
IDSNN: Towards High-Performance and Low-Latency SNN Training via Initialization and Distillation

Abstract
:1. Introduction
2. Related Works
2.1. ANN-to-SNN Conversion
2.2. Directly Training SNNs
3. Materials and Methods
3.1. Spiking Neuron Model
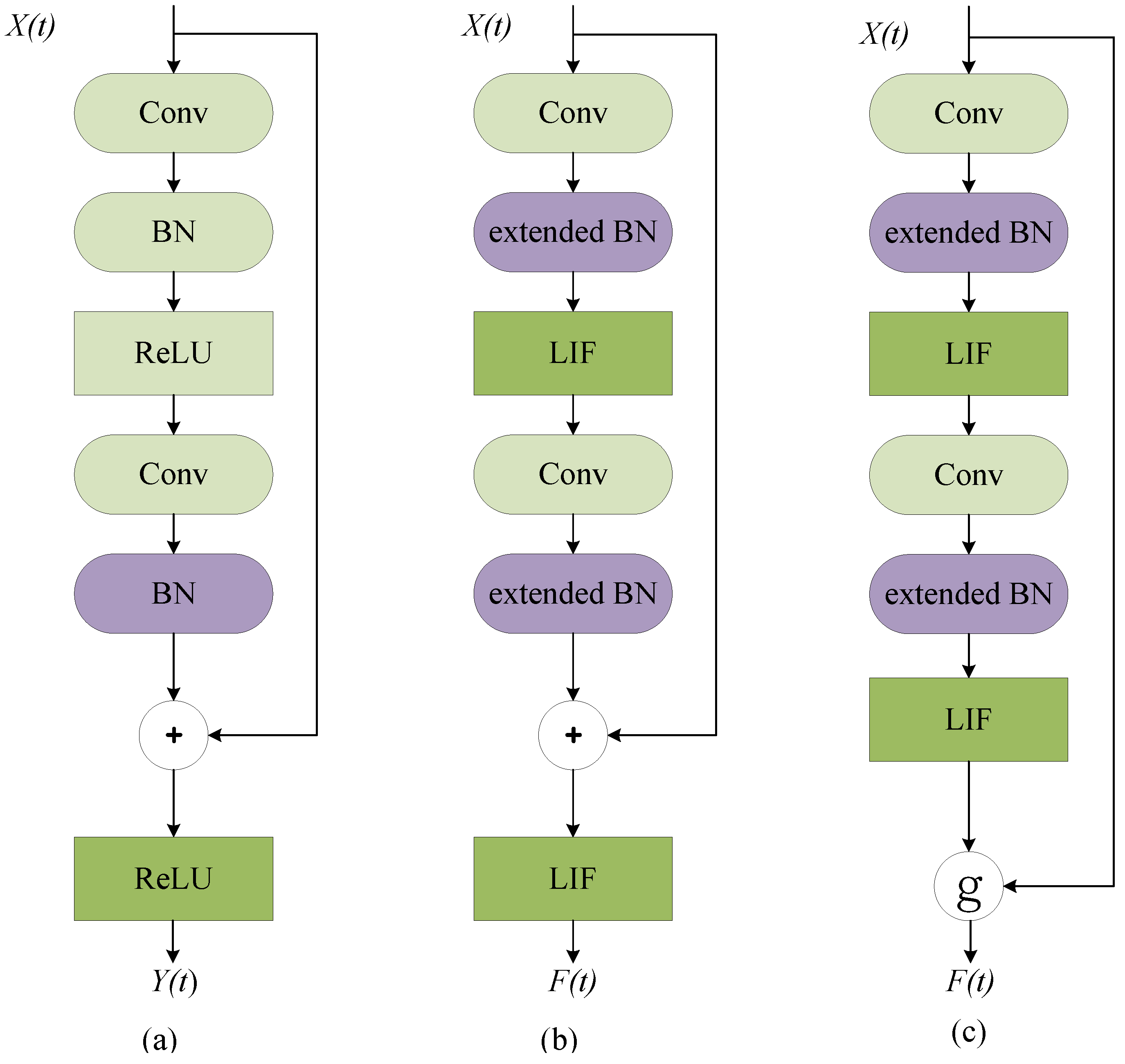
3.2. Connect ANNs and SNNs through Initialization
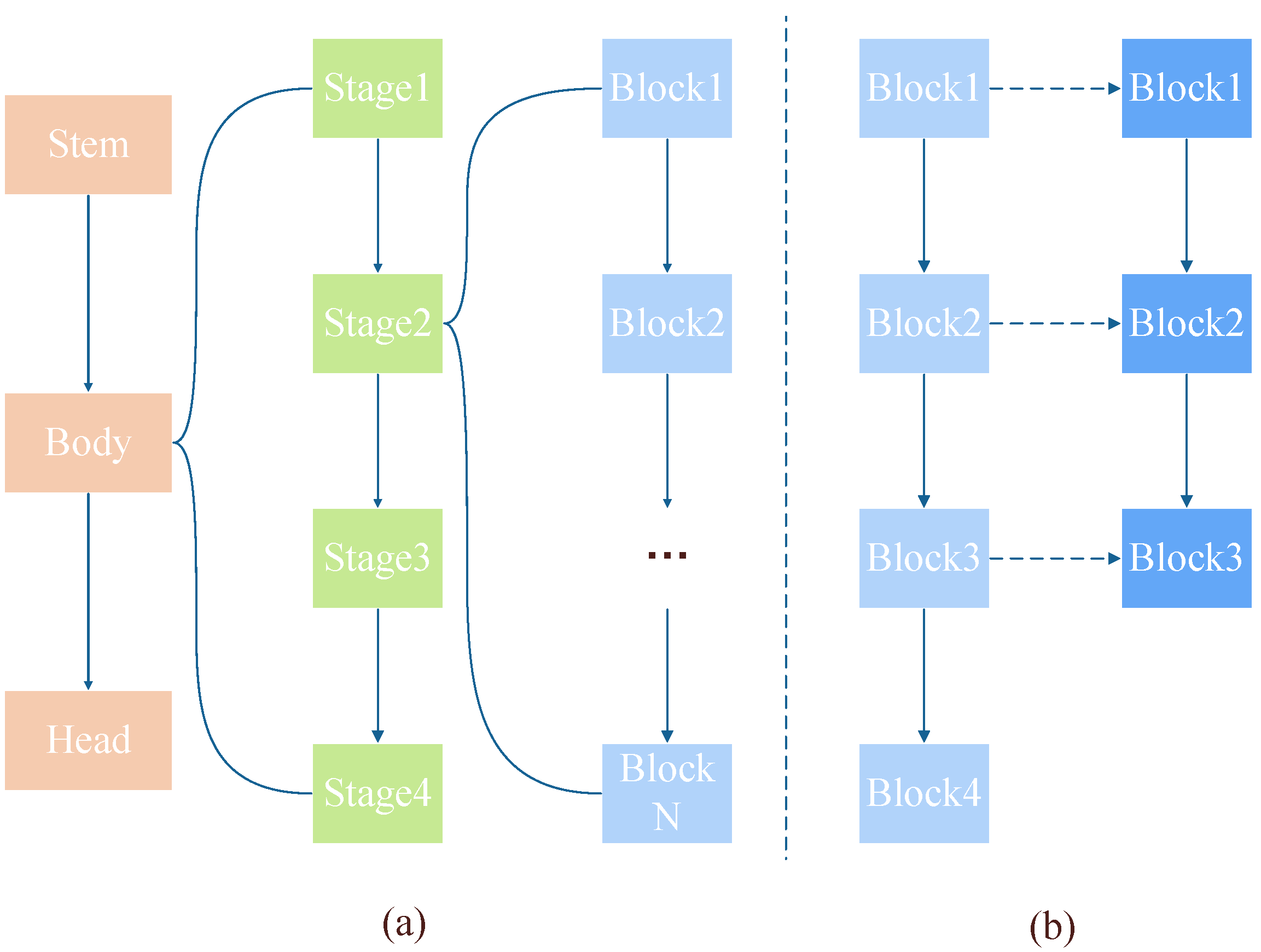
3.2.1. The Relationship between Spiking ResNet and ResNet
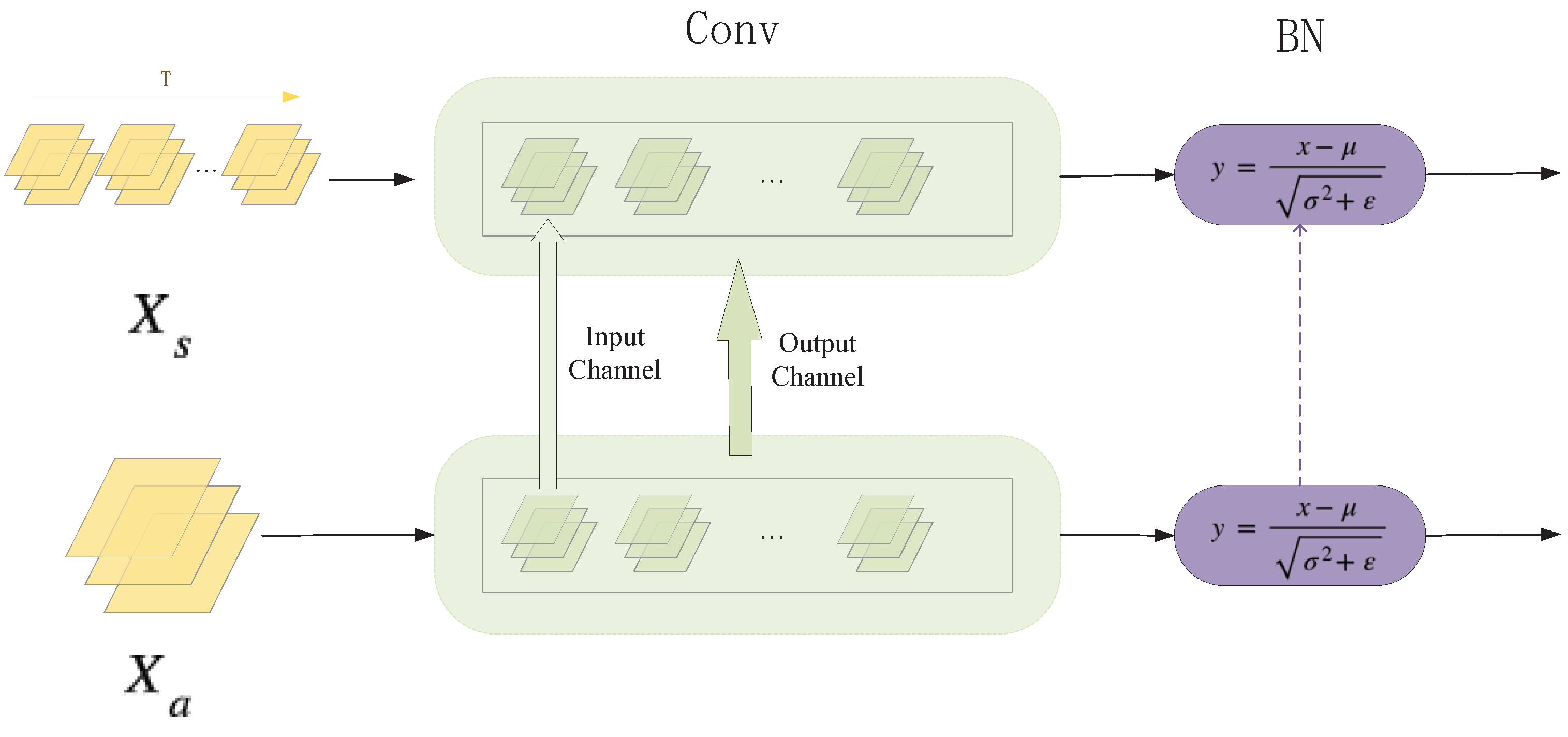
3.2.2. SNN Initialization through ANN
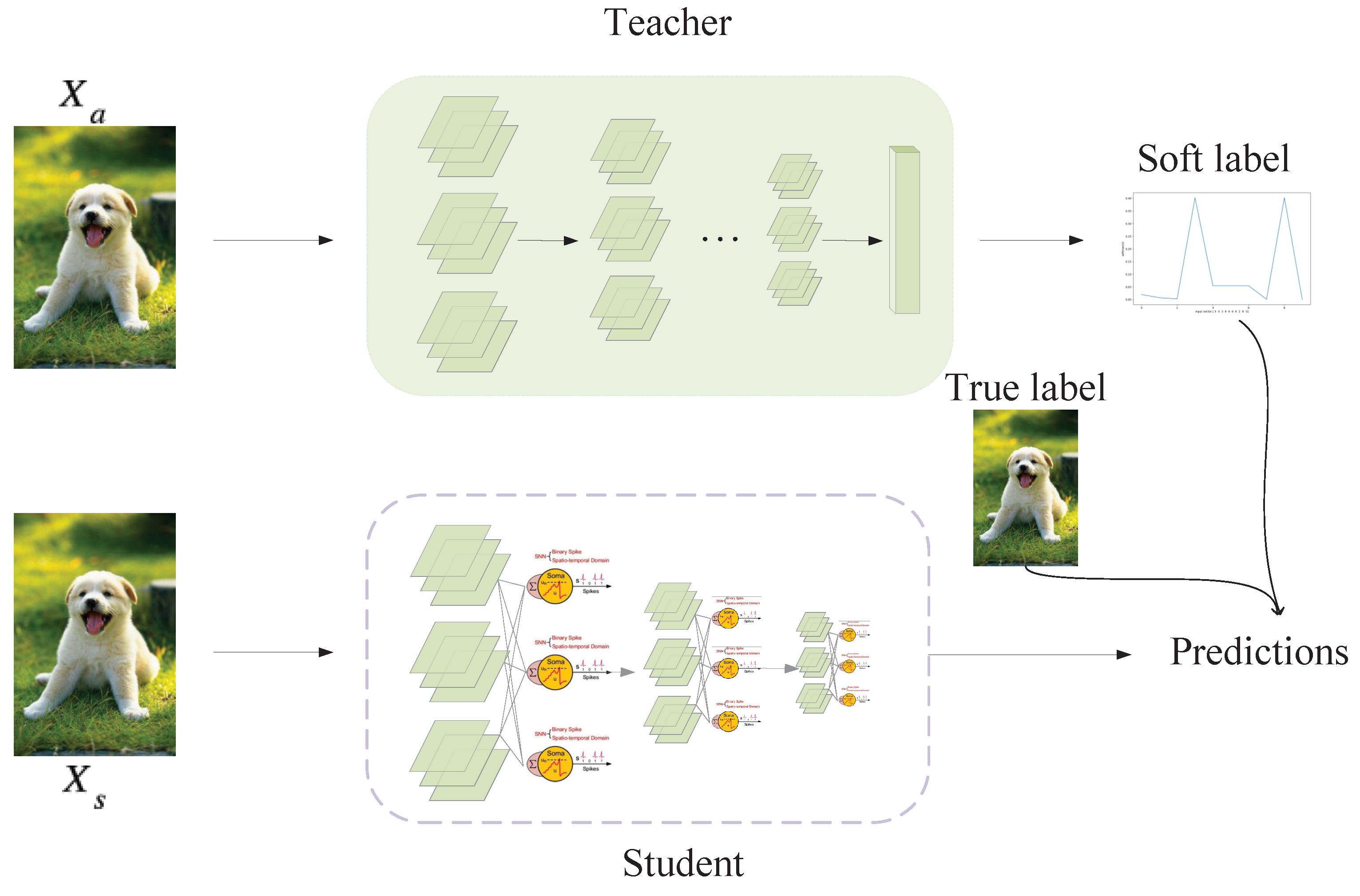
3.3. IDSNN
3.3.1. ANN-to-SNN Distillation
3.3.2. IDSNN Training Process
| Algorithm 1 Training pipeline |
Require:
Pre-trained ANN , target SNN , input samples X, true label Ensure:
and are both ResNet-based # initialization # forward propagation for to T do for to do if then end if # receive input from the previous layer and accumulate membrane potential end for end for # calculate total loss # Backward Propagation for to 1 do for to 1 do end for end for |
4. Results and Discussion
4.1. Experiments Setting
4.2. Performance Comparison with Other Methods

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Training Method | ANN | SNN | ANN Acc (%) | SNN Acc (%) | Time-Step |
|---|---|---|---|---|---|---|
| [31] | KD training | – | VGG16 | – | 74.42 | 5 |
| Dspike [27] | SNN training | – | ResNet18 | – | 73.35 | 4 |
| Real Spike [29] | SNN training | – | ResNet20 | – | 64.87 | 4 |
| SNN Calibration [11] | Conversion | – | ResNet20 | – | 72.33 | 16 |
| COS [30] | Conversion | – | ResNet20 | – | 70.29 | 32 |
| Parameter Calibration [28] | Conversion | – | ResNet20 | 81.51 | 71.86 | 8 |
| IDSNN | Hybrid training | ResNet34 | ResNet18 | 77.26 | 75.24 75.41 | 4 6 |
4.3. Ablation Experiments
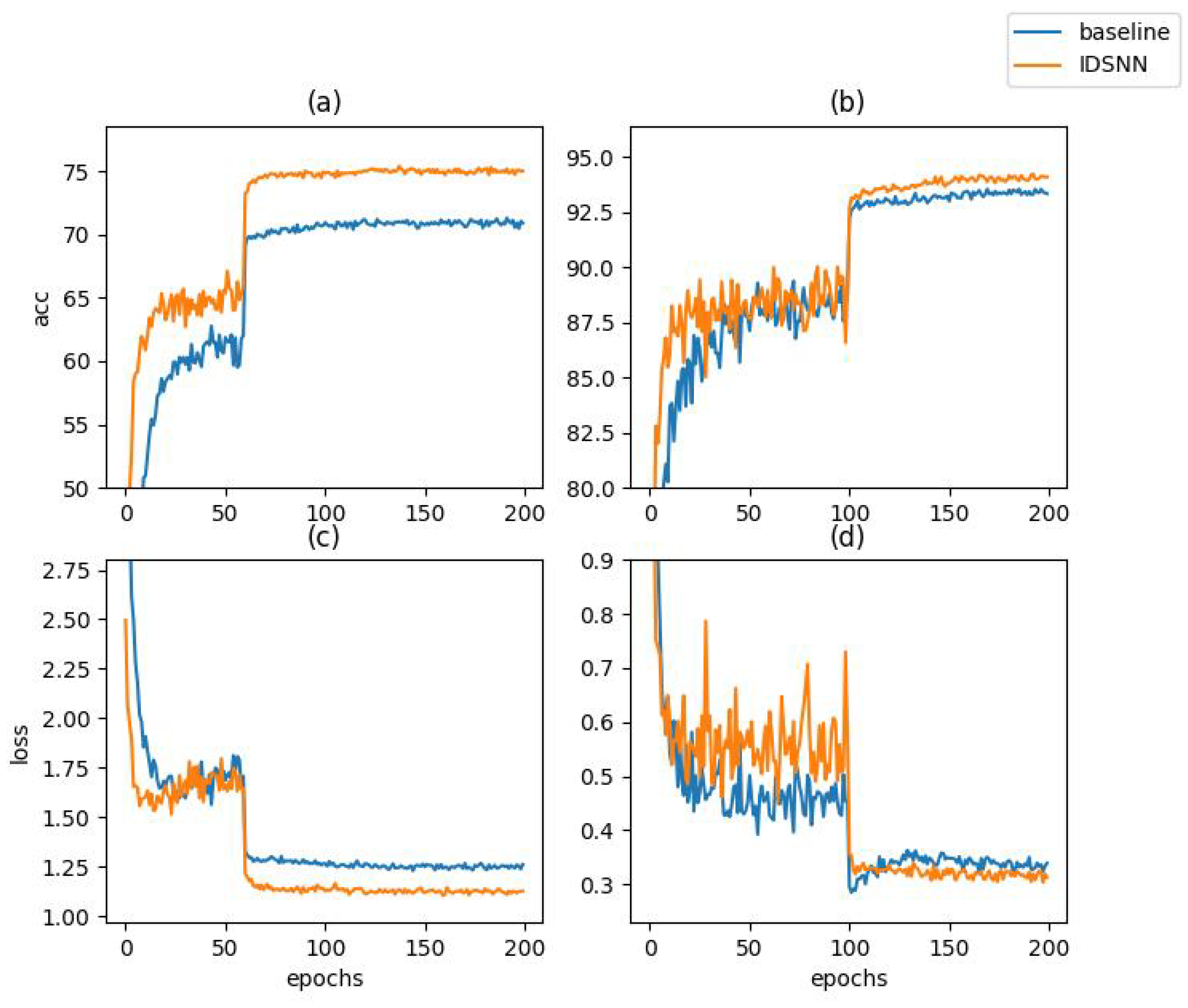
4.4. Convergence Speed Experiments
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ANNs | Artificial neural networks |
| SNNs | Spiking neural networks |
| BN | Batch normalization |
| LIF | Leaky Integrate-and-Fire |
| STBP | Spatio-temporal back propagation |
| SGD | Stochastic gradient descent |
References
- Zenke, F.; Agnes, E.J.; Gerstner, W. Diverse synaptic plasticity mechanisms orchestrated to form and retrieve memories in spiking neural networks. Nat. Commun. 2015, 6, 6922. [Google Scholar] [CrossRef] [PubMed]
- Ding, J.; Bu, T.; Yu, Z.; Huang, T.; Liu, J. Snn-rat: Robustness-enhanced spiking neural network through regularized adversarial training. Adv. Neural Inf. Process. Syst. 2022, 35, 24780–24793. [Google Scholar]
- Ostojic, S. Two types of asynchronous activity in networks of excitatory and inhibitory spiking neurons. Nat. Neurosci. 2014, 17, 594–600. [Google Scholar] [CrossRef] [PubMed]
- Neftci, E.O.; Mostafa, H.; Zenke, F. Surrogate gradient learning in spiking neural networks: Bringing the power of gradient-based optimization to spiking neural networks. IEEE Signal Process. Mag. 2019, 36, 51–63. [Google Scholar] [CrossRef]
- Bu, T.; Fang, W.; Ding, J.; Dai, P.; Yu, Z.; Huang, T. Optimal ANN-SNN conversion for high-accuracy and ultra-low-latency spiking neural networks. arXiv 2023, arXiv:2303.04347. [Google Scholar]
- Cao, Y.; Chen, Y.; Khosla, D. Spiking deep convolutional neural networks for energy-efficient object recognition. Int. J. Comput. Vis. 2015, 113, 54–66. [Google Scholar] [CrossRef]
- Diehl, P.U.; Neil, D.; Binas, J.; Cook, M.; Liu, S.C.; Pfeiffer, M. Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), IEEE, Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar]
- Ding, J.; Yu, Z.; Tian, Y.; Huang, T. Optimal ann-snn conversion for fast and accurate inference in deep spiking neural networks. arXiv 2021, arXiv:2105.11654. [Google Scholar]
- Gigante, G.; Mattia, M.; Del Giudice, P. Diverse population-bursting modes of adapting spiking neurons. Phys. Rev. Lett. 2007, 98, 148101. [Google Scholar] [CrossRef]
- Kobayashi, R.; Tsubo, Y.; Shinomoto, S. Made-to-order spiking neuron model equipped with a multi-timescale adaptive threshold. Front. Comput. Neurosci. 2009, 3, 9. [Google Scholar] [CrossRef]
- Li, Y.; Deng, S.; Dong, X.; Gong, R.; Gu, S. A free lunch from ANN: Towards efficient, accurate spiking neural networks calibration. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 6316–6325. [Google Scholar]
- Rueckauer, B.; Lungu, I.A.; Hu, Y.; Pfeiffer, M.; Liu, S.C. Conversion of continuous-valued deep networks to efficient event-driven networks for image classification. Front. Neurosci. 2017, 11, 682. [Google Scholar] [CrossRef]
- Sengupta, A.; Ye, Y.; Wang, R.; Liu, C.; Roy, K. Going deeper in spiking neural networks: VGG and residual architectures. Front. Neurosci. 2019, 13, 95. [Google Scholar] [CrossRef]
- Fang, W.; Yu, Z.; Chen, Y.; Huang, T.; Masquelier, T.; Tian, Y. Deep residual learning in spiking neural networks. Adv. Neural Inf. Process. Syst. 2021, 34, 21056–21069. [Google Scholar]
- Lin, Y.; Hu, Y.; Ma, S.; Yu, D.; Li, G. Rethinking Pretraining as a Bridge From ANNs to SNNs. IEEE Trans. Neural Net. Learn. Syst. 2022, 1–14. [Google Scholar] [CrossRef]
- Hong, D.; Shen, J.; Qi, Y.; Wang, Y. LaSNN: Layer-wise ANN-to-SNN Distillation for Effective and Efficient Training in Deep Spiking Neural Networks. arXiv 2023, arXiv:2304.09101. [Google Scholar]
- Xu, Q.; Li, Y.; Shen, J.; Liu, J.K.; Tang, H.; Pan, G. Constructing deep spiking neural networks from artificial neural networks with knowledge distillation. arXiv 2023, arXiv:2304.05627. [Google Scholar]
- Maass, W. Networks of spiking neurons: The third generation of neural network models. Neural Net. 1997, 10, 1659–1671. [Google Scholar] [CrossRef]
- Wu, Y.; Deng, L.; Li, G.; Zhu, J.; Xie, Y.; Shi, L. Direct training for spiking neural networks: Faster, larger, better. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 1311–1318. [Google Scholar]
- Hu, Y.; Tang, H.; Pan, G. Spiking deep residual networks. IEEE Trans. Neural Net. Learn. Syst. 2021, 5200–5205. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.; Sarwar, S.S.; Panda, P.; Srinivasan, G.; Roy, K. Enabling spike-based backpropagation for training deep neural network architectures. Front. Neurosci. 2020, 14, 119. [Google Scholar] [CrossRef]
- Zheng, H.; Wu, Y.; Deng, L.; Hu, Y.; Li, G. Going deeper with directly-trained larger spiking neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 11062–11070. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Kushawaha, R.K.; Kumar, S.; Banerjee, B.; Velmurugan, R. Distilling spikes: Knowledge distillation in spiking neural networks. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), IEEE, Milan, Italy, 10–15 January 2021; pp. 4536–4543. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Li, H.; Lone, A.H.; Tian, F.; Yang, J.; Sawan, M.; El-Atab, N. Novel Knowledge Distillation to Improve Training Accuracy of Spin-based SNN. In Proceedings of the 2023 IEEE 5th International Conference on Artificial Intelligence Circuits and Systems (AICAS), IEEE, Hangzhou, China, 11–13 June 2023; pp. 1–5. [Google Scholar]
- Li, Y.; Guo, Y.; Zhang, S.; Deng, S.; Hai, Y.; Gu, S. Differentiable spike: Rethinking gradient-descent for training spiking neural networks. Adv. Neural Inf. Process. Syst. 2021, 34, 23426–23439. [Google Scholar]
- Li, Y.; Deng, S.; Dong, X.; Gu, S. Converting artificial neural networks to spiking neural networks via parameter calibration. arXiv 2022, arXiv:2205.10121. [Google Scholar]
- Guo, Y.; Zhang, L.; Chen, Y.; Tong, X.; Liu, X.; Wang, Y.; Huang, X.; Ma, Z. Real spike: Learning real-valued spikes for spiking neural networks. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27 2022; pp. 52–68. [Google Scholar]
- Hao, Z.; Ding, J.; Bu, T.; Huang, T.; Yu, Z. Bridging the Gap between ANNs and SNNs by Calibrating Offset Spikes. arXiv 2023, arXiv:2302.10685. [Google Scholar]
- Takuya, S.; Zhang, R.; Nakashima, Y. Training low-latency spiking neural network through knowledge distillation. In Proceedings of the 2021 IEEE Symposium in Low-Power and High-Speed Chips (COOL CHIPS), IEEE, Tokyo, Japan, 14–16 April 2021; pp. 1–3. [Google Scholar]





| Model | Training Method | ANN | SNN | ANN Acc (%) | SNN Acc (%) | Time-Step |
|---|---|---|---|---|---|---|
| KDSNN [17] | KD training | Pyramidnet18 | ResNet18 | 95.10 | 93.41 | 4 |
| LaSNN [16] | KD training | – | VGG16 | – | 91.22 | 100 |
| [26] | KD training | – | 6Conv+2FC | – | 85.43 | 8 |
| Dspike [27] | SNN training | – | ResNet18 | – | 93.66 | 4 |
| STBP-tdBN [22] | SNN training | – | ResNet19 | – | 92.92 | 4 |
| QCFS [5] | Conversion | – | ResNet18 | 96.04 | 90.43 | 4 |
| Parameter Calibration [28] | Conversion | – | ResNet20 | 96.72 | 92.98 | 8 |
| IDSNN | Hybrid training | ResNet34 | ResNet18 | 95.10 | 94.03 94.22 | 4 6 |
| Model | Initialization | KD | ANN Teacher | Acc. on CIFAR10 (%) | Acc. on CIFAR100 (%) |
|---|---|---|---|---|---|
| ResNet18 | ✗ | ✗ | – | 93.54 | 71.31 |
| ✓ | ✗ | ResNet34 | 93.64 (↑0.10) | 74.47 (↑3.16) | |
| ✗ | ✓ | ResNet34 | 93.98 (↑0.44) | 73.71 (↑2.40) | |
| ✓ | ✓ | ResNet34 | 94.22 (↑0.68) | 75.41 (↑4.10) |
| LR Strategy | [60, 120, 160] | [20, 40, 60] | [10, 20, 30] | ||
|---|---|---|---|---|---|
| Acc (%) | |||||
| Model | |||||
| baseline | 71.31(e192) | 68.96(e74) | 63.95(e85) | ||
| K-L divergence distillation | 73.71(e195) | 70.35(e49) | 66.02(e37) | ||
| IDSNN | 75.41(e138) | 74.45(e54) | 73.02(e57) 71.37(e14) | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, X.; Zhang, H.; Zhang, Y. IDSNN: Towards High-Performance and Low-Latency SNN Training via Initialization and Distillation. Biomimetics 2023, 8, 375. https://doi.org/10.3390/biomimetics8040375
Fan X, Zhang H, Zhang Y. IDSNN: Towards High-Performance and Low-Latency SNN Training via Initialization and Distillation. Biomimetics. 2023; 8(4):375. https://doi.org/10.3390/biomimetics8040375
Chicago/Turabian StyleFan, Xiongfei, Hong Zhang, and Yu Zhang. 2023. "IDSNN: Towards High-Performance and Low-Latency SNN Training via Initialization and Distillation" Biomimetics 8, no. 4: 375. https://doi.org/10.3390/biomimetics8040375