1. Introduction
The proliferation of communication networks and the Internet has created a paradigm shift in how organizations manage their operations. This great influence of technology, along with the rapid digitization of various spheres of life [
1] and the emergence of cloud and edge computing [
2,
3], has ushered in a new era of communication with a huge number of interconnected devices [
4]. Unfortunately, this interconnectedness has also given rise to frightening and unprecedented levels of cyber attacker activity. The ongoing spread of new and sophisticated cyber-attacks targeting critical infrastructure, government agencies, and the financial sector poses significant challenges at both the individual and societal levels. These sophisticated cyber attacks rely heavily on malicious software, commonly referred to as malware [
5]. Malware serves diverse purposes, including identity theft, financial theft, disruptive activities, cyber espionage, and illegal extraction of sensitive data, driven by various personal or political motives [
6].
Malware is classified into different categories based on harmful behavior such as Trojan, virus, worm, and ransomware [
7,
8,
9]. The behavior of each type is characterized by the spreading method and the impact on the targeted machine; for instance, the worms have the ability to independently spread into other networks without the need for file attachment or user action. Contradictorily, the virus spreads by attaching itself to files on the host, and user interaction is required to function. Malware harms the targeted system in different ways to break the framework of IT security CIA (confidentiality, integrity, and availability) [
10]. Some malware, such as keyloggers, leads to the leakage of sensitive information which compromises the confidentiality term, while worms can affect the availability of the system. Also, some malware can be created to modify or delete data on the system which compromises the integrity of data.
The fast development of cyber threats has witnessed the rise of more complicated and harmful forms of malware such as metamorphic and polymorphic malicious code [
11]. Polymorphic malware changes the binary form every time it targets a new system. The change affects the code structure while keeping the same behavior. A common method used to achieve such transformation is packing using encryption and compression to transfer the binary. In the same context, metamorphic malware takes the same idea of polymorphic malware a step further by transforming the binary and behavior with each new infection. These techniques make the detection of traditional signature-based solutions a challenging process.
According to a report by Cybercrime Magazine [
12], only one malware type (ransomware) had a devastating impact in 2021, causing a global financial loss of USD 20 billion. It is estimated that this number will grow exponentially, reaching US
$265 billion by 2031. Alongside cutting-edge strategies employed by attackers, the proliferation of malware is also escalating rapidly. Kaspersky’s detection models identified an average of 400,000 new attacks being distributed daily during 2022, which is an increase of 5 percent compared to 2021 [
13]. This incessant generation of malware poses significant risks to enterprises, exposing them to a wide range of sophisticated attacks. Consequently, integrating smart security technologies into the network infrastructure becomes imperative for organizations in order to effectively address the diverse range of malware attacks and ensure the protection of data and systems.
Malware often exhibits signature characteristics that expose the malicious action; the leading antivirus applications heavily rely on such signatures for detection. However, this approach falls short in identifying newly emerged malware [
14]. Attackers further undermine the reliability of such solutions by employing elusive methods such as encryption and packing [
15]. Despite the ingenious ideas employed by attackers, malware execution and malicious activities still depend on the presence of a host’s operating system [
16]. Therefore, malware seeks to exploit the Windows API call service as a means to carry out malicious actions. By taking advantage of the resources and functions provided by the operating system, malware can manipulate and interact with critical system components, enabling unauthorized operations and potentially compromising the security of the target system. As a result of this interaction, harmful behaviors are exhibited that can be leveraged to detect the presence of malware. As stated in [
17], the use of the system API call cannot be hidden by malware, allowing for effective identification and detection of malicious activity. Despite the effective benefits of employing machine learning in detecting malware, particularly zero-day malware, by using data extracted from the execution phase, such as API calls, the process of gathering precise API call features to reliably differentiate between malware and goodware continues to present a formidable challenge. The accuracy provided by API call features has been emphasized in most research in this area [
18], rather than prioritizing the speed of solutions. Additionally, earlier studies have focused on complex feature sets or the utilization of neural networks, while simpler techniques remain relatively unexplored. Equally important, in a dynamic world, nothing remains static especially when talking about malware as the characteristics evolved over time. This effect changes the distribution of data used to train the detection models. Such a significant effect makes the detection models less effective in detecting zero-day malware.
Cybersecurity tools can be employed at different layers of the enterprise IT infrastructure. However, by implementing malware detection at the edge, it becomes possible to implement malware protection technologies directly at the point where data is generated. While this method offers the advantage of real-time operation, its effectiveness is restricted by resource availability, making execution time a critical factor to consider. To develop edge systems that accurately identify potentially harmful situations within the constraints of execution time and complexity, this study aims to investigate the following research questions:
The main contributions of this research can be summarized in the following way:
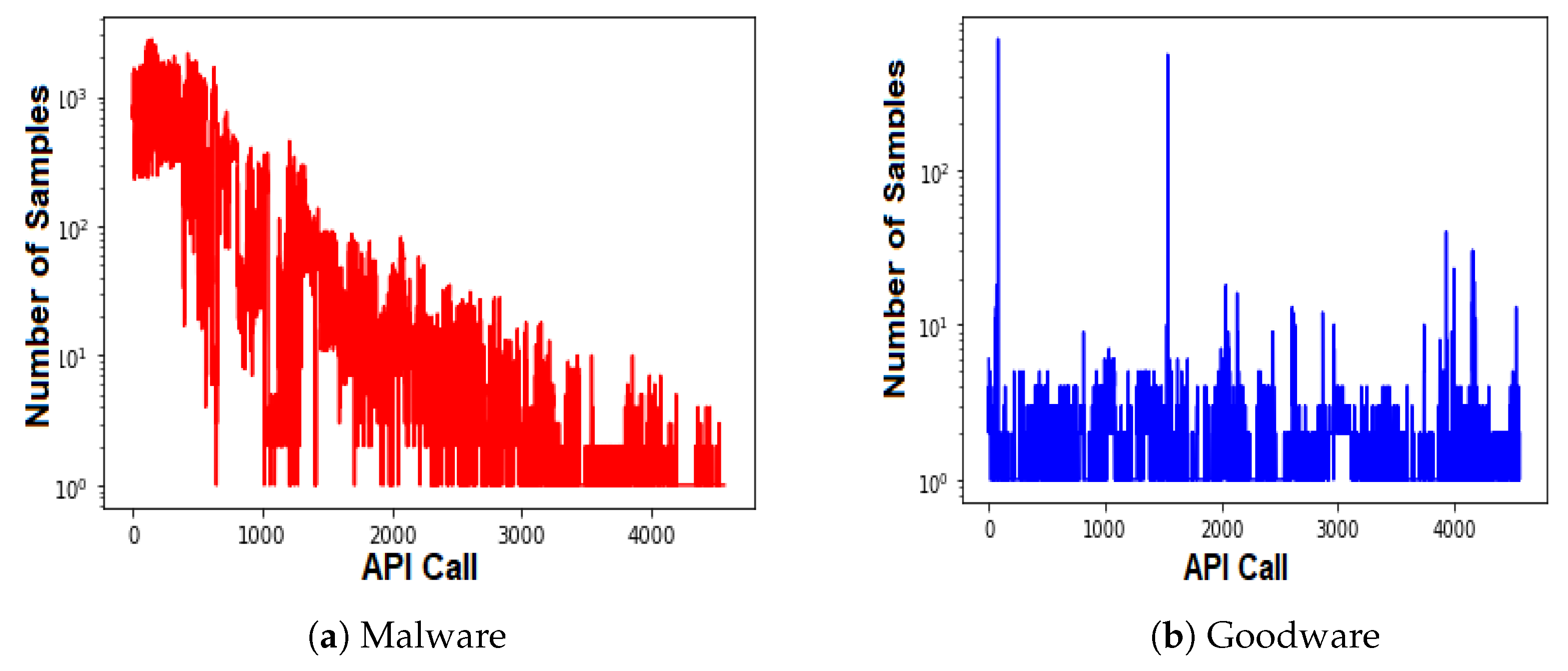
An analysis of API call behavior to uncover the reuse rate trends in both malware and goodware.
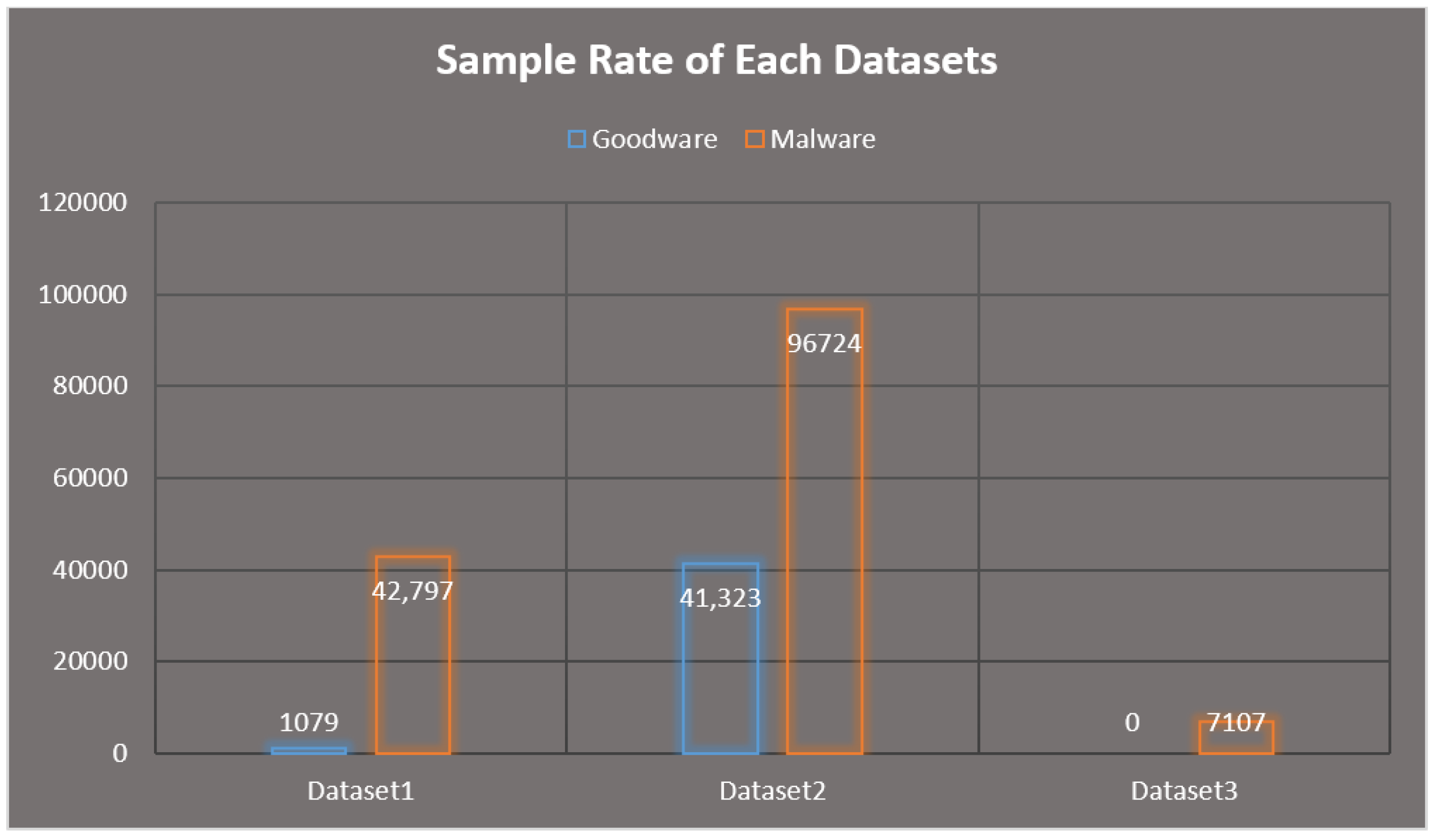
Utilization of distinct datasets for training and testing purposes.
Introduction of a straightforward feature representation method using API call dictionaries.
A recommendation that the statistical classifier (STC) serves as a simple yet robust classifier that can effectively combat model drift. Furthermore, it offers a solution with less complexity, rendering it highly suitable for edge environments.
The subsequent sections of this paper are structured as follows:
Section 2 discusses the malware analysis methods;
Section 3 presents the related works; the used datasets are elaborated in
Section 4; API call dictionaries are described in
Section 5;
Section 6 explains the STC model; the experimental results are presented in
Section 7;
Section 8 provides the comparison and limitation of this work; and finally, conclusions and future works are outlined in
Section 9.
3. Related Works
Dynamic detection methods are impervious to obfuscation techniques of static detection like encryption and packing. This resistance has garnered significant attention from the malware detection community, leading to a heightened interest in dynamic detection approaches. In dynamic detection, the use of API calls is considered a valuable technique to represent malware behavior. The extraction process of API call sequences requires executing the malware in an isolated environment in order to monitor and record the API calls made by the malware [
24]. The API call reveals the actions of malware such as changing the system registry, downloading infected files, extracting sensitive information, and other possible malicious activities. These API call sequences are used with different machine learning techniques to detect malware. The study referenced in [
25] used Cuckoo Sandbox to capture several API calls generated by different types of malware and according to [
26], the order of API calls can be thought of as a collection of transaction data, where each API call with the associated arguments constitutes a collection of elements. Consequently, identifying frequent itemsets within the sequence of API calls can unveil behavioral patterns. In this context, API call sequences and their frequency were utilized by Hansen et al. [
27] to identify and classify malware. The use of a random forest (RF) classifier yielded encouraging predictive performance. The study presented in [
22] introduced a process of two stages. Extracting API call frequency features using the Markov model is the first step followed by utilizing these features to train different machine learning models. The study by Daeef et al. [
28] used visualization methods and the Jaccard index to investigate which groups of API calls are present in each malware family, with the goal of revealing hidden patterns of malicious behavior. Then, the frequency of each API call is used as a feature with RF providing the best results for malware family classification. Moreover, Daeef et al. [
29] focused on utilizing the API calls’ frequency within the initial 100 sequences. The outcomes were highly encouraging, indicating that RF exhibited comparable performance to other models such as long short-term memory (LSTM) and deep graph convolutional neural networks (DGCNNs). The authors in [
30] employed the provided dataset from [
31] to train a diverse range of deep learning and machine learning methods. The results indicated that traditional machine learning classifiers demonstrated superior performance while demanding less training time. Additionally, other investigations [
32,
33] focused on converting API call sequences into term frequency-inverse document frequency (TF-IDF) feature representation and subsequently evaluated multiple machine learning classifiers. Despite the efficiency of the machine learning method on the tested set, these approaches represent API calls as a bag of words, limiting their applicability to scenarios requiring full-length analysis.
Deep learning has been shown to be very effective in processing sequence data over time, especially in the field of natural language processing. In their paper [
34], the authors used the recurrent neural networks (RNN) model to classify different malware families. They used long sequences of API calls to classify different types of malware. Furthermore, researchers in [
35] utilize RNNs along with features extracted from API requests to differentiate malware in binary detection scenarios. A deep neural network (DNN) is presented in [
36] to evaluate different malware datasets. Despite the promising analysis made, however, the methodology is not sufficient in representing the API call dependencies. The concept of transforming API calls into a graph structure was introduced by Oliveira et al. [
31]. To achieve this, a secure sandbox environment is used to execute the malware and legitimate goodware to extract the sequences of API calls. These sequences are subsequently utilized to generate a behavioral graph. For detection purposes, the DGCNN is employed as the model. In a similar vein, researchers [
37] have introduced a technique to represent the behavior of malware by converting API calls into images, by adhering to predefined criteria for color mapping. Then, these images’ features are then classified using a convolutional neural network (CNN). Capturing the contextual relationship among the API call sequences using word embedding is presented in [
38]. API calls are clustered according to the contextual similarity to generate a malware behavioral graph and a Markov chain technique is used for the detection process. Zhang et al. [
39] propose a feature extraction process with a deep neural network. Feature representation employs the trick of hashing to encode the API call’s category, parameters, and name. Multiple gated CNNs are used to transform the features of API calls and the output is fed into LSTM to learn the correlation relationship existing among the API calls.
In summary, the accuracy provided by API call features has been emphasized in most research in this area, rather than prioritizing the speed of solutions. Additionally, earlier studies have focused on complex feature sets which include an abundance of unnecessary information resulting in inefficient malware detection. The diversity of API call types, high-dimension features, and long sequences of API calls constitute a big challenge to creating lightweight detection models to be implemented in a real-time environment. Also, the utilization of neural networks makes things worse in this context due to the resource requirements. It is not logical to dive into complex solutions while simpler techniques remain relatively unexplored. Equally important, in a dynamic world, nothing remains static especially when talking about malware as the characteristics evolved over time. This effect changes the distribution of data used to train the detection models. Such a significant effect makes the detection models less effective in detecting zero-day malware. The concept of drift is another important issue not tackled in previous studies.
Author Contributions
Conceptualization, A.Y.D. and A.A.-N.; Data curation, A.Y.D.; Formal analysis, A.Y.D.; Funding acquisition, A.A.-N. and J.C.; Investigation, A.Y.D.; Methodology, A.Y.D. and A.A.-N.; Project administration, A.A.-N. and J.C.; Resources, A.Y.D.; Software, A.Y.D.; Validation, A.Y.D.; Writing—original draft, A.Y.D.; Writing—review & editing, A.A.-N. and J.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
All data were presented in the main text.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gobble, M.M. Digitalization, digitization, and innovation. Res.-Technol. Manag. 2018, 61, 56–59. [Google Scholar] [CrossRef]
- Jamsa, K. Cloud Computing; Jones & Bartlett Learning: Burlington, MA, USA, 2022. [Google Scholar]
- Hartmann, M.; Hashmi, U.S.; Imran, A. Edge computing in smart health care systems: Review, challenges, and research directions. Trans. Emerg. Telecommun. Technol. 2022, 33, e3710. [Google Scholar] [CrossRef]
- Sahani, A.; Sushree, B.B.P. The Emerging Role of the Internet of Things (Iot) in the Biomedical Industry. In The Role of the Internet of Things (Iot) in Biomedical Engineering; Apple Academic Press: Palm Bay, FL, USA, 2022; pp. 129–156. [Google Scholar]
- Conti, M.; Dargahi, T.; Dehghantanha, A. Cyber Threat Intelligence: Challenges and Opportunities; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Gandhi, R.; Sharma, A.; Mahoney, W.; Sousan, W.; Zhu, Q.; Laplante, P. Dimensions of cyber-attacks: Cultural, social, economic, and political. IEEE Technol. Soc. Mag. 2011, 30, 28–38. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, Q.; Chen, Y.; Jiang, X. A survey on machine learning against hardware trojan attacks: Recent advances and challenges. IEEE Access 2020, 8, 10796–10826. [Google Scholar] [CrossRef]
- Kim, J.Y.; Cho, S.B. Obfuscated malware detection using deep generative model based on global/local features. Comput. Secur. 2022, 112, 102501. [Google Scholar] [CrossRef]
- Ball, R. Computer Viruses, Computer Worms, and the Self-Replication of Programs. In Viruses in all Dimensions: How an Information Code Controls Viruses, Software and Microorganisms; Springer: Berlin/Heidelberg, Germany, 2023; pp. 73–85. [Google Scholar]
- Greubel, A.; Andres, D.; Hennecke, M. Analyzing Reporting on Ransomware Incidents: A Case Study. Soc. Sci. 2023, 12, 265. [Google Scholar] [CrossRef]
- Deng, X.; Mirkovic, J. Polymorphic malware behavior through network trace analysis. In Proceedings of the 2022 14th International Conference on COMmunication Systems & NETworkS (COMSNETS), Bangalore, India, 4–8 January 2022; pp. 138–146. [Google Scholar]
- Braue, D. Global Ransomware Damage Costs Predicted to Exceed $265 Billion by 2031. Available online: https://rb.gy/premy (accessed on 17 June 2022).
- Kaspersky. Cybercriminals Attack Users with 400,000 New Malicious Files Daily—That Is 5% More Than in 2021. Available online: https://rb.gy/xwak5 (accessed on 17 June 2022).
- Akhtar, M.S.; Feng, T. Malware Analysis and Detection Using Machine Learning Algorithms. Symmetry 2022, 14, 2304. [Google Scholar] [CrossRef]
- Kimmell, J.C.; Abdelsalam, M.; Gupta, M. Analyzing machine learning approaches for online malware detection in cloud. In Proceedings of the 2021 IEEE International Conference on Smart Computing (SMARTCOMP), Irvine, CA, USA, 23–27 August 2021; pp. 189–196. [Google Scholar]
- Catak, F.O.; Yazı, A.F. A benchmark API call dataset for windows PE malware classification. arXiv 2019, arXiv:1905.01999. [Google Scholar]
- Wagener, G.; State, R.; Dulaunoy, A. Malware behaviour analysis. J. Comput. Virol. 2008, 4, 279–287. [Google Scholar] [CrossRef]
- Aboaoja, F.A.; Zainal, A.; Ghaleb, F.A.; Al-rimy, B.A.S.; Eisa, T.A.E.; Elnour, A.A.H. Malware detection issues, challenges, and future directions: A survey. Appl. Sci. 2022, 12, 8482. [Google Scholar] [CrossRef]
- Ucci, D.; Aniello, L.; Baldoni, R. Survey of machine learning techniques for malware analysis. Comput. Secur. 2019, 81, 123–147. [Google Scholar] [CrossRef]
- Naz, S.; Singh, D.K. Review of machine learning methods for windows malware detection. In Proceedings of the 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, 6–8 July 2019; pp. 1–6. [Google Scholar]
- Banin, S.; Shalaginov, A.; Franke, K. Memory Access Patterns for Malware Detection. Available online: https://ntnuopen.ntnu.no/ntnu-xmlui/bitstream/handle/11250/2455297/memoryaccesspatterns.pdf?sequence=1 (accessed on 30 October 2023).
- Hwang, J.; Kim, J.; Lee, S.; Kim, K. Two-stage ransomware detection using dynamic analysis and machine learning techniques. Wirel. Pers. Commun. 2020, 112, 2597–2609. [Google Scholar] [CrossRef]
- Belaoued, M.; Boukellal, A.; Koalal, M.A.; Derhab, A.; Mazouzi, S.; Khan, F.A. Combined dynamic multi-feature and rule-based behavior for accurate malware detection. Int. J. Distrib. Sens. Netw. 2019, 15, 1550147719889907. [Google Scholar] [CrossRef]
- Aboaoja, F.A.; Zainal, A.; Ali, A.M.; Ghaleb, F.A.; Alsolami, F.J.; Rassam, M.A. Dynamic Extraction of Initial Behavior for Evasive Malware Detection. Mathematics 2023, 11, 416. [Google Scholar] [CrossRef]
- Yazi, A.F.; Çatak, F.Ö.; Gül, E. Classification of methamorphic malware with deep learning (LSTM). In Proceedings of the 2019 27th Signal Processing and Communications Applications Conference (SIU), Sivas, Turkey, 24–26 April 2019; pp. 1–4. [Google Scholar]
- Qiao, Y.; Yang, Y.; Ji, L.; He, J. Analyzing malware by abstracting the frequent itemsets in API call sequences. In Proceedings of the 2013 12th IEEE International Conference on Trust, Security and Privacy in Computing and Communications, Melbourne, VIC, Australia, 16–18 July 2013; pp. 265–270. [Google Scholar]
- Hansen, S.S.; Larsen, T.M.T.; Stevanovic, M.; Pedersen, J.M. An approach for detection and family classification of malware based on behavioral analysis. In Proceedings of the 2016 International Conference on Computing, Networking and Communications (ICNC), Kauai, HI, USA, 15–18 February 2016; pp. 1–5. [Google Scholar]
- Daeef, A.Y.; Al-Naji, A.; Chahl, J. Features Engineering for Malware Family Classification Based API Call. Computers 2022, 11, 160. [Google Scholar] [CrossRef]
- Daeef, A.Y.; Al-Naji, A.; Nahar, A.K.; Chahl, J. Features Engineering to Differentiate between Malware and Legitimate Software. Appl. Sci. 2023, 13, 1972. [Google Scholar] [CrossRef]
- Cannarile, A.; Dentamaro, V.; Galantucci, S.; Iannacone, A.; Impedovo, D.; Pirlo, G. Comparing deep learning and shallow learning techniques for api calls malware prediction: A study. Appl. Sci. 2022, 12, 1645. [Google Scholar] [CrossRef]
- Oliveira, A.; Sassi, R. Behavioral malware detection using deep graph convolutional neural networks. Techlixiv 2019. preprint. [Google Scholar] [CrossRef]
- Schofield, M.; Alicioglu, G.; Binaco, R.; Turner, P.; Thatcher, C.; Lam, A.; Sun, B. Convolutional neural network for malware classification based on API call sequence. In Proceedings of the 8th International Conference on Artificial Intelligence and Applications (AIAP 2021), Zurich, Switzerland, 23–24 January 2021. [Google Scholar]
- Ali, M.; Shiaeles, S.; Bendiab, G.; Ghita, B. MALGRA: Machine learning and N-gram malware feature extraction and detection system. Electronics 2020, 9, 1777. [Google Scholar] [CrossRef]
- Li, C.; Zheng, J. API call-based malware classification using recurrent neural networks. J. Cyber Secur. Mobil. 2021, 617–640. [Google Scholar] [CrossRef]
- Eskandari, M.; Khorshidpur, Z.; Hashemi, S. To incorporate sequential dynamic features in malware detection engines. In Proceedings of the 2012 European Intelligence and Security Informatics Conference, Odense, Denmark, 22–24 August 2012; pp. 46–52. [Google Scholar]
- Vinayakumar, R.; Alazab, M.; Soman, K.; Poornachandran, P.; Al-Nemrat, A.; Venkatraman, S. Deep learning approach for intelligent intrusion detection system. IEEE Access 2019, 7, 41525–41550. [Google Scholar] [CrossRef]
- Tang, M.; Qian, Q. Dynamic API call sequence visualisation for malware classification. IET Inf. Secur. 2019, 13, 367–377. [Google Scholar] [CrossRef]
- Amer, E.; Zelinka, I. A dynamic Windows malware detection and prediction method based on contextual understanding of API call sequence. Comput. Secur. 2020, 92, 101760. [Google Scholar] [CrossRef]
- Zhang, Z.; Qi, P.; Wang, W. Dynamic malware analysis with feature engineering and feature learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1210–1217. [Google Scholar]
- Oliveira, A. Malware Analysis Datasets: API Call Sequences. Available online: https://ieee-dataport.org/open-access/malware-analysis-datasets-api-call-sequences (accessed on 10 June 2023).
- Lalwani, P. MalwareData. Available online: https://github.com/saurabh48782/Malware_Classification (accessed on 10 June 2023).
- VirusTotal. VirusTotal API v3 Overview. Available online: https://developers.virustotal.com/reference/overview (accessed on 10 June 2023).
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}