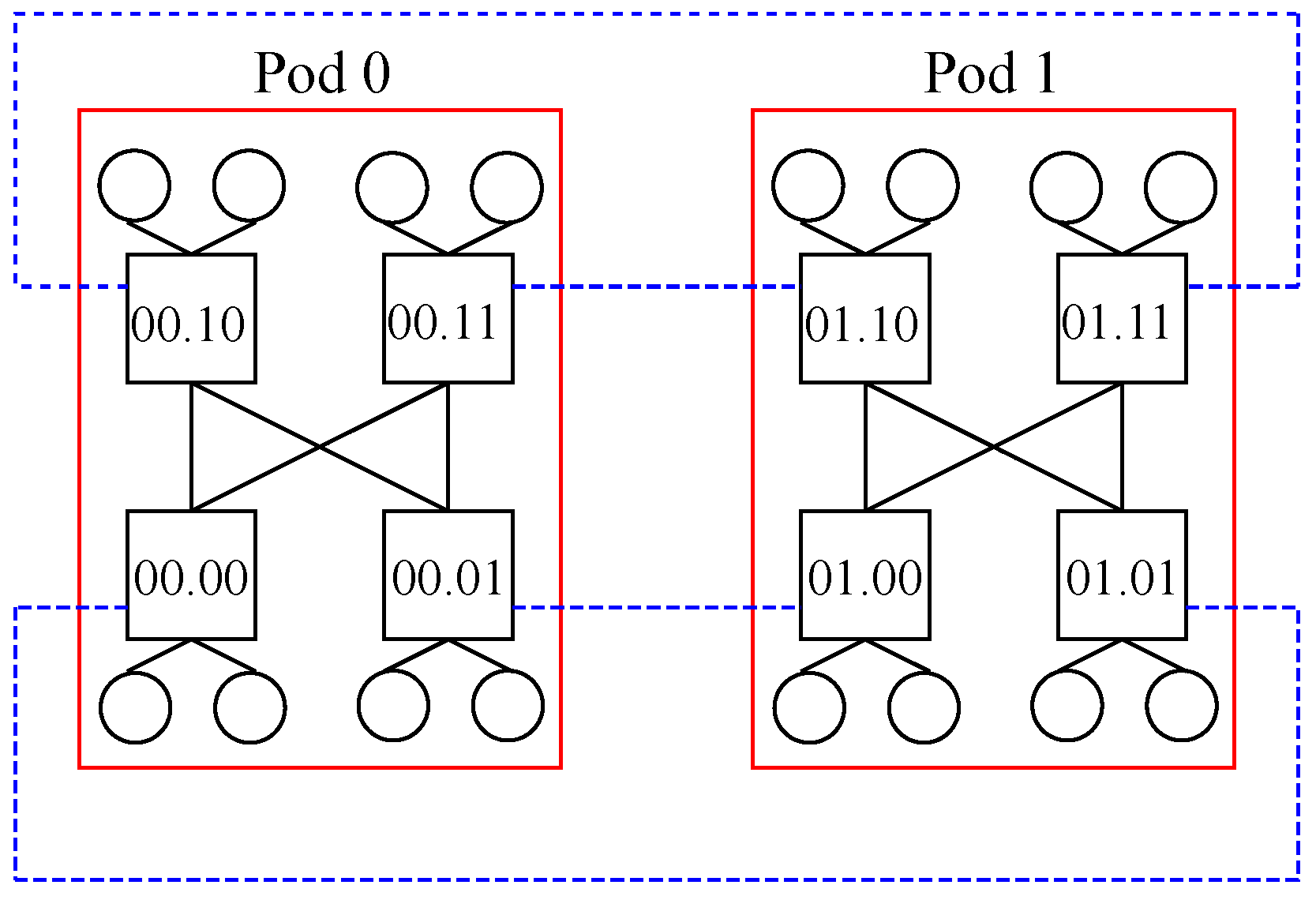
With regards to the tree-like designs, redundant hub and spoke presents a steady value of as all nodes are two hops away, whilst leaf and spine has an , because taking a given node, there is another node hanging on the same leaf and the other six nodes hang on different leaves. On the other hand, it results in for the former, as the two hubs are connected to the eight spokes and the other way around, whereas ityields for the latter. This outcome is because the eight nodes are connected to their corresponding leaves upwards, whilst each of the four leaves are connected to two nodes downwards and two spines upwards and each of the two spines are connected to all four leaves downwards.
Furthermore, the selected graph-like designs present the following values: and for the first one, and for the second one, and for the third one, whereas and for the fourth one.
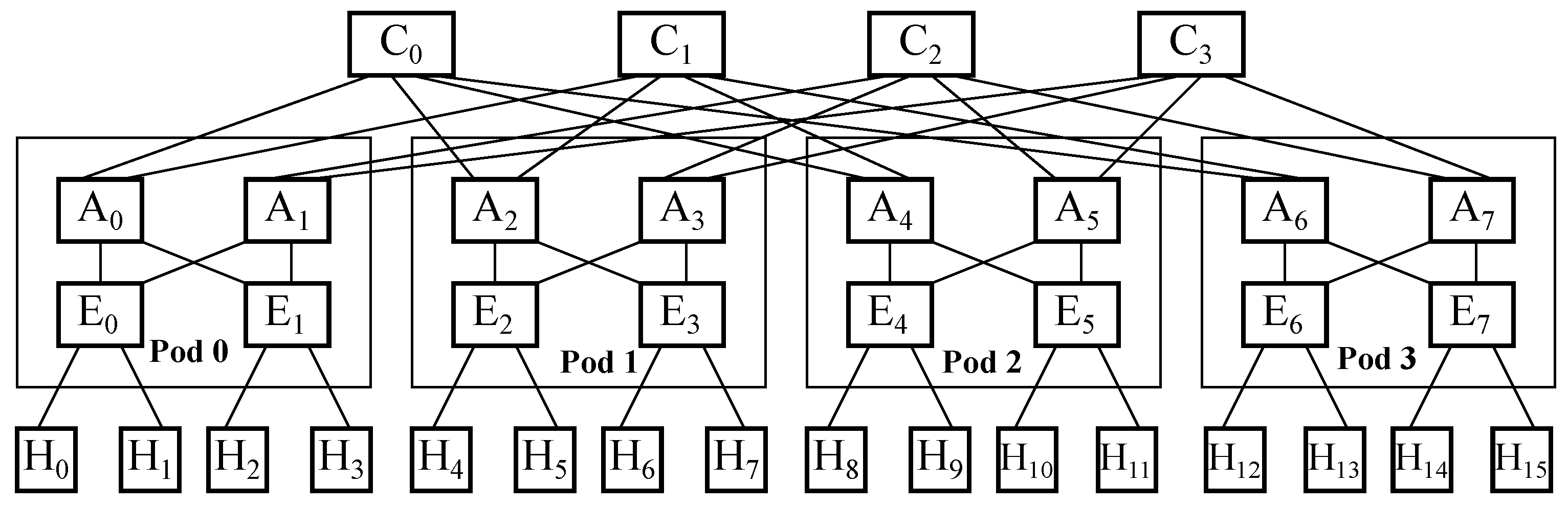
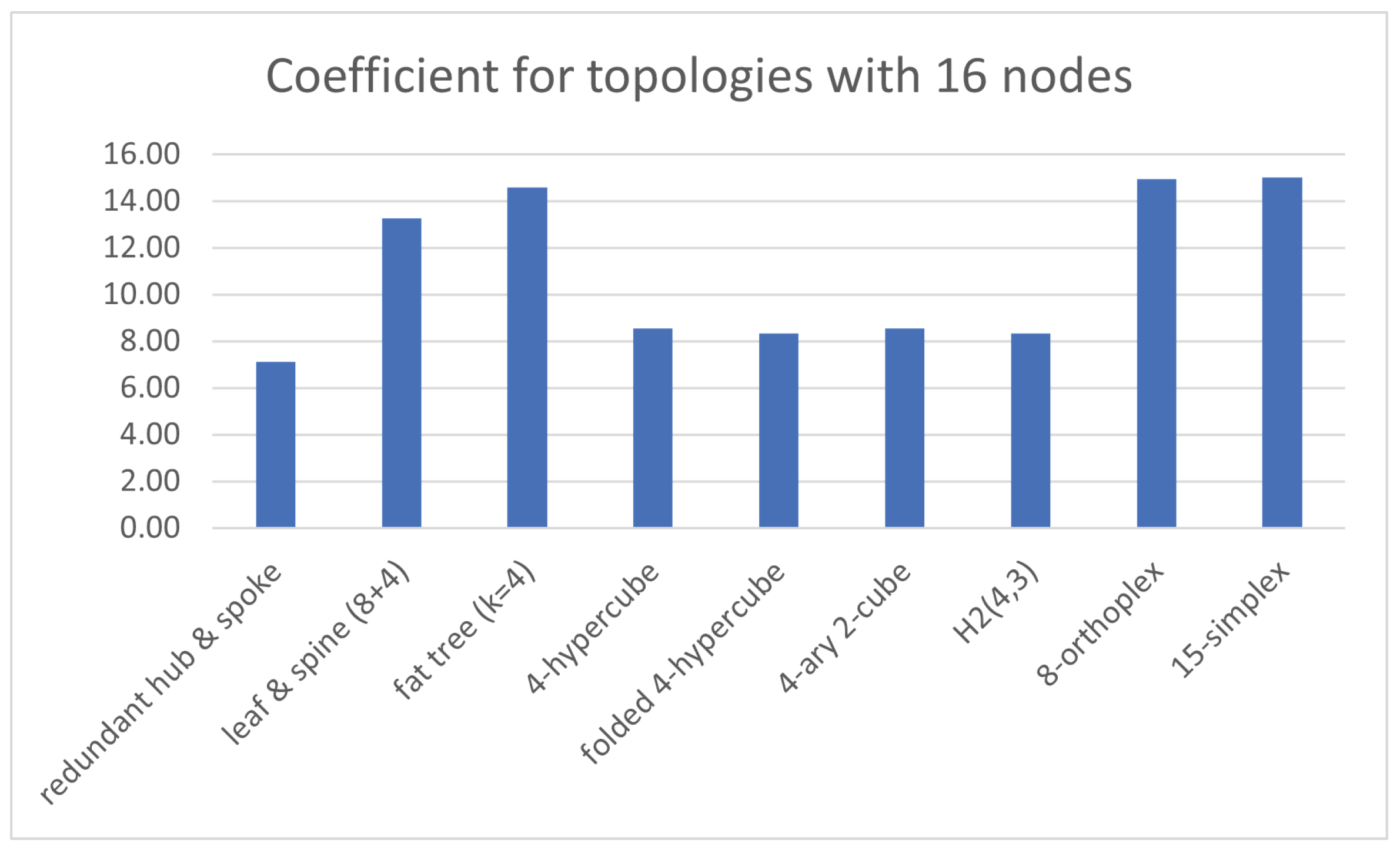
5.5. Sixteen Nodes within the Topology
The following case exhibits a number of nodes
. With respect to tree-like options, it is possible to deploy a redundant hub and spoke, a leaf and spine with four spines and eight leaves, where two hostsare connected to each of them, and even a fat tree with
,which accounts for four core switches, eight aggregation switches and eight edge switches, where two hostsare connected to each one of those. Otherwise, regarding graph-like alternatives, it is possible to go for a 4-hypercube, a folded 4-hypercube, a 4-ary 4-cube, a Hamming graph
, an 8-orthoplex and a 15-simplex.
Table 5 exhibits the relevant values of
for all those instances.
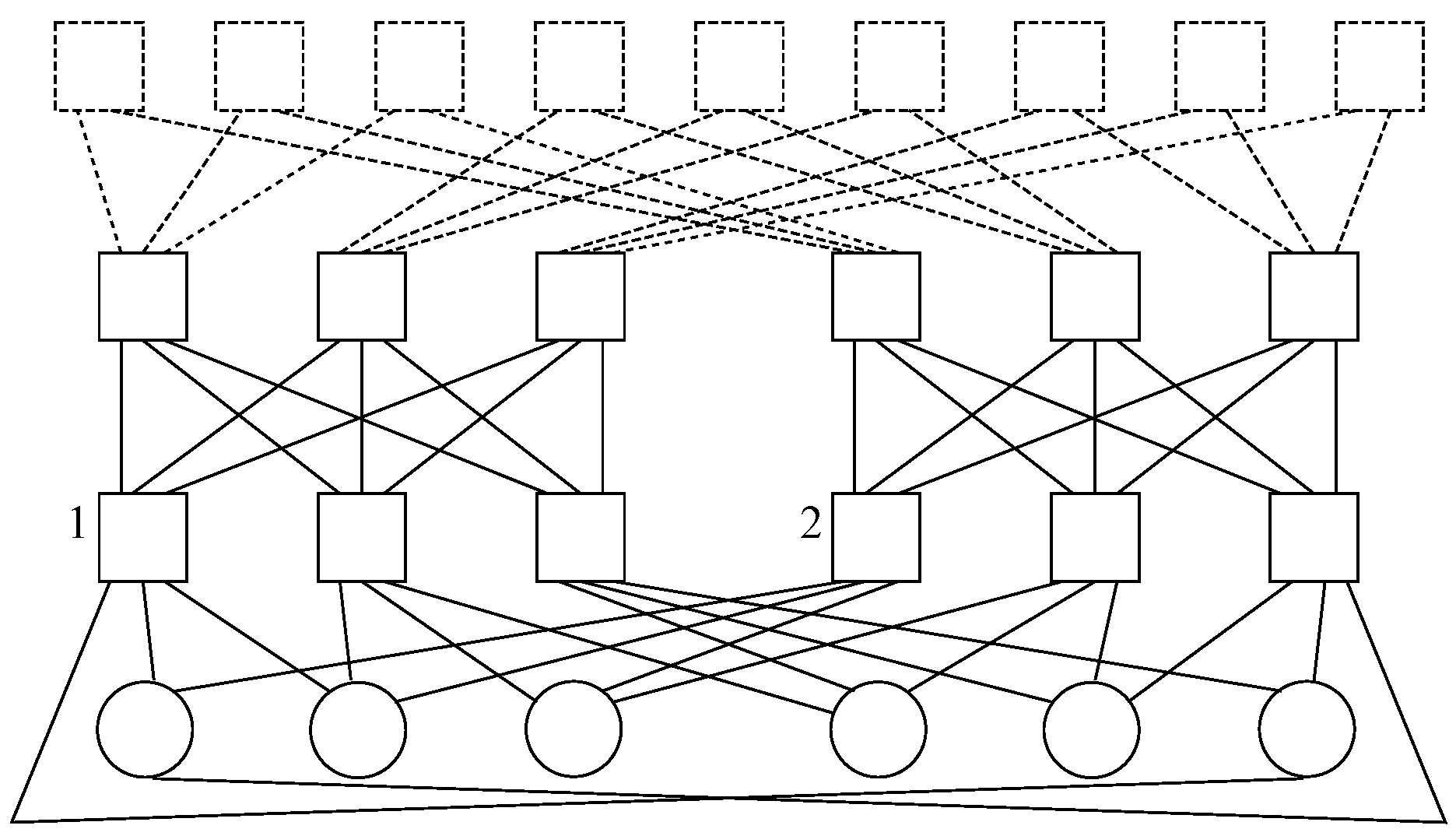
Focusing on the tree-like designs, redundant hub and spoke presents a steady value of , whereas leaf and spine has an , and fat tree has an . On the other hand, it results in for the first one, whereas for the second one, and for the third one.
Additionally, the chosen graph-like designs account for the following values: and for the first one, and for the second one, and for the third one, and for the fourth one, and for the fifth one, and and for the sixth one.
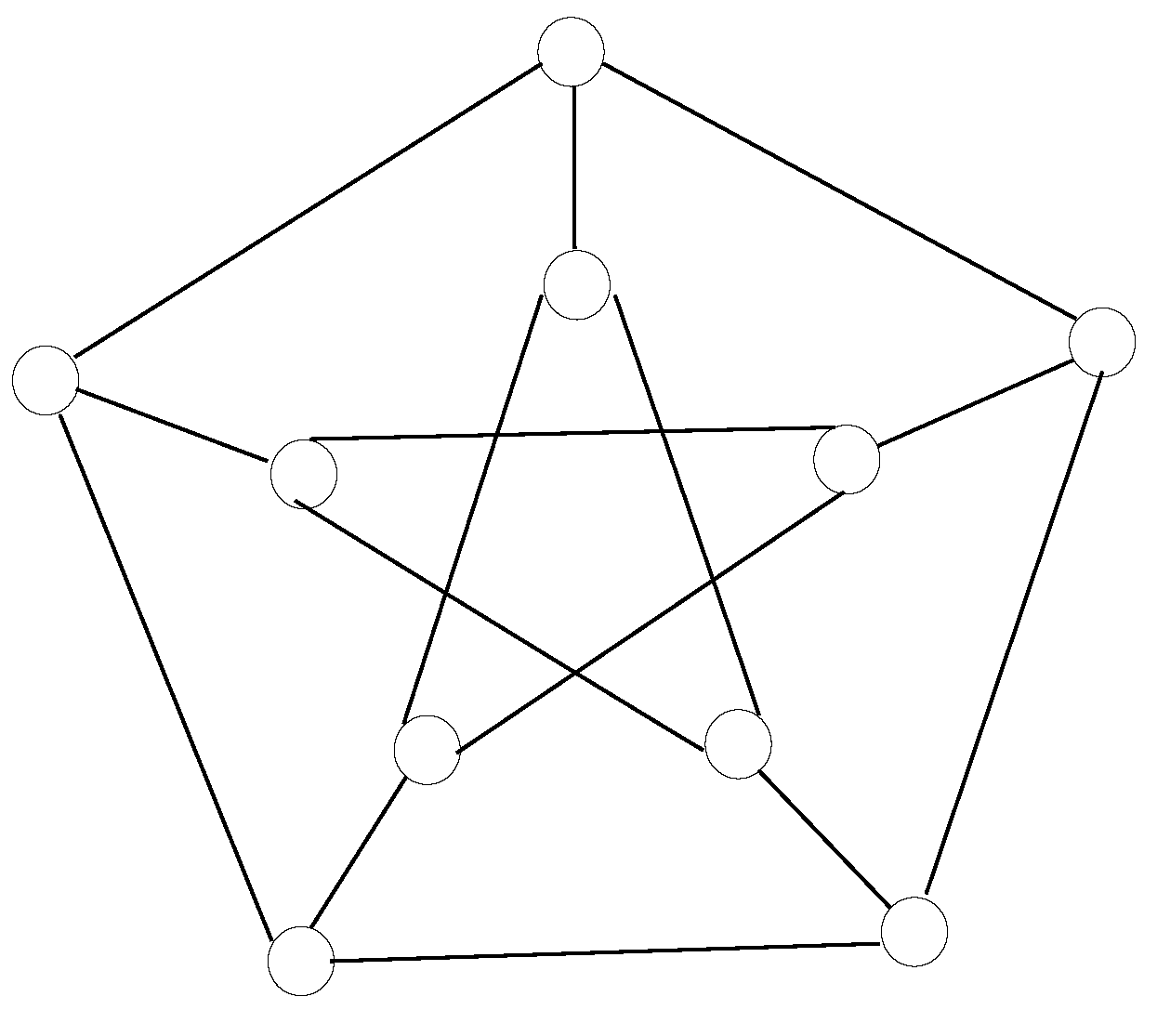
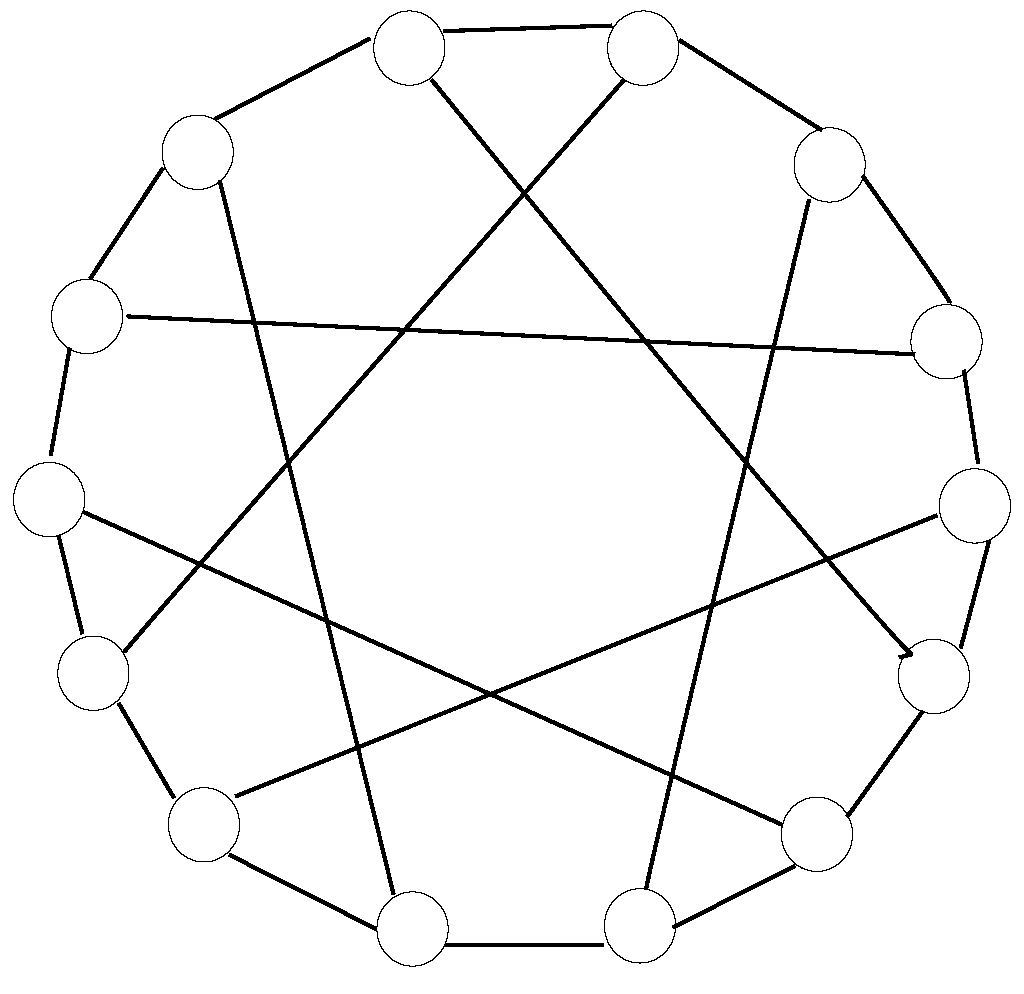
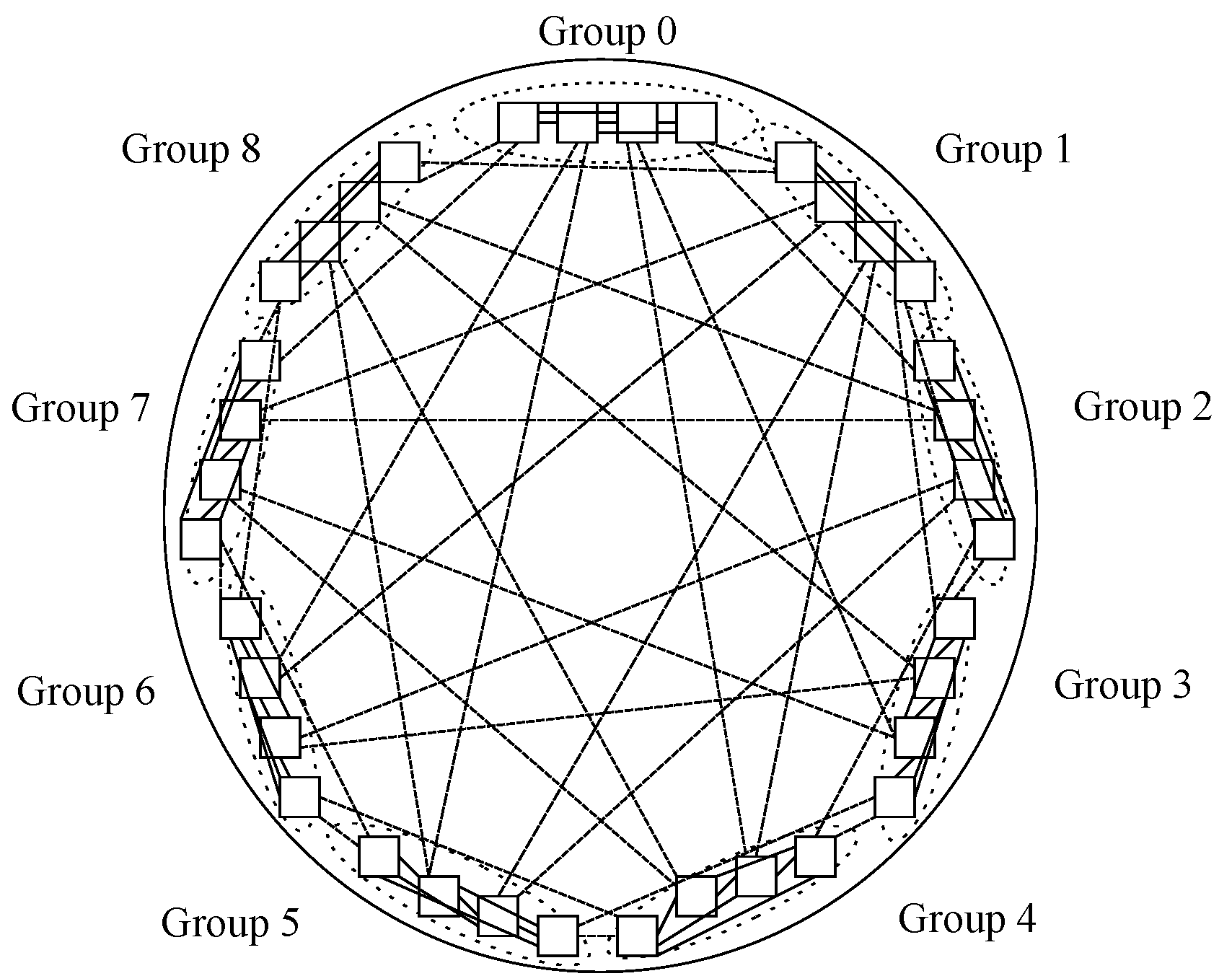
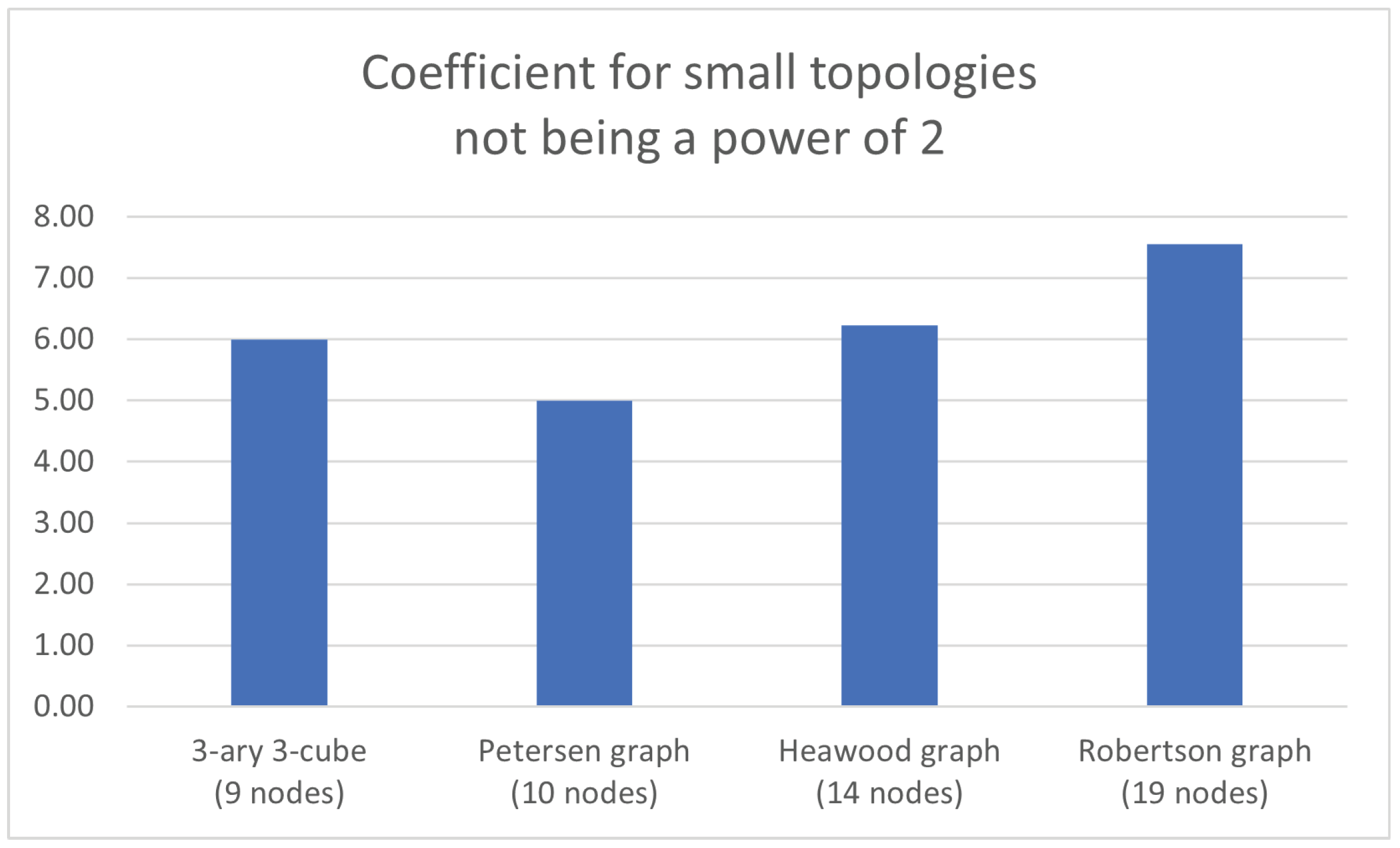
5.6. Other Numbers of Nodes within the Topology Not Being a Power of Two
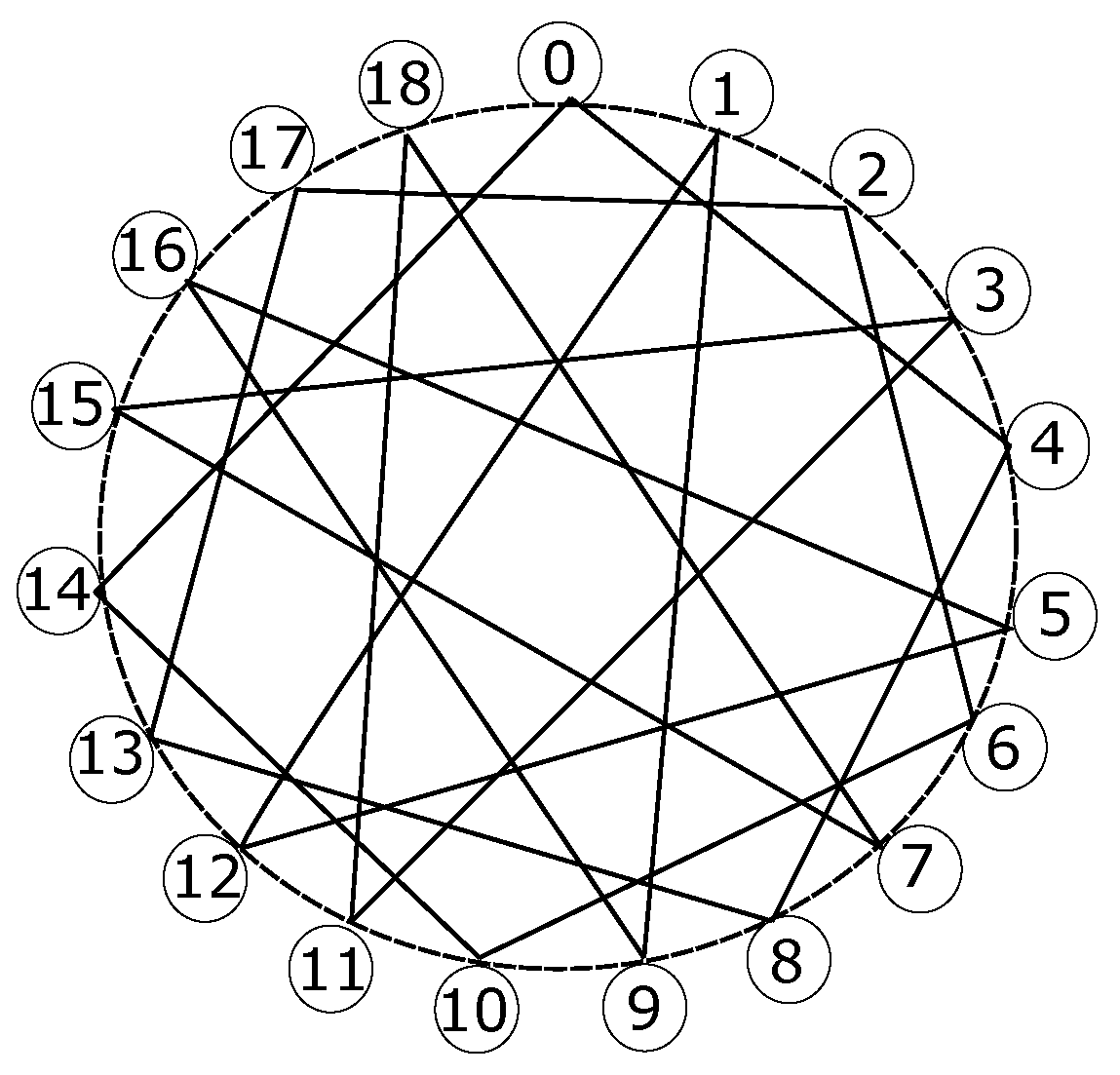
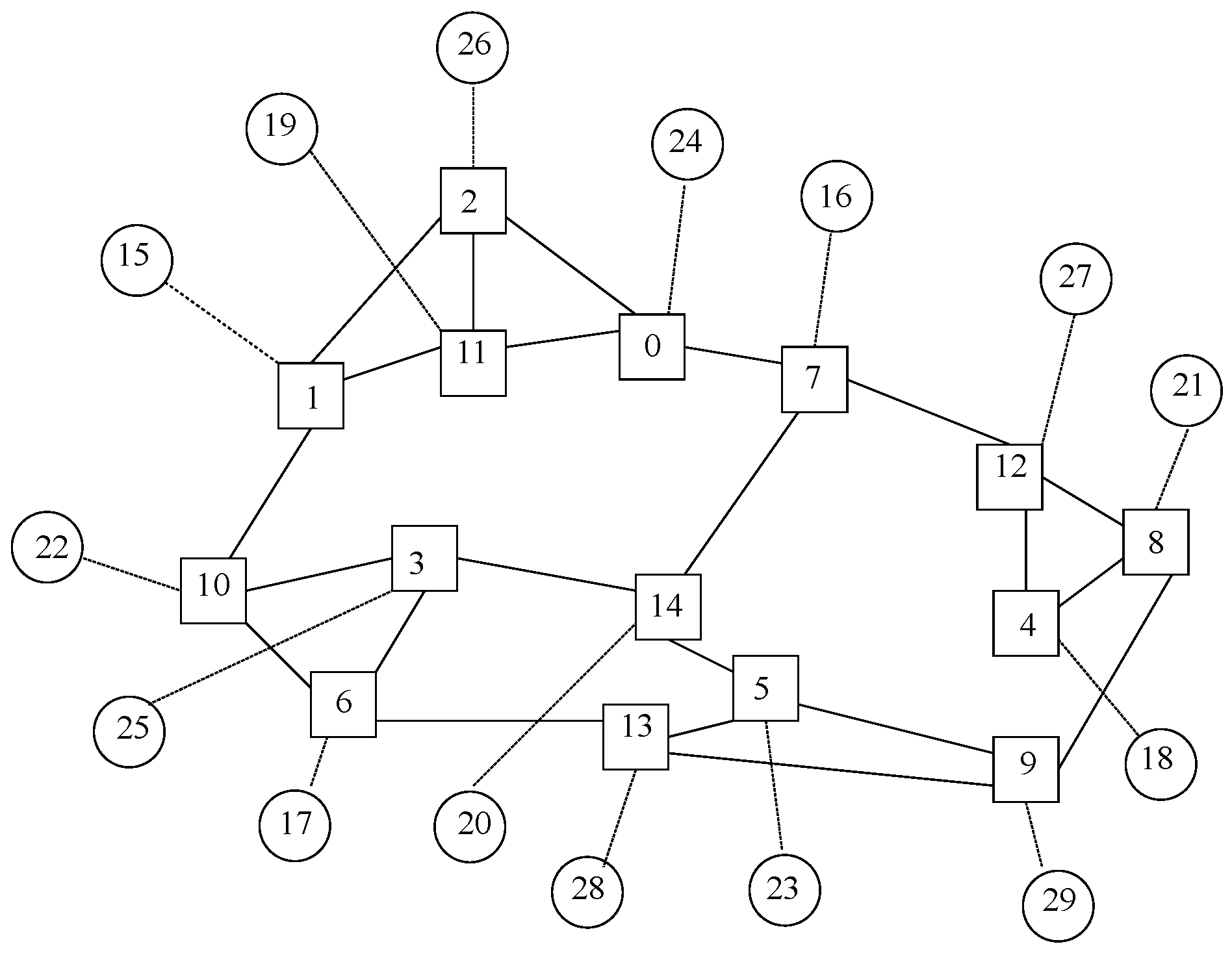
This additional case includes some topology layouts whose number of nodes is not a power of two, such as 3-ary 3-cube, Petersen graph, Heawood graph and Robertson graph, all of them being graph-like designs. As per the first one:
and
, whilst for the second one:
and
, whereas for the third one:
and
, while for the fourth one:
and
.
Table 6 exposes the relevant values of
for these instances.
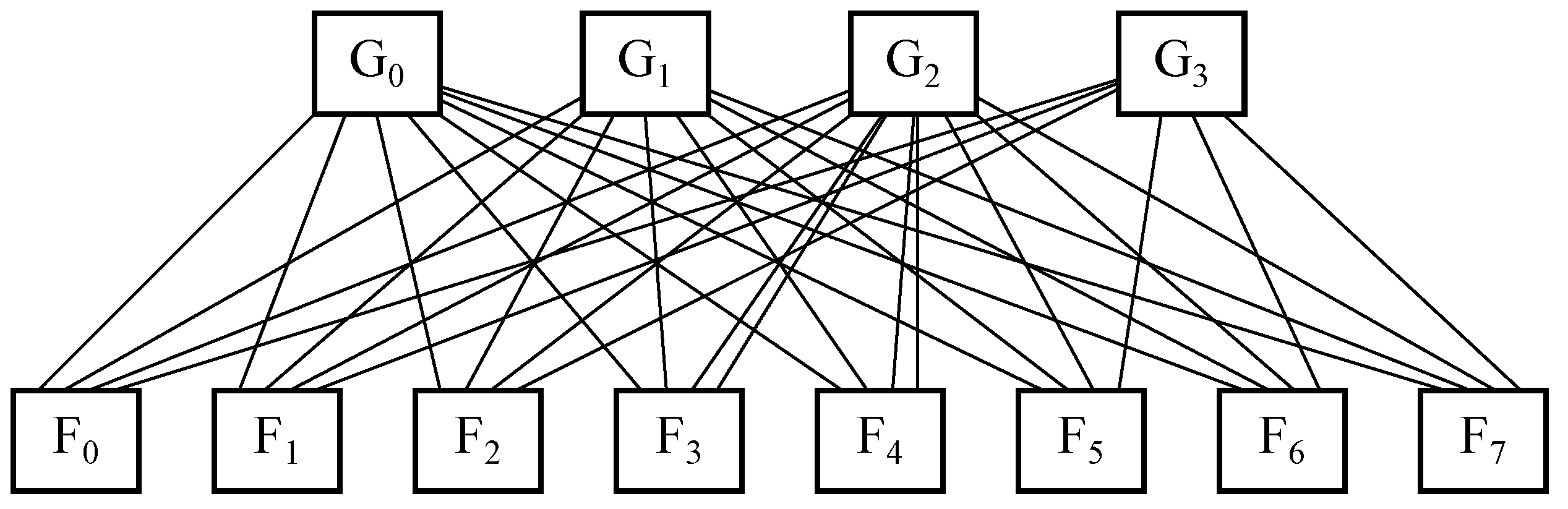
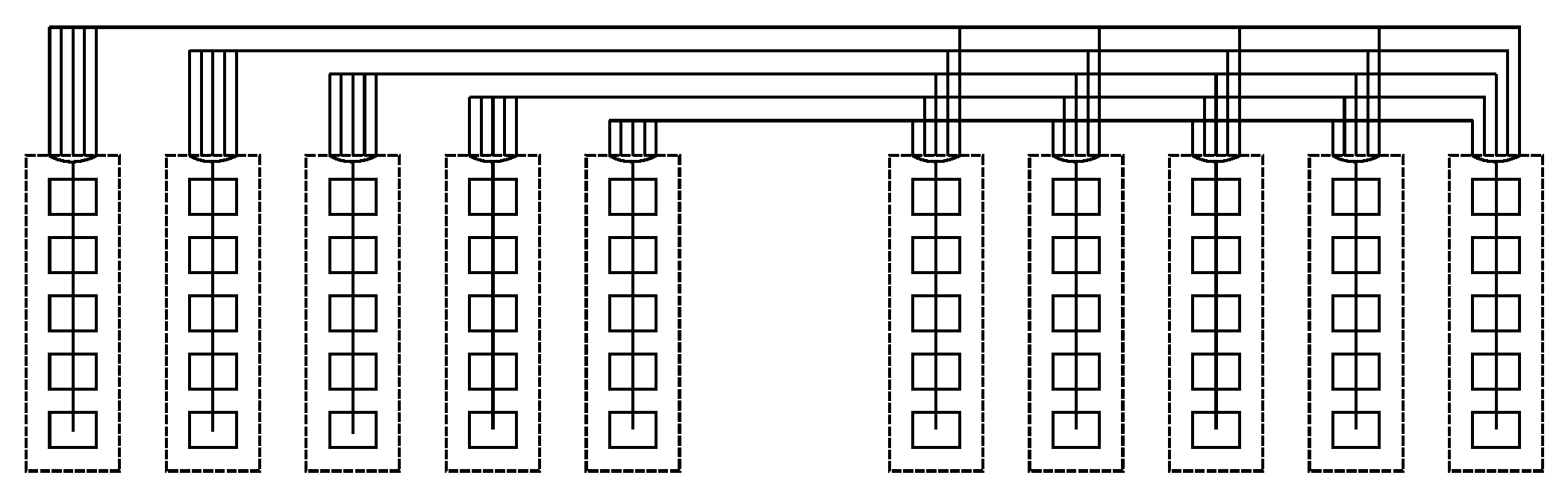
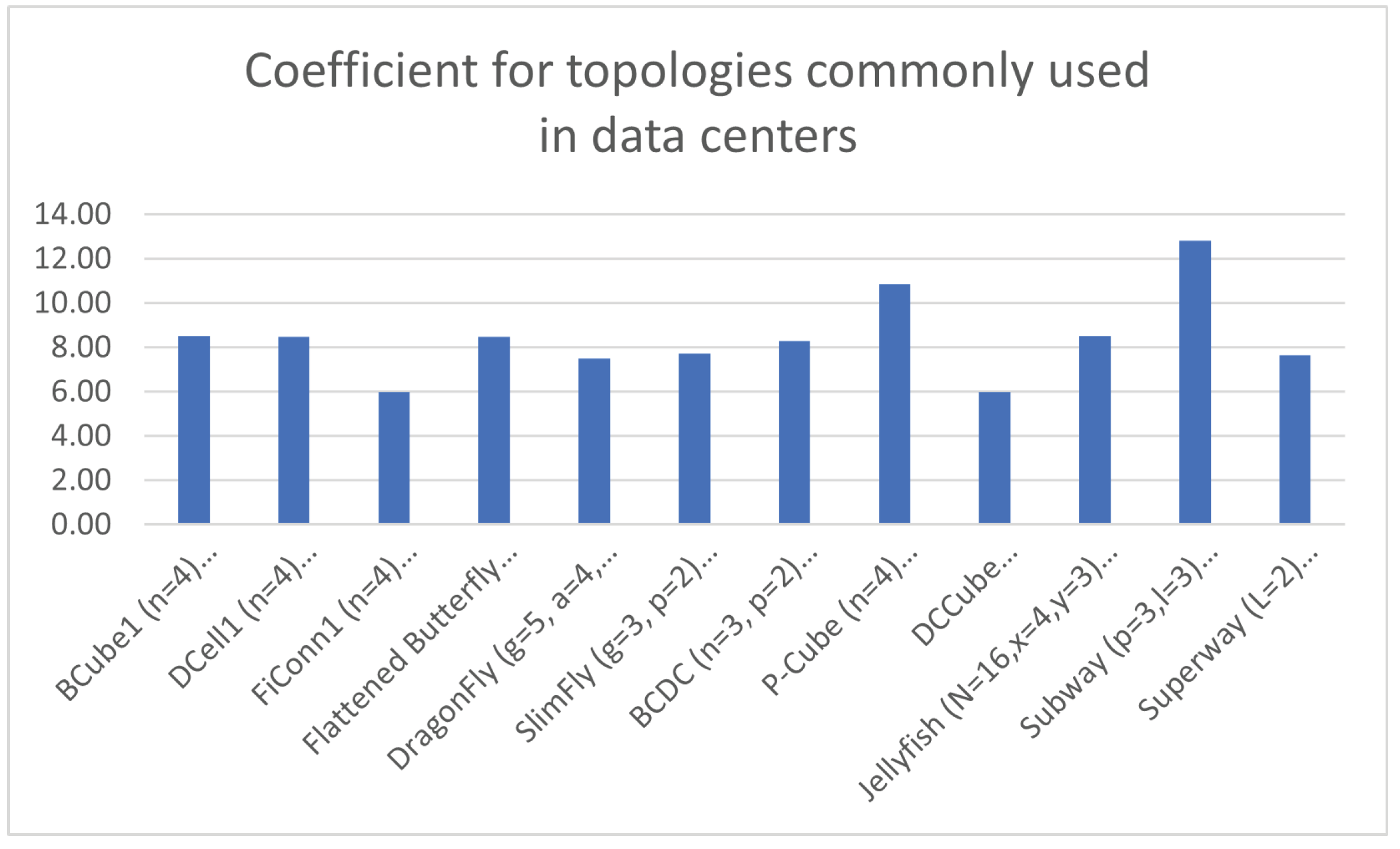
5.7. Some Other Commonly Used Network Topologies in Data Centers
In order to apply the aforementioned coefficient
to obtain a balance between performance and simplicity to network topologies being employed in large data centers, the topologies exposed in
Section 2.3 are going to be used to calculate the aforesaid coefficient
. This study is going to be made with the parameters exposed in that subsection that correspond to a data center with small to medium size. However, these parameters are higher in large deployments; hence, the use of coefficient
may be applied the same way as exposed in this section, although the results may vary depending on the values taken for the corresponding parameters.
Anyway,
Table 7 exposes the values for such a coefficient
regarding a compromise between performance and simplicity, where the parameters of each topology arealso shown, along with the number of nodes involved with those parameters, followed by the values for performance
and simplicity
for those specific parameters.
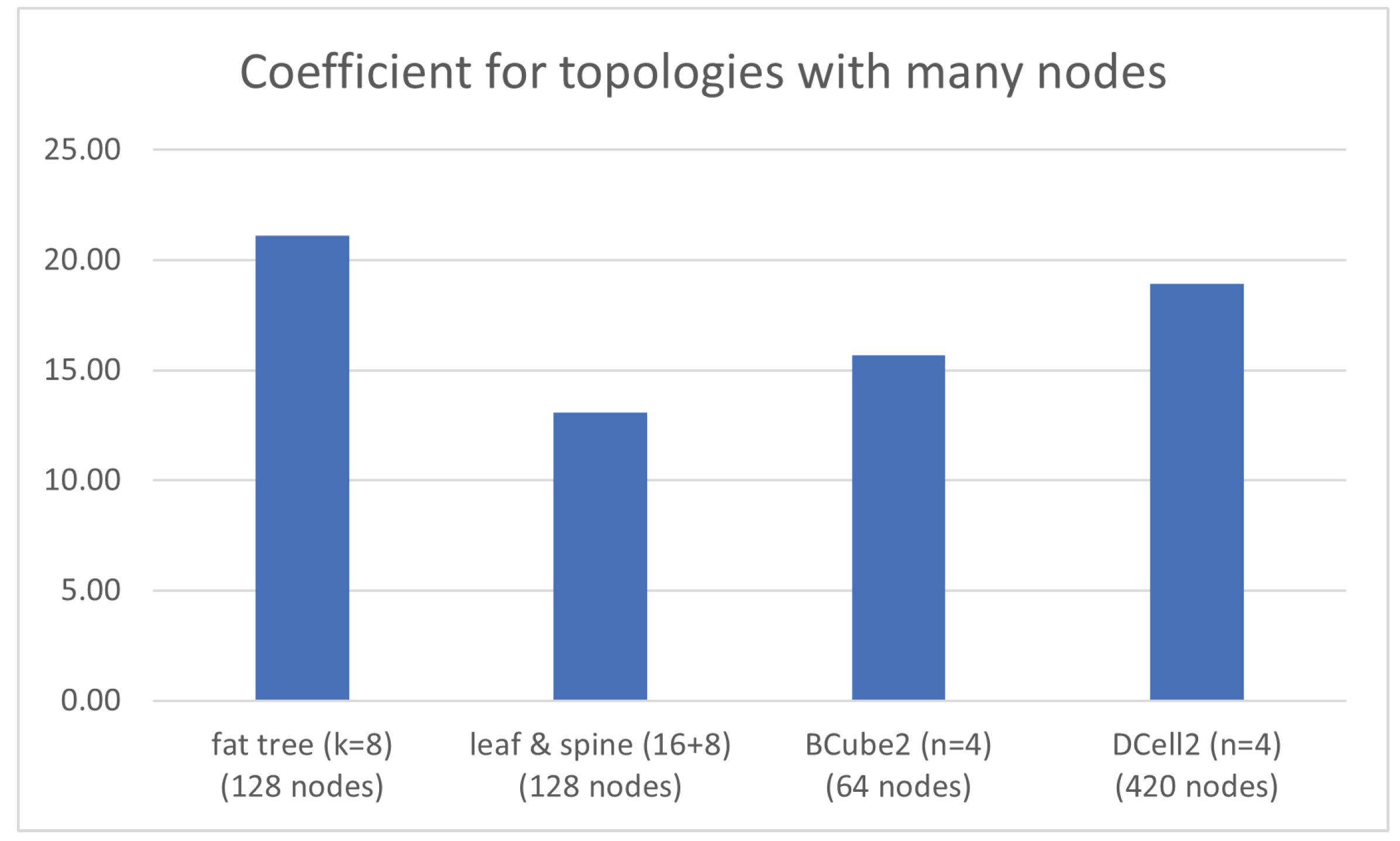
Additionally,
Table 8 exhibits the values for coefficient
when the number of nodes involved in diverse data center network topologies is increased. For this case, fat tree has been selected with parameter
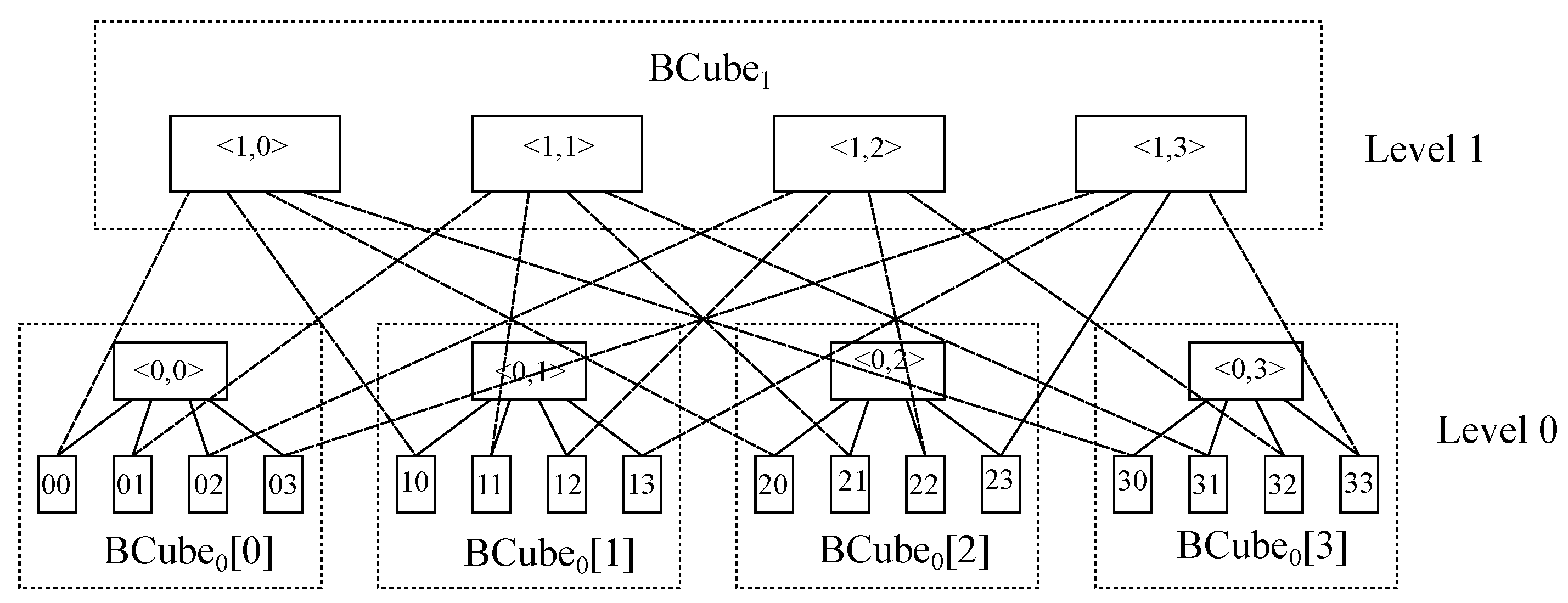
, which contains 128 hosts withjust 1 port, along with 32 edge switches, 32 aggregation switches and 16 core switches, where all of themhave 8 ports. Further, leaf and spine has also been set up to include 128 hosts with 1 port by taking 16 leaves and 8 spines, all of them being switches with 16 ports.
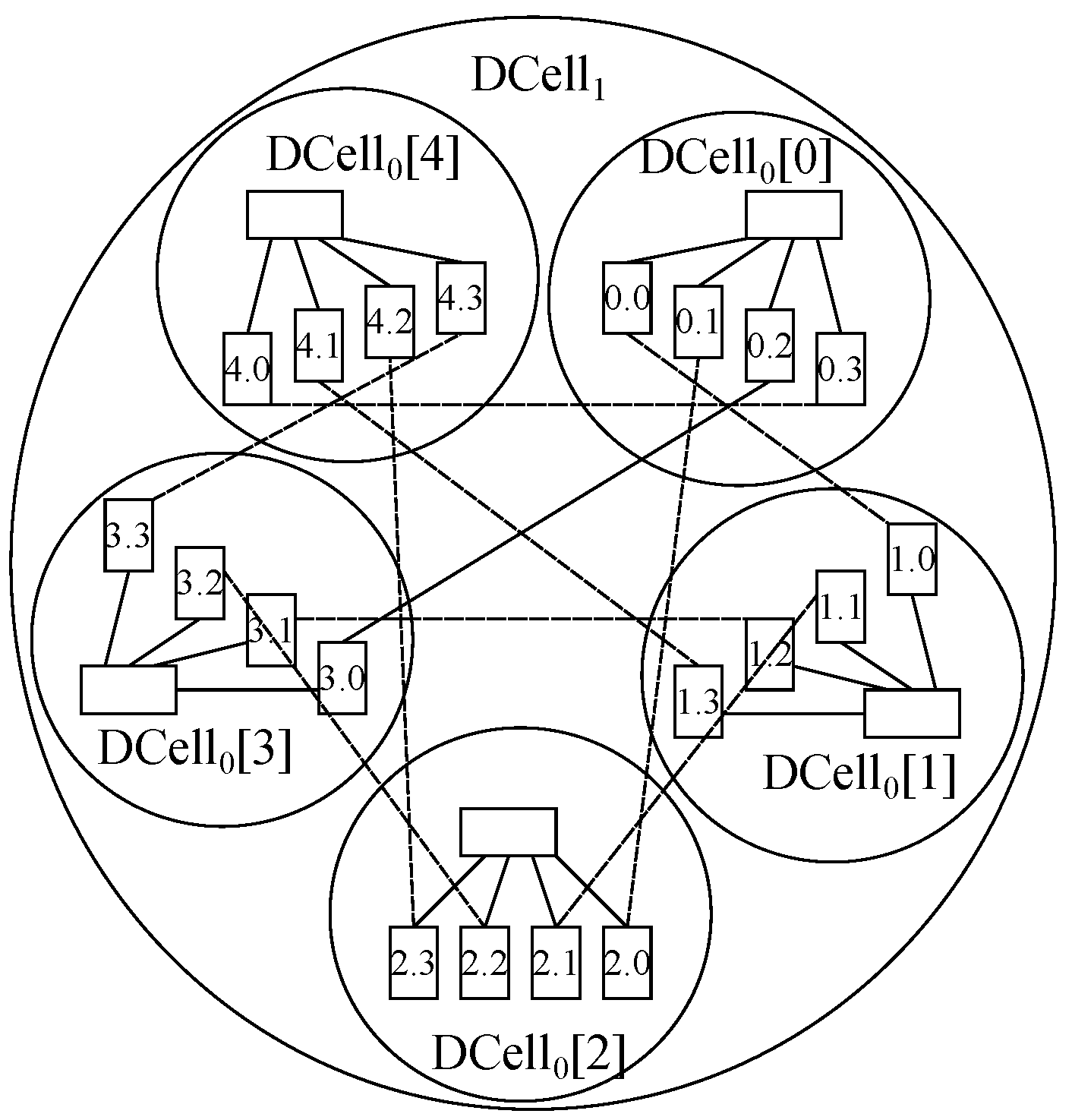
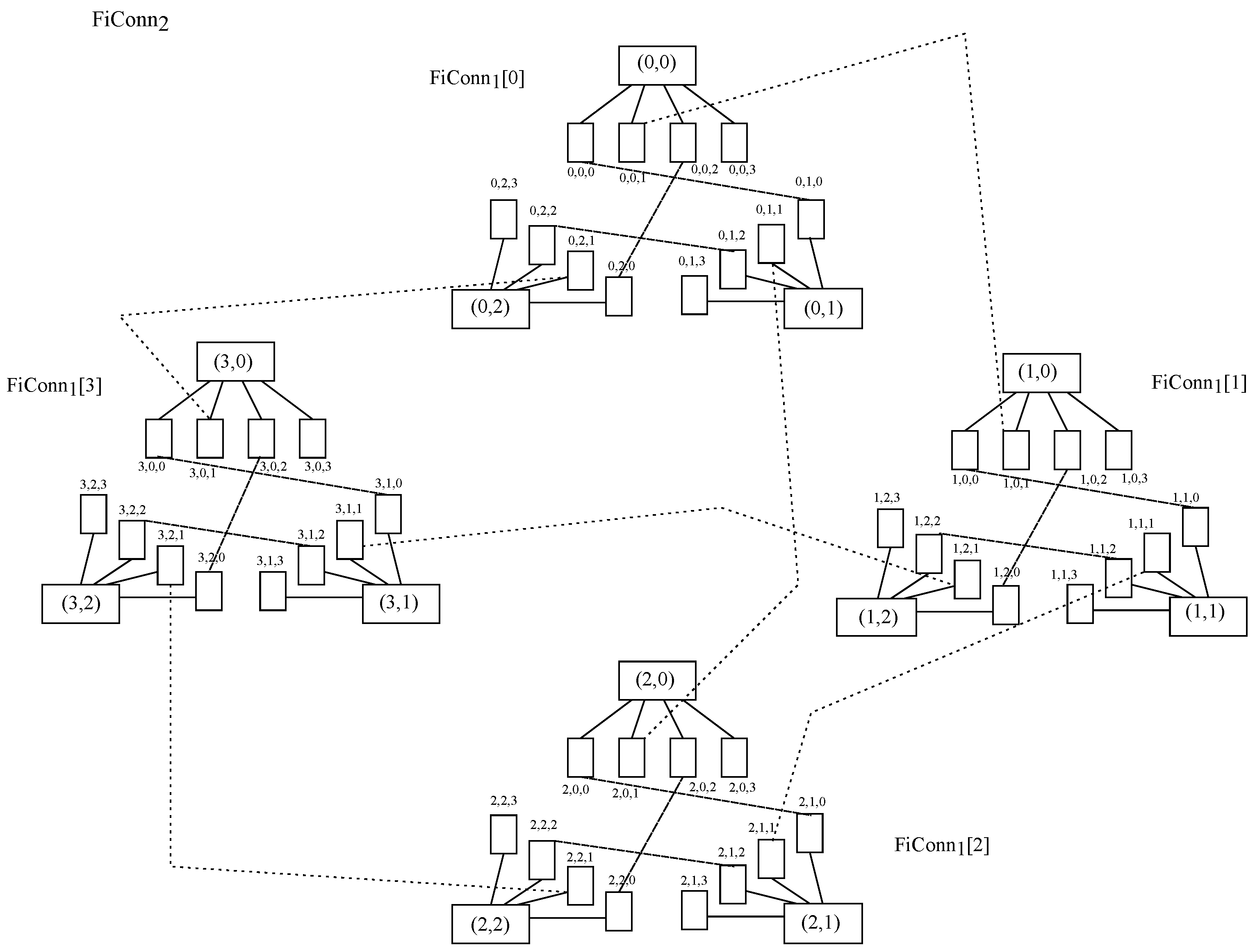
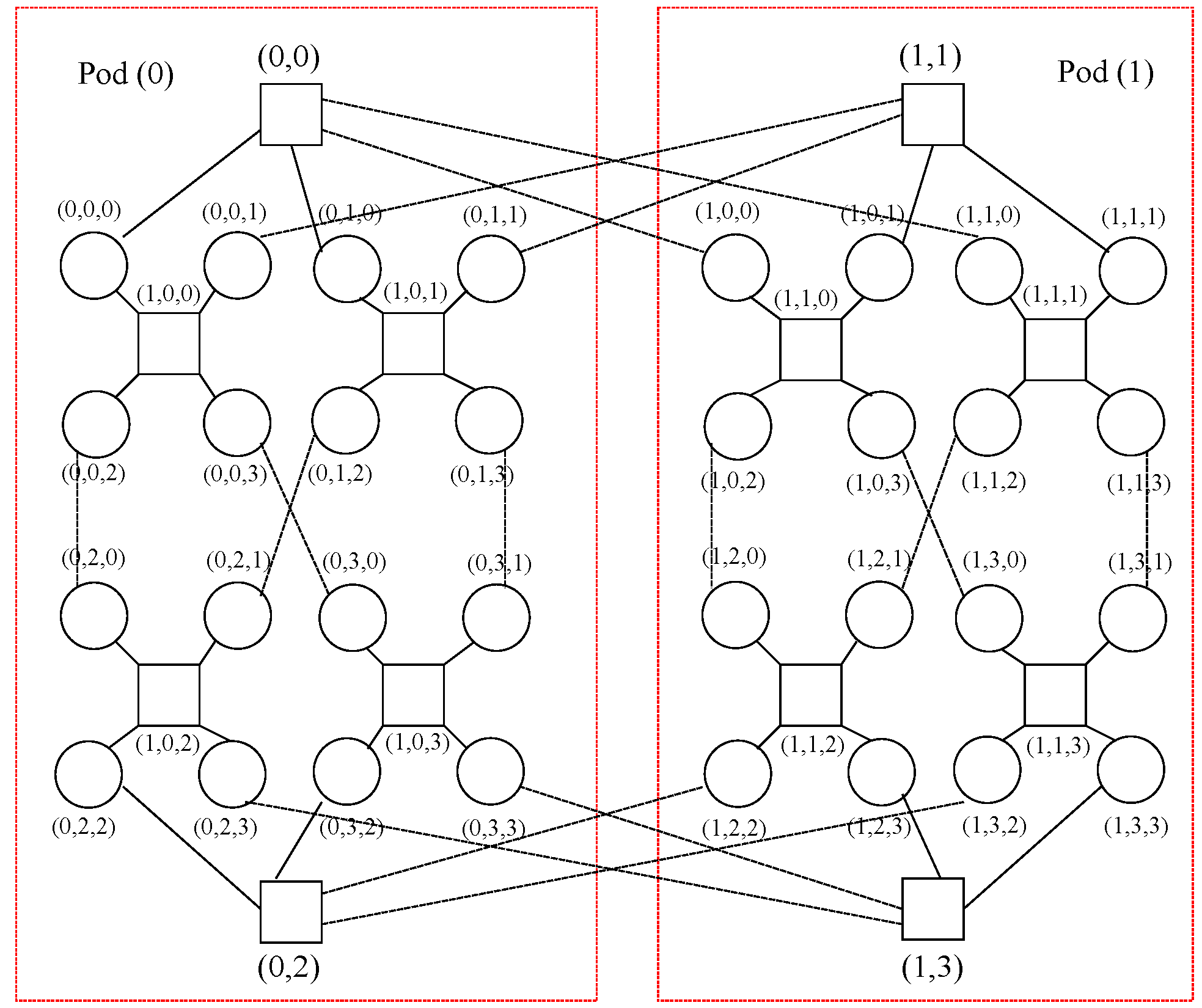
Furthermore, BCube with is chosen, whichcontains 64 hosts with 3 ports and 48 switcheswith 4 ports. It is to be noted that a third ofthose switches belong tothe 16 level-0 cells within this topology, with 4 nodes hanging on each of those, another third is located in 4 level-1 cells, with 4 level-0 cells hanging on each of these, and the other third one is situated within the level-2 cell, with 4 level-1 cells hanging on each of them. Moreover, DCell with is also selected, which holds 420 hosts with 3 ports and 105 switches with 4 ports. It is to be said that those switches are distributed into 21 DCell,where each of themhas 5 switches, such that each of those switches accounts for a DCell, which in turn is furnished by 4 connected nodes.
6. Discussion about the Results Obtained
The study carried out above, from the point of view of arithmetic, presents some conclusions to be taken into account. To start with, the values of obtained for tree-like designs are higher than those for graph-like designs when it comes to , although regarding it is the other way around. In other words, the average number of hops is greater for tree-like instances because of the excess of links due to the switching hierarchy, whilst this hierarchical nature allows nodes to have no interconnection with their peers, as those are undertaken among switches.
Further, the different topologies proposed for a given number of hosts result in higher values of as the number of redundant paths grows, which happens for both tree-like and graph-like designs. Focusing on the former, the redundant hub and spoke presents the lowest value, followed by leaf and spine, and finally, fat tree. Centering on the latter, partial mesh topologies attain lower values of , although the values grow as the number of links rises, increasing to maximum values for full-mesh topologies.
Additionally, in tree-like designs, the average number of links among hosts increases with redundancy, whilst the average number of links per device decreases, resulting in going higher, which shows that the weight of is bigger than in tree-like topologies. On the contrary, in graph-like designs, the average number of links among hosts decreases with redundancy, whereas the average number of links per device increases, resulting in going higher, which points out that the weight of is bigger than in graph-like topologies.
Having said that, further research could add some correction factor in order to try to balance the opposite relationship between and for both kinds of architectures when using the proposed expression of .
On the other hand, the values of performance and simplicity achieved with the other commonly used network topologies typically employed in data centers, described in
Section 2.3 and calculated in
Section 5.7, are significantly lower than their counterparts analyzed in the previous subsections within
Section 5 for similar or even higher numbers of nodes. The reason of this is because the interconnections among nodes are optimized related to fat tree or leaf and spine, thus not presenting a pure tree structure butdisplaying more direct connections among nodes in many cases, and additionally, several instances furnish nodes with multiple ports to connect to different destinations.
Basically, large data centers employ optimized data center network topologies in order to attain shorter paths among nodes while facilitating scalability by means of setting the appropriate values for the parameters involved in such topologies. Therefore, it may be said that the coefficient proposed herein still stands for large scale topologies.
In order to facilitate discussion, the results obtained in
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8 have been graphically represented. It is to be said that
Table 1 offers a trivial case where coefficient
is null, so it has not been drawn. On the other hand, the correspondence of tables and figures is the following:
Table 2 goes with
Figure 26,
Table 3 does with
Figure 27,
Table 4 does with
Figure 28,
Table 5 does with
Figure 29,
Table 6 goes with
Figure 30,
Table 7 goes with
Figure 31, and
Table 8 goes with
Figure 32.
In summary, by reviewing the results obtained in
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5 for the coefficient proposed herein, namely
, it may be seen that the values attained for both tree-like and graph-like cases increase as the number of nodes rises. Further, the results shown in
Table 6 are reasonable comparing the values achieved with those shown in the previous tables according to the number of nodes, as they are all within the same range.
Regarding the other commonly used data center network topologies presented in
Table 7, the results are also coherent according to the amount of nodes included in each topology compared to those seen in the aforesaid tables. It is to be taken into account that
Table 7 represents topologies where the number of nodes cover a wide range of values, as each topology has its own specifications. Nonetheless, most of the results obtained for
are located in the lower range in the previous tables despite
Table 7 instances having a larger number of nodes in many cases.
Therefore, it seems that this coefficient offers significant results for data center network topologies focused onsmall deployments. However, as exposed in previous sections, this coefficient is just another tool to select the most convenient data center network design, not the definitive one. In this sense, it might be used as a tie-breaker to choose among some designs offering different strengths, such as throughput or robustness.
It is to be reminded that the scope ofsmall data centers isusually local, which implies that they are used by a limited number of end users; hence, the number of nodes involved to serve such users may usually be farlower than in large data centers located in the cloud. In spite of that, some of the commonly used data center network architectures presented in
Table 7 for edge deployments have been extended to involve far more users, which makes them ready to be employed in larger cloud data center scenarios.
Those results have been exposed in
Table 8, where the outcome is higher than that viewed in
Table 7, which was expected because coefficient
grows with the number of nodes, as was seen in the first tables. However, the figures obtained may be seen as coherent with the ones exhibited in the previous tables as values obtainedseem to increase steadily as the number of nodes rises with a relatively small slope.
Hence, it may be concluded that the coefficient
has been established for data center network topologies, offering a balance between performance, measured in average number of links between any pair of nodes, and simplicity, measured in the average number of links per device within the topology. It was initially thought of forsmall data centers because of itslower number of nodes compared to a normal cloud data center scenario, and the tests carried out in
Table 1 to
Table 7 proved that
offers an increasing value on average as the number of nodes in a network topologygrows.
However, further tests have been undertaken for larger data centers, such as those being deployed in normal cloud data center scenarios, shown in
Table 8, where results proved that
offers coherent results with those obtained for smaller data centers. Therefore, it may be said that this coefficient
may be used in data center network topologies of any size, where the greater the number of nodes, the higher the value obtained for
.
Apart from the values obtained in order to measure the efficiency of a certain topology, other considerations could be taken into account in further research, such as the need for redundancy or the requirement for steady values of latency in real-time implementations, where the former is more likely attained with topologies incorporating more links to get extra paths, and the latter is more easily done by using tree-like designs.
7. Conclusions
In this paper, an arithmetic study about efficiency in data centers has been carried out. First of all, a range of possible topologies with a limited number of nodeshave been proposed asa collection of convenient architectures for dealing withlow computing traffic.
Those topologies have been divided into tree-like designs and graph-like designs, where in the former, nodes are interconnected through a hierarchy of switches, whereas in the latter, such interconnections are made directly between pairs of nodes.
The arithmetic study has consisted in the definition of two parameters, those being the average number of hops among nodes and the average number of links among devices, and in turn, a coefficient called has been defined as the product of both in order to provide a balance between both parameters.
On the one hand, the first parameter is related to performance, as the lower number of hops among nodes, the better, whilst on the other hand, the second parameter is related to simplicity, as the lower number of links per device, the better.
After having tested those parameters in different topologies mainly focused onsmall data centers, where the number of nodes is small to middle sized, it appears thatin tree-like designs, the value of coefficient grows as the average number of hops among nodes increases, even though the average number of links per device decreases at the same time. Otherwise, it seems thatin graph-like designs, the value of coefficient rises as the average number of links per device increases, although the average number of hops decreases at the same time.
Furthermore, some of the most commonly used network topologies in large data centers have also been studied, leading to coherent results obtained by coefficient , which implies that this coefficient may be employed in data center networks of any size.




































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}