

Development and Practical Applications of Computational Intelligence Technology
Abstract
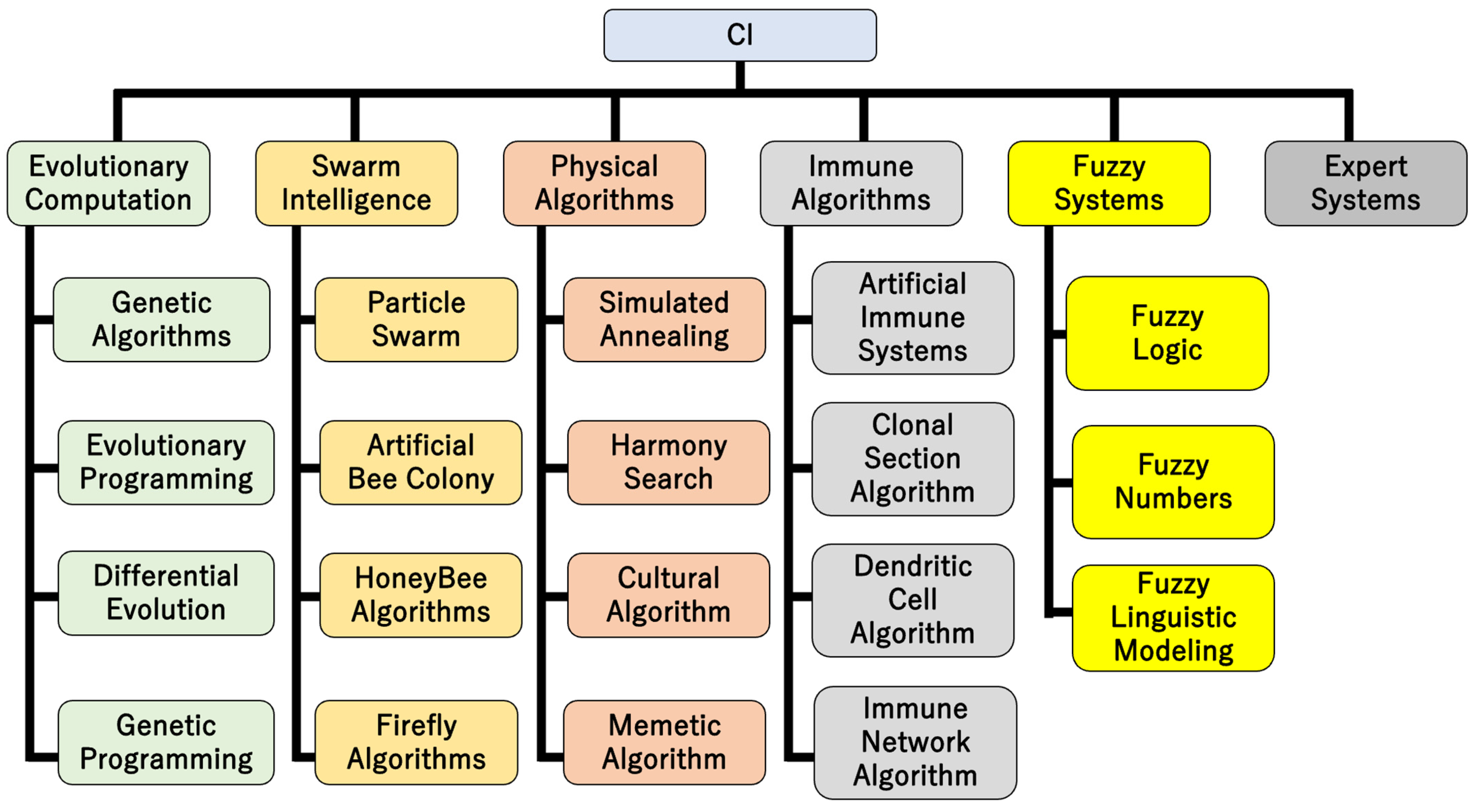
:1. Introduction
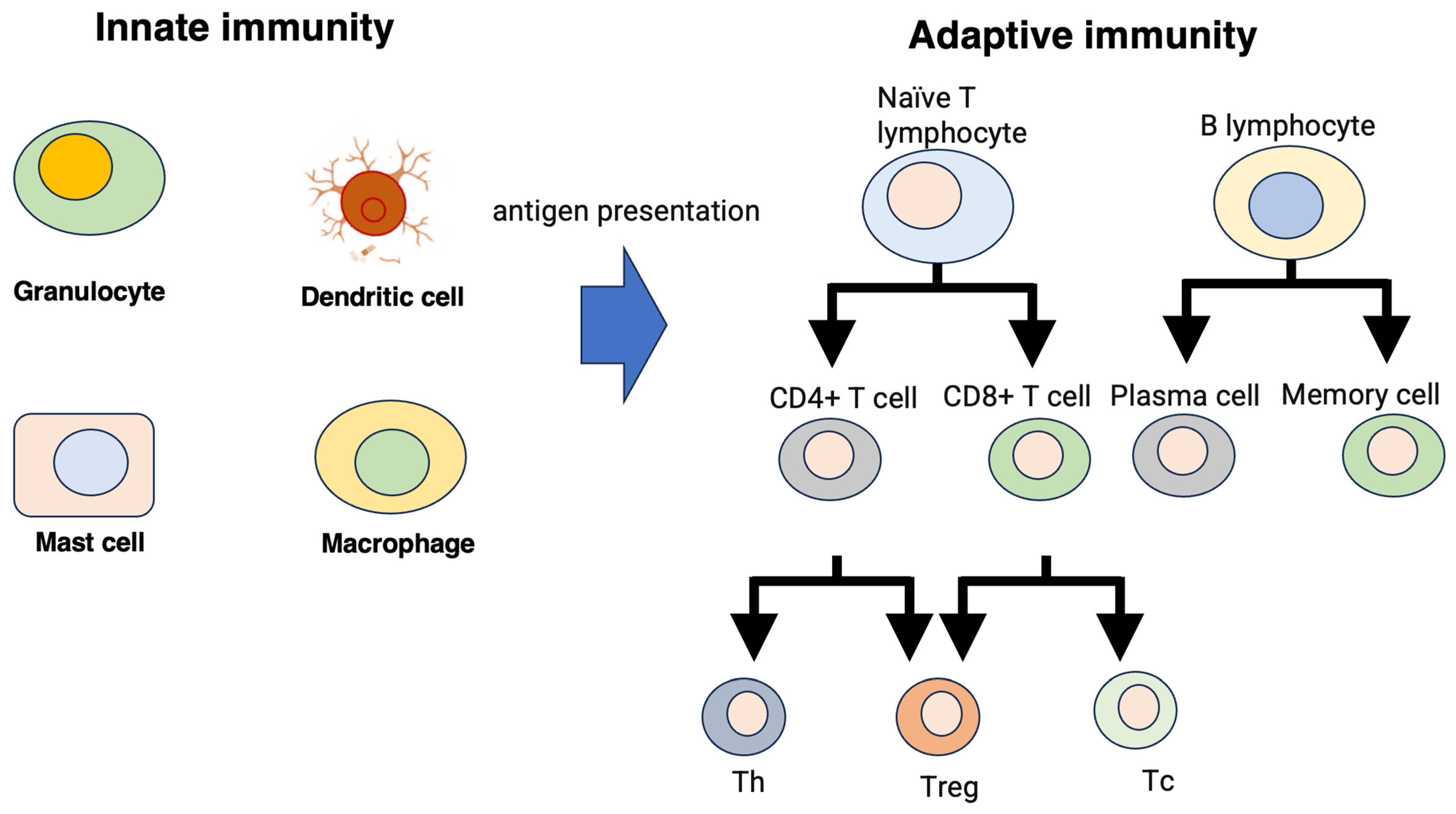
2. Immune System and Computer System
2.1. Immune System In Vivo
2.2. Modeling of the Biological Immune System
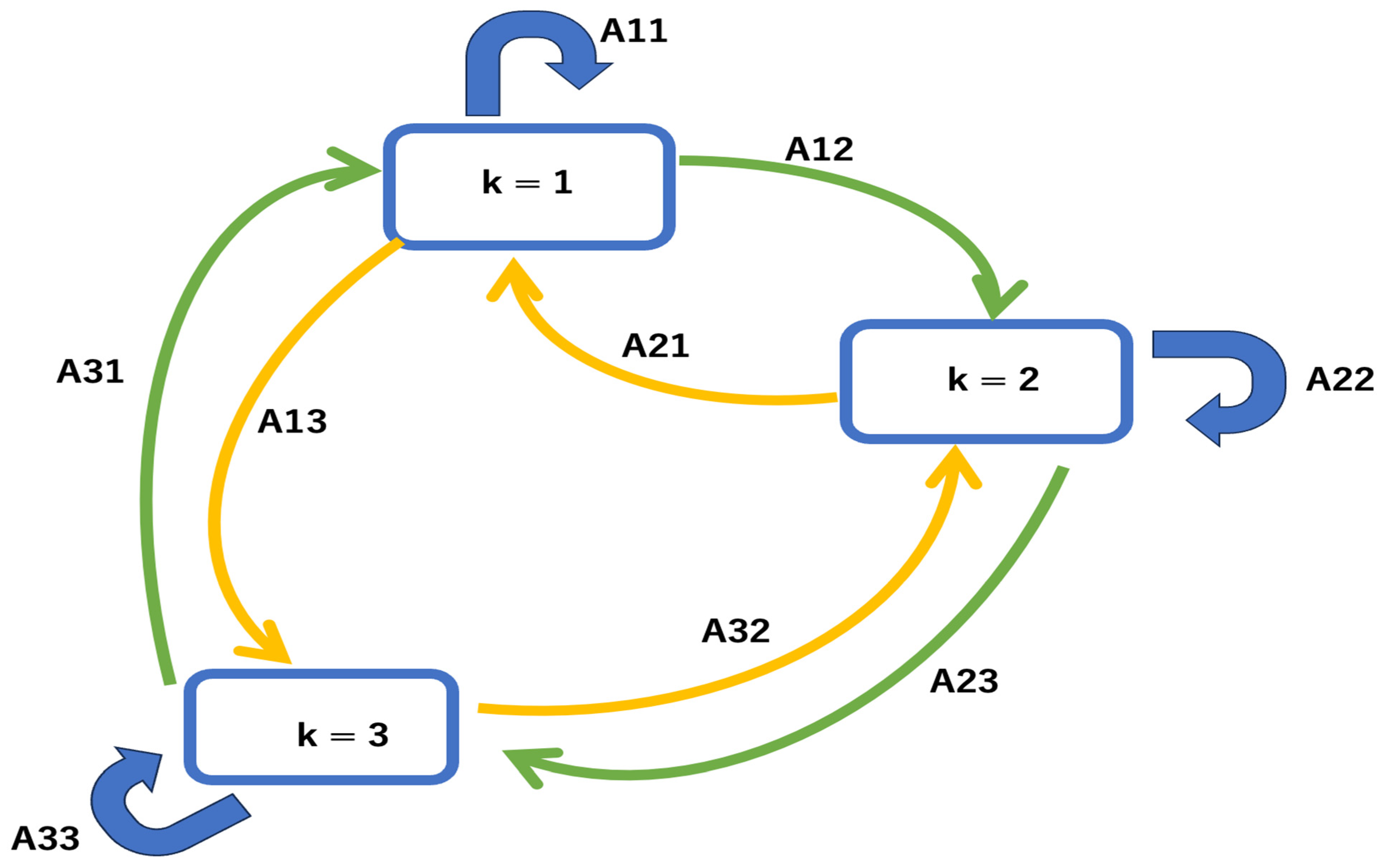
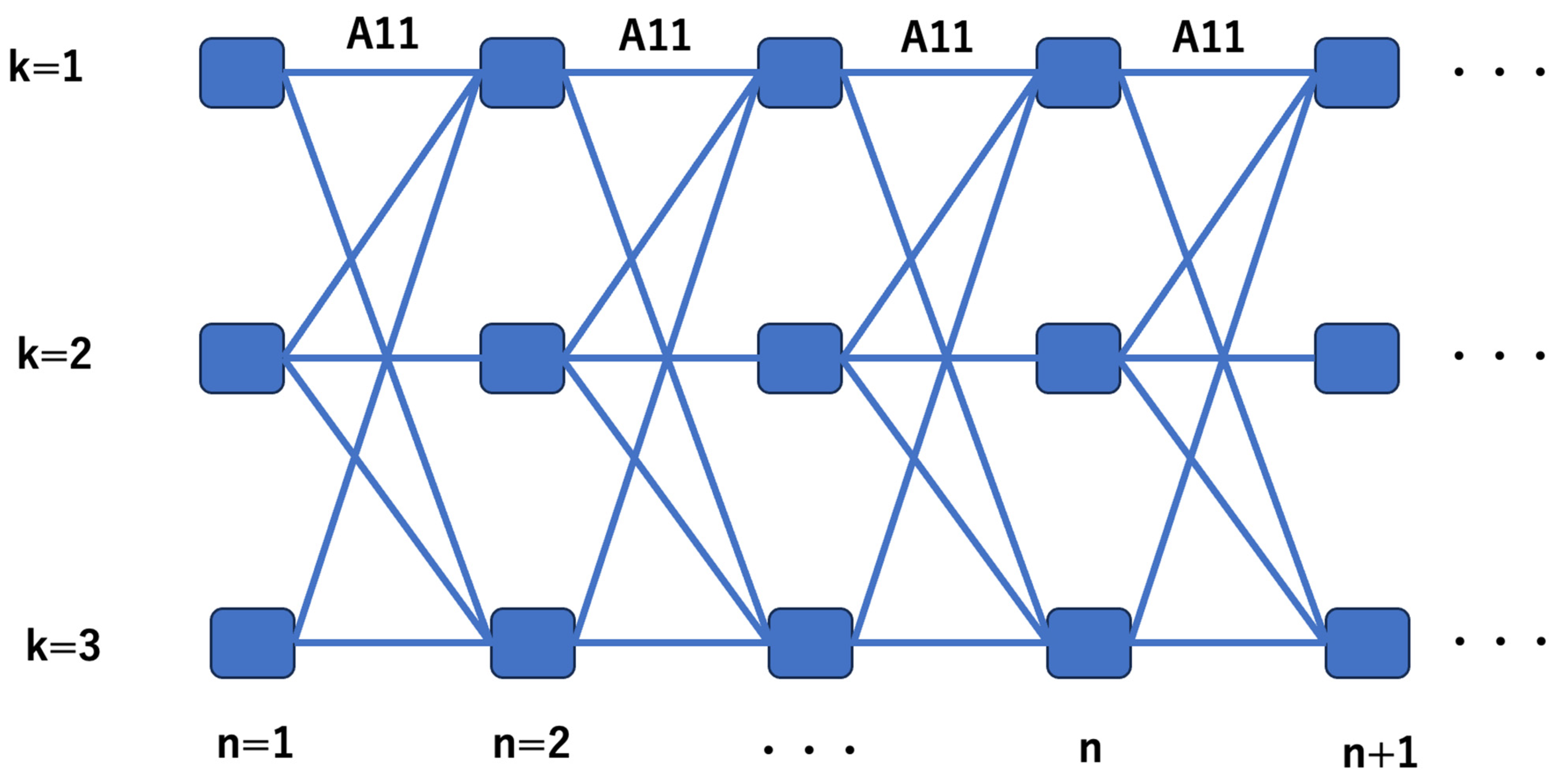
3. Neural Network
4. Pattern Recognition
4.1. Target Example of Pattern and Speech Recognition
4.2. Recognition Technology
- (1)
- For each state of the HMM, forward and backward probabilities are calculated.
- (2)
- Based on this calculation, the frequency of the values of the transition–output pair is determined and divided by the probability of the entire string. This corresponds to the calculation of the expected number of times for a particular transition–output pair. Each time a specific transition is found, the value of the transition quotient divided by the probability of the entire string increases, and this becomes the new value of the transition.
4.3. Evaluation Index
+ Number of deleted words)/(Number of correct words)
+ Number of deleted characters)/(Number of correct characters)
4.4. Speech Recognition Practices and Issues
4.5. Speech Recognition Technology under Development
4.6. Practical Examples of Speech Recognition
4.7. Optical Character Recognition (OCR)
- Data entry from business documents (checks, passports, invoices, bank statements, receipts, etc.);
- Automobile license plate reader (N system);
- Passport recognition and information extraction at airports;
- Automatic insurance document key information extraction;
- Traffic sign recognition systems;
- Extraction of contact information from business card information;
- Rapid creation of text versions of printed documents (e.g., Project Gutenberg book scans);
- Making electronic images of printed documents searchable (e.g., Google Books);
- Recognizing handwritten characters in real time (pen computing);
- Breaking through the CAPTCHA anti-bot system;
- Assistive technology for the visually impaired;
- Instructing vehicles by identifying CAD images in the database that are suitable for real-time-changing vehicle designs;
- Converting scanned documents to searchable PDFs and making them searchable;
- Score OCR to read printed sheet music;
- StotOCR for character recognition of images cut from desktops with screenshots;
- Pre-treatment: OCR software often “pre-processes” images to improve recognition rates;
- Tilt correction: If the document is not aligned correctly when scanned, the document can be tilted clockwise or counterclockwise a few degrees to make the lines of text perfectly horizontal or vertical;
- Speckle removal: Smoothing out contours by removing black and white speckles;
- Binarization: Converting an image from color or grayscale to a black and white binary image. The binarization task is an easy way to separate the desired text or image from the background. Most commercial recognition algorithms only work on binary images; therefore, the task of binarization is essential. In addition, the binarization method should be carefully selected for a particular input image type, because the results of the binarization process greatly affect the quality of the character recognition stage;
- Removing borders: Erasing non-glyph rules and lines;
- Layout analysis, and zoning: Identifying columns, paragraphs, footnotes, etc., as separate blocks, which is especially important in layouts with columns and tables;
- Line and word detection: Establishing a baseline for word and letter shapes, and breaking words as needed;
- Script recognition: In multilingual documents, scripts may change at the word level, requiring script identification before involving the appropriate OCR to process a particular script;
- Aspect ratio and scale normalization: Monospaced font segmentation is achieved relatively simply by aligning the image to a uniform grid based on where vertical grid lines least frequently cross black areas. Proportional fonts require more sophisticated techniques because the whitespace between characters can be larger than the whitespace between words, and vertical lines can intersect multiple characters.
4.8. Index String Extraction Method
- Search word frequency in documents;
- Parsing HTML tags;
- tf-idf: TF indicates the frequency of appearance of a word, and IDF indicates the degree to which words are concentrated in a part of all documents;
- Page rank: Ranking is based on the principle that “pages linked from high-importance pages are important”.
4.9. Computer Vision (CV) for Image Recognition
- Image sensor
- -
- Camera,
- -
- Range finder;
- Two-dimensional image processing
- -
- Background subtraction,
- -
- Inter-frame difference method,
- -
- Optical flow,
- -
- Motion vector;
- Three-dimensional image processing
- -
- Stereo method (computer stereo vision),
- -
- Epipolar geometry,
- -
- Shape from X,
- -
- Factorization;
- Recognition/Identification
- -
- Machine learning algorithms (k-nn, k-means, svm, etc.),
- -
- Deep learning algorithms (CNN, RNN, etc.);
- Information presentation
- -
- Virtual reality,
- -
- Mixed reality/augmented reality.
- CV;
- Natural language understanding;
- Passing the Turing test.
4.10. Biometrics (Biometric Authentication or Biometrics Authentication)
- Fingerprint
- DNA
- Hand shape
- Retina
- Iris
- Face
- Blood vessels
- Audio
- Ear shape
- Body odor
- Handwriting
- Lip movement
- Blinking
- Walking
4.11. Gesture Recognition
4.12. Sign Language Recognition
4.13. Sketch Recognition
5. Data Mining
- Association rule extraction: A technology that extracts events that frequently occur at the same times as highly correlated events, or association rules, from a large amount of data stored in a database;
- Other frequent patterns;
- Time series and graphs.
6. Modeling and Optimization
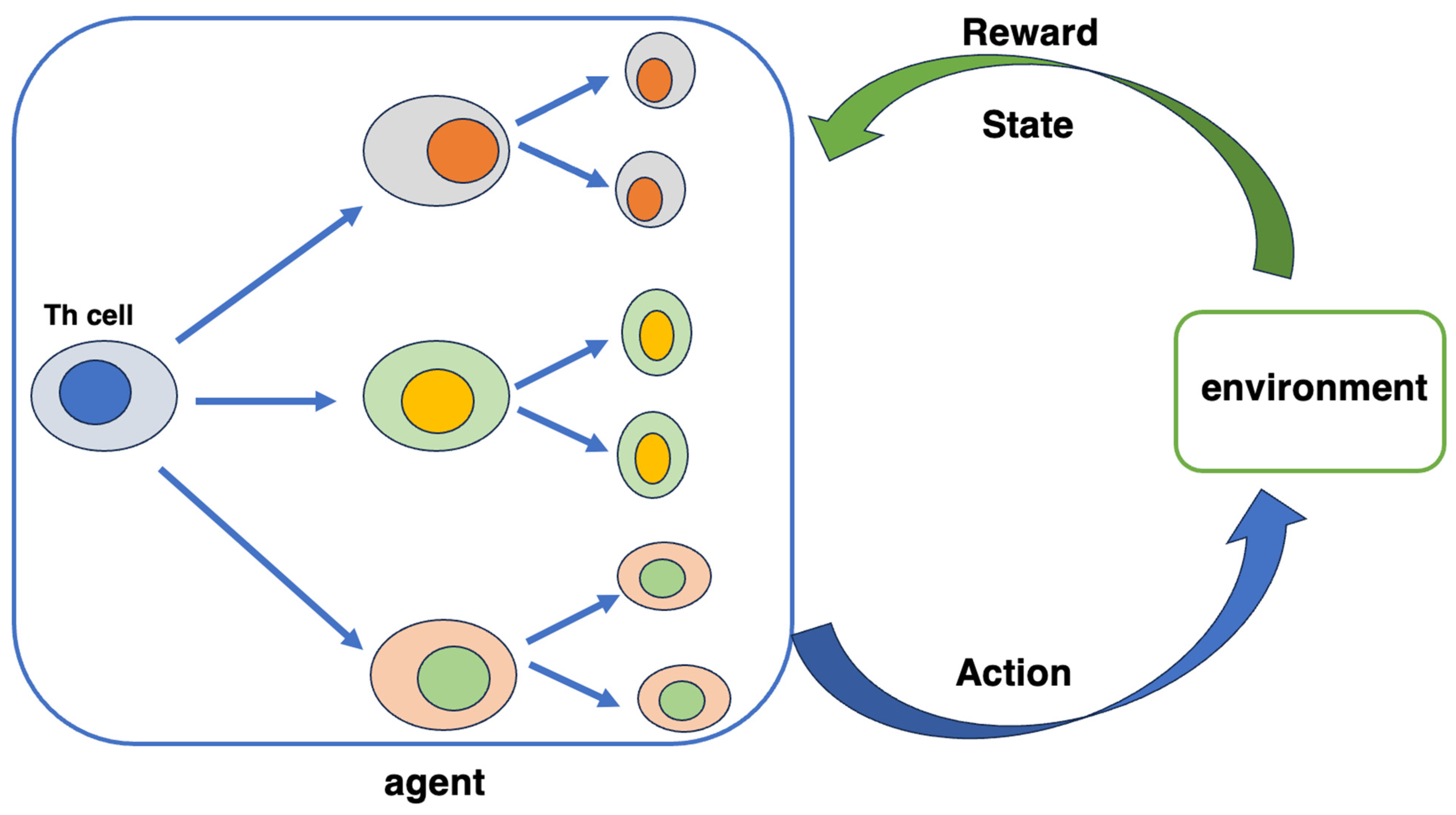
6.1. T Cell Networks and Reinforcement Learning
6.2. Automatic Tracking of Immune Cells with Deep Learning
7. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Badura, P.; Pietka, E. Soft computing approach to 3D lung nodule segmentation in CT. Comput. Biol. Med. 2014, 53, 230–243. [Google Scholar] [CrossRef]
- Green, D.; Lavesson, N. Chaos theory and artificial intelligence may provide insights on disability outcomes. Dev. Med. Child. Neurol. 2019, 61, 1120. [Google Scholar] [CrossRef]
- Wang, Z.; Tang, X.; Liu, H.; Peng, L. Artificial immune intelligence-inspired dynamic real-time computer forensics model. Math. Biosci. Eng. 2020, 17, 7221–7233. [Google Scholar] [CrossRef]
- Alghamdi, M.; Maray, M.; Alazzam, M.B. Diagnosis of Breast Cancer Using Computational Intelligence Models and IoT Applications. Comput. Intell. Neurosci. 2022, 2022, 2143510. [Google Scholar] [CrossRef]
- Matarneh, F.M.; Alqaralleh, B.A.Y.; Aldhaban, F.; AlQaralleh, E.A.; Kumar, A.; Gupta, D.; Joshi, G.P. Swarm Intelligence with Adaptive Neuro-Fuzzy Inference System-Based Routing Protocol for Clustered Wireless Sensor Networks. Comput. Intell. Neurosci. 2022, 2022, 7940895. [Google Scholar] [CrossRef]
- Chetty, M.; Hallinan, J.; Ruz, G.A.; Wipat, A. Computational intelligence and machine learning in bioinformatics and computational biology. Biosystems 2022, 222, 104792. [Google Scholar] [CrossRef]
- Zheng, P.; Dou, Y.; Wang, Q. Immune response and treatment targets of chronic hepatitis B virus infection: Innate and adaptive immunity. Front. Cell Infect Microbiol. 2023, 13, 1206720. [Google Scholar] [CrossRef]
- Martins, Y.C.; Ribeiro-Gomes, F.L.; Daniel-Ribeiro, C.T. A short history of innate immunity. Mem. Inst. Oswaldo. Cruz. 2023, 118, e230023. [Google Scholar] [CrossRef]
- Zhang, H.; Gao, J.; Tang, Y.; Jin, T.; Tao, J. Inflammasomes cross-talk with lymphocytes to connect the innate and adaptive immune response. J. Adv. Res. 2023, 54, 181–193. [Google Scholar] [CrossRef]
- Yang, H.; Li, T.; Hu, X.; Wang, F.; Zou, Y. A survey of artificial immune system based intrusion detection. Sci. World J. 2014, 2014, 156790. [Google Scholar] [CrossRef]
- Al-Enezi, J.R.; Abbod, M.F.; Alsharhan, S. Artificial Immune Systems—Models, Algorithms and Applications. IJRRAS 2010, 3, 118–131. [Google Scholar]
- Kephart, J.O. A biologically inspired immune system for computers. In Artificial Life IV: The Fourth International Workshop on the Synthesis and Simulation of Living Systems; MIT Press: Cambridge, MA, USA, 1994; pp. 130–139. [Google Scholar]
- Peng, X.; Feng, J.; Zhou, J.T.; Lei, Y.; Yan, S. Deep Subspace Clustering. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 5509–5521. [Google Scholar] [CrossRef]
- Itoh, K.; Miwa, H.; Takanobu, H.; Takanishi, A. Application of neural network to humanoid robots-development of co-associative memory model. Neural Netw. 2005, 18, 666–673. [Google Scholar] [CrossRef]
- Jordanou, J.P.; Antonelo, E.A.; Camponogara, E. Echo State Networks for Practical Nonlinear Model Predictive Control of Unknown Dynamic Systems. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 2615–2629. [Google Scholar] [CrossRef]
- Peng, W.; Varanka, T.; Mostafa, A.; Shi, H.; Zhao, G. Hyperbolic Deep Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach Intell. 2022, 44, 10023–10044. [Google Scholar] [CrossRef]
- Renganathan, V. Overview of artificial neural network models in the biomedical domain. Bratisl. Lek. Listy. 2019, 120, 536–540. [Google Scholar] [CrossRef]
- Zhang, Y.; Lin, H.; Yang, Z.; Wang, J.; Sun, Y.; Xu, B.; Zhao, Z. Neural network-based approaches for biomedical relation classification: A review. J. Biomed. Inform. 2019, 99, 103294. [Google Scholar] [CrossRef]
- Wang, X.; Lin, X.; Dang, X. Supervised learning in spiking neural networks: A review of algorithms and evaluations. Neural Netw. 2020, 125, 258–280. [Google Scholar] [CrossRef]
- Behler, J. Four Generations of High-Dimensional Neural Network Potentials. Chem. Rev. 2021, 121, 10037–10072. [Google Scholar] [CrossRef]
- Shamir, L.; Delaney, J.D.; Orlov, N.; Eckley, D.M.; Goldberg, I.G. Pattern recognition software and techniques for biological image analysis. PLoS Comput. Biol. 2010, 6, e1000974. [Google Scholar] [CrossRef]
- Partila, P.; Voznak, M.; Tovarek, J. Pattern Recognition Methods and Features Selection for Speech Emotion Recognition System. Sci. World J. 2015, 2015, 573068. [Google Scholar] [CrossRef]
- Dinges, L.; Al-Hamadi, A.; Elzobi, M.; El-Etriby, S. Synthesis of Common Arabic Handwritings to Aid Optical Character Recognition Research. Sensors 2016, 16, 346. [Google Scholar] [CrossRef] [PubMed]
- Ho, S.Y.; Hsieh, C.H.; Chen, H.M.; Huang, H.L. Interpretable gene expression classifier with an accurate and compact fuzzy rule base for microarray data analysis. Biosystems 2006, 85, 165–176. [Google Scholar] [CrossRef] [PubMed]
- He, T.; Wang, T.; Abbey, R.; Griffin, J. High-Performance Support Vector Machines and Its Applications. arXiv 2019, arXiv:1905.00331v1. [Google Scholar]
- Gil-Herrera, E.; Aden-Buie, G.; Yalcin, A.; Tsalatsanis, A.; Barnes, L.E.; Djulbegovic, B. Rough set theory based prognostic classification models for hospice referral. BMC Med. Inform. Decis. Mak. 2015, 15, 98. [Google Scholar] [CrossRef]
- Buss, E.; Miller, M.K.; Leibold, L.J. Maturation of Speech-in-Speech Recognition for Whispered and Voiced Speech. J. Speech Lang. Hear Res. 2022, 65, 3117–3128. [Google Scholar] [CrossRef] [PubMed]
- Lee, L.M.; Jean, F.R. High-order hidden Markov model for piecewise linear processes and applications to speech recognition. J. Acoust. Soc. Am. 2016, 140, EL204. [Google Scholar] [CrossRef] [PubMed]
- Moreira, B.S.; Perkusich, A.; Luiz, S.O.D. An Acoustic Sensing Gesture Recognition System Design Based on a Hidden Markov Model. Sensors 2020, 20, 4803. [Google Scholar] [CrossRef] [PubMed]
- You, H.; Byun, S.H.; Choo, Y. Underwater Acoustic Signal Detection Using Calibrated Hidden Markov Model with Multiple Measurements. Sensors 2022, 22, 5088. [Google Scholar] [CrossRef]
- Rohrmeier, M.; Fu, Q.; Dienes, Z. Implicit learning of recursive context-free grammars. PLoS ONE 2012, 7, e45885. [Google Scholar] [CrossRef]
- Ríos-Toledo, G.; Posadas-Durán, J.P.F.; Sidorov, G.; Castro-Sánchez, N.A. Detection of changes in literary writing style using N-grams as style markers and supervised machine learning. PLoS ONE 2022, 17, e0267590. [Google Scholar] [CrossRef]
- Yu, X.; Xiong, S. A Dynamic Time Warping Based Algorithm to Evaluate Kinect-Enabled Home-Based Physical Rehabilitation Exercises for Older People. Sensors 2019, 19, 2882. [Google Scholar] [CrossRef]
- Polur, P.D.; Miller, G.E. Experiments with fast Fourier transform, linear predictive and cepstral coefficients in dysarthric speech recognition algorithms using hidden Markov Model. IEEE Trans. Neural Syst. Rehabil. Eng. 2005, 13, 558–561. [Google Scholar] [CrossRef]
- Chen, X.; Zhu, X.; Zhang, D. Use of the discriminant Fourier-derived cepstrum with feature-level post-processing for surface electromyographic signal classification. Physiol. Meas. 2009, 30, 1399–1413. [Google Scholar] [CrossRef]
- Ezaki, T.; Himeno, Y.; Watanabe, T.; Masuda, N. Modelling state-transition dynamics in resting-state brain signals by the hidden Markov and Gaussian mixture models. Eur. J. Neurosci. 2021, 54, 5404–5416. [Google Scholar] [CrossRef]
- Lammert, A.C.; Narayanan, S.S. On Short-Time Estimation of Vocal Tract Length from Formant Frequencies. PLoS ONE 2015, 10, e0132193. [Google Scholar] [CrossRef]
- Gudivada, V.N.; Rao, D.; Raghavan, V.V. Chapter 9—Big Data Driven Natural Language Processing Research and Applications. In Handbook of Statistics; Elsevier: Amsterdam, The Netherlands, 2015; Volume 33, pp. 203–238. [Google Scholar]
- Ali, A.; Renals, S. Word Error Rate Estimation Without ASR Output: E-WER2. arXiv 2020, arXiv:2008.03403v1. [Google Scholar]
- Sawata, R.; Kashiwagi, Y.; Takahashi, S. Improving Character Error Rate Is Not Equal to Having Clean Speech: Speech Enhancement for ASR Systems with Black-box Acoustic Models. arXiv 2021, arXiv:2110.05968. [Google Scholar]
- He, B.; Radfar, M. The Performance Evaluation of Attention-Based Neural ASR under Mixed Speech Input. arXiv 2021, arXiv:2108.01245v1. [Google Scholar]
- Poder, T.G.; Fisette, J.F.; Déry, V. Speech Recognition for Medical Dictation: Overview in Quebec and Systematic Review. J. Med. Syst. 2018, 42, 89. [Google Scholar] [CrossRef] [PubMed]
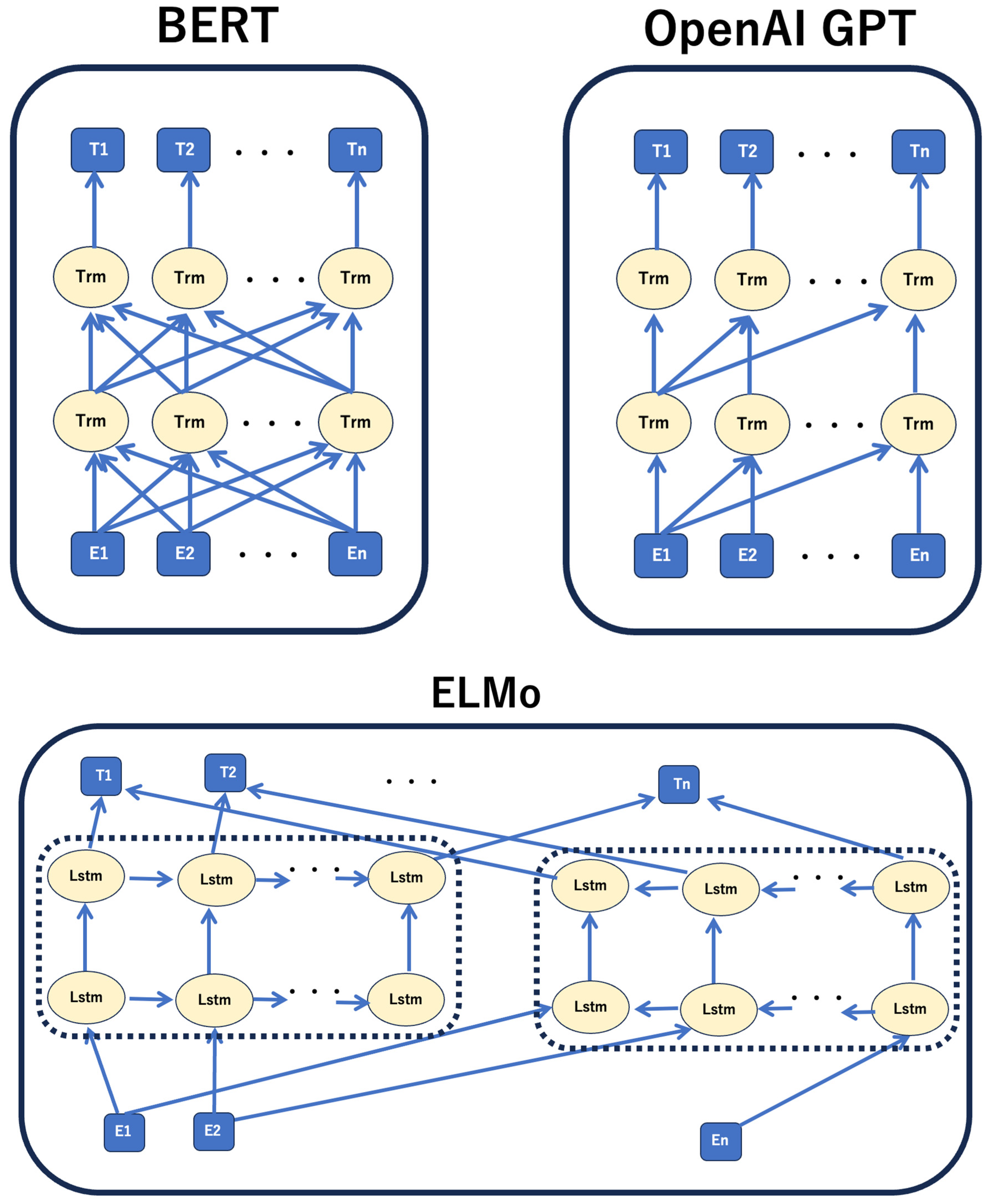
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805v2. [Google Scholar]
- Valin, J.-M. Auditory System for a Mobile Robot. arXiv 2016, arXiv:1602.06652v1. [Google Scholar]
- Segbroeck, M.V. Van hamme, H. Advances in Missing Feature Techniques for Robust Large-Vocabulary Continuous Speech Recognition. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 123–137. [Google Scholar] [CrossRef]
- Chen, C.; Zhou, Y.; Liu, H. A DNN-based Post Filter for Geometric Source Separation. J. Phys. Conf. Ser. 2019, 1176, 032039. [Google Scholar] [CrossRef]
- Nakajima, H.; Nakadai, K.; Hasegawa, Y.; Tsujino, H. High performance sound source separation adaptable to environmental changes for robot audition. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 22–26. [Google Scholar] [CrossRef]
- Hom, J.; Nikowitz, J.; Ottesen, R.; Niland, J.C. Facilitating clinical research through automation: Combining optical character recognition with natural language processing. Clin. Trials 2022, 19, 504–511. [Google Scholar] [CrossRef]
- Li, M.; Lv, T.; Chen, J.; Cui, L.; Lu, Y.; Florencio, D.; Zhang, C.; Li, Z.; Wei, F. TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models. arXiv 2021, arXiv:2109.10282v5. [Google Scholar] [CrossRef]
- Zhang, Z.; Sun, J.; Dai, Y.; Zhou, D.; Song, X.; He, M. End-to-end Learning the Partial Permutation Matrix for Robust 3D Point Cloud Registration. arXiv 2021, arXiv:2110.15250v2. [Google Scholar] [CrossRef]
- Shi, D.; Diao, X.; Shi, L.; Tang, H.; Chi, Y.; Li, C.; Xu, H. CharFormer: A Glyph Fusion based Attentive Framework for High-precision Character Image Denoising. arXiv 2022, arXiv:2207.07798v2. [Google Scholar]
- Randika, A.; Ray, N.; Xiao, X.; Latimer, A. Unknown-box Approximation to Improve Optical Character Recognition Performance. arXiv 2021, arXiv:2105.07983v. [Google Scholar]
- Da, C.; Wang, P.; Yao, C. Levenshtein OCR. arXiv 2022, arXiv:2209.03594v2. [Google Scholar]
- Wang, Y.; Huang, H.; Liu, Z.; Pang, Y. Improving N-gram Language Models with Pre-trained Deep Transformer. arXiv 2019, arXiv:1911.10235v1. [Google Scholar]
- Kelbessa, I.W. The effects of having lists of synonyms on the performance of Afaan Oromo Text Retrieval system. arXiv 2021, arXiv:2103.02900v1. [Google Scholar]
- Wu, W.; Xie, E.; Zhang, R.; Wang, W.; Luo, P.; Zhou, H. Polygon-free: Unconstrained Scene Text Detection with Box Annotations. arXiv 2020, arXiv:2011.13307v3. [Google Scholar]
- Rost, M.; Schmid, S. NP-Completeness and Inapproximability of the Virtual Network Embedding Problem and Its Variants. arXiv 2018, arXiv:1801.03162. [Google Scholar]
- Zhou, F.; Zhao, T. A Survey on Biometrics Authentication. arXiv 2022, arXiv:2212.08224v1. [Google Scholar]
- Purnapatra, S.; Miller-Lynch, C.; Miner, S.; Liu, Y.; Bahmani, K.; Dey, S.; Schuckers, S. Presentation Attack Detection with Advanced CNN Models for Noncontact-based Fingerprint Systems. arXiv 2023, arXiv:2303.05459v1. [Google Scholar]
- Li, W.; Shi, P.; Yu, H. Gesture Recognition Using Surface Electromyography and Deep Learning for Prostheses Hand: State-of-the-Art, Challenges, and Future. Front. Neurosci. 2021, 15, 621885. [Google Scholar] [CrossRef] [PubMed]
- van Amsterdam, B.; Clarkson, M.J.; Stoyanov, D. Gesture Recognition in Robotic Surgery: A Review. IEEE Trans. Biomed. Eng. 2021, 68, 2021–2035. [Google Scholar] [CrossRef]
- Kudrinko, K.; Flavin, E.; Zhu, X.; Li, Q. Wearable Sensor-Based Sign Language Recognition: A Comprehensive Review. IEEE Rev. Biomed. Eng. 2021, 14, 82–97. [Google Scholar] [CrossRef]
- Amin, M.S.; Rizvi, S.T.H.; Hossain, M.M. A Comparative Review on Applications of Different Sensors for Sign Language Recognition. J. Imaging 2022, 8, 98. [Google Scholar] [CrossRef]
- Xu, P.; Joshi, C.K.; Bresson, X. Multi-Graph Transformer for Free-Hand Sketch Recognition. arXiv 2019, arXiv:1912.11258v3. [Google Scholar]
- Raschka, S. Naive Bayes and Text Classification I—Introduction and Theory. arXiv 2014, arXiv:1410.5329v4. [Google Scholar]
- Izza, Y.; Ignatiev, A.; Marques-Silva, J. On Explaining Decision Trees. arXiv 2020, arXiv:2010.11034v1. [Google Scholar]
- Davies, L. Linear Regression, Covariate Selection and the Failure of Modelling. arXiv 2021, arXiv:2112.08738v4. [Google Scholar]
- Domínguez-Almendros, S.; Benítez-Parejo, N.; Gonzalez-Ramirez, A.R. Logistic regression models. Allergol. Immunopathol. 2011, 39, 295–305. [Google Scholar] [CrossRef]
- Tanner, S.D.; Baranov, V.I.; Ornatsky, O.I.; Bandura, D.R.; George, T.C. An introduction to mass cytometry: Fundamentals and applications. Cancer Immunol. Immunother. 2013, 62, 955–965. [Google Scholar] [CrossRef]
- Shalev-Shwartz, S.; Wexler, Y. Minimizing the Maximal Loss: How and Why? arXiv 2016, arXiv:1602.01690. [Google Scholar]
- Kato, T.; Kobayashi, T.J. Understanding Adaptive Immune System as Reinforcement Learning. Phys. Rev. Res. 2021, 3, 013222. [Google Scholar] [CrossRef]
- Kusunose, S.; Shinomiya, Y.; Ushiwaka, T.; Maeda, N.; Hoshino, Y. A proposal for automatic tracking of immune cells using deep learning. In Proceedings of the Annual Conference of Biomedical Fuzzy Systems Association, Hachijo Island, Japan, 5–8 December 2020; Volume 33, pp. 68–71. [Google Scholar] [CrossRef]
- Joshi, G.; Jain, A.; Araveeti, S.R.; Adhikari, S.; Garg, H.; Bhandari, M. FDA approved Artificial Intelligence and Machine Learning (AI/ML)-Enabled Medical Devices: An updated landscape. Electronics 2024, 13, 498. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model or Technique Description | Aspects of the BIS Modeled | Type of Representation Used | Applications |
|---|---|---|---|
| Meta-stable memory immune system for multivariate data analysis | Immune Networks | Real-valued | Data analysis |
| An immunity clonal strategy algorithm (ICS) to solve multi-objective optimization tasks | Clonal Selection | Real-valued vectors | Optimization |
| A chaos artificial immune algorithm (CAIF) via integration of chaotic search and CLONALG | Clonal Selection | Real-valued vectors | Optimization |
| Techno-streams model for detecting an unknown number of evolving clusters in a noisy data stream | Immune Networks | Real-valued | Clustering |
| An artificial immune system for email classification (AISEC) | Immune Networks | Two-part word vector | Classification |
| An adaptive clonal selection (ACS) algorithm that suggests some modifications to the CLONALG | Clonal Selection | Real-valued vectors | Optimization |
| A self-adaptive negative selection algorithm for anomaly detection | Negative Selection | Binary strings, real-valued | Anomaly Detection |
| An improved clonal selection algorithm based on CLONALG | Clonal Selection Ag-Ab Binding | Binary strings | Machine Learning |
| An adaptive immune clonal strategy algorithm (AICSA) | Ag-Ab Binding Clonal Selection | Real-valued vectors | Numerical Optimization problems |
| A fractal immune network model combining the ideas of fractal proteins with immune networks | Immune Networks | Real-valued | Classification, Clustering |
| A reactive immune network (RIN) for mobile robot learning navigation strategies within unknown environments | Immune Networks | Real-valued | Robots |
| A real-coded clonal selection algorithm (RCSA) that enables the treatment of real-valued variables for optimization problems | Clonal Selection | Real-valued vectors | Electromagnetic design optimization |
| A modified algorithm named doptaiNet as an improved version of opt-aiNet to deal with time-varying fitness functions | Immune Networks | Real-valued vector | Optimization |
| A novel unsupervised fuzzy KMeans (FKM) clustering anomaly detection algorithm based on clonal selection algorithm | Clonal Selection | Numeric characteristic variables | Computer Security |
| Immunological algorithm for continuous global optimization problems named OPI-IA | Clonal Selection | Binary String | Optimization |
| An improved version of OPT-IA called Opt–IMMALG | Clonal Selection | Real-code | Optimization |
| An immune-based network Intrusion detection system (AINIDS) | Immune Networks | Rules | Computer Security |
| An adaptive clonal algorithm that suggests some modifications to the CLONALG | Clonal Selection, Receptor Editing | Binary strings | Optimization |
| A hybrid model that combines clonal selection principles and gene expression programming | Clonal Selection | Symbol strings | Data Mining |
| A modified algorithm of aiNet to solve function optimization problems | Immune Networks | Real-valued vector | Optimization |
| Artificial immune network classification algorithm (AINC) for fault diagnosis of power transformer | Immune Networks | Real-valued | Classification |
| A tree-structured artificial immune network (TSAIN) model for data clustering and classification | Immune Networks, Clonal Section | Real-valued | Classification, Clustering |
| A hybrid artificial immune network that uses swarm learning | Immune Networks | Real-valued | Optimization |
| A chaos immune network algorithm combining chaos idea with immune network to improve its ability of searching peaks | Immune Networks | Real-valued | Optimization |
| A feedback negative selection algorithm (FNSA) for anomaly detection | Negative Selection | Real-valued | Anomaly Detection |
| An artificial immune kernel clustering network (IKCN) for unsupervised image segmentation | Immune Networks | Real-valued, Image feature sets | Clustering |
| A technique that combines gene expression programming with clonal selection algorithm for system modeling and knowledge discovery | Clonal Selection | Symbol strings, Binary string | System Modeling |
| A local network neighborhood artificial immune system (LNNAIS) model for data clustering | Immune Networks | Real-valued | Clustering |
| An improved clonal selection algorithm based on CLONALG with a novel mutation method, self-adaptive chaotic mutation | Clonal Selection | Real-valued | Optimization |
| A differential immune clonal selection algorithm (DICSA) combining the mechanism of clonal selection and differential evolution | Clonal Selection | Real-valued | Optimization |
| A novel anomaly detection algorithm based on real-valued negative selection system | Negative Selection | Real-valued vectors | Anomaly Detection |
| A parallel clonal selection algorithm for solving the graph coloring problem | Clonal Selection | Real-valued | Optimization |
| A fuzzy artificial immune network (FaiNet) algorithm for lead classification that includes three parts, AIN learning algorithm, MST algorithm, and fuzzy C-means algorithm | Immune Networks | Real-valued vectors | Classification |
| A clonal chaos adjustment algorithm (CCAA) that improves the search efficiency of CLONALG | Clonal Selection, Immune Networks | Real-valued | Multi-Modal Function Optimization |
| Artificial negative selection classifier (ANSC) that combines the negative selection algorithm with clonal selection mechanism | Negative Selection, Clonal Selection | Real-valued | Multi-Class Classification |
| Tool | Caffe | Chainer | Theano | Torch7 | DL4J |
|---|---|---|---|---|---|
| Developer | Univ. of California, Berkeley | Preferred Networks Inc. (Tokyo, Japan) | Univ. de Montral | Facebook, Twitter, Google | Skymind |
| Language | Python, MATLAB, C/C++ | Python | Python | Lua, C/C++ | Java, Scala, Clojure, Python, Rudy, etc. |
| Target | Image | Image, audio, text, etc. | Image, audio, text, etc. | Image, audio, text, etc. | Image, audio, text, etc. |
| OS | Ubuntu, RHEL/CentOS, OSX | Unspecified | Windows, Ubuntu, CentOS6+, OSV | Ubuntu12+, OSX | Windows, Ubuntu, OSX |
| Method | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| LEAD-3 | 40.42 | 17.62 | 36.67 |
| PTGEN | 36.44 | 15.66 | 33.42 |
| PTGEN + Coverage | 39.53 | 17.28 | 36.38 |
| S2S-ELMo | 41.56 | 18.94 | 38.47 |
| Bottom-up | 41.22 | 18.68 | 38.34 |
| BERTSUMABS | 41.72 | 19.39 | 38.76 |
| BERTSUMEXTABS | 42.13 | 19.60 | 39.18 |
| MASS | 42.12 | 19.50 | 39.01 |
| UniLM | 43.33 | 20.21 | 40.51 |
| ProphetNet | 43.68 | 20.64 | 40.72 |
| Method | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| OpenNMT | 36.73 | 17.86 | 33.68 |
| Re3Sum | 37.04 | 19.03 | 34.46 |
| MASS | 38.73 | 19.71 | 35.96 |
| UniLM | 38.45 | 19.45 | 35.75 |
| ProphetNet | 39.55 | 20.27 | 36.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Matsuzaka, Y.; Yashiro, R. Development and Practical Applications of Computational Intelligence Technology. BioMedInformatics 2024, 4, 566-599. https://doi.org/10.3390/biomedinformatics4010032
Matsuzaka Y, Yashiro R. Development and Practical Applications of Computational Intelligence Technology. BioMedInformatics. 2024; 4(1):566-599. https://doi.org/10.3390/biomedinformatics4010032
Chicago/Turabian StyleMatsuzaka, Yasunari, and Ryu Yashiro. 2024. "Development and Practical Applications of Computational Intelligence Technology" BioMedInformatics 4, no. 1: 566-599. https://doi.org/10.3390/biomedinformatics4010032