1. Introduction
The “no free lunch” theorem [
1] suggests that
“...for any algorithm, any elevated performance over one class of problems is offset by performance over another class”. This theorem also holds true in time-series forecasting settings, meaning that no model can optimally forecast all series and, consequently, that the most appropriate model should be identified per case to improve the overall forecasting accuracy. Indeed, if model selection could be carried out perfectly, then the accuracy gains would be substantial [
2]. Unfortunately, due to the uncertainty involved in the process [
3], the task of model selection has been proven to be very challenging in practice, especially when performed for numerous series [
4] or for data that involve anomalies, outliers, and shifts [
5]. To that end, the forecasting literature has developed various criteria, rules, and methods to improve model selection and automate forecasting.
Early attempts at model selection involved utilizing information criteria, such as Akaike’s information criterion (AIC; [
6]) and the Bayesian information criterion (BIC; [
7]), and choosing the most appropriate model by comparing their ability to fit the historical observations with the number of parameters used to produce forecasts. Other attempts include rule-based selections [
8], i.e., using a set of heuristics to define when a model should be preferred over another. These rules, which typically build on time-series features (e.g., strength of trend and seasonality), can also be determined analytically by processing the forecast errors of various models across different series of diverse features [
9]. The rise of machine learning has facilitated the development of such feature-based model selection algorithms, also called “meta-learners” [
10]. Another promising alternative is to select models judgmentally, thereby allowing the incorporation of human experience [
11] and avoiding making unreasonable choices [
12]. In any case, particular emphasis should be placed on the pool of candidate models considered for making selections [
13].
Another direction for selecting forecasting models is based on cross-validation [
14], which is specifically designed to overcome issues related to overfitting and to enhance the generalization of the forecasting methods used. In time-series forecasting applications, cross-validation variants include blocked approaches that mitigate the problem of serial correlations [
15,
16] and techniques that omit data close to the period used to evaluate performance [
17]. Therefore, along with information criteria, cross-validation is among the most popular approaches used nowadays for effective model selection [
18].
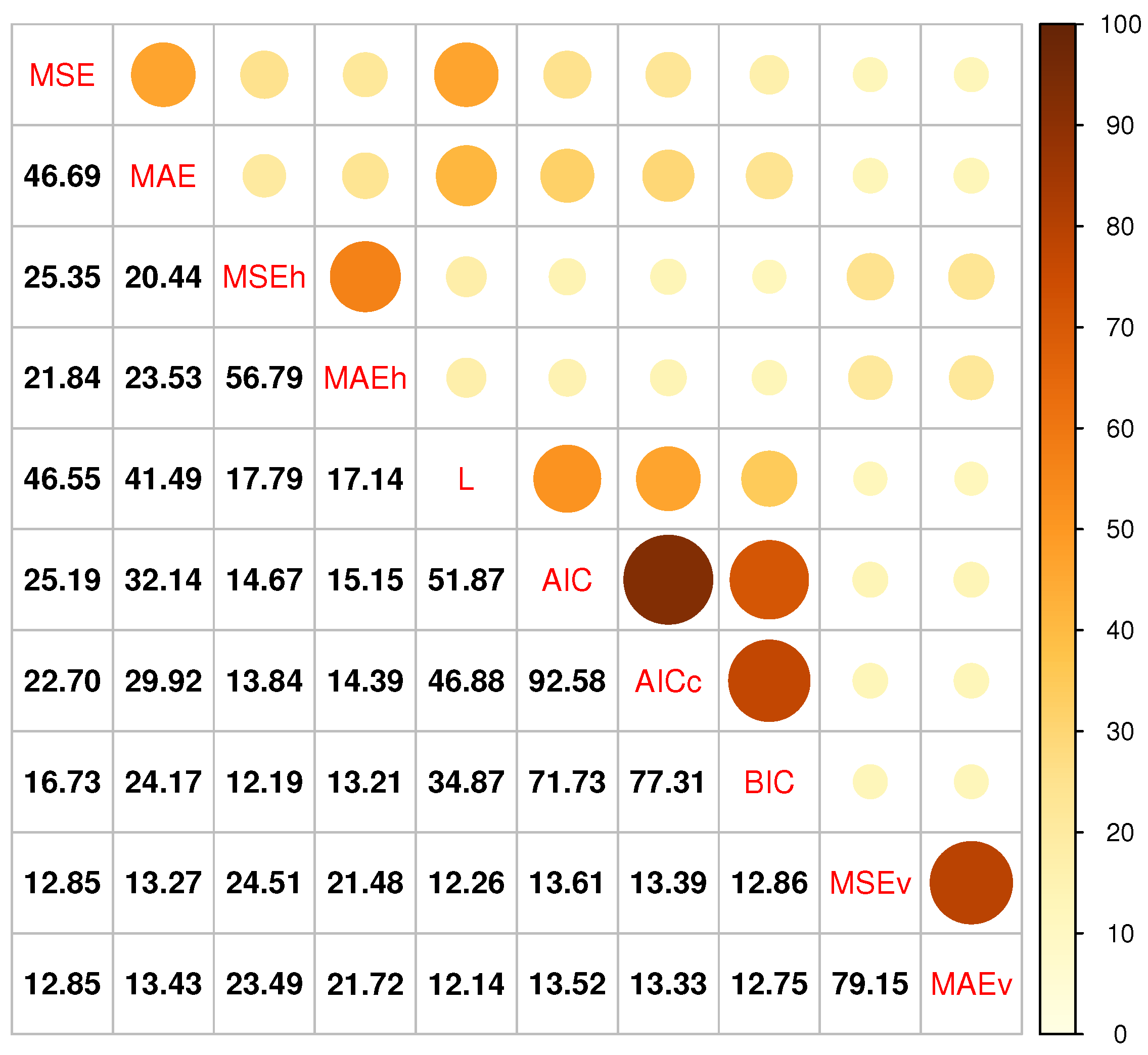
Despite the development of several model selection approaches, researchers and practitioners have been relatively indecisive about the criteria that they should use in practice for identifying the most accurate forecasting models. Each criterion comes with particular advantages and limitations, often rendering their use subject to the judgment and experience of the forecaster or even the settings of the software utilized to produce the forecasts. We argue that tuning model selection processes is critical for improving accuracy and that empirical evidence should be exploited to define which criterion should be considered for the data set and forecasting application at hand. To support our argument, we evaluated some of the most widely used model selection criteria on a large data set of real series with the exponential smoothing family of models, a standard method for time-series forecasting. Our analysis focused on both the precision of the criteria and the forecasting accuracy of the underlying selection approaches, providing evidence about the way that the two measures are correlated. We also investigated the disagreement between the examined criteria and discuss its implications for forecasting practice.
The rest of this paper is organized as follows.
Section 2 provides an introduction to the model selection criteria used in our study.
Section 3 presents the exponential smoothing family of models, forming the pool of candidate models used in our experiments.
Section 4 empirically evaluates the performance of the selection criteria, describes the experimental setup, and discusses the results. Finally,
Section 5 concludes the paper.
2. Model Selection Criteria
2.1. Criteria Based on In-Sample Accuracy Measurements
The simplest and fastest approach to selecting a forecasting model from a pool of candidate models is to compare their accuracy on the in-sample data of the series. This is because in-sample accuracy can be directly measured when fitting the models, requiring no further computations. The most common measures used in this direction are the mean squared error (MSE) and the mean absolute error (MAE), defined as follows:
where
n is the sample size (number of in-sample observations),
is the observed value of the series being forecast at point
t, and
is the forecast provided by the model given
n observations for estimating its parameters. Smaller values of MAE and MSE suggest a better fit.
Although other measures (e.g., measures based on percentage errors, relative errors, relative measures, and measures based on scaled errors) can be used instead of MSE and MAE, given their limitations [
19] and the fact that model selection is typically performed in a series-by-series fashion, the aforementioned scale-dependent measures can be considered sufficient for the described task.
In terms of statistical properties, MAE is an appropriate measure for evaluating the ability of a forecasting model to specify the median of the future values of a series [
20], while MSE is suitable for measuring the ability of a model to specify its mean [
21]. Moreover, since MSE builds on squared errors, it penalizes more large errors than small ones and is therefore more sensitive to outliers than MAE [
22]. Therefore, although MSE has long been the standard measure of choice for selecting and optimizing time-series forecasting models, it becomes evident that there may be settings where MAE provides superior results.
Model selection criteria that build on in-sample measurements theoretically come with two major issues. First, since they just focus on how well the model fits the historical observations, they are prone to overfitting. In general, sophisticated models that consist of multiple parameters have the capacity to fit series better than simpler models, although the latter may result in more accurate post-sample forecasts. Second, since in-sample measurements evaluate accuracy across the complete sample of historical observations, they may favor models that do not necessarily perform well in the most recent past. Typically, the latest information available is of higher importance for producing accurate post-sample forecasts, meaning that models should put particular emphasis on the last part of the series, especially when its underlying patterns (e.g., seasonality and trend) have changed.
Although the first issue can be tackled by the criteria presented in the following two subsections, the second one can be mitigated by simply adjusting the time window in which the accuracy measures are computed. For the sake of simplicity, in this study, we considered some variants of the MSE and MAE measures, called MSEh and MAEh, that capture the in-sample accuracy of the examined models in the last
h observations of the series, as follows:
where
h is the forecasting horizon, i.e., the number of periods the model is tasked to forecast in the post-sample. Although
h can in principle be selected based on the particular requirements of the forecasting task at hand (e.g., set equal to a full calendar year or the last observation), we argue that the forecasting horizon is a reasonable and practical alternative for determining the time window. Moreover, by selecting a sufficiently large evaluation window (e.g., greater than 1 observation), the results are expected to be more representative and less sensitive to potential extreme values.
2.2. Information Criteria
Information criteria have become particularly popular for model selection, as they are fast to compute but can also mitigate overfitting [
23]. To do so, instead of selecting the model that best fits the series, as measured by an accuracy measure in the in-sample data, they make choices by penalizing the in-sample accuracy of the candidate models according to their complexity, as realized based on the number of parameters that have to be estimated to form each model.
Specifically, information criteria build on complexity-penalized maximum likelihood estimations (as described in
Section 3 for the case of exponential smoothing models). The most notable variants of information criteria include AIC, AIC corrected for small sample sizes (AICc), and BIC, defined as follows:
where
L is the likelihood, and
k is the total number of parameters. In all cases, smaller values imply better performance. As seen in the equations, by definition, BIC assigns larger penalties to more sophisticated models than AIC, thus favoring simpler models of comparable likelihood. The same applies to AICc, provided that the sample size is relatively small (AICc approximates AIC as the sample size increases).
Although there have been theoretical arguments over the use of particular information criteria over others, Burnham and Anderson [
24] demonstrate that AIC and AICc can be derived in the same Bayesian framework as BIC, just by using different prior probabilities. As a result, information criterion selection should be based on the assumptions made about reality and models while also taking into consideration empirical evidence about the forecasting performance of each criterion in the application at hand. Simulation studies suggest that AICc tends to outperform BIC and also recommend its use over AIC, even when sample sizes are relatively large [
25,
26]. This may justify the utilization of AICc in popular model selection software, such as the
auto.arima and
ets functions of the
forecast package for R, which allow the automatic selection of ARIMA and exponential smoothing models, respectively [
27].
2.3. Criteria Based on Cross-Validation
Cross-validation is another approach for selecting among forecasting models. The greatest advantage of this approach is that it focuses on the post-sample accuracy of the candidate models, thus selecting models that perform well in their actual tasks, regardless of how well they managed to fit the historical data, while also making no assumptions about how model complexity should be measured or penalized. As a result, cross-validation has become very popular for model selection and optimization, especially in applications that involve sophisticated models (e.g., neural networks), where standard selection criteria are either challenging to compute or sensitive to overfitting. On the negative side, cross-validation is applicable only to series that have enough observations to allow the creation of hold-out samples and is computationally expensive (the more hold-out samples created, the greater the cost becomes).
In time-series forecasting settings, where data are non-stationary and have serial dependencies, cross-validation is typically implemented using the rolling-origin evaluation approach [
28]. According to this approach, a period of historical data
is first used to fit a forecasting model. Then, the model is used to produce
h-step-ahead forecasts, and its accuracy is assessed based on the actual values of the series in the corresponding period using the measure of choice (e.g., MSE or MAE). Subsequently, the forecast origin is shifted by
T periods, the model is re-fitted using the new in-sample data (
), and new forecasts are produced, contributing another assessment. This process is repeated until there are no data left for testing, and the overall performance of the model is determined based on its average accuracy over the conducted evaluations.
For the sake of simplicity, and to accelerate computations, in this study, we considered a fixed-origin evaluation, i.e., a single evaluation set that consists of the last
h observations of the original in-sample data (
). In addition, in accordance with the in-sample selection measures used in our study, we used MSE and MAE to assess the post-sample forecasting accuracy. The examined cross-validation approaches, called MSEv and MAEv, are defined as follows:
Note that MSEv/MAEv are computed on the same sample as MSEh/MAEh. The only difference is that the forecasts used with the MSEv/MAEv criteria are computed using observations, while the forecasts used with the MSEh/MAEh criteria use the complete in-sample data (n observations).
3. Forecasting Models
Exponential smoothing, originally introduced by Brown [
29], is considered the workhorse of time-series forecasting, being among the oldest and simplest yet one of the most effective and widely used methods for univariate predictions (for an encyclopedic review on exponential smoothing, please refer to Section 2.3.1 of [
30]). The key advantage of the method is that it is fast to compute [
31], easy to implement in software [
32], and results in competitive accuracy compared to more sophisticated methods in various applications, including financial, economic, demographic, and demand data, among others, as demonstrated empirically by recent forecasting competitions [
33,
34]. In addition, the forecasts are produced based on intuitive models that are closely connected to key time-series features (e.g., trend and seasonality), thus being easy to communicate to managers or adjust based on judgment [
12].
The key idea behind exponential smoothing is that more recent observations are more valuable to forecasting. As a result, the method produces forecasts by putting exponentially more weight on the most recent past of the series. The degree to which the weight is decreased as we move further to the past is determined by the smoothing parameters of the model. Moreover, according to its state-space expression [
23], typically referred to as ETS, exponential smoothing can be realized as a combination of three components, namely, the error (E), trend (T), and seasonal (S) components. The error component can be either additive (A) or multiplicative (M), while the trend and seasonal components can be none (N), additive (A), or multiplicative (M). In addition, additive and multiplicative trends can be damped (d), if needed. Consequently, the ETS framework involves a total of 30 exponential smoothing models (or model forms) that can be acronymized using the respective symbols of the three components, as shown in
Table 1. From these models, some may result in infinite forecast variances for long forecast horizons [
35], while others involve a multiplicative trend that is not recommended to use in practice [
36]. Therefore, the
ets function of the
forecast package for R, which was used to implement exponential smoothing in our study, limits the candidate models to 15 for seasonal data and 6 for non-seasonal data.
As an example, the simplest form of exponential smoothing that accounts just for level variations (simple exponential smoothing or ANN) can be expressed as:
where
is the state of the level component at period
t, and
is the smoothing parameter of that level. Note that calculating the state of the component at
(
) requires the estimation of some initial state values (
). Effectively, this is another parameter of the model, and its estimation is part of the fitting process.
As more components are added to the model, more equations and parameters are considered for producing the forecasts. This results in more generic models that can effectively account for more complicated time-series patterns, such as the trend [
37] and seasonality [
38]. However, as discussed earlier, more sophisticated models involve more parameters and, as a result, higher parameter uncertainty [
3], possibly rendering their use less accurate compared to other, simpler model forms. By default,
ets uses the likelihood to estimate the parameters of the models and AICc to select the most appropriate model form. Depending on the form of the error component, likelihood is defined as follows:
where
and
correspond to the likelihood of models that involve additive and multiplicative error components, respectively.
In terms of the parameters
k used, all exponential smoothing models involve a minimum of three parameters, namely,
,
, and
, which corresponds to the standard deviation of the residuals. Then, models with a trend component will involve two additional parameters (for smoothing and initializing the trend), and models with a damped trend component will involve three additional parameters (for initializing, smoothing, and damping the trend), while models with a seasonal component will involve
additional parameters (
s for initializing and one for smoothing seasonality), where
s is equal to the seasonal periods of the data (e.g., 12 for monthly and 4 for quarterly series). For the sake of simplicity, and to allow comparisons between series of different seasonal periods, in this study, we categorized ETS models into four categories based on their complexity, namely, “Low”, “Moderate”, “Significant”, and “High” complexity, as presented in
Table 2. As can be seen, models of low complexity involve only estimations about the level of the series, models of moderate complexity involve estimations about either the trend or the seasonality of the series, models of significant complexity involve estimations about either a damped trend or seasonality, and models of high complexity are both damped and seasonal.
5. Conclusions
We empirically evaluated the forecasting performance of popular model selection criteria using more than 90,000 real-time series and considering 15 models from the exponential smoothing family. We found that criteria that build on cross-validation can result in better forecasts overall but observed cases (seasonal data) where simple in-sample accuracy measurements can produce significantly more accurate results. We also noticed that information criteria offered a fair balance between the approaches that build on either in-sample or post-sample accuracy measurements but identified notable discrepancies among their choices, driven by the different penalties they impose to avoid the use of unnecessarily sophisticated models. Moreover, we concluded that the measure used to assess the forecasting accuracy (e.g., absolute versus squared errors) has a lower impact on forecasting performance compared to the criteria used for model selection per se.
A key finding of our study is that, when it comes to model selection, robustness is probably more important than precision. In other words, in order for a selection criterion to result in accurate forecasts, it is more crucial to systematically avoid choosing the worst forecasting models than to more frequently select the most accurate model. In this respect, it should not be surprising that two criteria with significant disagreement and different precision scores resulted in similar forecasting performance. An interesting direction to improve the robustness of model selection approaches would be to introduce criteria that concurrently balance the in-sample accuracy, forecast representativeness, and model complexity. According to our results, the first component allows the use of sufficiently sophisticated models, the second improves the precision of the selection process, and the third offers a “safety net” against overfitting.
Our findings are relevant to forecasting research and practice. Over the years, some model selection approaches have become so standard that forecasters often ignore the alternatives available and overlook the improvements that more appropriate criteria could offer. This is especially true in large-scale forecasting applications, such as in the retail, energy, and financial industries, where the number of series to be forecast is so great that using automated and off-the-shelf forecasting software has become a necessity. We argue that tuning the model selection options provided by such software is critical, yet practical if based on empirical assessments. Moreover, in some cases, they may even prove to be more computationally efficient with no loss in forecasting accuracy. Therefore, future work could expand the findings of our study by examining the performance of model selection criteria on data sets that are more focused on particular forecasting applications and also extending their examination to different families of models commonly used for automatic batch forecasting, such as ARIMA, regression trees, and neural networks.




{kind=link}
