1. Introduction
The COVID-19 pandemic, caused by the novel coronavirus SARS-CoV-2, has had a profound impact on the world in the past few years. It has affected nearly every aspect of human life, causing significant disruptions to healthcare systems, economies, and social structures across the globe. The developments in the fight against the pandemic, mainly the vaccination, provided a crucial tool to protect individuals and communities against the virus and help to mitigate its spread.
Vaccination efforts are ongoing worldwide to combat the COVID-19 pandemic. In November 2023, over 13.5 billion (
https://ourworldindata.org/covid-vaccinations, accessed on 21 November 2023) doses of COVID-19 vaccines have been administered globally. The US government has taken significant steps to ensure vaccine availability and accessibility, including funding vaccine production, distribution, and administration. Vaccination rates have been highest among older adults and healthcare workers, but efforts are ongoing to ensure that all eligible individuals have access to the vaccine. Despite challenges such as vaccine hesitancy and supply chain issues, vaccination efforts are critical to reducing the spread of the coronavirus and protecting public health.
According to data from Our World in Data, in November 2023, the US has administered over 676 million doses of COVID-19 vaccines, with more than
of the eligible population having received at least one dose and over
fully vaccinated (
https://covid.cdc.gov/covid-data-tracker, accessed on 21 November 2023). This puts the US ahead of many other countries in terms of vaccination rates, but disparities in vaccination coverage remain among different age groups and communities. Globally, vaccination rates vary widely across countries, with some countries still struggling to acquire and distribute enough vaccines.
Consequently, the use of statistical techniques to analyze pandemic data has been widespread in the US and other countries. A comprehensive study by [
1] examines the correlation between vaccination rates and social vulnerability at the county-level, revealing significant disparities in vaccination coverage across counties. Despite limited data on vaccination safety and efficacy during pregnancy, a recent study by [
2] found that vaccination coverage increased across all racial and ethnic groups during the study period. Other studies by [
3,
4,
5] revealed a correlation with determinant factors and the COVID-19 vaccination rate.
In this instance, the study aims to determine the factors that explain the COVID-19 vaccination rate by constructing a new regression model based on the
generalized odd log-logistic Lindley (GOLLL) distribution. In their study, ref. [
6] elucidated the advantages of the introduced family of distributions and its applicability across various fields, highlighting its superiority over well-known generators. For example, ref. [
7] proposed a parametric and a partially linear regression model called genralized odd log-logistic Birnbaum–Saunders distribution, and ref. [
8] defined the generalized odd log-logistic Maxwell mixture model to analyze COVID-19 Chinese data.
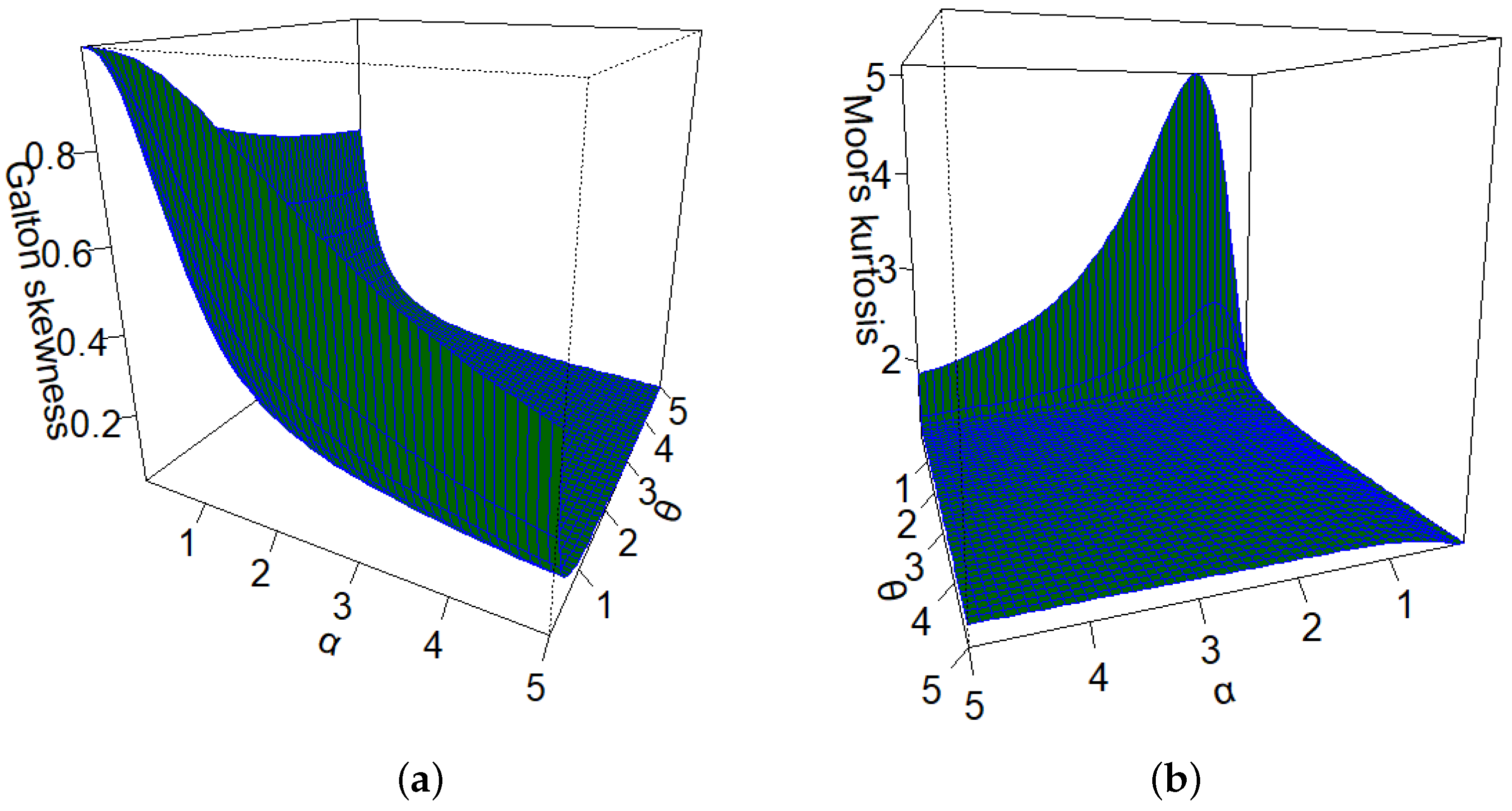
This particular distribution offers advantages compared to other competing models, as elaborated in the upcoming sections. Researchers have made significant contributions to the field by introducing and studying various generalizations of the Lindley distribution. Some notable examples of these generalizations include: the study of the Lomax-Lindley distribution in lifetime data [
9], the perspective of the Lindley distribution on the unit interval [
10], the application of the Marshall-Olkin Lindley distribution in reliability data [
11], and the application of the modified-Lindley distribution in three real data sets [
12].
Several studies have explored the relationships between various factors that are determinants of vaccination rates, such as demographics, social-economics, and comorbidities, among others. The construction of new models that capture the complexity of the data is crucial to addressing research gaps related to COVID-19. Due to the extra shape parameters, the new distribution has great flexibility in modeling a wide range of data shapes, and link covariates to explain the response variable. The novel GOLLL regression aims to be an efficient model for identifying the factors that influence vaccination and can be considered an alternative for future work to help vaccination efforts.
Therefore, the focus of this study is the analysis of the COVID-19 completed primary vaccination series at a county-level within the state of Texas. The main objective is to investigate the influence of explanatory variables on the response variable, with a specific focus on examining the impact of vaccination in the US. Through this study, the goal is to make a significant contribution to the literature on this topic and provide valuable insights into the factors that influence the response variable.
The paper is organized as follows.
Section 2 defines the GOLLL distribution and its main features. A linear representation and some of its mathematical properties are presented. The maximum likelihood estimation method is utilized, and some simulations examine the accuracy of the estimators. In
Section 3, a new GOLLL regression model with a systematic structure for the shape parameter is constructed, and the consistency of the estimators is examined. Some measures for model checking are provided. In
Section 4, an application of the proposed model to COVID-19 vaccination rate data is considered, and its performance is compared with other models. Diagnostic analysis and deviance residuals confirme that the model is the best fit to explain the current data. In addition, in
Section 5, the study supports its conclusions with valuable findings that corroborate those from other studies. Future works can verify the proposed model in other scenarios (states, countries, etc.). Finally,
Section 6 summarizes the key results of the study.
3. The GOLLL Regression Model
In recent years, new regression models have been proposed to handle various types of data without any transformation. The development accommodates non-normal data and captures the complexity and diversity of real data sets, providing accurate results. Ref. [
23] proved the applicability of the utilized family in real engineering data sets. Another work [
24] studied the COVID-19 ICU survival times in a Brazilian hospital.
In this situation, new models represent an important step to improve the analysis of different outcomes. Therefore, using the proposed GOLLL distribution, a new regression model is constructed as a tool to investigate any dataset that does not satisfy normality assumptions.
3.1. Definition
The systematic component of the GOLLL regression model takes into account the fact that the parameter
in Equation (
6) varies across observations (
) as
where
is a twice continuously differentiable log-linear link function, and
is the p-dimensional parameter vector associated with the explanatory variables
. The components of
are assumed to be independent. Therefore, the non-linear function
plays the link with the covariates and the new regression model.
Consider a sample of
n independent observations
. The log-likelihood function for the parameter vector
in this regression model has the form
Numerical maximization is employed using the optim routine in [
22] to estimate
in Equation (
12). The likelihood ratio (LR) statistic is adopted to compare the proposed regression with its nested models.
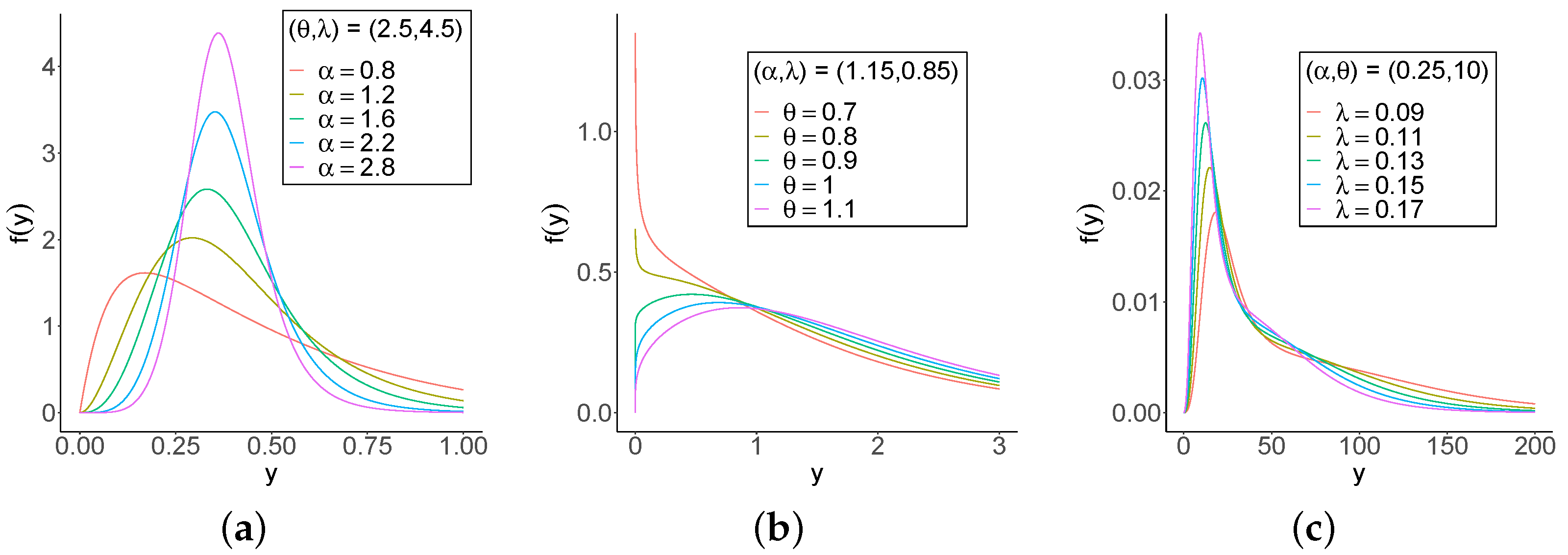
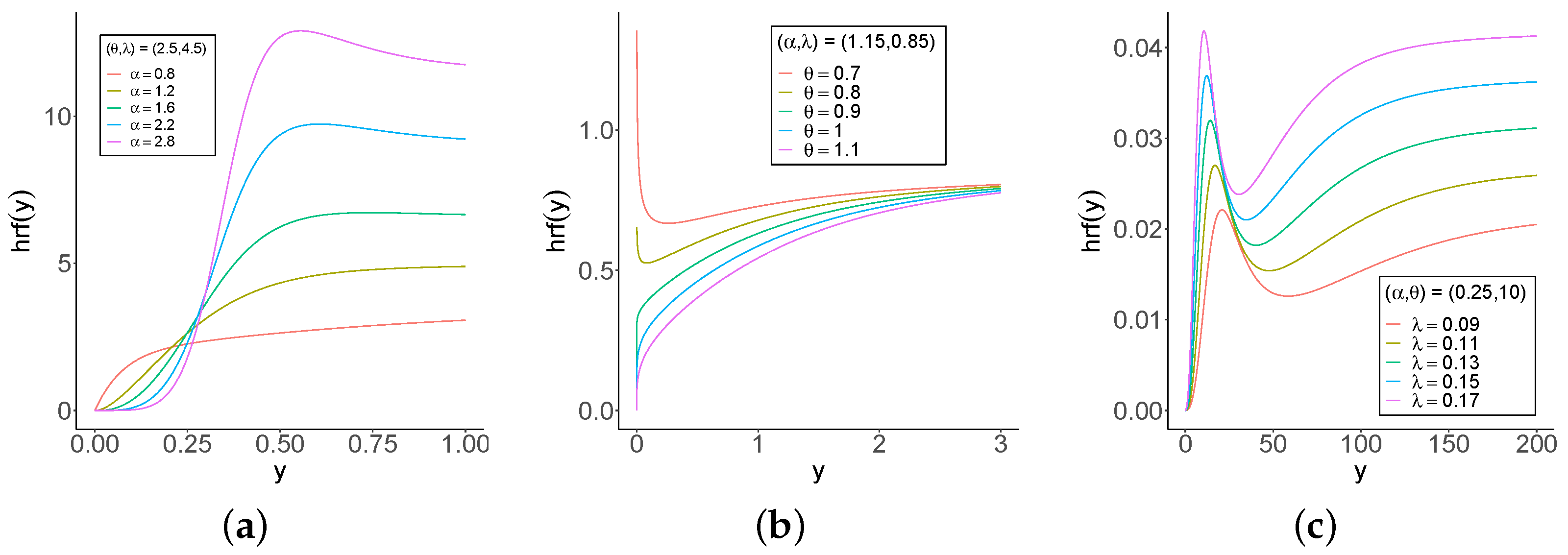
3.2. Simulations of the Regression Model
The accuracy of the MLEs in the GOLLL regression model can be assessed using the measures: bias, MSE, estimated average length (AL), and coverage probability (CP). The measures are
and
for
.
One-thousand samples of sizes
are generated from Equation (
8) by setting
,
,
, and
. The Monte Carlo simulation provides a versatile approach to analyzing the parameters of the model, enabling researchers to explore the behavior of a distribution under various conditions.
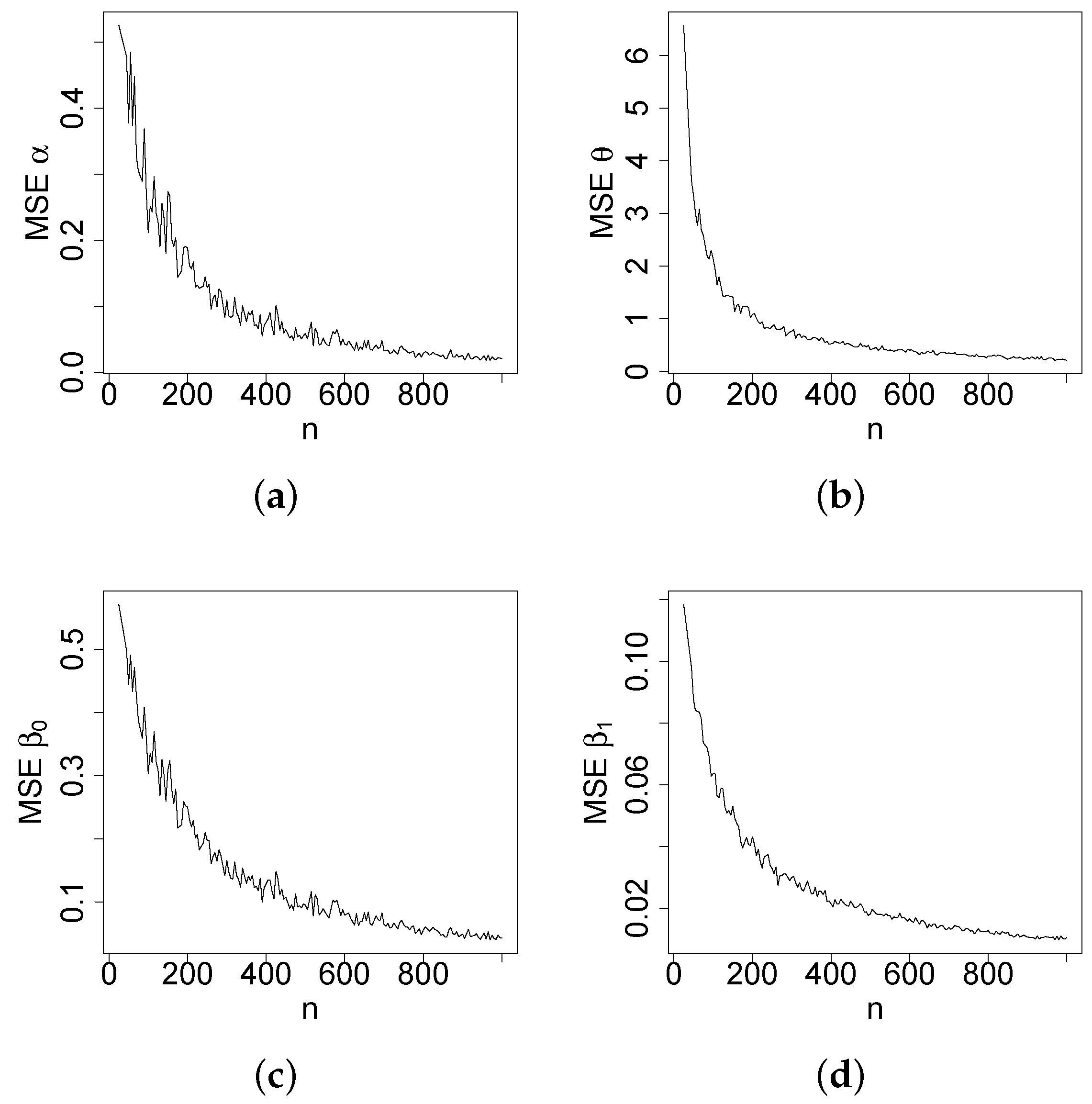
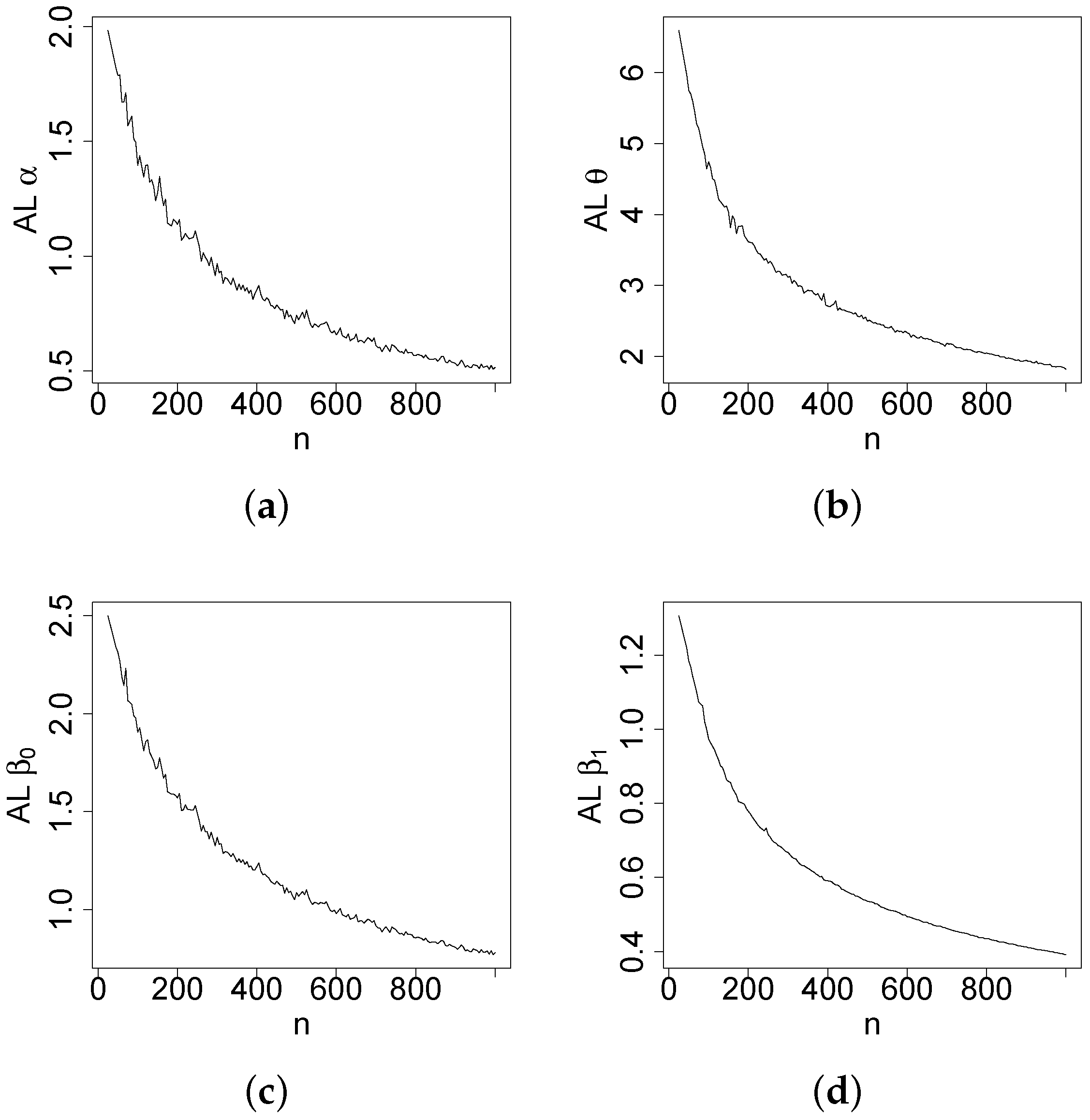
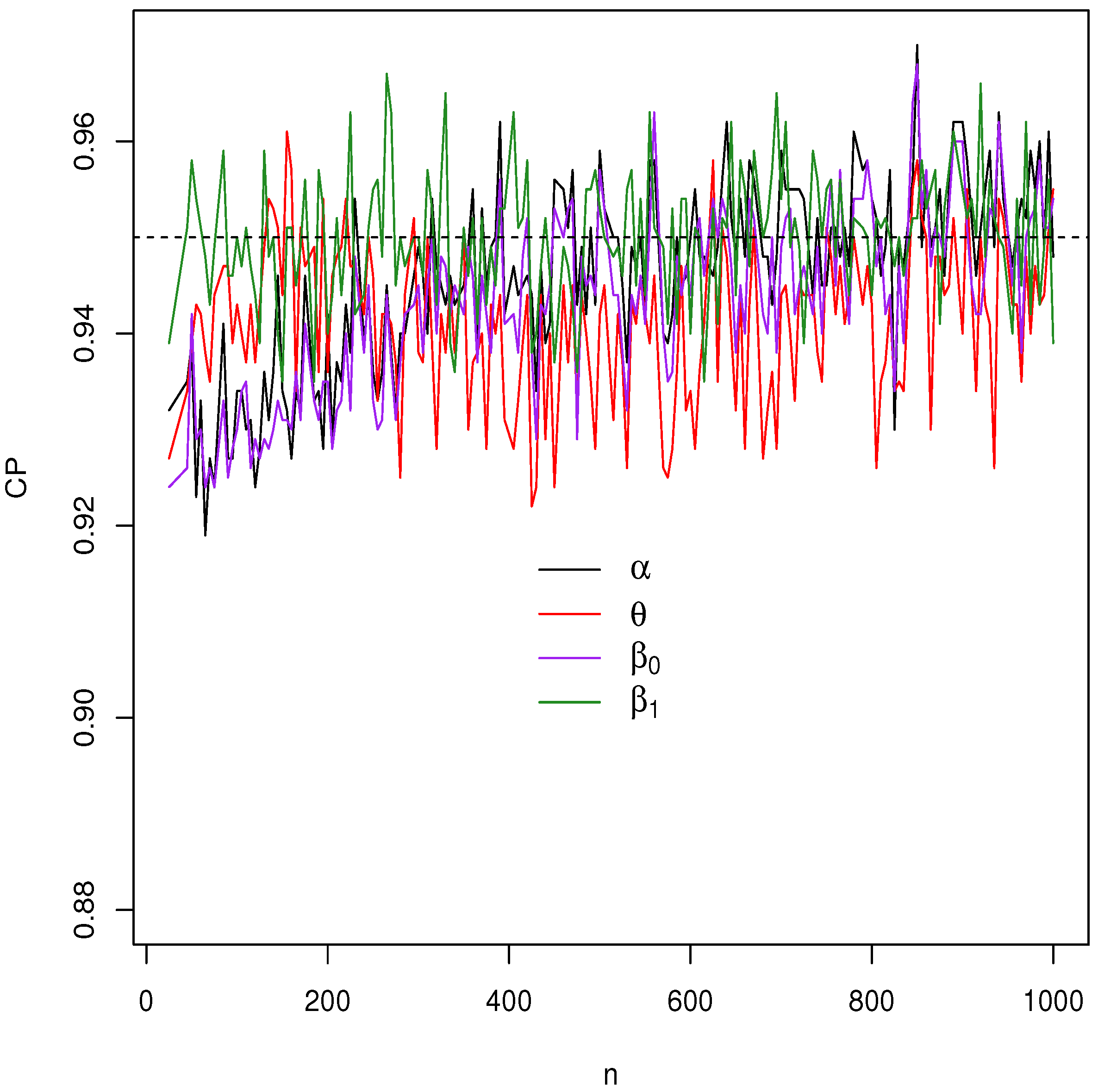
Figure 4,
Figure 5,
Figure 6 and
Figure 7 report how the measure values change with respect to the sample size. The biases, MSEs, and ALs decay toward zero when
n increases. Additionally, the CPs approach the true value of
if
n increases. These findings provide strong evidence of the consistency of the MLEs. The simulation contributed to the reliability and comprehensiveness of the new regression model.
3.3. Model Checking
Diagnostic measures and residual analysis are employed to know if the model accurately represents the data. This involves investigating whether the sample contains any outliers or influential observations that may affect the model’s performance.
Measures based on case deletion are considered in the systematic component to identify influential observations in the regression model
Here, the effect of excluding the
ith observation is examined on the parameter estimates. Hence, the log-likelihood function for
from model (
13) by deleting the
ith observation is
, and the MLE of the parameter vector is
.
The influence of the ith observation is measured by comparing the difference between the estimated parameter and the original MLE . If excluding the ith observation leads to a substantial change in the estimated parameters, then this observation is influential.
A popular influence measure is the generalized Cook distance (GCD), namely
where
is the estimated observed information matrix.
Another commonly used influence measure is the likelihood distance (LD), namely
In addition to global influence measures, analyzing residuals can also be an effective way to assess model adequacy and check for incompatibilities with the response distribution. The deviance residuals for the GOLLL regression are
where
are the martingale residuals (see [
25]), and
takes value
if the argument is positive/negative.
4. Application
Initially, a comparative analysis of the GOLLL model against some alternative models is conducted. The EL, beta Lindley (BL) [
26], Kumaraswamy Lindley (KwL) [
27], and gamma-Lindley (GL) [
28] distributions are given by
The parameters of all distributions are positive real numbers, and
is the Lindley distribution. For all fitted models, the
goodness.fit function, using the BFGS method from the AdequacyModel package [
29], computes the MLEs (SEs in parentheses). The selection of the best fitted model is based on several well-known measures, including Cramér-von Mises (
), Anderson-Darling (
), and Kolmogorov-Smirnov (KS) (
p-values in parentheses).
4.1. COVID-19 Vaccination Rates on County-Level
To demonstrate the usefulness of the new GOLLL regression model over other competitive models, we provide an application that utilizes county-level COVID-19 vaccination rates in the state of Texas, USA.
The data set refers to 254 percentages of the population in counties with a completed vaccination (aged adjust) to COVID-19 extracted from CDC (
https://covid.cdc.gov/covid-data-tracker/#datatracker-home, accessed on 22 February 2023). This data set is used since Texas is the state with the highest number of counties in the US. Further investigation with other data sets (states, countries, and counties) should be addressed to examine the accuracy of the new model.
Additional research has examined the impact of covariates on the COVID-19 vaccination. Ref. [
30] analyzed the COVID-19 vaccination coverage associated with social vulnerability and urbanity. Ref. [
31] verified the impact of some variables in vaccination coverage and suggested that interventions be undertaken to improve COVID-19 vaccine acceptance and future uptake. The study conducted by [
32] utilized machine learning to study the vaccination rate in the USA. The findings provide insights to increase vaccination acceptance and combat the COVID-19 pandemic. Other investigations, Refs. [
33,
34] demonstrate some predictors for vaccine hesitancy using variables such as social-demographics and comorbidities and conclude a strong association. Therefore, the inclusion of the study variables is based on past research, comparisons, and investigations of possible new associations to aid vaccination campaigns.
The explanatory variables were extracted from County Health Rankings (
https://www.countyhealthrankings.org/, data from 2020, accessed on 22 February 2023) are outlined below (for
):
VR: Population rate with complete primary series of COVID-19 vaccination (response variable);
HP: Total number of hospitals reporting vaccination;
PR: Poverty rate (percentage of individuals with income below the poverty line);
MS: Metropolitan status ( non-metropolitan, metropolitan);
HR: High school completion rate (proportion of individuals aged 25 and above who have completed high school or its equivalent);
BA: Broadband access (percentage of households that have access to broadband internet);
HT: Heart disease rate (percentage of individuals that have chronic heart disease).
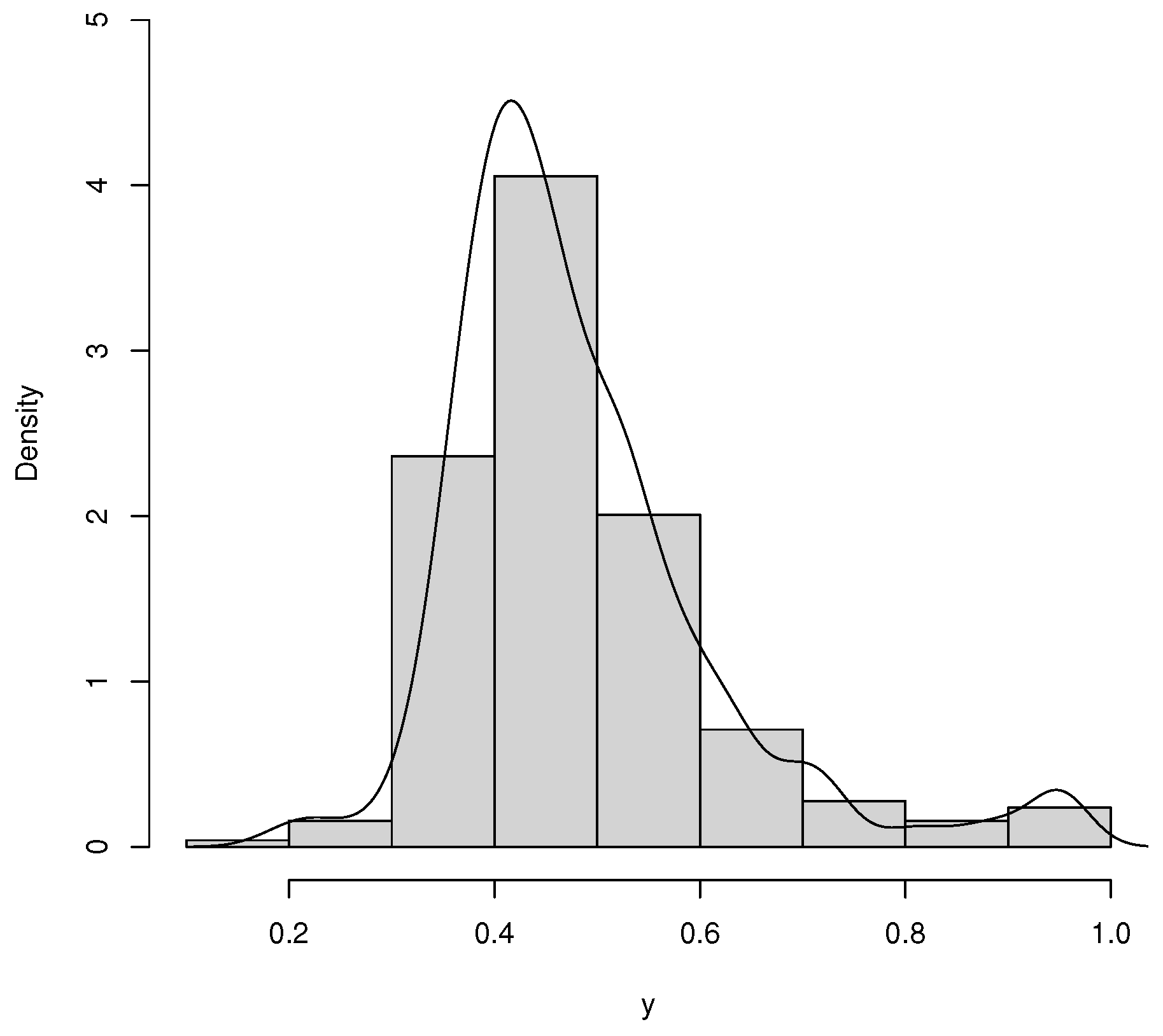
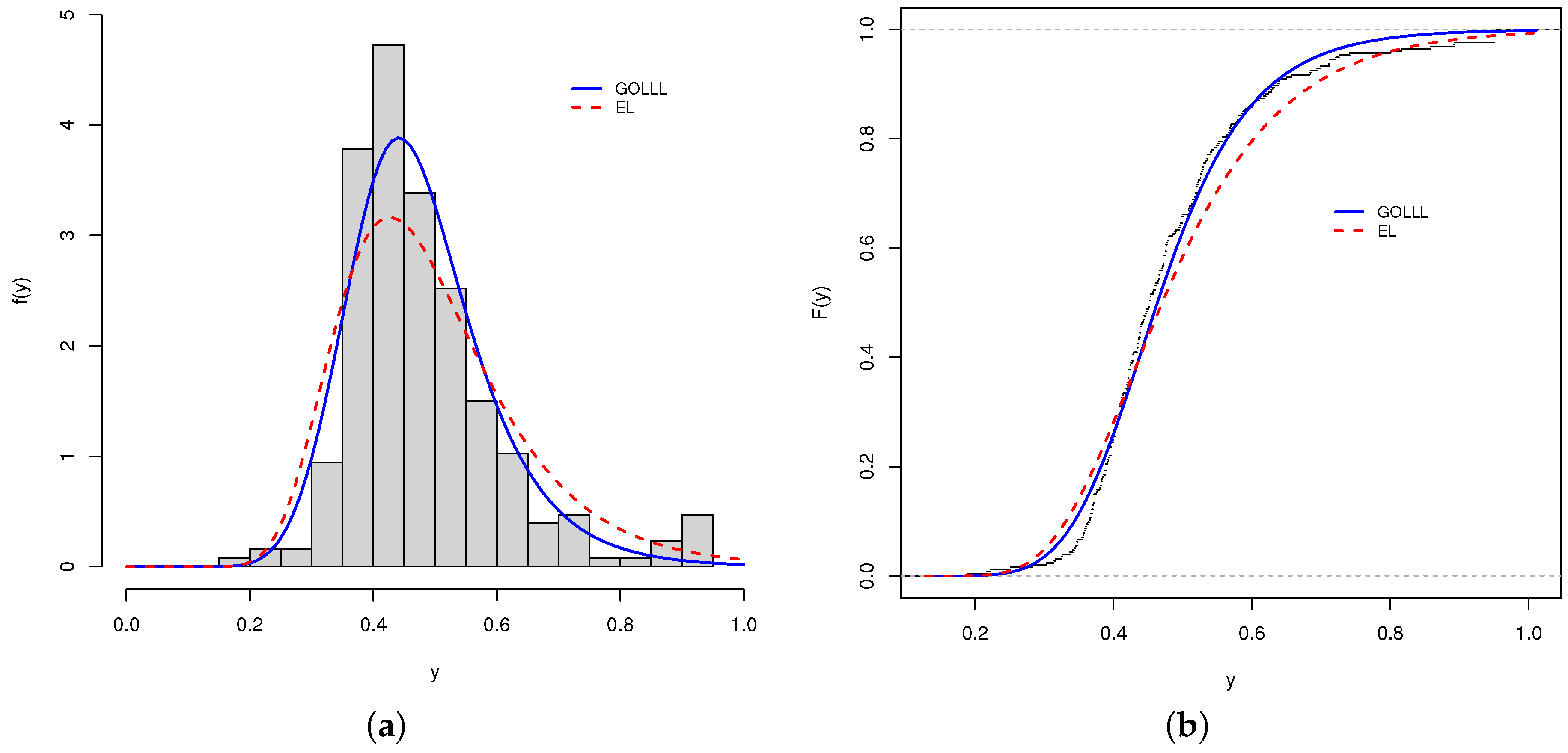
Table 3 reports the descriptive statistics for the data set, and the histogram is given in
Figure 8. The average rate of vaccination in counties was 0.483 in the period of the study. The standard deviation is 0.132, which can be explained by the range of 0.189 and 0.950, respectively, the minimum and the maximum. Furthermore, the skewness and kurtosis are positive.
First, the analysis involves modeling only the response variable by fitting the GOLLL, OLLL, EL, L, BL, KwL, and GL distributions. The MLEs, SEs, and the previous statistics (with the
p-values of KS) are reported in
Table 4 for the fitted distributions to the COVID-19 vaccination rate data. The GOLLL distribution is the most suitable model for the current data based on these measures.
Three LR tests compare the GOLLL distribution with its nested models. The numbers in
Table 5 indicate that the inclusion of extra parameters is significant for accurately modeling the current data.
The histogram and fitted densities of the two best models are illustrated in
Figure 9a. Further, the estimated cdfs of these models are reported in
Figure 9b. Although the model presents a good fit to the current data, it is not enough to know whether the model will be suitable for other datasets at different time or space scales. Future research can test other datasets in different states and at different spatial scales or county levels to investigate the accuracy of the new model.
4.2. Results New Regression
Next, utilizing the new regression model proposed, the systematic component is considered (for
)
Table 6 reports the MLEs, SEs, and
p-values for the fitted GOLLL regression model to the current data. The numbers support that all six explanatory variables are significant (at the level of
).
4.3. Diagnostic and Residual Analysis
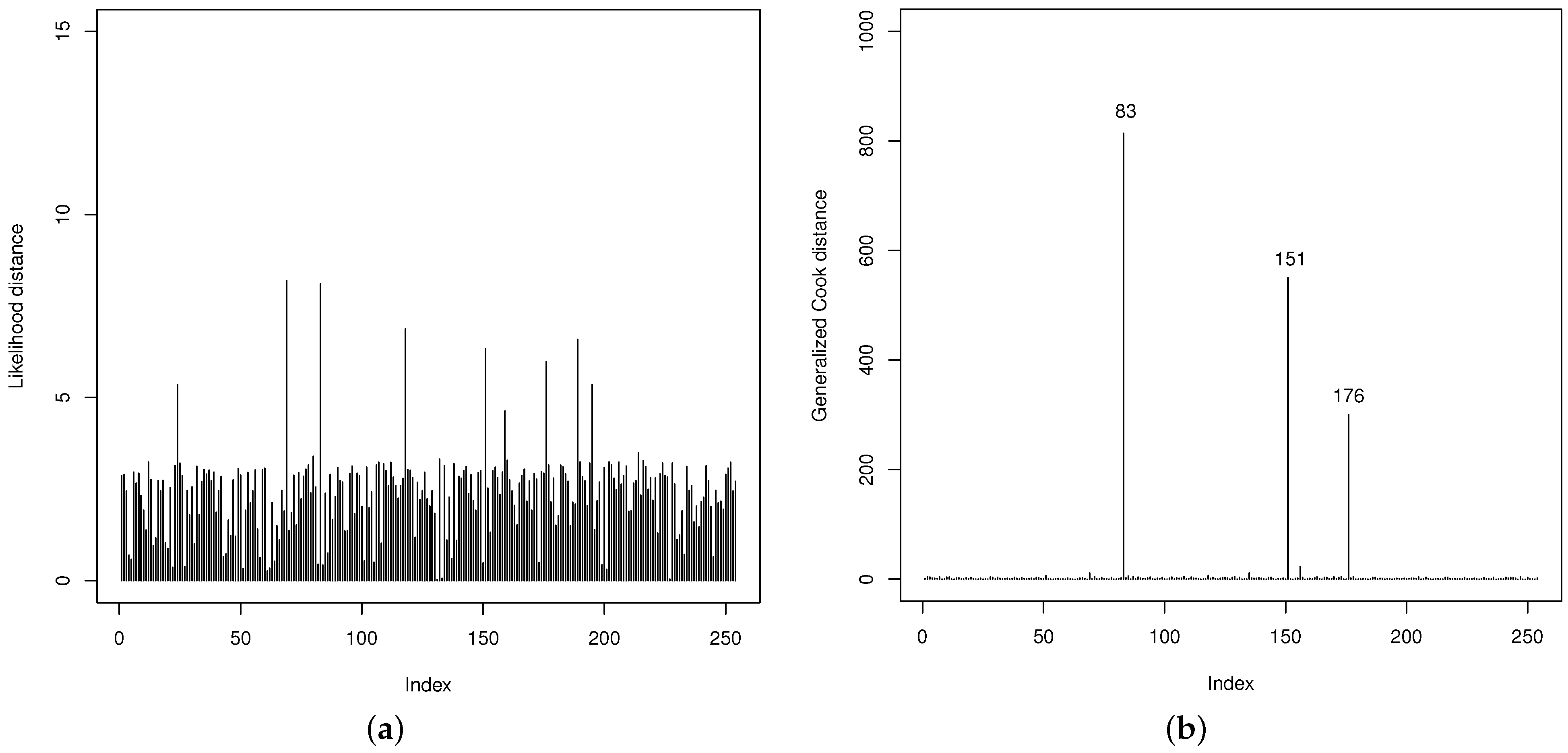
Thereafter, the quality of the fit of the GOLLL regression model is examined. The LD and GCD measures in
Figure 10 are useful to identify potentially influential observations. They show that the 83th, 151th, and 176th observations (referring to the counties below) are possibly influential. However, their impacts on the regression model are not particularly significant.
83th: Gaines county with VR: , HP: 1, PR: , MS: 0, HR: , BA: and HT: ;
151th: Loving county with VR: , HP: 0, PR: , MS: 0, HR: , BA: and HT: ;
176th: Newton county with VR: , HP: 0, PR: , MS: 1, HR: , BA: and HT: .
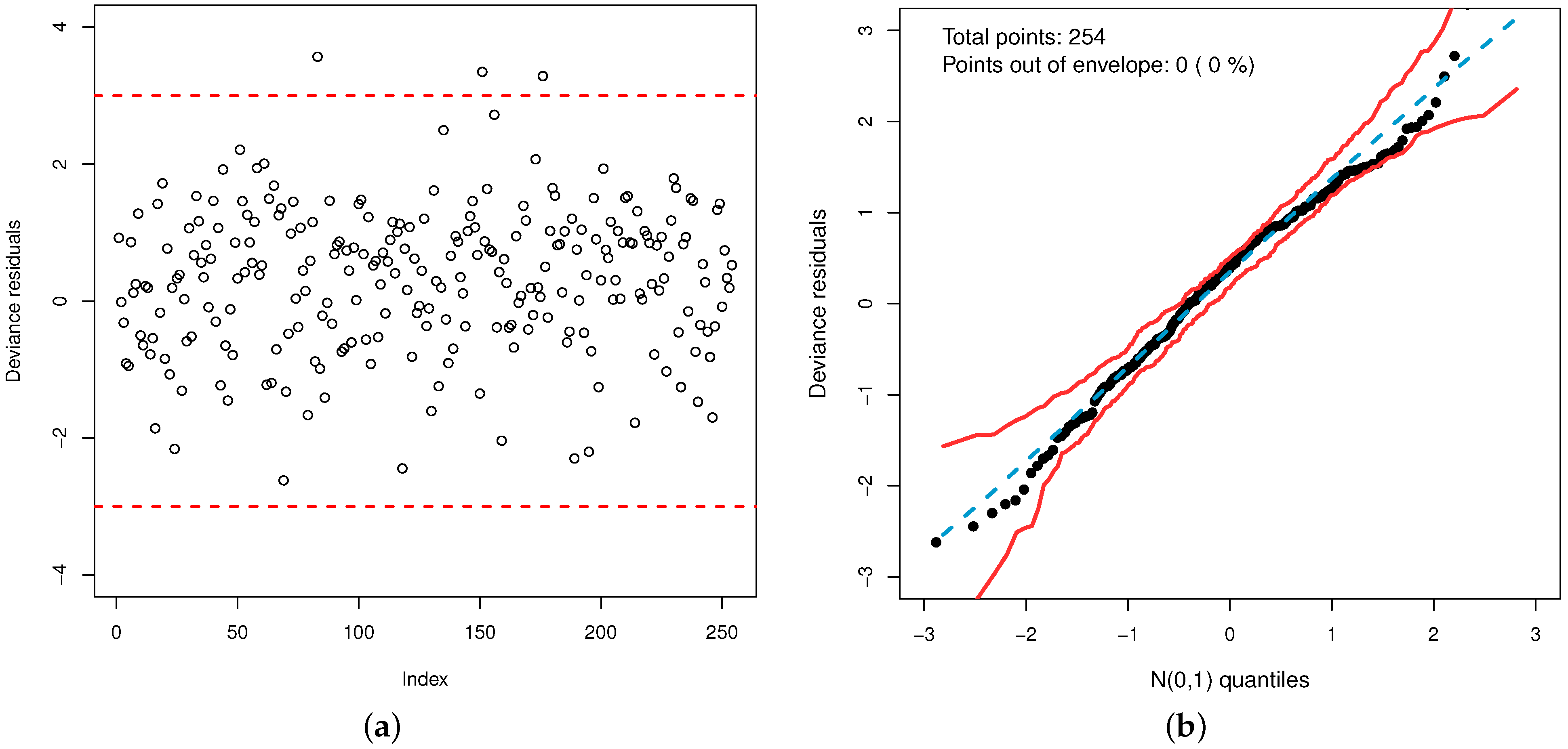
Additionally, the plot of the deviance residuals in
Figure 11a shows that they fall randomly within the bands. The normal probability plot with simulated envelope in
Figure 11b proves the accuracy of the model to fit the data set. So, the GOLLL regression model provides a good fit.
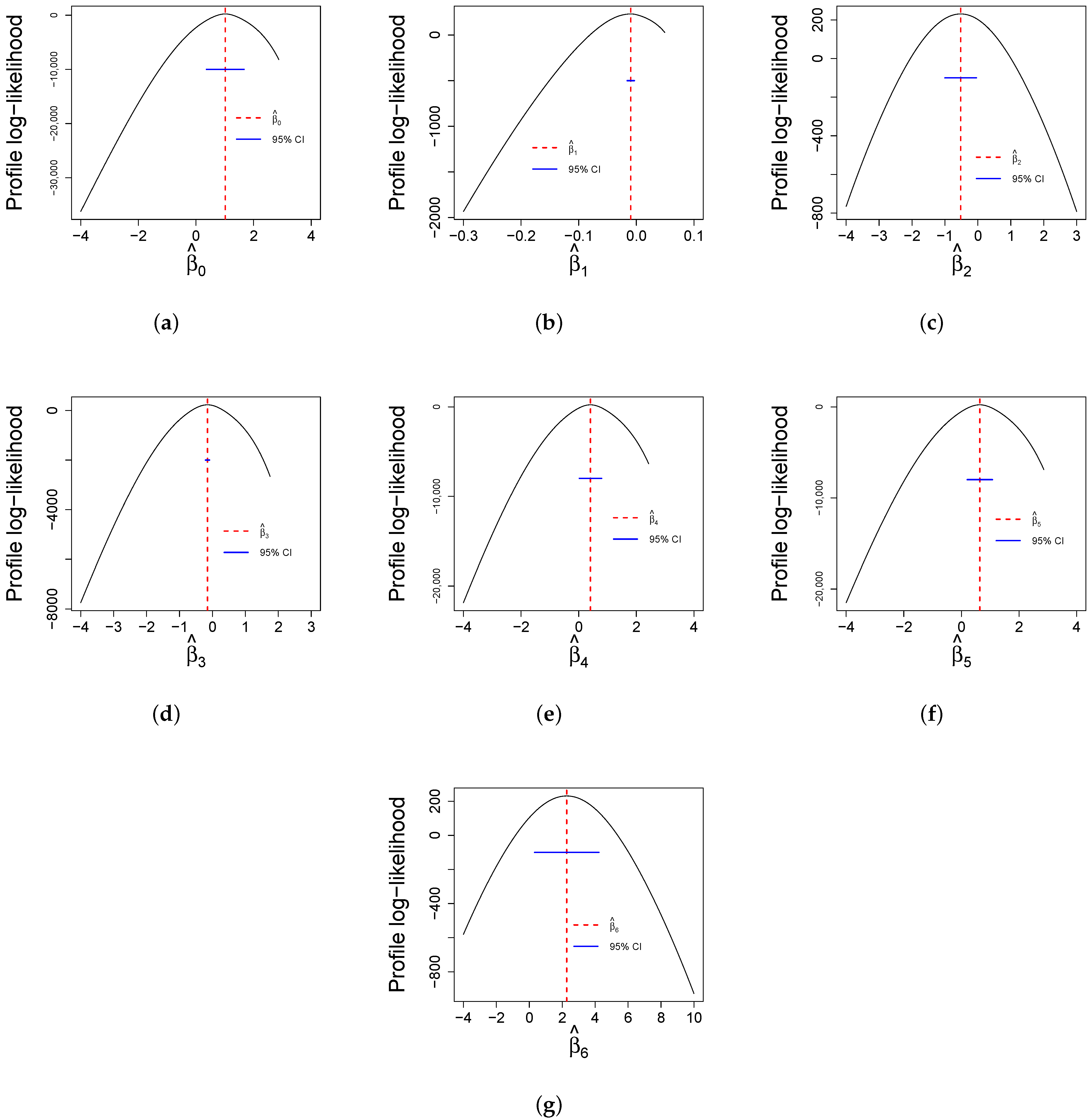
Finally,
Figure 12 reports profile log-likelihood plots for the parameters while keeping all other estimates constant. These plots are useful for determining confidence intervals for estimates and the reliability of statistical analyses. The curves of all parameters provide the accuracy and uncertainty associated with parameter estimates.
6. Conclusions
This article investigated the factors that explain the COVID-19 vaccination rate using the generalized odd log-logistic Lindley regression model with a shape systematic component. Some mathematical properties of this model were provided, and the maximum likelihood method was used to estimate the parameters. A Monte Carlo simulation evaluated the parameters of the proposed regression model, which revealed the consistency of the estimators and the approach to the nominal level of the coverage probabilities. Diagnostic analysis and deviance residuals proved the suitability of the new model.
The analysis of COVID-19 vaccination rates at the county level in Texas, US, uncovered significant findings. The total number of hospitals reporting vaccination is a slight predictor of vaccination, and it is suggested to be considered in future work for further investigations. Poverty rate and metropolitan status are evidenced in this work as determinants. The first one discussed in [
35,
36,
37,
38], among others, reveals the lack of access to the COVID-19 vaccine among individuals living in poverty. The second one examined in [
30,
41,
42] presented disparities in COVID-19 vaccination coverage between urban and rural counties, corroborating with this study. The education level was also identified as a determinant of increasing the vaccination rate. Supporting studies by [
43,
44,
46] indicated that the high school rate is a significant variable in coverage, access, and hesitancy vaccination. Another important variable is broadband access. The internet, supported by websites and social media platforms, disseminates information about vaccines, as suggested by prior studies [
47,
48,
49], and is consistent with the findings of this study. Several studies [
50,
51,
52] worldwide demonstrated how comorbidities influence COVID-19. Countries prioritized the availability of vaccines for people in the risk group, as highlighted in [
53]. Subsequent studies [
54,
55], illustrate findings similar to the current study, including heart disease.
The new model showed that it was more flexible than some competitive models. Hence, it is possible to conclude that the proposed model can provide better insights into the relationship between the explanatory variables and the response variable and serve as an alternative model to evaluate other research. It is recommended to apply the regression model introduced in other states, countries, or cities and verify if the same covariates would be significant in future works.
















{kind=link}
{kind=link}
{kind=link}
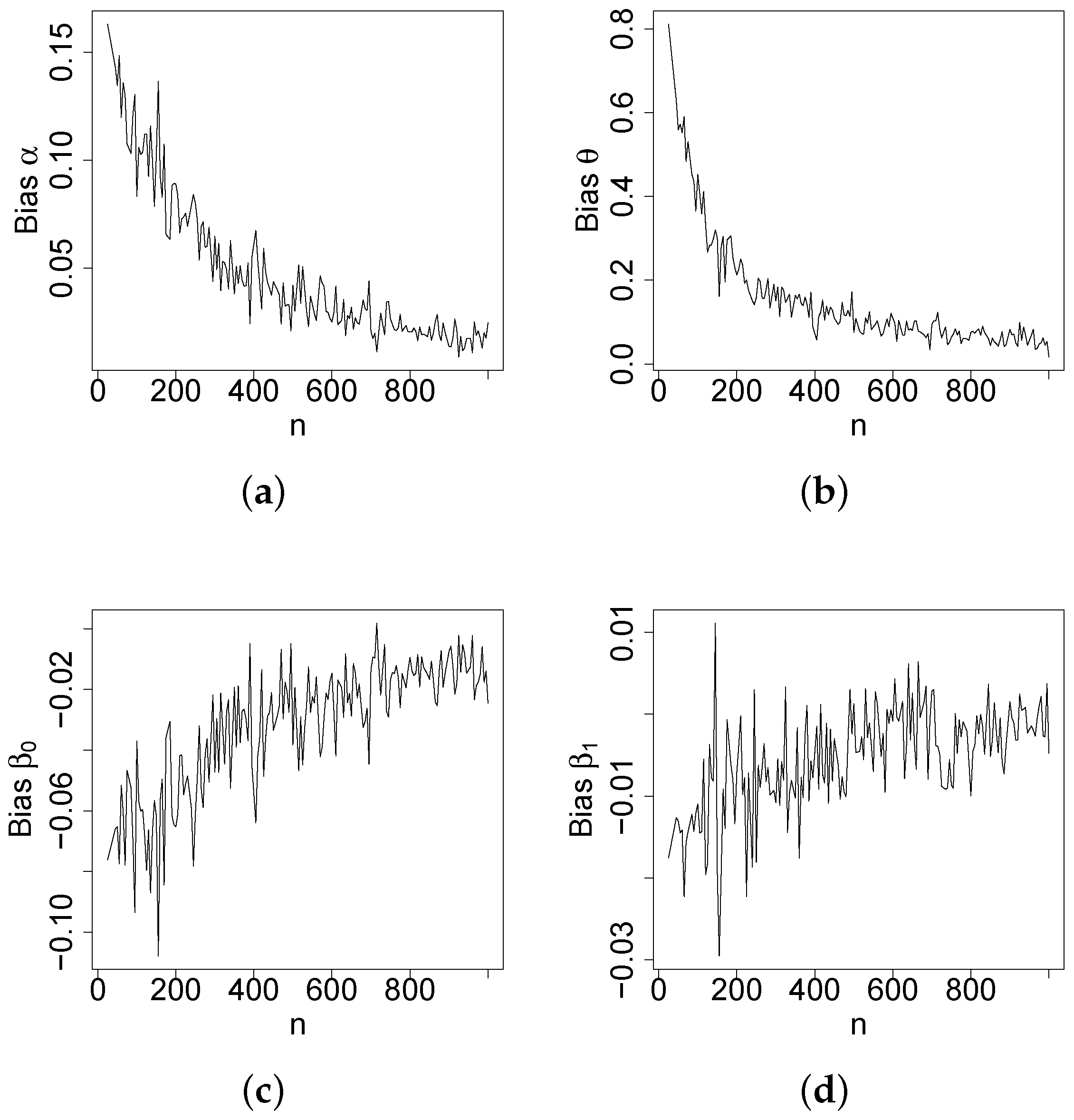{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}