
Reservoir Capacity Estimation by the Gould Probability Matrix, Drought Magnitude, and Behavior Analysis Methods: A Comparative Study Using Canadian Rivers

Abstract
:1. Introduction
2. Preliminaries on the Gould Probability Matrix (GPM) Method
3. Data and Computational Algorithms of Reservoir Volumes

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name, Location, and the Numeric Identifier of the River in Figure 1 | Data Size (Year) | Area (km2) | µ0 (m3/s) | cva | cvo | cvm | cvav | ρa | ρm1 ρm2 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| [1] Bow River at Banff (51°10′30″ N, 115°34′10″ W) [2] Beaver River at Cold Lake Reserve (54°21′18″ N, 110°13′2″ W) [3] Churchill River above Otter Bridge (55°38′47″ N, 104°44′5″ W) [4] Sturgeon River Weir (54°26′20″ N, 103°10′30″ W) [5] Island Lake River near Island Lake (54°03′34″ N, 94°39′ 34″ W) [6] Gods River below Allen Rapids (55°01′35″ N, 93°50′10″ W) [7] English River at Umfreville (49°52′30″ N, 91°27′30″ W) [8] Neebing River at Thunder Bay (48°23′00″ N, 89°18′23″ W) [9] Pic River near Marathon (48°46′26″ N, 86°17′49″ W) [10] Pagwachaun River at Highway11 (49°46′00″ N, 85°14′00″ W) [11] Goulis River near Searchmont (46°51′37″ N, 83°38′18″ W) [12] Becancour A Lyster (46°22′08″ N, 71°37′21″ W) [13] Beaurivage Sainte Entiene (46°39′33″ N, 71°17′19″ W) [14] Lepraue River at Lepraue (45°10′11″ N, 66°28′05″ W) [15] Upper Humber River (49°14′34″ N, 57°21′36″ W) [16] Torrent River at Bristol pool (50°36′26″ N, 57°09′05″ W) | 110 (1911-20) 65 (1956-20) 57 (1964-20) 35 (1961-95) 46 (1948-93) 61 (1934-94) 99 (1922-20) 66 (1954-19) 50 (1971-20) 53 (1968-20) 53 (1968-20) 53 (1923-68) 75 (1926-00) 101 (1919-19) 68 (1953-20) 61 (1960-20) | 2210 4505 119,000 14,600 25,900 14,000 6230 187 4270 2020 1160 1410 709 239 2210 624 | 39.01 18.81 296.29 46.91 86.18 154.58 58.54 1.62 50.21 23.01 18.33 30.59 14.19 7.41 80.21 24.79 | 0.13 0.72 0.37 0.49 0.28 0.28 0.32 0.37 0.24 0.25 0.21 0.20 0.26 0.22 0.13 0.15 | 1.05 1.49 0.50 0.53 0.54 0.42 0.74 1.48 1.03 1.18 1.05 1.08 1.19 0.81 0.87 0.88 | 0.41 1.24 0.48 0.66 0.45 0.44 0.85 2.01 1.08 1.63 1.04 1.06 1.38 1.02 0.75 0.75 | 0.24 0.98 0.43 0.49 0.38 0.38 0.51 0.81 0.56 0.62 0.58 0.62 0.62 0.59 0.44 0.44 | 0.06 0.36 0.59 0.62 0.27 0.36 0.20 0.20 0.13 0.06 0.08 0.03 0.19 0.10 0.18 0.18 | 0.50 0.76 0.77 0.90 0.94 0.97 0.91 0.98 0.87 0.92 0.94 0.96 0.76 0.88 0.43 0.73 0.41 0.71 0.36 0.69 0.33 0.66 0.26 0.65 0.24 0.64 0.23 0.62 0.13 0.56 0.16 0.59 |
3.1. Computational Procedure for the GPM Method
3.2. Computational Procedure for the DM Method
3.3. Computational Procedure for the BA Method
4. Results and Discussion
4.1. Identifying the Number of Zones (Nz) for Use in the GPM Method
4.2. Inter-Comparison of Reservoir Capacity (CR) for Rivers with Independent Flows
4.3. Inter-Comparison of Reservoir Capacity (CR) for Rivers with Dependent Flows
| River # as Shown in Table 1, Figure 1 | Reservoir Capacity (CR, 106 m3) at Draft Ratio = 0.75 | Reservoir Capacity (CR, 106 m3) at Draft Ratio = 0.50 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| PF (%) | GPM | BA | DM | Parameters of DM Method | GPM | BA | DM | Parameters of DM Method | |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| [2] Beaver cva = 0.72, ρa = 0.36, N = 65 | 10.0 | 450.0, 810.0 | 1200.0 | 1180.0 | MT1, Φ = 0.24(2) | 116.0, 118.3 | 165.0 | 166.0 | MT0, Φ = 0.70(2) * |
| 5.0 | 677.0, 1360.8 | 1860.0 | 1880.0 | MT1V, Φ = 0.55(2) | 175.0, 180.3 | 363.0 | 368.0 | MT0V, Φ = 0.61(2) | |
| 2.5 | 936.0, 2059.2 | 2510.0 | 2460.0 | MT1V, Φ = 0.25(2) | 244.0, 253.8 | 541.0 | 530.0 | MT1, Φ = 0.66(2) | |
| [3] Churchill cva = 0.37, ρa = 0.59, N = 57 | 10.0 | 1580.0, 3175.8 | 3800.0 | 3790.0 | MT1, Φ = 0.71(3) | 65.0, 71.5 | 64.0 | na | na |
| 5.0 | 2800.0, 5684.0 | 6100.0 | 6100.0 | MT1, Φ = 0.27(3) | 260.0, 397.8 | 420.0 | 423.0 | MT0, Φ = 0.45(1) | |
| 2.5 | 4080.0, 8445.6 | 9100.0 | 9276.0 | MT1, Φ = 0.66(3) | 720.0, 1188.0 | 1150.0 | 1130.0 | MT0V, Φ = 0.25(3) | |
| [4] Sturgeon cva = 0.43, ρa = 0.62, N = 35 | 10.0 | 286.0, 606.3 | 850.0 | 863.0 | MT1, Φ = 0.38(3) | 11.5, 21.9 | 12.0 | na | na |
| 5.0 | 497.0, 804.3 | 1550.0 | 1530.0 | MT1V, Φ = 0.58(3) | 38.0, 76.4 | 93.0 | 97.5 | MT0V, Φ = 1.0(3) | |
| 2.5 | 712.0, 1780.0 | 1970.0 | 1940.0 | MT0, Φ = 0.30(3) | 74.0, 162.8 | 270.0 | 265.0 | MT1, Φ = 0.83(3) | |
| [5] Islands, cva = 0.28 ρa = 0.27, N = 46 | 10.0 | 282.0, 513.0 | 280.0 | 273.0 | MT0, Φ = 0.78(3) | 10.0, 18.0 | 10.0 | na | MT1, Φ = na(3) |
| 5.0 | 490.0, 950.6 | 572.0 | 547.0 | MT1, Φ = 0.67(3) | 40.2, 73.2 | 44.0 | 42.2 | MT0, Φ = 0.1(3) | |
| 2.5 | 682.0, 1091.2 | 830.0 | 826.0 | MT1, Φ = 0.31(3) | 74.0, 117.0 | 88.0 | 87.3 | MT0, Φ = 0.20(3) | |
| [6] Gods, cva = 0.28 ρa = 0.36, N = 46 | 10.0 | 390.0, 393.9 | 470.0 | 444.0 | MT0V, Φ = 0.77(3) | na | na | na | na |
| 5.0 | 816.0, 1003.7 | 1123.0 | 1110.0 | MT1, Φ = 0.84(3) | 14.5, 23.0 | 20.0 | na | na | |
| 2.5 | 1480.0, 1998.0 | 1440.0 | 1470.0 | MT1, Φ = 0.61(3) | 147.0, 188.2 | 145.0 | 146.0 | MT0, Φ = 0.20(3) | |
| [7] English, cva = 0.32, ρa = 0.20, N = 99 | 10.0 | 320.0, 329.6 | 354.0 | 351.0 | MT1, Φ = 0.92(3) | 49.0, 56.4 | 57.0 | 55.0 | MT0, Φ = 0.90(3) |
| 5.0 | 505.0, 681.8 | 645.0 | 643.0 | MT1, Φ = 0.61(3) | 107.0, 123.0 | 136.0 | 134.0 | MT0, Φ = 0.05(3) | |
| 2.5 | 712.0, 996.9 | 960.0 | 960.0 | MT1, Φ = 0.28(3) | 157.0, 175.8 | 280.0 | 274.0 | MT1, Φ = 0.66(3) | |
| [8] Neebing, cva = 0.37, ρa = 0.20, N = 66, N = 66 | 10.0 | 21.0, 29.4 | 22.0 | 22.0 | MT1V, Φ = 0.95(3) | 10.4, 12.0 | 9.3 | 9.1 | MT1, Φ = 0.61(3) |
| 5.0 | 28.0, 40.6 | 30.0 | 30.0 | MT1, Φ = 0.60(3) | 10.3, 11.9 | 12.2 | 12.0 | MT1, Φ = 0.38(3) | |
| 2.5 | 33.8, 52.40 | 39.0 | 38.0 | MT1, Φ = 0.28(3) | 11.4, 12.8 | 15.0 | 15.0 | MT0V, Φ = 0.42(3) | |
| [13] Beaurivage, cva = 0.26, ρa= 0.19, N = 75 | 10.0 | 92.0, 103.0 | 92.0 | 91.1 | MT0V, Φ = 0.24(3) | 33.0, 35.3 | 33.0 | 33.0 | MT0, Φ = 0.58(3) |
| 5.0 | 118.0, 139.2 | 117.5 | 116.0 | MT1, Φ = 0.25(3) | 44.0, 48.0 | 47.0 | 46.0 | MT1, Φ = 0.49(3) | |
| 2.5 | 140.0, 182.0 | 149.0 | 147.0 | MT0V, Φ = 0.46(3) | 58.5, 64.3 | 61.5 | 60.7 | MT1, Φ = 0.21(3) | |
| River # as Shown in Table 1, Figure 1 | PF (%) | Reservoir Capacity (CR, 106 m3) Draft Ratio = 0.75 | Reservoir Capacity (CR, 106 m3) Draft Ratio = 0.50 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| GPM | BA | Ratio CR/µa | CF (lit) * | CF (ob) | GPM | BA | Ratio CR/µa | CF (lit) * | CF (ob)) | ||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| [2] Beaver µa = 592.5 × 106 ρa= 0.36, cva = 0.72 | 10.0 | 450.0 | 1200.0 | 0.76, 2.03 † | 1.80 * | 2.67 | 116.0 | 165.0 | 0.20, 0.28 † | 1.02 | 1.42 |
| 5.0 | 677.0 | 1860.0 | 1.14, 3.14 | 2.01 | 2.75 | 175.0 | 363.0 | 0.30, 0.61 | 1.03 | 2.07 | |
| 2.5 | 936.0 | 2510.0 | 1.58, 4.23 | 2.20 | 2.68 | 244.0 | 541.0 | 0.41, 0.58 | 1.04 | 2.21 | |
| [3] Churchill µa = 9345.0 × 106, ρa = 0.59, cva = 0.37 | 10.0 | 1580.0 | 3800.0 | 0.17, 0.41 | 2.01 | 2.41 | 65.0 | 64.0 | 0.007, 0.01 | 1.10 | 0.98 |
| 5.0 | 2800.0 | 6100.0 | 0.30, 0.65 | 2.03 | 2.18 | 260.0 | 420.0 | 0.028, 0.06 | 1.53 | 1.62 | |
| 2.5 | 4080.0 | 9100.0 | 0.44, 0.97 | 2.07 | 2.23 | 720.0 | 1150.0 | 0.078, 0.12 | 1.65 | 1.60 | |
| [4] Sturgeon µa = 1479.5 × 106 ρa = 0.62, cva = 0.43 | 10.0 | 286.0 | 850.0 | 0.19, 0.57 | 2.12 | 2.97 | 11.5 | 12.0 | 0.008, 0.008 | 1.90 | 1.04 |
| 5.0 | 497.0 | 1550.0 | 0.34, 1.05 | 2.30 | 3.12 | 38.0 | 93.0 | 0.026, 0.062 | 2.01 | 2.45 | |
| 2.5 | 712.0 | 1970.0 | 0.48, 1.33 | 2.50 | 2.77 | 74.0 | 270.0 | 0.050, 0.18 | 2.20 | 3.65 | |
| [5] Islands lake µa = 2718.1 × 106, ρa = 0.27, cva = 0.28 | 10.0 | 282.0 | 280.0 | 0.10, 0.10 | 1.82 | 0.99 | 10.0 | 10.0 | 0.004, 0.004 | 1.80 | 1.00 |
| 5.0 | 490.0 | 572.0 | 0.18, 0.21 | 1.94 | 1.17 | 40.2 | 44.0 | 0.015, 0.016 | 1.82 | 1.09 | |
| 2.5 | 682.0 | 830.0 | 0.25, 0.31 | 1.60 | 1.22 | 74.0 | 88.0 | 0.027, 0.032 | 1.58 | 1.19 | |
| [6] Gods µa = 4875.5 × 106, ρa = 0.36, cva = 0.28 | 10.0 | 390.0 | 470.0 | 0.08, 0.10 | 1.01 | 1.21 | na | na | na | na ** | na |
| 5.0 | 816.0 | 1123.0 | 0.17, 0.23 | 1.23 | 1.38 | 14.5 | 20.0 | 0.003, 0.004 | 1.21 | 1.38 | |
| 2.5 | 1480.0 | 1440.0 | 0.30, 0.30 | 1.35 | 0.97 | 147.0 | 145.0 | 0.03, 0.03 | 1.28 | 0.99 | |
| [7] English µa = 1846.4 × 106 ρa = 0.20, cva = 0.32 | 10.0 | 320.0 | 354.0 | 0.17, 0.19 | 1.03 | 1.11 | 49.0 | 57.0 | 0.026, 0.031 | 1.01 | 1.16 |
| 5.0 | 505.0 | 645.0 | 0.27, 0.35 | 1.35 | 1.28 | 107.0 | 136.0 | 0.056, 0.074 | 1.05 | 1.27 | |
| 2.5 | 712.0 | 960.0 | 0.38, 0.52 | 1.40 | 1.35 | 157.0 | 280.0 | 0.082, 0.15 | 1.10 | 1.78 | |
| [8] Neebing µa = 51.1 × 106 ρa = 0.20, cva = 0.37 | 10.0 | 21.0 | 22.0 | 0.41, 0.43 | 1.40 | 1.05 | 10.4 | 9.3 | 0.20, 0.18 | 1.15 | 0.89 |
| 5.0 | 28.0 | 30.0 | 0.55, 0.59 | 1.45 | 1.07 | 10.3 | 12.2 | 0.20, 0.24 | 1.15 | 1.18 | |
| 2.5 | 33.8 | 39.0 | 0.66, 0.76 | 1.55 | 1.15 | 11.4 | 15.0 | 0.22, 0.29 | 1.12 | 1.32 | |
| [13] Beaurivage µa = 447.6 × 106 ρa = 0.19, cva = 0.27 | 10.0 | 92.0 | 92.0 | 0.21, 0.21 | 1.12 | 1.00 | 33.0 | 33.0 | 0.074, 0.74 | 1.07 | 1.00 |
| 5.0 | 118.0 | 117.5 | 0.27, 0.27 | 1.18 | 1.00 | 44.0 | 47.0 | 0.10, 0.11 | 1.09 | 1.07 | |
| 2.5 | 140.0 | 149.0 | 0.31, 0.33 | 1.30 | 1.06 | 58.5 | 61.5 | 0.13, 0.14 | 1.10 | 1.05 | |
5. Conclusions
- For the analysis using the GPM method, 15 zones in a reservoir are sufficient to yield reliable estimates of the reservoir capacity.
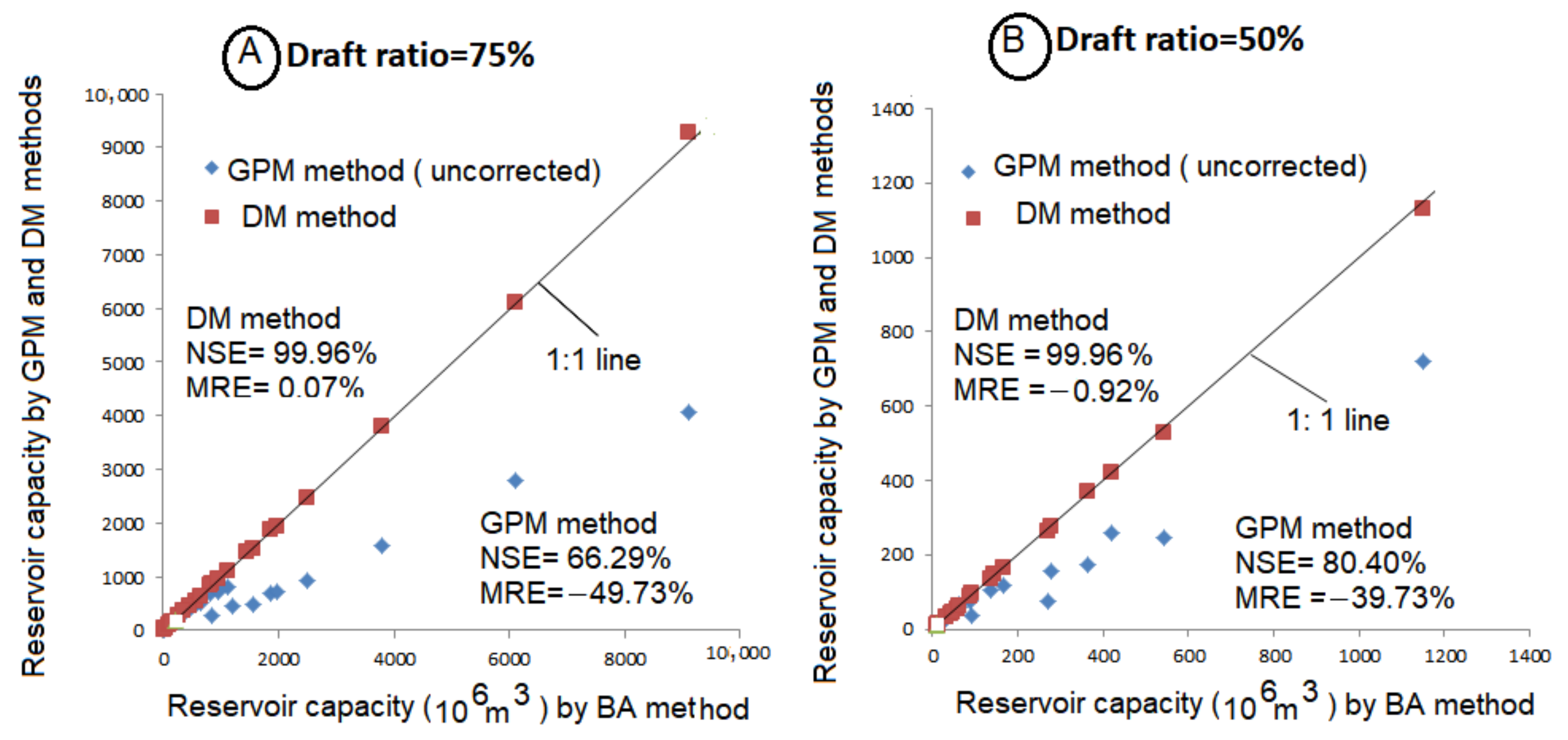
- The estimates of the reservoir capacity (CR) by the BA and the DM methods in this study were found to be nearly equal to each other for all values ρa and cva, which implies that the DM method is a competent substitute for the BA method.
- In the DM method, which requires the standardized monthly data, i.e., the SHI sequences, the Markov chain order 1 (MC1) or MC0 model yielded the drought lengths, which when multiplied by drought intensity, resulted in the drought magnitudes. The drought magnitude (MT) multiplied by the average standard deviation of 12 months (σav) resulted in satisfactory estimates of reservoir capacity (CR). Both the BA and the GPM methods can be implemented on the non-standardized monthly flow sequences.
- For annual flows with ρa < 0.20, the estimates of reservoir capacity (CR) by the GPM method were found in parity with the estimates of the BA or DM methods. The BA method, being simplest in terms of calculation rigor, enjoys a slight edge over the DM and the GPM methods.
- The estimates of reservoir capacity (CR) tend to become smaller in the GPM method when the values of ρa > 0.20 or become remarkably low with high values of ρa, say 0.5 or greater. These low values of CR can be improved by invoking the correction factors as a multiplier while using the available graphical values from the literature. However, there is a need to further refinement of the correction factors (CFs).
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
An Illustration of the Computational Procedure for the GPM on the Sturgeon River
| Zone | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Max vol. | 0 | 38.15 | 76.30 | 114.46 | 152.62 | 190.77 | 228.92 | 267.08 | 305.23 | 343.38 | 381.54 | 419.67 | 457.85 | 496.0 | 496.0 |
| Min. vol. | 0 | 0 | 38.15 | 76.30 | 114.46 | 152.62 | 190.77 | 228.92 | 267.10 | 305.23 | 343.38 | 381.49 | 419.69 | 457.85 | 496.0 |
| Zone | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| nf | 117 | 104 | 79 | 64 | 52 | 41 | 33 | 23 | 19 | 14 | 9 | 6 | 3 | 2 | 1 |
| pf | 0.279 | 0.248 | 0.188 | 0.152 | 0.124 | 0.100 | 0.077 | 0.056 | 0.045 | 0.033 | 0.021 | 0.014 | 0.007 | 0.005 | 0.002 |
| Zone | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 9 | 9 | 8 | 7 | 7 | 5 | 5 | 5 | 5 | 5 | 3 | 3 | 2 | 1 | 1 |
| 1 | 1 | 1 | 2 | 2 | 1 | 3 | 0 | 0 | 0 | 0 | 2 | 0 | 1 | 1 | 0 |
| 2 | 2 | 2 | 0 | 1 | 1 | 0 | 3 | 0 | 0 | 0 | 0 | 2 | 0 | 1 | 2 |
| 3 | 2 | 1 | 3 | 1 | 1 | 1 | 0 | 3 | 3 | 0 | 0 | 0 | 2 | 0 | 0 |
| 4 | 0 | 1 | 0 | 2 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 |
| 5 | 2 | 0 | 1 | 0 | 2 | 1 | 1 | 1 | 1 | 3 | 0 | 0 | 0 | 0 | 2 |
| 6 | 3 | 5 | 1 | 1 | 0 | 2 | 1 | 1 | 1 | 0 | 3 | 0 | 0 | 0 | 0 |
| 7 | 1 | 1 | 5 | 2 | 2 | 1 | 3 | 1 | 1 | 1 | 0 | 3 | 0 | 0 | 0 |
| 8 | 0 | 0 | 0 | 4 | 1 | 1 | 0 | 3 | 3 | 1 | 1 | 0 | 3 | 0 | 0 |
| 9 | 0 | 0 | 0 | 0 | 4 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 3 | 2 |
| 10 | 0 | 0 | 0 | 0 | 0 | 4 | 1 | 1 | 1 | 3 | 1 | 1 | 1 | 0 | 1 |
| 11 | 1 | 1 | 0 | 0 | 0 | 0 | 4 | 2 | 2 | 1 | 4 | 2 | 2 | 2 | 2 |
| 12 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 3 | 3 | 1 | 0 | 3 | 2 | 2 | 2 |
| 13 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 4 | 3 | 3 |
| 14 | 13 | 14 | 14 | 14 | 15 | 15 | 15 | 15 | 15 | 16 | 17 | 18 | 18 | 20 | 20 |
| total | 35 | 35 | 35 | 35 | 35 | 35 | 35 | 35 | 35 | 35 | 35 | 35 | 35 | 35 | 35 |
| Zone | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.257 | 0.257 | 0.229 | 0.200 | 0.2 | 0.143 | 0.143 | 0.143 | 0.143 | 0.143 | 0.086 | 0.086 | 0.057 | 0.028 | 0.028 |
| 1 | 0.028 | 0.028 | 0.057 | 0.057 | 0.028 | 0.086 | 0 | 0 | 0 | 0 | 0.057 | 0 | 0.028 | 0.028 | 0 |
| 2 | 0.057 | 0.028 | 0 | 0.028 | 0.028 | 0 | 0.086 | 0 | 0 | 0 | 0 | 0.057 | 0 | 0.028 | 0.057 |
| 3 | 0.057 | 0.028 | 0.086 | 0.028 | 0.028 | 0.028 | 0 | 0.086 | 0.086 | 0 | 0 | 0 | 0.057 | 0 | 0 |
| 4 | 0 | 0.028 | 0 | 0.057 | 0.028 | 0.028 | 0.028 | 0 | 0 | 0 | 0 | 0 | 0 | 0.057 | 0 |
| 5 | 0.057 | 0 | 0.028 | 0 | 0.057 | 0.028 | 0.028 | 0.028 | 0.028 | 0.086 | 0 | 0 | 0 | 0 | 0.057 |
| 6 | 0.028 | 0.143 | 0.028 | 0.028 | 0 | 0.057 | 0.028 | 0.028 | 0.028 | 0 | 0.086 | 0 | 0 | 0 | 0 |
| 7 | 0.028 | 0.028 | 0.143 | 0.057 | 0.057 | 0.028 | 0.086 | 0.057 | 0.028 | 0.028 | 0 | 0.086 | 0 | 0 | 0 |
| 8 | 0 | 0 | 0 | 0.114 | 0.028 | 0.028 | 0 | 0.086 | 0.086 | 0.028 | 0.028 | 0 | 0.086 | 0 | 0 |
| 9 | 0 | 0 | 0 | 0 | 0.114 | 0.028 | 0.028 | 0 | 0 | 0.028 | 0.028 | 0.028 | 0 | 0.086 | 0.057 |
| 10 | 0 | 0 | 0 | 0 | 0 | 0.114 | 0.028 | 0.028 | 0.028 | 0.114 | 0.028 | 0.028 | 0.028 | 0 | 0.028 |
| 11 | 0.028 | 0.028 | 0 | 0 | 0 | 0 | 0.114 | 0.057 | 0.057 | 0.028 | 0.114 | 0.057 | 0.057 | 0.057 | 0.057 |
| 12 | 0 | 0 | 0.028 | 0 | 0 | 0 | 0 | 0.086 | 0.086 | 0.028 | 0 | 0.086 | 0.057 | 0.057 | 0.057 |
| 13 | 0.028 | 0 | 0 | 0.028 | 0 | 0 | 0 | 0 | 0 | 0.086 | 0.086 | 0.086 | 0.114 | 0.086 | 0.086 |
| 14 | 0.371 | 0.40 | 0.400 | 0.400 | 0.429 | 0.429 | 0.429 | 0.429 | 0.429 | 0.457 | 0.457 | 0.514 | 0.514 | 0.571 | 0.571 |
| total | ≈1.0 | ≈1.0 | ≈1.0 | ≈1.0 | ≈1.0 | ≈1.0 | ≈1.0 | ≈1.0 | ≈1.0 | ≈1.0 | ≈1.0 | ≈1.0 | ≈1.0 | ≈1.0 | ≈1.0 |
| Zone | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.084 | 0.084 | 0.084 | 0.084 | 0.084 | 0.084 | 0.084 | 0.084 | 0.084 | 0.084 | 0.084 | 0.084 | 0.084 | 0.084 | 0.084 |
| 1 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 |
| 2 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 |
| 3 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 |
| 4 | 0.008 | 0.008 | 0.008 | 0.008 | 0.008 | 0.008 | 0.008 | 0.008 | 0.008 | 0.008 | 0.008 | 0.008 | 0.008 | 0.008 | 0.008 |
| 5 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 |
| 6 | 0.017 | 0.017 | 0.017 | 0.017 | 0.017 | 0.017 | 0.017 | 0.017 | 0.017 | 0.017 | 0.017 | 0.017 | 0.017 | 0.017 | 0.017 |
| 7 | 0.019 | 0.019 | 0.019 | 0.019 | 0.019 | 0.019 | 0.019 | 0.019 | 0.019 | 0.019 | 0.019 | 0.019 | 0.019 | 0.019 | 0.019 |
| 8 | 0.011 | 0.011 | 0.011 | 0.011 | 0.011 | 0.011 | 0.011 | 0.011 | 0.011 | 0.011 | 0.011 | 0.011 | 0.011 | 0.011 | 0.011 |
| 9 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 | 0.042 |
| 10 | 0.028 | 0.028 | 0.028 | 0.028 | 0.028 | 0.028 | 0.028 | 0.028 | 0.028 | 0.028 | 0.028 | 0.028 | 0.028 | 0.028 | 0.028 |
| 11 | 0.050 | 0.050 | 0.050 | 0.050 | 0.050 | 0.050 | 0.050 | 0.050 | 0.050 | 0.050 | 0.050 | 0.050 | 0.050 | 0.050 | 0.050 |
| 12 | 0.045 | 0.045 | 0.045 | 0.045 | 0.045 | 0.045 | 0.045 | 0.045 | 0.045 | 0.045 | 0.045 | 0.045 | 0.045 | 0.045 | 0.045 |
| 13 | 0.068 | 0.068 | 0.068 | 0.068 | 0.068 | 0.068 | 0.068 | 0.068 | 0.068 | 0.068 | 0.068 | 0.068 | 0.068 | 0.068 | 0.068 |
| 14 | 0.516 | 0.516 | 0.516 | 0.516 | 0.516 | 0.516 | 0.516 | 0.516 | 0.516 | 0.516 | 0.516 | 0.516 | 0.516 | 0.516 | 0.516 |
| total | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| Zone | Steady-State Probability (from Table A5) | Failure Probability in Zones (from Table 2) | Product of Probabilities Column(2) × Column(3) |
|---|---|---|---|
| (1) | (2) | (3) | (4) |
| 0 | 0.278571 | 0.084124 | 0.023435 |
| 1 | 0.247619 | 0.014667 | 0.003632 |
| 2 | 0.188095 | 0.042007 | 0.007901 |
| 3 | 0.152381 | 0.014852 | 0.002263 |
| 4 | 0.123810 | 0.007977 | 0.000988 |
| 5 | 0.097619 | 0.041791 | 0.00408 |
| 6 | 0.078571 | 0.017031 | 0.001338 |
| 7 | 0.054762 | 0.019094 | 0.001046 |
| 8 | 0.045238 | 0.010877 | 0.000492 |
| 9 | 0.033333 | 0.042222 | 0.001407 |
| 10 | 0.021429 | 0.027646 | 0.000592 |
| 11 | 0.014286 | 0.049574 | 0.000708 |
| 12 | 0.007143 | 0.044497 | 0.000318 |
| 13 | 0.004762 | 0.067693 | 0.000322 |
| 14 | 0.002381 | 0.515947 | 0.001228 |
| PF = | sum of column (4) | 0.050 |
References
- McMahon, T.A.; Pegram, G.G.S.; Vogel, R.M.; Peel, M.C. Revisiting reservoir storage—Yield relationships using a global streamflow database. Adv. Water Resour. 2007, 30, 1858–1872. [Google Scholar] [CrossRef]
- McMahon, T.A.; Vogel, R.M.; Pegram, G.G.S.; Peel, M.C.; Etkin, D. Global streamflows—Part 2: Reservoir storage yield performance. J. Hydrol. 2007, 347, 260–261. [Google Scholar] [CrossRef]
- McMahon, T.A.; Mein, R.G. River and Reservoir Yield; Water Resources Publications: Littleton, CO, USA, 1986; p. 149. [Google Scholar]
- McMahon, T.A.; Adeloye, A.J. Water Resources Yield; Water Resources Publications: Littleton, CO, USA, 2005; p. 88. [Google Scholar]
- Sharma, T.C.; Panu, U.S. A drought magnitude based method for reservoir sizing: A case of annual and monthly flows from Canadian rivers. J. Hydrol. Reg. Stud. 2021, 36, 100829. [Google Scholar] [CrossRef]
- Sharma, T.C.; Panu, U.S. Reservoir sizing at the draft Level of 75% of mean annual flow using drought magnitude-based method on Canadian rivers. Hydrology 2021, 8, 79. [Google Scholar] [CrossRef]
- Thomas, H.A.; Burden, R.P. Operation Research in Water Quality Management; Division of Engineering and Applied Physics, Harvard University: Cambridge, MA, USA, 1963. [Google Scholar]
- Loucks, D.P.; Stedinger, J.R.; Haith, D.A. Water Resources Systems Planning; Prentice-Hall: Englewood, NJ, USA, 1981; p. 33. [Google Scholar]
- Linsley, R.K.; Franzini, J.B.; Freyburg, D.L.; Tchobanoglous, G. Water Resources Engineering, 4th ed.; Irwin McGraw-Hill: New York, NY, USA, 1992; p. 192. [Google Scholar]
- Lele, S.M. Improved algorithm for reservoir capacity calculation incorporating storage-dependent and reliability norm. Water Resour. Res. 1987, 23, 1819–1823. [Google Scholar] [CrossRef] [Green Version]
- Nagy, T.V.; Asante-Dua, K.; Zsuffa, I. Hydrological Dimensioning and Operation of Reservoirs. Practical Design Concepts and Principles; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2002; p. 192. [Google Scholar]
- Alrayess, H.; Zeybekoglu, U.; Ulke, A. Different design techniques in determining reservoir capacity. Eur. Water 2017, 60, 107–115. [Google Scholar]
- Moran, P.A.P. Probability theory of dams. Aust. J. Appl. Sci. 1954, 5, 116. [Google Scholar]
- Moran, P.A.P. Theory of Storage; Methuen: London, UK, 1959. [Google Scholar]
- Gould, B.W. Statistical methods for estimating the design capacity of dams. J. Inst. Eng. Aust. 1961, 33, 405–416. [Google Scholar]
- Gould, B.W. Discussion of paper by Alexander. In Water Resources Use and Management; Melbourne University Press: Melbourne, Australia, 1964; pp. 161–164. [Google Scholar]
- McMahon, T.A. Preliminary estimation of reservoir storage for Australian streams. Eng. Australia CE 1976, 18, 55–59. [Google Scholar]
- Theo, C.H.; McMahon, T.A. Evaluation of rapid reservoir yield procedure. Adv. Water Resour. 1982, 5, 202–215. [Google Scholar]
- Parks, Y.P.; Farquharson, F.A.K.; Plinston, D.T. Use of the Gould probability matrix method of reservoir design in arid and semi-arid regions. In Proceedings of the Sahel Forums on the State-of-the-Art of Hydrology and Hydrogeology of the Arid and Semi-Arid Areas of Africa, Ouagadougou, Burkina Faso, 7–12 November 1988; Demiossie, M., Stout, E., Eds.; IWRA: Urbana, IL, USA, 1989; pp. 129–136. [Google Scholar]
- Otieno, F.A.O.; Ndiritu, J.G. The effect of serial correlation on reservoir capacity using the modified Gould probability matrix method. Water S. Afr. 1997, 23, 63–70. [Google Scholar]
- Ragab, R.; Austin, B.; Modinis, D. The HYDROMED model and its application to semi-arid and Mediterranean catchments with hilly reservoirs 3: Reservoir storage capacity and probability of failure model. Hydrol. Earth Syst. Sci. 2001, 5, 563–568. [Google Scholar] [CrossRef] [Green Version]
- Ibn Abubakar, B.S.U. Assessment of reservoir storage in a semi-arid environment using the Gould probability matrix method. Afr. Res. Rev. 2008, 2, 35–45. [Google Scholar]
- Kraus, A.; Rice, M.; Watson, G. Comparative Analysis of Reservoir Sizing Inclusive of the Gould Probability Matrix Method; An unpublished undergraduate technical report of the civil engineering; Faculty of Engineering, Lakehead University: Thunder Bay, ON, Canada, May 2022. [Google Scholar]
- Srikanthan, R.; McMahon, T.A. Gould’s Probability matrix method the annual autocorrelation problem. J. Hydrol. 1985, 77, 135–139. [Google Scholar] [CrossRef]
- Environment Canada. HYDAT CD-ROM Version 96-1.04 and HYDAT-ROM User’s Manual. In Surface Water and Sediment Data; Water Survey of Canada: Gatineau, QC, Canada, 2020. [Google Scholar]
- Dracup, J.A.; Lee, K.S.; Paulson, E.G. On the statistical characteristics of drought events. Water Resour. Res. 1980, 16, 289–296. [Google Scholar] [CrossRef]
- Sharma, T.C.; Panu, U.S. A semi-empirical method for predicting hydrological drought magnitudes in the Canadian prairies. Hydrol. Sci. J. 2013, 58, 549–569. [Google Scholar] [CrossRef] [Green Version]
- Sharma, T.C.; Panu, U.S. Modelling of hydrological drought durations and magnitudes: Experiences on Canadian streamflows. J. Hydrol. Reg. Stud. 2014, 1, 92–106. [Google Scholar] [CrossRef] [Green Version]
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models: Part 1—A discussion of Principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Phatarfod, R.M. The Effect of serial correlation on reservoir size. Water Resour. Res. 1986, 22, 927–934. [Google Scholar] [CrossRef]




| River and Relevant Parameters | CR (106 m3) at Draft Ratio = 0.75 | CR (106 m3) at Daft Ratio = 0.50 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Nz = 20 | Nz = 15 | Nz = 20 | Nz = 15 | |||||||||
| PF Level (%) | PF Level (%) | PF Level (%) | PF Level (%) | |||||||||
| 10 | 5 | 2.5 | 10 | 5 | 2.5 | 10 | 5 | 2.5 | 10 | 5 | 2.5 | |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| Bow River, cva = 0.13, ρa = 0.06 | 290.0 | 321.0 | 337.2 | 290.0 | 321.0 | 339.0 | 133.0 | 150.0 | 160.0 | 133.0 | 149.0 | 160.5 |
| Beaver River, cva = 0.72, ρa = 0.36 | 442.0 | 690.0 | 935.0 | 450.0 | 677.0 | 936.0 | 115.0 | 175.5 | 246.0 | 116.0 | 175.0 | 244.0 |
| Sturgeon River, cva = 0.43, ρa = 0.63 | 287.0 | 500.0 | 712.0 | 286.0 | 497.0 | 712.0 | 11.5 | 38.0 | 74.8 | 11.5 | 38.0 | 74.0 |
| Islands lake River, cva = 0.28, ρa = 0.27 | 280.0 | 493.0 | 680.0 | 282.0 | 490.0 | 682.0 | 10.0 | 40.0 | 74.0 | 10.0 | 40.2 | 74.0 |
| English River cva = 0.32, ρa = 0.20 | 322.0 | 500.0 | 712.0 | 320.0 | 505.0 | 712.0 | 50.0 | 107.0 | 158.0 | 49.0 | 107.0 | 157.0 |
| Beconcour River cva = 0.20, ρa = 0.03 | 176.5 | 235.0 | 281.0 | 177.0 | 234.0 | 281.0 | 60.3 | 86.7 | 112.8 | 60.3 | 86.7 | 112.8 |
| U. Humber River cva = 0.13, ρa = 0.18 | 277.0 | 358.0 | 430.0 | 277.0 | 358.0 | 429.0 | 103.0 | 142.0 | 185.0 | 103.0 | 142.0 | 185.0 |
| River # as Shown in Table 1, Figure 1 | Reservoir Capacity (CR, 106 m3) at Draft Ratio = 0.75 | Reservoir Capacity (CR, 106 m3) at Draft Ratio = 0.50 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| PF (%) | GPM | BA | DM | Parameters on DM Method | GPM | BA | DM | Parameters on DM Method | |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| [1] Bow River, cva = 0.13, ρa = 0.06, N = 110 | 10.0 | 290.0 | 286.0 | 283.0 | MT1V, Φ = 0.64(1) | 133.0 | 133.0 | 128.0 | MT1, Φ = 0.35(1) * |
| 5.0 | 321.0 | 323.0 | 317.0 | MT1V, Φ = 0.54(1) | 149.0 | 151.0 | 147.0 | MT1, Φ = 0.21(1) | |
| 2.5 | 339.0 | 343.0 | 336.0 | MT1V, Φ = 0.49(1) | 160.5 | 164.8 | 160.0 | MT1, Φ = 0.12(1) | |
| [9] Pic River, cva = 0.24, ρa = 0.13, N = 50 | 10.0 | 340.0 | 325.0 | 317.0 | MT1, Φ = 0.48(3) | 134.0 | 133.0 | 126.0 | MT1, Φ = 0.78(3) |
| 5.0 | 480.0 | 490.0 | 483.0 | MC1, Φ = 0.04(3) | 193.0 | 195.0 | 192.0 | MT1, Φ = 0.45(3) | |
| 2.5 | 579.0 | 588.0 | 578.0 | MC1V, Φ = 0.61(3) | 255.0 | 270.0 | 255.0 | MT1, Φ = 0.13(3) | |
| [10] Pagwa- chaun, cva = 0.25 ρa = 0.06, N = 53 | 10.0 | 208.0 | 182.0 | 177.0 | MT1, Φ = 0.43(3) | 108.0 | 75.0 | 73.3 | MT1, Φ = 0.69(3) |
| 5.0 | 237.0 | 240.0 | 239.0 | MT1, Φ = 0.12(3) | 127.0 | 108.0 | 106.0 | MT1, Φ = 0.38(3) | |
| 2.5 | 250.0 | 300.0 | 296.0 | MT1V, Φ = 0.62(3) | 130.0 | 152.0 | 150.0 | MT0V, Φ = 0.20(3) | |
| [11] Goulis cva = 0.24, ρa = 0.13, N = 53 | 10.0 | 100.0 | 99.0 | 98.0 | MT1, Φ = 0.62(3) | 31.5 | 31.0 | 30.2 | MT1, Φ = 0.93(3) |
| 5.0 | 135.0 | 138.5 | 136.0 | MT1, Φ = 0.35(3) | 44.5 | 45.0 | 45.4 | MT1, Φ = 0.69(3) | |
| 2.5 | 166.0 | 169.0 | 167.0 | MT1, Φ = 0.13(3) | 65.0 | 66.0 | 64.4 | MT1, Φ = 0.39(3) | |
| [12] Becancour cva = 0.20, ρa = 0.03, N = 53 | 10.0 | 177.0 | 175.0 | 172.0 | MT1, Φ = 0.57(3) | 60.3 | 61.2 | 61.1 | MT1, Φ = 0.88(3) |
| 5.0 | 234.0 | 230.0 | 231.0 | MT1, Φ = 0.32(3) | 86.7 | 86.7 | 86.03 | MT1, Φ = 0.64(3) | |
| 2.5 | 281.0 | 275.0 | 281.0 | MT1, Φ = 0.12(3) | 112.8 | 114.0 | 112.1 | MT1, Φ = 0.40(3) | |
| [14] Lepraue cva = 0.22, ρa = 0.10, N = 101 | 10.0 | 39.9 | 38.0 | 35.5 | MT1, Φ = 0.69(3) | 8.0 | 13.1 | 13.4 | MT0, Φ = 0.67(3) |
| 5.0 | 45.0 | 48.0 | 47.2 | MT1, Φ = 0.50(3) | 16.0 | 20.0 | 20.4 | MT1, Φ = 0.64(3) | |
| 2.5 | 61.5 | 61.7 | 60.8 | MT1, Φ = 0.28(3) | 24.2 | 27.5 | 27.7 | MT1, Φ = 0.40(3) | |
| [15] U. Humber cva = 0.13, ρa = 0.18, N = 68 | 10.0 | 277.0 | 277.0 | 275.0 | MT0, Φ = 0.23(3) | 103.0 | 104.0 | 98.9 | MT1, Φ = 0.32(3) |
| 5.0 | 358.0 | 355.0 | 351.0 | MT1, Φ = 0.20(3) | 142.0 | 136.0 | 134.0 | MT1, Φ = 0.52(3) | |
| 2.5 | 429.0 | 412.0 | 402.0 | MT0V, Φ = 0.63(3) | 185.0 | 184.5 | 179.0 | MT1, Φ = 0.20(3) | |
| [16] Torrent cva = 0.15, ρa = 0.18, N = 61 | 10.0 | 97.0 | 97.0 | 95.3 | MT1, Φ = 0.62(1) | 35.2 | 34.5 | 32.5 | MTV0, Φ = 0.90(1) |
| 5.0 | 125.0 | 125.0 | 122.0 | MT1, Φ = 0.43(1) | 49.0 | 49.0 | 48.1 | MT1, Φ = 0.80(1) | |
| 2.5 | 146.0 | 147.0 | 146.0 | MT1, Φ = 0.75(1) | 63.0 | 63.0 | 59.7 | MT1, Φ = 0.46(1) | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharma, T.C.; Panu, U.S. Reservoir Capacity Estimation by the Gould Probability Matrix, Drought Magnitude, and Behavior Analysis Methods: A Comparative Study Using Canadian Rivers. Hydrology 2023, 10, 53. https://doi.org/10.3390/hydrology10020053
Sharma TC, Panu US. Reservoir Capacity Estimation by the Gould Probability Matrix, Drought Magnitude, and Behavior Analysis Methods: A Comparative Study Using Canadian Rivers. Hydrology. 2023; 10(2):53. https://doi.org/10.3390/hydrology10020053
Chicago/Turabian StyleSharma, Tribeni C., and Umed S. Panu. 2023. "Reservoir Capacity Estimation by the Gould Probability Matrix, Drought Magnitude, and Behavior Analysis Methods: A Comparative Study Using Canadian Rivers" Hydrology 10, no. 2: 53. https://doi.org/10.3390/hydrology10020053