
Research in Computational Expressive Music Performance and Popular Music Production: A Potential Field of Application?




Abstract
:1. Introduction
[...] performers are able to use systematic variations in performance parameters to convey emotion and structure to listeners in a musically sensitive manner ([1] p. 64).
When playing a piece, expert performers shape various parameters (tempo, timing, dynamics, intonation, articulation, etc.) in ways that are not prescribed by the notated score, in this way producing an expressive rendition that brings out dramatic, affective, and emotional qualities that may engage and affect the listeners ([2] p. 1).
2. Commercial Products
- Expressiveness;
- Expressive performance;
- Virtual performance;
- Virtual performer.
2.1. Common Tools
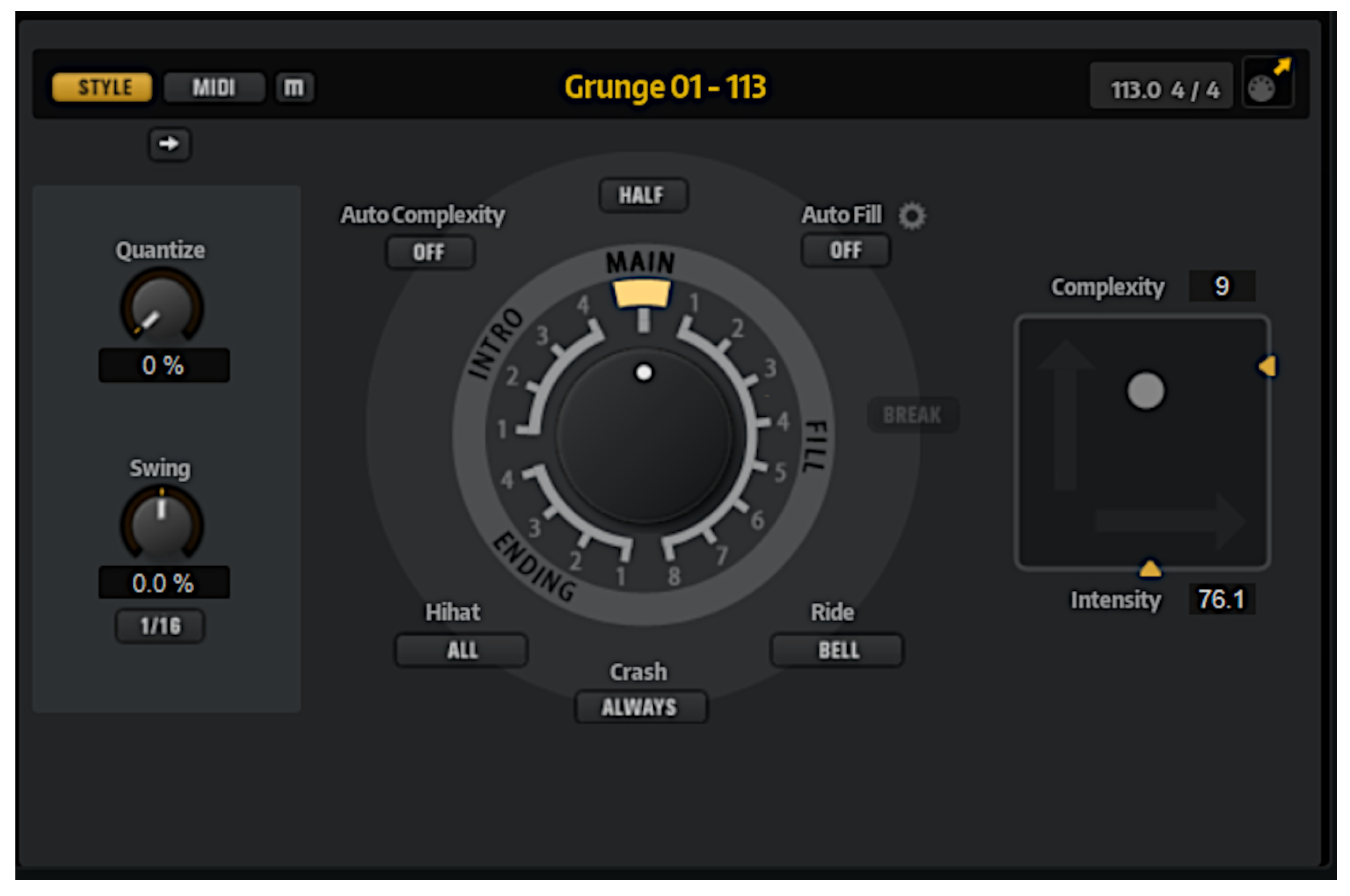
2.2. Triggerable Instrument-Specific Patterns
- Steinberg Groove Agent 5;
- UJAM collection (Virtual Guitarist, Virtual Bassist, Virtual Drummer, Virtual Pianist);
- Native Instruments Action Strings and Emotive Strings.
[…] my completely virtual band of session musicians just needing pointing in the right direction. Add in some ’human’ with a few guitar overdubs and some vocals, and a song idea can be fleshed out very quickly. Moreover, the virtual band sounds very polished indeed.
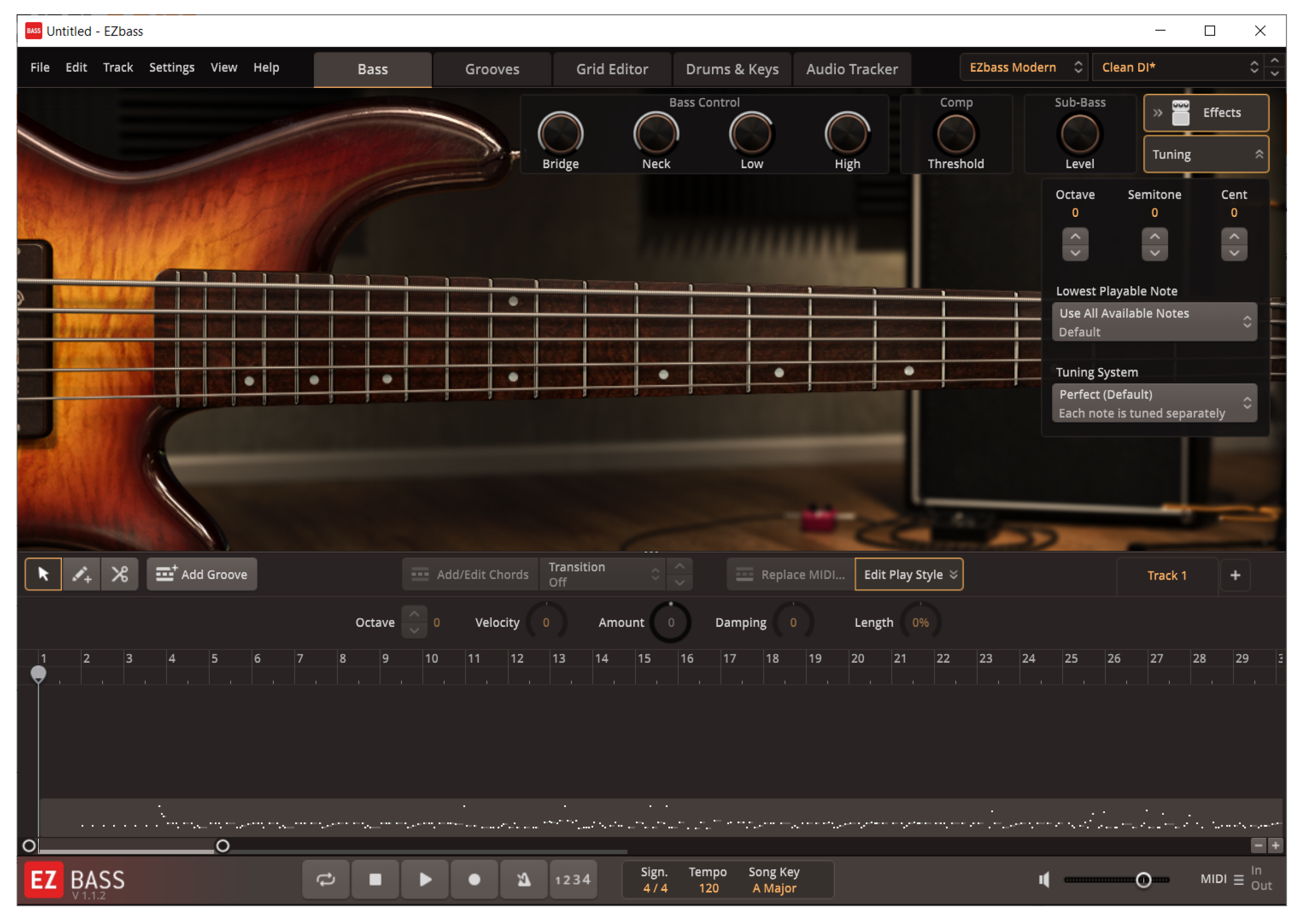
2.3. Triggerable Instrument Articulations
2.4. Advanced Hardware Timbre and Expressivity Control
- The pioneering Kurzweil XM1 Expression Mate, which dates to 2000;
- ROLI Seaboard family, whose operation is traditionally based on the MPE (MIDI Polyphonic Expression) protocol (Figure 2);
- Expressive E Touché and Osmose;
- Keith McMillen SoftStep 2;
- Erae Touch (which makes use of MIDI 2.0).
2.5. Automatic Analysis of the Rhythmic and Harmonic Structures and Generation of New Musical Parts
2.6. The Missing Link
3. Research Products
3.1. A Multifaceted Field of Research
- Visual representation of expressive performance features;
- Relation between expressiveness and structure of the musical piece;
- Local expressiveness;
- Score marking interpretation;
- Relationship between emotional intention and expressive parameters;
- Relationship between sensory experiences and expressive parameters;
- Identification and modeling of the performative styles of real musicians;
- Identification of physical and psychological limits of the performer;
- Ensemble music modeling;
- Conductor systems.
- Technologies involved;
- User interaction;
- Main goal(s).
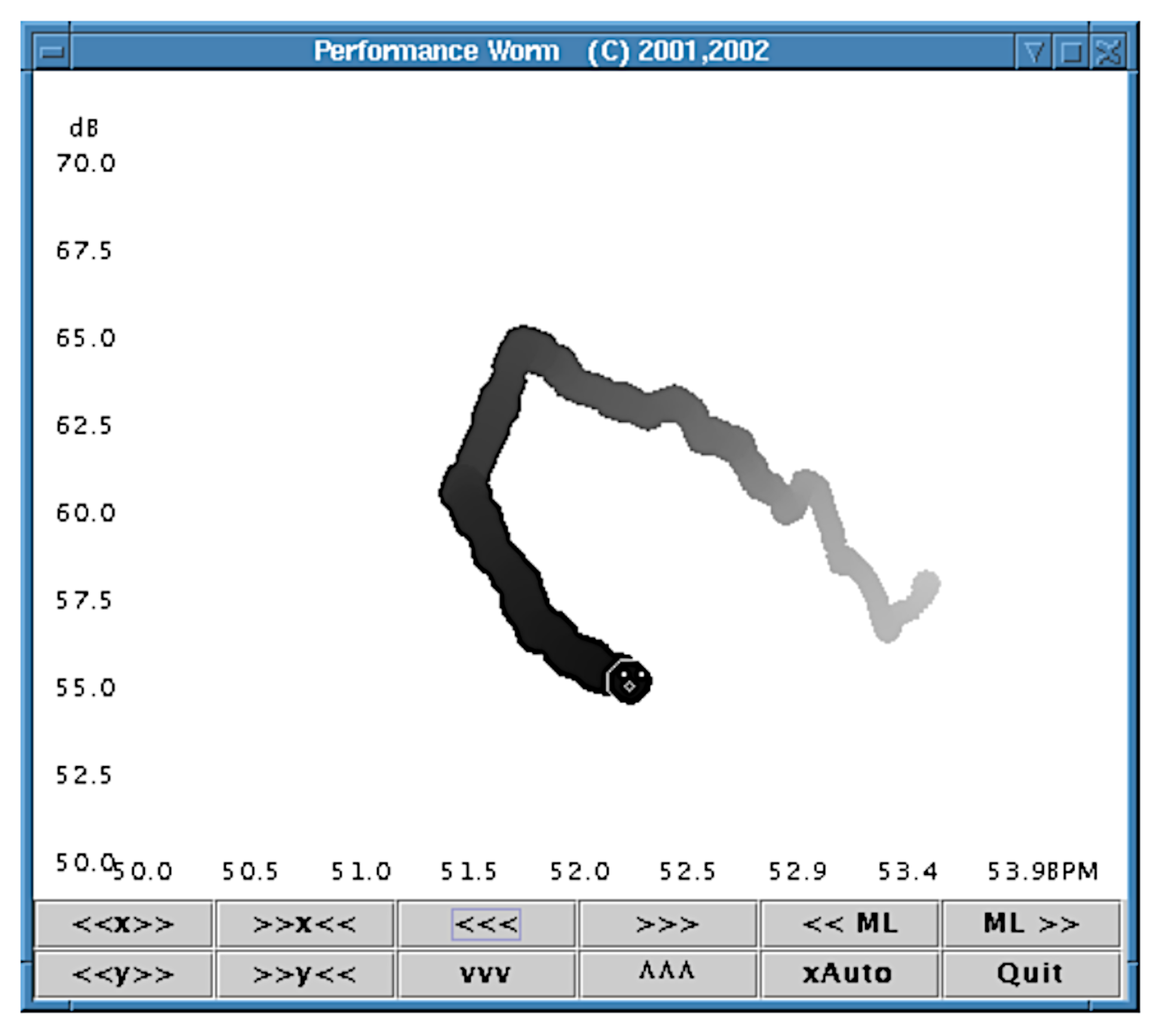
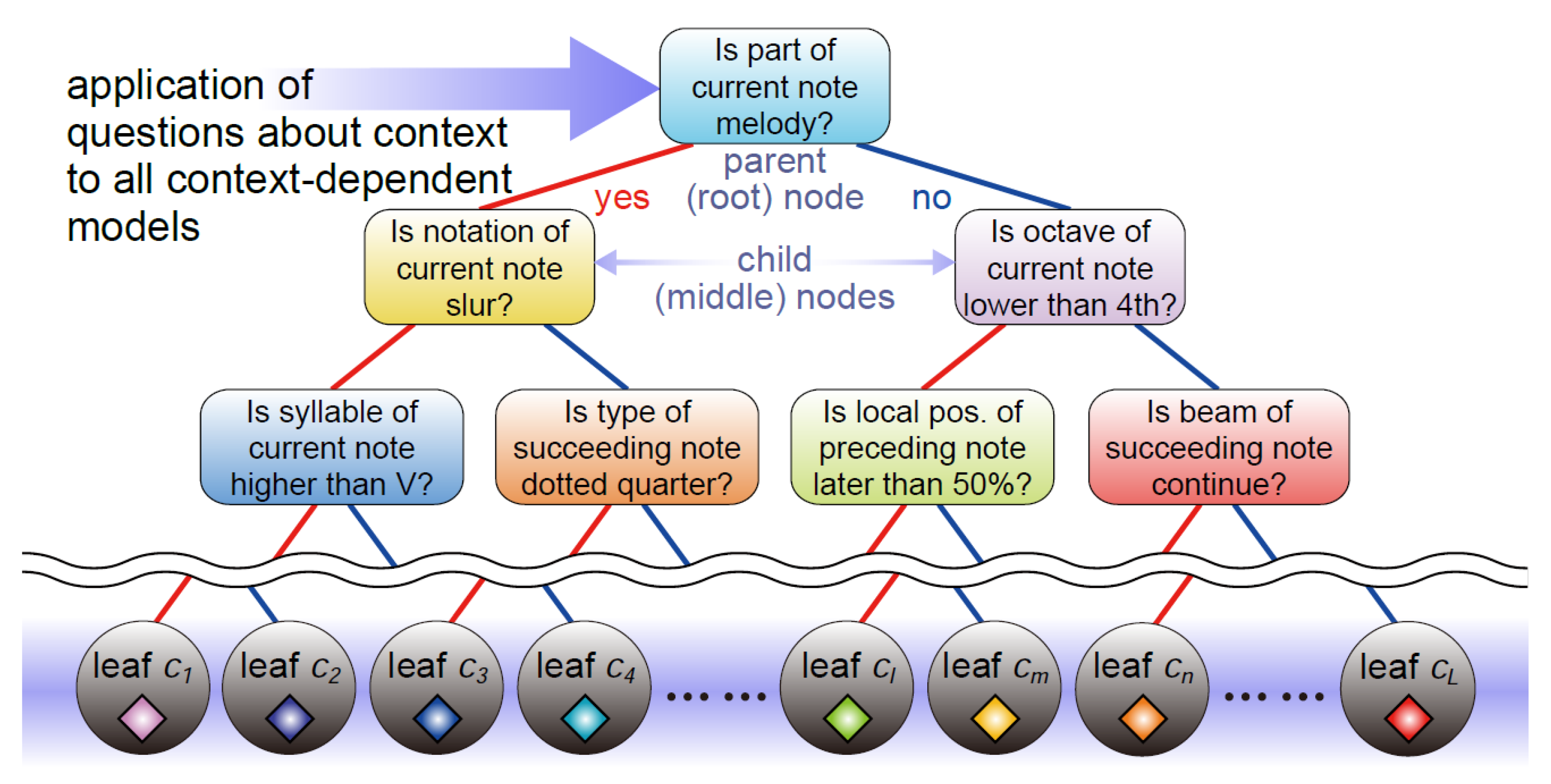
3.2. Visual Representation of Expressive Performance Features
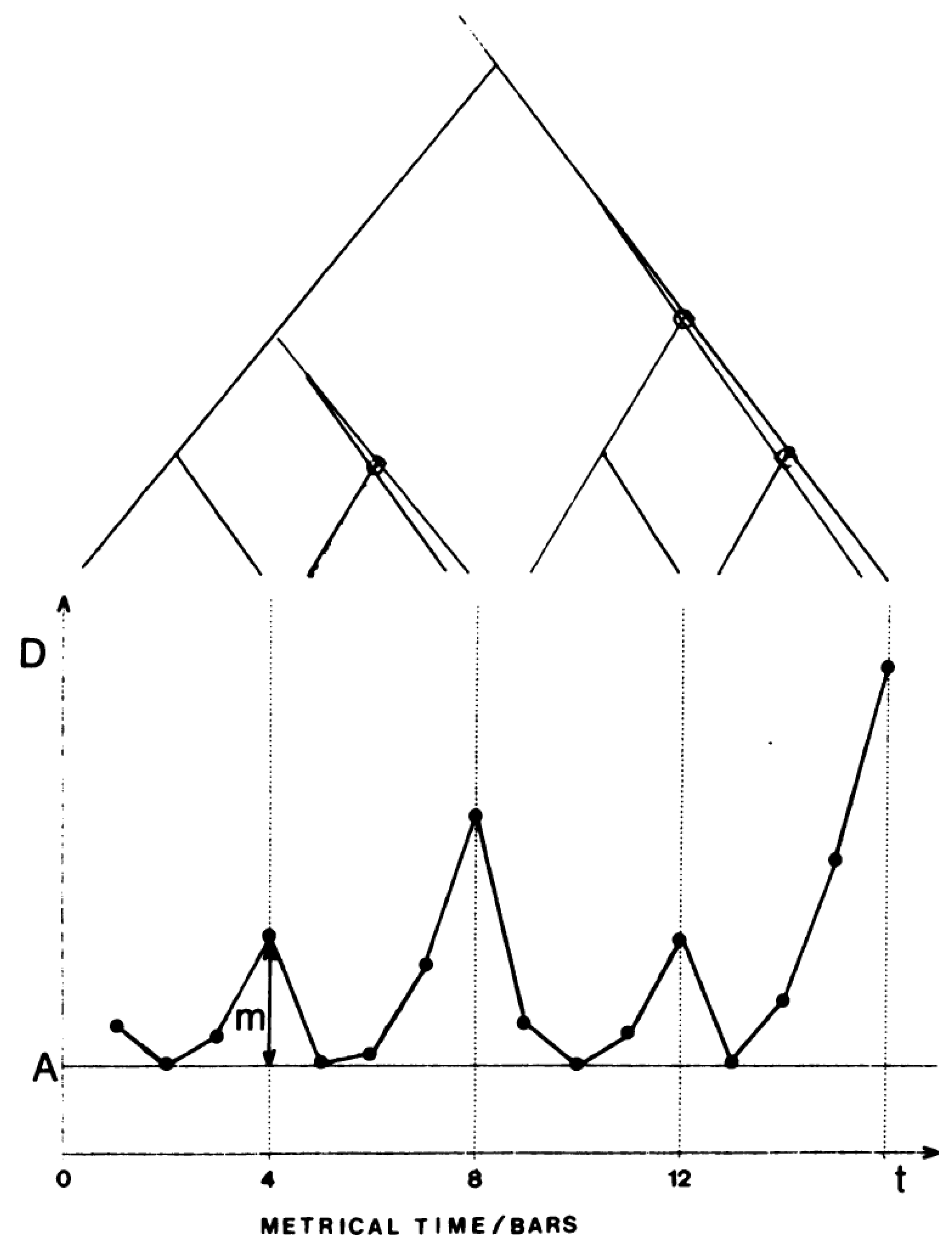
3.3. Relation between Expressiveness and Structure of the Musical Piece
3.4. Local Expressiveness
It seems safe to assume that such differences in performance are not primarily made in order to affect the perceived structure, but rather to contribute to a proper motional-emotional character of the music in question. ([48] p. 79)
3.5. Score Markings Interpretation
3.6. Relationship between Emotional Intention and Expressive Parameters
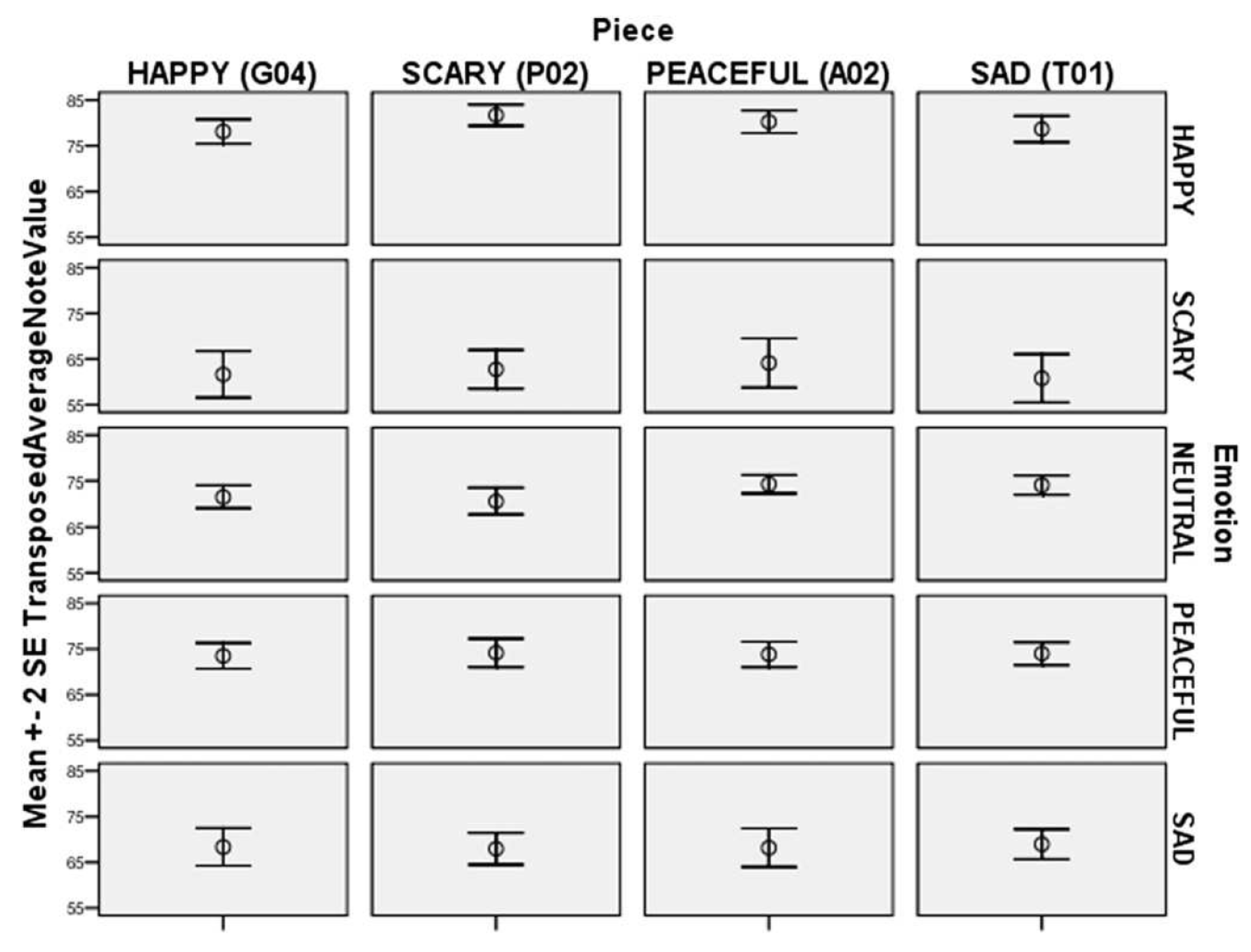
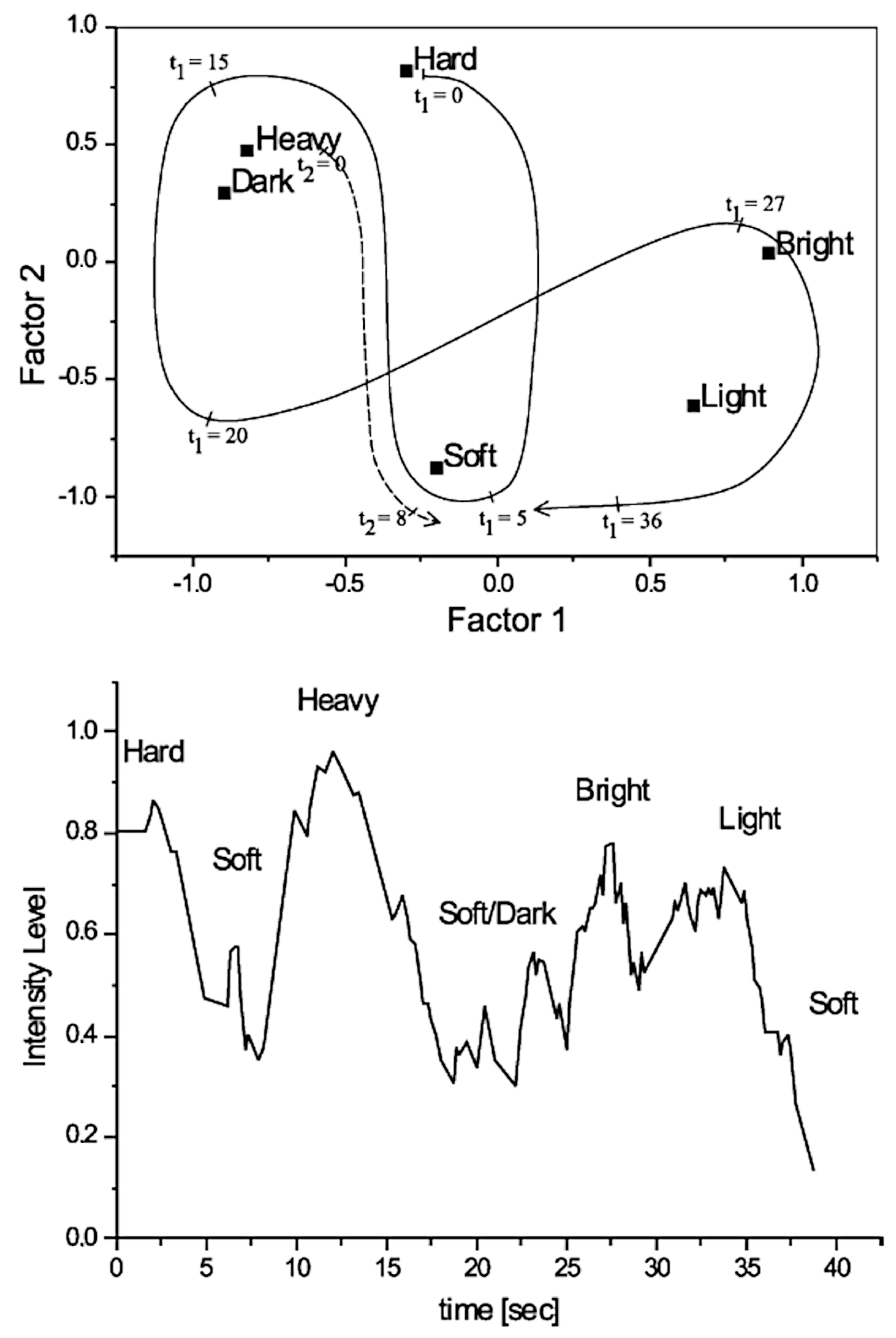
3.7. Relationship between Sensory Experiences and Expressive Parameters
3.8. Identification and Modeling of the Performative Styles of Real Musicians
3.9. Identification of Physical and Psychological Limits of the Performer
3.10. Ensemble Music Modeling
3.11. Conductor Systems
3.12. Summary Table
- Visual representation: Vis
- Structure-based expressiveness: Str
- Local-based expressiveness: Loc
- Score markings: Sco
- Emotion: Emo
- Sensory experience: Sen
- Identification and modeling of performers: Per
- Physical and psychological limits: Lim
- Ensemble modeling: Ens
- Conductor systems: Con

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Technologies | User Interaction | Main Goal (s) |
|---|---|---|---|
| Performance worm [27,28,29,128] Vis | MIR through analysis of MIDI or audio data | Tempo and loudness control using hand gestures or PC mouse [128] | Real-time graphical representation of tempo and loudness, user control of tempo and loudness |
| ESP [44] Str Loc | Hierarchical hidden Markov model (HHMM) | / | Expressive performance generation based on the score structure |
| KTH rule system [47,63,87,101,115,124,129] Str Emo Loc Sen Per Con | Rules, ANN [63] | Interaction with the ANN [63], Director Musices and pDM applications [101,124,129] | Expressive music performance generation, modeling of real performers or music performing styles |
| SYVARs [48,59,60,61] Loc | Statistical research of regularities | / | Find and validate systematic expressive variations in specific contexts |
| Expert system [62] Loc | Analysis by synthesis rule-based expert system | / | Rendition of expressive performances of Bach’s fugues |
| Gaussian process regression [65] Loc | Gaussian process ML | / | Expressive performance generation |
| YQX [51] Loc | Bayesian networks | / | Expressive performance generation |
| This time with a feeling [64] Loc | LSTM | / | Generation of solo piano musical parts and their expressive performances at the same time |
| Tonal tension in expressive piano performance [53] Str Loc | RNN LSTM | / | Expressive music performance generation based on the analysis of tonal tensions |
| Laminae [67,68] Loc | Tree-based clustering, Gaussian distributions | / | Expressive performance generation |
| Maximum entropy [69] Loc | Maximum entropy | / | Expressive performance generation, given a specific musical style |
| LBM and NBM [70,71,72,73,75] Loc | Linear-weighted combination of parameters [70,71], FFNN RNN LSTM [72,73,75] | / | Modeling of the influence of explicit score markings on expressive parameters. Music expectations considered in [75] |
| Rule system for modifying the score and performance to express emotions [84] Loc | Rules | / | Express emotions modifying not only the performance parameters but also score ones |
| CaRo and CaRo 2.0 [24,95,96,97] Con Loc Sen | Statistical analysis (principal component) | Real-time interaction through an abstract two-dimensional control space | Graphical description of performances, generation of expressive music performances starting from neutral ones, through user interaction |
| GERM model [1] Str Emo Loc Lim | Rules | / | Expressive performance generation |
| ML approach to jazz guitar solos [102,103,130] Loc Lim | ML ANN, decision trees, SVM, feature selection | / | Discover rules for expressive performance in jazz guitar and expressive model creation through ML techniques |
4. Conclusions
- The reference repertoire is the classical Euro-cultural one, which presumably may be subject to different rules and practices than popular music. This seems to be confirmed by the fact that similarities and differences between machine learning-induced rules in expressive jazz guitar and rules reported in the literature were found [102];
- Most of the existing EMP literature studies deal with piano. The fact that this is the instrument of choice for research on musical expressiveness can be traced back to technical reasons: being based on the percussion of the strings and not allowing a continuous control of the timbre, as it happens for example in the violin, it is relatively simple to build functional expressive models taking into account a minimum number of parameters (timing and dynamics/velocity) [32,64]. Moreover, hybrid acoustic/digital instruments, such as the Yamaha Disklavier, allow for easy recording of MIDI data from human performances. Furthermore, the piano has a leading role in the western classical repertoire, while in the popular context, its relevance varies according to the genre and artist. It would be useful to extend the instrumental scope of interest to other instruments that are particularly significant in pop music, including drums, electric bass, and guitars;
- The role of music scores is also profoundly different between the classical and popular contexts. While in classical music, the performer offers an interpretation of the composer’s intention (given the score written by the latter), in popular music there can be many different situations. Musical parts can be improvised, or there can be only chord charts or lead sheets, which respectively show the harmonic skeleton or the reference melody, which can be embellished and modified even in depth during the performance. If we take into account the declared objective of this contribution, which is to understand which research products could be useful to the contemporary producer in conferring expressiveness to pre-defined parts, and not in the automatic generation of new parts, it is possible to leave out the specific case of free improvisation. As for the relationship and alignment between the real performance and lead sheet, the topic was dealt with in relation to the jazz guitar by S.I. Giraldo and R. Ramirez [103,130];
- In art music, particularly classical music, artists have a lot of freedom to express their individuality [28], while in popular music production, there tend to be more constraints, if only for the fact that often the pieces are recorded with constant metronome tempos, at least in studio productions in recent times (the focus of this contribution). On the other hand, as R. B. Dannenberg and S. Mohan observed [131], in live performances, the metronomic tempo can change both long-term and locally. Dannenberg and Mohan also suggest that statistical models based on the analysis of tempo variations in real performances could be used to generate tempo variations in expressive performance models. This would probably be far from the sensitivity of contemporary pop music producers, but could nonetheless open up new paths in the future;
- In modern popular music, there are usually many instruments and vocal parts played or sung at the same time; most past studies on EMP deal with solo instruments (notably solo piano), which for obvious reasons have greater freedom of expression, in particular with respect to tempo and timing.
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ANN | artificial neural network |
| CC | continuous controller/control change |
| DAW | digital audio workstation |
| DOS | duration of shift |
| EMP | expressive music performance |
| EQ | equalization |
| EST | end of shift |
| FFNN | feed forward neural network |
| HHMM | hierarchical hidden Markov model |
| HPF | high-pass filter |
| IOI | inter-onset interval |
| LBM | linear basis model |
| LSTM | long short-term memory |
| MIDI | musical instrument digital interface |
| MIR | music information retrieval |
| ML | machine learning |
| MPE | midi polyphonic expression |
| NBM | non-linear basis model |
| NIME | new interfaces for musical expression international conference |
| PCM | pulse code modulation |
| RPM | reconstructive phrase modeling |
| RNN | recurrent neural network |
| SVM | support vector machine |
| SYVAR | systematic variations |
References
- Juslin, P.N.; Friberg, A.; Bresin, R. Toward a computational model of expression in music performance: The GERM model. Music Sci. 2001, 5, 63–122. [Google Scholar] [CrossRef]
- Cancino-Chacón, C.E.; Grachten, M.; Goebl, W.; Widmer, G. Computational models of expressive music performance: A comprehensive and critical review. Front. Digit. Humanit. 2018, 5, 25. [Google Scholar] [CrossRef] [Green Version]
- Furini, D. From recording performances to performing recordings. Recording technology and shifting ideologies of authorship in popular music. Trans. Rev. Transcult. Música 2010, 14, 1–8. [Google Scholar]
- Schmeling, P. Berklee Music Theory Book 2; Berklee Press: Boston, MA, USA, 2011. [Google Scholar]
- Moir, Z.; Medbøe, H. Reframing popular music composition as performance-centred practice. J. Music Technol. Educ. 2015, 8, 147–161. [Google Scholar] [CrossRef] [PubMed]
- Moy, R. Authorship Roles in Popular Music: Issues and Debates; Routledge: London, UK, 2015. [Google Scholar] [CrossRef]
- Dibben, N. Understanding performance expression in popular music recordings. In Expressiveness in Music Performance: Empirical Approaches Across Styles and Cultures; Oxford University Press: Oxford, UK, 2014; pp. 117–132. [Google Scholar] [CrossRef]
- Collins, M. A Professional Guide to Audio Plug-Ins and Virtual Instruments; Routledge: London, UK, 2012. [Google Scholar]
- Owsinski, B. The Music Producer’s Handbook; Hal Leonard: Milwaukee, WI, USA, 2016. [Google Scholar]
- Marrington, M. Composing with the digital audio workstation. In The Singer-Songwriter Handbook; Williams, J.A., Williams, K., Eds.; Bloomsbury Academic: London, UK, 2017; pp. 77–89. [Google Scholar]
- Yun, Y.; Cha, S.H. Designing virtual instruments for computer music. Int. J. Multimed. Ubiquitous Eng. 2013, 8, 173–178. [Google Scholar] [CrossRef]
- Tanev, G.; Božinovski, A. Virtual Studio Technology inside music production. In Proceedings of the ICT Innovations 2013, Ohrid, Macedonia, 12–15 September 2013; Trajkovik, V., Anastas, M., Eds.; Springer: Heidelberg, Germany, 2014; pp. 231–241. [Google Scholar] [CrossRef]
- Moog, B. MIDI. J. Audio Eng. Soc. 1986, 34, 394–404. [Google Scholar]
- Hennig, H.; Fleischmann, R.; Fredebohm, A.; Hagmayer, Y.; Nagler, J.; Witt, A.; Theis, F.J.; Geisel, T. The nature and perception of fluctuations in human musical rhythms. PLoS ONE 2011, 6, e26457. [Google Scholar] [CrossRef]
- Organic mixdowns. Comput. Music 2015, 224, 34–52.
- Walden, J. UJAM Virtual Bassist: Royal, Mellow & Rowdy. Sound Sound 2019, 34/9, 128–130. [Google Scholar]
- Carnovalini, F.; Rodà, A. Computational Creativity and Music Generation Systems: An Introduction to the State of the Art. Front. Artif. Intell. 2020, 3, 14. [Google Scholar] [CrossRef] [Green Version]
- Lindemann, E. Music Synthesis with Reconstructive Phrase Modeling. IEEE Signal Process. Mag. 2007, 24, 80–91. [Google Scholar] [CrossRef]
- Tzanetakis, G. Natural human-computer interaction with musical instruments. In Digital Tools for Computer Music Production and Distribution; Politis, D., Miltiadis, T., Ioannis, I., Eds.; IGI Global: Hershey, PA, USA, 2016; Chapter 6; pp. 116–136. [Google Scholar] [CrossRef] [Green Version]
- Fasciani, S.; Goode, J. 20 NIMEs: Twenty years of new interfaces for musical expression. In Proceedings of the International Conference on New Interfaces for Musical Expression (NIME), Shanghai, China, 14–18 June 2021. [Google Scholar] [CrossRef]
- Lamb, R.; Robertson, A. Seaboard: A New Piano Keyboard-related Interface Combining Discrete and Continuous Control. In Proceedings of the International Conference on New Interfaces for Musical Expression, Oslo, Norway, 30 May–1 June 2011; pp. 503–506. [Google Scholar] [CrossRef]
- Gabrielsson, A. Music performance research at the millennium. Psychol. Music 2003, 31, 221–272. [Google Scholar] [CrossRef]
- Widmer, G.; Goebl, W. Computational models of expressive music performance: The state of the art. J. New Music Res. 2004, 33, 203–216. [Google Scholar] [CrossRef] [Green Version]
- De Poli, G. Expressiveness in Music Performance. Algorithms for Sound and Music Computing. 2018. Available online: https://www.researchgate.net/publication/223467441_Algorithms_for_Sound_and_Music_Computing (accessed on 23 December 2022).
- Kirke, A.; Miranda, E.R. A survey of computer systems for expressive music performance. ACM Comput. Surv. 2009, 42, 1–41. [Google Scholar] [CrossRef]
- Delgado, M.; Fajardo, W.; Molina-Solana, M. A state of the art on computational music performance. Expert Syst. Appl. 2011, 38, 155–160. [Google Scholar] [CrossRef]
- Langner, J.; Goebl, W. Representing expressive performance in tempo-loudness space. In Proceedings of the ESCOM Conference on Musical Creativity, Liége, Belgium, 5–8 April 2002. [Google Scholar]
- Dixon, S.; Goebl, W.; Widmer, G. Real time tracking and visualisation of musical expression. In Proceedings of the International Conference on Music and Artificial Intelligence (ICMAI), Scotland, UK, 12–14 September 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 58–68. [Google Scholar] [CrossRef]
- Dixon, S.; Goebl, W.; Widmer, G. The performance worm: Real time visualisation of expression based on Langner’s tempo-loudness animation. In Proceedings of the International Computer Music Conference (ICMC), Gothenburg, Sweden, 16–21 September 2002; Michigan Publishing: East Lansing, MI, USA, 2002. [Google Scholar]
- Stanyek, J. Forum on transcription. Twentieth-Century Music 2014, 11, 101–161. [Google Scholar] [CrossRef] [Green Version]
- Dannenberg, R.B. Music representation issues, techniques, and systems. Comput. Music J. 1993, 17, 20–30. [Google Scholar] [CrossRef]
- Raphael, C. Symbolic and structural representation of melodic expression. J. New Music Res. 2010, 39, 245–251. [Google Scholar] [CrossRef] [Green Version]
- Drabkin, W. Motif [motive]. 2001. Available online: https://www.oxfordmusiconline.com/grovemusic/view/10.1093/gmo/9781561592630.001.0001/omo-9781561592630-e-0000019221#omo-9781561592630-e-0000019221 (accessed on 5 June 2022).
- Phrase. 2001. Available online: https://www.oxfordmusiconline.com/grovemusic/view/10.1093/gmo/9781561592630.001.0001/omo-9781561592630-e-0000021599 (accessed on 5 June 2022).
- Ratner, L.G. Period. 2001. Available online: https://www.oxfordmusiconline.com/grovemusic/view/10.1093/gmo/9781561592630.001.0001/omo-9781561592630-e-0000021337#omo-9781561592630-e-0000021337 (accessed on 5 June 2022).
- Palmer, C. Music performance. Annu. Rev. Psychol. 1997, 48, 115–138. [Google Scholar] [CrossRef] [Green Version]
- Clarke, E.F. Generative principles in music performance. In Generative Processes in Music: The Psychology of Performance, Improvisation, and Composition; Sloboda, J., Ed.; Clarendon Press/Oxford University Press: Oxford, UK, 2001; pp. 1–26. [Google Scholar] [CrossRef]
- Lerdahl, F.; Jackendoff, R. A Generative Theory of Tonal Music; The MIT Press: Cambridge, MA, USA, 1983. [Google Scholar]
- Todd, N. A model of expressive timing in tonal music. Music Percept. Interdiscip. J. 1985, 3, 33–57. [Google Scholar] [CrossRef]
- Todd, N. A computational model of rubato. Contemp. Music Rev. 1989, 3, 69–88. [Google Scholar] [CrossRef]
- McAngus Todd, N.P. The dynamics of dynamics: A model of musical expression. J. Acoust. Soc. Am. 1992, 91, 3540–3550. [Google Scholar] [CrossRef]
- Windsor, W.L.; Clarke, E.F. Expressive timing and dynamics in real and artificial musical performances: Using an algorithm as an analytical tool. Music Percept. 1997, 15, 127–152. [Google Scholar] [CrossRef]
- Clarke, E.F.; Windsor, W.L. Real and simulated expression: A listening study. Music Percept. 2000, 17, 277–313. [Google Scholar] [CrossRef]
- Grindlay, G.; Helmbold, D. Modeling, analyzing, and synthesizing expressive piano performance with graphical models. Mach. Learn. 2006, 65, 361–387. [Google Scholar] [CrossRef] [Green Version]
- Widmer, G.; Tobudic, A. Playing Mozart by analogy: Learning multi-level timing and dynamics strategies. J. New Music Res. 2003, 32, 259–268. [Google Scholar] [CrossRef]
- Widmer, G. Discovering simple rules in complex data: A meta-learning algorithm and some surprising musical discoveries. Artif. Intell. 2003, 146, 129–148. [Google Scholar] [CrossRef] [Green Version]
- Friberg, A.; Bresin, R.; Sundberg, J. Overview of the KTH rule system for musical performance. Adv. Cogn. Psychol. 2006, 2, 145–161. [Google Scholar] [CrossRef]
- Gabrielsson, A. Interplay between analysis and synthesis in studies of music performance and music experience. Music Percept. 1985, 3, 59–86. [Google Scholar] [CrossRef]
- Carnovalini, F.; Rodà, A. A multilayered approach to automatic music generation and expressive performance. In Proceedings of the International Workshop on Multilayer Music Representation and Processing (MMRP), Milano, Italy, 24–25 January 2019; pp. 41–48. [Google Scholar] [CrossRef]
- Meyer, L.B. Emotion and Meaning in Music; University of Chicago Press: Chicago, IL, USA, 1956. [Google Scholar]
- Narmour, E. The Analysis and Cognition of Basic Melodic Structures: The Implication-Realization Model; University of Chicago Press: Chicago, IL, USA, 1990. [Google Scholar]
- Herremans, D.; Chew, E. Tension ribbons: Quantifying and visualising tonal tension. In Proceedings of the International Conference on Technologies for Music Notation and Representation (TENOR), Cambridge, UK, 27–29 May 2016; Hoadley, R., Nash, C., Fober, D., Eds.; Anglia Ruskin University: Cambridge, UK, 2016; pp. 8–18. [Google Scholar]
- Cancino-Chacón, C.; Grachten, M. A computational study of the role of tonal tension in expressive piano performance. arXiv 2018, arXiv:1807.01080. [Google Scholar] [CrossRef]
- Tagg, P. Everyday Tonality II—Towards a Tonal Theory of What Most People Hear; Mass Media Music Scholars Press: Larchmont, NY, USA, 2018. [Google Scholar]
- Marsden, A. Schenkerian analysis by computer: A proof of concept. J. New Music Res. 2010, 39, 269–289. [Google Scholar] [CrossRef] [Green Version]
- Hamanaka, M.; Hirata, K.; Tojo, S. Implementing “A generative theory of tonal music”. J. New Music Res. 2006, 35, 249–277. [Google Scholar] [CrossRef]
- Orio, N.; Rodà, A. A measure of melodic similarity based on a graph representation of the music structure. In Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), Kobe, Japan, 26–30 October 2009; pp. 543–548. [Google Scholar] [CrossRef]
- Simonetta, F.; Carnovalini, F.; Orio, N.; Rodà, A. Symbolic music similarity through a graph-based representation. In Proceedings of the Audio Mostly Conference on Sound in Immersion and Emotion, Wrexham, UK, 12–14 September 2018; pp. 1–7. [Google Scholar] [CrossRef] [Green Version]
- Gabrielsson, A. Performance of rhythm patterns. Scand. J. Psychol. 1974, 15, 63–72. [Google Scholar] [CrossRef]
- Gabrielsson, A. Performance and Training of Musical Rhythm. Psychol. Music, Spec. Issue 1982, 42–46. Available online: https://psycnet.apa.org/record/1984-14591-001 (accessed on 23 December 2022).
- Gabrielsson, A.; Bengtsson, I.; Gabrielsson, B. Performance of musical rhythm in 3/4 and 6/8 meter. Scand. J. Psychol. 1983, 24, 193–213. [Google Scholar] [CrossRef]
- Johnson, M.L. Toward an expert system for expressive musical performance. Computer 1991, 24, 30–34. [Google Scholar] [CrossRef]
- Bresin, R. Artificial neural networks based models for automatic performance of musical scores. J. New Music Res. 1998, 27, 239–270. [Google Scholar] [CrossRef]
- Oore, S.; Simon, I.; Dieleman, S.; Eck, D.; Simonyan, K. This time with feeling: Learning expressive musical performance. Neural Comput. Appl. 2020, 32, 955–967. [Google Scholar] [CrossRef] [Green Version]
- Teramura, K.; Okuma, H.; Taniguchi, Y.; Makimoto, S.; Maeda, S.i. Gaussian process regression for rendering music performance. In Proceedings of the International Conference on Music Perception and Cognition (ICMPC), Sapporo, Japan, 25–29 August 2008; pp. 167–172. [Google Scholar]
- Flossmann, S.; Grachten, M.; Widmer, G. Expressive performance rendering with probabilistic models. In Guide to Computing for Expressive Music Performance; Springer: Berlin/Heidelberg, Germany, 2013; pp. 75–98. [Google Scholar] [CrossRef]
- Okumura, K.; Sako, S.; Kitamura, T. Stochastic modeling of a musical performance with expressive representations from the musical score. In Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), Miami, FL, USA, 24–28 October 2011; pp. 531–536. [Google Scholar]
- Okumura, K.; Sako, S.; Kitamura, T. Laminae: A stochastic modeling-based autonomous performance rendering system that elucidates performer characteristics. In Proceedings of the International Computer Music Conference (ICMC), Athens, Greece, 14–20 September 2014. [Google Scholar]
- Moulieras, S.; Pachet, F. Maximum entropy models for generation of expressive music. arXiv 2016, arXiv:1610.03606. [Google Scholar] [CrossRef]
- Grachten, M.; Widmer, G. Linear basis models for prediction and analysis of musical expression. J. New Music Res. 2012, 41, 311–322. [Google Scholar] [CrossRef]
- Grachten, M.; Cancino Chacón, C.E.; Widmer, G. Analysis and prediction of expressive dynamics using Bayesian linear models. In Proceedings of the 1st International Workshop on Computer and Robotic Systems for Automatic Music Performance, Venice, Italy, 18–19 July 2014; pp. 545–552. [Google Scholar]
- Cancino Chacón, C.E.; Grachten, M. An evaluation of score descriptors combined with non-linear models of expressive dynamics in music. In Proceedings of the 18th International Conference on Discovery Science (DS), Banff, AB, Canada, 4–6 October 2015; Springer: Banff, AB, Canada, 2015. [Google Scholar] [CrossRef]
- Cancino-Chacón, C.E.; Gadermaier, T.; Widmer, G.; Grachten, M. An evaluation of linear and non-linear models of expressive dynamics in classical piano and symphonic music. Mach. Learn. 2017, 106, 887–909. [Google Scholar] [CrossRef] [Green Version]
- Graves, A. Generating sequences with recurrent neural networks. arXiv 2013, arXiv:1308.0850. [Google Scholar] [CrossRef]
- Cancino-Chacón, C.; Grachten, M.; Sears, D.R.; Widmer, G. What were you expecting? Using expectancy features to predict expressive performances of classical piano music. arXiv 2017, arXiv:1709.03629. [Google Scholar] [CrossRef]
- Juslin, P.N.; Laukka, P. Expression, perception, and induction of musical emotions: A review and a questionnaire study of everyday listening. J. New Music Res. 2004, 33, 217–238. [Google Scholar] [CrossRef]
- Juslin, P.N.; Sloboda, J. Handbook of Music and Emotion: Theory, Research, Applications; Oxford University Press: Oxford, UK, 2011. [Google Scholar] [CrossRef]
- Eerola, T.; Vuoskoski, J.K. A review of music and emotion studies: Approaches, emotion models, and stimuli. Music Percept. 2013, 30, 307–340. [Google Scholar] [CrossRef] [Green Version]
- Gabrielsson, A. Emotion perceived and emotion felt: Same or different? Music. Sci. 2001, 5, 123–147. [Google Scholar] [CrossRef]
- Evans, P.; Schubert, E. Relationships between expressed and felt emotions in music. Music. Sci. 2008, 12, 75–99. [Google Scholar] [CrossRef]
- Russell, J.A. A circumplex model of affect. J. Personal. Soc. Psychol. 1980, 39, 1161. [Google Scholar] [CrossRef]
- Gabrielsson, A. Intention and emotional expression in music performance. In Proceedings of the Stockholm Music Acoustics Conference (SMAC), 28 July–1 August 1993; pp. 108–111. Available online: https://discover.musikverket.se/cgi-bin/koha/opac-detail.pl?biblionumber=1530332 (accessed on 23 December 2022).
- Gabrielsson, A. Expressive intention and performance. In Music and the Mind Machine; Springer: Berlin/Heidelberg, Germany, 1995; pp. 35–47. [Google Scholar] [CrossRef]
- Livingstone, S.R.; Muhlberger, R.; Brown, A.R.; Thompson, W.F. Changing musical emotion: A computational rule system for modifying score and performance. Comput. Music J. 2010, 34, 41–64. [Google Scholar] [CrossRef] [Green Version]
- Bresin, R.; Friberg, A. Emotion rendering in music: Range and characteristic values of seven musical variables. Cortex 2011, 47, 1068–1081. [Google Scholar] [CrossRef]
- Bresin, R.; Friberg, A.; Sundberg, J. Director musices: The KTH performance rules system. Proc. SIGMUS-46 2002, 2002, 43–48. [Google Scholar]
- Bresin, R.; Friberg, A. Emotional coloring of computer-controlled music performances. Comput. Music J. 2000, 24, 44–63. [Google Scholar] [CrossRef]
- Eerola, T.; Friberg, A.; Bresin, R. Emotional expression in music: Contribution, linearity, and additivity of primary musical cues. Front. Psychol. 2013, 4, 487. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bhatara, A.; Laukka, P.; Levitin, D.J. Expression of emotion in music and vocal communication: Introduction to the research topic. Front. Psychol. 2014, 5, 399. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sievers, B.; Polansky, L.; Casey, M.; Wheatley, T. Music and movement share a dynamic structure that supports universal expressions of emotion. Proc. Natl. Acad. Sci. USA 2013, 110, 70–75. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Juslin, P.N. Emotional reactions to music. In The Oxford Handbook of Music Psychology; Oxford University Press: Oxford, UK, 2014; pp. 197–213. [Google Scholar] [CrossRef]
- Schubert, E. Emotion in popular music: A psychological perspective. Vol. Rev. Des Musiques Pop. 2013, 1, 265–266. [Google Scholar] [CrossRef] [Green Version]
- Song, Y.; Dixon, S.; Pearce, M.T.; Halpern, A.R. Perceived and induced emotion responses to popular music: Categorical and dimensional models. Music Percept. Interdiscip. J. 2016, 33, 472–492. [Google Scholar] [CrossRef]
- Canazza, S.; Poli, G.D.; Rinaldin, S.; Vidolin, A. Sonological analysis of clarinet expressivity. In Proceedings of the Joint International Conference on Cognitive and Systematic Musicology, Brugge, Belgium, 8–11 September 1996; Springer: Berlin/Heidelberg, Germany, 1996; pp. 431–440. [Google Scholar] [CrossRef]
- Canazza, S.; Poli, G.; Rodà, A.; Vidolin, A. An abstract control space for communication of sensory expressive intentions in music performance. J. New Music Res. 2003, 32, 281–294. [Google Scholar] [CrossRef]
- Canazza, S.; De Poli, G.; Drioli, C.; Roda, A.; Vidolin, A. Modeling and control of expressiveness in music performance. Proc. IEEE 2004, 92, 686–701. [Google Scholar] [CrossRef]
- Canazza, S.; De Poli, G.; Rodà, A. Caro 2.0: An interactive system for expressive music rendering. Adv. -Hum.-Comput. Interact. 2015, 2015, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Friberg, A. Home conducting-control the overall musical expression with gestures. In Proceedings of the International Computer Music Conference (ICMC), Barcelona, Spain, 4–10 September 2005; Michigan Publishing: Ann Arbor, MI, USA, 2005. [Google Scholar]
- Friberg, A.; Sundberg, J. Does music performance allude to locomotion? A model of final ritardandi derived from measurements of stopping runners. The J. Acoust. Soc. Am. 1999, 105, 1469–1484. [Google Scholar] [CrossRef] [Green Version]
- Porcello, T. Speaking of sound: Language and the professionalization of sound-recording engineers. Soc. Stud. Sci. 2004, 34, 733–758. [Google Scholar] [CrossRef]
- Sundberg, J.; Friberg, A.; Bresin, R. Attempts to reproduce a pianist’s expressive timing with director musices performance rules. J. New Music Res. 2003, 32, 317–325. [Google Scholar] [CrossRef]
- Giraldo, S.; Ramirez, R. A machine learning approach to ornamentation modeling and synthesis in jazz guitar. J. Math. Music 2016, 10, 107–126. [Google Scholar] [CrossRef]
- Giraldo, S.I.; Ramirez, R. A machine learning approach to discover rules for expressive performance actions in jazz guitar music. Front. Psychol. 2016, 7, 1965. [Google Scholar] [CrossRef] [Green Version]
- Saunders, C.; Hardoon, D.R.; Shawe-Taylor, J.; Widmer, G. Using string kernels to identify famous performers from their playing style. In Proceedings of the Machine Learning: ECML 2004, Pisa, Italy, 20–24 September 2004; Boulicaut, J.F., Esposito, F., Giannotti, F., Pedreschi, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 384–395. [Google Scholar] [CrossRef] [Green Version]
- Stamatatos, E.; Widmer, G. Automatic identification of music performers with learning ensembles. Artif. Intell. 2005, 165, 37–56. [Google Scholar] [CrossRef] [Green Version]
- Ramirez, R.; Maestre, E.; Pertusa, A.; Gomez, E.; Serra, X. Performance-based interpreter identification in saxophone audio recordings. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 356–364. [Google Scholar] [CrossRef]
- Costalonga, L.L.; Pimenta, M.S.; Miranda, E.R. Understanding biomechanical constraints for modeling expressive performance: A guitar case study. J. New Music Res. 2019, 48, 331–351. [Google Scholar] [CrossRef]
- Metcalf, C.D.; Irvine, T.A.; Sims, J.L.; Wang, Y.L.; Su, A.W.; Norris, D.O. Complex hand dexterity: A review of biomechanical methods for measuring musical performance. Front. Psychol. 2014, 5, 414. [Google Scholar] [CrossRef] [Green Version]
- Wristen, B.G. Avoiding piano-related injury: A proposed theoretical procedure for biomechanical analysis of piano technique. Med Probl. Perform. Artist. 2000, 15, 55–64. [Google Scholar] [CrossRef]
- Parncutt, R.; Sloboda, J.A.; Clarke, E.F.; Raekallio, M.; Desain, P. An ergonomic model of keyboard fingering for melodic fragments. Music Percept. 1997, 14, 341–382. [Google Scholar] [CrossRef] [Green Version]
- Jacobs, J.P. Refinements to the ergonomic model for keyboard fingering of Parncutt, Sloboda, Clarke, Raekallio, and Desain. Music Percept. 2001, 18, 505–511. [Google Scholar] [CrossRef]
- Visentin, P.; Li, S.; Tardif, G.; Shan, G. Unraveling mysteries of personal performance style; biomechanics of left-hand position changes (shifting) in violin performance. PeerJ 2015, 3, e1299. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Repp, B.H. Relational invariance of expressive microstructure across global tempo changes in music performance: An exploratory study. Psychol. Res. 1994, 56, 269–284. [Google Scholar] [CrossRef] [PubMed]
- Marchini, M.; Ramirez, R.; Papiotis, P.; Maestre, E. The sense of ensemble: A machine learning approach to expressive performance modeling in string quartets. J. New Music Res. 2014, 43, 303–317. [Google Scholar] [CrossRef] [Green Version]
- Sundberg, J.; Friberg, A.; Frydén, L. Rules for automated performance of ensemble music. Contemp. Music Rev. 1989, 3, 89–109. [Google Scholar] [CrossRef] [Green Version]
- Friberg, A.; Sundström, A. Swing Ratios and Ensemble Timing in Jazz Performance: Evidence for a Common Rhythmic Pattern. Music Percept. 2002, 19, 333–349. [Google Scholar] [CrossRef] [Green Version]
- Ellis, M.C. An Analysis of “Swing” Subdivision and Asynchronization in Three Jazz Saxophonists. Percept. Mot. Ski. 1991, 73, 707–713. [Google Scholar] [CrossRef]
- Mathews, M.V. The radio baton and conductor program, or: Pitch, the most important and least expressive part of music. Comput. Music J. 1991, 15, 37–46. [Google Scholar] [CrossRef]
- Lawson, J.; Mathews, M.V. Computer program to control a digital real-time sound synthesizer. Comput. Music J. 1977, 1, 16–21. [Google Scholar]
- Mathews, M.V. The conductor program and mechanical baton. In Proceedings of the 1989 International Symposium on Music and Information Science, Ohio, OH, USA, 2–5 November 1989; pp. 58–70. [Google Scholar]
- Lee, E.; Nakra, T.M.; Borchers, J. You’re the conductor: A realistic interactive conducting system for children. In Proceedings of the International Conference on New Interfaces for Musical Expression (NIME), Hamamatsu, Japan, 3–5 June 2004; pp. 68–73. [Google Scholar] [CrossRef]
- Baba, T.; Hashida, M.; Katayose, H. “VirtualPhilharmony”: A conducting system with heuristics of conducting an orchestra. In Proceedings of the International Conference on New Interfaces for Musical Expression (NIME), Sydney, Australia, 15–18 June 2010; Volume 2010, pp. 263–270. [Google Scholar] [CrossRef]
- Mathews, M.V.; Friberg, A.; Bennett, G.; Sapp, C.; Sundberg, J. A marriage of the Director Musices program and the conductor program. In Proceedings of the Stockholm Music Acoustics Conference (SMAC), Stockholm, Sweden, 6–9 August 2003; Volume 1, pp. 13–16. [Google Scholar]
- Friberg, A. pDM: An expressive sequencer with real-time control of the KTH music-performance rules. Comput. Music J. 2006, 30, 37–48. [Google Scholar] [CrossRef]
- Canazza, S.; Friberg, A.; Rodà, A.; Zanon, P. Expressive Director: A system for the real-time control of music performance synthesis. In Proceedings of the Stockholm Music Acoustics Conference (SMAC), Stockholm, Sweden, 6–9 August 2003; Volume 2, pp. 521–524. [Google Scholar]
- Canazza, S.; De Poli, G. Four decades of music research, creation, and education at Padua’s Centro di Sonologia Computazionale. Comput. Music J. 2020, 43, 58–80. [Google Scholar] [CrossRef]
- Canazza, S.; De Poli, G.; Vidolin, A. Gesture, Music and Computer: The Centro di Sonologia Computazionale at Padova University, a 50-Year History. Sensors 2022, 22, 3465. [Google Scholar] [CrossRef] [PubMed]
- Dixon, S.; Goebl, W.; Widmer, G. The “air worm”: An interface for real-time manipulation of expressive music performance. In Proceedings of the International Computer Music Conference (ICMC), Barcelona, Spain, 4–10 September 2005; Michigan Publishing: Ann Arbor, MI, USA, 2005. [Google Scholar]
- Friberg, A.; Colombo, V.; Frydén, L.; Sundberg, J. Generating musical performances with director musices. Comput. Music J. 2000, 24, 23–29. [Google Scholar] [CrossRef]
- Giraldo, S.; Ramírez, R. Performance to score sequence matching for automatic ornament detection in jazz music. In Proceedings of the International Conference of New Music Concepts (ICMNC), Treviso, Italy, 7–8 March 2015; Volume 8. [Google Scholar]
- Dannenberg, R.B.; Mohan, S. Characterizing tempo change in musical performances. In Proceedings of the International Computer Music Conference (ICMC), Huddersfield, UK, 31 July–5 August 2011. [Google Scholar]
- Dannenberg, R.B.; Derenyi, I. Combining instrument and performance models for high-quality music synthesis. J. New Music Res. 1998, 27, 211–238. [Google Scholar] [CrossRef] [Green Version]
- Smith, J.J.; Amershi, S.; Barocas, S.; Wallach, H.; Wortman Vaughan, J. REAL ML: Recognizing, Exploring, and Articulating Limitations of Machine Learning Research. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, Seoul, Republic of Korea, 21–24 June 2022; pp. 587–597. [Google Scholar] [CrossRef]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bontempi, P.; Canazza, S.; Carnovalini, F.; Rodà, A. Research in Computational Expressive Music Performance and Popular Music Production: A Potential Field of Application? Multimodal Technol. Interact. 2023, 7, 15. https://doi.org/10.3390/mti7020015
Bontempi P, Canazza S, Carnovalini F, Rodà A. Research in Computational Expressive Music Performance and Popular Music Production: A Potential Field of Application? Multimodal Technologies and Interaction. 2023; 7(2):15. https://doi.org/10.3390/mti7020015
Chicago/Turabian StyleBontempi, Pierluigi, Sergio Canazza, Filippo Carnovalini, and Antonio Rodà. 2023. "Research in Computational Expressive Music Performance and Popular Music Production: A Potential Field of Application?" Multimodal Technologies and Interaction 7, no. 2: 15. https://doi.org/10.3390/mti7020015