


Graph-Based Semi-Supervised Deep Learning for Indonesian Aspect-Based Sentiment Analysis

Abstract
:1. Introduction
2. Literature Review
Contribution
- Graph dependency parse is used to extract aspect and opinion relationship words.
- The extraction results are used to assist the multi-label labeling process. In addition, semi-supervised learning is used to overcome problems in data labeling by utilizing little labeled data and many unlabeled data.
- GCN and GRN are used for aspect and opinion extraction. CNN and RNN are used for sentiment classification.
- The experimental results show an improvement in our proposed model in the Indonesian-language ABSA task.
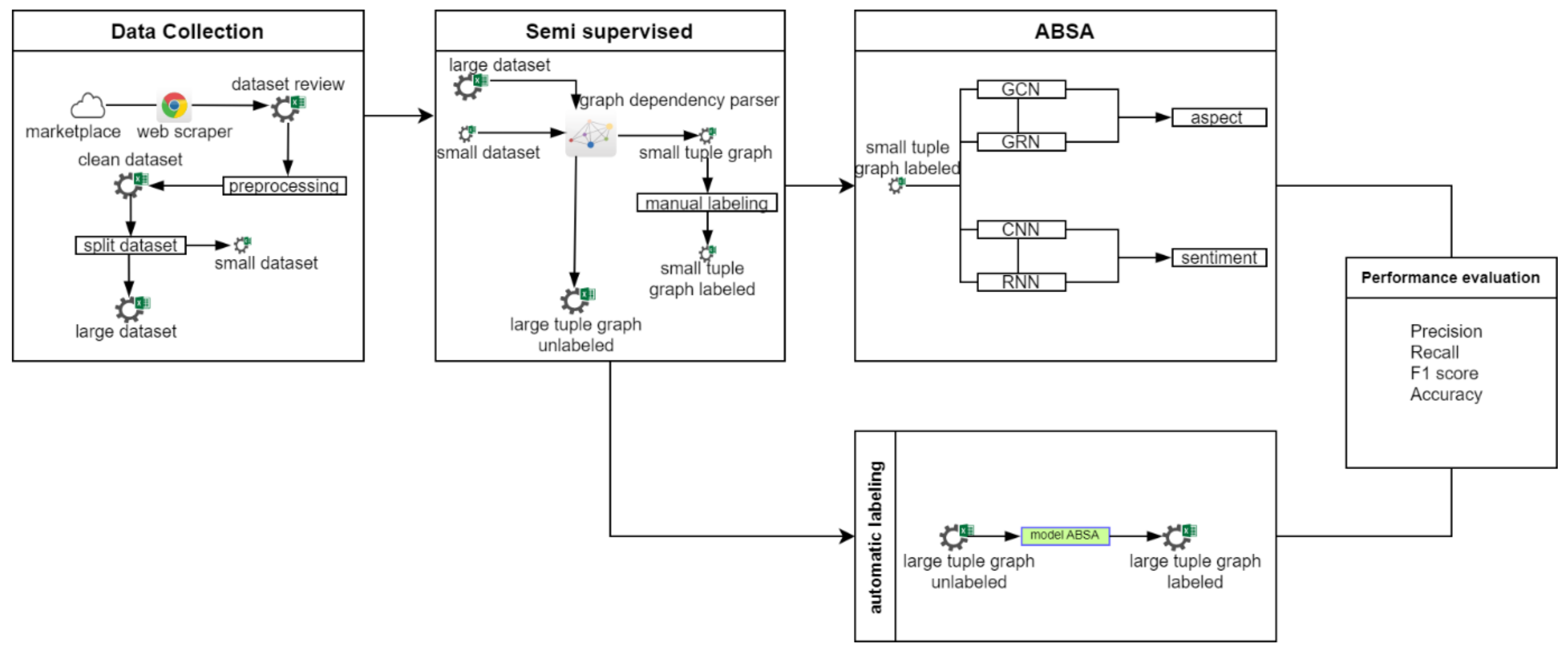
3. Materials and Methods
3.1. Data Collection
3.2. Semi-Supervised and Graph-Based
3.3. Build Model
3.4. Automatic Labeling
3.5. Performance Evaluation
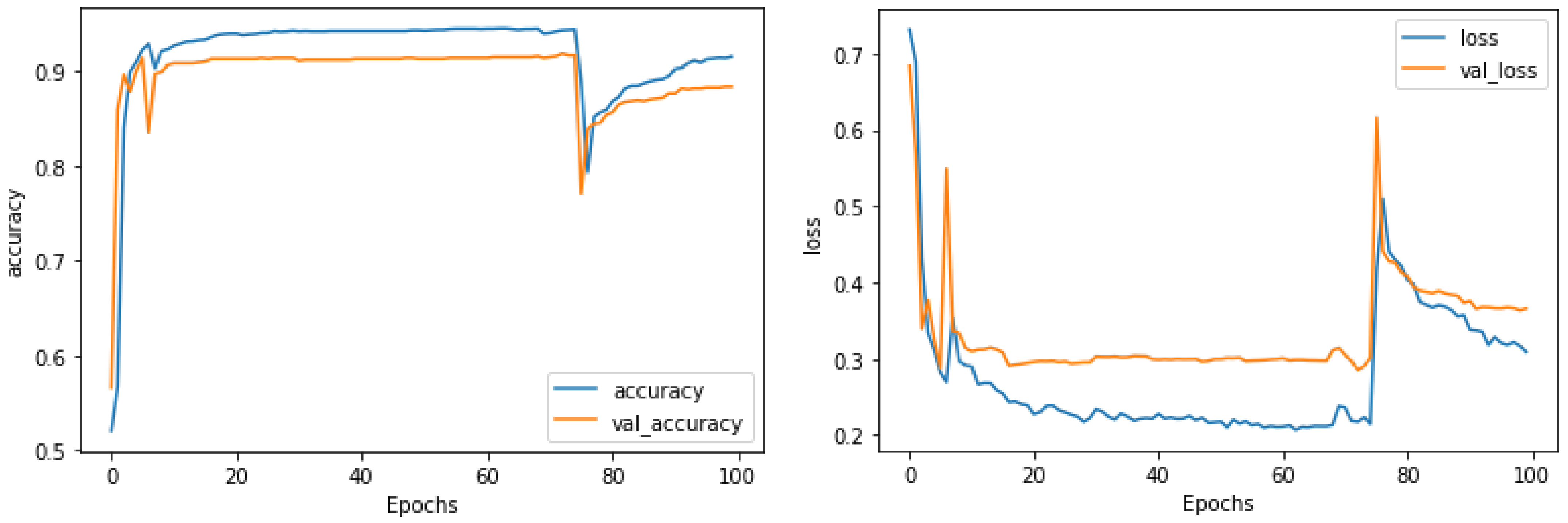
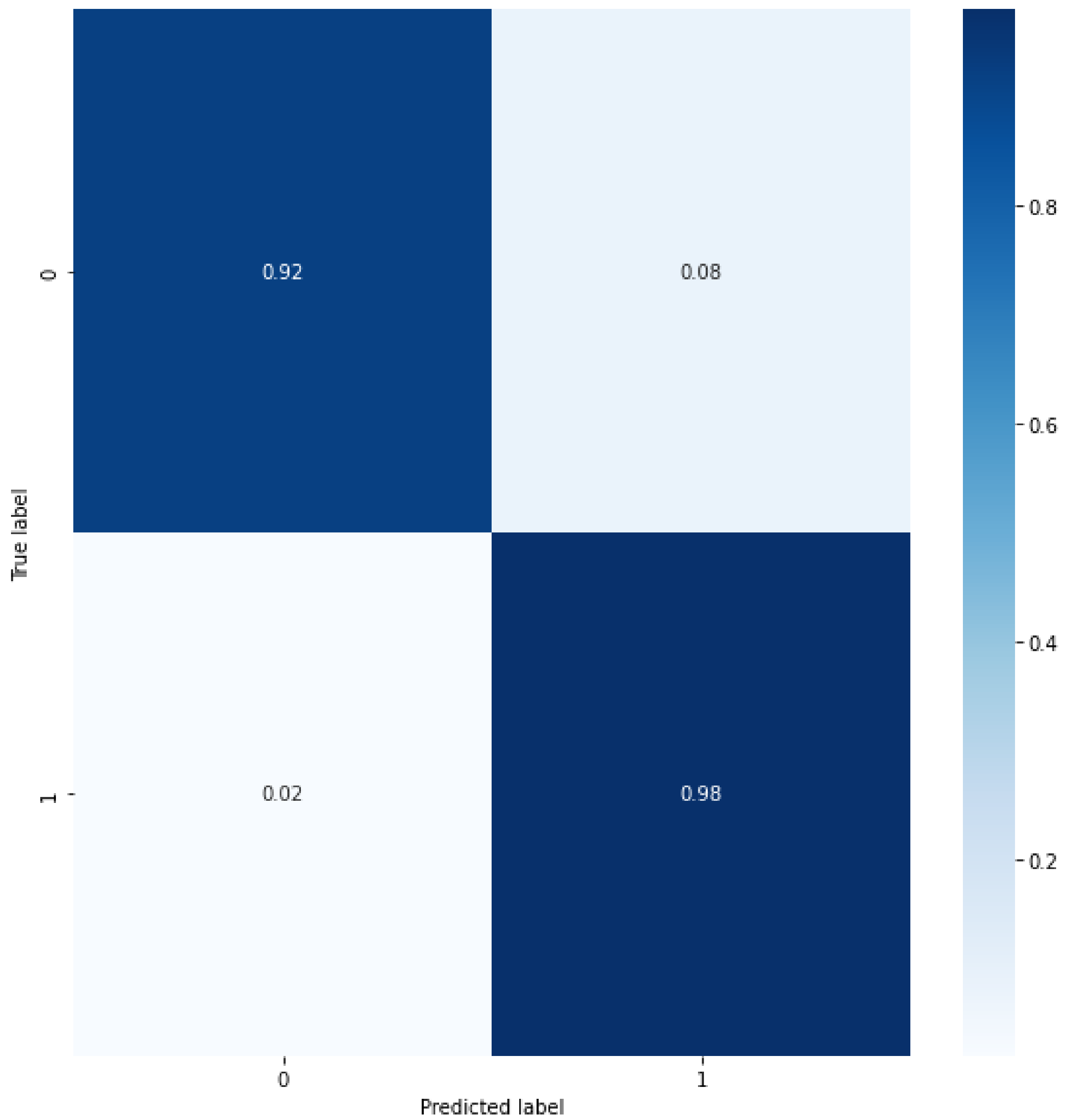
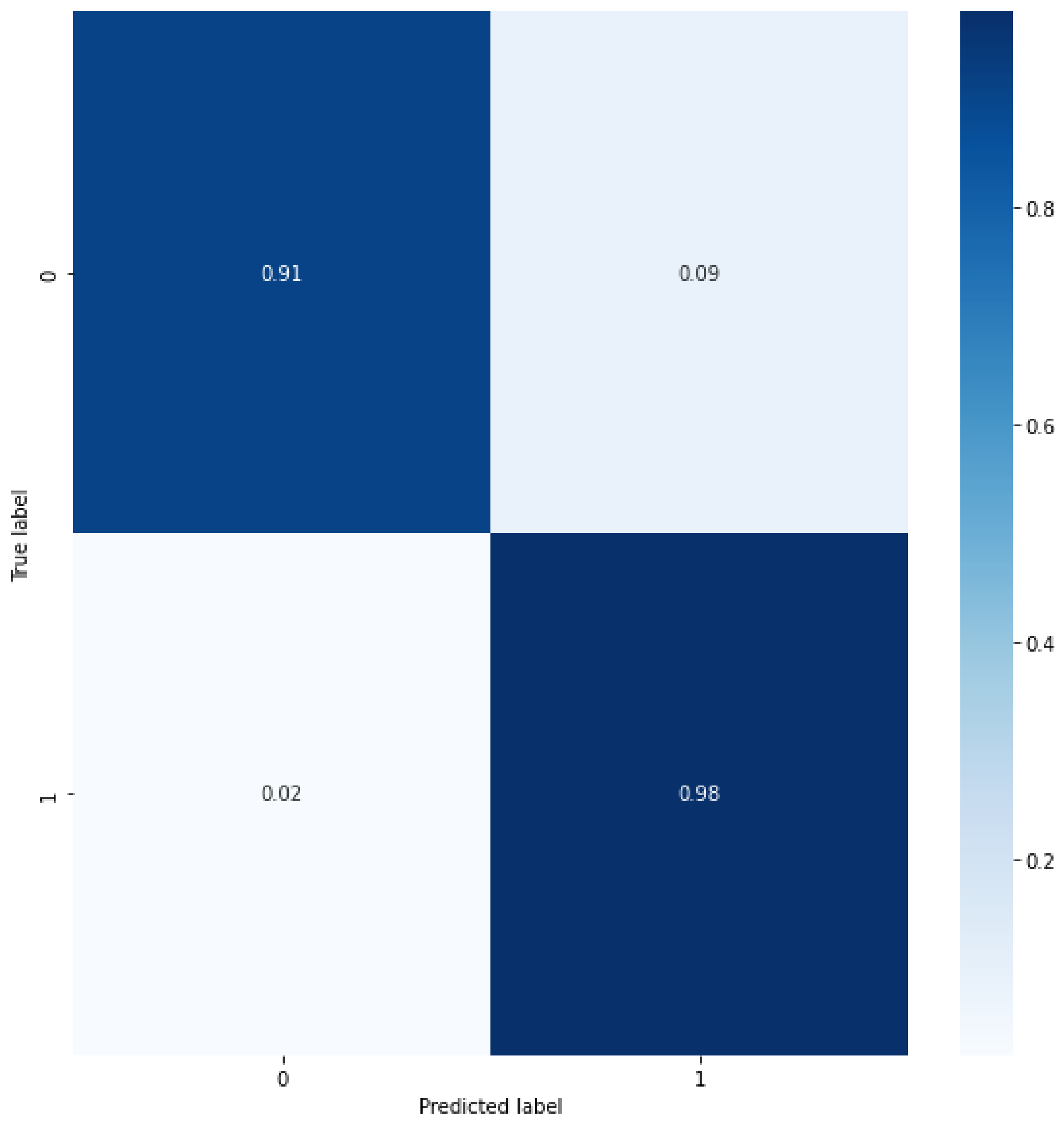
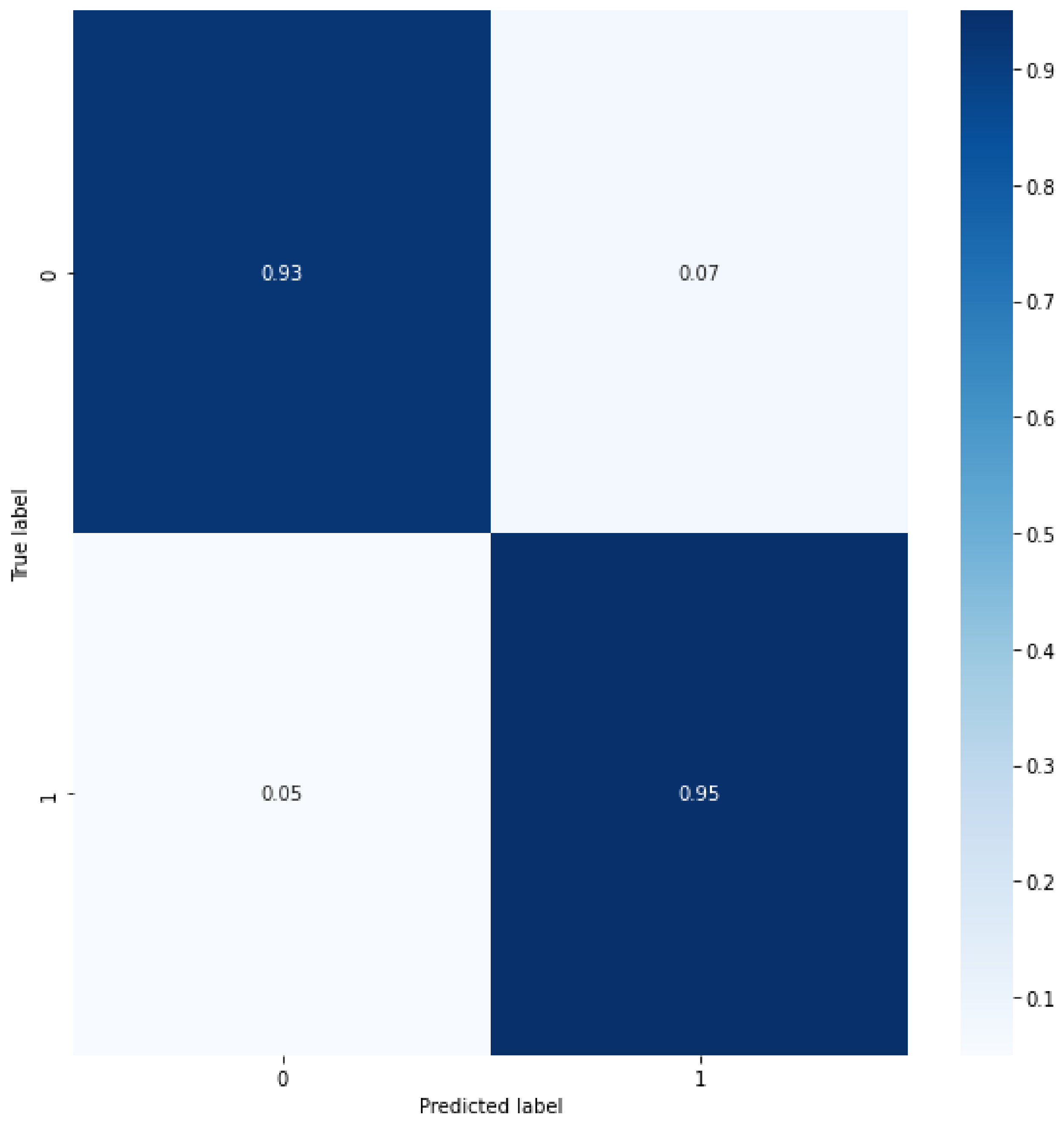
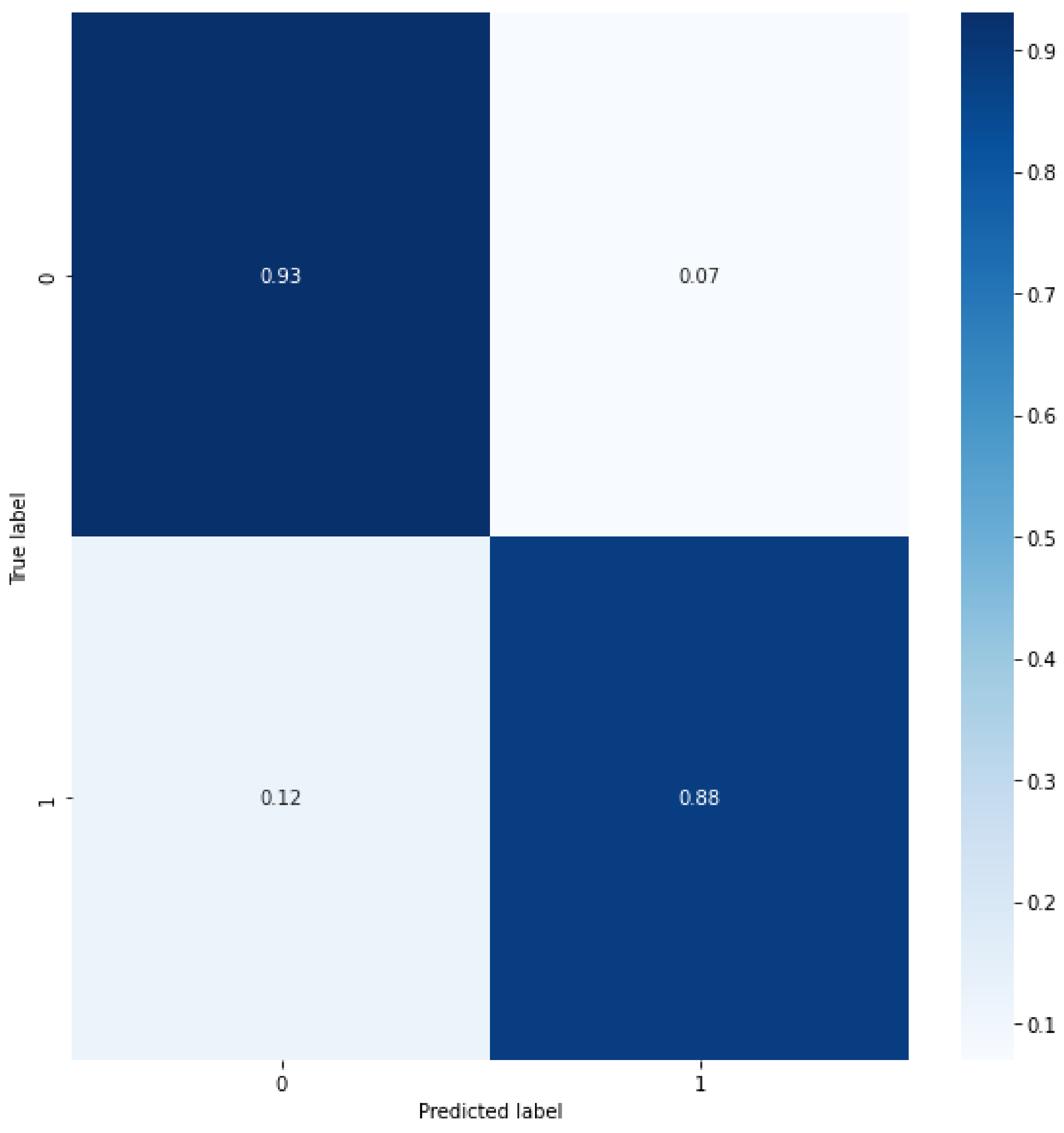
4. Results and Discussion
- Aspect: “jahitan” “sewing”; opinion: “baik” “good”; sentiment: “positif” “positive”; class_aspect: “jahitan” “sewing”.
- Aspect: “respon” “response”; opinion: “lama” “long”; sentiment: “negatif” “negative”; class_aspect: “pelayanan” “service”.
- Aspect: “pengiriman” “delivery”; opinion: “cepat” “fast”; sentiment: “positif” “positive”; class_aspect: “pengiriman” “delivery”.
- Aspect: “harga” “price”; opinion: “murah” “cheap”’; sentiment: “positif” “positive”; class_aspect: “harga” “price”.
- Aspect: “ukuran” “size”; opinion: “kekecilan” “too small”; sentiment: “negatif” “negative”; class_aspect: “ukuran” “size”.
- Aspect: “warna” “color”; opinion: “kusam” “dull”; sentiment: “negatif” “negative”; class_aspect: “warna” “color”.
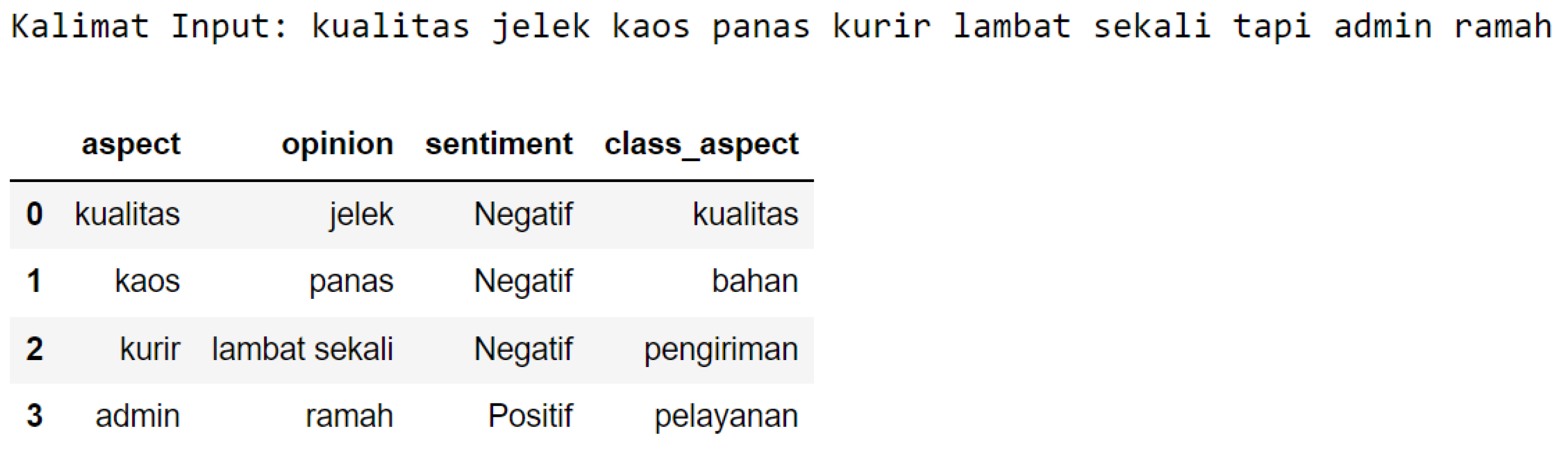
- Aspect: “kualitas” “quality”; opinion: “jelek” “bad”; sentiment: “negatif” “negative”; class_aspect: “kualitas” “quality”.
- Aspect: “kaos” “t-shirts”; opinion: “panas” “hot”; sentiment: “negatif” “negative”; class_aspect: “bahan” “material”.
- Aspect: “kurir” “courier”; opinion: “lambat sekali” “very slow”; sentiment: “negatif” “negative”; class_aspect: “pengiriman” “delivery”.
- Aspect: “admin” “admin”; opinion: “ramah” “friendly”; sentiment: “positif” “positive”; class_aspect: “pelayanan” “service”.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yeasmin, N.; Mahbub, N.I.; Baowaly, M.K.; Singh, B.C.; Alom, Z.; Aung, Z.; Azim, M.A. Analysis and Prediction of User Sentiment on COVID-19 Pandemic Using Tweets. Big Data Cogn. Comput. 2022, 6, 65. [Google Scholar] [CrossRef]
- Al Shamsi, A.A.; Abdallah, S. Sentiment Analysis of Emirati Dialects. Big Data Cogn. Comput. 2022, 6, 57. [Google Scholar] [CrossRef]
- Khabour, S.M.; Al-Radaideh, Q.A.; Mustafa, D. A New Ontology-Based Method for Arabic Sentiment Analysis. Big Data Cogn. Comput. 2022, 6, 48. [Google Scholar] [CrossRef]
- Ettaleb, M.; Barhoumi, A.; Camelin, N.; Dugué, N. Evaluation of weakly-supervised methods for aspect extraction. Procedia Comput. Sci. 2022, 207, 2688–2697. [Google Scholar] [CrossRef]
- Venugopalan, M.; Gupta, D. An enhanced guided LDA model augmented with BERT based semantic strength for aspect term extraction in sentiment analysis. Knowl.-Based Syst. 2022, 246, 108668. [Google Scholar] [CrossRef]
- Shi, L.; Han, D.; Han, J.; Qiao, B.; Wu, G. Dependency graph enhanced interactive attention network for aspect sentiment triplet extraction. Neurocomputing 2022, 507, 315–324. [Google Scholar] [CrossRef]
- Almalis, I.; Kouloumpris, E.; Vlahavas, I. Sector-level sentiment analysis with deep learning. Knowl.-Based Syst. 2022, 258, 109954. [Google Scholar] [CrossRef]
- Sharma, M.; Kandasamy, I.; Vasantha, W.B. Comparison of neutrosophic approach to various deep learning models for sentiment analysis. Knowl.-Based Syst. 2021, 223, 107058. [Google Scholar] [CrossRef]
- Yu, H.; Lu, G.; Cai, Q.; Xue, Y. A KGE Based Knowledge Enhancing Method for Aspect-Level Sentiment Classification. Mathematics 2022, 10, 3908. [Google Scholar] [CrossRef]
- Al-Dabet, S.; Tedmori, S.; AL-Smadi, M. Enhancing Arabic aspect-based sentiment analysis using deep learning models. Comput. Speech Lang. 2021, 69, 101224. [Google Scholar] [CrossRef]
- Ismail, H.; Khalil, A.; Hussein, N.; Elabyad, R. Triggers and Tweets: Implicit Aspect-Based Sentiment and Emotion Analysis of Community Chatter Relevant to Education Post-COVID-19. Big Data Cogn. Comput. 2022, 6, 99. [Google Scholar] [CrossRef]
- Cendani, L.M.; Kusumaningrum, R.; Endah, S.N. Aspect-Based Sentiment Analysis of Indonesian-Language Hotel Reviews Using Long Short-Term Memory with an Attention Mechanism; Springer International Publishing: Berlin/Heidelberg, Germany, 2023; Volume 147, ISBN 9783031151910. [Google Scholar] [CrossRef]
- Ayetiran, E.F. Attention-based aspect sentiment classification using enhanced learning through CNN-BiLSTM networks. Knowl.-Based Syst. 2022, 252, 109409. [Google Scholar] [CrossRef]
- Chen, L.; Wang, Y.; Li, H. Enhancement of DNN-based multilabel classification by grouping labels based on data imbalance and label correlation. Pattern Recognit. 2022, 132, 108964. [Google Scholar] [CrossRef]
- Jasmir, J.; Nurmaini, S.; Tutuko, B. Fine-grained algorithm for improving knn computational performance on clinical trials text classification. Big Data Cogn. Comput. 2021, 5, 60. [Google Scholar] [CrossRef]
- Kanavos, A.; Iakovou, S.A.; Sioutas, S.; Tampakas, V. Large scale product recommendation of supermarket ware based on customer behaviour analysis. Big Data Cogn. Comput. 2018, 2, 11. [Google Scholar] [CrossRef] [Green Version]
- Didi, Y.; Walha, A.; Wali, A. COVID-19 Tweets Classification Based on a Hybrid Word Embedding Method. Big Data Cogn. Comput. 2022, 6, 58. [Google Scholar] [CrossRef]
- Ebrahimi, P.; Basirat, M.; Yousefi, A.; Nekmahmud, M.; Gholampour, A.; Fekete-farkas, M. Social Networks Marketing and Consumer Purchase Behavior: The Combination of SEM and Unsupervised Machine Learning Approaches. Big Data Cogn. Comput. 2022, 6, 35. [Google Scholar] [CrossRef]
- Ng, Q.X.; Yau, C.E.; Lim, Y.L.; Wong, L.K.T.; Liew, T.M. Public sentiment on the global outbreak of monkeypox: An unsupervised machine learning analysis of 352,182 twitter posts. Public Health 2022, 213, 1–4. [Google Scholar] [CrossRef]
- García-Pablos, A.; Cuadros, M.; Rigau, G. W2VLDA: Almost unsupervised system for Aspect Based Sentiment Analysis. Expert Syst. Appl. 2018, 91, 127–137. [Google Scholar] [CrossRef]
- Yadav, A.; Jha, C.K.; Sharan, A.; Vaish, V. Sentiment analysis of financial news using unsupervised approach. Procedia Comput. Sci. 2020, 167, 589–598. [Google Scholar] [CrossRef]
- Kaur, G.; Kaushik, A.; Sharma, S. Cooking is creating emotion: A study on hinglish sentiments of youtube cookery channels using semi-supervised approach. Big Data Cogn. Comput. 2019, 3, 37. [Google Scholar] [CrossRef] [Green Version]
- Macrohon, J.J.E.; Villavicencio, C.N.; Inbaraj, X.A.; Jeng, J. A Semi-Supervised Approach to Sentiment Analysis of Tweets during the 2022 Philippine Presidential Election. Information 2022, 13, 484. [Google Scholar] [CrossRef]
- Deng, Y.; Zhang, C.; Yang, N.; Chen, H. FocalMatch: Mitigating Class Imbalance of Pseudo Labels in Semi-Supervised Learning. Appl. Sci. 2022, 12, 10623. [Google Scholar] [CrossRef]
- Tu, E.; Wang, Z.; Yang, J.; Kasabov, N. Deep semi-supervised learning via dynamic anchor graph embedding in latent space. Neural Networks 2022, 146, 350–360. [Google Scholar] [CrossRef] [PubMed]
- Zaks, G.; Katz, G. ReCom: A deep reinforcement learning approach for semi-supervised tabular data labeling. Inf. Sci. 2022, 589, 321–340. [Google Scholar] [CrossRef]
- Riyadh, M.; Omair Shafiq, M. Towards Multi-class Sentiment Analysis with Limited Labeled Data. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021. [Google Scholar] [CrossRef]
- De Santo, A.; Galli, A.; Moscato, V.; Sperlì, G. A deep learning approach for semi-supervised community detection in Online Social Networks. Knowl.-Based Syst. 2021, 229, 107345. [Google Scholar] [CrossRef]
- Li, N.; Chow, C.Y.; Zhang, J.D. SEML: A semi-supervised multi-task learning framework for aspect-based sentiment analysis. IEEE Access 2020, 8, 189287–189297. [Google Scholar] [CrossRef]
- Zheng, H.; Zhang, J.; Suzuki, Y.; Fukumoto, F.; Nishizaki, H. Semi-Supervised Learning for Aspect-Based Sentiment Analysis. In Proceedings of the 2021 International Conference on Cyberworlds (CW), Caen, France, 28–30 September 2021. [Google Scholar] [CrossRef]
- Ilmania, A.; Abdurrahman; Cahyawijaya, S.; Purwarianti, A. Aspect Detection and Sentiment Classification Using Deep Neural Network for Indonesian Aspect-Based Sentiment Analysis. In Proceedings of the 2018 International Conference on Asian Language Processing, Bandung, Indonesia, 15–17 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 62–67. [Google Scholar] [CrossRef]
- Cahyadi, A.; Khodra, M.L. Aspect-Based Sentiment Analysis Using Convolutional Neural Network and Bidirectional Long Short-Term Memory. In Proceedings of the 2018 5th International Conference on Advanced Informatics: Concept Theory and Applications (ICAICTA), Krabi, Thailand, 14–17 August 2018; pp. 124–129. [Google Scholar] [CrossRef]
- Wahyudi, E.; Kusumaningrum, R. Aspect Based Sentiment Analysis in E-Commerce User Reviews Using Latent Dirichlet Allocation (LDA) and Sentiment Lexicon. In Proceedings of the 3rd International Conference on Informatics and Computational Sciences, Semarang, Indonesia, 29–30 October 2019. [Google Scholar]
- Kim, D.; Kim, Y.J.; Jeong, Y.S. Graph Convolutional Networks with POS Gate for Aspect-Based Sentiment Analysis. Appl. Sci. 2022, 12, 134. [Google Scholar] [CrossRef]
- An, W.; Tian, F.; Chen, P.; Zheng, Q. Aspect-Based Sentiment Analysis with Heterogeneous Graph Neural Network. IEEE Trans. Comput. Soc. Syst. 2022; early access. [Google Scholar] [CrossRef]
- Gu, T.; Zhao, H.; He, Z.; Li, M.; Ying, D. Integrating external knowledge into aspect-based sentiment analysis using graph neural network. Knowl.-Based Syst. 2022, 259, 110025. [Google Scholar] [CrossRef]
- Yang, J.; Dai, A.; Xue, Y.; Zeng, B.; Liu, X. Syntactically Enhanced Dependency-POS Weighted Graph Convolutional Network for Aspect-Based Sentiment Analysis. Mathematics 2022, 10, 3353. [Google Scholar] [CrossRef]
- Wu, H.; Zhang, Z.; Shi, S.; Wu, Q.; Song, H. Phrase dependency relational graph attention network for Aspect-based Sentiment Analysis. Knowl.-Based Syst. 2022, 236, 107736. [Google Scholar] [CrossRef]
- Wang, K.; Shen, W.; Yang, Y.; Quan, X.; Wang, R. Relational Graph Attention Network for Aspect-based Sentiment Analysis. In Proceedings of the Association for Computational Linguistics; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 3229–3238. [Google Scholar] [CrossRef]
- Nayoan, R.A.N.; Fathan Hidayatullah, A.; Fudholi, D.H. Convolutional Neural Networks for Indonesian Aspect-Based Sentiment Analysis Tourism Review. In Proceedings of the 9th International Conference on Information and Communication Technology (ICoICT), Yogyakarta, Indonesia, 3–5 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 60–65. [Google Scholar] [CrossRef]
- Tedjojuwono, S.M.; Neonardi, C. Aspect Based Sentiment Analysis: Restaurant Online Review Platform in Indonesia with Unsupervised Scraped Corpus in Indonesian Language. In Proceedings of the 1st International Conference on Computer Science and Artificial Intelligence (ICCSAI), Jakarta, Indonesia, 28 October 2021; Volume 1, pp. 213–218. [Google Scholar] [CrossRef]
- Manik, L.P.; Febri Mustika, H.; Akbar, Z.; Kartika, Y.A.; Ridwan Saleh, D.; Setiawan, F.A.; Atman Satya, I. Aspect-Based Sentiment Analysis on Candidate Character Traits in Indonesian Presidential Election. In Proceedings of the 2020 International Conference on Radar, Antenna, Microwave, Electronics, and Telecommunications (ICRAMET), Tangerang, Indonesia, 18–20 November 2020; pp. 224–228. [Google Scholar] [CrossRef]
- Yanuar, M.R.; Shiramatsu, S. Aspect Extraction for Tourist Spot Review in Indonesian Language using BERT. In Proceedings of the 2020 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Fukuoka, Japan, 19–21 February 2020; pp. 298–302. [Google Scholar] [CrossRef]
- Chakraborty, A. Aspect Based Sentiment Analysis Using Spectral Temporal Graph Neural Network. arXiv 2022, arXiv:2202.06776v1. [Google Scholar]
- Li, R.; Chen, H.; Feng, F.; Ma, Z.; Wang, X.; Hovy, E. Dual graph convolutional networks for aspect-based sentiment analysis. In Proceedings of the ACL-IJCNLP 2021—59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Proceedings of the Conference, Online, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 6319–6329. [Google Scholar] [CrossRef]
- Liang, B.; Su, H.; Gui, L.; Cambria, E.; Xu, R. Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks. Knowl.-Based Syst. 2022, 235, 107643. [Google Scholar] [CrossRef]
- Phan, H.T.; Nguyen, N.T.; Hwang, D. Aspect-level sentiment analysis: A survey of graph convolutional network methods. Inf. Fusion 2023, 91, 149–172. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Model | Dataset | Result |
|---|---|---|---|
| Aspect-Based Sentiment Analysis in Indonesia | |||
| Nayoan et al. [40] | CNN + POS tag | Tripadvisor (Indonesian tourism review) | Accuracy: sentiment analysis = 0.9522 and aspect category = 0.9551 |
| Cendani et al. [12] | LSTM + attention mechanism | Indonesian hotel review | F1 score = 0.7628 |
| Manik et al. [42] | Support vector machine | Twitter (Indonesian presidential election campaigns in 2018 and 2019) | Accuracy: Aspect = 68.41% Sentiment = 87.56% |
| Yanuar et al. [43] | BERT | Tripadvisor (Indonesian tourist spot review) | F1 score = 0.738 |
| Cahyadi and Khodra [32] | CNN and B-LSTM | Indonesian restaurant reviews | F1 score: Aspect = 0.870 Sentiment = 0.764 |
| Ilmania et al. [31] | GRU, lexicon, and CNN | Indonesian review from the online marketplace Tokopedia | F1 score = 0.8855 |
| Aspect-Based Sentiment Analysis in English | |||
| Kim et al. [34] | GCN + RNN | Restaurant reviews of SemEval 2014, 2015, and 2016. Laptop review of SemEval 2014. Twitter review. | F1 score = 66.64~76.80% |
| Chakraborty [44] | Spectral temporal GNN | Laptop and restaurant review from SemEVal-14. Men’s t-shirt and television review. | F1 score = 78.77 |
| Wang et al. [39] | Relational graph attention network (R-GAT) | SemEval 2014 (domain: restaurant and laptop) and Twitter | F1 score = 81.35 |
| Li et al. [45] | Dual GCN | SemEval 2014 (domain: restaurant and laptop) and Twitter | F1 score = 78.08 |
| Liang et al. [46] | Sentic GCN | SemEval 2014, SemEval 2015, and SemEval 2016 (domain laptop and restaurants) | F1 score = 75.91 |
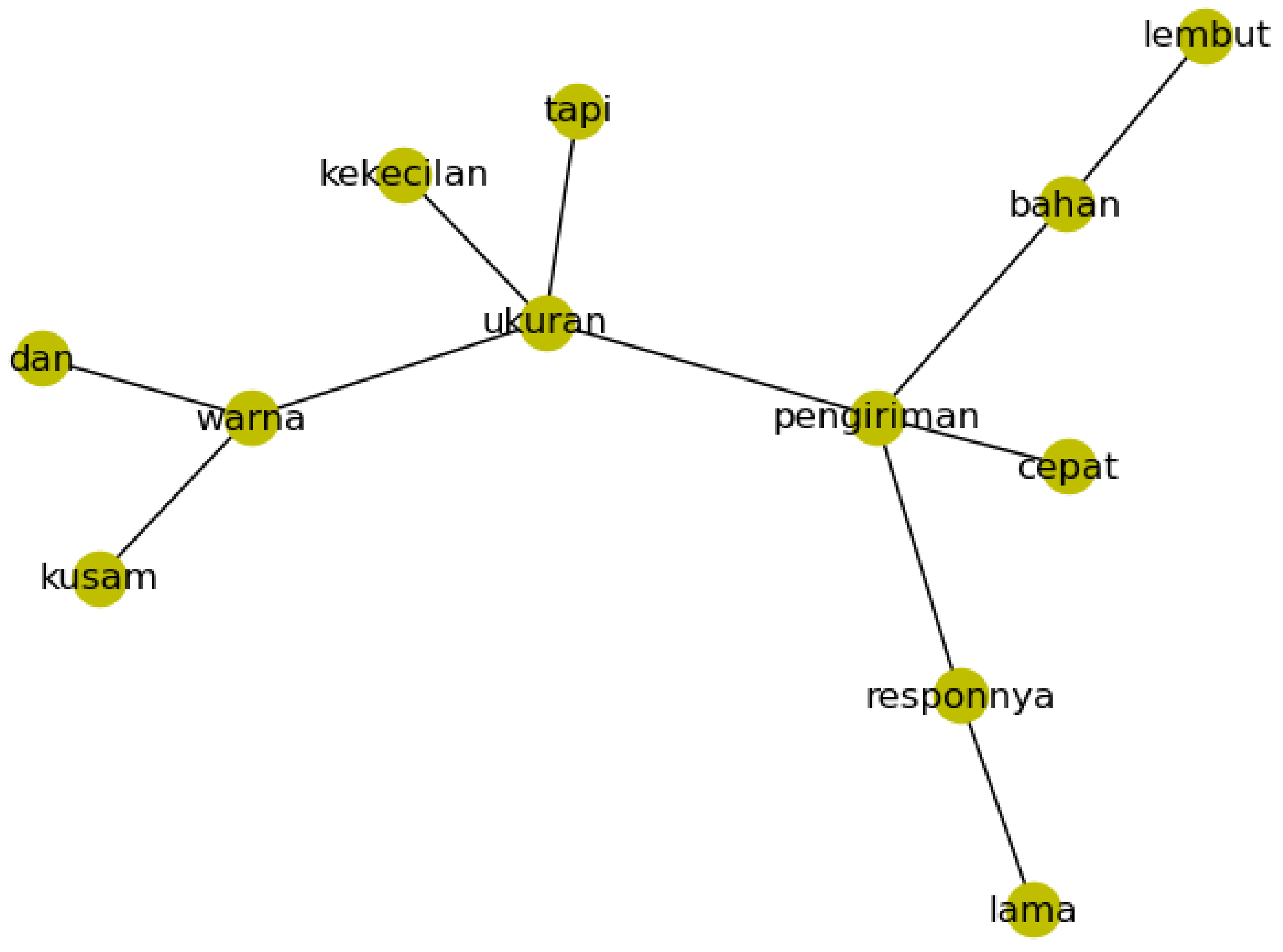
| Review | Aspect | Opinion | True Tuple | Sentiment | Class Aspect |
|---|---|---|---|---|---|
| responnya lama pengiriman cepat bahan lembut tapi ukuran kekecilan dan warna kusam | respon | lama | 1 | −1 | pelayanan |
| responnya lama pengiriman cepat bahan lembut tapi ukuran kekecilan dan warna kusam | pengiriman | cepat | 1 | 1 | pengiriman |
| responnya lama pengiriman cepat bahan lembut tapi ukuran kekecilan dan warna kusam | bahan | lembut | 1 | 1 | bahan |
| responnya lama pengiriman cepat bahan lembut tapi ukuran kekecilan dan warna kusam | ukuran | kekecilan | 1 | −1 | ukuran |
| responnya lama pengiriman cepat bahan lembut tapi ukuran kekecilan dan warna kusam | warna | kusam | 1 | −1 | warna |
| Aspect | Total | Positive | Negative |
|---|---|---|---|
| bahan | 1291 | 615 | 629 |
| kualitas | 240 | 142 | 89 |
| pelayanan | 503 | 248 | 152 |
| jahitan | 123 | 101 | 21 |
| harga | 207 | 176 | 26 |
| ukuran | 479 | 127 | 332 |
| warna | 547 | 112 | 152 |
| pengiriman | 283 | 92 | 182 |
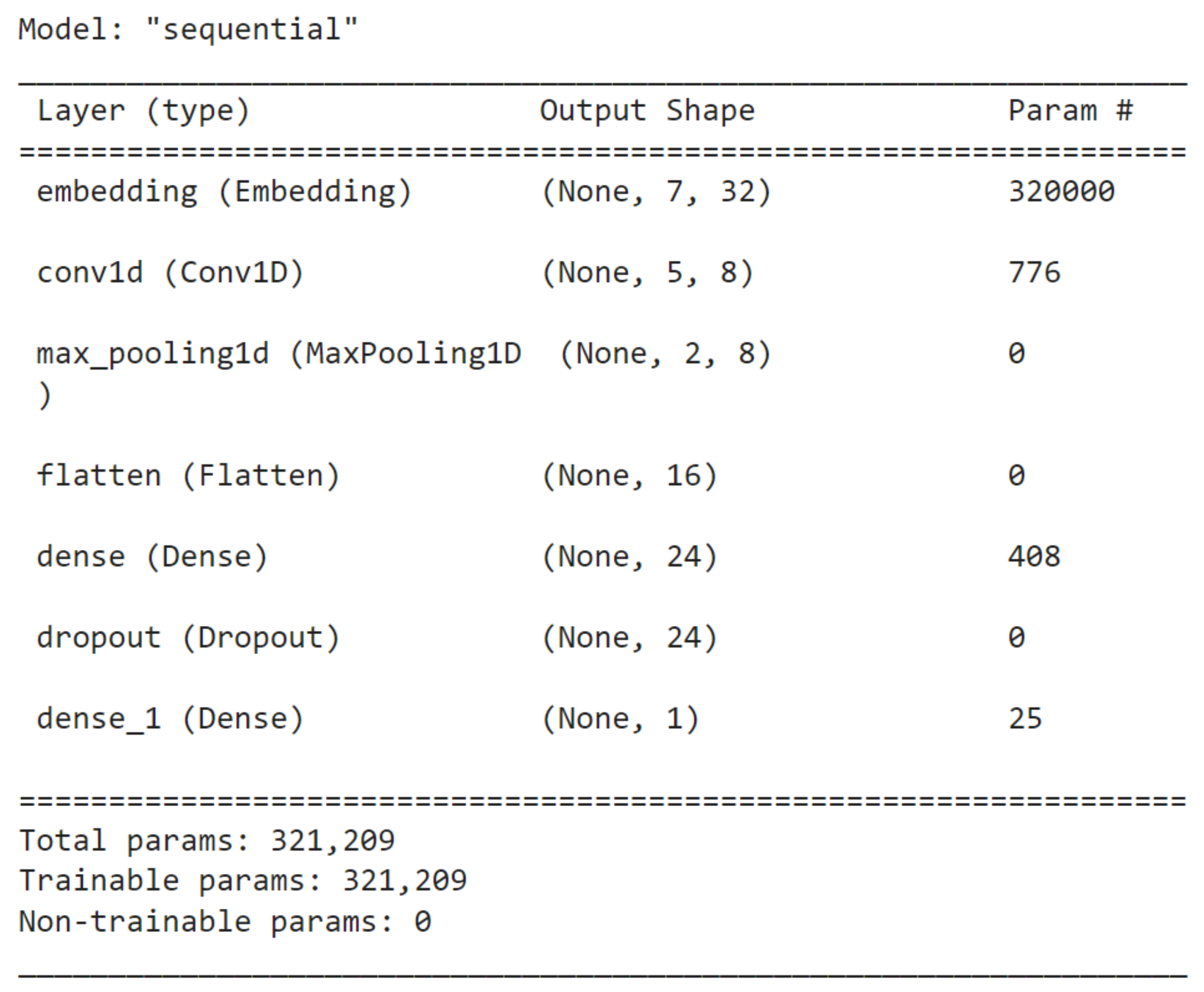
| Model | Number of Units | Batch Size | Number of Filters | Kernel Size | Dropout |
|---|---|---|---|---|---|
| GCN | 321,209 | 32 | 8 | 3 | 0.5 |
| GRN | 64,177 | 32 | - | - | - |
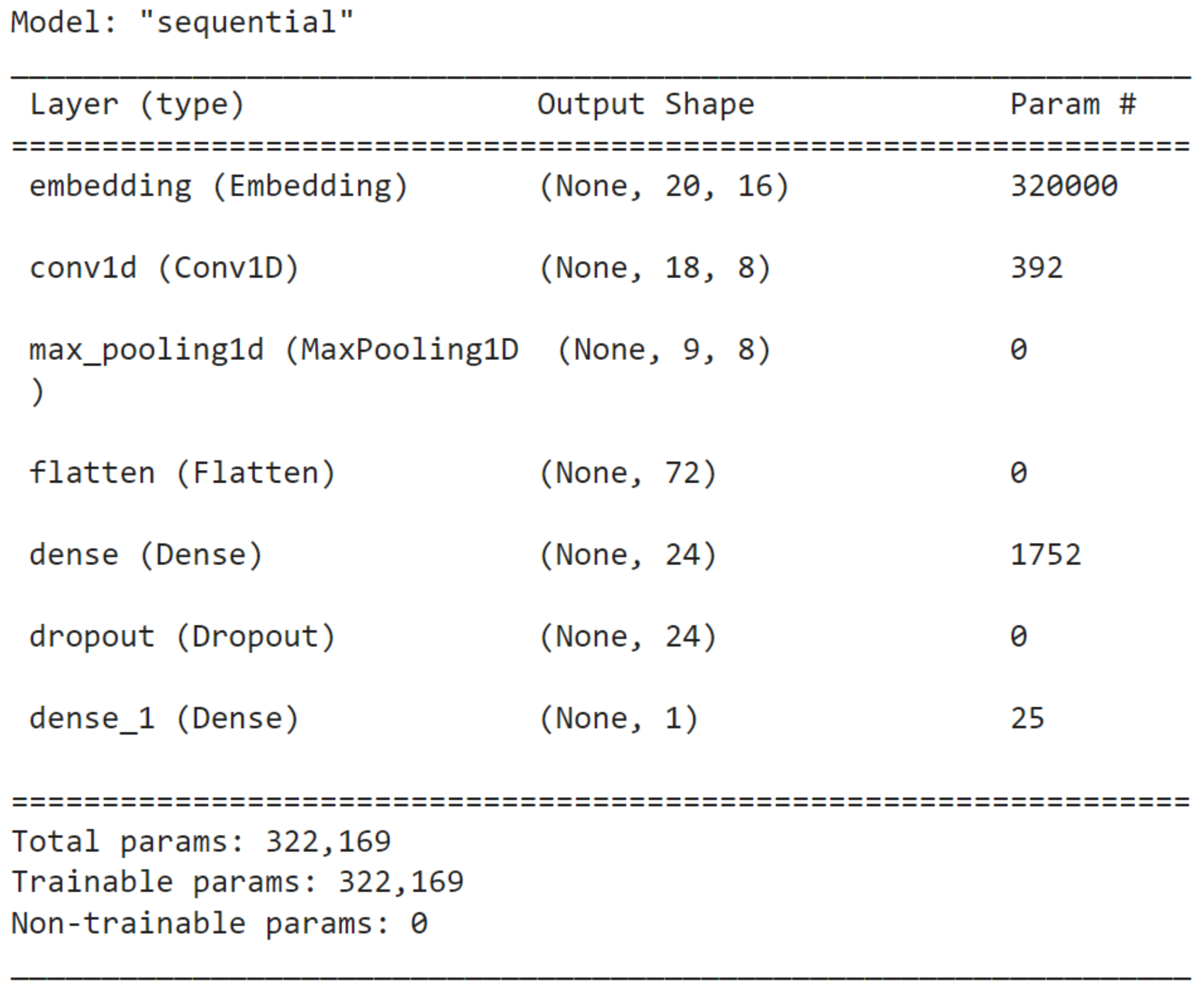
| Model | Number of Units | Batch Size | Number of Filters | Kernel Size | Dropout |
|---|---|---|---|---|---|
| CNN | 322,169 | 32 | 8 | 3 | 0.5 |
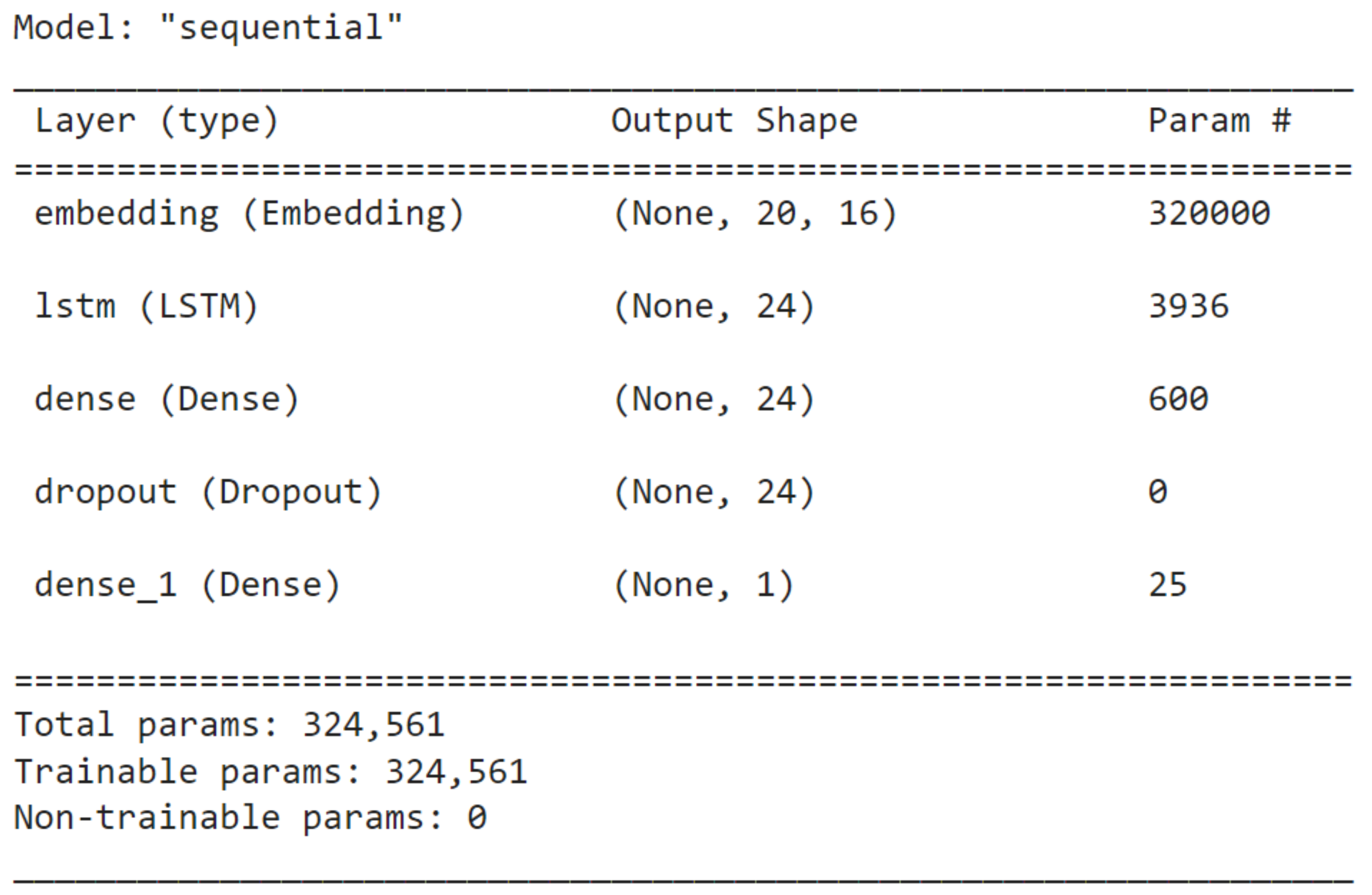
| RNN | 324,561 | 32 | - | - | 0.5 |
| Aspect | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| bahan | 0.98141 | 0.98141 | 0.98141 | 0.98141 |
| kualitas | 0.98750 | 0.98750 | 0.98750 | 0.98750 |
| pelayanan | 0.94632 | 0.94632 | 0.94632 | 0.94632 |
| jahitan | 0.98374 | 0.98374 | 0.98374 | 0.98374 |
| harga | 0.98068 | 0.98068 | 0.98068 | 0.98068 |
| ukuran | 0.97077 | 0.97077 | 0.97077 | 0.97077 |
| warna | 0.98355 | 0.98355 | 0.98355 | 0.98355 |
| pengiriman | 0.96820 | 0.96820 | 0.96820 | 0.96820 |
| Aspect | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| bahan | 0.98296 | 0.98296 | 0.98296 | 0.98296 |
| kualitas | 0.98750 | 0.98750 | 0.98750 | 0.98750 |
| pelayanan | 0.97416 | 0.97416 | 0.97416 | 0.97416 |
| jahitan | 0.98374 | 0.98374 | 0.98374 | 0.98374 |
| harga | 0.97585 | 0.97585 | 0.97585 | 0.97585 |
| ukuran | 0.96869 | 0.96869 | 0.96869 | 0.96869 |
| warna | 0.98720 | 0.98720 | 0.98720 | 0.98720 |
| pengiriman | 0.98940 | 0.98940 | 0.98940 | 0.98940 |
| Aspect | Sentiment | Count Sentiment | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|
| bahan | Positive | 615 | 0.97236 | 0.97236 | 0.97236 | 0.97236 |
| Negative | 673 | 0.92125 | 0.92125 | 0.92125 | 0.92125 | |
| kualitas | Positive | 142 | 0.96479 | 0.96479 | 0.96479 | 0.96479 |
| Negative | 97 | 0.91753 | 0.91753 | 0.91753 | 0.91753 | |
| pelayanan | Positive | 248 | 0.96371 | 0.96371 | 0.96371 | 0.96371 |
| Negative | 254 | 0.90158 | 0.90158 | 0.90158 | 0.90158 | |
| jahitan | Positive | 101 | 0.98020 | 0.98020 | 0.98020 | 0.98020 |
| Negative | 22 | 0.81818 | 0.81818 | 0.81818 | 0.81818 | |
| harga | Positive | 176 | 0.99432 | 0.99432 | 0.99432 | 0.99432 |
| Negative | 31 | 0.80645 | 0.80645 | 0.80645 | 0.80645 | |
| ukuran | Positive | 127 | 0.91339 | 0.91339 | 0.91339 | 0.91339 |
| Negative | 349 | 0.90831 | 0.90831 | 0.90831 | 0.90831 | |
| warna | Positive | 112 | 0.72321 | 0.72321 | 0.72321 | 0.72321 |
| Negative | 432 | 0.97917 | 0.97917 | 0.97917 | 0.97917 | |
| pengiriman | Positive | 92 | 0.97826 | 0.97826 | 0.97826 | 0.97826 |
| Negative | 191 | 0.97906 | 0.97906 | 0.97906 | 0.97906 |
| Aspect | Sentiment | Count Sentiment | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|
| bahan | Positive | 615 | 0.90569 | 0.90569 | 0.90569 | 0.90569 |
| Negative | 673 | 0.92571 | 0.92571 | 0.92571 | 0.92571 | |
| kualitas | Positive | 142 | 0.87324 | 0.87324 | 0.87324 | 0.87324 |
| Negative | 97 | 0.92784 | 0.92784 | 0.92784 | 0.92784 | |
| pelayanan | Positive | 248 | 0.87903 | 0.87903 | 0.87903 | 0.87903 |
| Negative | 254 | 0.91732 | 0.91732 | 0.91732 | 0.91732 | |
| jahitan | Positive | 101 | 0.95050 | 0.95050 | 0.95050 | 0.95050 |
| Negative | 22 | 0.86364 | 0.86364 | 0.86364 | 0.86364 | |
| harga | Positive | 176 | 0.94318 | 0.94318 | 0.94318 | 0.94318 |
| Negative | 31 | 0.83871 | 0.83871 | 0.83871 | 0.83871 | |
| ukuran | Positive | 127 | 0.79528 | 0.79528 | 0.79528 | 0.79528 |
| Negative | 349 | 0.91118 | 0.91118 | 0.91118 | 0.91118 | |
| warna | Positive | 112 | 0.65179 | 0.65179 | 0.65179 | 0.65179 |
| Negative | 432 | 0.95139 | 0.95139 | 0.95139 | 0.95139 | |
| pengiriman | Positive | 92 | 0.90217 | 0.90217 | 0.90217 | 0.90217 |
| Negative | 191 | 0.95288 | 0.95288 | 0.95288 | 0.95288 |
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
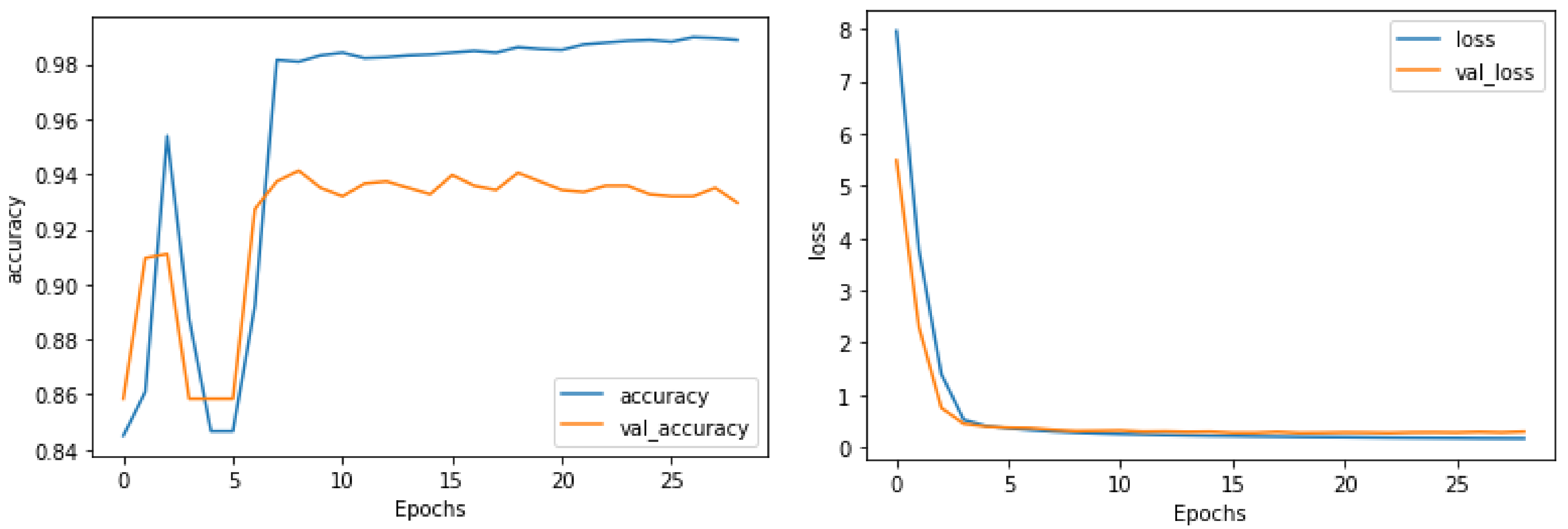
| GCN | 0.96889 | 0.96889 | 0.96889 | 0.96889 |
| GRN | 0.97144 | 0.97144 | 0.97144 | 0.97144 |
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
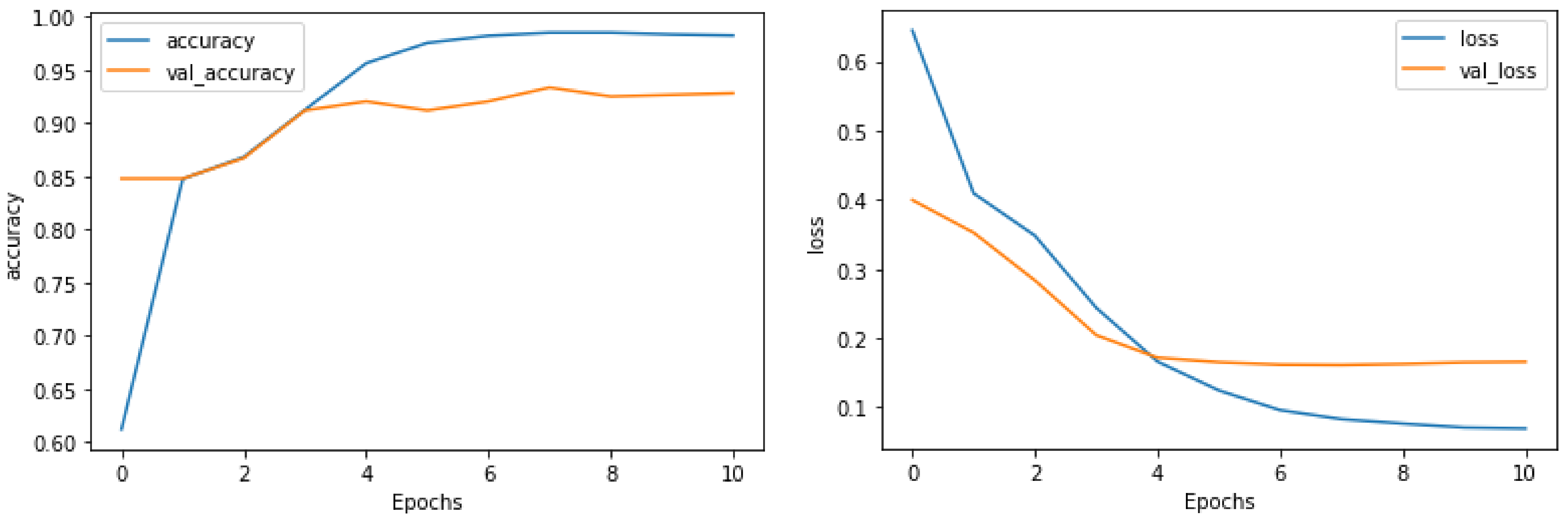
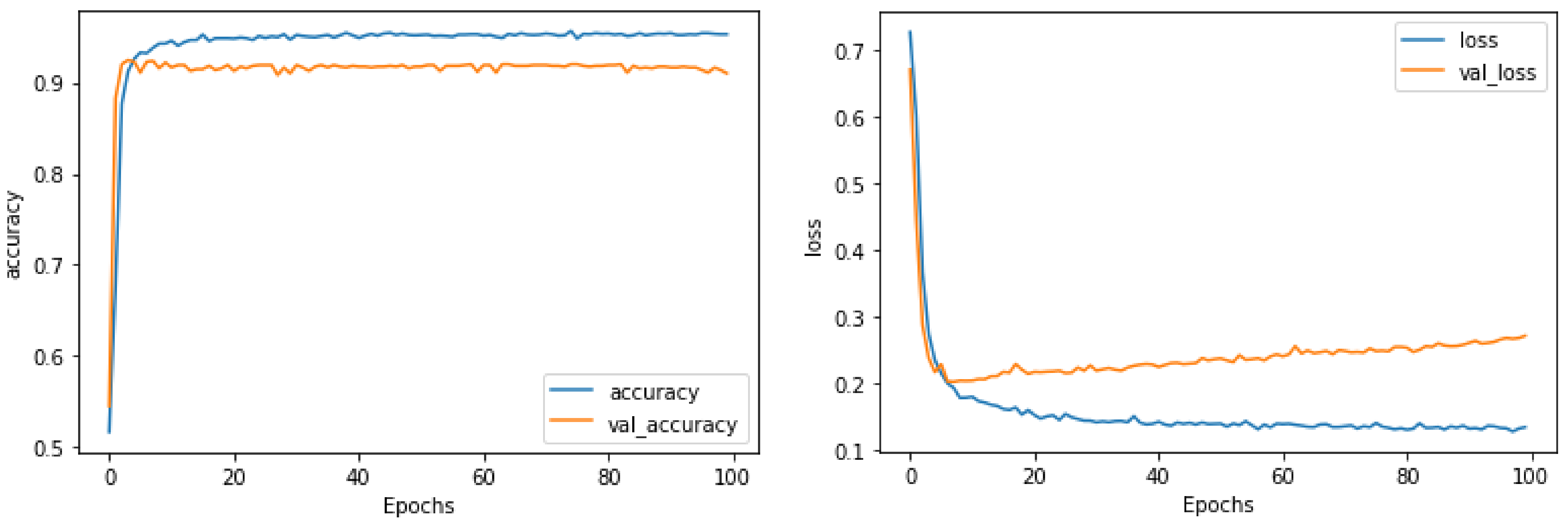
| CNN | 0.94020 | 0.94020 | 0.94012 | 0.94020 |
| RNN | 0.90661 | 0.90661 | 0.90661 | 0.90661 |
| Aspect | Positive | Negative | Count Aspect |
|---|---|---|---|
| bahan | 2876 | 3419 | 6295 |
| kualitas | 100 | 199 | 299 |
| jahitan | 132 | 103 | 235 |
| harga | 84 | 441 | 525 |
| ukuran | 295 | 111 | 406 |
| pelayanan | 511 | 764 | 1275 |
| warna | 126 | 357 | 483 |
| pengiriman | 657 | 407 | 1064 |
| Total aspects | 4781 | 5801 | 10,582 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chamid, A.A.; Widowati; Kusumaningrum, R. Graph-Based Semi-Supervised Deep Learning for Indonesian Aspect-Based Sentiment Analysis. Big Data Cogn. Comput. 2023, 7, 5. https://doi.org/10.3390/bdcc7010005
Chamid AA, Widowati, Kusumaningrum R. Graph-Based Semi-Supervised Deep Learning for Indonesian Aspect-Based Sentiment Analysis. Big Data and Cognitive Computing. 2023; 7(1):5. https://doi.org/10.3390/bdcc7010005
Chicago/Turabian StyleChamid, Ahmad Abdul, Widowati, and Retno Kusumaningrum. 2023. "Graph-Based Semi-Supervised Deep Learning for Indonesian Aspect-Based Sentiment Analysis" Big Data and Cognitive Computing 7, no. 1: 5. https://doi.org/10.3390/bdcc7010005