



Comparative Analysis of Algorithms to Cleanse Soil Micro-Relief Point Clouds
 ,
,  ,
,  and
and
Abstract
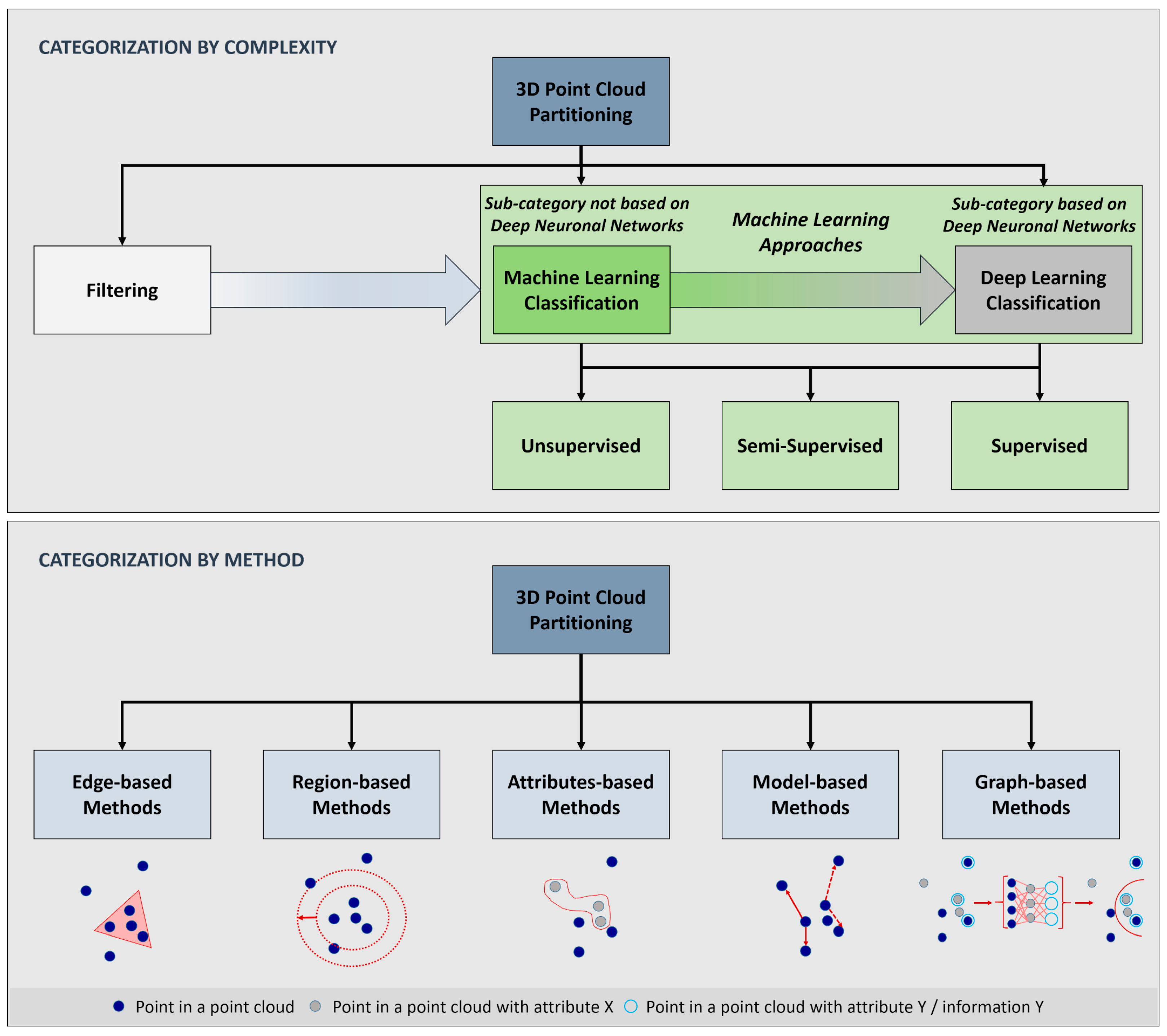
:1. Introduction
- (1)
- Can well-known methods provide sufficiently accurate results in separating vegetation from soil at the plot scale?
- (2)
- Can these algorithms maintain their level of accuracy at different epochs during the examined vegetation growing period and different plots?
- (3)
- To what extent does the choice of the algorithm affect the results?
- (4)
- Does the complexity of the application increase the accuracy of the results?
2. Materials and Methods
2.1. Data Acquisition
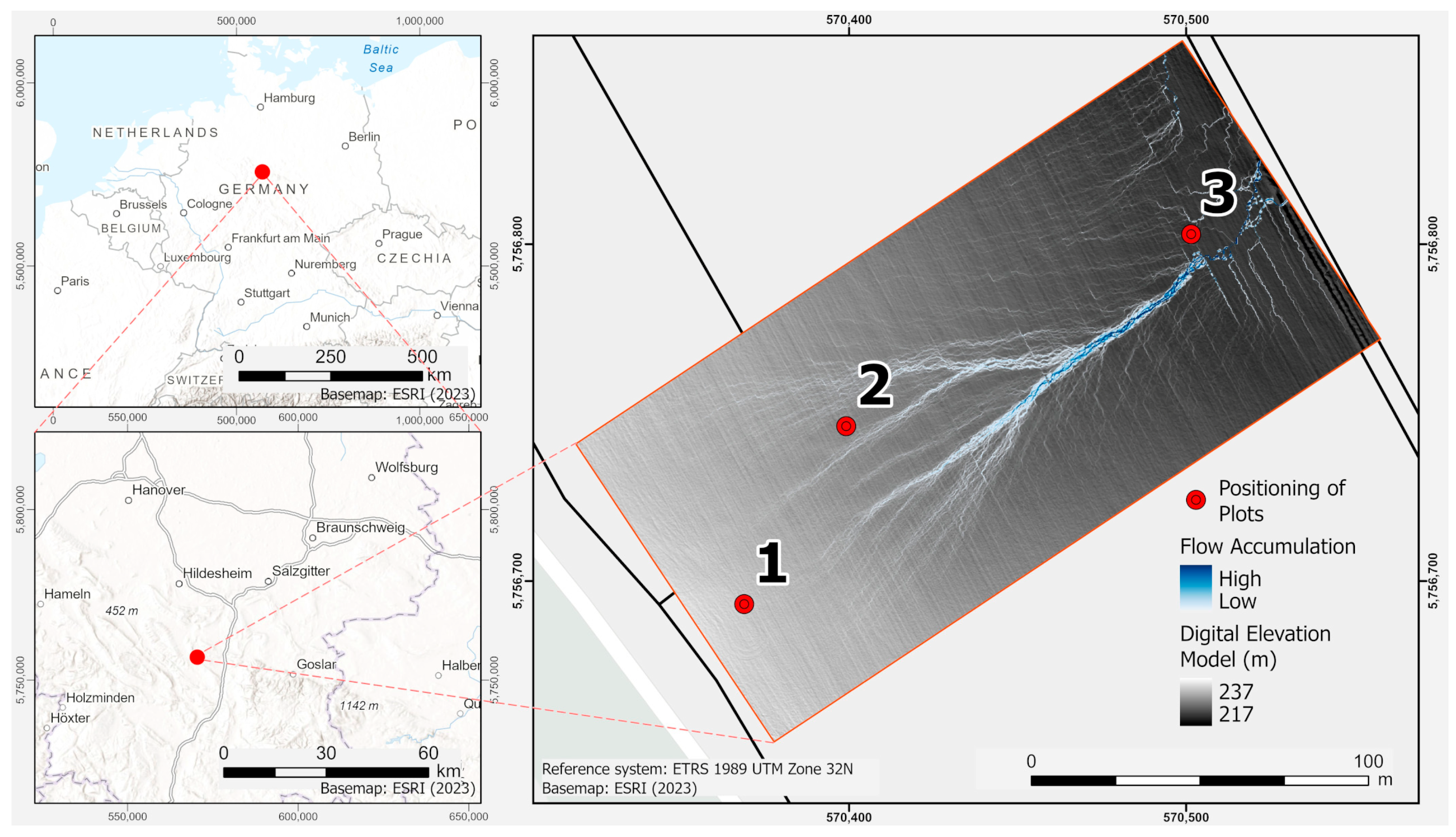
2.1.1. Study Site
2.1.2. Field Campaign
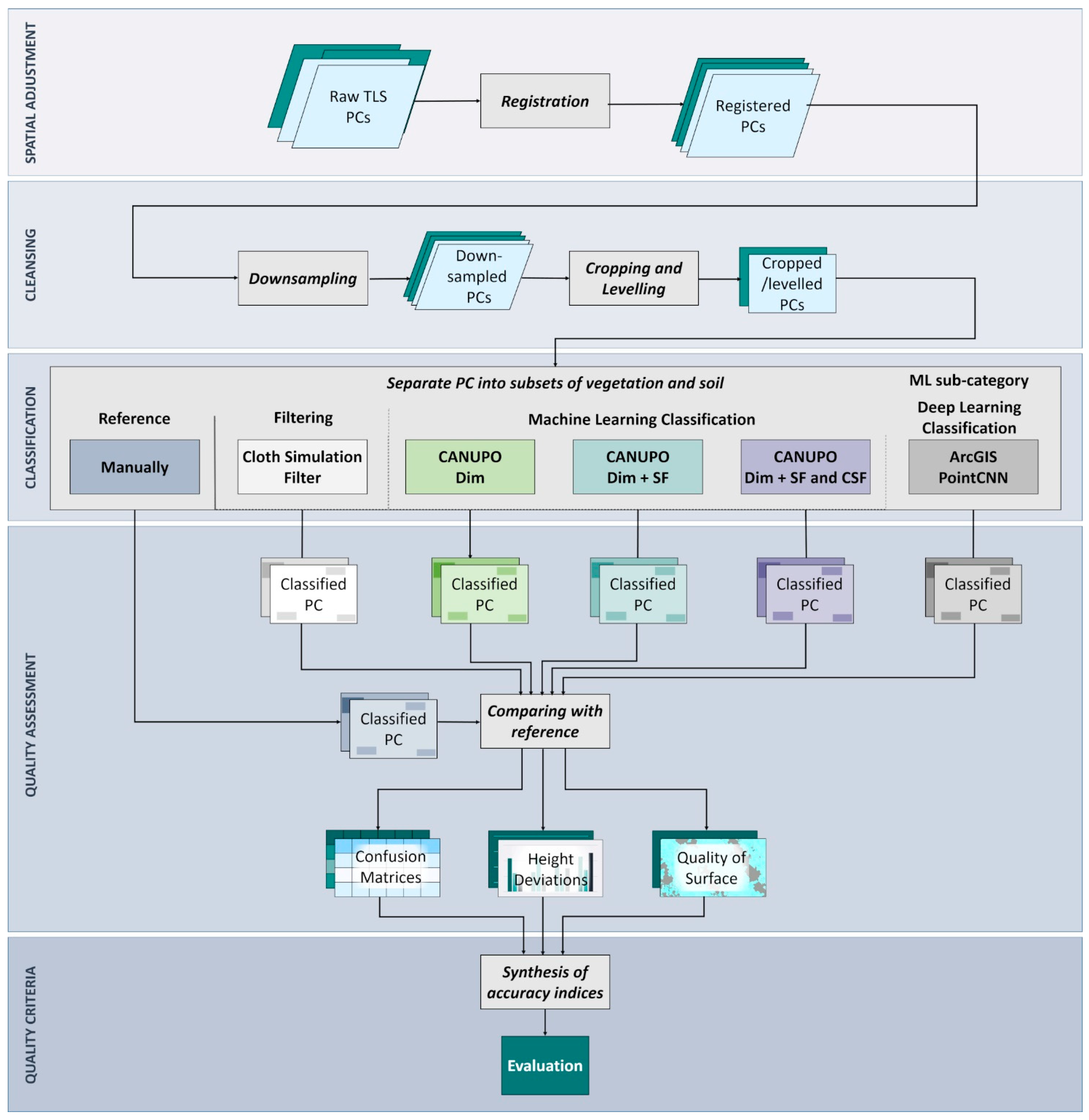
2.2. Data Processing
2.2.1. Spatial Adjustment and Cleansing of Point Clouds
2.2.2. Vegetation Detection
2.2.3. Quality Assessment
3. Results
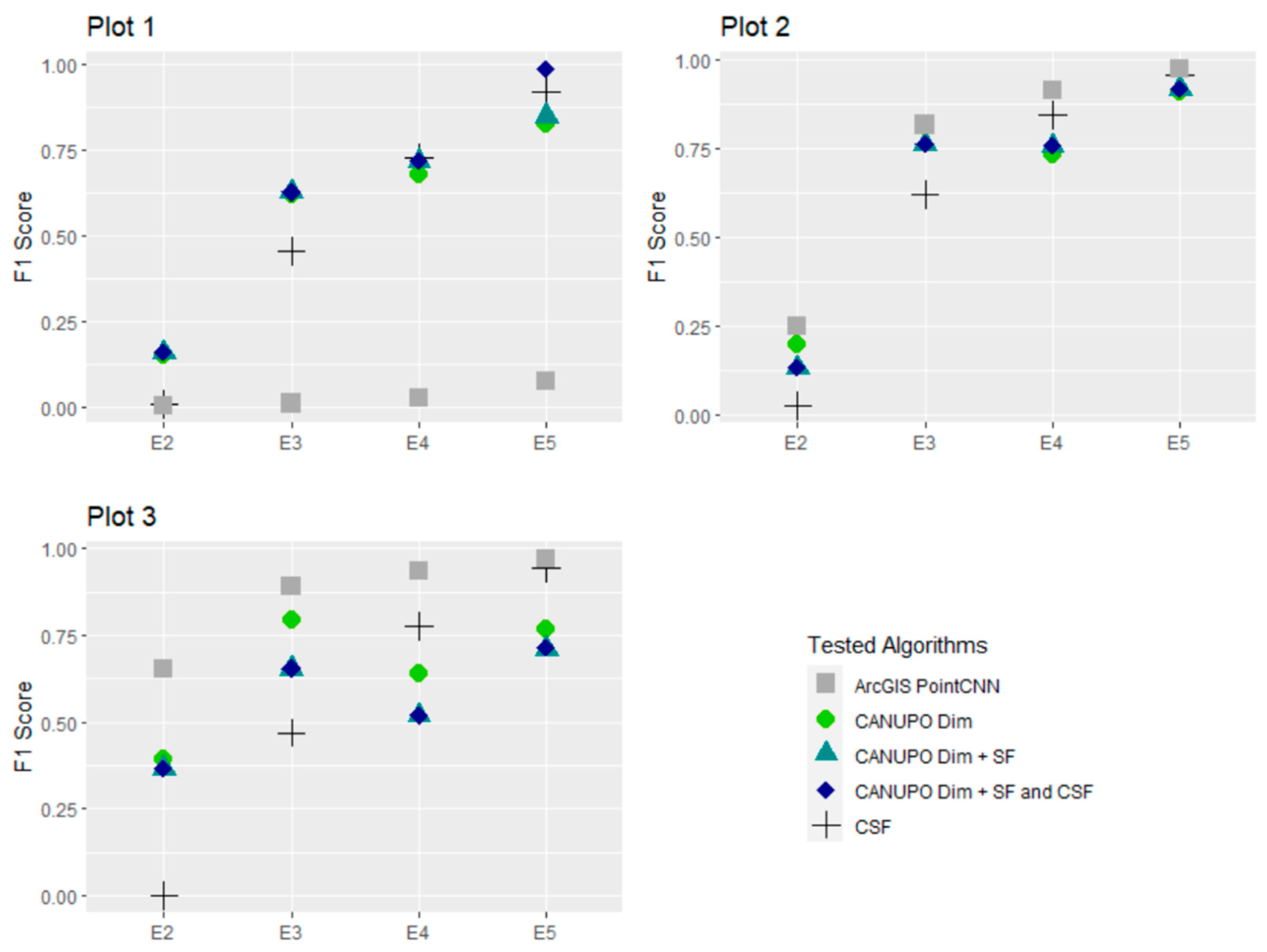
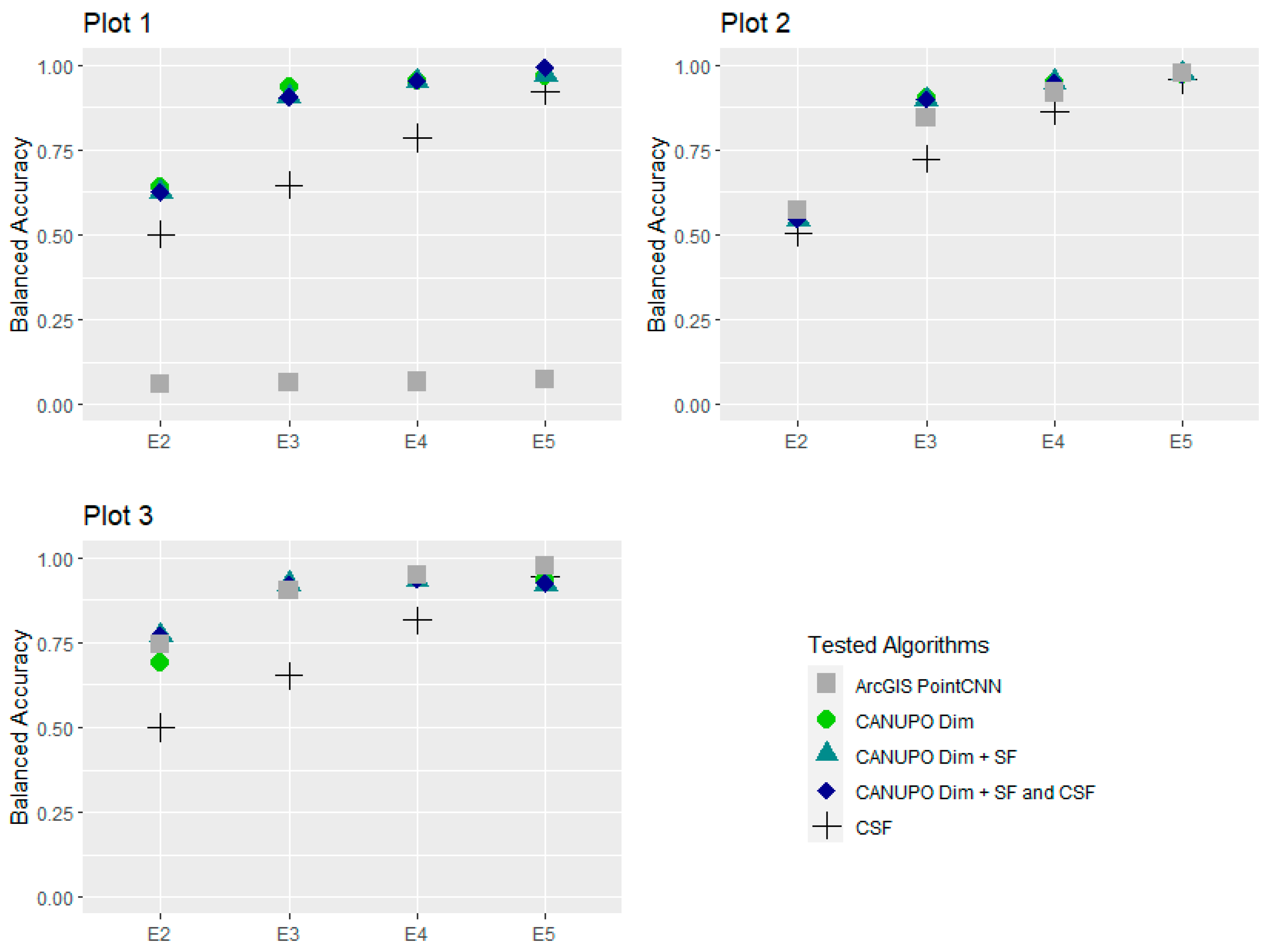
3.1. Accuracy Assessment
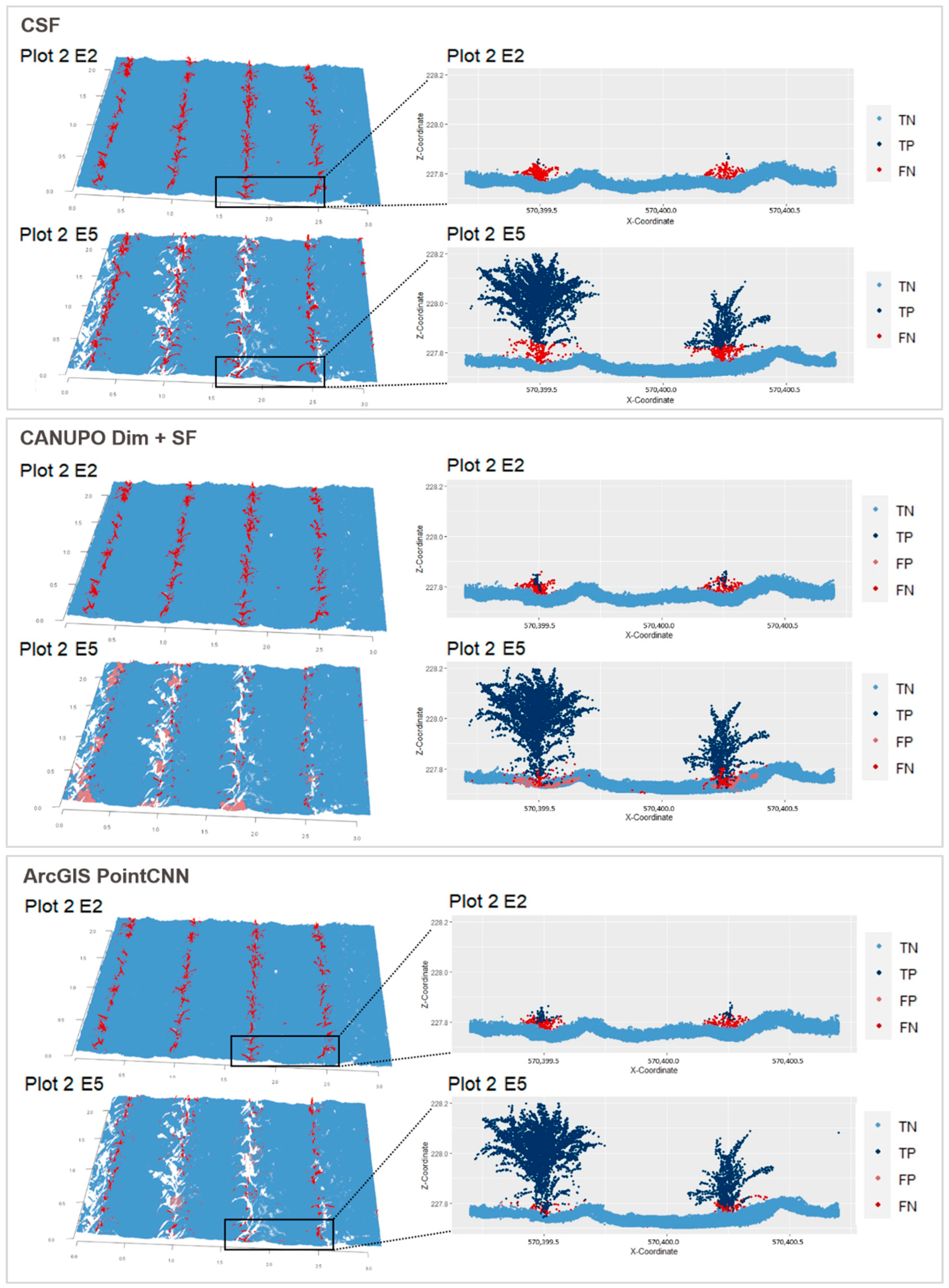
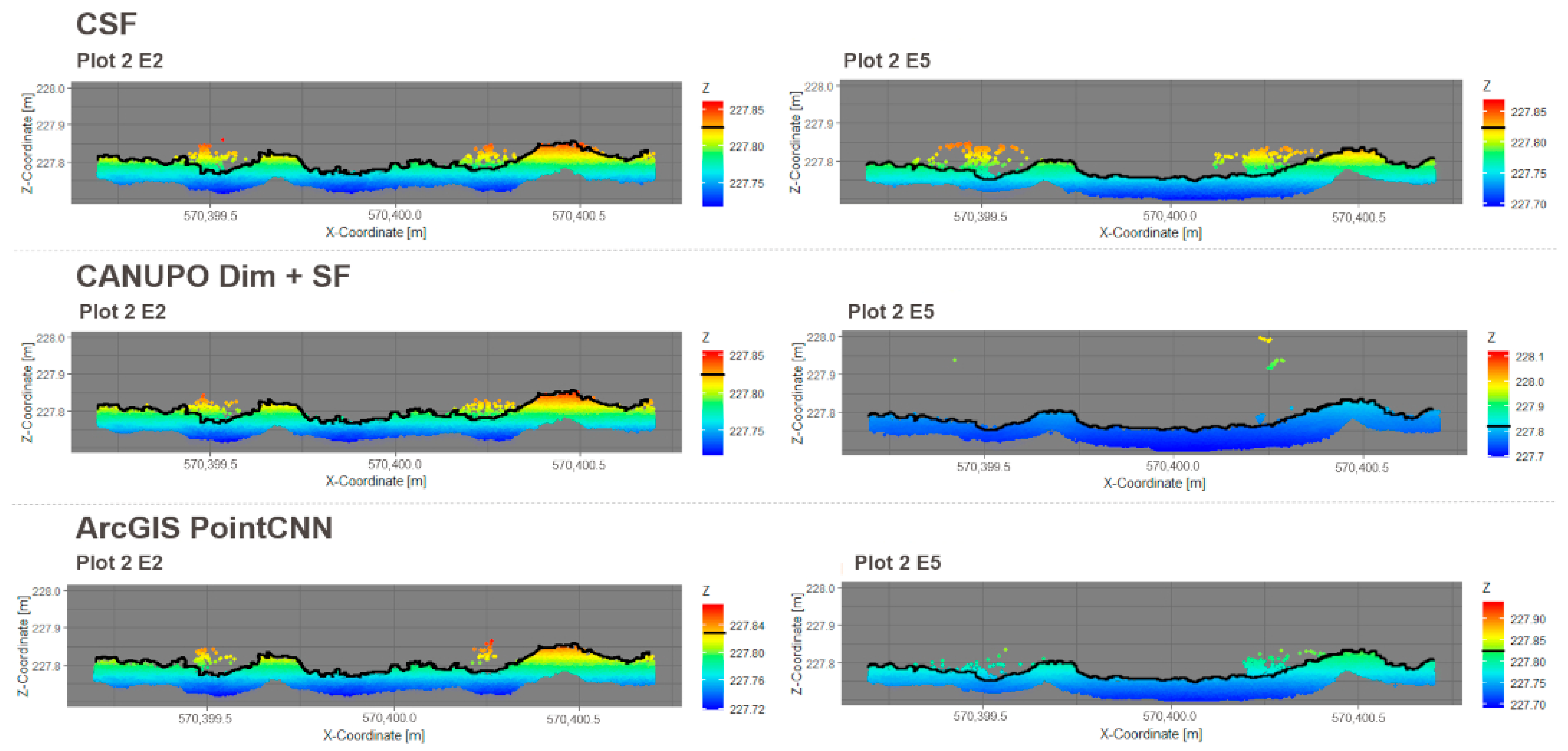
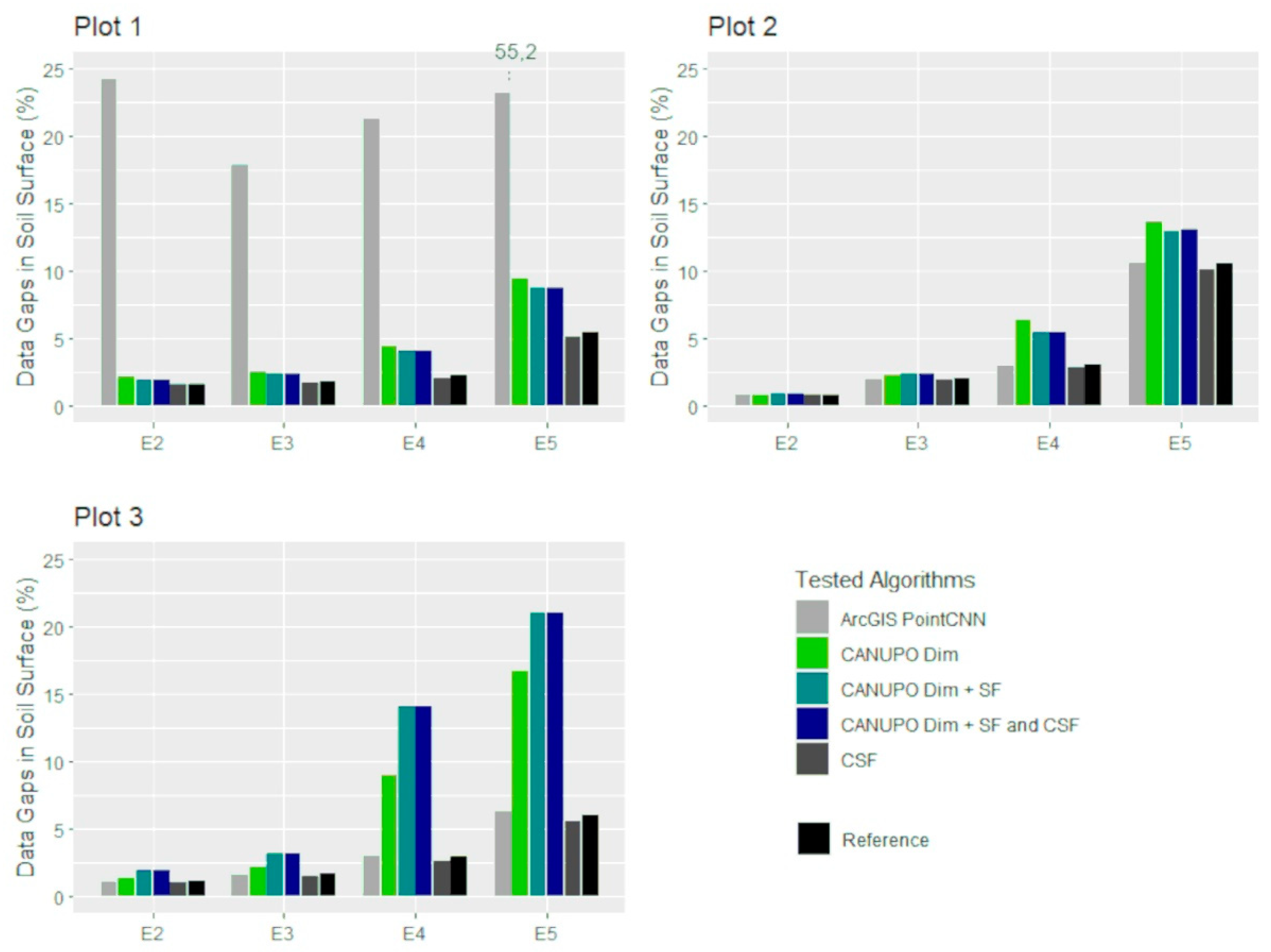
3.2. Effects of Algorithms on Soil Surface Detection
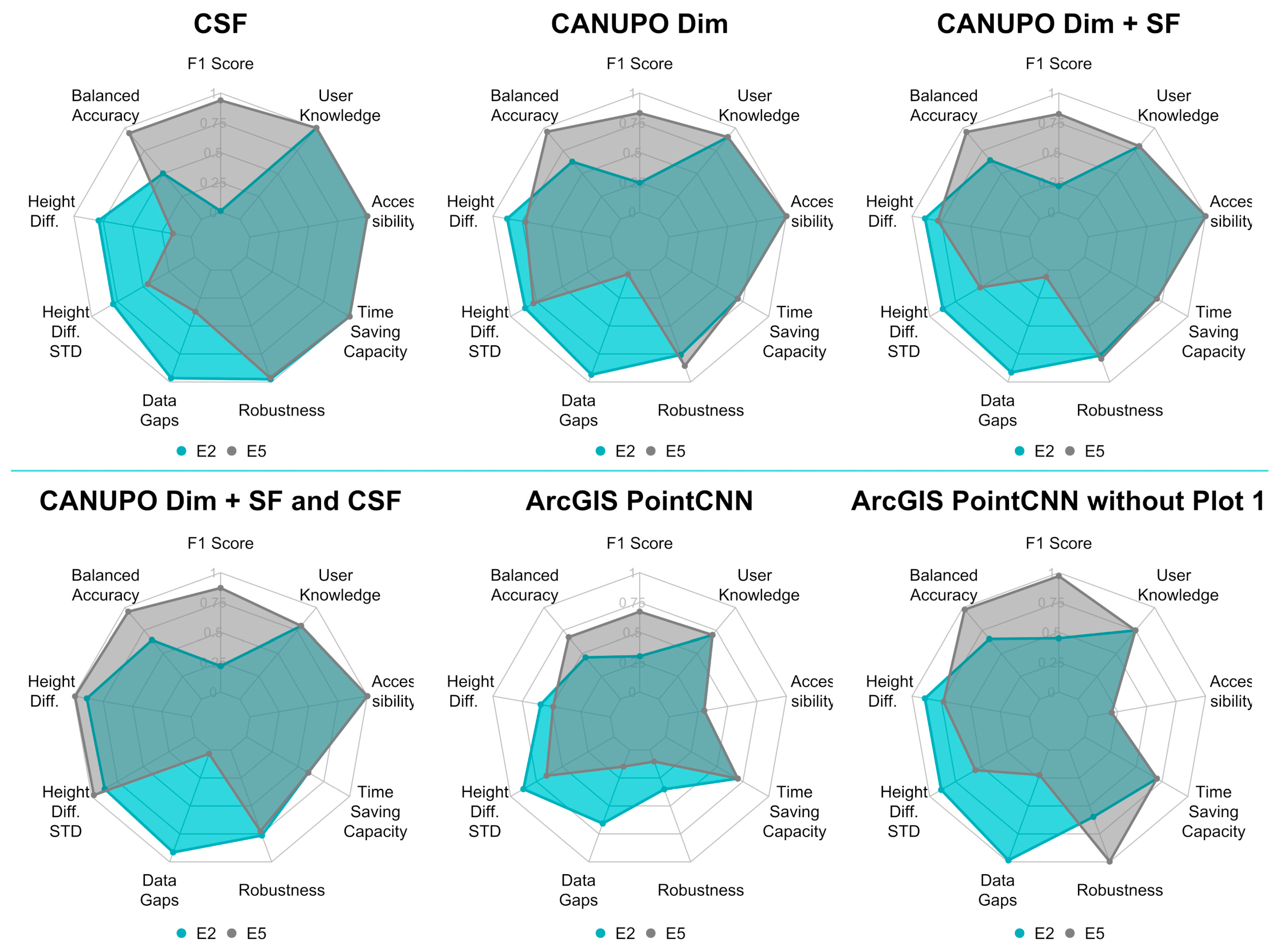
3.3. Quality Criteria for Evaluation of the Tested Algorithms
4. Discussion
5. Conclusions
- (1)
- Can well-known methods provide sufficiently accurate results in separating vegetation from soil at the plot scale?
- (2)
- Can these algorithms maintain their level of accuracy at different epochs during the examined vegetation growing period and different plots?
- (3)
- To what extent does the choice of the algorithm affect the results?
- (4)
- Does the complexity of the application increase the accuracy of the results?
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wuepper, D.; Borrelli, P.; Finger, R. Countries and the global rate of soil erosion. Nat. Sustain. 2020, 3, 51–55. [Google Scholar] [CrossRef]
- Eekhout, J.P.C.; de Vente, J. Global impact of climate change on soil erosion and potential for adaptation through soil conservation. Earth-Sci. Rev. 2022, 226, 103921. [Google Scholar] [CrossRef]
- Eltner, A.; Mulsow, C.; Maas, H.-G. Quantitative measurement of soil erosion from tls and uav data. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2013, XL-1/W2, 119–124. [Google Scholar] [CrossRef]
- Cândido, B.M.; Quinton, J.N.; James, M.R.; Silva, M.L.N.; de Carvalho, T.S.; de Lima, W.; Beniaich, A.; Eltner, A. High-resolution monitoring of diffuse (sheet or interrill) erosion using structure-from-motion. Geoderma 2020, 375, 114477. [Google Scholar] [CrossRef]
- Cucchiaro, S.; Carretta, L.; Nasta, P.; Cazorzi, F.; Masin, R.; Romano, N.; Tarolli, P. Multi-temporal geomorphometric analysis to assess soil erosion under different tillage practices: A methodological case study. J. Agric. Eng. 2022, 53, 1279. [Google Scholar] [CrossRef]
- Pineux, N.; Lisein, J.; Swerts, G.; Bielders, C.L.; Lejeune, P.; Colinet, G.; Degré, A. Can DEM time series produced by UAV be used to quantify diffuse erosion in an agricultural watershed? Geomorphology 2017, 280, 122–136. [Google Scholar] [CrossRef]
- Balaguer-Puig, M.; Marqués-Mateu, Á.; Lerma, J.L.; Ibáñez-Asensio, S. Estimation of small-scale soil erosion in laboratory experiments with Structure from Motion photogrammetry. Geomorphology 2017, 295, 285–296. [Google Scholar] [CrossRef]
- Kaiser, A.; Erhardt, A.; Eltner, A. Addressing uncertainties in interpreting soil surface changes by multitemporal high-resolution topography data across scales. Land Degrad. Dev. 2018, 29, 2264–2277. [Google Scholar] [CrossRef]
- Luo, J.; Zheng, Z.; Li, T.; He, S. Changes in micro-relief during different water erosive stages of purple soil under simulated rainfall. Sci. Rep. 2018, 8, 3483. [Google Scholar] [CrossRef]
- Grilli, E.; Menna, F.; Remondino, F. A review of point clouds segmentation and classification algorithms. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2017, XLII-2/W3, 339–344. [Google Scholar] [CrossRef]
- Weinmann, M.; Schmidt, A.; Mallet, C.; Hinz, S.; Rottensteiner, F.; Jutzi, B. Contextual classification of point cloud data by exploiting individual 3d neigbourhoods. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2015, II-3/W4, 271–278. [Google Scholar] [CrossRef]
- Pinto, M.F.; Melo, A.G.; Honório, L.M.; Marcato, A.L.M.; Conceição, A.G.S.; Timotheo, A.O. Deep Learning Applied to Vegetation Identification and Removal Using Multidimensional Aerial Data. Sensors 2020, 20, 6187. [Google Scholar] [CrossRef] [PubMed]
- Štroner, M.; Urban, R.; Lidmila, M.; Kolář, V.; Křemen, T. Vegetation Filtering of a Steep Rugged Terrain: The Performance of Standard Algorithms and a Newly Proposed Workflow on an Example of a Railway Ledge. Remote Sens. 2021, 13, 3050. [Google Scholar] [CrossRef]
- Kermarrec, G.; Yang, Z.; Czerwonka-Schröder, D. Classification of Terrestrial Laser Scanner Point Clouds: A Comparison of Methods for Landslide Monitoring from Mathematical Surface Approximation. Remote Sens. 2022, 14, 5099. [Google Scholar] [CrossRef]
- Nguyen, A.; Le, B. 3D point cloud segmentation: A survey. In Proceedings of the 2013 6th IEEE Conference on Robotics, Automation and Mechatronics (RAM), Manila, Philippines, 12–15 November 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 225–230, ISBN 978-1-4799-1201-8. [Google Scholar]
- Sarker, I.H. Deep Learning: A Comprehensive Overview on Techniques, Taxonomy, Applications and Research Directions. SN Comput. Sci. 2021, 2, 420. [Google Scholar] [CrossRef]
- Zhang, W.; Qi, J.; Wan, P.; Wang, H.; Xie, D.; Wang, X.; Yan, G. An Easy-to-Use Airborne LiDAR Data Filtering Method Based on Cloth Simulation. Remote Sens. 2016, 8, 501. [Google Scholar] [CrossRef]
- Brodu, N.; Lague, D. 3D terrestrial lidar data classification of complex natural scenes using a multi-scale dimensionality criterion: Applications in geomorphology. ISPRS J. Photogramm. Remote Sens. 2012, 68, 121–134. [Google Scholar] [CrossRef]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution On X-Transformed Points. In Proceedings of the NIPS’18: Proceedings of the 32nd International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 3–8 December 2018; pp. 828–838. [Google Scholar]
- Steinhoff-Knopp, B.; Burkhard, B. Soil erosion by water in Northern Germany: Long-term monitoring results from Lower Saxony. CATENA 2018, 165, 299–309. [Google Scholar] [CrossRef]
- DWD Climate Data Center (CDC). Multi-Annual Grids of Precipitation Height over Germany 1981–2010, version v1.0; Deutscher Wetterdienst (DWD): Offenbach/Main, Germany, 2018.
- Wischmeier, W.H.; Smith, D.D. Predicting Rainfall-Erosion Losses from Cropland East of the Rocky Mountains: Guide for Selection of Practices for Soil and Water Conservation; Agricultural Research Service, U.S. Dept. of Agriculture in cooperation with Purdue Agricultural Experiment Station: Washington, DC, USA, 1965.
- Fischer, F.K.; Winterrath, T.; Junghänel, T.; Walawender, E.; Auerswald, K. Mean Annual Precipitation Erosivity (R Factor) Based on RADKLIM Version 2017.002; Deutscher Wetterdienst (DWD): Offenbach/Main, Germany, 2019. [CrossRef]
- Rusu, R.B.; Cousins, S. 3D is here: Point Cloud Library (PCL). In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1–4. [Google Scholar] [CrossRef]
- Pingel, T.J.; Clarke, K.C.; McBride, W.A. An improved simple morphological filter for the terrain classification of airborne LIDAR data. ISPRS J. Photogramm. Remote Sens. 2013, 77, 21–30. [Google Scholar] [CrossRef]
- Wu, Y.; Sang, M.; Wang, W. A Novel Ground Filtering Method for Point Clouds in a Forestry Area Based on Local Minimum Value and Machine Learning. Appl. Sci. 2022, 12, 9113. [Google Scholar] [CrossRef]
- Jia, C.C.; Wang, C.J.; Yang, T.; Fan, B.H.; He, F.G. A 3D Point Cloud Filtering Algorithm based on Surface Variation Factor Classification. Procedia Comput. Sci. 2019, 154, 54–61. [Google Scholar] [CrossRef]
- Ao, Z.; Wu, F.; Hu, S.; Sun, Y.; Su, Y.; Guo, Q.; Xin, Q. Automatic segmentation of stem and leaf components and individual maize plants in field terrestrial LiDAR data using convolutional neural networks. Crop J. 2022, 10, 1239–1250. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6999–7019. [Google Scholar] [CrossRef]
- Fareed, N.; Flores, J.P.; Das, A.K. Analysis of UAS-LiDAR Ground Points Classification in Agricultural Fields Using Traditional Algorithms and PointCNN. Remote Sens. 2023, 15, 483. [Google Scholar] [CrossRef]
- Ting, K.M. Confusion Matrix. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2010; p. 209. ISBN 978-0-387-30164-8. [Google Scholar]
- Zhang, E.; Zhang, Y. F-Measure. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer: Boston, MA, USA, 2009; p. 1147. ISBN 978-0-387-39940-9. [Google Scholar]
- Wegier, W.; Ksieniewicz, P. Application of Imbalanced Data Classification Quality Metrics as Weighting Methods of the Ensemble Data Stream Classification Algorithms. Entropy 2020, 22, 849. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Guo, J.; Wu, H.; Li, Y.; Shi, B. Performance Comparison of Filtering Algorithms for High-Density Airborne LiDAR Point Clouds over Complex LandScapes. Remote Sens. 2021, 13, 2663. [Google Scholar] [CrossRef]
- Jayakumari, R.; Nidamanuri, R.R.; Ramiya, A.M. Object-level classification of vegetable crops in 3D LiDAR point cloud using deep learning convolutional neural networks. Precis. Agric. 2021, 22, 1617–1633. [Google Scholar] [CrossRef]
- Jurado, J.M.; Cárdenas, J.L.; Ogayar, C.J.; Ortega, L.; Feito, F.R. Semantic Segmentation of Natural Materials on a Point Cloud Using Spatial and Multispectral Features. Sensors 2020, 20, 2244. [Google Scholar] [CrossRef]
- Bailey, G.; Li, Y.; McKinney, N.; Yoder, D.; Wright, W.; Herrero, H. Comparison of Ground Point Filtering Algorithms for High-Density Point Clouds Collected by Terrestrial LiDAR. Remote Sens. 2022, 14, 4776. [Google Scholar] [CrossRef]
- Hoffer, E.; Hubara, I.; Soudry, D. Train longer, generalize better: Closing the generalization gap in large batch training of neural networks. Adv. Neural Inf. Process. Syst. 2017, 30, 1729–1739. [Google Scholar] [CrossRef]
- Wolpert, D.H. The Lack of A Priori Distinctions Between Learning Algorithms. Neural Comput. 1996, 8, 1341–1390. [Google Scholar] [CrossRef]
- Goodfellow, I.; Courville, A.; Bengio, Y. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016; ISBN 0262035618. [Google Scholar]
- Wong, T.-T. Performance evaluation of classification algorithms by k-fold and leave-one-out cross validation. Pattern Recognit. 2015, 48, 2839–2846. [Google Scholar] [CrossRef]
- Nti, I.K.; Nyarko-Boateng, O.; Aning, J. Performance of Machine Learning Algorithms with Different K Values in K-fold Cross Validation. Int. J. Inf. Technol. Comput. Sci. 2021, 13, 61–71. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Plot Name | Previously Recorded Erosion [t/ha·a] * | Elevation [m.a.s.l.] | Slope Gradient [°] | Soil Texture Top Soil (0–5 cm) | ||||
|---|---|---|---|---|---|---|---|---|
| Sand [%] | Silt [%] | Clay [%] | Soil Organic Carbon [%] | K-Factor ** | ||||
| Plot 1 | 0.2–1.0 | 235 | 13.8 | 5 | 65 | 30 | 6.8 | 0.4 |
| Plot 2 | 1.0–2.0 | 228 | 13.3 | 5 | 75 | 20 | 6.0 | 0.5 |
| Plot 3 | 3.0–6.0 | 218 | 5.5 | 5 | 75 | 10 | 6.0 | 0.5 |
| Parameters | CSF | CANUPO Dimensionality | CANUPO Dimensionality + SF | CANUPO + CSF Dimensionality + SF | ArcGIS PointCNN |
|---|---|---|---|---|---|
| Scene * | Relief | - | - | Relief | - |
| Slope processing ** | No | - | - | No | - |
| Cloth resolution (m) | 0.1 | - | - | 0.1 | - |
| Max. iterations | 500 | - | - | 500 | - |
| Classification Threshold (m) *** | 0.1 | - | - | 0.1 | - |
| Scales | - | 0.1–1.0; 0.001 | 0.1–1.0; 0.001 | 0.1–1.0; 0.001 | - |
| Scales after tuning | - | 300 | 300 | 300 | - |
| Max. core Points | - | 10,000 | 10,000 | 10,000 | - |
| Ratio training data Vegetation–soil | - | ~1:5 | ~1:5 | ~1:5 | - |
| Ratio training data- whole point cloud | - | ~1:5 | ~1:5 | ~1:5 | ~1:6 |
| Ratio validation data-whole point cloud | - | ~1:5 | ~1:5 | ~1:5 | ~1:6 |
| Block size (cm) | - | - | - | - | 40 |
| Block point limit | - | - | - | - | 8192 |
| Model selection criteria | - | - | - | - | F1 score |
| Plot | Class | E1 | E2 | E3 | E4 | E5 |
|---|---|---|---|---|---|---|
| Plot 1 | Vegetation | 0 | 12,099 | 33,108 | 88,216 | 225,683 |
| Soil | 2,289,748 | 1,947,945 | 1,746,486 | 2,028,377 | 1,744,019 | |
| Proportion | 0% | 0.62% | 1.86% | 4.17% | 11.46% | |
| Plot 2 | Vegetation | 0 | 26,227 | 50,101 | 126,938 | 343,693 |
| Soil | 2,193,646 | 2,387,142 | 1,861,216 | 2,187,462 | 1,726,862 | |
| Proportion | 0% | 1.09% | 2.62% | 5.48% | 16.60% | |
| Plot 3 * | Vegetation | - | 20,000 | 42,238 | 112,365 | 319,714 |
| Soil | - | 1,884,898 | 1,549,683 | 1,912,494 | 1,764,541 | |
| Proportion | - | 1.05% | 2.65% | 5.55% | 15.34% |
| Plot | Epoch | CSF | CANUPO Dimensionality | CANUPO Dimensionality + SF | CANUPO + CSF Dimensionality + SF | ArcGIS PointCNN | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall | ||
| Plot 1 | E2 | 1.0 | 0.0 | 0.1 | 0.3 | 0.1 | 0.3 | 0.1 | 0.3 | 0.0 | 0.0 |
| E3 | 1.0 | 0.3 | 0.5 | 0.9 | 0.5 | 0.8 | 0.5 | 0.8 | 0.0 | 0.0 | |
| E4 | 1.0 | 0.6 | 0.5 | 0.9 | 0.6 | 0.9 | 0.6 | 0.9 | 0.0 | 0.0 | |
| E5 | 1.0 | 0.8 | 0.7 | 1.0 | 0.7 | 1.0 | 1.0 | 1.0 | 0.1 | 0.1 | |
| Mean | 1.0 | 0.4 | 0.5 | 0.8 | 0.5 | 0.8 | 0.5 | 0.8 | 0.0 | 0.0 | |
| Plot 2 | E2 | 1.0 | 0.0 | 0.6 | 0.1 | 0.2 | 0.1 | 0.2 | 0.1 | 1.0 | 0.1 |
| E3 | 1.0 | 0.4 | 0.8 | 0.8 | 0.7 | 0.8 | 0.7 | 0.8 | 1.0 | 0.7 | |
| E4 | 1.0 | 0.7 | 0.6 | 0.9 | 0.6 | 0.9 | 0.6 | 0.9 | 1.0 | 0.8 | |
| E5 | 1.0 | 0.9 | 0.8 | 1.0 | 0.9 | 1.0 | 0.9 | 1.0 | 1.0 | 1.0 | |
| Mean | 1.0 | 0.5 | 0.7 | 0.7 | 0.6 | 0.7 | 0.6 | 0.7 | 1.0 | 0.7 | |
| Plot 3 | E2 | 1.0 | 0.0 | 0.4 | 0.4 | 0.3 | 0.6 | 0.3 | 0.6 | 1.0 | 0.5 |
| E3 | 1.0 | 0.3 | 0.7 | 0.8 | 0.5 | 0.9 | 0.5 | 0.9 | 1.0 | 0.8 | |
| E4 | 1.0 | 0.6 | 0.5 | 0.9 | 0.4 | 1.0 | 0.4 | 1.0 | 1.0 | 0.9 | |
| E5 | 1.0 | 0.9 | 0.6 | 1.0 | 0.6 | 1.0 | 0.6 | 1.0 | 1.0 | 1.0 | |
| Mean | 1.0 | 0.5 | 0.6 | 0.8 | 0.4 | 0.8 | 0.4 | 0.8 | 1.0 | 0.8 | |
| Plot | Epoch | CSF | CANUPO Dimensionality | CANUPO Dimensionality + SF | CANUPO + CSF Dimensionality + SF | ArcGIS PointCNN | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Height dif. [mm] | SD [mm] | Height dif. [mm] | SD [mm] | Height dif. [mm] | SD [mm] | Height dif. [mm] | SD [mm] | Height dif. [mm] | SD [mm] | ||
| Plot 1 | E2 | 0.1 | 2.2 | 0.1 | 1.6 | 0.1 | 1.5 | 0.1 | 1.5 | 2.2 | 1.9 |
| E3 | 0.5 | 5.2 | 0.0 | 1.0 | 0.1 | 1.9 | 0.1 | 1.9 | 2.4 | 2.4 | |
| E4 | 0.7 | 6.4 | 0.0 | 0.9 | 0.0 | 1.0 | 0.0 | 0.9 | 2.4 | 2.1 | |
| E5 | 0.8 | 7.1 | 0.1 | 4.9 | 0.1 | 4.9 | 0.0 | 0.5 | 2.5 | 2.1 | |
| Mean | 0.6 | 5.2 | 0.1 | 2.1 | 0.1 | 2.3 | 0.1 | 1.2 | 2.4 | 2.1 | |
| Plot 2 | E2 | 0.2 | 2.8 | 0.2 | 2.3 | 0.2 | 2.4 | 0.2 | 2.4 | 0.2 | 2.1 |
| E3 | 0.5 | 5.0 | 0.1 | 1.3 | 0.1 | 1.4 | 0.1 | 1.4 | 0.2 | 2.5 | |
| E4 | 0.5 | 5.2 | 0.0 | 1.0 | 0.1 | 1.3 | 0.0 | 1.1 | 0.2 | 3.3 | |
| E5 | 0.6 | 5.5 | 0.1 | 3.7 | 0.0 | 1.4 | 0.0 | 0.9 | 0.1 | 2.3 | |
| Mean | 0.5 | 4.6 | 0.1 | 2.1 | 0.1 | 1.6 | 0.1 | 1.5 | 0.2 | 2.5 | |
| Plot 3 | E2 | 0.2 | 2.8 | 0.1 | 1.7 | 0.1 | 1.2 | 0.1 | 1.2 | 0.1 | 0.9 |
| E3 | 0.7 | 5.8 | 0.1 | 1.5 | 0.1 | 1.3 | 0.1 | 1.2 | 0.1 | 0.9 | |
| E4 | 0.8 | 6.3 | 0.1 | 1.8 | 0.0 | 1.0 | 0.0 | 0.4 | 0.1 | 0.8 | |
| E5 | 0.7 | 6.2 | 0.5 | 11.3 | 0.4 | 10.7 | 0.0 | 0.3 | 0.3 | 8.0 | |
| Mean | 0.6 | 5.3 | 0.2 | 4.1 | 0.1 | 3.5 | 0.0 | 0.8 | 0.1 | 2.7 | |
| Categorization | Criteria | Process |
|---|---|---|
| Hard evaluation criteria | F1 Score | RS 1 0–1 |
| Balanced Accuracy | RS 0–1 | |
| Height Difference | Transfer to RS 0–1 | |
| Height Difference STD | Transfer to RS 0–1 | |
| Data Gaps | Transfer to RS 0–1 | |
| Robustness | Range of F1 scores for all three plots transferred to RS 0–1 | |
| Soft evaluation criteria | User Knowledge | Estimated based on simplicity of handling in RS 0–1 |
| Accessibility | Estimated based on acquisition cost in RS 0–1 | |
| Time-Saving Capacity | Estimated compared to manual processing in RS 0–1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ott, S.; Burkhard, B.; Harmening, C.; Paffenholz, J.-A.; Steinhoff-Knopp, B. Comparative Analysis of Algorithms to Cleanse Soil Micro-Relief Point Clouds. Geomatics 2023, 3, 501-521. https://doi.org/10.3390/geomatics3040027
Ott S, Burkhard B, Harmening C, Paffenholz J-A, Steinhoff-Knopp B. Comparative Analysis of Algorithms to Cleanse Soil Micro-Relief Point Clouds. Geomatics. 2023; 3(4):501-521. https://doi.org/10.3390/geomatics3040027
Chicago/Turabian StyleOtt, Simone, Benjamin Burkhard, Corinna Harmening, Jens-André Paffenholz, and Bastian Steinhoff-Knopp. 2023. "Comparative Analysis of Algorithms to Cleanse Soil Micro-Relief Point Clouds" Geomatics 3, no. 4: 501-521. https://doi.org/10.3390/geomatics3040027