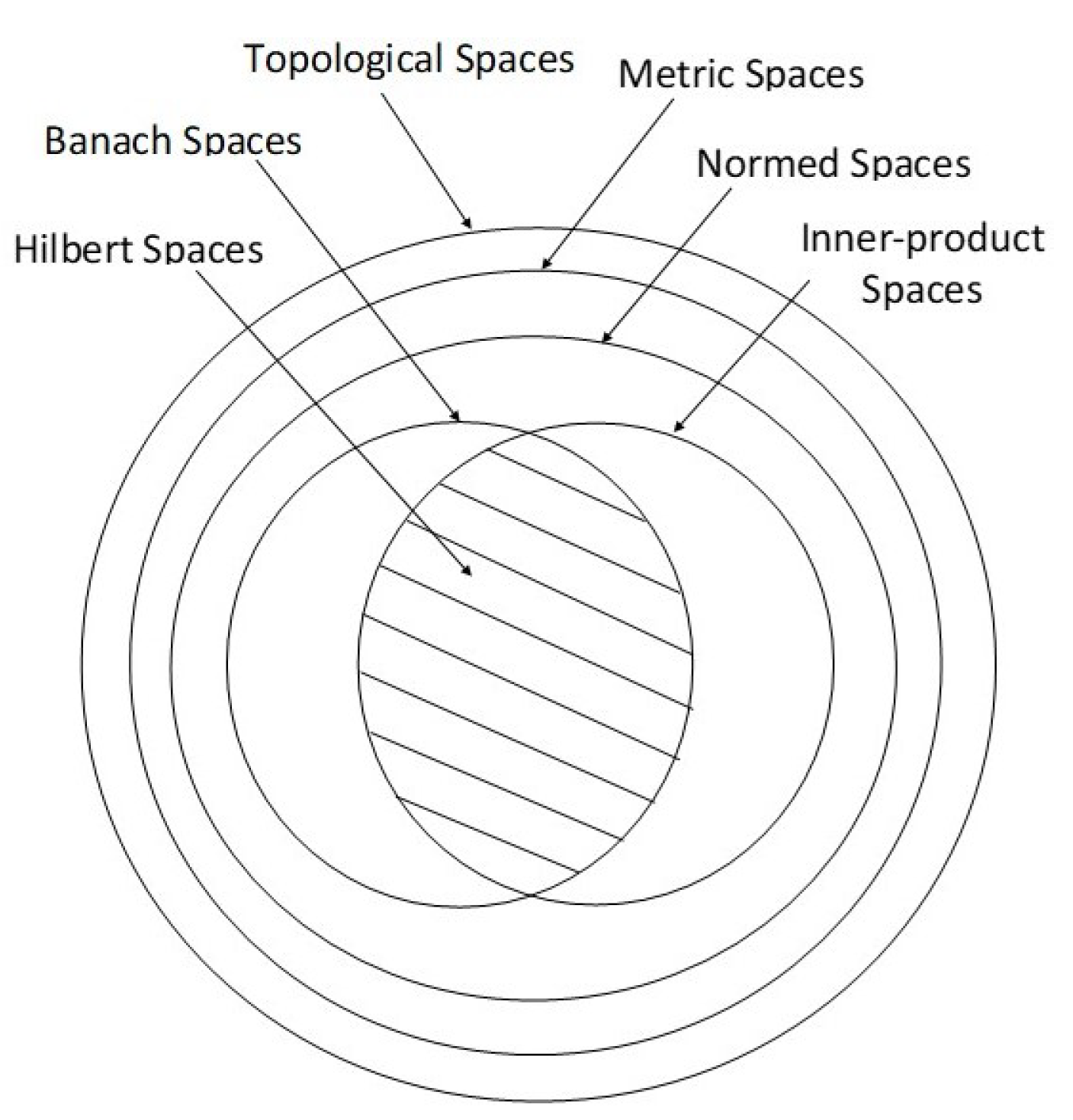
2.1. Introduction to Banach Spaces
We start this subsection with the definition of a Banach space which is a complete normed space as defined below.
Definition 1 (Banach Spaces). Let a vector space X be defined over a field , where examples of are the field of real numbers and the field of complex numbers . Let a function , called norm and denoted as , have the following properties:
(positivity) , and if and only if .
(homogeneity) and .
(triangular inequality) .
Then, is called a normed vector space, where the norm serves as a metric. A real (resp. complex) normed linear space that is complete (i.e., where every Cauchy sequence converges in the space) is called a real (resp. complex) Banach space.
Example 1. The spaces of sequences, , form an important class of Banach spaces, which are extensively used in digital signal processing. These are linear vector spaces of all real (resp. complex) sequences such that , where the -norm is defined as: Some of the theorems on
spaces [
2], which are extensively used in the analyses of discrete-time signals, are presented below.
Theorem 1 (Hölder Inequality [
2])
. Let and . If and , then and . Proof. See pp. 550–551 in Naylor and Sell [
2]. □
It is noted that Hölder Inequality also holds for and .
Theorem 2 (Minkowski inequality [
2])
. If and , then . Proof. See pp. 550–551 in Naylor and Sell [
2]. □
It is noted that Lebesgue-integrable versions of
spaces, for applications to continuous signal processing, are called
spaces [
4]. In
spaces, Hölder inequality and Minkowski inequality are similar to their respective
-versions in Theorems 1 and 2.
Next we focus on a few systems-theoretic applications of Banach spaces, which would require the operation of convolution.
Theorem 3 (Convolution inequality [
13])
. For the sequences for and , the convolution product and . Proof. See p. 241 in Desoer and Vidyasagar [
13]. □
Lemma 1 (Barbalat Lemma). If for some , then .
Proof. Let us assume that is true. Then, there exists a subsequence bounded below by a real number , which implies that is bounded below by so that as . This contradicts the assertion . □
Let a linear discrete-time dynamical system with an impulse response be excited by an input signal to yield an output signal .
Definition 2 (BIBO-stability). A system is said to be bounded-input-bounded-output (BIBO)-stable if every . More generally, the system is called -stable if , where .
For a linear shift-invariant (LSI) system, the impulse response
takes the form
, where the output is given by the convolution
as [
14]:
Using Theorem 3, if
and
for some
, then it follows that [
13]:
It is noted that is a sufficient condition for the system to be -stable. Furthermore, using Lemma 1, it follows that if for some , then as . This information is useful, for example, in the design of a linear shift-invariant estimation system, where the output signal represents the estimation error. If the system impulse response is , then the estimation error is bounded and converges asymptotically to zero if the input signal for some .
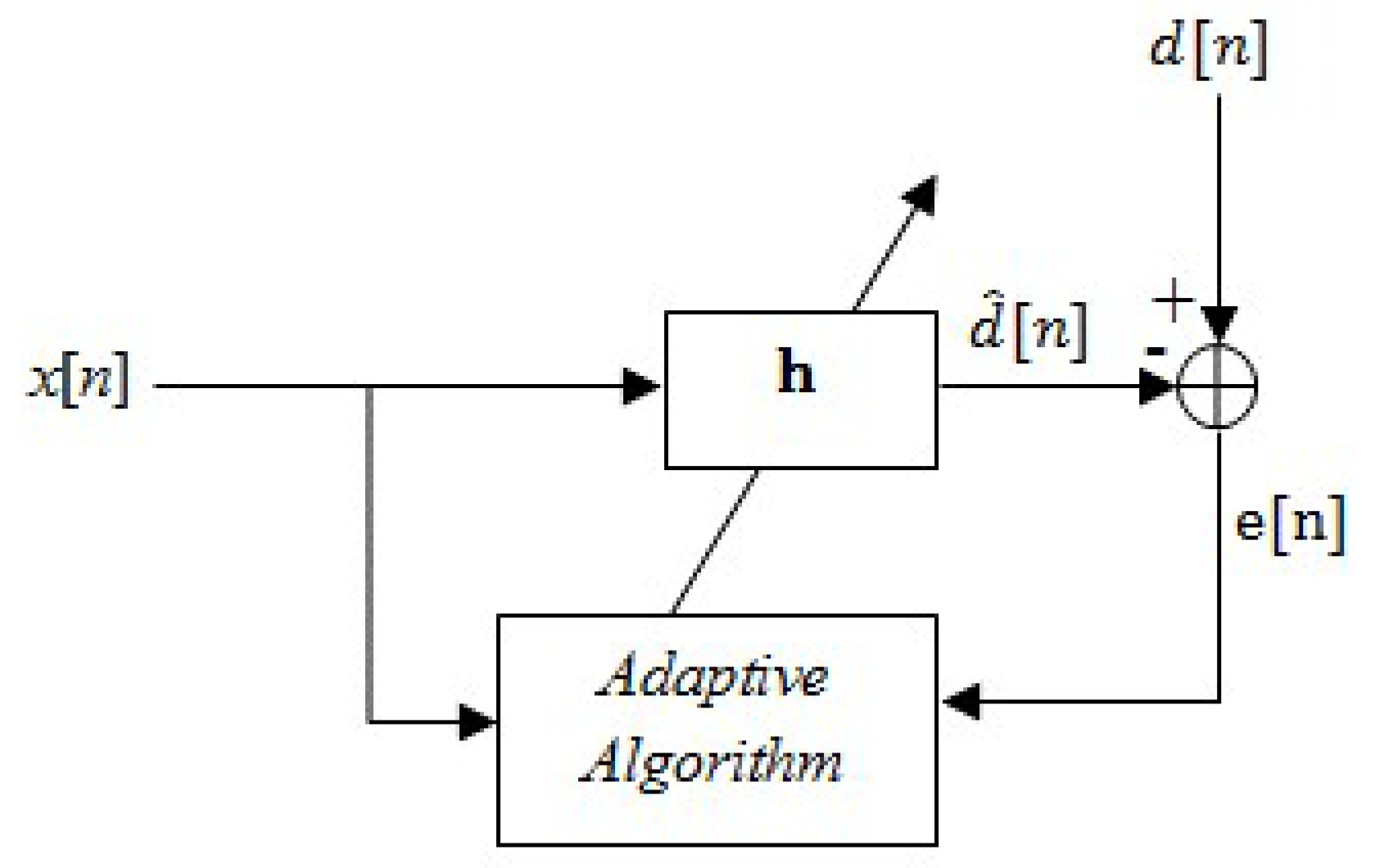
Example 2 (Adaptive Filtering)
. In a general setting, let us consider an adaptive filtering problem in Figure 2, where a measurement vector is used to construct an estimate, , of the desired signal by a linear shift-variant filter [7]. Then, the task is to synthesize an adaptive algorithm to update the filter such that the estimation error as . Using Lemma 1, this could be achieved if for some in the adaptive algorithm. If a dynamical system at any time
n does not depend on the future (i.e., the system is only dependent on the past and the present) input(s), then the system is said to be
causal [
15] and the convolution in Equation (
1) reduces to
If, in addition,
, then it follows that
2.2. Hardy Spaces and Spectral Factorization for Signal Processing
This subsection introduces the concept of Hardy spaces
,
, which constitute a class of Banach spaces with a special structure; this structure is very useful for digital signal processing [
3]. In particular,
and
spaces are of importance in robust control theory and it will be seen later in this section that the
space also plays an important role for power spectrum factorization in digital signal processing.
Recalling that, for a linear shift-invariant system with an impulse response
and input
, the output
is obtained by convolution [
14] as:
. Then, by setting
where
is the frequency in radians, the
z-transform of the impulse response
is defined as:
which is known as the
system transfer function (The one-dimensional z-transform of the discrete-time impulse response
is the ratio of two polynomials:
, where the degree of
is less than or equal to that of
for physically realizable systems. However, for the multi (i.e.,
n)-dimensional
z-transform, where
, the resulting transfer function is given as the ratio of the numerator and denominator multinomials:
The analysis of multi-dimensional z-transform (e.g., in signal processing of spatio-temporal processes) is significantly more complicated than that of one-dimensional z-transform, because the fundamental theorem of algebra may not be applicable to multinomials while it is always applicable to polynomials.) in the z-domain.
The system
is
stable if the sum in Equation (
4) converges, and the region of convergence (ROC) is called the
stablity region, where all poles of
are located inside the unit circle with its center at zero in the complex
z-plane. The system is said to be
minimum-phase if all zeros of
are located inside the unit circle. If all zeros of
are located outside the unit circle, then the system is called
maximum-phase [
16], and the system is called
non-minimum-phase if at least one zero of
is located outside the unit circle.
Definition 3 (Analytic Functions). Let be the open disc of radius with center at . A complex-valued function , where , is said to be analytic in if the derivative of exists at each point of .
Given
, the Hardy space
is a set of analytic functions
with bounded
-norm defined as:
The following theorem, due to Paley and Wiener [
14], presents a fundamental result in the
-space, which is important for spectral factorization in signal processing and for innovation representation of random processes.
Theorem 4 (Paley-Wiener)
. Let be a complex-valued function of the complex variable z. If , then there exists a real positive constant and a complex-valued function corresponding to a causal stable system with a causal stable inverse such thatwhere the superscript “her" indicates the Hermitian
, i.e., complex conjugate of transpose of a vector/matrix, and is the complex conjugate of z. If, in addition, is a rational polynomial, the above factors and are minimum-phase and maximum-phase components, respectively. This is called the Paley-Wiener condition.
Proof. The proof of the Paley-Wiener Theorem is given in details by Therrian [
14]. □
It follows from Equation (
1) that, for a linear shift-invariant stable system with a deterministic LSI impulse response
and a wide sense stationary (WSS) input signal
, the expected value of the output
is:
Since the input
is WSS, expected values,
and
, of the output
and input
, respectively, are related as:
Autocorrelation of a random vector
is denoted as
, and the cross-correlation between the output
and the input
is given by
The above equation leads to the following important relations between correlation functions [
14]:
where the superscript
her indicates the Hermitian, i.e., the complex conjugate of transpose of a vector/matrix.
The Fourier transform of
for a WSS random sequence
is called the
power spectral density function [
7], defined as:
and its inverse Fourier transform, which is equal to the autocorrelation function, is obtained as:
The z-transform of the autocorrelation function for a WSS random sequence
is called the
complex spectral density function and is defined as:
and its inverse is given by the contour integral
Since the autocorrelation function of a zero-mean white noise with variance is given by , the power spectral density is a constant for a stationary white noise.
Using the property that the convolution in the time domain is a product in the Fourier transform domain and using Equation (
9), it follows that
where
is the system transfer function (i.e., the Fourier transform of
). A few algebraic computations yield the following relation [
14]:
In a similar manner, the following relations are obtained for the complex spectral density
Let us consider a WSS random sequence
whose complex spectral density satisfies the Paley-Wiener condition:
Then, by Theorem 4, there exists a real positive constant
and a complex-valued transfer function
of a causal stable system with a causal stable inverse such that
Remark 1. A process, whose (complex) spectral density satisfies Equation (17), is called a regular process (see [7,14]). The spectral density factorization given by Equation (18) has important applications in signal processing. This includes what is called innovations representation of the random process [14], in view of which, any regular process can be realized as the output of a causal linear filter driven by a white noise with variance as shown in Figure 3. It is worth-mentioning that this type of process covers a wide range of random processes. In particular, any process whose complex spectral density is a rational function of z is a regular process.
Example 3 ([
14])
. Consider a random sequence with a complex spectral density function:which could be re-written as:Using Paley-Wiener Theorem, can be realized as the output of a causally stable system, given by:excited by a zero-mean white noise with unit variance . It is important to note that since is a rational polynomial, should be minimum-phase. This is the case for the one given by Equation (19). Since the function can be factored as:a possible pitfall here is to choose The term in Equation (20) is not minimum-phase because it has a zero at . Moreover, the inverse is not causal. Therefore, the spectral factorization with given by Equation (20) is not physically realizable for the given random sequence . As mentioned before, any random process whose complex spectral density is a rational polynomial is a regular process, and therefore it satisfies the Paley-Wiener condition. However, this is not a necessary condition for being a regular process as seen in the following example.
Example 4 ([
14])
. Let a random sequence have a complex spectral density .Then, the corresponding power spectral density satisfies the Paley-Wiener condition that is given as: Therefore, the given random sequence is regular and has an innovations representation. The spectral factorization can be done as follows: Then, the causal factor is given bywhich converges everywhere except at . The impulse response of the filter is: , where is the unit (discrete) step function, because So, the given random sequence can be realized as the output of a system, with a transfer function given by Equation (21), which is driven by a zero-mean white noise with a unit variance (i.e., ). In fact, a regular process is related to the corresponding
predictable process that can be predicted with zero error. The relation between these two processes are given by the following fundamental theorem [
7].
Theorem 5 (Wold Decomposition Theorem)
. A general random sequence can be written as the sum of two processes as:where is a regular process and is a predictable process, with being orthogonal to , i.e., . Proof. The proof is given in [
7]. □
2.3. Weak Topology in a Banach Space
It follows from the
Appendix A that an appropriate collection of open sets in a metric space defines its topology, and such a topology is called a
metric topology or
strong topology. In fact, a base for the strong topology on a Banach space
X is the collection of all open balls, i.e., sets of the form:
where the center
g is a vector/function in
X and the radius
r is a positive real number. In this topology, convergence of a sequence,
, of functions in
X to a limit
g in
X is referred to as
strong convergence, which implies that
and is denoted by
. Besides strong convergence, other notions of convergence (e.g.,
weak convergence and
uniform convergence) have been introduced in the literature, which play significant roles in the theory of Banach algebra [
1].
We now introduce the notions of weak convergence and weak topology. Given a Banach space X over a field
, let
be a set of bounded linear functionals (A functional is a mapping of a vector space
X into its field
. Then, the set of all linear bounded (equivalently, linear continuous) functionals in
X is called the dual space
.) on
X, i.e., each
is an element in the dual space
and hence
. Given an
and a vector/function
, let us define the set:
A class of such sets is obtained by varying
in Equation (
24) to establish the notions of weak convergence and weak topology. Some of these convergence concepts in the space of linear bounded operators are briefly explained in the following definitions, which are introduced for different notions of convergence of sequences
of bounded linear operators in Banach spaces.
Definition 4 (Convergence in operator norm or uniform convergence). Let be a bounded linear operator from V into V. Then, the sequence converges to some in the operator norm (also called uniform convergence) if the induced norm , which is denoted as: .
Definition 5 (Strong convergence). Let be a bounded linear operator from V into V. Then, the sequence converges strongly to some if , which is denoted as .
Definition 6 (Weak convergence)
. Let be a bounded linear operator from V into V. Then, the sequence converges weakly to some ifwhich is denoted as . Remark 2 (Convergence in operator norm). ⇒ (Strong convergence) ⇒ (Weak Convergence). The converse is not true, in general.
To show () ⇒ (), we proceed as:
, implies that, given , i.e., , it follows that .
To show () ⇒ ():, we proceed as:
. Let ; then, it follows from linearity and boundedness of the functional f that . Therefore,
We demonstrate the falsity of the converse by two counterexamples, one for each case.
(Strong convergence) ⇏ (Convergence in operator norm): Let us define and a sequence of bounded linear operators as: Therefore, is a bounded linear operator, i.e., . Since , it follows that However, the limit may not converge in the induced norm, as seen by choosing with .
Therefore, (Strong convergence) ⇏ (Convergence in operator norm).
(Weak convergence) ⇏ (Strong convergence): Let us define a sequence of bounded linear operators as:where . It is given that is a sequence of bounded linear operators, i.e., each . Furthermore, in this Hilbert space setting, it follows from the Riesz Representation Theorem that every can be represented as: It follows by Cauchy-Schwarz inequality that, as Therefore, (Weak convergence) ⇏ (Strong convergence).
Remark 3. It is noted that, for finite-dimensional vector spaces, the notions of strong convergence and weak convergence are indistinguishable. Equivalently, we make the following statement:In a finite-dimensional Banach space V, the weak topology generated by is the same as the strong topology generated by V.
However, in the analysis of stochastic processes, we deal with infinite-dimensional spaces of signal functions, which may not have the same criteria for weak convergence and strong convergence. This is especially applicable to statistical signal processing, where the expectation of the estimation error is required to weakly converge to zero without having the strong convergence of the error signal itself to zero.
Based on the concept of weak convergence, weak topology is defined as follows:
Definition 7 (Convergence in weak topology). Given a Banach space X, let there be a class of bounded linear functionals , and let be the topology in X generated by . Then, for a given vector/function , a sequence is said to converge to g in the weak topology , denoted as in , provided that converges strongly to , denoted as .
Weak convergence in Definition 7 is a generalization of weak convergence as introduced in the functional analysis literature, which implies that a sequence
converges weakly to some
if
[
10].
Remark 4. The concept of topological spaces and weak topology are important for learning using statistical invariants (LUSI). In a machine learning paradigm, learning machines often compute statistical invariants for specific problems with the objective of reducing the expected values of errors in a such way that preserves these invariants. In contrast to classical machine learning that employs the mechanism of strong convergence for approximations to the desired function, LUSI can significantly increase the rate of convergence by combining the mechanisms of strong convergence and weak convergence [17]. Furthermore, the notion of weak topology is also important when dealing with shift spaces for signal analysis that uses symbolic dynamics, as explained in [18,19]. 


{kind=link}
{kind=link}
{kind=link}
{kind=link}



