1. Introduction
1.1. Importance of Daily Discharge Forecasting
The analysis of daily discharge holds significant importance in the field of hydrology and water resource management due to its numerous practical applications. Daily discharge data provides crucial insights into the temporal variations in river flow, enabling effective management of water resources [
1,
2,
3]. The availability of accurate and reliable daily discharge data is crucial for various applications, including flood forecasting, water allocation, irrigation planning, and hydropower generation. Flood forecasting models heavily rely on daily discharge data to assess and predict potential flood events, aiding in disaster management and mitigation strategies [
4,
5,
6,
7]. Water allocation decisions aimed at optimizing water resource distribution among different users depend on accurate daily discharge data [
8,
9,
10]. Moreover, daily discharge data plays a critical role in irrigation planning, ensuring efficient water use in agricultural practices [
11]. Additionally, hydropower generation, a key renewable energy source, relies on accurate daily discharge data to optimize power generation and ensure the sustainability of water resources [
10]. Beyond water resource management, daily discharge data contributes to ecological studies and environmental assessments. It influences the health and functioning of aquatic ecosystems, affecting aquatic biodiversity and species composition [
12,
13]. Overall, the availability of reliable and accurate daily discharge data is paramount for effective water resource management, decision-making processes, and maintaining the ecological integrity of river systems [
14].
1.2. Review of Existing Approaches
The existing approaches for estimating river flow discharge can be generally classified into two main groups: (1) Traditional physical hydrologic/hydraulic models, (2) machine learning models. Physical models for flood calculation take into account various factors such as topography, land use, rainfall data, river network characteristics, and hydraulic properties of the channels and floodplains [
15,
16]. They simulate water flow behavior in river systems and predict flood extents, water levels, and flow velocities [
17,
18]. By simulating the interactions between rainfall, runoff, and river systems, numerical models can provide valuable insights into flood dynamics and help in understanding the potential impacts of flooding. HEC-RAS (Hydrologic Engineering Center’s River Analysis System) [
19,
20], MIKE 11 [
21,
22], SWAT (Soil and Water Assessment Tool) [
23] and are three widely used numerical models in the field of flood prediction. These models offer advanced capabilities, such as providing detailed spatial information on flood inundation, simulating hydraulic behavior, and assisting in flood risk assessment and emergency planning [
24,
25]. However, they do have some limitations. Numerical models require high-resolution input data and substantial computational resources to run effectively [
26]. The calibration and validation process can be time-consuming, as it involves fine-tuning the model to match observed data. Additionally, these models heavily rely on accurate topographic [
25,
26,
27] and bathymetric data, which can pose challenges in areas where such data is limited or unavailable.
Bruno et al. [
19] utilized HEC-RAS and HEC-HMS to examine linked modeling in a small urban waterway. They employed detailed data to simulate flood events in this urban channel. The models were calibrated using historical data spanning 2015 to 2018. The input variables included flow sensors, water level, rain gauges, land cover, land use, and topographic information. Flood scenarios were generated using synthetic rainfall with return times of 5, 10, 50, and 100 years for a specific basin. The calibration process yielded highly accurate models. The authors noted that certain stretches of the channel are naturally predisposed to flooding, which is exacerbated by local conditions and changes in land use and coverage. Filianoti et al. [
20] introduced a novel “performance matrix” to assess flood prediction accuracy achieved by various models, taking into account stakeholders’ opinions and different evaluation parameters. Additionally, they analyzed the advantages and disadvantages of software user experience. The authors evaluated four conceptual physical-based models for predicting floods in a midsized Mediterranean watershed in Southern Italy. According to their findings, HEC-HMS and MIKE 11 emerged as the most favorable computer models. These two models demonstrated superior performance due to their low complexity and computational requirements, alongside their user-friendly interface and accurate flood prediction capabilities. Yang et al. [
23] utilized both hourly and daily rainfall data from a large number of stations as inputs for the SWAT model to simulate daily streamflow. The simulation findings indicated that the SWAT model, when fed with hourly rainfall inputs, outperformed the model with daily rainfall inputs in daily streamflow simulation. The primary reason for this superior performance was its enhanced ability to accurately simulate peak flows.
Recently, attention has been significantly increased towards models based on machine learning techniques in river calculation. These models have the capability to handle nonlinear relationships, capture intricate patterns, adapt to changing conditions, integrate diverse data sources, and effectively learn from historical flood data [
28], meteorological inputs [
29], topographic features [
28], and other relevant variables. The application of machine learning in flood calculation has shown promising results in terms of improved accuracy, efficiency, and scalability [
30]. Machine learning effectiveness is highly dependent on several factors that pose challenges. One such challenge is the need for extensive data preprocessing, including data cleaning, normalization, and feature engineering [
31], to ensure the reliability and quality of the dataset. Furthermore, selecting relevant parameters and identifying the best input combination are critical challenges in applying machine learning techniques to flood calculation [
32,
33,
34,
35]. Another challenge lies in the model selection and tuning process. Various machine learning algorithms can be applied to flood calculation. The choice of the most suitable algorithm depends on the specific characteristics of the dataset and the nature of the problem. Additionally, model tuning, including parameter optimization and regularization techniques, is crucial to achieve the best performance and prevent overfitting or underfitting. Interpretability is another consideration in machine learning models for flood calculation. Interpreting complex machine learning models and extracting actionable insights from them can be a challenge, especially in critical decision-making processes.
In recent years, several machine learning models have been developed that utilize precipitation and temperature data to predict daily discharge, as evident in studies conducted by Kostić et al. [
36], Stoichev et al. [
37], and Stojković et al. [
38]. As these models were evaluated by a variety of samples, they might suffer from certain limitations in peak flood prediction. The complex dynamics of river systems pose challenges for accurately capturing extreme events, which can result in underestimation or overestimation of peak discharge. Additionally, these models may exhibit limited applicability when applied to different geographical areas, as they are often developed and calibrated using data specific to a particular region. Recalibration efforts may be insufficient to overcome the inherent differences in hydrological processes across diverse locations. Another limitation is the constrained input selection and problem formulation in non-machine learning models. Additional variables, such as flow rate or average flow rate, cannot be readily included. This lack of flexibility restricts the model’s ability to incorporate valuable information and potential predictors. In contrast, machine learning models offer greater flexibility in defining inputs and have the capability to incorporate a wider range of variables. This adaptability allows researchers to include historical parameters and relevant meteorological variables in the modeling process, which can contribute to improved accuracy. By leveraging machine learning algorithms, the model can capture complex relationships and patterns in the data, leading to enhanced performance in daily discharge forecasting tasks.
In the realm of hydrology, Long Short Term Memory (LSTM) has gained significant popularity as a prominent deep learning approach, particularly for rainfall-runoff prediction. Nevertheless, there is a growing interest in employing techniques capable of addressing the problem through straightforward associations. Among these methods is the group method of data handling (GMDH). The GMDH has several potential benefits over LSTM networks. Here are some key differences and advantages of GMDH in contrast to LSTM:
Interpretability: GMDH is known for its transparent and interpretable nature. It builds a set of polynomial regression equations that explicitly represent the relationships between input variables and the output. This allows for easy interpretation and understanding of how each input variable contributes to the final prediction. In contrast, LSTM is a black-box model, and it can be challenging to interpret how the model arrives at its predictions, making it less transparent.
Data Efficiency: GMDH is known for its ability to handle smaller datasets effectively. It can create complex models with high accuracy even when the data is limited. LSTM, on the other hand, typically requires large amounts of data for training to achieve good generalization, which might be a limitation in scenarios where data availability is scarce.
Computational Efficiency: GMDH is generally computationally efficient and can rapidly derive models based on its self-organizing algorithm. LSTM, being a deep learning model, requires more computational resources and time for training, especially when dealing with large datasets and complex architectures.
Overfitting: GMDH is less prone to overfitting due to its self-organizing feature selection mechanism, which helps it find the best set of input features for a given problem. LSTM, on the other hand, can be prone to overfitting, especially if the model architecture is complex and the dataset is limited.
Feature Selection: GMDH automatically performs feature selection by determining the most relevant input variables for the model. In contrast, LSTM typically requires manual feature engineering, and selecting the most important features can be a challenging and time-consuming task.
Model Complexity: GMDH can build relatively simple and interpretable models that can be useful for some applications, especially when transparency and simplicity are desired. LSTM, as a deep learning model, has a higher level of complexity.
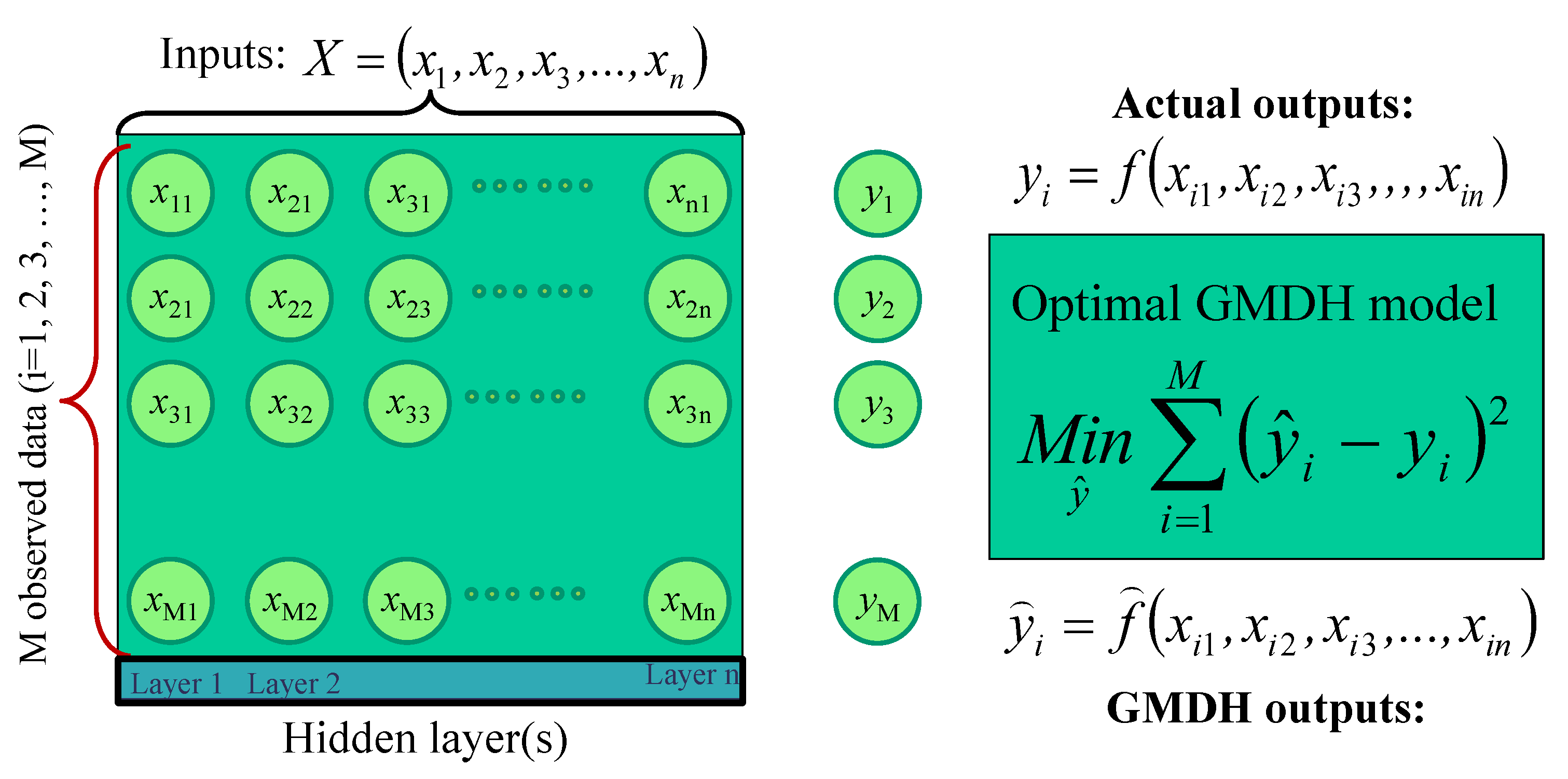
Previous research has shown that the Group Method of Data Handling (GMDH) technique can capture the nonlinear relationships between independent variables and the dependent variable [
39]. However, this technique has certain limitations when applied to daily river flow prediction. Some limitations of the classical GMDH in daily river flow predictions are as follows:
Limited polynomial structure: The classical GMDH is restricted to first-order polynomials, which may not capture complex nonlinear relationships adequately. In contrast, the ASGMDH introduces a new polynomial scheme that allows for the inclusion of second and third-order polynomials, providing more flexibility and enhancing the model’s ability to capture nonlinear dynamics.
Fixed number of inputs: The classical GMDH has a fixed number of inputs in each polynomial, which limits its capacity to consider a broader range of variables. In ASGMDH, the number of inputs can vary, allowing for more comprehensive modeling by incorporating two or three different inputs in each polynomial.
Limited model types: The classical GMDH only offers 2nd-order polynomial models, which may not be sufficient to capture higher-order interactions and complex relationships in the data. ASGMDH introduces second and third-order polynomial models, resulting in a total of four model types, providing a more diverse and comprehensive range of modeling options.
To overcome these limitations, a modified version called the Adaptive Structure of GMDH (ASGMDH) has been introduced in this study. The ASGMDH not only modifies the main structure of the polynomial used in the classical GMDH but also incorporates a feature selection technique, improving the model’s performance and flexibility. The new polynomial scheme in ASGMDH allows for the inclusion of second and third-order polynomials with two or three different inputs in each polynomial. This leads to creating four distinct types of models, enabling a more comprehensive representation of the underlying relationships between variables. The authors have done the generalization structure of the GMDH in the projection of different hydrological variables, such as flood forecasting at the Saint-Charles River [
40], daily water level prediction [
41], forecasting monthly fluctuations of lake surface [
42].
1.3. Research Objectives
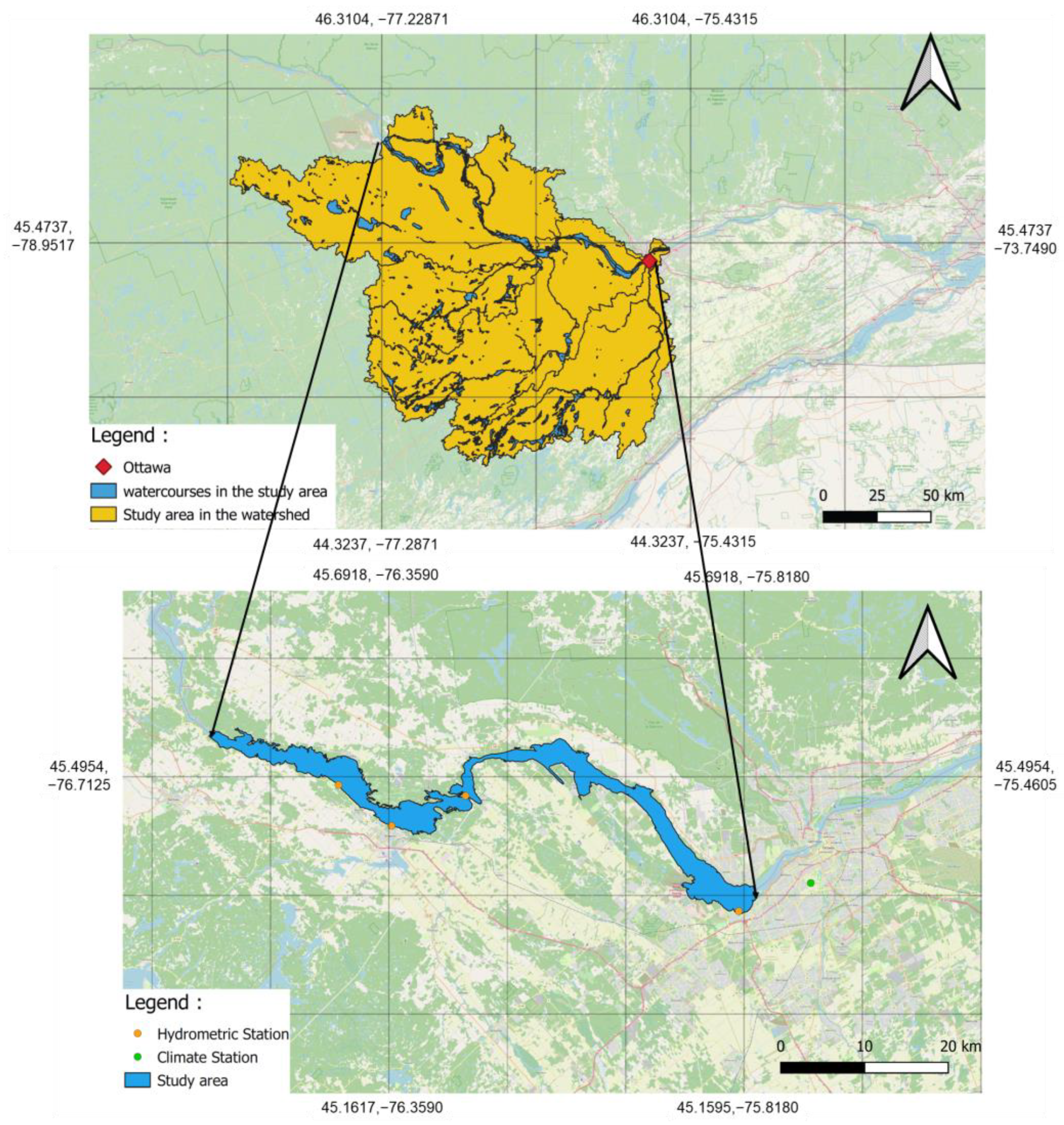
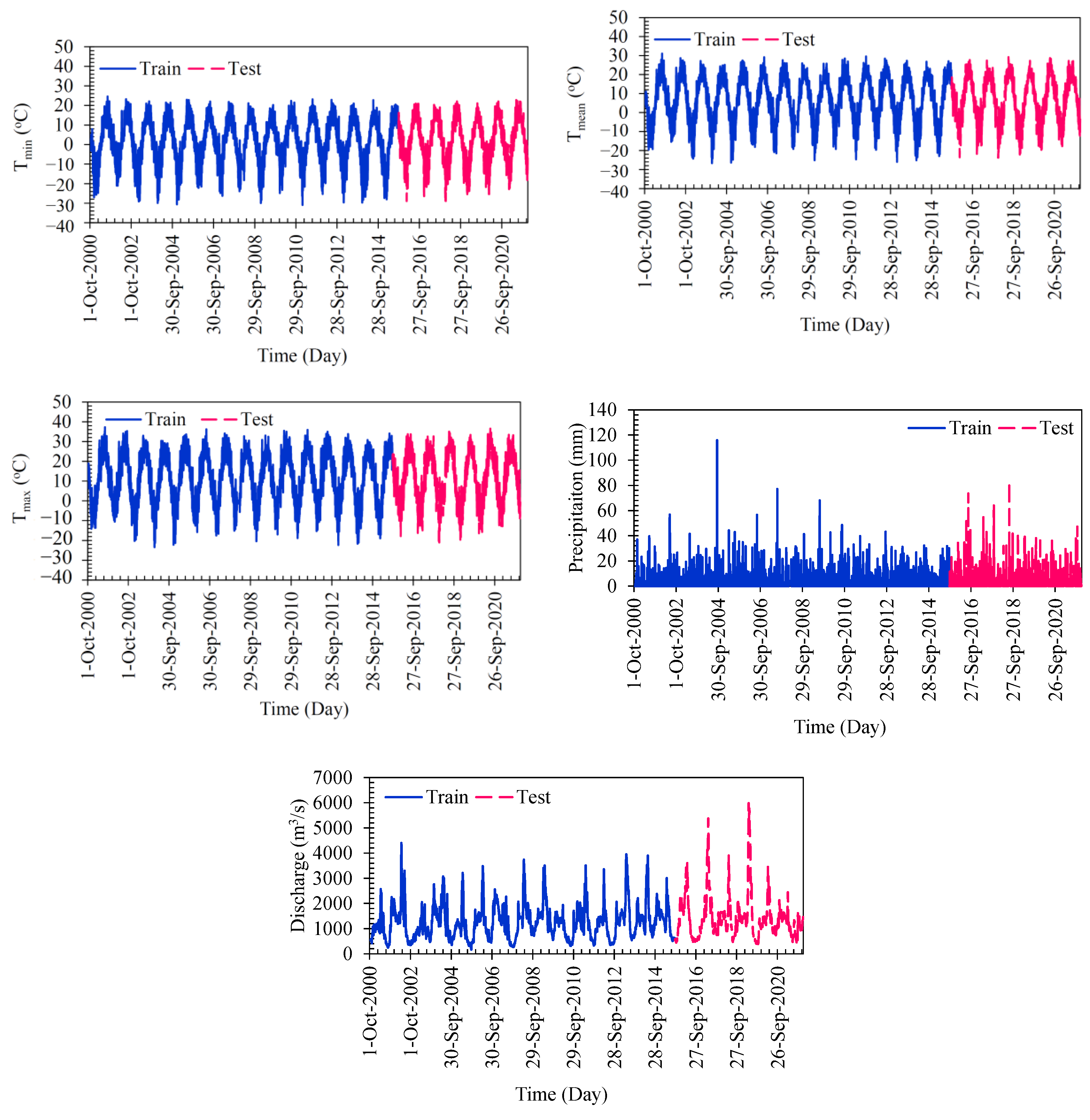
The main objective of this study is to develop a practical model for daily river flow modeling by fusing machine learning algorithms. In this study, the input variables used for daily river flow discharge forecasting include minimum, mean, and maximum temperature, precipitation, and discharge with a single lead time. The dataset utilized for model training and evaluation was collected from 21 October 2000, to 31 December 2021, encompassing a total of 7546 samples. Once the ASGMDH model was calibrated, its performance was thoroughly assessed through qualitative and quantitative evaluations. Additionally, uncertainty and reliability analyses were conducted to further scrutinize the model’s performance and provide insights into its reliability in real-world applications. Furthermore, the sensitivity of the developed model to each of the input variables was examined using partial derivative sensitivity analysis, enabling a better understanding of the significance of each variable in the modeling process. These comprehensive assessments and analyses contribute to a thorough understanding of the ASGMDH model’s capabilities and provide valuable insights for its practical application in daily river flow forecasting, supporting water resource management, and decision-making processes.
3. Results and Discussions
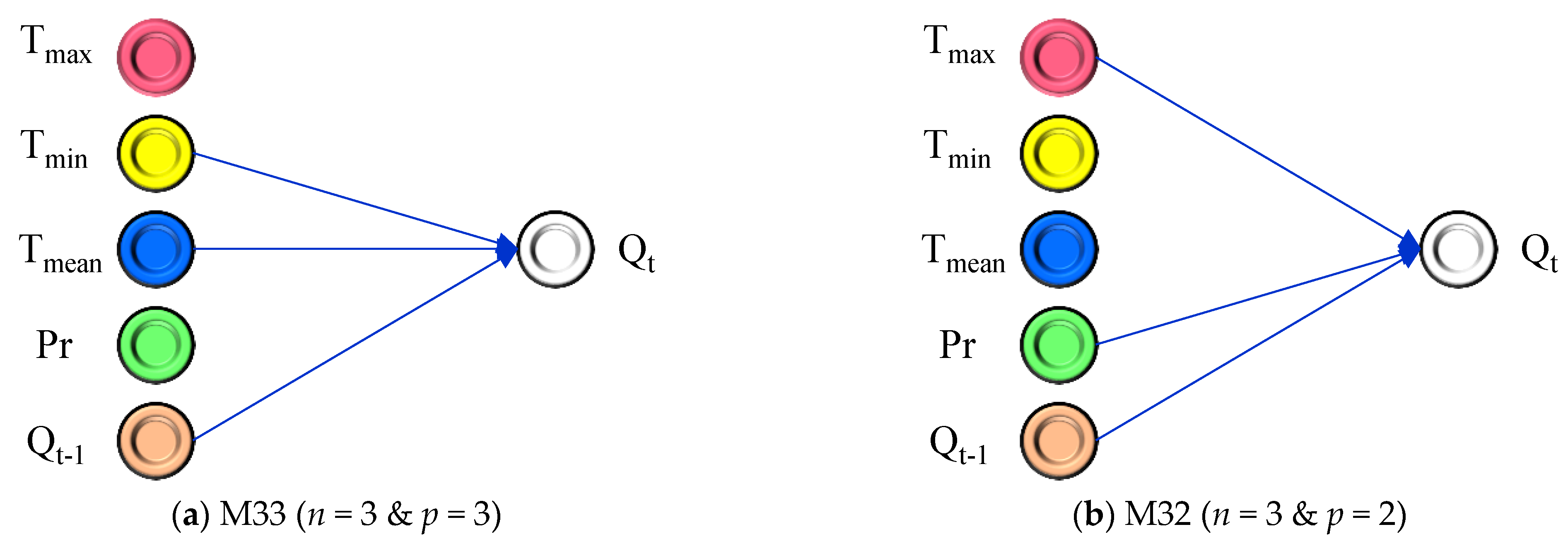
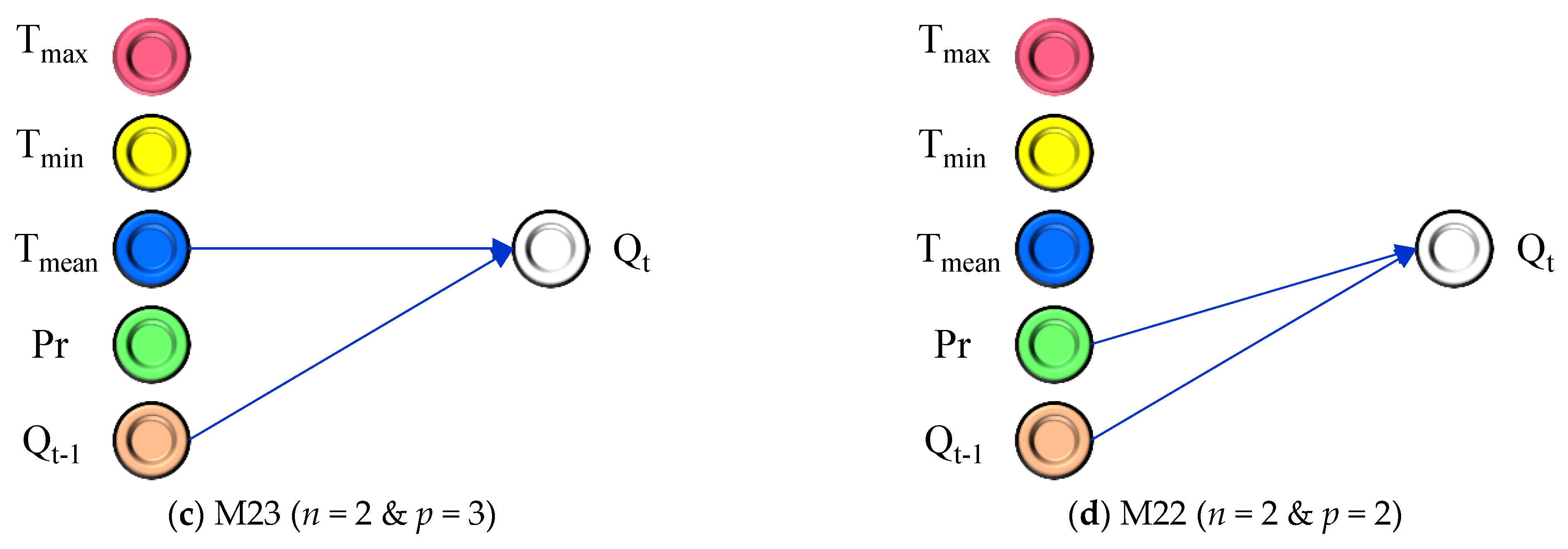
The river flow prediction in this study involved the consideration of five different inputs. These inputs included the measured discharge from the previous day, which served as a historical record summarizing watershed characteristics. Additionally, real-time data on air temperatures (minimum, maximum, and mean) and precipitation were incorporated. The development of the Adaptive algorithm, known as ASGMDH, introduced significant improvements to the traditional GMDH approach. ASGMDH allowed for the inclusion of second and third-order polynomials, with two or three different inputs in each polynomial. This enhancement resulted in four distinct scenarios, as illustrated in
Figure 4. These scenarios not only improved the main structure of the polynomial used in the classical GMDH but also incorporated a feature selection technique. This feature selection technique enhanced the model’s performance and flexibility.
Figure 4 demonstrates the different combinations of variables used in each scenario. In the case of model M33, T
min, T
mean, and Q
t−1 were utilized to predict the output, employing a polynomial equation with a degree of three. In M32, T
max, Pr, and Q
t−1 were used with a polynomial equation of degree two. For model M23, T
mean and Q
t−1 were combined in a polynomial equation of degree three. Lastly, in model M22, Pr and Q
t−1 were employed with a polynomial equation of degree two. By incorporating these different scenarios, the ASGMDH model demonstrated improved adaptability and accuracy in predicting river flow. The selection of specific variables and the utilization of polynomial equations with varying degrees contributed to the model’s effectiveness in capturing the complex relationships within the data. As highlighted in
Figure 4, it is evident that all the models have a single layer in their final structure. However, there are three key differences in the structure of these developed models: (i) the number of inputs in the generated polynomial, (ii) the polynomial degree for each one, and (iii) the type of input variables. Referring to
Figure 4, the models with three inputs are M33 (Equation (13)) and M32 (Equation (14)), while the models with two input variables are M23 (Equation (15)) and M22 (Equation (16)). Additionally, the models M32 (Equation (14)) and M22 (Equation (16)) employ 2nd-order polynomials, whereas the models M33 (Equation (13)) and M23 (Equation (15)) utilize 3rd-order polynomials.
In the case of input variables for river flow discharge forecasting, it is observed that the selected inputs from the five provided options are below the maximum limit. Across all the developed models, which vary in polynomial types and the allowed number of inputs in each polynomial, different inputs have been identified as the most influential variables for daily river flow forecasting.
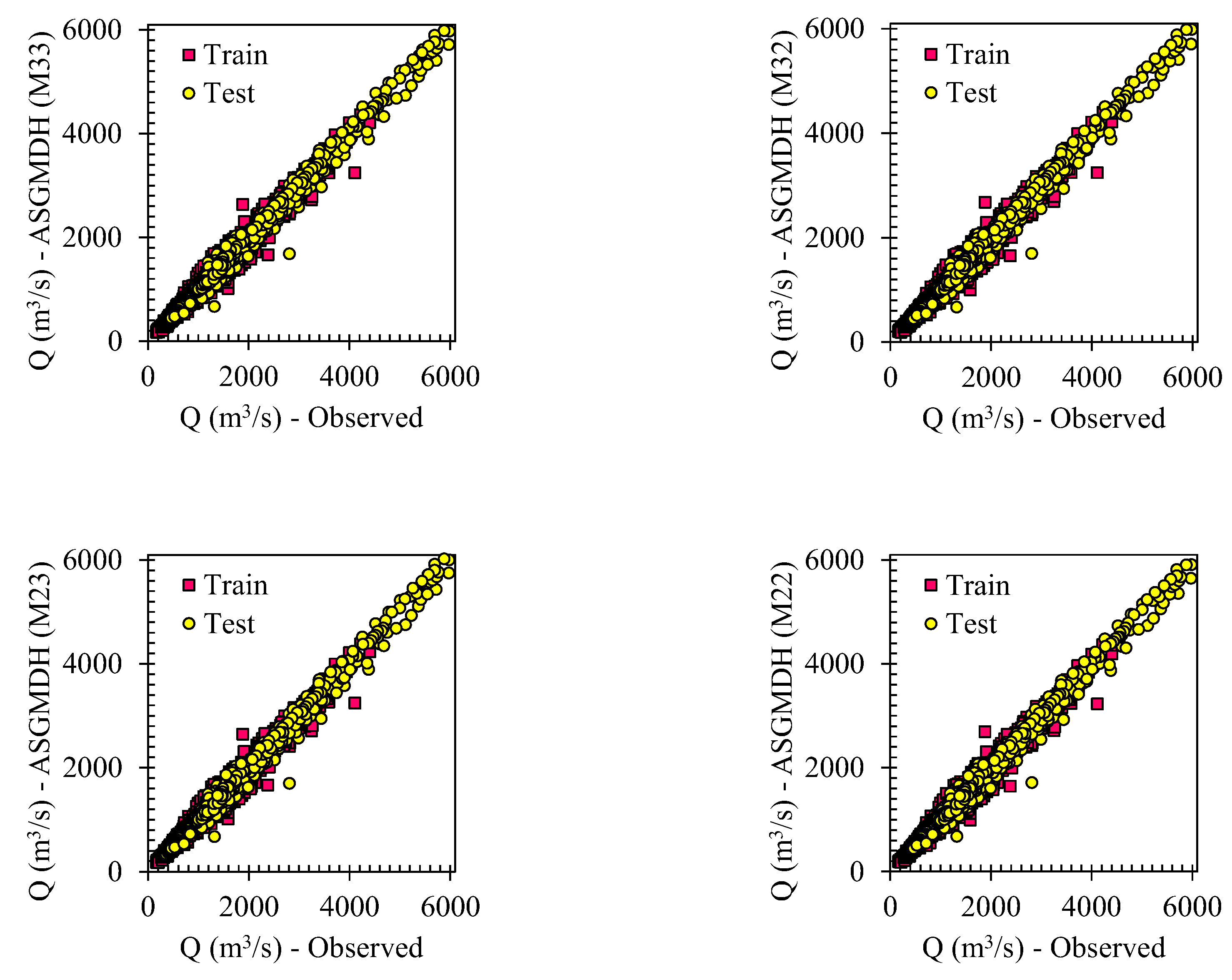
Scatter plots depicting the daily river flow discharge for four ASGMDH-based models during both the training and testing stages are presented in
Figure 5. The grand line in the scatter plot represents a perfect match between the observed daily discharge values (Q) and the predicted values from all four equations in the train and test stages. A diagonal line signifies a strong positive linear relationship between observed and predicted values. Closer proximity to the grand line indicates a higher degree of agreement and a better fit of the equation to the observed data. The predicted values in all four scenarios follow almost the same prediction pattern compared to the observed values. The similarity in prediction patterns suggests that all four equations are capable of capturing the underlying patterns and trends in the observed daily discharge. This consistency in predictions further supports the reliability and effectiveness of the equations in estimating the daily discharge values.
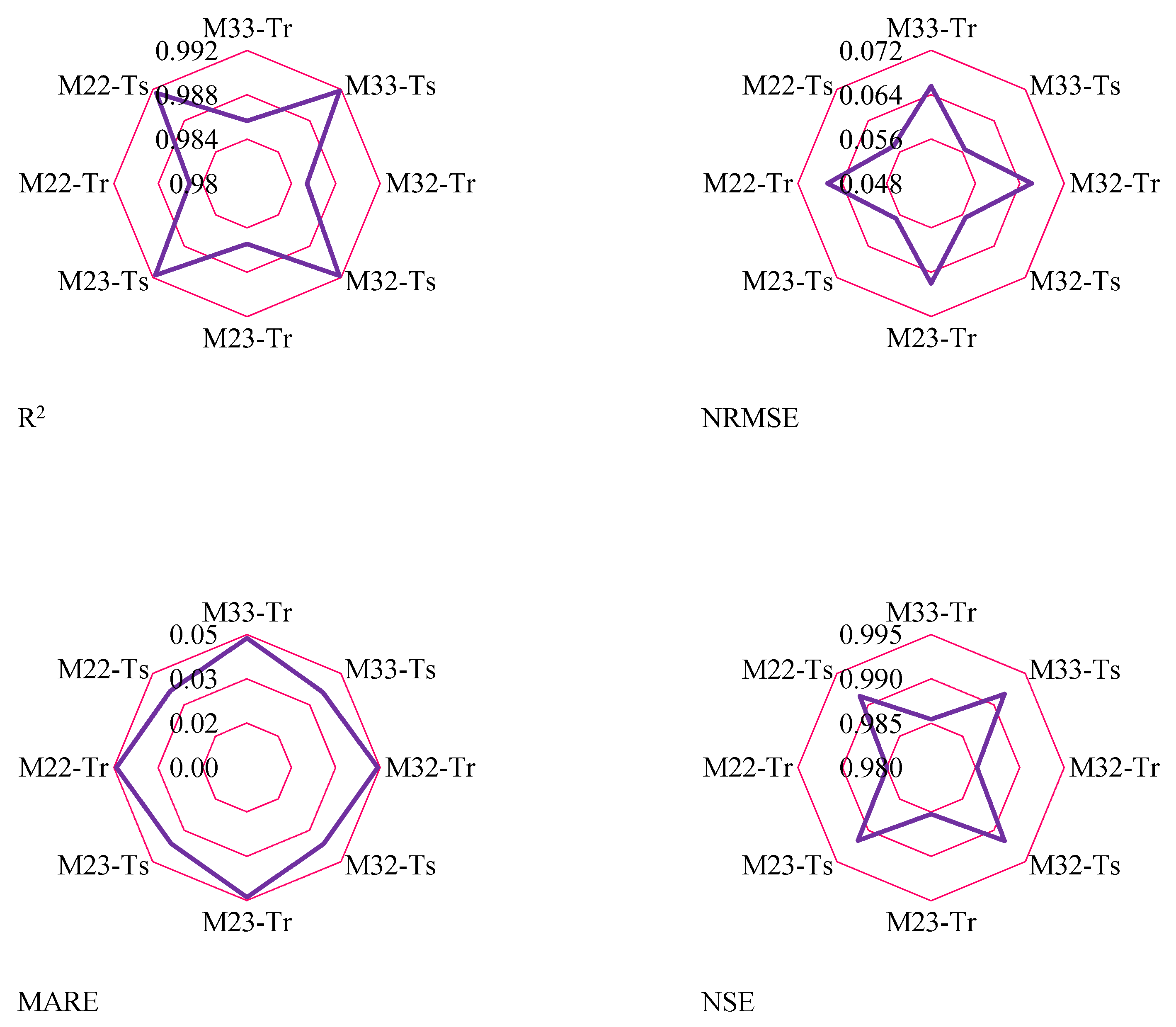
Figure 6 displays the statistical indices for the ASGMDH-based models developed for daily river flow forecasting. The R
2 values for all models and datasets range from 0.985 to 0.992, indicating a strong correlation between the predicted and observed river flow values. The models explain a significant portion of the variance in the data, suggesting their effectiveness in capturing the underlying patterns. The NRMSE values for all models and datasets are relatively low, ranging from 0.057 to 0.067. This indicates that the models have a good level of accuracy in predicting river flow values, with small deviations from the observed data. The MARE values for all models and datasets range from 0.036 to 0.044, indicating a low average relative error in the predictions. The models perform well in estimating the river flow values with good precision. The NSE values for all models and datasets are high, ranging from 0.985 to 0.992. This indicates a strong agreement between the predicted and observed values, highlighting the models’ ability to accurately reproduce the observed river flow patterns. Overall, the statistical indices demonstrate the strong performance and accuracy of the developed models. The high R
2, low NRMSE, MARE, and high NSE values indicate that the models can effectively capture the relationships between the input variables and river flow, providing reliable predictions. These results validate the effectiveness of the proposed ASGMDH approach for daily river flow modeling and emphasize its potential for practical applications in water resource management and decision-making processes.
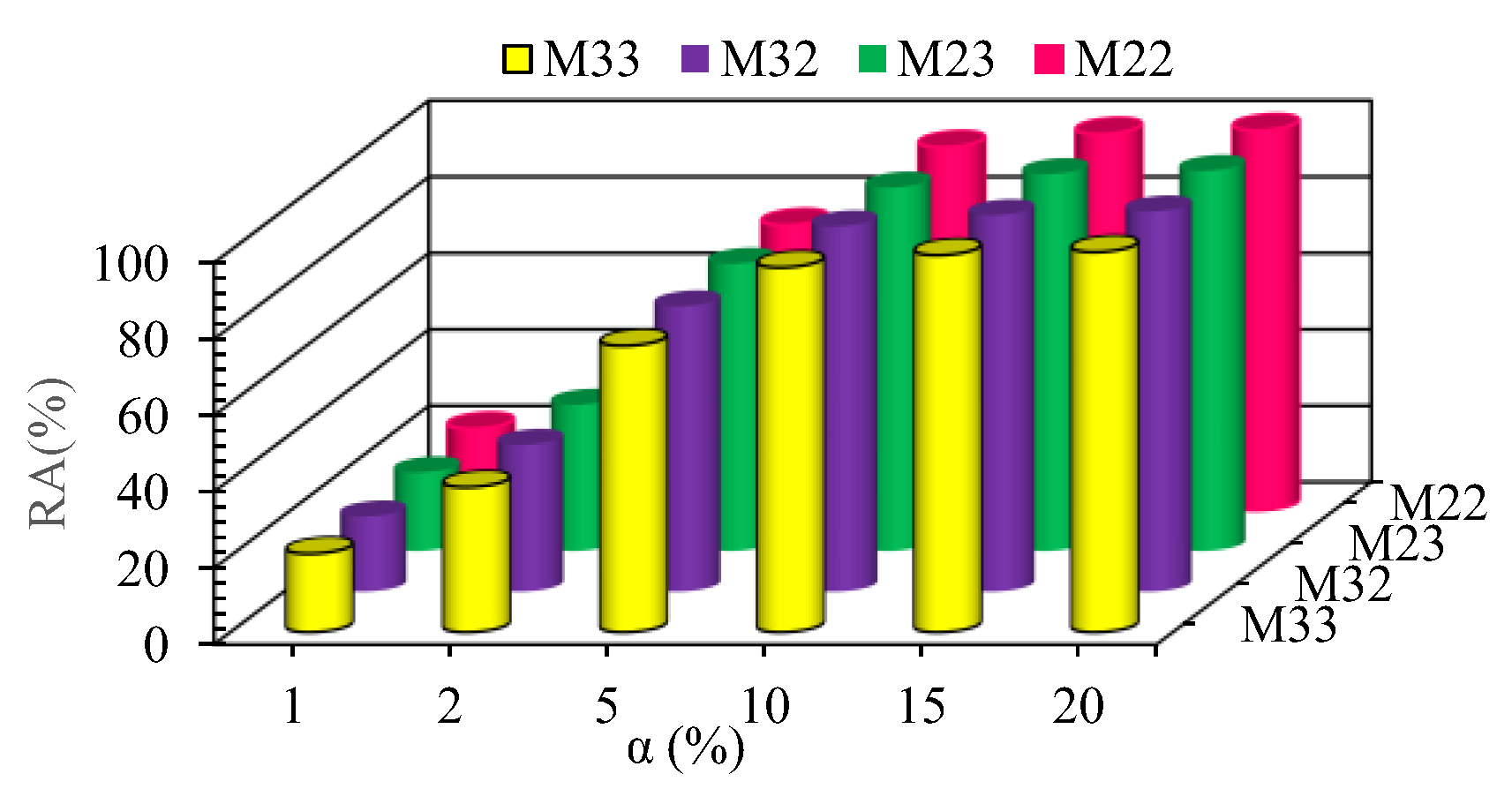
Figure 7 illustrates the reliability analysis results conducted for the ASGMDH-based models, considering different values of α as provided in Equation (15). The figure reveals a clear correlation between the α value and the reliability analysis (RA) value. Specifically, the models exhibit the highest (or lowest) RA values corresponding to the highest (or lowest) α values. Notably, the α values experience a relatively modest increase of less than 10%. For α values greater than or equal to 10, all models demonstrate an RA value exceeding 95%. These findings indicate the satisfactory performance of the presented ASGMDH models in accurately predicting daily river flow discharge. The RA values in
Figure 7 offer more detailed insights into the model’s predictive performance. Approximately 20% of all predicted samples during the test mode exhibited a relative error of less than 1%, while 38% demonstrated a relative error of less than 2%. Furthermore, a significant proportion of samples, approximately 75%, exhibited a relative error of less than 5%. These results showcase the models’ ability to provide accurate predictions within a narrow margin of error. Additionally, the reliability analysis shows that more than 95% of all predicted samples during the test mode had a relative error of less than 10%. Moreover, approximately 98% of the samples demonstrated a relative error of less than 15%, while 99% exhibited a relative error of less than 20%. These findings indicate the high reliability and effectiveness of the developed ASGMDH models in accurately forecasting daily river flow discharge. The robust performance of the models, as evidenced by the high percentage of samples falling within the desired relative error thresholds, confirms their reliability in real-world flood prediction scenarios. These results provide valuable information to decision-makers in water resource management and related fields, as they can rely on the ASGMDH-based models to make informed decisions and implement effective flood mitigation and response strategies.
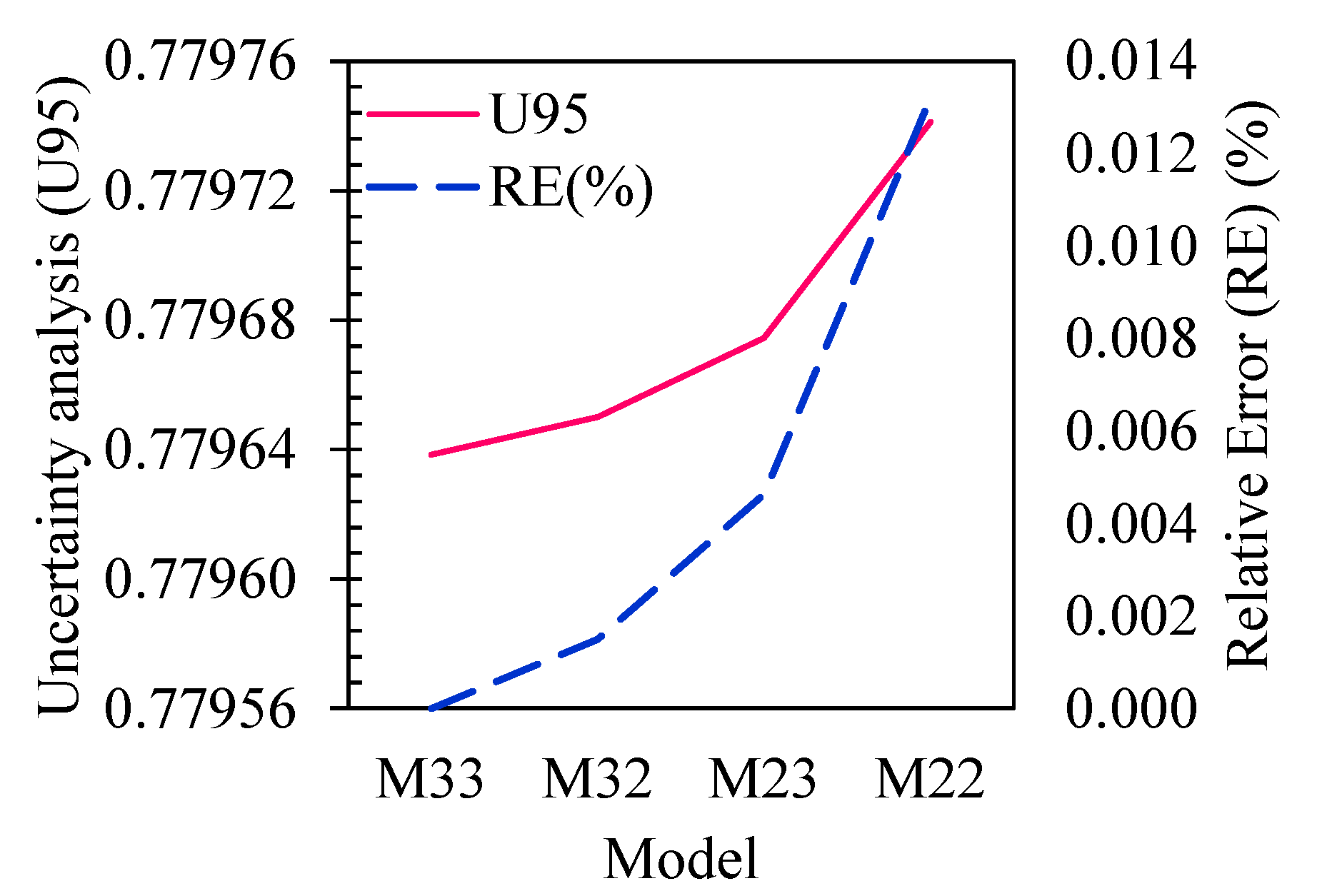
The U95 value is a measure of uncertainty and represents the upper 95% prediction interval around the predicted values. In the context of the ASGMDH-based models for daily river flow discharge, a lower U95 value indicates a narrower prediction interval. It suggests a higher level of confidence in the model’s predictions.
Figure 8 presents the outcomes of the uncertainty analysis conducted on the ASGMDH-based models. The results showcase notable differences in the U95 values among the different models. Particularly, model M33, which is the most complex with 20 terms, exhibits the lowest U95 value, indicating higher confidence in its predictions. On the other hand, the simplest model, M22, consisting of only six terms, displays the highest U95 value, indicating a larger uncertainty in its predictions. A noteworthy comparison arises between two models of similar complexity, namely M33 and M32, consisting of ten terms. Surprisingly, M32, which employs a second-order polynomial with three inputs, demonstrates a lower U95 value compared to M23, which employs a third-order polynomial with two inputs. This unexpected result suggests that the predictive performance of M32 is superior, despite its lower model complexity. Furthermore, when comparing the U95 values of different models with the benchmark model M33, it is observed that the relative error values for all three cases are negligible, measuring less than 1%. These findings emphasize the high accuracy and reliability of the ASGMDH models in predicting daily river flow discharge, even for the models with lower complexity. Consequently, these results instill confidence in the effectiveness of the developed models and their capability to deliver accurate predictions with minimal uncertainty.
After evaluating the different developed models using the ASGMDH method, a model based on classical GMDH is introduced to facilitate a comparison with existing methods.
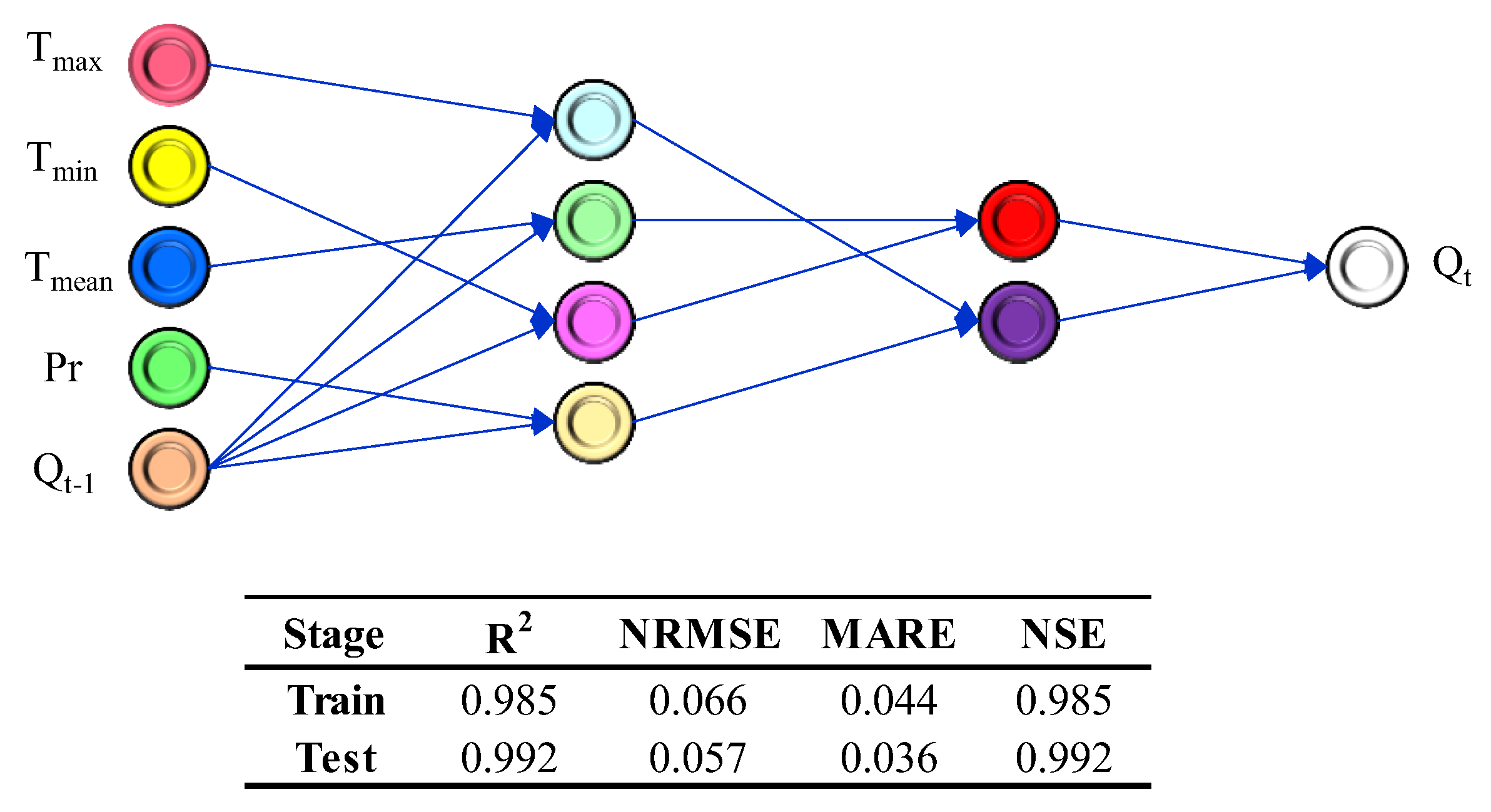
Figure 9 represents the final structure of the classical GMDH model and its accuracy, where all input variables (T
max, T
min, T
mean, Pr, Q
t−1) are included. The high R
2 values indicate a strong correlation between the observed and predicted values in the training and testing stages. The low values of NRMSE and MARE suggest that the model has a small overall error, with the predicted values being close to the observed values. The NSE value of 0.985 in the training stage and 0.992 in the testing stage indicate a good model fit, where values close to 1 indicate a high level of accuracy.
However, in the presented ASGMDH models (Equations (17)–(20)), only two or three inputs are included in the final model structure. This indicates that the classical method, constrained by its limitations, fails to produce a simpler model. In contrast, the ASGMDH method employs the corrected Akaike Information Criterion (AICc) for small sample sizes to determine the final model structure, taking into account both model complexity and accuracy. This inherent feature selection capability of ASGMDH, combined with AICc, results in a simpler model with improved predictive performance. Adopting the AICc index provides a robust and objective approach for model comparison. By considering both simplicity and accuracy, it ensures that the selected model not only captures the underlying relationships in the data but also avoids overfitting and unnecessary complexity.
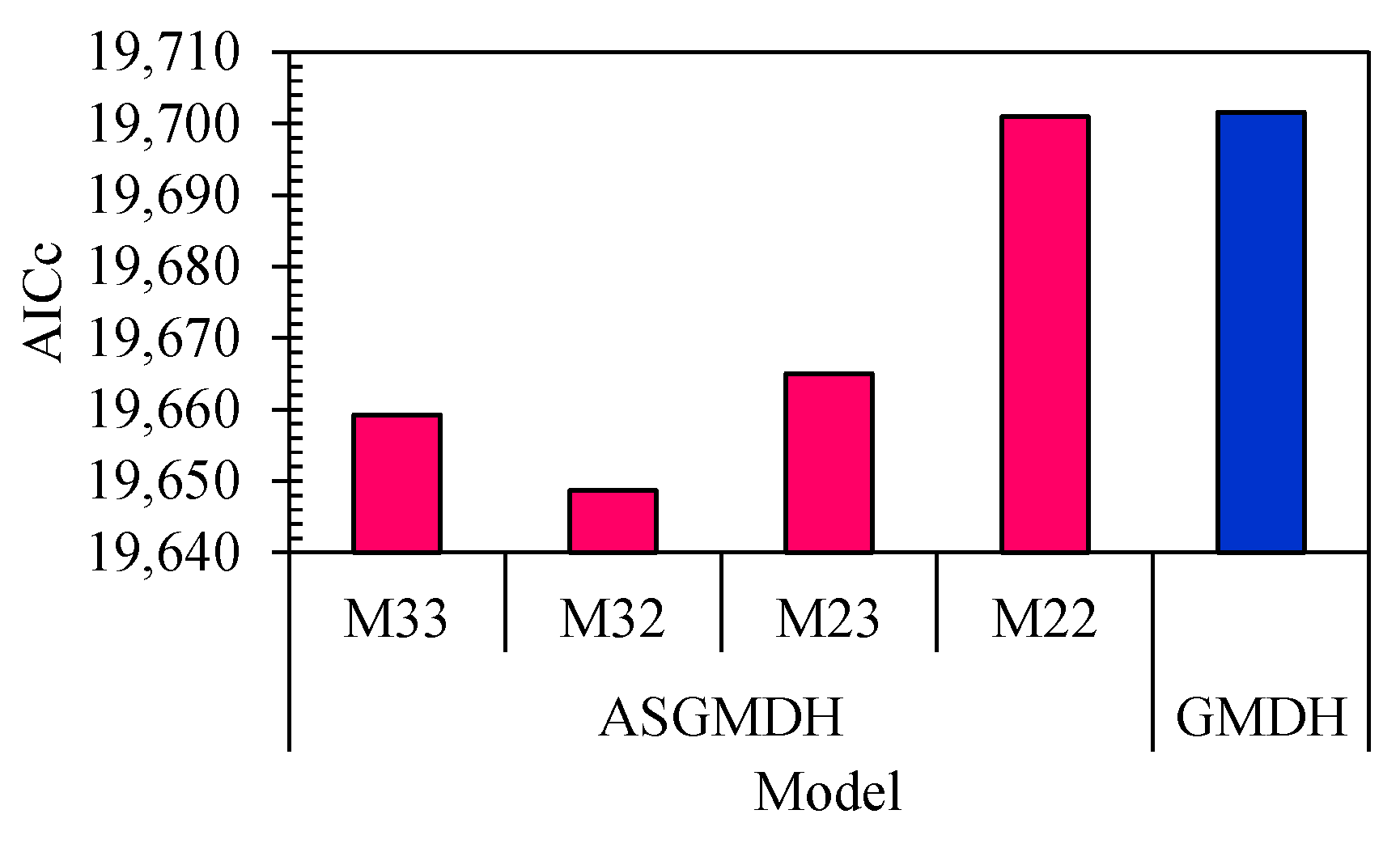
To ensure a fair comparison between the classical GMDH and ASGMDH models, the AICc index, which accounts for both simplicity and accuracy, is employed. The results depicted in
Figure 10 clearly indicate that the majority of ASGMDH models have smaller AICc values compared to the GMDH model. This implies that the ASGMDH models achieve a better balance between model complexity and accuracy. Among the presented ASGMDH models, the lowest AICc value is attributed to M32, with a value of 19,648.71. Consequently, based on the AICc criterion, M32 is identified as the superior model in this study. The superiority of M32 based on the AICc criterion highlights the effectiveness of the ASGMDH method in producing a simpler yet accurate model for predicting daily river flow discharge. It is important to highlight that both models demonstrate exceptional speed in forecasting daily flow discharge. The execution time for each model is impressively quick, taking less than 2 s to complete.
To examine the changing pattern of daily river flow discharge in relation to the input variables in the ASGMDH-based model (M32), the analysis of sensitivity using the partial derivatives (PDSA) technique is utilized [
53,
54,
55]. This approach entails assessing the sensitivity of the outcomes by measuring the partial difference between the output variable (Q
t) and each individual input variable (T
max, Pr, Q
t−1). Notably, a larger partial derivative value indicates a more significant impact of the input variables on the results. When the partial derivative is positive, an increase in the input variables corresponds to a rise in the output variable, and vice versa. This approach of utilizing the PDSA technique provides valuable insights into the changing patterns of daily river flow discharge concerning the input variables. By quantifying the sensitivity of the model outputs, it enables a deeper understanding of the influence of each input variable, namely maximum temperature (T
max), precipitation (Pr), and previous discharge (Q
t−1), on the resultant river flow discharge (Q
t). The magnitude and direction of the partial derivatives help identify the relative importance and directionality of the impacts.
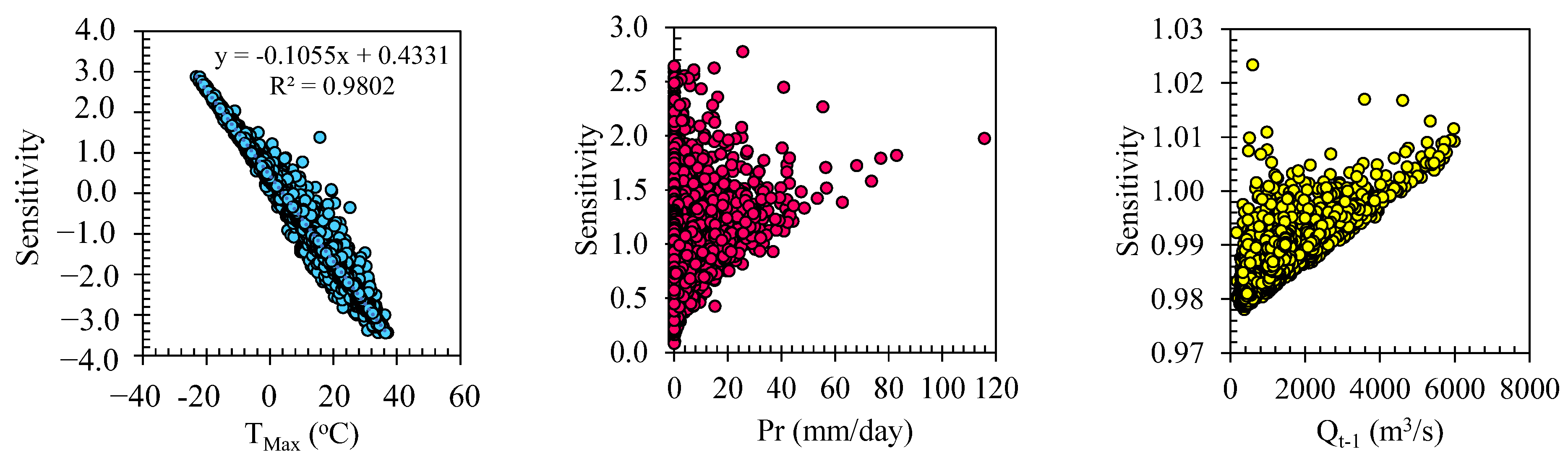
This sensitivity analysis sheds light on the intricate dynamics between the maximum temperature and river flow discharge in the ASGMDH-based model (M32). The observed linear relationship, with a negative slope, emphasizes the role of the maximum temperature as a critical driving factor for changes in daily flow discharge. Understanding this relationship enables researchers and practitioners to anticipate the effects of temperature variations on river systems and their potential impact on water resources management and flood risk assessment. These findings provide valuable insights into the model’s sensitivity and contribute to a more comprehensive understanding of the complex interplay between temperature and river flow dynamics.
Figure 11 illustrates the sensitivity analysis of the ASGMDH-based model (M32) concerning the input variables utilized in the model. The graph displays the partial derivatives that reflect the sensitivity of the relationship investigated in this study, particularly concerning the maximum temperature. Overall, it can be observed that positive values of the maximum temperature correspond to negative sensitivity values, whereas negative values of the maximum temperature yield positive sensitivity values. This indicates a linear relationship with a slope of −0.1 between the maximum temperature threshold and sensitivity. As a result, when dealing with negative maximum temperature values, increasing the variable value lead to an increase in the flow discharge. Conversely, within the range of positive values, an increase in the maximum temperature result in a decrease in the daily flow discharge value calculated by the model. Indeed, suppose the model assigns greater importance to the maximum temperature value than the actual recorded value. In that case, it can lead to lower calculated flow discharge c than the expected values. This discrepancy occurs because the model becomes more sensitive to changes in the maximum temperature parameter, causing it to disproportionately influence the overall flow discharge prediction.
Among the variables examined, the maximum temperature demonstrates the highest sensitivity. The sensitivity values associated with the maximum temperature show a clear linear relationship, with negative values for positive maximum temperature values and positive values for negative maximum temperature values. This indicates that an increase in the maximum temperature leads to a decrease in the daily flow discharge, while a reduction in the maximum temperature corresponds to a rise in the discharge. Regarding precipitation, the sensitivity values consistently exhibit positive values across all ranges. For small precipitation values (Pr < 10 mm), the sensitivity values vary within the range of [0, 3]. As the precipitation value increases, the sensitivity becomes more constrained within the narrower range of [1, 2]. This suggests that precipitation positively impacts daily flow discharge, with larger precipitation events having a relatively more pronounced effect. Similarly, the sensitivity analysis reveals that Qt−1, the previous day’s flow discharge, also exerts a positive influence on the current day’s discharge. The sensitivity values for Qt−1 range from 0.97 to 1.03, indicating a relatively smaller sensitivity range compared to the other two variables. Nevertheless, an increase in the previous day’s discharge corresponds to a rise in the current day’s discharge, although the magnitude of this increase may vary across different domains. The sensitivity analysis on the input variables utilized in the developed ASGMDH-based model for daily river flow discharge prediction reveals that the maximum temperature exhibits the highest sensitivity among the variables. Following that, precipitation and Qt−1 rank as the second and third most influential variables, respectively.
4. Conclusions
This study highlights the significance of understanding flood prediction and management’s underlying factors and dynamics. Using the Adaptive Strcutre of Group Method of Data Handling (ASGMDH) model, with its explicit equations and optimization capabilities, valuable insights and accurate predictions were obtained. Notably, the sensitivity analysis revealed that the maximum temperature exhibited the highest sensitivity among the variables, followed by precipitation and Qt−1. This emphasizes the importance of considering temperature fluctuations and precipitation patterns when predicting and managing floods. Reliability and validity were ensured through a comprehensive reliability analysis, confirming the robustness of the proposed model. Furthermore, the uncertainty analysis of the ASGMDH models revealed notable differences in the U95 values across different models. Interestingly, the most complex model displayed the lowest U95 value, indicating its ability to provide more precise predictions. In addition, simpler models with fewer terms demonstrated superior predictive performance, suggesting that model complexity alone does not guarantee accuracy. This highlights the importance of model selection based on both complexity and accuracy considerations. Additionally, comparing ASGMDH models with the classical GMDH model using the AICc index demonstrated the superiority of the ASGMDH models. The ASGMDH models consistently outperformed the classical GMDH model, as indicated by their lower AICc values. The ASGMDH-based model shows a second-order polynomial (AICc = 19,648.71) in its final form, while the classical GMDH-based model has seven second-order polynomials (AICc = 19,701.56). This indicates that the ASGMDH models strike a better balance between accuracy and model complexity, offering a more robust and efficient approach for daily river flow discharge prediction. These models offer a reliable tool for water management practitioners and decision-makers, facilitating effective planning and decision-making in various water management applications. By gaining a deeper comprehension of the influence of temperature and the occurrence of spring floods, researchers and practitioners can enhance the effectiveness and applicability of machine learning techniques in flood prediction and management. The findings of this study highlight the importance of considering temperature fluctuations, precipitation levels, and historical discharge data in flood modeling. These insights, along with the reliable predictions provided by the ASGMDH model, empower decision-makers to make more accurate and effective decisions in flood management strategies, leading to improved mitigation and adaptation measures in the face of increasing flood risks. Given the valuable insights provided by the current study into historical discharge patterns, it is essential to consider the potential impact of climate change on the reliability and applicability of this model in the future. Therefore, as a natural extension of this research, the next step will comprehensively evaluate the developed model under various climate change scenarios. This evaluation will encompass the incorporation of climate projections and the utilization of the developed machine learning model, which has demonstrated promising capabilities in the current study. By integrating climate projections and advanced modeling techniques, we aim to assess the sensitivity of the model to changing climatic conditions and its ability to accurately predict future discharge patterns. This investigation is crucial, particularly for flood-prone areas along the Ottawa River, as it will enhance our understanding of the hydrological dynamics and provide a solid foundation for developing more robust and adaptive hydrological models in the face of an uncertain climate future. Moreover, this evaluation will enable us to identify the key drivers of change in discharge patterns, including the influence of climate dynamics and the intricate interactions within hydrological processes. By employing a numerical model, we can quantitatively analyze the interplay between these factors and gain insights into the mechanisms that govern the river’s response to changing climatic conditions.
The ultimate goal of this research is to improve our understanding of the Ottawa River’s hydrological behavior and its vulnerability to climate change. Refining and validating the model through this evaluation can enhance its reliability and applicability in flood forecasting and water resource management. This knowledge will empower decision-makers and stakeholders with valuable information to mitigate risks, develop effective adaptation strategies, and safeguard communities in the face of an uncertain climate future.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}