
A Recognition Method for Soft Objects Based on the Fusion of Vision and Haptics

Abstract
:1. Introduction
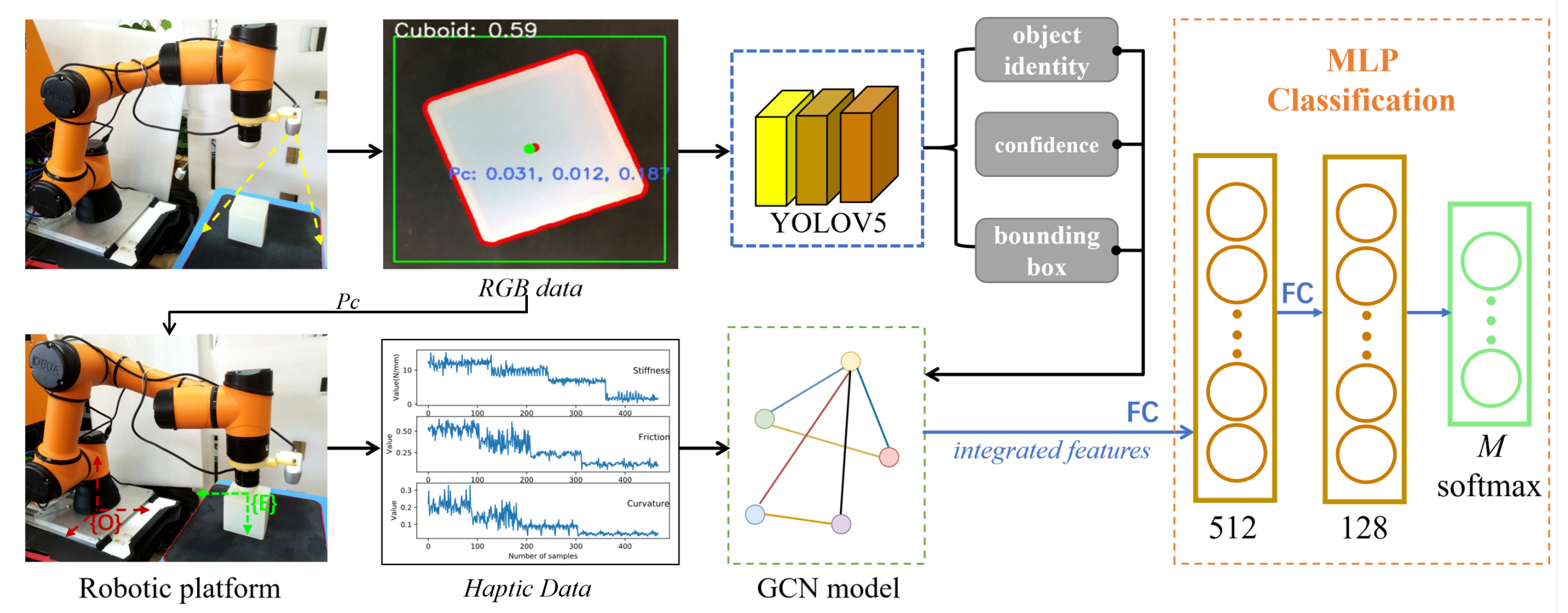
2. Materials and Methods
2.1. Vision Perception Model
2.2. Haptic Explorations
2.2.1. Primary Work
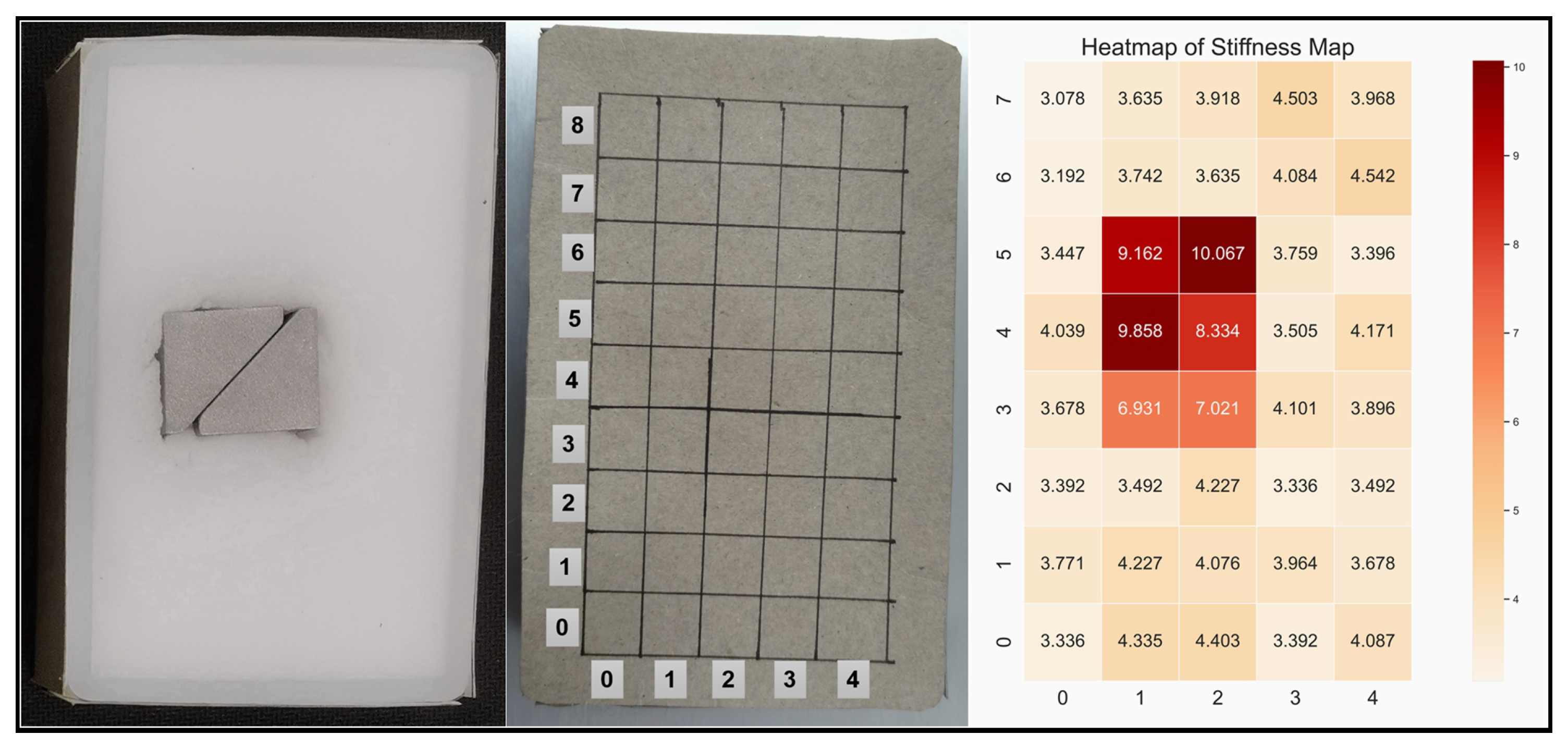
2.2.2. Robot Arm Control and Exploration Procedures
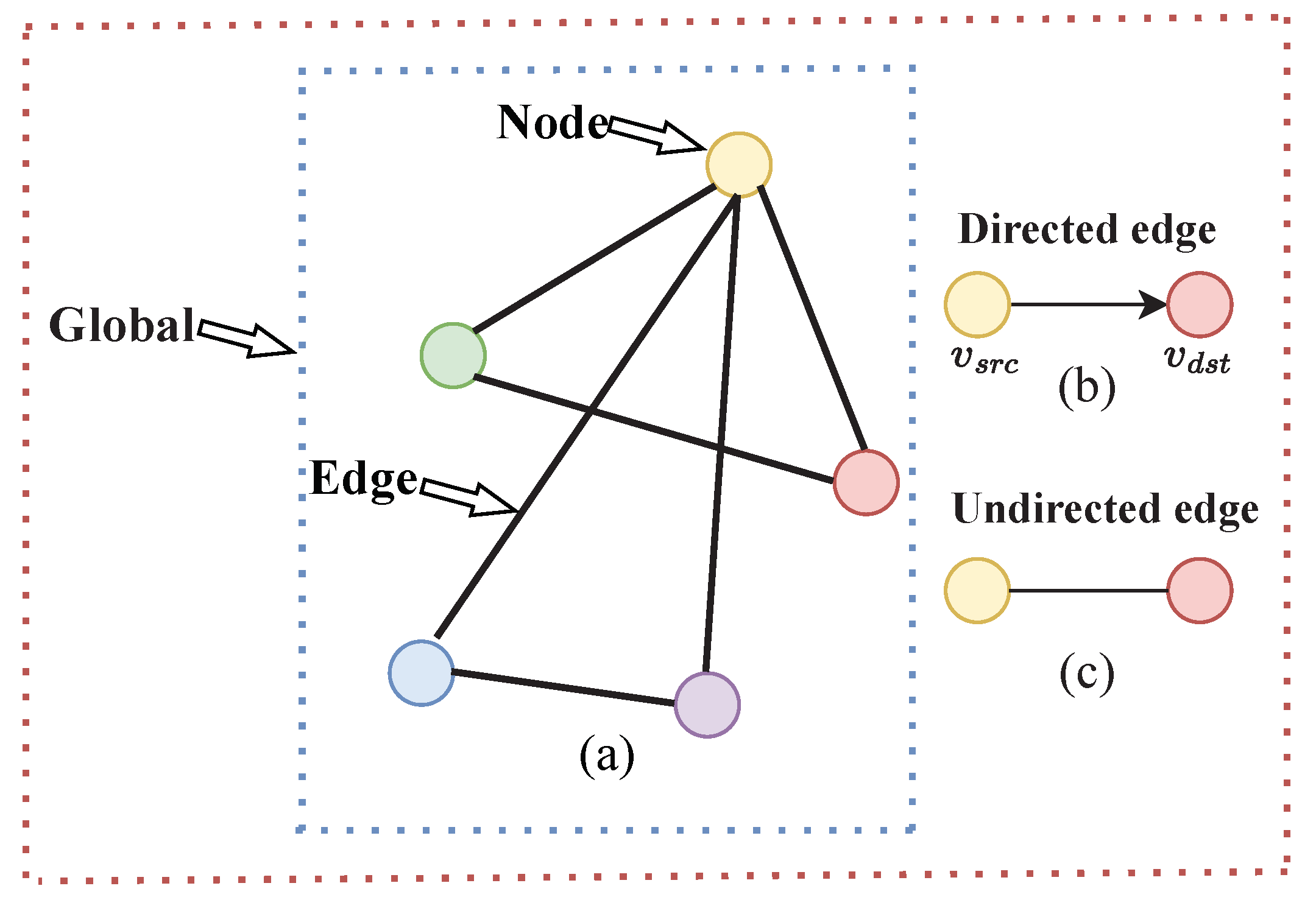
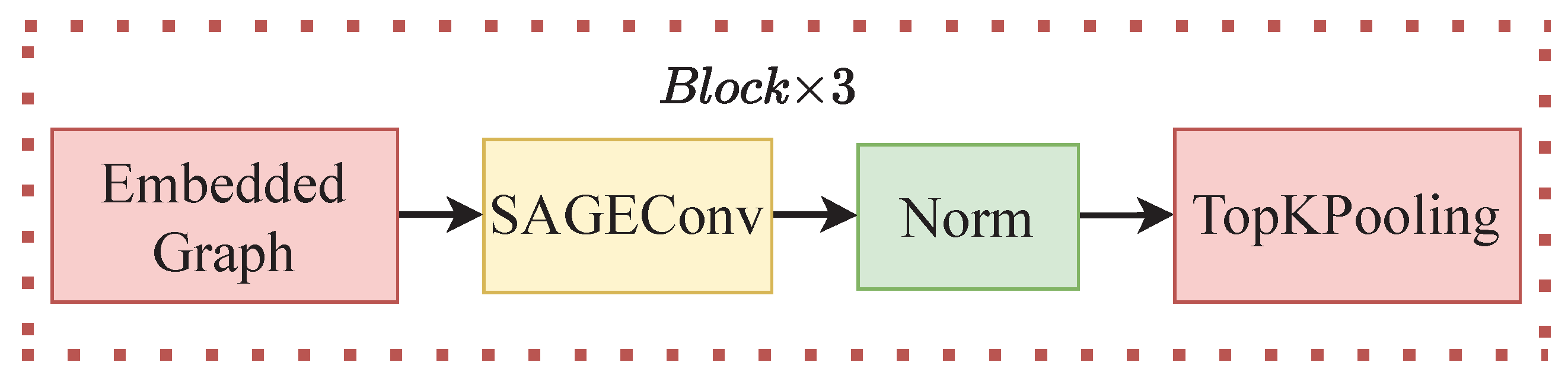
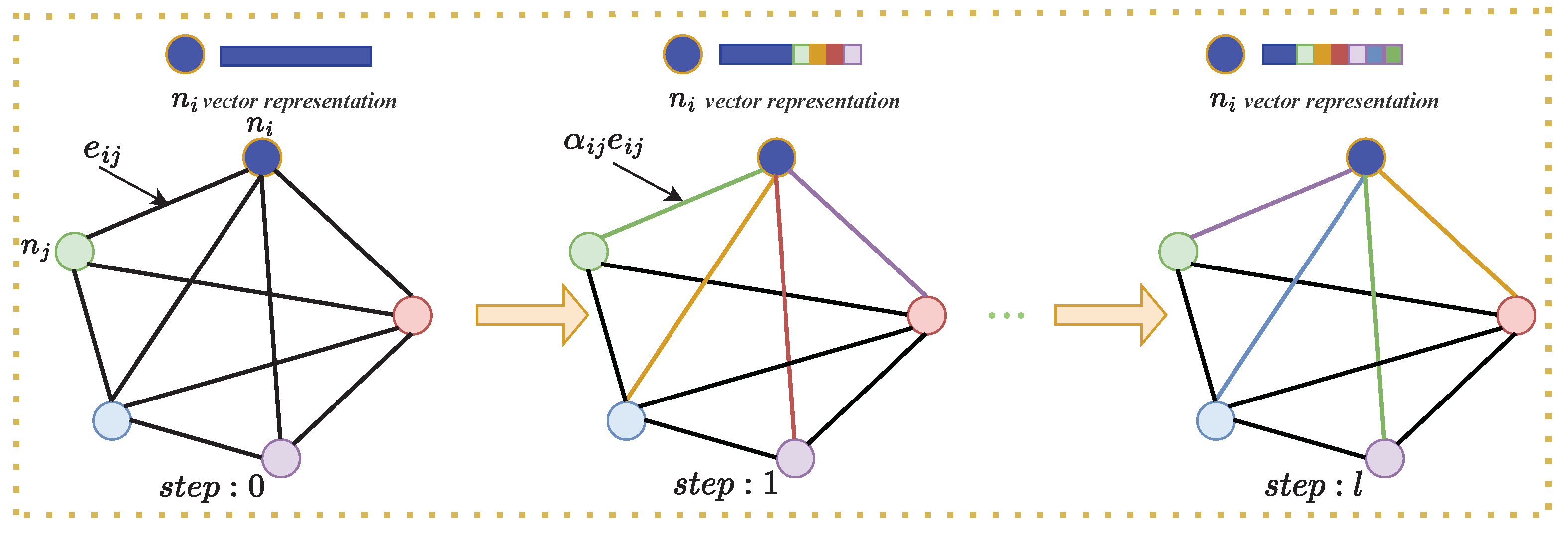
2.3. Features Fusion with GCN
3. Experimental Validations
3.1. Robot Platform and Task Description
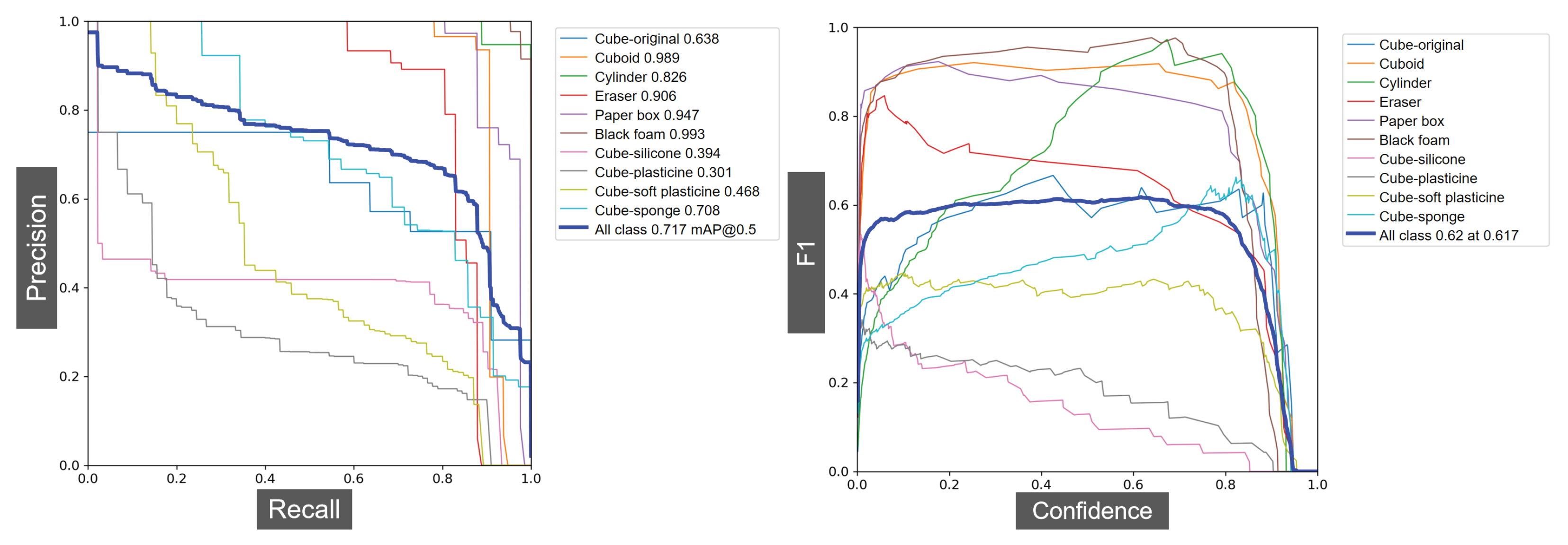
3.2. Objects Creation and Vision Model Training
3.3. Implementation Procedures
- 1.
- Initialise all the required variables. Check whether the robot has returned to the “work position”; if no, return it to that position. If yes, move it to the “vision position” and detect the object using the RGB data through the obtained YOLOv5 model, and record the results (confidence score, boxes and object identity).
- 2.
- Check if the maximum confidence exceeds the pre-set threshold; if yes, output the corresponding object identity. If no, detect the reaching position of the object with the RGBD data and calculate the control angles for the robot arm joints.
- 3.
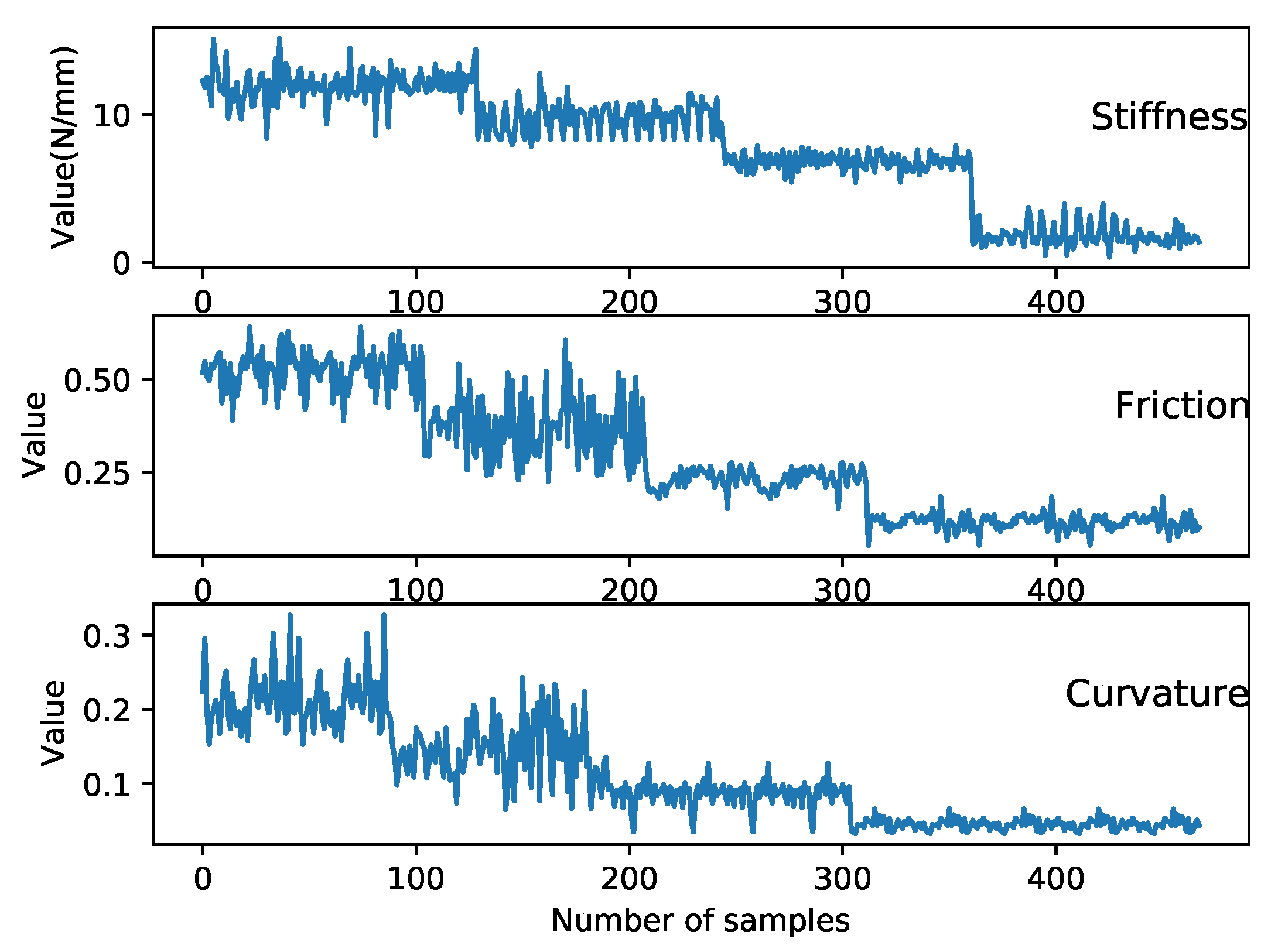
- Control the robot arm to reach the object surface (“touch position”). Implement the compression action at five random locations and record the force changes. Then, return the robot to the top middle of the object to carry out the surface following within the object surface and record the contact forces and locations. After that, calculate the average stiffness and surface friction (mean and standard deviation).
- 4.
- Normalise the collected features to fix the data between [0,1]. Carry out the data embedding with the normalised data and feed the embedded data into the GCN network, which is then connected with a three-layer MLP classifier. Using the classifier to process the integrated features, output the object identity with the highest probability. More details will be introduced in the following sections.
- 5.
- Check whether the new confidence is satisfied. If “yes”, inform that the object has been detected successfully and print out the result. If “no”, return to the first step and repeat the perception process. In either case, the robot arm must return to the “work position”. Please check the Supplementary Video S1 for more details about the experiemnts.
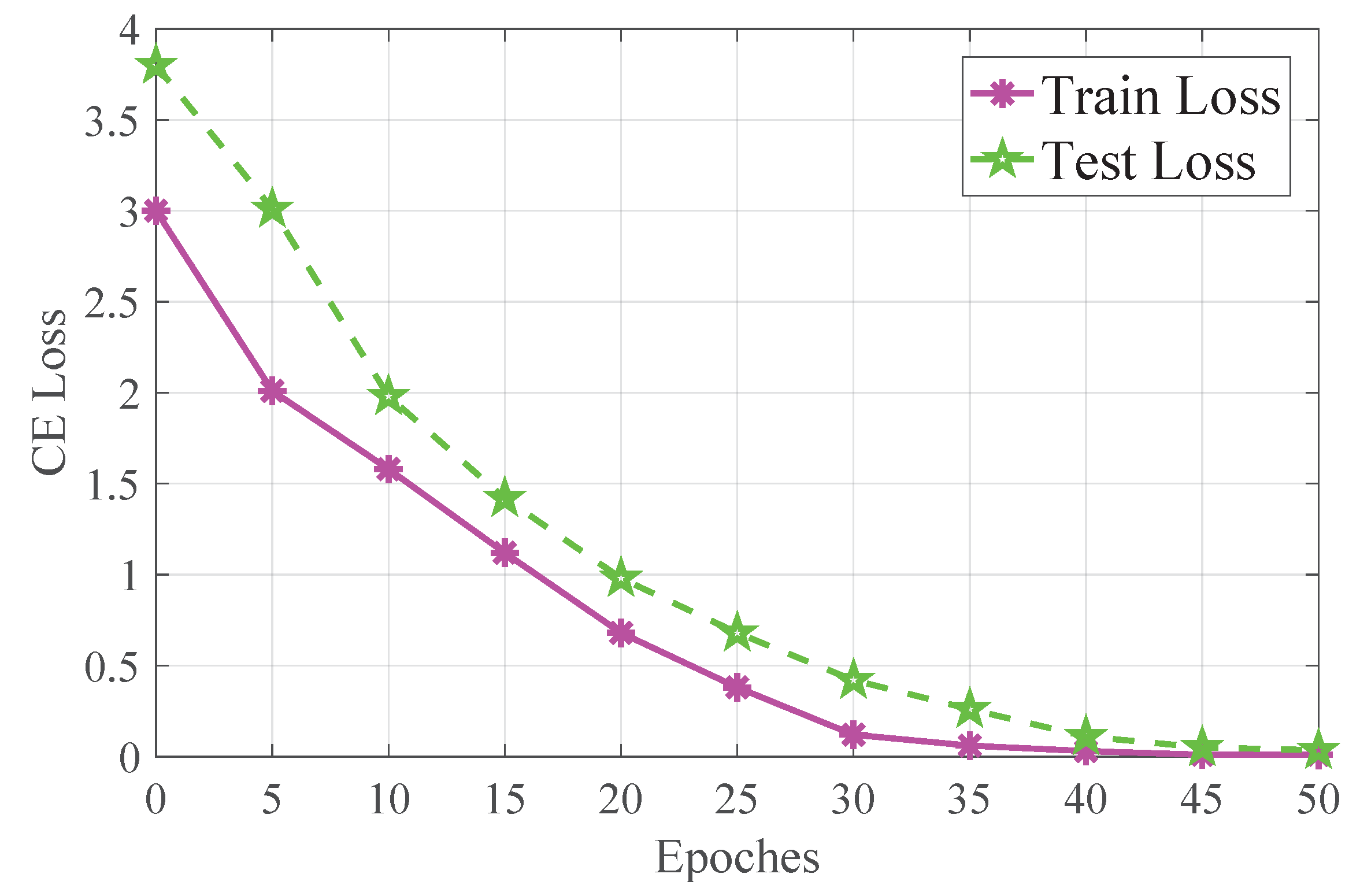
3.3.1. Data Processing
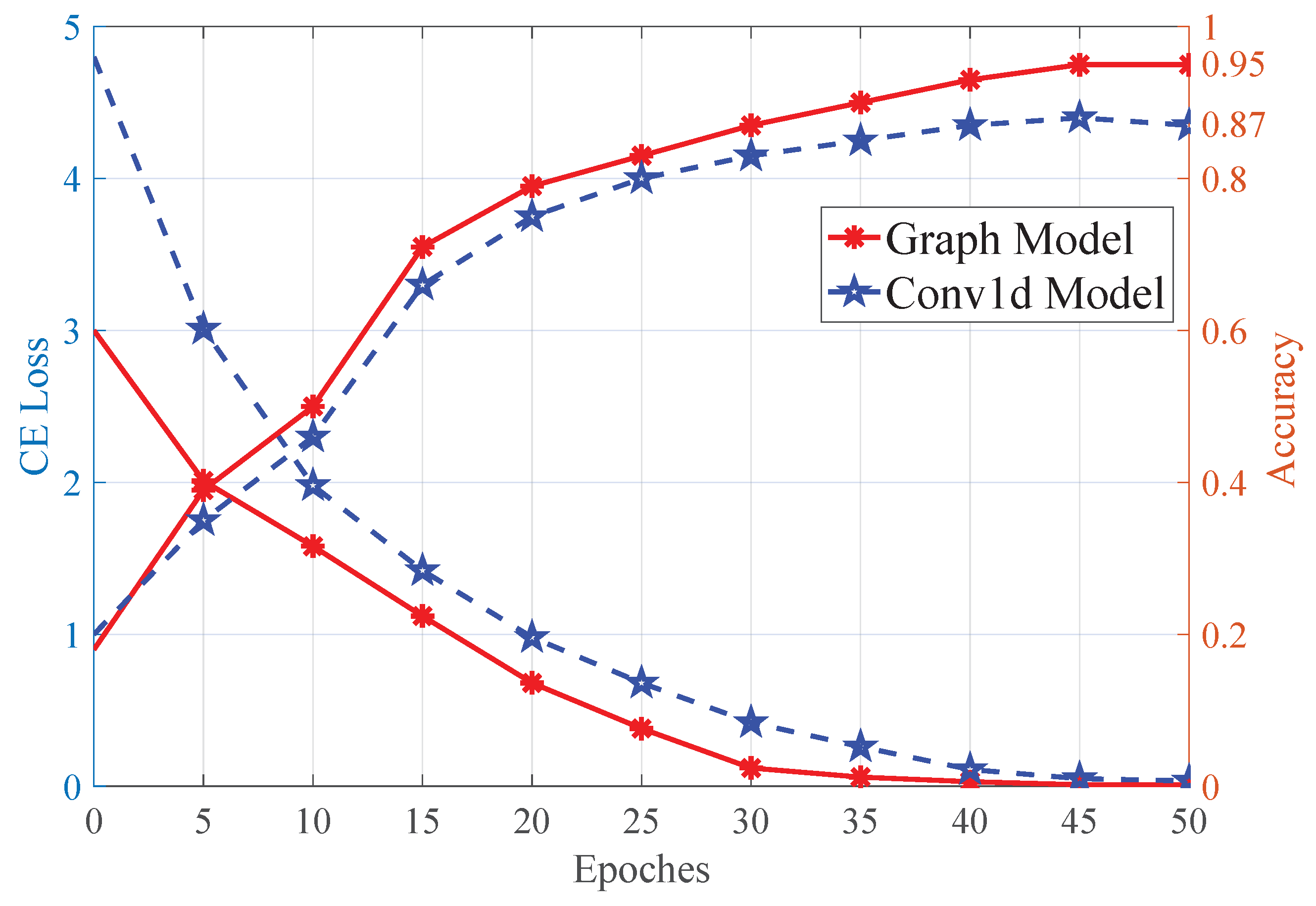
3.3.2. Object Recognition Tests
3.4. Perception for Adaptive Force Control
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bohg, J.; Hausman, K.; Sankaran, B.; Brock, O.; Kragic, D.; Schaal, S.; Sukhatme, G.S. Interactive Perception: Leveraging Action in Perception and Perception in Action. IEEE Trans. Robot. 2017, 33, 1273–1291. [Google Scholar] [CrossRef]
- Lee, M.A.; Zhu, Y.; Zachares, P.; Tan, M.; Srinivasan, K.; Savarese, S.; Fei-Fei, L.; Garg, A.; Bohg, J. Making Sense of Vision and Touch: Learning Multimodal Representations for Contact-Rich Tasks. IEEE Tran. Robot. 2020, 36, 582–596. [Google Scholar] [CrossRef] [Green Version]
- Lacey, S.; Sathian, K. Crossmodal and Multisensory Interactions between Vision and Touch. Scholarpedia 2015, 10, 7957. [Google Scholar] [CrossRef]
- Klatzky, R.L.; Lederman, S.J.; Metzger, V.A. Identifying objects by touch: An “expert system”. Percept. Psychophys. 1985, 37, 299–302. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lederman, S.J.; Klatzky, R.L. Haptic perception: A tutorial. Attention, Percept. Psychophys. 2009, 71, 1439–1459. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Klatzky, R.L.; Lederman, S.J.; Matula, D.E. Haptic exploration in the presence of vision. Hum. Percept. Perform. 1993, 19, 726–743. [Google Scholar] [CrossRef] [PubMed]
- Desmarais, G.; Meade, M.; Wells, T.; Nadeau, M. Visuo-haptic integration in object identification using novel objects. Percept. Psychophys. 2017, 79, 2478–2498. [Google Scholar] [CrossRef] [Green Version]
- Calandra, R.; Owens, A.; Jayaraman, D.; Lin, J.; Yuan, W.; Malik, J.; Adelson, E.H.; Levine, S. More Than a Feeling: Learning to Grasp and Regrasp Using Vision and Touch. In Proceedings of the 2018 International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 3300–3307. [Google Scholar]
- Gao, Y.; Hendricks, L.A.; Kuchenbecker, K.J.; Darrell, T. Deep learning for tactile understanding from visual and haptic data. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 536–543. [Google Scholar]
- Lee, J.T.; Bollegala, D.; Luo, S. “Touching to See” and “Seeing to Feel”: Robotic Cross-modal Sensory Data Generation for Visual-Tactile Perception. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4276–4282. [Google Scholar]
- Yu, K.T.; Rodriguez, A. Realtime State Estimation with Tactile and Visual Sensing for Inserting a Suction-held Object. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1628–1635. [Google Scholar]
- Fazeli, N.; Oller, M.; Wu, J.; Wu, Z.; Tenenbaum, J.B.; Rodriguez, A. See, feel, act: Hierarchical learning for complex manipulation skills with multisensory fusion. Sci. Robot. 2019, 4, eaav3123. [Google Scholar] [CrossRef]
- van Hoof, H.; Chen, N.; Karl, M.; van der Smagt, P.; Peters, J. Stable reinforcement learning with autoencoders for tactile and visual data. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 3928–3934. [Google Scholar]
- Wang, S.; Wu, J.; Sun, X.; Yuan, W.; Freeman, W.T.; Tenenbaum, J.B.; Adelson, E.H. 3D Shape Perception from Monocular Vision, Touch, and Shape Priors. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1606–1613. [Google Scholar]
- Li, Y.; Zhu, J.Y.; Tedrake, R.; Torralba, A. Connecting Touch and Vision via Cross-Modal Prediction. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–17 June 2019; pp. 10609–10618. [Google Scholar]
- Levine, S.; Pastor, P.; Krizhevsky, A.; Ibarz, J.; Quillen, D. Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection. Int. J. Robot. Res. 2018, 37, 421–436. [Google Scholar] [CrossRef]
- Watkins-Valls, D.; Varley, J.; Allen, P. Multi-Modal Geometric Learning for Grasping and Manipulation. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 7339–7345. [Google Scholar]
- Lambert, A.S.; Mukadam, M.; Sundaralingam, B.; Ratliff, N.; Boots, B.; Fox, D. Joint Inference of Kinematic and Force Trajectories with Visuo-Tactile Sensing. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 3165–3171. [Google Scholar]
- Gemici, M.C.; Saxena, A. Learning haptic representation for manipulating deformable food objects. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2014), Chicago, IL, USA, 14–18 September 2014; pp. 638–645. [Google Scholar]
- Yim, S.; Jeon, S.; Choi, S. Data-Driven Haptic Modeling and Rendering of Viscoelastic and Frictional Responses of Deformable Objects. IEEE Trans. Haptics 2016, 9, 548–559. [Google Scholar] [CrossRef]
- Schuwerk, C.; Xu, X.; Steinbach, E. On the Transparency of Client/Server-Based Haptic Interaction with Deformable Objects. IEEE Trans. Haptics 2017, 10, 240–253. [Google Scholar] [CrossRef]
- McConachie, D.; Dobson, A.; Ruan, M.; Berenson, D. Manipulating deformable objects by interleaving prediction, planning, and control. Int. J. Robot. Res. 2020, 39, 957–982. [Google Scholar] [CrossRef]
- Xiao, S.; Wang, S.; Dai, Y.; Guo, W. Graph neural networks in node classification: Survey and evaluation. Mach. Vis. Appl. 2021, 33, 1–19. [Google Scholar] [CrossRef]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017; Volume 1050, p. 20. [Google Scholar]
- Andrychowicz, O.M.; Baker, B.; Chociej, M.; Józefowicz, R.; McGrew, B.; Pachocki, J.; Petron, A.; Plappert, M.; Powell, G.; Ray, A.; et al. Learning dexterous in-hand manipulation. Int. J. Robot. Res. 2020, 39, 3–20. [Google Scholar] [CrossRef] [Green Version]
- Jocher, G.; Stoken, A.; Borovec, J.; Chaurasia, A.; Changyu, L.; Laughing, A.; Hogan, A.; Hajek, J.; Diaconu, L.; Marc, Y. ultralytics/yolov5: V5.0-YOLOv5-P6 1280 models, AWS, Supervise.ly and YouTube Integrations. Zenodo 2021, 11. [Google Scholar] [CrossRef]
- Liu, H.; Nguyen, K.C.; Perdereau, V.; Bimbo, J.; Back, J.; Godden, M.; Seneviratne, L.D.; Althoefer, K. Finger contact sensing and the application in dexterous hand manipulation. Auton. Robot. 2015, 39, 25–41. [Google Scholar] [CrossRef] [Green Version]
- Sun, T.; Liu, H. Adaptive force and velocity control based on intrinsic contact sensing during surface exploration of dynamic objects. Auton. Robot. 2020, 44, 773–790. [Google Scholar] [CrossRef] [Green Version]
- Seenivasan, L.; Islam, M.; Ng, C.F.; Lim, C.M.; Ren, H. Biomimetic Incremental Domain Generalization with a Graph Network for Surgical Scene Understanding. Biomimetics 2022, 7, 68. [Google Scholar] [CrossRef]
- Kolda, T.G.; Pinar, A.; Plantenga, T.; Seshadhri, C. A scalable generative graph model with community structure. SIAM J. Sci. Comput. 2014, 36, C424–C452. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Variational graph auto-encoders. arXiv 2016, arXiv:1611.07308. [Google Scholar]
- Ciotti, S.; Sun, T.; Battaglia, E.; Bicchi, A.; Liu, H.; Bianchi, M. Soft tactile sensing: Retrieving force, torque and contact point information from deformable surfaces. In Proceedings of the 2019 IEEE International Conference on Robotics and Automation, ICRA, Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Liu, H.; Wu, C.; Lin, S.; Li, Y.; Chen, Y. Double-Acting Soft Actuator for Soft Robotic Hand: A Bellow Pumping and Contraction Approach. Biomimetics 2022, 7, 171. [Google Scholar] [CrossRef] [PubMed]
- Dong, W.; Wu, J.; Zhang, X.; Bai, Z.; Wang, P.; Woźniak, M. Improving performance and efficiency of Graph Neural Networks by injective aggregation. Knowl.-Based Syst. 2022, 254, 109616. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object I | Confidence | Bounding Box | Stiffness | Surface Friction | Roughness |
|---|---|---|---|---|---|
| 0 | 0.85 | (0.96,0.45,0.58,0.69) | - | - | - |
| 1 | 0.90 | (0.36,0.65,0.21,0.47) | - | - | - |
| 2 | 0.87 | (0.18,0.57,0.38,0.79) | - | - | - |
| 3 | 0.88 | (0.26,0.35,0.88,0.69) | - | - | - |
| 4 | 0.95 | (0.06,0.25,0.58,0.79) | - | - | - |
| 5 | 0.638 | (0.66,0.25,0.38,0.59) | 0.753 | 0.255 | 0.091 |
| 6 | 0.394 | (0.16,0.55,0.61,0.87) | 10.014 | 0.394 | 0.108 |
| 7 | 0.301 | (0.38,0.47,0.68,0.59) | 12.059 | 0.052 | 0.034 |
| 8 | 0.468 | (0.36,0.65,0.78,0.89) | 6.817 | 0.114 | 0.056 |
| 9 | 0.708 | (0.16,0.05,0.88,0.49) | 1.859 | 0.034 | 0.052 |
| Accurary | Confidence | Bounding Box | Stiffness | Surface Friction | Roughness |
|---|---|---|---|---|---|
| 0.72 | ✓ | ✓ | ✓ | - | - |
| 0.73 | ✓ | ✓ | - | ✓ | - |
| 0.73 | ✓ | ✓ | - | - | ✓ |
| 0.80 | ✓ | ✓ | ✓ | ✓ | - |
| 0.82 | ✓ | ✓ | ✓ | - | ✓ |
| 0.83 | ✓ | ✓ | - | ✓ | ✓ |
| 0.63 | ✓ | - | ✓ | ✓ | ✓ |
| 0.62 | - | ✓ | ✓ | ✓ | ✓ |
| 0.95 | ✓ | ✓ | ✓ | ✓ | ✓ |
| Method | Accurary |
|---|---|
| SVM | 0.82 |
| KNN | 0.81 |
| Bayesian filter | 0.83 |
| Conv1d Model | 0.87 |
| Graph Model | 0.95 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, T.; Zhang, Z.; Miao, Z.; Zhang, W. A Recognition Method for Soft Objects Based on the Fusion of Vision and Haptics. Biomimetics 2023, 8, 86. https://doi.org/10.3390/biomimetics8010086
Sun T, Zhang Z, Miao Z, Zhang W. A Recognition Method for Soft Objects Based on the Fusion of Vision and Haptics. Biomimetics. 2023; 8(1):86. https://doi.org/10.3390/biomimetics8010086
Chicago/Turabian StyleSun, Teng, Zhe Zhang, Zhonghua Miao, and Wen Zhang. 2023. "A Recognition Method for Soft Objects Based on the Fusion of Vision and Haptics" Biomimetics 8, no. 1: 86. https://doi.org/10.3390/biomimetics8010086