1. Introduction
The Internet of Things has emerged as a disruptive and transformative technology that enables ubiquitous connectivity and seamless integration of physical devices, data networks, and intelligent algorithms. Its pervasiveness and versatility have led to a plethora of diverse applications in various domains, such as smart cities [
1], smart homes [
2], smart car networking systems [
3], medical care [
4] and other industries. The Internet of Drones is an extension of the concept of the Internet of Things, where ‘Things’ are replaced by ‘Drones’. As a layered network control architecture, the IoD plays a crucial role in the advancement of unmanned aerial vehicles (UAVs) or drones [
5,
6].
The IoD is a vast network of numerous information-sensing devices engaged in communication and collaboration to facilitate reliable decision-making and problem-solving. However, the use of off-the-shelf components and software in IoD systems makes them vulnerable to sophisticated attacks. This poses a significant threat to their safe operation and reliability, which is crucial for ensuring the safe and normal functioning of UAVs. For an IoD system to be reliable, the information it communicates must be credible. The presence of malicious devices within the IoD system that supply false information and collude with others to mislead the system can undermine its reliability and cause considerable loss.
Network intrusion detection systems (NIDS) [
7] serve as proactive security defense technology, providing real-time monitoring of attacks from the intranet and extranet. When an attack is detected, timely alarms can be triggered, and appropriate solutions can be provided [
8]. Researchers have successfully applied machine and deep learning to intrusion detection, achieving significant progress [
9,
10]. NIDS has evolved over the years in terms of efficiency. However, attackers have also developed advanced techniques to evade detection, particularly in the complex network layers of unmanned aerial vehicles (UAVs). Although lightweight intrusion detection algorithms have been proposed [
11], many of them sacrifice recognition accuracy. Therefore, there is an urgent need to develop lightweight intrusion detection algorithms that are applicable to individual nodes.
Reinforcement learning (RL) has witnessed significant growth in research and applications, offering solutions for complex decision-making tasks in recent years [
12]. In this paper, to improve the accuracy of intrusion detection decision-making, we propose a Q-learning-based two-layer cooperative intrusion detection algorithm to improve the effectiveness of intrusion detection in IoD systems. Specifically, at the host level, nodes employ Q-learning to gradually learn and optimize their individual voting strategies, enhancing collaborative decision-making among multiple nodes. At the system level, intelligent auditing is performed on the host-level voting results, followed by appropriate rewards or penalties based on the audit findings. The audit strategy is optimized using Q-learning, leading to a significant improvement in the accuracy of intrusion detection. The system level is a supplementary defense mechanism against the omission or miscalculation of the voting process at the host level.
The main contributions of this paper can be summarized as follows:
A new intelligent voting algorithm for IoD intrusion detection is proposed, which applies Q-learning to the node voting intrusion detection. The proposed algorithm is equipped with continuous automatic learning capabilities for IoD nodes. It can interact with the network environment and cooperate with other nodes to optimize group interests and enhance their intrusion detection capabilities.
A Q-learning-based two-layer cooperative intrusion detection algorithm (Q-TCID) is proposed for the host level and the system level, respectively. As a supplementary defense mechanism to the host-level intelligent voting algorithm, the system-level intelligent audit algorithm cooperates with the host level to effectively reduce the probability of false positives and false negatives while also reducing the energy consumption.
The simulation results show that the proposed Q-TCID algorithm optimizes the defense strategy of the IoD system, which not only saves more energy and improves the accuracy of intrusion detection but also effectively improves the MTTF of the system.
The paper is organized as follows:
Section 2 presents the related work.
Section 3 explains the network architecture and problem formulation. The proposed approach is discussed in
Section 4. Simulation results are presented in
Section 5, and
Section 6 concludes the paper.
2. Related Work
In recent years, the increasing utilization of unmanned aerial vehicles integrated with IoT technologies has led to rising concerns about the security of drone networks. Intrusion detection plays a crucial role in protecting these networks from malicious activity and safeguarding sensitive data.
Numerous research efforts have focused on developing efficient intrusion detection systems specifically designed for IoD. These efforts can be broadly classified into two primary approaches: signature-based and anomaly-based detection techniques.
Signature-based detection looks for similarities between a collection of network data and a database containing features, relying on predefined patterns or signatures of known attacks to identify and block malicious activity. Early works on intrusion detection systems (IDS) for IoD-involved signature-based intrusion detection methods [
5]. Kacem et al. [
13] proposed an IDS to detect B messages, incorporating knowledge from cyber defense mechanisms and aircraft motion to identify potential attacks and preserve digital evidence for forensic investigation. Condomines et al. [
14] proposed a hybrid IDS for UAV spectral traffic analysis with a robust controller/observer to accurately detect anomalies and mitigate Distributed Denial of Service (DDoS) attacks and demonstrate its effectiveness through real traffic traces and practical applications. However, signature-based IDSs are complex to manage and require manual intervention for rule configuration and signature updates, which are not capable of detecting unknown attacks.
Anomaly-based intrusion detection techniques collect and analyze data on legitimate user behavior to determine if the currently observed behavior is malicious or legitimate. These technologies are effective in detecting unknown attacks [
15,
16]. The second research direction focuses on developing lightweight classifiers utilizing AI techniques [
17,
18], such as Machine Learning (ML) and Deep Learning (DL) [
19,
20,
21]. J. Tao et al. [
22] proposed a UAV IDS using deep reinforcement learning (DRL) for airborne communication systems. They also discussed the fundamentals of UAVs, conducted a case study on the effectiveness of their DRL-based IDS, and verified its effectiveness through simulations. A. Heidari et al. [
23] proposed a blockchain-based radial basis function neural network (RBFNN) model to enhance the performance of the IoD network, improving data integrity, intelligent decision-making, and decentralized predictive analytics while outperforming state-of-the-art methods in network intrusion detection. Rui Fu et al. [
24] integrated Convolutional Neural Networks(CNN) and long short-term memory (LSTM) into the CNN-LSTM algorithm to build an agricultural Internet of Things IDS. Abu Al-Haija et al. [
21] proposed an autonomous IDS using a deep convolution neural network to effectively detect malicious threats from invading UAVs. Complex classification algorithms based on deep learning have also been promoted to effectively classify malicious and benign devices in IoD scenarios. Most of these attack detection methods are complex and consume high energy. The main challenge is reducing the computational cost and energy consumption of training the classifier so that it can run on IoD with limited resources. Wang et al. [
11] presented a novel IDS attack–defense game that incorporates occasional system audits while relying on sensor nodes for intrusion detection through a distributed approach. However, there is a high probability of misjudgments and missed judgments in the design of their work. Therefore, an appropriate strategy is needed to realize cooperation in the system and reduce the probability of false positives and negatives in intrusion detection. The purpose of this paper is to optimize the performance of IDS by training an intrusion detection strategy.
However, most of the current research has not been discussed from the point of view of a single node, and it is based only on the system level. This consideration cannot be directly applied to the nodes of the IoD, so it is necessary to consider each node individually. To address this limitation, this paper proposes a Monte Carlo simulation method in which the host-level and the system-level agents cooperate to perform distributed intrusion detection.
4. Proposed Methodology
This section describes the overall framework of the proposed method and introduces the IDS cooperation scheme based on Q-learning optimization. This paper proposes an advanced stochastic Petri Net (SPN) model [
11,
28,
29] as shown in
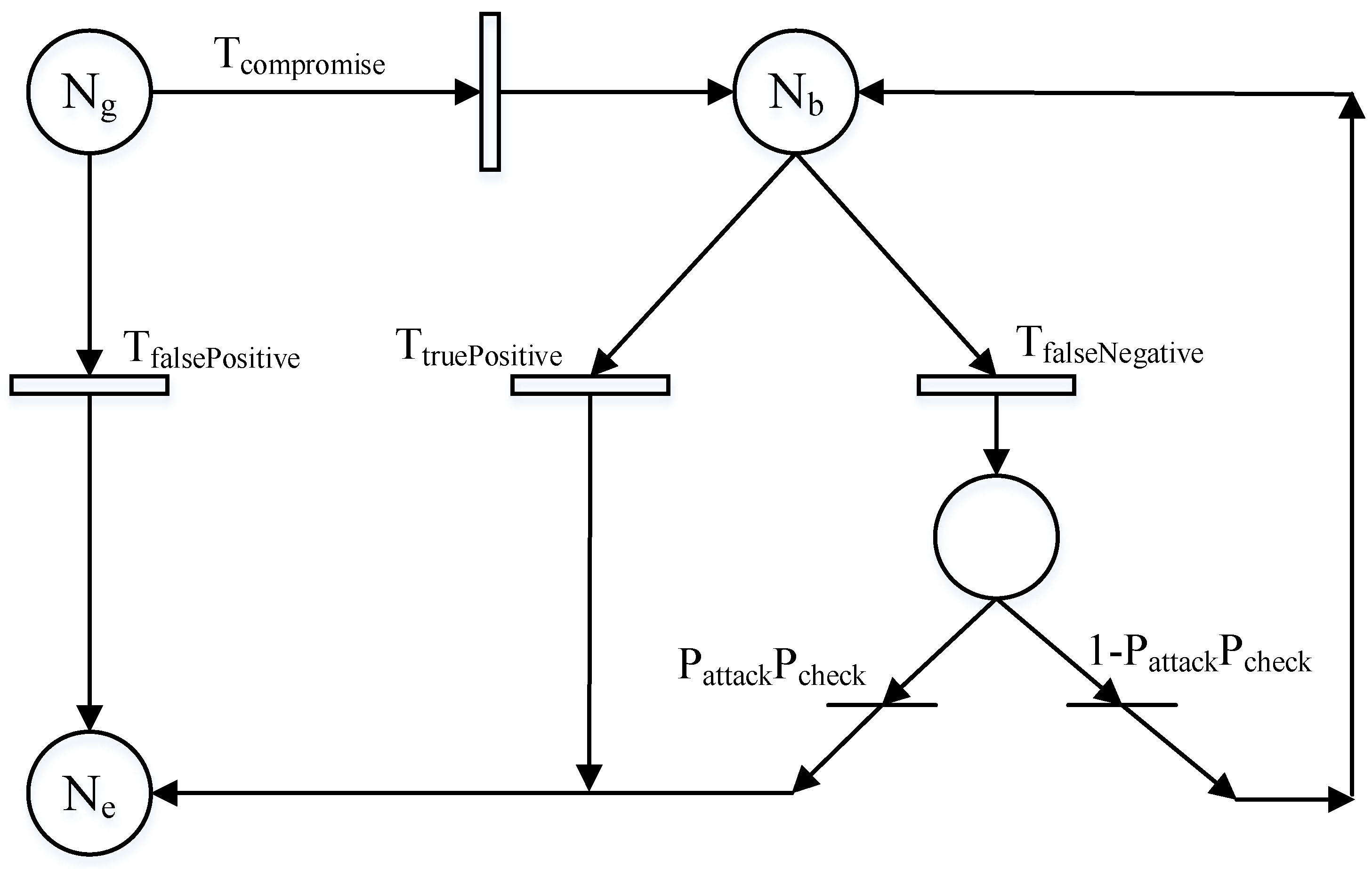
Figure 2 to analyze the dynamics of the IDS game.
The SPN model is initially set up with all nodes being good nodes, and tokens are placed in . Due to the invasion of attackers, every node has a probability of being captured and transformed into a bad node. This is modeled by relating the transition . Firing will move tokens from place to place one at a time. The tokens in place represent compromised nodes that are not detected.
During IDS voting, especially when no audit is performed, good nodes can be misidentified as bad nodes. If a good node is misjudged as a bad node, it will be removed from the IoD directly. is triggered in this situation, and the good node needs to be moved from place to place , where tokens in the set represent the nodes that were evicted from the system (in the EVICTED state).
Bad nodes in the system will encounter two situations. The first situation is when bad nodes are correctly identified in the IDS and removed from the system. At this time,
is triggered, and the token of the bad node is transferred from
to
. In another case, the bad nodes missed judgment during IDS voting, and
was triggered. These “false negative” bad nodes were temporarily stored in a temporary placeholder (where there is no label in
Figure 2), waiting for the selection of a system-level attack–defense strategy.
In the IDS voting process, a bad node has a probability of to launch an attack, and the system can decide whether to execute the audit in consideration of the overall benefits of the system. If a bad node attack and the system audit occur simultaneously, the system detects inconsistencies between the voting result of the bad node and the audit outcome. As a penalty, the system expels the bad node from the system, causing the token of the bad node to move from the temporary placeholder to place . In addition to this situation, in other cases, the token of the bad node returns to from the temporary placeholder, waiting for the next IDS vote.
In order to reduce the probability of false positives and false negatives, this paper proposes a two-layer cooperative intrusion detection algorithm based on Q-learning (Q-TCID). Q-learning is a reinforcement learning mechanism that is based on a finite Markov decision process (FMDP). It aims to find the optimal solution in the current state by maximizing the utility function of subsequent strategies. Q-learning can be used in both single-agent and multi-agent systems. In a single-agent system, the agent evaluates its utility function based on its own expected return and immediate return, then chooses the response action strategy according to the maximum Q-value. In a multi-agent system, agents have to consider the joint optimal returns of other related agents. The agent should not only choose its own optimal return strategy but also consider other agents’ selection strategies. The optimal strategy criterion depends on the joint actions of all agents.
In this paper, at the host level, a Q-learning multi-agent algorithm is used. Each voting node plays a game with the malicious node as an agent and learns a cooperation strategy to vote for the target node in the interaction, which reduces the false positive probability in the voting process. At the system level, a Q-learning single-agent algorithm is used. The system can learn the audit strategy of voting results in the interaction with malicious nodes, thus reducing the false negative probability.
Algorithm 1 describes the Q-TCID algorithm, which is used to calculate the Mean Time To Failure (MTTF) in a monitoring system. The algorithm takes several input parameters, including (the set of states and locations of all nodes), and (the length and width of the simulation region), (the IDS interval), (the initial energy of each node), (the cost of performing an audit), (the minimum energy required for a sensor node to remain operational), and (the communication distance per sensor node).
The algorithm begins by randomizing the positions of the nodes within the specified simulation region of length and width . It then proceeds with a loop that runs 1000 simulations. Within each simulation, the algorithm initializes each node’s attribute as GOOD (Line 1–5).
A perpetual loop is initiated, where the algorithm iterates over each sensor node and checks if it is in the GOOD state. If the node is captured, its attribute is updated to BAD (Line 7–14). At intervals defined by , the algorithm invokes Algorithm 2, obtaining the values of the action-value functions and for the host-level intelligent dynamic voting algorithm and the system-level intelligent audit algorithm, respectively. It then iterates over each sensor node that is not in the EVICTED state, determining the current state and performing the corresponding action based on the obtained and values. Following this step, the algorithm updates the residual energy of each node (Line 16–23).
If a Byzantine failure occurs or the system power becomes too low, the algorithm records the current time as the MTTF value and breaks out of the loop. The algorithm increments the time variable for each iteration of the perpetual loop (Line 24–28).
At the completion of the 1000 simulations, the algorithm returns the calculated MTTF value.
| Algorithm 1 Q-TCID |
- Input:
, , , , , , , : Sets of states and locations of all nodes. : Simulation region length. : Simulation region width. : IDS interval. : Initial energy of each node. : Cost of performing an audit. :Minimum energy required for a sensor node to remain operational. : Communication distance per sensor node. - Output:
MTTF (Mean Time To Failure) - 1:
Randomly deploy node positions (L, W) in the simulation area - 2:
for each simulation q = 1, 2, 3,..., 1000 do - 3:
for each node of do - 4:
Initialize node with attribute = GOOD - 5:
end for - 6:
while true do - 7:
for each sensor node do - 8:
if is in GOOD state then - 9:
Inspect whether the node is captured and transformed - 10:
if node is captured then - 11:
Update node attribute to BAD - 12:
end if - 13:
end if - 14:
end for - 15:
if mod (time,)==0 then - 16:
Run Algorithm 2 and obtain and - 17:
for each sensor node do - 18:
if not in EVICTED state then - 19:
Determining the historical voting strategy and status of the node and the target node - 20:
Perform the corresponding action according to and - 21:
Update and review the remaining energy of each node - 22:
end if - 23:
end for - 24:
if Byzantine failure occurs or system power is too low then - 25:
Set MTTF to current time and break the loop - 26:
end if - 27:
end if - 28:
Increment time - 29:
end while - 30:
end for
|
4.1. Host Level: Intelligent Dynamic Voting of Nodes
The host level of intrusion detection is concerned with the interaction between each voting node and its corresponding attacker and affects the dynamic change of each node’s state. Intelligent voting means that good nodes keep learning voting strategies in the game with malicious nodes and formulate adaptive joint voting strategies to prevent attacks from malicious nodes. The objective of each good node is to maximize its cumulative reward.
In the process of IDS voting, the voting results of the voted nodes are related to the number of voting nodes (when = 5, there may be six kinds of voting results: five members all vote for “good”; four members vote for “good”, and one member votes for “bad”; three members vote for “good”, and two members vote for “bad"; two members vote for “good”, and three members vote for “bad”; one member votes for “good” and four members vote for “bad”; five members all vote for “bad”). The action space of voting nodes is defined as , where action indicates that the corresponding strategy is allocated according to the proportion of voting results of voting nodes.
The malicious nodes in the system may choose to attack or “silence” during IDS voting, just behave like a good node. Similarly, the actions of malicious nodes are defined as .
The state space of IDS intelligent voting game is defined by , where represents the state of the target node (“good” or “bad”). The payoff of the voting result is that good nodes hope to minimize the proportion of malicious nodes in the system. Therefore, in all strategies, if all voting nodes can correctly identify the target node, the strategy reward is set to the maximum. If all voting nodes misjudge the target node, the strategy reward is set to the minimum.
In order to solve the optimal strategy, after observing the actions
, the reward
, and the state transition from
to
, the value functions
can be updated according to Equation (
7),
where
and
denotes the learning rate and discount factor, respectively.
is the next state.
To prevent the system from falling into a local optimum, there should be an appropriate trade-off between exploitation and exploration in the Q-learning procedure. In this paper, the -greedy algorithm is employed for exploration.
During the exploration phase, the next action is randomly selected with a probability of
(
), ensuring a focus on long-term gains. The selection strategy of the greedy algorithm is represented by Equation (
8):
In this equation, a random number is generated from a uniform distribution between 0 and 1. This random number is assigned before taking any action. If , the agent randomly selects a behavior from the set of behaviors . On the other hand, if , the agent explores all the actions in the behavior set and ultimately executes the action that yields the maximum value.
4.2. System Level: Intelligent Audit of System
The system level is concerned with the interaction between the system and malicious nodes. This layer is a defense mechanism added at the system level when the host-level intelligent dynamic voting link is missed, that is, auditing the voting results at the host level. If the voting results of a node are found not to match the audit results, the node will be punished and expelled. To preserve the energy of IoD nodes, the system cannot audit the voting results too frequently. Hence, the system uses Q-learning to optimize its own audit strategy, which is similar to the host-level intelligent dynamic voting method.
In the intelligent dynamic voting process, malicious nodes have a probability of
for selection attack and a probability of 1−
for not attacking, which corresponds to the state space
in the intelligent audit of the system. The system can decide whether to perform the audit in consideration of reducing energy consumption. The action space of voting nodes is defined as
. When the malicious node is audited by the system, it means that the malicious node fails to act. At this time, the system gets corresponding rewards. Otherwise, the system gets corresponding punishments. The possible situations can be classified into four types, as shown in
Table 1:
Best Choice for System: the system chooses to check; the malicious node chooses to attack;
False Negative: the system chooses not to check; the malicious node attacks;
False Positive: the system chooses to check; the malicious node chooses to be silent;
Least Damage: the system chooses to trust; the malicious node chooses to be silent.
The reward value for each type of interaction is evaluated using Equation (
3).
This paper introduces a constant reward value, denoted as
B, which represents the gain of the system when it correctly finds the malicious node of the attack. Conversely, if the system fails to protect the IoD while a malicious node is attacking, the payoff of the system is represented as
. In addition,
denotes the cost of performing an audit. This paper define the reward function as
, which is given by Equation (
9):
To acquire knowledge about the correct audit strategy, the system engages in interactions with its surroundings. The objective is to determine the cumulative reward value over time. This is achieved through the use of a learning function, denoted as
, which is defined as Equation (
10):
where
and
denotes the learning rate and discount factor, respectively.
is the next state.
The action selection strategy adopted in the system-level intelligent audit algorithm is consistent with the host-level intelligent dynamic voting algorithm. The execution action selected by the system for the current state during the exploration process is determined by Equation (
2).
The two method flows proposed above are described in Algorithm 2.
| Algorithm 2 Collaborative Q-learning for IDS |
- Input:
NODE, , , , , , Maximum number of iterations NODE: Sets of states and locations of all nodes. : State. : Action. : Reward table. : Learning rate. : Discount factor. - Output:
Final value - 1:
Initialization: ; - 2:
Determine the current state ; - 3:
while ( do is not convergence); - 4:
use -greedy to choose an action “” based on current and state; - 5:
run action “” to get the reward value “”, and reach to new state ; - 6:
update and using (2) and (4), respectively; - 7:
update the current state to ; - 8:
end while
|
5. Simulation and Analysis
The aim of this section is to comprehensively assess the effectiveness and performance of the proposed method and to explore the effect of different parameters on the system behavior. This section first describes the configuration of the simulation platform and the setting of the experimental conditions. Then, the superiority of the proposed method is analyzed by comparing its performance with existing methods. Finally, an in-depth study of the variation of key parameters in the system is carried out to explore their impact on the system’s performance. Through these comprehensive analyses, this paper aims to reveal the advantages of the proposed method in various aspects as well as its adaptability.
5.1. Simulation Setting
The platform environment used for all experiments in this paper was a personal computer with an Intel (R) Core (TM) i7 processor and 16 GB of RAM. The operating system used was Windows 10 with MATLAB R2019a version installed. In this paper, the required algorithms and models were implemented using MATLAB programming, which could be used for data processing, simulation, algorithm development, etc.
In the simulation experiment, the IoD comprised a group of
= 128 sensor nodes randomly deployed. Once deployed, the sensors were fixed in their positions. All nodes had a probability
of being maliciously captured by external attacks, thus being transformed into malicious nodes, which would attack in the IoD. In this experiment, the proposed algorithm’s effectiveness was evaluated by simulating different attack probabilities of malicious nodes and comparing it with the basic voting strategy (BVS) [
11] and the single-layer optimized intrusion detection algorithm (SOID).
Table 2 lists the design parameters of attack and defense strategy for intrusion detection in this IoD system.
The system’s intrusion detection voting occurs periodically at every moment. In the process of intrusion detection voting, each node in the system takes turns to vote for it by neighboring nodes, and the voting result is judged according to the rule that the minority is subordinate to the majority.
Malicious nodes have a probability to attack in the voting process of intrusion detection; that is, when the target node is a malicious node, vote “good” for it, with the intention of leaving more malicious nodes in the system to attack and increasing the proportion of malicious nodes, and when the target node is a normal node, vote “bad” for it, with the intention of expelling good nodes from the system. Accordingly, there is a 1− probability that a malicious node will not launch an attack, and at this time, its behavior is consistent with that of a normal node.
In the process of learning its own voting strategy before voting and learning its own auditing strategy in intrusion detection, the learning rate, exploration rate, and discount factor of Q-learning are all set according to its learning and training degree, which are somewhat different.
Once a Byzantine fault occurs in the system or the system energy is exhausted, the IoD system will fail.
5.2. Performance Comparision
To verify the performance, this paper compares the proposed algorithm Q-TCID with the basic voting strategy (BVS) [
11] and the single-layer optimized intrusion detection algorithm (SOID)in terms of attack probability, accuracy, and energy consumption. Both the proposed algorithm and the comparison algorithms utilize identical values for their basic parameters.
5.2.1. Attack Probability
The results depicted in
Figure 3 illustrate the superior performance of the Q-TCID algorithm over the basic voting strategy (BVS) proposed in [
11] and the single-layer optimized intrusion detection algorithm (SOID). The MTTF values obtained using Q-TCID are consistently higher under different attack probabilities (
), indicating that Q-TCID is more efficient in detecting and defending against malicious nodes in IoD systems. This algorithm is especially effective when the
values are small (e.g.,
from 50 to 250), as it leverages Q-learning to optimize the intrusion detection strategy, thereby reducing the probability of false positive and false negative. In addition, when the frequency of intrusion detection is higher, the advantage of Q-TCID is more obvious.
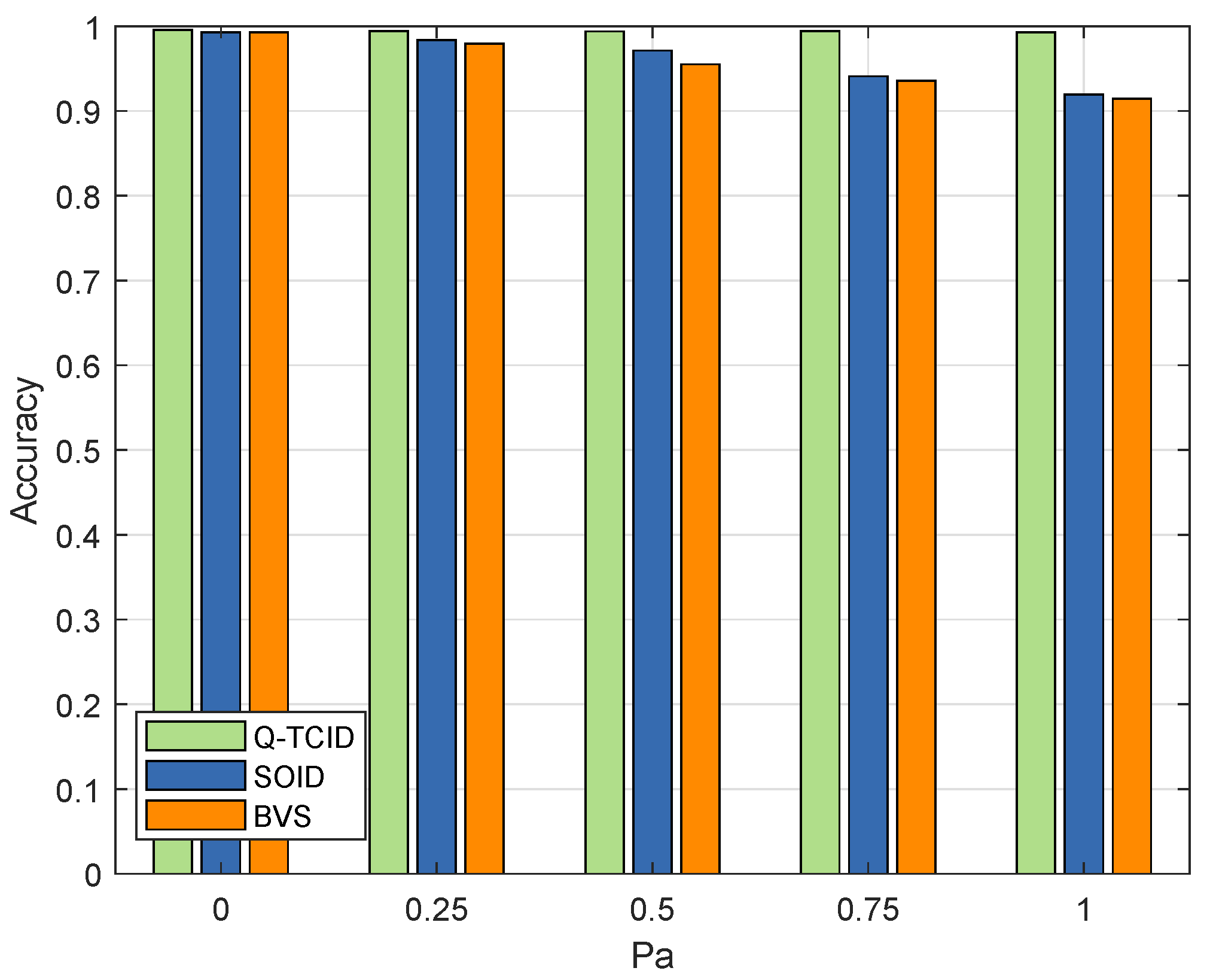
5.2.2. Accuracy
Accuracy is a widely employed metric for evaluating the performance of intrusion detection models, representing the ratio of correct decisions made by the model to the total number of decisions. In the context of intrusion detection, accuracy is determined by correctly identifying nodes (true negative, TN), accurately detecting malicious nodes (true positive, TP), misclassifying benign nodes (false positive, FP), and identifying malicious nodes (false negative, FN). Equation (
11) offers a formal definition of accuracy.
Figure 4 shows the comparison of Q-TCID with the basic voting strategy (BVS) [
11] and the single-layer optimized intrusion detection algorithm (SOID). It can be seen that the identification accuracy of BVS and SOID decreases with the increase of the attack probability of malicious nodes. In contrast, Q-TCID demonstrates strong adaptability to the attacks of malicious nodes, with little difference in recognition accuracy under different attack probabilities of malicious nodes. Overall, the improved intrusion detection algorithm achieves higher recognition accuracy and better intrusion detection performance when compared to BVS and SOID.
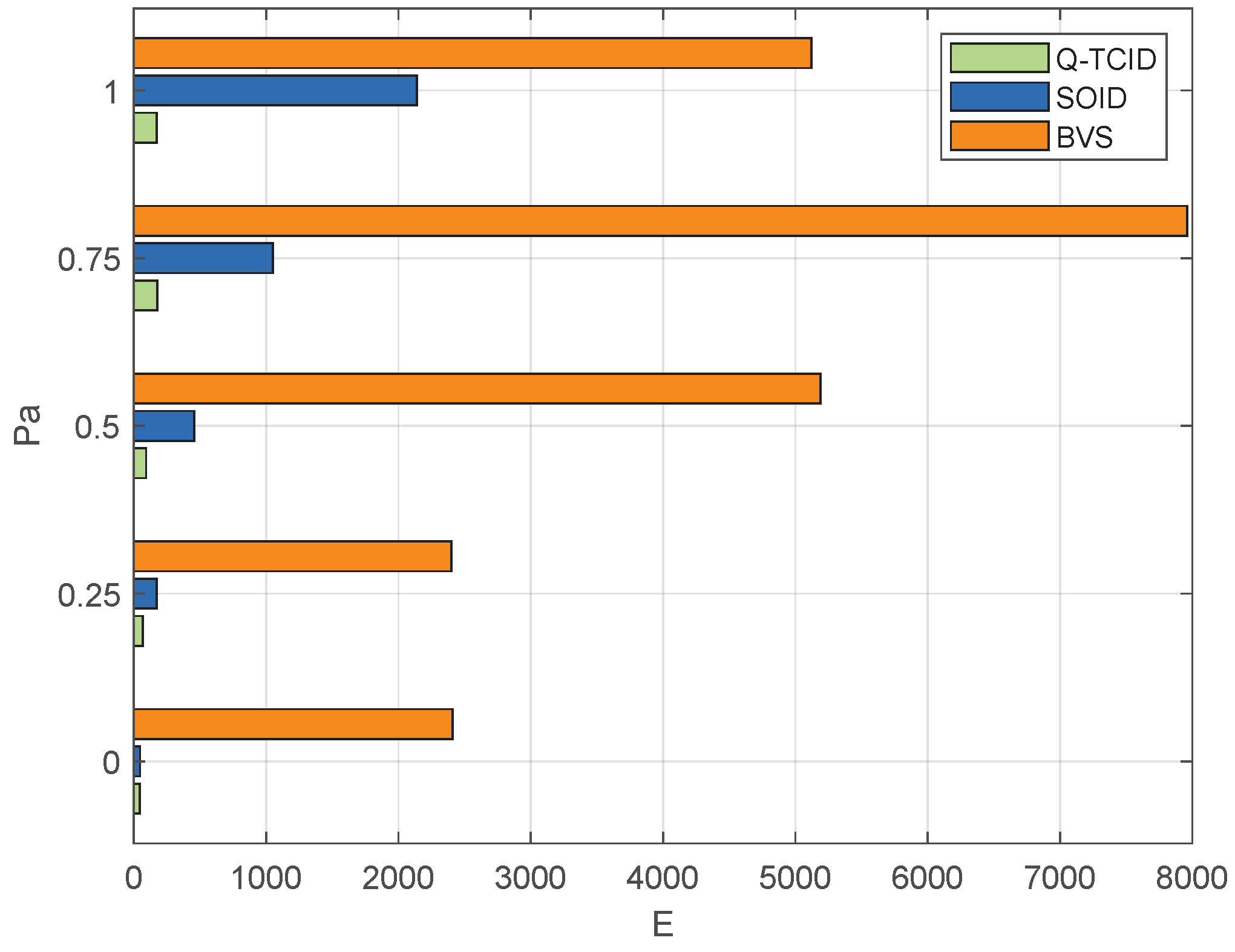
5.2.3. Energy Consumption
To evaluate the feasibility of the suggested algorithm, considering energy consumption related to intrusion detection is crucial. In this regard, energy consumption primarily arises from the system-level audit process.
Figure 5 shows the comparison of energy consumption of Q-TCID, BVS, and SOID under the same
and different attack probabilities of malicious nodes. As the figure illustrates, Q-TCID exhibits significantly lower energy consumption compared to BVS and SOID. This is mainly because the proposed algorithm reduces the number of nodes misjudged or missed during the host-level voting process, and the optimized system-level audit strategy reduces the number of audits required, thereby significantly reducing the energy consumption of intrusion detection.
5.3. Impact of Different Parameters
This section presents the performance of the Q-TCID algorithm through a series of experimental simulations, which evaluate its effectiveness in terms of the attack probability of malicious nodes, the number of voting nodes, the proportion of energy consumed, and the per-node capture rate.
5.3.1. Attack Probability
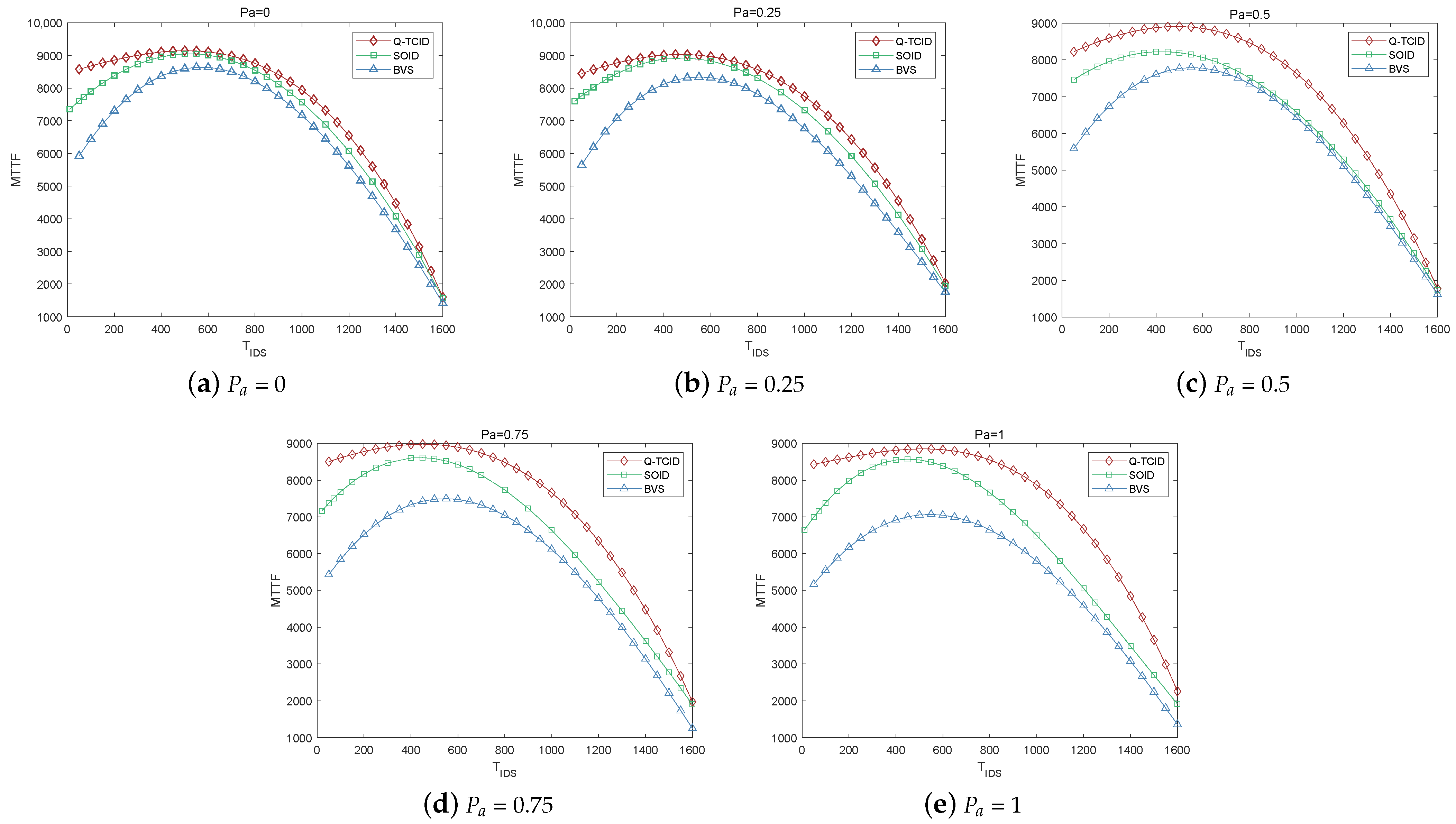
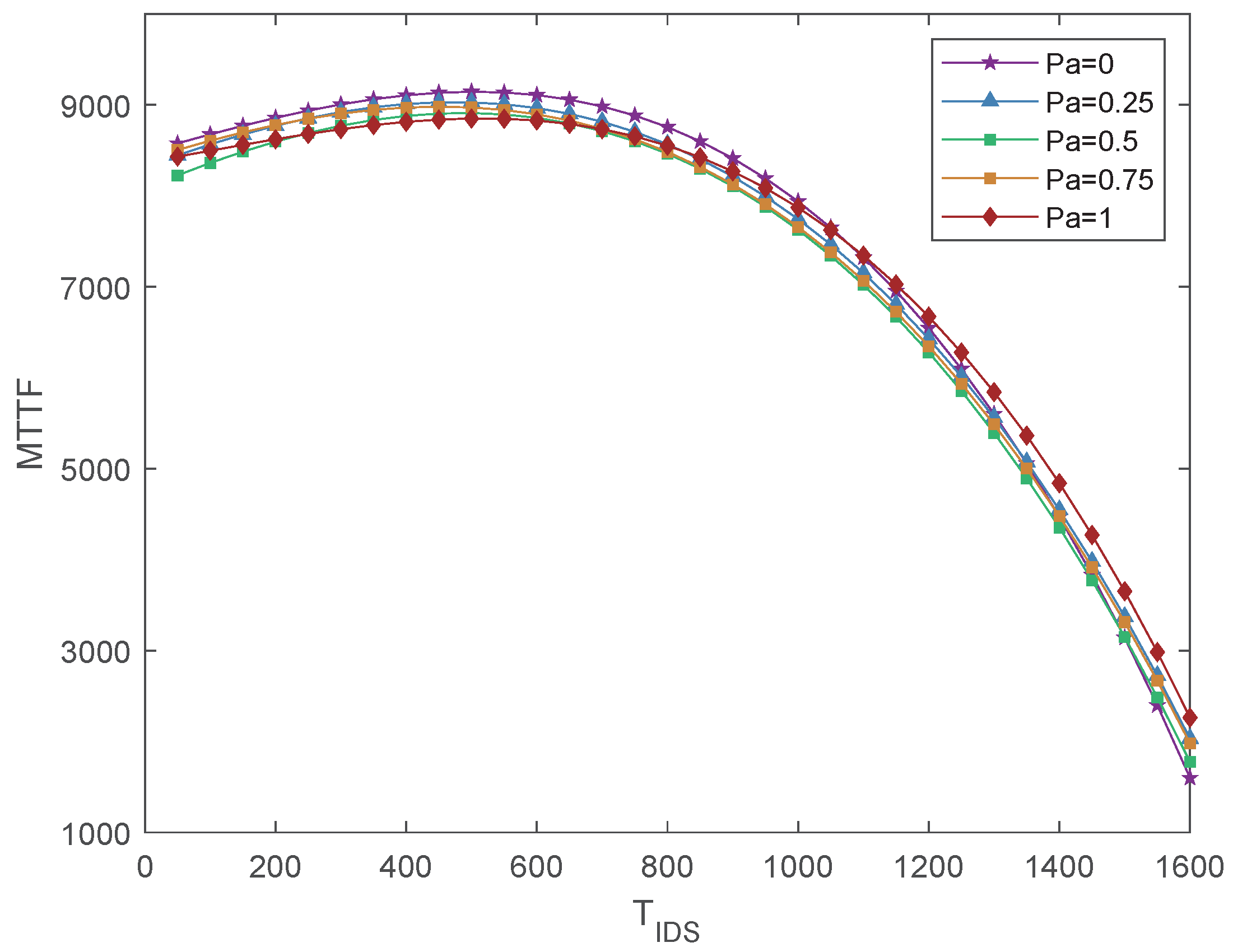
Figure 6 shows the impact of various attack probabilities
on MTTF. It is evident from the plot that there is an optimal value for
, which maximizes the MTTF. This optimal value achieves a balance between the energy consumption during audits and the effectiveness of defense measures in prolonging the system’s lifetime. When
is too small, intrusion detection occurs too frequently, resulting in excessive energy consumption and a short running time of the IoD system. With the increase of
, the system can save more energy and extend the network running time. However, when
is too large, although it can save more energy, the system cannot catch malicious nodes in time, which leads to an excessive proportion of bad nodes, leading to Byzantine failure.
Moreover, by evaluating the impact of different attack probabilities of malicious nodes on the MTTF of the IoD system, it is found that the MTTF of the system remains stable within a certain range, regardless of the value of . This indicates that the intrusion detection method proposed in this paper exhibits strong adaptability to attacks by malicious nodes.
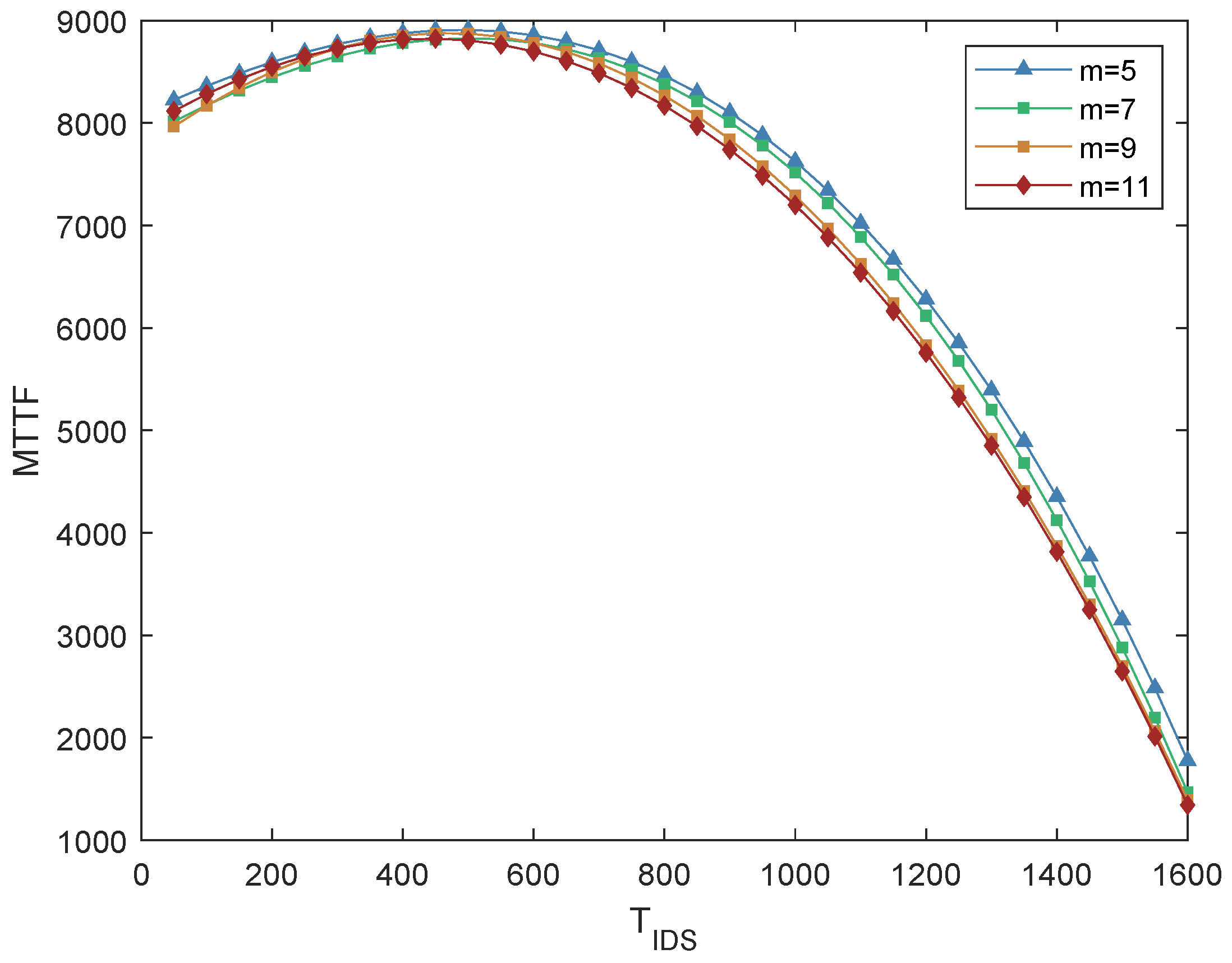
5.3.2. Number of Voting Nodes
Figure 7 illustrates the impact of the number of voters (
) on the MTTF of the IoD system under the attack probability of malicious nodes
= 0.5. As the number of voters increases (
rises from 5 to 7, 9, and 11), the number of nodes participating in a single intrusion detection vote also increases, and the energy consumed by each intrusion detection also increases, resulting in a decrease in MTTF. However, when
is too small, the frequency of intrusion detection increases, leading to higher energy consumption and potentially shorter MTTF. In this case, the number of voters (
) does not have a significant impact on the MTTF.
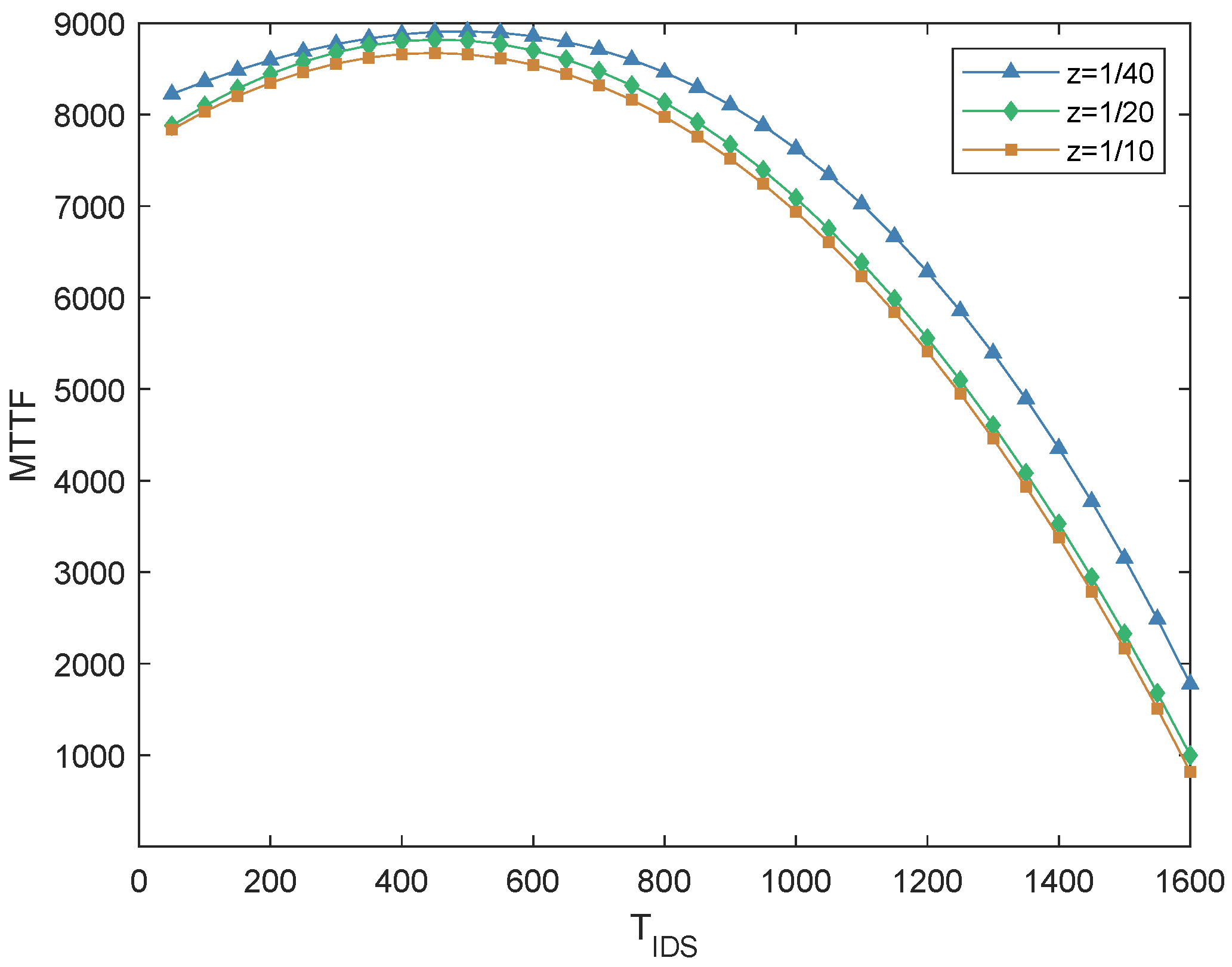
5.3.3. Energy Consumption Rate
The energy consumption rate of a single intrusion detection (z) is the ratio of the energy consumed by performing one intrusion detection to the total available energy. A higher value indicates that the system can detect more intrusions with the available energy. Equation (
12) provides a formal definition of z.
Figure 8 presents the impact of z on the MTTF of the IoD system when
= 0.5. By evaluating the impact of different z values on MTTF, it is found that as z increases, MTTF gradually decreases. It is also noted that the optimal
value decreases with the increase of z. The reason is that with the increase in energy consumption rate, the less intrusion detection times can be borne by the disposable energy in the system.
5.3.4. Per-Node Capture Rate
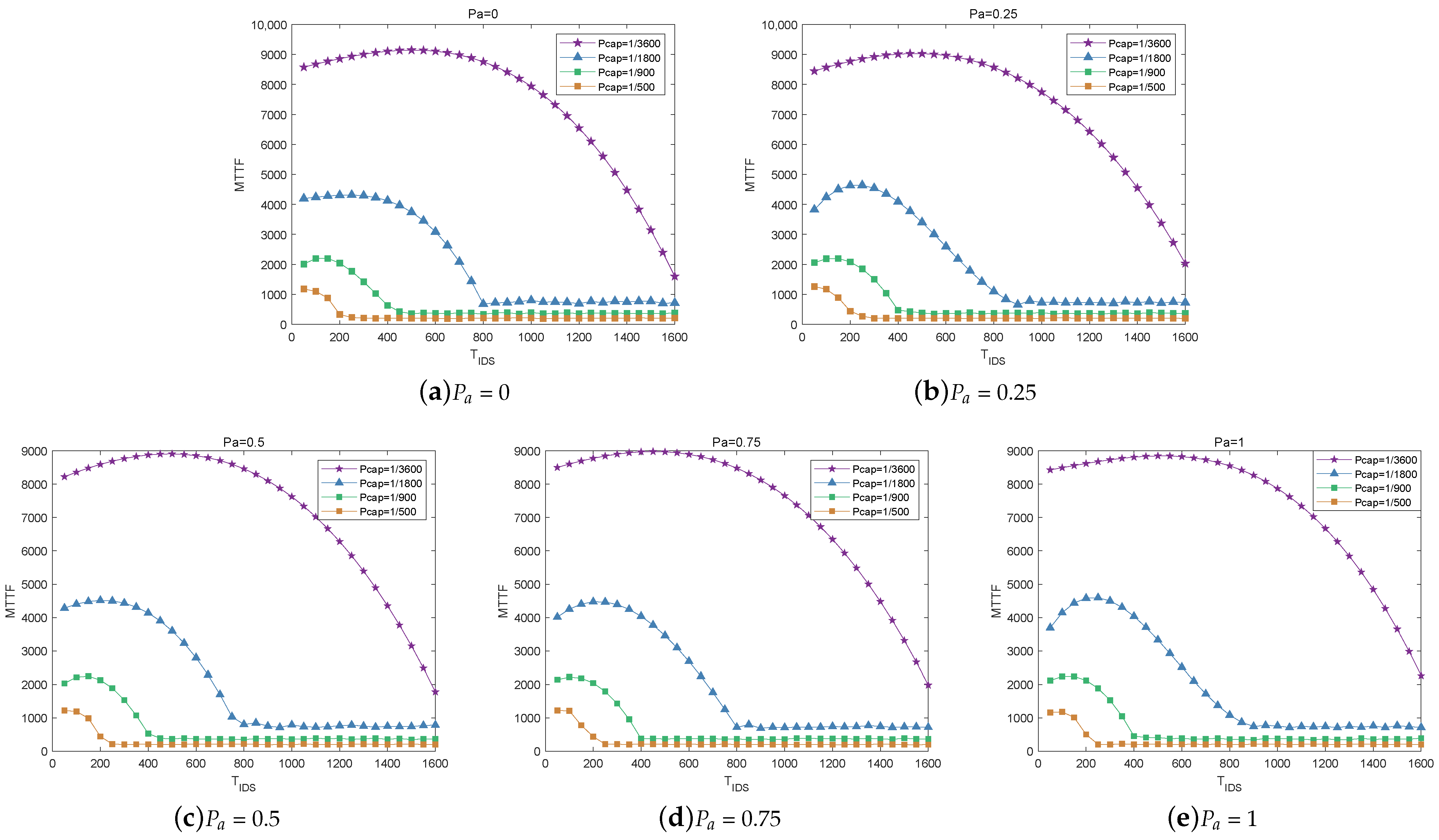
Figure 9 shows the influence of per-node capture rate
on MTTF under different attack probabilities of malicious nodes. A larger
means that the good nodes are more likely to be captured maliciously, and the proportion of malicious nodes in the system is greater. Therefore, when
increases, the MTTF of the system decreases. Moreover, as
rises, the optimal
value that maximizes MTTF also increases. This is because when the per-node capture rate is higher, there is a higher possibility that there will be more malicious nodes in each IDS voting cycle that need to be correctly judged and evicted from the system. If the IDS voting interval is too long, it raises the risk of Byzantine failure, which occurs when at least one third of the nodes are malicious.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}