
Neural Coreference Resolution for Dutch Parliamentary Documents with the DutchParliament Dataset


Abstract
:1. Introduction
- We present a new coreference resolution dataset consisting of Dutch parliamentary documents annotated with coreference resolution links and a rich set of metadata features, called DutchParliament.
- We performed a comparative analysis of the DutchParliament corpus with two other Dutch coreference resolution datasets, namely the SoNaR-1 corpus and the RiddleCoref corpus. We investigated the overall structure and size of the corpus, and compare various lexical statistics.
- We evaluated two existing models for Dutch coreference resolution on the DutchParliament dataset and discuss their performance in comparison with the SoNaR-1 and RiddleCoref datasets.
- We conducted several experiments regarding the addition of metadata to the e2eDutch model and found that, for the parliamentary meetings, the addition of metadata about the speaker of utterances has a substantial positive effect on the performance of the model. The addition of the metadata about the gender of speakers does not seem to have any significant effect on the model.
2. Related Work
3. Materials and Methods
3.1. Annotation Scheme
Official Documents Class
3.2. Annotation Process
Inter Annotator Agreement
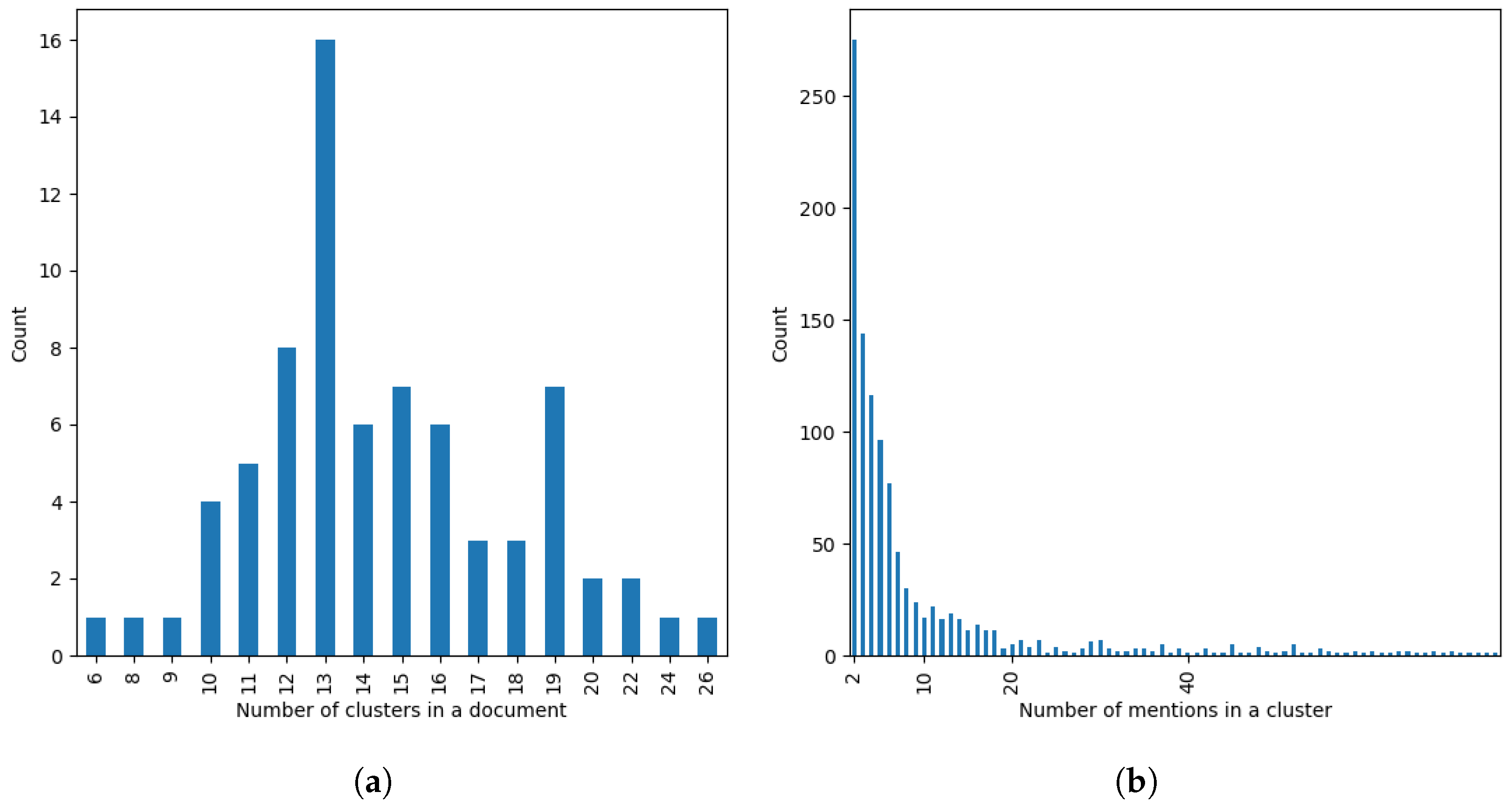
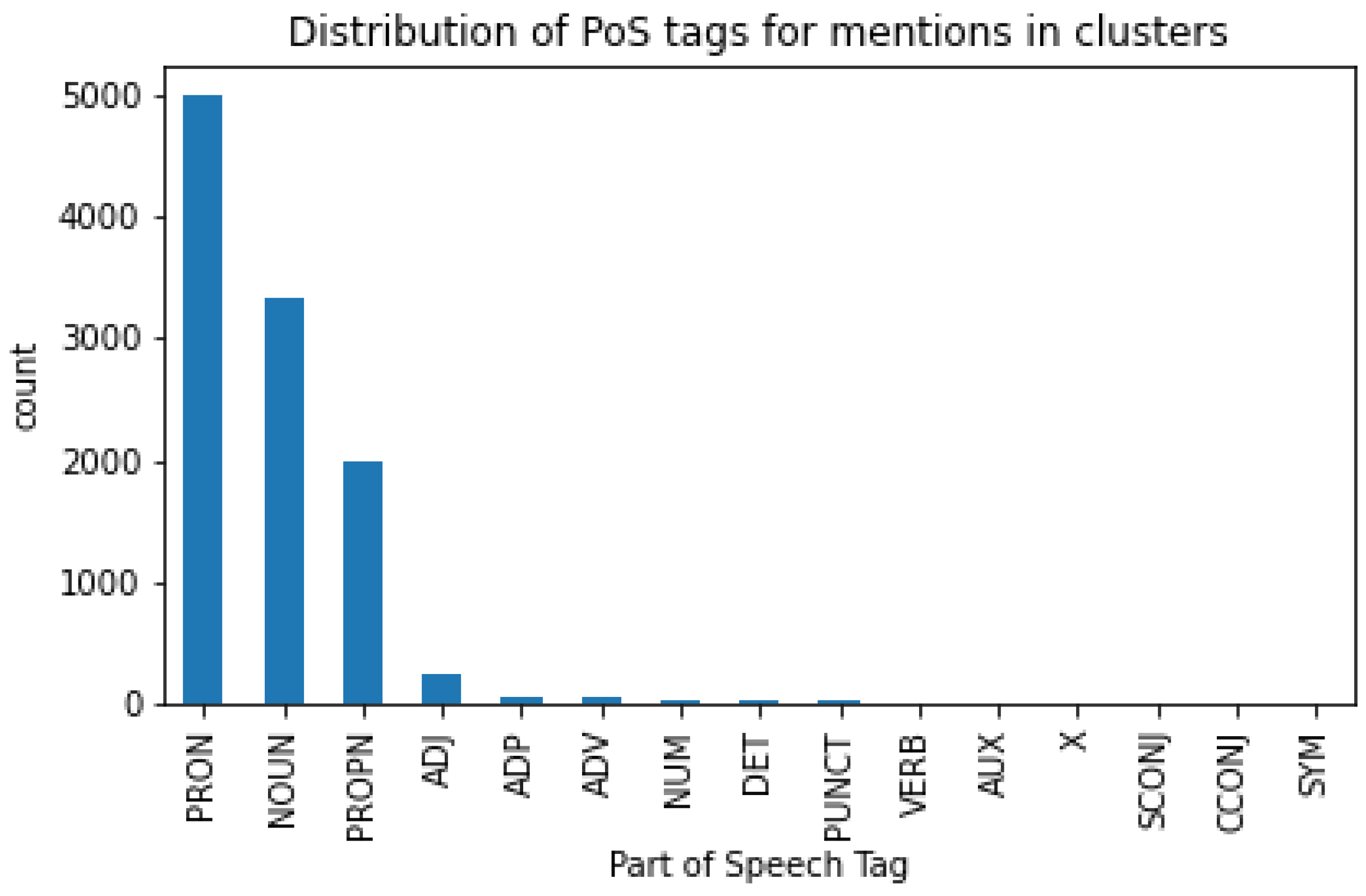
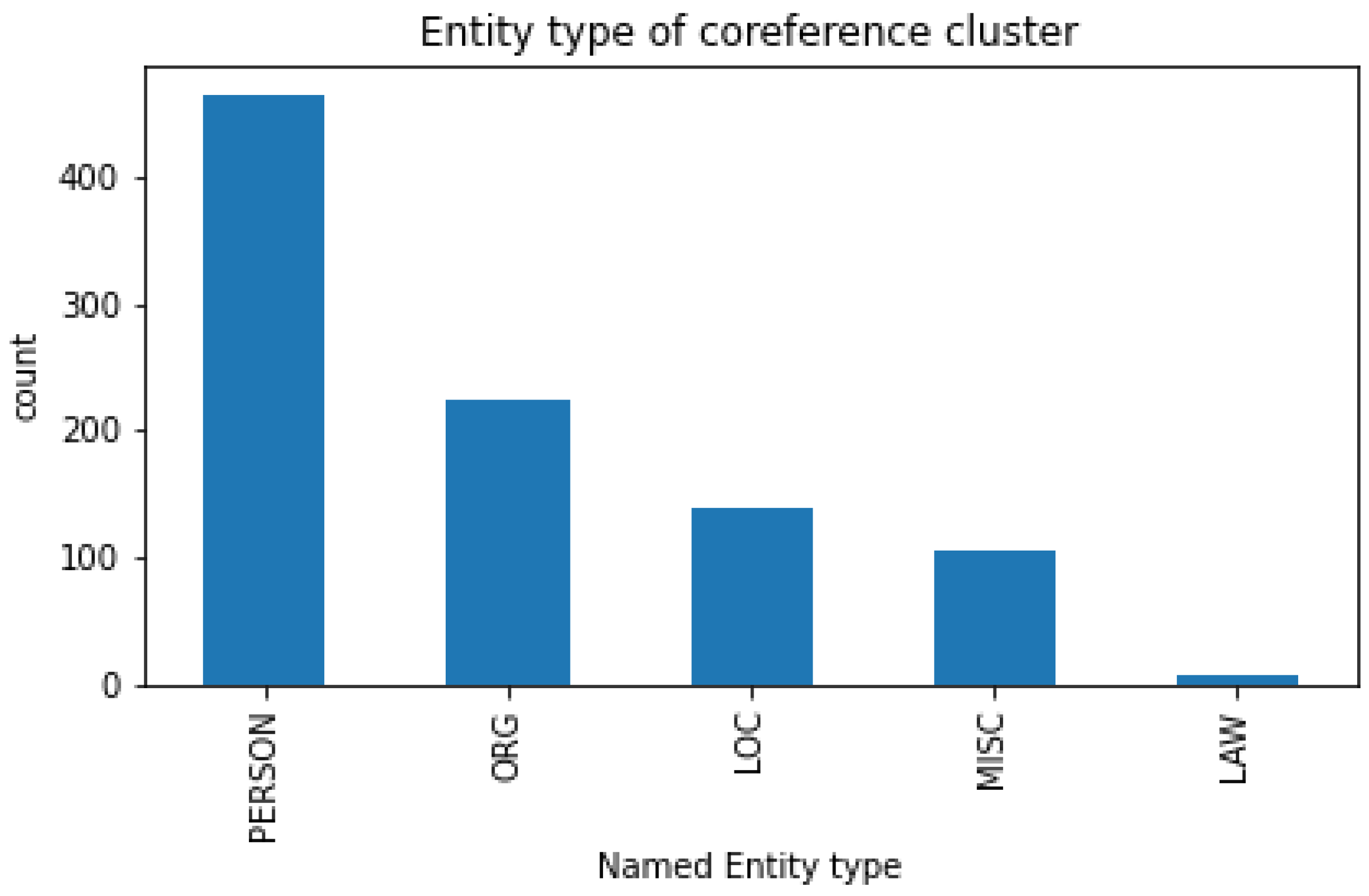
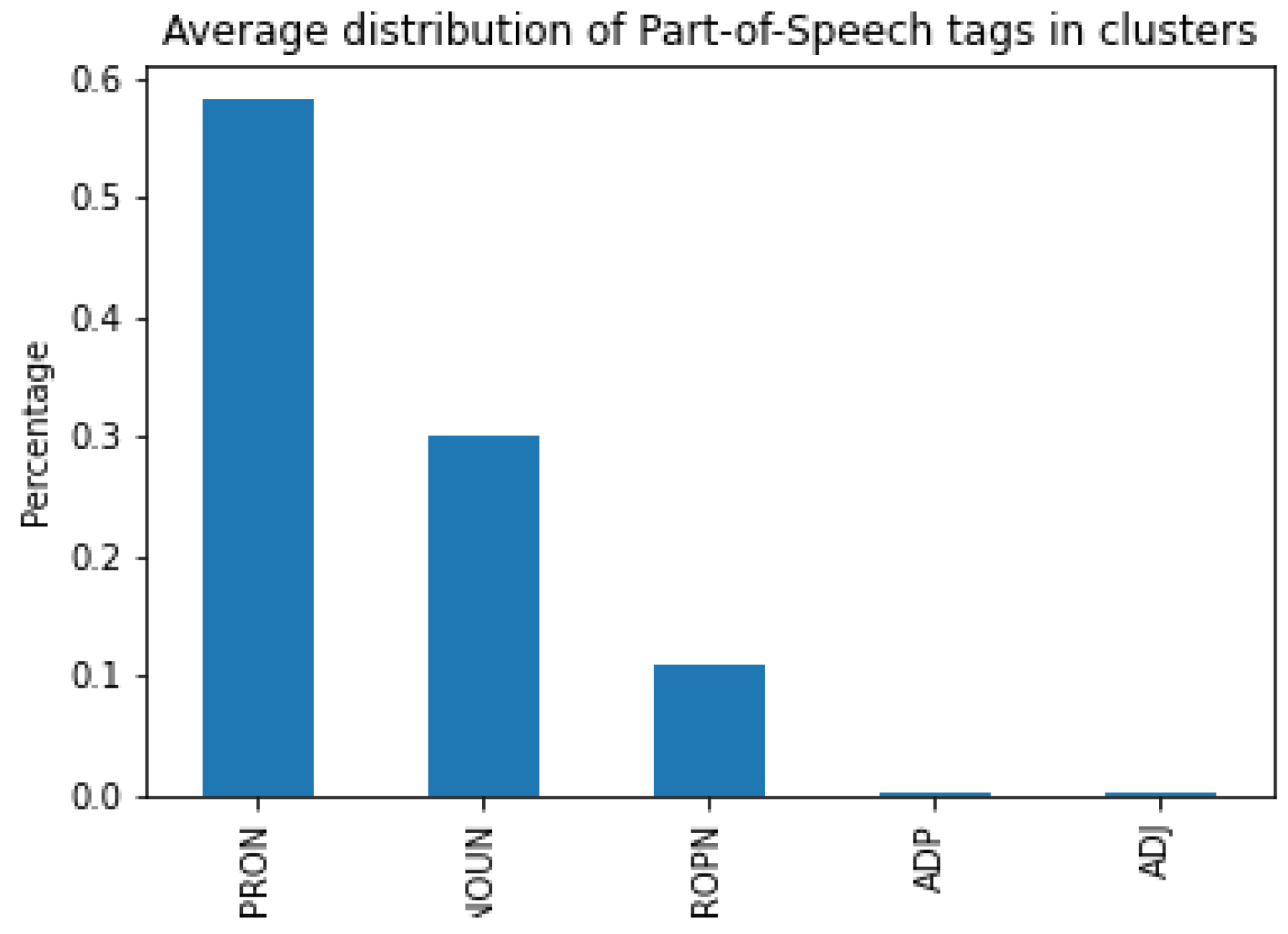
3.3. Dataset Statistics
4. Dataset Comparison
4.1. General Structure Analysis
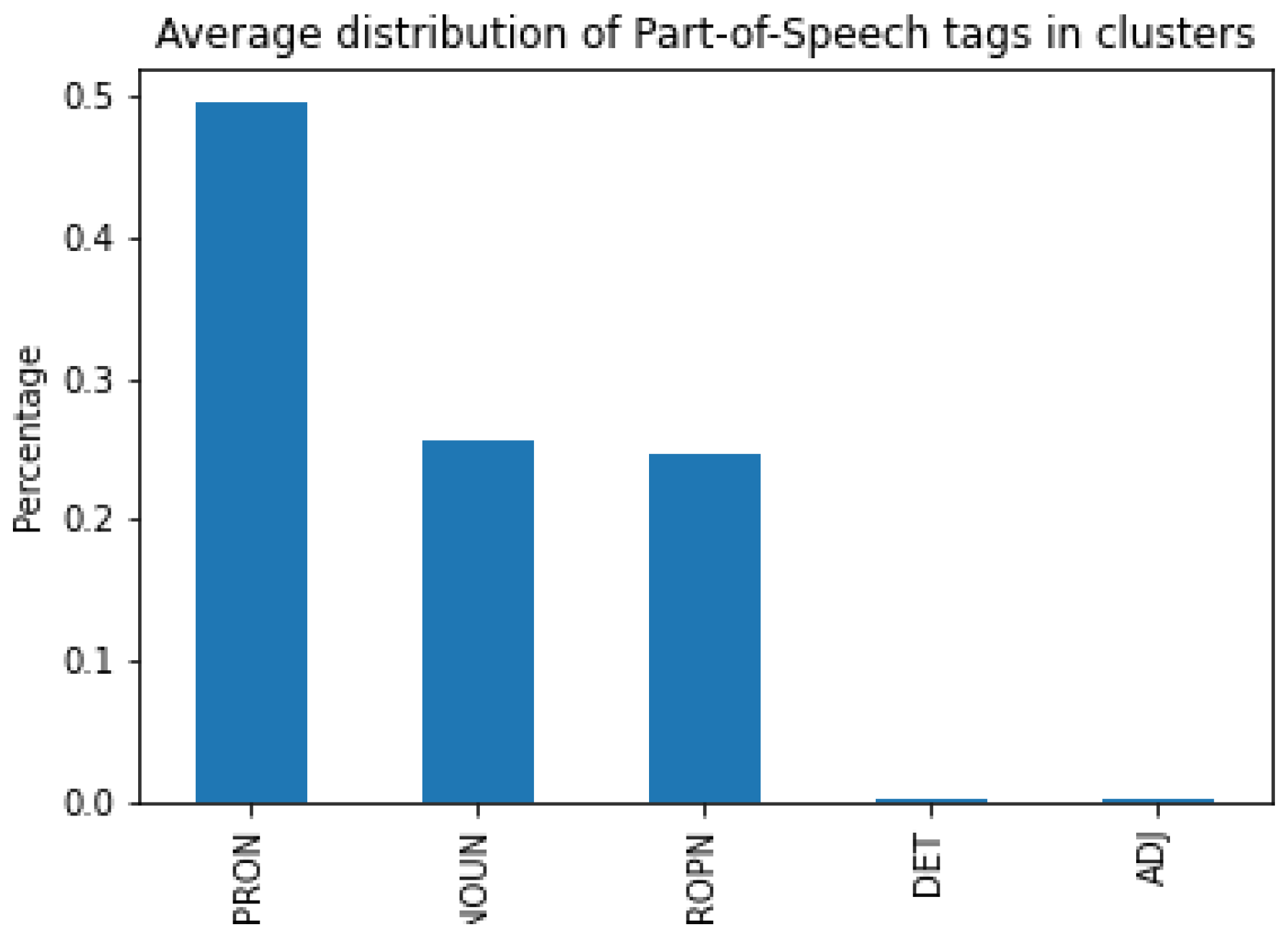
4.2. Lexical Statistics Comparison
4.3. Model Performance Comparison
4.3.1. DutchCoref Rule-Based System
4.3.2. e2eDutch
4.3.3. Evaluation
5. Metadata Addition
5.1. Inclusion of Speaker Metadata
5.2. Inclusion of Gender Metadata
5.3. Results
5.4. Error Analysis
- a.
- (correct) Daar verheug ook op, maar dat is echt een ander verhaal.
- b.
- (incorrect) zegt dat er veel lokale bedrijven worden ingezet, ook uit Drenthe en Friesland, en dat er zo ’ n 2.500 vakkrachten, zzp’ers, worden ingehuurd en kunnen worden ingehuurd. Dat klinkt mooi, maar daarom was zo verbaasd over het artikel en dan met name over het citaat dat een soort monopoliepositie zou hebben doordat het alle touwtjes in handen heeft.
- c.
- (incorrect) had een specifieke vraag gesteld over het gesprek dat en .
- a.
- (correct) Is bereid die uitzonderingsregel ook voor hen te overwegen? De regel rond het wettelijk doorwerkvereiste is natuurlijk iets voor . verzoek dan ook om het bij aan de orde te stellen.
6. Discussion and Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
| 1 | https://easy.dans.knaw.nl/ui/datasets/id/easy-dataset:224705/tab/2 (Accessed on 29 January 2023). |
| 2 | https://universaldependencies.org/format.html (Accessed on 29 January 2023). |
| 3 | https://github.com/andreasvc/dutchcoref (Accessed on 29 January 2023). |
| 4 | https://github.com/wietsedv/bertje (Accessed on 29 January 2023). |
| 5 | https://github.com/RubenvanHeusden/DutchParliamentCoreference/blob/main/README.md (Accessed on 29 January 2023). |
| 6 | https://easy.dans.knaw.nl/ui/datasets/id/easy-dataset:224705 (Accessed on 29 January 2023). |
| 7 | https://github.com/RubenvanHeusden/DutchParliamentCoreference/blob/main/README.md (Accessed on 29 January 2023). |
References
- Hobbs, J.R. Resolving Pronoun References. Lingua 1978, 44, 311–338. [Google Scholar] [CrossRef]
- Kameyama, M. A Property-Sharing Constraint in Centering. In Proceedings of the ACL’86: 24th Annual Meeting on Association for Computational Linguistics, New York, NY, USA, 10–13 July 1986; Association for Computational Linguistics: New York, NY, USA, 1986; pp. 200–206. [Google Scholar] [CrossRef]
- Lappin, S.; Leass, H.J. An Algorithm for Pronominal Anaphora Resolution. Comput. Linguist. 1994, 20, 535–561. [Google Scholar]
- Connolly, D.; Burger, J.D.; Day, D.S. A Machine Learning Approach to Anaphoric Reference. In Proceedings of the New Methods in Language Processing, Sydney, Australia, 11–17 January 1997; pp. 133–144. [Google Scholar]
- Cardie, C.; Wagstaff, K. Noun Phrase Coreference as Clustering. In Proceedings of the 1999 Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora, College Park, MD, USA, 21–22 June 1999. [Google Scholar]
- Ng, V. Machine Learning for Coreference Resolution: From Local Classification to Global Ranking. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics, Ann Arbor, MI, USA, 25–30 June 2005; pp. 157–164. [Google Scholar]
- Lee, K.; He, L.; Lewis, M.; Zettlemoyer, L. End-to-end Neural Coreference Resolution. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 188–197. [Google Scholar]
- Pradhan, S.; Ramshaw, L.; Marcus, M.; Palmer, M.; Weischedel, R.; Xue, N. Conll-2011 Shared Task: Modeling Unrestricted Coreference in OntoNotes. In Proceedings of the Fifteenth Conference on Computational Natural Language Learning: Shared Task, Portland, OR, USA, 23–24 June 2011; pp. 1–27. [Google Scholar]
- Oostdijk, N.; Reynaert, M.; Hoste, V.; Schuurman, I. The Construction of a 500-Million-Word Reference Corpus of Contemporary Written Dutch. In Essential Speech and Language Technology for Dutch; Springer: Berlin/Heidelberg, Germany, 2013; pp. 219–247. [Google Scholar]
- Recasens, M.; Martí, M.A. AnCora-CO: Coreferentially Annotated Corpora for Spanish and Catalan. Lang. Resour. Eval. 2010, 44, 315–345. [Google Scholar] [CrossRef]
- Recasens, M.; Màrquez, L.; Sapena, E.; Martí, M.A.; Taulé, M.; Hoste, V.; Poesio, M.; Versley, Y. Semeval-2010 Task 1: Coreference Resolution in Multiple Languages. In Proceedings of the 5th International Workshop on Semantic Evaluation, Uppsala, Sweden, 15–16 July 2010; pp. 1–8. [Google Scholar]
- van Cranenburgh, A. A Dutch Coreference Resolution System with an Evaluation on Literary Fiction. Comput. Linguist. Neth. J. 2019, 9, 27–54. [Google Scholar]
- Brennan, S.E.; Friedman, M.W.; Pollard, C. A Centering Approach to Pronouns. In Proceedings of the 25th Annual Meeting of the Association for Computational Linguistics, Stanford CA, USA, 6–9 July 1987; pp. 155–162. [Google Scholar]
- Strube, M.; Hahn, U. Functional Centering. arXiv 1996, arXiv:cmp-lg/9605021. [Google Scholar]
- Iida, R.; Inui, K.; Takamura, H.; Matsumoto, Y. Incorporating contextual cues in trainable models for coreference resolution. In Proceedings of the EACL Workshop on the Computational Treatment of Anaphora, Budapest, Hungary, 14 April 2003; pp. 23–30. [Google Scholar]
- Liang, T.; Wu, D.S. Automatic Pronominal Anaphora Resolution in English Texts. Int. J. Comput. Linguist. Chin. Lang. Process. 2001, 9, 21–40. [Google Scholar]
- van Kuppevelt, D.; Attema, J. e2e-Dutch. 2020. Available online: https://github.com/Filter-Bubble/e2e-Dutch (accessed on 29 January 2023). [CrossRef]
- Soon, W.M.; Ng, H.T.; Lim, D.C.Y. A machine learning approach to coreference resolution of noun phrases. Comput. Linguist. 2001, 27, 521–544. [Google Scholar] [CrossRef]
- Kobdani, H.; Schütze, H. Sucre: A modular system for coreference resolution. In Proceedings of the 5th International Workshop on Semantic Evaluation, Uppsala, Sweden, 15–16 July 2010; pp. 92–95. [Google Scholar]
- Hendrickx, I.; Bouma, G.; Coppens, F.; Daelemans, W.; Hoste, V.; Kloosterman, G.; Mineur, A.M.; Van Der Vloet, J.; Verschelde, J.L. A Coreference Corpus and Resolution System for Dutch. In Proceedings of the LREC, Citeseer, Marrakech, Morocco, 28–30 May 2008. [Google Scholar]
- Poot, C.; van Cranenburgh, A. A Benchmark of Rule-Based and Neural Coreference Resolution in Dutch Novels and News. In Proceedings of the Third Workshop on Computational Models of Reference, Anaphora and Coreference, Barcelona, Spain, 12 December 2020; Association for Computational Linguistics: Barcelona, Spain, 2020; pp. 79–90. [Google Scholar]
- Erjavec, T.; Ogrodniczuk, M.; Osenova, P.; Ljubešić, N.; Simov, K.; Grigorova, V.; Rudolf, M.; Pančur, A.; Kopp, M.; Barkarson, S.; et al. Linguistically Annotated Multilingual Comparable Corpora of Parliamentary Debates ParlaMint.ana 2.1, 2021. Slovenian Language Resource Repository CLARIN. SI. Online Resource. Available online: https://link.springer.com/article/10.1007/s10579-021-09574-0 (accessed on 29 January 2023). [CrossRef]
- Schoen, A.; van Son, C.; van Erp, M.; van Vliet, H. NewsReader Document-Level Annotation Guidelines-Dutch TechReport 2014-8; Technical Report; VU University: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Reiter, N. CorefAnnotator—A New Annotation Tool for Entity References. In Proceedings of the Abstracts of EADH: Data in the Digital Humanities, Galway, Ireland, 7–9 December 2018. [Google Scholar] [CrossRef]
- Hendrickx, I.; Hoste, V.; Daelemans, W. Semantic and Syntactic Features for Dutch Coreference Resolution. In Lecture Notes in Computer Science, Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, Haifa, Israel, 17–23 February 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 351–361. [Google Scholar]
- Honnibal, M.; Montani, I. spaCy 2: Natural Language Understanding with Bloom Embeddings, Convolutional Neural Networks and Incremental Parsing. Online Resource. Available online: https://sentometrics-research.com/publication/72/ (accessed on 29 January 2023).
- Laufer, B. The Lexical Profile of Second Language Writing: Does It Change Over Time? RELC J. 1994, 25, 21–33. [Google Scholar] [CrossRef]
- Vanmassenhove, E.; Shterionov, D.; Gwilliam, M. Machine Translationese: Effects of Algorithmic Bias on Linguistic Complexity in Machine Translation. arXiv 2021, arXiv:2102.00287. [Google Scholar]
- Keuleers, E.; Brysbaert, M.; New, B. SUBTLEX-NL: A New Measure for Dutch Word Frequency Based on Film Subtitles. Behav. Res. Methods 2010, 42, 643–650. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beek, L.V.D.; Bouma, G.; Malouf, R.; van Noord, G. The Alpino dependency treebank. In Proceedings of the Computational linguistics in the Netherlands, Twente, The Netherlands, 30 November 2001. [Google Scholar]
- Moosavi, N.S.; Strube, M. Which Coreference Evaluation Metric Do You Trust? A Proposal for a Link-Based Entity Aware Metric. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 632–642. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cluster | Cluster Words |
|---|---|
| Wet op kinderopvang | de Wet op de kinderopvangtoeslag, die regeling, de Wet kinderopvang, die wet |
| De woningwet | de Niewe Woningwet, de wet, die wet |
| Brief | brief aan de kamer, deze brief, die brief |
| SoNaR-1 | RiddleCoref | DutchParliament | |
|---|---|---|---|
| Number of files | 862 | 33 | 74 |
| Number of tokens | approx. 1,000,000 | approx. 160,000 | approx. 180,000 |
| Number of sentences | 59,602 | 9864 | 11,038 |
| Average sentence length in tokens | 16.6 | 17.6 | 16.3 |
| Number of clusters | 205,103 | 14,692 | 1082 |
| Number of mentions | 289,955 | 38,647 | 10,771 |
| Fraction of coreference tokens | 0.29 | 0.24 | 0.60 |
| Average document length in tokens | 1160 | 4897 | 2432 |
| Average document length in sentences | 69.1 | 298.9 | 149.1 |
| Corpus | Number of Unique Tokens | Token/Type Ratio | B1 | B2 | B3 | Yule’s K |
|---|---|---|---|---|---|---|
| DutchParliament | 10,749 | 16.313 | 0.73 | 0.05 | 0.22 | 99.86 |
| SoNaR-1 | 65,632 | 13.827 | 0.58 | 0.06 | 0.37 | 102.19 |
| Model | DutchParliament | RiddleCoref | SoNaR-1 | |||
|---|---|---|---|---|---|---|
| Mentions F1 | LEA F1 | Mentions F1 | LEA F1 | Mentions F1 | LEA F1 | |
| DutchCoref | 46.99 | 32.00 | 80.56 | 48.15 | 63.57 | 39.71 |
| e2eDutch | 76.57 | 45.54 | 79.94 | 45.31 | 67.08 | 46.18 |
| Geert Wilders | 1 | 1 | 1 | 1 |
|---|---|---|---|---|
| Sentence | Doe | eens | normaal | man |
| Mark Rutte | 2 | 2 | 2 | |
| Sentence | Doe | zelf | normaal |
| Model | LEA | Mentions | ||
|---|---|---|---|---|
| Precision | Recall | F1 | F1 | |
| e2e-Dutch | 52.06 | 41.57 | 45.54 | 76.57 |
| e2e Dutch + speakers | 54.59 | 50.60 | 51.95 | 77.83 |
| e2e Dutch + gender | 51.20 | 45.20 | 47.48 | 75.44 |
| e2e Dutch + both | 58.35 | 42.24 | 47.71 | 74.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
van Heusden, R.; Kamps, J.; Marx, M. Neural Coreference Resolution for Dutch Parliamentary Documents with the DutchParliament Dataset. Data 2023, 8, 34. https://doi.org/10.3390/data8020034
van Heusden R, Kamps J, Marx M. Neural Coreference Resolution for Dutch Parliamentary Documents with the DutchParliament Dataset. Data. 2023; 8(2):34. https://doi.org/10.3390/data8020034
Chicago/Turabian Stylevan Heusden, Ruben, Jaap Kamps, and Maarten Marx. 2023. "Neural Coreference Resolution for Dutch Parliamentary Documents with the DutchParliament Dataset" Data 8, no. 2: 34. https://doi.org/10.3390/data8020034