
Smart Work Injury Management (SWIM) System: A Machine Learning Approach for the Prediction of Sick Leave and Rehabilitation Plan
 , ,
, ,
Abstract
:1. Introduction
2. Literature Review
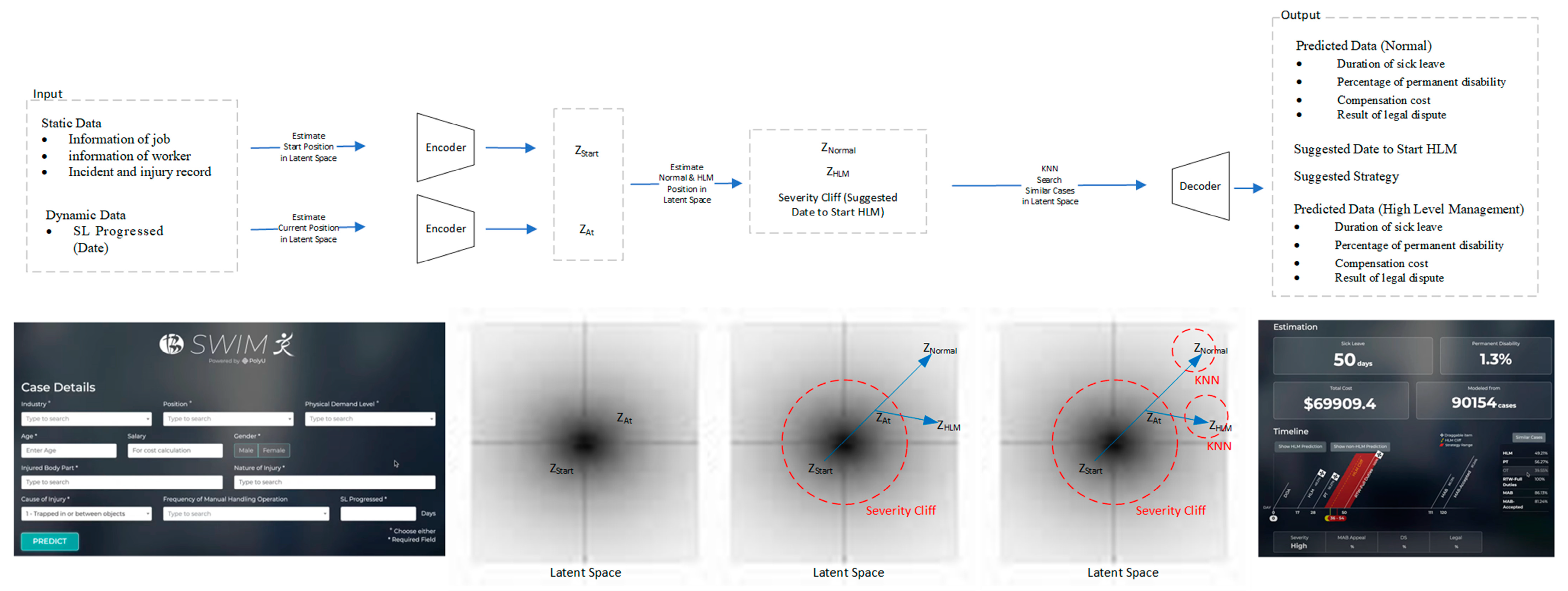
3. Methodology
3.1. Input Data
3.1.1. Static Data Information
3.1.2. Dynamic Data Information
3.1.3. Data Preprocessing
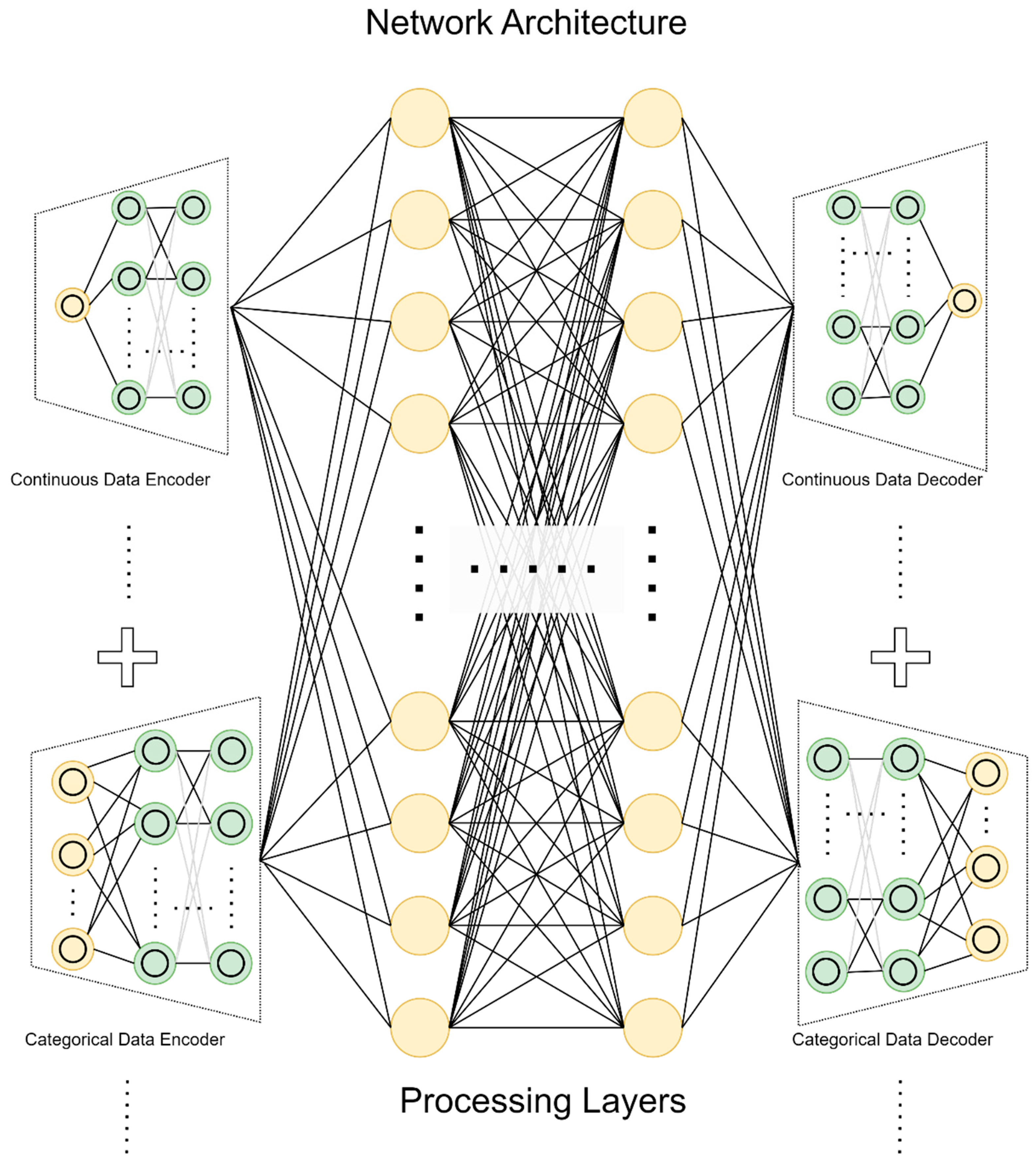
3.2. Latent Space and VAE
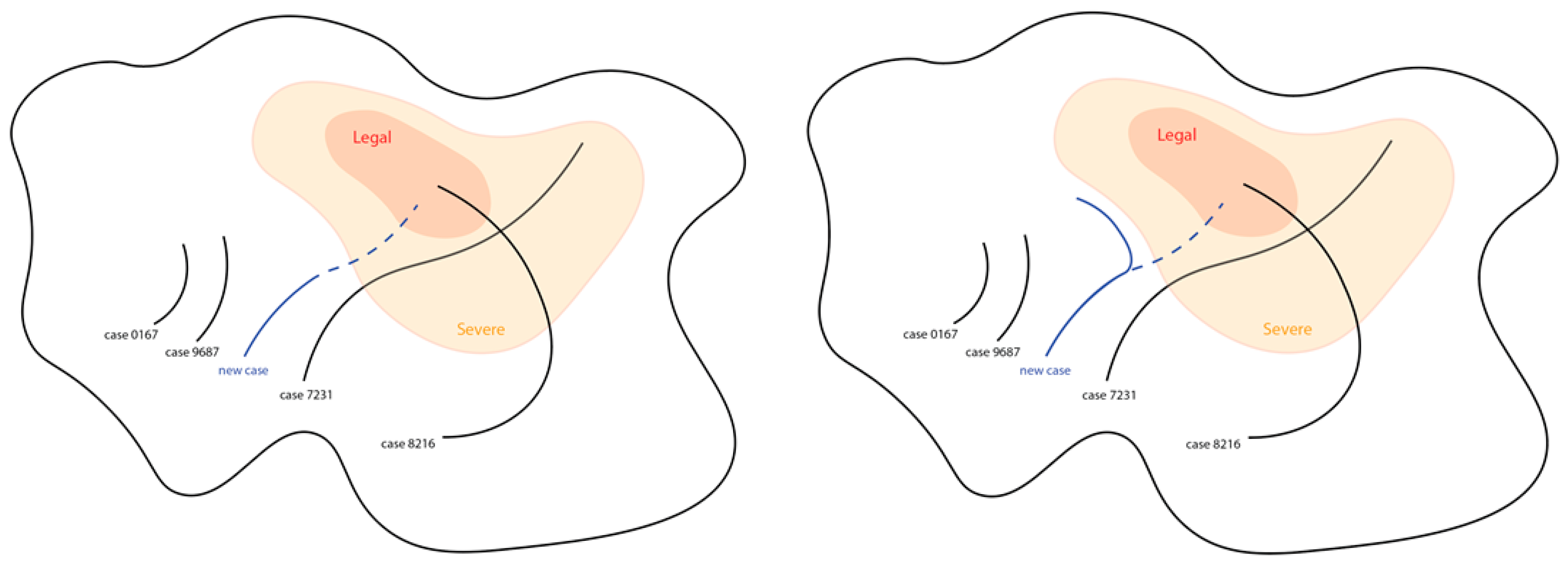
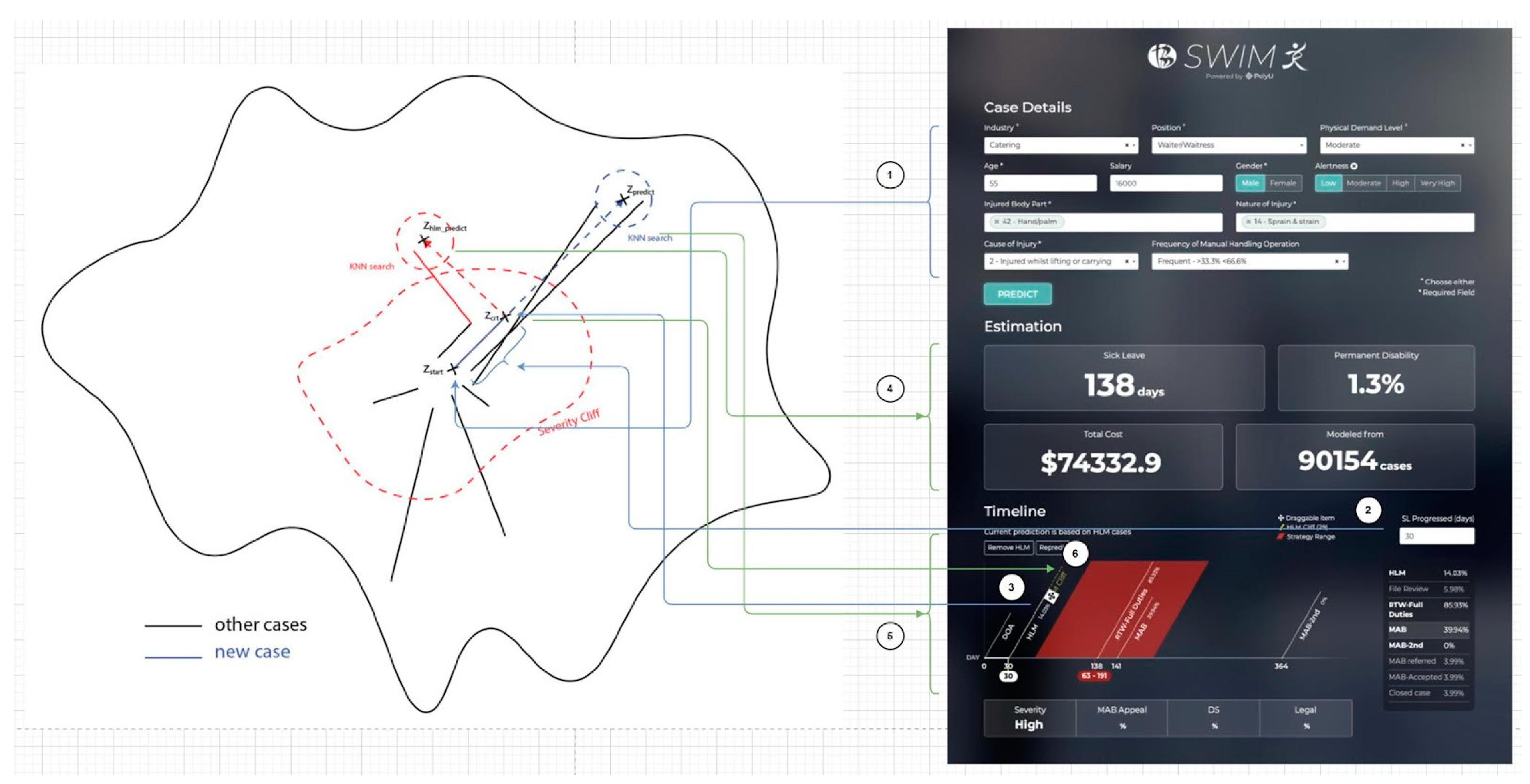
3.3. KNN
4. Result and Discussion
4.1. Result of the Prediction
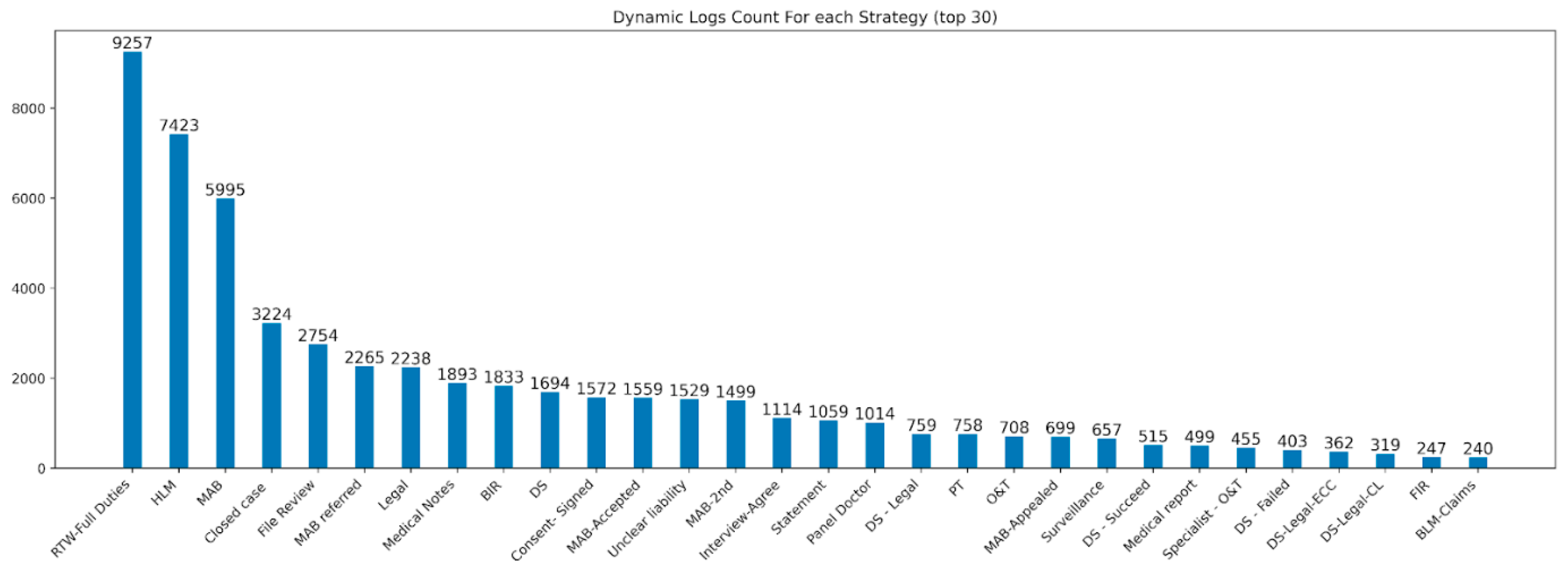
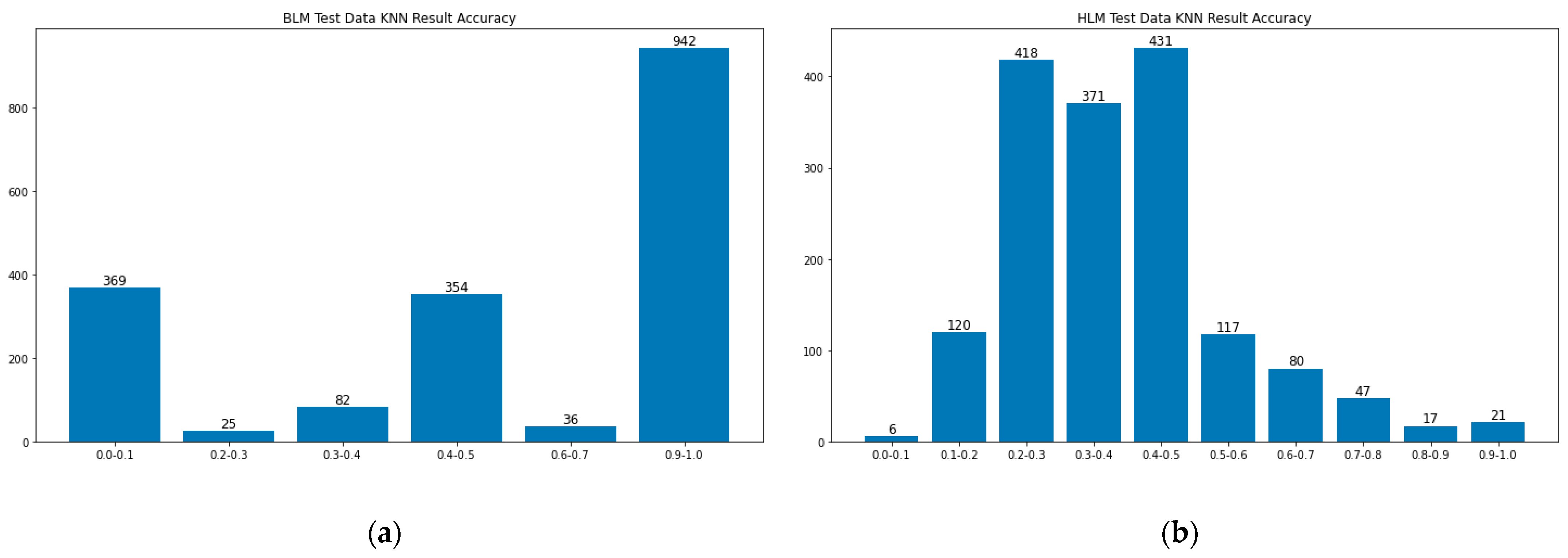
4.2. Result of KNN
5. Limitation and Further Improvement
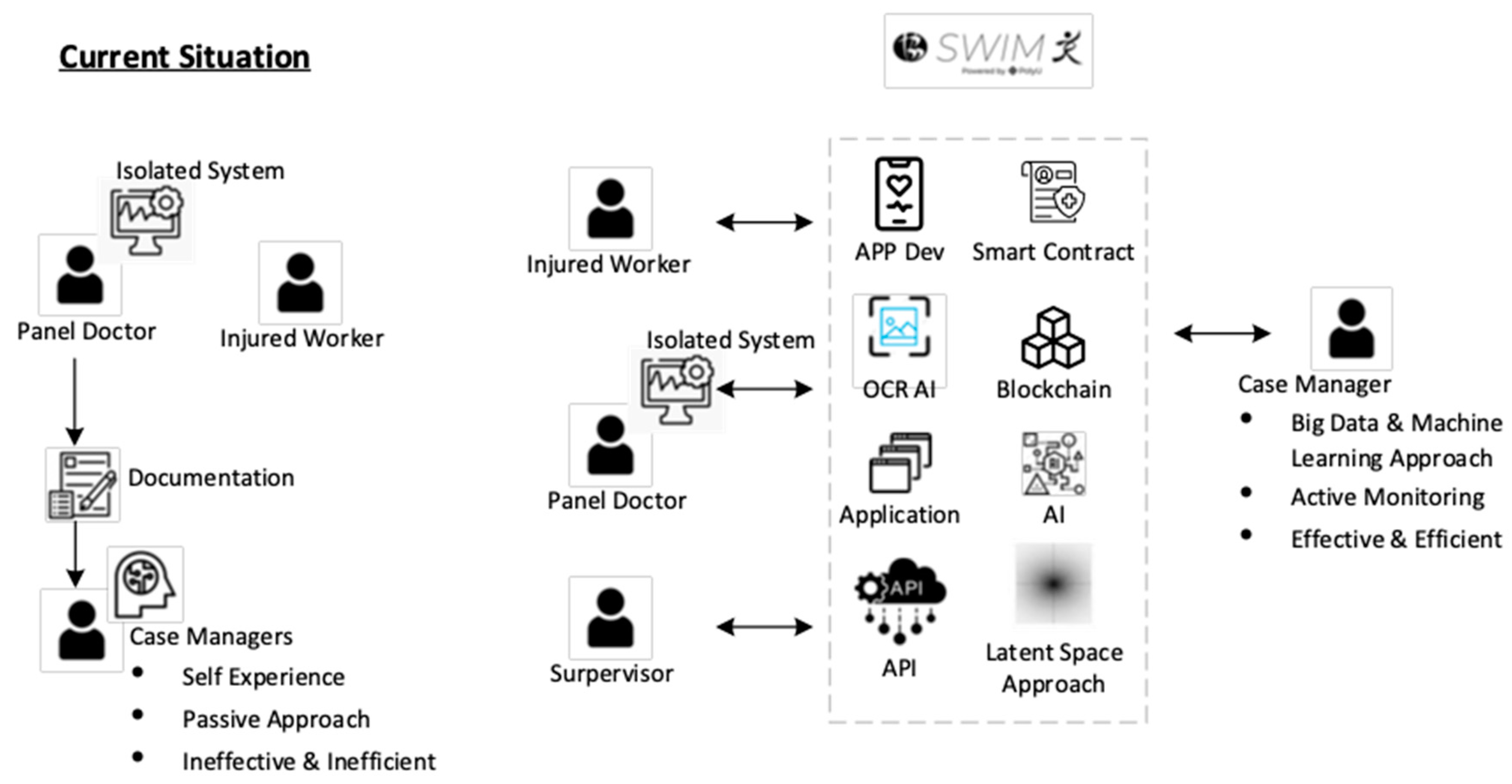
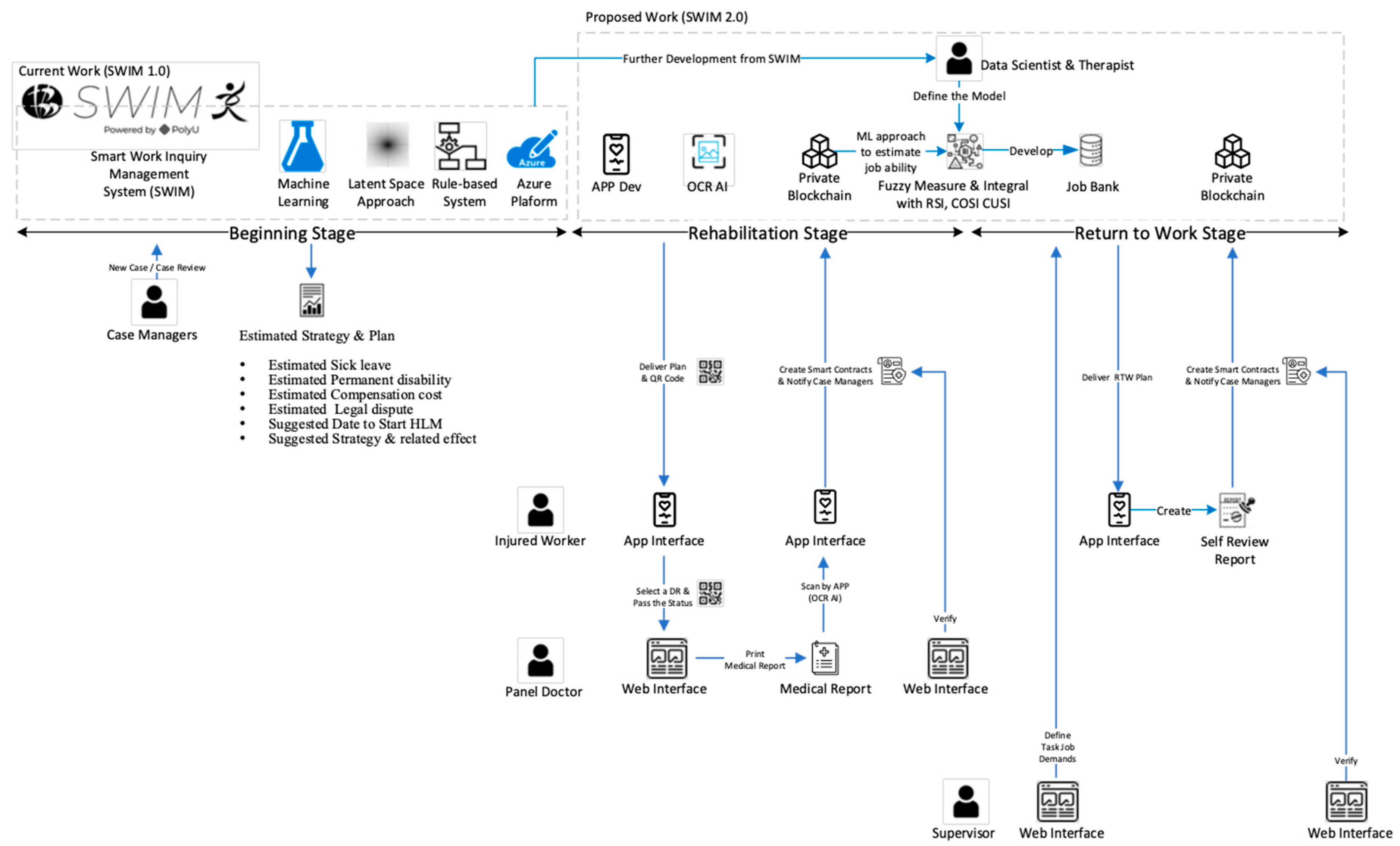
- Enhance communication by APP and QR code technology. We will develop a user-friendly APP which involves QR code technology to replace document/email communication between the injured worker, case manager and panel doctor.
- Enhance communication through APP and OCRAI technology. We will embed the OCRAI technology to replace document exchange, data entry and verification between the injured worker and case manager.
- Enhance communication with smart contracts and blockchain technology. We will use the decentralized approach to handle the data storage and synchronization of a different isolated system among the stakeholders.
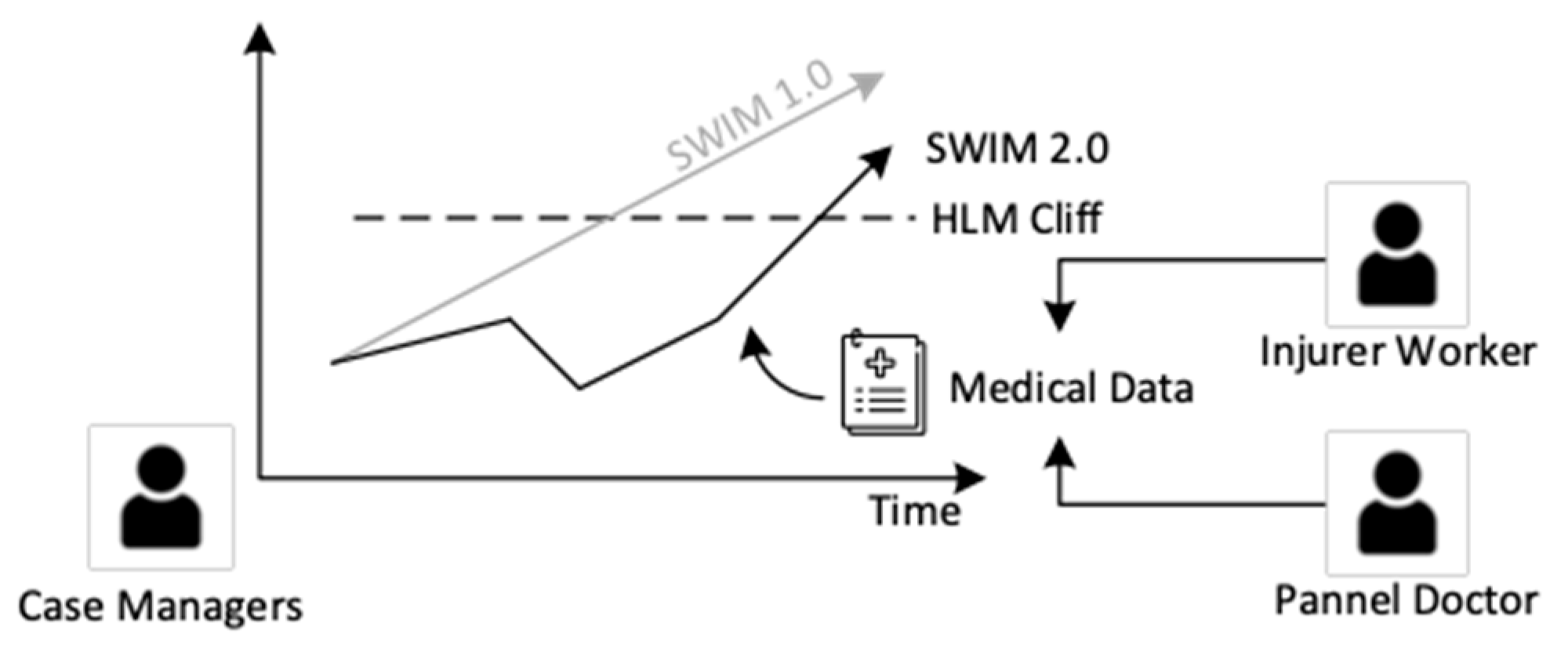
- Enhance job matching with artificial intelligence. We will improve SWIM 1.0 from a one-off prediction from the beginning stage to a continuous prediction and monitoring system. The medical data will enhance the latent space of SWIM 1.0 to estimate the job ability of injured workers in different stages. Various artificial intelligence types, such as rule-based, fuzzy measure and integral, will be used to develop a job-matching system, as shown in Figure 11.
- Enhance the job review with workflow management technology. We will adopt a paperless approach by using workflow management. All the documents will be changed into digital form and embedded into a well-defined structure in workflow management applications to enhance the job review process in RTW as shown in Figure 12.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, S.; Vahedian, F.; Hachen, D.; Lizardo, O.; Poellabauer, C.; Striegel, A.; Milenković, T. Heterogeneous Network Approach to Predict Individuals’ Mental Health. ACM Trans. Knowl. Discov. Data 2021, 15, 1–26. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, W.; Pi, D.; Yue, L. Adversarially regularized medication recommendation model with multi-hop memory network. Knowl. Inf. Syst. 2021, 63, 125–142. [Google Scholar] [CrossRef]
- Yao, L.; Zhang, Y.; Wei, B.; Zhang, W.; Jin, Z. A Topic Modeling Approach for Traditional Chinese Medicine Prescriptions. IEEE Trans. Knowl. Data Eng. (TKDE) 2018, 30, 1007–1021. [Google Scholar] [CrossRef]
- Spiotta, M.; Terenziani, P.; Dupré, D.T. Temporal Conformance Analysis and Explanation of Clinical Guidelines Execution: An Answer Set Programming Approach. IEEE Trans. Knowl. Data Eng. 2017, 29, 2567–2580. [Google Scholar] [CrossRef]
- Solares, J.R.; Raimondi, F.E.; Zhu, Y.; Rahimian, F.; Canoy, D.; Tran, J.; Gomes, A.C.; Payberah, A.H.; Zottoli, M.; Nazarzadeh, M.; et al. Deep learning for electronic health records: A comparative review of multiple deep neural architectures. J. Biomed. Inform. 2020, 101, 103337. [Google Scholar] [CrossRef] [PubMed]
- Hemingway, H.; Asselbergs, F.W.; Danesh, J.; Dobson, R.; Maniadakis, N.; Maggioni, A.; Van Thiel, G.J.; Cronin, M.; Brobert, G.; Vardas, P.; et al. Big data from electronic health records for early and late translational cardiovascular research: Challenges and potential. Eur. Heart J. 2018, 39, 1481–1495. [Google Scholar] [CrossRef] [Green Version]
- Guo, R.; Shi, H.; Zhao, Q.; Zheng, D. Secure Attribute-Based Signature Scheme With Multiple Authorities for Blockchain in Electronic Health Records Systems. IEEE Access. 2018, 6, 11676–11686. [Google Scholar] [CrossRef]
- Mayer, A.H.; da Costa, C.A.; Righi, R.D. Electronic health records in a Blockchain: A systematic review. Health Inform. J. 2020, 26, 1273–1288. [Google Scholar] [CrossRef] [Green Version]
- Brisimi, T.S.; Chen, R.; Mela, T.; Olshevsky, A.; Paschalidis, I.C.; Shi, W. Federated learning of predictive models from federated Electronic Health Records. Int. J. Med. Inform. 2018, 112, 59–67. [Google Scholar] [CrossRef] [PubMed]
- Koleck, T.A.; Dreisbach, C.; Bourne, P.E.; Bakken, S. Natural language processing of symptoms documented in free-text narratives of electronic health records: A systematic review. J. Am. Med. Inform. Assoc. 2019, 26, 364–379. [Google Scholar] [CrossRef]
- Zhang, J.; Xu, W.; Guo, J.; Gao, S. A temporal model in Electronic Health Record search. Knowl.-Based Syst. 2017, 126, 56–67. [Google Scholar] [CrossRef]
- Saha, B.; Gupta, S.; Phung, D.; Venkatesh, S. Effective sparse imputation of patient conditions in electronic medical records for emergency risk predictions. Knowl. Inf. Syst. 2017, 53, 179–206. [Google Scholar] [CrossRef]
- Engelhard, M.; Xu, H.; Carin, L.; Oliver, J.A.; Hallyburton, M.; McClernon, F.J. Predicting Smoking Events with a Time-Varying Semi-Parametric Hawkes Process Model. Proc. Mach. Learn. Res. 2018, 85, 312–331. [Google Scholar]
- Wang, S.; Li, X.; Chang, X.; Yao, L.; Sheng, Q.Z.; Long, G. Learning Multiple Diagnosis Codes for ICU Patients with Local Disease Correlation Mining. ACM Trans. Knowl. Discov. Data 2017, 11, 1–21. [Google Scholar] [CrossRef]
- Duclos, C.; Bouaud, J.; Section Editors for the IMIA Yearbook Section on Decision Support. Pragmatic Considerations on Clinical Decision Support from the 2019 Literature. Yearb. Med. Inform. 2020, 29, 155–158. [Google Scholar] [CrossRef]
- Chen, J.; Pu, H.; Wang, D. Artificial Intelligence Analysis of EEG Amplitude in Intensive Heart Care. J. Healthc. Eng. 2021, 2021, 6284035. [Google Scholar] [CrossRef]
- Huang, Z.; Lu, Y.; Dong, W. Utilizing electronic health records to predict multi-type major adverse cardiovascular events after acute coronary syndrome. Knowl. Inf. Syst. 2019, 60, 1725–1752. [Google Scholar] [CrossRef]
- Jha, K.; Xun, G.; Gopalakrishnan, V.; Zhang, A. DWE-Med: Dynamic Word Embeddings for Medical Domain. ACM Trans. Knowl. Discov. Data 2019, 13, 1–21. [Google Scholar] [CrossRef]
- Rajkomar, A.; Oren, E.; Chen, K.; Dai, A.M.; Hajaj, N.; Hardt, M.; Liu, P.J.; Liu, X.; Marcus, J.; Sun, M.; et al. Scalable and accurate deep learning with electronic health records. NPJ Digit Med. 2018, 8, 18. [Google Scholar] [CrossRef]
- Rahimian, F.; Salimi-Khorshidi, G.; Payberah, A.H.; Tran, J.; Ayala Solares, R. Predicting the risk of emergency admission with machine learning: Development and validation using linked electronic health records. PLoS Med. 2018, 15, e1002695. [Google Scholar] [CrossRef]
- Cheng, L.; Shi, Y.; Zhang, K.; Wang, X.; Chen, Z. GGATB-LSTM: Grouping and Global Attention-based Time-aware Bidirectional LSTM Medical Treatment Behavior Prediction. ACM Trans. Knowl. Discov. Data 2021, 15, 1–16. [Google Scholar] [CrossRef]
- Xu, H.; Wu, W.; Nemati, S.; Zha, H. Patient Flow Prediction via Discriminative Learning of Mutually-Correcting Processes. IEEE Trans. Knowl. Data Eng. 2017, 29, 157–171. [Google Scholar] [CrossRef]
- Lin, B.; Luo, W.; Luo, Z.; Wang, B.; Deng, S.; Yin, J.; Zhou, M. Bradykinesia Recognition in Parkinson’s Disease via Single RGB Video. ACM Trans. Knowl. Discov. Data 2020, 14, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Shi, Z.; Zuo, W.; Chen, W.; Yue, L.; Hao, Y.; Liang, S. DMMAM: Deep Multi-source Multi-task Attention Model for Intensive Care Unit Diagnosis. In Database Systems for Advanced Applications, Proceedings of the 24th International Conference, DASFAA 2019, Chiang Mai, Thailand, 22–25 April 2019; Proceedings, Part II; Springer: Berlin/Heidelberg, Germany, 2019; pp. 53–69. [Google Scholar]
- Shi, Z.; Wang, S.; Yue, L.; Pang, L.; Zuo, X.; Zuo, W.; Li, X. Deep dynamic imputation of clinical time series for mortality prediction. Inf. Sci. 2021, 579, 607–622. [Google Scholar] [CrossRef]
- Johnson, A.E.; Pollard, T.J.; Shen, L.; Lehman, L.W.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Anthony Celi, L.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Mo, T.; Wang, X.; Chen, W.; He, Q.; Li, X.; Zhang, S.; Yang, R.; Wu, J.; Gu, X.; et al. A hierarchical fusion framework to integrate homogeneous and heterogeneous classifiers for medical decision-making. Knowl.-Based Syst. 2021, 212, 106517. [Google Scholar] [CrossRef]
- Cheng, A.S.K.; Ng, P.H.F.; Sin, Z.P.T.; Lai, S.H.S.; Law, S.W. Smart Work Injury Management (SWIM) System: Artificial Intelligence in Work Disability Management. J. Occup. Rehabil. 2020, 30, 354–361. [Google Scholar] [CrossRef] [PubMed]
- Jolliffe, I.T.; Cadima, J. Principal component analysis: A review and recent developments. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2016, 374, 20150202. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114v11. [Google Scholar]
- Guo, G.; Wang, H.; Bell, D.; Bi, Y.; Greer, K. KNN Model-Based Approach in Classification. In On The Move to Meaningful Internet Systems 2003: CoopIS, DOA, and ODBASE, Proceedings of the OTM Confederated International Conferences, CoopIS, DOA, and ODBASE 2003, Catania, Sicily, Italy, 3–7 November 2003; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Sheikhi, A.; Mesiar, R.; Holeňa, M. A dimension reduction in neural network using copula matrix. Int. J. Gen. Syst. 2022, 1–16. [Google Scholar] [CrossRef]
- Krause, N.; Dasinger, L.K.; Neuhauser, F. Modified Work and Return to Work: A Review of the Literature. J. Occup. Rehabil. 1998, 8, 113–139. [Google Scholar] [CrossRef]
- Nag, N.; Jain, R. A Navigational Approach to Health: Actionable Guidance for Improved Quality of Life. Computer 2019, 52, 12–20. [Google Scholar] [CrossRef]
- Nag, N.; Pandey, V.; Jain, R. Health Multimedia: Lifestyle Recommendations Based on Diverse Observations. In Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval, Bucharest, Romania, 6–9 June 2017. [Google Scholar]
- Rey, L.A. Disentanglement with Hyperspherical Latent Spaces using Diffusion Variational Autoencoders. arXiv 2020, arXiv:2003.08996v1. [Google Scholar]
- Deudon, M. Learning semantic similarity in a continuous space. In Proceedings of the Neural Information Processing Systems (NeurIPS 2018), Montreal, ON, Canada, 3–8 December 2018; pp. 994–1005. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2016. [Google Scholar] [CrossRef]
- Zhao, Q.; Adeli, E.; Honnorat, N.; Leng, T.; Pohl, K.M. Variational AutoEncoder For Regression: Application to Brain Aging Analysis. arXiv 2019, arXiv:1511.06434v2. [Google Scholar]
- Connor, M.; Canal, G.; Rozell, C. Variational Autoencoder with Learned Latent Structure. In Proceedings of the 24th International Conference on Artificial Intelligence and Statistics, San Diego, CA, USA, 13–15 April 2021. [Google Scholar] [CrossRef]
- Hoff, P.D.; Raftery, A.E.; Handcock, M.S. Latent Space Approaches to Social Network Analysis. J. Am. Stat. Assoc. 2002, 97, 1090–1098. [Google Scholar] [CrossRef]
- Pulgar, F.J.; Charte, F.; Rivera, A.J.; Del Jesus, M.J. AEkNN: An AutoEncoder kNN-based classifier with built-in dimensionality reduction. arXiv 2018, arXiv:1802.08465. [Google Scholar] [CrossRef] [Green Version]
- Nalisnick, E.; Hertel, L.; Smyth, P. Approximate Inference for Deep Latent Gaussian Mixtures. In Proceedings of the NIPS Workshop on Bayesian Deep Learning, Barcelona, Spain, 10 December 2016; Volume 2. [Google Scholar]
- Burda, Y.; Grosse, R.; Salakhutdinov, R. Importance weighted autoencoders. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Pransky, G.; Gatchel, R.; Linton, S.J.; Loisel, P. Improving Return to Work Research. J. Occup. Rehabil. 2005, 15, 453–457. [Google Scholar] [CrossRef]
- Russell, E.; Kosny, A. Communication and collaboration among return-to-work stakeholders. Disabil. Rehabil. 2019, 41, 2630–2639. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Algorithms | Name of Paper |
|---|---|
| Supervised Learning | Adversarially regularized medication recommendation model with multi-hop memory network [2] Deep learning for electronic health records: a comparative review of multiple deep neural architectures [5] Artificial intelligence analysis of EEG amplitude in intensive heart care [16] Utilizing electronic health records to predict multi-type major adverse cardiovascular events after acute coronary syndrome [17] DWE-Med: dynamic word embeddings for medical domain [18] Scalable and accurate deep learning with electronic health records [19] Predicting the risk of emergency admission with machine learning: development and validation using linked electronic health records [20] GGATB-LSTM: grouping and global attention-based time-aware bidirectional LSTM medical treatment Behaviour prediction [21] Bradykinesia recognition in Parkinson’s disease via single RGB video [23] DMMAM: deep multi-source multi-task attention model for intensive care unit diagnosis [24] Deep dynamic imputation of clinical time series for mortality prediction, information sciences [25] |
| Unsupervised Learning | Heterogeneous network approach to predict individuals’ mental health [1] |
| A hierarchical fusion framework to integrate homogeneous and heterogeneous classifiers for medical decision making [27] |
| Data Category | Name of Fields | Data Type |
|---|---|---|
| Input | Age | |
| Salary | ||
| Sick Leave Total Days (SL) | ||
| Days Until HLM | Continuous | |
| Alertness Score | ||
| Date of Accident (DOA) | ||
| Date of Case Closed | ||
| Injured Body Parts | ||
| Nature of Loss | ||
| Cause | ||
| Industry | ||
| Position | Categorical | |
| Position Physical Demand Level | ||
| Position Handling Frequency | ||
| Output | Form7 PD (PD) | |
| Sick Leave Total Days (SL) | Continuous | |
| Alertness Score | ||
| BLM/HLM | Categorical |
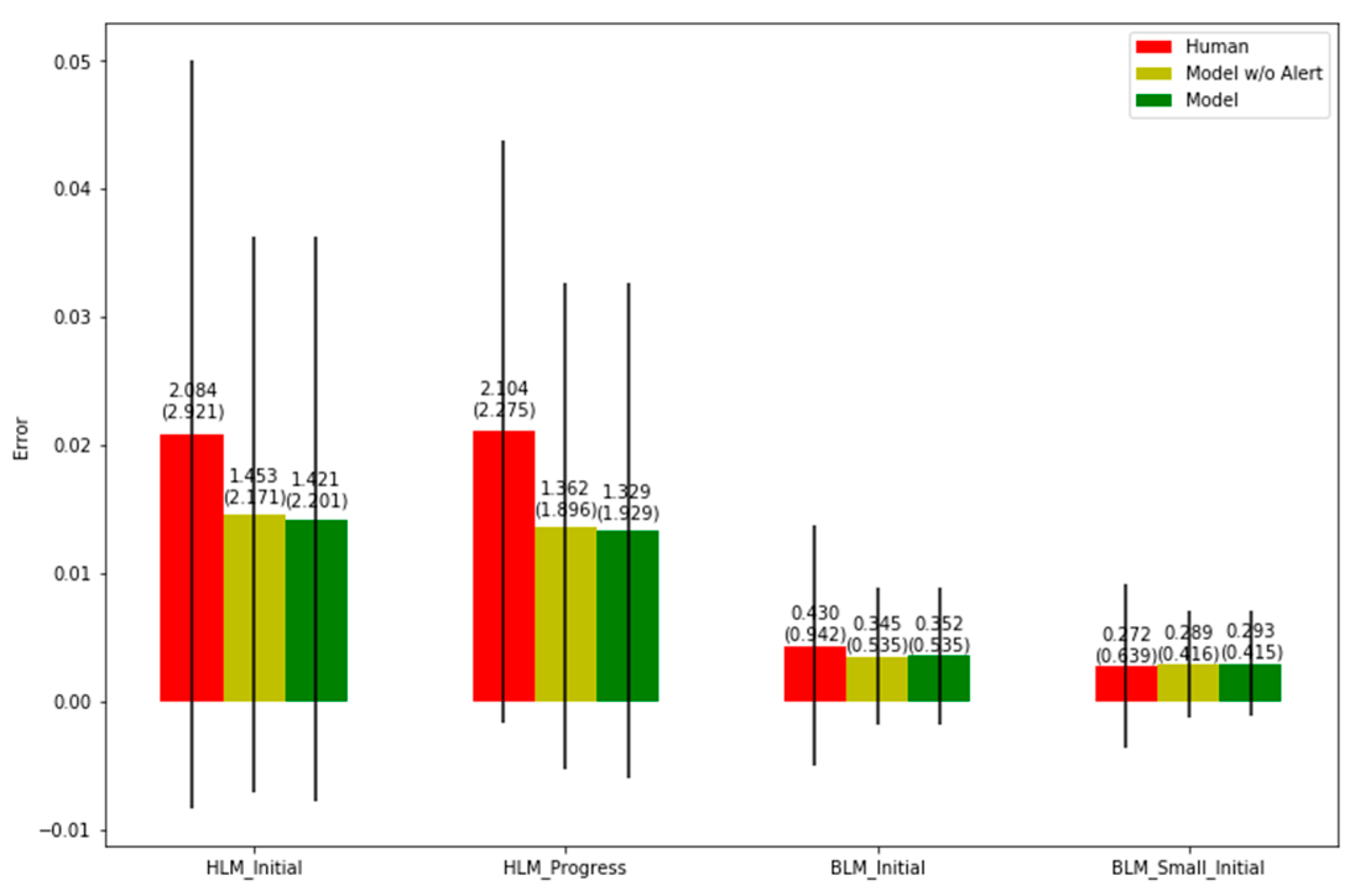
| SL Prediction Error (Days) | PD Estimation Error (%) | |||
|---|---|---|---|---|
| BLM | HLM | BLM | HLM | |
| Model w Alertness | 9.727 | 107.447 | 0.293 | 1.329 |
| Model w/o Alertness | 9.663 | 121.373 | 0.289 | 1.362 |
| Subjective (Human) | 16.344 | 154.857 | 0.272 | 2.104 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ng, P.H.F.; Chen, P.Q.; Sin, Z.P.T.; Lai, S.H.S.; Cheng, A.S.K. Smart Work Injury Management (SWIM) System: A Machine Learning Approach for the Prediction of Sick Leave and Rehabilitation Plan. Bioengineering 2023, 10, 172. https://doi.org/10.3390/bioengineering10020172
Ng PHF, Chen PQ, Sin ZPT, Lai SHS, Cheng ASK. Smart Work Injury Management (SWIM) System: A Machine Learning Approach for the Prediction of Sick Leave and Rehabilitation Plan. Bioengineering. 2023; 10(2):172. https://doi.org/10.3390/bioengineering10020172
Chicago/Turabian StyleNg, Peter H. F., Peter Q. Chen, Zackary P. T. Sin, Sun H. S. Lai, and Andy S. K. Cheng. 2023. "Smart Work Injury Management (SWIM) System: A Machine Learning Approach for the Prediction of Sick Leave and Rehabilitation Plan" Bioengineering 10, no. 2: 172. https://doi.org/10.3390/bioengineering10020172