
Reconstructed Phase Spaces and LSTM Neural Network Ensemble Predictions †


Abstract
:1. Introduction
2. Related Work
- Ref. [7]: This publication presents a method to determine if images are blurry. For this purpose, the second derivatives of grey-scale images are taken, and the corresponding variance over all pixels is analyzed. This concept is used in the presented article. We adapted the idea of variances of second derivatives, which is discussed in Section 4.2.
- Ref. [3]: This publication presents a novel stochastic interpolation technique where the idea of a Brownian bridge, i.e., a constrained fractional Brownian motion (fBm), is extended to more than two points, i.e., to multi-point fractional Brownian bridges. This method is the basis for the employed interpolation techniques and provides the population of random interpolations for the genetic algorithm.
- Ref. [2]: In this publication, a fractal interpolation to interpolate univariate time-series data is presented. This research suggests that different interpolation methods for univariate time-series data may yield predictions of different quality. Thus, as presented here, employing an attractor-based interpolation is an obvious next step compared to a fluctuation-based interpolation.
- Ref. [5]: This publication is a continuation of [2]. The fractal interpolation and LSTM neural network approach is continued as ensembles of predictions. Randomly parameterized LSTM neural networks are generated from non-, linear-, and fractal-interpolated data. Afterward, these predictions are filtered based on their signal complexities. Contrary to this publication, we test LSTM neural network predictions of stochastically interpolated data.
- Ref. [4]: This publication validates a stochastic interpolation based on the smoothness of reconstructed phase space trajectories and Brownian Bridges, i.e., the PhaSpaSto interpolation. The basic idea is to filter/improve a multitude of stochastic interpolations of the same time-series data using a genetic algorithm and the variance of second derivatives along a reconstructed phase space trajectory to generate smooth phase space embeddings.The interpolation technique developed in this paper is briefly described in Section 4 and used to improve the presented predictions.
3. Phase Space Reconstruction
4. PhaSpaSto Interpolation
4.1. Multi-Point Fractional Brownian Bridges
4.2. Genetic Algorithm
5. Datasets
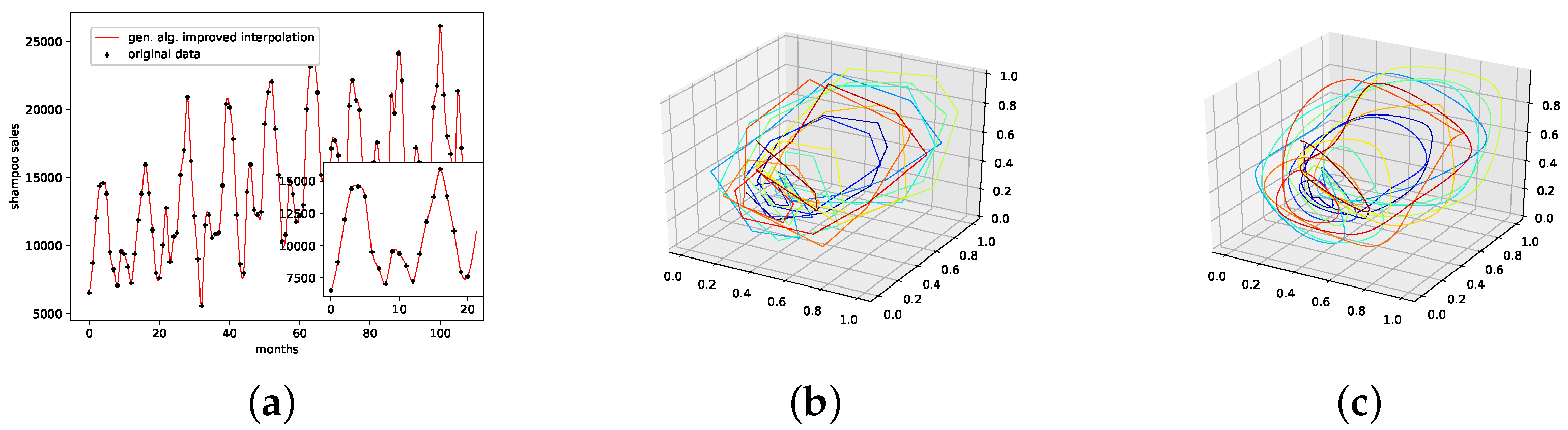
5.1. Car Sales in Quebec Dataset
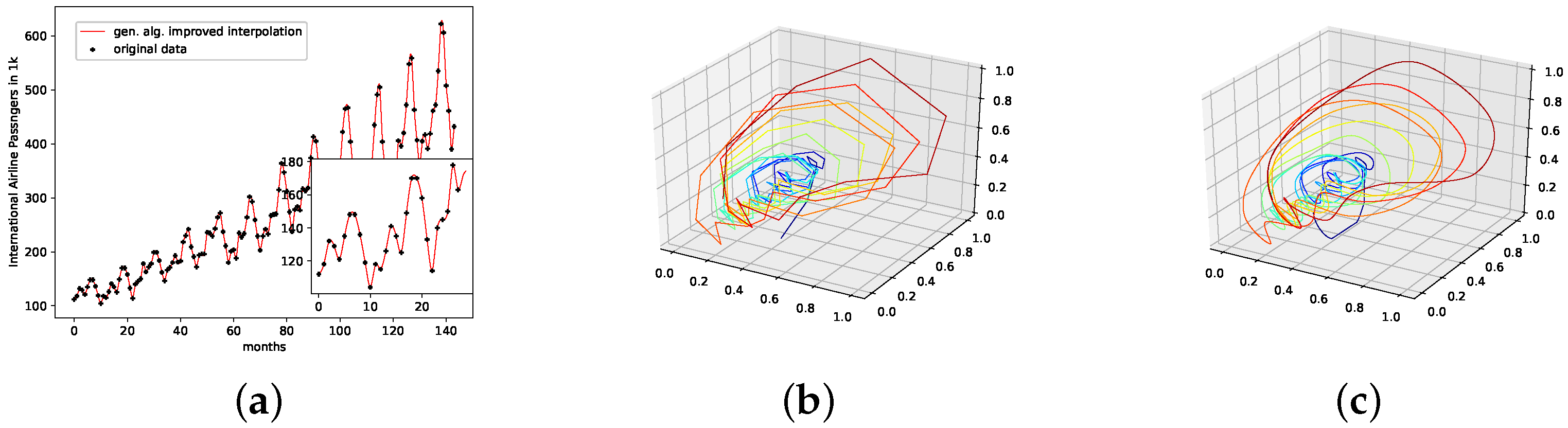
5.2. Monthly International Airline Passengers Dataset
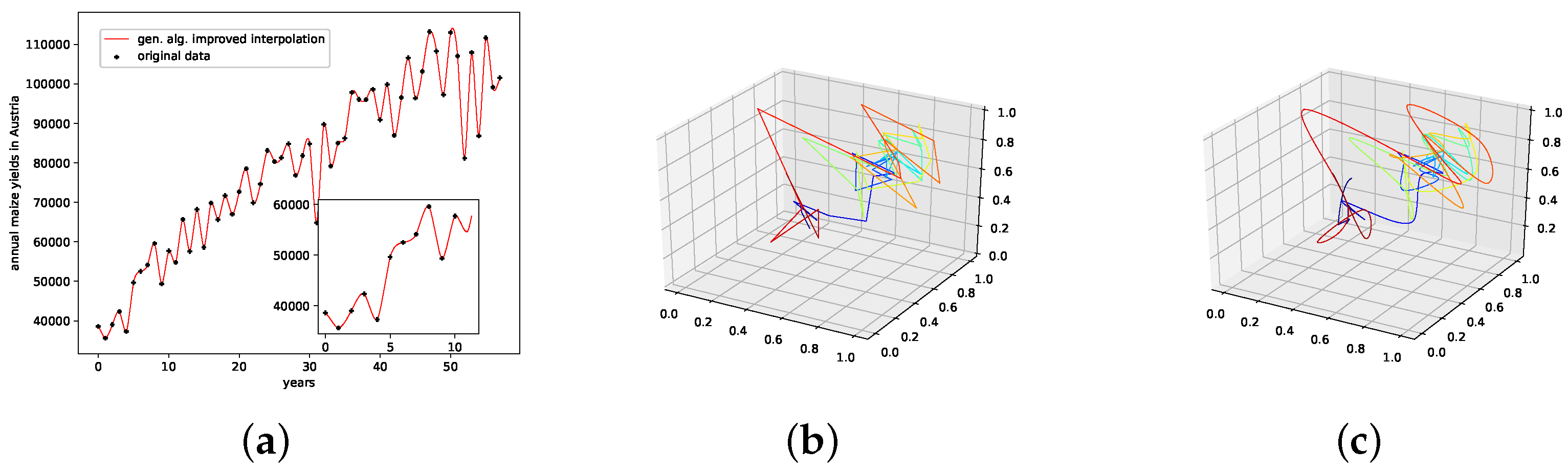
5.3. Annual Maize Yields in Austria
5.4. Data Preprocessing
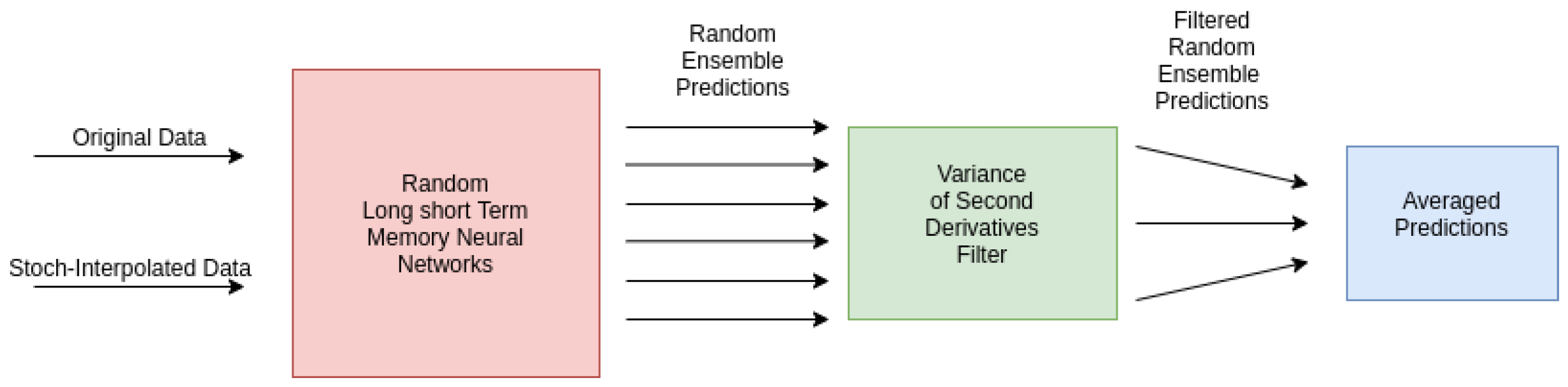
6. LSTM Neural Network Time-Series Prediction
6.1. Randomly Parameterized Neural Networks
- Number of input nodes: 1 → size of the training data − 1
- Number of neurons for each hidden layer: 1 → 50
- Batchsizes: 2 → 128
- Epochs: 1 → 50
6.2. Prediction Filter
7. Experiments and Results
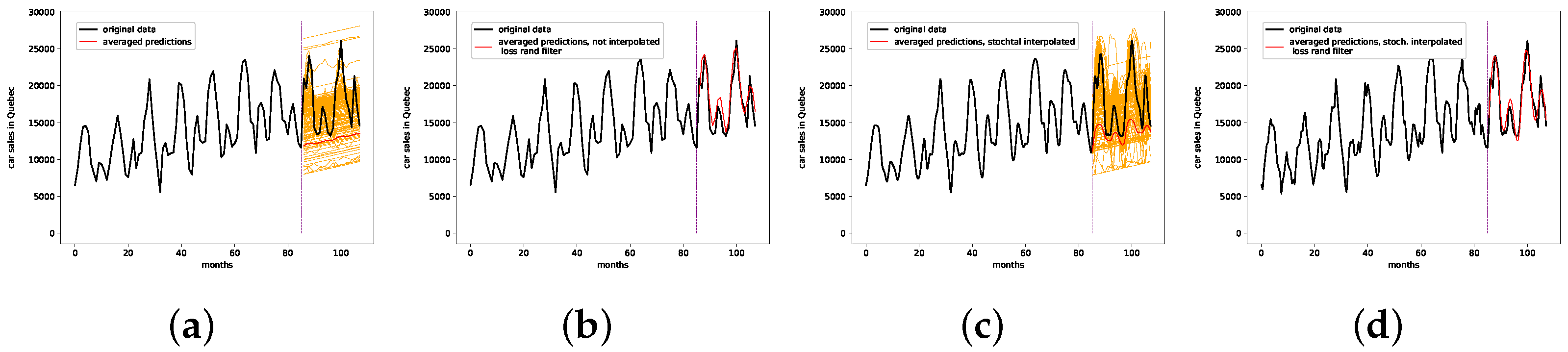
7.1. Car Sales in Quebec Dataset
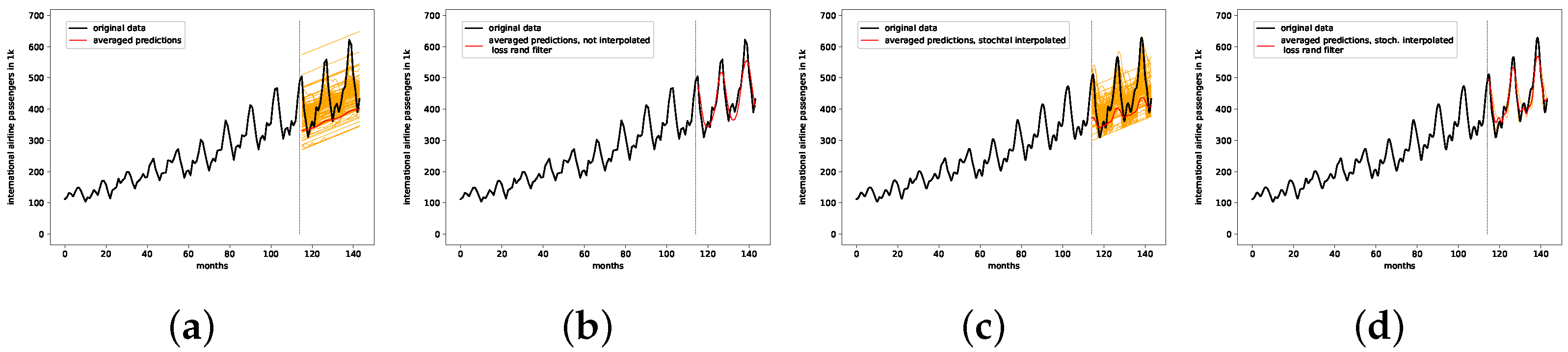
7.2. Monthly International Airline Passengers
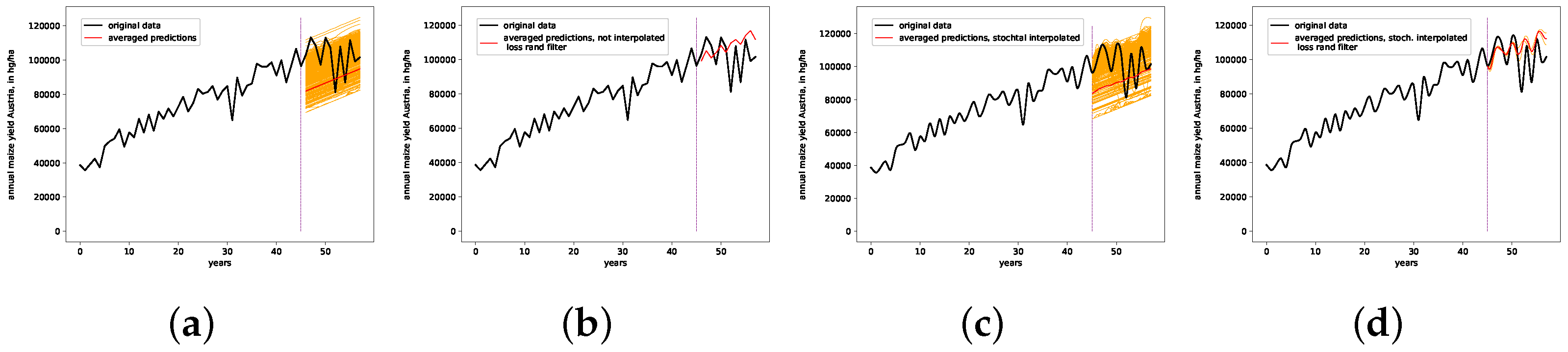
7.3. Annual Maize Yields in Austria Dataset
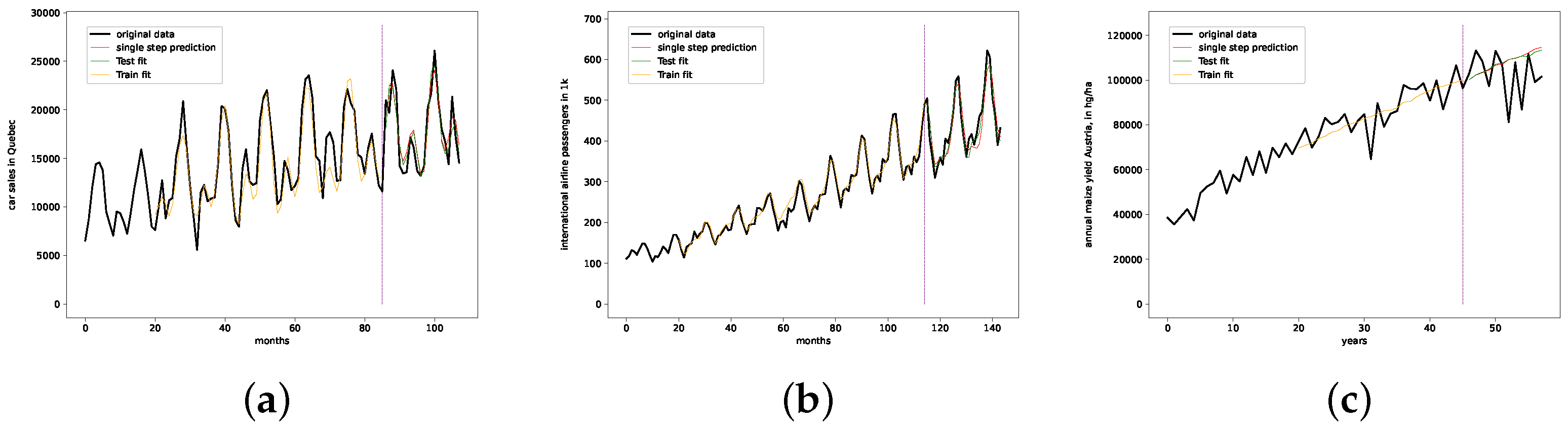
7.4. Benchmark and Baseline Predictions
7.5. Summary
- (1)
- The presented stochastic interpolation method—for simplicity, referred to as PhaSpaSto interpolation—can be used to improve retrogressive neural network time-series predictions. This is supported by the findings of Table 1. Here, we can see that both the filtered and unfiltered interpolated results outperformed those without interpolation. The same is true for all filtered results, i.e., the interpolated results always outperformed the unfiltered ones. These results are depicted in Figure 5, Figure 6 and Figure 7.
- (2)
- (3)
- The presented interpolated and filtered approach outperformed the baseline and benchmark predictions for the monthly car sales in Quebec dataset, discussed in Section 7.4.Though the interpolated and filtered ensemble approach did outperform a given baseline prediction for the monthly international airline passengers dataset, the featured benchmark prediction from the literature still outperformed our approach on this dataset.We provide a baseline prediction for the annual maize yields in Austria dataset, which was outperformed using our interpolated and filtered ensemble approach, discussed in Section 7.4. We cannot provide a benchmark result from the literature for this dataset.
- (4)
- The employed neural network ensembles were not individually parameterized for each dataset. Instead, we filtered the predictions according to the phase space properties of each dataset. Thus, we could circumvent the problem of parameterizing neural networks.
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Voyant, C.; Notton, G.; Kalogirou, S.; Nivet, M.L.; Paoli, C.; Motte, F.; Fouilloy, A. Machine learning methods for solar radiation forecasting: A review. Renew. Energy 2017, 105, 569–582. [Google Scholar] [CrossRef]
- Raubitzek, S.; Neubauer, T. A fractal interpolation approach to improve neural network predictions for difficult time series data. Expert Syst. Appl. 2021, 169, 114474. [Google Scholar] [CrossRef]
- Friedrich, J.; Gallon, S.; Pumir, A.; Grauer, R. Stochastic Interpolation of Sparsely Sampled Time Series via Multipoint Fractional Brownian Bridges. Phys. Rev. Lett. 2020, 125, 170602. [Google Scholar] [CrossRef] [PubMed]
- Raubitzek, S.; Neubauer, T.; Friedrich, J.; Rauber, A. Interpolating Strange Attractors via Fractional Brownian Bridges. Entropy 2022, 24, 718. [Google Scholar] [CrossRef] [PubMed]
- Raubitzek, S.; Neubauer, T. Taming the Chaos in Neural Network Time Series Predictions. Entropy 2021, 23, 1424. [Google Scholar] [CrossRef] [PubMed]
- Raubitzek, S.; Neubauer, T. Combining Measures of Signal Complexity and Machine Learning for Time Series Analyis: A Review. Entropy 2021, 23, 1672. [Google Scholar] [CrossRef] [PubMed]
- Pech-Pacheco, J.; Cristobal, G.; Chamorro-Martinez, J.; Fernandez-Valdivia, J. Diatom autofocusing in brightfield microscopy: A comparative study. In Proceedings of the 15th International Conference on Pattern Recognition, ICPR-2000, Barcelona, Spain, 3–7 September 2000; Volume 3, pp. 314–317. [Google Scholar] [CrossRef]
- Takens, F. Detecting strange attractors in turbulence. In Dynamical Systems and Turbulence, Warwick 1980, Lecture Notes in Mathematics; Rand, D., Young, L.S., Eds.; Springer: Berlin/Heidelberg, Germany, 1981; Volume 898, pp. 366–381. [Google Scholar]
- Packard, N.H.; Crutchfield, J.P.; Farmer, J.D.; Shaw, R.S. Geometry from a Time Series. Phys. Rev. Lett. 1980, 45, 712–716. [Google Scholar] [CrossRef]
- Fraser, A.M.; Swinney, H.L. Independent coordinates for strange attractors from mutual information. Phys. Rev. A 1986, 33, 1134–1140. [Google Scholar] [CrossRef] [PubMed]
- Rhodes, C.; Morari, M. The false nearest neighbors algorithm: An overview. Comput. Chem. Eng. 1997, 21, S1149–S1154. [Google Scholar] [CrossRef]
- Delorme, M.; Wiese, K.J. Extreme-value statistics of fractional Brownian motion bridges. Phys. Rev. E 2016, 94, 052105. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sottinen, T.; Yazigi, A. Generalized Gaussian bridges. Stoch. Process. Appl. 2014, 124, 3084–3105. [Google Scholar] [CrossRef] [Green Version]
- Quarteroni, A.; Sacco, R.; Saleri, F. Numerical Mathematics, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2007; Volume 37. [Google Scholar] [CrossRef] [Green Version]
- Hyndman, R.; Yang, Y. Time Series Data Library v0.1.0. 2018. Available online: pkg.yangzhuoranyang.com/tsdl (accessed on 1 July 2022).
- Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Domingos, S.d.O.; de Oliveira, J.F.; de Mattos Neto, P.S. An intelligent hybridization of ARIMA with machine learning models for time series forecasting. Knowl.-Based Syst. 2019, 175, 72–86. [Google Scholar]
- Shah, V. A Comparative Study of Univariate Time-Series Methods for Sales Forecasting. Master’s Thesis, University of Waterloo, Waterloo, ON, Canada, 2020. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Approach | RMSE [0, 1] | RMSE |
|---|---|---|---|
| Car Sales in Quebec | not interpolated, unfiltered | 0.31148 | 6395.04838 |
| Car Sales in Quebec | not interpolated, filtered | 0.11635 | 1927.52494 |
| Car Sales in Quebec | stoch. interpolated, , unfiltered | 0.24762 | 5104.42560 |
| Car Sales in Quebec | stoch. interpolated, , filtered | 0.07958 | 1617.40461 |
| Monthly International Airline Passengers | not interpolated, unfiltered | 0.19676 | 101.92294 |
| Monthly International Airline Passengers | not interpolated, filtered | 0.06823 | 35.34095 |
| Monthly International Airline Passengers | stoch. interpolated, , unfiltered | 0.17180 | 86.28560 |
| Monthly International Airline Passengers | stoch. interpolated, , filtered | 0.05286 | 21.20474 |
| Annual Maize Yields Austria | not interpolated, unfiltered | 0.23536 | 18,253.10327 |
| Annual Maize Yields Austria | not interpolated, filtered | 0.16424 | 12,737.42487 |
| Annual Maize Yields Austria | stoch. interpolated, , unfiltered | 0.20499 | 15,442.32505 |
| Annual Maize Yields Austria | stoch. interpolated, , filtered | 0.14563 | 11,227.39159 |
| Data | Architecture | RMSE [0, 1] | RMSE |
|---|---|---|---|
| Car Sales in Quebec | 20 input nodes 30 hidden layer neurons 45 training epochs | 0.08593 | 1764.38996 |
| Monthly International Airline Passengers | 20 input nodes 30 hidden layer neurons 40 training epochs | 0.05899 | 30.56100 |
| Annual Maize Yields Austria | 20 input nodes 30 hidden layer neurons 18 training epochs | 0.16617 | 12,886.99962 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Raubitzek, S.; Neubauer, T. Reconstructed Phase Spaces and LSTM Neural Network Ensemble Predictions. Eng. Proc. 2022, 18, 40. https://doi.org/10.3390/engproc2022018040
Raubitzek S, Neubauer T. Reconstructed Phase Spaces and LSTM Neural Network Ensemble Predictions. Engineering Proceedings. 2022; 18(1):40. https://doi.org/10.3390/engproc2022018040
Chicago/Turabian StyleRaubitzek, Sebastian, and Thomas Neubauer. 2022. "Reconstructed Phase Spaces and LSTM Neural Network Ensemble Predictions" Engineering Proceedings 18, no. 1: 40. https://doi.org/10.3390/engproc2022018040