
Text-to-Image Generation Using Deep Learning †


Abstract
:1. Introduction
- Building a deep learning model RC-GAN for generating more realistic images.
- Generating more realistic images from given textual descriptions.
- Improving the inception score and PSNR value of images generated from text.
2. Related Work
3. Dataset and Preprocessing
3.1. Dataset
3.2. Data Preprocessing
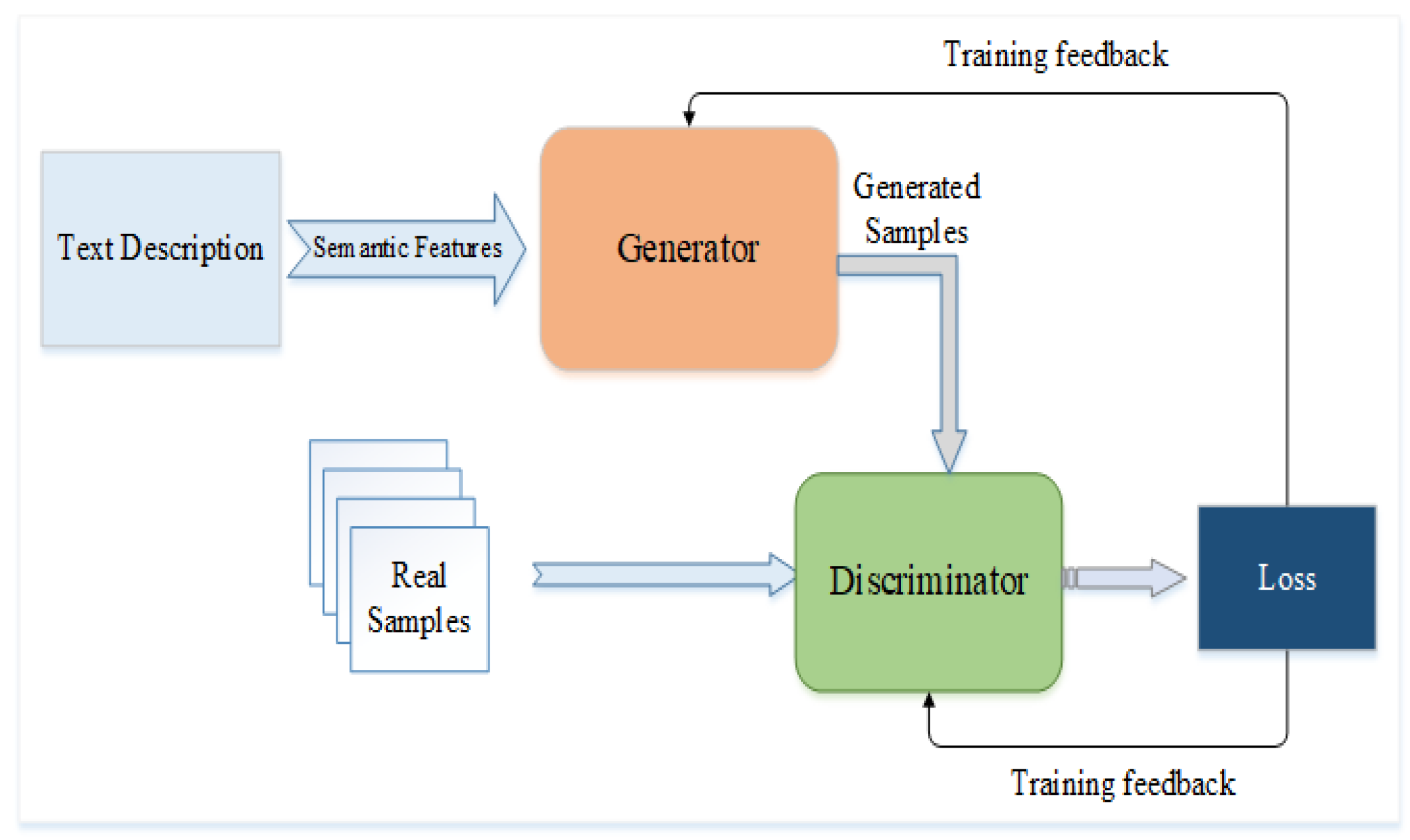
4. Proposed Methodology
5. Results and Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kosslyn, S.M.; Ganis, G.; Thompson, W.L. Neural foundations of imagery. Nat. Rev. Neurosci. 2001, 2, 635–642. [Google Scholar] [CrossRef] [PubMed]
- Karpathy, A.; Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Kim, P. Convolutional neural network. In MATLAB Deep Learning; Springer: Berlin/Heidelberg, Germany, 2017; pp. 121–147. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. arXiv 2016, arXiv:1605.05396. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the Advances in Neural Information Processing Systems 29 (NIPS 2016), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Zia, T.; Arif, S.; Murtaza, S.; Ullah, M.A. Text-to-Image Generation with Attention Based Recurrent Neural Networks. arXiv 2020, arXiv:2001.06658. [Google Scholar]
- Liu, R.; Ge, Y.; Choi, C.L.; Wang, X.; Li, H. Divco: Diverse conditional image synthesis via contrastive generative adversarial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16377–16386. [Google Scholar]
- Gao, L.; Chen, D.; Zhao, Z.; Shao, J.; Shen, H.T. Lightweight dynamic conditional GAN with pyramid attention for text-to-image synthesis. Pattern Recognit. 2021, 110, 107384. [Google Scholar] [CrossRef]
- Dong, Y.; Zhang, Y.; Ma, L.; Wang, Z.; Luo, J. Unsupervised text-to-image synthesis. Pattern Recognit. 2021, 110, 107573. [Google Scholar] [CrossRef]
- Berrahal, M.; Azizi, M. Optimal text-to-image synthesis model for generating portrait images using generative adversarial network techniques. Indones. J. Electr. Eng. Comput. Sci. 2022, 25, 972–979. [Google Scholar] [CrossRef]
- Zhang, Y.; Han, S.; Zhang, Z.; Wang, J.; Bi, H. CF-GAN: Cross-domain feature fusion generative adversarial network for text-to-image synthesis. Vis. Comput. 2022, 1–11. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5907–5915. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan++: Realistic image synthesis with stacked generative adversarial networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1947–1962. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Z.; Xie, Y.; Yang, L. Photographic text-to-image synthesis with a hierarchically-nested adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6199–6208. [Google Scholar]
- Cai, Y.; Wang, X.; Yu, Z.; Li, F.; Xu, P.; Li, Y.; Li, L. Dualattn-GAN: Text to image synthesis with dual attentional generative adversarial network. IEEE Access 2019, 7, 183706–183716. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Ref. | Models | Inception Score |
|---|---|---|
| Reed et al. [8] | GAN-INT-CLS | 2.66 ± 0.03 |
| Zhang et al. [16] | StackGAN | 3.20 ± 0.01 |
| Zhang et al. [17] | StackGAN++ | 3.26 ± 0.01 |
| Zhang et al. [18] | HDGAN | 3.45 ± 0.05 |
| Cai et al. [19] | DualAttn-GAN | 4.06 ± 0.05 |
| Proposed Method | RC-GAN | 4.15 ± 0.03 |
| Ref. | Model | PSNR Value |
|---|---|---|
| Proposed Method | RC-GAN | 30.12 dB |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramzan, S.; Iqbal, M.M.; Kalsum, T. Text-to-Image Generation Using Deep Learning. Eng. Proc. 2022, 20, 16. https://doi.org/10.3390/engproc2022020016
Ramzan S, Iqbal MM, Kalsum T. Text-to-Image Generation Using Deep Learning. Engineering Proceedings. 2022; 20(1):16. https://doi.org/10.3390/engproc2022020016
Chicago/Turabian StyleRamzan, Sadia, Muhammad Munwar Iqbal, and Tehmina Kalsum. 2022. "Text-to-Image Generation Using Deep Learning" Engineering Proceedings 20, no. 1: 16. https://doi.org/10.3390/engproc2022020016