
A Hierarchical Framework for Quadruped Robots Gait Planning Based on DDPG

Abstract
:1. Introduction
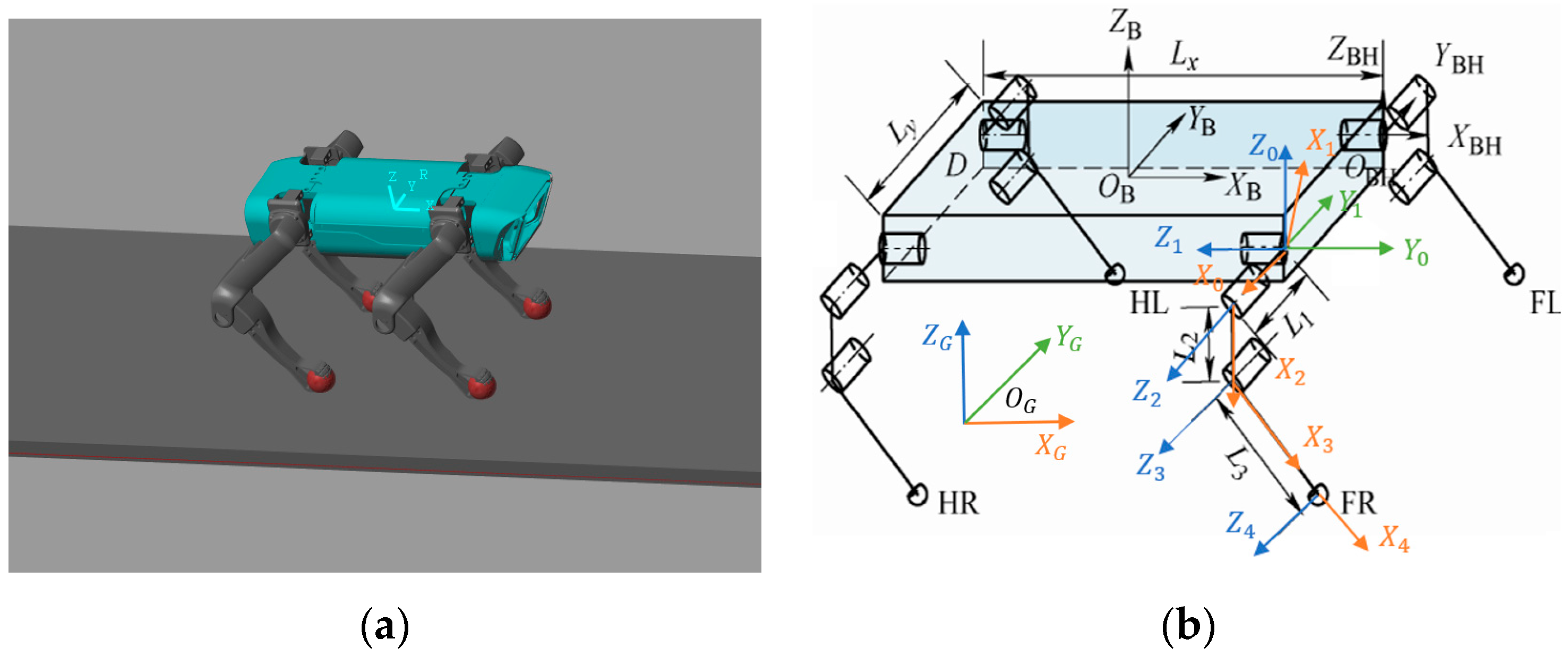
2. Kinematic and Dynamic Analyses
2.1. Kinematic Analysis
2.2. Dynamic Analysis
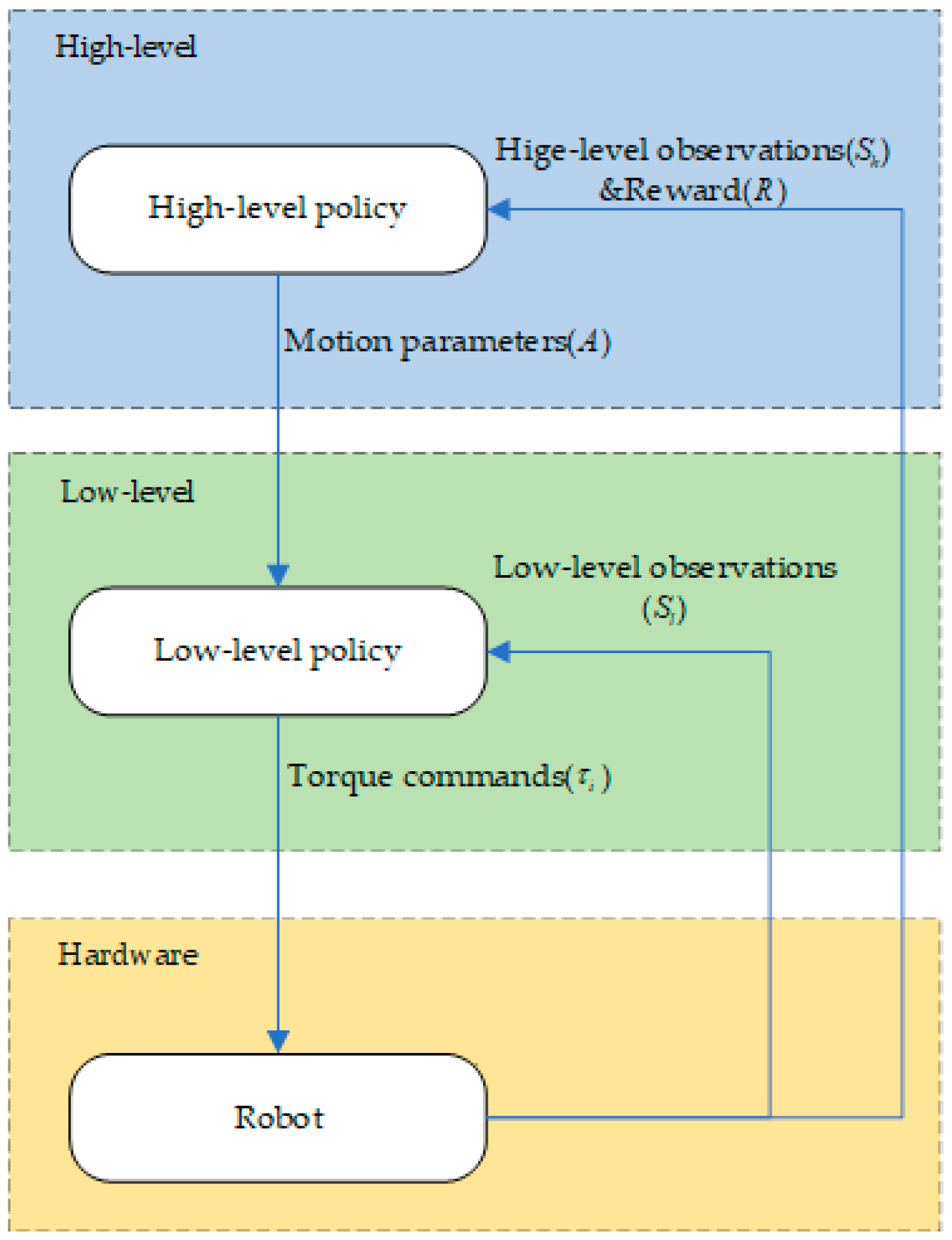
3. Hierarchical Framework
3.1. Algorithm Overview
| Algorithm 1. Executing a Hierarchical Policy |
| Require: Initialize replay buffer Initialize network parameters; 1: for 0 < epochs < N maxepochs do 2: Initialize observation, action, etc.; 3: for 0 < step < N maxsteps and not reach termination conditions do 4: The high-level network receives high-level observations and outputs motion parameters 5: The low-level controller receives the motion parameters and low-level observations, and outputs the required torque for each motor 6: Run robot to obtain the next observation; 7: Get reward; 8: Store memory; 9: Update network 10: If step = N maxsteps or reach termination conditions then 11: Calculate the total reward value 12: Send messages to reset environment and robot position; 13: End 14: End 15: End |
3.2. High-Level Planner
3.3. Low-Level Controller
3.3.1. Support Leg Controller
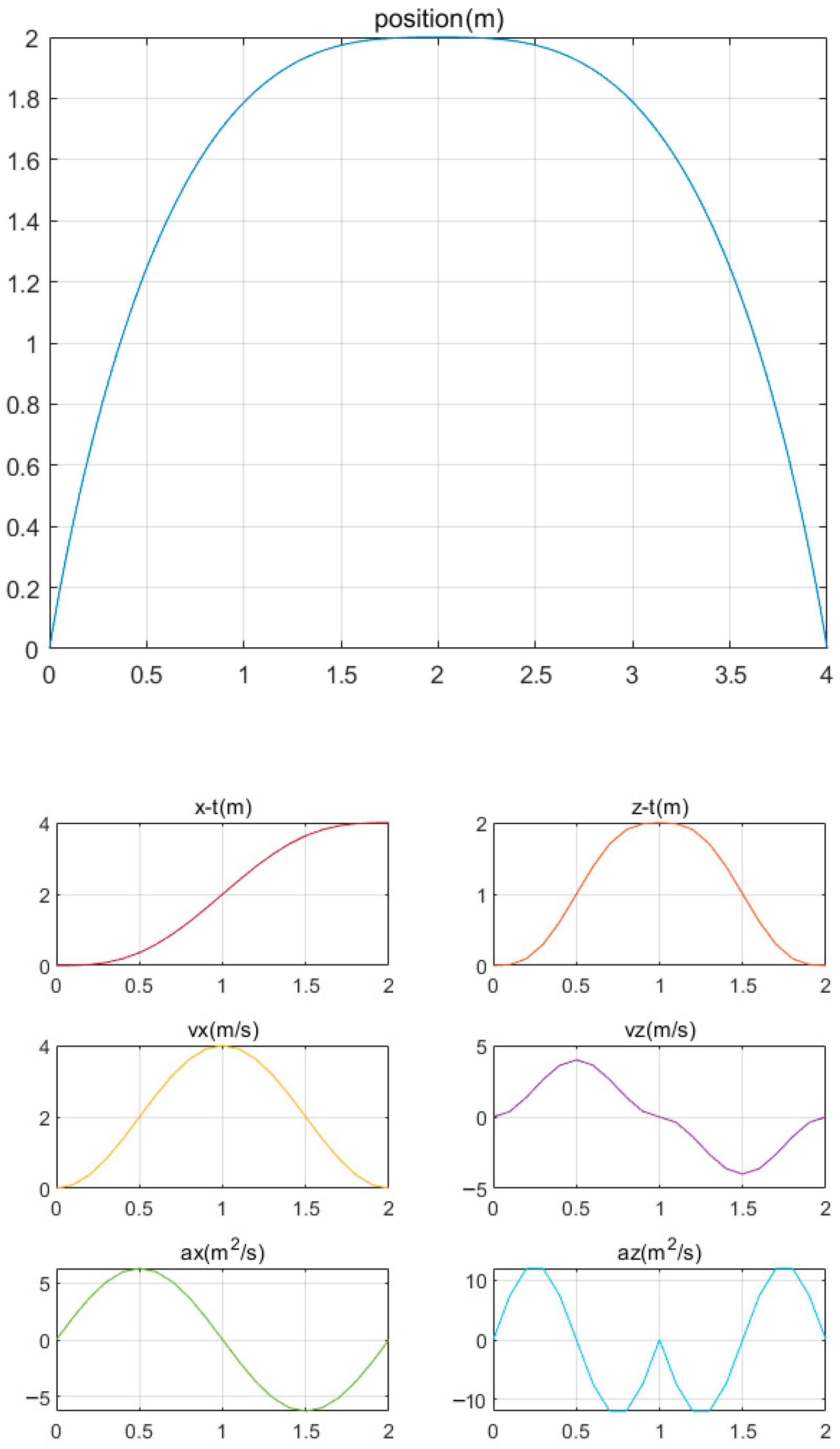
3.3.2. Swing Leg Controller
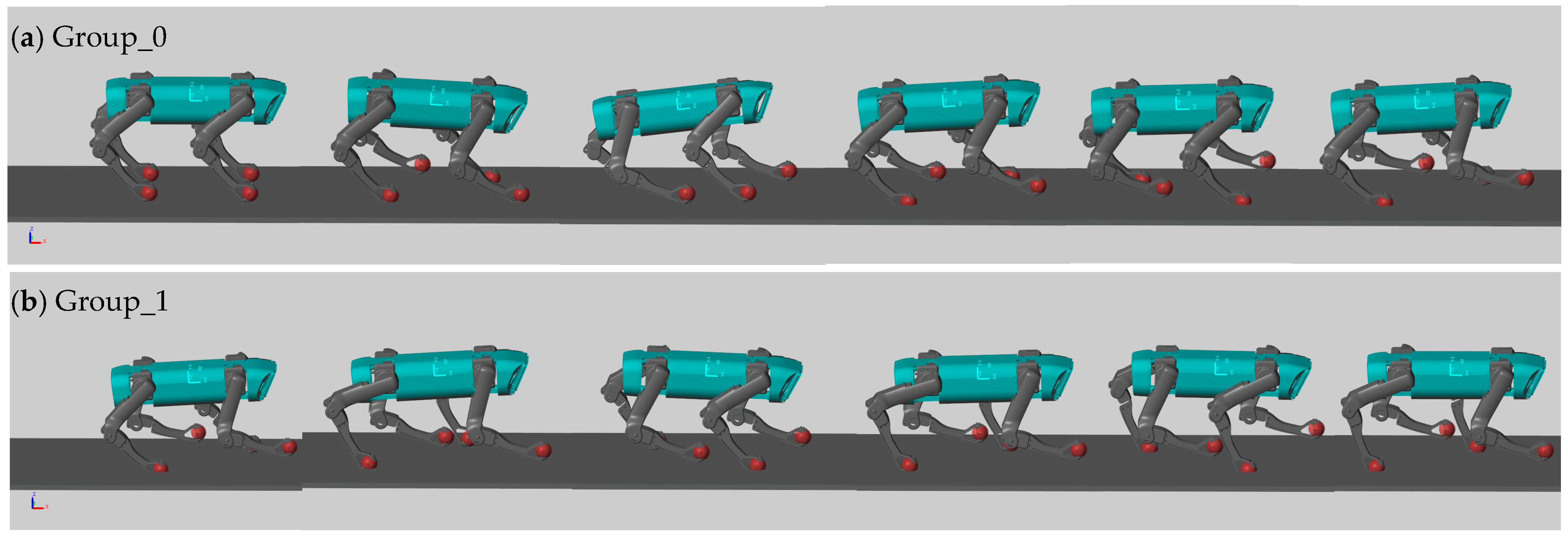
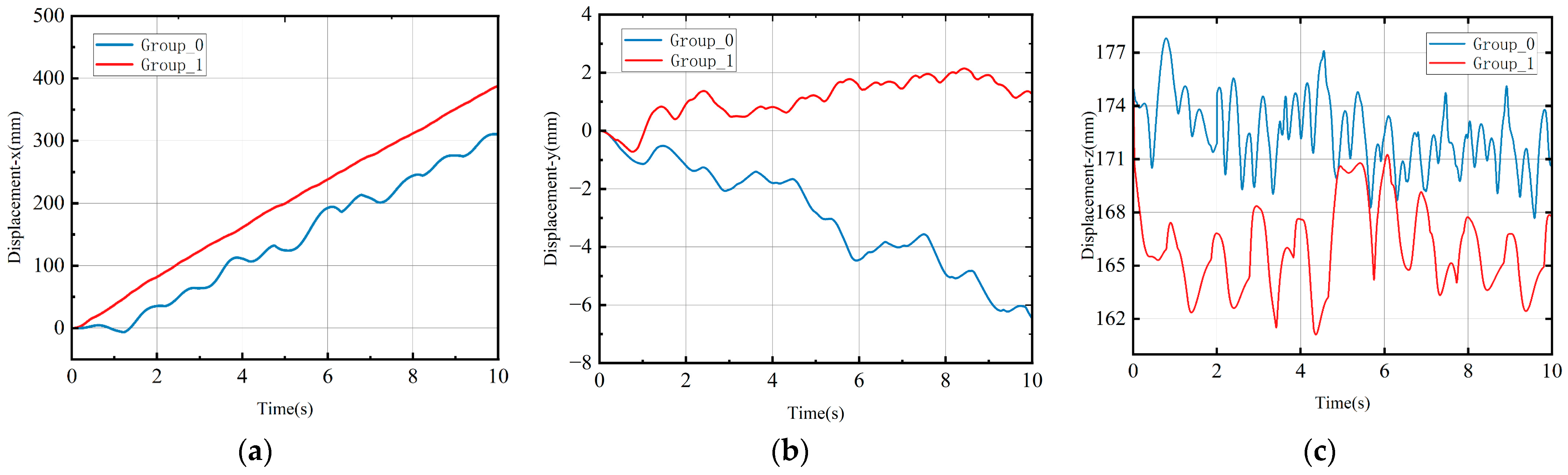
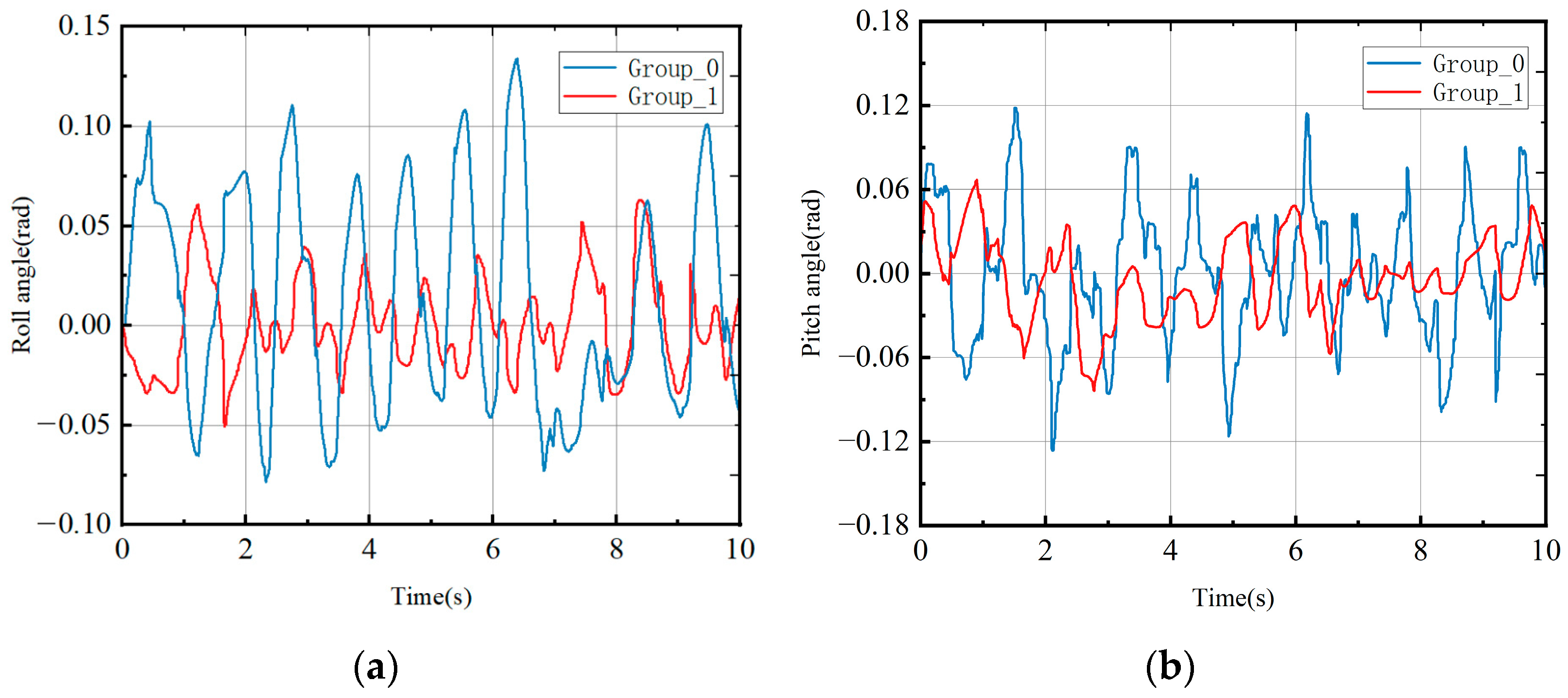
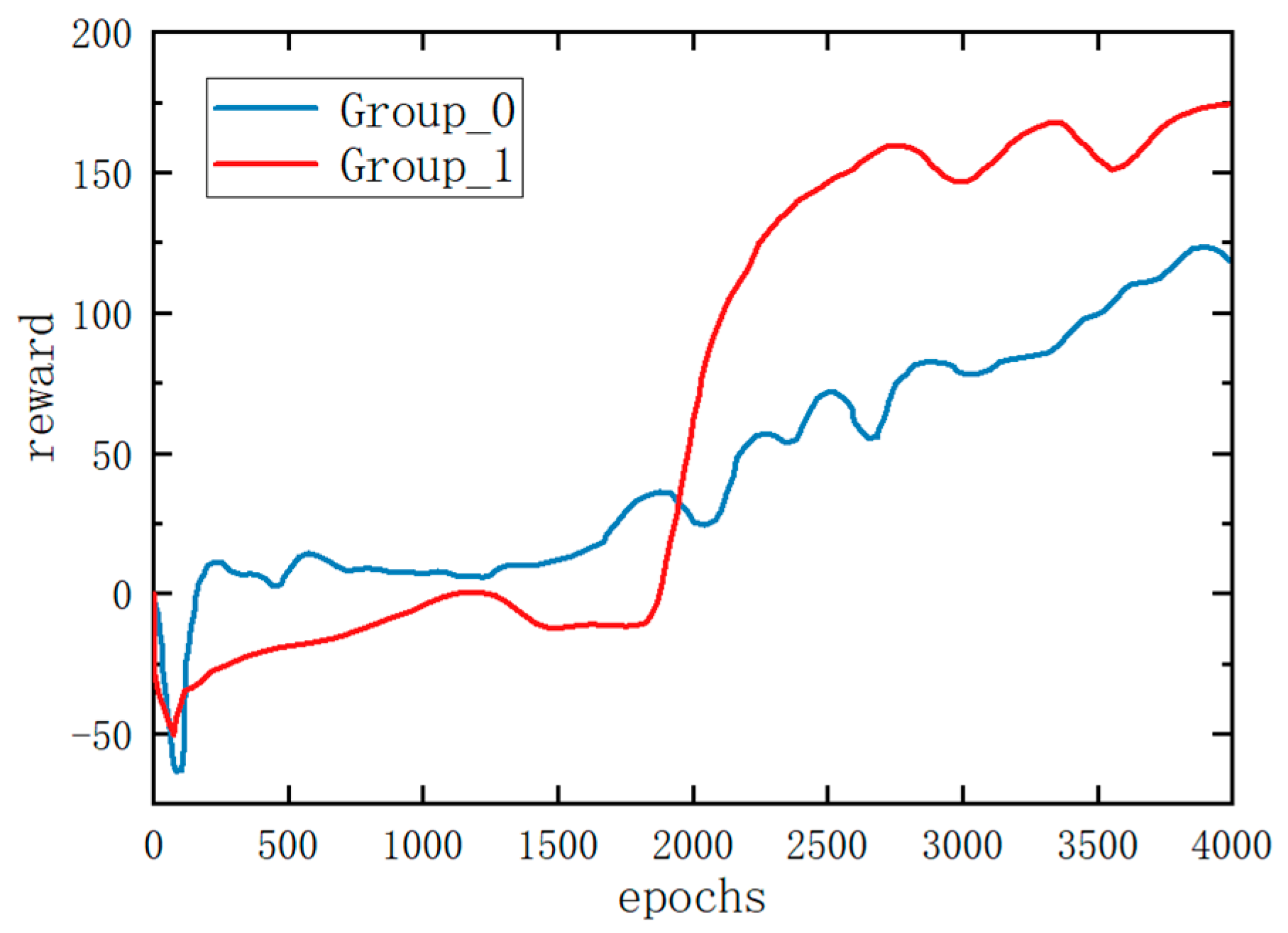
4. Results
5. Conclusions
- (1)
- In this study, kinematic and dynamic analyses of a quadruped robot were conducted. The D–H method was utilized to analyze the kinematics of a single leg in the quadruped robot, enabling the determination of the mapping relationship between the center of mass and the foot-end position, as well as the calculation of the Jacobian matrix. Following this, the dynamic models of the robot were simplified, resulting in the representation of a single-rigid-body state.
- (2)
- An HRL framework was designed, consisting of a high-level planner and a low-level controller. Drawing inspiration from the concept of HRL, the complex control task of the quadruped robot was decomposed into two levels: high-level planning and low-level control. The high-level planner employed the DDPG algorithm to generate motion parameters for the robot. The leg motions were categorized into the support and swing phases. For the support leg, an optimization problem based on the MPC method was formulated to determine the optimal foot-end force. In the swing leg, a composite swing trajectory was employed to achieve the desired foot-end position at each time step, and a PD controller was utilized to generate a virtual foot-end force. The required torque for each joint motor was then calculated using the Jacobian matrix.
- (3)
- The quadruped robot was simulated in Simulink, incorporating the aforementioned approaches. Simulation experiments were conducted using both deep reinforcement learning and hierarchical reinforcement learning methods. The results of these experiments confirmed the superiority of the hierarchical reinforcement learning method.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Jenelten, F.; Miki, T.; Vijayan, A.E.; Bjelonic, M.; Kheddar, A. Perceptive locomotion in rough terrain—Online foothold optimization. IEEE Robot. Autom. Lett. 2020, 5, 5370–5376. [Google Scholar] [CrossRef]
- Yang, C.; Yuan, K.; Zhu, Q.; Yu, W.; Li, Z. Multi-expert learning of adaptive legged locomotion. Sci. Robot 2020, 5, eabb2174. [Google Scholar] [CrossRef] [PubMed]
- Meng, F.; Huang, Q.; Yu, Z.; Chen, X.; Fan, X.; Zhang, W.; Ming, A. Explosive Electric Actuator and Control for Legged Robots. Engineering 2022, 12, 39–47. [Google Scholar] [CrossRef]
- Hutter, M.; Gehring, C.; Jud, D.; Lauber, A.; Bellicoso, C.D.; Tsounis, V.; Hwangbo, J.; Bodie, K.; Fankhauser, P.; Bloesch, M.; et al. Anymal-a highly mobile and dynamic quadrupedal robot. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 38–44. [Google Scholar]
- Wang, L.; Meng, L.; Kang, R.; Liu, B.; Gu, S.; Zhang, Z.; Meng, F.; Ming, A. Design and Dynamic Locomotion Control of Quadruped Robot with Perception-Less Terrain Adaptation. Cyborg Bionic Syst. 2022, 2022, 9816495. [Google Scholar] [CrossRef] [PubMed]
- Kang, R.; Meng, F.; Chen, X.; Yu, Z.; Fan, X.; Ming, A.; Huang, Q. Structural design and crawling pattern generator of a planar quadruped robot for high-payload locomotion. Sensors 2020, 20, 6543. [Google Scholar] [CrossRef] [PubMed]
- Chen, G.; Qiao, L.; Zhou, Z.; Richter, L.; Ji, A. Development of a Lizard-Inspired Robot for Mars Surface Exploration. Biomimetics 2023, 8, 44. [Google Scholar] [CrossRef] [PubMed]
- Sun, P.; Gu, Y.; Mao, H.; Chen, Z.; Li, Y. Research on walking gait planning and simulation of a novel hybrid biped robot. Biomimetics 2023, 8, 258. [Google Scholar] [CrossRef] [PubMed]
- Bledt, G.; Powell, M.J.; Katz, B.; Di Carlo, J.; Wensing, P.M.; Kim, S. MIT Cheetah 3: Design and Control of a Robust, Dynamic Quadruped Robot. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 2245–2252. [Google Scholar]
- Yang, Y.; Caluwaerts, K.; Iscen, A.; Zhang, T.; Tan, J.; Sindhwani, V. Data efficient reinforcement learning for legged robots. arXiv 2020, arXiv:1907.03613. [Google Scholar]
- Lee, Y.H.; Koo, J.C.; Choi, H.R.; Lee, Y.H.; Moon, H. Whole-Body Motion and Landing Force Control for Quadrupedal Stair Climbing. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4746–4751. [Google Scholar]
- Jenelten, F.; Hwangbo, J.; Bellicoso, C.D.; Tresoldi, F.D.; Hutter, M. Dynamic locomotion on slippery ground. IEEE Robot. Autom. Lett. 2019, 4, 4170–4176. [Google Scholar] [CrossRef]
- Saputra, A.A.; Toda, Y.; Takesue, N.; Kubota, N. A Novel Capabilities of Quadruped Robot Moving through Vertical Ladder without Handrail Support. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2020; pp. 1448–1453. [Google Scholar]
- Tan, W.; Fang, X.; Zhang, W.; Song, R.; Chen, T.; Zheng, Y.; Li, Y. A Hierarchical Framework for Quadruped Locomotion Based on Reinforcement Learning. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 8462–8468. [Google Scholar]
- Kim, Y.; Son, B.; Lee, D. Learning multiple gaits of quadruped robot using hierarchical reinforcement learning. arXiv 2021, arXiv:2112.04741. [Google Scholar]
- Iscen, A.; Caluwaerts, K.; Tan, J.; Zhang, T.; Coumans, E.; Sindhwani, V.; Vanhoucke, V. Policies Modulating Trajectory Generators. arXiv 2018, arXiv:1910.02812. [Google Scholar]
- Wang, Y.; Jia, W.; Sun, Y. A Hierarchical Reinforcement Learning Framework based on Soft Actor-Critic for Quadruped Gait Generation. In Proceedings of the 2022 IEEE International Conference on Robotics and Biomimetics (ROBIO), Jinghong, China, 5–9 December 2022; pp. 1970–1975. [Google Scholar]
- Carlo, J.D.; Wensing, P.M.; Katz, B.; Bledt, G.; Kim, S. Dynamic Locomotion in the MIT Cheetah 3 Through Convex Model-Predictive Control. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–9. [Google Scholar]
- Zhang, G.; Liu, H.; Qin, Z.; Moiseev, G.V.; Huo, J. Research on Self-Recovery Control Algorithm of Quadruped Robot Fall Based on Reinforcement Learning. Actuators 2023, 12, 110. [Google Scholar] [CrossRef]
- Heess, N.; Dhruva, T.B.; Sriram, S.; Lemmon, J.; Silver, D. Emergence of Locomotion Behaviours in Rich Environments. arXiv 2017, arXiv:1707.02286. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Coordinate System | ||||
|---|---|---|---|---|
| 0 | ||||
| 1 | 0 | 0 | ||
| 2 | 0 | |||
| 3 | 0 | 0 | ||
| 4 | 0 | 0 | 0 | |
| Parameter | Definition | Value |
|---|---|---|
| Distance between front and rear rolling hip joints | 141 mm | |
| Distance between left and right rolling hip joints | 78 mm | |
| Hip joint connecting rod length | 49 mm | |
| Thigh length | 125.6 mm | |
| Calf length | 136 mm | |
| Roll hip angle | / | |
| Pitch hip angle | / | |
| Pitch knee angle | / |
| Entity | Value |
|---|---|
| Base mass | 12 kg |
| Leg mass | 0.4 × 4 kg |
| Number of joints | 3 × 4 |
| Max motor torque | 30 N·m |
| Initial position | [0, 0, 0.175] |
| Initial motor angles | [0, 0.85, −1.7] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Chen, Z.; Wu, C.; Mao, H.; Sun, P. A Hierarchical Framework for Quadruped Robots Gait Planning Based on DDPG. Biomimetics 2023, 8, 382. https://doi.org/10.3390/biomimetics8050382
Li Y, Chen Z, Wu C, Mao H, Sun P. A Hierarchical Framework for Quadruped Robots Gait Planning Based on DDPG. Biomimetics. 2023; 8(5):382. https://doi.org/10.3390/biomimetics8050382
Chicago/Turabian StyleLi, Yanbiao, Zhao Chen, Chentao Wu, Haoyu Mao, and Peng Sun. 2023. "A Hierarchical Framework for Quadruped Robots Gait Planning Based on DDPG" Biomimetics 8, no. 5: 382. https://doi.org/10.3390/biomimetics8050382