1. Introduction
Semantic segmentation is one of the essential tasks in computer vision and has a wide range of applications in autonomous driving, mobile robotics, virtual reality, image editing, intelligent medicine, and other fields [
1,
2,
3]. Semantic segmentation aims to perform dense semantic label prediction for all pixels in an image and provide high-level semantic representations for other tasks. Segmentation methods based on artificial neural networks (ANNs) have become mainstream since the fully convolutional network (FCN) [
4] was proposed for solving semantic segmentation problems.
With the widespread interest in autonomous mobile robots, autonomous driving technologies, and other edge computing scenarios, the existing semantic segmentation research has the following trends. The first trend is lightweight and low-power segmentation networks. It is difficult for mobile computing devices to support large-scale, high-energy network operations, and low-power networks are preferred for such scenarios. The second trend is semantic segmentation systems based on event cameras. Event cameras, or dynamic vision sensors (DVS) [
5], mainly record the light intensity changes in the environment and have many advantages over traditional frame-based cameras, including high temporal resolution, high dynamic range, and low power consumption. Event cameras have higher robustness in some special cases, such as motion blur and low-light scenes. Currently, there is no method that can complete the high-performance semantic segmentation of both frame and event-based images with low power consumption.
For addressing the above low-power requirement and the capability of adapting DVS data, a segmentation algorithm based on spiking neural networks (SNNs) is a good choice. The spiking neural network is a bionic neuron model inspired by biological neuron models based on spiking signals. Spiking neurons consume energy only when the spike is generated, and this spike activity is usually much sparser than ANNs. Thus, SNN is very energy-efficient when implemented on neuromorphic hardware [
6,
7]. Meanwhile, SNN has complex temporal dynamics [
8], and the bionic activation-based model fits well with the asynchronous nature of sequential streams from event cameras.
In this paper, the semantic segmentation task is considered from the perspective of direct-training SNNs, in order to accomplish dense semantic predictions for images from both conventional cameras and DVS with low power consumption. In the field of SNNs, ANN-SNN conversion is a commonly used method to deploy SNNs. This conversion uses the integrate-and-fire (IF) neurons to replace the rectified linear unit (ReLU) activation function in a pre-trained ANN [
9], thereby replacing the whole network with a SNN. Additionally, the corresponding SNN can usually achieve an accuracy comparable to the ANN. However, the SNNs obtained by this approach usually require thousands of time steps, resulting in a high-latency network contrary to the original intention [
10,
11,
12]. Further, the ANN-SNN conversion needs to ensure that the structures and input–output patterns of ANN and SNN are identical. This leads to the inability to complete the training on the DVS dataset and limits the deployment of the method on neuromorphic systems [
13]. Therefore, this paper adopts a direct-training approach using backpropagation to optimize the parameters of the SNN directly. The direct-training method expands the SNN through time dimension and adopts backpropagation through time framework (BPTT) [
14] for backpropagation. To overcome the non-differentiable characteristic of the step function in spiking neurons, the surrogate gradient function is used [
15] to replace the gradient and complete the gradient propagation. The direct-training method can adopt tiny time step configurations [
16,
17], allowing us to focus on designing the spiking semantic segmentation network structure.
In semantic segmentation or scene understanding tasks, human vision systems tend to recognize the focused pixels with the help of the surrounding context and global scene information [
1]. Inspired by the contextual learning of human vision systems, a direct-training spiking context guided network (Spiking CGNet) is designed with substantially lower energy consumption and high performance for both frame and event-based images. This paper adopts the encoder–decoder architecture of ANN CGNet, and modifies the basic module to complete effective contextual learning with only spike computations.
The main contributions of this paper are as follows:
This paper proposes a spiking context-guided block with spiking neurons and membrane shortcut connections to learn local feature and contextual information under the SNN computing paradigm. Furthermore, to learn global context better, the global context extractor is revised to refine the feature with minimal energy cost.
This paper designs appropriate input representations and encoding layers for both frame and event-based images, respectively. On this basis, the direct-training Spiking CGNet is established with several modifications from ANN CGNet, including the stem network, multi-scale membrane connection, and the spike decoder.
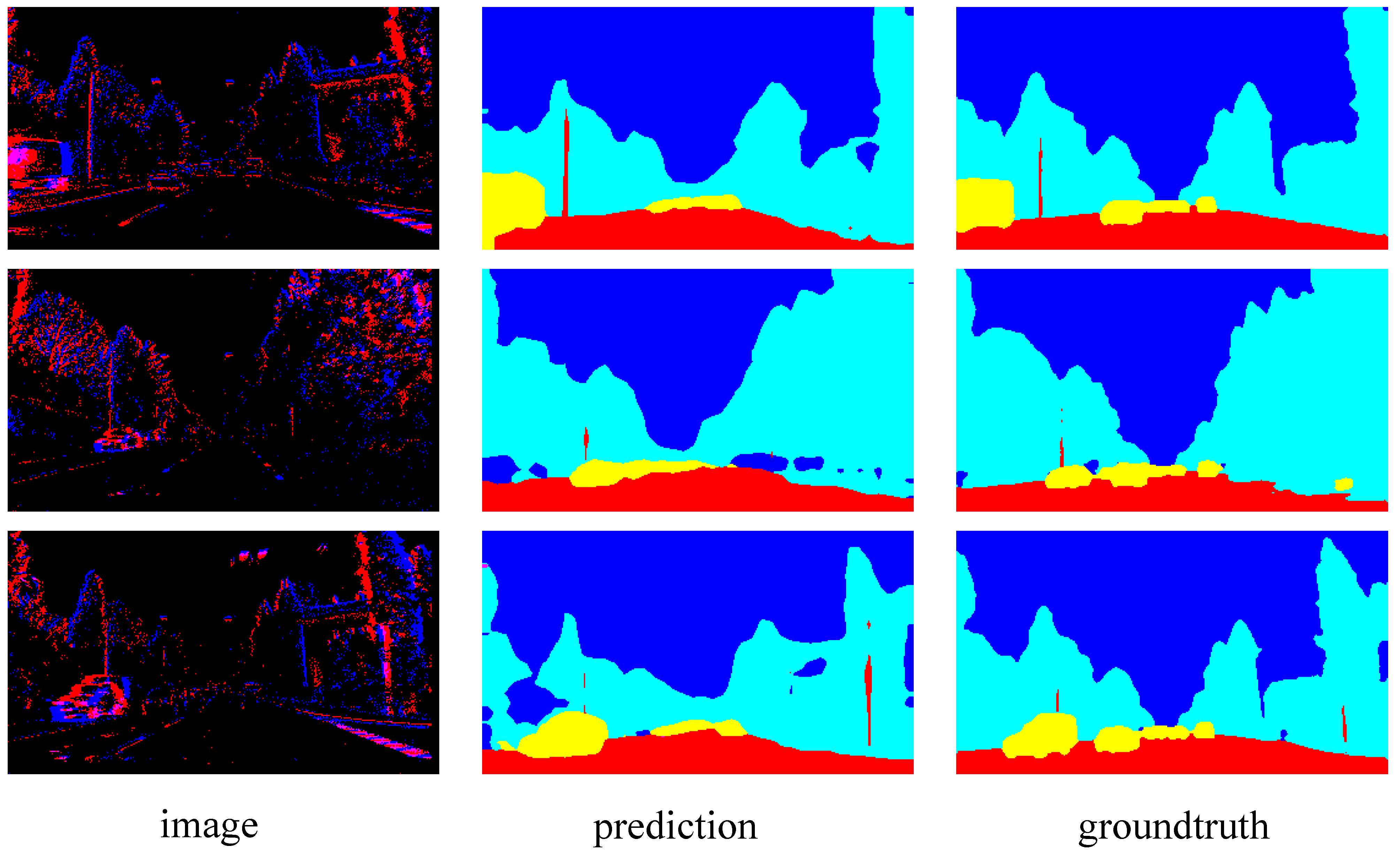
This paper validates the performance of Spiking CGNet by comparing it to the ANN and SNN segmenters in the literature on the frame-based Cityscapes dataset and event-based DAVIS driving dataset 2017 (DDD17).
The rest of this paper is structured as follows. In
Section 2, the ANN-based semantic segmentation methods and recent studies on spiking neural networks are reviewed. In
Section 3, the critical technologies in Spiking CGNet are presented, including input representation, design of spiking context guided block, the whole structure of Spiking CGNet, and the overall training algorithm in this paper. In
Section 4, Spiking CGNet is validated on both frame and event-based image datasets. Finally, the conclusion and future works are discussed in
Section 5.
3. Materials and Methods
In this section, after briefly explaining the spiking neuron dynamics as a preliminary, this paper first presents our representations for frame and event-based inputs. Then, the structure of the spiking context-guided block is illustrated, which is the basic module for Spiking CGNet. Next, the structure of ANN CGNet is redesigned to meet the SNN paradigm. Finally, the overall training algorithm in this paper is described.
3.1. Spiking Neuron Model
The spiking neuron is the activation function in SNNs and plays a vital role in the conversion and transmission of spiking signals. The discrete-time dynamics of the well-known leaky integrate-and-fire (LIF) [
8] neuron can be formulated as follows:
where
represents the membrane potential at time
, and
is the hidden membrane potential before trigger time
t.
is the synaptic current.
represents the resting potential. Once
exceeds the firing threshold
, the neuron will file a spike expressed as follows:
where
denotes the output, and
is the Heaviside step function. Then, membrane potential at time
t will be updated as:
In addition to LIF, this paper also uses the IF and parametric leaky integrate-and-fire (PLIF) [
41] neurons in this work. Their integration dynamics differ from LIF expressed in Equation (
1), while the fire and reset processes remain unchanged. The IF neuron abandons the leakage of membrane voltage, and its integrate dynamics is shown in Equation (
4). The PLIF neuron replaces the time constant of LIF with a learnable parameter
a, thus expanding the network’s learning ability. The discrete-time dynamics of PLIF are shown in Equation (
5).
In the field, it is generally believed that multiplication operations that contain spike values as inputs are spike computations, such as spike-float and spike-spike multiplications. The multiplications of two non-spike inputs as spike computations are not considered, such as integer-float and float-float multiplications. The general criterion for SNN design is to ensure that the input of the main convolution module is a spike value, which can ensure that the convolution calculation is a spike computation.
3.2. Input Representation
Our method can handle two types of data: static and DVS images. For the sake of input consistency, both types of inputs should be converted to representations of dimension , where T is the time step of the SNN, and c, h, and w are the channel numbers, height, and width of static or DVS images.
For a static image whose dimensions are , a standard convolution is used as the encoding layer. Then this paper copies the encoded image along the time dimension, which means that the encoded images serve as the time-invariant inputs for the subsequent SNN at all time steps.
Raw DVS data are often recorded as an event stream. A single event can be described by a four-value tuple
, where
t is the time at which the event occurred, usually a continuous time value.
p denotes the polarity of the event, indicating whether the light intensity increases or decreases. In addition,
indicates the two-dimensional pixel coordinates of the event in the camera. Therefore, an event stream with
N input events can be represented as
. For convenience of calculation, continuous time needs to be discretized, and the common way is to divide the time interval into
B discrete bins. In order to obtain the voxel grid
, the polarity of events is used as the channel dimension, and then discretize
S to
V with Equation (
6).
where
and
is the bilinear sampling kernel defined as
. For the DDD17 dataset, this paper accumulates positive and negative events separately, resulting
. To reduce the simulation time step
T of the network and retain a high time resolution of the data, this paper moves the information of adjacent time bins to the channel dimension. That is, reshape
to
.
3.3. Spiking Context Guided Block
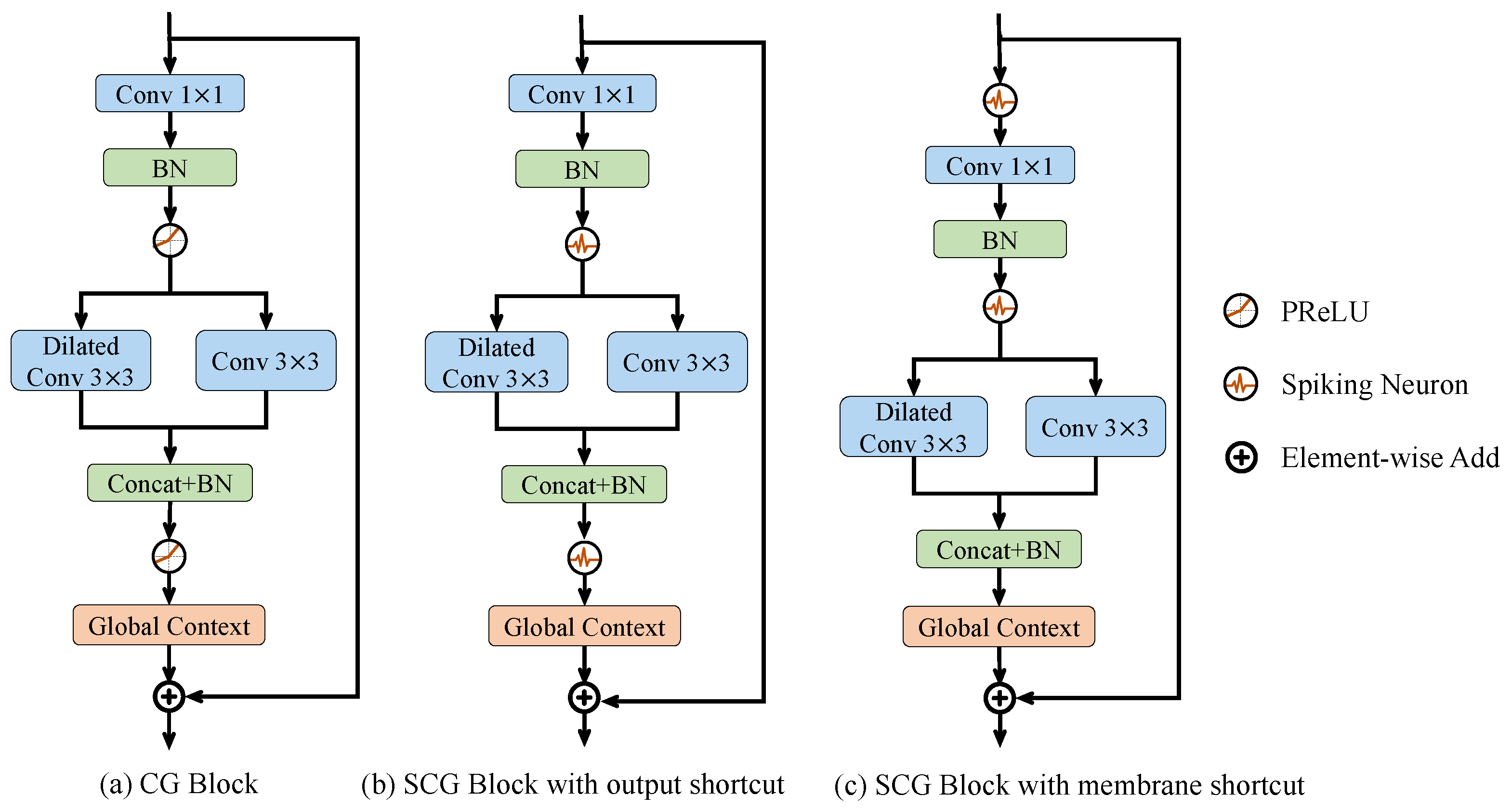
The spiking context-guided (SCG) block is the basic module of Spiking CGNet. It can efficiently extract local features and contextual information using the SNN computing paradigm. The overall design concept is shown in
Figure 1, which plots the ANN context-guided block (
Figure 1a) and the two proposed spiking context-guided blocks (
Figure 1b and
Figure 1c). In semantic segmentation or scene understanding tasks, human vision systems tend to recognize the focused pixels with the help of the surrounding context and global scene information [
1]. From a functionality perspective, critical operators in
Figure 1 include Conv 1 × 1, Dilated conv 3 × 3, Conv 3 × 3, and Global Context. Conv 1 × 1 is responsible for the projection of features and is also the network’s primary source of complexity growth. Dilated conv 3 × 3 is a surrounding context extractor. Conv 3 × 3 stands for a local feature extractor. Global Context is the global context extractor of the whole image.
Figure 1a shows the human visual-inspired context-guided (CG) block in ANN CGNet. After a 1 × 1 convolutional transformation, it uses standard 3 × 3 convolution and dilated 3 × 3 convolution (which has a larger receptive field) to extract local features and the corresponding surrounding context of the image, respectively. Then, this module combines concatenation and batch normalization to fuse local features with the surrounding context to form joint features. Finally, the global context extractor based on channel-wise attention is adopted to extract the global context of the image and refine the joint features.
3.3.1. SCG Block with Output and Membrane Shortcut
Convolution determines the weight connection between neurons in the previous and current layers, making it suitable for both artificial and spiking neurons. For simple structures such as VGGNet [
59], replacing artificial neurons with spiking neurons can convert the network into a SNN. It is worth mentioning that the CG block uses a shortcut structure from input to output to solve the problem of gradient disappearance. By directly replacing the parametric rectified linear unit (PReLU) in
Figure 1a with a spiking neuron, the SCG block can be obtained with the output shortcut shown in
Figure 1b.
In
Figure 1b, the module’s output is a non-spike value because of the scale of the global context extractor and output shortcut. At the same time, as the basic module is sequentially connected, the inputs of all modules (except for the first one) are non-spike. Therefore, the first convolution in the module does not use spike computation, which makes the structure unacceptable.
To address this issue, this paper uses the idea of membrane shortcut to improve the structure of the SCG block, as shown in
Figure 1c. It has two key points. First, the shortcut connection is set at the input of the spiking neuron, corresponding to the input membrane of the neuron. Second, a spiking neuron is set before each convolutional layer to ensure the input a spiking signal. In
Figure 1c, the inputs of all convolutional layers are the output spikes from spiking neurons, ensuring that all multiplications are spike computations. At the same time, the output of each block serves as the input of the first neuron in the subsequent block, avoiding float-float multiplication, which meets the design criteria of SNN. Therefore, the SCG block with membrane shortcut is suitable as the basic unit used in Spiking CGNet. In the remaining part of this article, the SCG block refers to this structure.
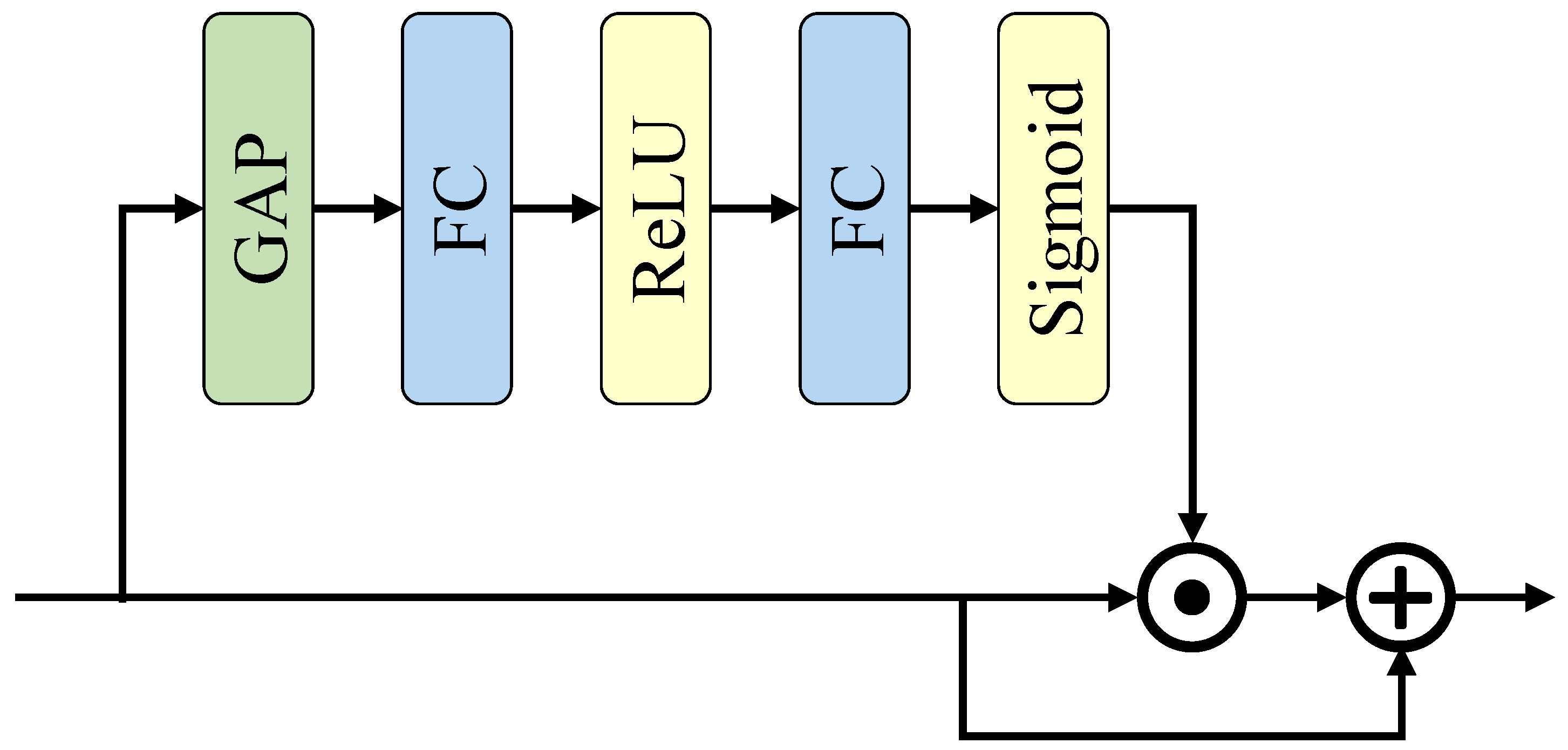
3.3.2. Global Context Extractor
In
Figure 1, the SCG block uses a global context extractor (GCE) to refine the joint feature. Its detailed structure is shown in
Figure 2. First, a global average pooling is used to squeeze the joint feature along the channel dimension. Then, two fully connected layers are used to extract the global context, which is finally used to refine the joint feature. The reduction ratio
r is used to reduce the computational cost of the fully connected layers. Consider FC1 and FC2 as the first and second fully connected layers in
Figure 2, and assume that the input channels of FC1 and the output channels of FC2 are both
c. This paper reduces the output channels of FC1 and input channels of FC2 to
using the reduction ratio
r. Therefore, the total computation of the layers is
, which is
r times lower than that without reduction, which is
.
Our design has two main differences from the global context extractor in CGNet. First, the module’s input X contains an additional time dimension, which means . T, c, h, and w denotes the time step, channel number, height, and width, respectively. Therefore, our global average pooling (GAP) is 3-dimensional for time, width, and height, and the final weight dimension goes to . Second, the convergence of SNN is more complicated than ANN, so this paper adds residual connections in the GCE so that the unrefined features can directly affect the final loss.
Unlike the convolution layers, the non-spike computation is retained in GCE because it only brings minimal computational burden. The total energy consumption of the GCE module is only 2.03% of the entire network, which will be analyzed in detail in
Section 4.
3.4. Spiking Context Guided Network
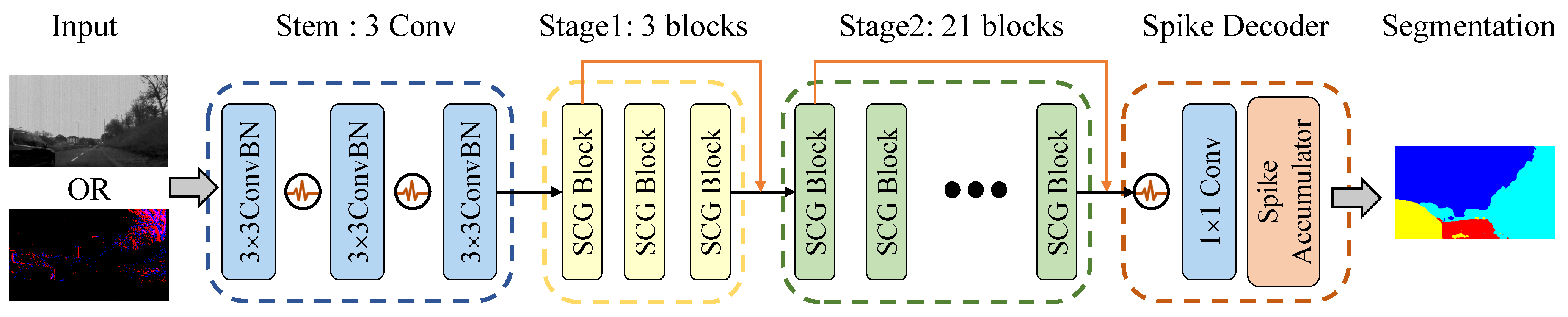
The high-level structure of the Spiking CGNet is shown in
Figure 3, which includes a stem, two stages with SCG blocks, and a spike decoder. The stem takes static images or DVS data as input and contains three sequentially placed convolutional layers. The middle two stages have 3 and 21 SCG blocks, respectively, and the first block of each stage downsamples the feature map by a factor of 2. After the two stages, the spike decoder decodes the spiking features into the final segmentation prediction. The overall structure of Spiking CGNet is similar to ANN CGNet. However, to adapt to spike computation and improve segmentation performance, several improvements have been achieved.
Firstly, all PReLU activations of the stem are replaced by spiking neurons. Therefore, the stem not only downsamples the input data but also encodes non-spike inputs into spike features. The first convolutional layer is regarded as the encoding layer. Moreover, the encoding layer varies according to the two types of input data. For static image input, it is a standard 2-dimensional convolutional layer. For the voxel representation of event streams input, it changes to a spiking convolutional layer which performs convolution with the same kernel at all time steps.
Secondly, this paper concatenates the output of the first SCG block in the middle stages into the corresponding stage output, shown as the skip connections in orange arrows in
Figure 3. This operation can fully utilize the multi-scale features and improve the segmentation accuracy. Moreover, all skip connections use the membrane shortcuts mentioned in
Section 3.3. The concatenated inputs are the membrane potentials of spiking neurons, which ensure that the corresponding calculations are all spike computations.
Finally, the spike decoder is redesigned to decode the spiking feature maps to predictions. This paper uses the combination of a spiking neuron and a 1 × 1 convolutional layer to transform the feature maps so that the channel numbers correspond to semantic categories. Then, the spike accumulator calculates the firing rate of the spiking feature maps as the semantic predictions.
By changing the number of channels in
Figure 3, two configurations of Spiking CGNet are proposed: SCGNet-S and SCGNet-L, which mean the small and large configurations in model complexity. The channel numbers in the stem, stage1, and stage2 of SCGNet-S are 32, 64, and 128, respectively. Its parameter quantity and accuracy are close to ANN CGNet. All channel numbers of SCGNet-L are twice that in SCGNet-S, making it a model with higher accuracy and more parameters.
3.5. Overall Training Algorithm
SCGNet is trained using the direct-training method, and the backward gradient is calculated through the backpropagation through time framework. In error backpropagation, the final output
Q is determined by the spike decoder, which is:
where
denote the feature map at time step
t output by the last 1 × 1 convolutional layer, and
T is the total time steps.
n is the number of semantic classes in the dataset, and
h and
w are the height and width of the output. Then, this paper makes the output
pass through a softmax layer to obtain the final 2-dimensional probability map. For every pixel location
, the predicted semantic label vector
p is calculated as follows:
During training, the loss function is determined as the cross-entropy. Given the predicted label vector
and the ground truth
, loss function
L is defined by:
where
N is a normalization factor, and
stands for logarithmic function with a base of 10. To avoid class imbalance in the training dataset, this paper uses a class weighting scheme [
60] defined as
, where
denotes the weight of
l-th semantic category. This paper restricts the weight to interval
according to
, which is the ratio of the total number of pixels in category
i to the total number of all pixels.
For the last layer, the gradient of weight parameters can be calculated by the final loss. By applying the chain rule, the gradients of loss
L with respect to the weight parameter
at the
l-th hidden layer can be calculated as follows:
where
and
represents the output spike and membrane potential at time step
t, respectively. Because of the non-differentiable spiking activities,
does not exist in practice. Thus, during training, the arc tangent (ArcTan) function (
) is used as the surrogate function to calculate the gradients of all spiking neurons.
5. Conclusions and Future Works
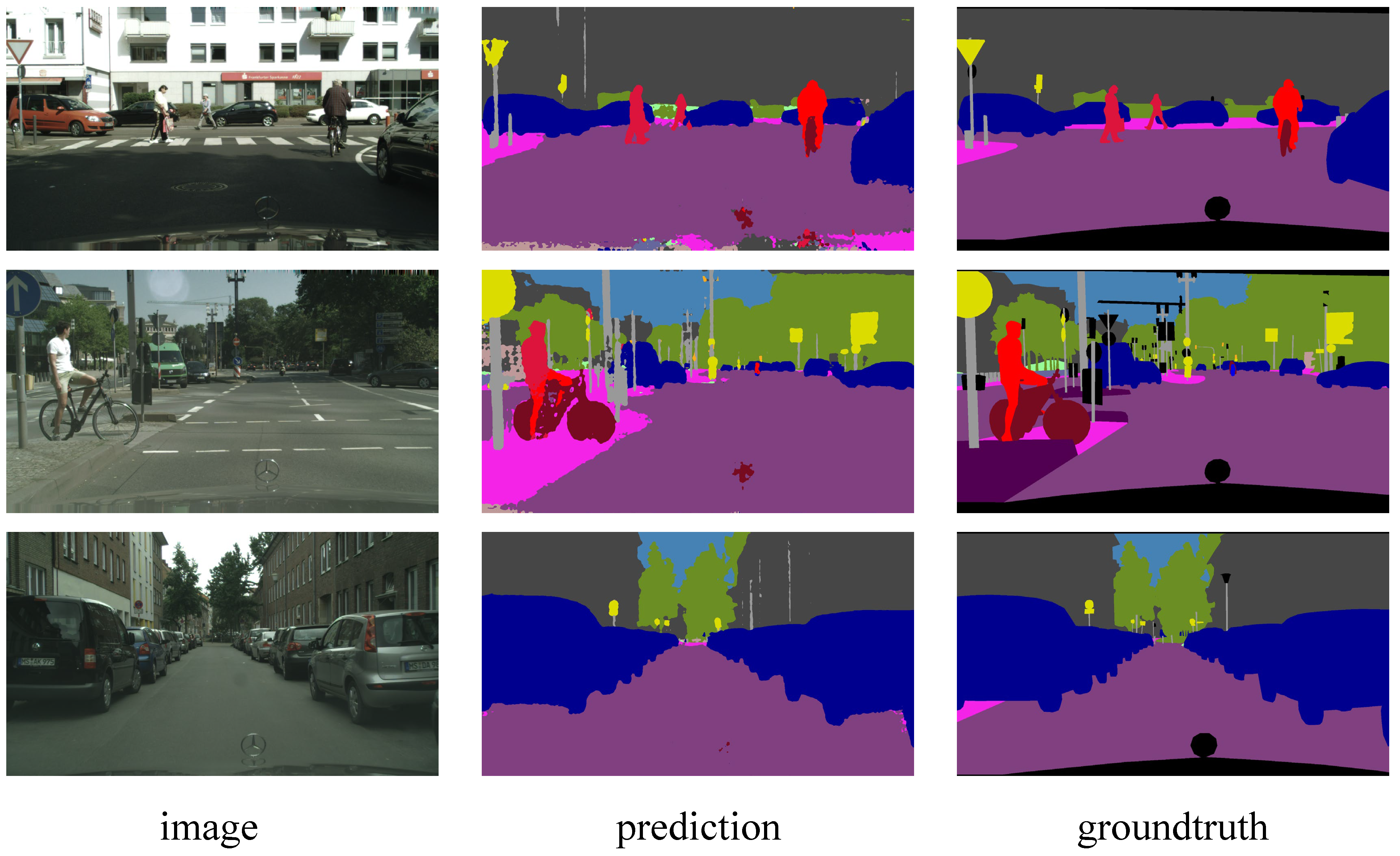
In this paper, a spiking segmenter is proposed with substantially lower energy consumption and comparable performance for both frame and event-based images. Utilizing the spiking neurons and membrane shortcut, this paper develops a novel spiking context-guided block with spike computations. Furthermore, this paper establishes the spiking context-guided network with well-designed spike encoding and decoding layers. Experiments on the Cityscapes and DDD17 datasets show high energy-efficiency and performance. On the static dataset Cityscapes, the proposed SCGNet-L achieved a mIoU of 66.5%, which is 1.7% higher than ANN CGNet with 1.29 × higher energy-efficiency. On the event dataset DDD17, SCGNet achieve a mIoU of 51.42%, which is much higher than the 34.20% of the previous method spiking FCN.
In summary, spiking neural networks have the potential to achieve better performance with lower energy consumption. This work is a good practice of deep SNNs in semantic segmentation, which may promote the practical applications of SNNs.
For future work, research on semantic segmentation algorithms will be continued based on spiking neural networks. On the one hand, the fusion of information will be investigated from the frame and event-based images and design semantic segmentation networks with multi-modality inputs to further improve the accuracy. On the other hand, future research could start from the structure-level techniques and complete semantic segmentation tasks more efficiently based on more advanced spiking structures such as spiking transformers.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}