
Research on the Intelligent Construction of UAV Knowledge Graph Based on Attentive Semantic Representation

Abstract
:1. Introduction
- At the level of UAV knowledge and data, several challenges need to be addressed. Firstly, the authority of UAV data is often lacking. These data primarily originate from encyclopedias and news pages, where a direct binding connection between data producers and data credibility is absent. Secondly, the accuracy of UAV knowledge suffers from deficiencies, leading to conflicts and noticeable errors among different UAV data sources. Thirdly, there is a scarcity of systematic data within the UAV domain, and publicly available UAV data are in unstructured text format. Extracting fine-grained knowledge directly from such data becomes challenging, thus hindering comprehensive system research in this field.
- At the level of UAV knowledge graph construction and application, knowledge extraction is the core task in the construction process. The classical knowledge extraction methods can be commendable in the general domain. However, in the face of UAV domain data, it is necessary to develop an algorithmic extraction model adapted to the domain properties, to improve the efficiency and accuracy of extraction, and thus to enhance the generalization ability of the traditional methods. In the face of downstream UAV task applications, there is no direct reference case for the development of domain-oriented system engineering for user requirements and visual interaction. The overall architecture of the system needs to be explored and developed under the guidance of the requirements, in combination with application models from other domains.
- A fine-grained knowledge ontology is formed by defining the concept and relation attributes of UAVs based on a collection of unstructured UAV data of a significant scale. From this ontology, a UAV knowledge extraction dataset is created by selecting high-quality texts that align with predefined UAV ontology entities and relation annotations.
- A UASR knowledge extraction model is proposed, taking into account the characteristics of UAV knowledge extraction data. The BERT pre-trained language model is utilized to generate character feature encoding. In the decoder stage, the model incorporates the MLP attention mechanism to enhance the representation of relation types in the text for relation prediction. Additionally, a relationship-aware attention approach is employed to assign higher weights to tokens closely associated with relation classification and entity recognition tasks, thus enhancing the contextual semantic representation of subject–object entities.
- The UASR knowledge extraction model undergoes extensive comparison and ablation experiments using a self-built dataset. The experimental results demonstrate the model’s effectiveness in solving knowledge extraction challenges within the UAV corpus. Furthermore, the knowledge graph generated by the UASR model’s extraction enables visual storage applications. These quantitative and qualitative experiments substantiate the efficacy and validity of the UASR framework.
2. Related Works
2.1. Construction of UAV Knowledge Graph
2.2. UAV Knowledge Extraction Approach
3. Construction of UAV Knowledge Graph Based on UASR
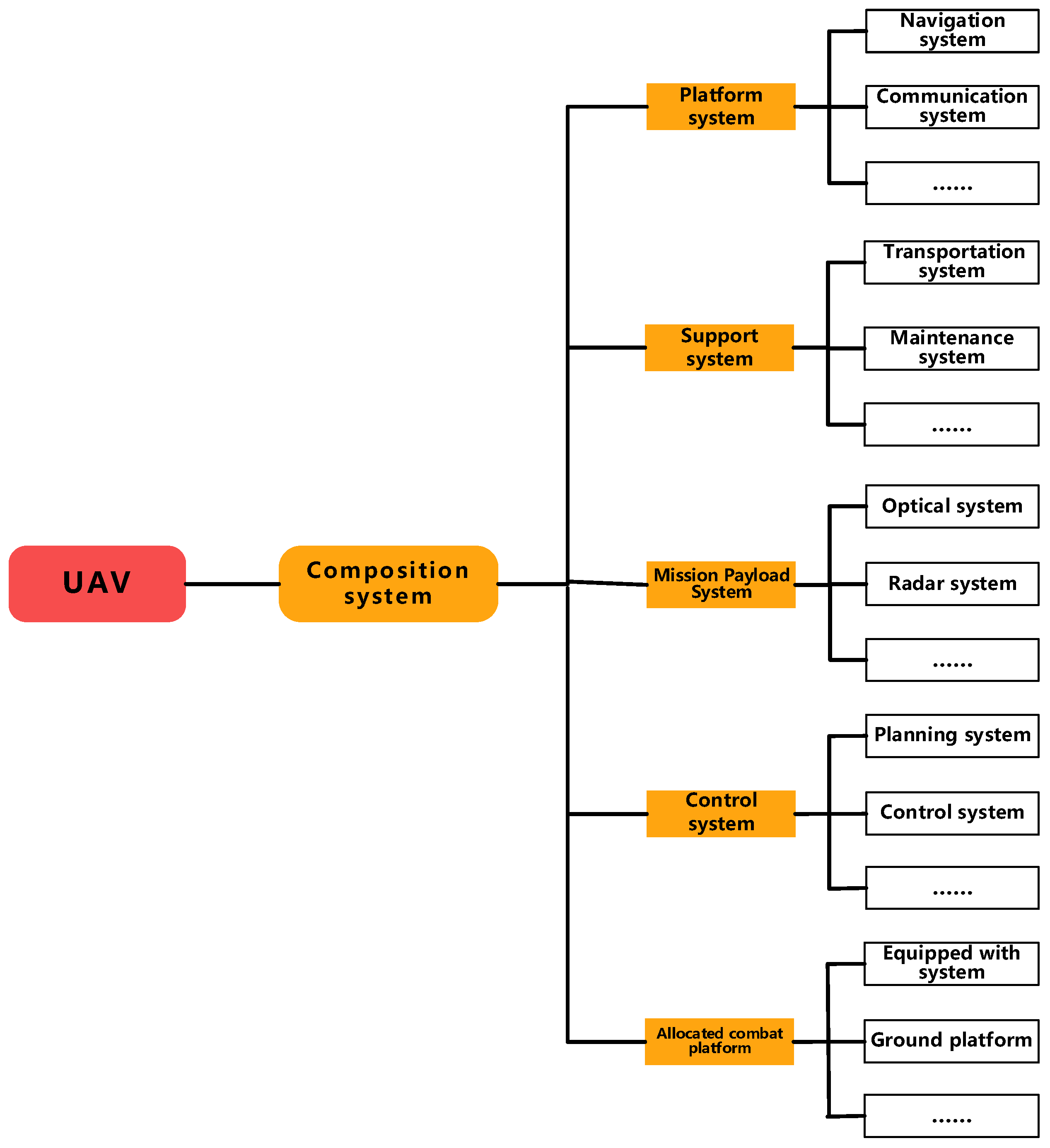
3.1. UAV Ontology Definition
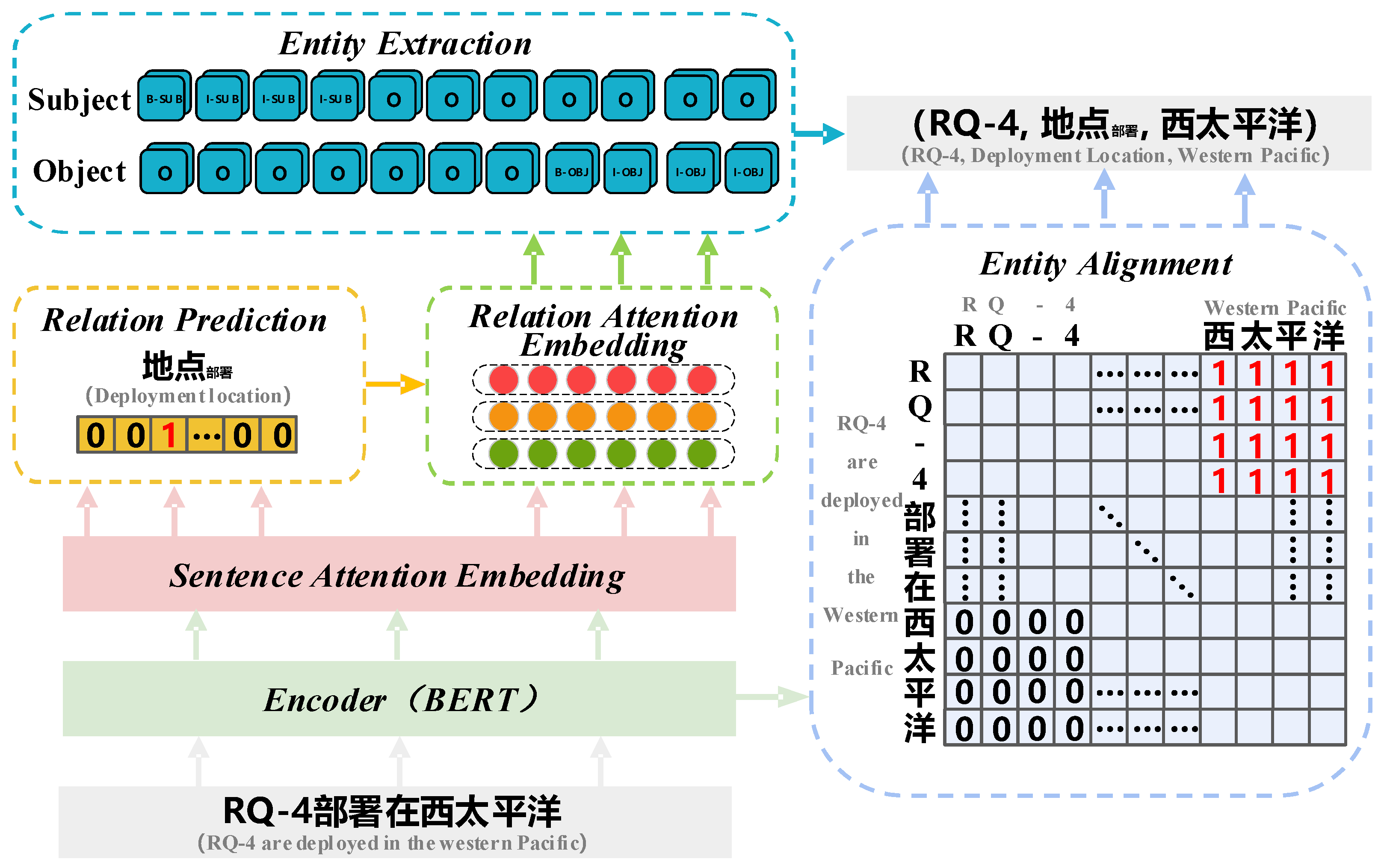
3.2. UASR Knowledge Extraction Model
3.2.1. Problem Formulation
3.2.2. Relation Prediction
3.2.3. Subject and Object Extraction
3.2.4. Training and Inference
4. UAV Knowledge Extraction Experiments
4.1. Experimental Setup
4.1.1. Dataset
4.1.2. Model Setting
4.2. Experimental Results
4.2.1. Pre-Experiment Result
4.2.2. Overall Comparison
4.2.3. Ablation Experiments
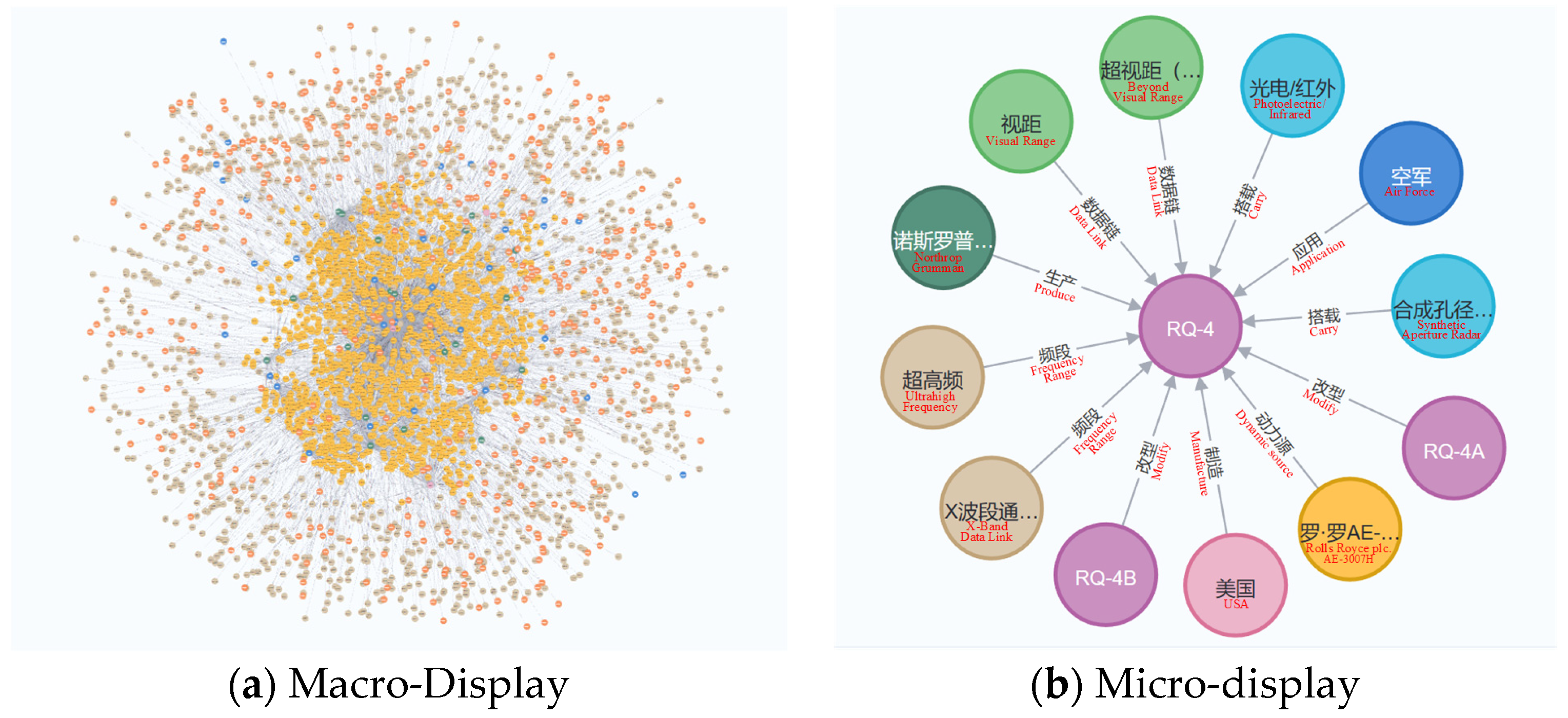
4.3. UAV Knowledge Graph Visualization
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mohsan, S.A.H.; Khan, M.A.; Alsharif, M.H.; Uthansakul, P.; Solyman, A.A.A. Intelligent Reflecting Surfaces Assisted UAV Communications for Massive Networks: Current Trends, Challenges, and Research Directions. Sensors 2022, 22, 5278. [Google Scholar] [CrossRef] [PubMed]
- Baigang, M.; Yi, F. A review: Development of named entity recognition (NER) technology for aeronautical information intelligence. Artif. Intell. Rev. 2022, 56, 1515–1542. [Google Scholar] [CrossRef]
- Huo, C.; Ma, S.; Liu, X. Hotness prediction of scientific topics based on a bibliographic knowledge graph. Inf. Process. Manag. 2022, 59, 102980. [Google Scholar] [CrossRef]
- Wu, X.; Duan, J.; Pan, Y.; Li, M. Medical Knowledge Graph: Data Sources, Construction, Reasoning, and Applications. Big Data Min. Anal. 2023, 6, 201–217. [Google Scholar] [CrossRef]
- Cheng, D.; Yang, F.; Wang, X.; Zhang, Y.; Zhang, L. Knowledge Graph-based Event Embedding Framework for Financial Quantitative Investments. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), Electr Network, online, 25–30 July 2020; pp. 2221–2230. [Google Scholar]
- Chen, Z.; Deng, Q.; Ren, H.; Zhao, Z.; Peng, T.; Yang, C.; Gui, W. A new energy consumption prediction method for chillers based on GraphSAGE by combining empirical knowledge and operating data. Appl. Energy 2022, 310, 118410. [Google Scholar] [CrossRef]
- Shao, B.; Li, X.; Bian, G. A survey of research hotspots and frontier trends of recommendation systems from the perspective of knowledge graph. Expert Syst. Appl. 2021, 165, 113764. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Q.; Sun, Y.; Chen, J. Aviation equipment fault information fusion based on ontology. In Proceedings of the 2014 International Conference on Computer, Communications and Information Technology (CCIT 2014), Beijing, China, 16–17 January 2014; pp. 8–10. [Google Scholar]
- Mi, B.; Fan, Y.; Sun, Y. Ontology Intelligent Construction Technology for NOTAM. In Proceedings of the 2021 11th International Conference on Intelligent Control and Information Processing (ICICIP), Dali, China, 3–7 December 2021; pp. 137–142. [Google Scholar]
- Qiu, L.; Zhang, A.; Zhang, Y.; Li, S.; Li, C.; Yang, L. An application method of knowledge graph construction for UAV fault diagnosis. Comput. Eng. Appl. 2023, 59, 280–288. [Google Scholar]
- Nie, T.; Zeng, j.; Cheng, Y.; Ma, L. Knowledge graph construction technology and its application aircraft power sys tem fault diagnosis. Acta Aeronaut. Et Astronaut. Sin. 2022, 43, 46–62. [Google Scholar]
- Li, Z.; Dai, Y.; Li, X. Construction of sentimental knowledge graph of Chinese government policy comments. Knowl. Manag. Res. Pract. 2022, 20, 73–90. [Google Scholar] [CrossRef]
- Molina-Villegas, A.; Muñiz-Sanchez, V.; Arreola-Trapala, J.; Alcántara, F. Geographic named entity recognition and disambiguation in Mexican news using word embeddings. Expert Syst. Appl. 2021, 176, 114855. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, J.; Zhu, S.; Gu, Y.; Dai, H.; Xu, J.; Zhu, Y.; Wu, T. Knowledge Graph Construction for Foreign Military Unmanned Systems. In Proceedings of the CCKS 2022-Evaluation Track: 7th China Conference on Knowledge Graph and Semantic Computing Evaluations, CCKS 2022, Qinhuangdao, China, 24–27 August 2022; Revised Selected Papers. pp. 127–137. [Google Scholar]
- Bao, Y.; An, Y.; Cheng, Z.; Jiao, R.; Zhu, C.; Leng, F.; Wang, S.; Wu, P.; Yu, G. Named entity recognition in aircraft design field based on deep learning. In Proceedings of the International Conference on Web Information Systems and Applications, Guangzhou, China, 23–25 September 2020; pp. 333–340. [Google Scholar]
- Wang, H.; Zhu, H.; Lin, H. Research on Causality Extraction of Civil Aviation Accident. Comput. Eng. Appl. 2020, 56, 6. [Google Scholar]
- Goldberg, Y.; Levy, O. word2vec Explained: Deriving Mikolov et al.’s negative-sampling word-embedding method. arXiv 2014, arXiv:1402.3722. preprint. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Sarzynska-Wawer, J.; Wawer, A.; Pawlak, A.; Szymanowska, J.; Stefaniak, I.; Jarkiewicz, M.; Okruszek, L. Detecting formal thought disorder by deep contextualized word representations. Psychiatry Res. 2021, 304, 114135. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J. Relation classification via convolutional deep neural network. In Proceedings of the COLING 2014, the 25th international conference on computational linguistics: Technical papers, Dublin, Ireland, 23–29 August 2014; pp. 2335–2344. [Google Scholar]
- Zeng, D.; Liu, K.; Chen, Y.; Zhao, J. Distant supervision for relation extraction via piecewise convolutional neural networks. In Proceedings of the 2015 conference on empirical methods in natural language processing, Lisbon, Portugal, 17–21 September 2015; pp. 1753–1762. [Google Scholar]
- Xu, Y.; Mou, L.; Li, G.; Chen, Y.; Peng, H.; Jin, Z. Classifying relations via long short term memory networks along shortest dependency paths. In Proceedings of the 2015 conference on empirical methods in natural language processing, Lisbon, Portugal, 17–21 September 2015; pp. 1785–1794. [Google Scholar]
- Zhang, N.; Deng, S.; Sun, Z.; Wang, G.; Chen, X.; Zhang, W.; Chen, H. Long-tail relation extraction via knowledge graph embeddings and graph convolution networks. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; pp. 3016–3025. [Google Scholar]
- E, H.; Zhang, W.; Xiao, S.; Cheng, R.; Hu, Y.; Zhou, Y.; Niu, P. Survey of Entity Relationship Extraction Based on Deep Learning. J. Sofrware 2019, 30, 1793–1818. [Google Scholar]
- Zhong, Z.; Chen, D. A Frustratingly Easy Approach for Entity and Relation Extraction. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, Virtual, Online, 6–11 June 2021; pp. 50–61. [Google Scholar]
- Yu, B.; Zhang, Z.; Shu, X.; Liu, T.; Wang, Y.; Wang, B.; Li, S. Joint extraction of entities and relations based on a novel decomposition strategy. In Proceedings of the 24th European Conference on Artificial Intelligence, ECAI 2020, including 10th Conference on Prestigious Applications of Artificial Intelligence, PAIS 2020, Santiago de Compostela, Spain, 29 August–8 September 2020; pp. 2282–2289. [Google Scholar]
- Wei, Z.; Su, J.; Wang, Y.; Tian, Y.; Chang, Y. A novel cascade binary tagging framework for relational triple extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Virtual, Online, 5–10 July 2020; pp. 1476–1488. [Google Scholar]
- Wang, Y.; Yu, B.; Zhang, Y.; Liu, T.; Zhu, H.; Sun, L. TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking. In Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020, Virtual, Online, 8–13 December 2020; pp. 1572–1582. [Google Scholar]
- Zheng, H.; Wen, R.; Chen, X.; Yang, Y.; Zhang, Y.; Zhang, Z.; Zhang, N.; Qin, B.; Xu, M.; Zheng, Y. PRGC: Potential relation and global correspondence based joint relational triple extraction. In Proceedings of the Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL-IJCNLP 2021, Virtual, Online, 1–6 August 2021; pp. 6225–6235. [Google Scholar]
- Noy, N.F.; McGuinness, D.L. Ontology Development 101: A Guide to Creating Your First Ontology; Stanford University: Stanford, CA, USA, 2001. [Google Scholar]
- Wu, Y.; Zhu, Y.; Li, J.; Zhang, C.; Gong, T.; Du, X.; Wu, T. Unmanned Aerial Vehicle Knowledge Graph Construction with SpERT. In Proceedings of the China Conference on Knowledge Graph and Semantic Computing, Shenyang, China, 24–27 August 2023; pp. 151–159. [Google Scholar]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Wang, S.; Hu, G. Revisiting pre-trained models for Chinese natural language processing. In Proceedings of the Findings of the Association for Computational Linguistics, ACL 2020: EMNLP 2020, Virtual, Online, 16–20 November 2020; pp. 657–668. [Google Scholar]
- Eberts, M.; Ulges, A. Span-based joint entity and relation extraction with transformer pre-training. In Proceedings of the 24th European Conference on Artificial Intelligence, ECAI 2020, including 10th Conference on Prestigious Applications of Artificial Intelligence, PAIS 2020, Santiago de Compostela, Spain, 29 August–8 September 2020; pp. 2006–2013. [Google Scholar]
- Yan, M.; Lou, X.; Chan, C.A.; Wang, Y.; Jiang, W. A semantic and emotion-based dual latent variable generation model for a dialogue system. CAAI Trans. Intell. Technol. 2023, 1–12. [Google Scholar] [CrossRef]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Yang, Z. Pre-training with whole word masking for chinese bert. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3504–3514. [Google Scholar] [CrossRef]
- Riedel, S.; Yao, L.; McCallum, A. Modeling relations and their mentions without labeled text. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2010, Barcelona, Spain, 20–24 September 2010; Proceedings, Part III 21. pp. 148–163. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Relation | Examples | Number |
|---|---|---|
| UAV and Engine | RQ-4 Global Hawk—Rolls-Royce AE 3007 | 88 |
| UAV and UAV | RQ-4 Global Hawk—ACTD Prototype | 974 |
| UAV and Events | RQ-4 Global Hawk—Afghanistan War | 135 |
| UAV and Country | RQ-4 Global Hawk—United States | 363 |
| UAV and Organization | RQ-4 Global Hawk—Northrop Grumman | 702 |
| Hyperparameter | Value |
|---|---|
| Batch size | 8 |
| Sequence length | 256 |
| 0.5 | |
| 0.1 | |
| Warmup proportion | 0.05 |
| Decay rate | 0.5 |
| Learning rate | 1 × 10−3 |
| Embedding learning rate | 1 × 10−4 |
| Dropout | 0.3 |
| Loss | CE |
| Optimizer algorithm | Adam |
| Model | P (%) | R (%) | F1 (%) |
|---|---|---|---|
| CasRel | 87.71 | 90.53 | 89.10 |
| TPLinker | 89.35 | 90.67 | 90.01 |
| PGCN | 93.54 | 91.62 | 92.57 |
| UASR (Our Model) | 93.58 | 92.24 | 92.91 |
| Model | P (%) | R (%) | F1 (%) |
|---|---|---|---|
| CasRel | 67.12 | 60.16 | 63.86 |
| TPLinker | 62.13 | 67.58 | 64.74 |
| PGCN | 64.93 | 68.35 | 66.59 |
| UASR (Our Model) | 67.79 | 72.86 | 70.23 |
| Model | P (%) | R (%) | F1 (%) |
|---|---|---|---|
| UASR (Our Model) | 67.79 | 72.86 | 70.23 |
| MLP attention | 66.21 | 67.83 | 67.01 |
| Relation attention | 62.51 | 73.49 | 67.55 |
| Model | P (%) | R (%) | F1 (%) |
|---|---|---|---|
| UASR (Our Model) | 67.79 | 72.86 | 70.23 |
| Relation loss | 57.32 | 73.90 | 64.56 |
| Sequence loss | Null | Null | Null |
| Global loss | 39.26 | 28.70 | 33.16 |
| Model | P (%) | R (%) | F1 (%) |
|---|---|---|---|
| RoBERTa-wwm (Our Model) | 67.79 | 72.86 | 70.23 |
| BERT-base | 66.71 | 69.62 | 68.13 |
| BERT-wwm | 65.22 | 73.77 | 69.23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, Y.; Mi, B.; Sun, Y.; Yin, L. Research on the Intelligent Construction of UAV Knowledge Graph Based on Attentive Semantic Representation. Drones 2023, 7, 360. https://doi.org/10.3390/drones7060360
Fan Y, Mi B, Sun Y, Yin L. Research on the Intelligent Construction of UAV Knowledge Graph Based on Attentive Semantic Representation. Drones. 2023; 7(6):360. https://doi.org/10.3390/drones7060360
Chicago/Turabian StyleFan, Yi, Baigang Mi, Yu Sun, and Li Yin. 2023. "Research on the Intelligent Construction of UAV Knowledge Graph Based on Attentive Semantic Representation" Drones 7, no. 6: 360. https://doi.org/10.3390/drones7060360