
Vehicle State Estimation and Prediction for Autonomous Driving in a Round Intersection

Abstract
:1. Introduction
2. State Estimation Based on Kalman Filter
2.1. The Unscented Kalman Filter
| Algorithm 1. Unscented Kalman filter |
| Input state dynamic equation and (1) Initialize the UKF with: (2) For : (2.1) Calculate the Sigma Points of the state: (2.2) Prediction: (2.3) Measurement update: (2.4) Estimation: (3) Next (4) End |
2.2. Motion Models
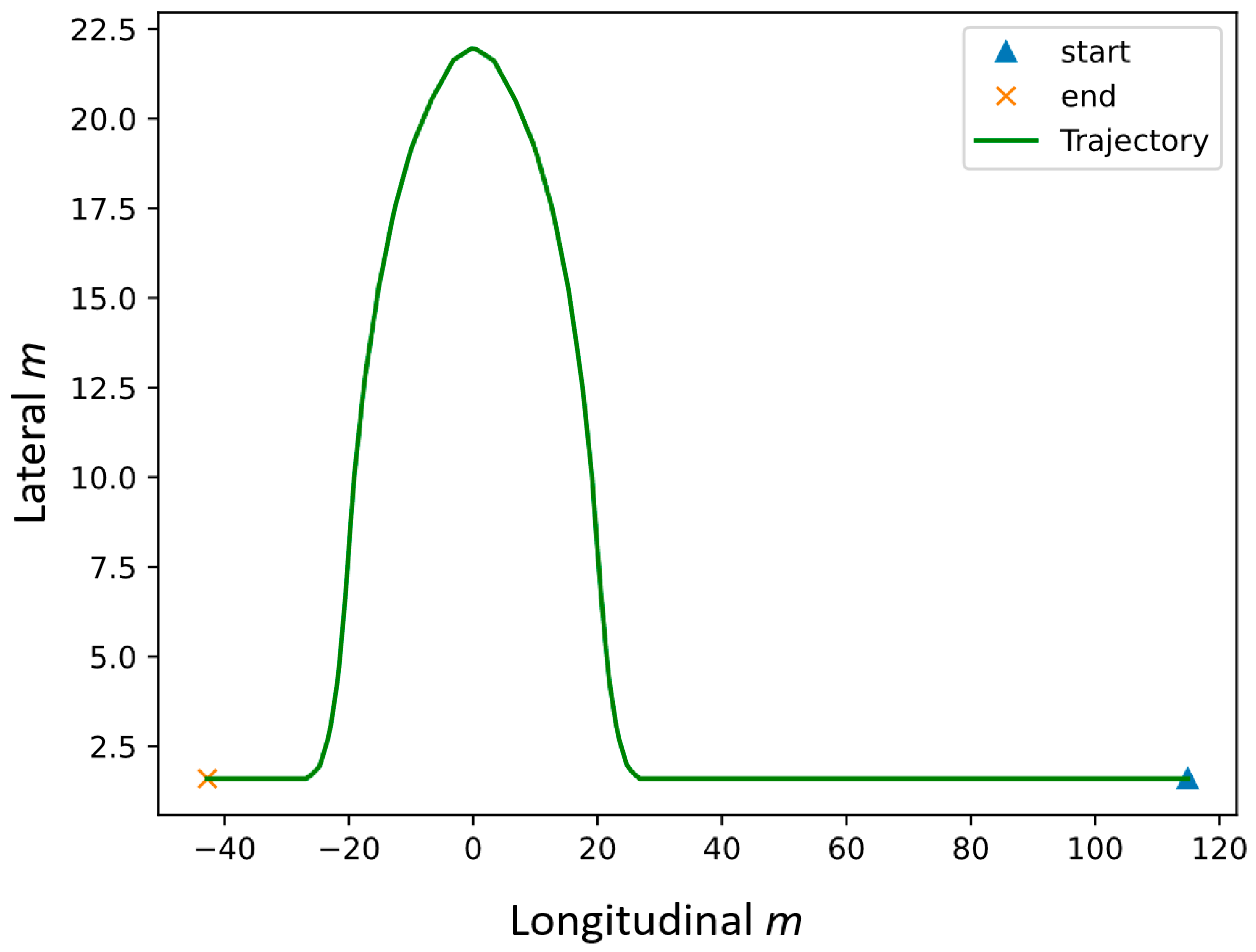
2.3. Simulation Experiment Setup and Results
3. Change Point Detection-Based Behavior Prediction
3.1. Problem Formulation for Vehicle Behavior Prediction
3.2. The Multipolicy Approach for Driver Model Prediction
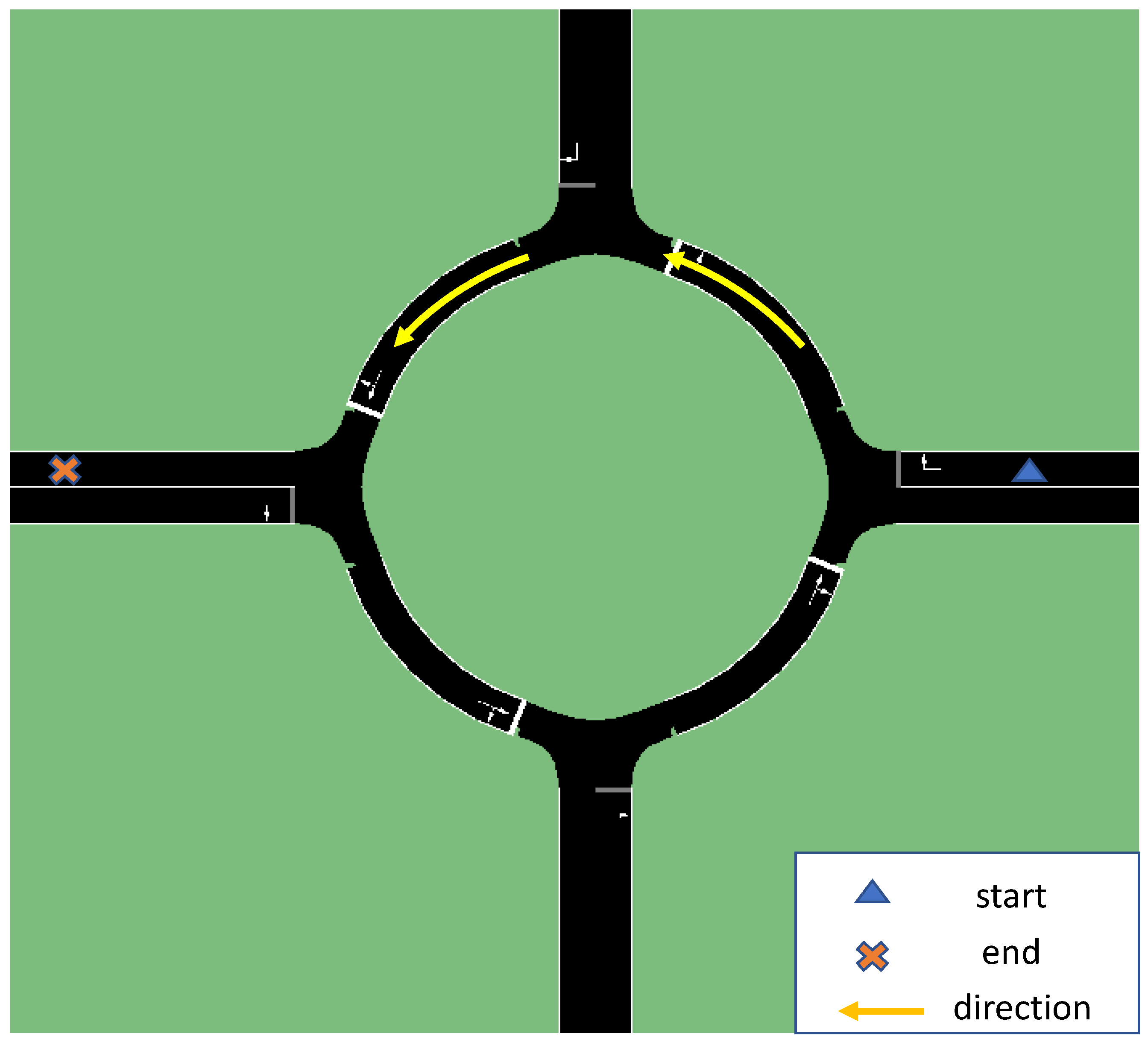
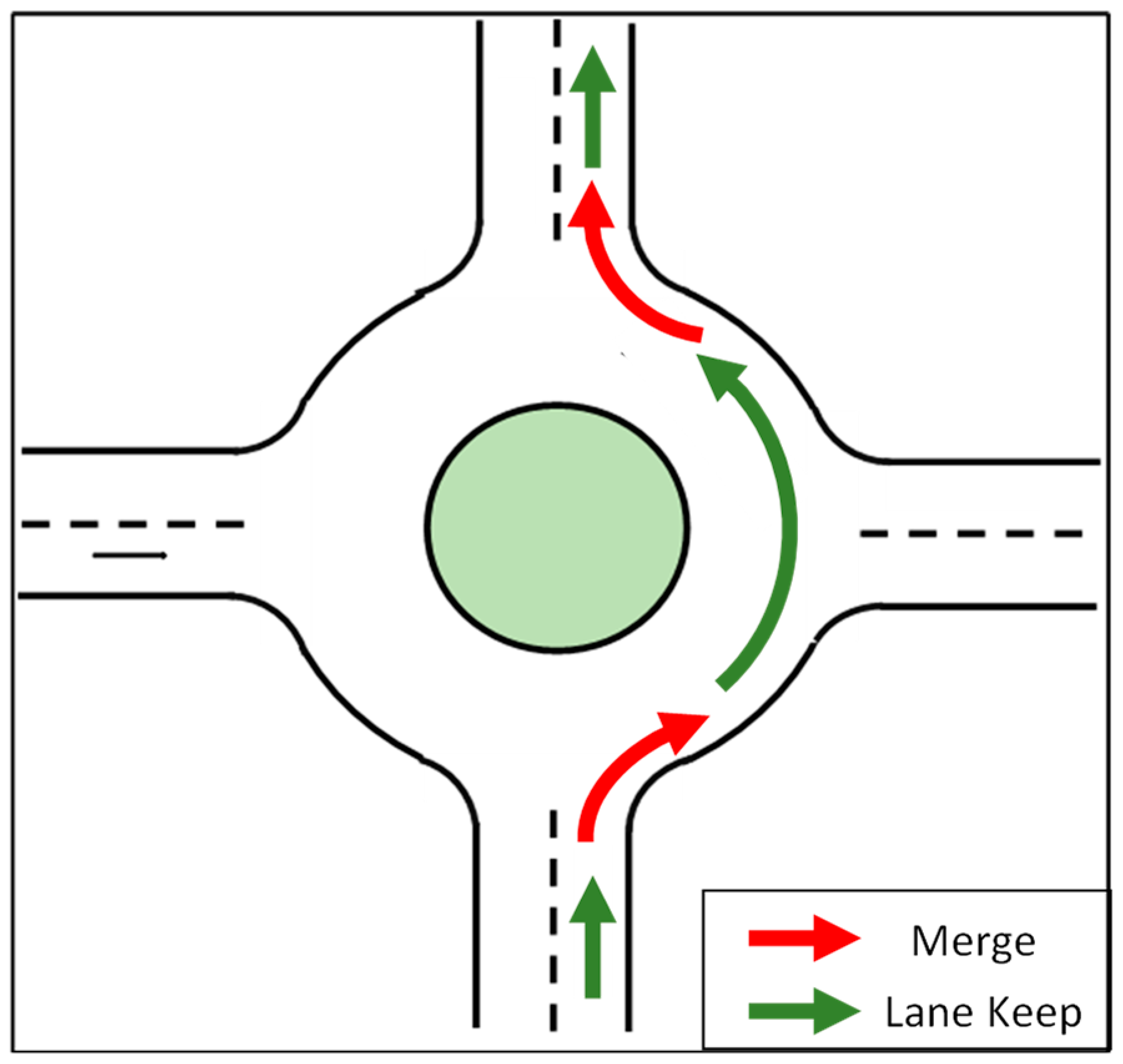
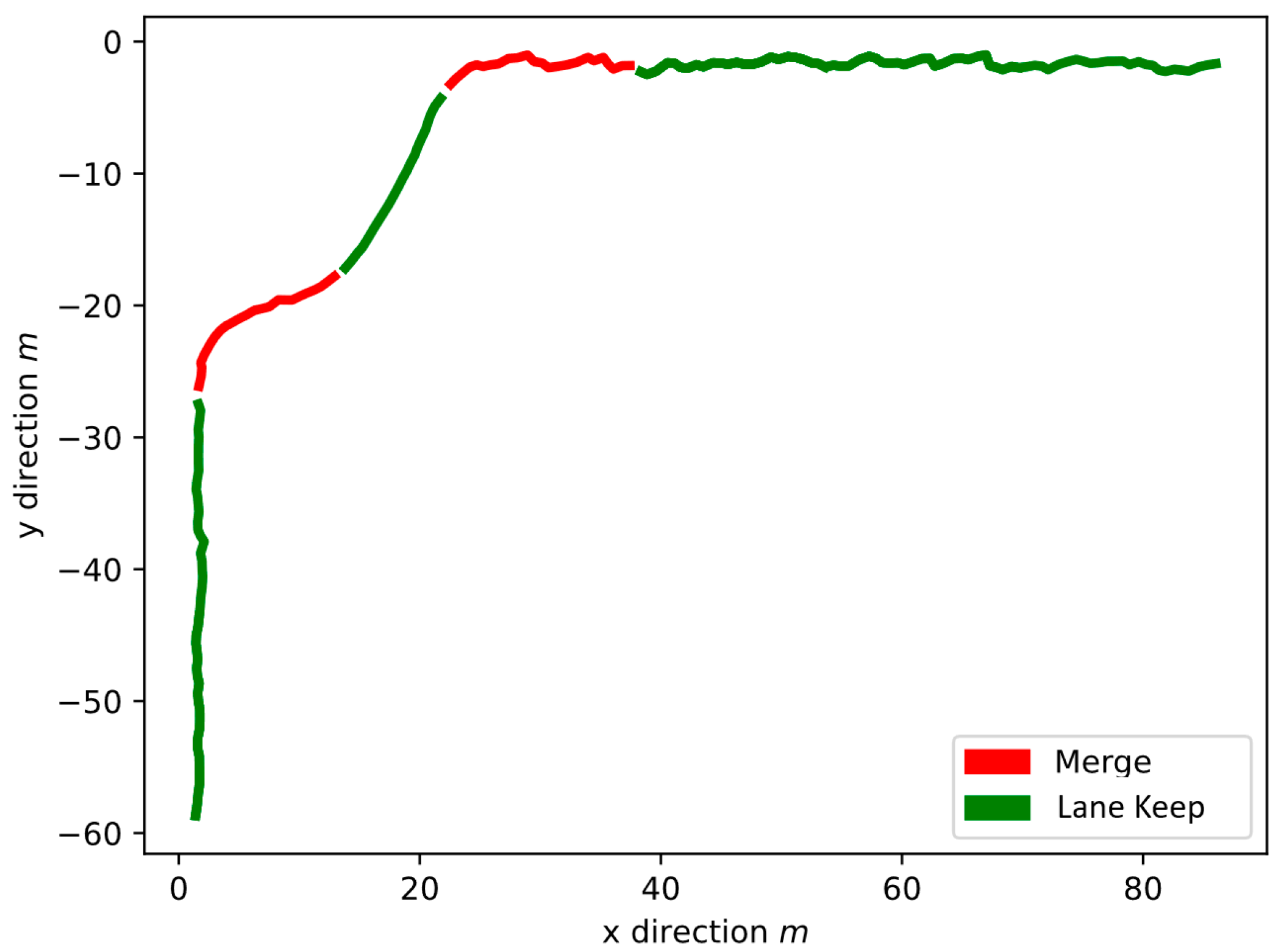
3.3. Behavior Prediction for Round Intersection
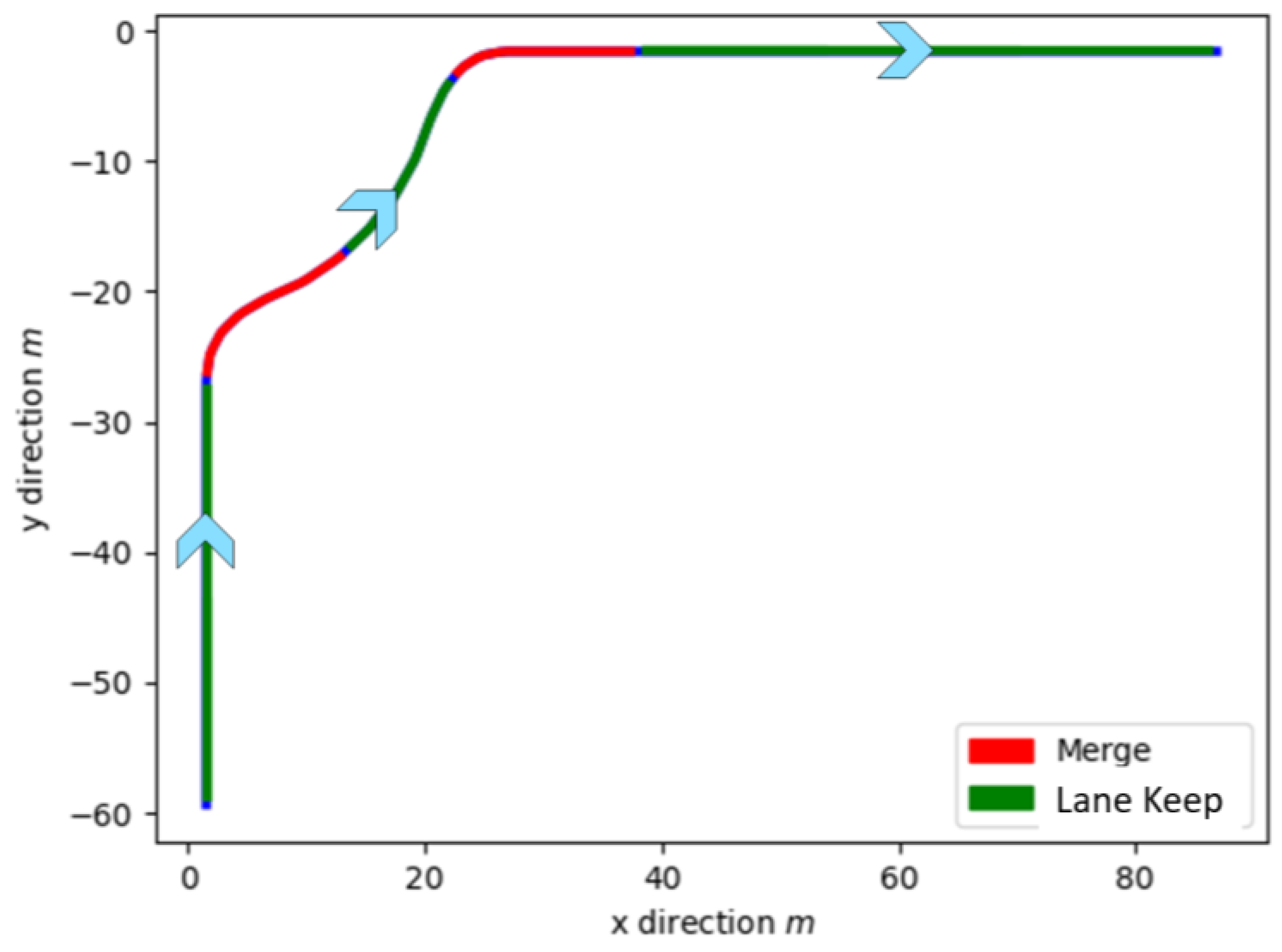
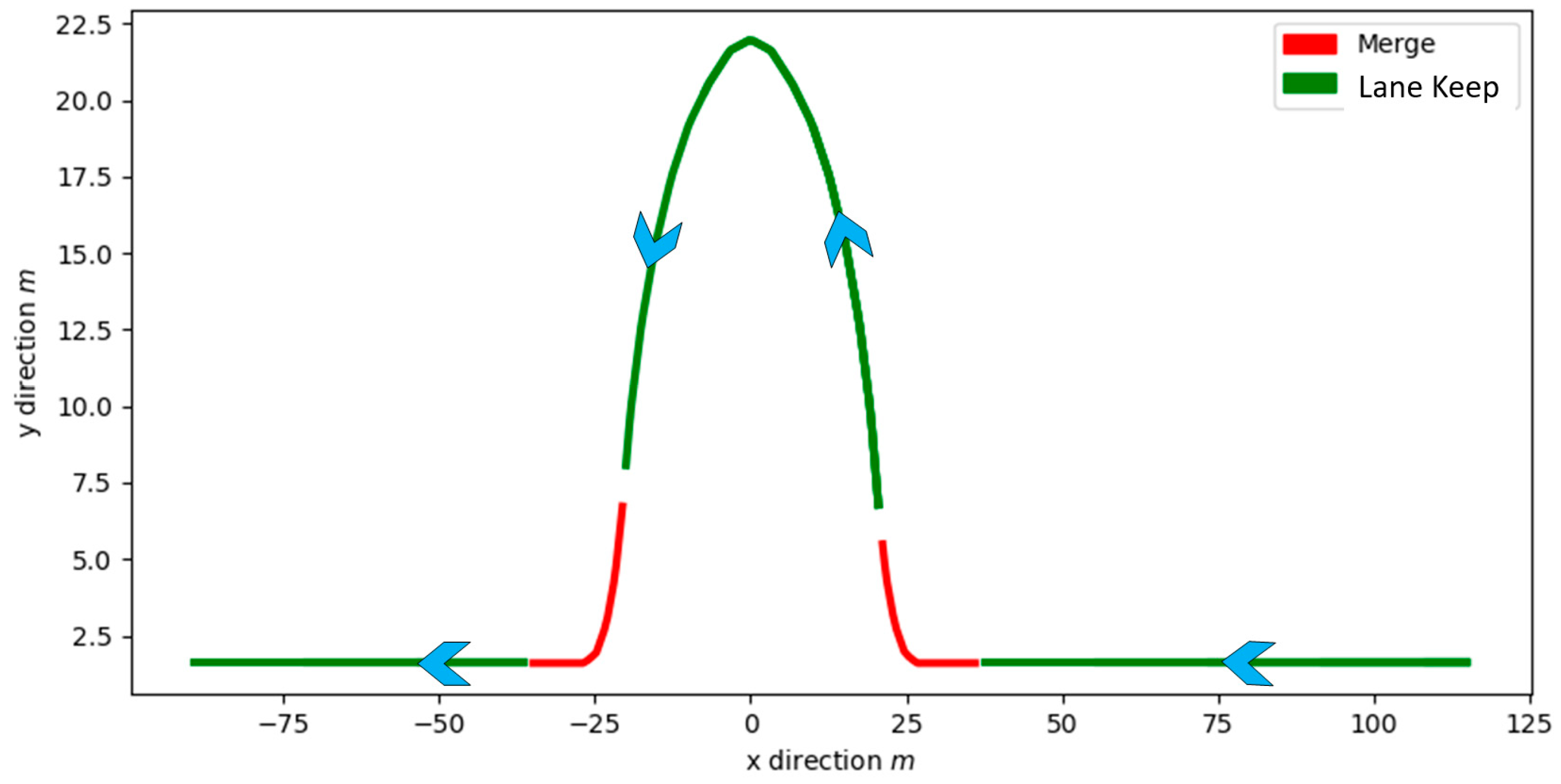
3.4. Simulation and Test Results of Policy Prediction
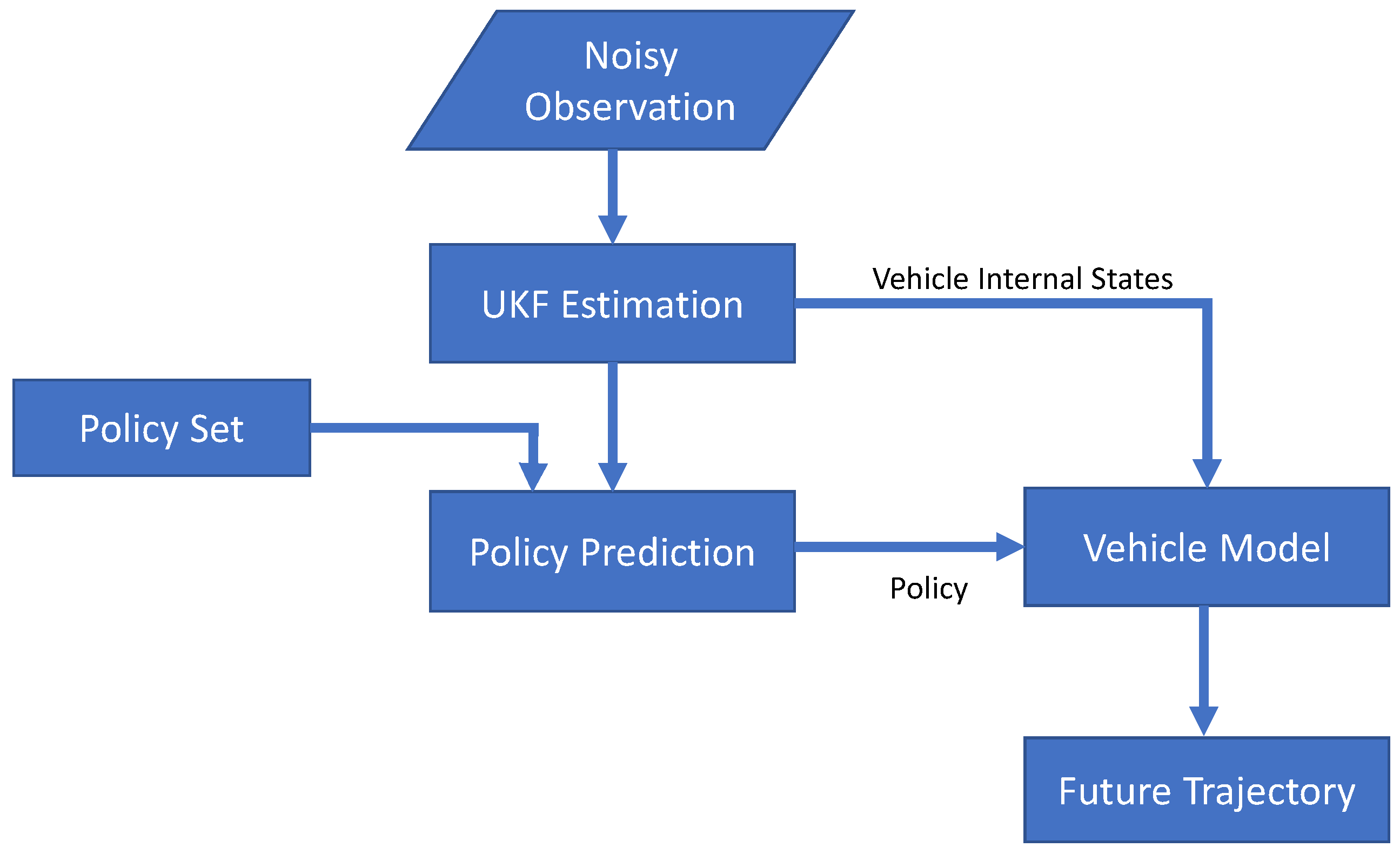
4. Vehicle Trajectory Estimation Based on UKF and Policy Prediction Method
4.1. Vehicle Trajectory Estimation
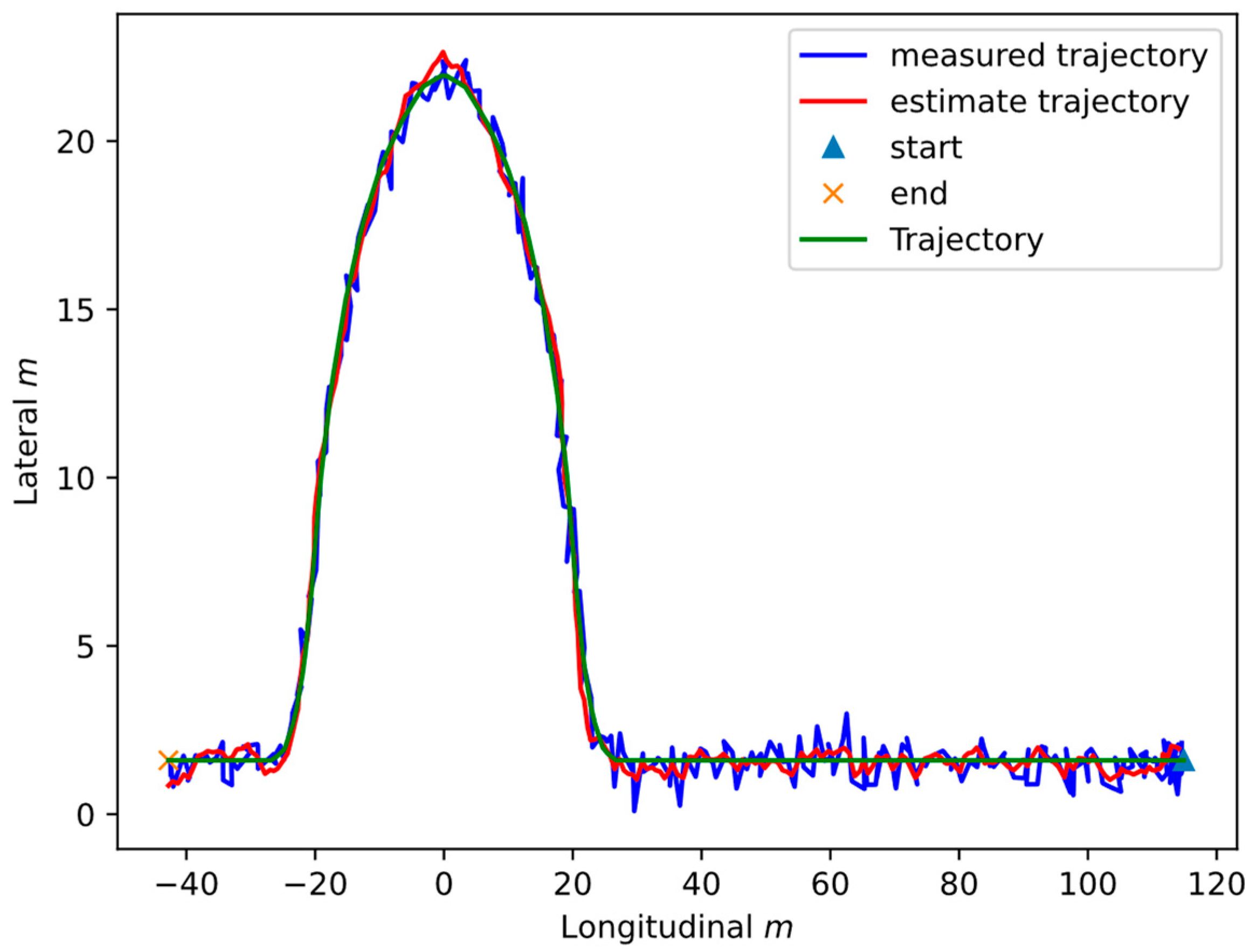
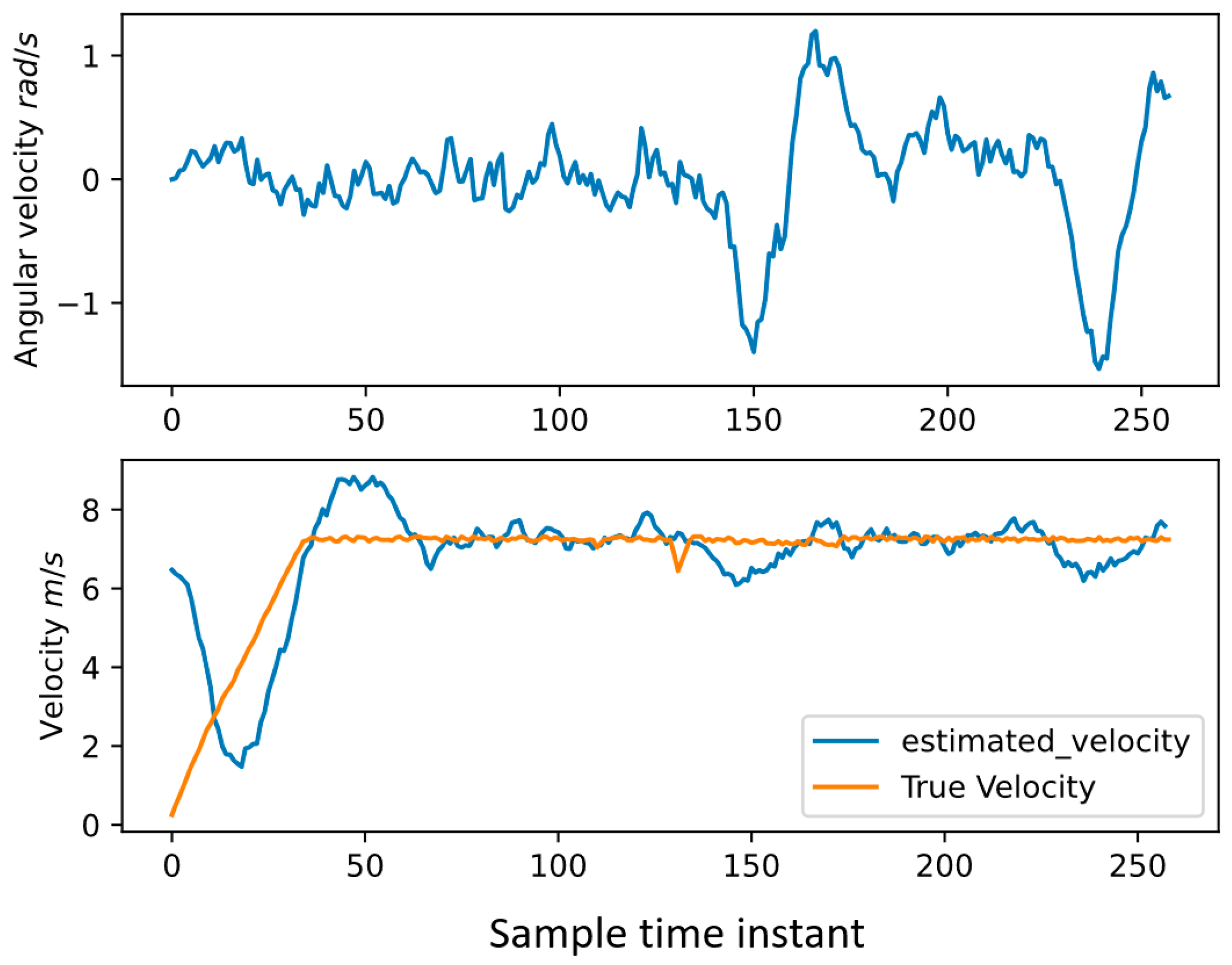
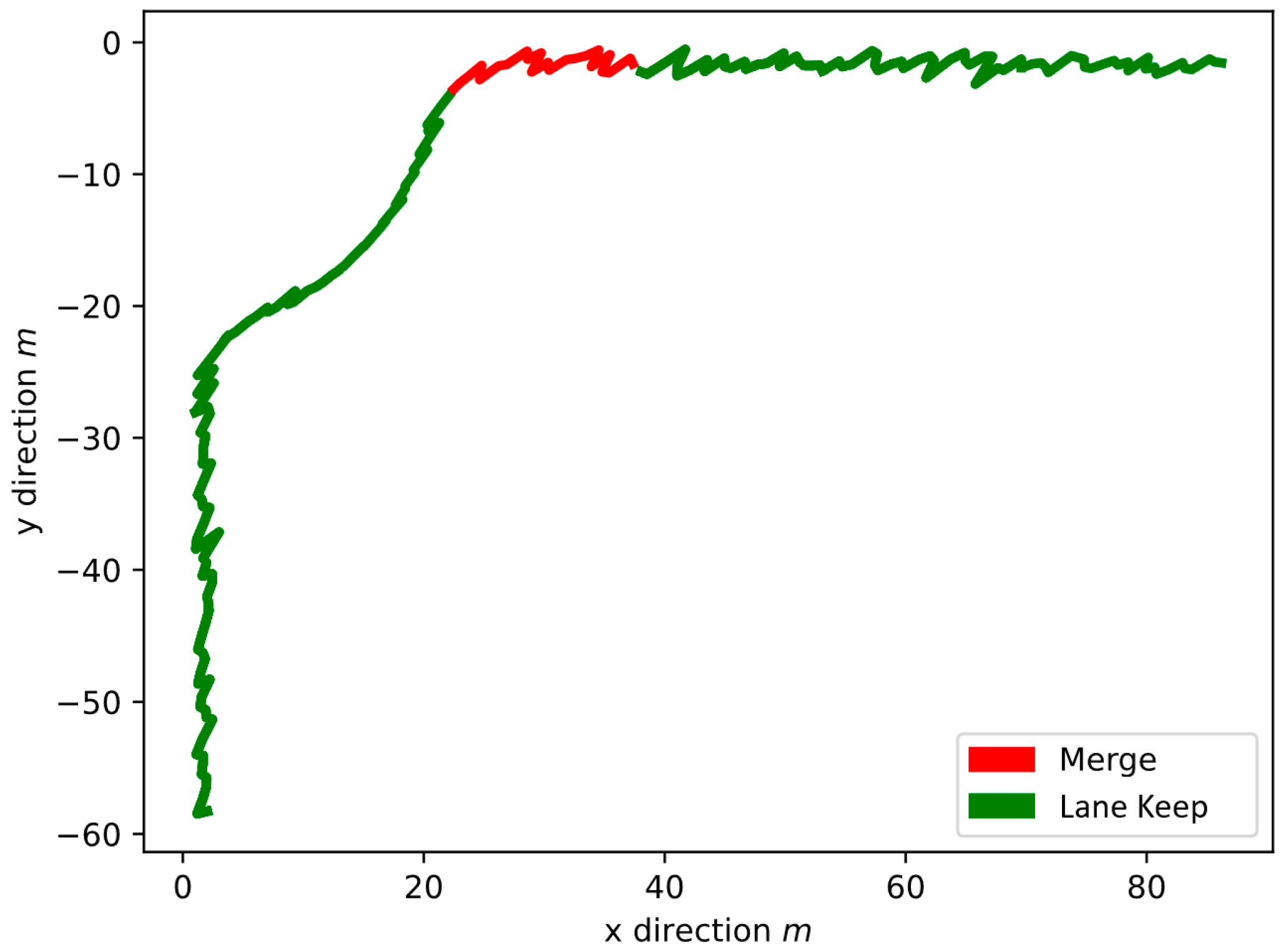
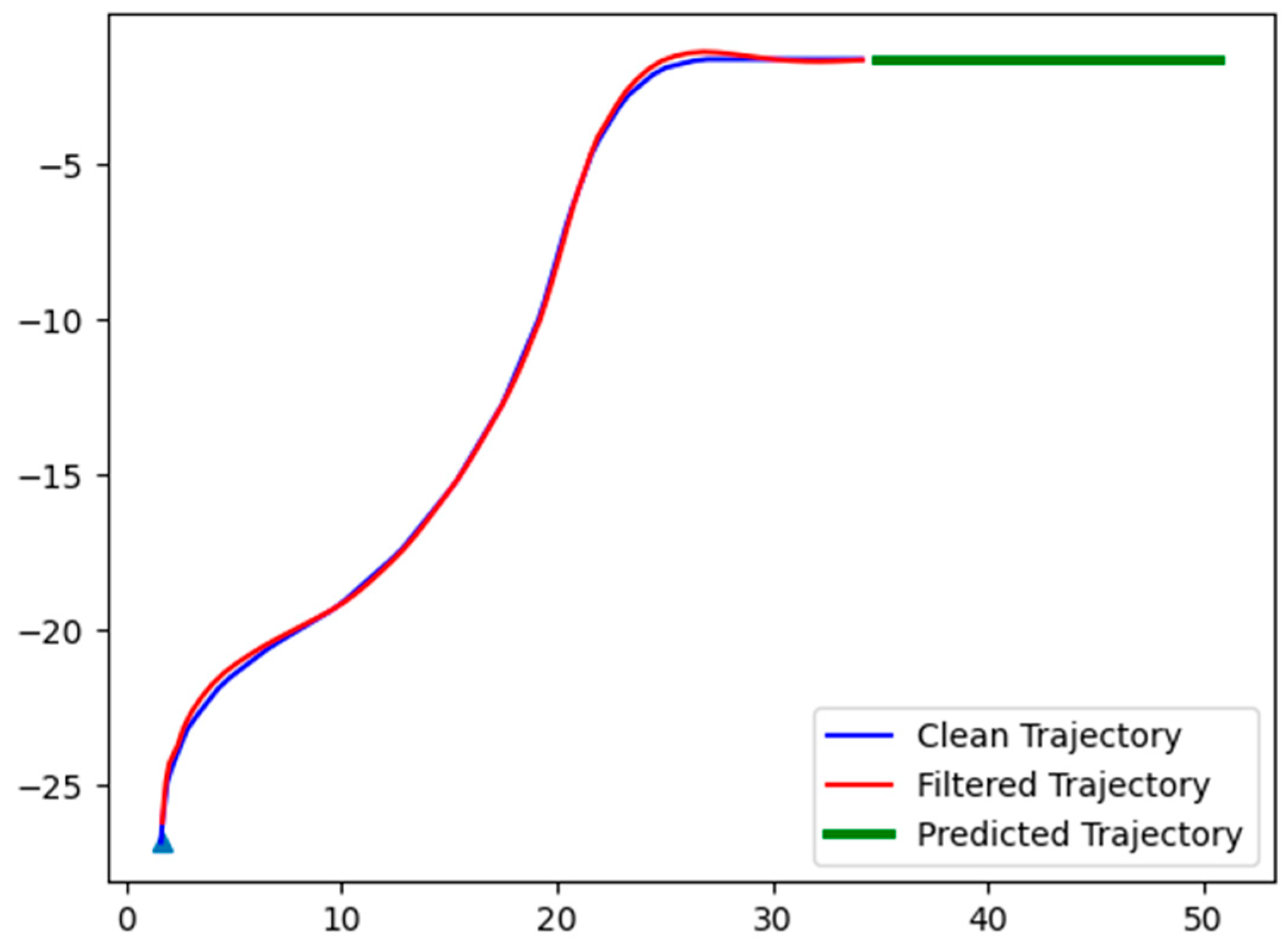
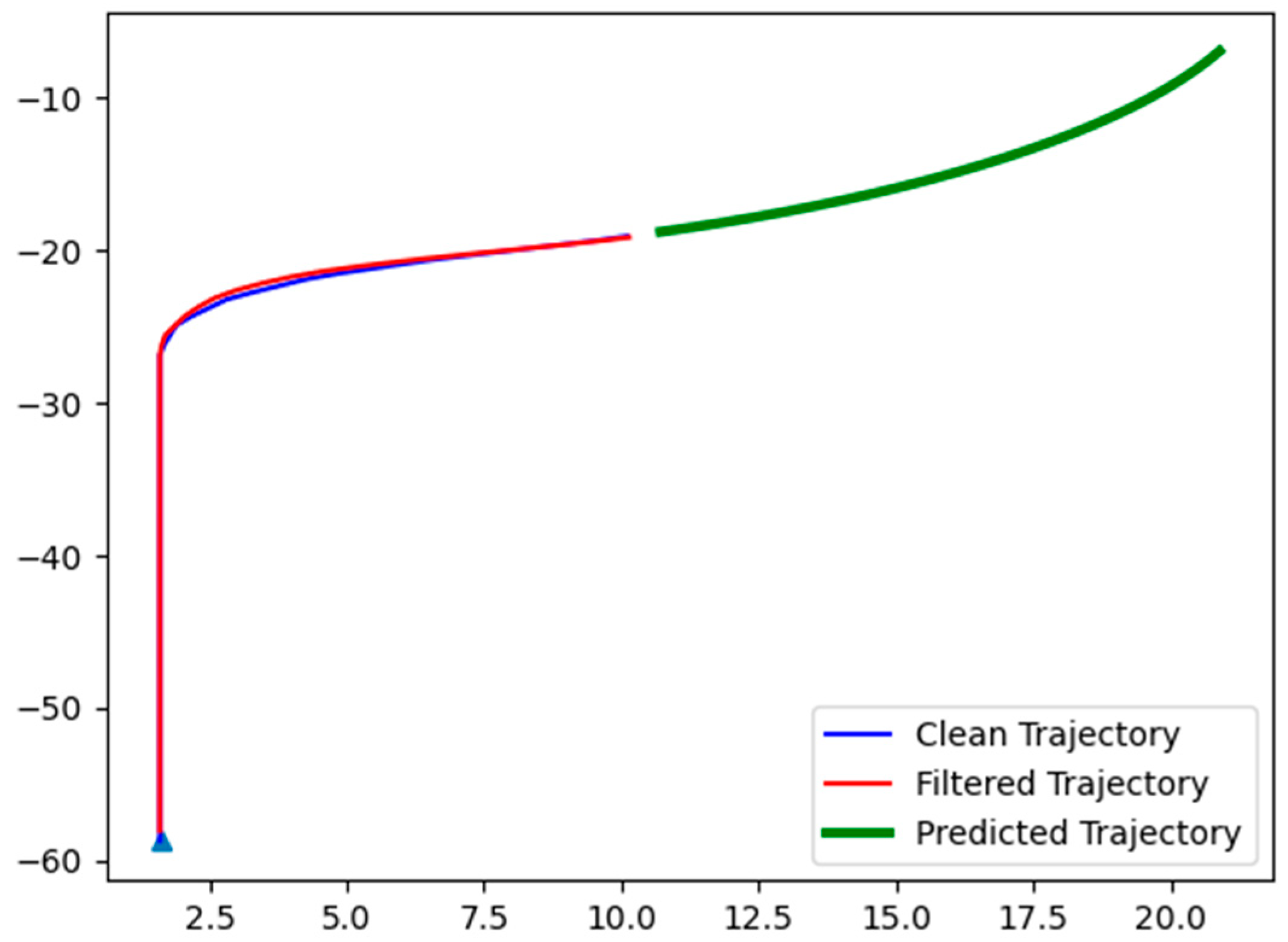
4.2. Test Results on the Vehicle Trajectory Estimation Method
5. Conclusions and Recommendations
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Guvenc, L.; Aksun-Guvenc, B.; Emirler, M.T. Connected and Autonomous Vehicles. In Internet of Things/Cyber-Physical Systems/Data Analytics Handbook; Geng, H., Ed.; Wiley: New York, NY, USA, 2017; pp. 581–596. [Google Scholar]
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A Survey of Autonomous Driving: Common Practices and Emerging Technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Claussmann, L.; Revilloud, M.; Gruyer, D.; Glaser, S. A Review of Motion Planning for Highway Autonomous Driving. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1826–1848. [Google Scholar] [CrossRef]
- Paden, B.; Cap, M.; Yong, S.Z.; Yershov, D.; Frazzoli, E. A Survey of Motion Planning and Control Techniques for Self-Driving Urban Vehicles. IEEE Trans. Intell. Veh. 2016, 1, 33–55. [Google Scholar] [CrossRef]
- Guvenc, L.; Aksun-Guvenc, B.; Zhu, S.; Gelbal, S.Y. Autonomous Road Vehicle Path Planning and Tracking Control, 1st ed.; Book Series on Control Systems Theory and Application; Wiley: Hoboken, NJ, USA; IEEE Press: New York, NY, USA, 2021. [Google Scholar]
- Glaser, S.; Vanholme, B.; Mammar, S.; Gruyer, D.; Nouveliere, L. Maneuver-Based Trajectory Planning for Highly Autonomous Vehicles on Real Road with Traffic and Driver Interaction. IEEE Trans. Intell. Transp. Syst. 2010, 11, 589–606. [Google Scholar] [CrossRef]
- Kuutti, S.; Bowden, R.; Jin, Y.; Barber, P.; Fallah, S. A Survey of Deep Learning Applications to Autonomous Vehicle Control. IEEE Trans. Intell. Transp. Syst. 2021, 22, 712–733. [Google Scholar] [CrossRef]
- Hubmann, C.; Schulz, J.; Becker, M.; Althoff, D.; Stiller, C. Automated Driving in Uncertain Environments: Planning with Interaction and Uncertain Maneuver Prediction. IEEE Trans. Intell. Veh. 2018, 3, 5–17. [Google Scholar] [CrossRef]
- Li, L.; Ota, K.; Dong, M. Humanlike Driving: Empirical Decision-Making System for Autonomous Vehicles. IEEE Trans. Veh. Technol. 2018, 67, 6814–6823. [Google Scholar] [CrossRef]
- Kuwata, U.; Teo, J.; Fiore, G.; Karaman, S.; Frazzoli, E.; How, J.P. Real-Time Motion Planning with Applications to Autonomous Urban Driving. IEEE Trans. Control Syst. Technol. 2009, 17, 1105–1118. [Google Scholar] [CrossRef]
- Rajamani, R. Vehicle Dynamics and Control; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Schubert, R.; Richter, E.; Wanielik, G. Comparison and evaluation of advanced motion models for vehicle tracking. In Proceedings of the 11th International Conference on Information Fusion, IEEE, Cologne, Germany, 30 June–3 July 2008. [Google Scholar]
- Bersani, M.; Vignati, M.; Mentasti, S.; Arrigoni, S.; Cheli, F. Vehicle state estimation based on kalman filters. In Proceedings of the AEIT International Conference of Electrical and Electronic Technologies for Automotive (AEIT AUTOMOTIVE) 2019, Turin, Italy, 2–4 July 2019; pp. 1–6. [Google Scholar]
- Chandra, R.; Guan, T.; Panuganti, S.; Mittal, T.; Bhattacharya, U.; Bera, A.; Manocha, D. Forecasting Trajectory and Behavior of Road-Agents Using Spectral Clustering in Graph-LSTMs. IEEE Robot. Autom. Lett. 2020, 5, 4882–4890. [Google Scholar] [CrossRef]
- Mohamed, A.; Qian, K.; Elhoseiny, M.; Claudel, C. Social-stgcnn: A social spatio-temporal graph convolutional neural network for human trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 13–19 June 2020; pp. 14424–14432. [Google Scholar]
- Sriram, N.; Liu, B.; Pittaluga, F.; Chandraker, M. Smart: Simultaneous multi-agent recurrent trajectory prediction. In Proceedings of the European Conference on Computer Vision 2020, Glasgow, UK, 23–28 August 2020; pp. 463–479. [Google Scholar]
- Wan, E.A.; Van Der Merwe, R. The unscented Kalman filter for nonlinear estimation. In Proceedings of the IEEE 2000 Adaptive Systems for Signal Processing, Communications, and Control Symposium (Cat. No. 00EX373), Lake Louise, AB, Canada, 4 October 2000; pp. 153–158. [Google Scholar]
- Julier, S.J.; Uhlmann, J.K. New extension of the Kalman filter to nonlinear systems. In Signal Processing, Sensor Fusion, and Target Recognition VI 1997; International Society for Optics and Photonics: Bellingham, WA, USA, 1997; pp. 182–193. [Google Scholar]
- Wan, E.A.; van der Merwe, R. The Unscented Kalman Filter. In Kalman Filtering and Neural Networks; Haykin, S., Ed.; Wiley: New York, NY, USA, 2001; pp. 221–280. [Google Scholar]
- Li, X.; Zhu, S.; Aksun-Guvenc, B.; Guvenc, L. Development and Evaluation of Path and Speed Profile Planning and Tracking Control for an Autonomous Shuttle Using a Realistic, Virtual Simulation Environment. J. Intell. Robot. Syst. 2021, 101, 42. [Google Scholar] [CrossRef]
- Galceran, E.; Cunningham, A.G.; Eustice, R.M.; Olson, E. Multipolicy decision-making for autonomous driving via changepoint-based behavior prediction: Theory and experiment. Auton. Robot. 2017, 41, 1367–1382. [Google Scholar] [CrossRef]
- Niekum, S.; Osentoski, S.; Atkeson, C.G.; Barto, A.G. CHAMP: Changepoint Detection Using Approximate Model Parameters; Carnegie-Mellon University: Pittsburgh, PA, USA, 2014. [Google Scholar]
- Fearnhead, P.; Liu, Z.J.S. Computing: Efficient Bayesian analysis of multiple changepoint models with dependence across segments. Stat. Comput. 2011, 21, 217–229. [Google Scholar] [CrossRef]
- Viterbi, A. Error bounds for convolutional codes and an asymptotically optimum decoding algorithm. IEEE Trans. Inf. Theory 1967, 13, 260–269. [Google Scholar] [CrossRef]
- Mirwald, J.; Ultsch, J.; de Castro, R.; Brembeck, J. Learning-Based Cooperative Adaptive Cruise Control. Actuators 2021, 10, 286. [Google Scholar] [CrossRef]
- Ren, P.; Jiang, H.; Xu, X. Research on a Cooperative Adaptive Cruise Control (CACC) Algorithm Based on Frenet Frame with Lateral and Longitudinal Directions. Sensors 2023, 23, 1888. [Google Scholar] [CrossRef] [PubMed]
- Kamal, M.A.S.; Hashikura, K.; Hayakawa, T.; Yamada, K.; Imura, J.-i. Adaptive Cruise Control with Look-Ahead Anticipation for Driving on Freeways. Appl. Sci. 2022, 12, 929. [Google Scholar] [CrossRef]
- Arevalo-Castiblanco, M.F.; Pachon, J.; Tellez-Castro, D.; Mojica-Nava, E. Cooperative Cruise Control for Intelligent Connected Vehicles: A Bargaining Game Approach. Sustainability 2023, 15, 11898. [Google Scholar] [CrossRef]
- Xie, H.; Xiao, P. Cooperative Adaptive Cruise Algorithm Based on Trajectory Prediction for Driverless Buses. Machines 2022, 10, 893. [Google Scholar] [CrossRef]
- Emirler, M.T.; Guvenc, L.; Aksun-Guvenc, B. Design and Evaluation of Robust Cooperative Adaptive Cruise Control Systems in Parameter Space. Int. J. Automot. Technol. 2018, 19, 359–367. [Google Scholar] [CrossRef]
- Ma, F.; Wang, J.; Zhu, S.; Gelbal, S.Y.; Yu, Y.; Aksun-Guvenc, B.; Guvenç, L. Distributed Control of Cooperative Vehicular Platoon with Nonideal Communication Condition. IEEE Trans. Veh. Technol. 2020, 69, 8207–8220. [Google Scholar] [CrossRef]
- Oncu, S.; Ploeg, J.; van de Wouw, N.; Nijmeijer, H. Cooperative Adaptive Cruise Control: Network-Aware Analysis of String Stability. IEEE Trans. Intell. Transp. Syst. 2014, 15, 1527–1537. [Google Scholar] [CrossRef]
- Hu, J.; Sun, S.; Lai, J.; Wang, S.; Chen, Z.; Liu, T. CACC Simulation Platform Designed for Urban Scenes. IEEE Trans. Intell. Veh. 2023, 8, 2857–2874. [Google Scholar] [CrossRef]
- Ma, F.; Yang, Y.; Wang, J.; Li, X.; Wu, G.; Zhao, Y.; Wu, L.; Aksun-Guvenc, B.; Guvenc, L. Eco-Driving-Based Cooperative Adaptive Cruise Control of Connected Vehicles Platoon at Signalized Intersections. Transp. Res. Part D Transp. Environ. 2021, 92, 102746. [Google Scholar] [CrossRef]
- Zhai, L.; Sun, T.; Wang, J. Electronic Stability Control Based on Motor Driving and Braking Torque Distribution for a Four In-Wheel Motor Drive Electric Vehicle. IEEE Trans. Veh. Technol. 2016, 65, 4726–4739. [Google Scholar] [CrossRef]
- Gao, F.; Zhao, F.; Zhang, Y. Research on Yaw Stability Control Strategy for Distributed Drive Electric Trucks. Sensors 2023, 23, 7222. [Google Scholar] [CrossRef] [PubMed]
- Seo, Y.; Cho, K.; Nam, K. Integrated Yaw Stability Control of Electric Vehicle Equipped with Front/Rear Steer-by-Wire Systems and Four In-Wheel Motors. Electronics 2022, 11, 1277. [Google Scholar] [CrossRef]
- Aksun-Guvenc, B.; Guvenc, L.; Ozturk, E.S.; Yigit, T. Model Regulator Based Individual Wheel Braking Control. In Proceedings of the IEEE Conference on Control Applications 2002, İstanbul, Turkey, 23–25 June 2002. [Google Scholar]
- Zhang, W.; Wang, Z.; Drugge, L.; Nybacka, M. Evaluating Model Predictive Path Following and Yaw Stability Controllers for Over-Actuated Autonomous Electric Vehicles. IEEE Trans. Veh. Technol. 2020, 69, 12807–12821. [Google Scholar] [CrossRef]
- Aksun-Guvenc, B.; Guvenc, L. The Limited Integrator Model Regulator and its Use in Vehicle Steering Control. Turk. J. Eng. Environ. Sci. 2022, 26, 473–482. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vehicle | Average Lateral Error (m) | Max Lateral Error (m) | Average Longitudinal Error (m) | Max Longitudinal Error (m) | Average Euclidean Distance (m) | Max Euclidean Distance (m) |
|---|---|---|---|---|---|---|
| V1 | 0.27 | 0.97 | 0.27 | 1.41 | 0.43 | 1.43 |
| V2 | 0.22 | 1.24 | 0.21 | 0.68 | 0.35 | 1.25 |
| V3 | 0.26 | 0.94 | 0.29 | 1.55 | 0.43 | 1.63 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Guvenc, L.; Aksun-Guvenc, B. Vehicle State Estimation and Prediction for Autonomous Driving in a Round Intersection. Vehicles 2023, 5, 1328-1352. https://doi.org/10.3390/vehicles5040073
Li X, Guvenc L, Aksun-Guvenc B. Vehicle State Estimation and Prediction for Autonomous Driving in a Round Intersection. Vehicles. 2023; 5(4):1328-1352. https://doi.org/10.3390/vehicles5040073
Chicago/Turabian StyleLi, Xinchen, Levent Guvenc, and Bilin Aksun-Guvenc. 2023. "Vehicle State Estimation and Prediction for Autonomous Driving in a Round Intersection" Vehicles 5, no. 4: 1328-1352. https://doi.org/10.3390/vehicles5040073