
A Comprehensive Dataset of Spelling Errors and Users’ Corrections in Croatian Language


Abstract
:1. Introduction
2. Data Description
- A user can have multiple cookies, one for each browser used;
- Users can disable or delete cookies in their browsers, so that a new cookie is set for each request from the same user;
- Multiple users can have the same cookie if some kind of intermediate application is used.
3. Methods
3.1. Data Collection
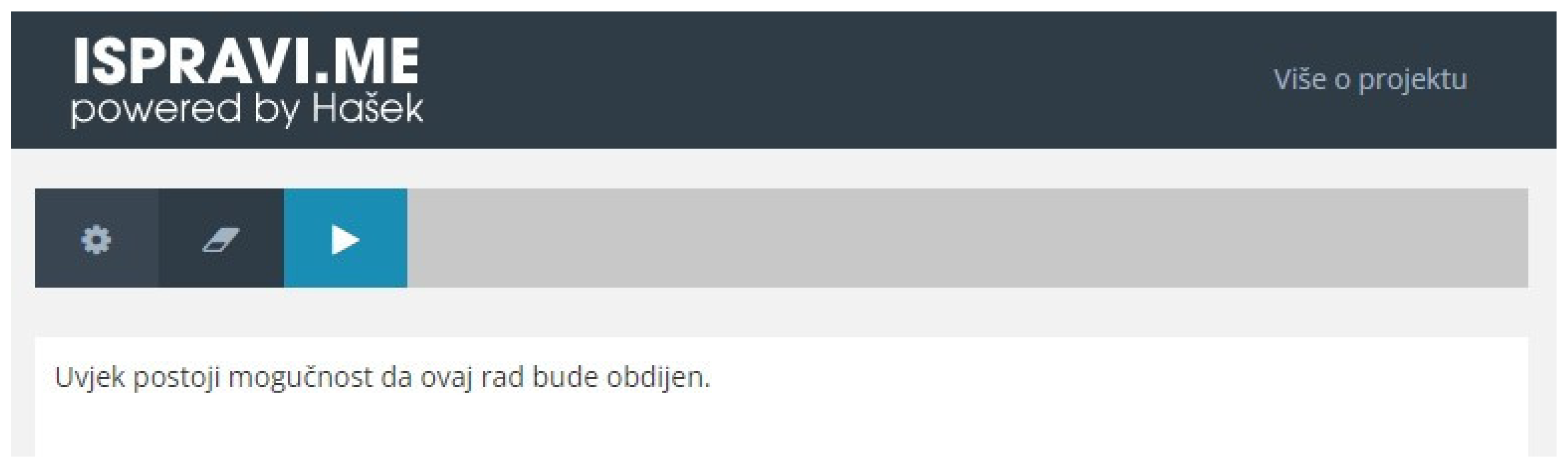
- When a user wants to check the spelling of a text, they write (or pastes) the text into the online form (Figure 1).
- 2.
- 3.
- The result is delivered to the client in JSON format, parsed by client-side JavaScript, and displayed in the browser.
| { “response” : { “errors” : 4, “error” : [ { “position” : [0], “length” : 5, “suspicious” : “Uvjek”, “suggestions” : [“Uvijek”,”Uv’jek”,”Usjek”,”Uvjet”], “class” : “minor”, “occurrences” : 1 }, { “position” : [14], “length” : 9, “suspicious” : “mogučnost”, “suggestions” : [“mogućnost”], “class” : “major”, “occurrences” : 1, }, { “position” : [41], “length” : 7, “suspicious” : “obdijen”, “suggestions” : [“odbijen”,”obijen”,“obvijen”], “class” : “moderate”, “occurrences” : 1, }, ] } } |
- 4.
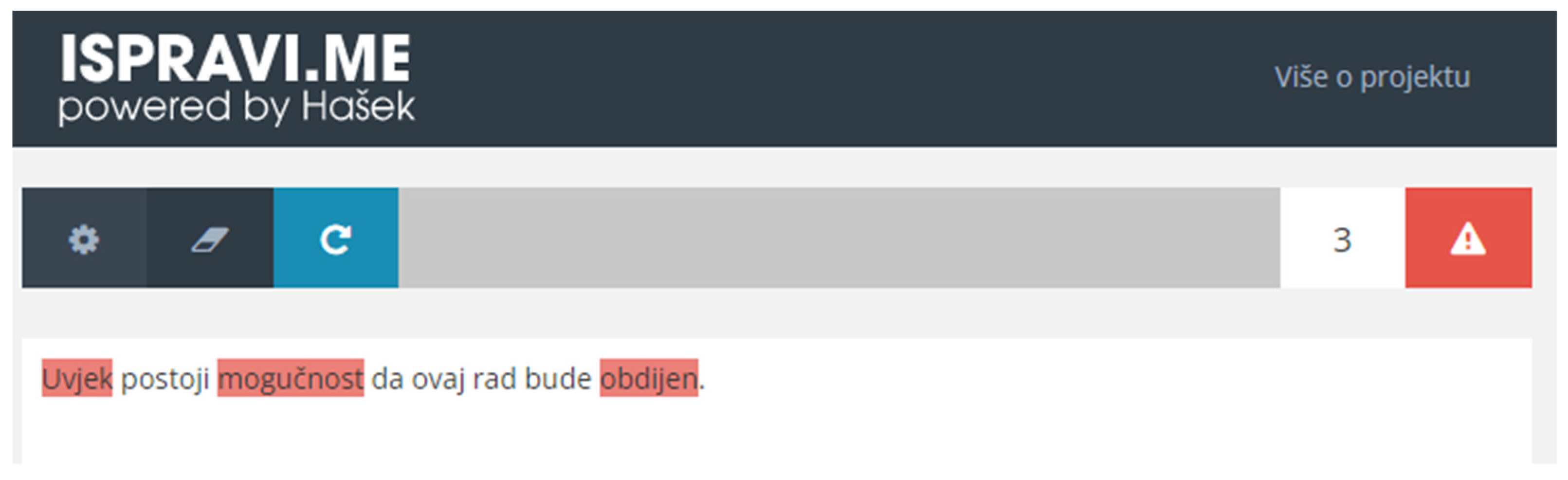
- Upon receiving the formatted JSON response, the client interface displays the entered text to the user, with suspicious words and phrases clearly marked on the screen (Figure 2).
- 5.
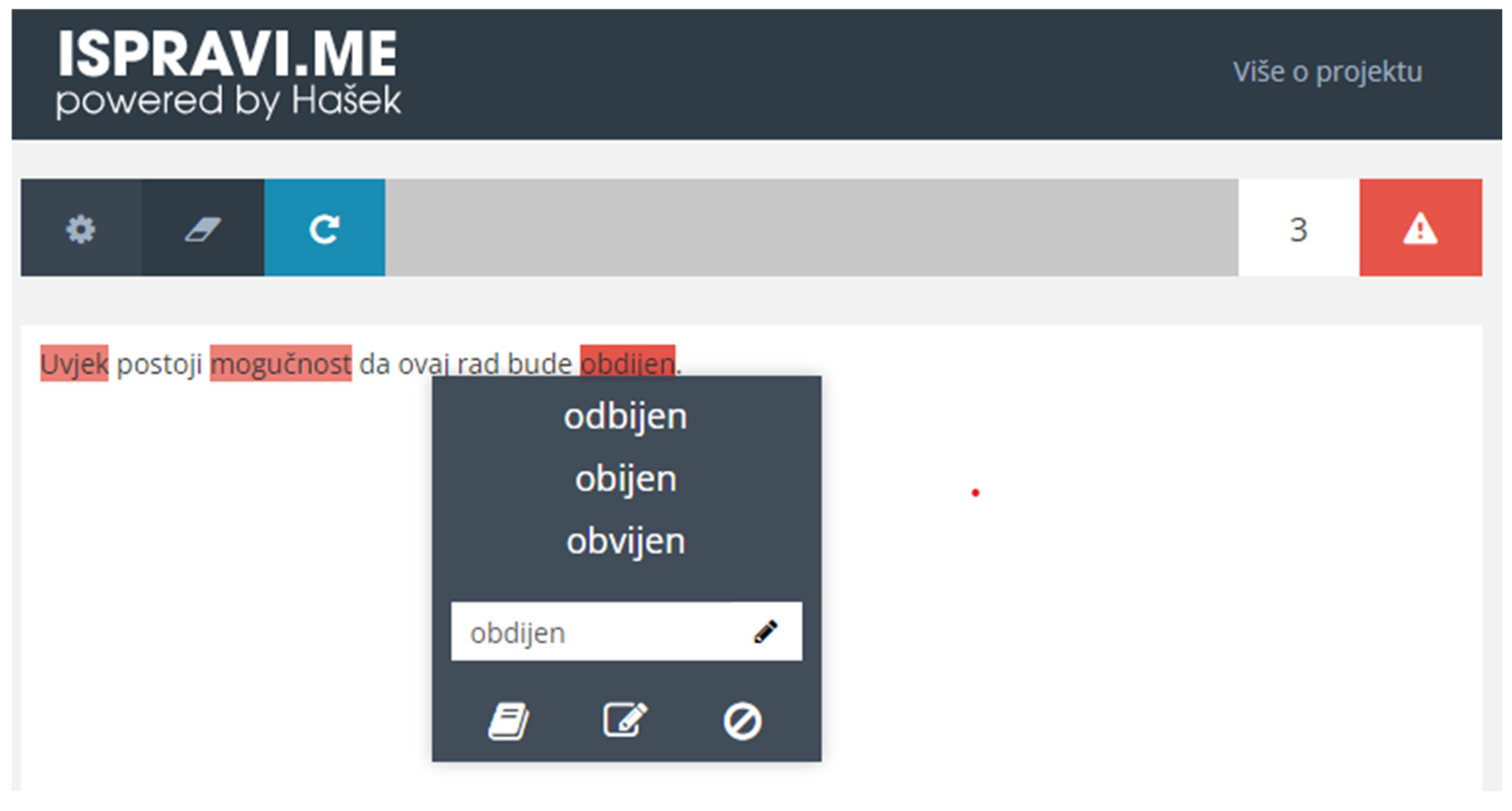
- By clicking on the highlighted word, a popup appears with suggested corrections for a possibly misspelled word (Figure 3): “odbijen” (rejected), “obijen” (broken open), “obvijen” (enveloped, enclosed).
- 6.
- The user can then click and select the correct word from the candidates, or enter the correct word into the input field in the pop-up menu if the service has not responded with the correct suggestion.
- 7.
- Once the selection is made, the user’s text is updated with the corrected word and the pair “error word → correct word” is sent to the server via a dedicated CGI script, which logs it and was later used together with the metadata (e.g., environment and query variables) for our research. The date stamp of the request is also logged. The output sent to the server for the example from the previous page has the following format:
| Uvjek -> Uvijek mogučnost -> mogućnost obdijen -> odbijen |
3.2. Creating the Dataset
3.3. Size of the Dataset
3.4. Dataset Distribution
3.5. Noise and Garbage in the Dataset
4. Findings
- To improve the accuracy of spellcheck services by logging the most frequent corrections made by users, thereby reducing the number of false positives and false negatives or enabling auto-corrections of misspellings;
- As a teaching tool for language learners to help them identify common errors and learn the correct spelling of words (e.g., a language learning app can use this database to provide instant feedback on the spelling of words entered by the user or automatically generate realistic spelling errors to test the user’s knowledge);
- For data analysis to identify trends and patterns in user errors (e.g., to identify the most frequently misspelled words or the most common types of spelling errors);
- For evaluating factors that affect input such as the type of error (typo, orthographic, or grammatical error, …) and the position of the error with respect to the length of the word;
- In natural language processing (NLP) applications to improve the accuracy of text recognition and automatic text analysis (e.g., to improve the accuracy of speech recognition software, optical character recognition (OCR) software, or to build an n-gram language model, as in the case of Polish [22,23], Czech [24,25], or Russian [26] as well as Slavic languages that also share similar research issues).
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dembitz, Š.; Gledec, G.; Randić, M. Spellchecker. In Wiley Encyclopedia of Computer Science and Engineering; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2009. [Google Scholar]
- Dembitz, Š.; Randić, M.; Gledec, G. Advantages of Online Spellchecking: A Croatian Example. Softw. Pract. Exp. 2011, 41, 1203–1231. [Google Scholar] [CrossRef]
- Gou, W.; Chen, Z. Think Twice: A Post-Processing Approach for the Chinese Spelling Error Correction. Appl. Sci. 2021, 11, 5832. [Google Scholar] [CrossRef]
- META-NET White Paper Series. Key Results and Cross-Language Comparison. Available online: http://www.meta-net.eu/whitepapers/overview (accessed on 12 April 2023).
- Tadić, M.; Brozović-Rončević, D.; Kapetanović, A. The Croatian Language in the Digital Age; Rehm, G., Uszkoreit, H., Eds.; Springer: Berlin, Heidelberg, 2012; ISBN 978-3-642-30881-9. [Google Scholar]
- Bañón, M.; Chichirau, M.; Esplà-Gomis, M.; Forcada, M.L.; Galiano-Jiménez, A.; García-Romero, C.; Kuzman, T.; Ljubešić, N.; van Noord, R.; Pla Sempere, L. Croatian Web Corpus MaCoCu-hr 2.0. Slovenian Language Resource Repository CLARIN.SI, ISSN 2820-4042. 2023. Available online: http://hdl.handle.net/11356/1806 (accessed on 12 April 2023).
- Šoić, R.; Vuković, M. N-Gram Based Croatian Language Network: Application in a Smart Environment. J. Commun. Softw. Syst. 2022, 18, 63–71. [Google Scholar] [CrossRef]
- Gledec, G.; Šoić, R.; Dembitz, Š. Dynamic N-Gram System Based on an Online Croatian Spellchecking Service. IEEE Access 2019, 7, 149988–149995. [Google Scholar] [CrossRef]
- Srdić, I.; Gledec, G. Contextual Spellchecking Based on N-Grams. In Proceedings of the 28th Central European Conference on Information and Intelligent Systems; Faculty of Organization and Informatics, Varaždin, Croatia, 27–29 September 2017; pp. 29–33. [Google Scholar]
- Babić, K.; Petrović, M.; Beliga, S.; Martinčić-Ipšić, S.; Matešić, M.; Meštrović, A. Characterisation of COVID-19-Related Tweets in the Croatian Language: Framework Based on the Cro-CoV-CseBERT Model. Appl. Sci. 2021, 11, 10442. [Google Scholar] [CrossRef]
- Damerau, F.J. A Technique for Computer Detection and Correction of Spelling Errors. Commun. ACM 1964, 7, 171–176. [Google Scholar] [CrossRef]
- Mitton, R. Fifty Years of Spellchecking. Writ. Syst. Res. 2010, 2, 1–7. [Google Scholar] [CrossRef]
- Hládek, D.; Staš, J.; Pleva, M. Survey of Automatic Spelling Correction. Electronics 2020, 9, 1670. [Google Scholar] [CrossRef]
- Šantić, N.; Šnajder, J.; Dalbelo Bašić, B. Automatic Diacritics Restoration in Croatian Texts. In The Future of Information Sciences, Digital Resources and Knowledge Sharing; Faculty of Humanities and Social Sciences, University of Zagreb: Zagreb, Croatia, 2009; pp. 309–318. [Google Scholar]
- Ispravi.me Croatian Academic Spellchecker. Available online: https://ispravi.me/ (accessed on 12 April 2023).
- Mitton, R. Spellcheckers. In The Routledge Handbook of the English Writing System; Cook, V., Ryan, D., Eds.; Routledge: Abingdon, UK, 2016; pp. 517–530. [Google Scholar]
- Mitton, R. Corpora of Misspellings for Download. Available online: https://www.dcs.bbk.ac.uk/~roger/corpora.html (accessed on 7 April 2023).
- Toleu, A.; Tolegen, G.; Mussabayev, R.; Krassovitskiy, A.; Ualiyeva, I. Data-Driven Approach for Spellchecking and Autocorrection. Symmetry 2022, 14, 2261. [Google Scholar] [CrossRef]
- Leach, P.; Mealling, M.; Salz, R. RFC 4122: A Universally Unique IDentifier (UUID) URN Namespace. Available online: https://www.rfc-editor.org/info/rfc4122 (accessed on 13 April 2023).
- Dembitz, Š.; Gledec, G.; Blašković, B. Architecture of Hascheck—An Intelligent Spellchecker for Croatian Language. In Knowledge-Based and Intelligent Information and Engineering Systems: 14th International Conference, KES 2010, Cardiff, UK, 8–10 September 2010, Proceedings, Part II 14; Setchi, R., Jordanov, I., Howlett, R.J., Jain, L.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6277, ISBN 3642153895. [Google Scholar]
- Dembitz, Š.; Gledec, G.; Sokele, M. An Economic Approach to Big Data in a Minority Language. Procedia Comput. Sci. 2014, 35, 427–436. [Google Scholar] [CrossRef]
- Banasiak, D.; Mierzwa, J.; Sterna, A. Extended N-Gram Model for Analysis of Polish Texts. In Man-Machine Interactions 5, In Proceedings of the 5th International Conference on Man-Machine Interactions, ICMMI 2017, Kraków, Poland, 3–6 October 2017; Gruca, A., Czachórski, T., Harezlak, K., Kozielski, S., Piotrowska, A., Eds.; Springer: Cham, Switzerland, 2018; pp. 355–364. [Google Scholar]
- Ziolko, B.; Skurzok, D.; Michalska, M. Polish N-Grams and Their Correction Process. In Proceedings of the 2010 4th International Conference on Multimedia and Ubiquitous Engineering, Cebu, Philippines, 11–13 August 2010; pp. 1–5. [Google Scholar]
- Procházka, V.; Pollák, P. Analysis of Czech Web 1T 5-Gram Corpus and Its Comparison with Czech National Corpus Data. In Text, Speech and Dialogue, In Proceedings of the 13th International Conference, TSD 2010, Brno, Czech Republic, 6–10 September 2010; Sojka, P., Horák, A., Kopeček, I., Pala, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 181–188. [Google Scholar]
- Ramasamy, L.; Rosen, A.; Stranák, P. Improvements to Korektor: A Case Study with Native and Non-Native Czech. In Proceedings of the ITAT 2015: Information Technologies—Applications and Theory, Slovensky Raj, Slovakia, 17–21 September 2015. [Google Scholar]
- Sorokin, A. Spelling Correction for Morphologically Rich Language: A Case Study of Russian. In Proceedings of the 6th Workshop on Balto-Slavic Natural Language Processing, Valencia, Spain, 4 April 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 45–53. [Google Scholar]
- Srdić, I.; Gledec, G. Confusion Matrices for Croatian Language. Available online: https://ispravi.me/confusion/ (accessed on 7 April 2023). (In Croatian).
- Šimunec, M.; Šoić, R.; Vuković, M. N-Gram Based Croatian Language Network. In Proceedings of the 2021 International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 23–25 September 2021; pp. 1–5. [Google Scholar]
- Plahuta, M.; Purver, M.; Mathioudakis, M. Gender, Language, and Society-Word Embeddings as a Reflection of Social Ine-Qualities in Linguistic Corpora. Available online: https://qmro.qmul.ac.uk/xmlui/bitstream/handle/123456789/65144/Purver%20Gender,%20Language%20and%20Society%202019%20Published.pdf?sequence=2 (accessed on 12 April 2023).
- Ulčar, M.; Supej, A.; Robnik-Šikonja, M.; Pollak, S. Slovene and Croatian Word Embeddings in Terms of Gender Occupational Analogies. Slov. 2.0 Empir. Appl. Interdiscip. Res. 2021, 9, 26–59. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Description |
|---|---|
| date | The date in YYYY-MM-DD format when the entry is logged. |
| UserID | Before 27 November 2016: 0 After 27 November 2016: universally unique identifier (UUID) of the user, represented as 32 hexadecimal digits, using uppercase, displayed in five groups separated by hyphens, in the form 8-4-4-4-12. |
| error_word | The original unknown word that user later replaced with one of the suggested words. |
| correct_word | The word the user chose from the dropdown menu of suggested words to replace the mistyped word. |
| edit_distance | Damerau–Levenshtein edit distance between the error word and the correct word—possible values are either 1 or 2. |
| Year | No. of Records | File Size (bytes) |
|---|---|---|
| 2008 * | 2008 | 68,703 |
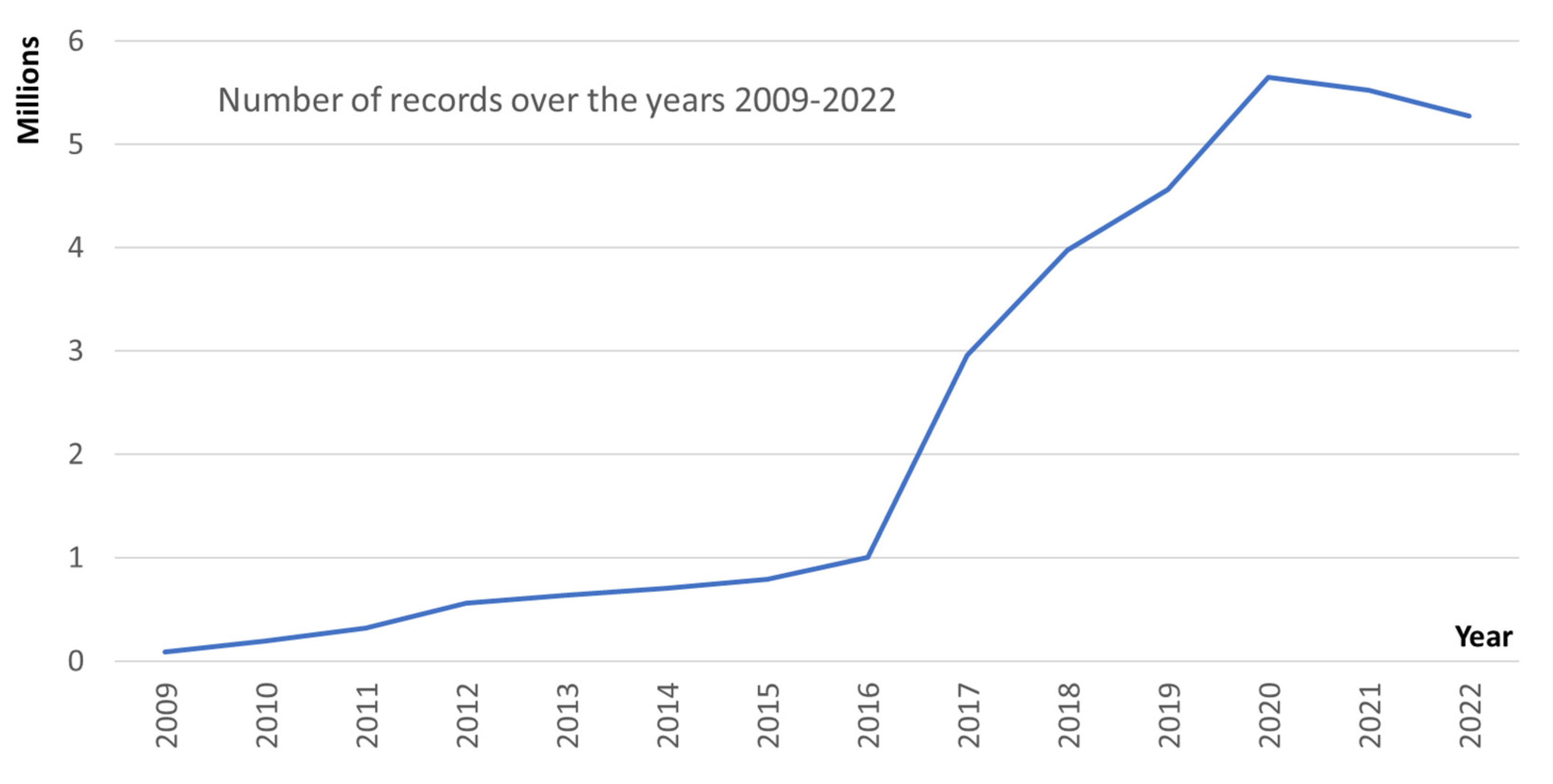
| 2009 | 85,906 | 2,917,640 |
| 2010 | 188,994 | 6,434,960 |
| 2011 | 315,821 | 10,748,864 |
| 2012 | 563,572 | 19,252,554 |
| 2013 | 639,414 | 21,940,712 |
| 2014 | 703,373 | 24,218,505 |
| 2015 | 794,094 | 27,337,889 |
| 2016 | 1,002,547 | 40,825,022 |
| 2017 | 2,956,906 | 206,155,833 |
| 2018 | 3,969,900 | 276,579,152 |
| 2019 | 4,565,391 | 318,131,677 |
| 2020 | 5,645,739 | 393,447,028 |
| 2021 | 5,524,501 | 385,070,748 |
| 2022 | 5,277,407 | 367,752,536 |
| 2023 ** | 1,146,757 | 80,006,348 |
| Total | 33,382,330 | 2,196,045,185 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gledec, G.; Horvat, M.; Mikuc, M.; Blašković, B. A Comprehensive Dataset of Spelling Errors and Users’ Corrections in Croatian Language. Data 2023, 8, 89. https://doi.org/10.3390/data8050089
Gledec G, Horvat M, Mikuc M, Blašković B. A Comprehensive Dataset of Spelling Errors and Users’ Corrections in Croatian Language. Data. 2023; 8(5):89. https://doi.org/10.3390/data8050089
Chicago/Turabian StyleGledec, Gordan, Marko Horvat, Miljenko Mikuc, and Bruno Blašković. 2023. "A Comprehensive Dataset of Spelling Errors and Users’ Corrections in Croatian Language" Data 8, no. 5: 89. https://doi.org/10.3390/data8050089