
Evaluation of Contributing Factors Affecting Number of Vehicles Involved in Crashes Using Machine Learning Techniques in Rural Roads of Cosenza, Italy

 ,
,  ,
,  , ,
, ,
Abstract
:1. Introduction
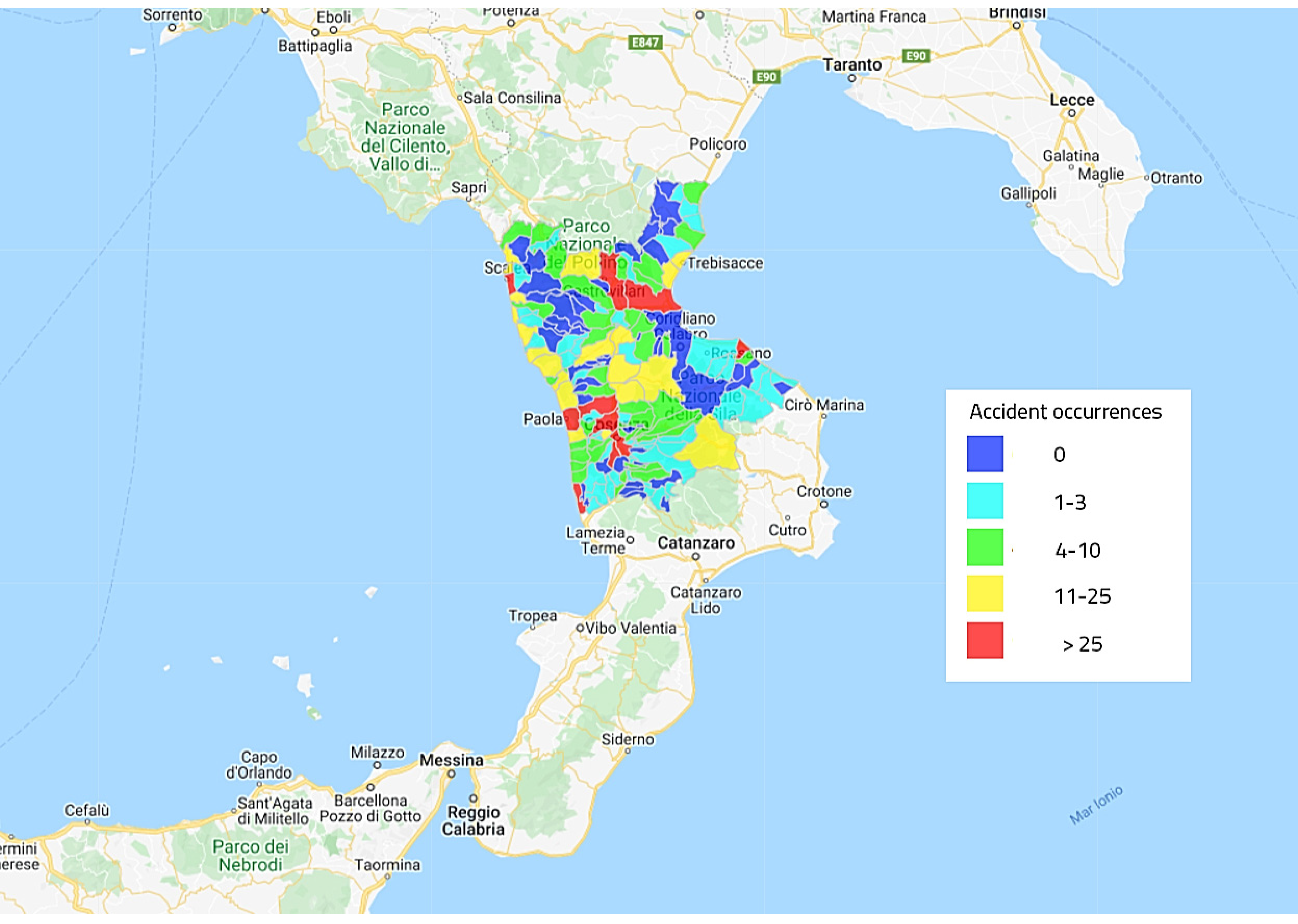
2. Site Description and Accident Monitoring
- - When there is a vehicle involved in an accident, label 0 is considered.
- - When there is more than one vehicle involved in an accident, label 1 is considered.
3. Methodology
3.1. Group Method of Data Handling-Type Neural Network
3.2. Support Vector Machine
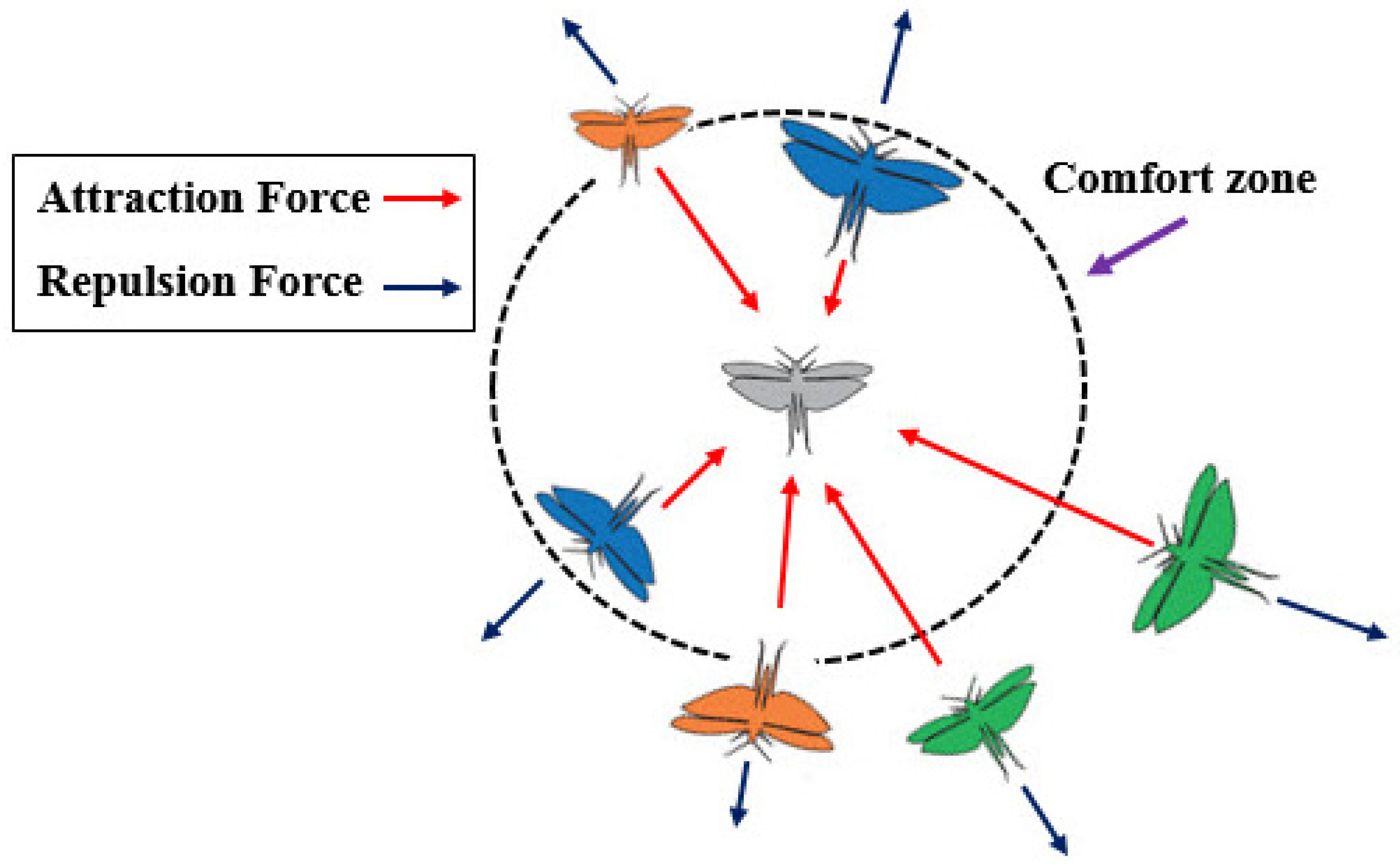
3.3. Grasshopper Optimization Algorithm
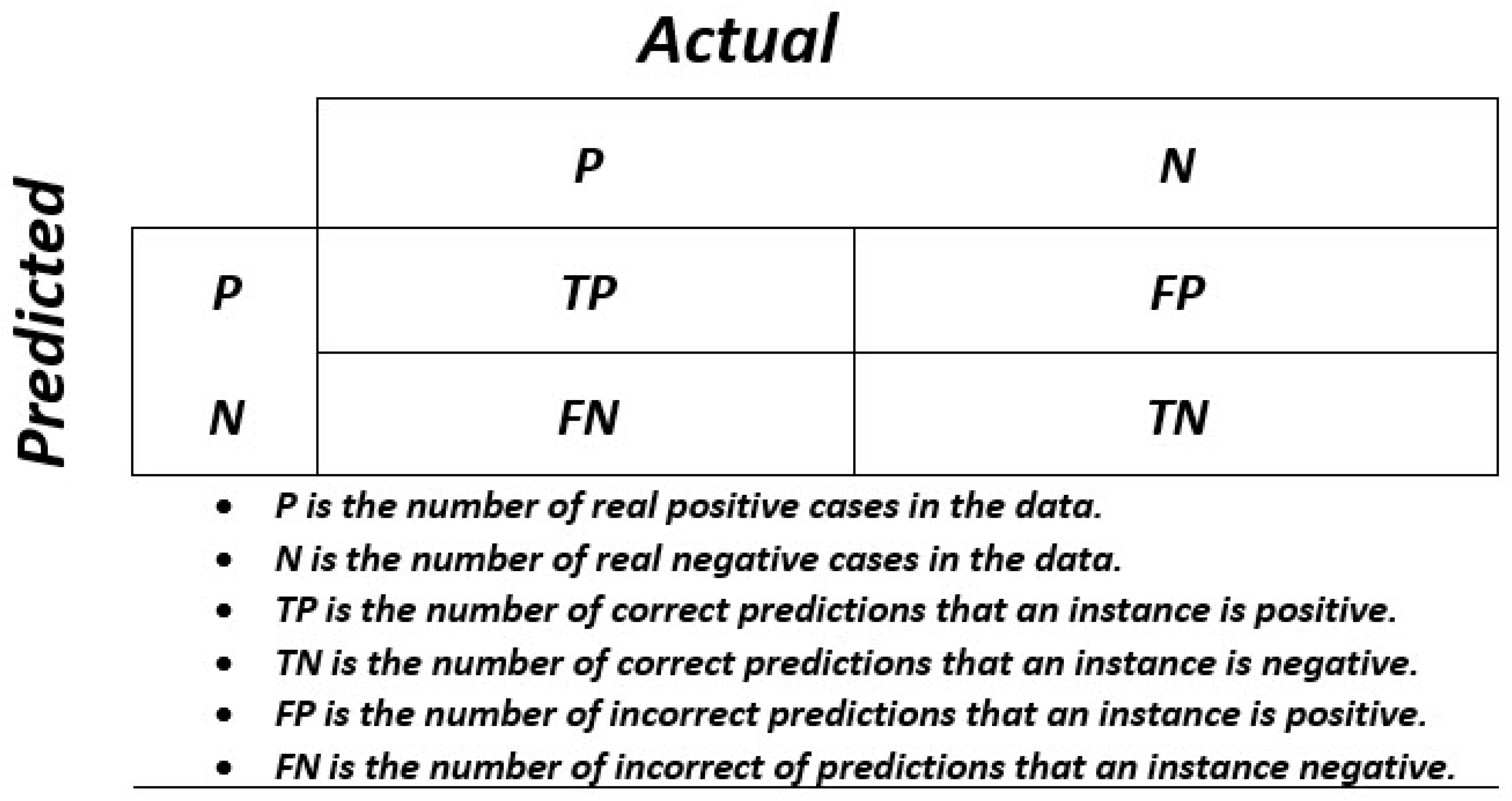
4. Results and Discussion
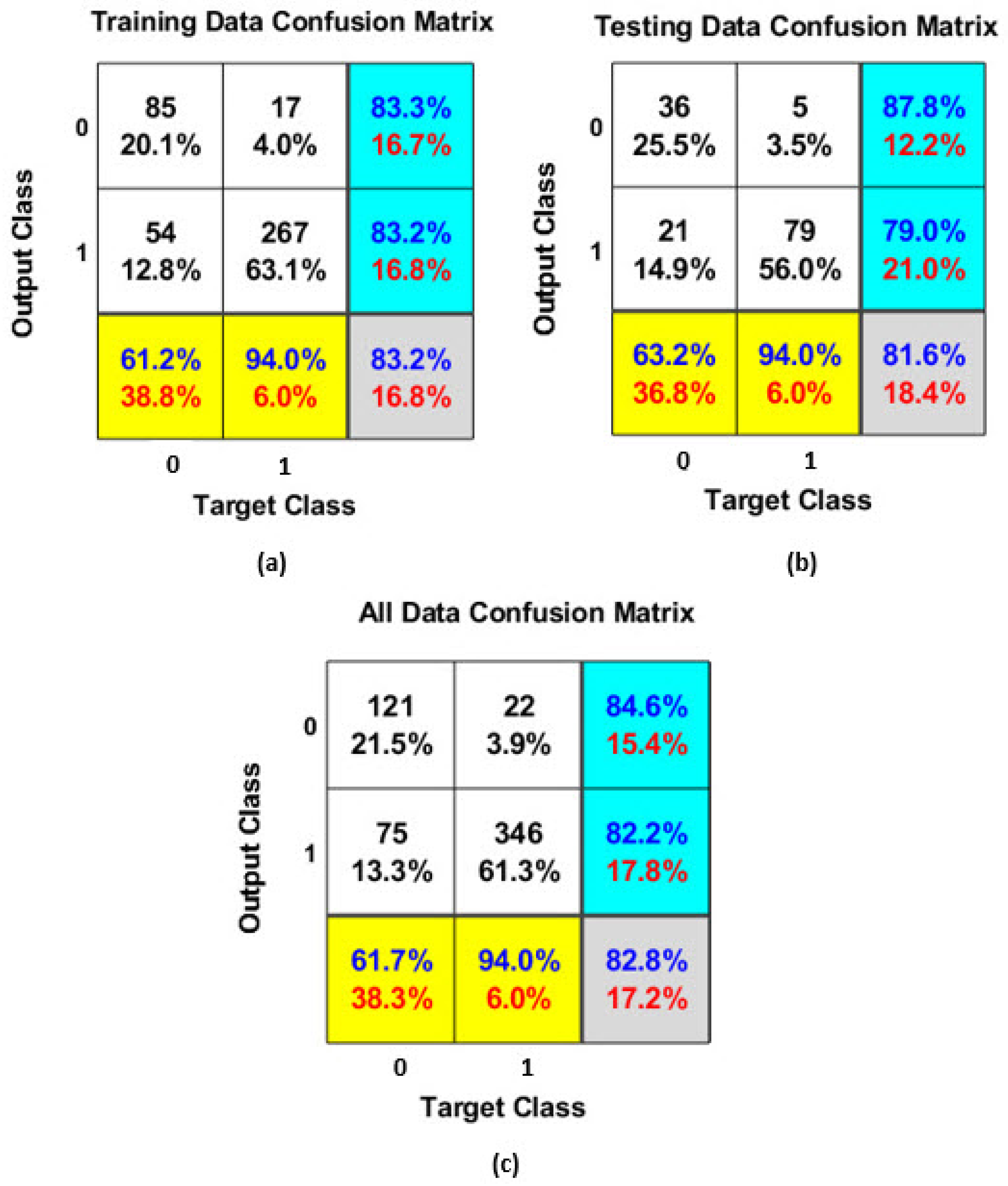
4.1. GMDH Modeling
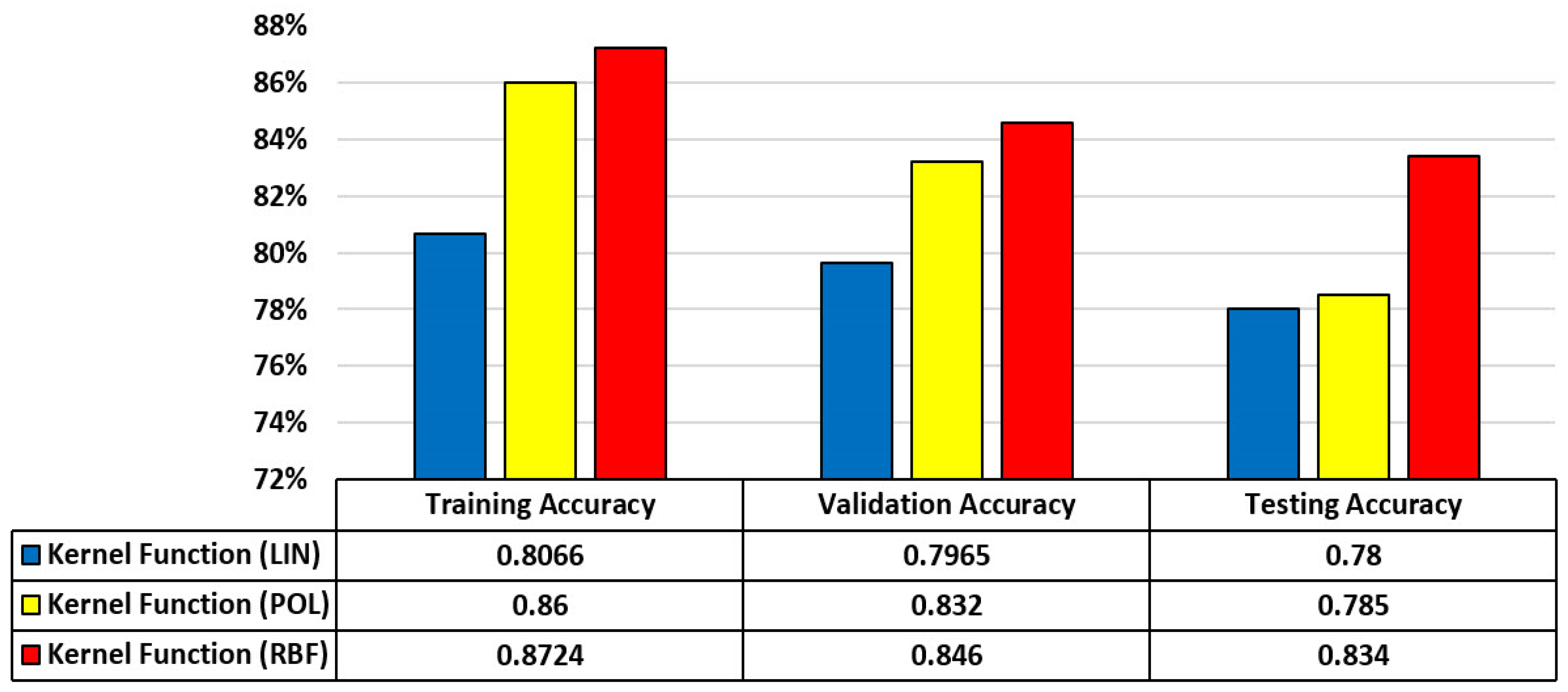
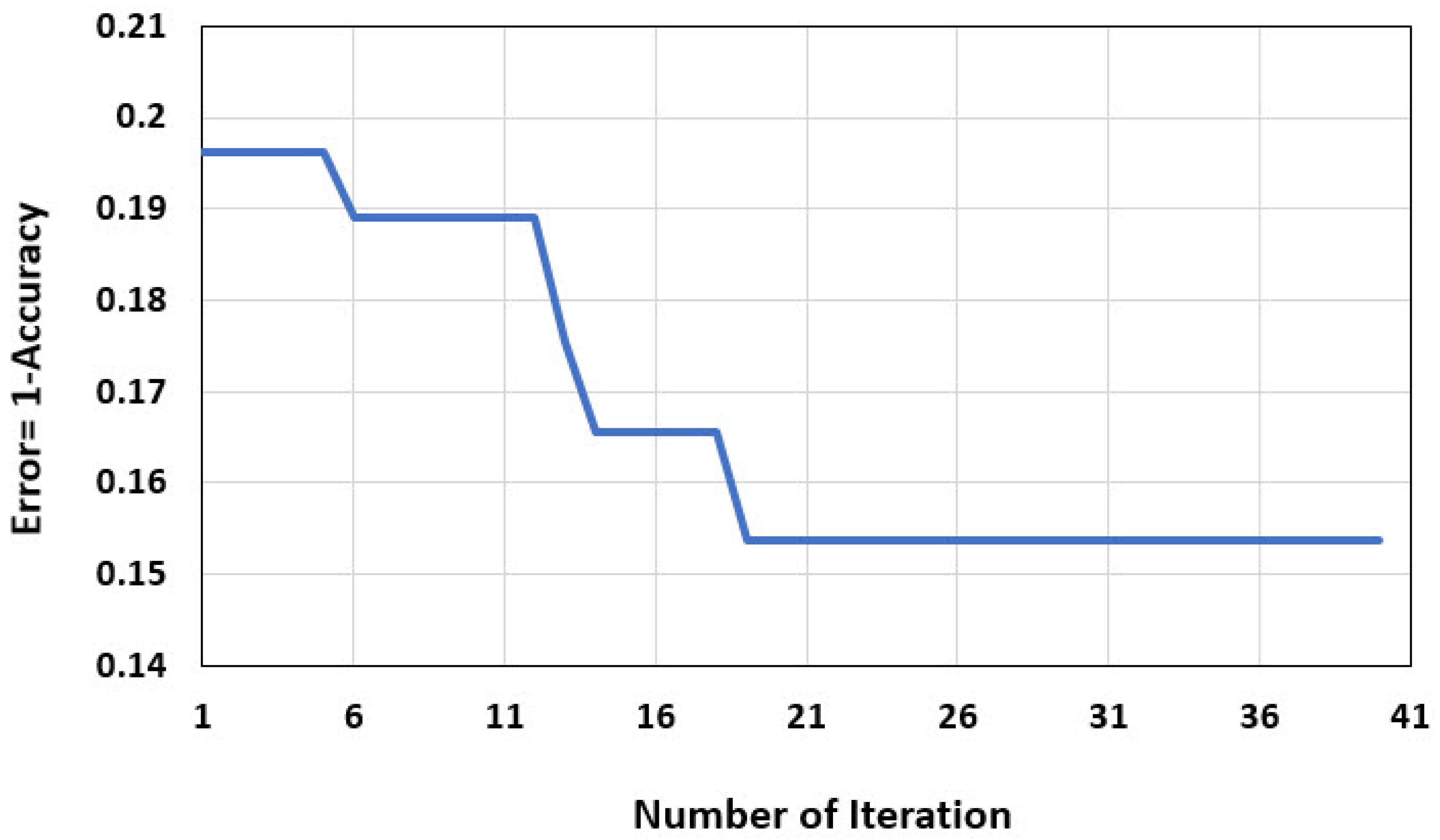
4.2. GOA-SVM Modeling
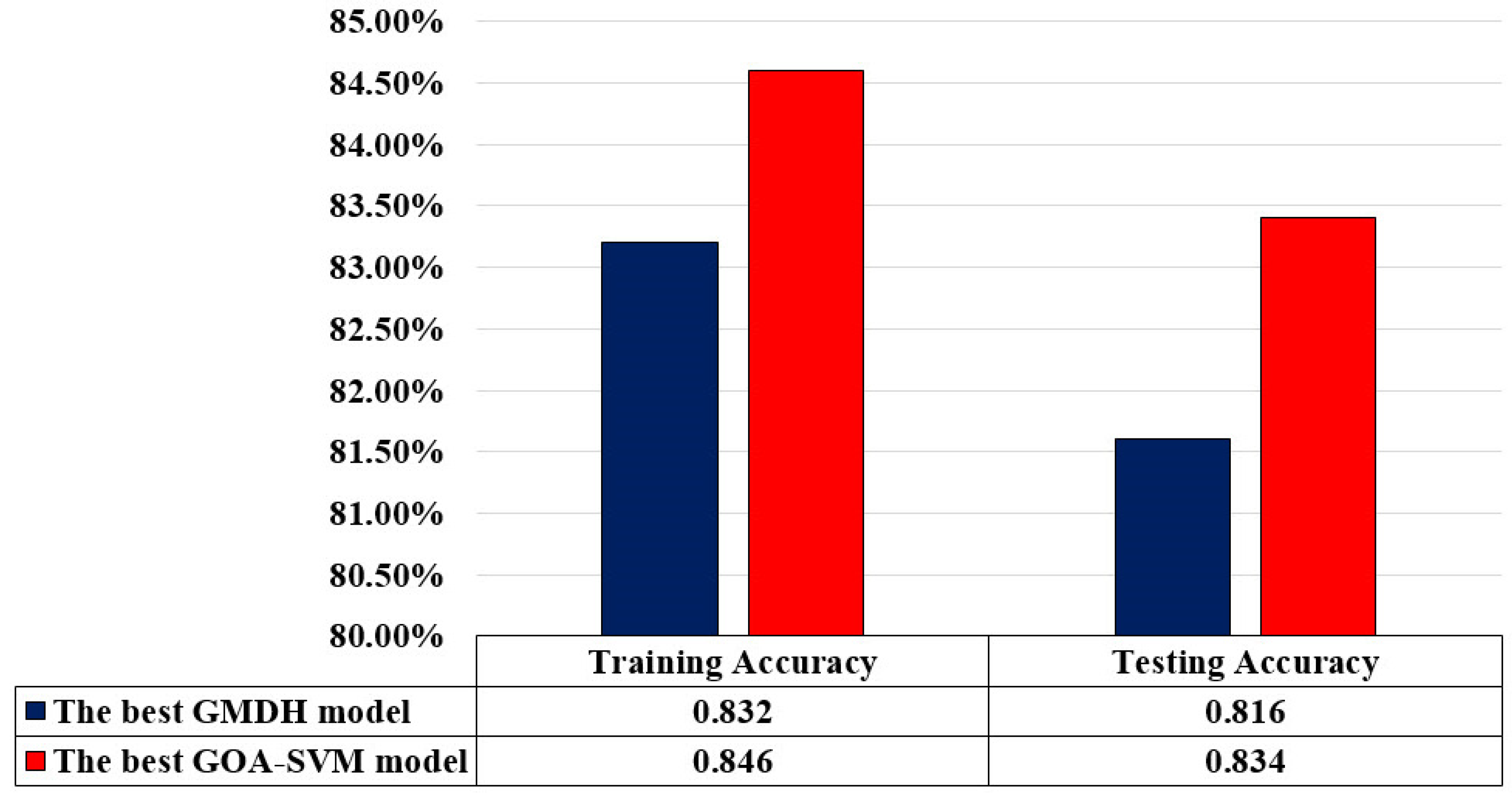
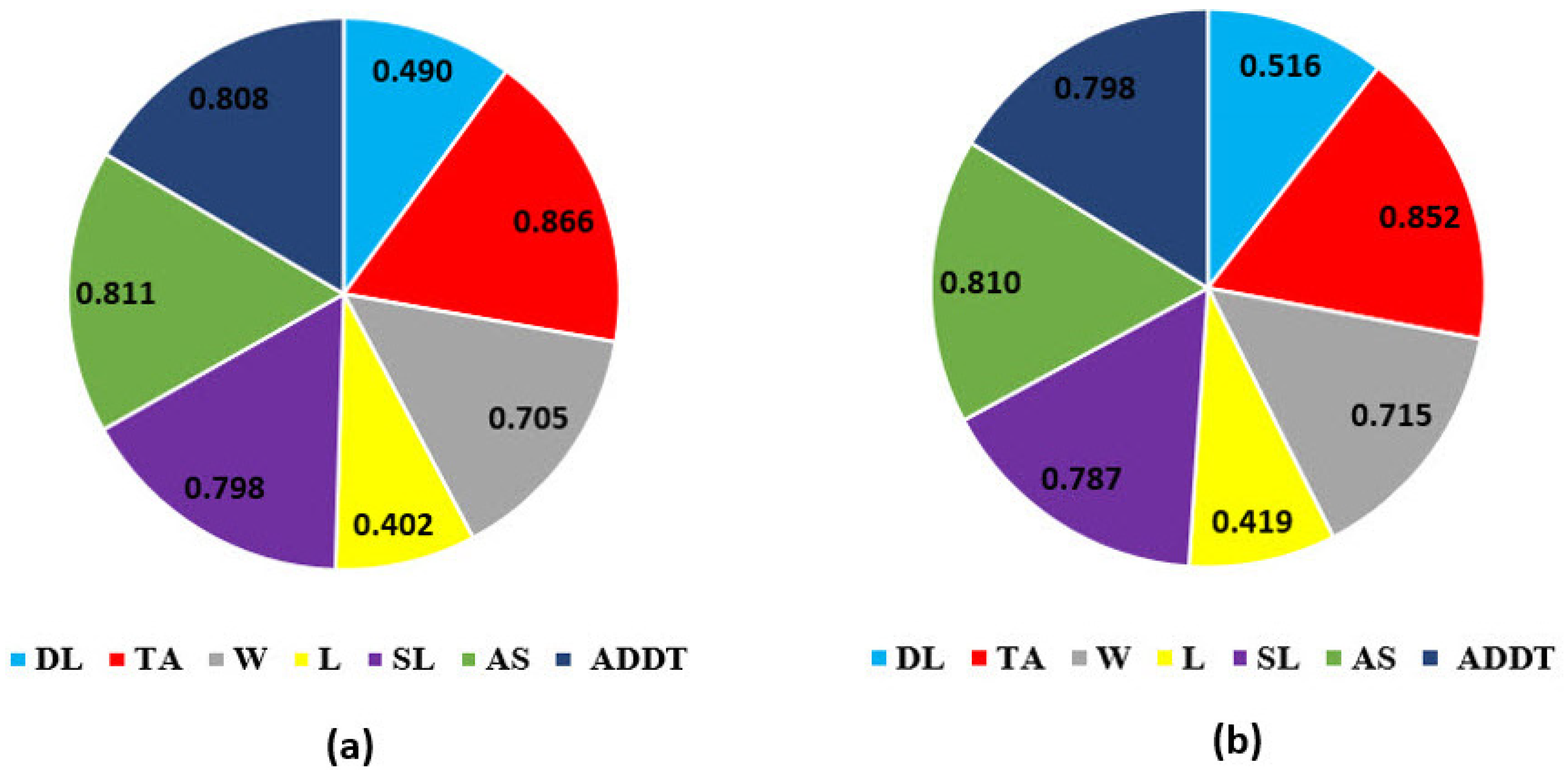
4.3. Comparison of Models’ Performance and Sensitivity Analysis
- -
- The type of accident was the most significant factor among other contributing factors that affected the number of vehicles involved in the crashes. In general, certain types of accidents can be caused by a variety of issues, including a lack of traffic signs and poor road quality. The type of accident has an important effect on the number of vehicles involved in an accident.
- -
- The next factor is the average speed, which can increase the risk of accidents. Some researchers discovered that controlling other factors, such as traffic volume, road geometry, and the number of lanes, can reduce or eliminate the effects of average speed [110,111]. When the average speed is higher, the driver’s response time is shorter, which can lead to an accident. Therefore, it is possible to control the impact of average speed by providing some types of measures, such as improvement to the location of road signs, speed limit enforcement methods, pavement markings, and vertical centerline treatments.
- -
- The third factor influencing the number of vehicles involved in an accident after the type of accident and the average speed is the annual average daily traffic that plays a key role in the development needs and priorities of road development for transportation planning. Moreover, some studies indicate that increasing the amount of AADT can lead to an increase in the frequency of accidents [112,113]. Therefore, to reduce the effects of AADT on this case study, it is recommended to consider other intercity transportation systems, such as trains, which are being considered in the review of coming urban development plans.
- -
- The subsequent contributing factor is the speed limit, which has a significant role in the behavior and decisions of drivers. Generally, it is considered that the speed limit is determined by the road conditions. If the speed limit is selected incorrectly on a part of the route and the driver is aware of this error due to the road conditions, they may lose confidence in the speed limits in other sections of the road and increase or decrease the speed based on their interpretation [114,115]. Hence, given the impact of this factor in this case study, it is suggested that a general review be considered in selecting the speed limit for rural roads in Cosenza.
- -
- Several appropriate studies have been conducted on the relationship between weekdays and accidents [116,117]. In line with national statistics, road accidents are more concentrated on holidays on the road network in Cosenza’s province. In the present study, out of the 564 accidents, 65% (367) occurred on holidays. Due to the geographical location of Cosenza, the amount of traffic on holidays has experienced a relative increase. To reduce the exposure to the risk, the intensification of controls and monitoring of roads during the holidays would mitigate the effect of this factor by increasing police enforcement.
- -
- Extensive studies have been conducted on the effect of daylight on the number of vehicles involved in accidents, which shows this factor’s high importance. This factor has been given priority in many studies, among other factors [50,118]. The amount of impact this factor has is heavily influenced by its geographic location and road lighting systems. This factor was determined as the sixth most effective factor out of seven factors, and this result was matched with the location and road lighting system of rural roads in Cosenza.
- -
- The last studied factor was the location that had the most negligible impact on the rate of vehicles involved in an accident, based on the results of both artificial intelligence models. Based on the type of structure of the rural roads in Cosenza, the location has not had much effect on the rate of accidents. Therefore, in future studies on this case study, the effect of this factor can be ignored.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nordfjærn, T.; Rundmo, T. Road traffic safety beliefs and driver behaviors among personality subtypes of drivers in the Norwegian population. Traffic Inj. Prev. 2013, 14, 690–696. [Google Scholar] [CrossRef] [PubMed]
- Ellison, A.B.; Greaves, S.P.; Bliemer, M.C. Driver behaviour profiles for road safety analysis. Accid. Anal. Prev. 2015, 76, 118–132. [Google Scholar] [CrossRef] [PubMed]
- Scott-Parker, B. Emotions, behaviour, and the adolescent driver: A literature review. Transp. Res. F Traffic Psychol. Behav. 2017, 50, 1–37. [Google Scholar] [CrossRef]
- Farooq, D.; Moslem, S.; Duleba, S. Evaluation of driver behavior criteria for evolution of sustainable traffic safety. Sustainability 2019, 11, 3142. [Google Scholar] [CrossRef] [Green Version]
- Farooq, D.; Juhasz, J. Statistical Evaluation of Risky Driver Behavior Factors That Influence Road Safety Based on Drivers Age and Driving Experience in Budapest and Islamabad. Eur. Transp. 2020, 80, 1–18. [Google Scholar] [CrossRef]
- Rosli, N.; Ambak, K.; Shahidan, N.N.; Sukor, N.S.A.; Osman, S.; Yei, L.S. Driving behaviour of elderly drivers in Malaysia. Int. J. Integr. Eng. 2020, 12, 268–277. [Google Scholar] [CrossRef]
- Alonso, B.; Astarita, V.; Dell’Olio, L.; Giofrè, V.P.; Guido, G.; Marino, M.; Sommario, W.; Vitale, A. Validation of simulated safety indicators with traffic crash data. Sustainability 2020, 12, 925. [Google Scholar] [CrossRef] [Green Version]
- Christoforou, Z.D.; Karlaftis, M.G.; Yannis, G. Heavy vehicle age and road safety. In Proceedings of the Institution of Civil Engineers-Transport, London, UK, 22–23 November 2010; Thomas Telford Ltd.: London, UK, 2010; Volume 163, pp. 41–48. [Google Scholar]
- Russo, F.; Biancardo, S.A.; Dell’Acqua, G. Road safety from the perspective of driver gender and age as related to the injury crash frequency and road scenario. Traffic Inj. Prev. 2014, 15, 25–33. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.; Kim, J.K. Road safety for an aged society: Compliance with traffic regulations, knowledge about traffic regulations, and risk factors of older drivers. Transp. Res. Rec. 2017, 2660, 15–21. [Google Scholar] [CrossRef]
- Casado-Sanz, N.; Guirao, B. Analysis of the impact of population ageing and territorial factors on crosstown roads safety: The Spanish case study. Transp. Res. Procedia 2018, 33, 283–290. [Google Scholar] [CrossRef]
- Török, Á. A Novel Approach in Evaluating the Impact of Vehicle Age on Road Safety. Promet Traffic Transp. 2020, 32, 789–796. [Google Scholar] [CrossRef]
- Lyon, C.; Mayhew, D.; Granie, M.A.; Robertson, R.; Vanlaar, W.; Woods-Fry, H.; Thevenetb, C.; Furian, G.; Soteropoulos, A. Age and road safety performance: Focusing on elderly and young drivers. IATSS Res. 2020, 44, 212–219. [Google Scholar] [CrossRef]
- Theofilatos, A.; Yannis, G. A review of the effect of traffic and weather characteristics on road safety. Accid. Anal. Prev. 2014, 72, 244–256. [Google Scholar] [CrossRef] [PubMed]
- Lazarev, Y.; Medres, C.; Raty, J.; Bondarenko, A. Method of Assessment and Prediction of Temperature Conditions of Roadway Surfacing as a Factor of the Road Safety. Transp. Res. Procedia 2017, 20, 393–400. [Google Scholar] [CrossRef]
- Malin, F.; Norros, I.; Innamaa, S. Accident risk of road and weather conditions on different road types. Accid. Anal. Prev. 2018, 122, 181–188. [Google Scholar] [CrossRef]
- Ivajnšič, D.; Horvat, N.; Žiberna, I.; Kotnik, E.; Davidović, D. Revealing the Spatial Pattern of Weather-Related Road Traffic Crashes in Slovenia. Appl. Sci. 2021, 11, 6506. [Google Scholar] [CrossRef]
- Abdella, G.M.; Shaaban, K. Modeling the impact of weather conditions on pedestrian injury counts using LASSO-based poisson model. Arab. J. Sci. Eng. 2021, 46, 4719–4730. [Google Scholar] [CrossRef]
- Bajwa, S.; Warita, M.; Kuwahara, M. Effects of road geometry, weather and traffic flow on road safety. In Proceedings of the 15th International Conference of Hong Kong Society for Transportation Study, Hong Kong, China, 11–14 December 2010; pp. 773–780. [Google Scholar]
- Orfila, O.; Coiret, A.; Do, M.; Mammar, S. Modeling of dynamic vehicle–road interactions for safety-related road evaluation. Accid. Anal. Prev. 2010, 42, 1736–1743. [Google Scholar] [CrossRef]
- Alian, S.; Baker, R.; Wood, S. Rural casualty crashes on the Kings Highway: A new approach for road safety studies. Accid. Anal. Prev. 2016, 95, 8–19. [Google Scholar] [CrossRef]
- Ewan, L.; Al-Kaisy, A.; Hossain, F. Safety Effects of Road Geometry and Roadside Features on Low-Volume Roads in Oregon. Transp. Res. Rec. 2016, 2580, 47–55. [Google Scholar] [CrossRef] [Green Version]
- Gooch, J.P.; Gayah, V.V.; Donnell, E.T. Quantifying the safety effects of horizontal curves on two-way, two-lane rural roads. Accid. Anal. Prev. 2016, 92, 71–81. [Google Scholar] [CrossRef] [PubMed]
- Roslak, J.; Wallaschek, J. Active lighting systems for improved road safety. In Proceedings of the IEEE Intelligent Vehicles Symposium, Parma, Italy, 14–17 June 2004; pp. 682–685. [Google Scholar]
- Magar, S.G. Adaptive Front Light Systems of Vehicle for Road Safety. In Proceedings of the 2015 International Conference on Computing Communication Control and Automation, Pune, India, 6–27 February 2015; pp. 551–554. [Google Scholar]
- Aldulaimi, M.; AmadorJimenez, L. 759 Road lighting and safety: A pilot study of Arthabaska region. Inj. Prev. 2016, 22, A272. [Google Scholar] [CrossRef] [Green Version]
- Tetervenoks, O.; Avotins, A.; Fedorjana, N.; Kluga, A.; Krasts, V. Potential Role of Street Lighting System for Safety Enhancement on the Roads in Future. In Proceedings of the 2019 IEEE 60th International Scientific Conference on Power and Electrical Engineering of Riga Technical University (RTUCON), Riga, Latvia, 7–9 October 2019; pp. 1–5. [Google Scholar]
- Liu, J.; Li, J.; Wang, K.; Zhao, J.; Cong, H.; He, P. Exploring factors affecting the severity of night-time vehicle accidents under low illumination conditions. Adv. Mech. Eng. 2019, 11, 1687814019840940. [Google Scholar] [CrossRef]
- Saljoqi, M.; Behnood, H.R.; Mirbaha, B. Developing the crash modification model for urban street lighting. Innov. Infrastruct. Solut. 2021, 6, 59. [Google Scholar] [CrossRef]
- Siliquini, R.; Piat, S.C.; Alonso, F.; Druart, A.; Kedzia, M.; Mollica, A.; Siliquini, V.; Vankov, D.; Villerusa, A.; Manzoli, L.; et al. A European study on alcohol and drug use among young drivers: The TEND by Night study design and methodology. BMC Public Health 2010, 10, 205. [Google Scholar] [CrossRef] [Green Version]
- Alonso, F.; Esteban, C.; Useche, S.A.; Faus, M. Smoking while driving: Frequency, motives, perceived risk and punishment. World J. Prev. Med. 2017, 5, 1–9. [Google Scholar]
- Zou, X.; Yue, W.L.; Vu, H.L. Visualization and analysis of mapping knowledge domain of road safety studies. Accid. Anal. Prev. 2018, 118, 131–145. [Google Scholar] [CrossRef]
- Elvik, R.; Vadeby, A.; Hels, T.; van Schagen, I. Updated estimates of the relationship between speed and road safety at the aggregate and individual levels. Accid. Anal. Prev. 2019, 123, 114–122. [Google Scholar] [CrossRef]
- Gichaga, F.J. The impact of road improvements on road safety and related characteristics. IATSS Res. 2017, 40, 72–75. [Google Scholar] [CrossRef] [Green Version]
- Sager, L. Estimating the effect of air pollution on road safety using atmospheric temperature inversions. J. Environ. Econ. Manag. 2019, 98, 102250. [Google Scholar] [CrossRef]
- Mahmud, S.M.S.; Ferreira, L.; Tavassoli, A. Traditional approaches to Traffic Safety Evaluation (TSE): Application challenges and future directions. In Proceedings of the 11th Asia Pacific Transportation Development Conference and 29th ICTPA Annual Conference, Hsinchu, Taiwan, 27–29 May 2016; pp. 242–262. [Google Scholar]
- Zheng, L.; Ismail, K.; Sayed, T.; Fatema, T. Bivariate extreme value modeling for road safety estimation. Accid. Anal. Prev. 2018, 120, 83–91. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Xu, C.; Dai, Y. A crash prediction method based on bivariate extreme value theory and video-based vehicle trajectory data. Accid. Anal. Prev. 2019, 123, 365–373. [Google Scholar] [CrossRef] [PubMed]
- Zheng, L.; Sayed, T.; Mannering, F. Modeling traffic conflicts for use in road safety analysis: A review of analytic methods and future directions. Anal. Methods Accid. Res. 2020, 29, 100142. [Google Scholar] [CrossRef]
- Jamal, A.; Rahman, M.T.; Al-Ahmadi, H.M.; Mansoor, U. The Dilemma of Road Safety in the Eastern Province of Saudi Arabia: Consequences and Prevention Strategies. Int. J. Environ. Res. Public Health 2019, 17, 157. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mussone, L.; Ferrari, A.; Oneta, M. An analysis of urban collisions using an artificial intelligence model. Accid. Anal. Prev. 1999, 31, 705–718. [Google Scholar] [CrossRef]
- Halim, Z.; Kalsoom, R.; Bashir, S.; Abbas, G. Artificial intelligence techniques for driving safety and vehicle crash prediction. Artif. Intell. Rev. 2016, 46, 351–387. [Google Scholar] [CrossRef]
- Castro, Y.; Kim, Y.J. Data mining on road safety: Factor assessment on vehicle accidents using classification models. Int. J. Crashworthiness 2015, 21, 104–111. [Google Scholar] [CrossRef]
- De Luca, M. A comparison between prediction power of artificial neural networks and multivariate analysis in road safety management. Transport 2017, 32, 379–385. [Google Scholar] [CrossRef] [Green Version]
- Shah, S.A.R.; Brijs, T.; Ahmad, N.; Pirdavani, A.; Shen, Y.; Basheer, M.A. Road safety risk evaluation using gis-based data envelopment analysis—Artificial neural networks approach. Appl. Sci. 2017, 7, 886. [Google Scholar] [CrossRef] [Green Version]
- Liu, M.; Wu, Z.; Chen, Y.; Zhang, X. Utilizing Decision Tree Method and ANFIS to Explore Real-Time Crash Risk for Urban Freeways. In Proceedings of the CICTP 2020, Xi’an, China, 14–16 August 2020; pp. 2495–2508. [Google Scholar]
- Guido, G.; Haghshenas, S.; Haghshenas, S.; Vitale, A.; Gallelli, V.; Astarita, V. Development of a Binary Classification Model to Assess Safety in Transportation Systems Using GMDH-Type Neural Network Algorithm. Sustainability 2020, 12, 6735. [Google Scholar] [CrossRef]
- Mokhtarimousavi, S.; Anderson, J.C.; Hadi, M.; Azizinamini, A. A temporal investigation of crash severity factors in worker-involved work zone crashes: Random parameters and machine learning approaches. Transp. Res. Interdiscip. Perspect. 2021, 10, 100378. [Google Scholar] [CrossRef]
- Kitali, A.E.; Mokhtarimousavi, S.; Kadeha, C.; Alluri, P. Severity analysis of crashes on express lane facilities using support vector machine model trained by firefly algorithm. Traffic Inj. Prev. 2020, 22, 79–84. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Ye, Z.; Wang, Y.; Wang, C.; Sun, C. Evaluating the influence of road lighting on traffic safety at accesses using an artificial neural network. Traffic Inj. Prev. 2018, 19, 601–606. [Google Scholar] [CrossRef] [PubMed]
- Amiri, A.M.; Sadri, A.; Nadimi, N.; Shams, M. A comparison between Artificial Neural Network and Hybrid Intelligent Genetic Algorithm in predicting the severity of fixed object crashes among elderly drivers. Accid. Anal. Prev. 2020, 138, 105468. [Google Scholar] [CrossRef]
- Guido, G.; Haghshenas, S.; Haghshenas, S.; Vitale, A.; Astarita, V.; Haghshenas, A. Feasibility of Stochastic Models for Evaluation of Potential Factors for Safety: A Case Study in Southern Italy. Sustainability 2020, 12, 7541. [Google Scholar] [CrossRef]
- Shiran, G.; Imaninasab, R.; Khayamim, R. Crash Severity Analysis of Highways Based on Multinomial Logistic Regression Model, Decision Tree Techniques, and Artificial Neural Network: A Modeling Comparison. Sustainability 2021, 13, 5670. [Google Scholar] [CrossRef]
- Mussone, L.; Bassani, M.; Masci, P. Analysis of factors affecting the severity of crashes in urban road intersections. Accid. Anal. Prev. 2017, 103, 112–122. [Google Scholar] [CrossRef]
- Ministero delle Infrastrutture e dei Trasporti. Nuovo Codice della Strada, Decreto Legislativo N. 285 del 30/4/1992, G.U. n. 114 del 18/5/1992. Gazzetta Ufficiale, 1992. [Google Scholar]
- Ministero delle Infrastrutture e dei Trasporti. Disposizioni urgenti per la sicurezza della circolazione dei veicoli e di specifiche categorie di utenti, Modifiche al Nuovo Codice della Strada, Decreto Legislativo n.121 del 10/9/2021, G.U. n. 267 del 9/9/2021. Gazzetta Ufficiale, 2021. [Google Scholar]
- Pan, G.; Fu, L.; Thakali, L. Development of a global road safety performance function using deep neural networks. Int. J. Transp. Sci. Technol. 2017, 6, 159–173. [Google Scholar] [CrossRef]
- Peng, Z.; Gao, S.; Li, Z.; Xiao, B.; Qian, Y. Vehicle Safety Improvement through Deep Learning and Mobile Sensing. IEEE Netw. 2018, 32, 28–33. [Google Scholar] [CrossRef]
- Silva, P.B.; Andrade, M.; Ferreira, S. Machine learning applied to road safety modeling: A systematic literature review. J. Traffic Transp. Eng. 2020, 7, 775–790. [Google Scholar] [CrossRef]
- Hernández, H.; Alberdi, E.; Pérez-Acebo, H.; Álvarez, I.; García, M.; Eguia, I.; Fernández, K. Managing Traffic Data through Clustering and Radial Basis Functions. Sustainability 2021, 13, 2846. [Google Scholar] [CrossRef]
- Amiri, A.M.; Naderi, K.; Cooper, J.F.; Nadimi, N. Evaluating the impact of socio-economic contributing factors of cities in California on their traffic safety condition. J. Transp. Health 2021, 20, 101010. [Google Scholar] [CrossRef]
- Jamal, A.; Zahid, M.; Tauhidur Rahman, M.; Al-Ahmadi, H.M.; Almoshaogeh, M.; Farooq, D.; Ahmad, M. Injury severity prediction of traffic crashes with ensemble machine learning techniques: A comparative study. Int. J. Inj. Contr. Saf. Promot. 2021, 28, 408–427. [Google Scholar] [CrossRef] [PubMed]
- Hosseinzadeh, A.; Moeinaddini, A.; Ghasemzadeh, A. Investigating factors affecting severity of large truck-involved crashes: Comparison of the SVM and random parameter logit model. J. Saf. Res. 2021, 77, 151–160. [Google Scholar] [CrossRef] [PubMed]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Flood susceptibility mapping using a novel ensemble weights-of-evidence and support vector machine models in GIS. J. Hydrol. 2014, 512, 332–343. [Google Scholar] [CrossRef]
- Jahed Armaghani, D.; Asteris, P.G.; Askarian, B.; Hasanipanah, M.; Tarinejad, R.; Huynh, V.V. Examining hybrid and single SVM models with different kernels to predict rock brittleness. Sustainability 2020, 12, 2229. [Google Scholar] [CrossRef] [Green Version]
- Mikaeil, R.; Haghshenas, S.S.; Ozcelik, Y.; Gharehgheshlagh, H.H. Performance evaluation of adaptive neuro-fuzzy inference system and group method of data handling-type neural network for estimating wear rate of diamond wire saw. Geotech. Geol. Eng. 2018, 36, 3779–3791. [Google Scholar] [CrossRef]
- Dormishi, A.R.; Ataei, M.; Khaloo Kakaie, R.; Mikaeil, R.; Shaffiee Haghshenas, S. Performance evaluation of gang saw using hybrid ANFIS-DE and hybrid ANFIS-PSO algorithms. JME 2019, 10, 543–557. [Google Scholar]
- Naderpour, H.; Mirrashid, M. Moment capacity estimation of spirally reinforced concrete columns using ANFIS. Complex Intell. Syst. 2019, 6, 97–107. [Google Scholar] [CrossRef] [Green Version]
- Shirani Faradonbeh, R.; Shaffiee Haghshenas, S.; Taheri, A.; Mikaeil, R. Application of self-organizing map and fuzzy c-mean techniques for rockburst clustering in deep underground projects. Neural Comput. Appl. 2019, 32, 8545–8559. [Google Scholar] [CrossRef]
- Noori, A.M.; Mikaeil, R.; Mokhtarian, M.; Haghshenas, S.S.; Foroughi, M. Feasibility of Intelligent Models for Prediction of Utilization Factor of TBM. Geotech. Geol. Eng. 2020, 38, 3125–3143. [Google Scholar] [CrossRef]
- Golafshani, E.M.; Behnood, A. Predicting the mechanical properties of sustainable concrete containing waste foundry sand using multi-objective ANN approach. Constr. Build. Mater. 2021, 291, 123314. [Google Scholar] [CrossRef]
- Ivakhnenko, A.G. Polynomial Theory of Complex Systems. IEEE Trans. Syst. Man Cybern. 1971, SMC-1, 364–378. [Google Scholar] [CrossRef] [Green Version]
- Sezavar, R.; Shafabakhsh, G.; Mirabdolazimi, S.M. New model of moisture susceptibility of nano silica-modified asphalt concrete using GMDH algorithm. Constr. Build Mater. 2019, 211, 528–538. [Google Scholar] [CrossRef]
- Dag, O.; Kasikci, M.; Karabulut, E.; Alpar, R. Diverse classifiers ensemble based on GMDH-type neural network algorithm for binary classification. Commun. Stat. Simul. Comput. 2019, 1–17. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Hasanipanah, M.; Amnieh, H.B.; Bui, D.T.; Mehrabi, P.; Khorami, M. Development of a novel hybrid intelligent model for solving engineering problems using GS-GMDH algorithm. Eng. Comput. 2019, 36, 1379–1391. [Google Scholar] [CrossRef]
- Harandizadeh, H.; Armaghani, D.J.; Mohamad, E.T. Development of fuzzy-GMDH model optimized by GSA to predict rock tensile strength based on experimental datasets. Neural Comput. Appl. 2020, 32, 14047–14067. [Google Scholar] [CrossRef]
- Jeddi, S.; Sharifian, S. A hybrid wavelet decomposer and GMDH-ELM ensemble model for Network function virtualization workload forecasting in cloud computing. Appl. Soft Comput. 2019, 88, 105940. [Google Scholar] [CrossRef]
- Morosini, A.F.; Haghshenas, S.S.; Geem, Z.W. Development of a Binary Model for Evaluating Water Distribution Systems by a Pressure Driven Analysis (PDA) Approach. Appl. Sci. 2020, 10, 3029. [Google Scholar] [CrossRef]
- Khandezamin, Z.; Naderan, M.; Rashti, M.J. Detection and classification of breast cancer using logistic regression feature selection and GMDH classifier. J. Biomed. Inform. 2020, 111, 103591. [Google Scholar] [CrossRef]
- Fiorini Morosini, A.; Shaffiee Haghshenas, S.; Shaffiee Haghshenas, S.; Choi, D.Y.; Geem, Z.W. Sensitivity Analysis for Performance Evaluation of a Real Water Distribution System by a Pressure Driven Analysis Approach and Artificial Intelligence Method. Water 2021, 13, 1116. [Google Scholar] [CrossRef]
- Pusat, S.; Akkaya, A.V. Explicit equation derivation for predicting coal moisture content in convective drying process by GMDH-type neural network. Int. J. Coal Prep. 2020, 1–14. [Google Scholar] [CrossRef]
- Vissol-Gaudin, E.; Kotsialos, A.; Groves, C.; Pearson, C.; Zeze, D.A.; Petty, M.C. Computing based on material training: Application to binary classification problems. In Proceedings of the 2017 IEEE International Conference on Rebooting Computing (ICRC), Washington, DC, USA, 8–9 November 2017; pp. 1–8. [Google Scholar]
- Li, D.; Armaghani, D.J.; Zhou, J.; Lai, S.H.; Hasanipanah, M. A GMDH predictive model to predict rock material strength using three non-destructive tests. J. Nondestruct. Eval. 2020, 39, 81. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1985, 20, 273–297. [Google Scholar] [CrossRef]
- Chen, W.H.; Hsu, S.H.; Shen, H.P. Application of SVM and ANN for intrusion detection. Comput. Oper. Res. 2005, 32, 2617–2634. [Google Scholar] [CrossRef]
- Yan, X.; Jia, M. A novel optimized SVM classification algorithm with multi-domain feature and its application to fault diagnosis of rolling bearing. Neural. Comput. Appl. 2018, 313, 47–64. [Google Scholar] [CrossRef]
- Zhou, S.; Chu, X.; Cao, S.; Liu, X.; Zhou, Y. Prediction of the ground temperature with ANN, LS-SVM and fuzzy LS-SVM for GSHP application. Geothermics 2019, 84, 101757. [Google Scholar] [CrossRef]
- Maldonado, S.; López, J.; Jimenez-Molina, A.; Lira, H. Simultaneous feature selection and heterogeneity control for SVM classification: An application to mental workload assessment. Expert Syst. Appl. 2020, 143, 112988. [Google Scholar] [CrossRef]
- Zeng, J.; Roussis, P.C.; Mohammed, A.S.; Maraveas, C.; Fatemi, S.A.; Armaghani, D.J.; Asteris, P.G. Prediction of Peak Particle Velocity Caused by Blasting through the Combinations of Boosted-CHAID and SVM Models with Various Kernels. Appl. Sci. 2021, 11, 3705. [Google Scholar] [CrossRef]
- Zhou, J.; Qiu, Y.; Zhu, S.; Armaghani, D.J.; Li, C.; Nguyen, H.; Yagiz, S. Optimization of support vector machine through the use of metaheuristic algorithms in forecasting TBM advance rate. Eng. Appl. Artif. Intell. 2021, 97, 104015. [Google Scholar] [CrossRef]
- Mikaeil, R.; Haghshenas, S.S.; Hoseinie, S.H. Rock penetrability classification using artificial bee colony (ABC) algorithm and self-organizing map. Geotech. Geol. Eng. 2018, 36, 1309–1318. [Google Scholar] [CrossRef]
- Salemi, A.; Mikaeil, R.; Haghshenas, S.S. Integration of finite difference method and genetic algorithm to seismic analysis of circular shallow tunnels (Case study: Tabriz urban railway tunnels). KSCE J. Civ. Eng. 2018, 22, 1978–1990. [Google Scholar] [CrossRef]
- Aryafar, A.; Mikaeil, R.; Haghshenas, S.S.; Haghshenas, S.S. Application of metaheuristic algorithms to optimal clustering of sawing machine vibration. MEAS 2018, 124, 20–31. [Google Scholar] [CrossRef]
- Mikaeil, R.; Haghshenas, S.S.; Sedaghati, Z. Geotechnical risk evaluation of tunneling projects using optimization techniques (case study: The second part of Emamzade Hashem tunnel). Nat. Hazards 2019, 97, 1099–1113. [Google Scholar] [CrossRef]
- Mikaeil, R.; Bakhshinezhad, H.; Haghshenas, S.S.; Ataei, M. Stability analysis of tunnel support systems using numerical and intelligent simulations (case study: Kouhin Tunnel of Qazvin-Rasht Railway). Rud. Geol. Naft. Zb. 2019, 34, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Haghshenas, S.S.; Faradonbeh, R.S.; Mikaeil, R.; Haghshenas, S.S.; Taheri, A.; Saghatforoush, A.; Dormishi, A. A new conventional criterion for the performance evaluation of gang saw machines. MEAS 2019, 46, 159–170. [Google Scholar] [CrossRef]
- Saremi, S.; Mirjalili, S.; Lewis, A. Grasshopper optimisation algorithm: Theory and application. Adv. Eng. Softw. 2017, 105, 30–47. [Google Scholar] [CrossRef] [Green Version]
- Mafarja, M.; Aljarah, I.; Faris, H.; Hammouri, A.I.; Ala’M, A.Z.; Mirjalili, S. Binary grasshopper optimisation algorithm approaches for feature selection problems. Expert Syst. Appl. 2019, 117, 267–286. [Google Scholar] [CrossRef]
- Saxena, A. A comprehensive study of chaos embedded bridging mechanisms and crossover operators for grasshopper optimisation algorithm. Expert Syst. Appl. 2019, 132, 166–188. [Google Scholar] [CrossRef]
- Pan, J.S.; Wang, X.; Chu, S.C.; Nguyen, T.T. A multi-group grasshopper optimisation algorithm for application in capacitated vehicle routing problem. Pattern Recognit. 2020, 4, 41–56. [Google Scholar]
- Goodarzizad, P.; Mohammadi Golafshani, E.; Arashpour, M. Predicting the construction labour productivity using artificial neural network and grasshopper optimisation algorithm. Int. J. Constr. Manag. 2021, 1–17. [Google Scholar] [CrossRef]
- Meraihi, Y.; Gabis, A.B.; Mirjalili, S.; Ramdane-Cherif, A. Grasshopper optimization algorithm: Theory, variants, and applications. IEEE Access 2021, 9, 50001–50024. [Google Scholar] [CrossRef]
- Nelson, M.M.; Illingworth, W.T. A Practical Guide to Neural Nets, Addison-Wesley; Addison-Wesley Longman Publishing Co., Inc.: Reading, MA, USA, 1991. [Google Scholar]
- Swingler, K. Applying Neural Networks: A Practical Guide; Morgan Kaufmann: London, UK, 1996. [Google Scholar]
- Looney, C.G. Advances in feedforward neural networks: Demystifying knowledge acquiring black boxes. IEEE Trans. Knowl. Data Eng. 1996, 8, 211–226. [Google Scholar] [CrossRef]
- Zorlu, K.; Gokceoglu, C.; Ocakoglu, F.; Nefeslioglu, H.A.; Acikalin, S.J.E.G. Prediction of uniaxial compressive strength of sandstones using petrography-based models. Eng. Geol. 2008, 96, 141–158. [Google Scholar] [CrossRef]
- Ataei, M.; Mohammadi, S.; Mikaeil, R. Evaluating performance of cutting machines during sawing dimension stones. J. Cent. South Univ. 2019, 26, 1934–1945. [Google Scholar] [CrossRef]
- Mikaeil, R.; Mokhtarian, M.; Haghshenas, S.S.; Careddu, N.; Alipour, A. Assessing the System Vibration of Circular Sawing Machine in Carbonate Rock Sawing Process Using Experimental Study and Machine Learning. Geotech. Geol. Eng. 2021, 40, 103–119. [Google Scholar] [CrossRef]
- Yang, Y.; Zhang, Q. A hierarchical analysis for rock engineering using artificial neural networks. Rock Mech. Rock Eng. 1997, 30, 207–222. [Google Scholar] [CrossRef]
- Quddus, M. Exploring the relationship between average speed, speed variation, and accident rates using spatial statistical models and GIS. J. Transp. Saf. 2013, 5, 27–45. [Google Scholar] [CrossRef]
- Borsati, M.; Cascarano, M.; Bazzana, F. On the impact of average speed enforcement systems in reducing highway accidents: Evidence from the Italian Safety Tutor. Econ. Transp. 2019, 20, 100123. [Google Scholar] [CrossRef]
- Dong, C.; Dong, Q.; Huang, B.; Hu, W.; Nambisan, S.S. Estimating Factors Contributing to Frequency and Severity of Large Truck–Involved Crashes. J. Transp. Eng. Part A Syst. 2017, 143, 4017032. [Google Scholar] [CrossRef]
- Chang, G.L.; Xiang, H. The Relationship between Congestion Levels and Accidents (No. MD-03-SP 208B46); The National Academies of Sciences, Engineering, and Medicine: Washington, DC, USA, 2003. [Google Scholar]
- Lee, Y.M.; Chong, S.Y.; Goonting, K.; Sheppard, E. The effect of speed limit credibility on drivers’ speed choice. Transp. Res. F Traffic Psychol. Behav. 2017, 45, 43–53. [Google Scholar] [CrossRef]
- Vadeby, A.; Forsman, Å. Traffic safety effects of new speed limits in Sweden. Accid. Anal. Prev. 2018, 114, 34–39. [Google Scholar] [CrossRef] [PubMed]
- Yu, R.; Abdel-Aty, M. Investigating the different characteristics of weekday and weekend crashes. J. Saf. Res. 2013, 46, 91–97. [Google Scholar] [CrossRef]
- Mokhtarimousavi, S.; Anderson, J.; Azizinamini, A.; Hadi, M. Factors affecting injury severity in vehicle-pedestrian crashes: A day-of-week analysis using random parameter ordered response models and Artificial Neural Networks. Int. J. Transp. Sci. Technol. 2020, 9, 100–115. [Google Scholar] [CrossRef]
- Asgarzadeh, M.; Fischer, D.; Verma, S.K.; Courtney, T.K.; Christiani, D.C. The impact of weather, road surface, time-of-day, and light conditions on severity of bicycle-motor vehicle crash injuries. Am. J. Ind. Med. 2018, 61, 556–565. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Researcher(s) | Type of Techniques | Description |
|---|---|---|
| Mussone et al. [41] | ANN | Modeling of urban vehicular accidents using ANN with an assessment of the main circumstances and causes of accidents. |
| Halim et al. [42] | Review of AI techniques such as: GA, GP, CRF, ANN, PCA, Fuzzy Logic, TD Learning, SVM | Assessment of studies based on AI approaches for accident prediction and identifying dangerous driving situations. |
| Castro et al. [43] | Bayesian Network, Decision Trees, and ANN | Evaluation of the impact of various factors on injury risk in order to improve the road safety level. |
| De Luca [44] | MVA, ANN | A comparison of road safety management prediction models on two-lane highways. |
| Shah et al. [45] | DEA-ANN | Identification and evaluation of the most important criteria in determining the level of road risk. |
| Liu et al. [46] | ANFIS, Logistic Regression, Decision Tree, and SVM | Examining real-time crash risk for urban freeways as a means of assessing road safety and traffic control decisions. |
| Guido et al. [47] | GMDH | Assessment of the effective parameters affecting accidents for the urban and rural areas. |
| Mokhtarimousavi et al. [48] | SVM, CS-SVM, and Logit Model | Temporal examination of accident severity determinants in worker-involved work zone crashes based on random parameters and machine learning methodologies. |
| Kitali et al. [49] | SVM-FA | Examination of the elements that influence the severity of injuries in crashes on express lanes facilities. |
| Xu et al. [50] | ANN | Study on the impact of road lighting on traffic safety. |
| Amiri et al. [51] | ANN, GA-ANN | Forecasting the severity of fixed object accidents among elderly drivers using two types of AI techniques. |
| Guido et al. [52] | GA, PSO | The use of clustering models to evaluate potential safety factors. |
| Shiran et al. [53] | ANN-MLP, CHAID, C5.0, and MLR | A comparison of collision severity analysis models for highways. |
| Data Field Type | Variable | Code/Unit | Description |
|---|---|---|---|
| Traffic flow characteristics | AADT (veh/day) | 1 2 3 4 | <5000 5000–9999 10,000–14,999 >14,999 |
| Avg Speed (km/h) | Not coded | Min 28 Max 122 Avg 91.43 | |
| Road environment | Location | 0 1 | Non intersection Intersection |
| Speed Limit (km/h) | 1 2 3 4 5 | 50 70 90 110 130 | |
| Environment characteristics | DayLight | 0 1 | Daylight Nighttime |
| Weekday | 0 1 | Weekend or Holiday Weekday | |
| Accident characteristic | Accident Type | 1 2 3 4 | Collision with vehicle Collision with pedestrian Collision with obstacle Other |
| No | Type of Kernel Function | Equations |
|---|---|---|
| 1 | Linear (LIN) | |
| 2 | Radial basis function (RBF) | |
| 3 | Polynomial (POL) |
| Models No. | SP | MNL | MNNL | Training Accuracy (%) | Testing Accuracy (%) |
|---|---|---|---|---|---|
| 1 | 0.5 | 5 | 5 | 78.5 | 78 |
| 2 | 0.5 | 5 | 10 | 79.9 | 73.8 |
| 3 | 0.5 | 5 | 20 | 79.7 | 74.5 |
| 4 | 0.5 | 5 | 40 | 80.1 | 73.8 |
| 5 | 0.5 | 5 | 50 | 80.9 | 77.3 |
| 6 | 0.5 | 10 | 5 | 78.3 | 75.2 |
| 7 | 0.5 | 10 | 10 | 77.8 | 76.6 |
| 8 | 0.5 | 10 | 20 | 77.8 | 76.6 |
| 9 | 0.5 | 10 | 40 | 79.2 | 75.9 |
| 10 | 0.5 | 10 | 50 | 82.7 | 80.1 |
| 11 | 0.5 | 20 | 5 | 78 | 75.9 |
| 12 | 0.5 | 20 | 10 | 80.9 | 73.8 |
| 13 | 0.5 | 20 | 20 | 79.9 | 77.3 |
| 14 | 0.5 | 20 | 40 | 82 | 80.9 |
| 15 | 0.5 | 20 | 50 | 83.2 | 81.6 |
| 16 | 0.5 | 40 | 5 | 79.9 | 77.3 |
| 17 | 0.5 | 40 | 10 | 80.1 | 78.7 |
| 18 | 0.5 | 40 | 20 | 82.7 | 78.7 |
| 19 | 0.5 | 40 | 40 | 81.3 | 79.4 |
| 20 | 0.5 | 40 | 50 | 80.1 | 76.6 |
| 21 | 0.5 | 50 | 5 | 77.8 | 76.6 |
| 22 | 0.5 | 50 | 10 | 80.9 | 74.5 |
| 23 | 0.5 | 50 | 20 | 77.8 | 76.6 |
| 24 | 0.5 | 50 | 40 | 78.3 | 75.2 |
| 25 | 0.5 | 50 | 50 | 82 | 77.3 |
| Models No. | SP | MNL | MNNL | Rating for Training Accuracy | Rating for Testing Accuracy | Total Rank |
|---|---|---|---|---|---|---|
| 1 | 0.5 | 5 | 5 | 16 | 20 | 36 |
| 2 | 0.5 | 5 | 10 | 19 | 14 | 33 |
| 3 | 0.5 | 5 | 20 | 18 | 15 | 33 |
| 4 | 0.5 | 5 | 40 | 20 | 14 | 34 |
| 5 | 0.5 | 5 | 50 | 21 | 19 | 40 |
| 6 | 0.5 | 10 | 5 | 15 | 16 | 31 |
| 7 | 0.5 | 10 | 10 | 13 | 18 | 31 |
| 8 | 0.5 | 10 | 20 | 13 | 18 | 31 |
| 9 | 0.5 | 10 | 40 | 17 | 17 | 34 |
| 10 | 0.5 | 10 | 50 | 24 | 23 | 47 |
| 11 | 0.5 | 20 | 5 | 14 | 17 | 31 |
| 12 | 0.5 | 20 | 10 | 21 | 14 | 35 |
| 13 | 0.5 | 20 | 20 | 19 | 19 | 38 |
| 14 | 0.5 | 20 | 40 | 23 | 24 | 47 |
| 15 | 0.5 | 20 | 50 | 25 | 25 | 50 |
| 16 | 0.5 | 35 | 5 | 19 | 19 | 38 |
| 17 | 0.5 | 35 | 10 | 20 | 21 | 41 |
| 18 | 0.5 | 35 | 20 | 24 | 21 | 45 |
| 19 | 0.5 | 35 | 40 | 22 | 22 | 44 |
| 20 | 0.5 | 35 | 50 | 20 | 18 | 38 |
| 21 | 0.5 | 50 | 5 | 13 | 18 | 31 |
| 22 | 0.5 | 50 | 10 | 21 | 15 | 36 |
| 23 | 0.5 | 50 | 20 | 13 | 18 | 31 |
| 24 | 0.5 | 50 | 40 | 15 | 16 | 31 |
| 25 | 0.5 | 50 | 50 | 23 | 19 | 42 |
| No | Control Parameters | Values |
|---|---|---|
| 1 | Grasshoppers’ populations | 40 |
| 2 | Number of iterations | 40 |
| 3 | k-fold | 3 |
| 4 | C | 897.25 |
| 5 | Gamma () of RBF kernel | 6.17 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guido, G.; Shaffiee Haghshenas, S.; Shaffiee Haghshenas, S.; Vitale, A.; Astarita, V.; Park, Y.; Geem, Z.W. Evaluation of Contributing Factors Affecting Number of Vehicles Involved in Crashes Using Machine Learning Techniques in Rural Roads of Cosenza, Italy. Safety 2022, 8, 28. https://doi.org/10.3390/safety8020028
Guido G, Shaffiee Haghshenas S, Shaffiee Haghshenas S, Vitale A, Astarita V, Park Y, Geem ZW. Evaluation of Contributing Factors Affecting Number of Vehicles Involved in Crashes Using Machine Learning Techniques in Rural Roads of Cosenza, Italy. Safety. 2022; 8(2):28. https://doi.org/10.3390/safety8020028
Chicago/Turabian StyleGuido, Giuseppe, Sina Shaffiee Haghshenas, Sami Shaffiee Haghshenas, Alessandro Vitale, Vittorio Astarita, Yongjin Park, and Zong Woo Geem. 2022. "Evaluation of Contributing Factors Affecting Number of Vehicles Involved in Crashes Using Machine Learning Techniques in Rural Roads of Cosenza, Italy" Safety 8, no. 2: 28. https://doi.org/10.3390/safety8020028