State Machine Approach for Lane Changing Driving Behavior Recognition



Abstract
:1. Introduction
2. Materials and Methods
2.1. Methodology
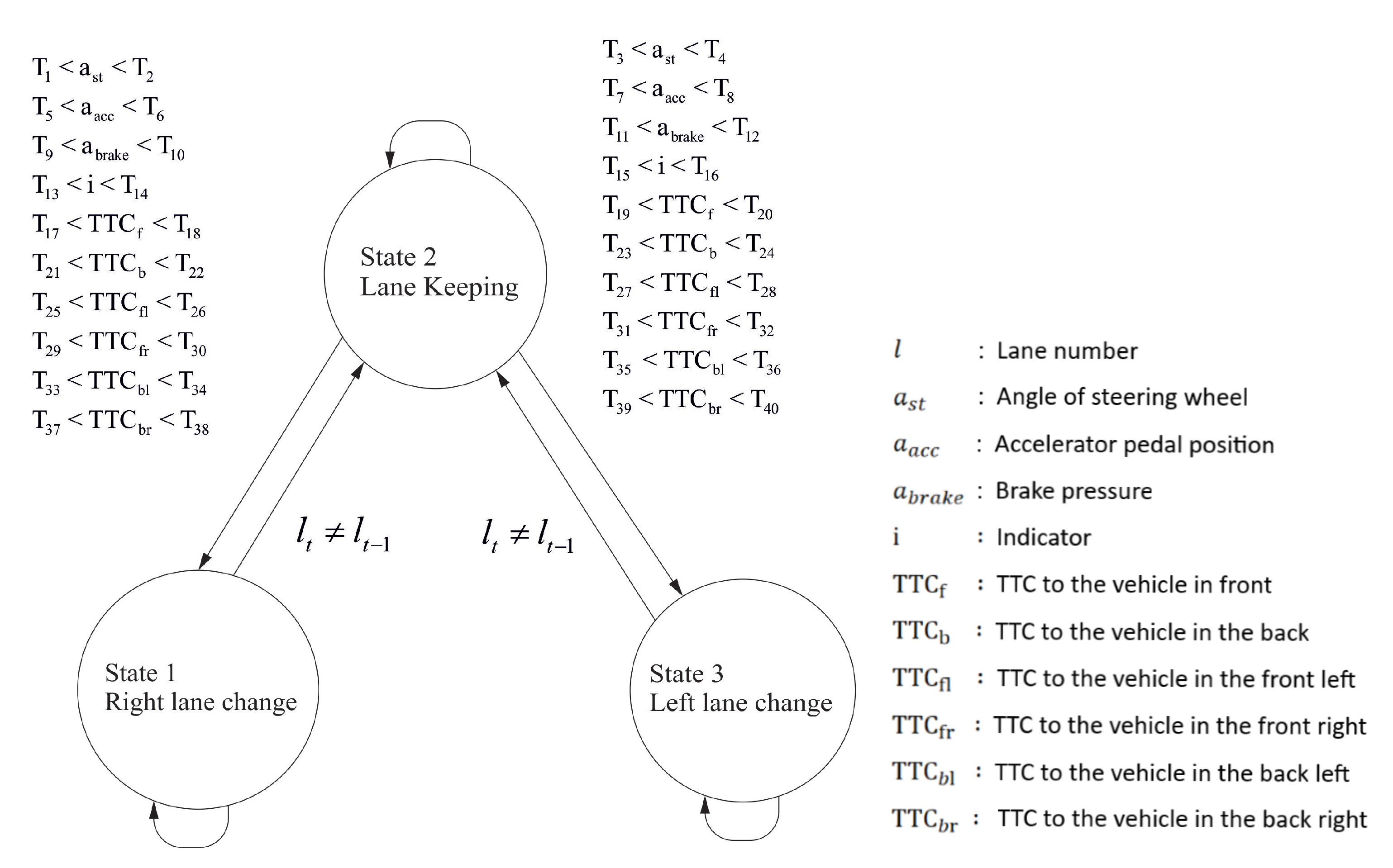
2.1.1. State Machine Approach
2.1.2. Integration of the State Machine Approach in Driving Behavior Prediction
2.2. Driving Behavior Model Based on the State Machine Approach
2.2.1. Driving Behavior Prediction Problem
2.2.2. State Machine-Based Problem Description
2.3. Application of the New Approach
2.3.1. Design of Experiment
2.3.2. Training and Test Procedure
- The NSGA-II generates transition parameters used in this experiment by using the training datasets.
- Based on the transition parameters, the driving behavior at each time point can be calculated based on the topology.
- Next, the calculated driving behaviors and the measured driving behaviors from the dataset are compared.
- This can be used to derive the ACC, DR, and FAR based on the calculated driving behavior.
- The values of the objective functions are derived.
- Processes (1) to (5) are repeated until convergence and the optimal model is obtained.
3. Results
Figures, Tables, and Schemes
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Statistisches Bundesamt (Destatis) Home Page. Available online: https://www.destatis.de/EN/Themes/Society-Environment/Traffic-Accidents/_Graphic/_Interactive/traffic-accidents-driver-related-causes.html (accessed on 15 July 2020).
- Gindele, T.; Brechtel, S.; Dillmann, R. Learning context sensitive behavior models from observations for predicting traffic situations. In Proceedings of the 16th International IEEE Conference on Intelligent Transportation Systems (ITSC 2013), The Hague, The Netherlands, 6–9 October 2013; pp. 1764–1771. [Google Scholar]
- Hurwitz, D.S.; Wang, H.; Knoldler, M.A., Jr.; Ni, D.; Moore, D. Fuzzy sets to describe driver behavior in the dilemma zone of high-speed signalized intersections. Transp. Res. Part F Traffic Psychol. Behav. 2012, 15, 132–143. [Google Scholar] [CrossRef]
- Tran, D.; Sheng, W.; Liu, L.; Liu, M. A Hidden Markov Model based driver intention prediction system. In Proceedings of the 5th Annual IEEE International Conference on Cyber Technology in Automation, Control and Intelligent Systems Psychology and Behaviour (CYBER 2015), Shenyang, China, 8–12 June 2015; pp. 112–120. [Google Scholar]
- Mahajan, V.; Katrakazas, C.; Antoniou, C. Prediction of Lane-Changing Maneuvers with Automatic Labeling and Deep Learning. Transp. Res. Rec. 2020, 2764, 336–347. [Google Scholar] [CrossRef]
- Mostert, W.; Malan, K.; Engelbrecht, A. Filter Versus Wrapper Feature Selection Based on Problem Landscape Features, Genetic and Evolutionary Computation Conference; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1489–1496. ISBN 9781450357647. [Google Scholar]
- Deng, Q.; Wang, J.; Söffker, D. Prediction of human driver behaviors based on an improved HMM approach. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 2066–2071. [Google Scholar]
- Deng, Q.; Söffker, D. Improved driving behaviors prediction based on Fuzzy Logic-Hidden Markov Model (FL-HMM). In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 2003–2008. [Google Scholar]
- Beganovic, N.; Söffker, D. Remaining lifetime modeling using State-of-Health estimation. Mech. Syst. Signal Process. 2017, 92, 107–123. [Google Scholar] [CrossRef]
- Jihin, R.; Kogler, F.; Söffker, D. Data Driven State Machine Model for Industry 4.0 Lifetime Modeling and Identification of Irrigation Control Parameters. In Proceedings of the 3rd Global IoT Summit (GIoTS 2019), Aarhus, Denmark, 17–21 June 2019; pp. 1–6. [Google Scholar]
- Deng, Q.; Söffker, D. Classifying Human Behaviors: Improving Training of Conventional Algorithms. In Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 1060–1065. [Google Scholar]
- Calle, P. Analytics Lab at University of Oklahoma Home Page. Available online: http://oklahomaanalytics.com/data-science-techniques/nsga-ii-explained/ (accessed on 8 March 2020).
- Mukhopadhyay, A.; Maulik, U.; Bandyopadhyay, S.; Coello, C.A.C. A Survey of Multiobjective Evolutionary Algorithms for Data Mining: Part I. IEEE Trans. Evol. 2014, 18, 4–19. [Google Scholar] [CrossRef]
- Song, L. MathWorks Home Page. Available online: http://www.mathworks.com/matlabcentral/fileexchange/31166-ngpm-a-nsga-ii-program-inmatlab-v1-4 (accessed on 19 November 2019).
- Deb, K. Multi-Objective Optimization Using Evolutionary Algorithms; John Wiley & Sons: New York, NY, USA, 2001; ISBN 978-0-471-87339-6. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A Fast and Elitist Multiobjective Genetic Algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Kumar, P.; Perrollaz, M.; Lefevre, S.; Laugier, C. Learning-Based Approach for Online Lane Change Intention Prediction. In Proceedings of the IEEE Intelligent Vehicles Symposium, Gold Coast, Australia, 23–26 June 2013; pp. 797–802. [Google Scholar]
- Hurwitz, D.S.; Knodler, M.A., Jr.; Nyquist, B. Evaluation of driver behavior in type II dilemma zones at high-speed signalized intersections. J. Transp. Eng. 2011, 137, 277–286. [Google Scholar] [CrossRef]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization and Machine Learning, 1st ed.; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1989; ISBN 978-0-201-15767-3. [Google Scholar]
- Bielser, D.; Glardon, P.; Teschner, M.; Gross, M. A state machine for real-time cutting of tetrahedral meshes. In Proceedings of the 11th Pacific Conference on Computer Graphics and Applications, Canmore, AB, Canada, 8–10 October 2003; pp. 377–386. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Variables | Design Parameters |
|---|---|---|
| Angle of steering wheel | [] [] | |
| Accelerator pedal position | [] [] | |
| Brake pedal pressure | [] [] | |
| i | Indicator | [] [] |
| Time To Collision (TCC) with the vehicle in front | [] [] | |
| TTC with the vehicle in the back | [] [] | |
| TTC with the vehicle in the front left | [] [] | |
| TTC with the vehicle in the front right | [] [] | |
| TTC with the vehicle in the back left | [] [] | |
| TTC with the vehicle in the back right | [] [] |
| Parameter | Value |
|---|---|
| Maximum population | 20 |
| Maximum generation | 50 |
| Crossover fraction | 10 |
| Mutation fraction | 1/number of variables = 1/40 |
| Crossover variable | Intermediate 1.2 |
| Mutation variable | Gaussian, 0.1, 0.05 |
| Objectives (%) | Training Dataset 1 | Testing Dataset 1 | Dataset 2 | Dataset 3 |
|---|---|---|---|---|
| 91.90 | 92.90 | 95.30 | 91.69 | |
| 95.03 | 96.02 | 97.70 | 98.61 | |
| 90.64 | 88.94 | 73.27 | 87.07 | |
| 4.76 | 3.32 | 1.41 | 0.82 | |
| 92.11 | 93.11 | 95.37 | 92.08 | |
| 92.13 | 93.32 | 97.37 | 91.99 | |
| 8.11 | 8.88 | 22.31 | 7.11 | |
| 96.66 | 96.66 | 97.53 | 93.23 | |
| 88.69 | 88.76 | 80.75 | 95.92 | |
| 2.94 | 2.94 | 1.58 | 6.92 |
| Objectives (%) | Dataset 1 | Training Dataset 2 | Testing Dataset 2 | Dataset 3 |
|---|---|---|---|---|
| 92.89 | 93.08 | 95.77 | 91.69 | |
| 96.22 | 94.97 | 97.48 | 98.56 | |
| 86.93 | 83.82 | 79.31 | 86.01 | |
| 3.32 | 4.35 | 1.41 | 0.82 | |
| 93.05 | 93.22 | 95.97 | 91.93 | |
| 93.40 | 94.12 | 97.22 | 91.74 | |
| 10.23 | 13.74 | 13.74 | 6.30 | |
| 96.45 | 97.97 | 98.08 | 92.88 | |
| 88.66 | 86.22 | 89.78 | 95.92 | |
| 3.15 | 1.33 | 1.42 | 7.28 |
| Objectives (%) | Dataset 1 | Dataset 2 | Training Dataset 3 | Testing Dataset 3 |
|---|---|---|---|---|
| 92.69 | 95.30 | 91.76 | 93.35 | |
| 96.22 | 97.70 | 98.62 | 96.22 | |
| 86.93 | 73.27 | 86.10 | 91.55 | |
| 3.32 | 0.98 | 0.74 | 1.12 | |
| 92.97 | 95.37 | 91.91 | 93.35 | |
| 93.40 | 97.37 | 91.70 | 93.74 | |
| 12.11 | 22.31 | 6.20 | 11.04 | |
| 96.30 | 97.53 | 92.99 | 94.75 | |
| 85.28 | 80.75 | 98.18 | 86.80 | |
| 3.14 | 1.58 | 7.29 | 4.88 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
David, R.; Rothe, S.; Söffker, D. State Machine Approach for Lane Changing Driving Behavior Recognition. Automation 2020, 1, 68-79. https://doi.org/10.3390/automation1010006
David R, Rothe S, Söffker D. State Machine Approach for Lane Changing Driving Behavior Recognition. Automation. 2020; 1(1):68-79. https://doi.org/10.3390/automation1010006
Chicago/Turabian StyleDavid, Ruth, Sandra Rothe, and Dirk Söffker. 2020. "State Machine Approach for Lane Changing Driving Behavior Recognition" Automation 1, no. 1: 68-79. https://doi.org/10.3390/automation1010006