1. Introduction
In this work, we tackled the problem of generating an automatic music transcription (AMT) of a given audio recording. Depending on the desired content of the transcription and the nature of the audio recording, there exist different formulations of this problem. We focused on the transcription of drum onsets (both their timings and instruments involved), a task known as automatic drum transcription (ADT) in the context of polyphonic audio tracks—tracks that contain both melodic and drum instruments—since they represent the majority of musical tracks in the real world (e.g., any radio song). This specification of ADT is a challenging problem known as drum transcription in the presence of melodic instruments (DTM).
The main challenge of DTM comes from the fact that multiple sounds can be associated with one instrument, and the same sound can be associated with multiple instruments. On the one hand, something that is true for AMT as a whole, any instrument can be played with different techniques (e.g., rimshots, ghost notes, and flams) and undergo distinct recording procedures (depending, for example, on the recording equipment used, the characteristics of the instruments, and the audio effects added during the post-processing sessions). On the other hand, something that is specific to polyphonic recordings seen in DTM, melodic and percussive instruments can overlap and mask each other (e.g., the bass guitar may hide a bass drum onset) or have similar sounds, thus creating confusion between instruments (e.g., a bass drum may be misinterpreted for a low tom or yield to the perception of an extra low tom on top of it).
Due to this complexity, the most promising methods for DTM, as identified by the review work of Wu et al. [
1], use supervised deep learning (DL) algorithms—large models trained with labeled datasets. However, despite their good performance, there is still a large margin for improvement. In fact, it is acknowledged that these algorithms are limited by the amount of training data available; by contrast, due to the fact that their generation is labor-intensive, existing datasets are usually small. Furthermore, because data are often copyrighted, datasets are made publicly available only in very few cases. As a result, the available data do not cover the huge diversity that is found in music and is needed to train DL algorithms to reach their full potential.
In response to this data paucity, most of the approaches either tackle a simplified variant of DTM or rely on techniques other than supervised learning. For example, the problem can be simplified by restricting the desired content of the transcription to a vocabulary that includes only the three most common drum instruments, i.e., the bass drum, snare drum, and hi-hat, or by using techniques such as transfer or unsupervised learning that can mitigate the lack of training data—indeed, one of the most competitive methods, proposed by Vogl et al., is based on transfer learning from a large amount of synthetic data [
2].
Nevertheless, limiting the scope of the problem and mitigating the data paucity are not satisfying solutions. Instead, it would be preferable to increase the amount of training data, which has been shown to be possible with two recent large-scale datasets: ADTOF [
3] and A2MD [
4]. Thanks to the large amount of crowdsourced, publicly available, non-synthetic data from the Internet, these datasets have improved the supervised training of DTM models. However, these datasets have not yet been well exploited for three reasons: no exploration of an optimal DL architecture has been conducted; due to crowdsourcing, the data contain discrepancies and are biased to specific music genres; only a few training procedures have been evaluated. Our goal was to explore how these datasets can be efficiently used by addressing all three aforementioned issues:
To identify an optimal architecture, we compared multiple architectures exploiting recent techniques in DL;
To mitigate noise and bias in crowdsourced datasets, we curated a new dataset to be used conjointly with existing ones;
To evaluate the datasets, we compared multiple training procedures by combining different mixtures of data.
We now present our three contributions in detail.
Before the current work, as the experiments involving ADTOF and A2MD were limited to the curation and validation of the datasets, different DL architectures able to leverage this data had still to be evaluated. In fact, only one architecture had been implemented with each dataset, without comparison to others. Here, instead, we present and assess a total of four different architectures that exploit two recent techniques: tatum synchronicity and self-attention mechanisms [
5,
6,
7]. In terms of accuracy (the F-measure), we found that all these architectures are practically equivalent; hence, we concluded that, to a large extent, the favorable performance of our algorithm is not due to these recent improvements in DL.
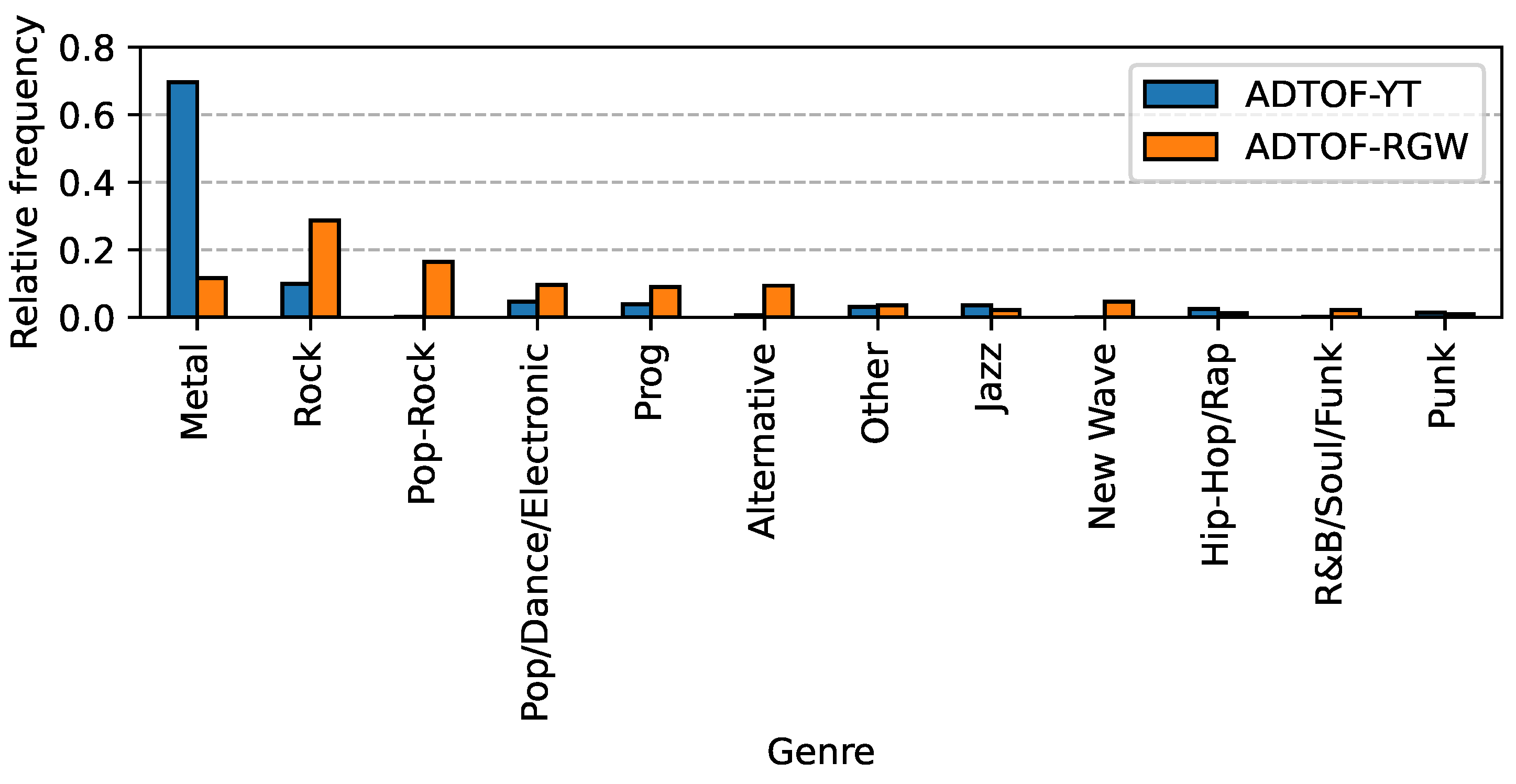
Second, recent studies involving ADTOF and A2MD showed that the crowdsourced nature of these datasets is likely to hinder the performance of the models trained on them. On the one hand, because different annotators have different levels of expertise, there are discrepancies in the annotations. To address this issue, we built a new dataset (adopting the same cleansing process employed in ADTOF), this time using tracks with high-quality annotations selected by the community of annotators. We named this set ADTOF-YT. The first part of the name (“ADTOF”) is a reference to the cleansing process, and the second part (“YT”) comes from the fact that many of the tracks curated are showcased on streaming platforms like YouTube. On the other hand, because this new set and ADTOF are biased toward different musical genres selected by the crowd, a model trained on either of them will suffer from a generalization error. To counter this issue, we trained on both sets at the same time; we then showed that the increased quantity and diversity of training data contributed largely to the performance of our algorithm.
Last, crowdsourced datasets have only been used to train models that were evaluated in a “zero-shot” setting (i.e., the models were evaluated on datasets that were not used for training), whereas the state-of-the-art model used as a reference was not (i.e., the model was evaluated on different divisions of the same datasets used for training). A zero-shot evaluation is more desirable than only splitting the datasets into “training” and “test” partitions because of the homogeneity inherent in the curation process; however, zero-shot evaluation is also a more challenging task. Since the crowdsourced datasets were previously evaluated only in zero-shot studies, their performance in non-zero-shot scenarios is still unknown. As a consequence, in this work we compared the training procedures as follows: We trained on a mixture of commonly used datasets, first with, and then without, a chosen dataset each time. Thus, we revealed both the contribution of the chosen dataset to the performance of the model when it was added to the training data, and the generalization capabilities of the model on the dataset when it was left out.
The remainder of this article is organized as follows: First, we present previous works on ADT in
Section 2. We then describe the materials and methods of our experiments on the deep learning architectures and training procedures in
Section 3. This part also presents the new dataset we curated. We continue by presenting and discussing the results in
Section 4, before concluding and outlining future work in
Section 5.
4. Results
To assess the potential of large crowdsourced datasets, we performed two studies: First, we investigated the impact of the model’s architecture, using the four versions described in
Section 3.1, when training on all the datasets described in
Section 3.2. Second, we investigated the contribution of the different datasets to the models’ performance and generalization capabilities.
To evaluate each trained model, we compared its detected onsets to the ground-truth annotations independently for each dataset. The evaluation was based on the hit rate: An estimation was considered correct (a hit) if it was within 50 ms of an annotation, and all estimations and annotations were matched at most once (for the actual implementation, refer to the package mir_eval [
37]). We counted the matched events as true positives (tp), the ground-truth annotations without a corresponding estimation as false negatives (fn), and the estimations not present in the ground-truth annotations as false positives (fp). Then, we computed the F-measure by summing the tp, fn, and fp across all tracks and all instruments in the test set of each dataset.
4.1. Evaluation of Architectures
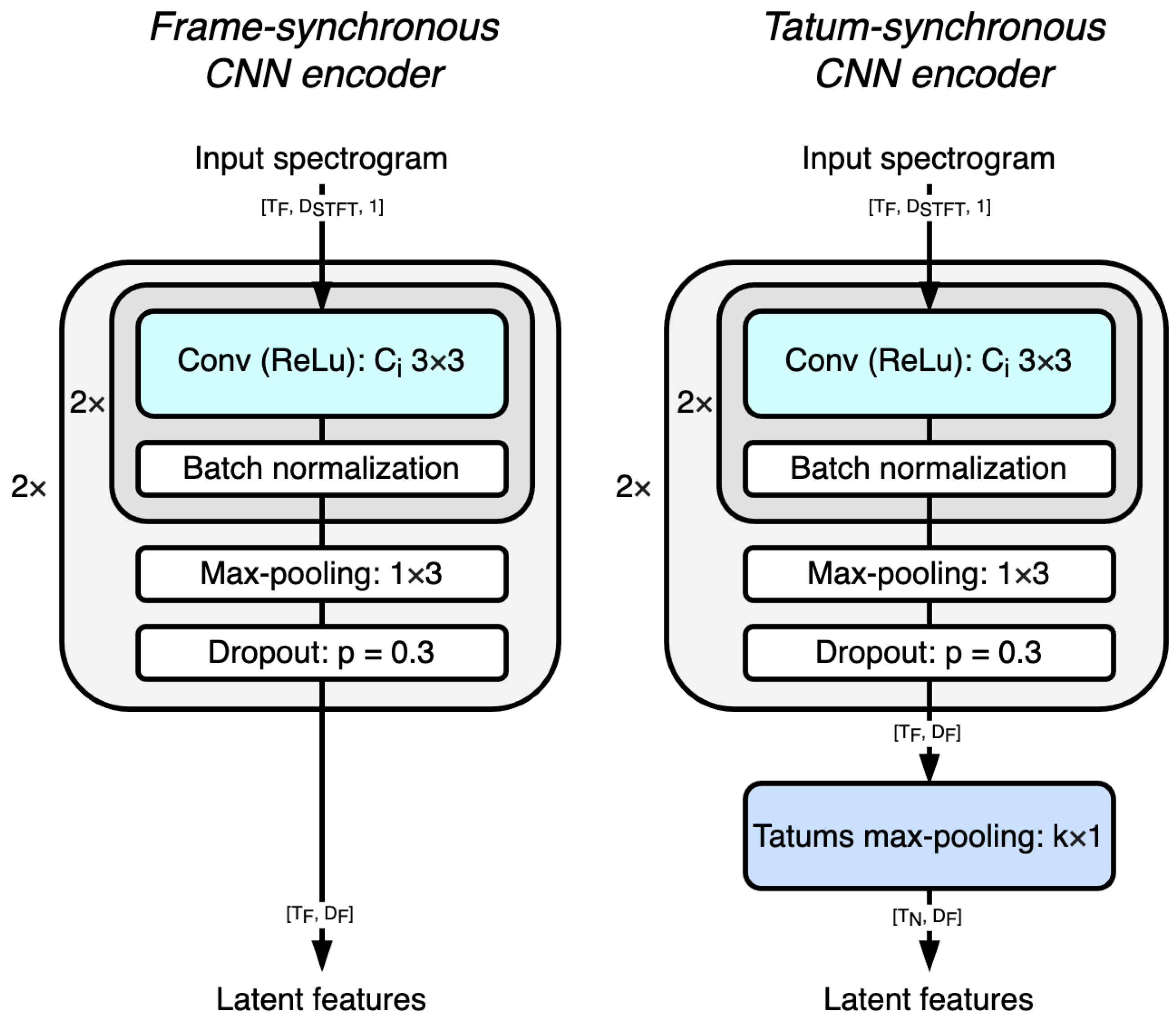
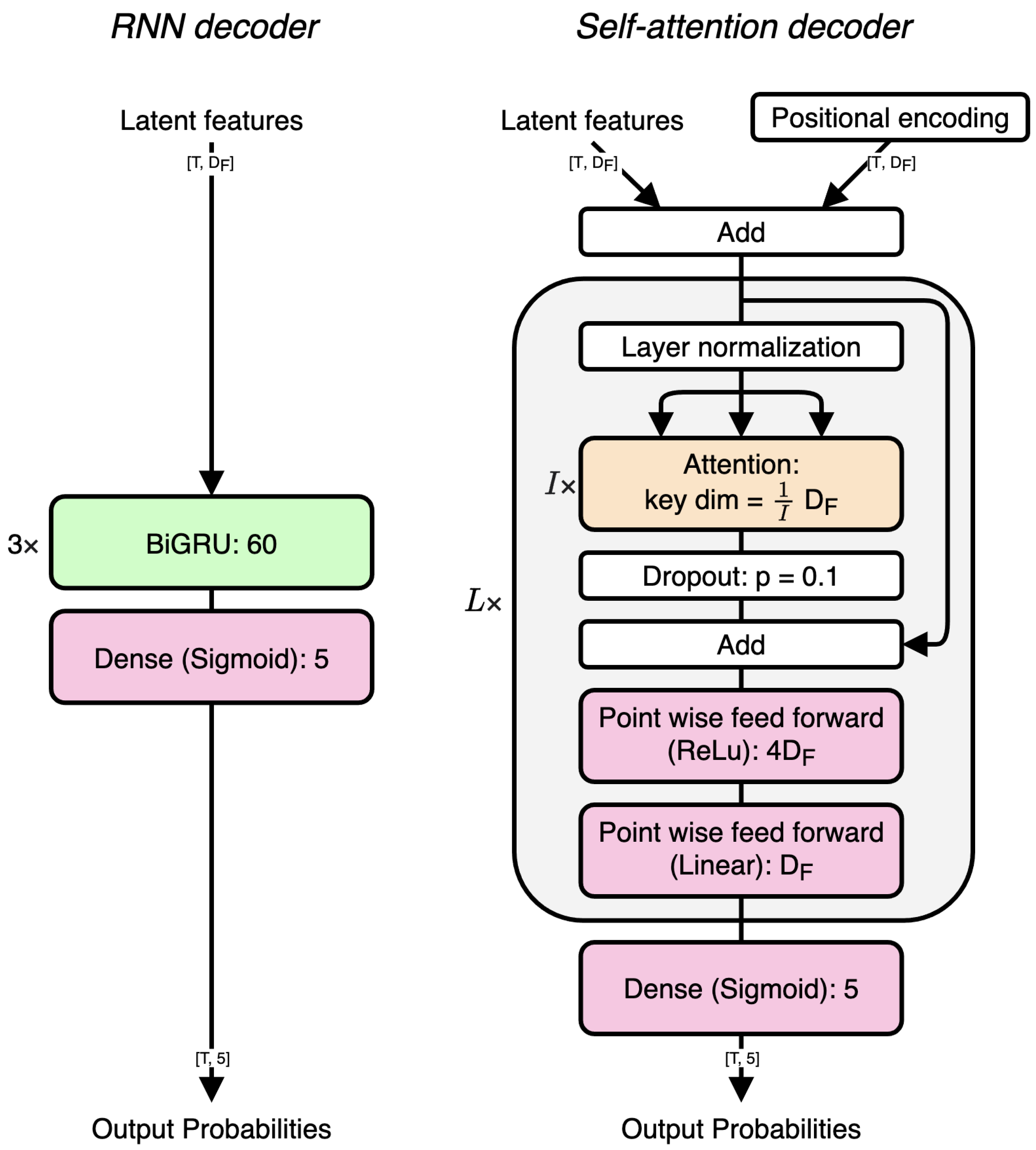
Table 4 lists the four architectures we evaluated, specifically, a frame- or tatum-synchronous encoder, in combination with an RNN or self-attention decoder. In the following, we refer to the architecture consisting of the frame-synchronous encoder and RNN decoder as the “reference”.
On average, the frame-synchronous models (top two rows in
Table 4) performed slightly better than the tatum-synchronous models (bottom two rows). This empirical finding contrasts with both our intuition and the results of Ishizuka et al. [
5,
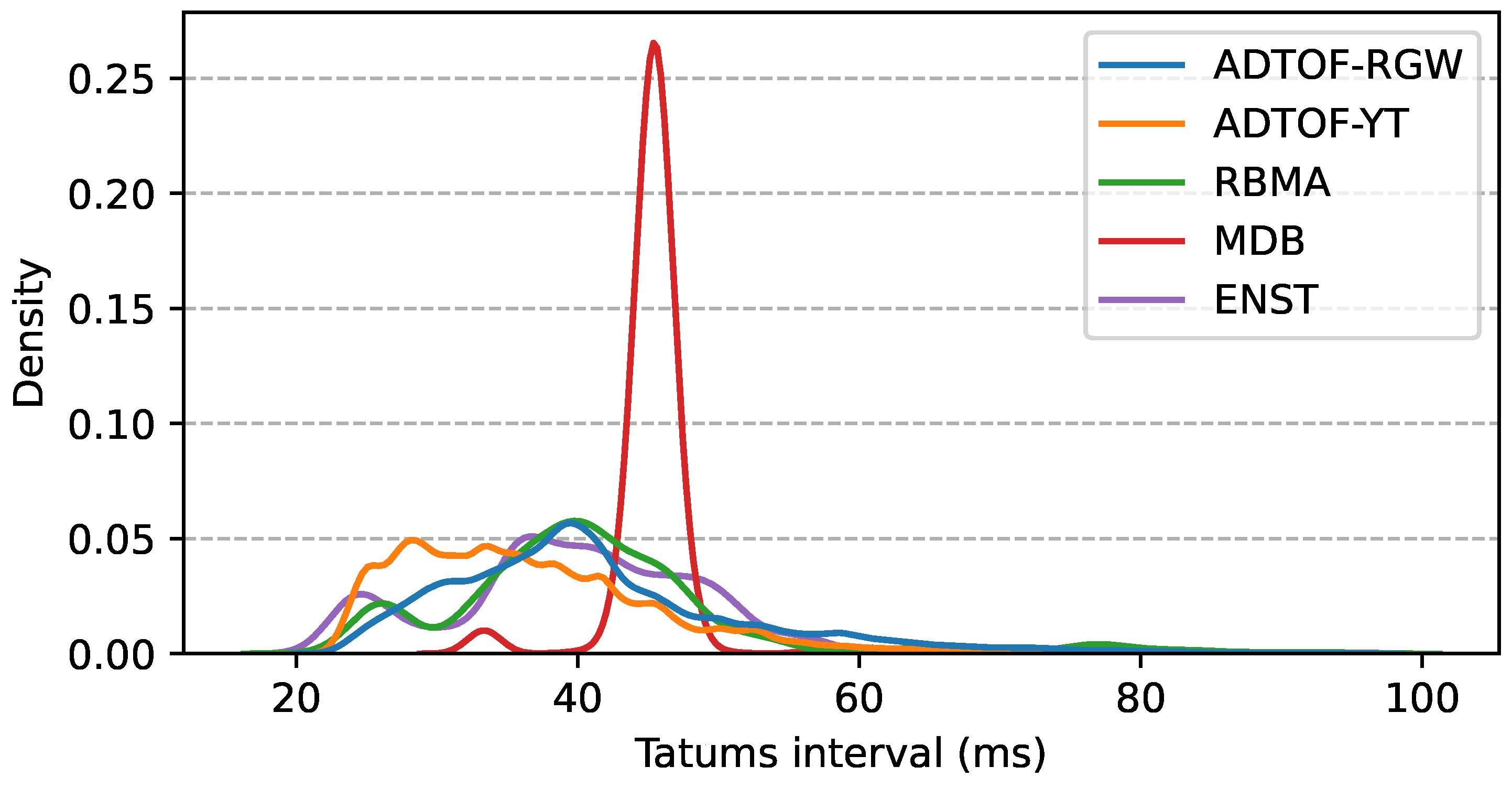
6], who observed that the tatum max-pooling layer always improved the F-measure achieved by the model. We hypothesize that the main reason behind the lower score for the tatum-synchronous models (compared to Ishizuka) lies in the lower quality of the tatum grid used for pooling. In fact, we computed an F-measure between Madmom and ground-truth beats of 0.71, 0.62, and 0.84 for ADTOF-RGW, ADTOF-YT, and RBMA, respectively, while Ishizuka et al. reported much higher scores of 0.93 and 0.96 on their two datasets. The disagreement between the estimated and annotated beats shows that the tatums we employed were likely based on erroneous beat positions, and this hindered the performance of the model.
By comparing the first two rows (frame-synchronous models) with one another, we conclude that the self-attention and RNN decoders obtained almost identical results. The same is true when comparing the third row with the fourth row (tatum-synchronous models). These results contrast with previous works, which tend to favor self-attention mechanisms over RNNs (see
Table 1), especially in the presence of a large amount of training data, as in this study. An explanation is that the input sequence was short enough (4 s or 16 beats,
T in
Figure 2) to be fully modeled by an RNN, so no benefit was gained by employing the global sequence modeling capabilities of the self-attention mechanism.
While a finer hyperparameter search could slightly change the values presented in
Table 4, the differences we observed among the four architectures were such that no clear winner emerged. Since neither the tatum synchronicity nor the self-attention mechanisms significantly improved the results, in the next experiment we focused on the simpler frame-synchronous RNN.
4.2. Evaluating Training Procedures
In the following, we evaluate the reference (frame-synchronous RNN) architecture when trained with nine different combinations of datasets. Specifically, we trained a model with and without specific datasets to measure (1) the contribution of the different datasets toward the model’s quality and (2) the generalization capabilities achieved on the datasets that were not used for the training. The results are presented in
Table 5, where the top five rows refer to models trained without pre-training, while the bottom four rows refer to models that were pre-trained on the TMIDT dataset.
A comparison of the first two rows of
Table 5 helps to understand the contribution (to the training) of the small non-crowdsourced datasets (RBMA, ENST, and MDB) when added to the crowdsourced data (ADTOF-RGW and YT). It can be observed that adding RBMA, ENST, and MDB to the training data did not improve the results of the model, except when testing on ADTOF-RGW, but only slightly (from 0.82 to 0.83). On the one hand, this reveals that the limited diversity of these datasets (RBMA, ENST, and MDB) prevented an improvement in the generalization of the model, even with the boosted sampling probability (
Section 3.2). On the other hand, this also shows that the model trained exclusively on ADTOF-RGW and ADTOF-YT already performed well on other datasets (zero-shot performance of ADTOF-RGW plus ADTOF-YT on RBMA, ENST, and MDB).
By comparing rows 2 and 3, and rows 2 and 4, one can see the contribution of the datasets ADTOF-YT and ADTOF-RGW with respect to the training carried out using both. As expected, since these datasets are biased towards different music genres, their joint usage achieved noticeably better results for zero-shot performance. For instance, the addition of ADTOF-RGW to ADTOF-YT brought the F-score on RBMA from 0.57 to 0.65; likewise, the addition of ADTOF-YT to ADTOF-RGW brought the F-score on ENST and MDB from 0.72 and 0.76 to 0.78 and 0.81, respectively. In other words, since mixing these datasets increased the diversity of the training data, the zero-shot performance of the model also increased.
However, it is rather surprising to notice that while the addition of ADTOF-YT improved the performance on ADTOF-RGW (from 0.79 to 0.82), no improvement was observed on ADTOF-YT when ADTOF-RGW was added (the F-score stayed at 0.85). We attribute this behavior to the fact that ADTOF-RGW contains mistakes in the annotations and is smaller than ADTOF-YT. This effectively prevented the model trained exclusively on ADTOF-RGW from achieving the best performance on this dataset. Nonetheless, as already observed in [
3], thanks to its large size and diversity, ADTOF-RGW was still better for training than any of the non-crowdsourced datasets (row 5).
Finally, we quantified the contribution of pre-training on the large synthetic dataset TMIDT, following a method suggested by Vogl et al. [
2] and known to counter the data paucity of real-word recordings. We identified three trends with TMIDT: (i) Already before undergoing any refinement, the pre-trained model attained a performance (row 9) that on average outweighed that of the same model trained on RBMA, ENST, and MDB (row 5). This result, already identified by Vogl et al., is remarkable considering that during training the model was only exposed to synthesized data, i.e., data with limited acoustic diversity. (ii) When refining on RBMA, ENST, and MDB, the F-measure increased on these same datasets, but not on ADTOF-RGW nor ADTOF-YT (row 8). This is another indication that RBMA, ENST, and MDB did not contribute extensively to the quality of the models trained on them. (iii) Lastly, pre-training on TMIDT and then refining on ADTOF-RGW and ADTOF-YT yielded a lower F-measure than when no pre-training was performed (rows 6–7 compared to rows 1–2). This phenomenon, known as “ossification”, suggests that pre-training may have prevented the model from adapting to the fine-tuning distribution in the high data regime [
38] (p. 7), that is, the model became stuck at a local minimum. Since pre-training did not help, this is an indication that ADTOF-RGW and ADTOF-YT likely contained enough (and diverse) data to train our model to its full potential.
We have so far discussed the results only for the reference architecture (frame- synchronous RNN). To ensure that the trends identified with the training data were not dependent on the architecture employed, we repeated the same evaluations with the frame-synchronous self-attention architecture, and we found scores that matched closely those in
Table 5. We are thus confident that the trends we described hold in general. Nonetheless, we identified two key differences among the different architectures: First, when few data were available (i.e., when training exclusively on RBMA, ENST, and MDB), the model with the self-attention mechanism performed worse than when trained with the RNN. This matched the empirical results found by Ishizuka et al. [
6], who claimed that the self-attention mechanism was affected more than the RNN by data size. Second, although pre-training on TMIDT still penalized the model through ossification, we noticed that the drop in performance was less significant with the self-attention mechanism than with the RNN. This occurred because the higher number of parameters in the self-attention architecture made it less prone to ossification, as Henandez suggested [
38] (p. 7).
5. Conclusions
Given an input audio recording, we considered the task of automatically transcribing drums in the presence of melodic instruments. In this study, we introduced a new large crowdsourced dataset and addressed three issues related to the use of datasets of this type: the lack of investigations of deep learning architectures trained on them, the discrepancies and bias in crowdsourced annotations, and their limited evaluation.
Specifically, we first investigated four deep learning architectures that are well suited to leveraging large datasets. Starting from the well-known convolutional recurrent neural network (CRNN) architecture, we extended it to incorporate one or both of two mechanisms: tatum max-pooling and self-attention. We then mitigated discrepancies and bias in the training data by creating a new non-synthetic dataset (ADTOF-YT), which was significantly larger than other currently available datasets. ADTOF-YT was curated by gathering high-quality crowdsourced annotations, applying a cleansing procedure to make them compatible with the ADT task, and mixing it with other datasets to further diversify the training data. Finally, we evaluated many training procedures to quantify the contribution of each dataset to the performance of the model, in both zero-shot and non-zero-shot settings.
The results can be summarized as follows: (1) No noticeable difference was observed among the four architectures we tested. (2) The combination of the newly introduced dataset ADTOF-YT with the existing ADTOF-RGW proved to train models better than any previously used datasets, synthetic or not. (3) We quantified the generalization capabilities of the model when tested on unseen datasets and concluded that good generalization was achieved only when large amounts of crowdsourced data were included in the training procedure.
Thanks to this evaluation, we explored how to leverage crowdsourced datasets with different DL architectures and training scenarios. By achieving better results than the current state-of-the-art models, we improved the ability to retrieve information from music, be it for musicians who desire to learn a new musical piece, or for researchers who need to retrieve information from the location of the notes. Further, the models were approaching the Bayes error rate (irreducible error). In order to quantify the improvements that one can expect from a perfect classifier, in future work we aim to estimate this theoretical limit.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




