
The Bootstrap for Testing the Equality of Two Multivariate Stochastic Processes with an Application to Financial Markets †


Abstract
:1. Introduction
2. A Distance Measure between Stochastic Processes
3. Testing for Equality of Quantile Cross-Spectral Densities of two MTS
3.1. A Test Based on the Moving Block Bootstrap
3.2. A Test Based on the Stationary Bootstrap
4. Simulation Study
4.1. Experimental Design
4.2. Results and Discussion
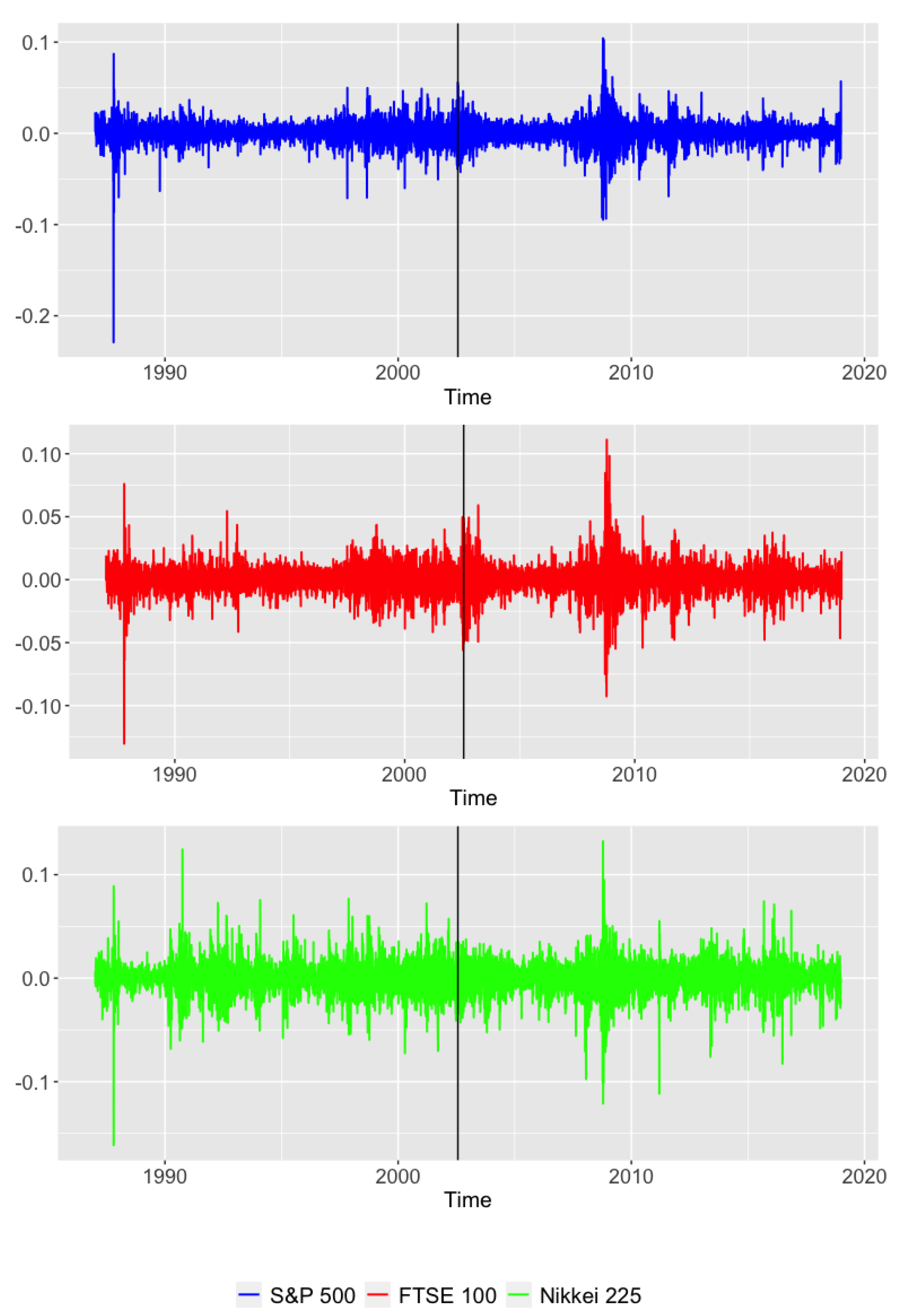
5. Case Study: Did the Dotcom Bubble Change the Global Market Behavior?
5.1. The Dotcom Bubble Crash
5.2. The Considered Data
- S&P 500. This index comprises 505 common stocks issued by 500 large-cap companies and traded on stock exchanges in the United States. The S&P 500 gives weights to the companies according to their market capitalization.
- FTSE 100. This market index includes the 100 companies listed in the London Stock Exchange with the highest market capitalization. It is also a weighted index with weights depending on the market capitalization of the different firms.
- Nikkei 225. This index is a price-weighted, stock market index for the Tokyo Stock Exchange. It measures the performance of 225 large, publicly owned companies in Japan from a wide array of industry sectors.
5.3. Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liao, T.W. Clustering of time series data—A survey. Pattern Recognit. 2005, 38, 1857–1874. [Google Scholar] [CrossRef]
- Wu, J.; Yao, L.; Liu, B. An overview on feature-based classification algorithms for multivariate time series. In Proceedings of the 2018 IEEE 3rd International Conference on Cloud Computing and Big Data Analysis (ICCCBDA), Chengdu, China, 20–22 April 2018; pp. 32–38. [Google Scholar]
- Blázquez-García, A.; Conde, A.; Mori, U.; Lozano, J.A. A Review on outlier/Anomaly Detection in Time Series Data. ACM Comput. Surv. (CSUR) 2021, 54, 1–33. [Google Scholar] [CrossRef]
- Tsay, R.S. Nonlinearity tests for time series. Biometrika 1986, 73, 461–466. [Google Scholar] [CrossRef]
- Lafuente-Rego, B.; Vilar, J.A. Clustering of time series using quantile autocovariances. Adv. Data Anal. Classif. 2016, 10, 391–415. [Google Scholar] [CrossRef]
- López-Oriona, Á.; Vilar, J.A. Quantile cross-spectral density: A novel and effective tool for clustering multivariate time series. Expert Syst. Appl. 2021, 185, 115677. [Google Scholar] [CrossRef]
- Preuß, P.; Hildebrandt, T. Comparing spectral densities of stationary time series with unequal sample sizes. Stat. Probab. Lett. 2013, 83, 1174–1183. [Google Scholar] [CrossRef] [Green Version]
- Dette, H.; Kinsvater, T.; Vetter, M. Testing non-parametric hypotheses for stationary processes by estimating minimal distances. J. Time Ser. Anal. 2011, 32, 447–461. [Google Scholar] [CrossRef] [Green Version]
- Jentsch, C.; Pauly, M. Testing equality of spectral densities using randomization techniques. Bernoulli 2015, 21, 697–739. [Google Scholar] [CrossRef]
- López-Oriona, Á.; Vilar, J.A.; D’Urso, P. Quantile-based fuzzy clustering of multivariate time series in the frequency domain. Fuzzy Sets Syst. 2022, 443, 115–154. [Google Scholar] [CrossRef]
- López-Oriona, Á.; D’Urso, P.; Vilar, J.A.; Lafuente-Rego, B. Quantile-based fuzzy C-means clustering of multivariate time series: Robust techniques. arXiv 2021, arXiv:2109.11027. [Google Scholar]
- Lopez-Oriona, A. Spatial weighted robust clustering of multivariate time series based on quantile dependence with an application to mobility during COVID-19 pandemic. IEEE Trans. Fuzzy Syst. 2021, 1. [Google Scholar] [CrossRef]
- Kunsch, H.R. The jackknife and the bootstrap for general stationary observations. Ann. Stat. 1989, 17, 1217–1241. [Google Scholar] [CrossRef]
- Liu, R.Y.; Singh, K. Moving blocks jackknife and bootstrap capture weak dependence. Explor. Limits Bootstrap 1992, 225, 248. [Google Scholar]
- Politis, D.N.; Romano, J.P. The stationary bootstrap. J. Am. Stat. Assoc. 1994, 89, 1303–1313. [Google Scholar] [CrossRef]
- Baruník, J.; Kley, T. Quantile coherency: A general measure for dependence between cyclical economic variables. Econom. J. 2019, 22, 131–152. [Google Scholar] [CrossRef] [Green Version]
- Kley, T.; Volgushev, S.; Dette, H.; Hallin, M. Quantile spectral processes: Asymptotic analysis and inference. Bernoulli 2016, 22, 1770–1807. [Google Scholar] [CrossRef]
- Engle, R. Dynamic conditional correlation: A simple class of multivariate generalized autoregressive conditional heteroskedasticity models. J. Bus. Econ. Stat. 2002, 20, 339–350. [Google Scholar] [CrossRef]
- Hall, P.; Horowitz, J.L.; Jing, B.Y. On blocking rules for the bootstrap with dependent data. Biometrika 1995, 82, 561–574. [Google Scholar] [CrossRef]
- Geier, B. What Did We Learn from the Dotcom Stock Bubble of 2000. Available online: https://time.com/3741681/2000-dotcom-stock-bust/ (accessed on 20 July 2021).
- Clarke, T. e Dot-Com Crash of 2000–2002. Available online: https://moneymorning.com/2015/06/12/the-dot-com-crash-of-2000-2002/ (accessed on 20 July 2021).
- Morris, J.J.; Alam, P. Value relevance and the dot-com bubble of the 1990s. Q. Rev. Econ. Financ. 2012, 52, 243–255. [Google Scholar] [CrossRef]


{kind=link}
| T | Method | Scenario | ||
|---|---|---|---|---|
| 1 | 2 | 3 | ||
| 500 | MBB | 0.080 | 0.070 | 0.080 |
| SB | 0.055 | 0.055 | 0.050 | |
| 1000 | MBB | 0.070 | 0.095 | 0.130 |
| SB | 0.040 | 0.060 | 0.060 | |
| T | Method | Scenario 1 | Scenario 2 | Scenario 3 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 100 | MBB | 0.160 | 0.575 | 0.980 | 0.540 | 0.775 | 0.990 | 0.080 | 0.395 | 0.950 |
| SB | 0.100 | 0.465 | 0.960 | 0.325 | 0.690 | 0.910 | 0.055 | 0.230 | 0.870 | |
| 200 | MBB | 0.185 | 0.790 | 0.995 | 0.780 | 0.925 | 1 | 0.185 | 0.725 | 1 |
| SB | 0.095 | 0.695 | 0.990 | 0.625 | 0.885 | 0.985 | 0.080 | 0.455 | 0.965 | |
| 300 | MBB | 0.225 | 0.835 | 1 | 0.885 | 0.990 | 1 | 0.255 | 0.840 | 1 |
| SB | 0.130 | 0.770 | 1 | 0.805 | 0.955 | 1 | 0.155 | 0.695 | 1 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
López-Oriona, Á.; Vilar, J.A. The Bootstrap for Testing the Equality of Two Multivariate Stochastic Processes with an Application to Financial Markets. Eng. Proc. 2022, 18, 38. https://doi.org/10.3390/engproc2022018038
López-Oriona Á, Vilar JA. The Bootstrap for Testing the Equality of Two Multivariate Stochastic Processes with an Application to Financial Markets. Engineering Proceedings. 2022; 18(1):38. https://doi.org/10.3390/engproc2022018038
Chicago/Turabian StyleLópez-Oriona, Ángel, and José A. Vilar. 2022. "The Bootstrap for Testing the Equality of Two Multivariate Stochastic Processes with an Application to Financial Markets" Engineering Proceedings 18, no. 1: 38. https://doi.org/10.3390/engproc2022018038