
Blockchain of Resource-Efficient Anonymity Protection with Watermarking for IoT Big Data Market

Abstract
:1. Introduction
2. Related Works
3. System Architecture and Proposed Scheme
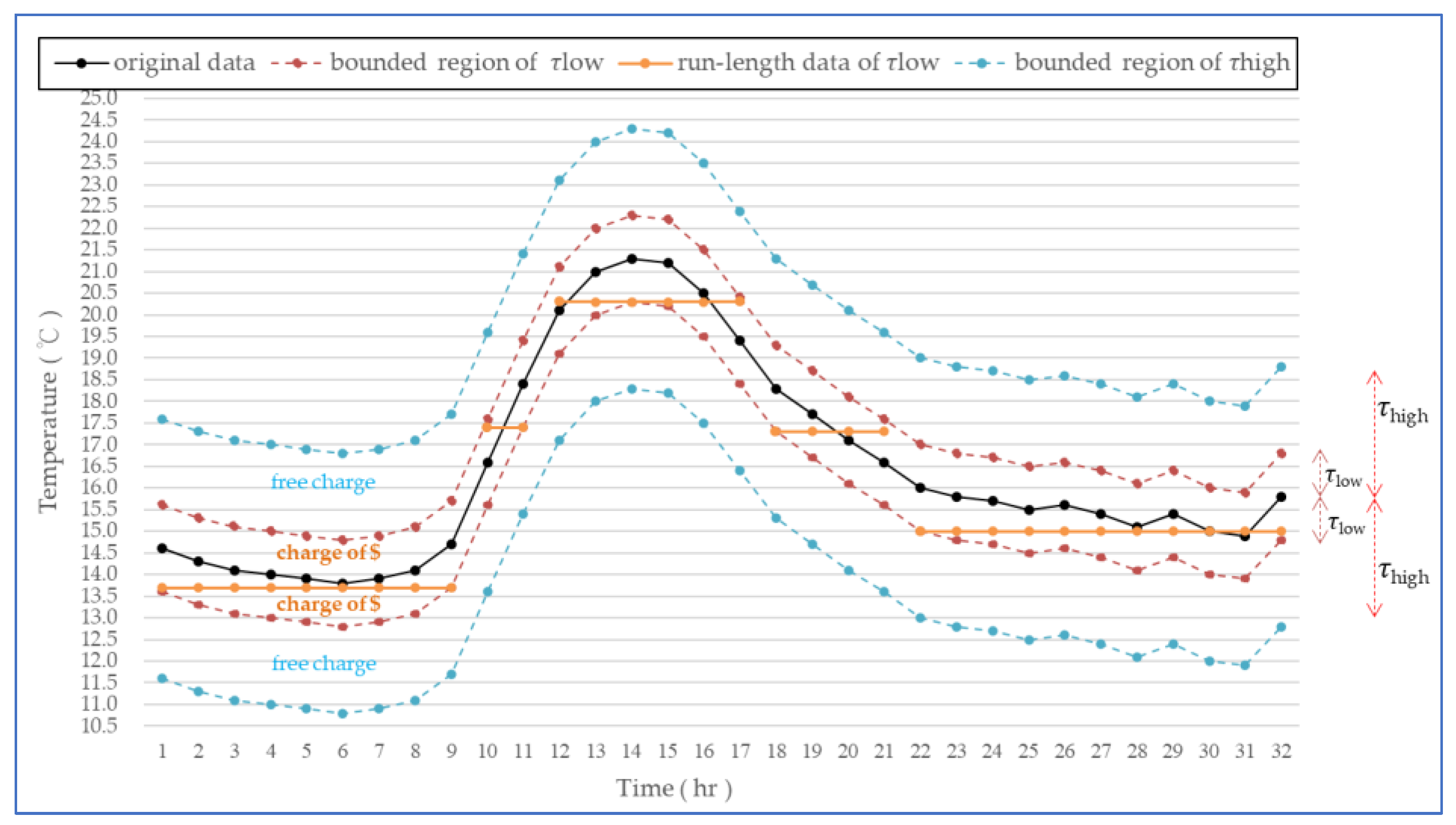
3.1. Preliminaries for Resource Efficiency in BEP IoT Big Data
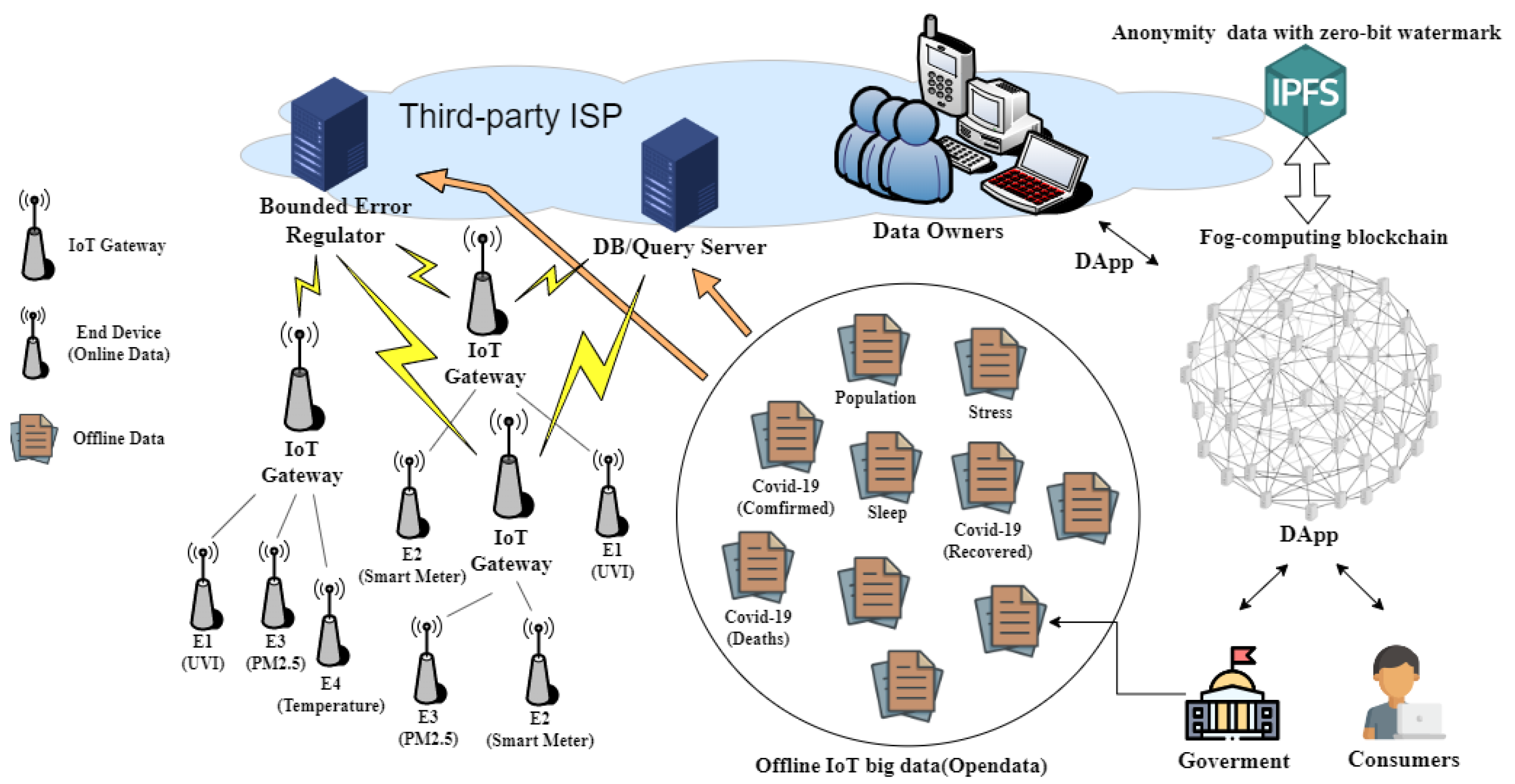
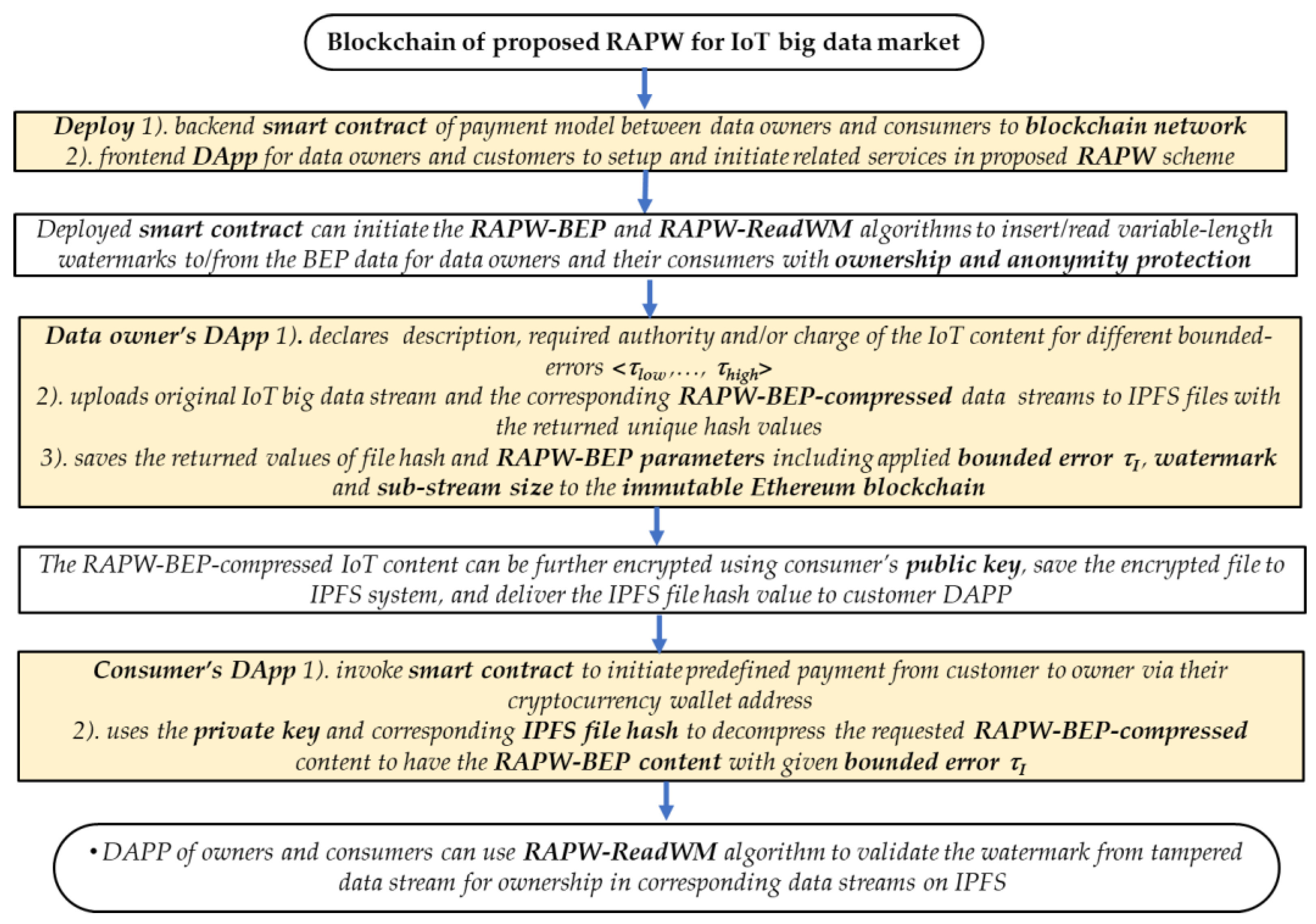
3.2. System Architecture for IoT Big Data Market Using Ethereum Blockchain
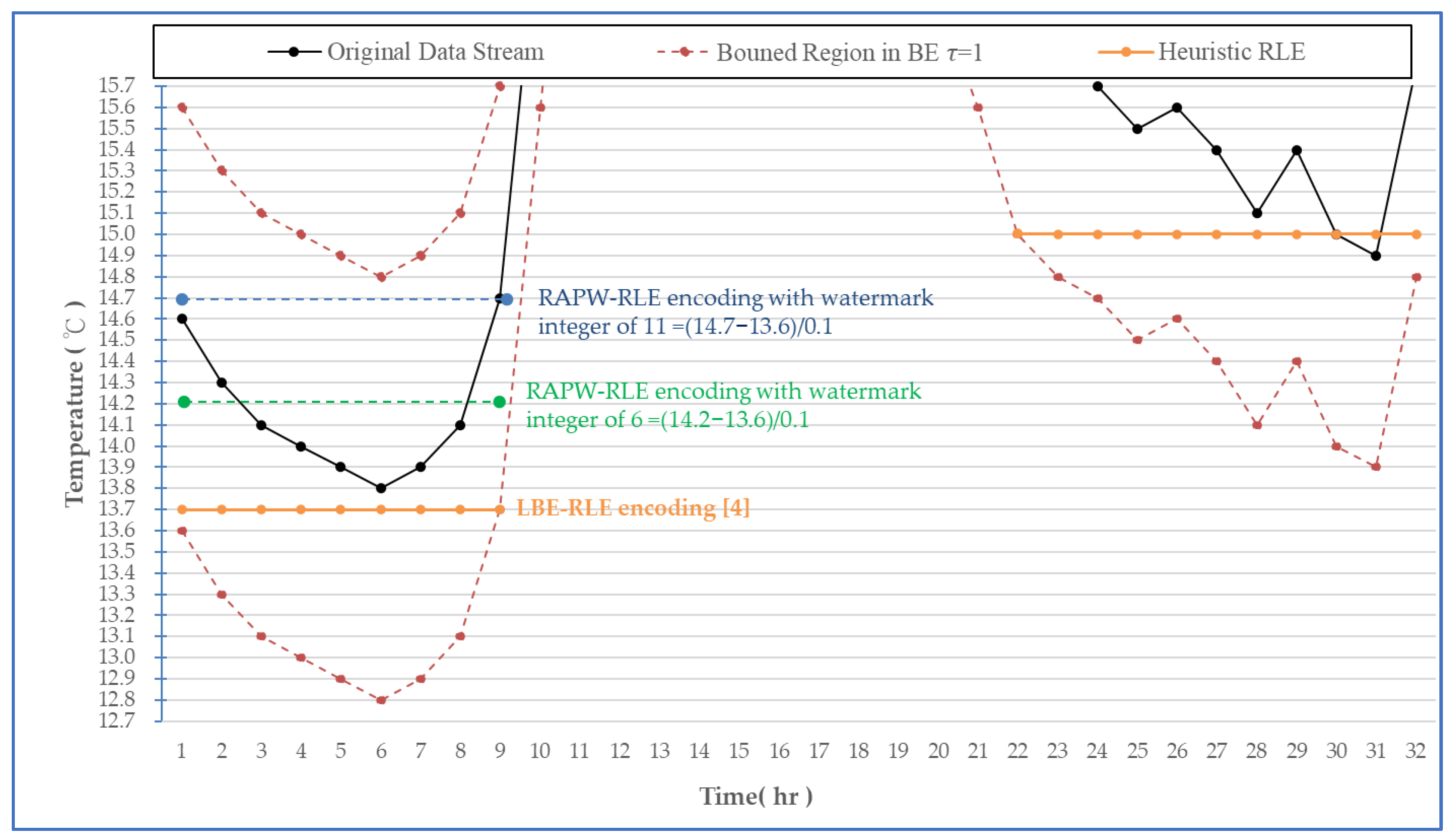
3.3. Resource-Efficient Anonymity Protection with Watermark (RAPW) Scheme
| Algorithm 1. RAPW-RLE algorithm for a IoT data sub-stream with single watermark integer . |
1: n = Si.dataSize 2: upperbound_Si[1:n].data = Si[1:n].data + τ 3: lowerbound_Si[1:n].data = Si[1:n].data − τ 4: Startindex = 1 5: Endindex = n 6: runLength = 1 7: while ( Startindex < n + 1) 8: startingData = lowerbound_Si[Startindex].data + wj 9: while (Endindex > Startindex) 10: if (startingData > upperbound_Si[Endindex].data) or (startingData < lowerbound_ Si[Endindex].data)) 11: runLength = 1 12: else 13: runLength ++ 14: end if 15: Endindex-- 16: end while 19: .append(startingData) 17: if (runLength > 1) 18: .append(runLength) 20: Startindex = Startindex + runLength 21: end while |
| Algorithm 2. RAPW-BEP algorithm for IoT data stream with watermark integer string. |
1: N = .dataSize 2: sizeRemained = N 3: I = j = 1 4: while (sizeRemained sizeMax) 5: Si.data = [(i − 1) sizeMax + 1:isizeMax] 6: Si.dataSize = sizeMax 7: wj = W[j] 8: .append(RAPW-RLE(τ, Si, wj)) /* in Algorithm 1 */ 9: j = j + 1 10: I = I + 1 11: if (j l + 1) /* l is defined in W[1:l] in Equation (14) or (15) */ 12: j = 1 13: end if 14: sizeRemained = sizeRemained sizeMax 15: end while 16: Si.data = [(i − 1)sizeMax + 1: (i − 1)sizeMax + sizeRemained] 17: Si.dataSize = sizeRemained 18: wj = W[j] 19: .append( RAPW-RLE(τ, Si, wj) ) /* in Algorithm 1 */ |
| Algorithm 3. RAPW-ReadWM algorithm for reading watermark from a RAPW-BEP data stream. |
1: N = .dataSize 2: sizeRemained = N 3: I = k = i = j = 1 4. countofDelimiter = 0 5. lowerboundData[:] = [:] τ 6. countofWK[0:lMAX] = 0 /* clear counts of all possible wk */ 7: while (sizeRemained sizeMax) 8: wk = ([I].di.staringPoint lowerboundData[j])/0.1 9: countofWK[wk]= countofWK[wk] + 1 /* count occurrence of wk */ 10: if (wk = ) 11: k = 1 12: countofDelimiter ++ 13: if (countofDelimiter = 2) 14: return W[] /* confirm the watermark integer list */ 15: end if 16: end if 17: j = j + [I].di.runLength 18: i = i + 1 19: if (j > sizeMax) 20: I++ /* jump to new sub-stream as defined in Equation (9) */ 21: MaxcntInx = index of maximum count in CountofWK[] 22: Othercnt = total of CountofWK[] except index of MaxcntInx 23: if( Othercnt wrThreshold) 24: W[k] = MaxcntInx 25: k = k + 1 26: else 27: return NIL /* return no watermark and exit*/ 28: end if 29: sizeRemained = sizeRemained sizeMax 30: i = j = 1 /* first data in new sub-stream */ 31: countofWK[0:lMAX] = 0 /*clear counts of all possible wk */ 32: end if 33: end while 34: /* check the remained sub-stream if meeting the conditions of step 13 to 15 in while loop, otherwise return no watermark and exit */ |
4. Experiments and Evaluations
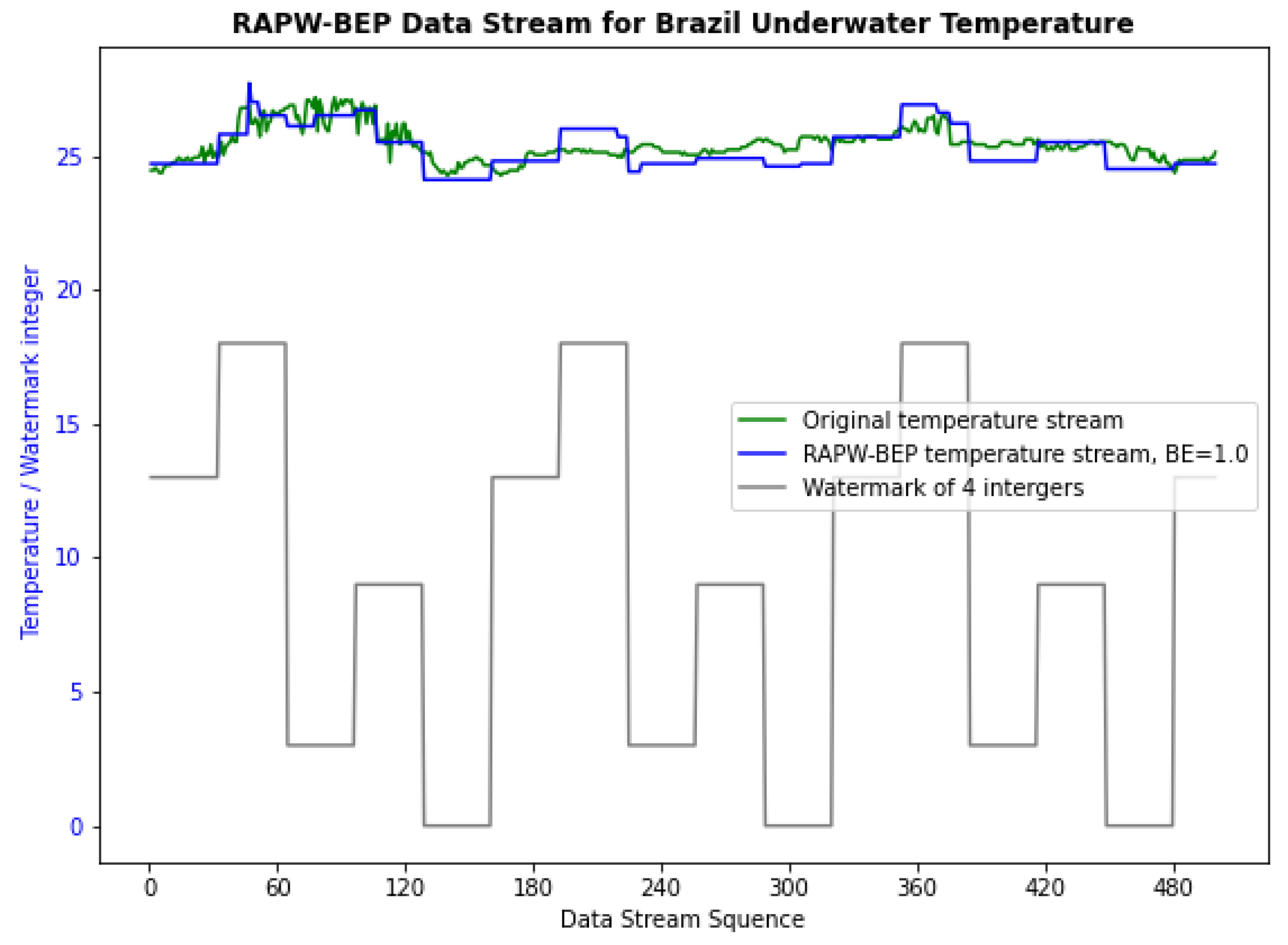
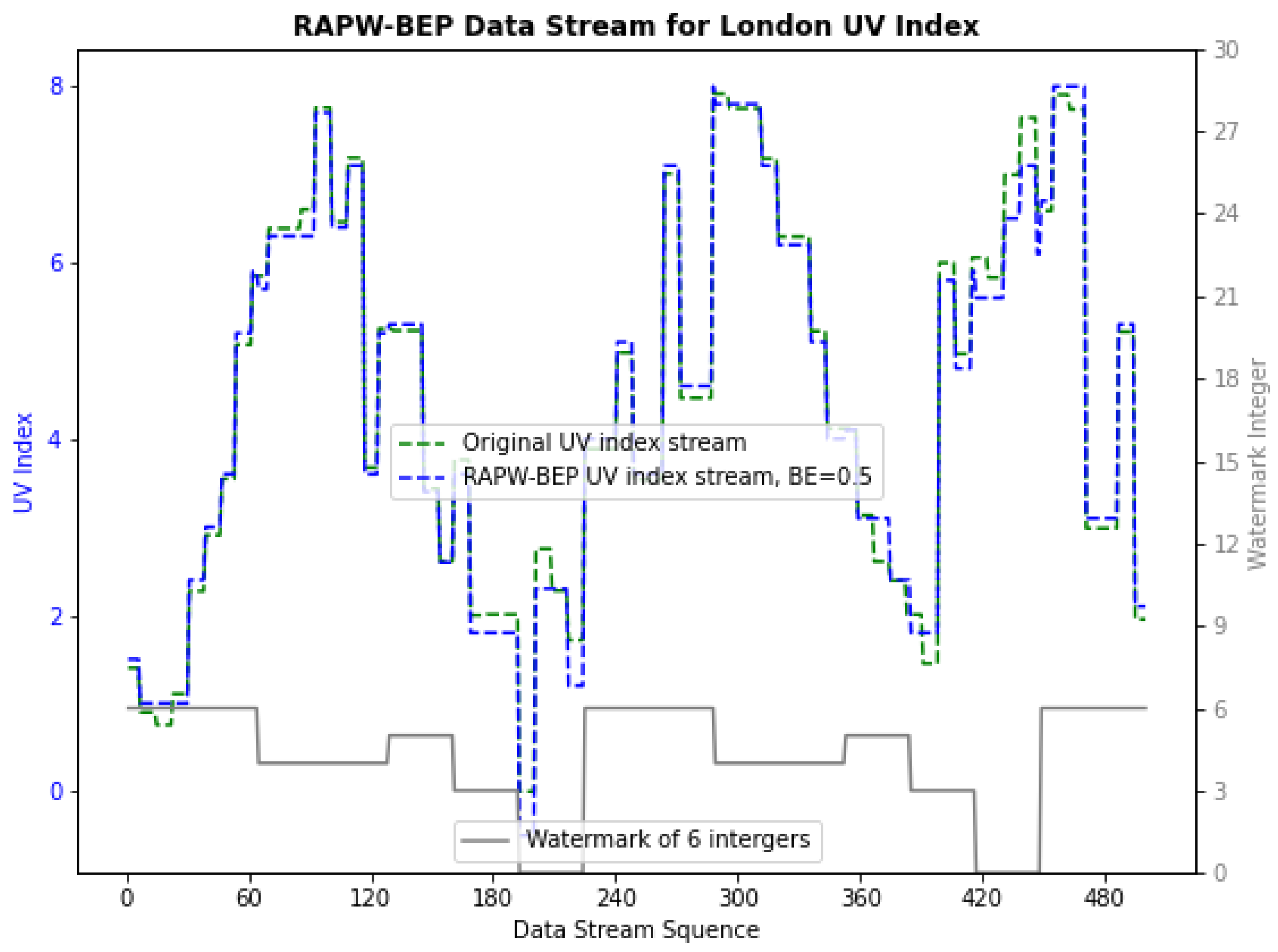
4.1. Preliminary Experiments for IoT Data Owners and Consumers
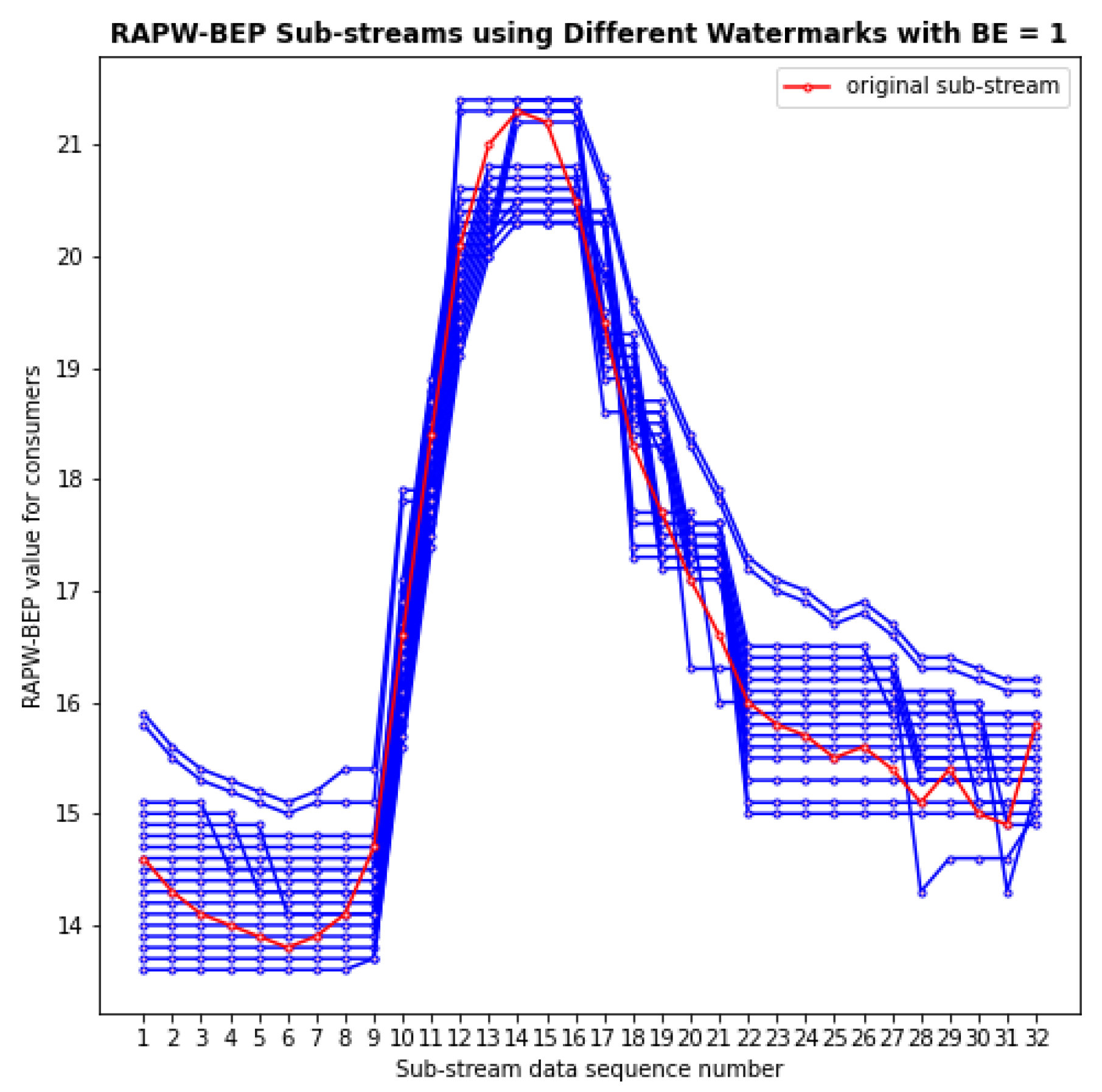
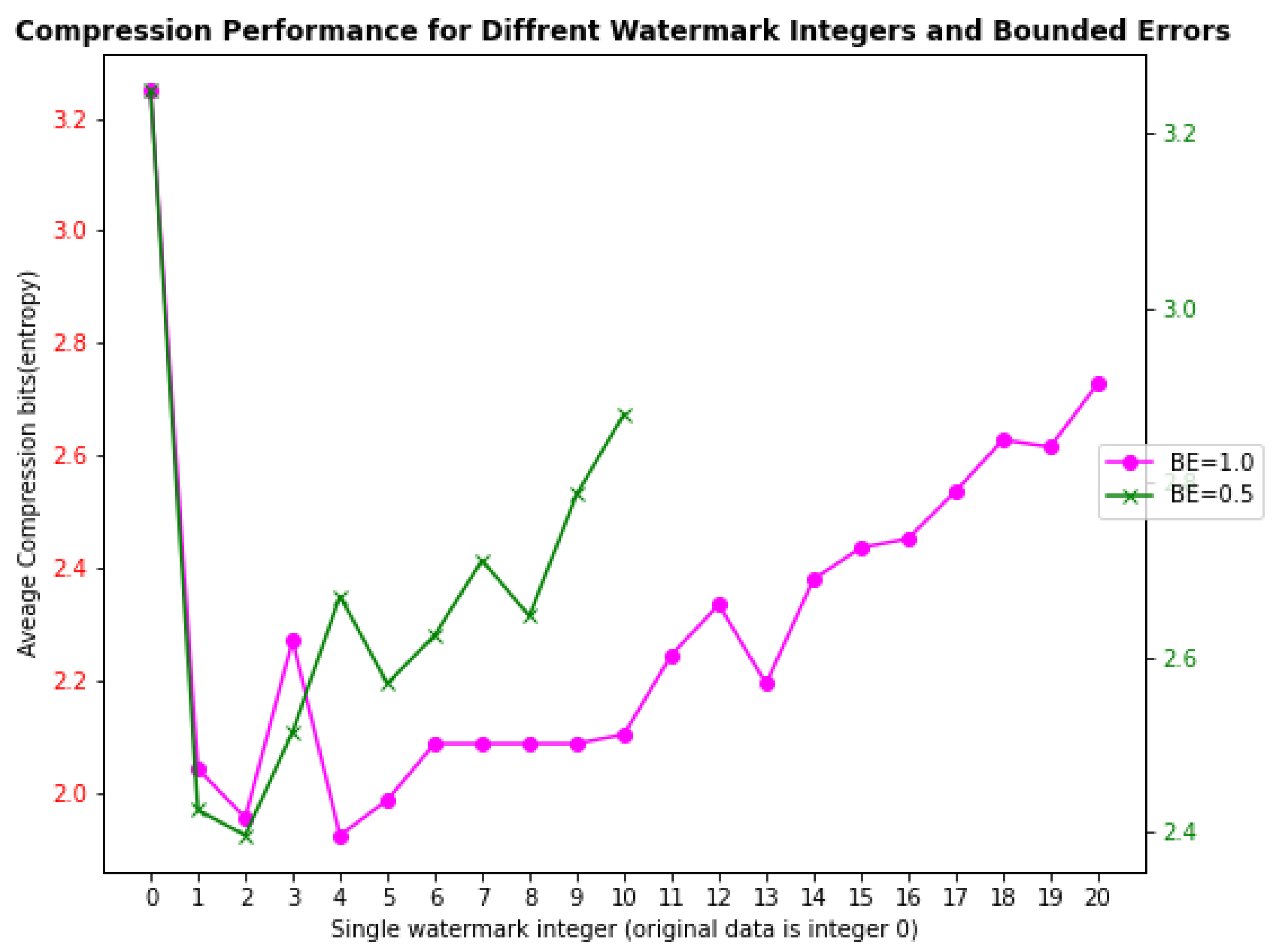
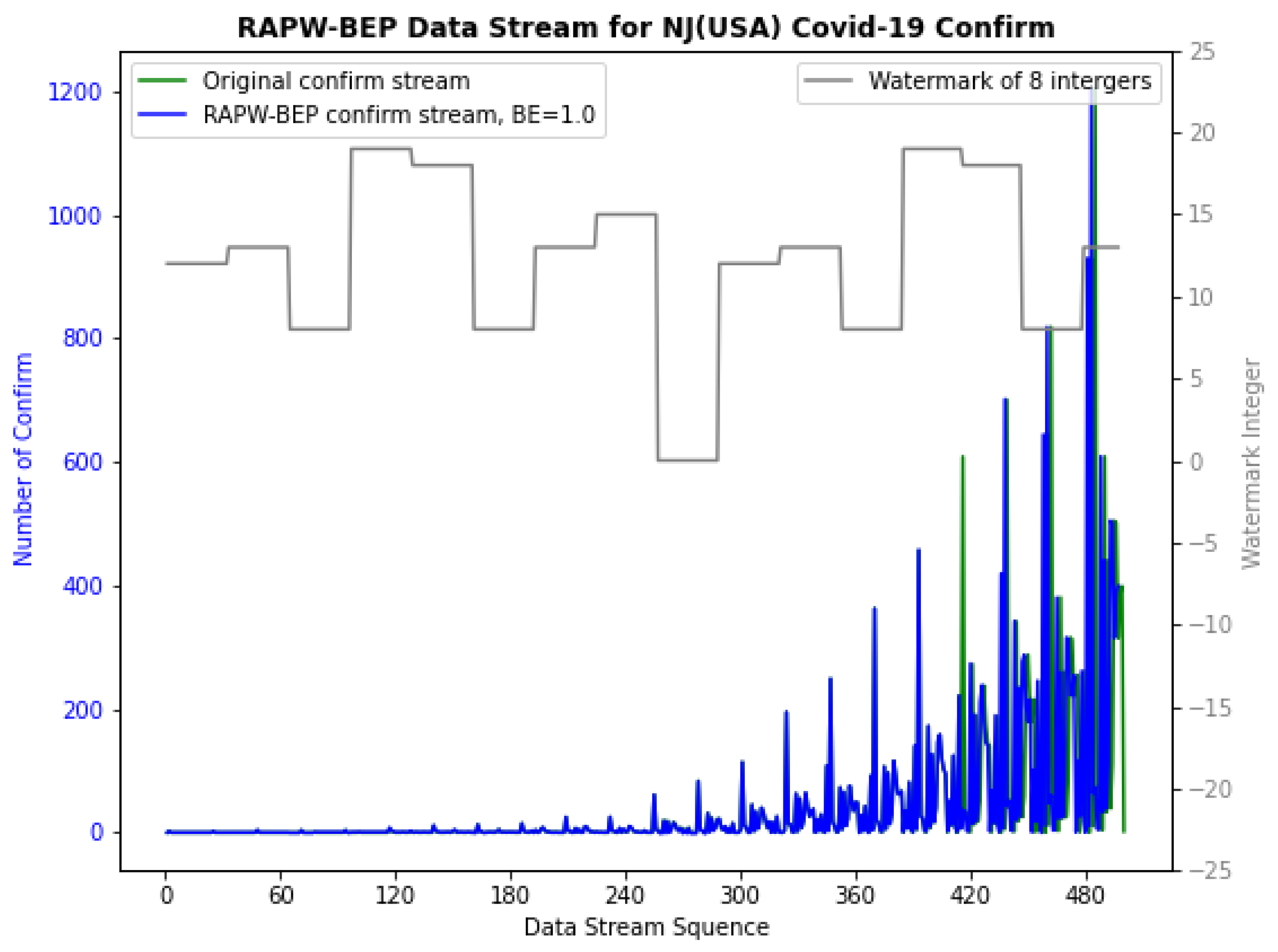
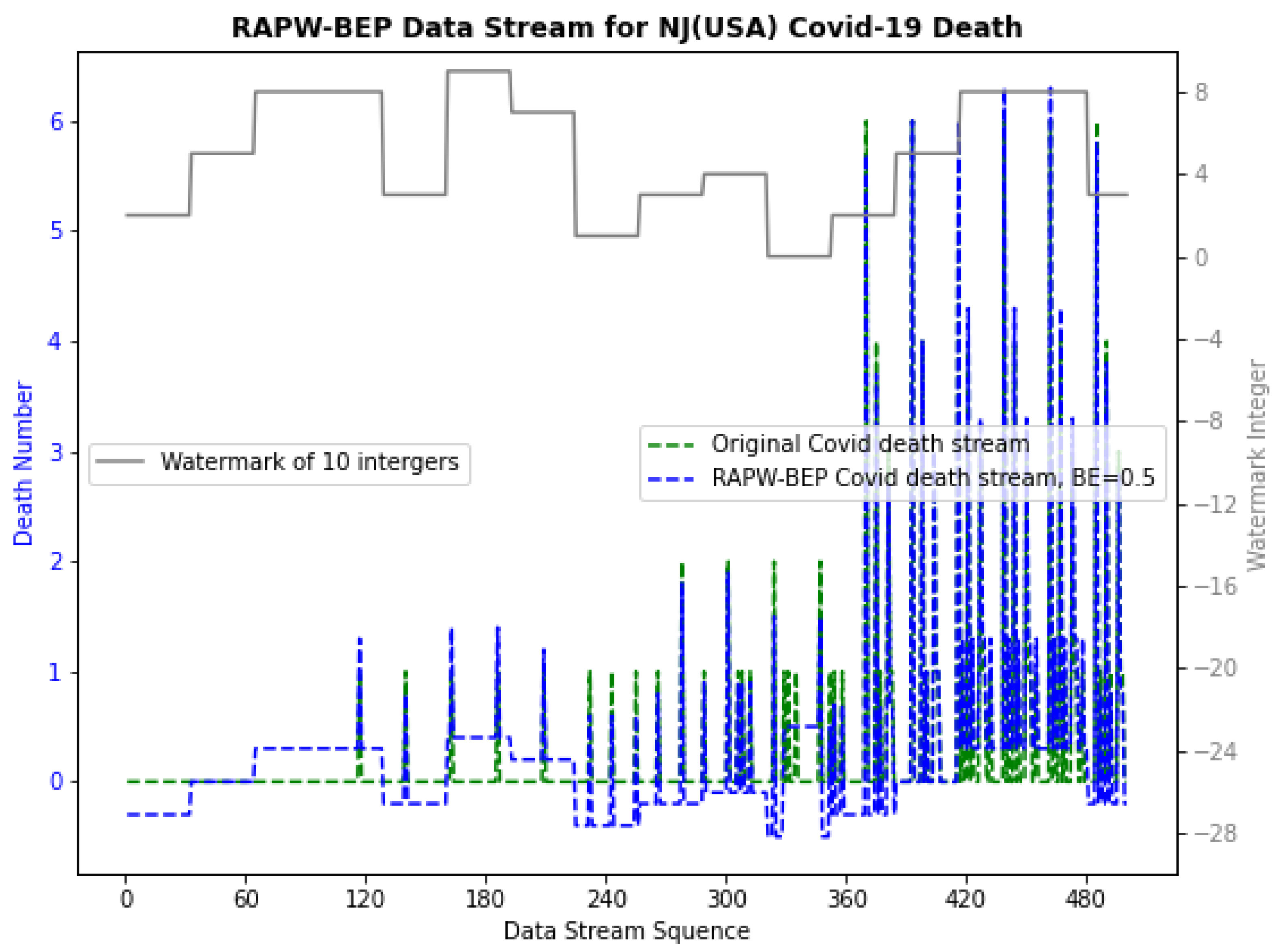
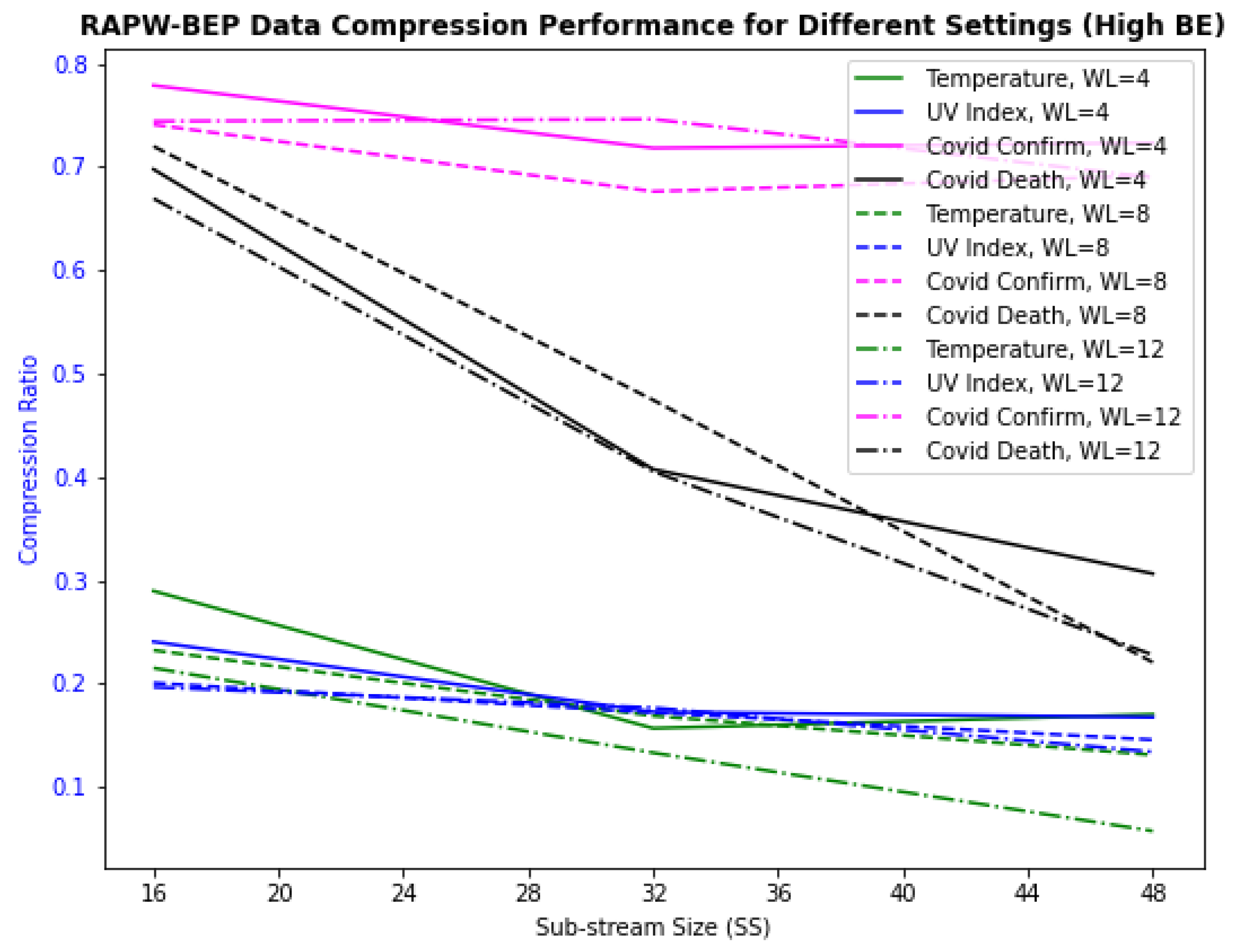
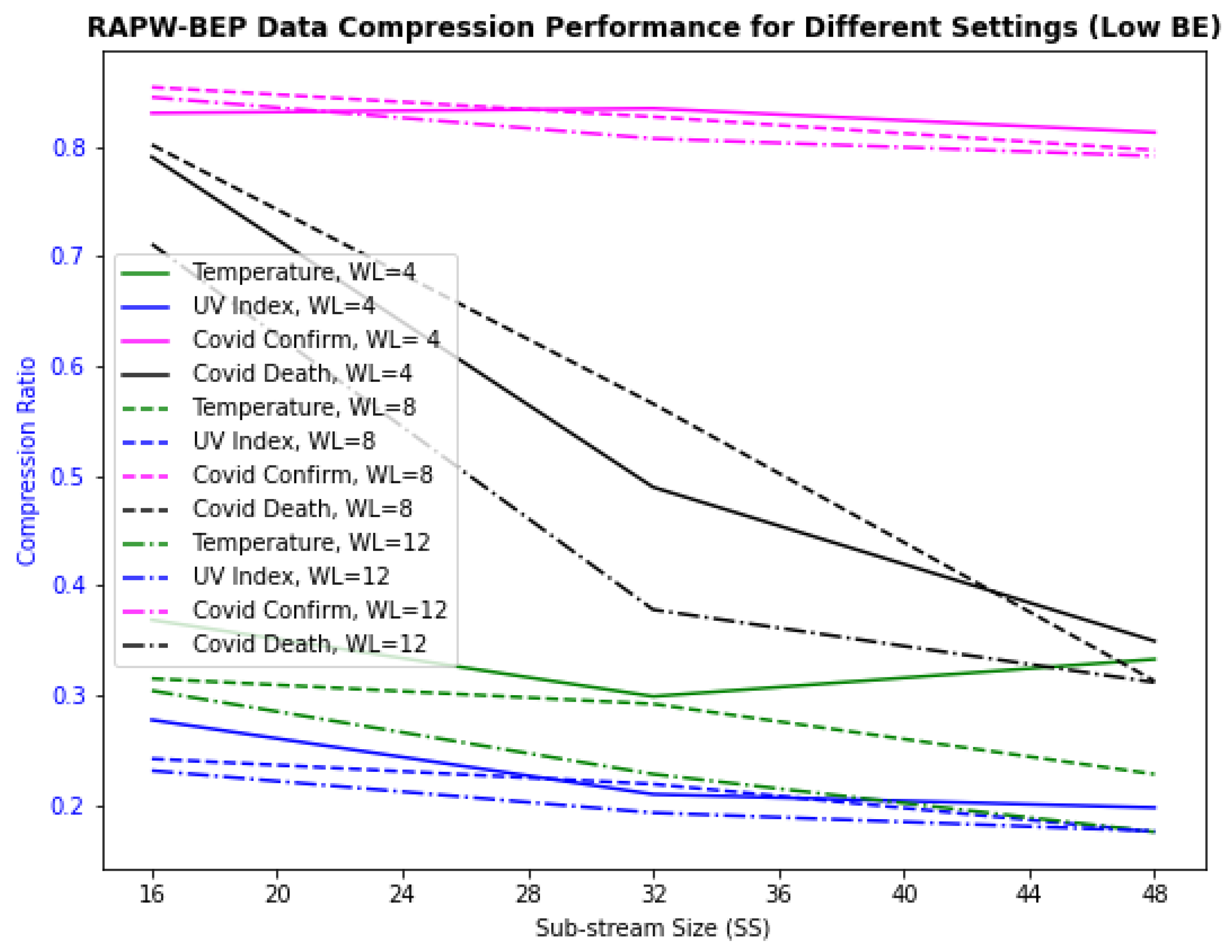
4.2. Examine for RAPW-BEP IoT Data Streams with Different Settings
4.3. Overall Performance Evaluation with Watermarking Robustness
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Garrido, G.M.; Sedlmeir, J.; Uludağ, Ö.; Alaoui, I.S.; Luckow, A.; Matthes, F. Revealing the landscape of privacy-enhancing technologies in the context of data markets for the IoT: A systematic literature review. J. Netw. Comput. Appl. 2022, 207, 103465. [Google Scholar] [CrossRef]
- Manzoor, A.; Braeken, A.; Kanhere, S.S.; Ylianttila, M.; Liyanage, M. Proxy re-encryption enabled secure and anonymous IoT data sharing platform based on blockchain. J. Netw. Comput. Appl. 2021, 176, 102917. [Google Scholar] [CrossRef]
- General Data Protection Regulation (GDPR). Available online: https://gdpr-info.eu (accessed on 21 December 2021).
- Chang, R.-I.; Wei, L.-C.; Wang, C.-H.; Tseng, Y.-K. Blockchain for bounded-error-pruned content protection. ICT Express 2021, 7, 295–299. [Google Scholar] [CrossRef]
- Furon, T. A Constructive and Unifying Framework for Zero-Bit Watermarking. IEEE Trans. Inf. Forensics Secur. 2007, 2, 149–163. [Google Scholar] [CrossRef]
- Gourrame, K.; Douzi, H.; Harba, R.; Riad, R.; Ros, F.; Amar, M.; Elhajji, M. A zero-bit Fourier image watermarking for print-cam process. Multimed. Tools Appl. 2019, 78, 2621–2638. [Google Scholar] [CrossRef]
- Roček, A.; Javorník, M.; Slavíček, K.; Dostál, O. Zero Watermarking: Critical Analysis of Its Role in Current Medical Imaging. J. Digit. Imaging 2021, 34, 204–211. [Google Scholar] [CrossRef] [PubMed]
- Oliva, G.A.; Hassan, A.E.; Jiang, Z.M. An exploratory study of smart contracts in the Ethereum blockchain platform. Empir. Softw. Eng. 2020, 25, 1864–1904. [Google Scholar] [CrossRef]
- Azar, J.; Makhoul, A.; Barhamgi, M.; Couturier, R. An energy efficient IoT data compression approach for edge machine learning. Future Gener. Comput. Syst. 2019, 96, 168–175. [Google Scholar] [CrossRef]
- Marcelloni, F.; Vecchio, M. Enabling energy-efficient and lossy-aware data compression in wireless sensor networks by multi-objective evolutionary optimization. Inf. Sci. 2010, 180, 1924–1941. [Google Scholar] [CrossRef]
- Liu, Y.; Di, S.; Zhao, K.; Jin, S.; Wang, C.; Chard, K.; Tao, D.; Foster, I.; Cappello, F. Optimizing Error-Bounded Lossy Compression for Scientific Data with Diverse Constraints. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 4440–4457. [Google Scholar] [CrossRef]
- Chang, R.-I.; Chu, Y.-H.; Wei, L.-C.; Wang, C.-H. Bounded-Error-Pruned Sensor Data Compression for Energy-Efficient IoT of Environmental Intelligence. Appl. Sci. 2020, 10, 6512. [Google Scholar] [CrossRef]
- Zheng, Z.; Xie, S.; Dai, H.N.; Chen, W.; Chen, X.; Weng, J.; Imran, M. An overview on smart contracts: Challenges, advances and platforms. Future Gener. Comput. Syst. 2020, 105, 475–491. [Google Scholar] [CrossRef]
- Benet, J. Ipfs-content addressed, versioned, p2p file system. arXiv 2014, arXiv:1407.3561. [Google Scholar]
- Ali, M.S.; Dolui, K.; Antonelli, F. IoT data privacy via blockchains and IPFS. In Proceedings of the Seventh International Conference on the Internet of Things, Linz, Austria, 22–25 October 2017; pp. 1–7. [Google Scholar]
- Radanliev, P.; De Roure, D.; Walton, R.; Van Kleek, M.; Montalvo, R.M.; Maddox, L.; Santos, O.; Burnap, P.; Anthi, E. Artificial intelligence and machine learning in dynamic cyber risk analytics at the edge. SN Appl. Sci. 2020, 2, 1773. [Google Scholar] [CrossRef]
- Wazirali, R.; Ahmad, R.; Al-Amayreh, A.; Al-Madi, M.; Khalifeh, A. Secure Watermarking Schemes and Their Approaches in the IoT Technology: An Overview. Electronics 2021, 10, 1744. [Google Scholar] [CrossRef]
- Buterin, V. A Next-generation Smart Contract and Decentralized Application Platform. Ethereum White Pap. 2017, 3, 1–2. [Google Scholar]
- Li, Z.N.; Drew, M.S.; Liu, J. Fundamentals of Multimedia; Pearson Prentice Hall: Upper Saddle River, NJ, USA, 2004. [Google Scholar]
- Chang, R.-I.; Tsai, J.-H.; Wang, C.-H. Edge Computing of Online Bounded-Error Query for Energy-Efficient IoT Sensors. Sensors 2022, 22, 4799. [Google Scholar] [CrossRef]
- An Underwater Temperature Dataset from Coastal Islands in Brazil. Available online: https://www.kaggle.com/datasets/shivamb/underwater-surface-temperature-dataset (accessed on 29 July 2022).
- UV Index Data Collected Local to West London (Heathrow and Northolt). Available online: https://www.kaggle.com/datasets/t5ra190/uv-index-dataset-local-to-west-london (accessed on 29 July 2022).
- COVID-19 Data Repository. Available online: https://github.com/CSSEGISandData/COVID-19 (accessed on 29 July 2022).
- Li, Q.; Memon, N. Security models of digital watermarking. In International Workshop on Multimedia Content Analysis and Mining; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Watermark Length, Sub-Stream Size/Dataset | WL = 4, SS = 16 | WL = 8, SS = 16 | WL = 12, SS = 16 | WL = 4, SS = 32 | WL = 8, SS = 32 | WL = 12, SS = 32 | WL = 4, SS = 48 | WL = 8, SS = 48 | WL = 12, SS = 48 |
|---|---|---|---|---|---|---|---|---|---|
| Temperature (BE = 1.0) | ok | ok | ok | ok | ok | ok | ok | ok | Incomp. |
| UV Index (BE = 1.0) | ok | ok | ok | ok | ok | ok | ok | ok | Incomp. |
| COVID Confirm (BE = 1.0) | ok | ok | ok | ok | ok | ok | ok | ok | Incomp. |
| COVID Death (BE = 1.0) | ok | ok | ok | ok | ok | ok | ok | ok | Incomp. |
| Temperature (BE = 0.5) | ok | ok | ok | ok | ok | ok | ok | ok | Incomp. |
| UV Index (BE = 0.5) | ok | ok | ok | ok | ok | ok | ok | ok | Incomp. |
| COVID Confirm (BE = 0.5) | ok | ok | ok | ok | ok | ok | ok | ok | Incomp. |
| COVID Death (BE = 0.5) | ok | ok | ok | ok | ok | ok | ok | ok | Incomp. |
| Tampered Ratio/Dataset | 1% | 2% | 10% | 20% |
|---|---|---|---|---|
| Temperature | 83% | 77% | 56% | 30% |
| UV index | 83% | 78% | 50% | 28% |
| COVID confirmed cases | 63% | 58% | 32% | 21% |
| COVID death | 83% | 76% | 41% | 14% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.-H.; Hsu, C.-H. Blockchain of Resource-Efficient Anonymity Protection with Watermarking for IoT Big Data Market. Cryptography 2022, 6, 49. https://doi.org/10.3390/cryptography6040049
Wang C-H, Hsu C-H. Blockchain of Resource-Efficient Anonymity Protection with Watermarking for IoT Big Data Market. Cryptography. 2022; 6(4):49. https://doi.org/10.3390/cryptography6040049
Chicago/Turabian StyleWang, Chia-Hui, and Chih-Hao Hsu. 2022. "Blockchain of Resource-Efficient Anonymity Protection with Watermarking for IoT Big Data Market" Cryptography 6, no. 4: 49. https://doi.org/10.3390/cryptography6040049