
A Systematic Review of Packages for Time Series Analysis †


Abstract
:1. Introduction
2. Related Work
3. Methodology
3.1. Research Questions
- RQ1 Which time series analysis tasks exist? And which of these are implemented in maintained Python packages?
- RQ2 How do the packages support the evaluation of the produced results?
- RQ3 How do the packages support their usage, and what insights can we gain to estimate the durability of a given package and make an informed choice about its long-term use?
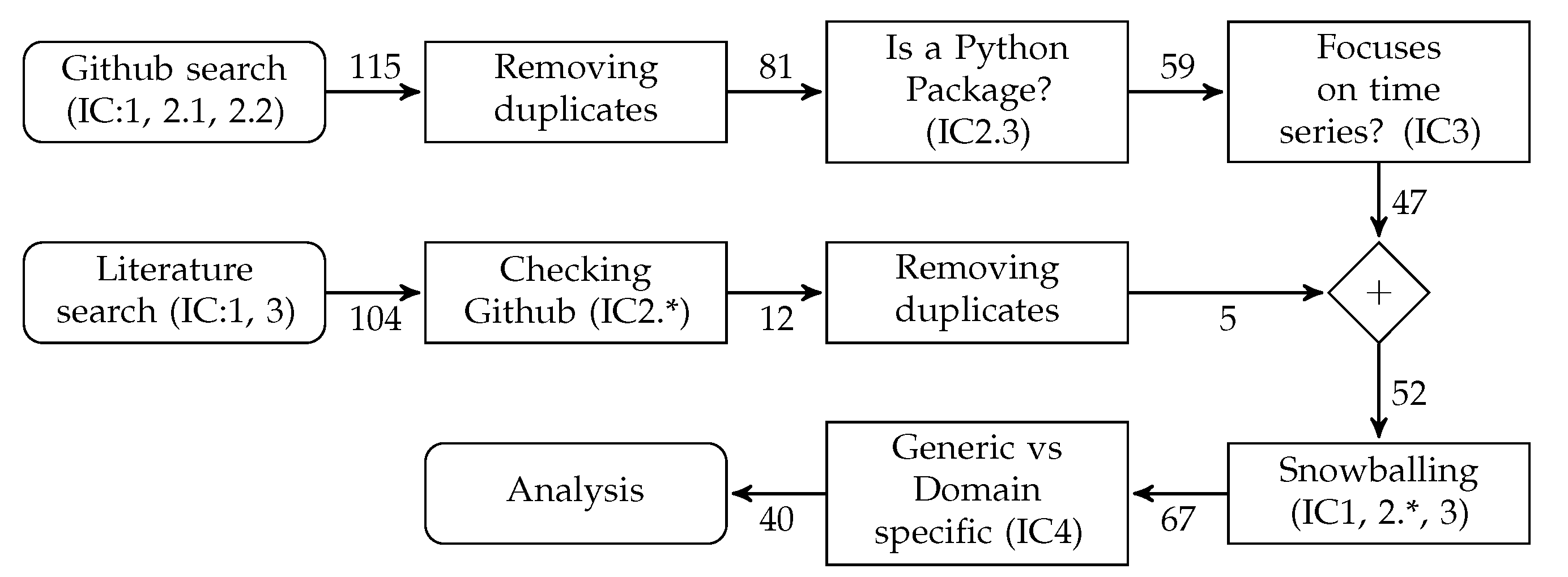
3.2. Inclusion Criteria
3.3. Searching Open-Source Repositories in GitHub
3.3.1. Removing Duplicates
3.3.2. Checking If the Repository Contains the Code of a Python Package
3.3.3. Including only Packages Focused on Time Series Analysis
3.4. Searching Scientific Bibliographic Databases
3.5. Snowballing
3.6. Generic vs. Domain-Specific Packages (IC4)
3.7. Data Extraction and Categorization
4. Results
4.1. RQ1: Implementation of the Time Series Analysis Tasks
4.1.1. Task Definitions
4.1.2. Implemented Tasks
4.2. RQ2: Evaluation of the Produced Results
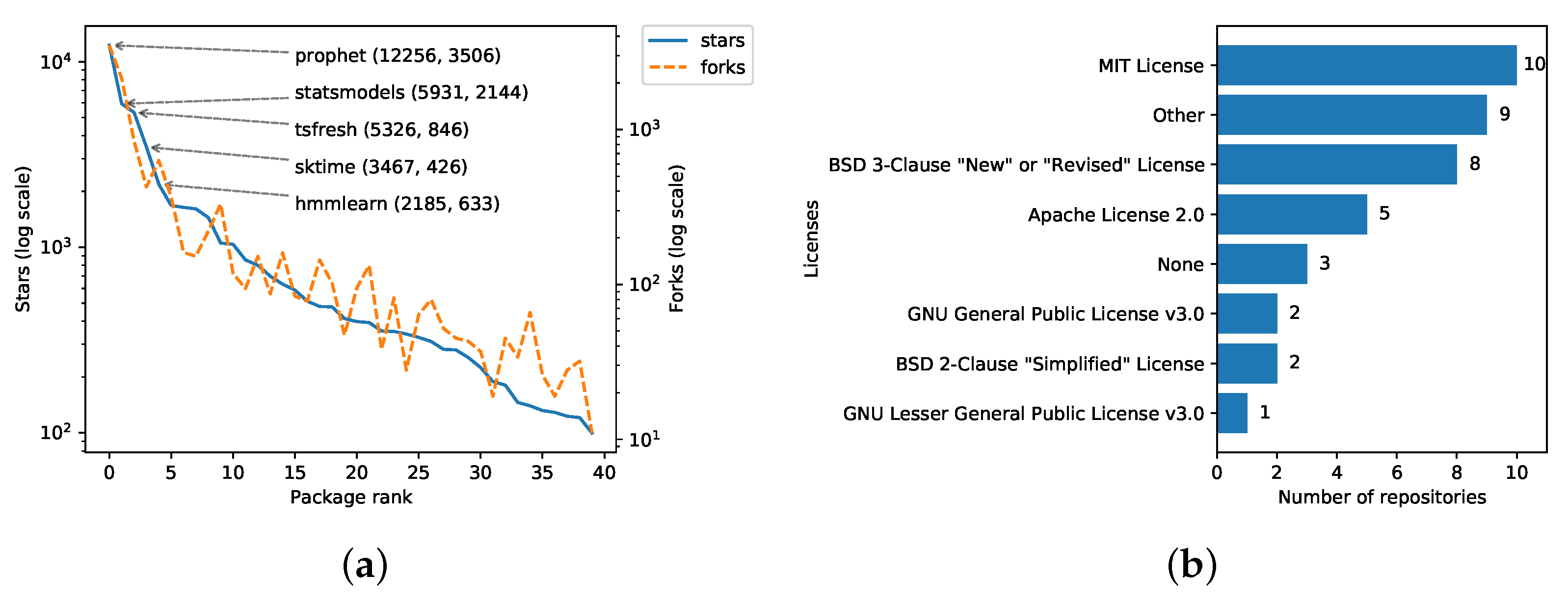
4.3. RQ3: Package Usage and Community
5. Discussion and Threats to Validity
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hendikawati, P.; Subanar; Abdurakhman; Tarno. A survey of time series forecasting from stochastic method to soft computing. J. Phys. Conf. Ser. 2020, 1613, 012019. [Google Scholar] [CrossRef]
- Mahalakshmi, G.; Sridevi, S.; Rajaram, S. A survey on forecasting of time series data. In Proceedings of the 2016 International Conference on Computing Technologies and Intelligent Data Engineering (ICCTIDE’16), Kovilpatti, India, 7–9 January 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Panigrahi, S.; Behera, H.S. Fuzzy Time Series Forecasting: A Survey. In Computational Intelligence in Data Mining; Advances in Intelligent Systems and Computing Ser; Behera, H.S., Nayak, J., Naik, B., Pelusi, D., Eds.; Springer: Singapore, 2020; pp. 641–651. [Google Scholar]
- Tealab, A. Time series forecasting using artificial neural networks methodologies: A systematic review. Future Comput. Inform. J. 2018, 3, 334–340. [Google Scholar] [CrossRef]
- Abanda, A.; Mori, U.; Lozano, J.A. A review on distance based time series classification. Data Min. Knowl. Discov. 2019, 33, 378–412. [Google Scholar] [CrossRef] [Green Version]
- Aghabozorgi, S.; Seyed Shirkhorshidi, A.; Ying Wah, T. Time-series clustering—A decade review. Inf. Syst. 2015, 53, 16–38. [Google Scholar] [CrossRef]
- Bagnall, A.; Lines, J.; Bostrom, A.; Large, J.; Keogh, E. The great time series classification bake off: A review and experimental evaluation of recent algorithmic advances. Data Min. Knowl. Discov. 2017, 31, 606–660. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef] [Green Version]
- Susto, G.A.; Cenedese, A.; Terzi, M. Time-Series Classification Methods: Review and Applications to Power Systems Data. In Big Data Application in Power Systems; Elsevier: Amsterdam, The Netherlands, 2018; pp. 179–220. [Google Scholar] [CrossRef]
- Ayadi, A.; Ghorbel, O.; Obeid, A.M.; Abid, M. Outlier detection approaches for wireless sensor networks: A survey. Comput. Netw. 2017, 129, 319–333. [Google Scholar] [CrossRef]
- Cook, A.A.; Misirli, G.; Fan, Z. Anomaly Detection for IoT Time-Series Data: A Survey. IEEE Internet Things J. 2020, 7, 6481–6494. [Google Scholar] [CrossRef]
- Wu, H.S. A survey of research on anomaly detection for time series. In Proceedings of the 2016 13th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 16–18 December 2016; Institute of Electrical and Electronics Engineers, Inc.: Piscataway, NJ, USA, 2016; pp. 426–431. [Google Scholar] [CrossRef]
- Aminikhanghahi, S.; Cook, D.J. A Survey of Methods for Time Series Change Point Detection. Knowl. Inf. Syst. 2017, 51, 339–367. [Google Scholar] [CrossRef] [Green Version]
- Sharma, S.; Swayne, D.A.; Obimbo, C. Trend analysis and change point techniques: A survey. Energy Ecol. Environ. 2016, 1, 123–130. [Google Scholar] [CrossRef] [Green Version]
- Truong, C.; Oudre, L.; Vayatis, N. Selective review of offline change point detection methods. Signal Process. 2020, 167, 107299. [Google Scholar] [CrossRef] [Green Version]
- Torkamani, S.; Lohweg, V. Survey on time series motif discovery. WIREs Data Min. Knowl. Discov. 2017, 7, e1199. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep Learning for Sensor-based Activity Recognition: A Survey. Pattern Recognit. Lett. 2018. [Google Scholar] [CrossRef] [Green Version]
- Badhiye, S.S. A Review on Time Series Dimensionality Reduction. HELIX 2018, 8, 3957–3960. [Google Scholar] [CrossRef]
- Sezer, O.B.; Gudelek, M.U.; Ozbayoglu, A.M. Financial time series forecasting with deep learning: A systematic literature review: 2005–2019. Appl. Soft Comput. 2020, 90, 106181. [Google Scholar] [CrossRef] [Green Version]
- Lepenioti, K.; Bousdekis, A.; Apostolou, D.; Mentzas, G. Prescriptive analytics: Literature review and research challenges. Int. J. Inf. Manag. 2020, 50, 57–70. [Google Scholar] [CrossRef]
- Mohammadi, M.; Al-Fuqaha, A.; Sorour, S.; Guizani, M. Deep Learning for IoT Big Data and Streaming Analytics: A Survey. IEEE Commun. Surv. Tutor. 2018, 20, 2923–2960. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.; Zhang, C.; Zhang, Y.; Wang, Z.; Li, J. A review of data mining technologies in building energy systems: Load prediction, pattern identification, fault detection and diagnosis. Energy Built Environ. 2019. [Google Scholar] [CrossRef]
- Zeger, S.L.; Irizarry, R.; Peng, R.D. On time series analysis of public health and biomedical data. Annu. Rev. Public Health 2006, 27, 57–79. [Google Scholar] [CrossRef] [Green Version]
- Esling, P.; Agon, C. Time-series data mining. ACM Comput. Surv. 2012, 45, 1–34. [Google Scholar] [CrossRef] [Green Version]
- Fakhrazari, A.; Vakilzadian, H. A survey on time series data mining. In Proceedings of the 2017 IEEE International Conference on Electro Information Technology (EIT), Lincoln, NE, USA, 14–17 May 2017; pp. 476–481. [Google Scholar] [CrossRef]
- Keogh, E.; Kasetty, S. On the Need for Time Series Data Mining Benchmarks: A Survey and Empirical Demonstration. Data Min. Knowl. Discov. 2003, 7, 349–371. [Google Scholar] [CrossRef]
- Cowpertwait, P.S.P.; Metcalfe, A.V. Introductory Time Series with R; Use R! Springer: Dordrecht, The Netherlands; New York, NY, USA, 2009. [Google Scholar]
- Shumway, R.H.; Stoffer, D.S. Time Series Analysis and Its Applications: With R Examples, 4th ed.; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Nielsen, A. Practical Time Series Analysis: Prediction with Statistics and Machine Learning, 1st ed.; O’Reilly: Beijing, China, 2019. [Google Scholar]
- Joo, R.; Boone, M.E.; Clay, T.A.; Patrick, S.C.; Clusella-Trullas, S.; Basille, M. Navigating through the r packages for movement. J. Anim. Ecol. 2020, 89, 248–267. [Google Scholar] [CrossRef] [Green Version]
- Slater, L.J.; Thirel, G.; Harrigan, S.; Delaigue, O.; Hurley, A.; Khouakhi, A.; Prosdocimi, I.; Vitolo, C.; Smith, K. Using R in hydrology: A review of recent developments and future directions. Hydrol. Earth Syst. Sci. 2019, 23, 2939–2963. [Google Scholar] [CrossRef] [Green Version]
- Thivaharan, S.; Srivatsun, G.; Sarathambekai, S. A Survey on Python Libraries Used for Social Media Content Scraping. In Proceedings of the International Conference on Smart Electronics and Communication (ICOSEC 2020), Trichy, India, 10–12 September 2020. [Google Scholar] [CrossRef]
- Ray, J.; Trovati, M. A survey of topological data analysis (TDA) methods implemented in python. Lect. Notes Data Eng. Commun. Technol. 2018, 8, 594–600. [Google Scholar]
- Stancin, I.; Jovic, A. An overview and comparison of free Python libraries for data mining and big data analysis. In Proceedings of the 2019 42st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 20–24 May 2019; pp. 977–982. [Google Scholar] [CrossRef]
- Januschowski, T.; Gasthaus, J.; Wang, Y. Open-Source Forecasting Tools in Python. Foresight Int. J. Appl. Forecast. 2019, 55, 20–26. [Google Scholar]
- Kitchenham, B.; Brereton, P. A systematic review of systematic review process research in software engineering. Inf. Softw. Technol. 2013, 55, 2049–2075. [Google Scholar] [CrossRef]
- Burns, D.M.; Whyne, C.M. Seglearn: A Python Package for Learning Sequences and Time Series. J. Mach. Learn. Res. 2018, 19, 3238–3244. [Google Scholar]
- Christ, M.; Braun, N.; Neuffer, J.; Kempa-Liehr, A.W. Time Series FeatuRe Extraction on basis of Scalable Hypothesis tests (tsfresh—A Python package). Neurocomputing 2018, 307, 72–77. [Google Scholar] [CrossRef]
- Alexandrov, A.; Benidis, B.; Bohlke-Schneider, M.; Flunkert, V.; Gasthaus, J.; Januschowski, T.; Maddix, D.C.; Rangapuram, S.; Salinas, D.; Schulz, J.; et al. GluonTS: Probabilistic and Neural Time Series Modeling in Python. J. Mach. Learn. Res. 2020, 21, 1–6. [Google Scholar]
- Faouzi, J.; Janati, H. Pyts: A python package for time series classification. J. Mach. Learn. Res. 2020, 21, 1–6. Available online: http://jmlr.org/papers/v21/19-763.html (accessed on 24 June 2021).
- Law, S. STUMPY: A Powerful and Scalable Python Library for Time Series Data Mining. J. Open Source Softw. 2019, 4, 1504. [Google Scholar] [CrossRef] [Green Version]
- Collenteur, R.; Bakker, M.; Caljé, R.; Schaars, F. Pastas: Open-Source Software for the Analysis of Hydrogeological Time Series. Available online: https://zenodo.org/record/4277358 (accessed on 24 June 2021).
- Miller, J.C.; Ting, T. EoN (Epidemics on Networks): A Fast, Flexible Python Package for Simulation, Analytic Approximation, and Analysis of Epidemics on Networks. 2020. Available online: https://zenodo.org/record/3572756 (accessed on 24 June 2021).
- Schölzel, C. Nonlinear Measures for Dynamical Systems. Available online: https://zenodo.org/record/3814723 (accessed on 24 June 2021).
- Silva, P.C.D.L.E.; Júnior, C.A.S.; Alves, M.A.; Silva, R.C.P.; Vieira, G.L.; Lucas, P.D.O.E.; Sadaei, H.J.; Guimarães, F.G. PYFTS/pyFTS: Stable Version 1.6. 2019. Available online: https://zenodo.org/record/2669398 (accessed on 24 June 2021).
- Snow, D.; Baltacı, F. firmai/atspy: Zenodo. 2020. Available online: https://zenodo.org/record/4270168 (accessed on 24 June 2021).
- Team, T.O.D. Obspy 1.0.0. 2016. Available online: https://zenodo.org/record/46151 (accessed on 24 June 2021).
- Fu, T.C. A review on time series data mining. Eng. Appl. Artif. Intell. 2011, 24, 164–181. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Data Source | Number of Hits | Number of Included Documents | Included References |
|---|---|---|---|
| IEEE Xplore | 1 | 0 | |
| ACM Digital Library | 2 | 1 | [37] |
| Web of Science | 10 | 4 | [37,38,39,40] |
| Scopus | 12 | 4 | [37,38,39,40] |
| JOSS | 21 | 1 | [41] |
| Zenodo | 68 | 6 | [42,43,44,45,46,47] |
| Package Name | Tasks | Data Preparation | Evaluation | Data | Documentation | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T1 | T2 | T3 | T4 | T5 | T6 | T7 | DP1 | DP2 | DP3 | DP4 | DP5 | E1 | E2 | E3 | D1 | D2 | Do1 | Do2 | Do3 | Do4 | Do5 | |
| arch | + | + | + | + | + | * | + | + | + | |||||||||||||
| atspy | + | + | + | + | + | + | + | + | + | + | ||||||||||||
| banpei | + | + | + | + | ||||||||||||||||||
| cesium | + | + | * | + | + | + | ||||||||||||||||
| darts | + | + | + | + | + | + | + | + | + | + | + | + | ||||||||||
| deeptime | + | + | + | + | + | + | + | + | + | + | + | + | ||||||||||
| deltapy | + | + | + | + | + | + | + | + | + | + | + | |||||||||||
| dtaidistance | + | + | + | + | + | + | + | + | ||||||||||||||
| EMD-signal | + | + | + | + | + | + | + | |||||||||||||||
| flood-forecast | + | + | + | + | + | + | + | + | + | + | ||||||||||||
| gluonts | + | + | + | + | + | + | + | + | + | + | + | |||||||||||
| hcrystalball | + | + | + | + | + | + | + | + | + | * | + | + | + | |||||||||
| hmmlearn | + | + | + | + | * | + | + | |||||||||||||||
| hypertools | + | + | + | + | + | + | * | + | + | + | ||||||||||||
| linearmodels | + | + | * | + | + | |||||||||||||||||
| luminaire | + | + | + | + | + | + | + | + | + | |||||||||||||
| matrixprofile | + | + | + | + | + | + | + | + | + | + | + | + | ||||||||||
| mcfly | + | + | + | + | + | + | ||||||||||||||||
| neuralprophet | + | + | + | + | + | + | * | + | + | + | ||||||||||||
| nolds | + | + | + | + | + | + | + | + | ||||||||||||||
| pmdarima | + | + | + | + | + | + | + | * | + | + | ||||||||||||
| prophet | + | + | + | + | + | + | * | + | + | + | ||||||||||||
| pyaf | + | + | + | + | + | + | + | + | + | + | + | + | ||||||||||
| pycwt | + | + | + | + | + | + | + | |||||||||||||||
| pydlm | + | + | + | + | + | + | * | + | + | + | ||||||||||||
| pyFTS | + | + | + | + | + | + | + | + | + | + | ||||||||||||
| pyodds | + | + | + | + | + | * | + | + | + | |||||||||||||
| pytorchts | + | + | + | + | + | + | + | + | + | + | + | |||||||||||
| pyts | + | + | + | + | + | + | + | + | + | + | + | + | * | + | + | |||||||
| PyWavelets | + | + | + | + | + | * | + | + | + | |||||||||||||
| ruptures | + | + | + | + | + | + | + | + | ||||||||||||||
| scikit-multiflow | + | + | + | + | + | + | + | + | + | * | + | + | ||||||||||
| seglearn | + | + | + | * | + | + | + | |||||||||||||||
| sktime | + | + | + | + | + | + | + | + | + | + | + | + | + | * | + | + | + | |||||
| sktime-dl | + | + | + | + | + | + | ||||||||||||||||
| statsmodels | + | + | + | + | + | + | + | + | + | + | * | + | + | + | ||||||||
| stumpy | + | + | + | + | * | + | + | + | ||||||||||||||
| tftb | + | + | + | + | + | + | + | + | + | + | ||||||||||||
| tsfresh | + | + | + | + | + | + | + | + | + | |||||||||||||
| tslearn | + | + | + | + | + | + | + | + | + | + | + | |||||||||||
| Total | 20 | 6 | 6 | 6 | 4 | 4 | 5 | 4 | 17 | 16 | 24 | 7 | 13 | 23 | 25 | 16 | 19 | 34 | 30 | 28 | 40 | 37 |
| T1 | T2 | T3 | T4 | T5 | T6 | T7 | DP1 | DP2 | DP3 | DP4 | DP5 | E1 | E2 | E3 | D1 | D2 | Do1 | Do2 | Do3 | Do4 | Do5 | |
| Tasks | Data Preparation | Evaluation | Data | Documentation | ||||||||||||||||||
| Package Name | Used | Rank | Package Name | Used | Rank |
|---|---|---|---|---|---|
| numpy | 37 | 1 | torch | 6 | 8 |
| scipy | 30 | 2 | numba | 6 | 8 |
| pandas | 23 | 3 | cython | 6 | 8 |
| scikit-learn | 21 | 4 | tensorflow | 5 | 9 |
| matplotlib | 16 | 5 | seaborn | 4 | 10 |
| statsmodels | 8 | 6 | future | 4 | 10 |
| tqdm | 7 | 7 | joblib | 4 | 10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Siebert, J.; Groß, J.; Schroth, C. A Systematic Review of Packages for Time Series Analysis. Eng. Proc. 2021, 5, 22. https://doi.org/10.3390/engproc2021005022
Siebert J, Groß J, Schroth C. A Systematic Review of Packages for Time Series Analysis. Engineering Proceedings. 2021; 5(1):22. https://doi.org/10.3390/engproc2021005022
Chicago/Turabian StyleSiebert, Julien, Janek Groß, and Christof Schroth. 2021. "A Systematic Review of Packages for Time Series Analysis" Engineering Proceedings 5, no. 1: 22. https://doi.org/10.3390/engproc2021005022