1. Introduction
Special vehicles refer to motorized machines that are distinct from conventional automobiles in terms of their physical characteristics, such as shape, size, and weight. Those vehicles are typically used for a variety of purposes, including traction, obstacle removal, cleaning, lifting, loading and unloading, mixing, excavation, bulldozing, and road rolling, etc.
The detection of special vehicles in oil and gas pipelines [
1], transmission lines [
2], urban illegal construction [
3], theft, and excavation scenarios is of great importance in order to ensure the security of these areas. This is because in the above scenarios, the presence of special vehicles often represents a high risk that these scenarios will occur, and the nature of special vehicles may cause damage to important property. The use of unmanned aerial vehicles to patrol and search for special vehicles in these scenarios has gradually become a mainstream application trend [
4]. However, due to the particular shape of special vehicles, manual interpretation has low efficiency, high misjudgment, and omission. The application of a deep neural network in the automatic detection of special vehicles has been applied to some extent, but it is not mature yet, and the accuracy of existing methods is relatively poor.
Experts and scholars have proposed a variety of depth neural network methods for target detection in UAV aerial images including various vehicles. Various techniques including CNNs, RNNs, autoencoders, and GANs have been used in vehicle detection and have yielded interesting results for many tasks [
5]. To detect small objects, some techniques divide the last layer of the neural network into multiple variable-sized chunks to extract features at different scales, while other approaches remove the deeper layers of the CNN, allowing the number of feature points of the target to increase [
6]. Liu W et al. proposed the YOLOV5-Tassel network, which combines CSPDarknet53 and BiFPN to efficiently extract minute features and introduces the SimAM attention mechanism in the neck module to extract the features of interest before each detection head [
7]. Zhou H et al. designed a data augmentation method including background replacement and noise increase in order to solve the detection of tiny targets such as cars and planes, and constructed the ADCSPDarkent53 backbone network based on YOLO, which was used to modify the loss of localization function and improve the detection accuracy [
8]. In order to solve the problems of low contrast, dense distribution, and weak features of small targets, Wang J et al. constructed corresponding feature mapping relations, solved the level of adjacency between misaligned features, adjusted and fused shallow spatial features and deep semantic features, and finally improved the recognition ability of small objects [
9]. Li Q et al. proposed a “rotatable region-based residual network (R3-Net)” to distinguish vehicles with different directions from aerial images and used VGG16 or ResNet101 as the backbone of R3-Net [
10]. Li et al. presented an algorithm for detecting sea targets based on UAV. This algorithm optimizes feature fusion calculation and enhances feature extraction at the same time, but the computational load is too large [
11]. Wang et al. used the Initial Horizontal Connection Network to enhance the Feature Pyramid Network. In addition, the use of the Semantic Attention Network to provide semantic features helps to distinguish interesting objects from cluttered backgrounds, but how the algorithm performs as expected in complex and variable aerial images needs further study [
12]. Mantau et al. used visible light and thermal infrared data taken from drones to find poachers. They used YOLOv5 as their basic network and optimized it using migration learning, but this method did not work well with the fusion of different data sources [
13]. Deng et al. proposed a network for detecting small objects in aerial images. They designed a Vehicle Proposal Network, which proposed areas similar to vehicles [
14]. Tian et al. proposed a bineural network review method, which classifies the secondary characteristics of the suspicious target area in the unmanned aerial vehicle image, quickly filters the missing targets in one-stage detection, and achieves high-quality detection of small targets [
15].
In terms of drone inspection of vehicles, Jianghuan Xie et al. proposed an anchor-free detector, called residual feature enhanced pyramid network (RFEPNet), for vehicle detection from the UAV perspective. RFEPNet contains a cross-layer context fusion network (CLCFNet) and a residual feature enhancement module (RFEM) based on pyramid convolution to achieve small target vehicle detection [
16]. Wan Y et al. proposed an adaptive region selection detection framework for the retrieval of targets, such as vehicles in the field of search and rescue, adding a new detection head to achieve better detection of small targets [
17]. Liu Mingjie et al. developed a detection method for small-sized vehicles in drone view, specifically optimized by connecting two ResNet units with the same width and height and adding convolutional operations in the early layers to enrich the spatial information [
18]. Zhongyu Zhang et al. proposed a YOLOv3-based Deeply Separable attention-guided network (DAGN) that combines feature cascading and attention blocks and improves the loss function and candidate merging algorithm of YOLOv3. With these strategies, the performance of vehicle detection is improved while sacrificing some detection speed [
19]. Wang Zhang et al. proposed a novel multiscale and occlusion-aware network (MSOA-Net) for UAV-based vehicle segmentation, which consists of two parts, including a multiscale feature adaptive fusion network (MSFAF-Net) and a region-attention-based three-headed network (RATH-Net) [
20]. Xin Luo et al. developed a fast automatic vehicle detection method for UAV images, constructed a vehicle dataset for target recognition, and proposed a YOLOv3 vehicle detection framework for relatively small and dense vehicle targets [
21]. Navaneeth Balamuralidhar proposed MultEYE that can detect, track, and estimate the velocity of a vehicle in a sequence of aerial images using a multi-task learning approach with a segmentation head added to the backbone of the object detector to form the MultEYE object detection architecture [
22].
When drones patrol oil and gas pipelines, power transmission lines, urban violations and other fields, the size of special vehicles in the images change greatly, and there are many small targets. The feature information carried by camera overhead is limited and changeable, which increases the difficulty of detection. Secondly, the UAV cruises across complex and changeable scenes such as cities, wilderness, green areas, bare soil, and so on. Some areas contain dense targets, which makes it difficult to distinguish some similar objects. Finally, the shooting angle also brings more noise interference, and the special vehicle will be weakened, obscured, or even camouflaged, unable to expose the characteristics of the target. Due to the characteristics of variable target scale, a number of small targets, and the complex background of special vehicles, it is difficult to meet the requirements of speed and accuracy for patrol tasks if the above research methods are directly applied to special vehicle detection from a UAV perspective.
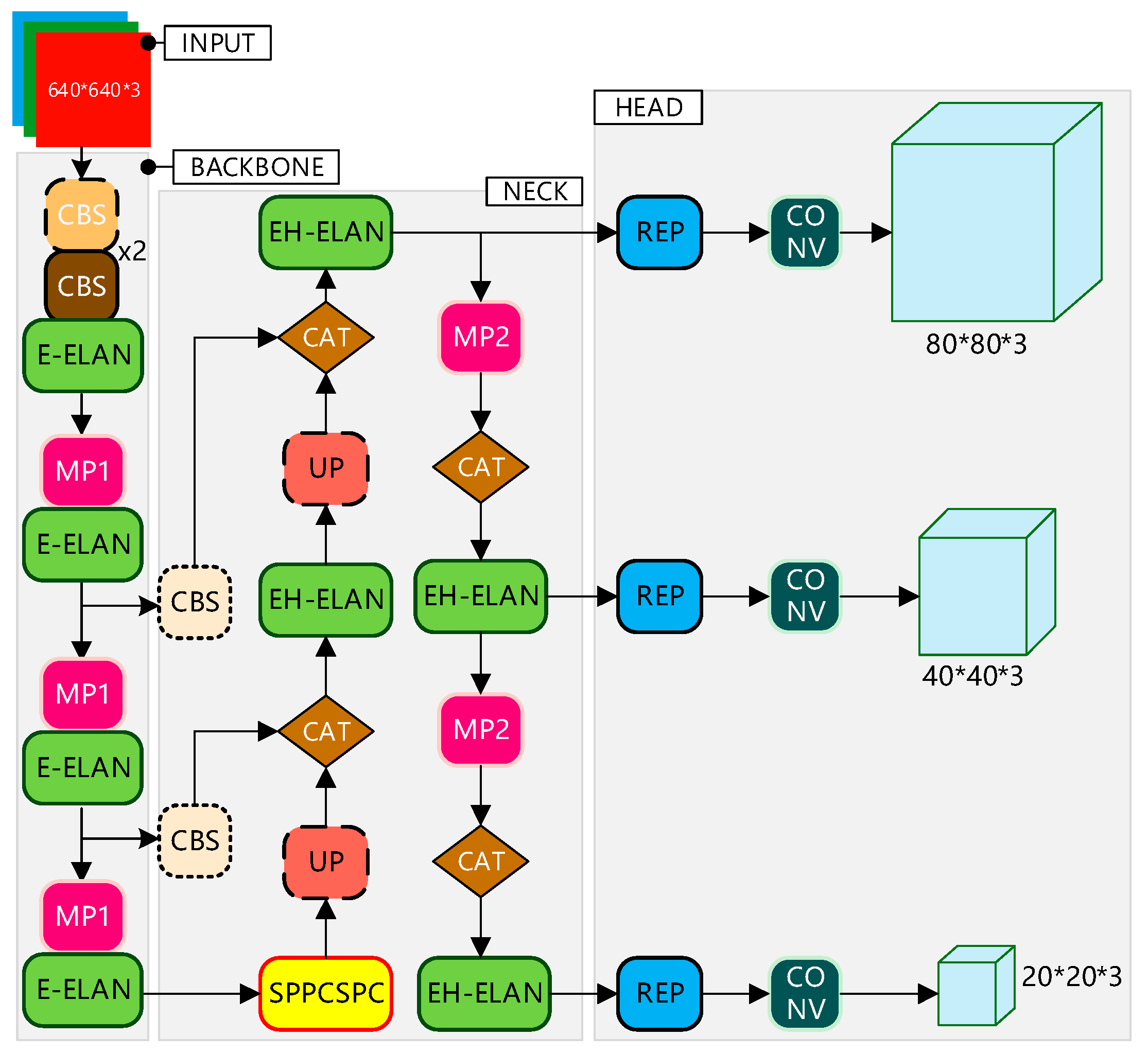
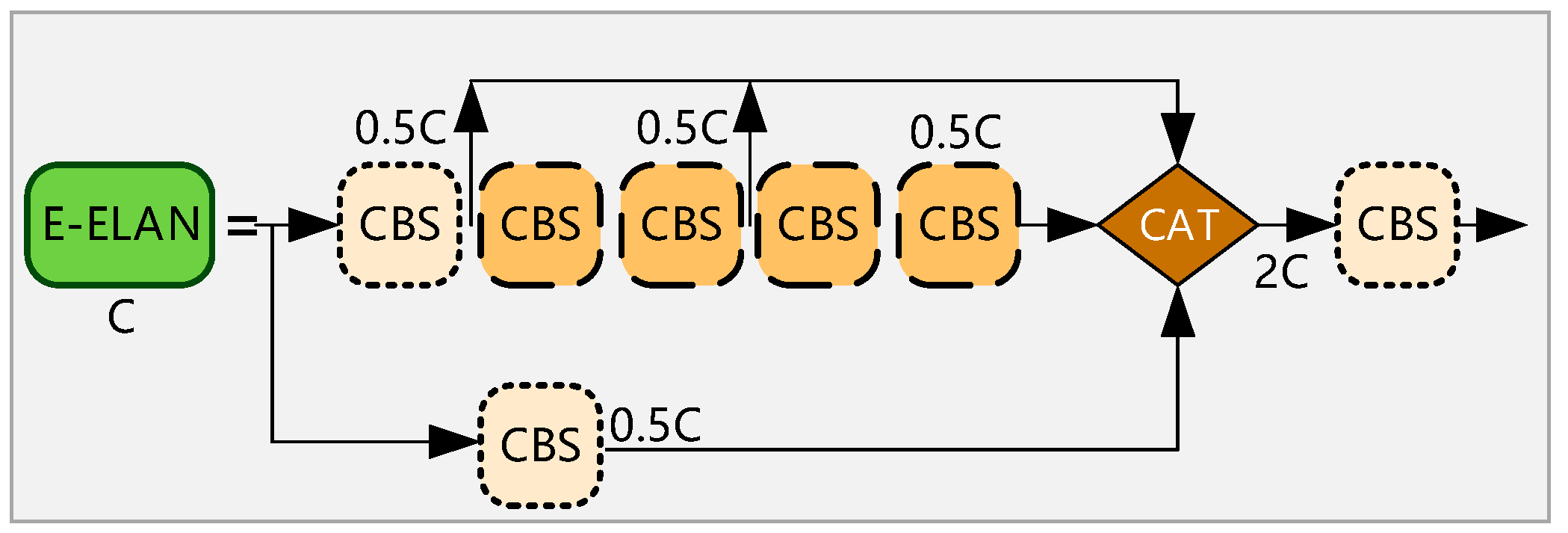
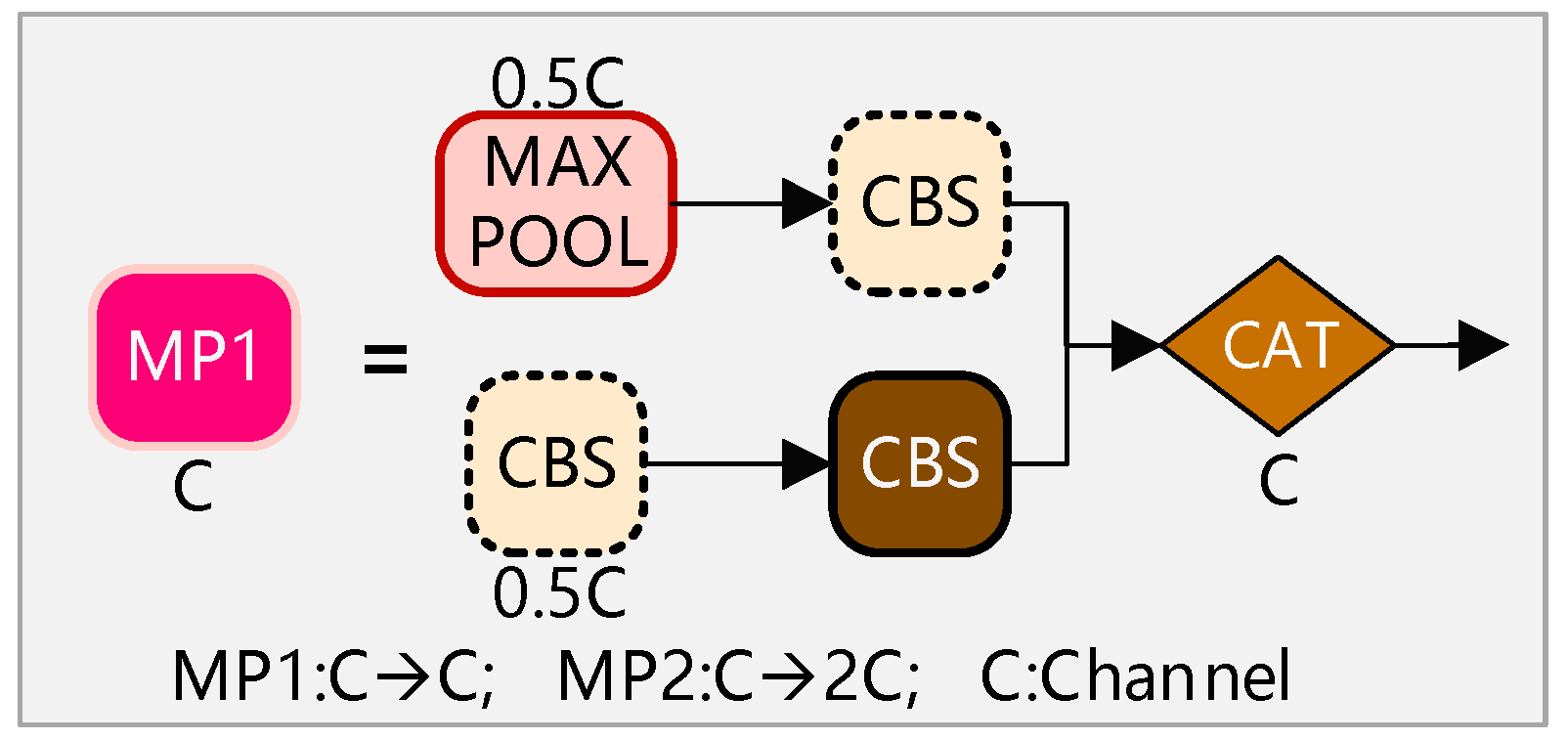
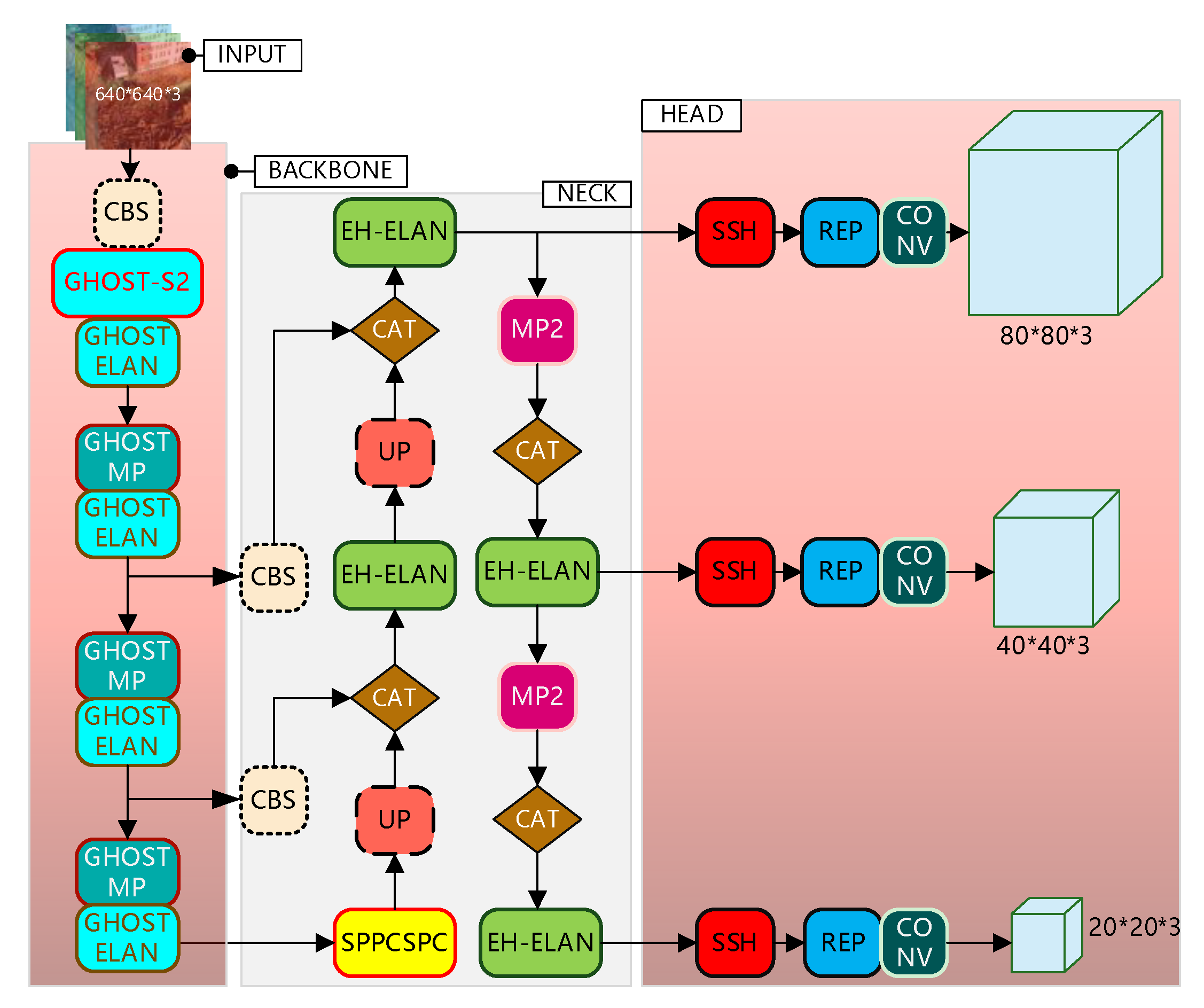
In order to solve the problem of special vehicle detection in complex backgrounds from the perspective of drones, we propose a deep neural network algorithm (YOLO-GNS) based on YOLO and optimized by GhostNet (GN) and Single Stage Headless (SSH), which can be used to detect special vehicles effectively. Firstly, the SSH network structure is added behind the FPN network to parallel several convolution layers, which enhances the convolution layer perception field and extracts the high semantic features of the special vehicle targets. Secondly, in order to improve the detection speed to meet the requirements of UAV, the GPU version of GN (G-GN) is used to reduce the computational consumption of the network. Finally, we have searched for a large number of rare places to take aerial photos and created a dataset containing a large number of special vehicle targets. We have experimented with YOLO-GS on the special vehicle (SEVE) dataset and public dataset to verify the effectiveness of the proposed method.
The rest of this paper is arranged as follows.
Section 2 describes the proposed target detection method YOLO-GNS and the necessary theoretical information.
Section 3 introduces the special data sets, evaluation methods, and detailed experimental results. In
Section 4, we draw conclusions and determine the direction of future research.
3. Results
In order to evaluate the special vehicle detection performance of YOLO-GNS algorithm in this paper, this experiment conducts training and testing on special vehicle (SEVE) dataset. Additionally, to evaluate the general performance of the algorithm, this experiment adds training and testing on the Microsoft COCO dataset.
3.1. Special Vehicle Dataset
Heretofore, there is no public data set of special vehicles from the perspective of drones. Therefore, from January 2021 to June 2022, we used UAV to shoot a large number of videos at multiple heights and angles over construction areas, wilderness, building sites, and other areas. After that, frames are extracted and labeled from these videos to form a special vehicle dataset. This dataset contains 17,992 pairs of images and labels, including 14,392 training sets, 1800 validation sets, and 1800 test sets. The image resolution in SEVE dataset is 1920 × 1080. The types of special vehicles include cranes, traction vehicles, tank trucks, obstacle removal vehicles, cleaning vehicles, lifting vehicles, loading and unloading vehicles, mixing vehicles, excavators, bulldozers, and road rollers. The different scene types include urban, rural, arable, woodland, grassland, construction land, roads, etc. Some examples of the dataset are shown in
Figure 12.
3.2. Experimental Environment and Settings
The experiment is based on 64-bit operating system Windows 10, the CPU is Intel Xeon Gold 6246R, the GPU uses NVIDIA GeForce RTX3090, and the deep learning framework is Pytorch v1.7.0. We use Frames Per Second (FPS) to measure the detection speed, which indicates the number of images processed by the specified hardware per second by the detection model. In the experiment, the FPS for each method is tested on a single GPU device. IOU is set to 0.5, The mAP (mean Average Precision), an index related to the IOU threshold, was used as the standard of detection accuracy. In multi-category target detection, the curve drawn by each category based on its accuracy (Precision) and recall (Recall) is called a P-R curve, in which the average recognition accuracy of a category is equal. AP@0.5 (Average Precision, IoU threshold greater than 0.5) is the size of the area below the P-R curve of this category. mAP@0.5 Average recognition accuracy by all categories AP@0.5 add up to get the average.
Precision and recall are defined as:
Among them, TP was the real case, FP was the false positive case, FN was the false negative case, and C was the total number of categories detected for the target.
Due to the limitation of the experimental device, the input image size is scaled to 800 × 800 pixels. The optimizer uses SGD; the learning rate is 1 × 10−2; the momentum is 0.9; the weight decay is 5 × 10−4, using the Cosine Annealing algorithm to adjust the learning rate; the batch size is 8; and the training durations are 300 epochs, 10 training epochs, and 1 test epochs alternately.
3.3. Experimental Results and Analysis
This paper conducts experiments on the open dataset COCO and the SEVE dataset created in this paper to verify the validity of the proposed methods. The experiment is divided into three parts:
(1) Experiments are carried out on the SEVE dataset to verify the feasibility of the proposed method, and to compare the results with those of other target detection methods on this dataset to illustrate the advantages of this method;
(2) Verify the universality of this method on COCO datasets;
(3) Designing an ablation experiment further demonstrates the validity of the method.
3.3.1. Experiments on SEVE Dataset
In this experiment, the YOLO-GNS algorithm is compared with the prevailing target detection algorithms in the SEVE dataset created in this paper. The experimental results are shown in
Table 1.
Table 1 contains nine categories: C, L, T, M, F, P, R, EL, and EX, corresponding to the SEVE dataset and referring to cranes, loader cars, tank cars, mixer cars, forklifts, piling machines, road rollers, elevate cars, and excavators. The resulting data AP@0.5 represent the average recognition accuracy of this category under different methods, while data in column mAP@0.5 represents the average recognition accuracy of all categories. Params represent the size of the paraments of each method. The resulting data represent the average recognition accuracy for all categories for different datasets under different methods.
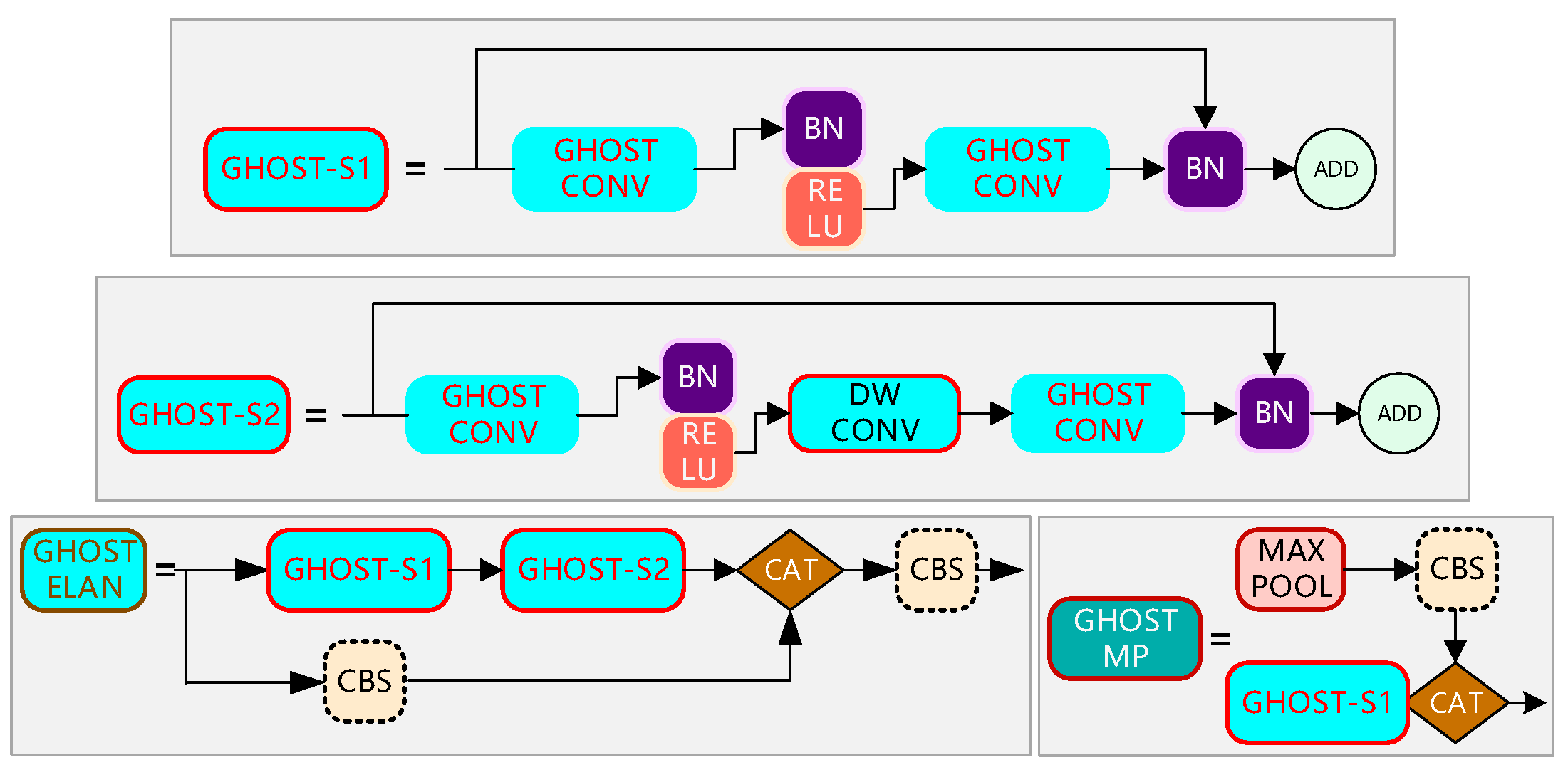
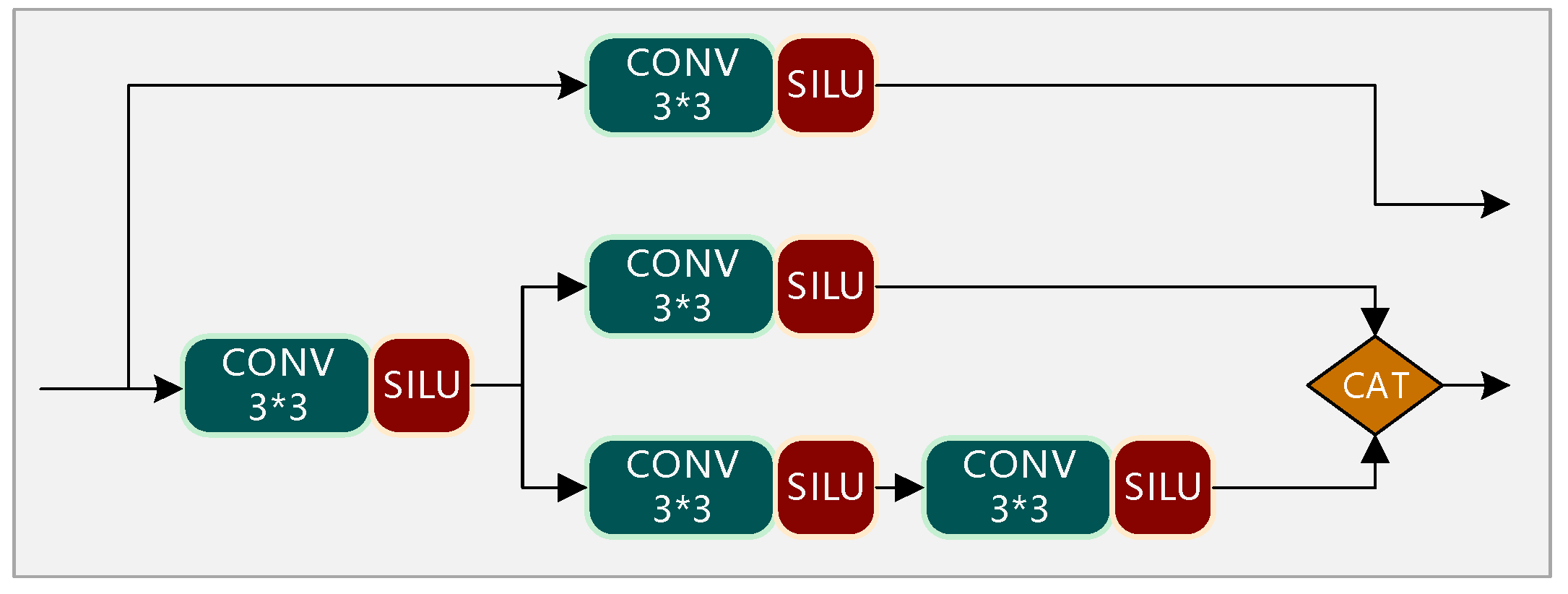
In the SEVE dataset, special vehicle targets vary greatly in scale and there are mostly small targets. The image background is complex and volatile, and it is difficult to distinguish the targets into the background, and some targets are also obscured, which brings some difficulty to the detection. The improved network in this paper has significant accuracy advantages compared with other mainstream target detection algorithms. The method in this paper achieves the best results on the SEVE dataset with 80.1%, which is 4.4% higher accuracy compared to YOLOV7; meanwhile, the mAP is 14.8%, 11.7%, 9.9%, and 8.7% higher compared to four target detection algorithms, namely Faster R-CNN, RetinaNet, YOLOV4, and YOLOV5, respectively; although the YOLOv7 and YOLOv5 detection speeds are close to that of YOLO-GNS, the mAPs are all lower than the methods in this paper. Owing to GhostNet applied in the backbone section, the parameters of YOLO-GNS are reduced by 6.2M. In the case of low differentiation of YOLO series backbone networks, the mAP of this paper’s method is higher and the detection speed is faster, which indicates that this paper’s method makes up for the difference of backbone networks and reflects greater advantages. Due to the reconstructed backbone network and the parallel SSH context network that makes the network structure of this paper in the case of increasing complexity, the detection speed is not reduced and can meet the needs of engineering applications.
The detection results of YOLOV7 and this paper’s method YOLO-GNS are shown in
Figure 13,
Figure 14 and
Figure 15. Column (a) shows the recognition results of the YOLO-GNS network, and column (b) shows the recognition results of the original YOLOV7 network. A comparison of the results of the two networks shows that the YOLO-GNS network in this paper has improved accuracy in terms of bounding box and category probabilities. On the other hand, the recognition of special vehicles, such as cranes, loader cars, tank cars, mixer cars, forklifts, and excavators, and their differences from ordinary vehicles are improved in the proposed model.
In
Figure 13, it is shown that in crowded environments such as cities and roads, YOLO-GNS can identify obscured special vehicles and does not cause false detections, while YOLOV7 produces false detections and missed detections and has lower class probability values than the modified model. In
Figure 14, it is shown that YOLO-GNS distinguishes special vehicles from ordinary vehicles by extracting smaller and more accurate features in environments with camouflage characteristics, such as construction sites, and can identify special vehicles that are highly similar to the background. In
Figure 15, it is shown that the YOLO-GNS network is able to identify different special vehicle types in complex and challenging conditions under poor lighting conditions and bad weather, while the original YOLOV7 model would show quite a few missed and false detections. In conclusion, the YOLO-GNS proposed in this paper is able to identify targets with a high prediction probability under a variety of complex scenarios. In some cases, the base model YOLOV7 cannot accurately identify special vehicles, or it has a lower probability than YOLO-GNS.
3.3.2. Experiments on COCO Datasets
The evaluation metrics are mAP0.5, mAP0.75, and mAP0.5:0.95. mAP0.5 and mAP0.75 are the average accuracy of all target categories calculated at IOU thresholds of 0.5 and 0.75. mAP0.5:0.95 is the average accuracy of 0.5 to 0.95 at 0.05 intervals of 10. mAP0.5:0.95 is the average accuracy at 10 threshold values from 0.5 to 0.95 at 0.05 intervals.
As shown in
Table 2, the experimental data show that the method in this paper also works well on the COCO dataset. The mAP0.5:0.95 is improved by 0.1% for YOLO-GNS compared to the original method with a similar speed. The mAP0.5 of YOLOV4 reaches 65.7% under this dataset; the mAP0.5 of YOLOV5-X is 68.8% under this dataset, but both networks are based on Darknet and its improvements with complex structures, and the detection speed is slightly lower than that of the present method. YOLO-GNS has 0.2% lower mAP0.75 than YOLOV7 on the COCO dataset but 0.1% higher mAP0.5; YOLO-GNS has improved detection speed and higher mAP than YOLOV4 and YOLOV5-X methods, indicating that the method in this paper is still effective on the public dataset COCO.
3.3.3. Ablation Experiment
Ablation experiments were conducted on the SEVE dataset to verify the effect of different network structures on the final detection results, and the experimental results are shown in
Table 3.
With the addition of GhostNet in YOLOV7, the mAP value is improved by 3.5%. GhostNet forms the backbone network by forming GhostMP and GhostELAN modules, which has the advantages of maintaining the recognition performance of similarity and reducing the convolution operation at the same time and continuing to effectively increase the exploitation of feature maps, which is beneficial to the recognition of small targets. The addition of SSH structure in YOLOV7 improves the mAP value by 3.2%. SSH contextual network structure incorporates more concrete information and enhances the recognition of multiple details of special vehicles by increasing the perceptual field of the features, thus improving the detection performance. After adding both GhostNet and SSH structures in YOLOV7, the AP increases by 4.4%, further demonstrating that GhostNet and SSH can improve detection accuracy.
4. Discussion
The evaluation metrics examined in this study were AP and mAP. In the modified network, the values obtained from these criteria were as follows. The AP of cranes was 85.9%, the AP of loader cars was 86.9%, the AP of tank cars was 89.4%, the AP of mixer cars was 91.3%, the AP of forklifts was 90.1%, the AP for piling machines is 89.6%, the AP for road rollers is 69.5%, the AP for elevate cars is 67.3%, and the AP for excavators is 50.8%. Based on the basic results of the YOLOv7 network, it can be said that the proposed network has improved on average by 4.4% in accuracy and 1.6 in FPS, indicating that the improved network has improved speed to some extent with improved accuracy.
In recent years, the employment of artificial intelligence and deep learning methods has become one of the most popular and useful approaches in object recognition. Scholars have made many efforts to better detect vehicles in the context of UAV observations. Jianghuan Xie et al. proposed the residual feature enhanced pyramid network (RFEPNet), which uses pyramidal convolution and residual connectivity structure to enhance the semantic information of vehicle features [
16]. One of the problems of these studies is the inability to detect small vehicles over long distances. Zhongyu Zhang et al. used a YOLOv3-based deep separable attention-guided network (DAGN), improved the loss function of YOLOv3, and combined feature tandem and attention blocks to enable the model to distinguish between important and unimportant vehicle features [
19]. One of the limitations of this study is the lack of types of vehicles and the lack of challenging images. Wang Zhang et al. helped the feature pyramid network (FPN) to handle the scale variation of vehicles by using the multi-scale feature adaptive fusion network (MSFAF-Net) and the region attention-based three-headed network (RATH-Net) [
20]. However, the study did not address the crowded background images, hidden regions, and vehicle target-sensor distance, etc. Xin Luo et al. constructed a vehicle dataset for target recognition and used it for vehicle detection by an improved YOLO [
21], but the dataset did not include special vehicles.
Previous research has focused on general vehicle detection, with a few studies examining the identification of different types of vehicles. In addition, the challenges of specialty vehicle identification, such as the small size of vehicles, crowded environments, hidden areas, and confusion with contexts such as construction sites, have not been comprehensively addressed in these studies. Thus, it can be argued that the unauthorized presence of specialty vehicles in challenging environments and the inaccurate identification of sensitive infrastructures remain some of the most important issues in ensuring public safety. The main goal of this study is to identify multiple types of specialty vehicles and distinguish them from ordinary vehicles at a distance, despite challenges such as the small size of specialty vehicles, crowded backgrounds, and the presence of occlusions.
In this study, the YOLOV7 network was modified to improve the challenges of specialty vehicle identification. A large number of visible images of different types of special vehicles and ordinary vehicles at close and long distances in different environments were collected and labeled to identify multiple types of special vehicles and distinguish them from ordinary vehicles. Considering the limited computational power of the airborne system, GhostNet is introduced to reduce the computational cost of the proposed algorithm. The proposed algorithm facilitates the deployment of airborne systems by using linear transformation to generate feature maps in GhostNet instead of the usual convolutional computation and requires less FLOP. On the other hand, the SSH structure is shown to have the ability to improve the detection accuracy of the algorithm. The context network is able to compute the contexts of pixels at different locations from multiple subspaces, which facilitates YOLO-GNS to extract important features from large-scale scenes. For example, in
Figure 13, there are examples of special vehicles that the basic model cannot recognize in some cases. However, the modified model is able to recognize them; moreover, in other cases, they operate with lower accuracy than the modified network. This result indicates that the current network has improved in identifying special vehicles compared to the basic network. By applying these changes in the network structure and using a wide range of data sets, the proposed method is able to identify all specialty vehicle types in challenging environments. In
Figure 14 and
Figure 15, examples of difficult images and poor lighting conditions are provided, all of which have higher recognition accuracy in the modified network than in the basic network.


















{kind=link}
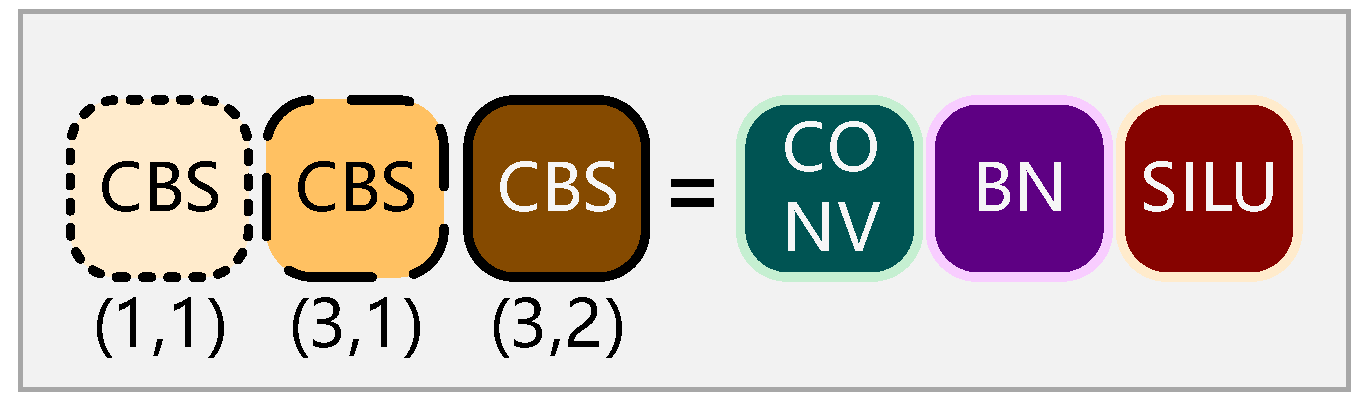{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}