
Reinforcement Learning for Multiple Daily Injection (MDI) Therapy in Type 1 Diabetes (T1D)


Abstract
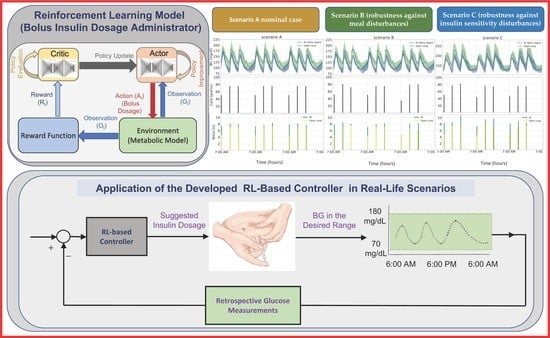
:
1. Introduction
2. Materials and Methods
2.1. Simulator
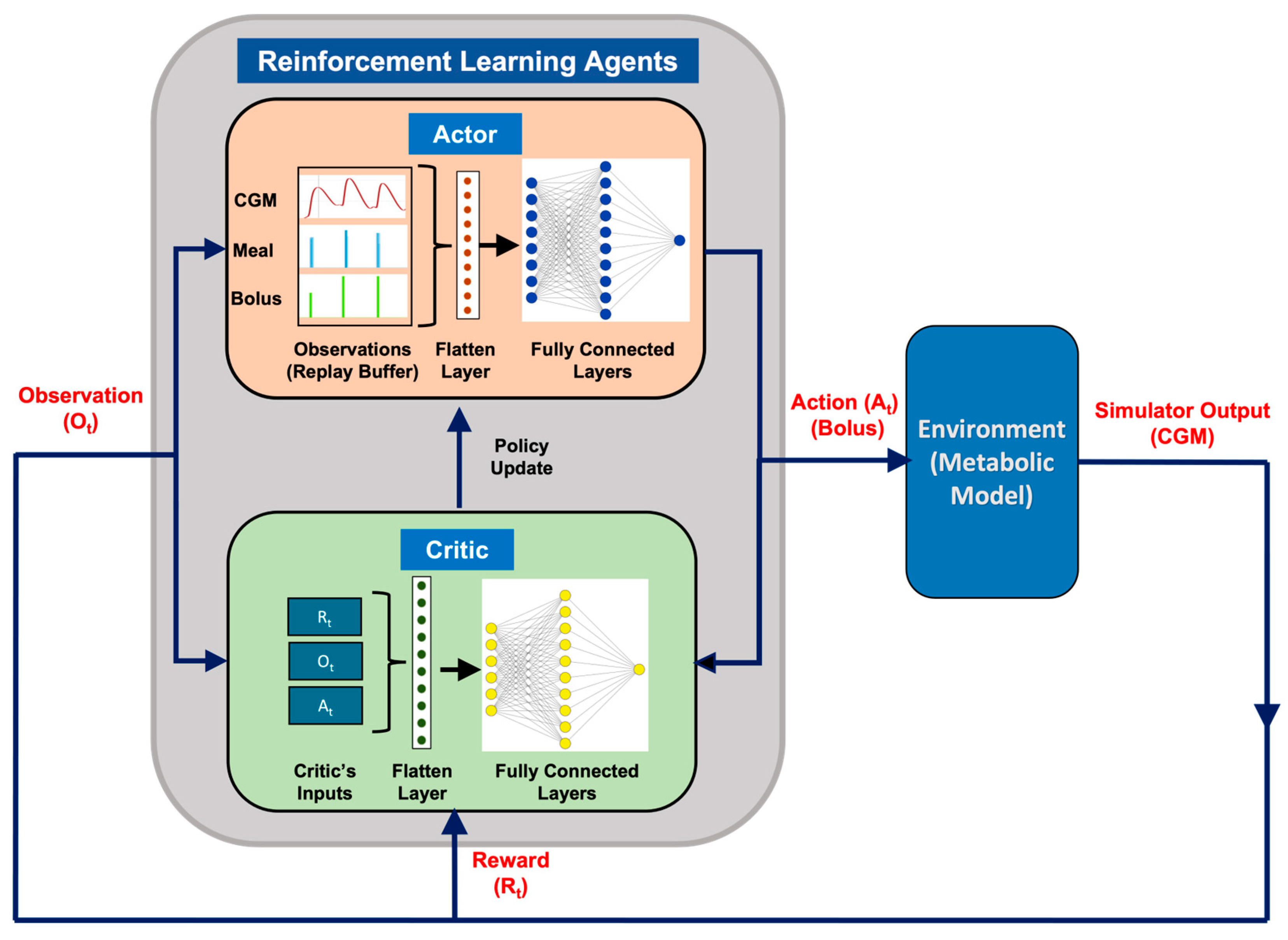
2.2. Reward Function
| Algorithm 1 Reward Function | |
| Initialize parameters , , Inputs: : Current continuous glucose monitor (CGM) readings : A buffer of CGM readings for the past 3 h. A buffer of previous meal intakes for the past 3 h. A buffer of previous insulin doses for the past 3 h. : Bounds of the BG readings, i.e., (70, 180) mg/dL Output: : Calculated reward for each episode | |
| ← 125 for each episode do for each step, being the number of steps in each episode do if and 0 then : ← else if 0 and 0 then : ← else ← end if if and then : ← else ← end if r (t) ← + end for end for | |
2.3. Simulation Scenarios
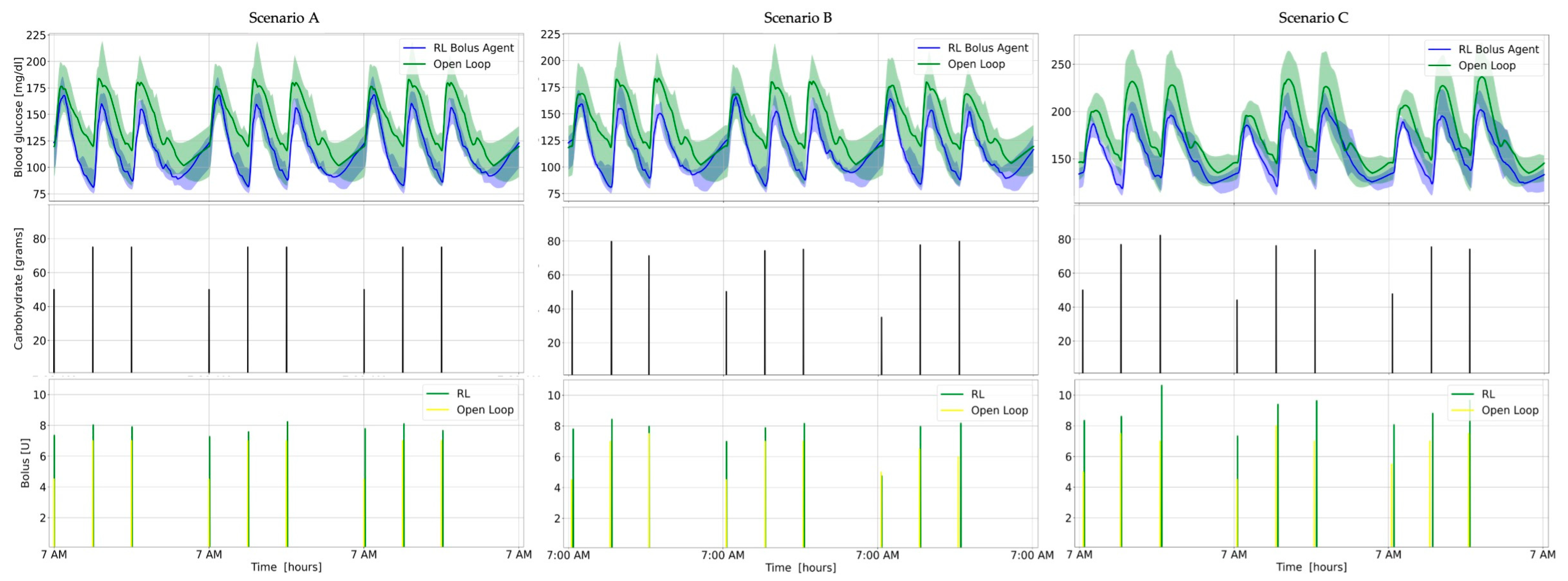
- Scenario A (nominal case). Each day, meals were at 7 a.m., 1 p.m., and 7 p.m., and the quantity of carbohydrate consumed each meal was 50 g, 75 g, and 75 g, for breakfast, lunch, and dinner, respectively. The rationale behind using this scenario was to evaluate the controller’s ability to maintain stable blood glucose levels under nominal conditions.
- Scenario B (robustness against meal disturbances). Meal timings for each meal were normally distributed, with means 30 min and standard deviation of 3 min. Further, the amount of carbohydrate for each meal was normally distributed with (50, 75, 75) g and standard deviations (5, 7.5, 7.5), for breakfast, lunch, and dinner, respectively. We used this scenario to test the controller’s robustness against meal disturbances, such as variations in meal timing and size, which are common in real-world situations. These variations can have a significant impact on blood glucose levels, and the controller should be able to adapt to them to maintain stable levels.
- Scenario C (robustness against insulin sensitivity disturbances). Scenario B dictated the meal times and amounts of carbohydrates consumed. Moreover, to assess the robustness of the suggested algorithm against fluctuations in insulin sensitivity, insulin resistance was induced by modifying the parameters in the metabolic model that affect insulin’s impact on glucose uptake and endogenous glucose production by 40%. The logic behind defining this scenario was to test the controller’s robustness against changes in insulin sensitivity, which can occur due to various factors such as stress, illness, or changes in physical activity. Insulin resistance can make it challenging to maintain stable blood glucose levels, and the controller should be able to adjust the insulin dosage appropriately.
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- American Diabetes Association Professional Practice (ADAPP) Committee. 2. Classification and diagnosis of diabetes: Standards of Medical Care in Diabetes—2022. Diabetes Care 2022, 45, S17–S38. [Google Scholar] [CrossRef] [PubMed]
- American Diabetes Association (ADA). 9. Pharmacologic approaches to glycemic treatment: Standards of medical care in diabetes-2020. Diabetes Care 2020, 43, S98–S110. [Google Scholar] [CrossRef] [PubMed]
- Solomon, T.P.J. Sources of inter-individual variability in the therapeutic response of blood glucose control to exercise in type 2 diabetes: Going beyond exercise dose. Front. Physiol. 2018, 9, 896. [Google Scholar] [CrossRef] [PubMed]
- Boiroux, D.; Aradóttir, T.B.; Nørgaard, K.; Poulsen, N.K.; Madsen, H.; Jørgensen, J.B. An adaptive nonlinear basal-bolus calculator for patients with type 1 diabetes. J. Diabetes Sci. Technol. 2017, 11, 29–36. [Google Scholar] [CrossRef]
- Cescon, M.; Deshpande, S.; Nimri, R.; Doyle, F.J., III.; Dassau, E. Using iterative learning for insulin dosage optimization in multiple-daily-injections therapy for people with type 1 diabetes. IEEE Trans. Biomed. Eng. 2020, 68, 482–491. [Google Scholar] [CrossRef]
- Linkeschova, R.; Raoul, M.; Bott, U.; Berger, M.; Spraul, M. Less severe hypoglycaemia, better metabolic control, and improved quality of life in Type 1 diabetes mellitus with continuous subcutaneous insulin infusion (CSII) therapy; an observational study of 100 consecutive patients followed for a mean of 2 years. Diabet. Med. 2002, 19, 746–751. [Google Scholar] [CrossRef]
- Tanenbaum, M.L.; Hanes, S.J.; Miller, K.M.; Naranjo, D.; Bensen, R.; Hood, K.K. Diabetes device use in adults with type 1 diabetes: Barriers to uptake and potential intervention targets. Diabetes Care 2017, 40, 181–187. [Google Scholar] [CrossRef]
- Campos-Delgado, D.U.; Femat, R.; Hernández-Ordoñez, M.; Gordillo-Moscoso, A. Self-tuning insulin adjustment algorithm for type 1 diabetic patients based on multi-doses regime. Appl. Bionics Biomech. 2005, 2, 61–71. [Google Scholar] [CrossRef]
- Campos-Delgado, D.U.; Hernández-Ordoñez, M.; Femat, R.; Gordillo-Moscoso, A. Fuzzy-based controller for glucose regulation in type-1 diabetic patients by subcutaneous route. IEEE Trans. Biomed. Eng. 2006, 53, 2201–2210. [Google Scholar] [CrossRef]
- Kirchsteiger, H.; Del Re, L.; Renard, E.; Mayrhofer, M. Robustness properties of optimal insulin bolus administrations for type 1 diabetes. In Proceedings of the 2009 American Control Conference, St. Louis, MO, USA, 10–12 June 2009; pp. 2284–2289. [Google Scholar]
- Cescon, M.; Stemmann, M.; Johansson, R. Impulsive predictive control of T1DM glycemia: An in-silico study. In Proceedings of the Dynamic Systems and Control Conference, Fort Lauderdale, FL, USA, 17–19 October 2012; American Society of Mechanical Engineers: New York, NY, USA; Volume 45295, pp. 319–326. [Google Scholar]
- Carrasco, D.S.; Matthews, A.D.; Goodwin, G.C.; Delgado, R.A.; Medioli, A.M. Design of MDIs for type 1 diabetes treatment via rolling horizon cardinality-constrained optimisation. IFAC-PapersOnLine 2017, 50, 15044–15049. [Google Scholar] [CrossRef]
- Cescon, M.; Deshpande, S.; Doyle, F.J.; Dassau, E. Iterative learning control with sparse measurements for long-acting insulin injections in people with type 1 diabetes. In Proceedings of the 2019 American Control Conference (ACC), Philadelphia, PA, USA, 10–12 July 2019; pp. 4746–4751. [Google Scholar]
- Owens, C.; Zisser, H.; Jovanovic, L.; Srinivasan, B.; Bonvin, D.; Doyle, F.J. Run-to-run control of blood glucose concentrations for people with type 1 diabetes mellitus. IEEE Trans. Biomed. Eng. 2006, 53, 996–1005. [Google Scholar] [CrossRef]
- Palerm, C.C.; Zisser, H.; Bevier, W.C.; Jovanovic, L.; Doyle, F.J., III. Prandial insulin dosing using run-to-run control: Application of clinical data and medical expertise to define a suitable performance metric. Diabetes Care 2007, 30, 1131–1136. [Google Scholar] [CrossRef]
- Zisser, H.; Palerm, C.C.; Bevier, W.C.; Doyle, F.J., III.; Jovanovic, L. Clinical update on optimal prandial insulin dosing using a refined run-to-run control algorithm. J. Diabetes Sci. Technol. 2009, 3, 487–491. [Google Scholar] [CrossRef] [PubMed]
- Woldaregay, A.Z.; Årsand, E.; Walderhaug, S.; Albers, D.; Mamykina, L.; Botsis, T.L.; Hartvigsen, G. Data-driven modeling and prediction of blood glucose dynamics: Machine learning applications in type 1 diabetes. Artif. Intell. Med. 2019, 98, 109–134. [Google Scholar] [CrossRef] [PubMed]
- Vettoretti, M.; Cappon, G.; Facchinetti, A.; Sparacino, G. Advanced diabetes management using artificial intelligence and continuous glucose monitoring sensors. Sensors 2020, 20, 3870. [Google Scholar] [CrossRef] [PubMed]
- Contreras, I.; Vehi, J. Artificial intelligence for diabetes management and decision support: Literature review. J. Med. Internet Res. 2018, 20, e10775. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Zhu, T.; Li, K.; Herrero, P.; Georgiou, P. Deep learning for diabetes: A systematic review. IEEE J. Biomed. Health Inform. 2020, 25, 2744–2757. [Google Scholar] [CrossRef]
- Bailey, T.S.; Walsh, J.; Stone, J.Y. Emerging technologies for diabetes care. Diabetes Technol. Ther. 2018, 20, S2–S78. [Google Scholar] [CrossRef]
- Jaloli, M.; Cescon, M. Predicting Blood Glucose Levels Using CNN-LSTM Neural Networks. 2020 Diabetes Technology Meeting Abstracts. J. Diabetes Sci. Technol. 2021, 15, A432. [Google Scholar] [CrossRef]
- Mirshekarian, S.; Shen, H.; Bunescu, R.; Marling, C. LSTMs and neural attention models for blood glucose prediction: Comparative experiments on real and synthetic data. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 706–712. [Google Scholar]
- Marling, C.; Bunescu, R. The OhioT1DM dataset for blood glucose level prediction: Update 2020. In Proceedings of the CEUR Workshop Proc, Siena, Italy, 16–20 November 2020; Volume 2675, p. 71. [Google Scholar]
- Jaloli, M.; Cescon, M. Demonstrating the Effect of Daily Physical Activities on Blood Glucose Level Variation in Type 1 Diabetes. Diabetes Technol. Ther. 2022, 24, A79, MARY ANN LIEBERT, INC 140 HUGUENOT STREET, 3RD FL, NEW ROCHELLE, NY 10801 USA. [Google Scholar]
- Jaloli, M.; Lipscomb, W.; Cescon, M. Incorporating the Effect of Behavioral States in Multi-Step Ahead Deep Learning Based Multivariate Predictors for Blood Glucose Forecasting in Type 1 Diabetes. BioMedInformatics 2022, 2, 715–726. [Google Scholar] [CrossRef]
- Tyler, N.S.; Mosquera-Lopez, C.M.; Wilson, L.M.; Dodier, R.H.; Branigan, D.L.; Gabo, V.B.; Guillot, F.H.; Hilts, W.W.; El Youssef, J.; Castle, J.R.; et al. An artificial intelligence decision support system for the management of type 1 diabetes. Nat. Metab. 2020, 2, 612–619. [Google Scholar] [CrossRef] [PubMed]
- Resalat, N.; El Youssef, J.; Tyler, N.; Castle, J.; Jacobs, P.G. A statistical virtual patient population for the glucoregulatory system in type 1 diabetes with integrated exercise model. PLoS ONE 2019, 14, e0217301. [Google Scholar] [CrossRef]
- Cappon, G.; Vettoretti, M.; Marturano, F.; Facchinetti, A.; Sparacino, G. A neural-network-based approach to personalize insulin bolus calculation using continuous glucose monitoring. J. Diabetes Sci. Technol. 2018, 12, 265–272. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Polydoros, A.S.; Nalpantidis, L. Survey of model-based reinforcement learning: Applications on robotics. J. Intell. Robot. Syst. 2017, 86, 153–173. [Google Scholar] [CrossRef]
- Komorowski, M.; Celi, L.A.; Badawi, O.; Gordon, A.C.; Faisal, A.A. The artificial intelligence clinician learns optimal treatment strategies for sepsis in intensive care. Nat. Med. 2018, 24, 1716–1720. [Google Scholar] [CrossRef]
- Zhu, T.; Li, K.; Herrero, P.; Georgiou, P. Basal glucose control in type 1 diabetes using deep reinforcement learning: An in silico validation. IEEE J. Biomed. Health Inform. 2020, 25, 1223–1232. [Google Scholar] [CrossRef]
- Zhu, T.; Li, K.; Kuang, L.; Herrero, P.; Georgiou, P. An insulin bolus advisor for type 1 diabetes using deep reinforcement learning. Sensors 2020, 20, 5058. [Google Scholar] [CrossRef] [PubMed]
- Kovatchev, B.P.; Breton, M.D.; Cobelli, C.; Dalla Man, C. Method, System and Computer Simulation Environment for Testing of Monitoring and Control Strategies in Diabetes United States. U.S. Patent 10,546,659, 28 January 2020. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the International Conference on Machine Learning, PMLR, Vienna, Austria, 25–31 July 2018; pp. 1861–1870. [Google Scholar]
- Available online: https://github.com/Advanced-Learning-and-Automation/RL_for_MDI_Therapy_in-_T1D (accessed on 1 May 2023).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter/Specification | Value |
|---|---|
| Critic optimizer | Adam |
| Critic learning rate | 1 × 10−4 |
| Critic gradient threshold | 1 |
| Critic L2 regularization factor | 2 × 10−4 |
| Actor optimizer | Adam |
| Actor learning rate | 1 × 10−4 |
| Actor gradient threshold | 1 |
| Actor L2 regularization factor | 1 × 10−4 |
| Target smooth factor | 1 × 10−3 |
| Mini batch size | 512 |
| Experience buffer length | 1 × 107 |
| Number of hidden units | 256 |
| Sample time | 5 min |
| Metrics | Open Loop | RL | p-Value | |
|---|---|---|---|---|
| Scenario A | min mg/dL | 40.22 | 15.67 | 0.13 |
| max mg/dL | 131.21 | 18.62 | 0.03 | |
| mean mg/dL | 57.26 | 7.93 | 0.07 | |
| % time ∈ (70, 180) mg/dL | 27.90 | 9.27 | 0.01 | |
| % time < 70 mg/dL | 24.98 | 9.32 | 0.26 | |
| % time < 54 mg/dL | 19.31 | 2.40 | 0.16 | |
| % time > 180 mg/dL | 27.65 | 3.29 | 0.02 | |
| % time > 250 mg/dL | 14.51 | 0 | 0.14 | |
| Bolus U | 5.62 | 31.47 | 0.08 | |
| Scenario B | min mg/dL | 40.32 | 15.89 | 0.15 |
| max mg/dL | 126.51 | 18.99 | 0.04 | |
| mean mg/dL | 55.72 | 8.11 | 0.08 | |
| % time ∈ (70, 180) mg/dL | 28.06 | 9.15 | 0.01 | |
| % time < 70 mg/dL | 26.11 | 9.10 | 0.25 | |
| % time < 54 mg/dL | 20.02 | 1.93 | 0.15 | |
| % time > 180 mg/dL | 26.43 | 2.63 | 0.02 | |
| % time > 250 mg/dL | 12.60 | 0 | 0.14 | |
| Bolus U | 5.81 | 31.31 | 0.09 | |
| Scenario C | min mg/dL | 27.06 | 27.83 | 0.3 |
| max mg/dL | 86.77 | 26.26 | 0.03 | |
| mean mg/dL | 49.30 | 23.81 | 0.1 | |
| % time ∈ (70, 180) mg/dL | 27.53 | 26.40 | 0.05 | |
| % time < 70 mg/dL | 11.18 | 0.08 | 0.17 | |
| % time < 54 mg/dL | 3.76 | 0 | 0.17 | |
| % time > 180 mg/dL | 29.80 | 0.11 | ||
| % time > 250 mg/dL | 19.10 | 0.77 | 0.1 | |
| Bolus U | 5.62 | 31.28 | 0.06 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jaloli, M.; Cescon, M. Reinforcement Learning for Multiple Daily Injection (MDI) Therapy in Type 1 Diabetes (T1D). BioMedInformatics 2023, 3, 422-433. https://doi.org/10.3390/biomedinformatics3020028
Jaloli M, Cescon M. Reinforcement Learning for Multiple Daily Injection (MDI) Therapy in Type 1 Diabetes (T1D). BioMedInformatics. 2023; 3(2):422-433. https://doi.org/10.3390/biomedinformatics3020028
Chicago/Turabian StyleJaloli, Mehrad, and Marzia Cescon. 2023. "Reinforcement Learning for Multiple Daily Injection (MDI) Therapy in Type 1 Diabetes (T1D)" BioMedInformatics 3, no. 2: 422-433. https://doi.org/10.3390/biomedinformatics3020028