1. Introduction
In emergency situations and natural disaster conditions, traditional IoT communications infrastructure, including sensor facilities, may be damaged. This can lead to communication service disruptions. One urgent issue to address is the ability to transition quickly from a faulty state to a normal state and ensure that ongoing communication services can continue smoothly without being affected by network failures. After infrastructure is damaged, drones communicate through wireless channels. These drones carry communication devices and communicate using wireless communication protocols. This enables the entire IoT system to restore its normal communication state. For example, in September 2023, certain regions in China were affected by Typhoon Dusuwei, resulting in floods and geological disasters. Relevant departments utilized drones to play a crucial role in communication support, disaster reconnaissance, and material delivery in challenging rescue environments and complex weather conditions [
1]. Reference [
2] addressed the inability to rescue disaster victims in remote areas due to traditional emergency communications not being successfully established in time. Therefore, they used drones to build a reliable communication network to conduct emergency rescue operations.
Unmanned aerial vehicles (UAVs) have the ability to create collaborative air-to-ground networks above disaster areas, regions with infrastructure challenges, or densely populated communication hotspots. They support and enhance existing cellular infrastructure to connect previously unconnected networks [
3,
4]. Due to their high mobility, strong line-of-sight signal transmission, rapid deployment, and strong adaptability to various environments, UAVs play a critical role in the Internet of Things. For instance, after Hurricane Ida hit Louisiana, AT&T used UAV-mounted cellular on wings (COW) to restore LTE coverage for cellular users [
5]. Moreover, He et al. utilized multiple UAVs to provide services to a wide range of users [
6]. To extend the overall duration of a communication network, load balancing can be implemented between adjacent UAVs and resource consumption can be shared, significantly increasing the overall coverage time of the UAV network. In addition, UAV cluster networks are a crucial component of air-to-ground collaborative networks and provide an essential foundation for achieving aerial networking and data transmission [
7,
8].
In the construction of a ground-based collaborative network for drone clusters, priority should be given to the privacy protection of user data. Federated learning (FL) provides an effective method for training machine learning models while ensuring user privacy. In an FL system, clients have various computing and communication resources [
9]. In recent years, researchers have been devoted to improving the communication efficiency of federated learning. One commonly used method is gradient compression, which directly reduces the size of model updates. Another widely adopted method is collaborative learning, where clients share local model predictions instead of transmitting model updates, thus reducing communication costs. Collaborative learning is one mode of knowledge distillation (KD). For example, in [
10], FL introduces KD to achieve efficient and low-cost information exchange, especially when dealing with heterogeneous models, with the aim of reducing communication expenses.
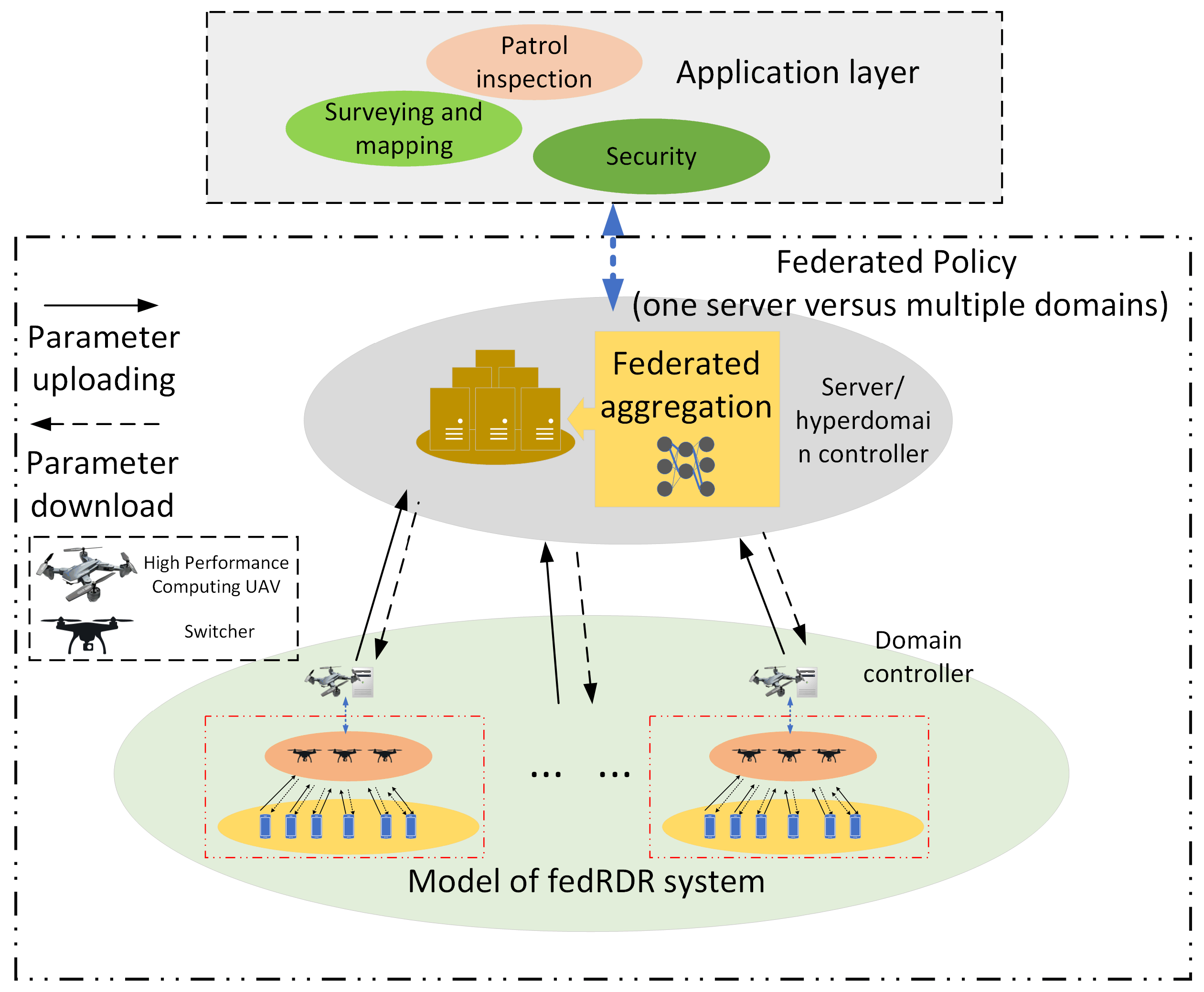
In the design of air-to-ground collaborative networking, drones mainly provide an access service to ground nodes. Due to the wide coverage area required for the service, the communication range supported by drones is limited. Therefore, we use multiple drones for multi-domain collaboration to achieve multi-domain coverage. At the same time, the drones are equipped with domain controllers to achieve relay communication of the collaborative network through the domain controllers. The network management of distributed and heterogeneous nodes may be challenging. Moreover, due to the dynamic changes in network conditions, link interruptions can easily occur, making transmission reliability difficult to ensure. This paper focuses on the application of air-to-ground collaborative networking and uses mobile edge computing technology to study network transmission strategies and routing mechanisms in highly dynamic networks. Based on the above network architecture, an intra-domain routing mechanism is designed. Considering the intelligent perception of the network state in the domain, we design a quality of service (QoS)-sensing routing mechanism based on deep reinforcement learning (DRL) to obtain the optimal forwarding path and improve the quality of service in the domain. To address the issues of the low intra-domain data volume and poor generalization ability of local decision models, a joint strategy is proposed to aggregate multi-domain data and accelerate intra-domain training while protecting intra-domain privacy and avoiding network information leakage. The difference between this paper and the existing UAV rescue network is that we adopt the hierarchical multi-domain air-ground cooperative network architecture used in SDN architectures and use a high-performance UAV as the domain controller to simplify the management difficulty and improve the scalability of large-scale networks. Moreover, our enhanced distillation learning algorithm is used as the intra-domain routing algorithm to improve the communication performance of the network and make it adapt to the disaster relief network faster.
The main contributions of this paper are as follows:
(1) First, we design an air–ground collaborative network architecture for UAV-assisted networks. This architecture utilizes SDN’s hierarchical multi-domain networking technology with a super domain controller responsible for obtaining global network state information and cross-domain business requests. The domain controller is responsible for collecting network state information within its domain and aggregating both local and cross-domain business requests, ultimately enhancing the network’s information processing capabilities and reducing communication latency. This architecture is the basis of the design of the intra-domain routing algorithm proposed in this paper.
(2) In order to achieve the real-time awareness of the network status, we introduce unmanned aerial vehicles (UAVs) for communication transmission, enabling the entire IoT system to handle tasks more flexibly. We adopt a federated reinforcement learning approach where the server sends the obtained model parameters to each domain, and the intelligent agent in the local domain controller is further trained and updated based on these parameters. This approach allows for the use of independent model parameters within each domain while protecting the privacy of network states within the domain.
(3) Considering the challenges of energy consumption and limited computational resources in UAVs, as well as the need to reduce the burden of handling large parameters, we introduce knowledge distillation and develop a routing algorithm based on federated reinforcement distillation (FedRDR). By combining federated reinforcement learning with knowledge distillation, we can address the issue of transmission overload caused by the presence of a large amount of parameter data in intelligent agent models. This enables us to achieve real-time awareness of the network status and adjust the data forwarding rules accordingly.
(4) To validate our method, we construct a simulation environment for a drone network using a Mininet network simulator and Ryu controller and conduct algorithm analysis using Python. Through our experiments, we demonstrate that FedRDR outperforms other routing algorithms based on joint learning. Specifically, compared to the federated forced learning routing algorithm, FedRDR can reduce parameter transmission by approximately 29% and significantly accelerate the convergence speed of the model.
2. Related Work
In recent years, natural disasters have had a significant impact on infrastructure, including communication base stations. Essential resources have become scarce, and disruptions in communication links have occurred as a result, making the delivery of critical services to individuals challenging [
11]. The process of reconstructing a fully operational communication backbone network after a disaster, which is crucial for restarting telecommunications and internet services, can take anywhere from several days to weeks [
12]. Hence, it is therefore imperative that we are able to harness the power of emerging artificial intelligence technologies to restore such emergency communication networks.
UAVs are highly effective in search and rescue missions due to their rapid deployment capabilities. By deploying drones in the air, it is possible to establish a local area network (LAN) and backbone network, even in locations without existing network infrastructure. This approach significantly reduces the data transmission time compared to relying solely on satellite links [
13]. Once a mission is completed, the retrieval of the drones minimizes the consumption of resources required for network construction. In the context of drone control strategies, G. B. Tarekegn et al. proposed a dynamic and mobile control strategy utilizing DRL [
14]. The objective was to maximize communication coverage and network connectivity for multiple real-time users within a specified timeframe. Additionally, Zhang et al. studied a communication system assisted by multiple drones equipped with base stations (BSs) to minimize the number of drones required and improve coverage by optimizing the three-dimensional positions of drones [
15], user clusters, and frequency band allocation. The above research relies on the perspective of ground users and fully leverages their geographical positions. However, GPS location errors resulting from disasters can pose challenges for air–ground drone communication.
Deploying multiple drones can significantly enhance network coverage within a specific area. Wang et al. utilized a particle swarm optimization algorithm to optimize the deployment positions of multiple drones with the aim of maximizing network coverage [
16]. Shi et al. employed a distributed deep Q network (DQN) approach in which each drone possesses its own DQN and shares action decisions. This algorithm focuses on maximizing throughput while considering fair service constraints [
17]. In a similar vein, Dai et al. proposed a drone network resource allocation algorithm based on multi-agent cooperative environment learning [
18]. This method adopts a distributed architecture, where each drone is treated as an independent agent. By dynamically making decisions related to deployment positions, transmission power, and occupied sub-channels, this algorithm enhances the utility of the drone network. However, in the aforementioned research, drones are required to maintain continuous communication to process network information, which can potentially result in reduced work efficiency.
In disaster areas, there is a significant demand for wireless communication, and the privacy of various types of sensitive data must be protected. Federated learning (FL) is a privacy-preserving approach that transmits only the model instead of the raw data during the training process. However, if model updates contain a large number of parameters, they can become excessively large, resulting in high communication costs that burden clients. To address this issue, Wu et al. proposed a federated learning method called FedKD [
19], which utilizes adaptive knowledge distillation and dynamic gradient compression techniques. This approach affords enhanced communication efficiency and effectiveness. Wang et al. introduced ProgFed [
20]. Furthermore, Yang et al. proposed another privacy-preserving method called partial variable training (PVT) [
21], which trains only a small subset of variables on edge devices to reduce memory usage and communication costs. However, all of these cost-reduction methods have been proposed for their respective scenarios and do not consider improving the overall workload problem from the perspective of the transmitted parameter data volume.
Since most of the existing studies focus on single UAVs and the communication coverage of a single UAV is limited, they are not applicable to resource-constrained networks, and many studies on multi-UAV networks need the support of ground base stations. In disaster scenarios, ground base stations may be destroyed at any time, so the above studies are not applicable to disaster scenarios due to the emergence of federal reinforcement learning. We should protect user privacy and reduce communication costs. However, these studies are presented for their own scenarios and do not consider the overall workload problem from the perspective of the amount of transmitted parameter data. Therefore, they do not apply to resource-constrained networks. Therefore, we propose a UAV-assisted software-defined networking framework to enhance the network’s information processing capability and reduce communication latency between the air and ground. Additionally, we design a state-aware routing algorithm based on deep reinforcement learning to achieve the real-time perception of the network status and adjust the data forwarding rules accordingly. Finally, we develop FedRDR to address the issue of transmission link overload caused by the large volume of intelligent agent model parameter data while also ensuring the privacy of the network status within the domain.
4. Algorithm Model
This paper proposes a routing algorithm based on federated enhanced distillation. In real network environments, each domain generates relatively small amounts of data. Agents deployed in a single-domain controller require extensive training to obtain a stable model, which significantly increases the model’s training time and the computational energy consumption of the UAVs acting as controllers. Moreover, since the agent can only use data within its own domain for training, the trained model exhibits personalized characteristics and is only suitable for local routing decisions. To address these challenges, we designed a federated reinforcement learning routing algorithm. This algorithm constructs multiple model training domains and aggregates data from multiple domains. Each domain controller can participate in the training of the complete model, thereby expanding the data samples and avoiding the leakage of network state information within each domain. This approach enhances the universality and generalization ability of the model.
To ensure that the model can better adapt to the task requirements and possess a greater generalization ability, larger-scale models are often utilized. However, the exchange of model parameters incurs significant costs. Communication between the server and the domain controller can lead to excessive link load when uploading large amounts of data. This can result in data loss within the domain, which, in turn, impacts the training of the decision-making model.
Therefore, in order to perform tasks within each domain, complex models need to be deployed, resulting in resource wastage. In the proposed federated reinforcement distillation approach, it is not the model parameters that are transmitted but rather the proxy experience memory. Through the federated reinforcement distillation algorithm, knowledge is transferred from one domain controller to a heterogeneous model in another domain controller. In complex task domains, agents with larger-scale neural networks are deployed to achieve a better task performance, while smaller-scale models are deployed in simpler task domains. This enables models in each domain to complete tasks more efficiently within their local domain, thus reducing the computational energy consumption of the domain controller.
In this study, the routing path is directly determined by the deep reinforcement learning algorithm with the aim of achieving the fastest forwarding of traffic from the source to the destination node. Furthermore, quality of service (QoS) is considered by taking into account link delay. After taking an action, the agent modifies the current network environment. Network state parameters are collected through the network state monitoring module and subsequently updated to reflect changes in the network state.
Therefore, we have designed a federated reinforcement distillation [
22] routing method—a distributed machine learning architecture that protects privacy and has high communication efficiency. We constructed a proxy for domain experience memory and exchanged data between the domain controller and the server. The proposed federated reinforcement distillation routing algorithm does not leak sensitive intra-domain data when combining multi-domain proxy experience memories and reduces the amount of data that needs to be transmitted compared to traditional federated distillation algorithms, thus lowering communication costs.
When there are data to be transmitted in the switch queue, the domain controller obtains the network state through the network state monitoring module and calculates the routing strategy so as to guide the specific forwarding process of the data. For each input state of the algorithm, a strategy is selected to obtain an output result, and an action is selected according to the output result. The input state (state), output action (action), and reward value (reward) of the algorithm are, respectively, defined as follows.
(1) The input state: At present, the training process of the reinforcement learning routing algorithm in most studies is based on the network traffic matrix. However, in an actual network, it is difficult to obtain a real-time and effective traffic matrix. In this paper, the switch traffic is used as the state input of the agent so that the actions made are more time-effective. The input state is specifically represented as a matrix. Every time the agent takes an action, the domain controller obtains the current state parameters, including the short-term traffic of the switch. We assume that there are
n nodes in the network, in which
represents the i-th node. The input status
of time
t is represented by Equation (
1):
where
represents the amount of traffic flowing through
from time
to time
t.
(2) The output action: After the agent receives the input state, the output value is calculated according to the neural network, and the output value is mapped to the corresponding action. According to the authors of [
23], the action output is the path of the data flow, but a routing algorithm based on Q-learning is used. When the traffic in the network increases, the state and action space increase sharply, resulting in a poor learning effect for the agent. This study considers all nodes from the source to the destination node as the candidate action set. The space size of this method is fixed, which facilitates the training process of the agent. The action candidate set of the current state contains all the next hop nodes connected to the current traffic node, which are expressed according to Equation (
2):
where
represents the current traffic node, and
represents all the next hop nodes of node
i, from node
j to node
k.
(3) The reward value: The reward value is an important parameter that affects the training of the agent. After the agent selects an action in the current state, the environment is subsequently affected. A reward value is then obtained based on the feedback of the environment to evaluate the quality of the action. At the same time, the network transitions to the next state. Common reward values in network traffic are designed for link bandwidth, latency, and throughput. The goal of this study is to minimize the delay of the link, so the reward set is the average delay of the link. The reward value is expressed as shown in Equation (
3):
where
m represents the number of flows in the network,
represents the link delay of the
jth flow, and
R is the average link delay. Because the agent needs to find the maximum reward value during training, the reward value is set as a negative value.
This study introduces deep reinforcement learning (DDQN) to compute routing decisions. The main network, the Q-network, and the target network, the target Q-network, are both four-layer networks, consisting of an input layer, two hidden layers, and an output layer. The values output by the output layer are mapped into the action space, corresponding one-to-one with the designed candidate actions. In the training process, the intelligent agent first interacts with the environment, takes actions
based on the state
, and receives a reward value
. After the agent takes action, the environment enters the next state, and these four parameters are stored in the experience pool. The network parameters are updated when the experience pool is full. Firstly, both
and
in memory
are input into the main network, the Q-network, obtaining the value function
and the optimal Q-value
, which can be calculated as shown in Equation (
4):
Next,
is input into the target network, and
is obtained through
. Then,
,
, and
are incorporated into the loss function to calculate the loss, which is illustrated by Equation (
5):
Then, the main network parameters are updated according to the loss function by being copied to the target network at regular intervals. According to the Bellman formula, the objective value function can be calculated from the estimated values
of
and
, as shown in Equation (
6):
The network parameters of the original network are then updated by Equation (
7):
During the training process of the primary Q-network, the experience replay technique is used to store a series of states, actions, rewards, and next states obtained by the intelligent agent interacting with the environment in an experience replay pool. During training, fixed batches of data can be randomly selected from the experience pool to increase the training speed of the intelligent agent. However, since each datum stored after the interaction between the intelligent agent and the environment contains the next moment state, there is a certain correlation between the samples. To reduce the correlation between data samples and prevent the intelligent agent from falling into the local optimum, a random strategy is adopted when selecting data sets. In addition, because each tuple has different contributions to training, some scholars have used the priority-based experience replay technique. This study adopts the method of directly selecting fixed batches of data from the total experience memory for training using the experience replay technique. When the memory is full, the principle of first-in-first-out (FIFO) is used to replace old data with new data.
The algorithm in this paper is mainly divided into four stages: local update, parameter upload, parameter aggregation, and parameter delivery. These stages are defined as follows. (1) Local update: The local update process adopts the routing algorithm based on DDQN to train the local model and update the parameters. (2) Parameter upload: The agent in each domain controller completes training via the local environment, and multiple domain controllers upload their own model parameters
to the server. Here, i denotes the ID of the domain controller, and
denotes the number of local iterations. (3) Parameter aggregation:
D represents the delay of all links, as shown in Equation (
8). The formula for parameter aggregation is presented in Equation (
9), in which
represents the ratio of the parameter data volume of the i-th domain controller to the total data volume, and
n represents the number of domain controllers. The calculation expression for
is shown in Equation (
10). The server trains the global model through the aggregated parameters to generate global model parameters. The model convergence judgment is performed before the global model parameters are issued. If the model converges, it means that the global model has been learned, and the federated reinforcement learning routing algorithm ends. Otherwise, the algorithm enters the parameter delivery stage. (4) Parameter delivery. In the parameter delivery stage, global parameters are delivered to each domain controller. The domain controllers assign the parameters to the local model and use local data to update the model training parameters. This four-stage process is executed cyclically.
The global loss function
is the weighted average of the loss functions of each domain controller, as shown in Equation (
11). The goal of the federated reinforcement learning routing algorithm is to minimize the loss function, as shown in Equation (
12).
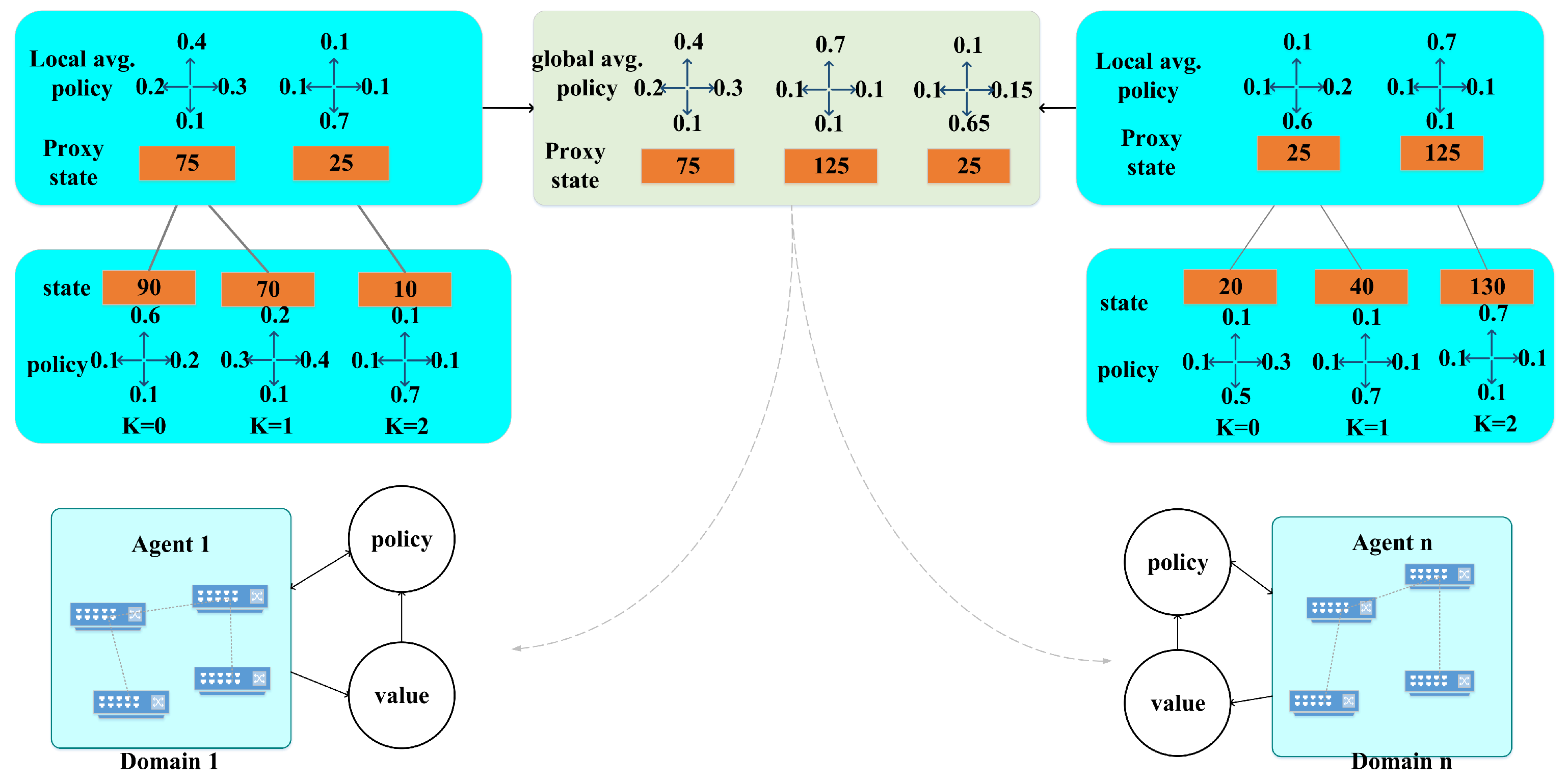
The formula for proxy experience memory is shown in Equation (
13):
where
indicates the proxy state in each domain controller,
i represents the ID of the domain controller, and
represents the average proxy strategy. The proxy state set
is a further division of the state space, and the aggregation of the proxy state set
is the entire state space
C.
N indicates the number of participating domains.
The interaction process of proxy experience memory between the server and domain controllers in the FedRDR algorithm is as follows:
The proxy state in the proxy experience memory in each domain is not the original state, and the actual policy corresponding to the proxy state is averaged over time. Therefore, sharing the local agent’s experience memory not only protects data privacy in the domain but also reduces the amount of communication data. The FedRDR algorithm model is shown in
Figure 2:
Firstly, the DDQN-based intra-domain routing algorithm is introduced, as shown in Algorithm 1. Secondly, the FedRDR algorithm is introduced, as shown in Algorithm 2.
| Algorithm 1 Federated reinforcement learning model training process. |
Require:Ensure:The routing path Initialize the hyperparameters of the DDQN agent; Initialize the virtual simulation environment env based on Mininet; initialize the current state S, the next state , the action A, and the reward value R; Initialize the switch flow table F, link delay, and network topology T; Obtain the network topology; Find all candidate nodes from the source node to the destination node according to T; Obtain the traffic information from switches ; for do Agent input state : Agent output action; According to the action , the domain controller selects the next hop from the candidate node P, changes the corresponding switch flow table, and forwards the data to the next hop node; , The domain controller obtains the network link delay and the switch flow meter; , ; ; The agent puts into the experience playback pool; if then Store the newly obtained result and overwrite the old result using the FIFO principle; Select a fixed batch of data from and update the main network parameters by minimizing the loss function; end if if then Update the target parameters ; end if if then The local proxy experience memory is constructed, the proxy experience memory of each domain controller is uploaded to the server, and the global proxy experience memory is obtained; After successfully building the global proxy experience memory, it will be distributed; All agents in the domain controller update the local model; if constant then Federal reinforcement distillation ends; end if end if end for return ;
|
| Algorithm 2 FedRDR: Federated reinforcement distillation-based routing algorithm |
Require:The main network parameters and target network parameters in DDQN, the network parameter update frequency , the federated reinforcement distillation model update frequency , the number of domain controllers n, and the local model for federated reinforcement distillation .
Ensure:Local decision model Initialize the local model parameters = ; Set the used to store the optimal results; Set the hyperparameters of DDQN according to Algorithm 1’s description with a time frame T; for do Perform the following operations on n domain controllers at the same time (take the domain controller i as an example): Initialize switch flow table F, link delay, and network topology T; Obtain network topology; Find all candidate nodes from source to destination according to T; Obtain the traffic information from switches ; Agent input state ; Agent output action; According to the action , the controller selects the next hop from the candidate node P, changes the corresponding switch flow table, and forwards the data to the next hop node; The controller obtains the network link delay and switch flow; ,; ; The agent puts into the experience playback pool; if then Store the newly obtained result and overwrite the old result using the FIFO principle; Select a fixed batch of data from and update the main network parameters by minimizing the loss function; end if if then Update the target network parameters ; end if if then Update the target network parameters ; end if end for
|
5. Evaluation and Discussion of Results
5.1. Experimental Environment
The simulation system described in this paper was implemented using a Mininet network simulator and a Ryu controller. The algorithm itself was implemented in Python, with pytorch serving as the overall framework for the algorithm. The experimental environment used in this study is presented in
Table 1.
5.2. Simulation System Design
This paper considers a distributed multi-domain data transmission architecture. In order to make the routing decision process efficient, we needed to minimize the amount of parameters to be transmitted, thus enabling quick generation of decision models. The number of drones required for the backbone network part does not necessarily have to be very large. This system was implemented by the design of four modules, as follows:
Network status monitoring module: The main function of the network status monitoring module is to obtain the network status information through echo and LLDP messages in the controller. The two types of messages interact between the SDN controller and the switch, obtaining the required states, rewards, and actions for our DDQN-based intelligent agent—more specifically, the short-term traffic information of switches, the network topology, and the link latency based on the topology structure.
Smart routing decision module: The DDQN-based intra-domain routing algorithm is the core of the decision module. The main function of this module is to make routing decisions based on the network status. This module can be divided into three parts: environment perception, the self-learning of intelligent agents, and handling of experience memory.
Routing decision execution module: This module is mainly used to guide the switches to forward traffic according to the routing decisions made by the controller. After the routing decision module calculates the routing paths, the controller installs the flow table to the switch. The switch updates its flow table and forwards traffic based on the new flow table.
Server processing module: The main task of the server processing module is to connect to the domain controller and receive the parameters transmitted by the domain controller. The Update_params function aggregates all the parameters uploaded by the domain controller and transmits the global parameters to each domain controller to accelerate the intra-domain training process and iterates this process until the model converges.
5.3. Performance Evaluation
Setting appropriate hyperparameters, such as the learning rate, batch size, and memory size for experience replay, during the process of training an intelligent agent can make the model converge faster. Therefore, we conducted experiments on the hyperparameters of the intelligent agent to select the optimal parameters.
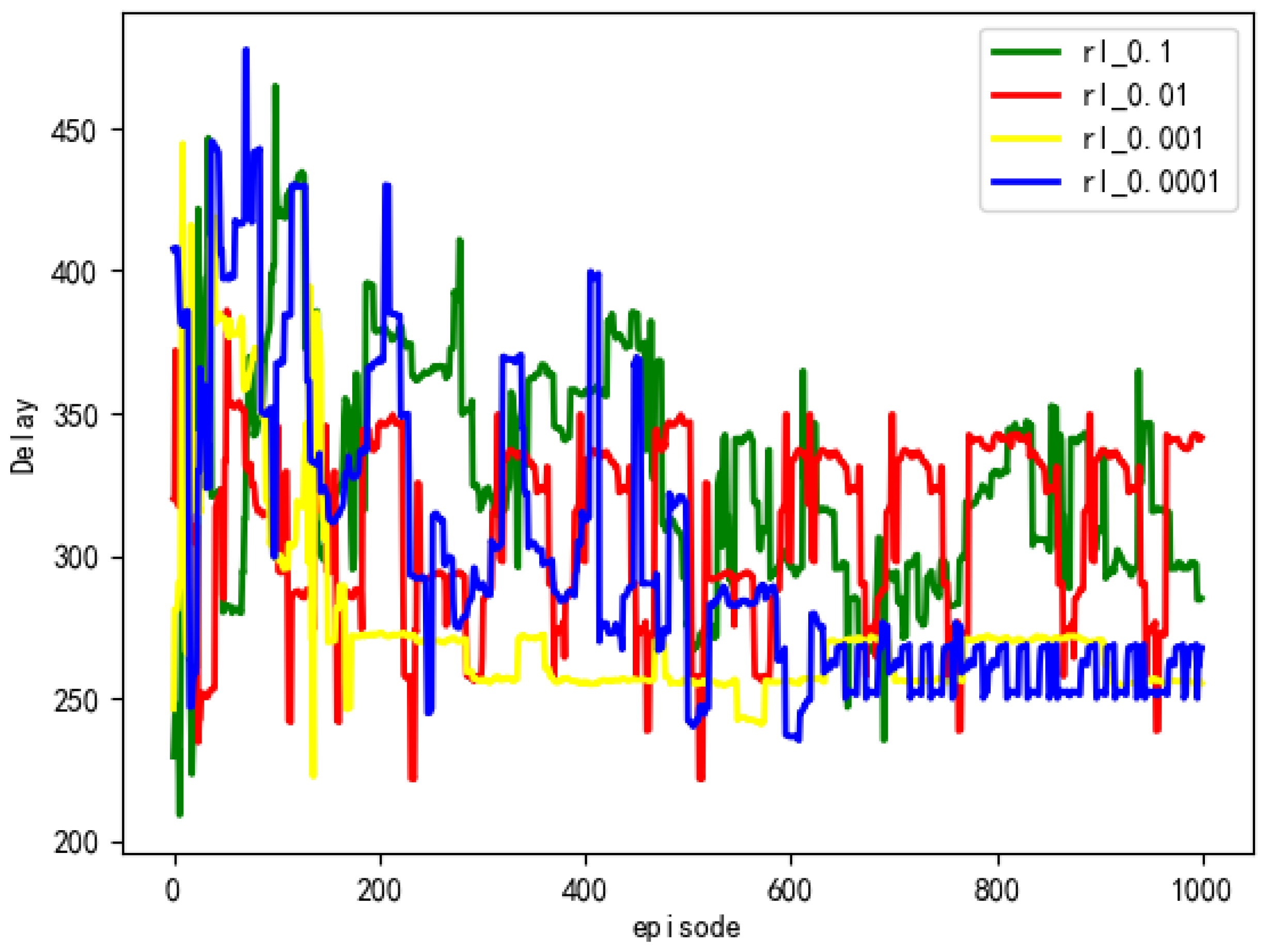
From
Figure 3, it can be seen that when the learning rate is set to 0.1 and 0.01, the intelligent agent shows rapid gradient descent in the early stages, but the convergence effect of the algorithm is poor in later stages. Compared with learning rates of 0.0001 and 0.001, the intelligent agent has already converged after 200 iterations with a learning rate of 0.001. Therefore, we set the parameter learning rate to 0.001.
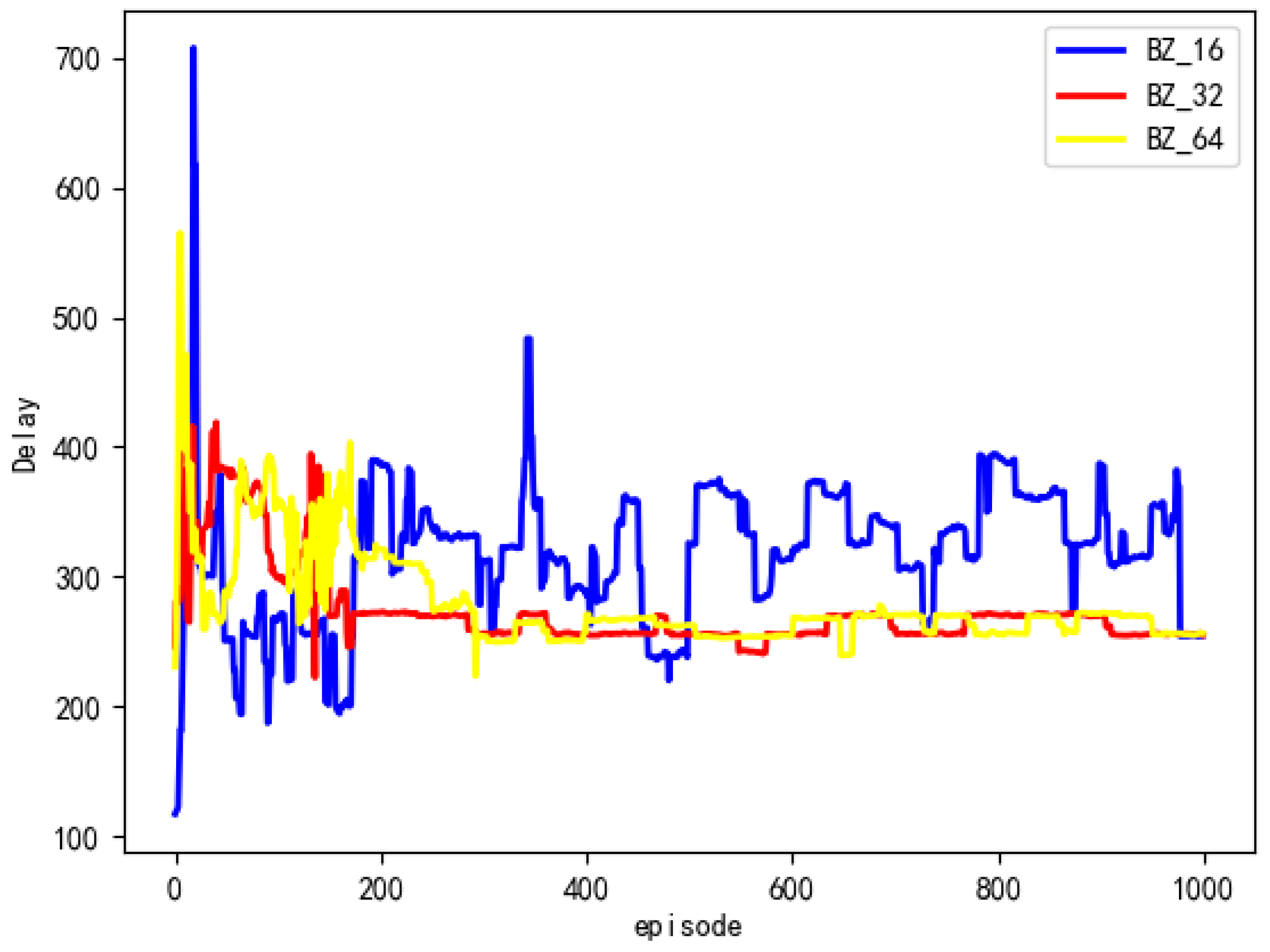
We set the batch sizes to 16, 32, and 64, and the experimental results are shown in
Figure 4. From the graph, it can be seen that when the batch size is set to 16, the algorithm cannot converge. Compared with a batch size of 64, the model has better convergence when the batch size is set to 32. Therefore, we set the batch size to 32.
We determined the other hyperparameters of the agent through experiments and finally set the hyperparameters of the agent as shown in
Table 2:
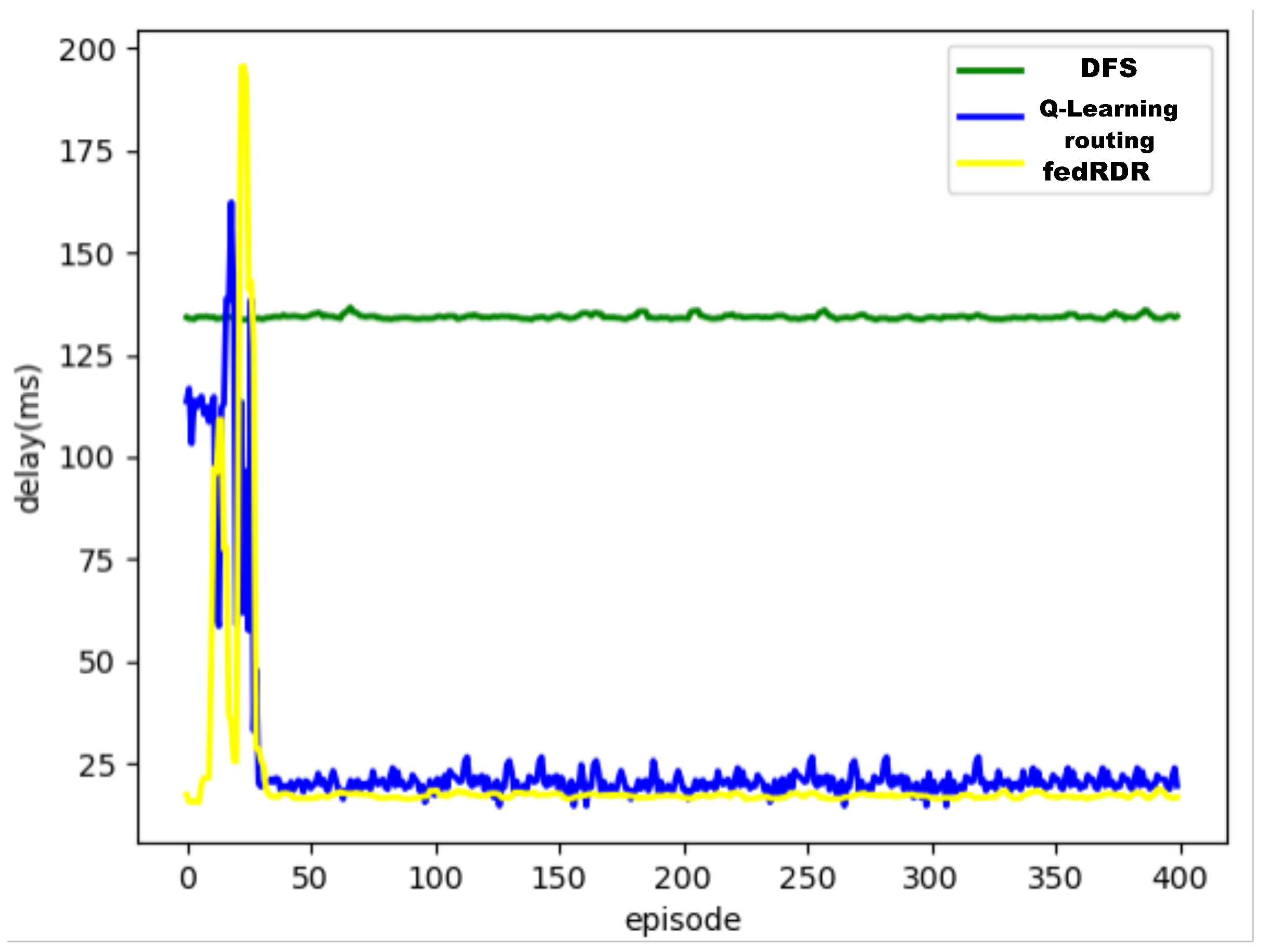
To verify the performance of the domain-based routing algorithm based on deep reinforcement learning, after determining the model hyperparameters of the intelligent agent, we conducted comparative experiments. The compared algorithms were the depth first search (DFS) algorithm and the Q-learning-based routing algorithm using reinforcement learning.
By sending network traffic packets through iperf, three traffic packets were sent from
,
, and
to
,
, and
, respectively. The bandwidth requirements for each stream were set as shown in Equations (
18)–(
20):
A comparative analysis of the three routing algorithms was conducted under this network state, and the experimental results are shown in
Figure 5. From the graph, we can see that the delay in the data transmission using the routing strategy designed by the DFS algorithm is about 130 ms, which is not the optimal forwarding path. However, when the traffic in the network increases, the DFS algorithm cannot implement the optimal forwarding strategy. For state-aware intelligent routing algorithms, the final link delay under the converged state of both is about 25 ms. For the same device, the Q-learning algorithm requires more time to reach convergence compared to the DDQN routing algorithm.
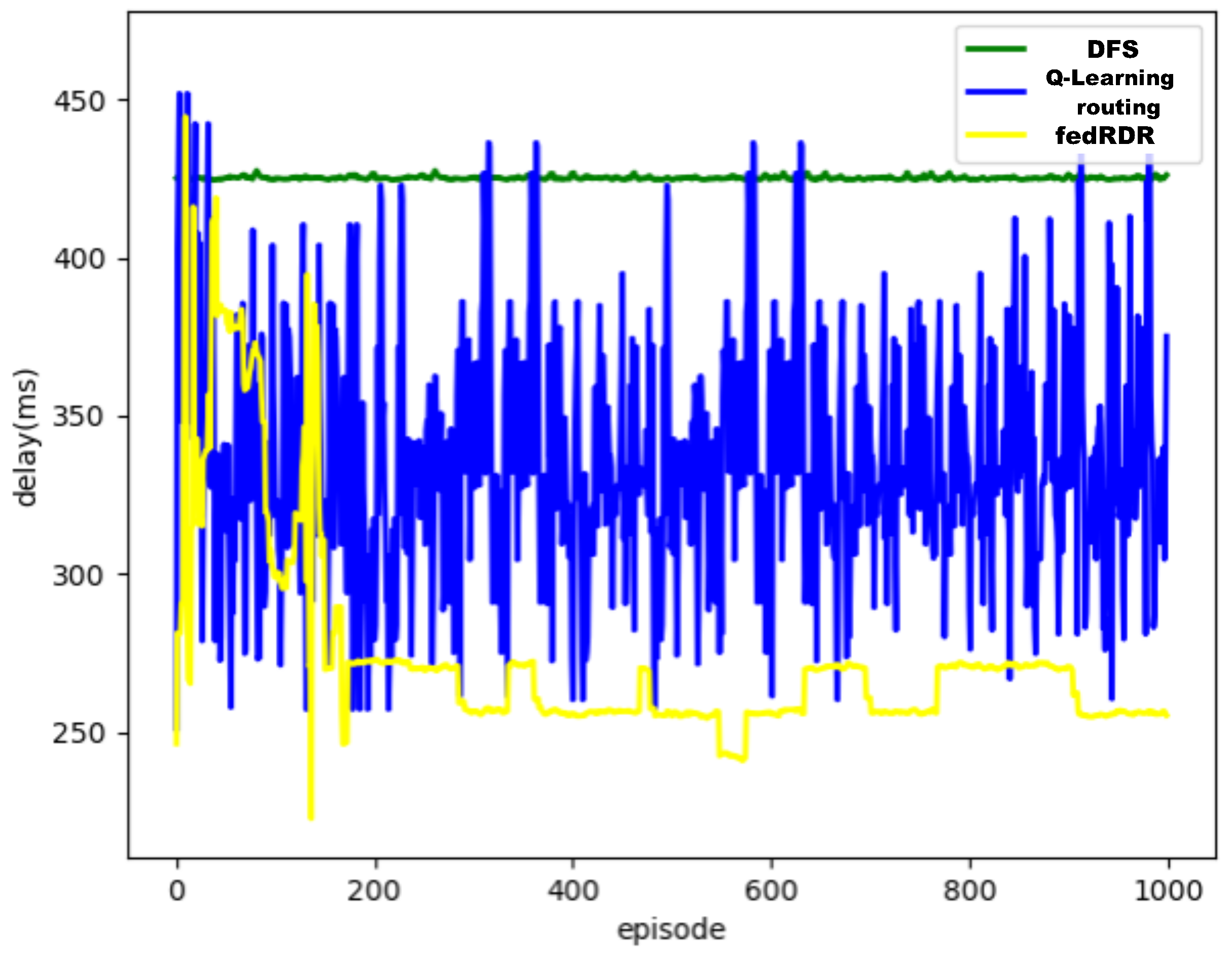
To demonstrate the advantages of our proposed algorithm, we increased the number of switches to 8 and the number of flows to be forwarded in the network to 8 and compared the performance of the three routing algorithms. The experimental results are shown in
Figure 6.
From the graph, it is evident that the routing strategy calculated by the DFS algorithm still leads to significant network delay. Furthermore, it was discovered in this study that the Q-learning-based routing algorithm failed to converge within 1000 iterations. When the number of switches and flows increases, the number of Q-table items also increases significantly, resulting in slow or even non-convergence of the algorithm. In contrast, our proposed DDQN-based routing algorithm is capable of quickly converging and guiding traffic forwarding, even in the presence of a large state space and action space.
In our approach, we designed a process for uploading the local model parameters to the server after every 100 iterations in each domain. The server then aggregates the parameters from the three domains. Based on the aggregated parameters, the server undergoes an additional 100 iterations of training before distributing the parameters back to the domain controllers. The domain controllers continue training the model based on the received parameters, and this process repeats until the model reaches a stable state. The experimental results of the federated reinforcement learning routing algorithm are depicted in
Figure 7. After receiving the aggregated parameters from the server, the model of each domain controller achieved convergence after around 20 iterations of training.
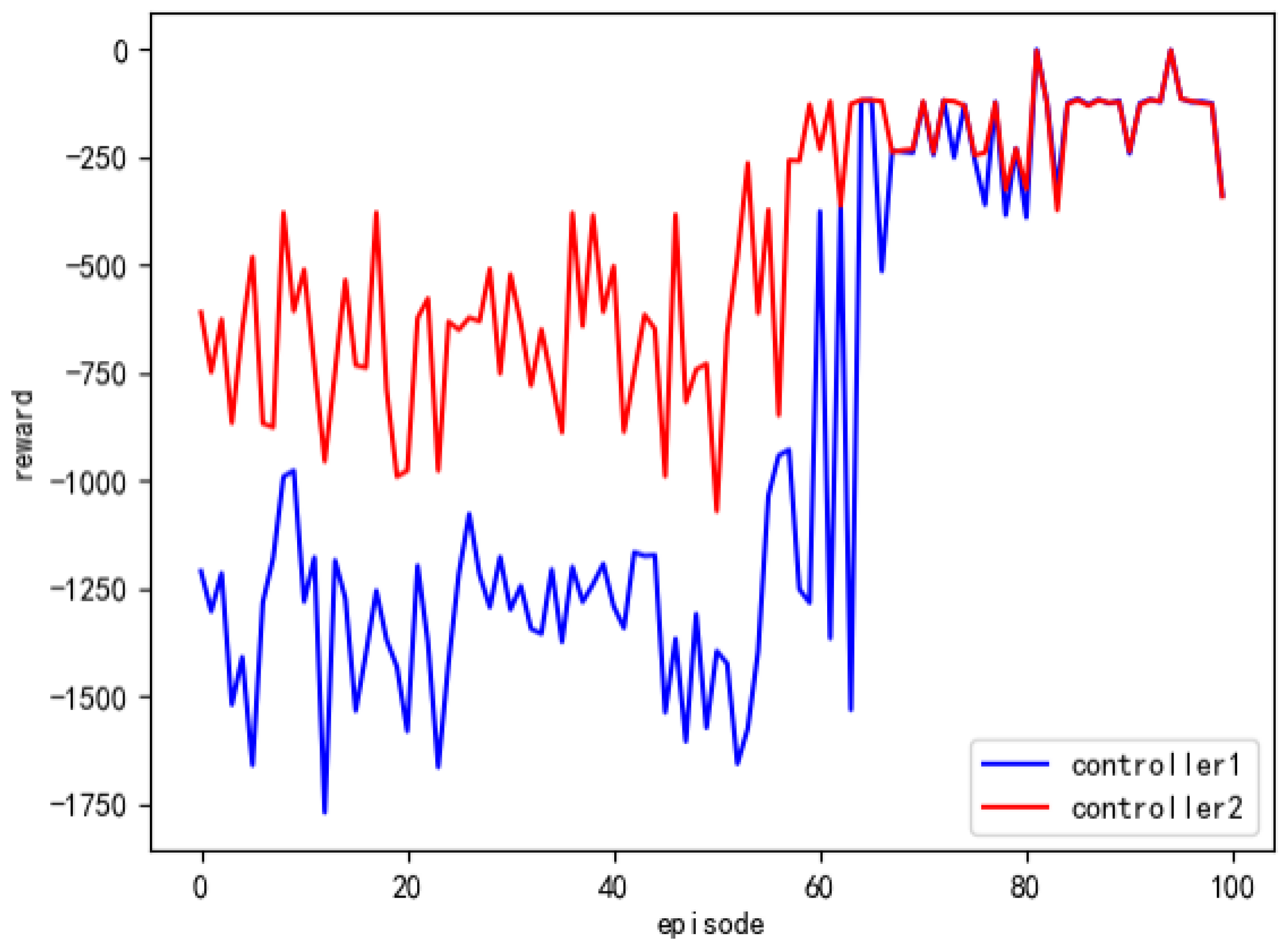
When a new task domain emerges, the model parameters that already exist in the server are sent to the new domain. The new domain does not need to train the local model from scratch, which saves time when it comes to agent training. We selected one of two domains with the same task for local training. After local model training is completed, the model parameters migrate to the other domain controller via the server to verify the impact of the model parameters within one domain on the acceleration effect of the agent in another domain. The experimental results are shown in
Figure 8.
In the experiment, Controller 1 represents an intelligent agent that has not undergone any parameter assignment training, while Controller 2 represents an intelligent agent after parameter assignment training. From the graph, it is evident that the intelligent agent in Controller 1 reaches a convergence state after almost 70 iterations, whereas the intelligent agent in Controller 2 achieves convergence after approximately 60 iterations. This experimental result demonstrates that the federated reinforcement learning-based intelligent routing algorithm can expedite the training process of intelligent agents within a single domain.
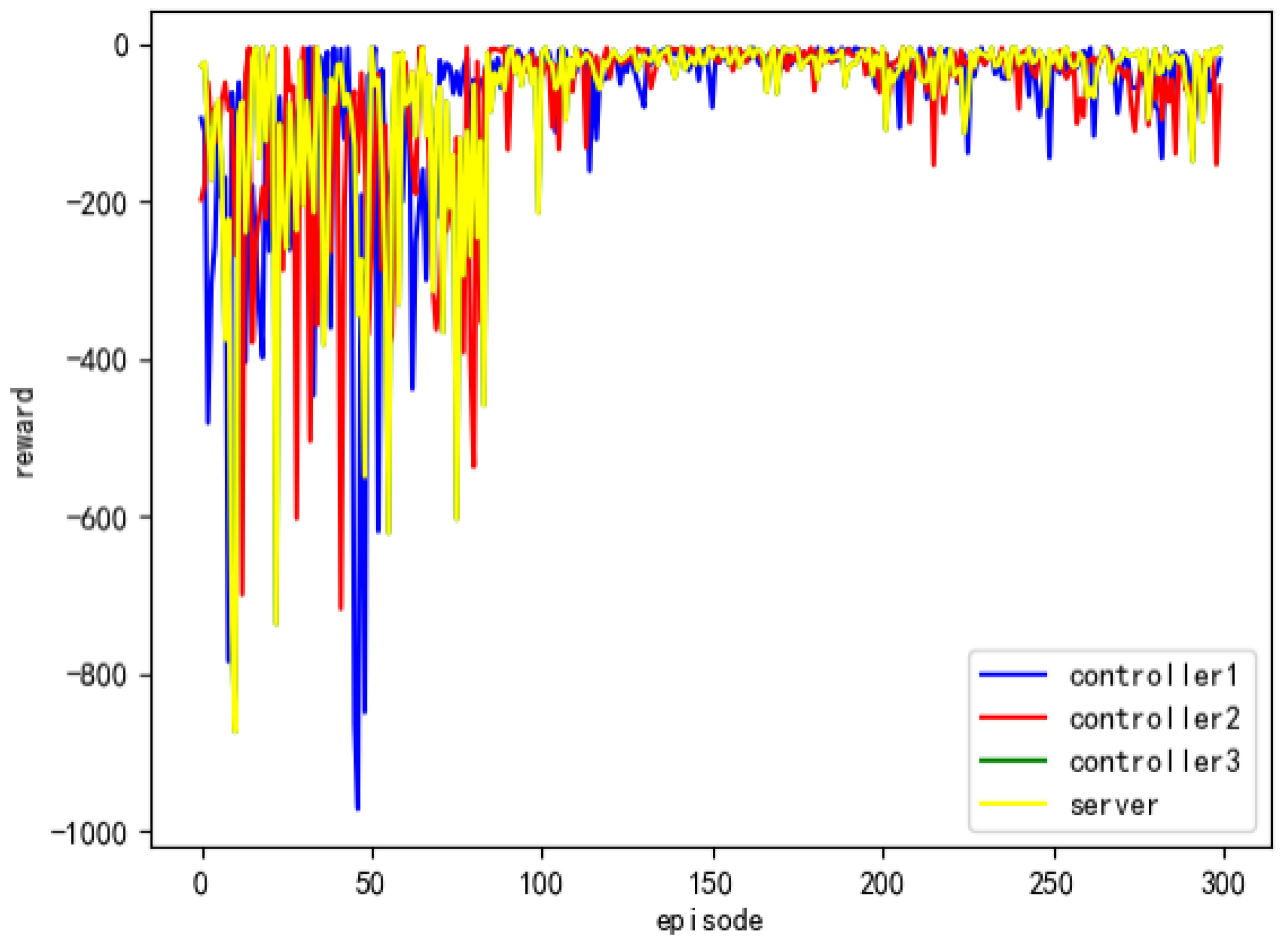
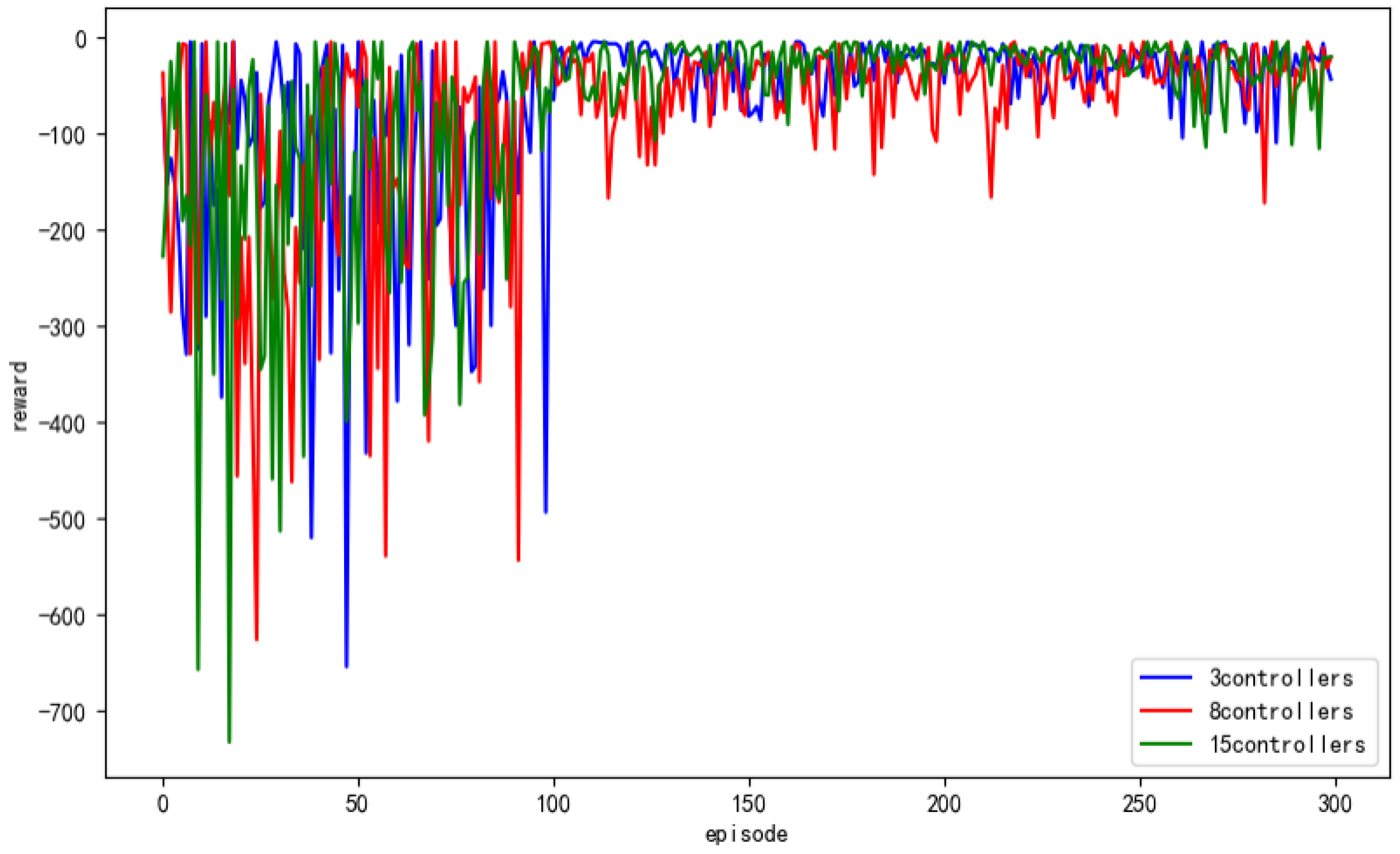
Next, we examined the impact of the number of domains on the convergence of the global model. We conducted experiments with 3, 5, and 8 domains. The training process was consistent across all experiments, where parameters were sent from the domain controller to the server every 100 iterations. The server then performed parameter aggregation and trained for an additional 100 iterations based on the aggregated parameters before distributing the parameters back to the domain controllers. This communication process was repeated three times.
The experimental results are depicted in
Figure 9. From the graph, it can be observed that when there are more domains, the model exhibits less fluctuation after nearly 100 iterations and achieves a slight advantage in terms of convergence speed. However, irrespective of whether 3, 5, or 8 domains participate in the federated reinforcement learning-based multi-domain joint process, the accuracy of the model is hardly affected. A smaller number of domains does not lead to inaccurate models in the federated reinforcement learning-based multi-domain joint process. However, as the number of domains increases, the amount of uploaded data also increases, thereby enhancing the generalizability and applicability of the trained model. The experimental results demonstrate the significant utility advantages of the federated reinforcement learning-based intelligent routing algorithm.
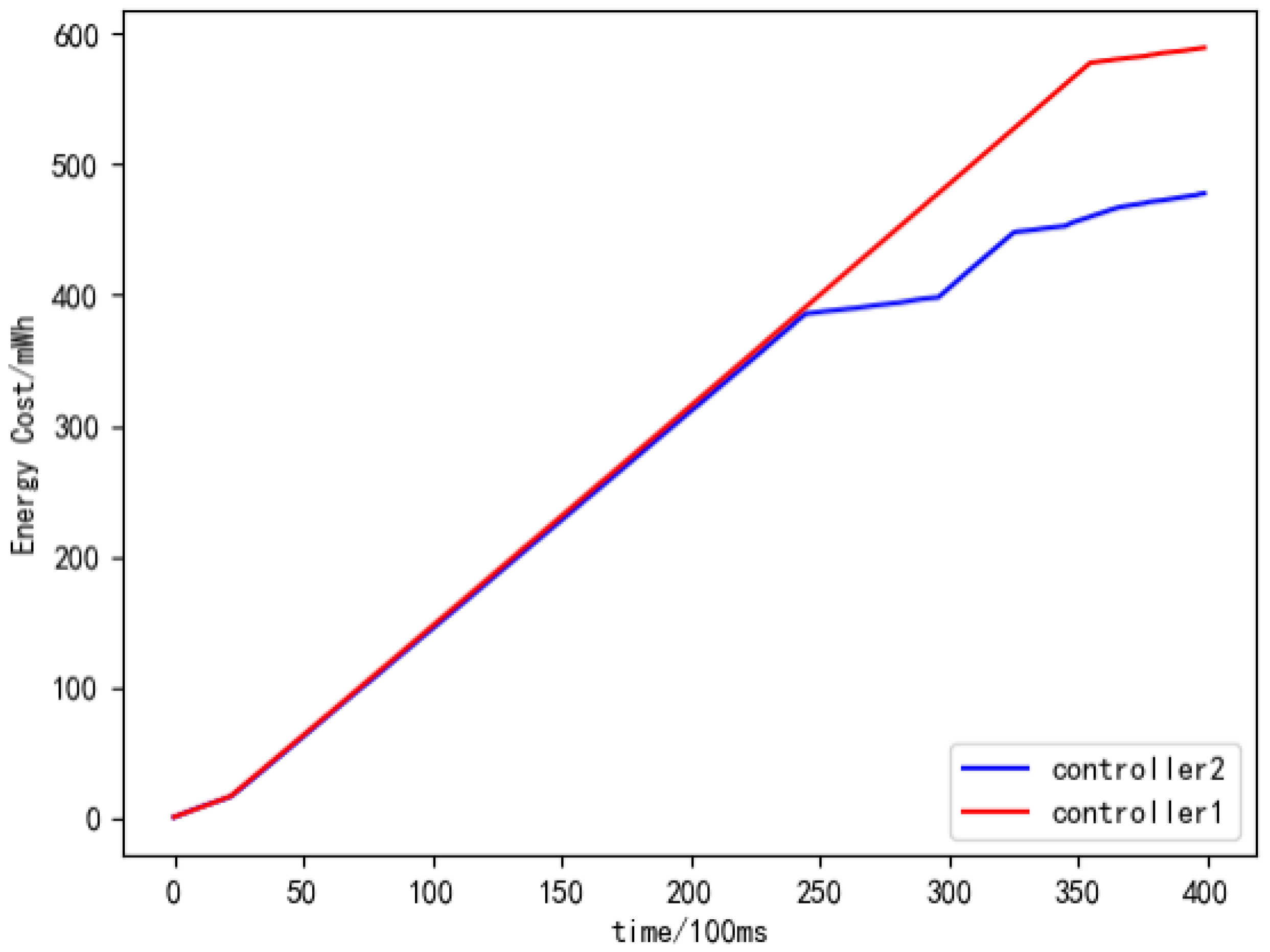
Next, we verified the effect of the federated reinforcement learning-based multi-domain intelligent routing algorithm on reducing the training energy consumption within a single domain. The results are shown in
Figure 10.
The horizontal axis represents time, with each recording interval being 100 ms. The vertical axis represents energy consumption, measured in milliwatt-hours (mWh). From the graph, it is evident that the energy consumption of the agents in both controllers is nearly identical until the 250th recording. However, since we assigned the model parameters from Controller 1 to Controller 2, the training speed in the second domain controller is accelerated, leading to faster model convergence. Consequently, the training process can be terminated once the model converges. As a result, the second controller concludes training earlier, reducing the energy consumption of the UAV acting as the domain controller due to reduced computation requirements. The federated reinforcement learning-based intelligent routing algorithm necessitates interaction and communication between domain controllers and servers to update the model parameters of intelligent agents. During the communication between the server and domain controllers, we collected data on the amount of exchanged data in model parameter interactions between domain controllers and servers, as illustrated in
Figure 11.
From the figure, we can observe the specific size of the data volume for each communication between the domain controllers and the server. The average communication data volume is approximately 63.6 KB.
In summary, the federated reinforcement learning routing algorithm can expedite the training process of intelligent agents within domains while reducing the computational energy consumption of domain controllers. The experimental results provide evidence of the significant utility advantages of the federated reinforcement learning-based multi-domain intelligent routing algorithm.
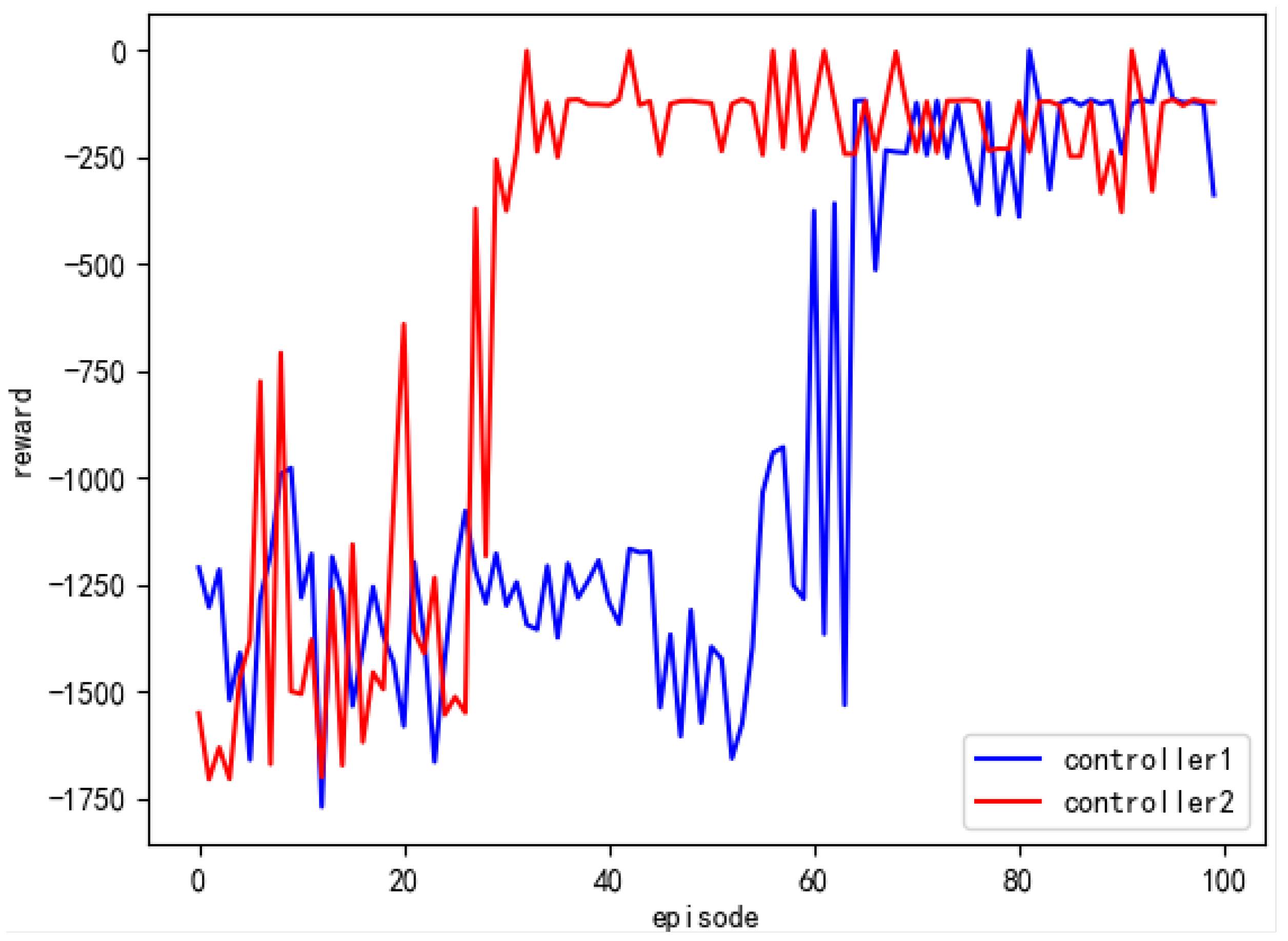
Initially, the experiment validated the effectiveness of the FedRDR algorithm in accelerating the training of intelligent agents within domains. In federated reinforcement distillation, the agent’s experience memory stored in domain controllers is uploaded to the server, and intelligent agents from other domains learn from this experience memory. The comparison results are depicted in
Figure 12.
The intelligent agent of domain Controller 1 undergoes local environment training to generate a local experience memory. Once the experience memory storage is full, it is sent to domain Controller 2 to observe its effect on accelerating the training of intelligent agents within the domain. From
Figure 12, it can be observed that the model in domain Controller 1 reaches convergence after approximately 70 iterations of training, while the intelligent agent in domain Controller 2 achieves convergence after around 40 iterations of training. This indicates that knowledge transfer can enhance the learning speed of intelligent agents. During the training process in domain Controller 2, the training data are not obtained through the interaction between the local intelligent agent and the environment; instead, they are provided by domain Controller 1. This reduction in the interaction process between the intelligent agent and the environment contributes to the acceleration of training. Therefore, the proposed federated reinforcement distillation-based intelligent routing algorithm can expedite the training process of intelligent agents within domains.
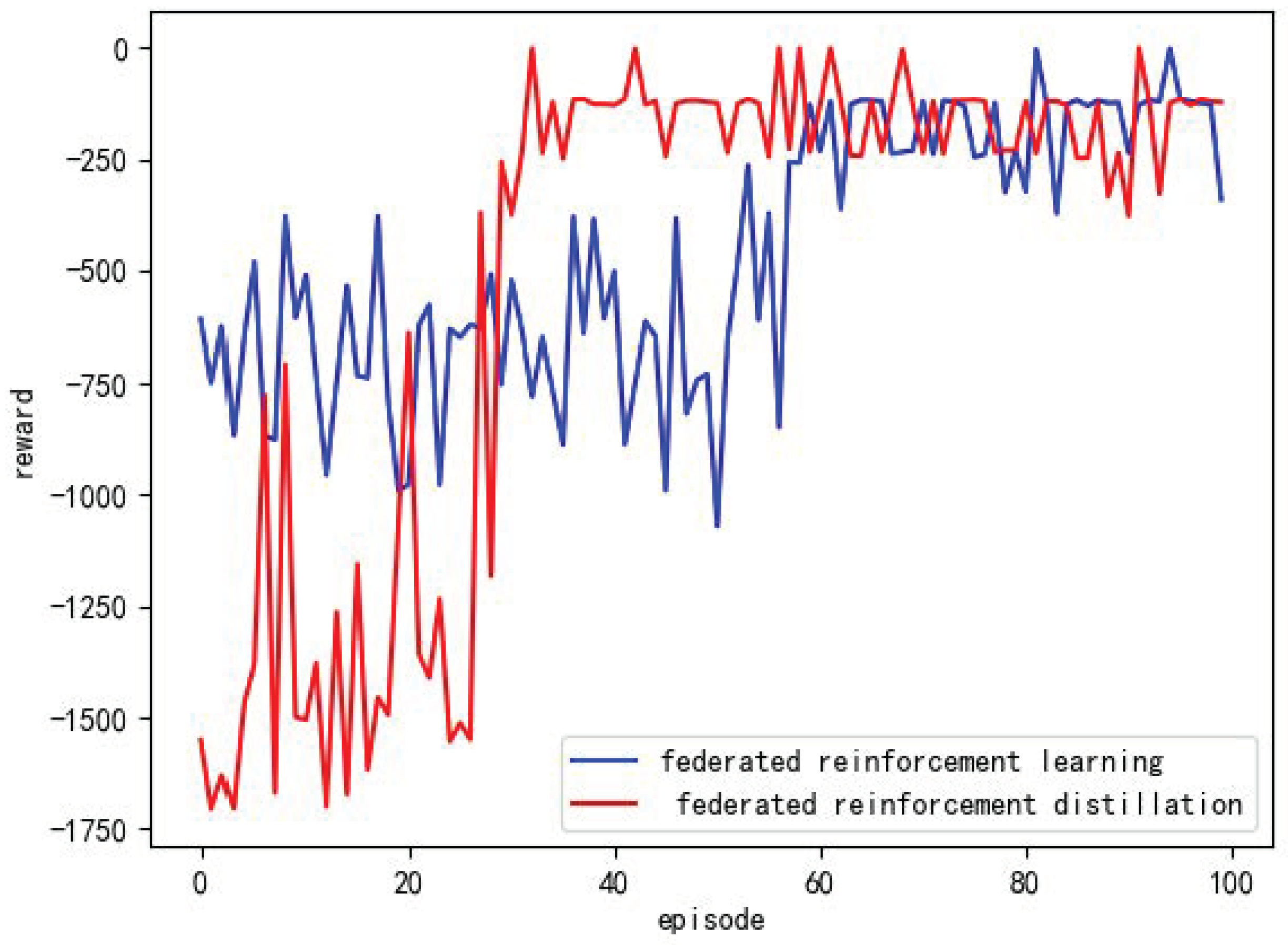
Both the federated reinforcement learning routing algorithm and the FedRDR algorithm demonstrate the capability of accelerating the training of intelligent agents within domains. We compare their effects on accelerating the training of intelligent agents, and the experimental results are illustrated in
Figure 13.
From the graph, it is evident that the federated reinforcement learning model achieves convergence after approximately 60 iterations of training. On the other hand, the federated reinforcement distillation model enters the convergence state after about 40 iterations of training. This indicates that knowledge transfer through federated reinforcement distillation has a better acceleration effect and reduces the training time for single-domain intelligent agents compared to parameter transfer through federated reinforcement learning.
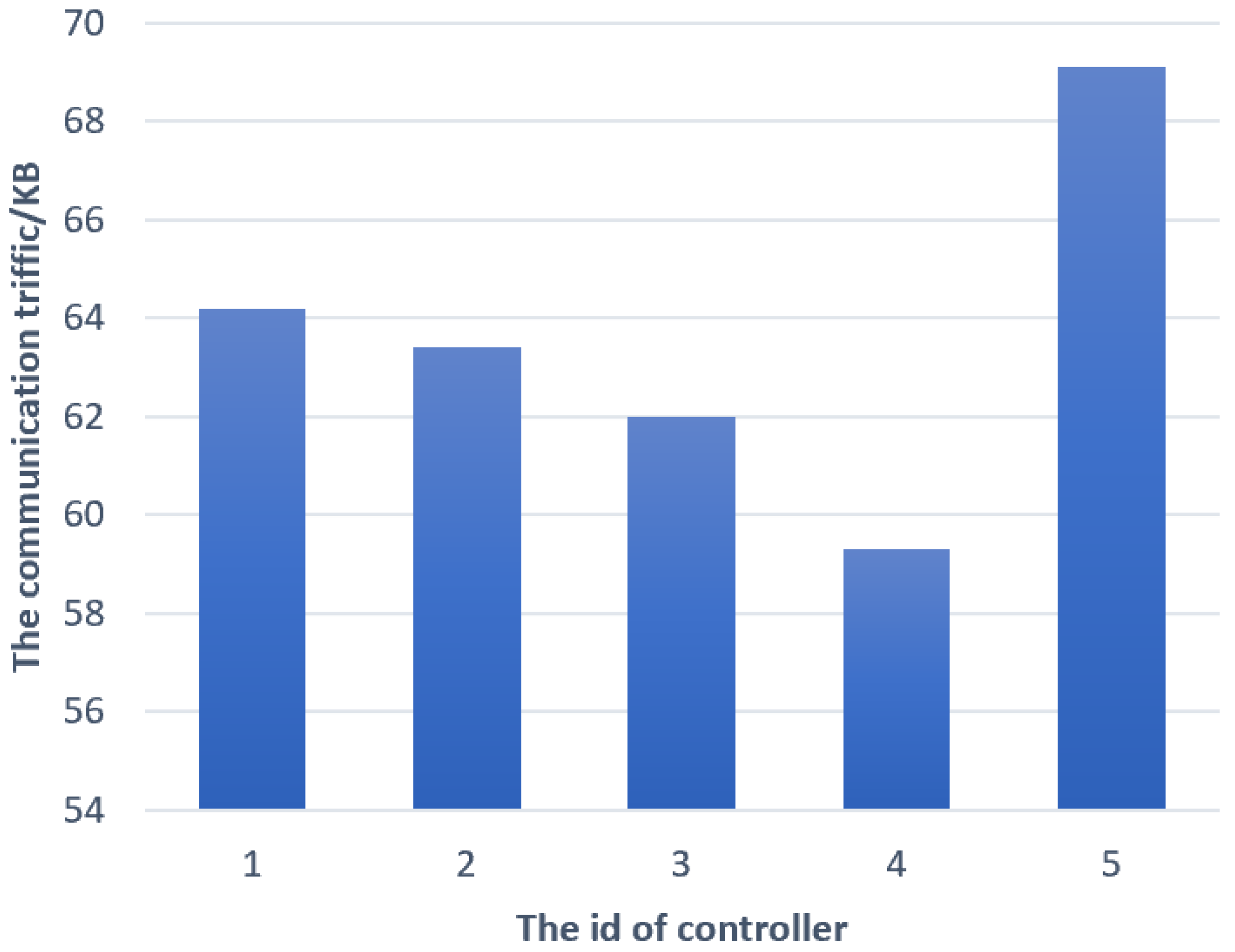
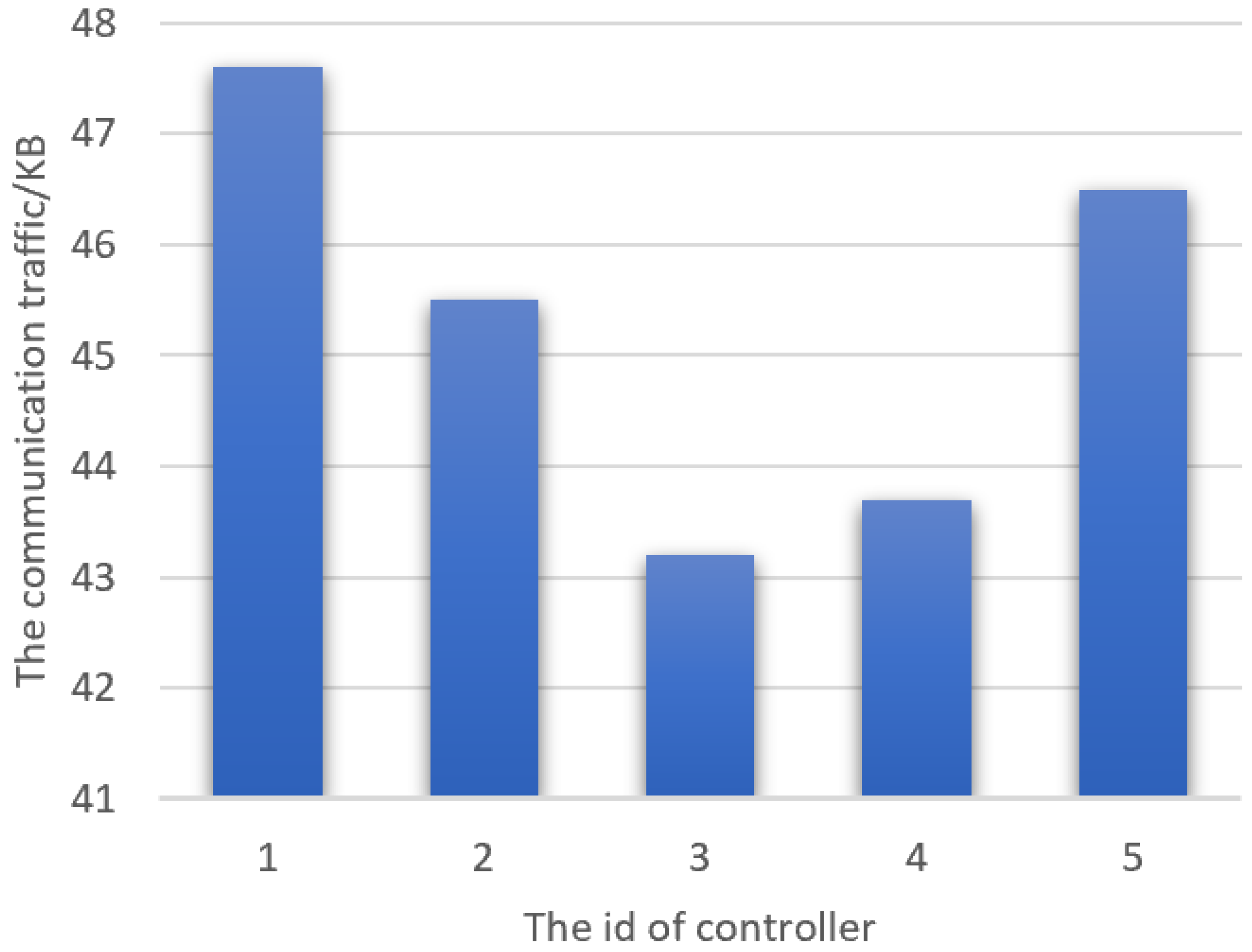
In the federated reinforcement learning routing algorithm, we also examined the size of communications between the server and domain controllers during their interactions, which averaged around 63.6 KB. Additionally, we collected the amount of data transferred between the five domain controllers and the server during each communication, as depicted in
Figure 14.
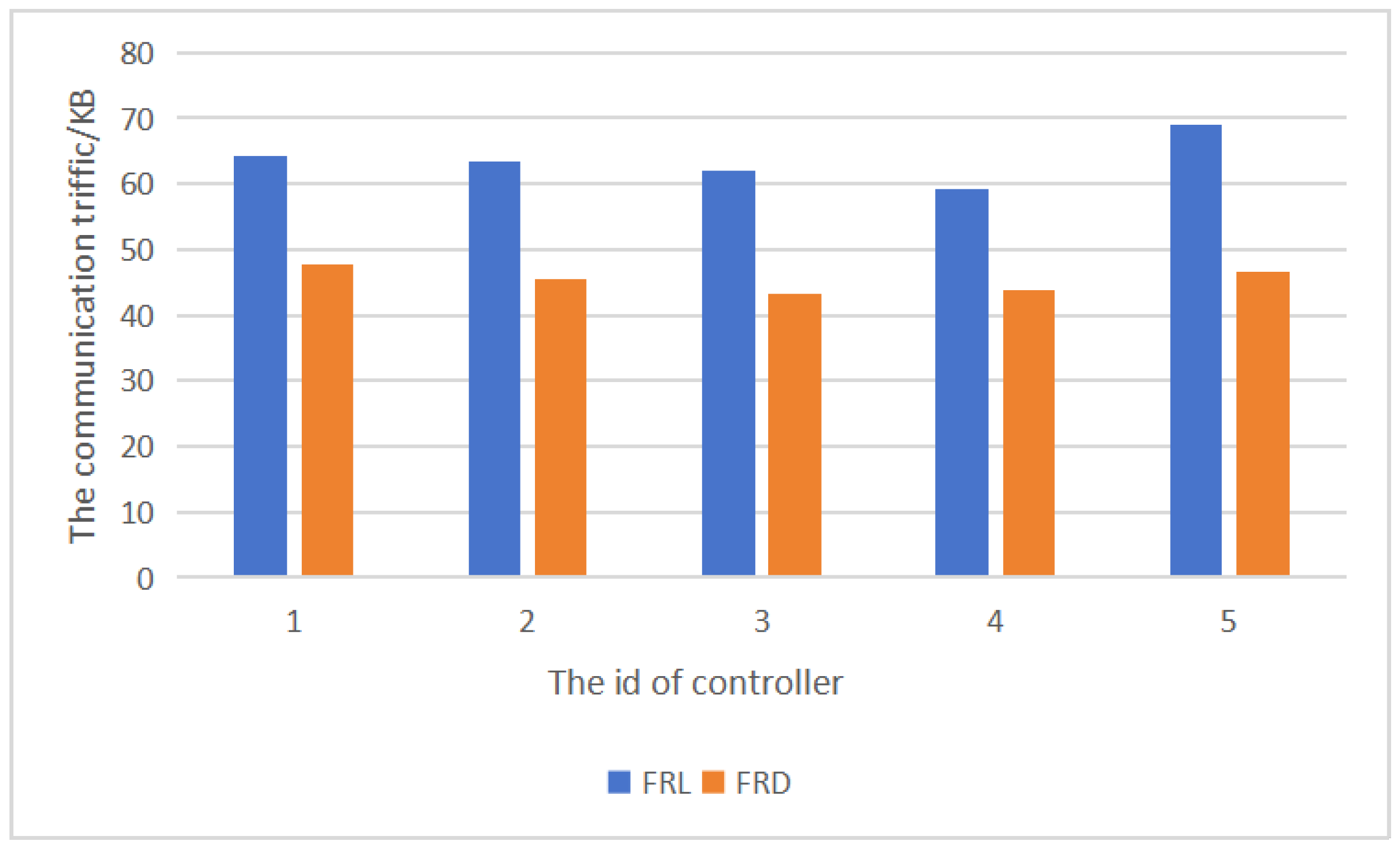
According to
Figure 15, the intelligent routing algorithm proposed in this paper can reduce communication volume by 25–33% compared to FRL. The results indicate that this algorithm reduces the amount of data that needs to be transmitted, improving model training performance.
The maximum amount of data transferred between each domain controller and the server during communication was 47.6 KB, whereas in the federated reinforcement learning routing algorithm, the lowest amount of communication data was 59.3 KB. Federated reinforcement distillation demonstrates better communication efficiency compared to federated reinforcement learning. By proxying the state and aggregating the policy of the states, federated reinforcement distillation reduces the communication overheads between the server and domain controllers. In the multi-domain framework utilizing federated reinforcement learning, the average amount of communication between each domain and the server per iteration is approximately 63.6 KB, while in the multi-domain framework based on federated reinforcement distillation, it is around 45.3 KB. Compared to parameter transmission through the federated reinforcement learning algorithm, FedRDR can reduce the amount of transmitted parameters by approximately 29%. The average communication amounts are presented in
Table 3.
As presented in the above table, the FedRDR algorithm offers a significant reduction in the transmitted data volume, thereby enhancing the training speed of single-domain intelligent agents. Additionally, when it comes to federated reinforcement distillation, the transmitted data only comprise the training data, irrespective of the intricacy of the models within each domain.
In a nutshell, the FedRDR algorithm not only expedites the training process of intelligent agents in individual domains but also diminishes the communication data between domain controllers and servers. Our empirical findings demonstrate that the efficacy of the FedRDR algorithm becomes more pronounced when confronted with intricate environments and tasks.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}